
零代码ETL入门:轻松搞定商业数据分析,实现订单利润分流
目录
前言
最近在学习数据分析时,接触到了一个很有意思的概念——ETL。
可能很多刚入门的同学会问:ETL到底是个啥?
简单来说,ETL是三个英文单词的缩写:
-
E(Extract,抽取):从各种数据源中把数据取出来
-
T(Transform,转换):对数据进行清洗、计算、关联等加工处理
-
L(Load,加载):把处理好的数据存到目标位置
举个生活中的例子,就像做菜:先把菜从冰箱拿出来(Extract),然后洗菜切菜炒菜(Transform),最后装盘上桌(Load)。ETL就是数据世界的“洗菜做饭”。
传统做ETL少不了写代码,SQL、Python轮番上阵。但最近我发现了一个良心平台——助睿数智(Uniplore),它能让你用拖拽组件的方式完成整个ETL流程,全程不需要写一行代码。产品官网是 https://www.uniplore.com/ ,实验环境在 https://lab.guilian.cn/ ,对学生党非常友好。
我用助睿平台完成了一个实战案例:订单利润分流,整个实验过程流程如下,希望能帮助到同样在学习数据分析的大家们
实验背景
我们要做什么?
企业的订单数据和产品信息通常存在不同的表里,现在我们需要:
-
把两张表关联起来,算出一笔订单到底赚了多少钱
-
按盈利和亏损把订单分成两类,分别导出成Excel文件
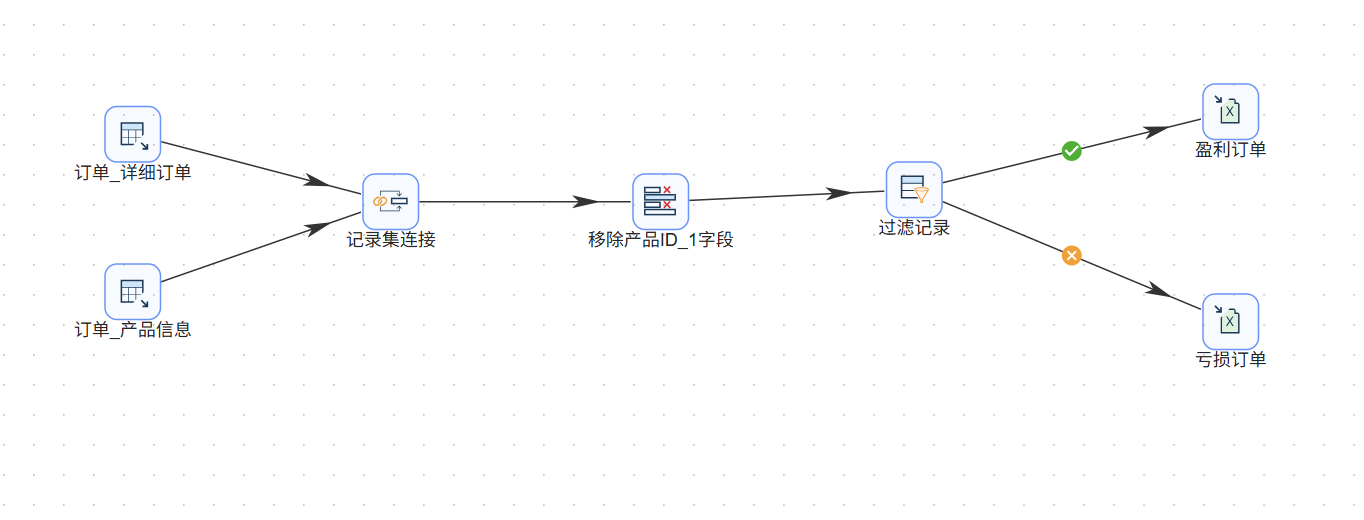
处理逻辑其实很简单:两张表通过产品ID关联 → 计算利润 → 按利润正负分流 → 输出结果。
总体流程如下:
上手实战
Step 1:登录注册
进来后看到页面如下:

Step 2:了解几个基本概念
在正式开工前,先熟悉一下平台里的几个术语,不然后面配置的时候会懵:
-
转换:一个完整的ETL任务就叫一个“转换”,相当于一个工程项目
-
步骤/组件:转换里的每个操作单元,比如“读取数据库”就是一个组件
-
跳:组件之间的箭头连线,代表数据流向
理解这三个词就够了,开搞!
