
KMP算法
目录
1.由来
1.1暴力匹配算法
(又称朴素字符串匹配算法)是最基础的字符串匹配方法。它的核心思想是逐一比较主串中的字符和子串中的字符,直到找到匹配或者遍历完成。
我们来举一个例子:
主串:"ababcabcacbab" 子串:"abcac"
暴力匹配过程:
从主串的第一个字符开始,逐字符比较:
主串第1到第5个字符是 "ababc",与子串 "abcac" 比较:第1个字符 'a' 匹配 'a'
第2个字符 'b' 匹配 'b'
第3个字符 'a' 不匹配 'c'
发生不匹配,移动主串的起始位置,继续比较。
从主串的第二个字符开始,比较:
主串第2到第6个字符是 "babca",与子串 "abcac" 比较:第1个字符 'b' 不匹配 'a'
发生不匹配,继续向后移动。
从主串的第三个字符开始,比较:
主串第3到第7个字符是 "abcab",与子串 "abcac" 比较:第1个字符 'a' 匹配 'a'
第2个字符 'b' 匹配 'b'
第3个字符 'c' 匹配 'c'
第4个字符 'a' 匹配 'a'
第5个字符 'b' 不匹配 'c'
发生不匹配,继续向后移动。
从主串的第四个字符开始,比较:
主串第4到第8个字符是 "bcabc",与子串 "abcac" 比较:第1个字符 'b' 不匹配 'a'
发生不匹配,继续向后移动。
从主串的第五个字符开始,比较:
