
助睿实验作业-订单利润分流数据加工
本文介绍了在助睿数智平台上进行的ETL实验过程。实验通过可视化拖拽方式构建数据流水线,实现订单数据与产品信息的关联处理,并按利润情况分流存储。主要步骤包括:创建转换流、配置表输入组件获取数据、使用记录集连接组件进行LEFT OUTER JOIN、通过字段选择组件移除重复字段、设置过滤条件实现数据分流,最终将盈利和亏损订单分别导出为Excel文件。实验过程中遇到的问题包括Hop连接类型错误和文件名冲
一、实验背景
1.1 实验目的
说实话,这学期的数据工程课要做的第一个实验就是用助睿平台做ETL。一开始我以为会很复杂,毕竟涉及到数据抽取、转换、加载这些概念,但实际用下来发现这个零代码平台还挺直观的。
本次实验主要是想搞清楚几件事:
- 怎么从头搭建一个ETL Pipeline
- 表输入、Join、过滤这些常用的ETL算子怎么配置
- 多表关联和数据分流这种常见场景怎么设计
搞定这些之后,后面遇到更复杂的数据清洗任务应该就有思路了。
1.2 实验环境
这次用的是助睿数智的在线平台,官网是 https://www.uniplore.com/,但我们是直接从贵兰在线跳转过去的 https://lab.guilian.cn/。这个平台挺有意思的,从数据接入到建模再到可视化,一条龙都能搞定。
数据库环境是MySQL,里面已经预置了两张表:business_anaylsis.order_detail(订单明细表)和 business_anaylsis.product(产品信息表)。
1.3 业务场景
实际业务场景其实挺常见的——企业要分析利润,但订单和产品信息分在不同表里,需要先关联起来,然后按盈利还是亏损把订单分流存储。这个需求用传统SQL写也行,但用可视化拖拽的方式会更直观。
