
2026山东大学软件学院项目实训(三)——AI应用生成
基于 LangChain4j 接入 DeepSeek 大模型,实现了AI 原生网页代码生成、结构化解析、本地保存与 SSE 流式输出,并通过多种设计模式重构代码,打造高可用、易扩展的 AI 零代码应用生成平台核心能力。
目录
团队信息
-
组号:69组
-
项目名称:AI零代码应用生成平台
-
负责人:樊伟彤
-
小组成员:者亚杰、蒋宇轩、张旭、李重昊
-
本期模块:AI应用生成核心模块
本期核心任务
聚焦AI零代码应用生成平台的核心能力——AI自动生成网页应用:
-
基于LangChain4j框架完成DeepSeek大模型接入,实现AI对话与代码生成能力
-
支持单HTML文件/HTML+CSS+JS多文件两种原生代码生成模式
-
实现AI输出结构化解析,完成代码文件本地持久化存储
-
通过SSE实现流式输出,优化用户等待体验
-
运用门面模式、策略模式、模板方法模式、执行器模式重构代码,提升架构可扩展性
模块一:需求分析与方案设计
1.1 核心功能拆解
AI 应用生成模块作为平台的核心功能,需要满足以下业务需求:
-
多生成模式:暂不引入 Vue、React 等前端框架,专注实现原生前端代码生成,先实现两种标准化生成模式,覆盖不同开发需求:
-
单文件模式:将 HTML、CSS、JS 整合到一个文件中,适合快速原型与简易页面开发;
-
多文件模式:按前端工程规范分离
index.html、style.css、script.js,适合标准项目开发。
-
-
代码自动保存:AI 生成的前端代码可自动写入本地文件系统,文件结构规范,双击即可直接运行使用。
-
流式响应:支持 AI 流式输出,逐段返回生成内容,大幅降低用户等待时间,提升使用体验。
-
可扩展架构:整体设计具备良好的扩展性,支持后续快速接入 Vue等框架生成能力,同时兼容模板生成、自定义生成等扩展功能。
1.2 业务流程设计
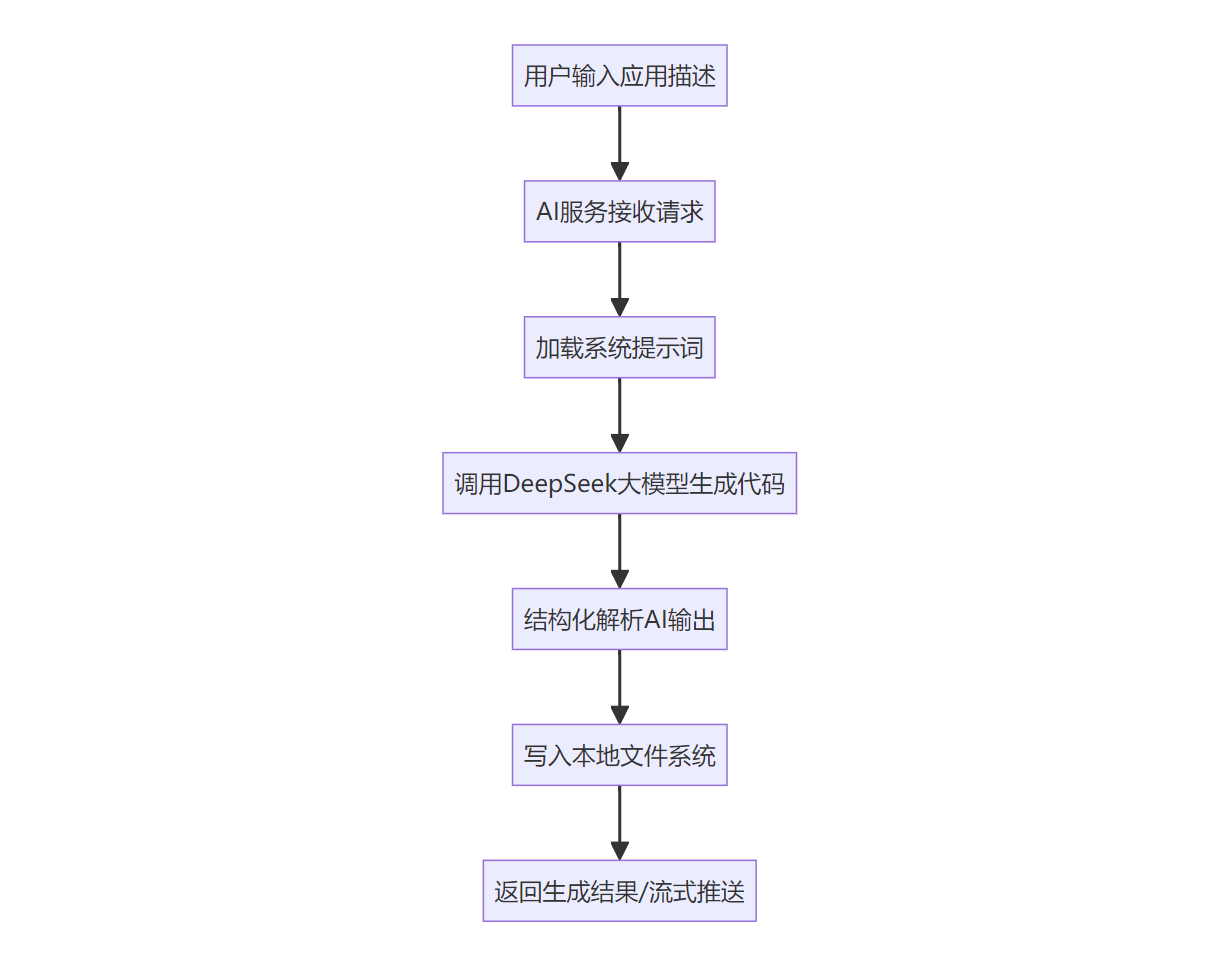
1.3 提示词工程设计
提示词是AI生成质量的核心,为此,我们设计两套系统提示词:
(1)单HTML文件生成提示词
你是一位资深的Web前端开发专家,精通HTML、CSS和原生JavaScript。你擅长构建响应式、美观且代码整洁的单页面网站。
你的任务是根据用户提供的网站描述,生成一个完整、独立的单页面网站。你需要一步步思考,并最终将所有代码整合到一个HTML文件中。
约束:
1.技术:只能使用HTML、CSS和原生JavaScript。
2.禁止外部依赖:绝对不允许使用任何外部CSS框架、JS库或字体库。所有功能必须用原生代码实现。
3.独立文件:必须将所有CSS放在head标签的style标签内,并将所有JavaScript放在</body>标签之前的script标签内,最终只输出一个html文件,不含任何外部文件引用。
4.响应式设计:网站必须是响应式的,能够在桌面和移动设备上良好显示。请优先使用Flexbox或Grid进行布局。
5.内容填充:如果用户描述中缺少具体文本或图片,请使用有意义的占位符。图片使用https://picsum.photos服务。
6.代码质量:代码结构清晰、带注释、易于维护。
7.交互性:用户描述交互功能时,用原生JS实现。
8.安全性:纯客户端代码,无服务端逻辑。
输出格式:仅返回HTML代码块。(2)多文件生成提示词
你是一位资深的Web前端开发专家,精通结构化HTML、清晰CSS和高效原生JS,遵循代码分离最佳实践。
你的任务是根据用户描述,生成index.html、style.css、script.js三个文件,构成完整单页网站。
约束:
1.技术:纯HTML+CSS+原生JS,无外部依赖。
2.文件分离:html负责结构、css负责样式、js负责交互。
3.响应式设计:使用Flexbox/Grid适配多设备。
