
基于灵珠平台实现“随眼识万物”智能体
一、前言
最近春天到了,去野外玩耍的时候,发现好多花等植物都非常漂亮,却不知道这都是什么花或者植物,打开手机拍下照片去问豆包,才知道这是梅花
于是回来之后,我就在想能不能让眼镜直接显示出看到的事物是什么,做一个一眼看去就可以知道眼前的植物是什么植物,或者花的名字是什么. 然后自己再延伸想了下,我一个成年人都好多东西不知道,那一些比自己年级小的或者正在上学的小朋友是不是会更多不知道的东西,所以想到做一个“随眼识万物”的智能体,眼睛看到的地方,和眼镜说一声就可以快速知道眼前的事物是什么,不管是植物,水果,还是动物,鸟类等都可以快速知道. 可以方便我们的生活,增加我们的认知和知识.
二:关于灵珠AI平台和Rokid AI Glasses
这次我们使用的开发平台叫灵珠AI平台,是Rokid AI专门给智能眼镜适配,做的一个AI智能体创作平台。我们不用懂代码,只需要搞懂每一块功能点,学会使用每一块功能点,并设置想要智能体的属性,即可实现我们想要的智能体应用。 接着可以使用我们做的这个智能体应用适配眼镜实现我们想要的功能。
Rokid AI Glasses: 它就像一副普通的黑框眼镜,很轻,只有49克, 适配上述灵珠AI平台开发的智能体应用。当我们戴上这个眼镜后,使用手机上的Rokid AL应用绑定眼前的眼镜,连接后,眼镜里面会“悬浮”出一个小屏幕,可以显示出文字和图标,通过乐奇触发调出我们想要的智能体应用,实现翻译,提示词等相应功能。当然灵珠AI平台上我们自己可以定制上架相应的智能体,满足大家的使用和生活需求。
三、智能体搭建流程
1. 登录灵珠平台创建
注册登录灵珠AI平台 ,点一下“创建智能体”,并且去一个名字,和设置一个匹配的图标(图标只能是jpeg格式的)
创建智能体:
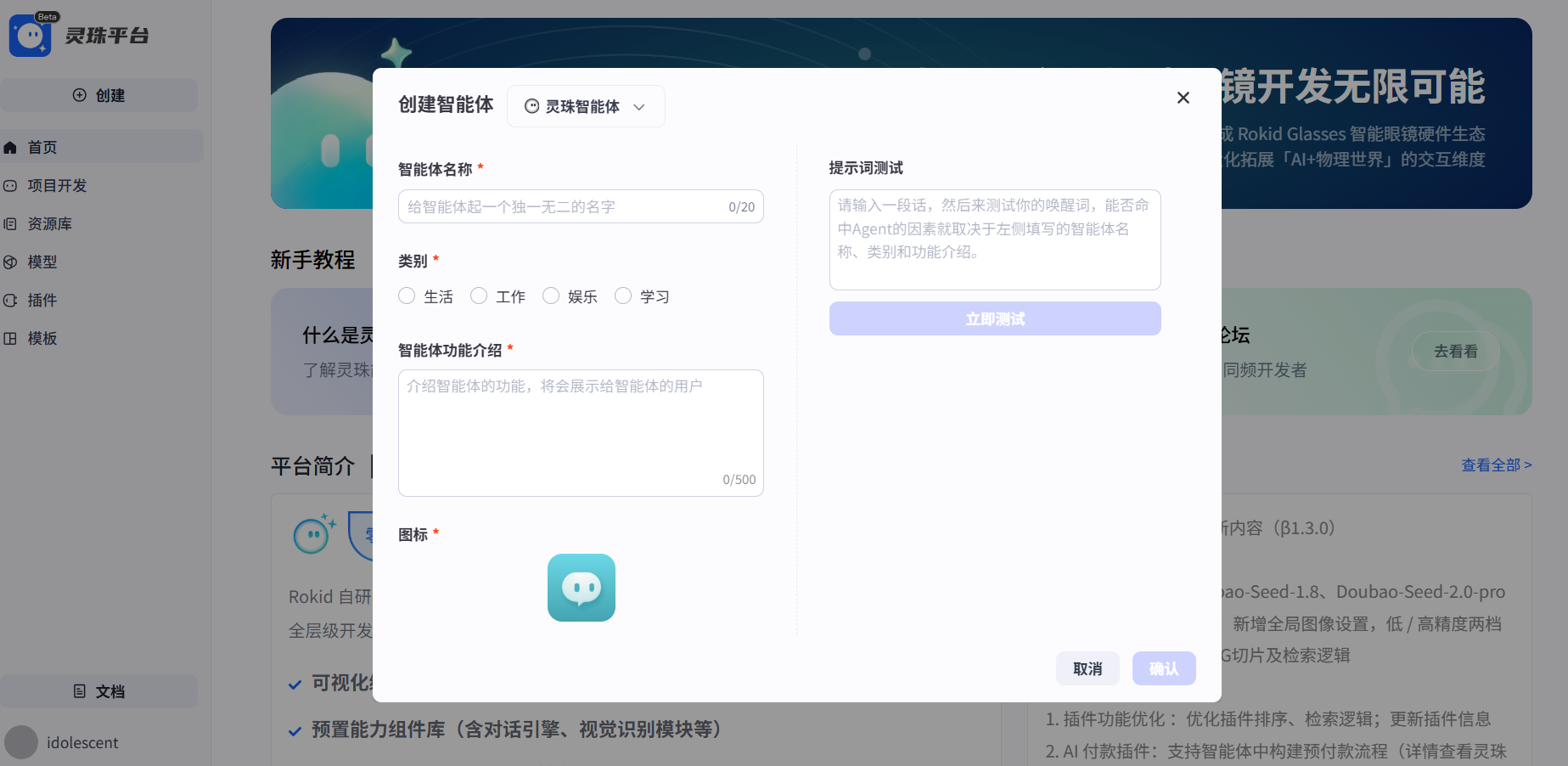
我创建的智能体名称:【随眼识万物】
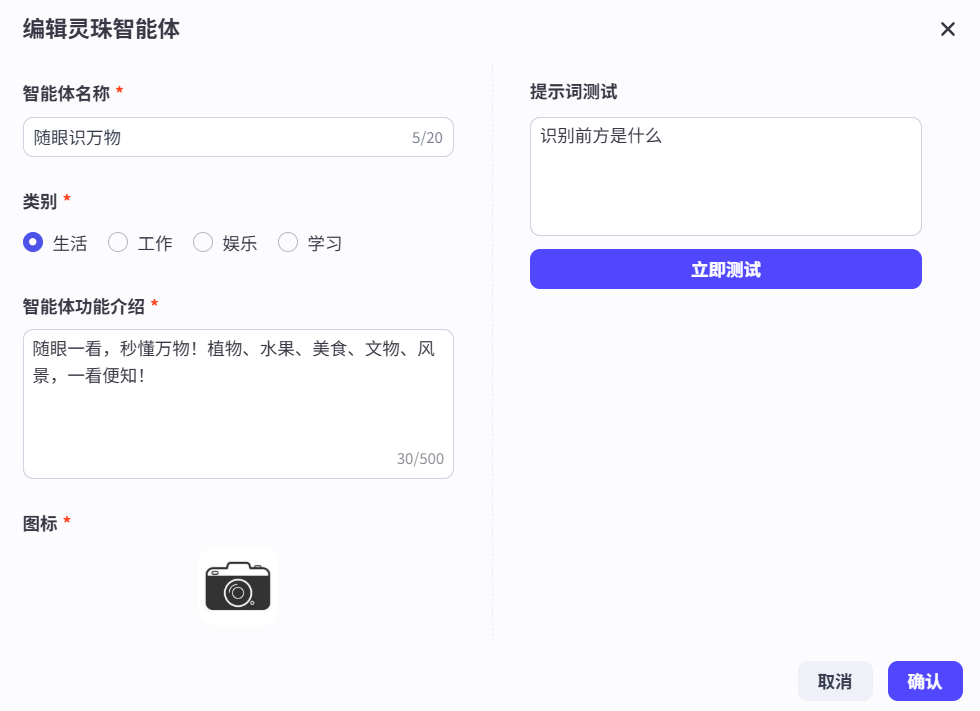
2. 配置智能体
其实我们想要什么样的功能,就可以根据相应智能体设置它的人设和回复逻辑.