1.4 数据加工流程
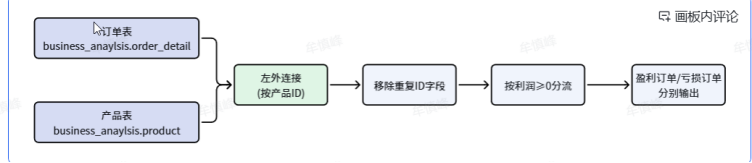
整个Pipeline的逻辑是这样的:
- 订单明细表 LEFT OUTER JOIN 产品信息表(用product_id关联)
- Join后会有重复的id字段,需要移除其中一个
- 按profit字段的正负做条件路由,profit >= 0的走True分支,< 0的走False分支
分别导出到盈利订单.xlsx和亏损订单.xlsx
二、实验步骤
2.1 登录实验平台
这个比较简单,从贵兰在线课程页面点进去就行。登录后平台会自动同步身份,不用单独注册账号。
具体如下:在贵兰在线对应的课程学习页面,点击"实验课1:助睿ETL入门实验"
点击课程实训说明中的"大数据实训平台",即可前往实验地址 https://lab.guilian.cn/
从贵兰在线进入实验平台可以自动登录,登录成功后进入实验平台
2.2 基本概念了解
做实验前先理解几个核心概念,不然后面配置会懵。
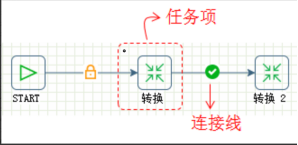
助睿的ETL平台基于典型的管道-过滤器架构:
- Pipeline(转换/转换流):面向数据流的处理单元,可以理解为一个完整的数据处理DAG,由多个Transform算子组成
- Workflow(作业):面向任务的编排单位,由多个Action组成,比如要定时调度一个Pipeline就得用Workflow
- Transform(步骤/转换步骤):Pipeline里的最小处理单元,每个Transform跑在独立线程上,像表输入、字段选择这些都是Transform
