
吃透订单利润分流!手把手搞定业务数据加工
一、实验背景
1.1 实验目的
本次实验旨在掌握零代码ETL数据集成平台的核心功能,熟悉新建转换、添加组件、执行转换等基本操作流程,并掌握常用组件的配置方法。通过本次实验,我将独立完成多表关联、数据过滤与分流处理等常见的数据加工任务,为后续更复杂的数据处理场景打下基础。
1.2 实验环境
-
实验平台:助睿数智(Uniplore)一站式数据科学实验平台,覆盖数据接入、ETL处理、机器学习建模到可视化分析的全链路Agentic零代码数据智能。
-
实验平台地址:https://lab.guilian.cn/
-
数据库:平台内置MySQL数据库
-
数据表:订单明细表(
business_anaylsis.order_detail)、产品信息表(business_anaylsis.product)
1.3 处理流程
本次实验的整体逻辑为:订单明细表与产品信息表进行左外连接 → 移除重复的ID字段 → 按利润是否大于等于零进行分流 → 最后分别输出盈利订单和亏损订单到两个Excel文件。
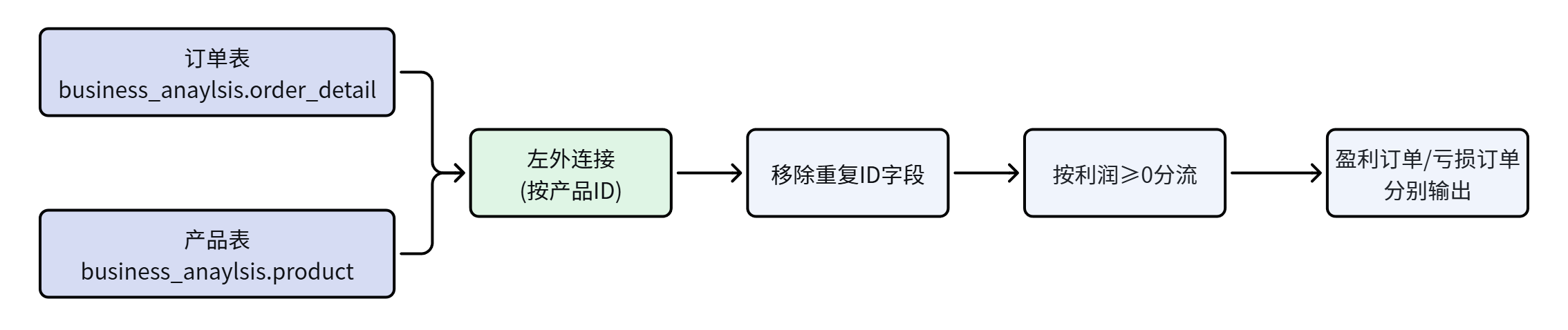
1.4 基本概念
是什么:助睿一站式大数据平台中的数据集成平台,通过可视化方式做数据 ETL(抽取、转换、加载)。
| 概念 | 说明 |
|---|---|
| Pipeline(转换) | 面向数据清洗、处理数据的一个功能单元,由多个 Transform 组成 |
| Workflow(作业) | 面向任务,完成一件完整的事,由多个 Action 组成,必须包含开始项 |
| Transform(步骤) | 转换内的最小单元,如 “Excel 输入”、“字段选择”,每个步骤独立线程运行 |
| Action(任务项) | 作业的执行单位,如 “启动”、“发送邮件” |
| Hops(节点连接) | 数据传输通道,连接步骤或任务项 |
二、实验步骤
步骤1:登录平台
操作说明:访问实验平台地址并登录账号。
配置要点:
-
打开浏览器,输入
https://lab.guilian.cn/ -
使用账号密码完成登录
-
登录成功后进入贵兰在线首页