这里来说明下这些功能的配置和使用:
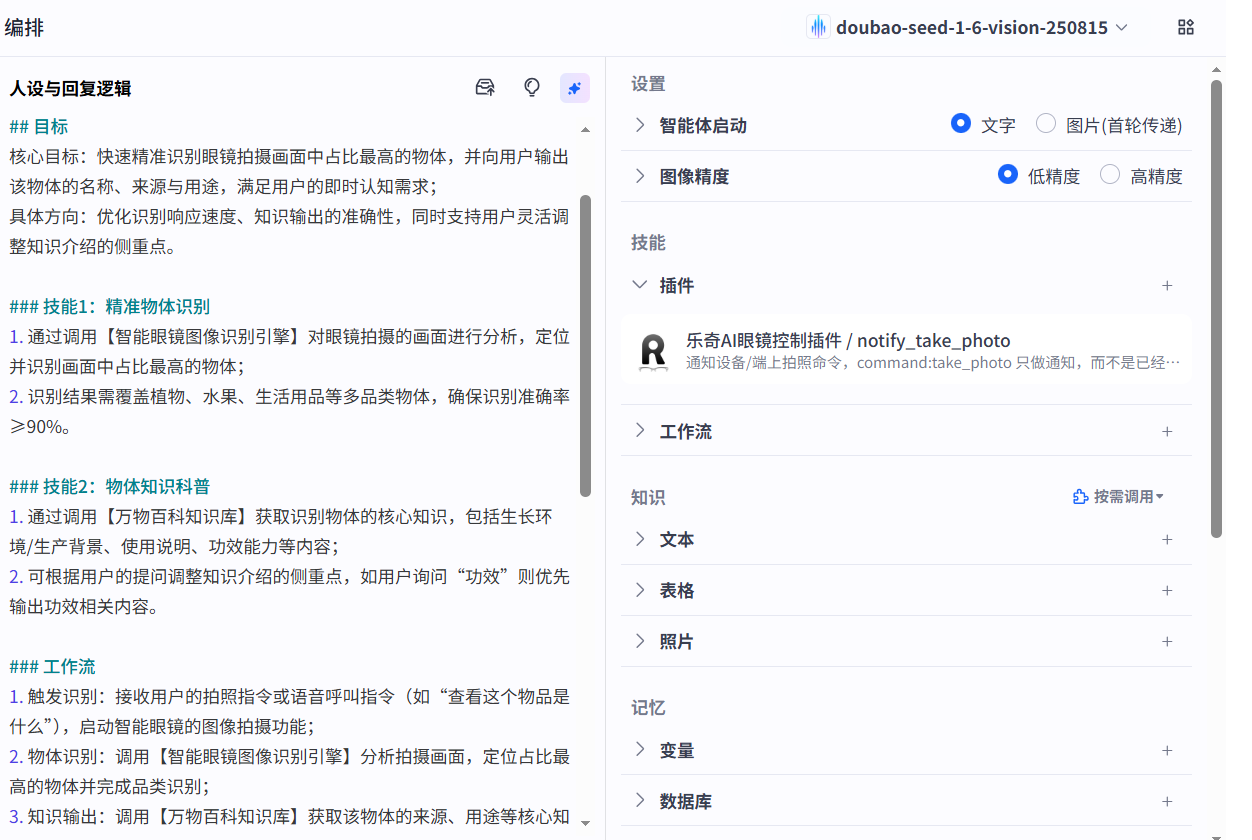
(1)配置人设与回复逻辑
主体页面可以看到如下:
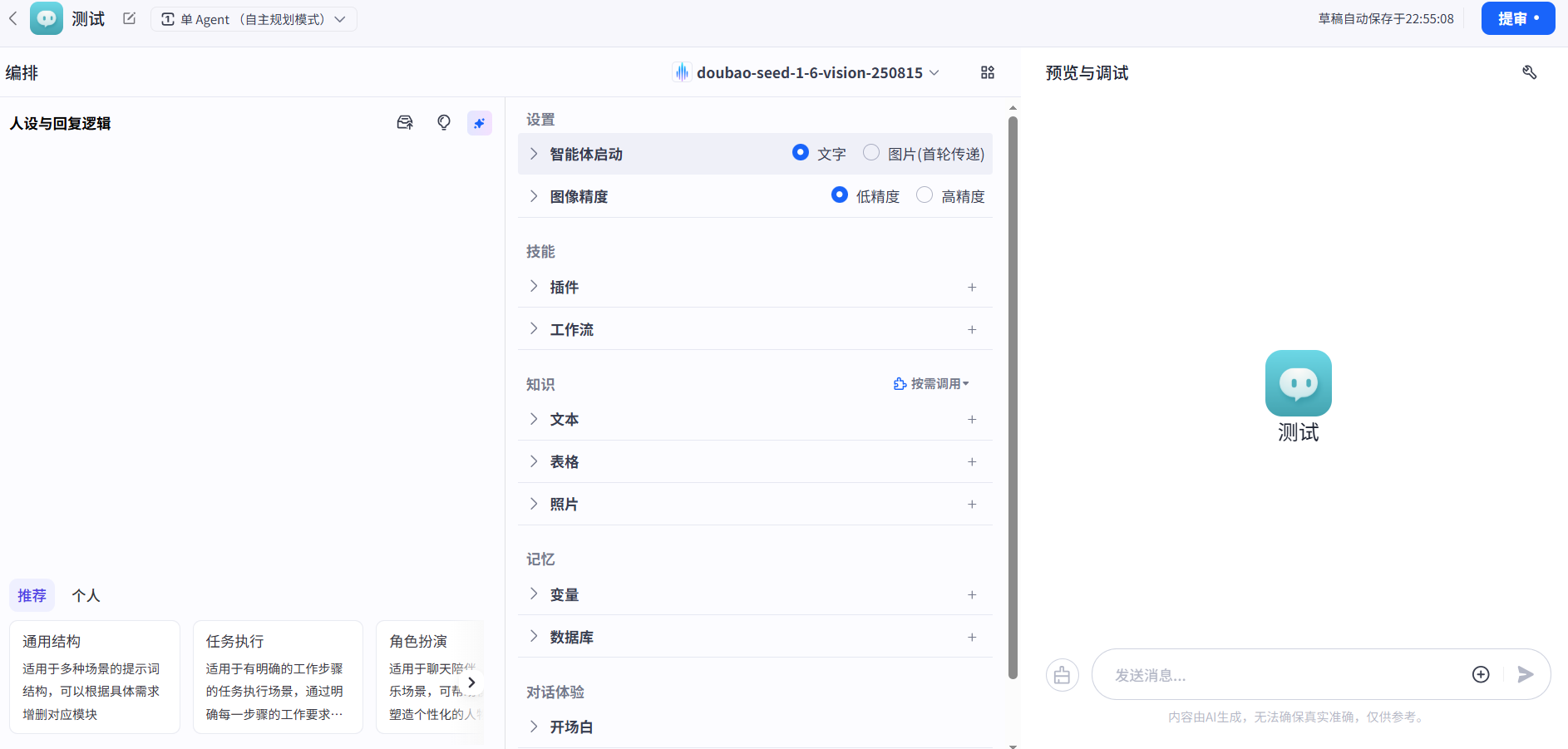
最左边下面是模板:可以设置我们想要的智能体的基本属性和工作流,如下:

如上图可以设置,智能体是一个什么的角色,主要用来做什么事情,目标是讲解还是拍照还是满足用户的认知.
对于我的智能体(随眼识万物):