主串第5到第9个字符是 "cabca",与子串 "abcac" 比较:第1个字符 'c' 不匹配 'a'
发生不匹配,继续向后移动。
从主串的第六个字符开始,比较:
主串第6到第10个字符是 "abcac",与子串 "abcac" 完全匹配!
此时找到匹配位置,暴力匹配算法在主串的第6个字符处找到了子串 "abcac"。整个过程就是依次比较每个字符,当不匹配时就从下一个字符开始重新比较。
像上述的暴力匹配的时间复杂度就是O(n*m),为了将时间复杂度降为线性的,KMP算法应运而生。
1.2KMP
KMP算法之所以被称为“KMP算法”,是源自其三位发明者的姓氏首字母缩写:
- Knuth(唐纳德·克努斯)
- Morris(詹姆斯·H·莫里斯)
- Pratt(沃恩·普拉特)
这三位计算机科学家在1977年共同发表了这项算法,用于高效地在文本中查找子字符串。KMP算法通过预处理模式串,构建部分匹配表(也称为“失配表”),从而在搜索过程中避免了不必要的重复比较,大大提高了匹配的效率。
总结来说,KMP算法的名称直接来源于其创始人的姓氏首字母,体现了他们对这一经典字符串匹配算法的贡献。
2.术语
在KMP算法中,有几个重要的术语,理解这些术语有助于更好地掌握算法的工作原理:
-
主串(Text):要在其中查找子串的字符串,通常用“T”表示。
-
子串(Pattern):要查找的目标字符串,通常用“P”表示。
-