Step 3:创建团队/项目和同步数据源
在数据集成中可以进行团队管理,方便后续团队成员的共同协作
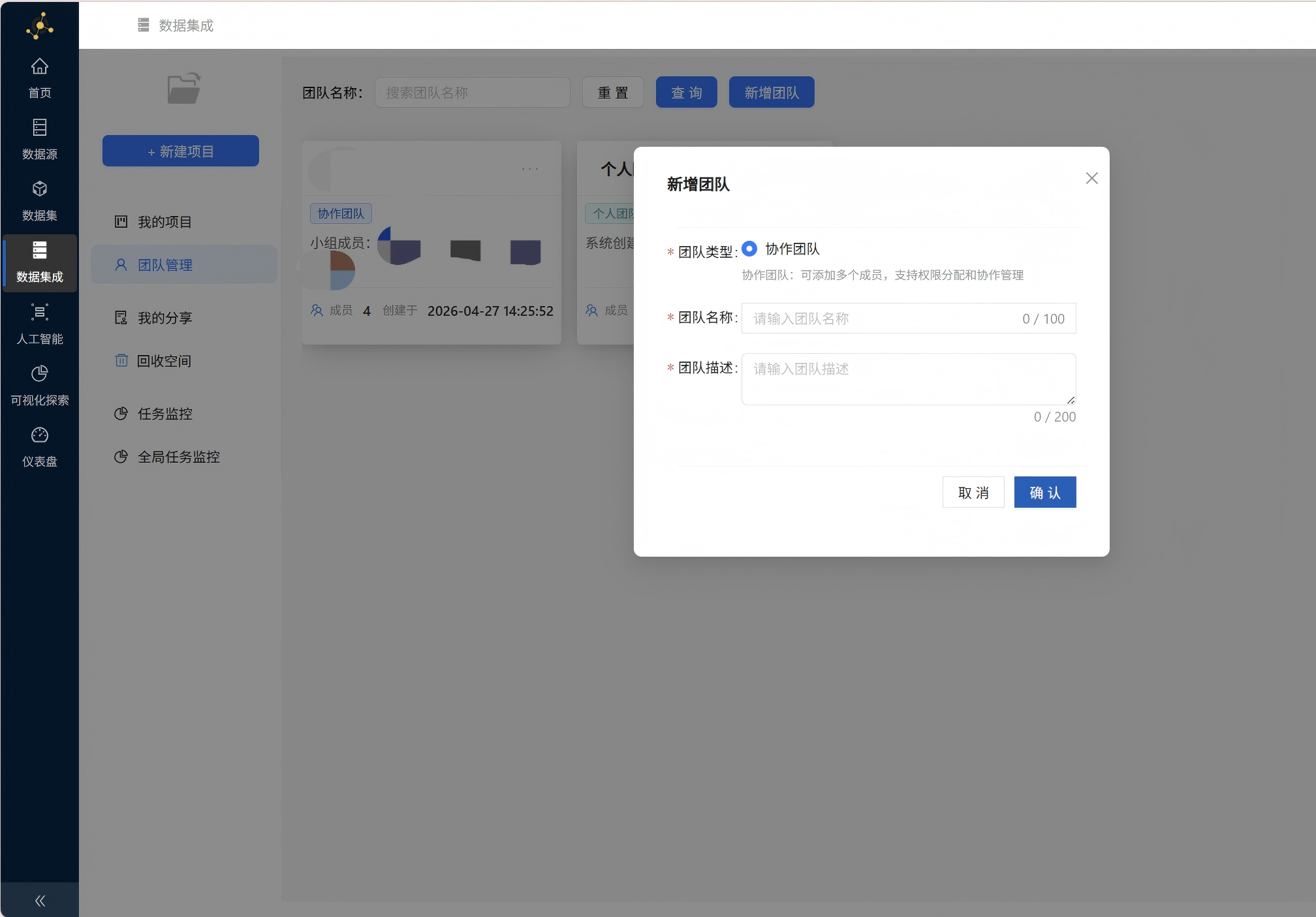
选择好项目所属的是团队还是个人,就可以新建项目了
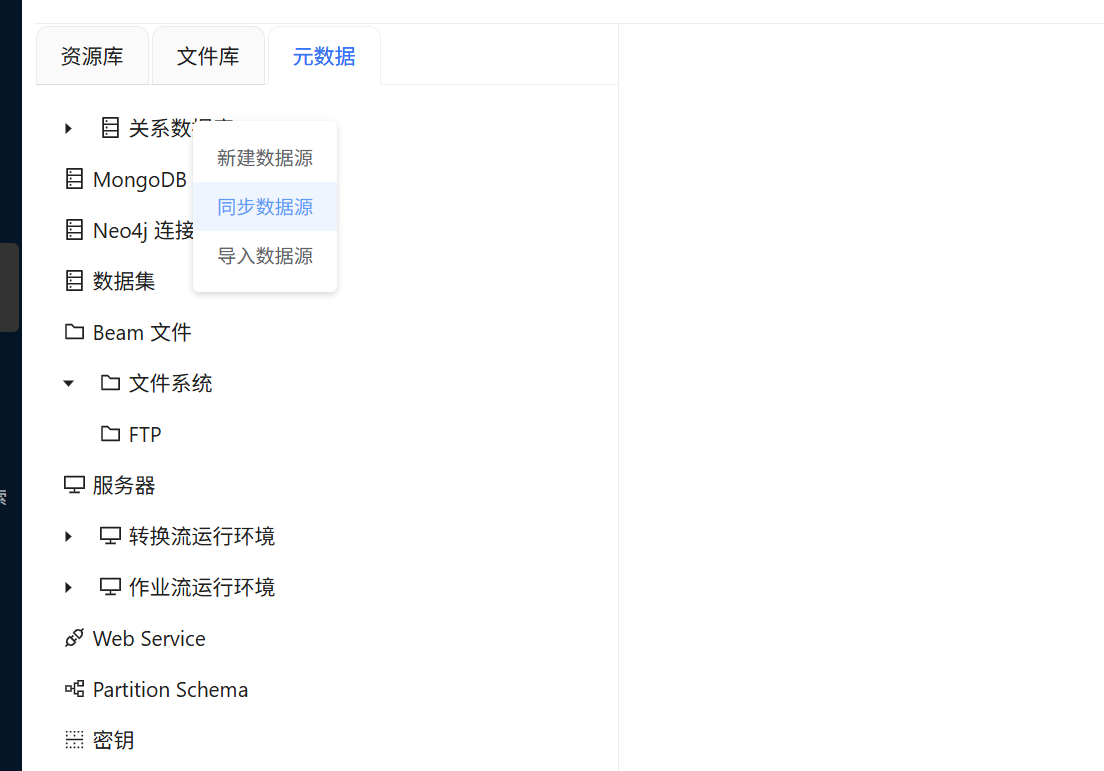
接下来要把数据库里的表同步进来。我们有两张表:
-
business_anaylsis.order_detail—— 订单明细表 -
business_anaylsis.product—— 产品信息表
进入项目的元数据部分,右键就可以添加数据源,点击同步数据源就可以使用已经有的公共数据源了
Step 4:新建转换,搭好组件骨架
在资源库里创建一个新的转换:
然后从左侧的组件面板里搜索我们要用的组件,直接拖出即可:
| 组件 | 数量 | 作用 |
|---|---|---|
| 表输入 | 2个 | 分别读取订单表和产品表 |
| 记录集连接 | 1个 | 把两张表关联起来 |
| 字段选择 | 1个 | 挑出需要的字段,顺便算利润 |
| 过滤记录 | 1个 | 按利润正负分流 |
| Excel输出 | 2个 | 输出盈利和亏损两个Excel |
双击组件就可以进行编辑,将组件名修改,并把组件连起来,数据流向是这样的:
表输入(订单)→
表输入(产品)→ 记录集连接 → 字段选择 → 过滤记录 → Excel输出(盈利)
↳ Excel输出(亏损)
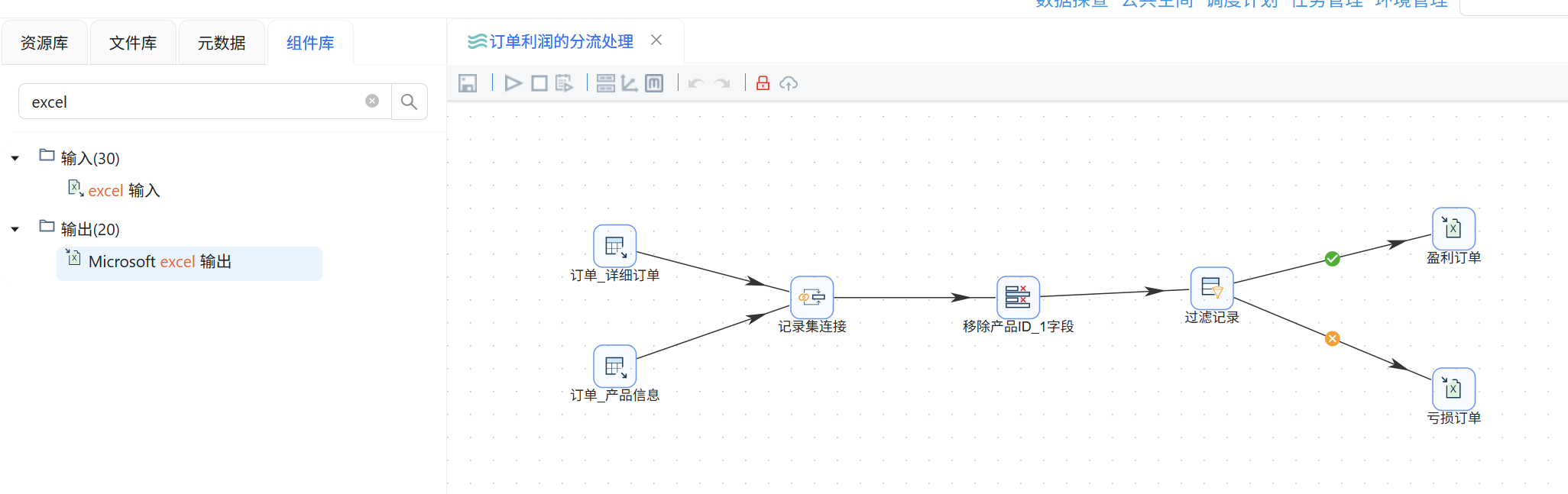
Step 5:逐个配置组件(核心环节)
好了,骨架搭完了,现在开始配置组件实际功能