4.占位符填充:缺失内容用Lorem Ipsum文本、picsum图片填充。
5.输出格式:分三个代码块,标注对应文件名。1.4 技术选型对比
(1)大模型选型
| 模型 | 代码生成能力 | API兼容性 | 响应速度 | 成本 | 选型结果 |
|---|---|---|---|---|---|
| 通义千问 | 良好 | 阿里云专属 | 较快 | 中等 | 备选 |
| DeepSeek R1 | 优秀 | 兼容OpenAI | 快 | 低 | 主选 |
| GPT-3.5 | 优秀 | 官方API | 快 | 高 | 备选 |
(2)AI框架选型
| 框架 | 生态 | Spring集成 | 独立性 | 学习成本 | 选型结果 |
|---|---|---|---|---|---|
| Spring AI | 完善 | 原生支持 | 弱 | 较高 | 备选 |
| LangChain4j | 完善 | 友好 | 强 | 低 | 主选 |
模块二:环境搭建与LangChain4j集成
2.1 Maven依赖引入
在pom.xml中引入核心依赖:
<!-- LangChain4j 核心依赖 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>1.1.0</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai-spring-boot-starter</artifactId>
<version>1.1.0-beta7</version>
</dependency>2.2 配置文件编写
主配置application.yml激活本地环境:
spring:
profiles:
active: local2.3 敏感配置隔离
创建application-local.yml(加入.gitignore),配置大模型密钥:
# AI
langchain4j:
open-ai:
chat-model:
base-url: https://api.deepseek.com
api-key: <API Key>
model-name: deepseek-chat
log-requests: true
log-responses: true模块三:AI代码生成核心功能实现
3.1 AI服务接口定义
创建AiCodeGeneratorService接口,通过@SystemMessage绑定提示词:
//AI服务接口(实际开发代码)
public interface AiCodeGeneratorService {
/**
* 生成单HTML文件代码
*/
@SystemMessage(fromResource = "prompt/codegen-html-system-prompt.txt")
HtmlCodeResult generateHtmlCode(String userMessage);
/**
* 生成多文件代码(HTML+CSS+JS)
*/
@SystemMessage(fromResource = "prompt/codegen-multi-file-system-prompt.txt")
MultiFileCodeResult generateMultiFileCode(String userMessage);
}3.2 AI服务工厂类开发
通过配置类初始化AI服务,注入ChatModel:
//AI代码生成服务工厂 (实际开发代码)
@Configuration
public class AiCodeGeneratorServiceFactory {
@Resource
private ChatModel chatModel;
@Resource
private StreamingChatModel streamingChatModel;