- Action(任务项):Workflow里的执行单位,比如启动Pipeline、发邮件通知
- Hops(连接线):Transform或Action之间的数据通路,定义了数据流向
转换工作流: 作业工作流:
2.3 团队管理
如果是分组实验的话,组长要先建个团队方便管理。我这次是一个人做的,所以跳过了这个步骤。不过流程很简单,点「团队管理」→「新增团队」,然后输入团队信息,再通过手机号添加成员就行。
2.4 创建实验项目
平台默认会有个项目,但为了自己实验方便,我还是建个专属项目。我建了个叫「助睿ETL入门实验」的项目,这样后面找资源也清晰。
2.5 同步数据源
这一步挺关键的,不同步数据源的话后面配置表输入会找不到库。操作步骤是:
- 点「元数据」菜单
- 右键「关系数据库」,选「同步数据源」
- 切换到「文件库」再切回来,就能看到「线上公共数据源(Readonly)」了
这里有个小坑,一开始我同步完没刷新,一直以为失败了。后来才发现要切换一下菜单才能看到效果。

2.6 新建转换流
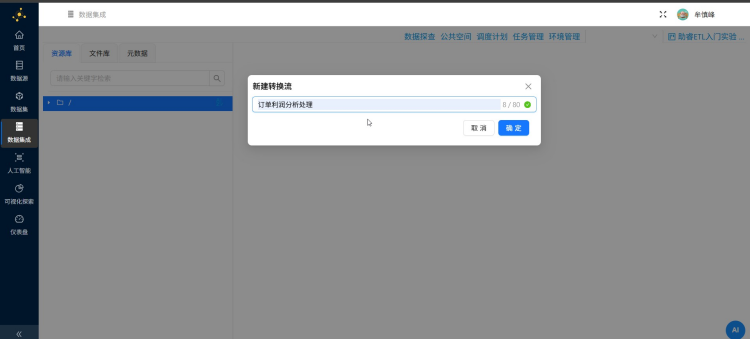
核心Pipeline来了。我建了个「订单利润分流处理」转换流,整体数据流设计如下:
- 订单表输入 -> LEFT OUTER JOIN -> 移除重复字段 -> 条件路由( profit >= 0 )
- -> True分支 -> Excel输出(盈利订单)
- -> False分支 -> Excel输出(亏损订单)
需要用到的组件及其作用:
|
组件 |
作用 |
|
表输入(订单/产品) |
读取MySQL中的原始表数据 |
|
记录集连接 |
执行LEFT OUTER JOIN,按product_id关联两张表 |
|
字段选择 |
