
(学校要求发的,请自行忽略)
这次实验让我直观感受到了零代码平台做数据集成的便利。以前要在代码里写一堆SQL和连接逻辑,现在只需要拖拖拽拽、点点选选,就能快速搭建出一个逻辑清晰的数据处理流水线。我对ETL中“抽取、转换、加载”的理解不再是抽象概念,而是变成了一个个看得见的组件和连线。
保姆级教程!基于零代码平台实现订单利润分流数据加工
一、实验背景
1.1 实验目的
本次实验,我的主要目标是上手体验助睿数智(Uniplore)一站式数据科学实验平台的数据集成模块。在真实业务中,经常需要将分散在不同数据表中的信息关联起来,按照某个条件进行分流,最终生成我们需要的文件。因此,我打算通过“订单利润分流处理”这个小任务,掌握以下技能:
-
如何创建和管理一个ETL转换任务。
-
学会使用几个最核心的组件:“表输入”、“记录集连接”、“字段选择”、“过滤记录”、“Excel输出”。
-
把一张订单表和一张产品表关联起来,根据利润正负,将数据分流成“盈利订单”和“亏损订单”,并分别输出到Excel文件里。
1.2 实验环境
-
实验平台:助睿数智(Uniplore)数据科学实验平台(地址:https://lab.guilian.cn/)。该平台覆盖了从数据接入、ETL处理到机器学习建模、可视化的全链路,主打零代码与Agentic智能。
-
数据环境:平台提供的MySQL数据库,里面有两个现成的数据表:
business_anaylsis.order_detail(订单明细)和business_anaylsis.product(产品信息),同步后即可使用。