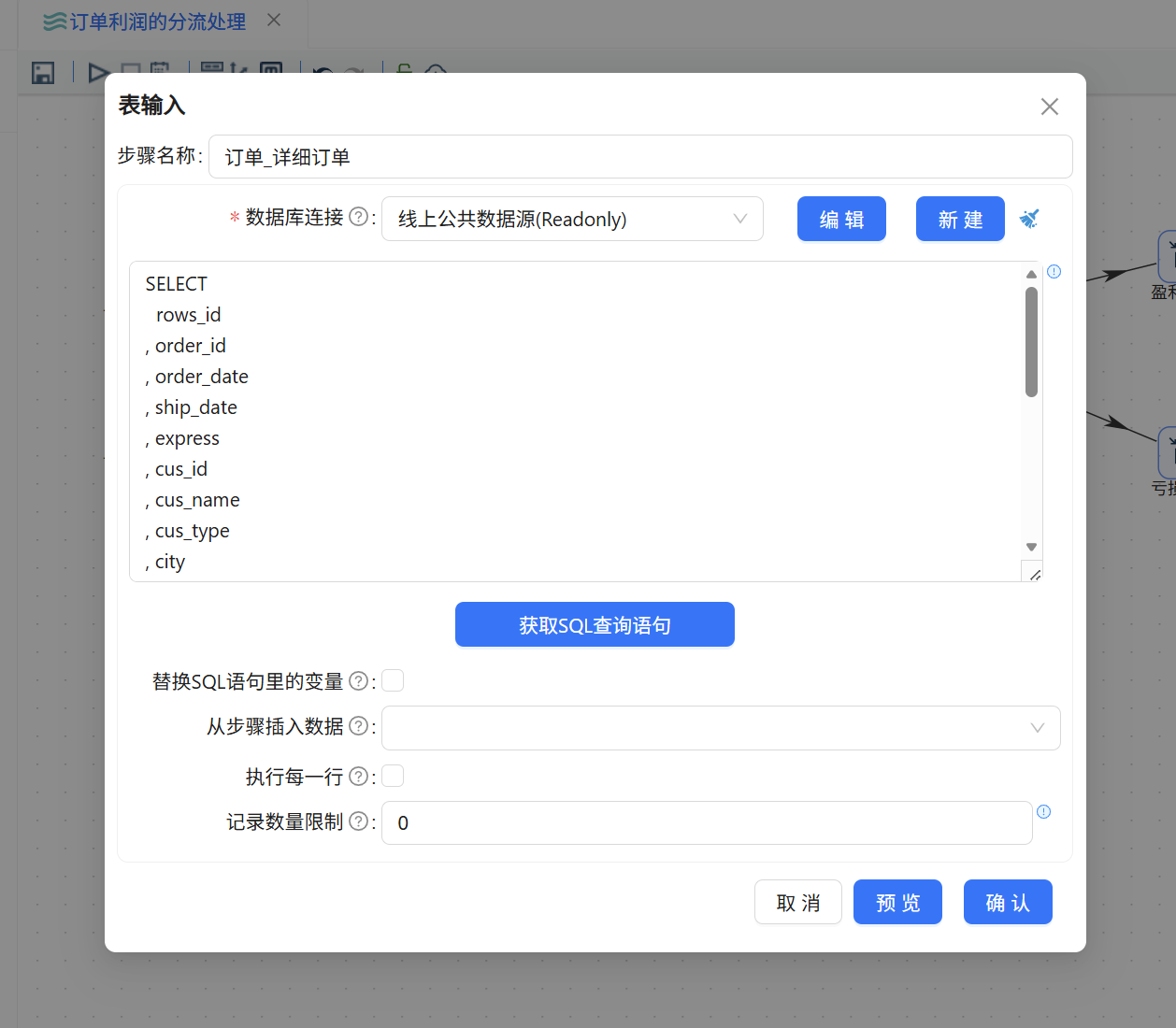
5.1 表输入
双击订单表输入组件的“订单_详细订单”,选择数据源里的 business_anaylsis.order_detail表。SQL语句也不用手动写,直接点击获取sql查询语句,就会出现对应语句,配置如下:
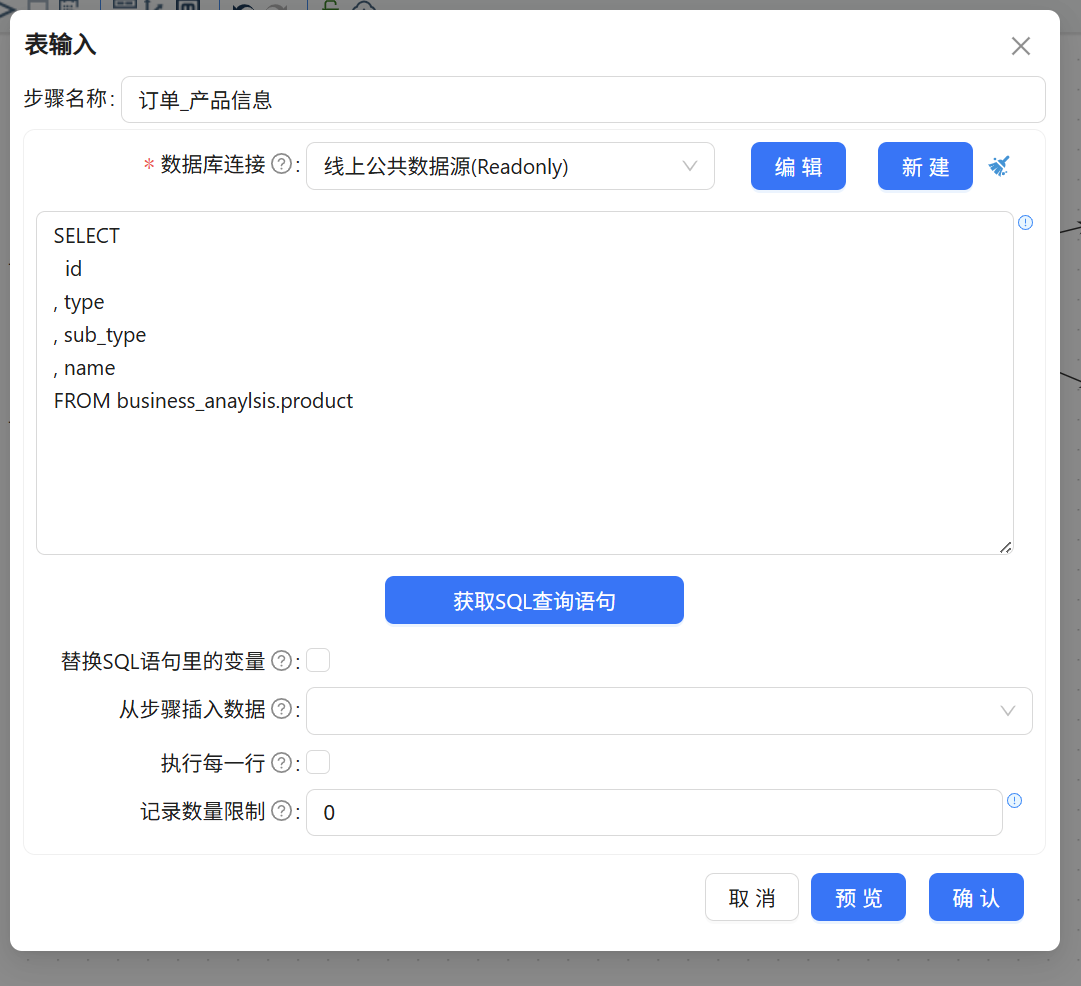
双击订单表输入组件的“订单_产品信息”,选择数据源里的business_anaylsis.product表,同上获取sql语句,配置完成。
5.2 记录集连接
这一步很关键。双击记录集连接组件,配置以下几个点:
-
第一步选订单表输入,第二步选产品表输入
-
连接类型选
LEFT OUTER JOIN(左外连接)。为啥用左外连接?因为我们希望所有订单都保留,哪怕某条订单的产品信息缺失也不丢失 -