移除Join后重复的id字段,保持数据一致性 |
|
过滤记录 |
条件路由,根据profit >= 0分流数据 |
|
Excel输出 |
分别导出盈利订单和亏损订单到Excel文件 |
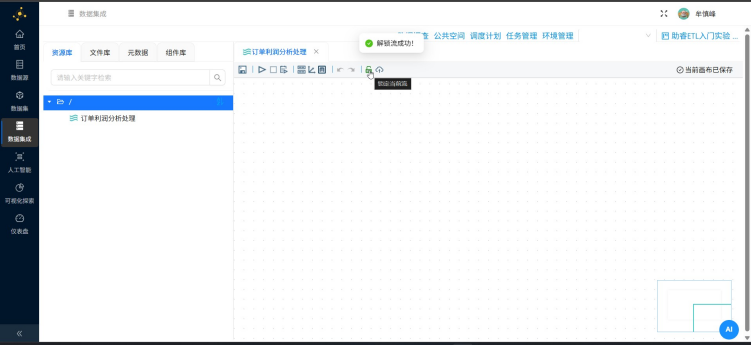
新建转换流要注意,每次打开画布都是锁定的,要点那个锁图标解锁后才能编辑。
2.7 添加组件
组件的添加逻辑是先搜索再拖拽,然后用Hop(连接线)把它们连起来。我来一步步说:
(1) 表输入组件
因为要关联订单和产品两张表,所以得加两个表输入组件。从组件库搜「表输入」,拖拽两个到画布,分别命名为「订单_详细订单」和「订单_产品信息」。
(2) 记录集连接组件
搜「记录集连接」,拖到画布上。然后创建两个表输入到这个组件的Hop。这里有个细节——建立Hop时会提示「排序需要」,说明记录集连接组件对输入数据顺序有依赖。
(3) 字段选择组件
搜「字段选择」拖到画布,命名为「移除产品ID_1字段」。这个组件主要是解决Join后字段重复的问题。从记录集连接连到字段选择。
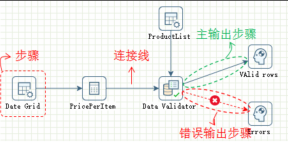
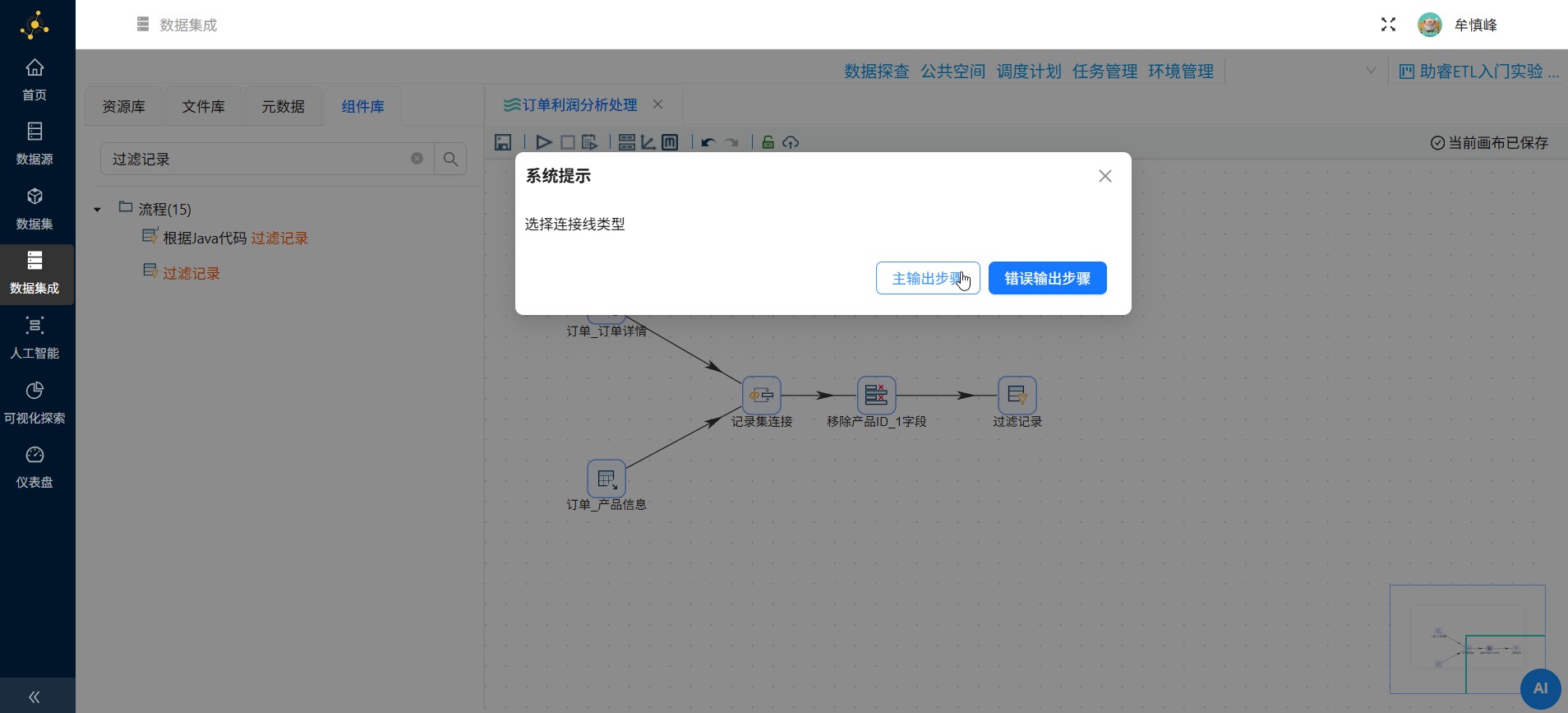
(4) 过滤记录组件
搜「过滤记录」拖到画布。从字段选择连过来,这次要选「主输出步骤」。这个组件是做条件路由的核心。
(5) Excel输出组件
搜「excel 输出」,拖两个到画布,分别命名为「盈利订单」和「亏损订单」。从过滤记录连到这两个Excel输出,一个选「True输出」,一个选「False输出」。
整个Pipeline就算搭好了。这个设计其实挺典型的ETL流水线模式,数据从源头进入,经过一系列变换算子的处理,最后分流到不同的输出端。