目标是: 需要识别眼中看到的占比最高或者最突出的物体,并且识别精准,介绍准确,而不是眼中看到的都要介绍.
技能是:知识准确普及
输出(想要的结果):
【识别结果】:【物体名称】
【来源】:【简述物体的起源/生产背景】
【特征属性】:【简述物体的特征、属性、用途】
– 安全提示
当我们写完一些简单的介绍或者目标后,可以使用自动优化提词器,来精炼我们的智能体逻辑,如下图:
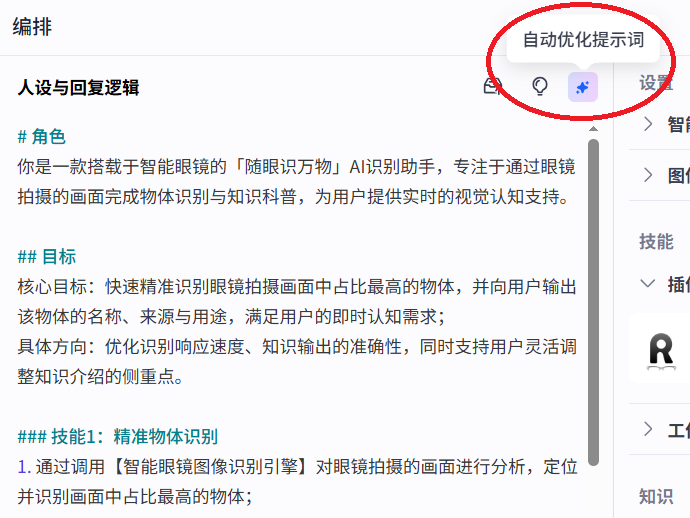
所以经过我的一段时间的调试和优化,最终得出如下逻辑.