步骤2:进入实训平台
操作说明:在贵兰在线首页,点击右上角头像,选择"我的学习",然后点击左侧菜单中的"实训平台",跳转至助睿数智实验平台首页。
配置要点:
-
导航路径:贵兰在线 → 我的学习 → 实训平台
-
进入实训平台后,可以看到平台提供的各类数据科学实验环境

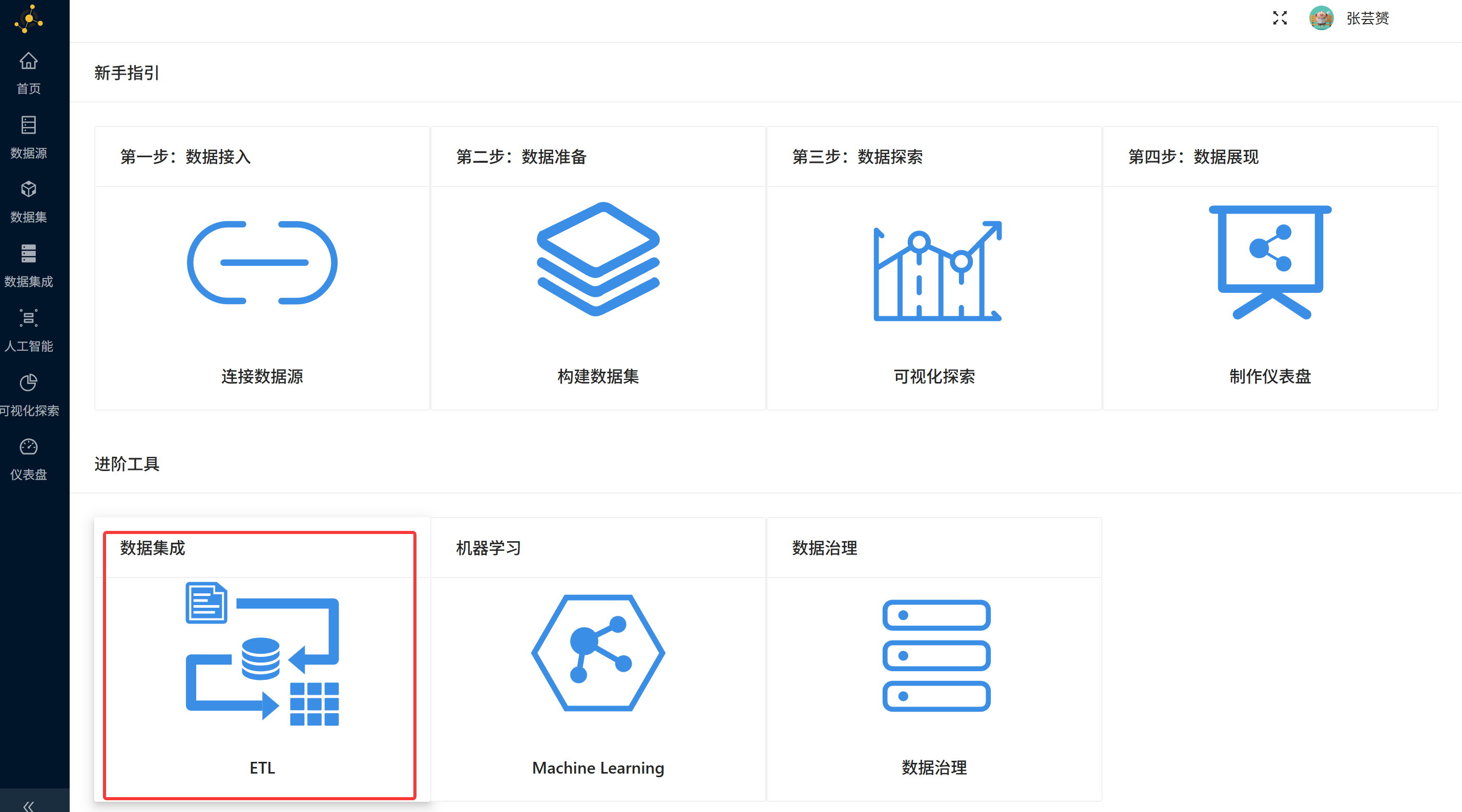
步骤3:新建转换(Pipeline)
操作说明:在平台首页,点击"新建"按钮,选择创建"转换"(Pipeline)。
配置要点:
-
转换(Pipeline)是面向数据流的功能单元,由多个步骤(Transform)组成
-
每个步骤都是独立线程运行的
-
本次实验主要使用转换来完成数据流处理
核心概念区分:
转换(Pipeline):面向数据流,处理数据的功能单元
作业(Workflow):面向任务,完成一件完整的事,由多个任务项(Action)组成,必须包含开始项
步骤4:添加表输入组件——订单明细表
操作说明:从左侧组件面板中找到"输入"分类,拖拽"表输入"组件到画布中央区域。
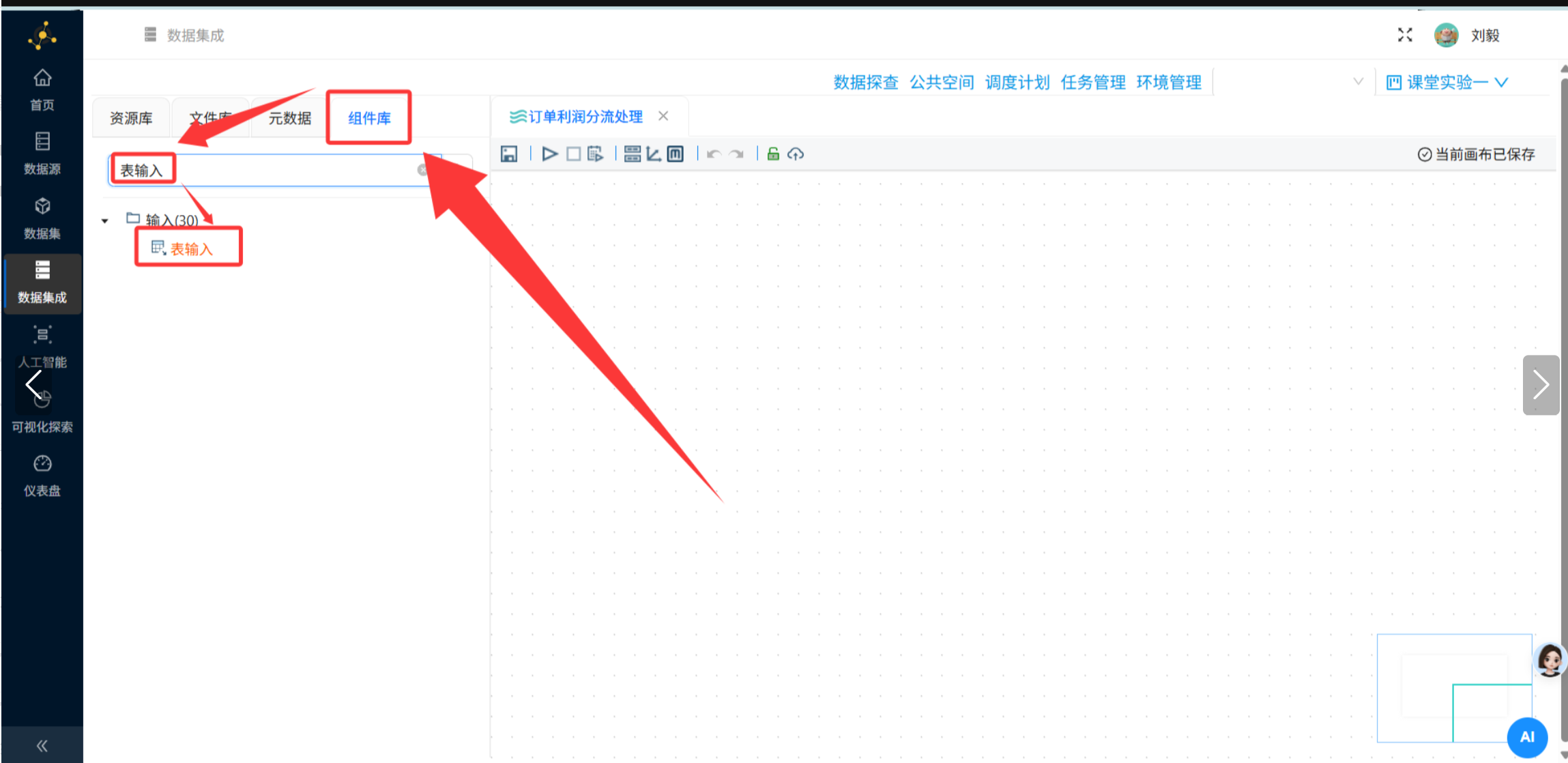
配置要点:
-
双击组件打开配置面板
-
数据库连接:选择平台内置的MySQL数据库连接
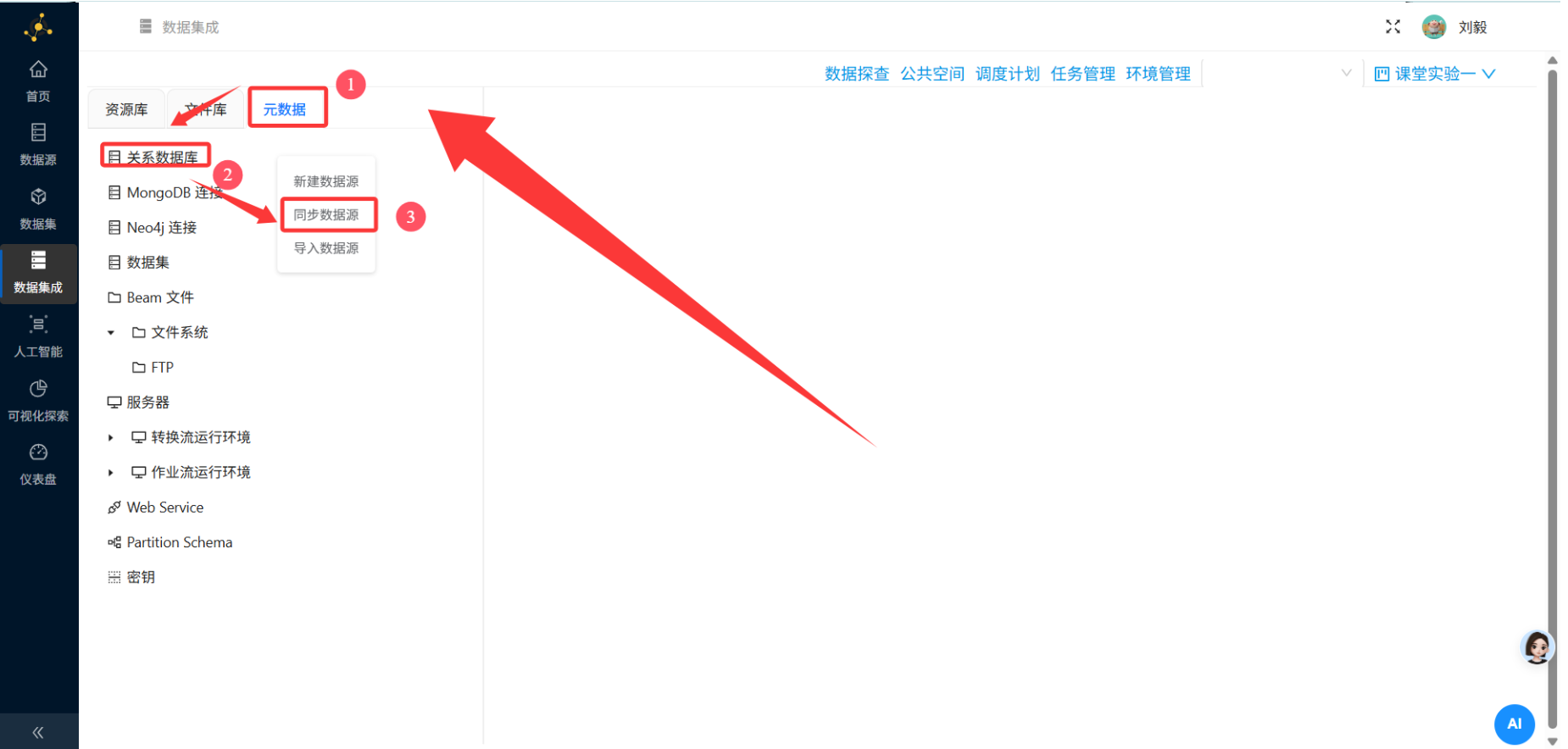
-
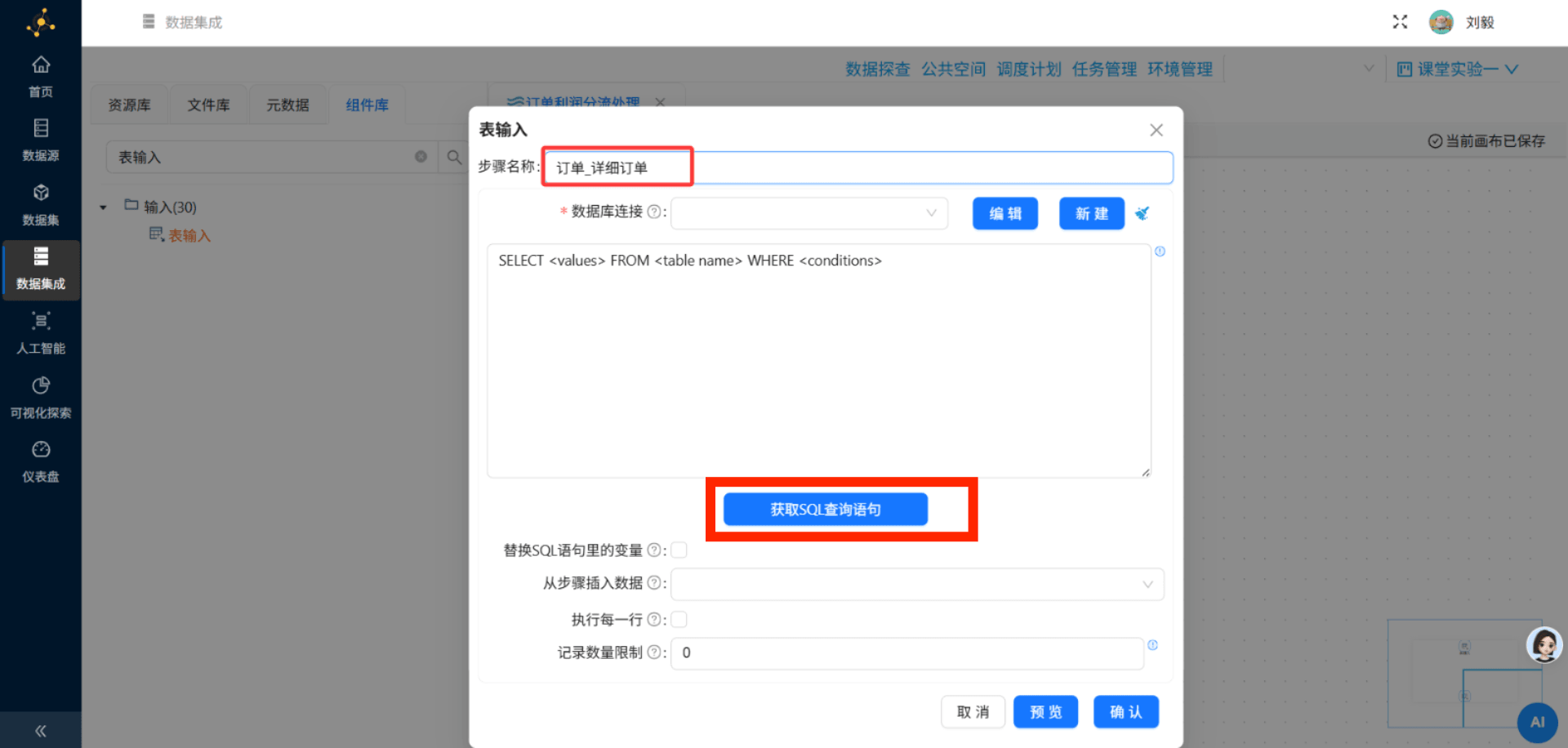
SQL语句:
SELECT * FROM business_anaylsis.order_detail-
可以点击"预览"按钮查看数据是否正确加载
-
确认字段包括:订单ID、产品ID、数量、单价等关键信息
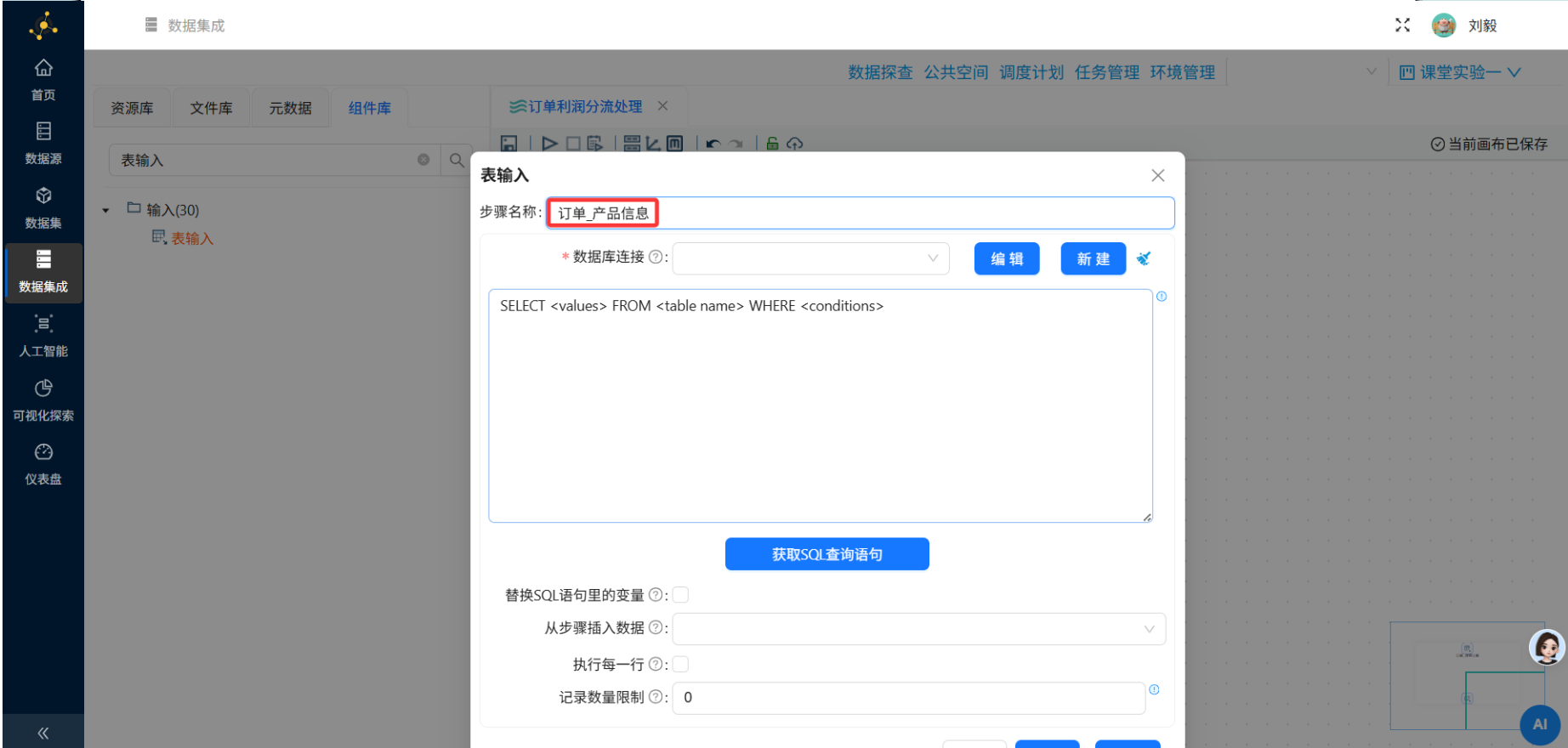
步骤5:添加表输入组件——产品信息表
操作说明:再次从组件面板拖拽一个"表输入"组件到画布,放置在订单明细表组件的右侧或下方。
配置要点:
-
双击组件打开配置面板
-
数据库连接:选择平台内置MySQL
-
SQL语句:
SELECT * FROM business_anaylsis.product-