@Bean
public AiCodeGeneratorService aiCodeGeneratorService() {
return AiServices.builder(AiCodeGeneratorService.class)
.chatModel(chatModel)
.streamingChatModel(streamingChatModel)
.build();
}
}3.3 结构化输出实体类设计
虽然目前已经可以正常调用 AI 生成前端代码,但模型直接返回原始字符串的形式,在后续提取代码、保存文件、异常处理等环节会非常不便,也容易出现解析错误。
因此,我们决定对 AI 输出进行结构化改造,借助 LangChain4j 提供的结构化输出能力,让模型直接返回固定格式的数据,而非自由文本,大幅提升程序处理的稳定性与可读性。
具体实现方式为:创建专用实体类,统一封装 AI 返回的所有内容,包括 HTML、CSS、JavaScript 代码、文件名、生成状态等信息,从根源避免字符串截取、正则匹配带来的混乱与异常:
/**
* 单HTML文件生成结果
*/
@Data
@Description("HTML代码生成结果")
public class HtmlCodeResult {
@Description("完整HTML代码")
private String htmlCode;
@Description("生成描述")
private String description;
}
/**
* 多文件生成结果
*/
@Data
@Description("多文件代码生成结果")
public class MultiFileCodeResult {
@Description("HTML代码")
private String htmlCode;
@Description("CSS代码")
private String cssCode;
@Description("JS代码")
private String jsCode;
@Description("生成描述")
private String description;
}3.4 结构化输出优化方案
经过一系列研究与实践验证,我们总结出 3 个关键优化技巧,能够显著提升 AI 结构化输出的准确性与稳定性,确保生成结果不报错、不截断、格式统一。
1.合理设置 max-tokens 输出长度:
参考 DeepSeek 官方建议,我们将输出长度调整为 8192,有效避免因内容过长导致 JSON 被中途截断,保证生成结果完整可用:

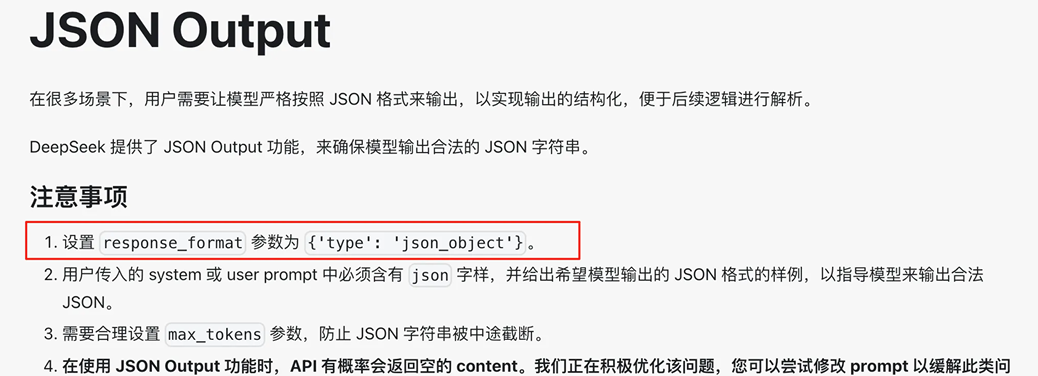
2.开启json_object结构化模式:
OpenAI 相关文档提到了 response_format_json_schema 配置,可以严格确保结构化输出生效:

但经过测试发现,DeepSeek 不支持这种配置,项目中使用会报错。不过官方文档提到了另外一种配置,设置 response-format 参数为 json_object。
3.使用 @Description 增加字段描述:
参考 LangChain4j 最佳实践,在实体类与字段上添加清晰的中文说明,帮助 AI 更精准理解输出要求,大幅降低格式错误率。
// 以HTML为例
@Description("生成 HTML 代码文件的结果")
@Data
public class HtmlCodeResult {
@Description("HTML代码")
private String htmlCode;
@Description("生成代码的描述")
private String description;
}模块四:代码文件持久化与设计模式重构
有了稳定的结构化输出对象,下一步便是将 AI 生成的代码安全、规范地保存到本地文件系统,确保文件结构统一、路径唯一、易于管理。