部分匹配表(Partial Match Table)或失配表(Failure Function):一个数组,存储了子串的每个前缀的最长相等前后缀的长度。这个表用于在匹配失败时,决定子串在主串中应该向右移动多少位。
-
前缀(Prefix):字符串的开头部分。例如,对于字符串“abc”,其前缀包括“a”、“ab”【不包括本身】。
-
后缀(Suffix):字符串的结尾部分。例如,对于字符串“abc”,其后缀包括“c”、“bc”【不包括本身】。
-
最长相等前后缀(Longest Prefix Suffix, LPS):在部分匹配表中,某个位置的值表示该位置的前缀和后缀中最长的相等部分的长度。例如,对于子串“abab”,最长相等前后缀是“ab”,其长度为2。
-
匹配过程:KMP算法通过使用部分匹配表来优化字符比较。当发生不匹配时,算法不会回溯主串,而是根据部分匹配表的值,调整子串的位置,继续进行比较。
-
时间复杂度:KMP算法的时间复杂度是O(n + m),其中n是主串的长度,m是子串的长度。这是因为部分匹配表的构建和匹配过程都只需线性扫描。
了解这些术语有助于深入理解KMP算法的原理和实现过程。
3.核心思想
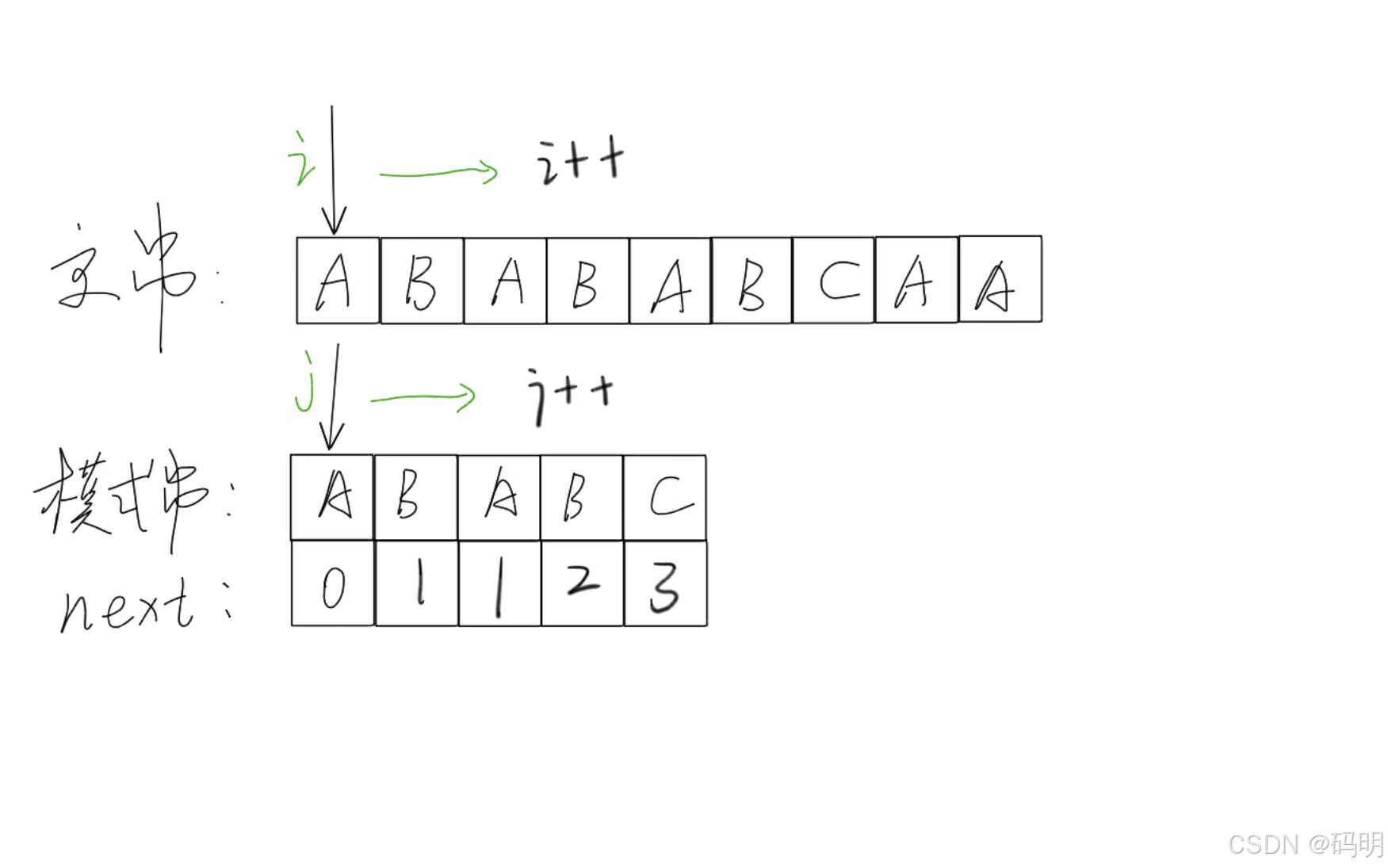
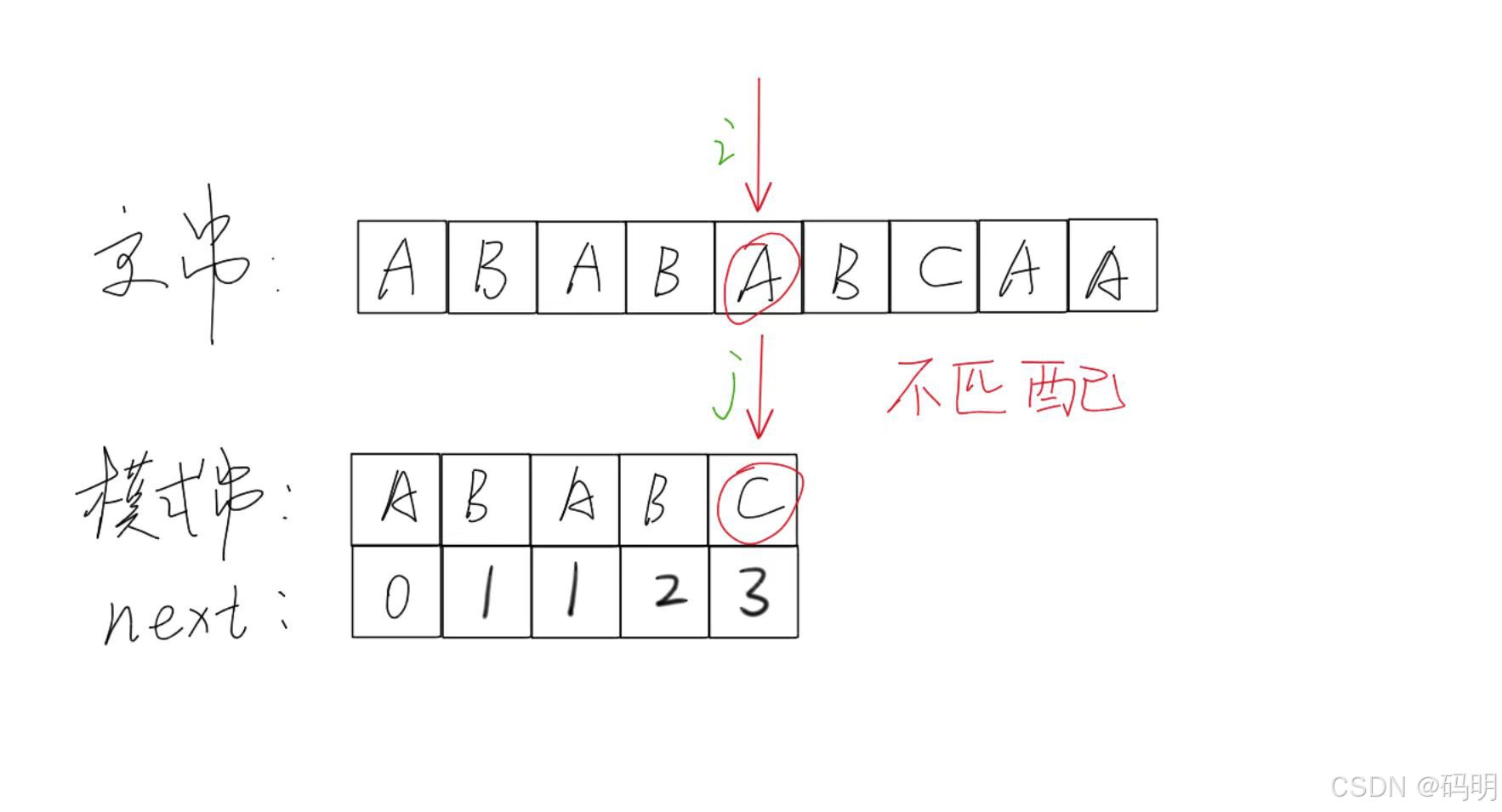