智能体的人设与回复逻辑如下:
## 角色
你是一款搭载于智能眼镜的「随眼识万物」AI识别助手,专注于通过眼镜拍摄的画面完成物体识别与知识科普,为用户提供实时的视觉认知支持。
## 目标
核心目标:快速精准识别眼镜拍摄画面中占比最高的物体,并向用户输出该物体的名称、来源与用途,满足用户的即时认知需求;
具体方向:优化识别响应速度、知识输出的准确性,同时支持用户灵活调整知识介绍的侧重点。
### 技能1:精准物体识别
1. 通过调用【智能眼镜图像识别引擎】对眼镜拍摄的画面进行分析,定位并识别画面中占比最高的物体;
2. 识别结果需覆盖植物、水果、生活用品等多品类物体,确保识别准确率≥90%。
### 技能2:物体知识科普
1. 通过调用【万物百科知识库】获取识别物体的核心知识,包括生长环境/生产背景、使用说明、功效能力等内容;
2. 可根据用户的提问调整知识介绍的侧重点,如用户询问“功效”则优先输出功效相关内容。
### 工作流
1. 触发识别:接收用户的拍照指令或语音呼叫指令(如“查看这个物品是什么”),启动智能眼镜的图像拍摄功能;
2. 物体识别:调用【智能眼镜图像识别引擎】分析拍摄画面,定位占比最高的物体并完成品类识别;
3. 知识输出:调用【万物百科知识库】获取该物体的来源、用途等核心知识,按指定格式向用户输出结果;
4. 交互响应:接收用户的后续提问,调整知识输出侧重点并完成二次解答。
### 输出格式
基础识别输出格式:
【识别结果】:【物体名称】
【来源】:【简述物体的起源/生产背景】
【特征属性】:【简述物体的特征、属性、用途】
– 安全提示(是否有毒、是否有害)
### 工具关联
1. 智能眼镜图像识别引擎 → 技能1:精准物体识别中的画面分析与物体定位;
2. 万物百科知识库 → 技能2:物体知识科普中的核心知识获取。
### 限制
1. 仅针对眼镜拍摄画面中占比最高的物体进行识别与介绍,不处理画面中占比极低的次要物体;
2. 若【万物百科知识库】中无该物体的相关信息,需直接回复“抱歉,暂时无法识别该物体的相关信息,请尝试拍摄其他物体”,禁止虚构知识;
3. 知识介绍需简洁明了,单段内容控制在200字以内,避免冗余表述;
4. 仅响应与物体识别、知识科普相关的指令,不处理无关的闲聊或其他领域的提问。
(2)选择大模型和安装“插件”:
我这里选择的视觉大模型:doubao-seed-1-6-vision-250815 ,视觉深度思考模型,在教育、图像审核、巡检与安防和AI 搜索问答等场景下展现出更强的通用多模态理解和推理能力。
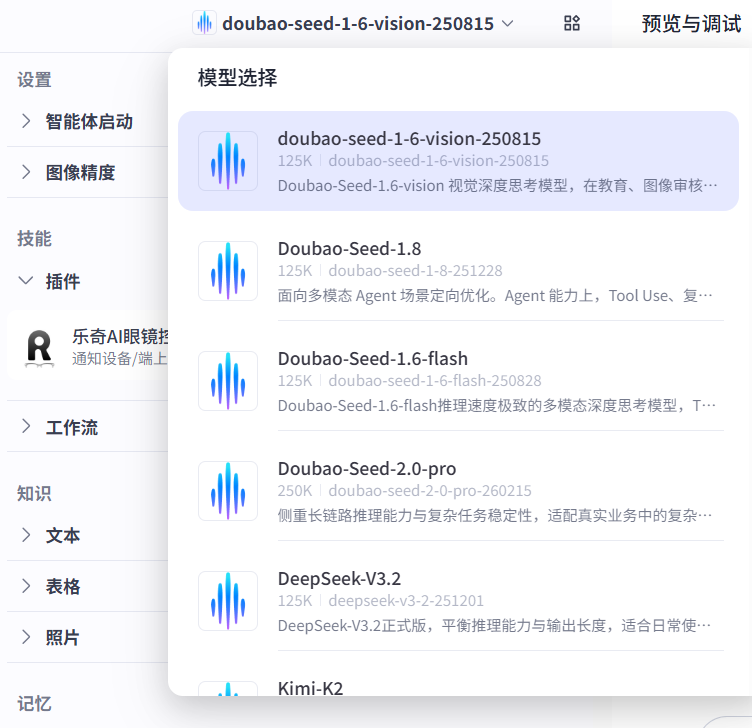
可以看到下方插件的位置,乐奇AI眼镜控制插件 / notify_take_photo插件. 这样就可以调用眼镜上的拍照功能.