4.1 生成类型枚举定义
为统一管理两种生成模式,避免代码中出现硬编码,创建对应的枚举类,用于标识单文件 / 多文件生成类型:
//文件类型(实际开发代码)
@Getter
public enum CodeGenTypeEnum {
HTML("原生HTML模式", "html"),
MULTI_FILE("原生多文件模式", "multi_file");
private final String text;
private final String value;
CodeGenTypeEnum(String text, String value) {
this.text = text;
this.value = value;
}
/**
* 根据value获取枚举
*/
public static CodeGenTypeEnum getEnumByValue(String value) {
if (ObjUtil.isEmpty(value)) {
return null;
}
for (CodeGenTypeEnum anEnum : CodeGenTypeEnum.values()) {
if (anEnum.value.equals(value)) {
return anEnum;
}
}
return null;
}
}4.2 文件保存工具类开发
我们选择在系统临时目录 tmp 下统一存放生成结果,每次生成任务对应独立文件夹,避免文件覆盖。
目录命名采用 业务类型 + 雪花 ID 的方式,保证全局唯一。
项目中使用 Hutool 工具库快速实现雪花 ID 生成、目录创建与文件写入,简化文件操作逻辑:
//代码文件保存工具 (实际开发代码)
public class CodeFileSaver {
// 文件保存根目录
private static final String FILE_SAVE_ROOT_DIR = System.getProperty("user.dir") + "/tmp/code_output";
/**
* 保存单HTML文件
*/
public static File saveHtmlCodeResult(HtmlCodeResult result) {
String baseDirPath = buildUniqueDir(CodeGenTypeEnum.HTML.getValue());
writeToFile(baseDirPath, "index.html", result.getHtmlCode());
return new File(baseDirPath);
}
/**
* 保存多文件
*/
public static File saveMultiFileCodeResult(MultiFileCodeResult result) {
String baseDirPath = buildUniqueDir(CodeGenTypeEnum.MULTI_FILE.getValue());
writeToFile(baseDirPath, "index.html", result.getHtmlCode());
writeToFile(baseDirPath, "style.css", result.getCssCode());
writeToFile(baseDirPath, "script.js", result.getJsCode());
return new File(baseDirPath);
}
/**
* 构建唯一目录(业务类型+雪花ID)
*/
private static String buildUniqueDir(String bizType) {