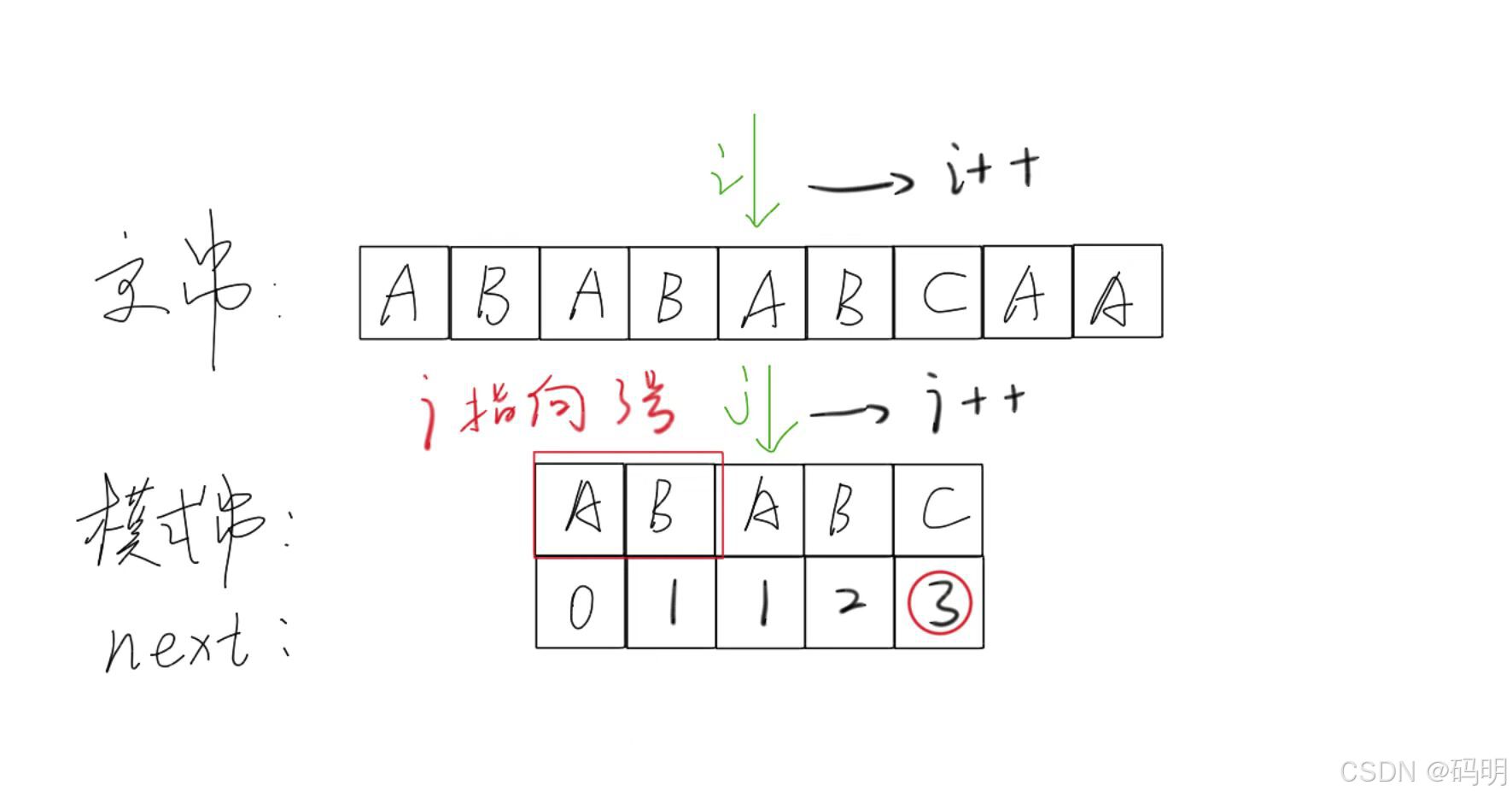
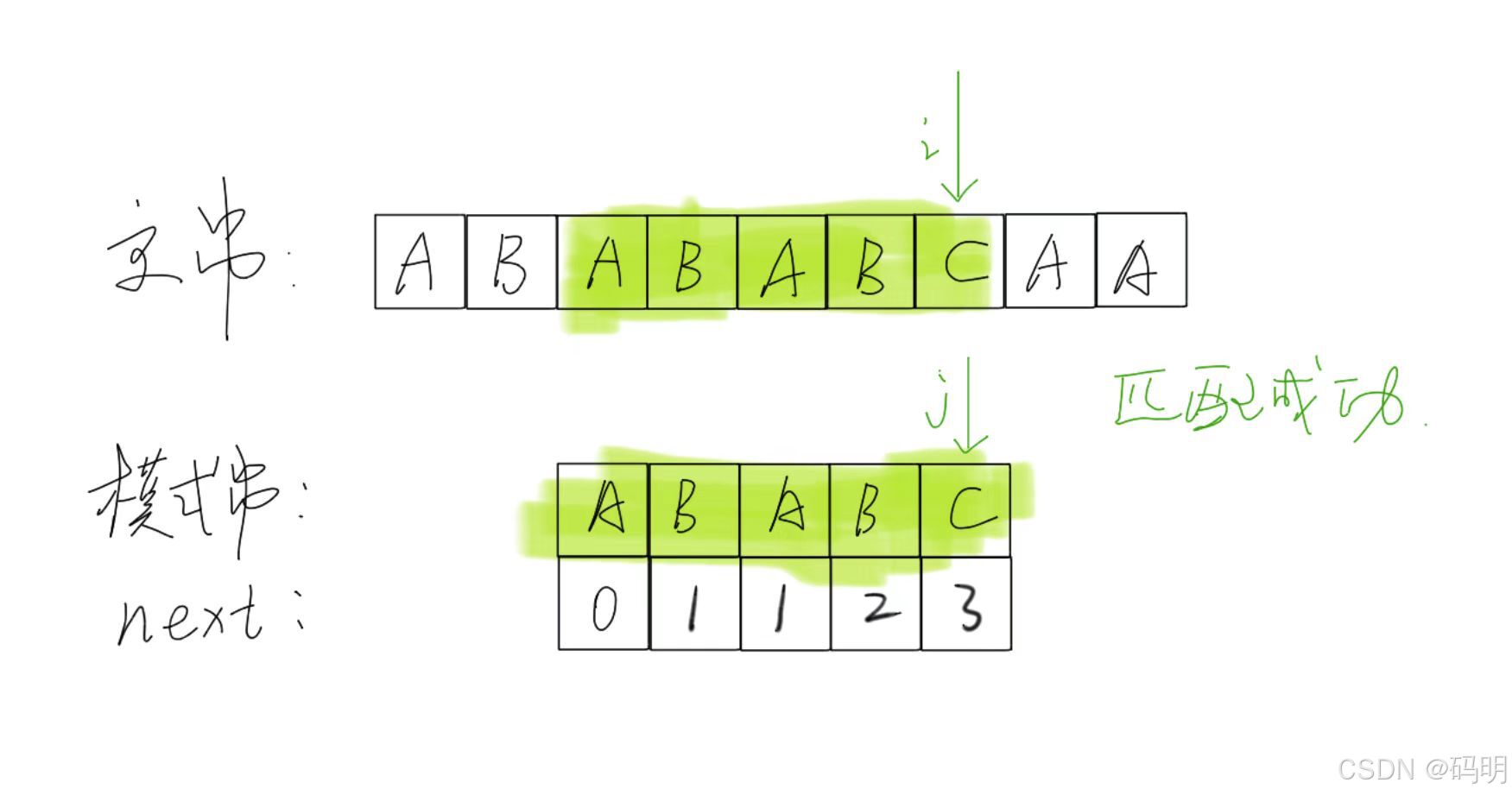
KMP算法由算法主体加上NEXT[ ]数组的构建组成。
核心思想是:用已经掌握的信息来规避重复的运算;
主串指针永远不回溯;
指针i指向主串S;
指针j指向模式串T。
当匹配过程产生失配时,指针i不变,指针j退回到 next[j]的位置并重新进行比较,并且当指针j为0时,指针i和j同时加1。即若主串的第i个位置和模式串的第1个字符不等,则应从主串的第 1+1个位置开始匹配。
建立NEXT[ ]数组也就是寻找模式串中相同前后缀的长度。
4.算法主体
int kmp_search(char *string, char *pattern) {
int n = strlen(string);
int m = strlen(pattern);
int next[m];
build_next(pattern, next);
int i = 0, j = 0;
while (i < n) {
if (string[i] == pattern[j]) {
i++;
j++;
}
if (j == m) {
return i - j; // 返回匹配的位置
} else if (i < n && string[i] != pattern[j]) {
if (j != 0) {