在建立转换任务后,可添加相应操作组件到转换任务中。
下面以订单数据(business_anaylsis.order_detail)和产品信息数据(business_anaylsis.product)生成盈利订单数据和亏损订单数据为例来构建转换任务,按如下顺序向转换中添加组件:
具体操作如下:
(1)添加表输入组件
本次实验需要将两类数据进行合并计算,所以需要添加2个表输入组件,读取2个不同表的数据。
点击"组件库",由于组件库的组件数量较多,可以通过关键字搜索快速获取
在搜索输入框中输入"表输入",即可查询到"表输入"组件
将表输入组件拖拽至画布中
再次拖拽表输入组件拖拽至画布中,即拖拽2个表输入组件至画布中
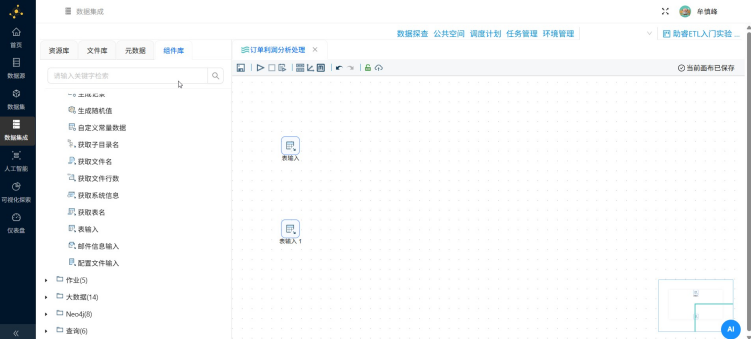
右键表输入组件,点击"编辑组件"
修改步骤名称中为订单_详细订单,点击"确认",此时画布中的对应表输入组件被命名为"订单_详细订单"
同样的,另一表输入组件修改为订单_产品信息
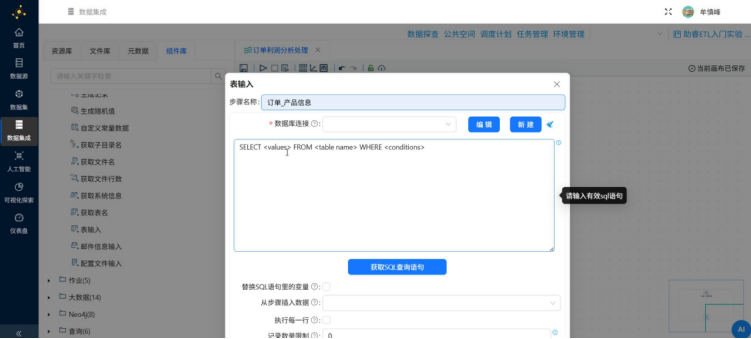
(2)添加记录集连接组件
使用表输入组件读取数据后,需要通过记录集连接组件将表输入组件的数据进行关联。
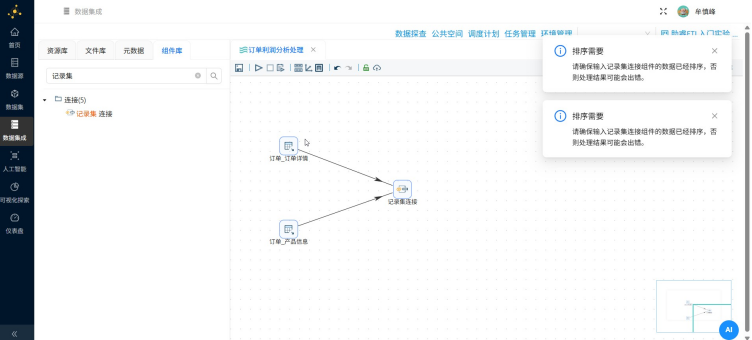
在搜索输入框中输入"记录集连接",将记录集连接组件拖拽至画布中
创建两个表输入组件到记录集连接组件的连接线
在建立连接线时,会出现"排序需要"的提示。这是由于记录集连接组件是按接收数据的顺序进行记录关联的,如果接收的数据是无序的,可能会造成记录连接结果出错。
(3)添加字段选择组件