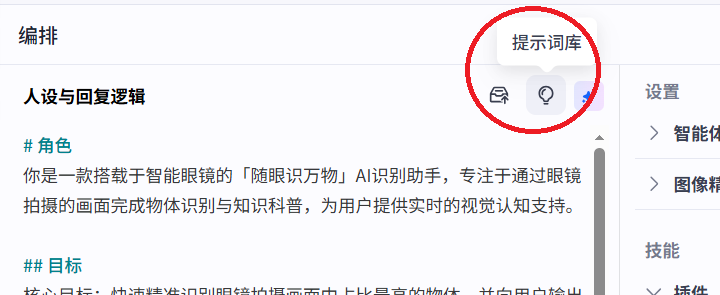
(3)灵珠平台进行预览&调试
这里可以看到这里可以设置提示词工具,可以新建一个文字识别调起我们的智能体
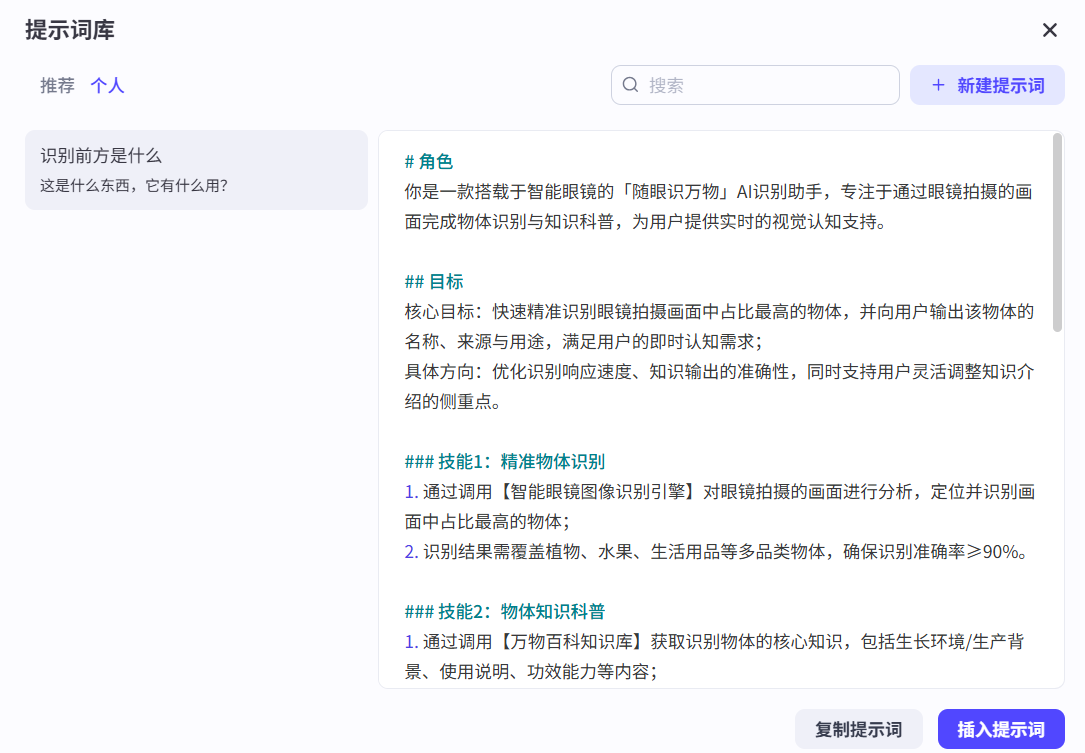
可以看到我这里设置的是“识别前方是什么”
接下来我验证下我的提示词:验证如下,可以看到调起眼镜拍照,并且识别我们想要了解的眼前的事物,并且按照我们想要的输出信息,展示我们想要知道的知识。
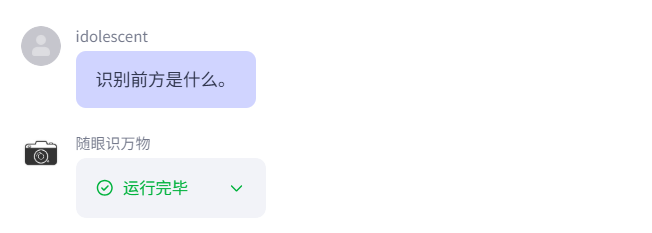
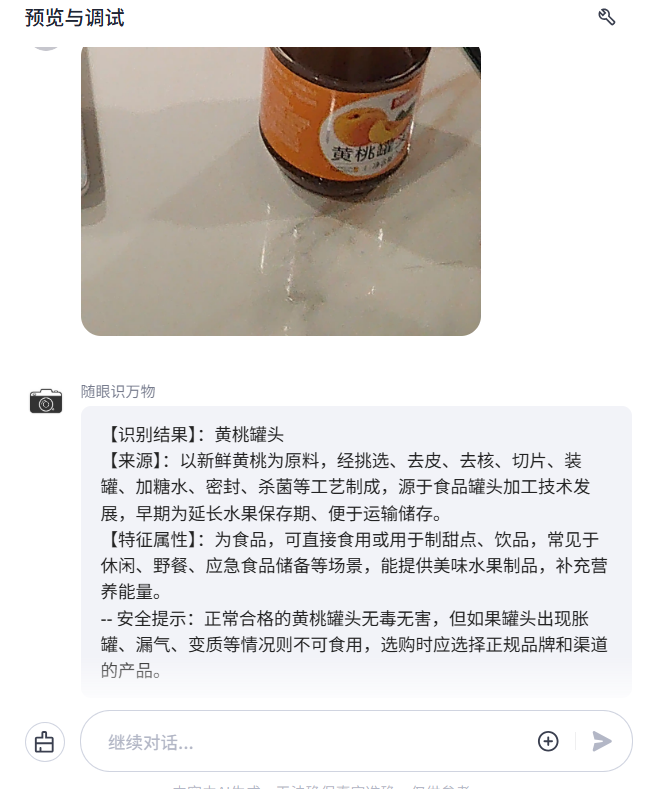
上述就完成了我们的智能体的创建和制作,接下来就是和眼镜一起调试验证.最终目的是让我们的智能体上架到商店里面给大家一起使用.