连接条件 这里直接点击获得连接字段即可,但是注意要把没用的字段右键选中删掉,只保留productd_id 和 id
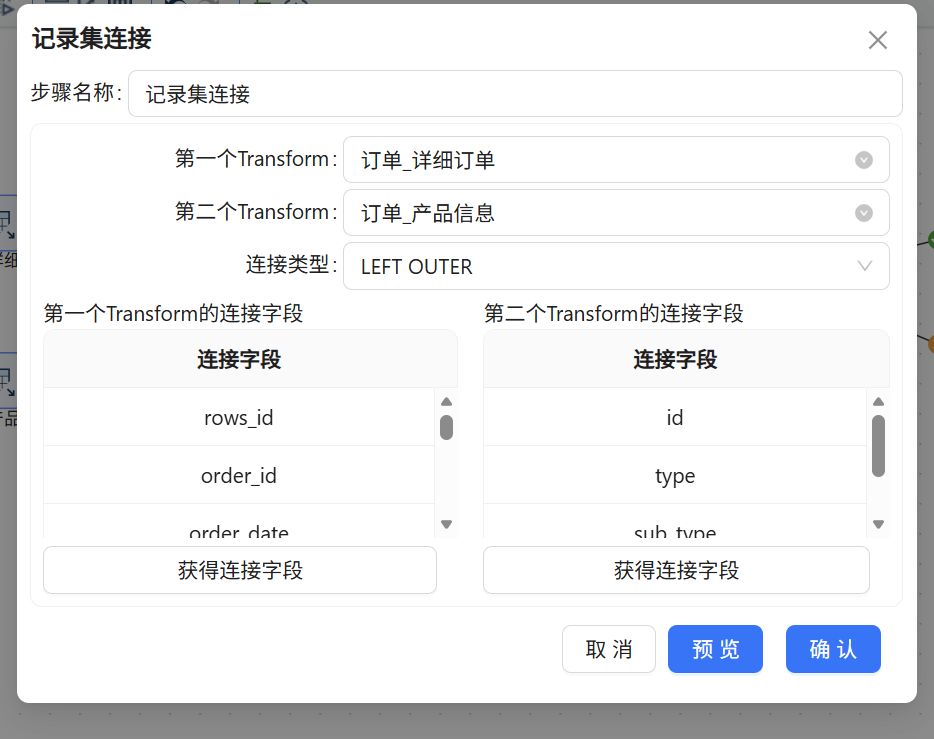
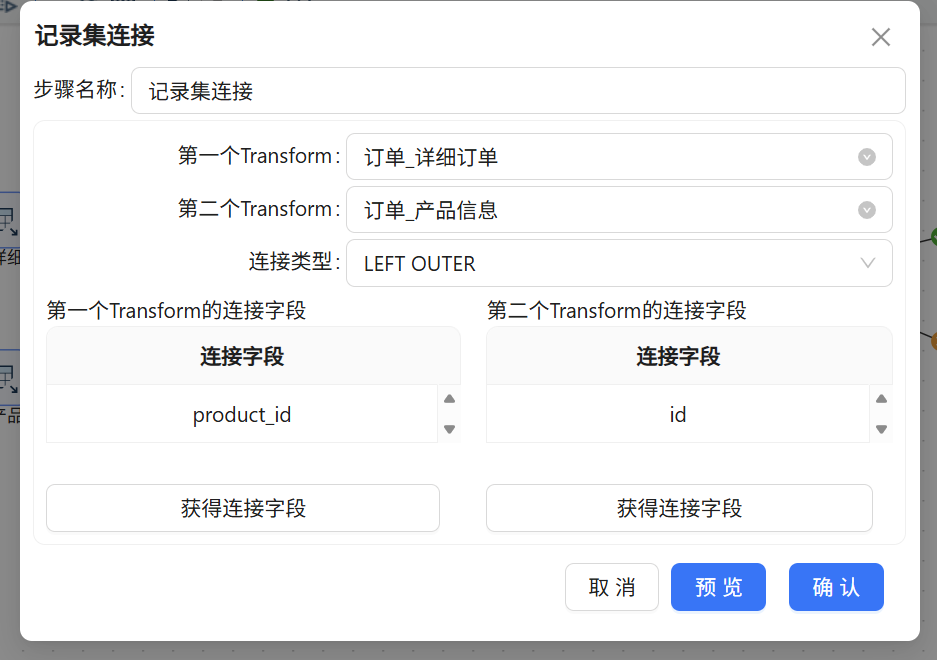
一个小收获: ETL里的表关联和我们平时写SQL的JOIN道理是一样的,只是换成了图形化操作。
5.3 字段选择
关联完之后,表里会出现两个 product_id 字段(两张表各带一个),需要把它去重,这里配置移除字段组件即可,注意:要把除了id的其他字段全部删掉,这样才不会误删其他字段
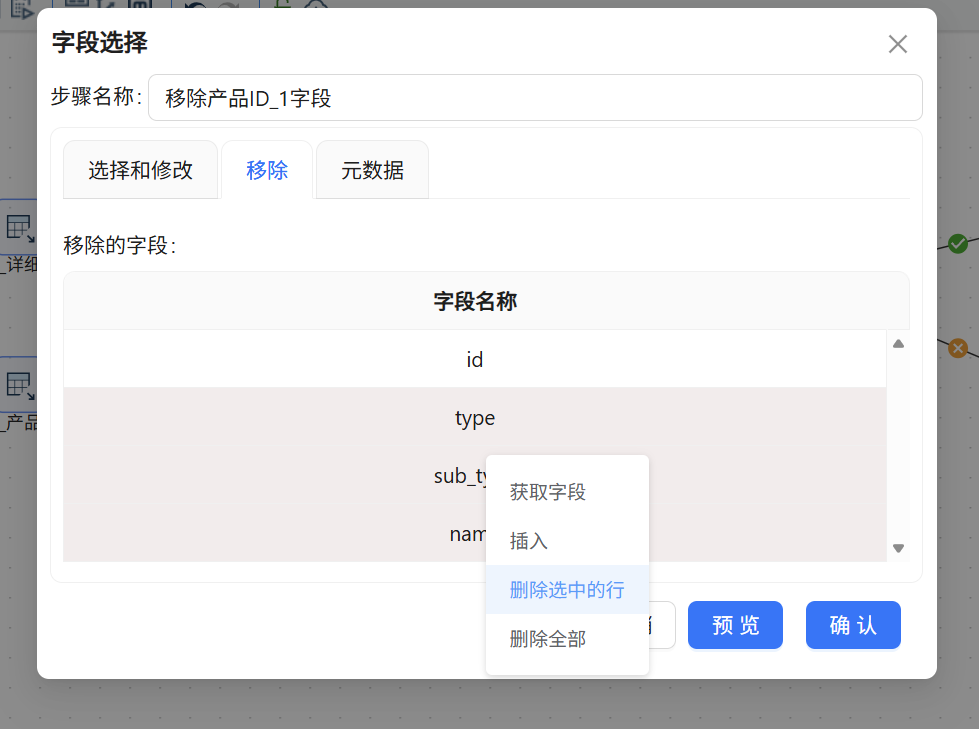
5.4 过滤记录