1.3 处理流程简述
整个ETL任务的逻辑非常清晰:
-
抽取:从数据库分别读取订单和产品数据。
-
转换:
-
用“记录集连接”对两表执行左外连接,关联字段是产品ID。
-
用“字段选择”移除连接后重复的ID字段。
-
用“过滤记录”设定条件
利润 >= 0,把数据分成两条支流。
-
-
加载:将盈利和亏损的数据流分别写入两个Excel文件。
二、实验步骤
2.1 环境准备:团队与项目创建
进入ETL页面后,我先是点击“团队管理”新建了一个团队,方便管理实验。之后回到主页面,点击“新建项目”,输入项目名称,一个专属的实验空间就建好了。
2.2 同步数据源
进入项目后,左侧菜单切到“元数据”,右键“关系数据库”选择“同步数据源”。几秒后,“线上公共数据源(Readonly)”就出现了,我们需要的订单表和产品表都在里面。

2.3 新建转换流
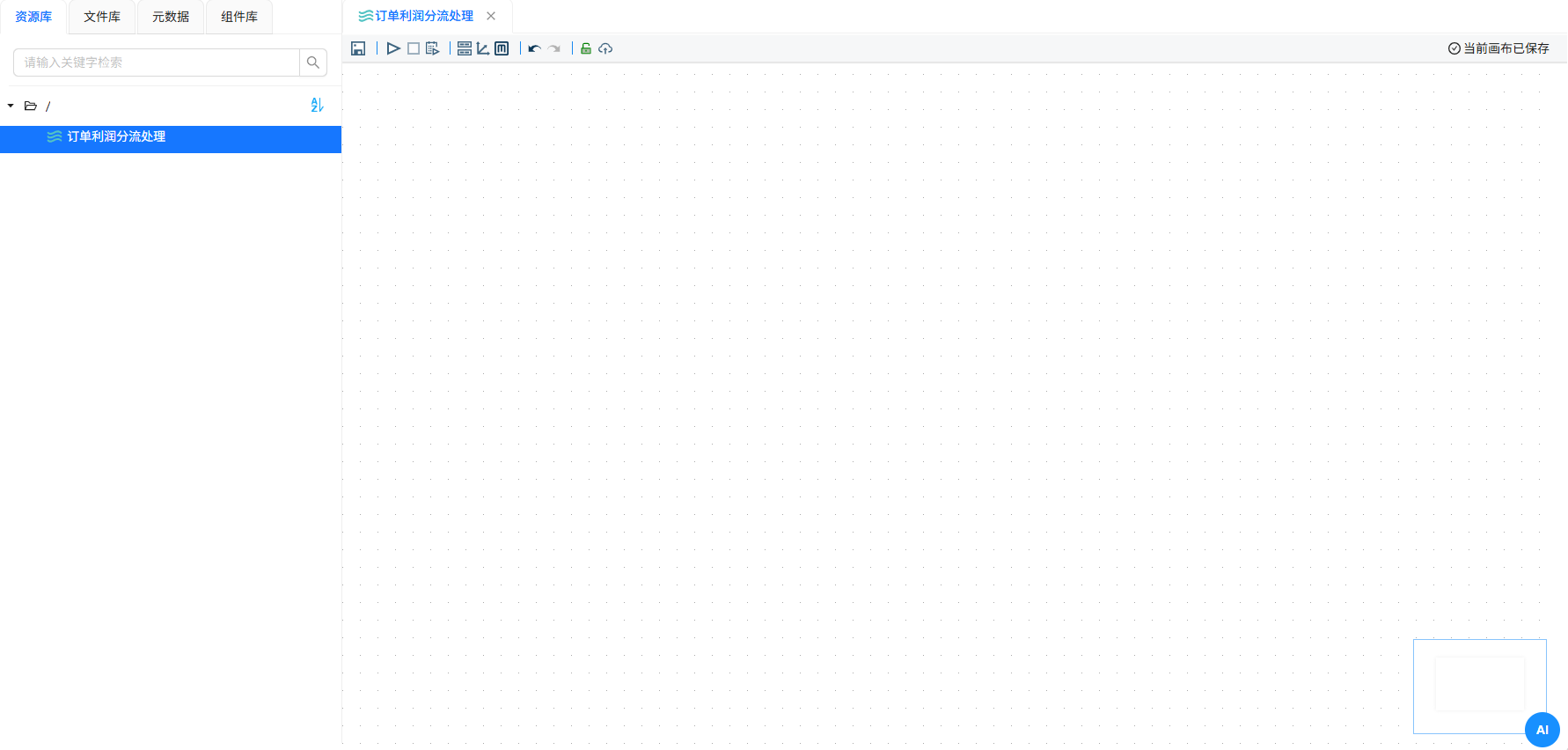
接下来就是动手搭建数据处理流程了。我切回“资源库”菜单,右键根目录,选择“新建转换流”,并为它取名“订单利润分流处理”。双击打开后,记得点击锁图标解锁画布,这样才能拖拽组件。
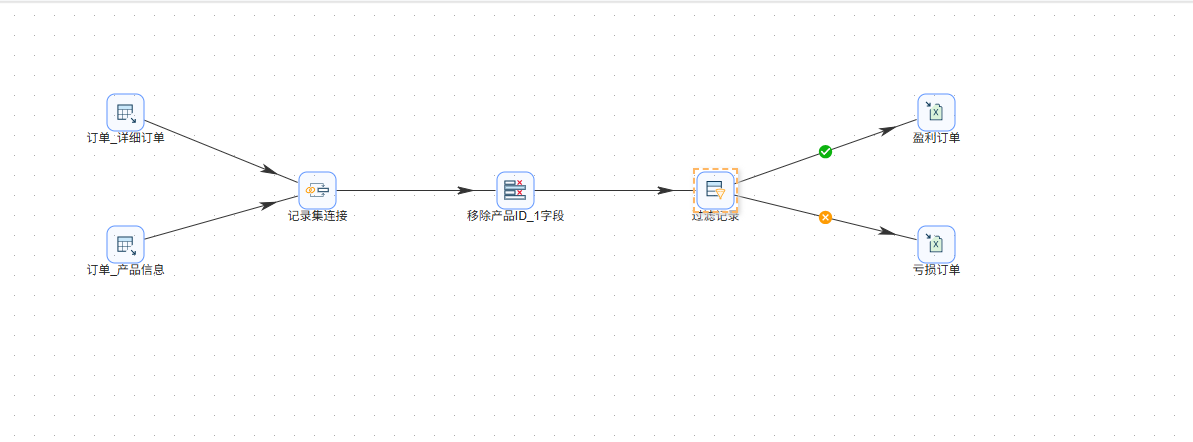
2.4 搭建工作流并配置组件
下面就是一步步拖拽组件、连线、配置参数的过程,也是整个实验最核心的部分。
第一步:表输入组件