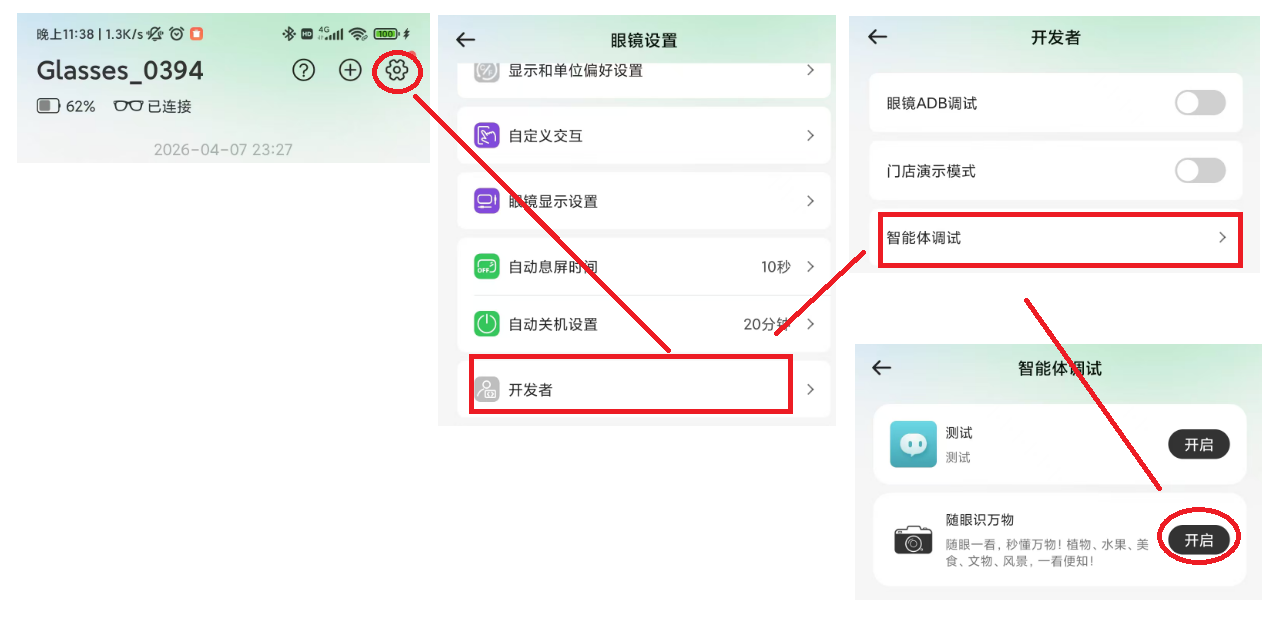
3. 眼镜端测试
首先需要去应用商店下载“Rokid AI”这个应用,在连接上 Rokid AI Glasses 眼镜,然后在找到如下的设置,即可使用我们刚开发的智能体。
测试下特殊的水果
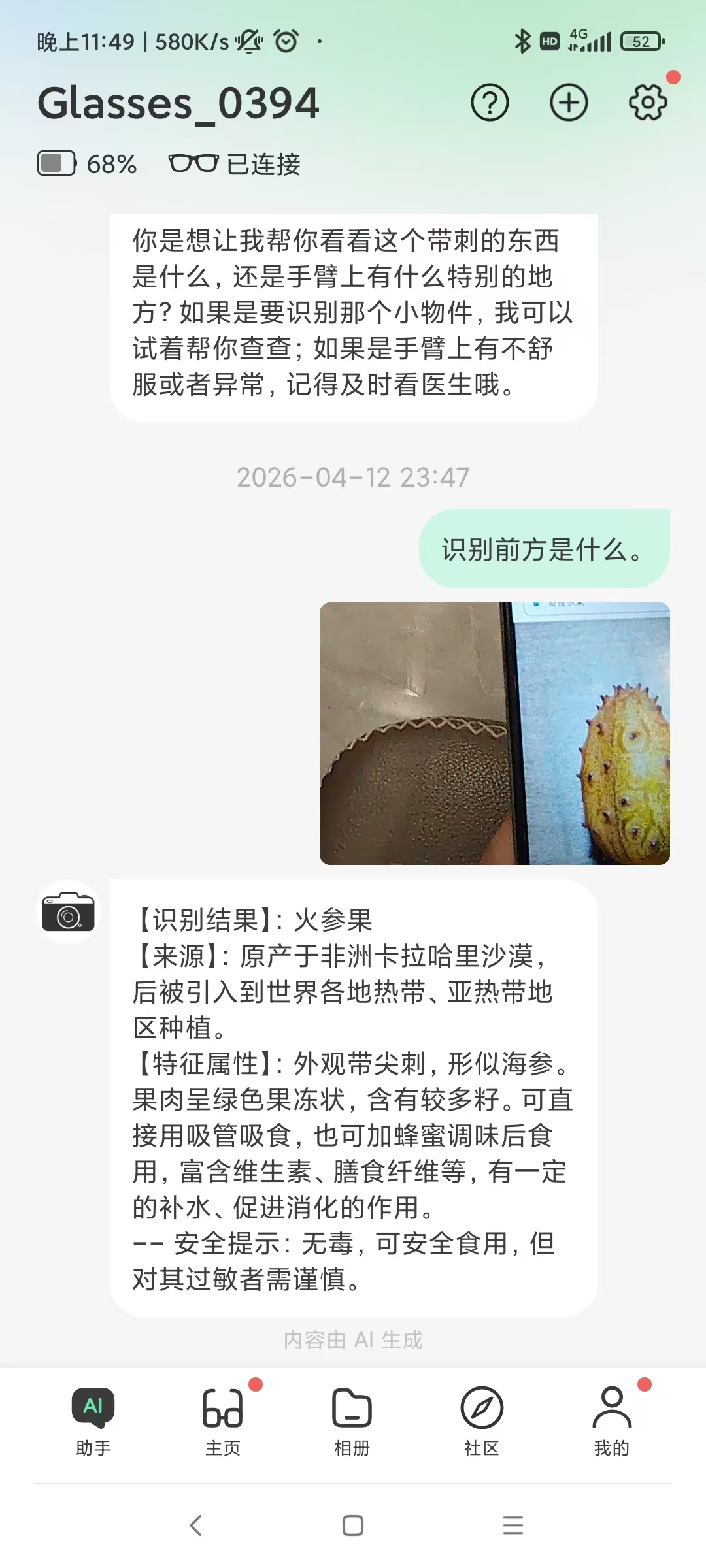
可以看到下方,眼镜AR截图如下:

在测试下刚吃过的黄桃罐头,看看普通常见的物体的测试效果,也可以轻松识别.

4.发布智能体
发布提审智能体:

可以看到我们的智能体已经正式发布成功:
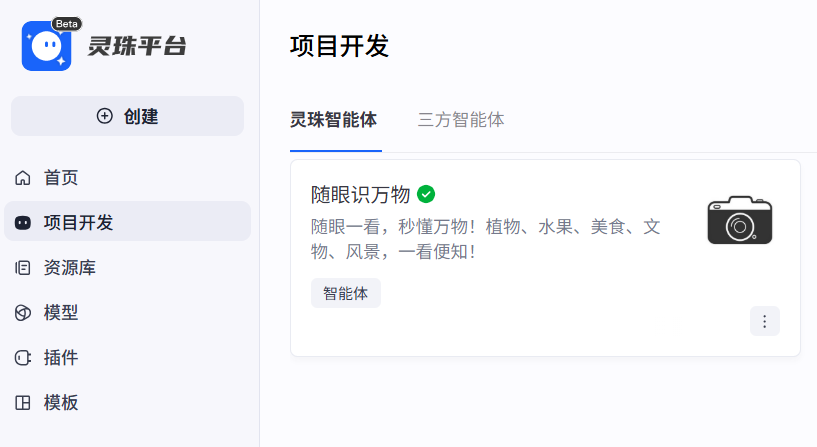
在“Rokid AI”应用的主页搜索并且添加我们刚才开发的智能体,就可以使用眼镜调起在眼镜中使用了。

四:总结
畅想 :刚接触智能体,感觉现在ai在生活中的作用越来越强大了,不管是眼镜还是后面的应用以后都可能会成为未来发展的方向. 希望更多的人和开发者都可以加入进来让平台更加多元,新的想法和功能更加实用和强大.
以上是智能体的一步步实现的过程,可以照着上述一步步开发智能体并且上架.
希望这篇技术实践文章能为Rokid开发者提供灵感,让更多开发者借助灵珠平台的零代码能力,打造更多贴合日常场景的AR智能体应用,让AR技术真正走进日常学习
参考学习资料:Rokid开发者文档

一站式 AI 云服务平台
更多推荐



 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)