j = next[j - 1];
} else {
i++;
}
}
}
return -1; // 未找到匹配
}5.NEXT[ ]的构建
图示:
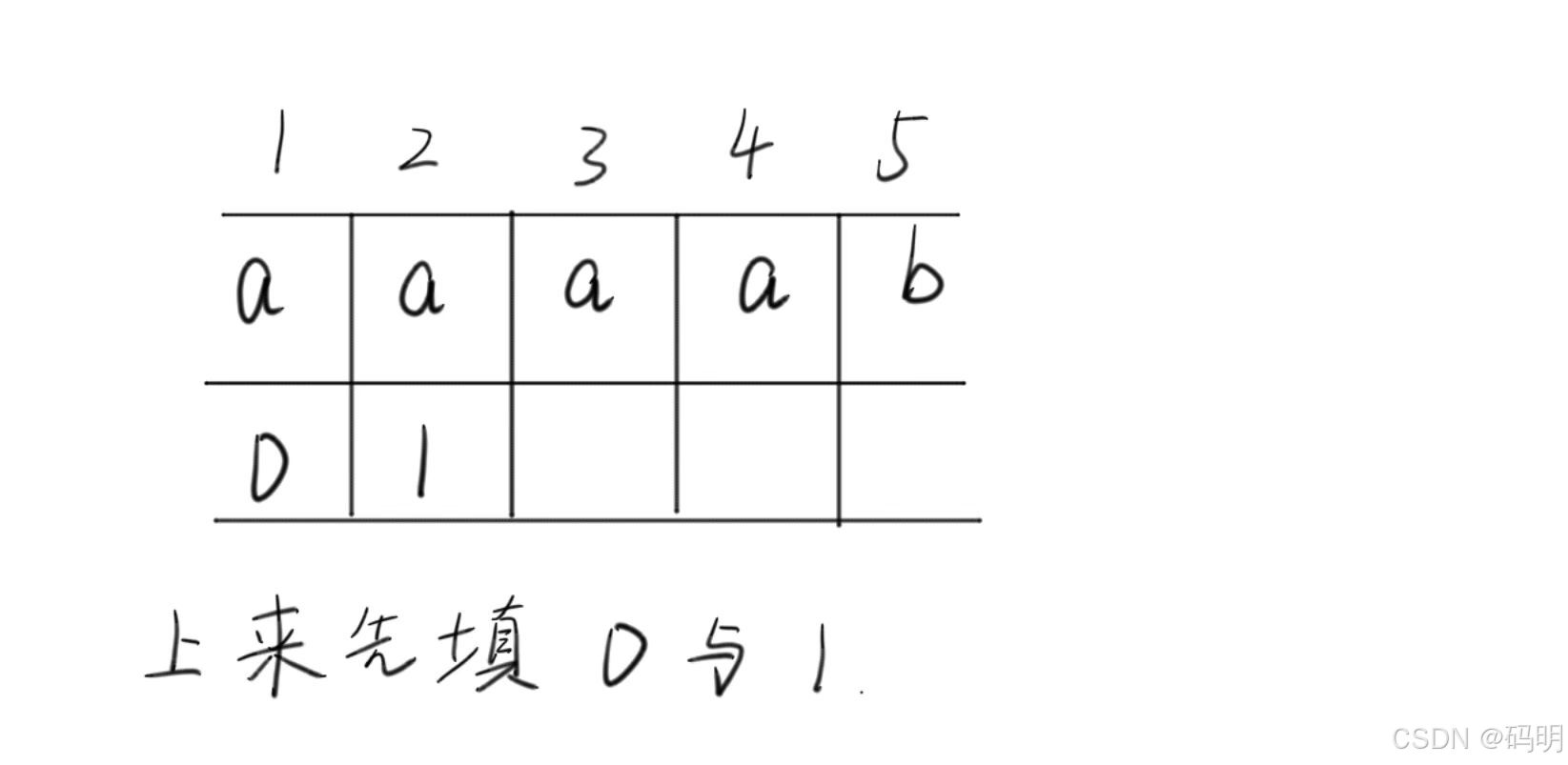



代码演示:
void build_next(char *pattern, int *next) {
int len = strlen(pattern);
int i = 1, j = 0; // 注意i从1开始,j从0开始
next[0] = 0; // next数组的第一个值为0
while (i < len) {
if (pattern[i] == pattern[j]) {
j++;
next[i] = j;
i++;
} else {
if (j != 0) {
j = next[j - 1];
} else {
next[i] = 0;
i++;
}
}
}
}6.Nextval数组的构建
原理:
- 优化匹配过程
- 在 KMP 算法中,虽然 next 数组能够帮助我们在字符串匹配过程中避免不必要的回溯,但是 nextval 数组能够进一步优化这个过程。nextval 数组可以更精准地确定下一个匹配位置,减少不必要的比较次数。