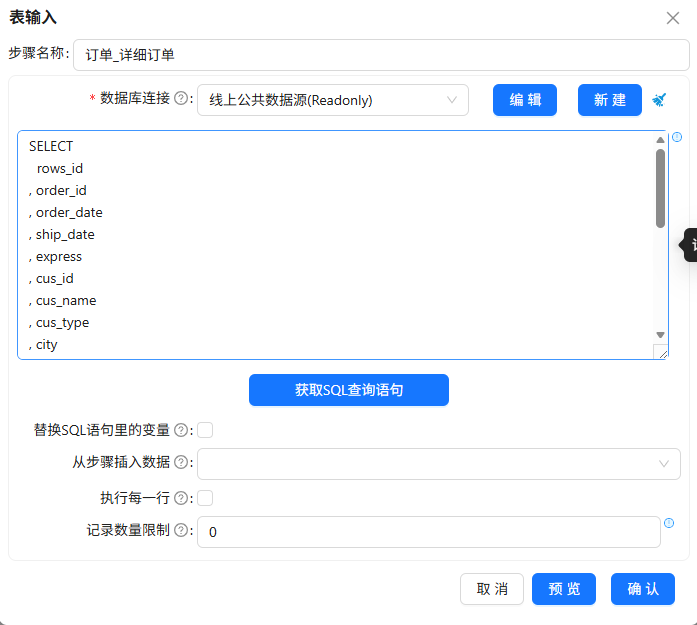
从组件库里搜索“表输入”,把两个组件拖到画布上。我给它们分别改名为“订单_详细订单”和“订单_产品信息”。
双击“订单_详细订单”进入配置:数据库连接选“线上公共数据源”,点击“获取SQL查询语句”,在弹出的表列表中找到business_anaylsis.order_detail,点击确定,SQL语句就自动填好了。另一个“订单_产品信息”组件如法炮制,选择business_anaylsis.product表。
第二步:记录集连接组件
拖入“记录集连接”组件,并从两个表输入组件拉出连接线指向它。双击组件开始配置:
-
第一个Transform选“订单_详细订单”,第二个选“订单_产品信息”。
-
连接类型选择
LEFT OUTER。 -
分别点击两个Transform的“获得连接字段”,指定用订单表的
produc_id和产品表的id进行关联。多余字段右键删除,只保留关联用的字段。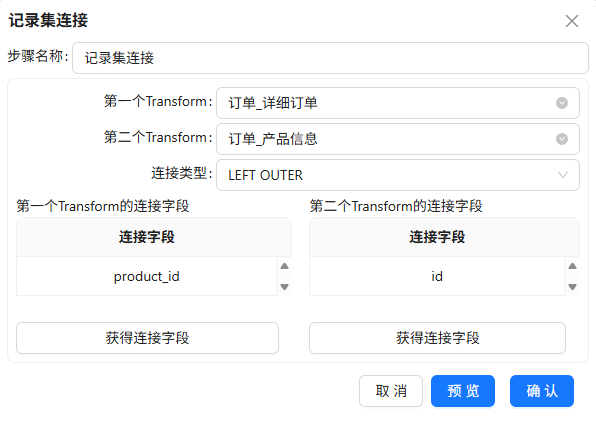
第三步:字段选择组件
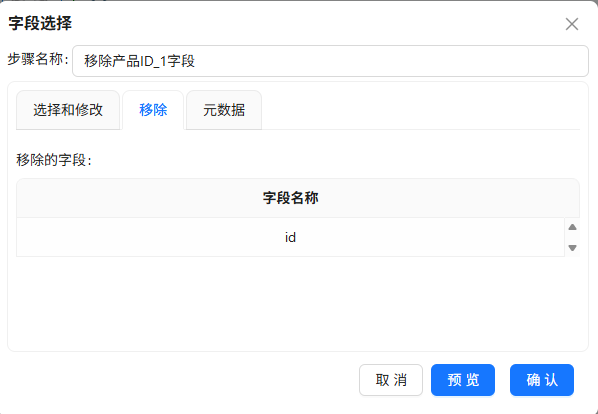
连接之后会产生两个重复含义的字段:produc_id 和 id。我拖入“字段选择”组件,命名为“移除产品ID_1字段”,并把它连到记录集连接组件后面。在配置界面的“移除”选项卡里,先“获取字段”,然后选中id字段删除即可,这样就不会有冗余列了。
第四步:过滤记录组件