确认字段包括:产品ID、产品名称、成本价等关键信息
-
两个表输入组件之间暂时不需要连接
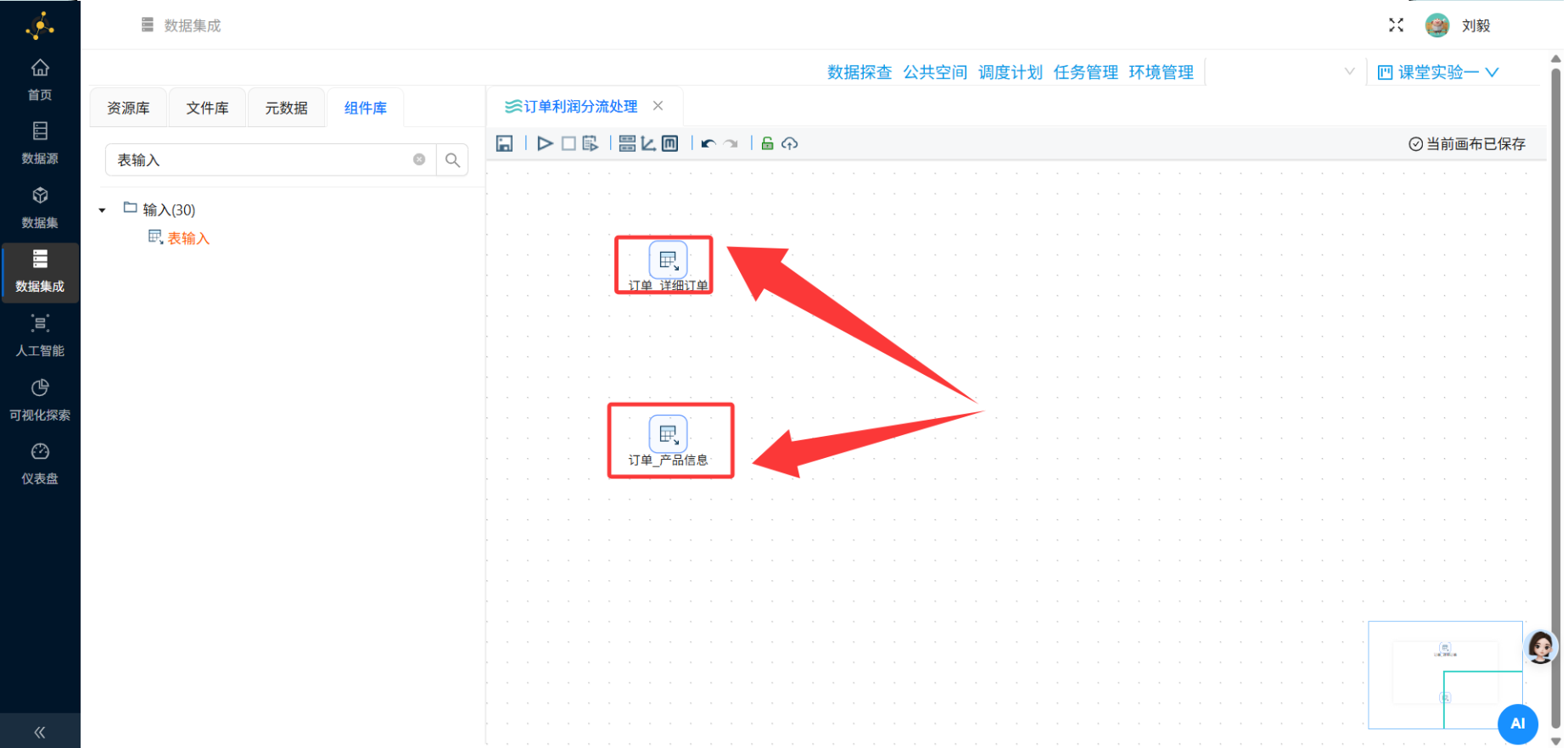
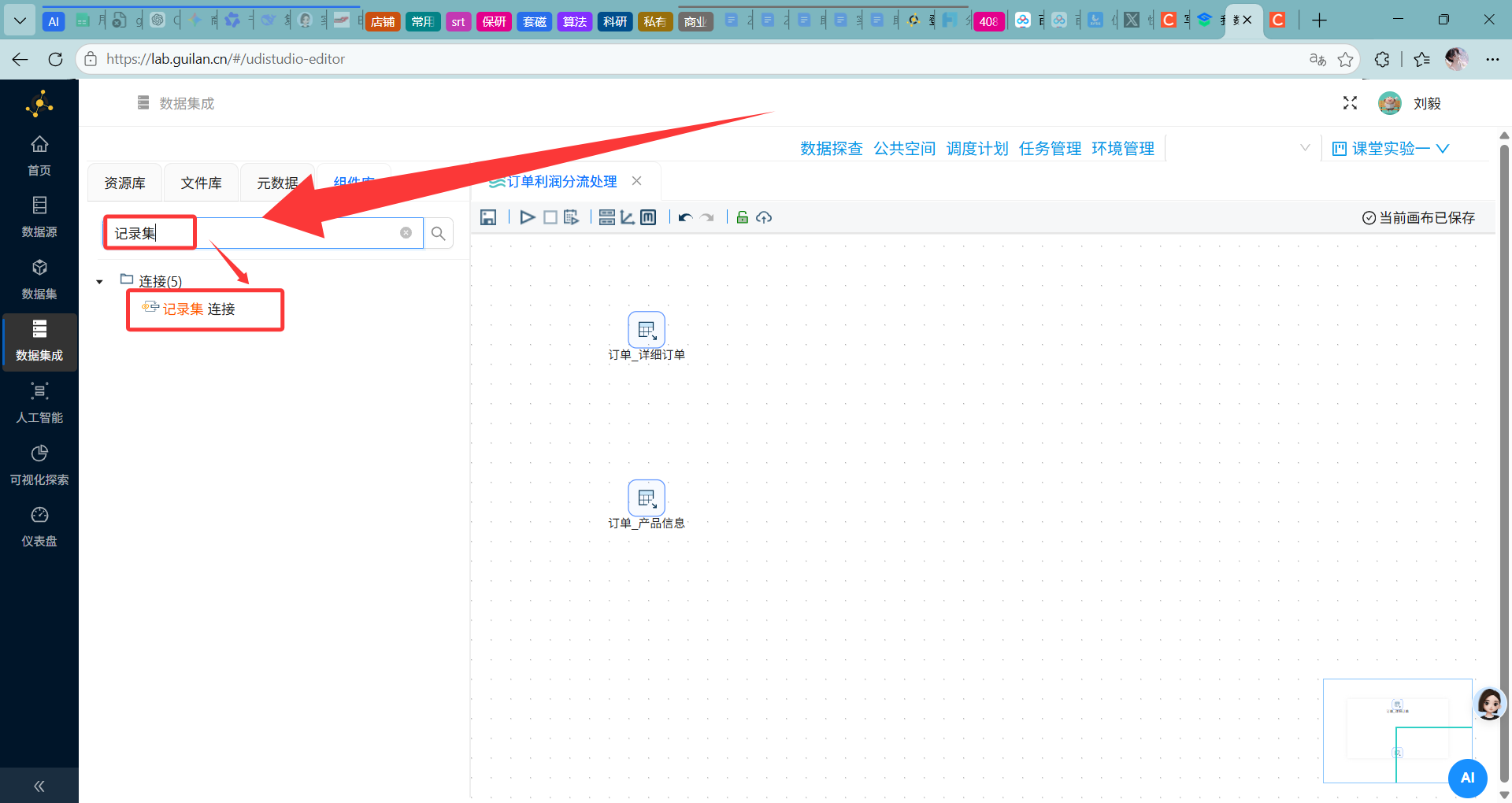
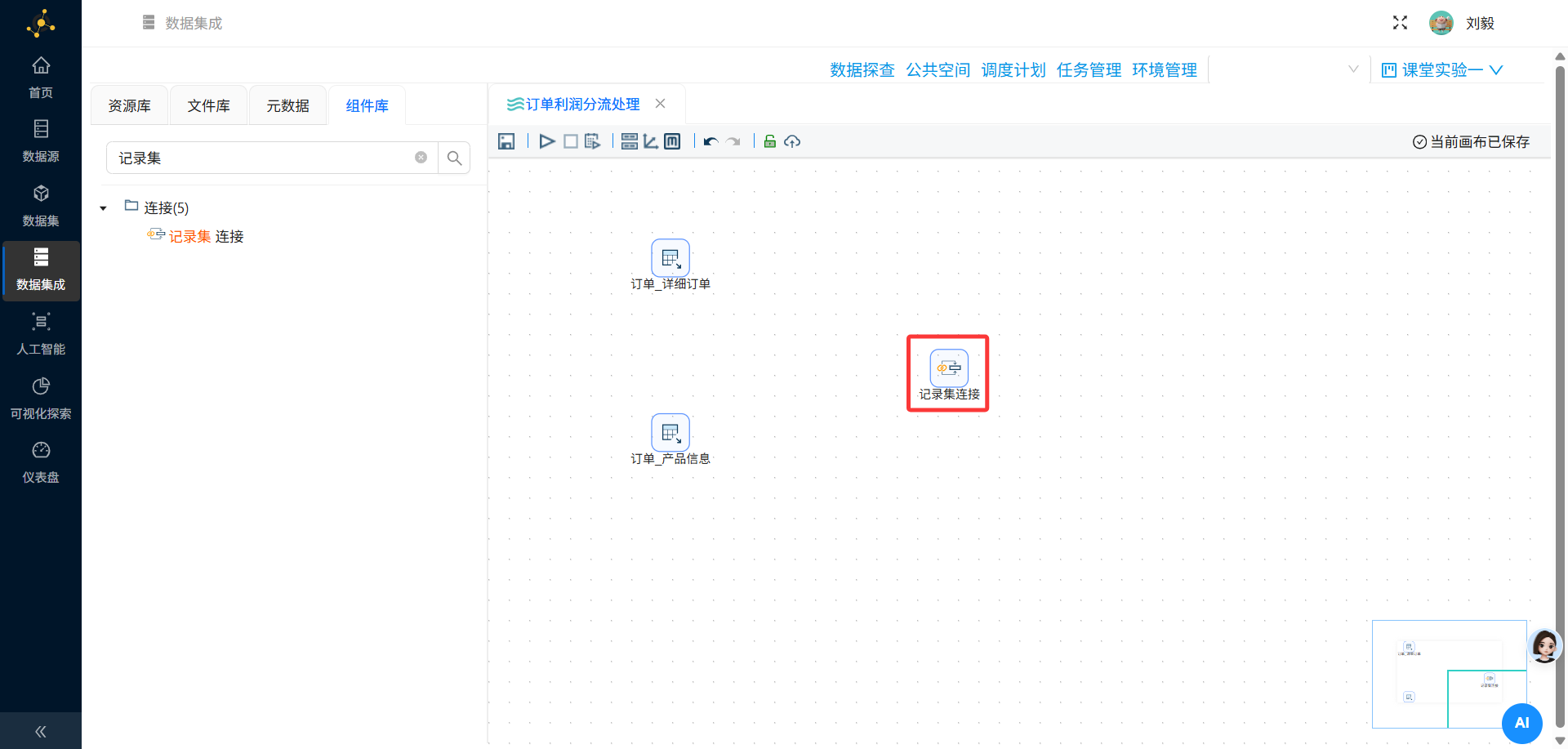
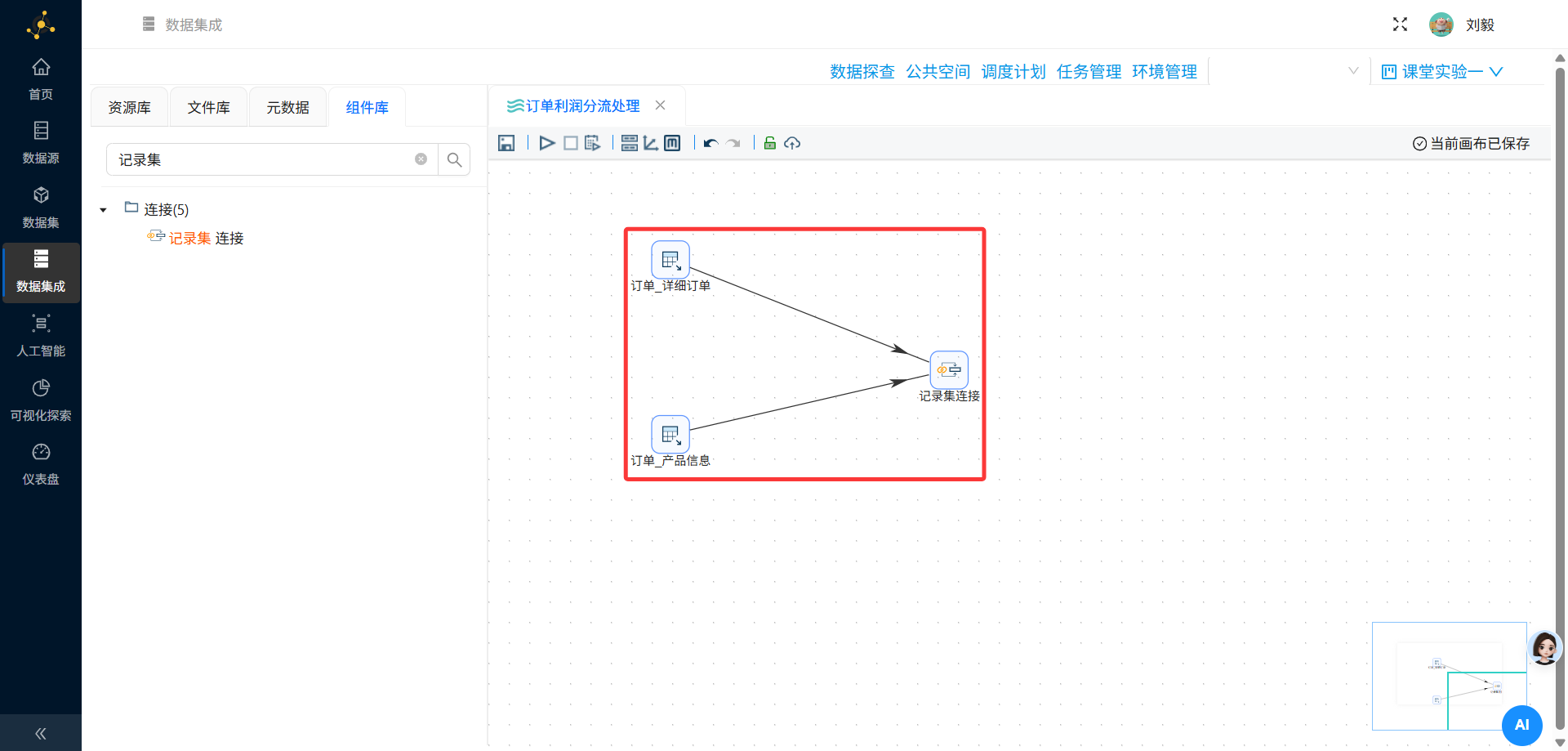
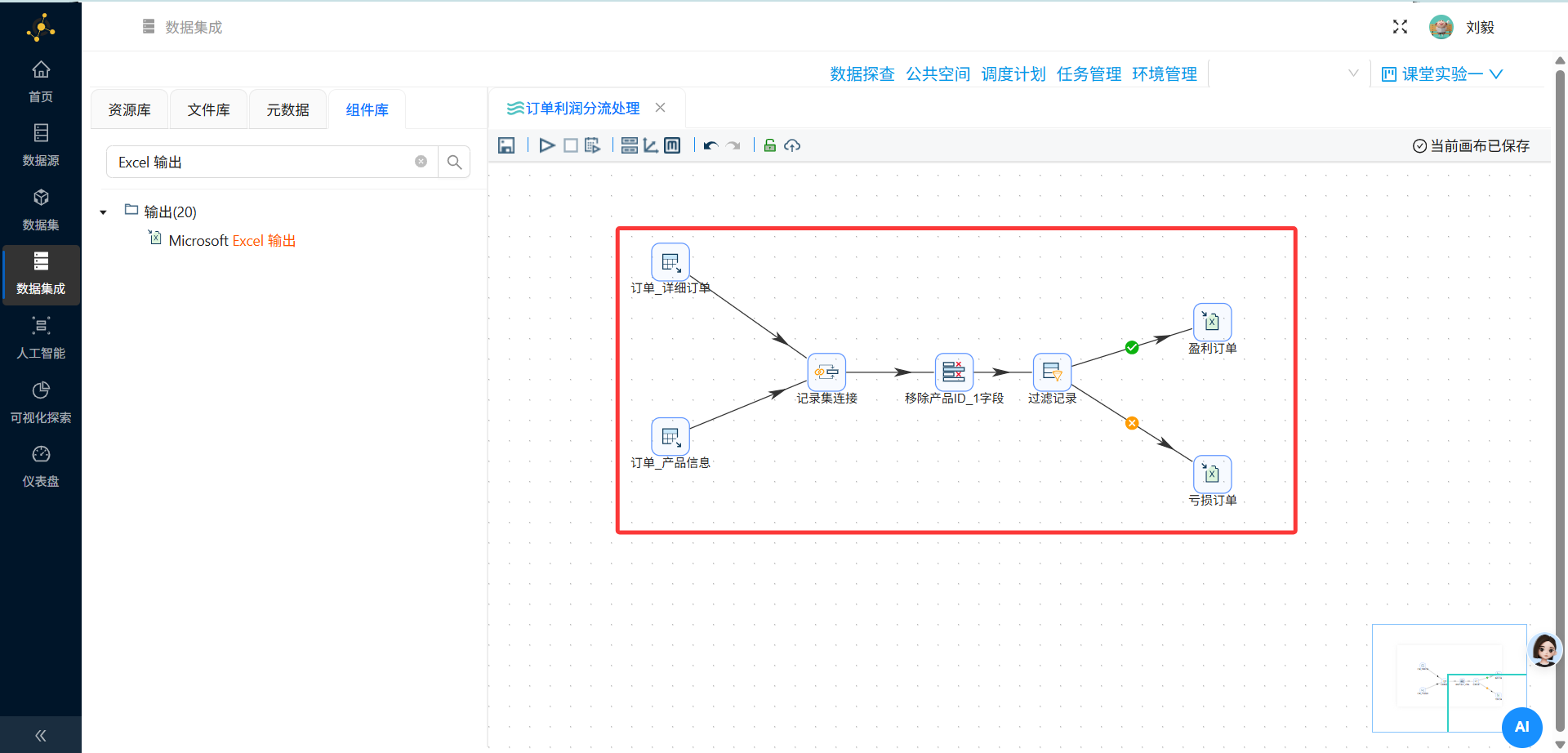
步骤6:添加记录集连接组件(多表关联)
操作说明:从组件面板"连接"分类中拖拽"记录集连接"组件到画布,将两个表输入组件通过Hops(节点连接)连接到该组件。
配置要点:
-
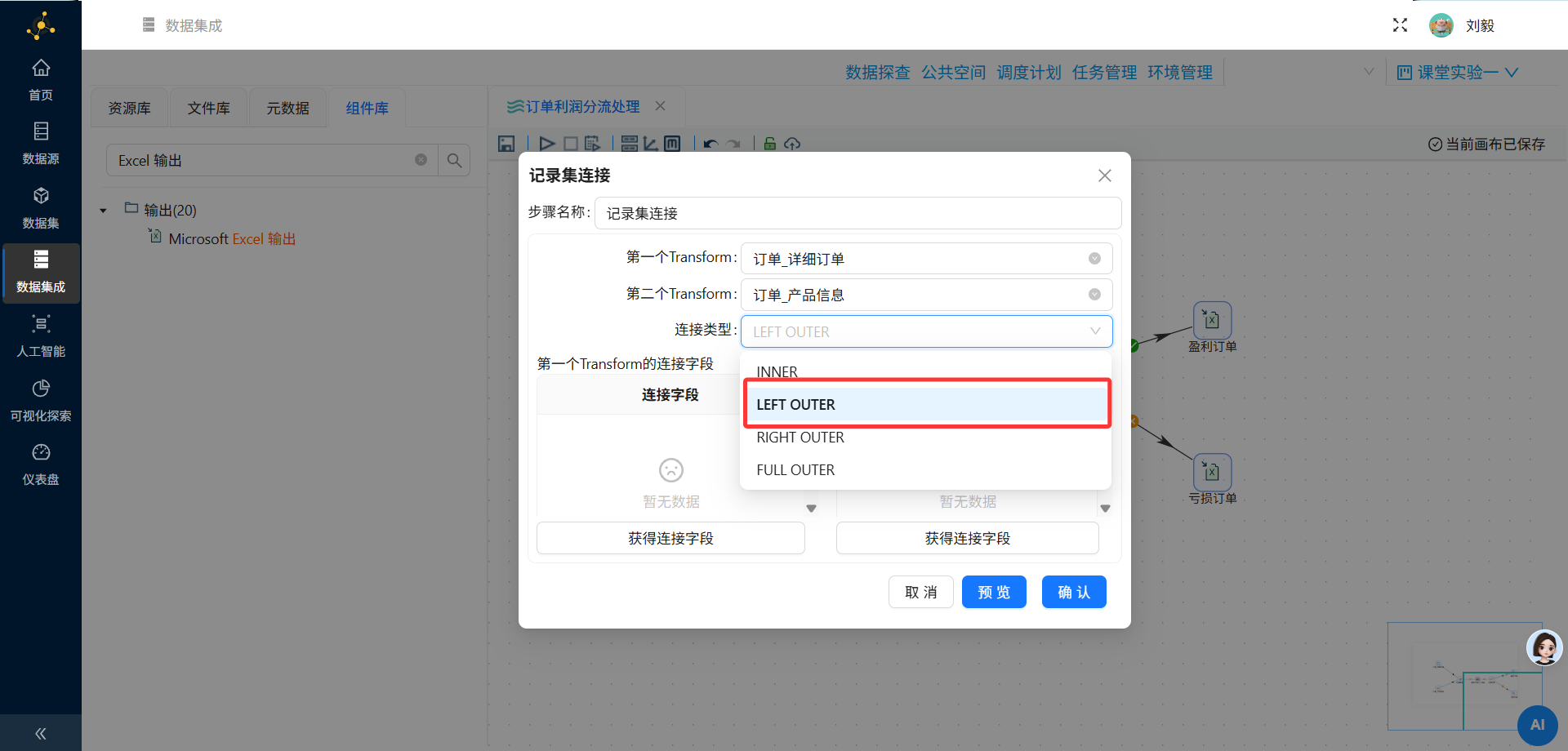
连接类型:选择 LEFT OUTER JOIN(左外连接)
-
左外连接会保留左表(订单明细表)的所有记录,即使右表(产品信息表)中没有匹配项
-
-
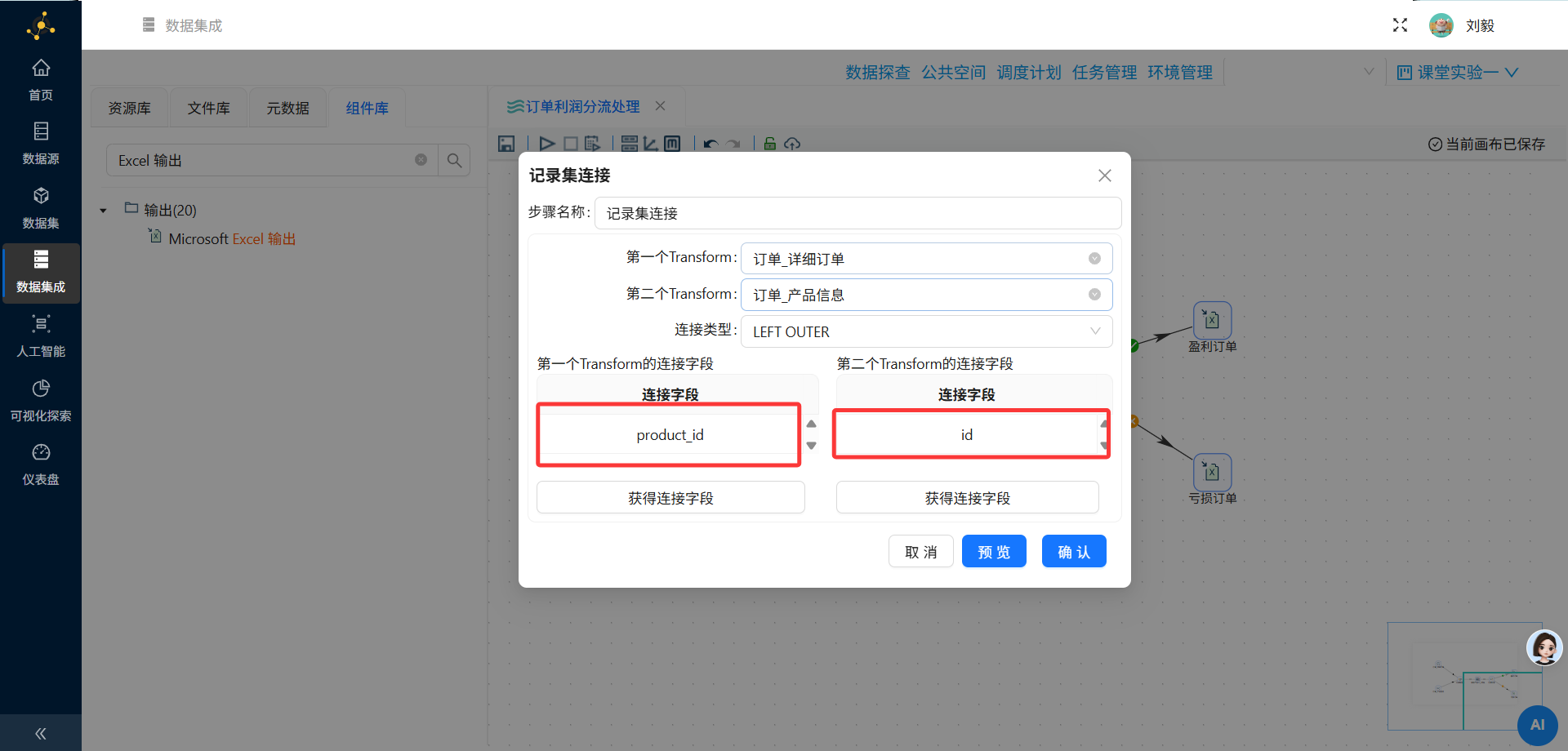
连接字段:选择两个表中用于关联的字段,通常是产品ID(product_id)
-
左表字段:订单明细表.product_id
-
右表字段:产品信息表.id
-
-
Hops连接方式:
-
从订单明细表的表输入组件拖拽连线到记录集连接组件(作为左表输入)
-
从产品信息表的表输入组件拖拽连线到记录集连接组件(作为右表输入)
-
核心概念:Hops是数据传输的通道,即在画布上将各个步骤连接起来的那根线。数据通过Hops从一个步骤流向另一个步骤。
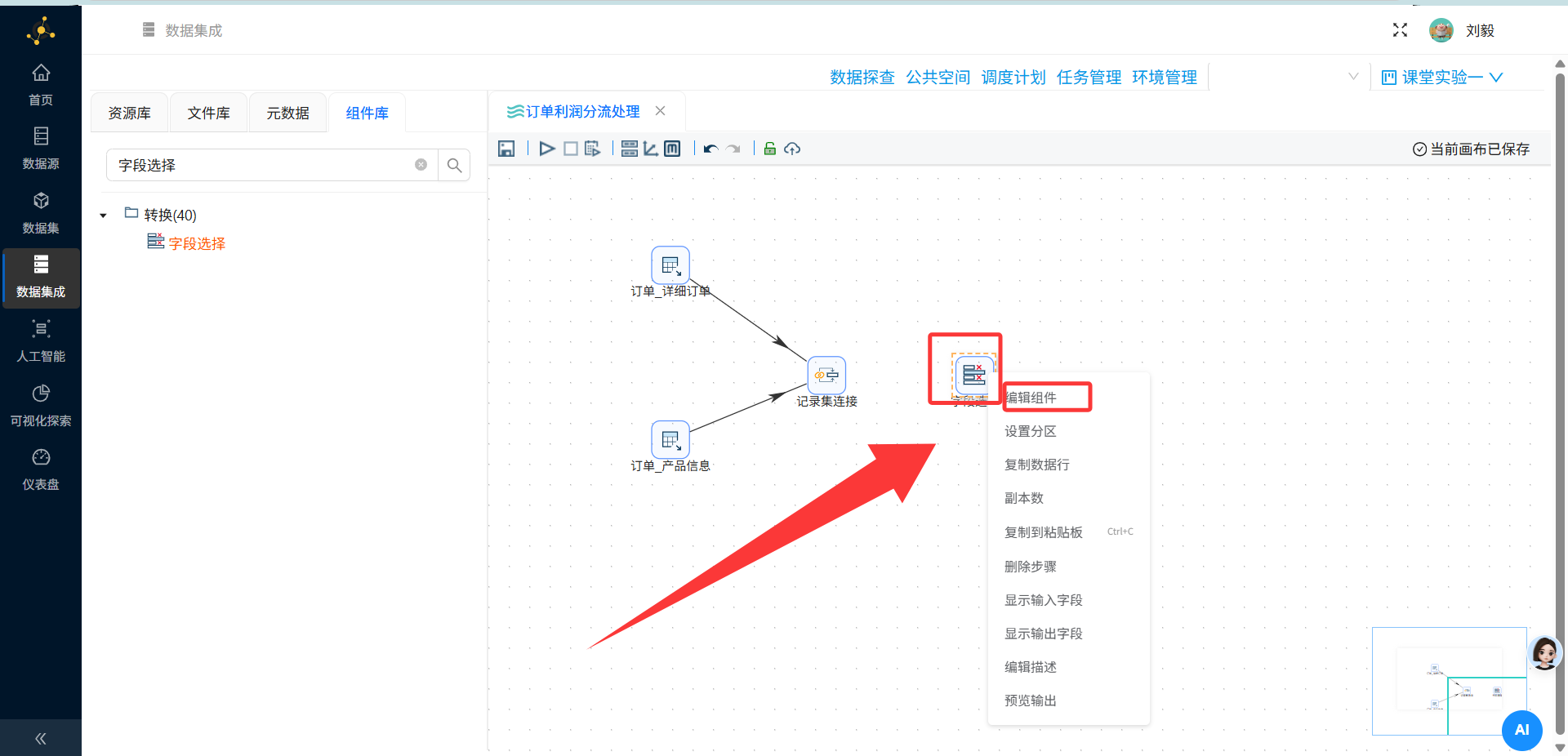
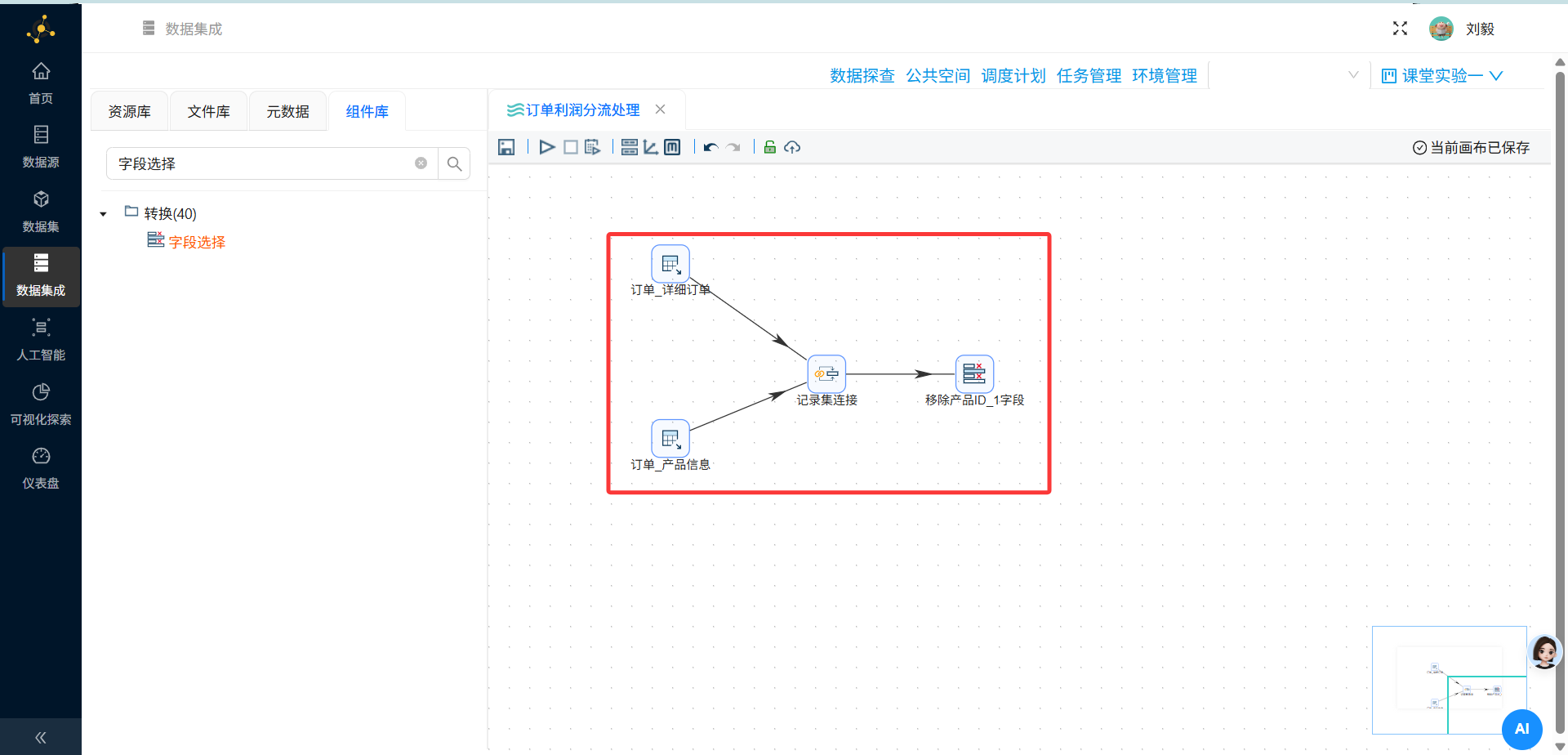
步骤7:添加字段选择组件(移除重复ID)
操作说明:从组件面板"转换"分类中拖拽"字段选择"组件到画布,连接至记录集连接组件的输出端。
配置要点:
-
双击打开字段选择配置面板
-
在"移除"标签页中,可以看到所有来自连接后的字段列表
-