两个表数据进行连接后,会出现重复的字段"产品ID"。我们可以通过"字段选择"组件移除这个多余字段。
在搜索输入框中输入"字段选择",将字段选择组件拖拽至画布中
将字段选择组件名字修改为"移除产品ID_1字段"
创建记录集连接组件到字段选择组件的连接线
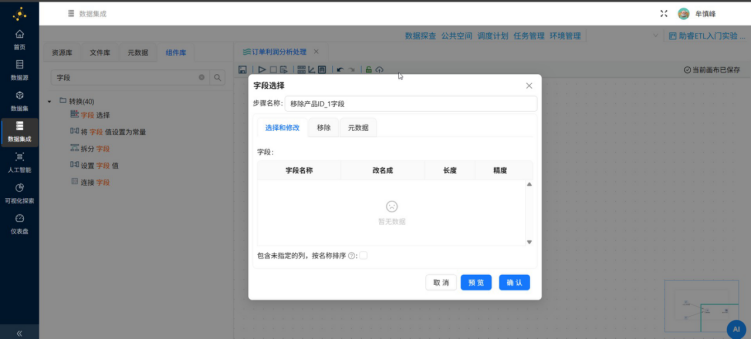
(4)添加过滤记录组件
本次实验是根据订单的利润情况对订单进行分流。使用"过滤记录"组件可以根据记录中某个字段的值进行记录分流。
在搜索输入框中输入"过滤记录",将过滤记录组件拖拽至画布中
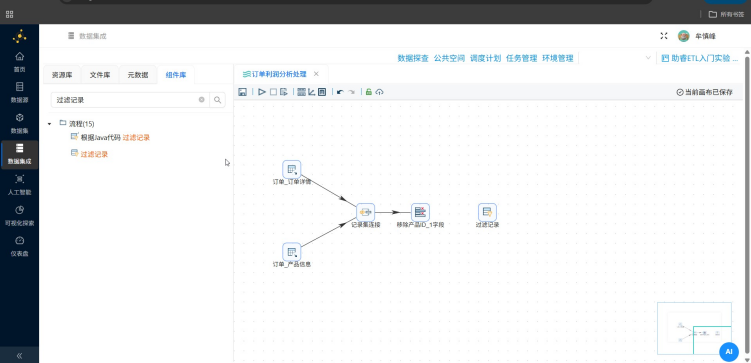
创建字段选择组件到过滤记录组件的连接线在选择连接线的弹窗中点击"主输出步骤"。由于在进行字段选择操作时,可能有记录不满足要求,导致记录被标记为错误。主输出步骤表示满足要求的记录通过该连接线传输数据。
(5)添加 excel 输出组件
记录经过"过滤记录"组件后会被分成2个记录流。我们可以根据业务需求将2个记录流输出到指定位置(文件、数据库表)。在本次实验中,我们选择将记录输出到 Excel 文件中。
在搜索输入框中输入"excel 输出",将2个表输出组件拖拽至画布中
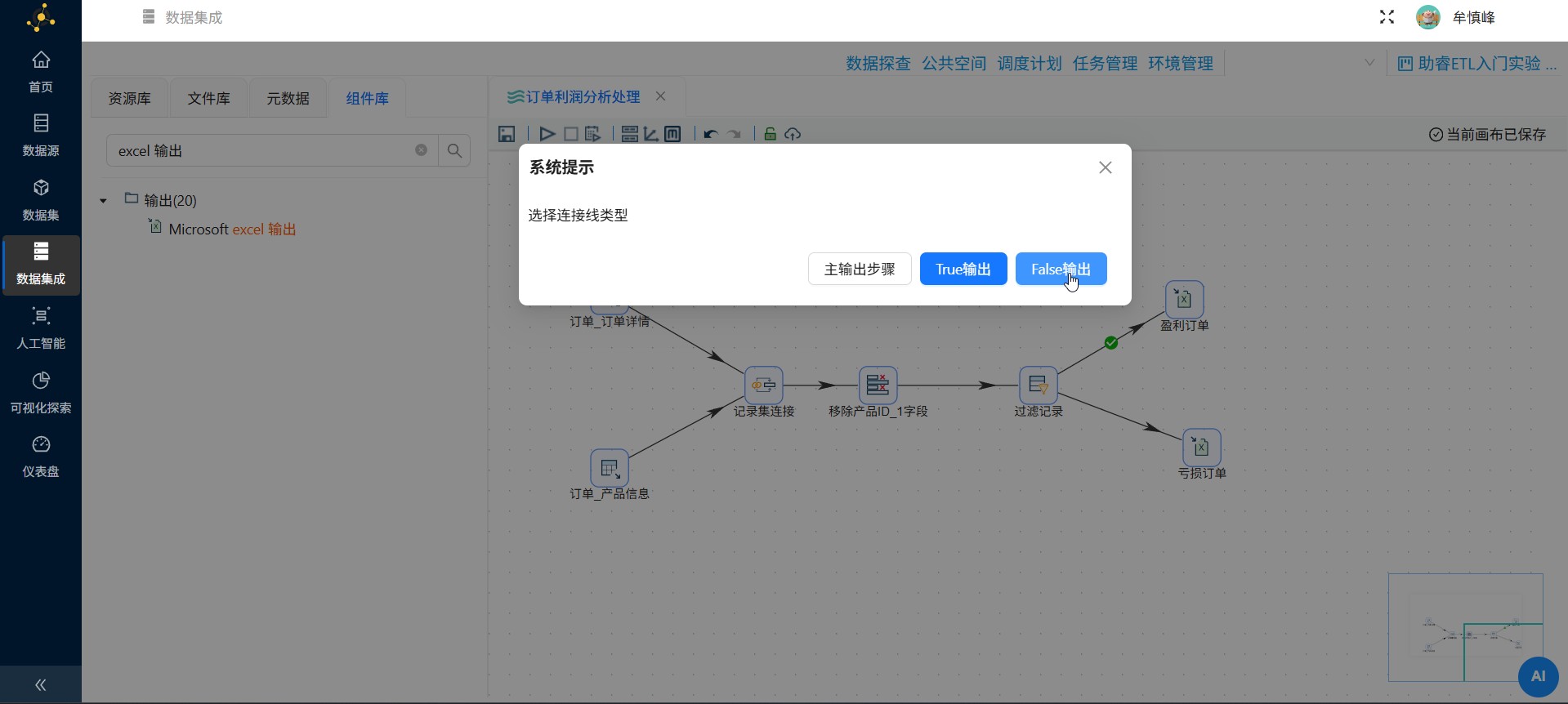
2个excel 输出组件分别命名为"盈利订单"和"亏损订单",并创建过滤记录组件到两个excel 输出组件的连接线,在选择连接线类型的弹窗中分别选择"True输出"和"False输出"
"True输出"表示满足过滤条件的记录输出。
"False输出"表示不满足过滤条件的记录输出。
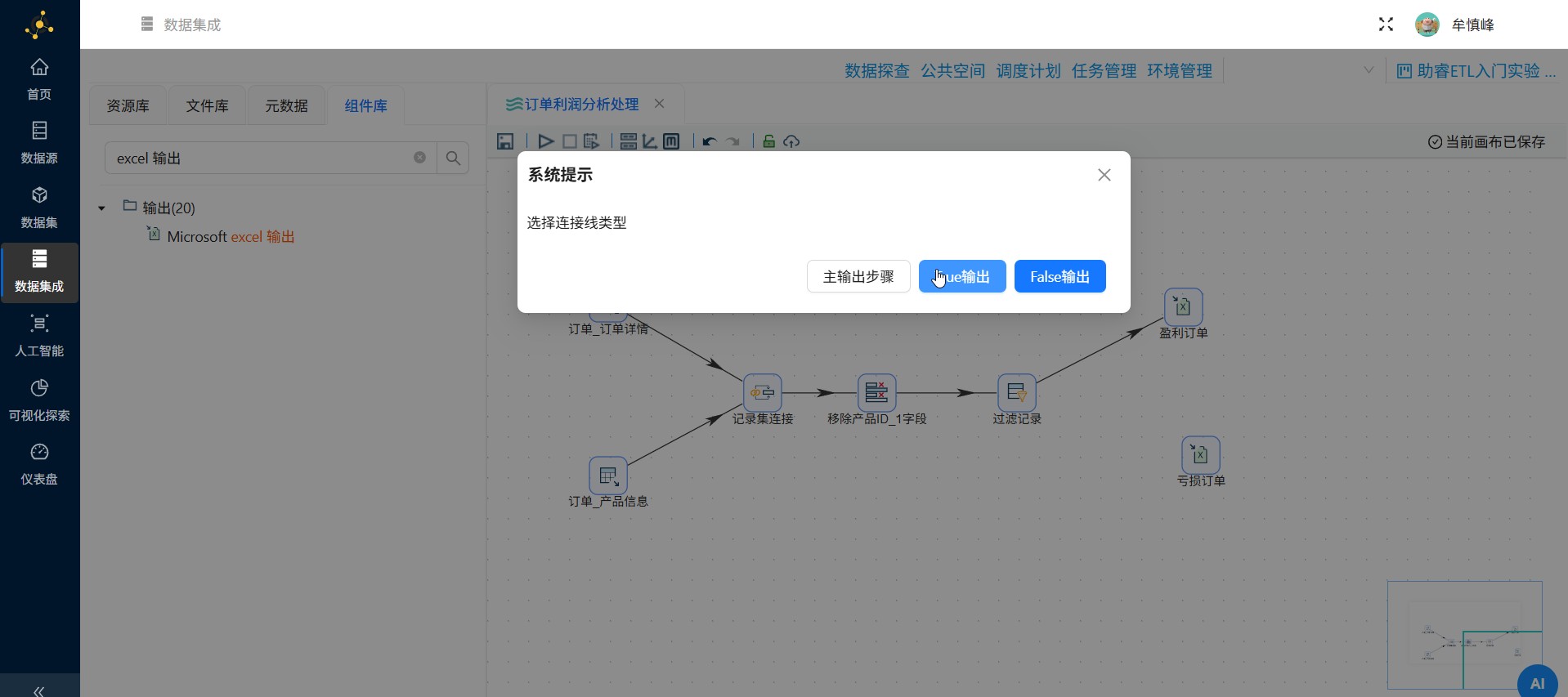