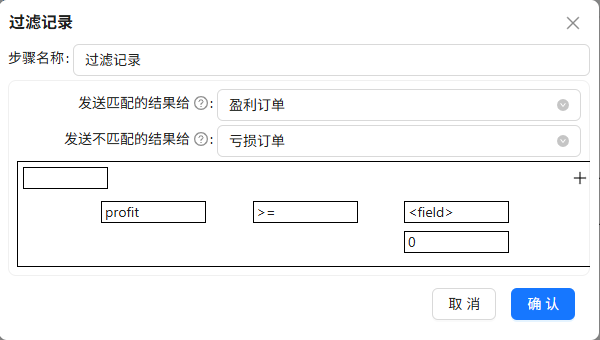
分流就靠它了。拖入“过滤记录”组件,接收来自“字段选择”组件的主输出步骤。双击配置,条件设置如下:
-
字段:
profit(Number) -
条件:
>= -
值:
Integer类型的0
这样一来,数据就被分成了 “True(利润≥0)”和“False(利润<0)”两条路。
第五步:Excel输出组件
最后,拖入两个“Excel输出”组件到画布,分别命名为“盈利订单”和“亏损订单”。将过滤记录组件的“True输出”连到“盈利订单”,“False输出”连到“亏损订单”。
分别双击配置这两个组件:
-
文件名分别写
盈利订单和亏损订单,扩展名选xlsx。 -
在“输出字段”选项卡下,右键空白处点击“获取字段”,所有字段就会自动列出来,点击确认保存。
2.5 执行任务并查看结果
一切就绪,点击画布左上角的“启动”按钮,在弹出的确认窗口中再次点击“启动”。很快,流程就跑完了,所有组件都显示绿色对勾,状态栏提示“执行成功”。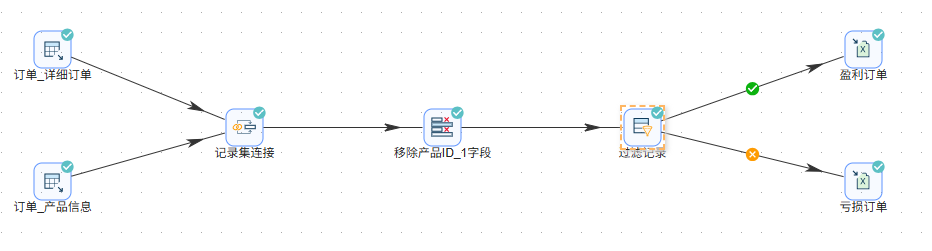
这时我切到“文件库”菜单,右键刷新,盈利订单.xlsx 和 亏损订单.xlsx 已经安安静静地躺在那里了,可以右键下载下来查看。
三、实验结果
下载并打开 盈利订单.xlsx,可以看到表格列包含了订单和产品的综合信息,并且 profit 列的所有值确实都大于等于0,符合我的过滤条件。另一个 亏损订单.xlsx 也同理,只包含利润小于0的记录。数据分流正确,整个零代码流程成功达成了目标。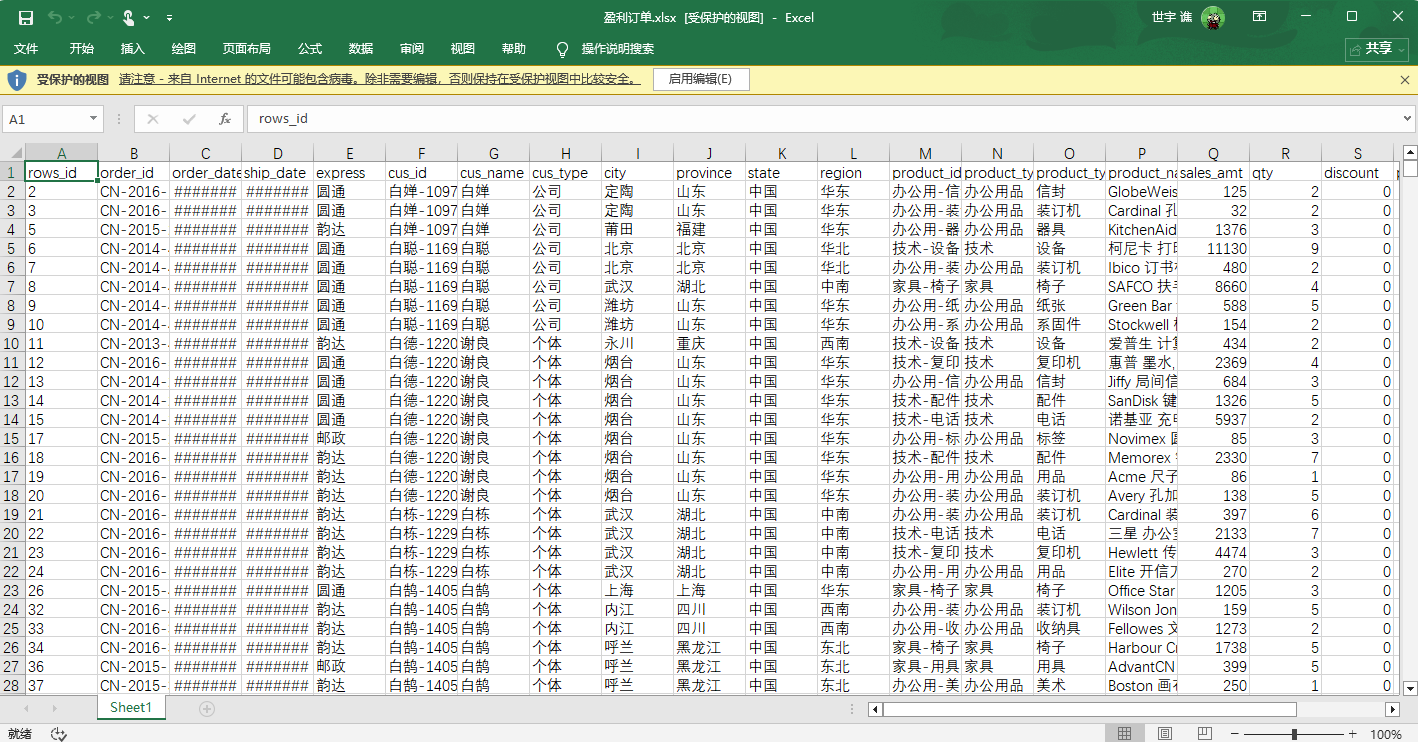