关键操作:在列表中选中除
id以外的所有字段,右键“删除选中的行”。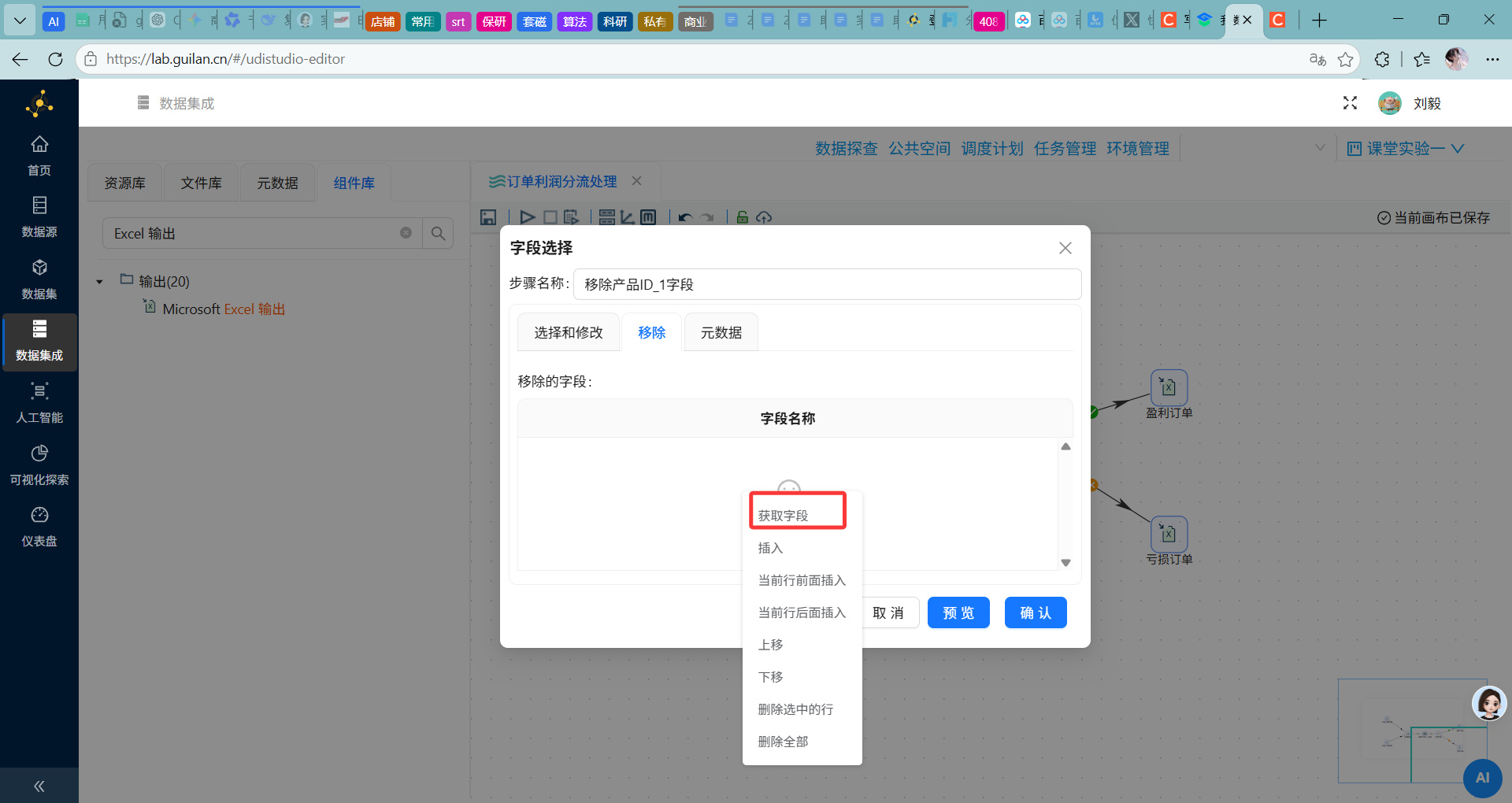
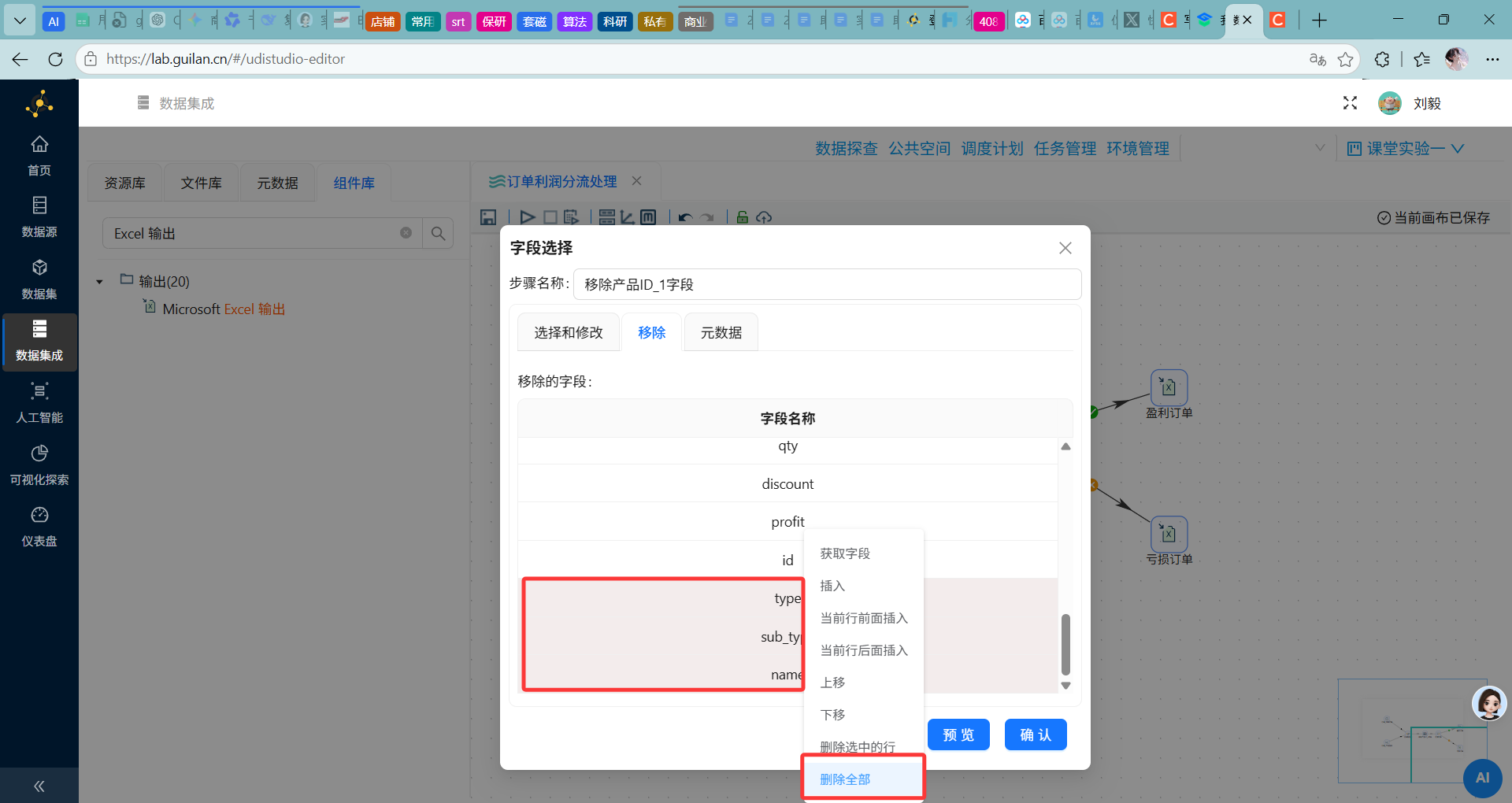
-
确认需要保留的字段
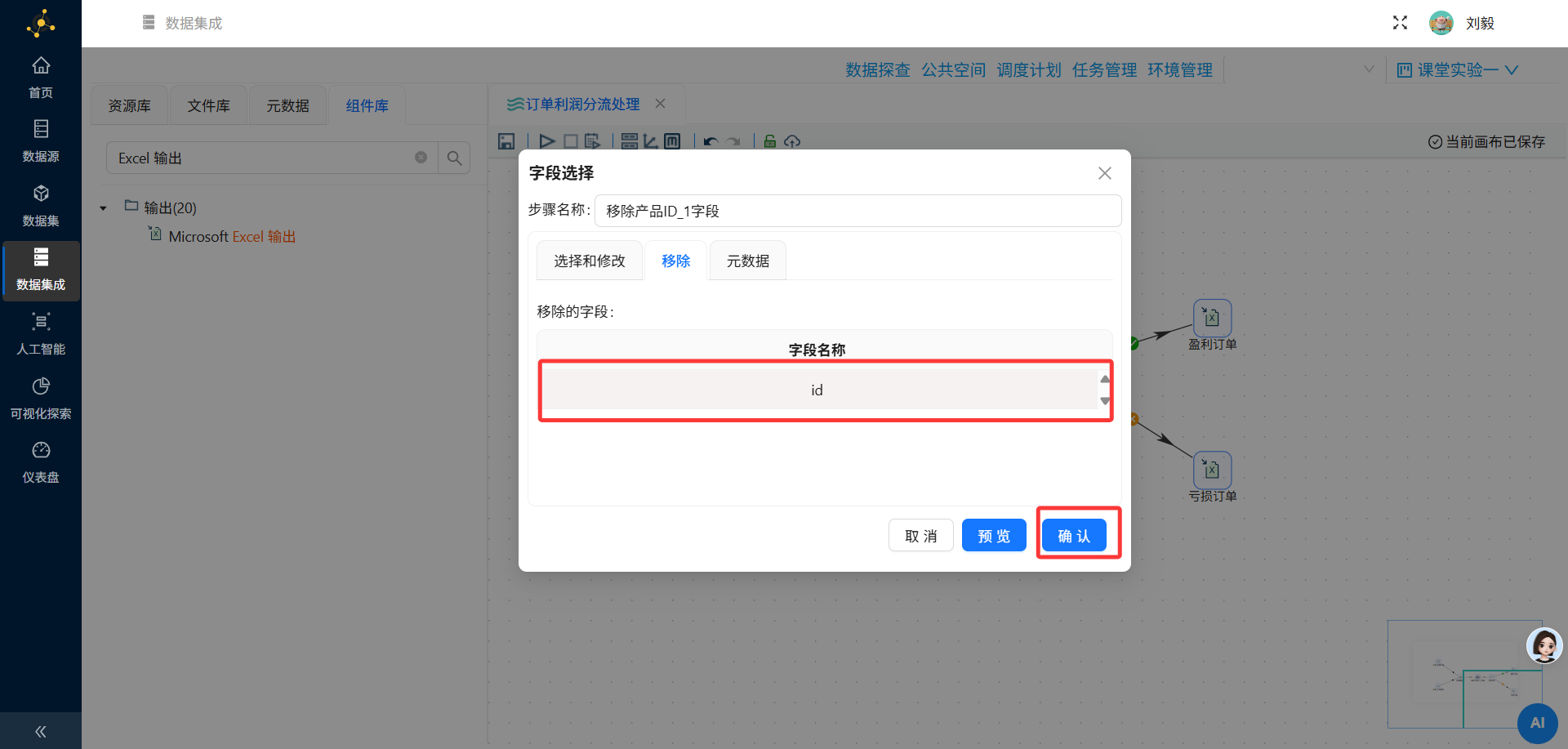
-
这一步的目的是避免后续处理中出现字段歧义
步骤8:添加过滤记录组件(按利润分流)
操作说明:从组件面板"流程"分类中拖拽"过滤记录"组件到画布,连接至字段选择组件的输出端。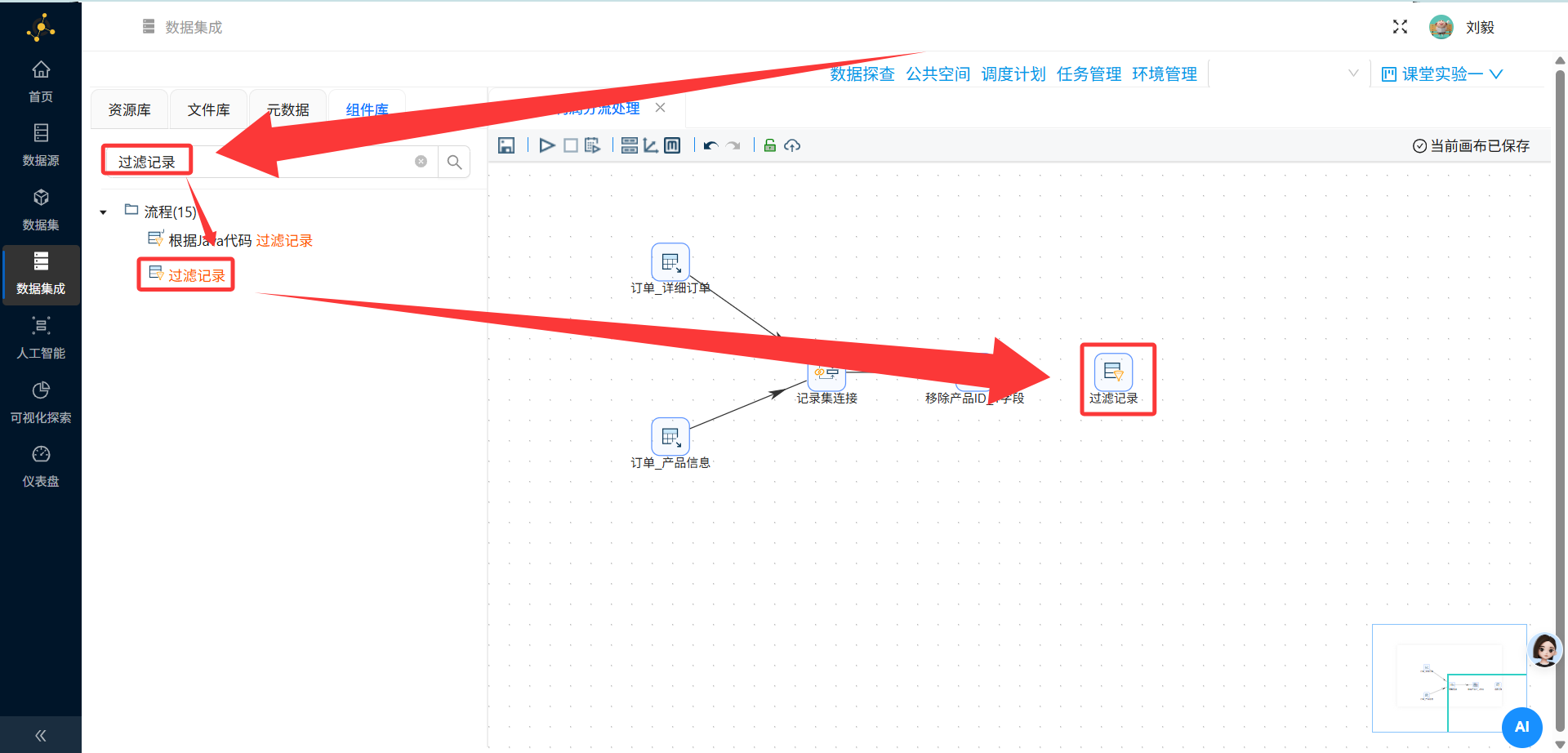
配置要点:
-
双击打开过滤记录配置面板
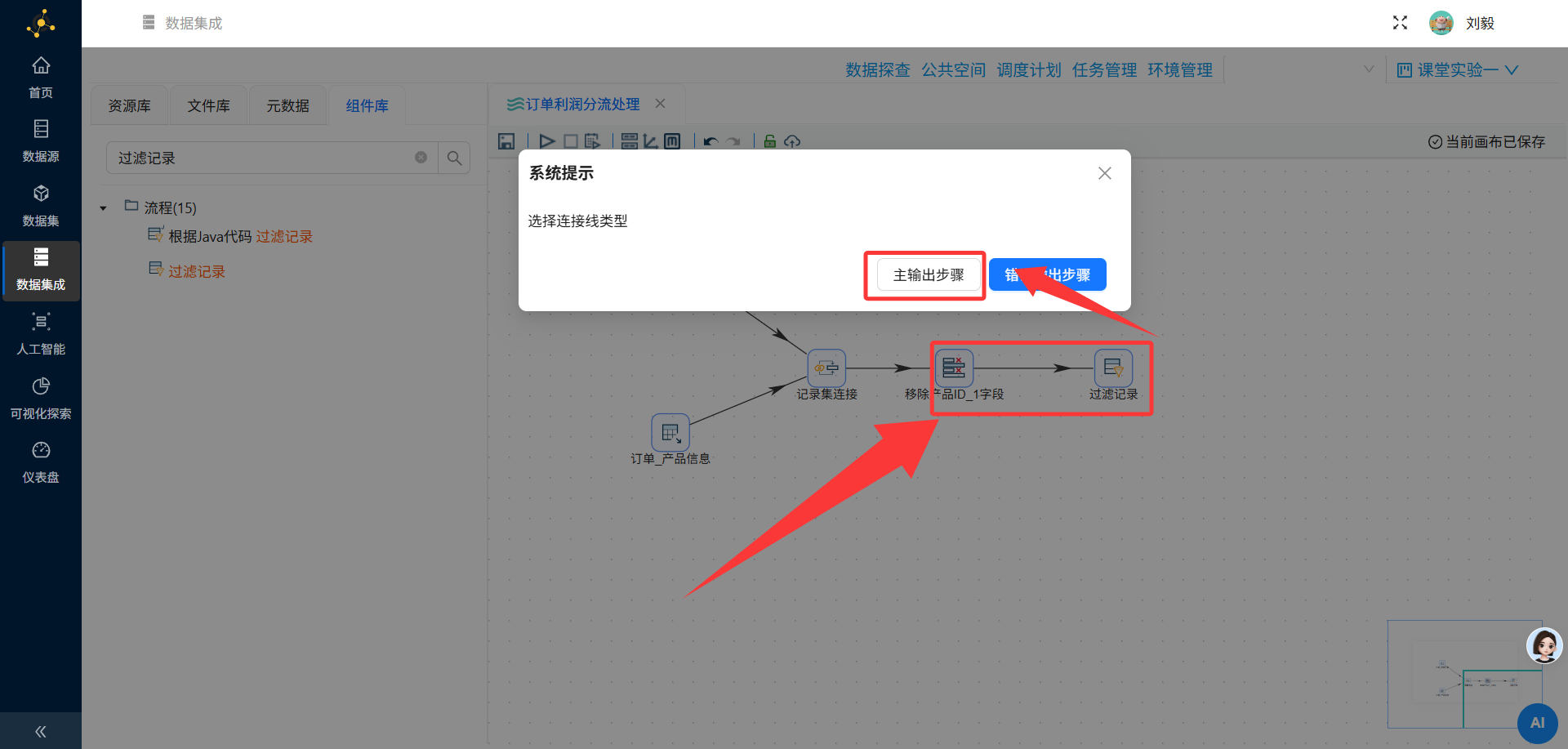
-
判断条件:
profit >= 0或amount - cost >= 0(根据实际字段名调整)-
如果平台中没有直接的profit字段,可能需要先通过"计算器"组件计算利润
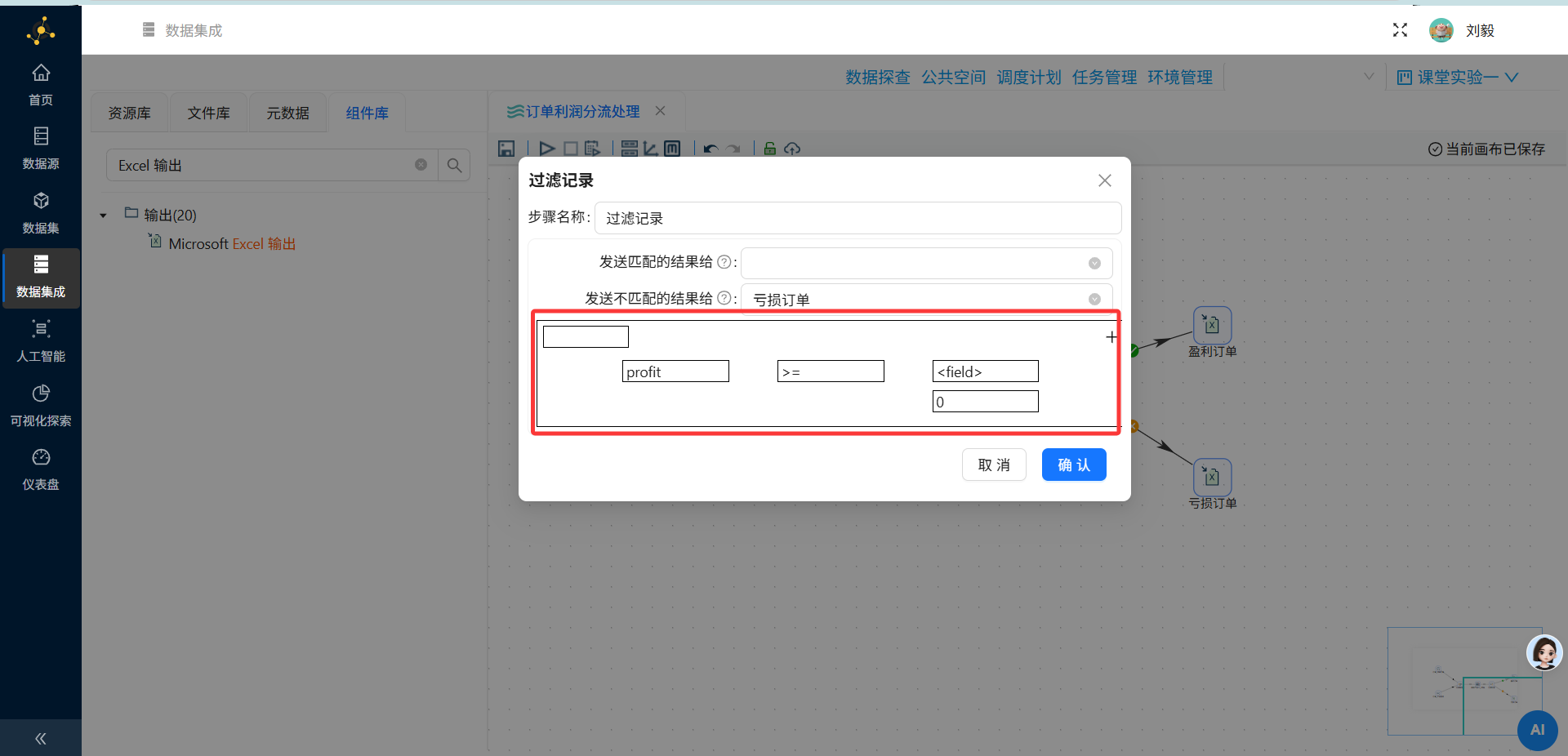
-
-
True输出路径:连接至盈利订单的Excel输出组件
-
条件满足时(profit >= 0),数据流向True分支
-
-
False输出路径:连接至亏损订单的Excel输出组件
-
条件不满足时(profit < 0),数据流向False分支
-
步骤9:添加Excel输出组件——盈利订单
操作说明:从组件面板"输出"分类中拖拽"Excel输出"组件到画布,连接至过滤记录组件的True输出端。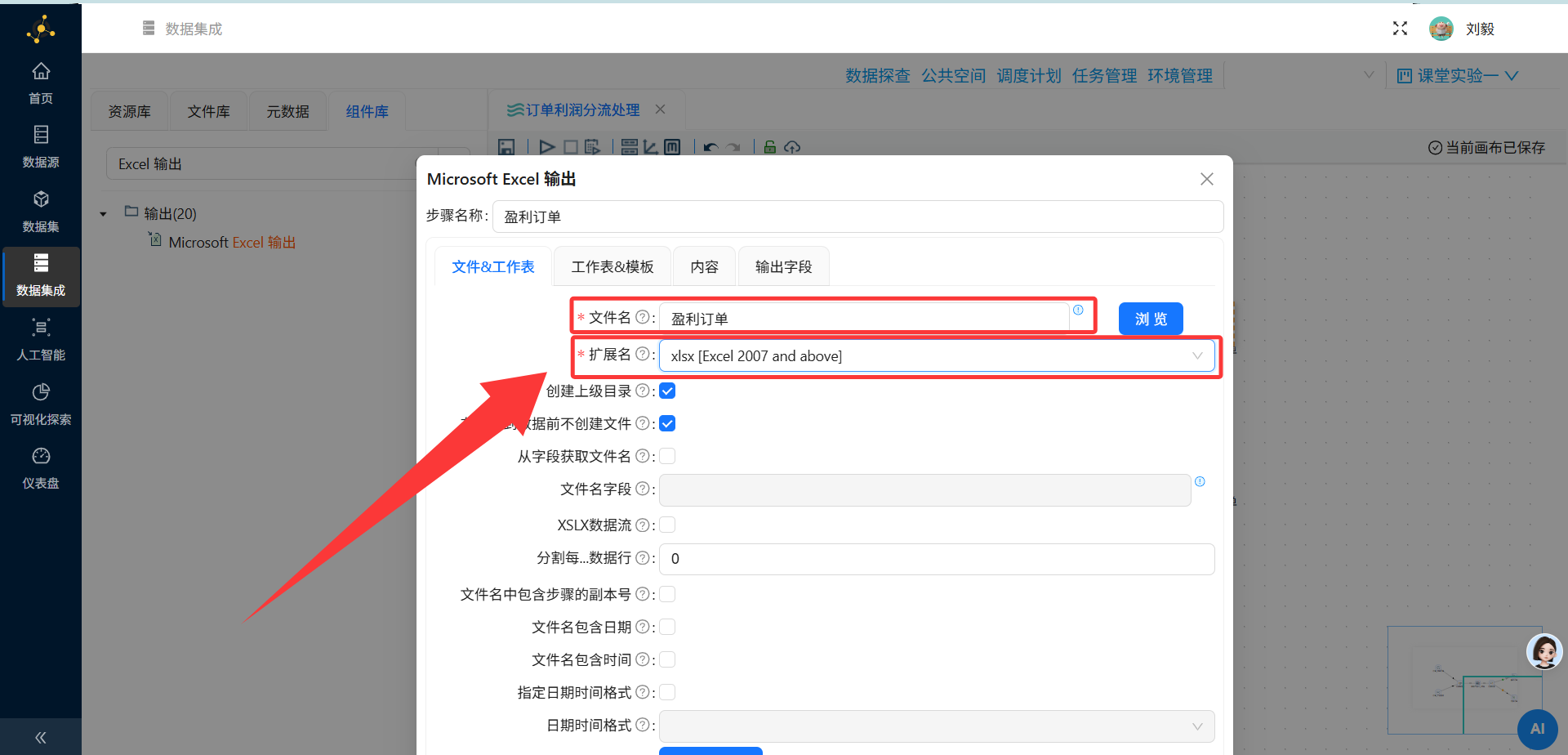
配置要点:
-
双击打开Excel输出配置面板
-
输出文件名:
盈利订单 -
文件格式:选择 xlsx [Excel 2007 and above]
-
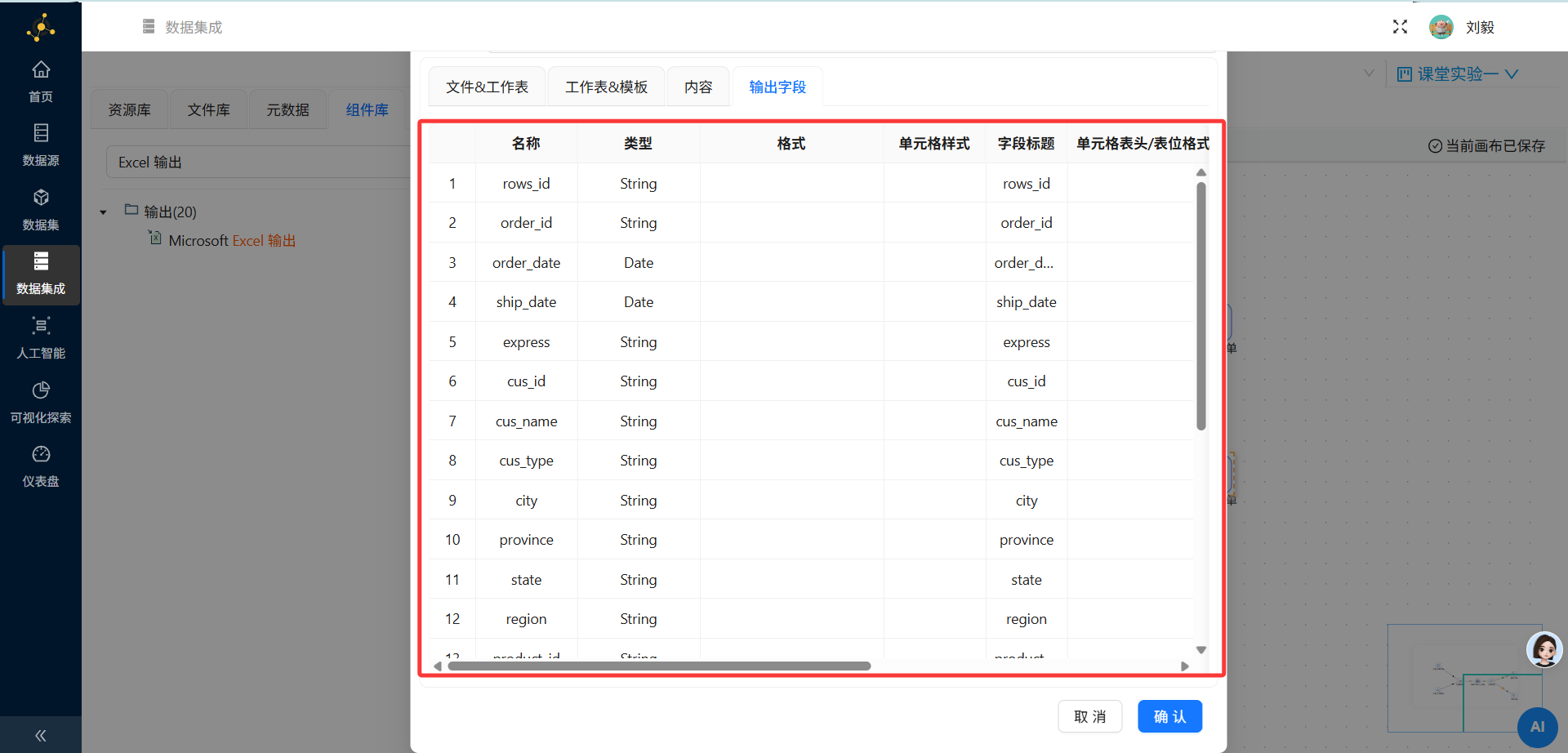
字段映射:确认所有需要输出的字段都已勾选
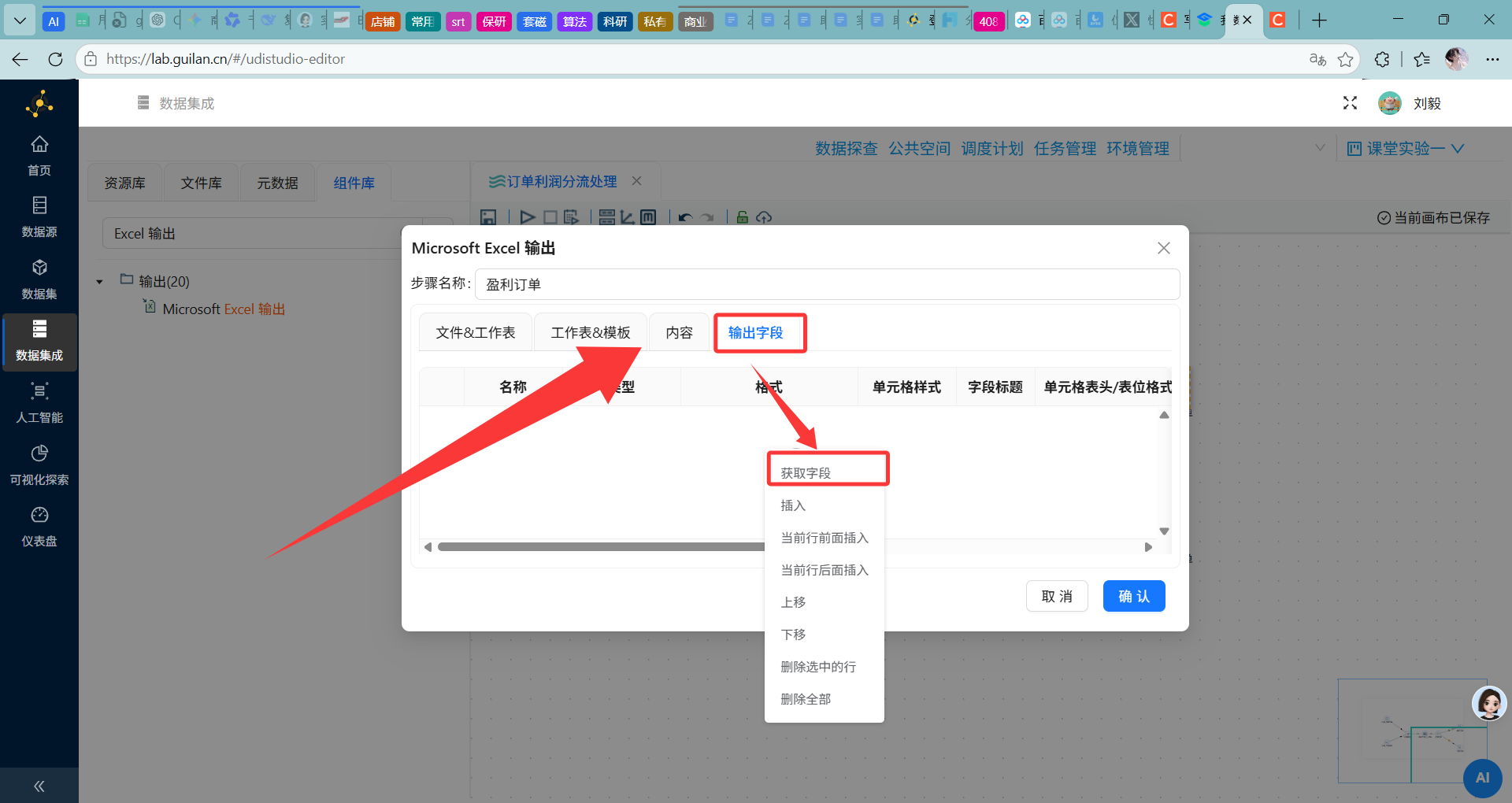
-
输出路径:选择或填写文件保存路径(如平台默认的输出目录)