至此,一个完整的转换任务流程构建完毕,如下图所示:
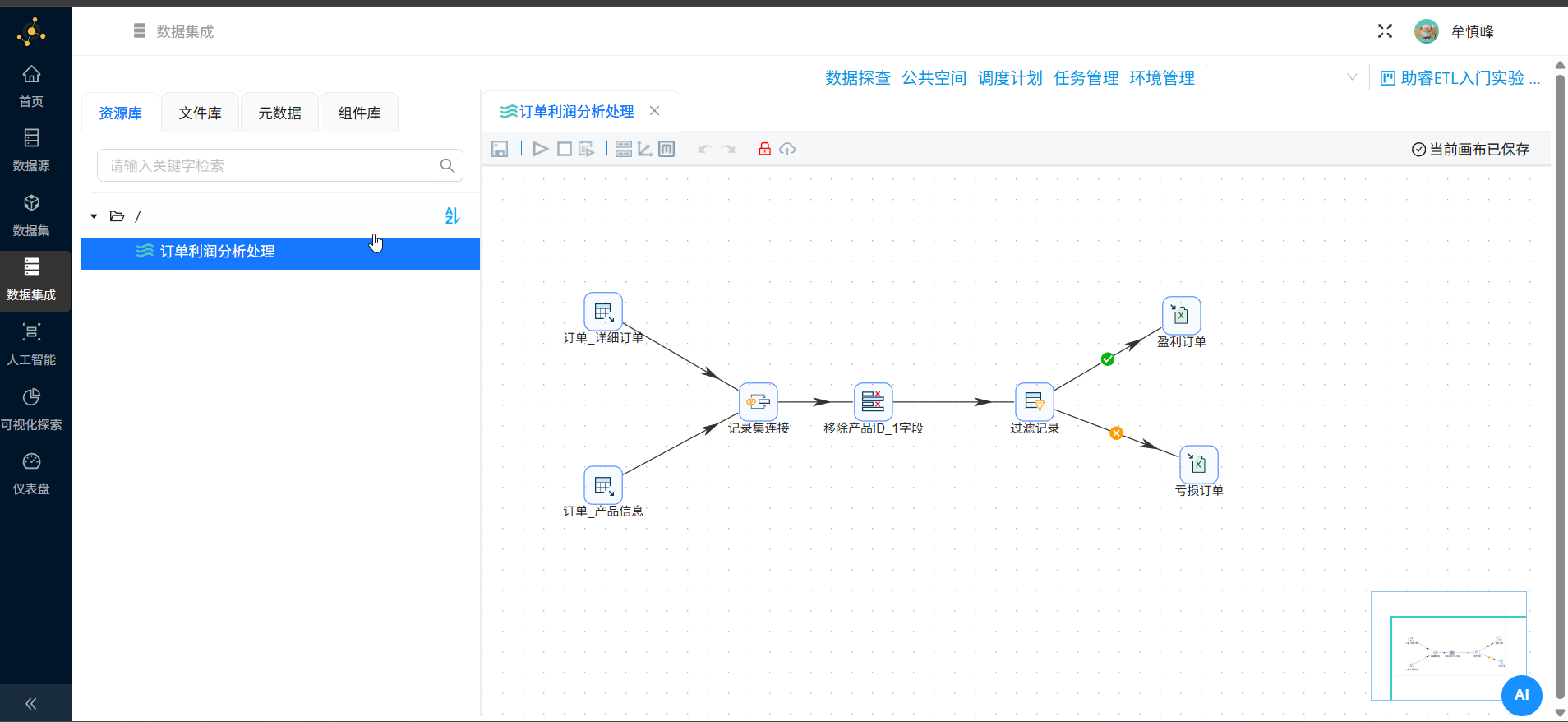
2.8 配置组件信息
2.8.1 表输入组件配置
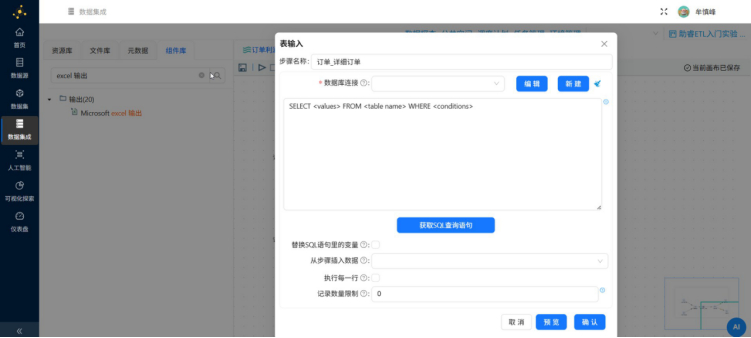
双击订单_详细订单表输入组件,弹出组件配置页面。在数据库连接下拉框中选择已同步的"线上公共数据源(Readonly)"如下图所示:
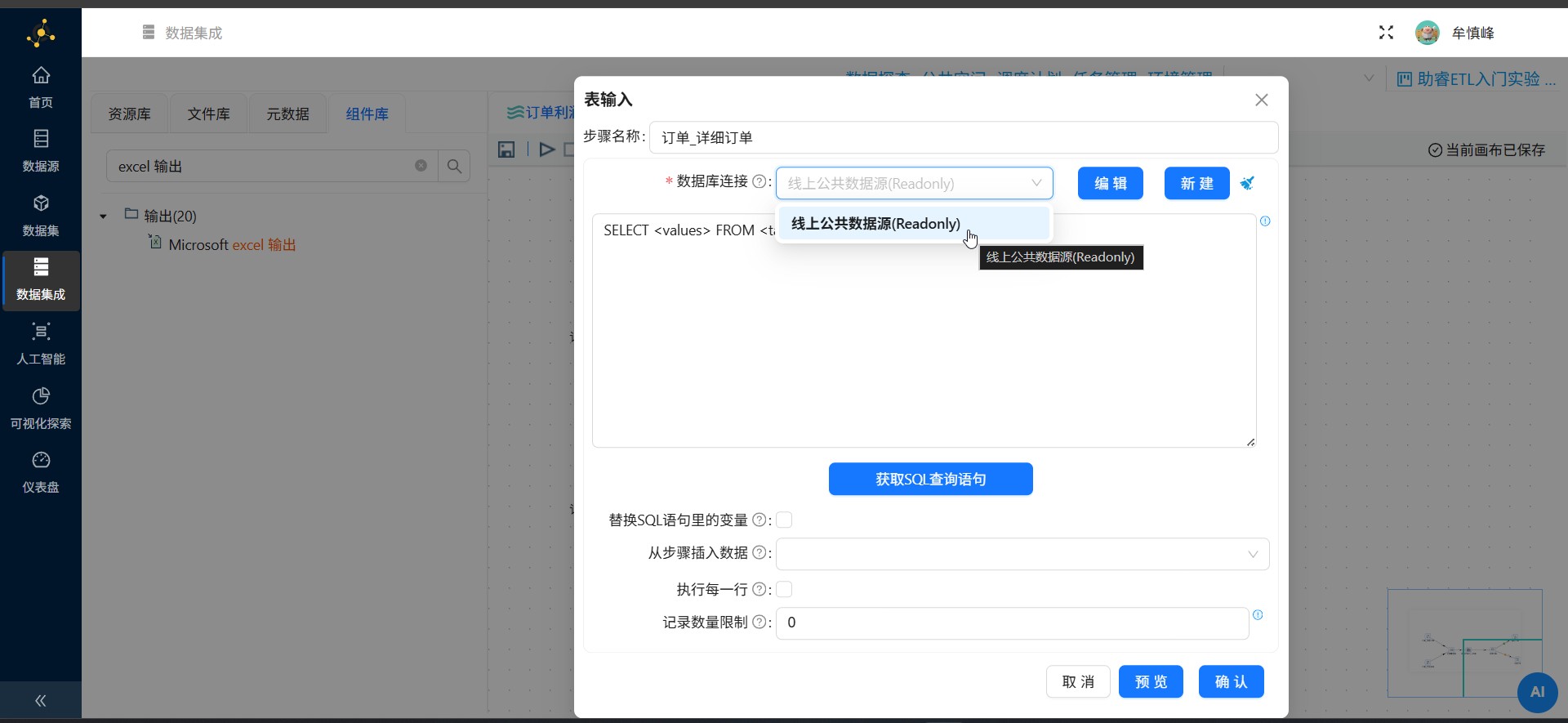
点击"获取SQL查询语句",自动生成SQL查询语句。
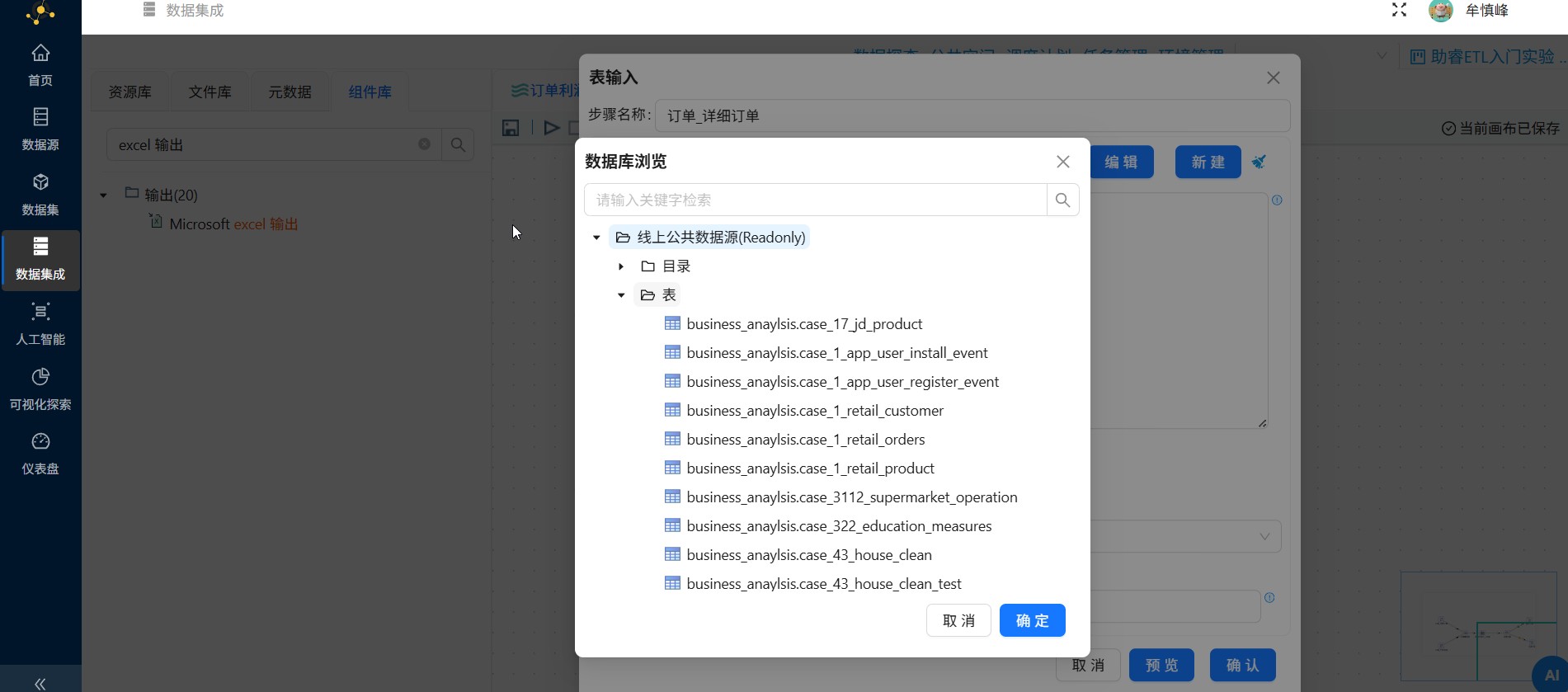
点开"线上公共数据源(Readonly)"-"表"目录
下滑找到"business_anaylsis.order_detail"并点击它,再点击"确定"
在系统提示弹窗中点击"确认"
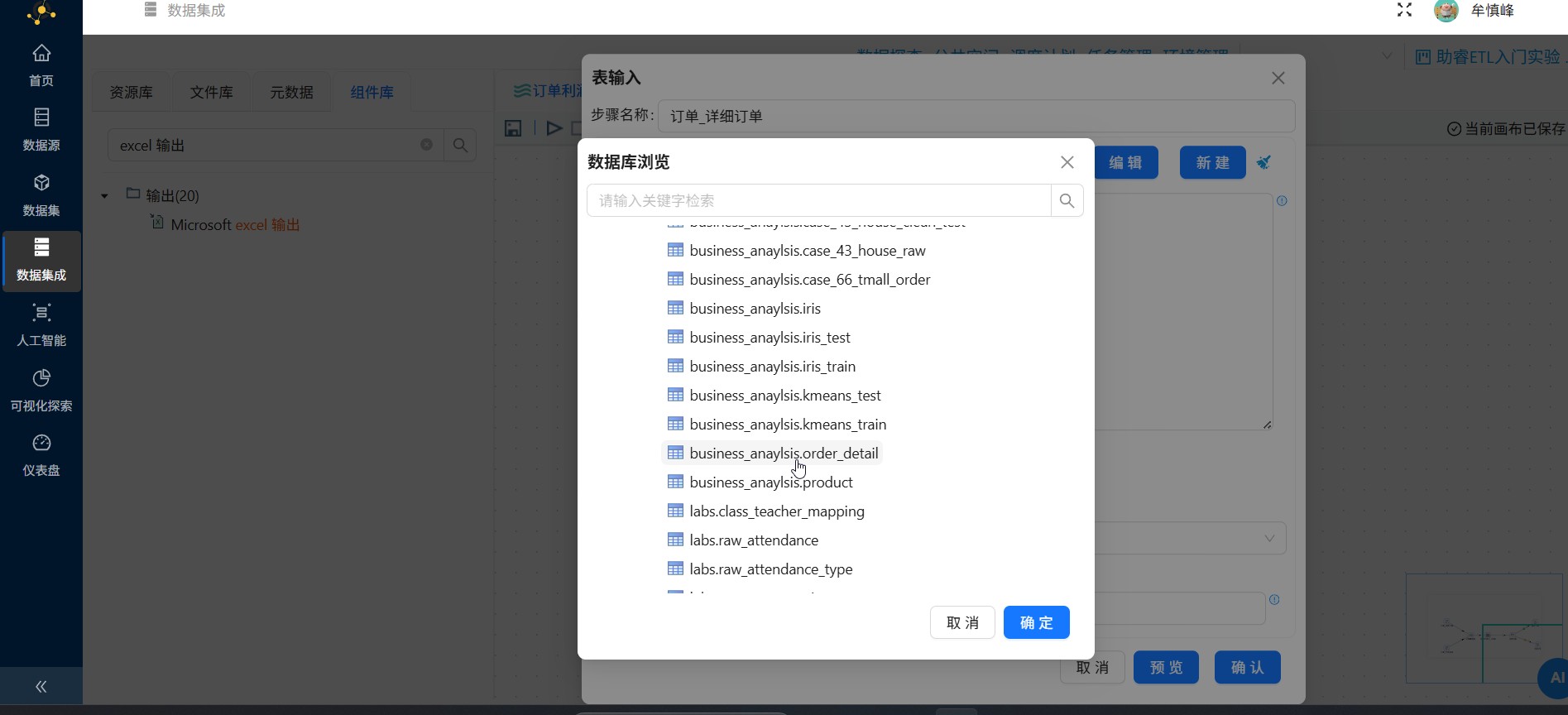
系统自动填写了完整的SQL查询语句,点击"确认"。当自动生成的SQL语句无法满足业务需求时,也可以通过在文本框输入自定义SQL语句。表输入组件的其他配置参数保持默认即可,
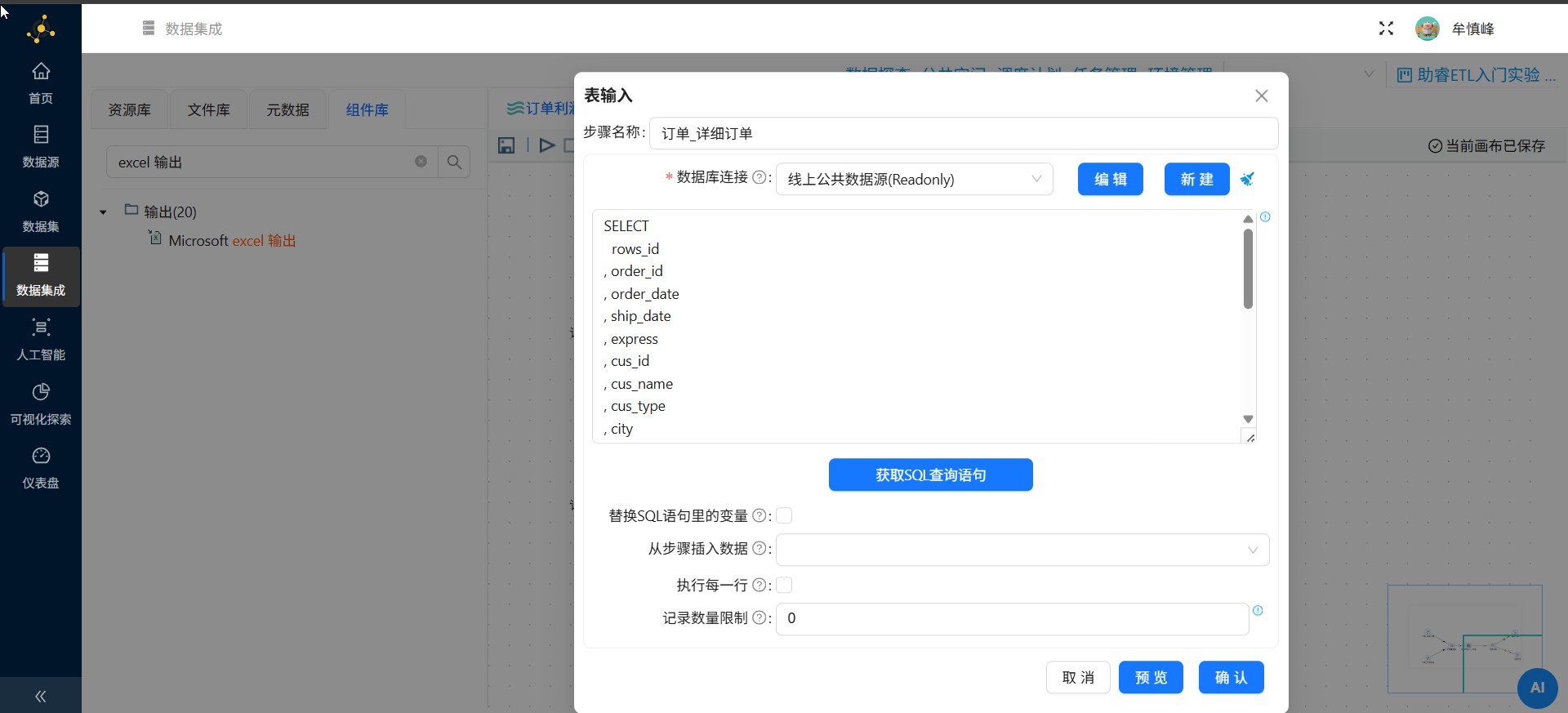
另一个订单_产品信息表输入也参考上述配置,获取"business_anaylsis.product"的SQL查询语句
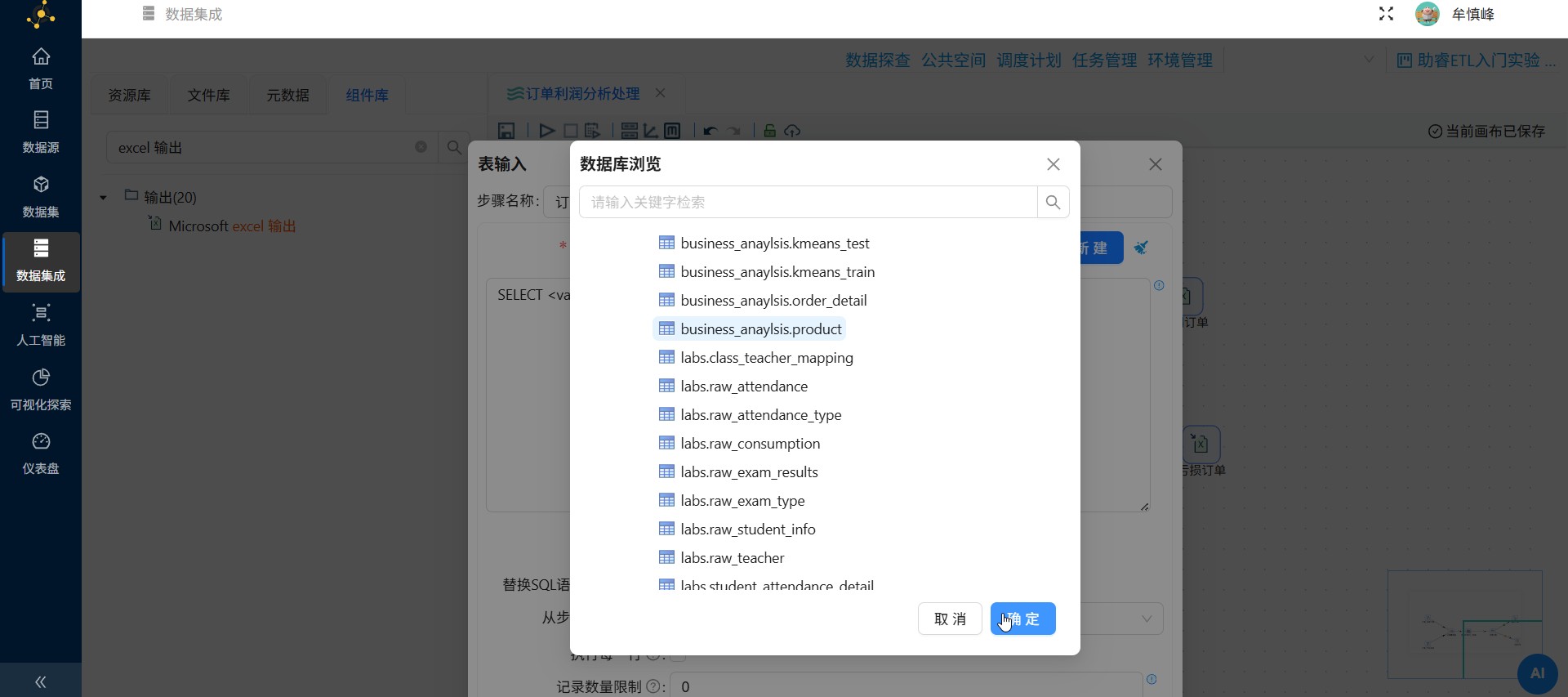
2.8.2 记录集连接组件配置
双击记录集连接组件,在下拉列表中选择需要连接的数据来源
第一个Transform选择订单_详细订单,第二个Transform选择订单_产品信息,连接类型选择LEFT OUTER