现在数据里已经有了利润字段,接下来按这个字段分流:
-
过滤条件:
利润 >= 0 -
满足条件的(true)送到“盈利”分支
-
不满足的(false)送到“亏损”分支
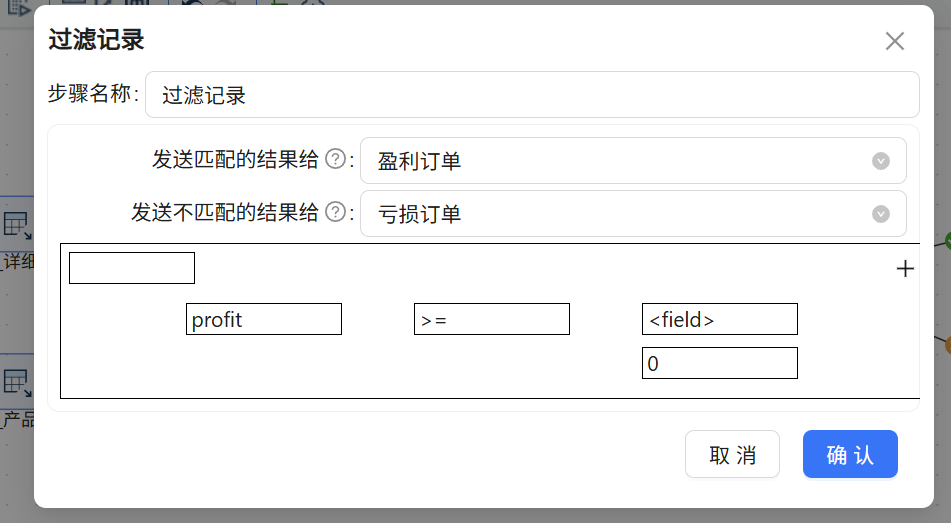
5.5 Excel输出
最后一步,把两个分支的结果输出成Excel:
-
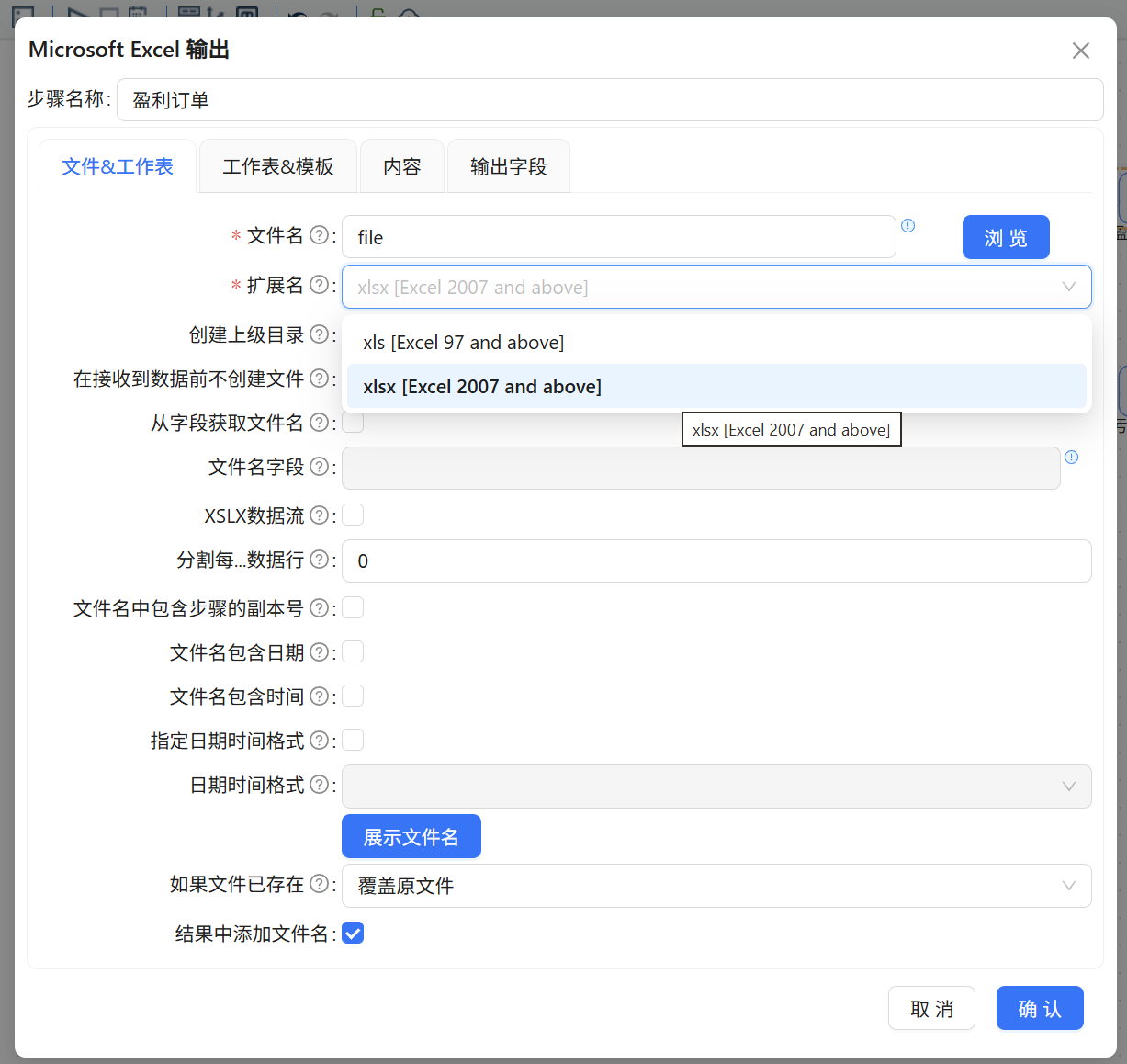
盈利分支:输出文件名设为
盈利订单,格式选xlsx -
亏损分支:输出文件名设为
亏损订单,格式选xlsx
这里可以自己选择输出哪些字段,像 product_id 这种重复的字段可以不输出,让最终文件干净一点。
Step 6:运行
所有组件配置完毕,点击工具栏上的运行按钮。平台会开始执行整个转换流程,运行过程中可以实时看到每一步的状态。