步骤10:添加Excel输出组件——亏损订单
操作说明:再次拖拽一个"Excel输出"组件到画布,连接至过滤记录组件的False输出端。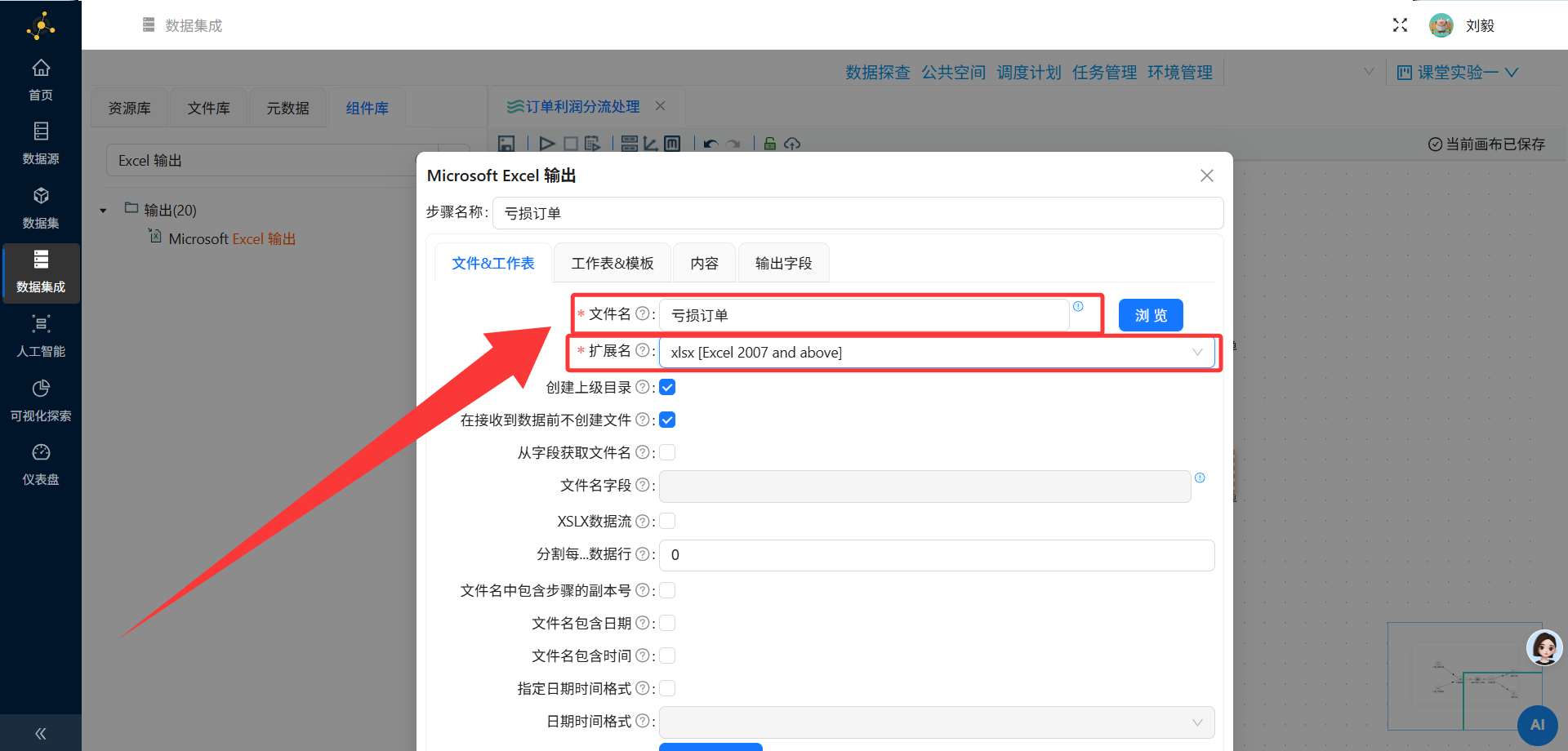
配置要点:
-
双击打开Excel输出配置面板
-
输出文件名:
亏损订单 -
文件格式:选择 xlsx [Excel 2007 and above]
-
字段映射:与盈利订单保持一致,便于后续对比分析
-
输出路径:与盈利订单保存在同一目录下
步骤11:执行转换并查看结果
操作说明:完成所有组件配置和连接后,点击画布上方的"执行"或"运行"按钮,启动转换流程。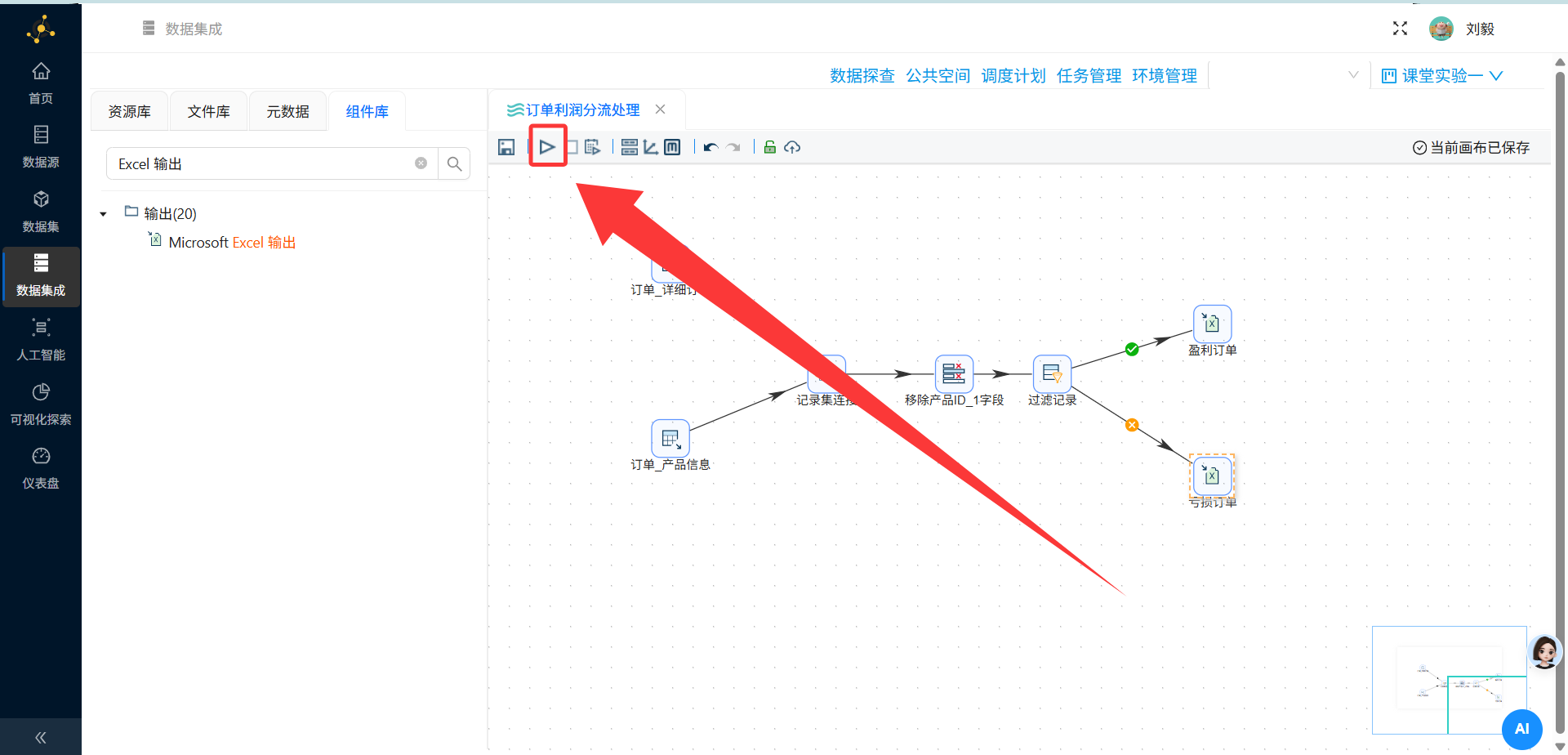
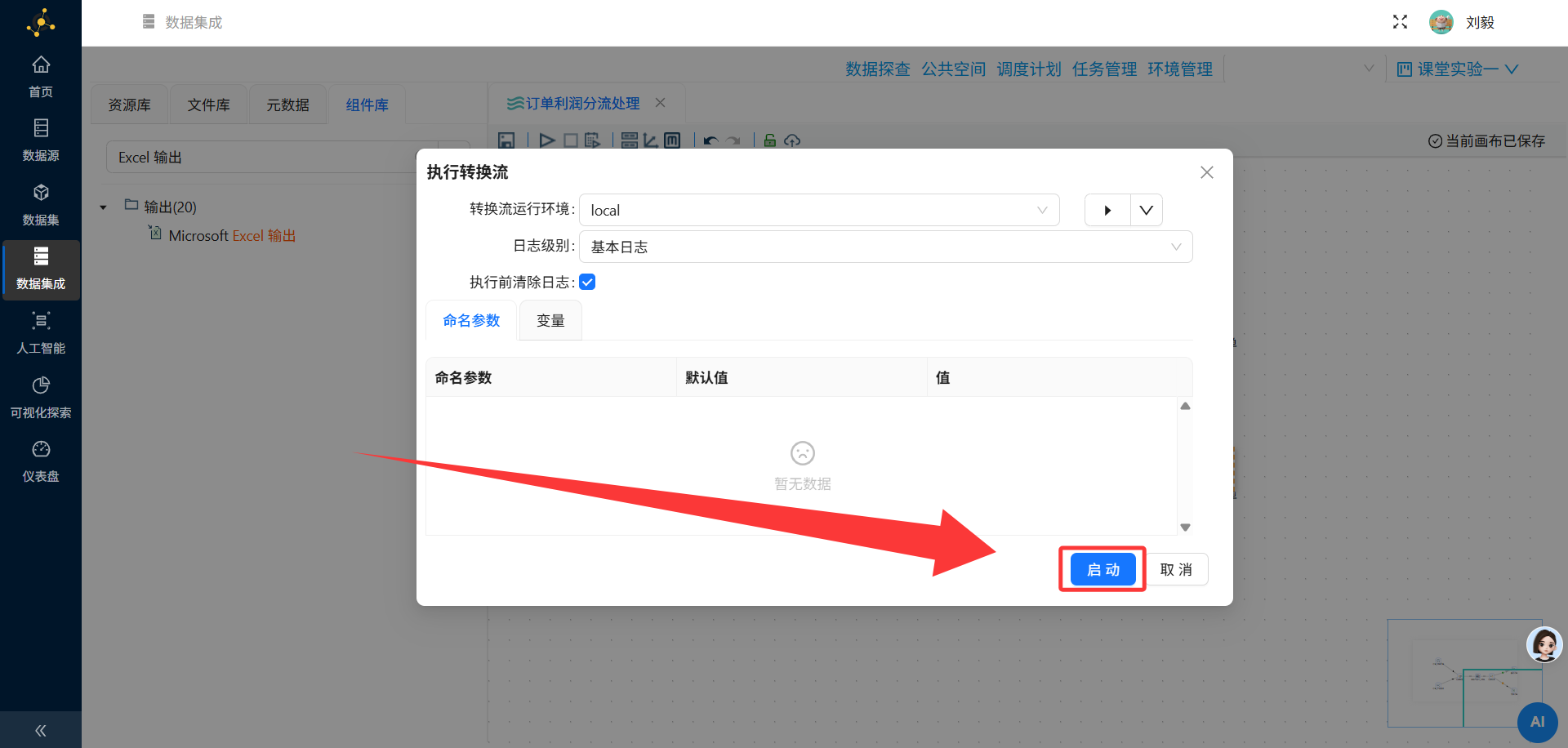
配置要点:
-
执行前检查清单:
-
[ ] 所有组件之间的Hops连接是否正确
-
[ ] 两个表输入组件是否都配置了正确的SQL语句
-
[ ] 记录集连接的连接类型是否为LEFT OUTER JOIN
-
[ ] 过滤记录的条件表达式是否正确
-
[ ] 两个Excel输出的文件名是否区分明确
-
-
执行后查看:
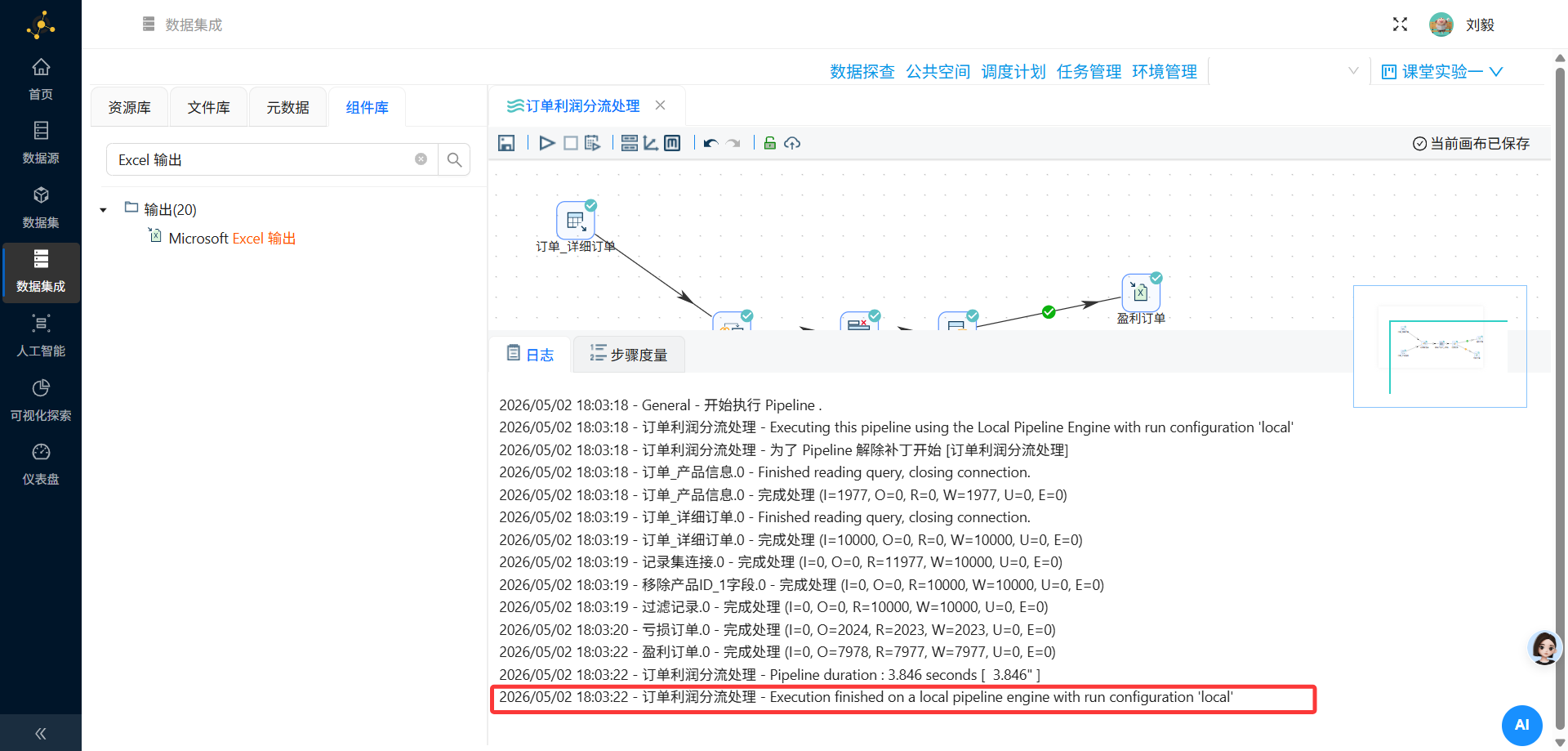
-
查看执行日志,确认每个步骤的输入/输出记录数
-
检查是否有报错信息(红色提示)
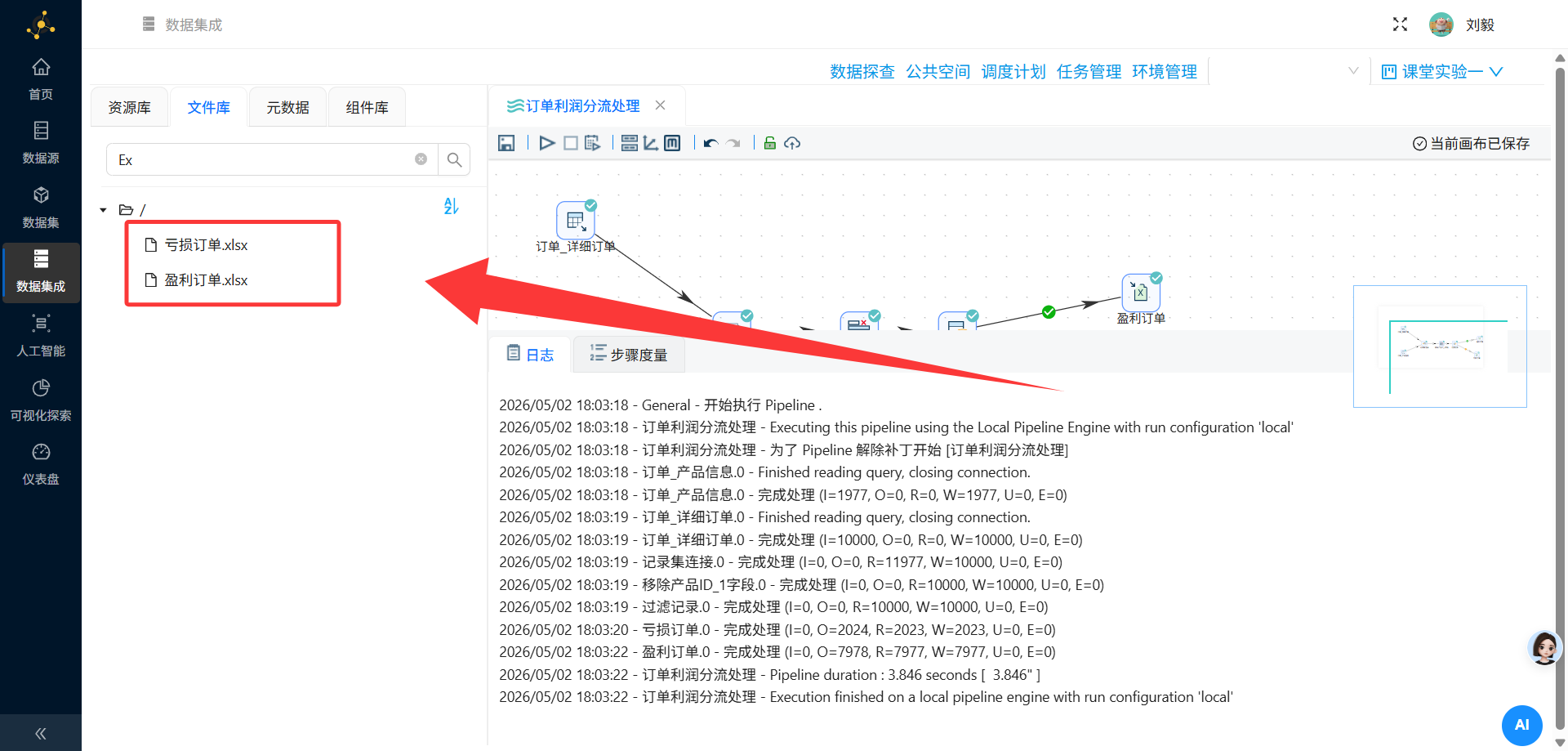
-
确认两个Excel文件是否成功生成
-
三、实验结果
3.1 输出文件
执行转换后,成功生成了两个Excel文件:
| 文件名 | 数据说明 | 业务说明 |
|---|---|---|
盈利订单.xlsx |
利润 ≥ 0 的订单数据 | 规范的优质数据底座,可供进一步分析高利润产品特征或爆款画像 |
亏损订单.xlsx |
利润 < 0 的订单数据 | 可直接分发给供应链或财务部门,用于追踪亏损原因并及时止损 |
盈利订单: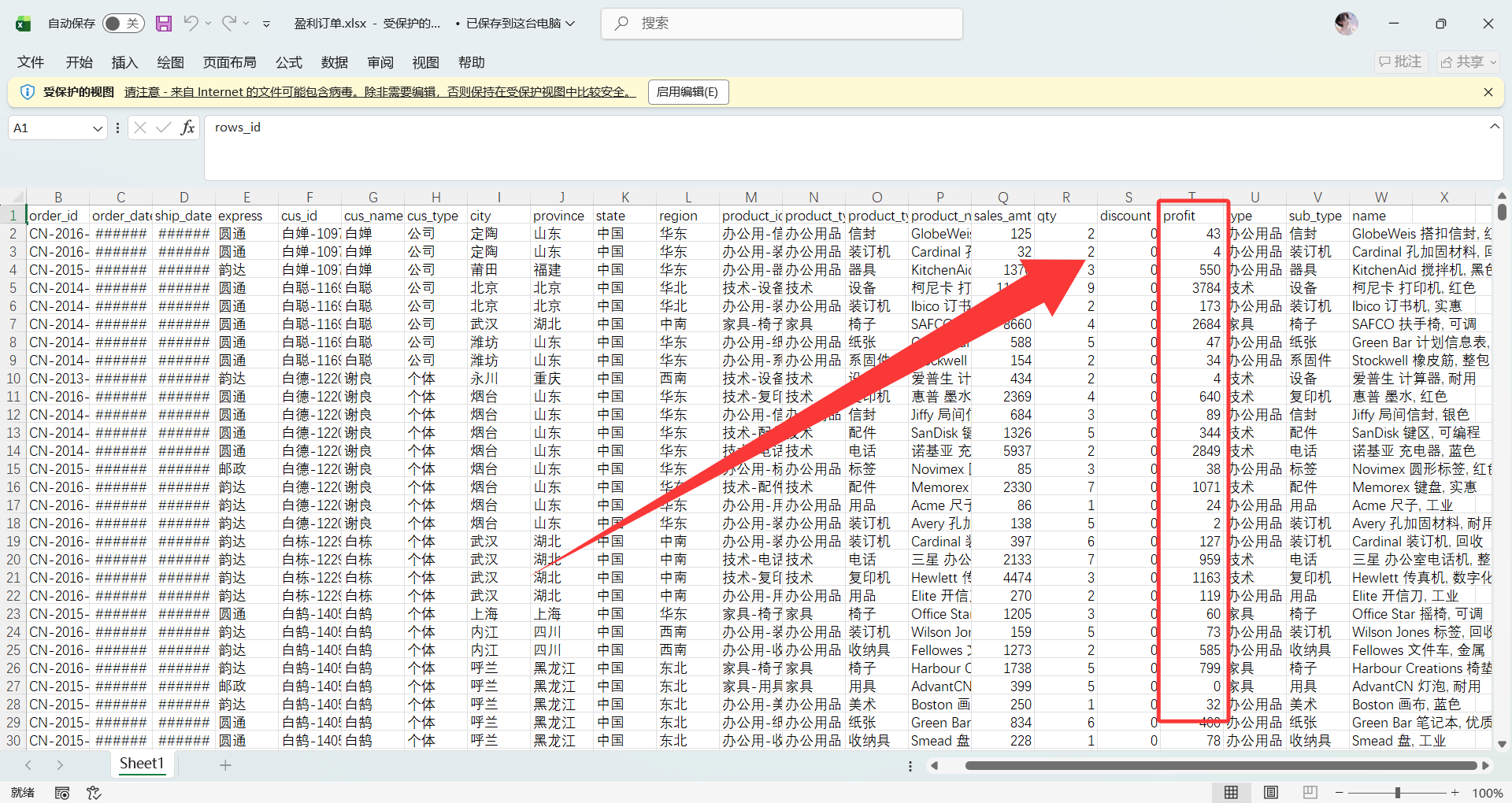