四、问题与解决
实验中我碰到一个小插曲:
-
问题现象:在把“表输入”连向“记录集连接”时,系统弹出一个“排序需要”的提示框。
-
问题原因:我查找了资料,原来“记录集连接”组件依赖已排序的数据流进行关联,如果数据未排序可能导致结果不准确,所以它给出了强制提示。
-
解决方法:考虑到实验数据量较小,且我预览发现即使不单独排序也能得到正确结果,就直接关闭了提示继续执行。不过,如果是处理海量数据,最好还是听从提示,在中间插入一个“排序”组件,以保证数据的准确性和性能。
五、实验总结
5.1 收获
这次实验让我直观感受到了零代码平台做数据集成的便利。以前要在代码里写一堆SQL和连接逻辑,现在只需要拖拖拽拽、点点选选,就能快速搭建出一个逻辑清晰的数据处理流水线。我对ETL中“抽取、转换、加载”的理解不再是抽象概念,而是变成了一个个看得见的组件和连线。
5.2 平台评价
总的来说,助睿数智平台的操作对新手很友好,组件种类也比较丰富,配置时的字段获取、自动生成SQL等功能极大地提高了效率。如果再多一些连接时的智能引导(比如自动询问是否添加排序),体验可能会更丝滑。实验下来,任务完成得轻松又愉快,是一次很棒的实践体验。

一站式 AI 云服务平台
更多推荐



 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)