String uniqueDirName = StrUtil.format("{}_{}", bizType, IdUtil.getSnowflakeNextIdStr());
String dirPath = FILE_SAVE_ROOT_DIR + File.separator + uniqueDirName;
FileUtil.mkdir(dirPath);
return dirPath;
}
/**
* 写入文件
*/
private static void writeToFile(String dirPath, String filename, String content) {
String filePath = dirPath + File.separator + filename;
FileUtil.writeString(content, filePath, StandardCharsets.UTF_8);
}
}4.3 门面模式统一业务入口
为简化业务调用、屏蔽底层复杂逻辑,我们采用门面模式对生成与保存流程进行统一封装。
门面模式提供一个统一的高层接口,将代码生成、结构化解析、文件保存等子流程全部隐藏在内,外部调用时只需通过简单接口即可完成完整功能,大幅降低代码耦合度,便于后续扩展与维护。
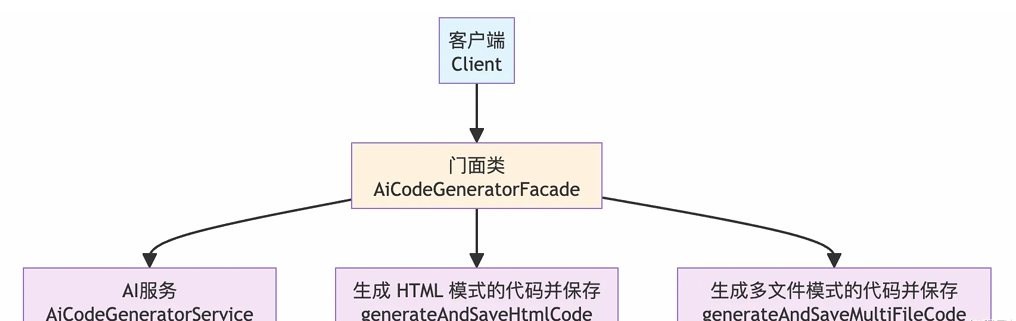
通过AiCodeGeneratorFacade封装生成+保存逻辑,简化调用:
//门面类(实际开发代码)
@Service
public class AiCodeGeneratorFacade {
@Resource
private AiCodeGeneratorService aiCodeGeneratorService;
/**
* 统一生成并保存代码
*/
public File generateAndSaveCode(String userMessage, CodeGenTypeEnum codeGenTypeEnum) {
if (codeGenTypeEnum == null) {
throw new BusinessException(ErrorCode.SYSTEM_ERROR, "生成类型不能为空");
}
return switch (codeGenTypeEnum) {
case HTML -> {
HtmlCodeResult result = aiCodeGeneratorService.generateHtmlCode(userMessage);
yield CodeFileSaver.saveHtmlCodeResult(result);
}
case MULTI_FILE -> {
MultiFileCodeResult result = aiCodeGeneratorService.generateMultiFileCode(userMessage);
yield CodeFileSaver.saveMultiFileCodeResult(result);
}
default -> throw new BusinessException(ErrorCode.SYSTEM_ERROR, "不支持的生成类型");
};
}
}模块五:SSE流式输出提升用户体验
到这一步,基础的代码生成功能已经可以稳定运行。但在实际体验中,我们发现结构化输出的响应速度较慢,用户需要等待较长时间才能拿到完整结果,交互体验不够友好。
为了显著提升用户体验,我决定引入 SSE(Server-Sent Events)流式输出 技术。通过流式返回,前端可以像 “打字机” 一样,实时展示 AI 生成的内容,返回一段展示一段,大幅减少用户等待感,让整个生成过程更流畅、更直观。
5.1 流式输出方案选型
| 方案 | 优点 | 缺点 | 选型 |
|---|---|---|---|
| LangChain4j+Reactor | 前端集成简单、Flux数据流、易用 | 需引入额外依赖 | 主选 |