Step 7:查看日志和结果
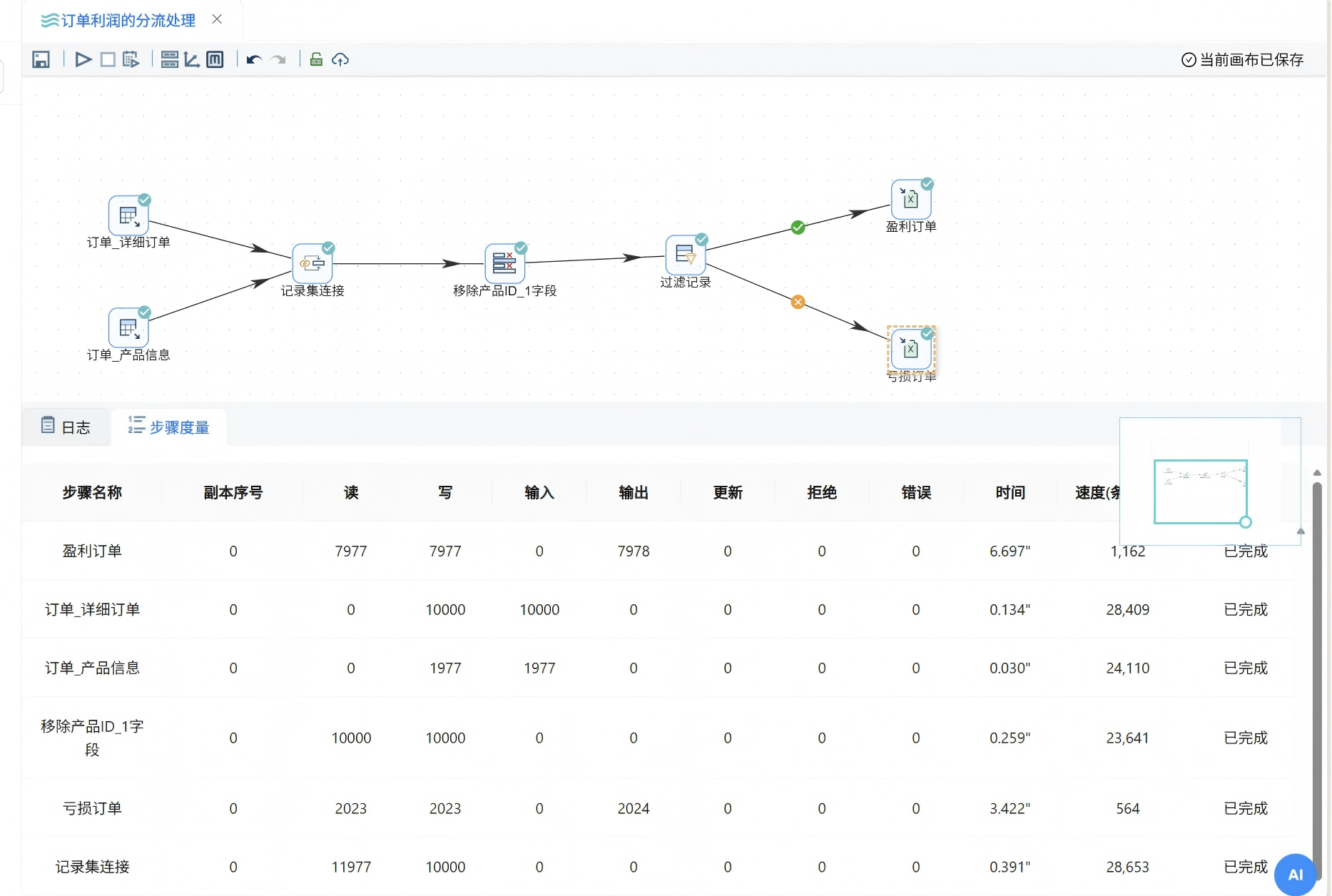
运行完成后,打开日志面板,可以看到每一步的详细统计信息:读取了多少行、写入了多少行、耗时多久。如果某一步报错,日志里也会有明确的提示。
确认所有步骤都是绿色对勾后,检查一下输出的两个Excel文件:
-
盈利订单.xlsx:利润列全部 ≥ 0,符合预期
-
亏损订单.xlsx:利润列全部 < 0,符合预期
验证一下数量:盈利订单数 + 亏损订单数 = 原始订单总数,数据完整,没有丢失。
到这里,整个实验就完成了!
总结
这次用助睿平台做订单利润分流,最大的感受就是:零代码ETL真不是噱头。
几个实实在在的收获:
-
理解了ETL的完整流程,从数据抽取到转换加工再到结果输出,一气呵成
-
掌握了表输入、记录集连接、字段选择、过滤记录、Excel输出这些核心组件的用法
-
体会到图形化操作的便利——拖拖拽拽配配置,比写一堆SQL快多了
对于平台本身,我的评价是比较务实的:组件覆盖了常见的数据处理需求,操作逻辑清晰,日志功能对于排查问题帮助很大。不管是用来入门数据工程,还是日常做一些简单的数据处理,都很合适。
后续打算试试平台上更高级的功能,比如机器学习建模和可视化分析,到时候再和大家分享~
有用的话希望大家多多点赞收藏关注哦!₍ •ᴗ• ₎
实验平台地址:https://lab.guilian.cn/
产品官网:https://www.uniplore.com/

一站式 AI 云服务平台
更多推荐

 20
20 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)