亏损订单: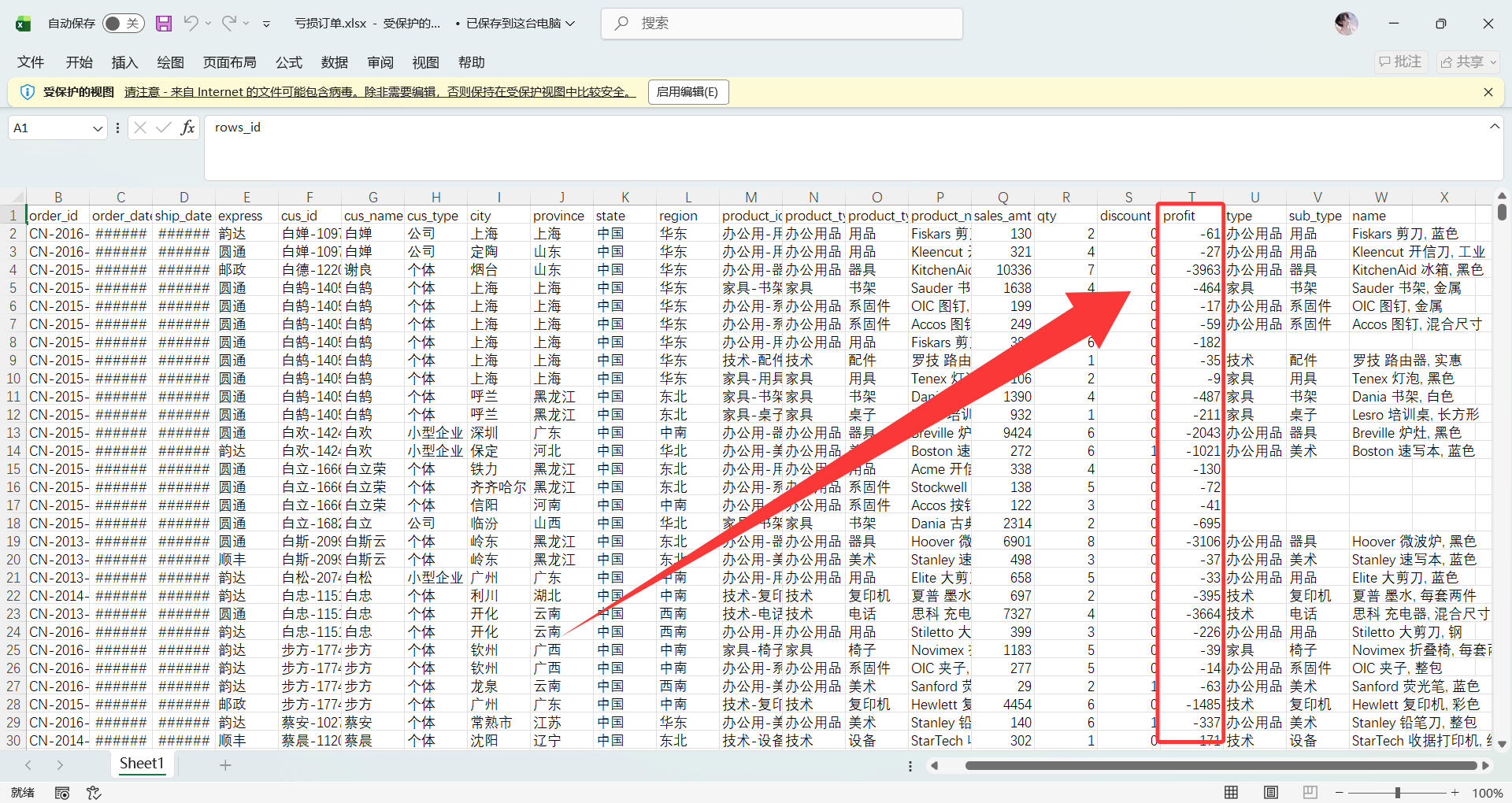
3.2 结果验证
我对输出结果进行了以下验证:
-
记录数核对:两个文件的数据量之和应与原始订单明细表的总记录数一致(考虑左外连接可能产生的NULL值情况)
-
利润计算抽查:随机抽取几条记录,手动计算
数量 × (单价 - 成本价),与文件中的利润值进行比对 -
边界值检查:检查利润恰好为0的订单是否被正确归类到盈利订单中(因为条件是
profit >= 0)
四、易错板块(问题与解决)
问题1:记录集连接后字段重复导致后续组件报错
问题现象:在执行转换时,"字段选择"或"过滤记录"组件提示存在重复的字段名,无法继续执行。
问题原因:订单明细表和产品信息表中都包含名为 id 或 product_id 的字段,经过LEFT OUTER JOIN连接后,这两个字段会同时出现在结果集中,导致字段名冲突。
解决方法:
-
在"记录集连接"组件的配置中,注意查看输出字段列表
-
在后续的"字段选择"组件中,明确取消勾选重复的字段,只保留其中一个
-
或者在表输入的SQL语句中使用
AS关键字为字段起别名,例如:
SELECT o.id AS order_id, p.id AS product_id, ...问题2:过滤记录条件表达式语法错误
问题现象:执行到"过滤记录"组件时失败,日志提示条件表达式解析错误。
问题原因:平台对条件表达式的语法有特定要求,可能使用了不支持的运算符或字段名拼写错误。例如,直接写 利润 >= 0 而不是字段名,或者使用了中文符号。
解决方法:
-
确认使用的字段名与上游组件输出的字段名完全一致(注意大小写)
-
使用标准的比较运算符:
>=、<、=、!=等 -
如果利润需要计算,应先在"计算器"组件中计算好,再在过滤记录中使用该计算字段
-
表达式示例:
profit >= 0或amount * (price - cost) >= 0
问题3:Excel输出文件路径配置错误导致文件找不到
问题现象:转换执行成功,但在指定的目录下找不到生成的Excel文件。
问题原因:输出路径配置不正确,或者平台对输出路径有特定要求(如必须使用绝对路径或特定目录)。