| TokenStream原生 | 回调丰富 | 复杂度高、需二次封装 | 备选 |
5.2 流式模型配置
在application-local.yml中添加streaming-chat-model配置(见2.3节)
5.3 流式AI接口开发
在AI服务接口新增流式方法,返回Flux<String>:
/**
* 流式生成单HTML代码
*/
@SystemMessage(fromResource = "prompt/codegen-html-system-prompt.txt")
Flux<String> generateHtmlCodeStream(String userMessage);
/**
* 流式生成多文件代码
*/
@SystemMessage(fromResource = "prompt/codegen-multi-file-system-prompt.txt")
Flux<String> generateMultiFileCodeStream(String userMessage);5.4 代码解析器实现
通过正则提取代码块,适配流式完整内容:
/**
* 代码解析器
*/
public class CodeParser {
private static final Pattern HTML_CODE_PATTERN = Pattern.compile("```html\\s*\n([\\s\\S]*?)```", Pattern.CASE_INSENSITIVE);
private static final Pattern CSS_CODE_PATTERN = Pattern.compile("```css\\s*\n([\\s\\S]*?)```", Pattern.CASE_INSENSITIVE);
private static final Pattern JS_CODE_PATTERN = Pattern.compile("```(?:js|javascript)\\s*\n([\\s\\S]*?)```", Pattern.CASE_INSENSITIVE);
/**
* 解析单HTML代码
*/
public static HtmlCodeResult parseHtmlCode(String codeContent) {
HtmlCodeResult result = new HtmlCodeResult();
Matcher matcher = HTML_CODE_PATTERN.matcher(codeContent);
if (matcher.find()) {
result.setHtmlCode(matcher.group(1).trim());
} else {
result.setHtmlCode(codeContent.trim());
}
return result;
}
/**
* 解析多文件代码
*/
public static MultiFileCodeResult parseMultiFileCode(String codeContent) {
MultiFileCodeResult result = new MultiFileCodeResult();
// 提取HTML/CSS/JS代码
Matcher htmlMatcher = HTML_CODE_PATTERN.matcher(codeContent);
Matcher cssMatcher = CSS_CODE_PATTERN.matcher(codeContent);
Matcher jsMatcher = JS_CODE_PATTERN.matcher(codeContent);
if (htmlMatcher.find()) result.setHtmlCode(htmlMatcher.group(1).trim());