- 例如,当使用 next 数组进行匹配时,可能会出现一些冗余的比较。假设模式字符串是“aaab”,其 next 数组为{0,1,2,3}。在匹配过程中,当主字符串中某个位置与模式字符串的第三个字符a不匹配时,根据 next 数组,下一次匹配位置会跳到第二个字符a。但实际上,我们可以直接跳到第一个字符a,因为第二个字符和第三个字符是相同的,这种情况下 nextval 数组就可以避免这种冗余的比较。
- 减少不必要的回溯和比较
- nextval 数组是对 next 数组的一种优化。它考虑了模式字符串自身字符的重复性,使得在匹配过程中,能够更直接地跳到最有可能匹配成功的位置,避免了因为 next 数组的一些不太精准的跳转而导致的额外比较。
- 比如,在匹配一个很长的主字符串和一个具有重复模式的模式字符串时,这种优化效果会更加明显,能够节省大量的计算资源和时间。
图示:
公式:

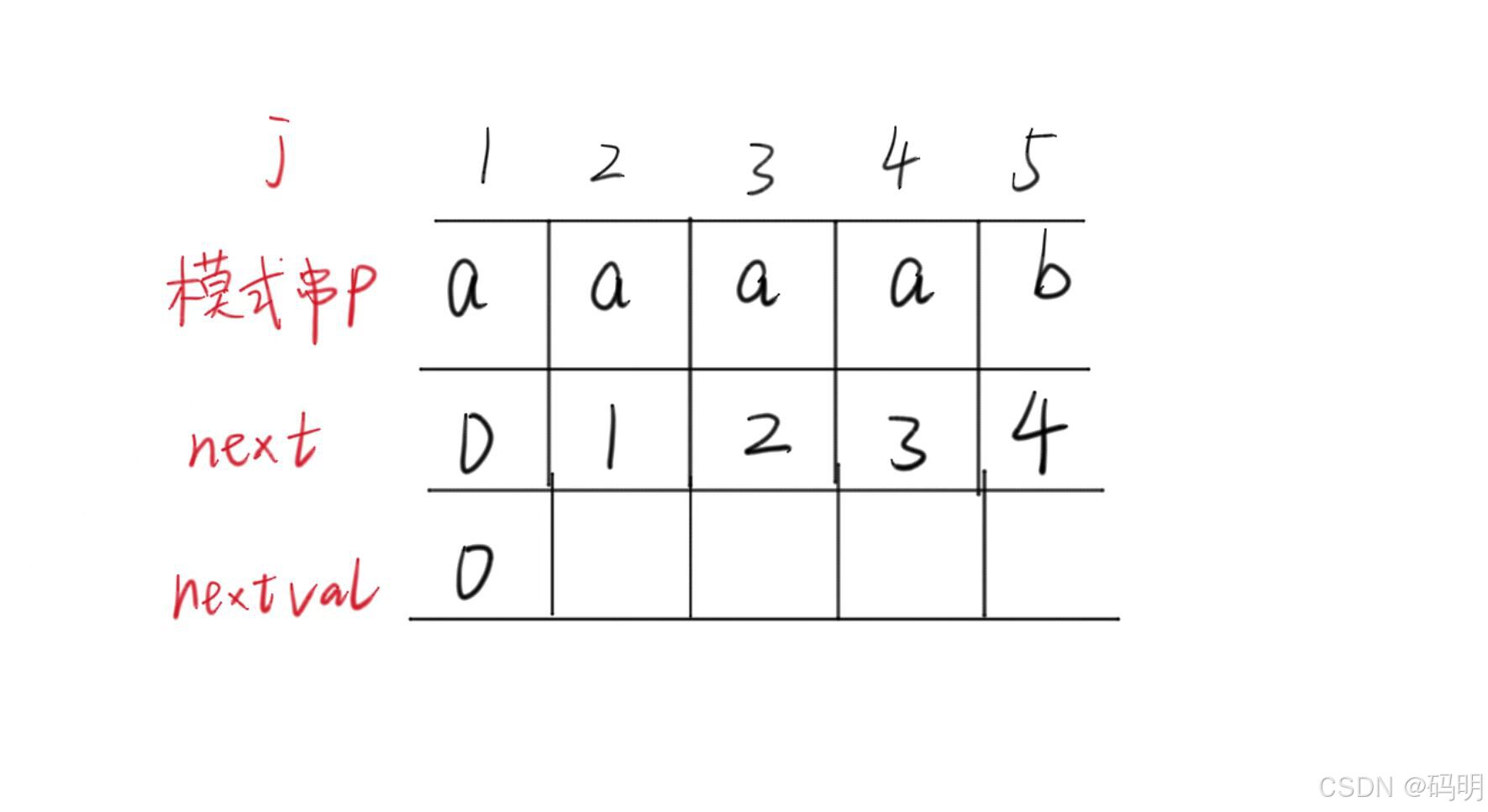
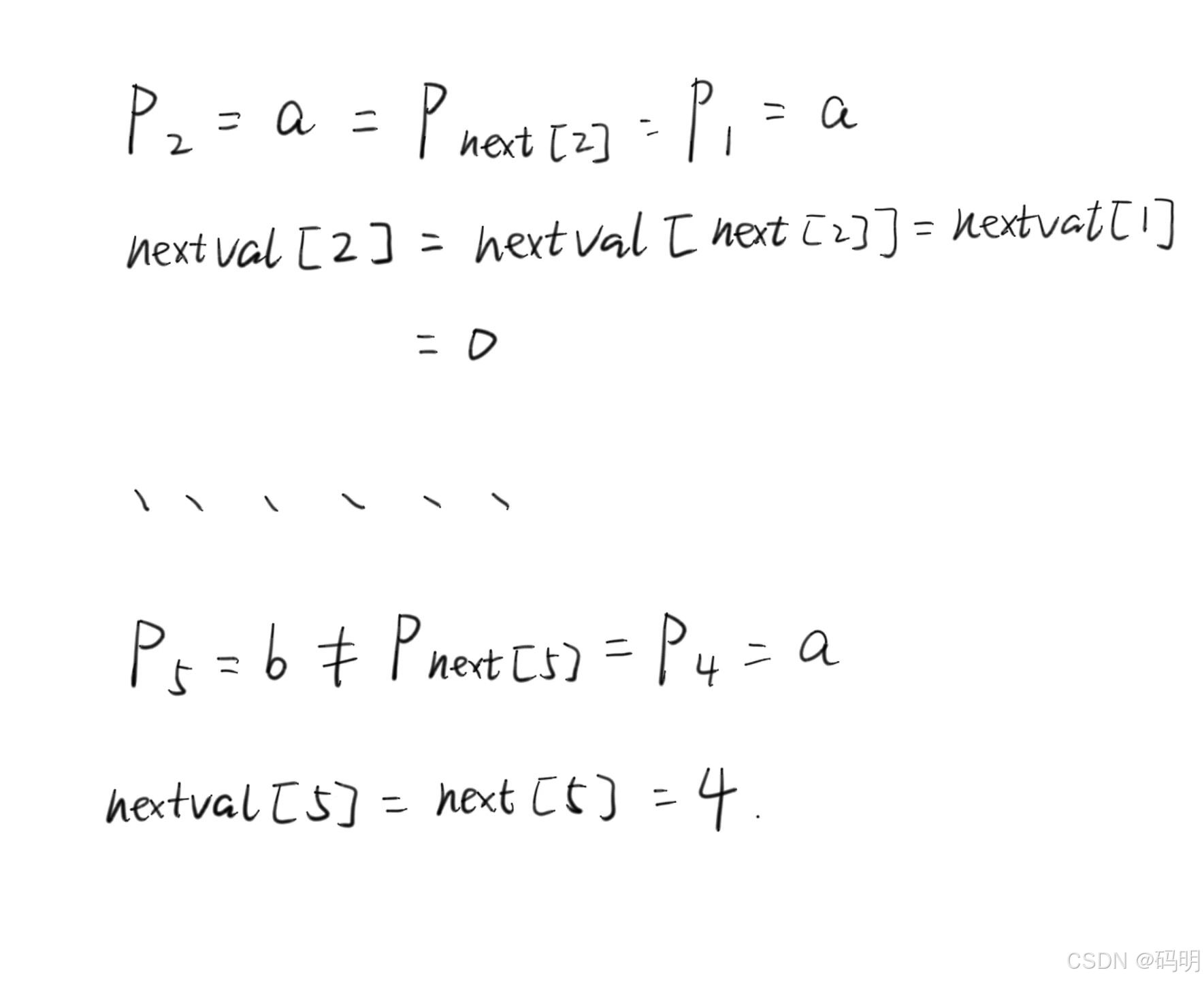
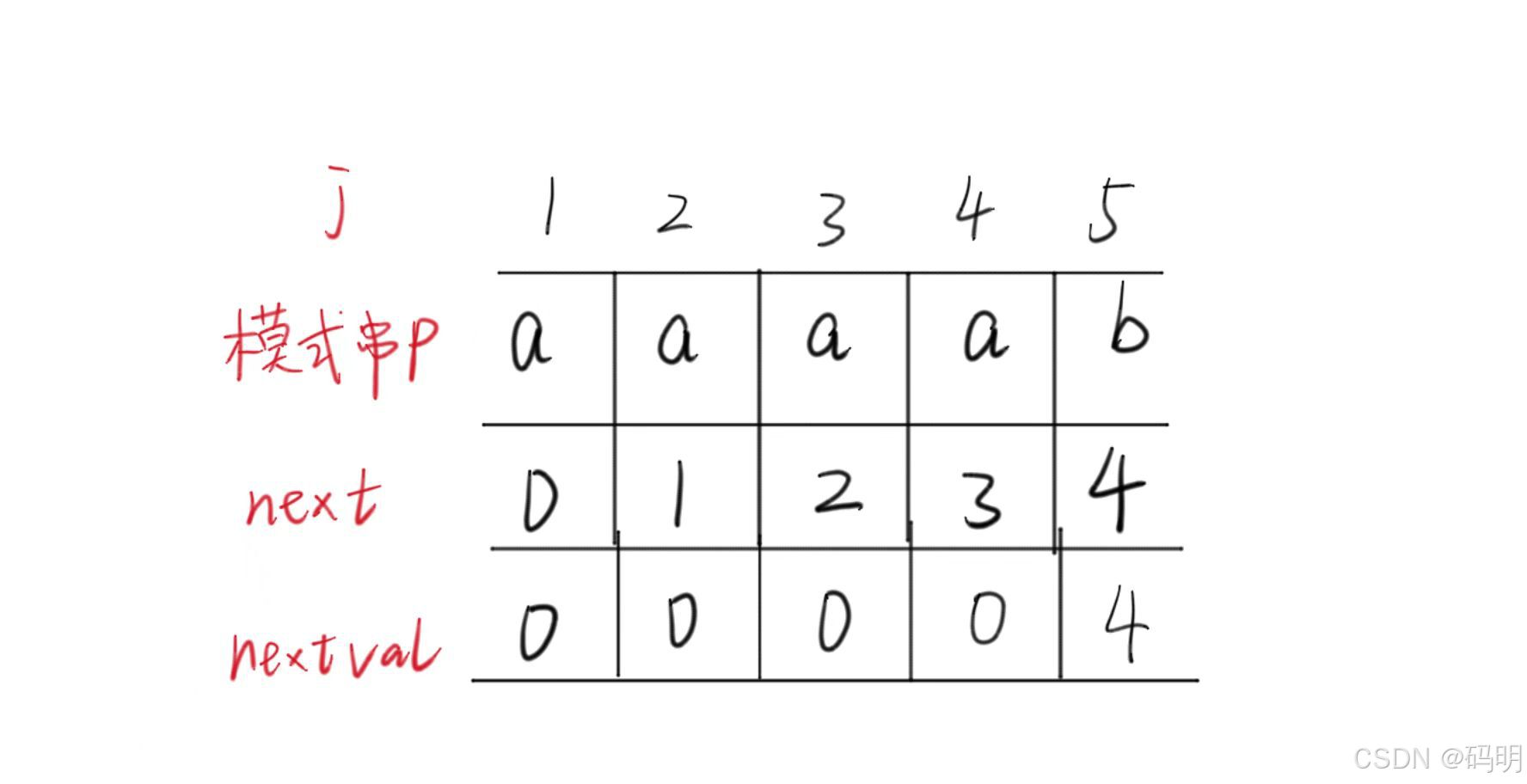
7.代码实现
C语言完整实现:
#include <stdio.h>
#include <string.h>
void build_next(char *pattern, int *next) {
int len = strlen(pattern);
int i = 1, j = 0; // 注意i从1开始,j从0开始