解决方法:
-
检查Excel输出组件中的"文件名"配置,确保包含完整路径或正确的相对路径
-
如果平台有默认的输出目录,尝试只填写文件名,不填写路径
-
执行完成后,在平台的"文件管理"或"输出目录"中查找生成的文件
-
也可以在配置中使用平台变量,如
${Internal.Entry.Current.Directory}/盈利订单.xlsx
问题4:左外连接导致大量NULL值
问题现象:连接后的数据中,产品信息表的字段出现大量NULL值。
问题原因:LEFT OUTER JOIN会保留左表的所有记录,如果右表(产品信息表)中没有匹配的产品ID,则右表字段会显示为NULL。这可能是因为产品ID不匹配或数据缺失。
解决方法:
-
首先检查两个表中的关联字段是否一致(如数据类型、是否有前导空格等)
-
如果NULL值是合理的(即确实存在没有对应产品信息的订单),可以在后续步骤中使用"空值处理"组件进行填充或过滤
-
如果希望只保留有匹配的记录,可以将连接类型改为INNER JOIN
问题5:Hops连接方向错误导致数据流异常
问题现象:转换执行后,某些组件没有数据流入,或者数据流向了错误的组件。
问题原因:在画布上连接Hops时,拖拽的方向决定了数据的流向。如果方向反了,数据就无法正确传递。
解决方法:
-
在画布上,Hops带有箭头,确保箭头方向指向数据流动的方向(从上游指向下游)
-
删除错误的Hops,重新拖拽连接
-
对于"过滤记录"组件,特别注意True和False两个输出端要分别连接到正确的下游组件
五、实验总结
5.1 收获
通过本次实验,我掌握了以下技能和知识:
-
零代码ETL流程设计:理解了如何在助睿数智平台上通过拖拽组件的方式构建完整的数据处理流程,无需编写复杂的SQL或Python代码。
-
核心概念理解:深入理解了转换(Pipeline)与作业(Workflow)的区别,以及步骤(Transform)、任务项(Action)、Hops等核心概念在实际操作中的体现。
-
多表关联操作:掌握了"记录集连接"组件的使用方法,理解了LEFT OUTER JOIN的语义及其在业务场景中的应用——保留主表全部记录的同时关联辅表信息。