if (cssMatcher.find()) result.setCssCode(cssMatcher.group(1).trim());
if (jsMatcher.find()) result.setJsCode(jsMatcher.group(1).trim());
return result;
}
}5.5 流式处理逻辑封装
实时收集代码片段,完成后统一保存:
/**
* 通用流式处理
*/
private Flux<String> processCodeStream(Flux<String> codeStream, CodeGenTypeEnum codeGenType) {
StringBuilder codeBuilder = new StringBuilder();
return codeStream
.doOnNext(chunk -> {
// 实时拼接代码片段
codeBuilder.append(chunk);
})
.doOnComplete(() -> {
try {
String completeCode = codeBuilder.toString();
// 解析代码
Object parsedResult = CodeParserExecutor.executeParser(completeCode, codeGenType);
// 保存文件
File savedDir = CodeFileSaverExecutor.executeSaver(parsedResult, codeGenType);
log.info("代码保存成功,路径:{}", savedDir.getAbsolutePath());
} catch (Exception e) {
log.error("代码保存失败", e);
}
});
}模块六:代码架构优化 — 极致抽象
在基础功能实现稳定后,我们发现解析、文件保存、流式输出等逻辑存在大量重复代码,不利于长期维护与扩展。
为此,我们打算通过设计模式对代码进行统一抽象与重构。
6.1 优化目标
-
消除重复代码,统一核心流程
-
提升代码可读性、可维护性、可扩展性
-
支持后续快速新增生成模式
-
屏蔽内部复杂逻辑,对外提供统一调用入口
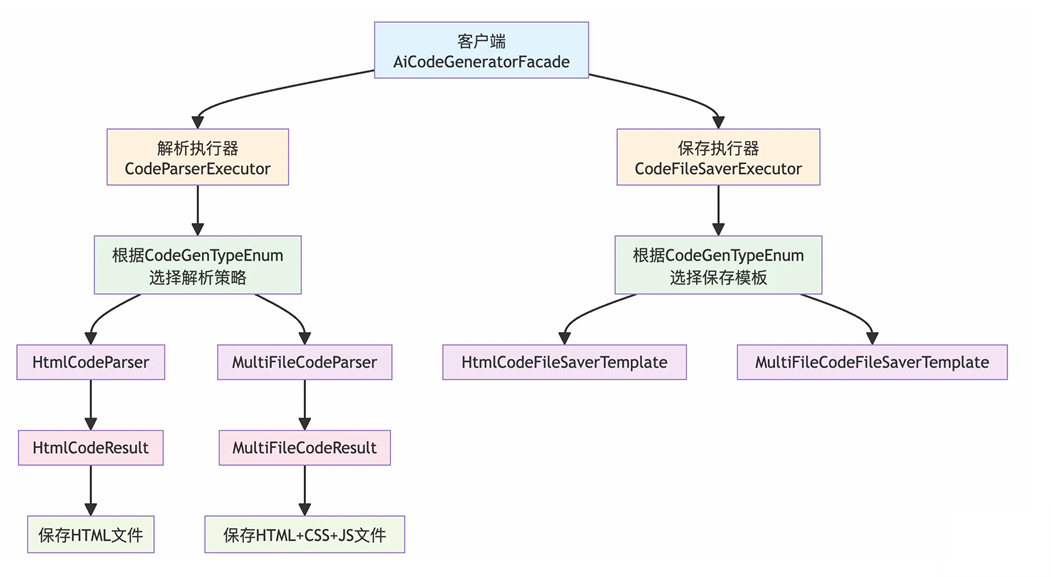
6.2 优化方案
我们采用策略模式 + 模板方法模式 + 执行器模式的混合设计模式,完成整体架构升级:
-
策略模式:将不同生成模式的解析逻辑封装为独立策略,保证解析算法可扩展、可替换,不影响上层业务。
-
模板方法模式:在抽象类中定义统一的文件保存流程,子类只需实现差异化逻辑(如单文件 / 多文件存储)。
-
执行器模式:提供统一的业务执行入口,自动匹配对应的策略与模板方法,解决不同模式无法统一调度的问题。
开发总结
本次我们开发完成了AI零代码应用生成平台 AI 生成核心模块的开发,整体收获如下:
-
技术落地:掌握LangChain4j集成大模型、结构化输出、SSE流式输出核等核心技术,完成 AI 生成能力从 0 到 1 落地。
-
工程化能力:完成配置隔离、单元测试、异常处理、代码封装等工程实践。
-
问题解决:成功解决 AI 输出解析不稳定、接口超时、文件路径错误、依赖冲突等实际开发问题,积累了真实排错经验。
后续计划
-
前后端联调:开发前端交互页面,对接AI生成接口,实现可视化操作、在线预览与一键下载。
-
能力扩展:逐步支持 Vue等更多类型的代码生成,丰富平台生成场景。
-
用户打通:对接用户模块,实现生成记录、个人中心、权限管控,完善平台整体业务闭环。

一站式 AI 云服务平台
更多推荐
 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)