next[0] = 0; // next数组的第一个值为0
while (i < len) {
if (pattern[i] == pattern[j]) {
j++;
next[i] = j;
i++;
} else {
if (j != 0) {
j = next[j - 1];
} else {
next[i] = 0;
i++;
}
}
}
}
int kmp_search(char *string, char *pattern) {
int n = strlen(string);
int m = strlen(pattern);
int next[m];
build_next(pattern, next);
int i = 0, j = 0;
while (i < n) {
if (string[i] == pattern[j]) {
i++;
j++;
}
if (j == m) {
return i - j; // 返回匹配的位置
} else if (i < n && string[i] != pattern[j]) {
if (j != 0) {
j = next[j - 1];
} else {
i++;
}
}
}
return -1; // 未找到匹配
}
int main() {
char string[] = "abcabcabcabcd";
char pattern[] = "abcabcd";
int result = kmp_search(string, pattern);
if (result != -1) {
printf("Pattern found at index %d\n", result);
} else {
printf("Pattern not found\n");
}
return 0;
}

8.考研408真题
2015年
【2015 统考真题】已知字符串S为'abaabaabacacaabaabcc',模式串t为'abaabc'采用 KMP 算法进行匹配,第一次出现“失配”(s[i]≠t[j])时,i=j=5,则下次开始匹配时,i和j的值分别是( 5,2 )。
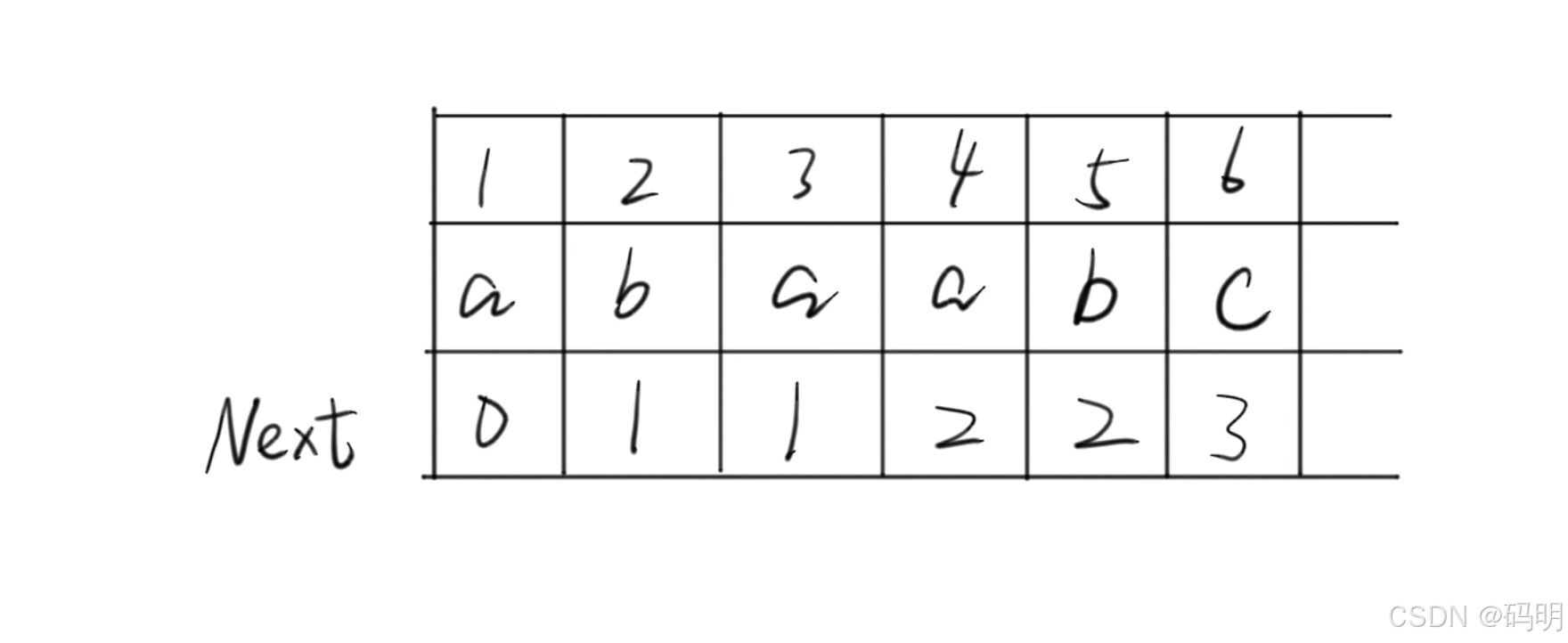
i不动(主串指针不回溯)
模式串指针指向j=2处。
故i=5,j=2。
2019年
【2019 统考真题】设主串 T='abaabaabcabaabc',模式串S='abaabc',采用 KMP算法进行模式匹配,到匹配成功时为止,在匹配过程中进行的单个字符间的比较次数是( 10 )。
求得模式串的next[] = {0,1,1,2,2,3}


一站式 AI 云服务平台
更多推荐

 53
53 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)