-
数据分流处理:学会了使用"过滤记录"组件根据条件将数据分流到不同的输出路径,这在实际业务中非常常见(如区分正常订单与异常订单、盈利客户与亏损客户等)。
-
数据清洗意识:通过"字段选择"组件移除重复字段的操作,让我意识到数据清洗在ETL流程中的重要性,避免后续分析出现歧义。
-
问题排查能力:在解决易错问题的过程中,我学会了查看执行日志、检查组件配置、验证数据流向等排查方法,这对后续独立完成更复杂的实验非常有帮助。
5.2 对平台的整体评价
-
优点:
-
零代码友好:对于没有编程基础的用户来说,拖拽式的操作方式大大降低了数据处理的门槛,能够快速上手。
-
可视化直观:画布式的流程设计让数据处理逻辑一目了然,便于理解和调试。
-
组件丰富:平台提供了从输入、转换、连接到输出的完整组件生态,能够满足大部分常见的ETL需求。
-
实时预览:部分组件支持数据预览功能,可以在执行前检查配置是否正确。
-
-
改进建议:
-
错误提示优化:某些组件报错信息不够明确,建议增加更详细的错误说明和解决方案指引。
-
表达式编辑器:过滤记录等组件的条件表达式编辑可以加入字段自动补全和语法检查功能,减少拼写错误。
-
文档完善:部分高级组件的使用说明可以更加详细,附带更多实际案例。
-
-
适用场景:
-
本次实验让我认识到,助睿数智平台非常适合用于教学培训、快速原型验证以及常规的数据清洗和整合任务。对于需要频繁进行多表关联、数据分流、格式转换的业务场景,使用该平台可以显著提升效率。
-
5.3 后续展望
本次实验只是一个入门级的ETL任务,后续我希望能够尝试更复杂的场景,例如:
-
多源数据(数据库 + API + Excel文件)的整合
-
使用"计算器"组件进行更复杂的业务指标计算
-
结合机器学习组件进行数据预测
-
使用作业(Workflow)将多个转换串联起来,实现定时调度
总的来说,本次实验让我对零代码数据集成有了直观的认识,也为后续深入学习数据科学打下了良好的基础。

一站式 AI 云服务平台
更多推荐

 21
21 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)