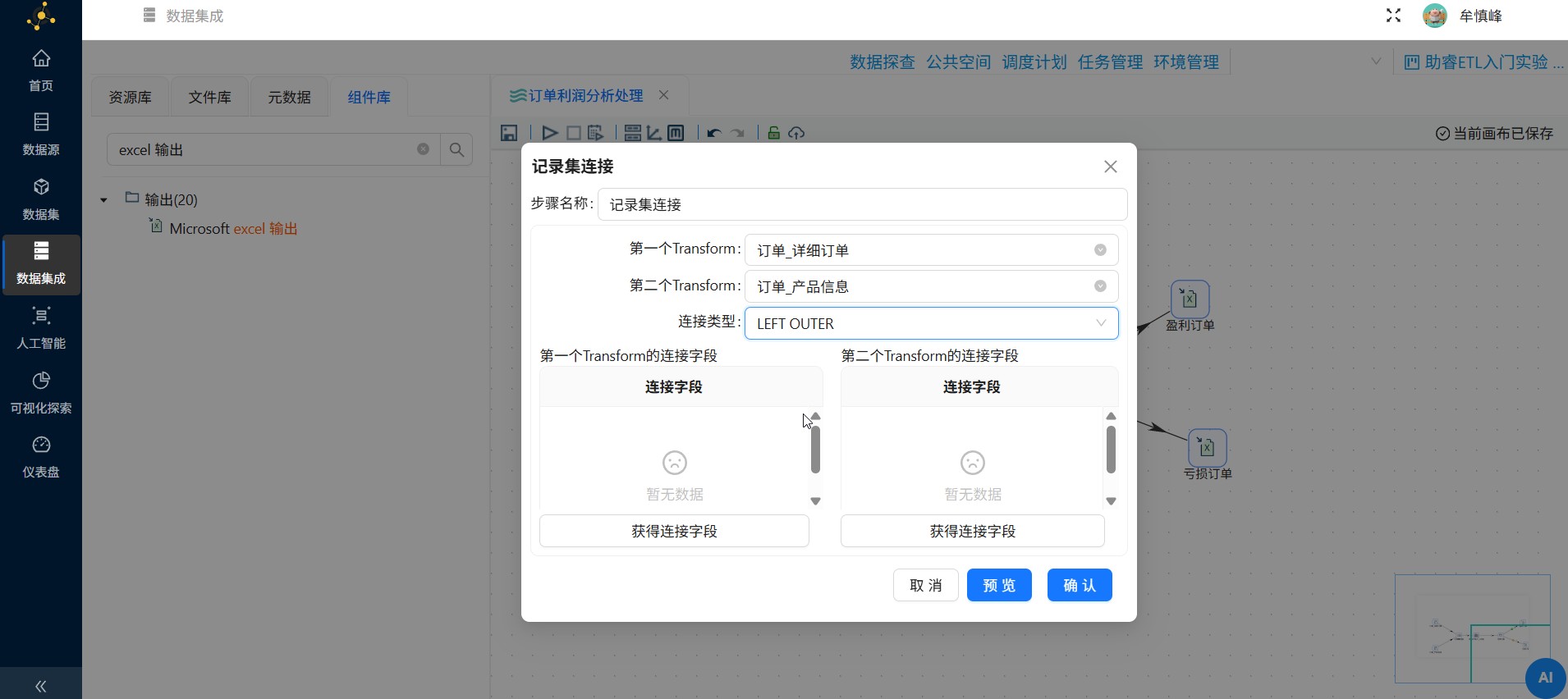
点击第一个Transform的连接字段中的"获得连接字段"按钮,即可获取表输入组件在订单_详细订单的查询到的字段
同样的,获取第二个Transform的连接字段
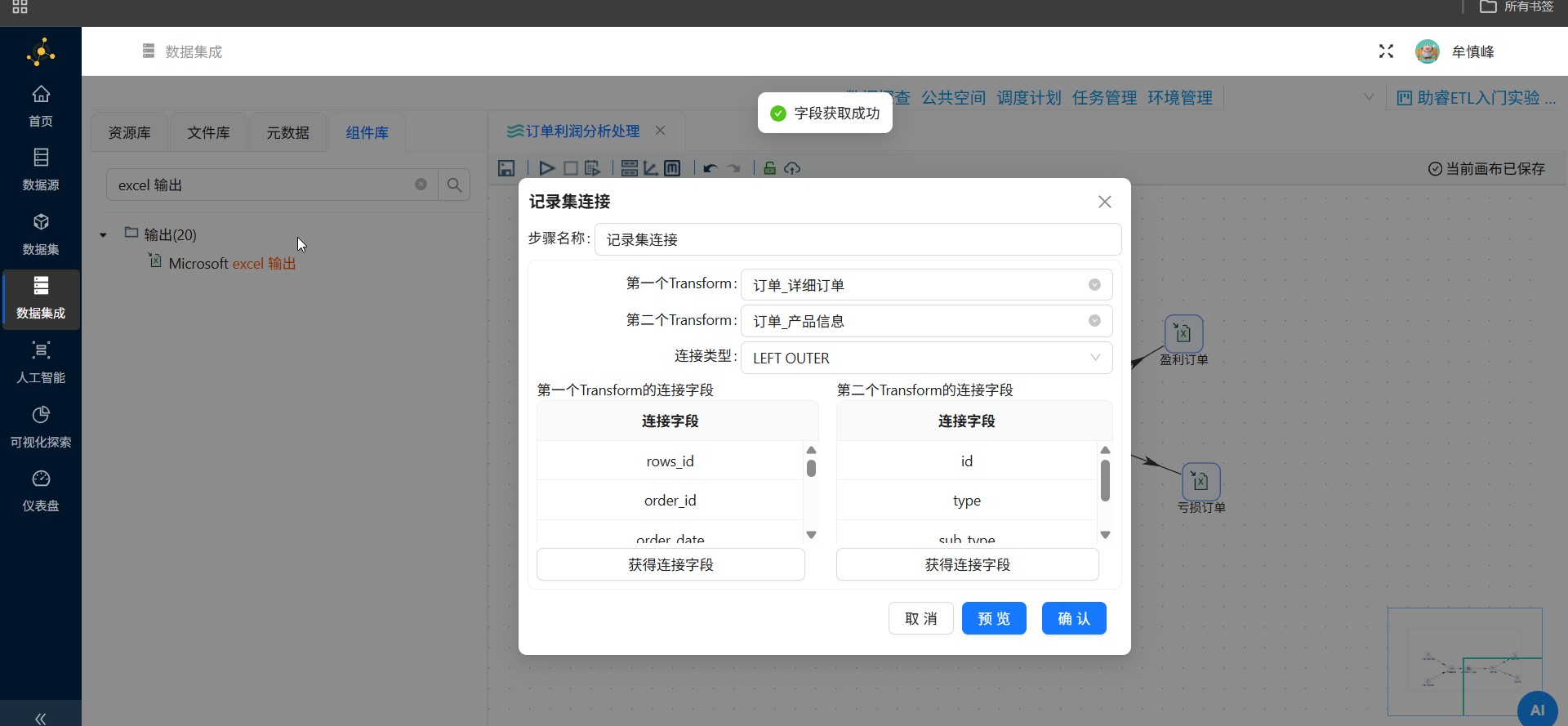
第一个Transform字段保留 product_id,第二个Transform的字段保留 id,连接类型选择LEFT OUTER,表示使用订单_详细订单的字段 product_id 与订单_产品信息的字段 id 进行左外连接
第一个Transform字段中除了 product_id 外的其他字段,右键点击"删除选中的行",第一个Transform字段中除了id 外的其他字段,右键点击"删除选中的行"
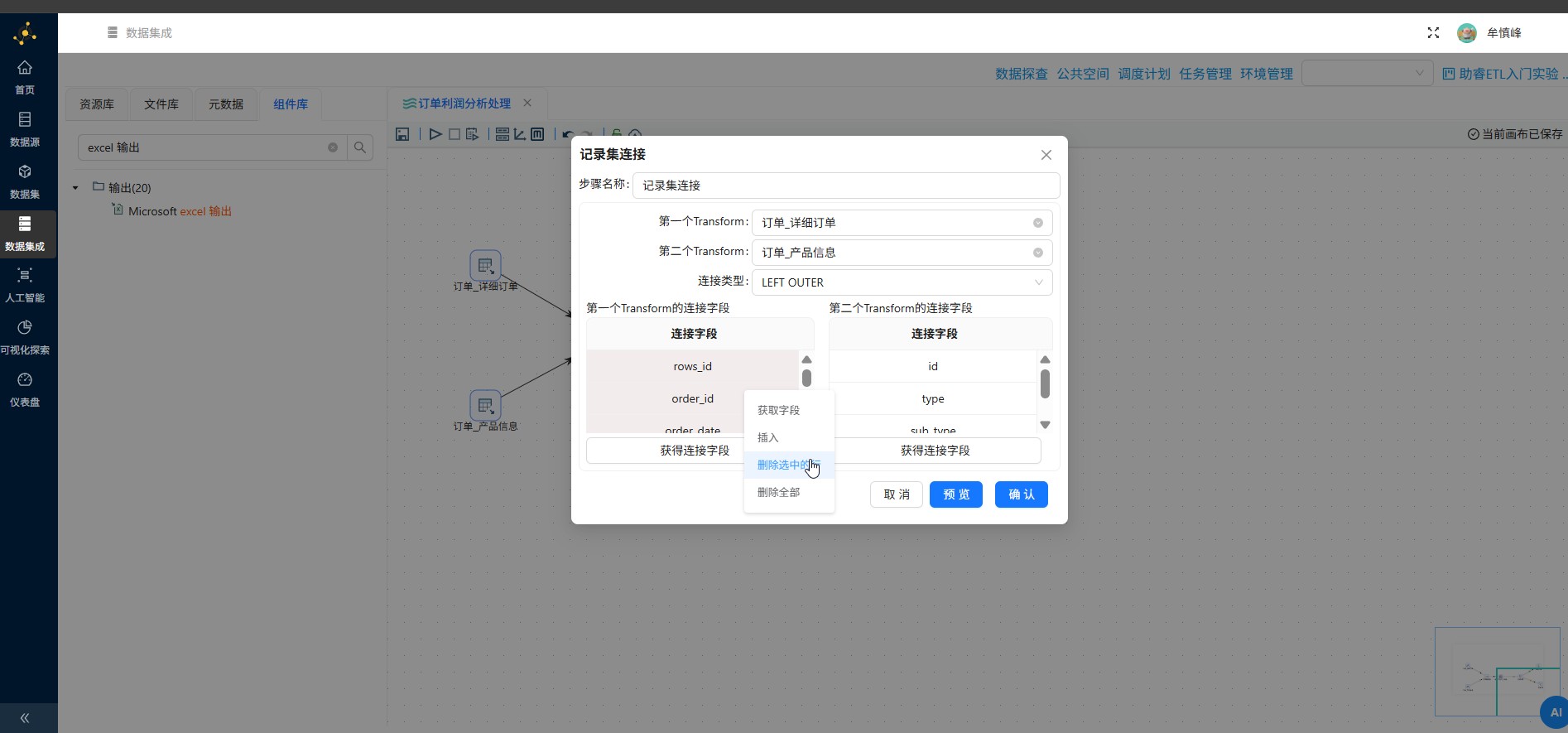
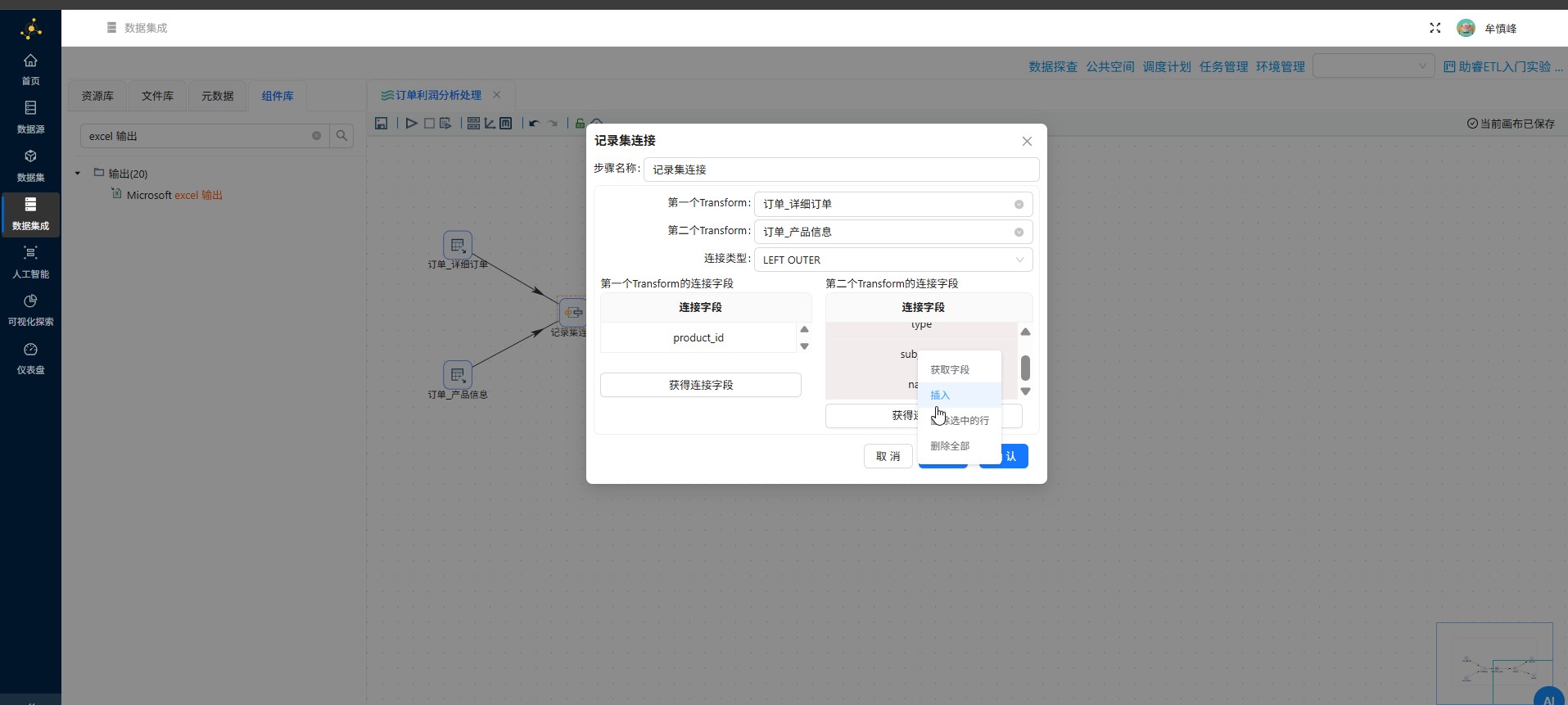
删除完后,点击"确认",若删除错误,可重新获取连接字段再进行删除
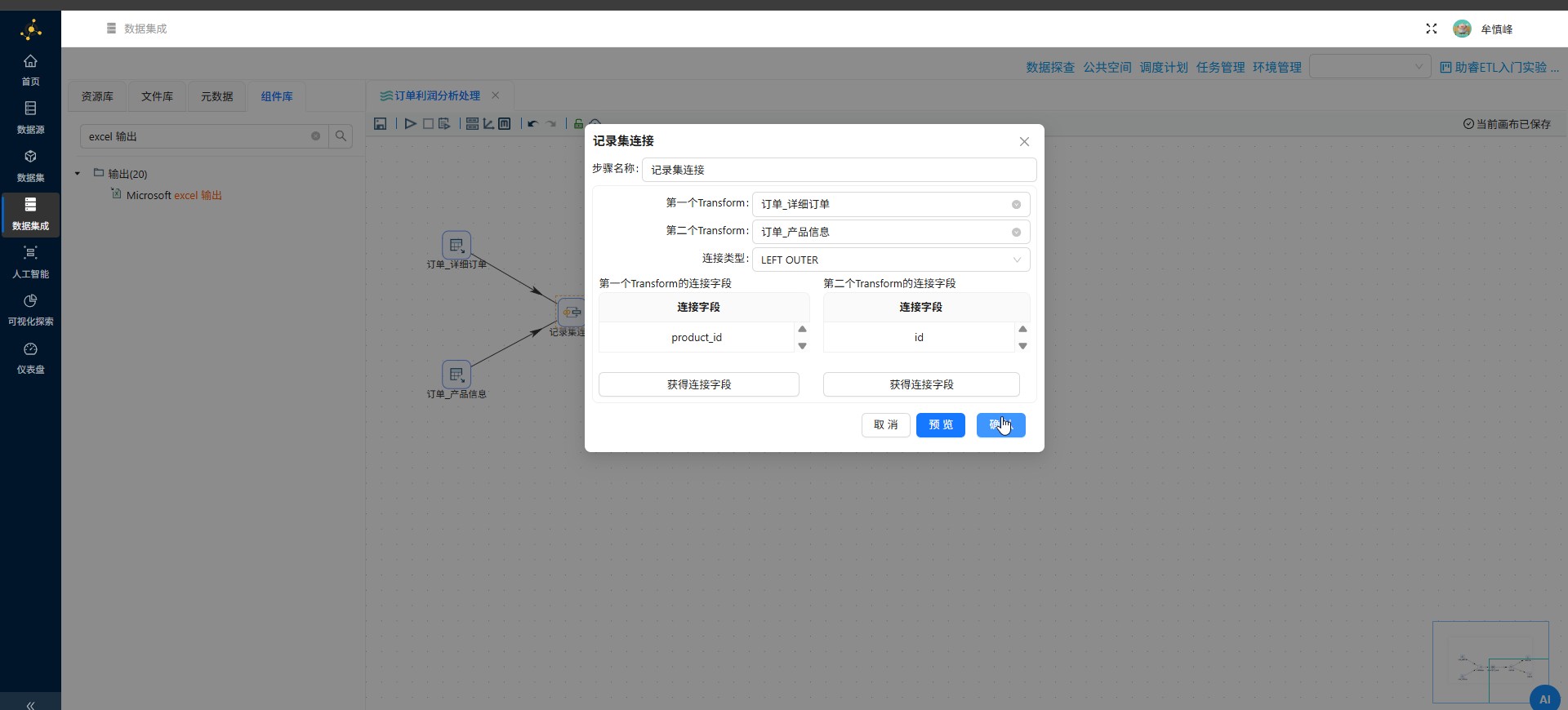
2.8.3 字段选择组件配置
通过记录集连接后,我们可以发现,字段 produc_id 与字段id 内容相同,只需要保留一个,因此,需要使用"移除产品ID_1字段"字段选择组件的移除选项移除字段 id,具体操作如下:
双击"移除产品ID_1字段"字段选择组件,点击"移除",并点击"获取字段"
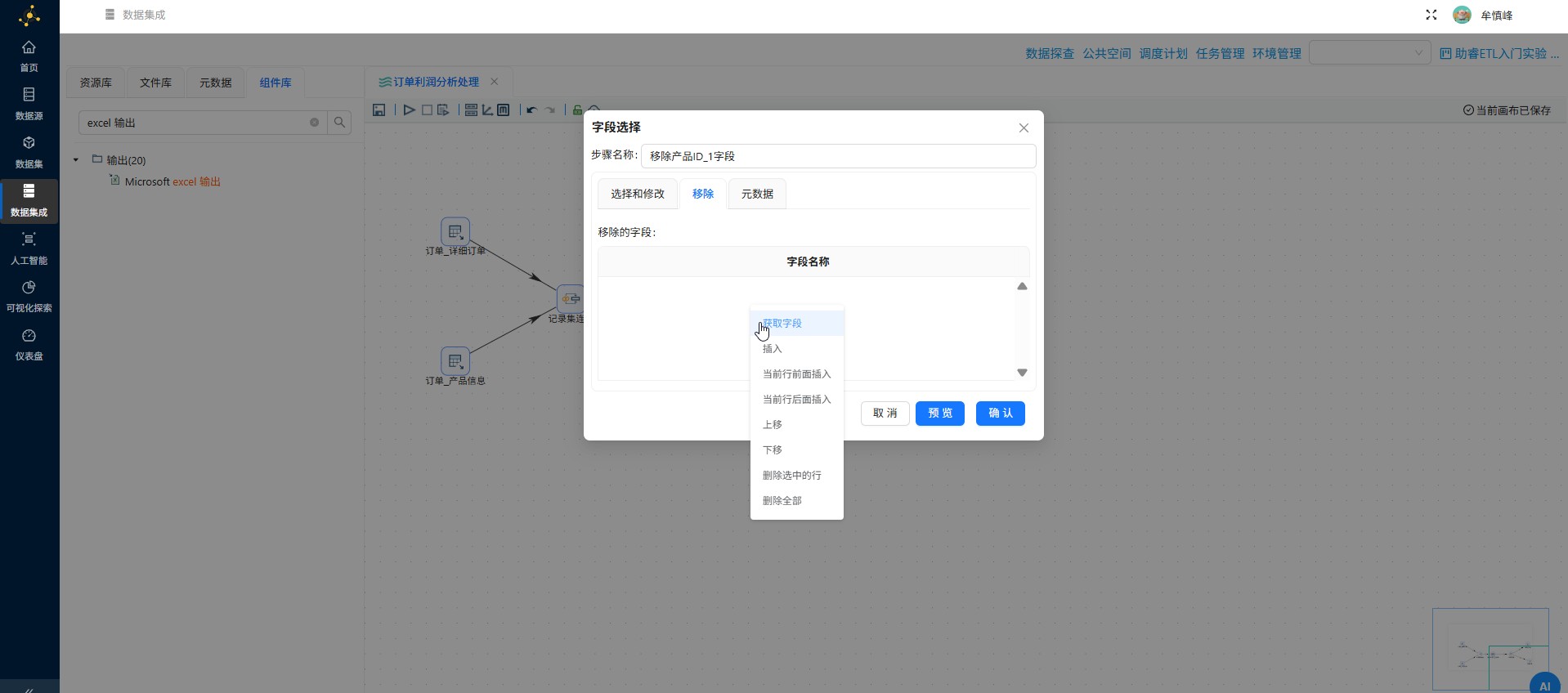
在获取的字段中选中除"id"字段以外的字段,右键点击"删除选中的行"
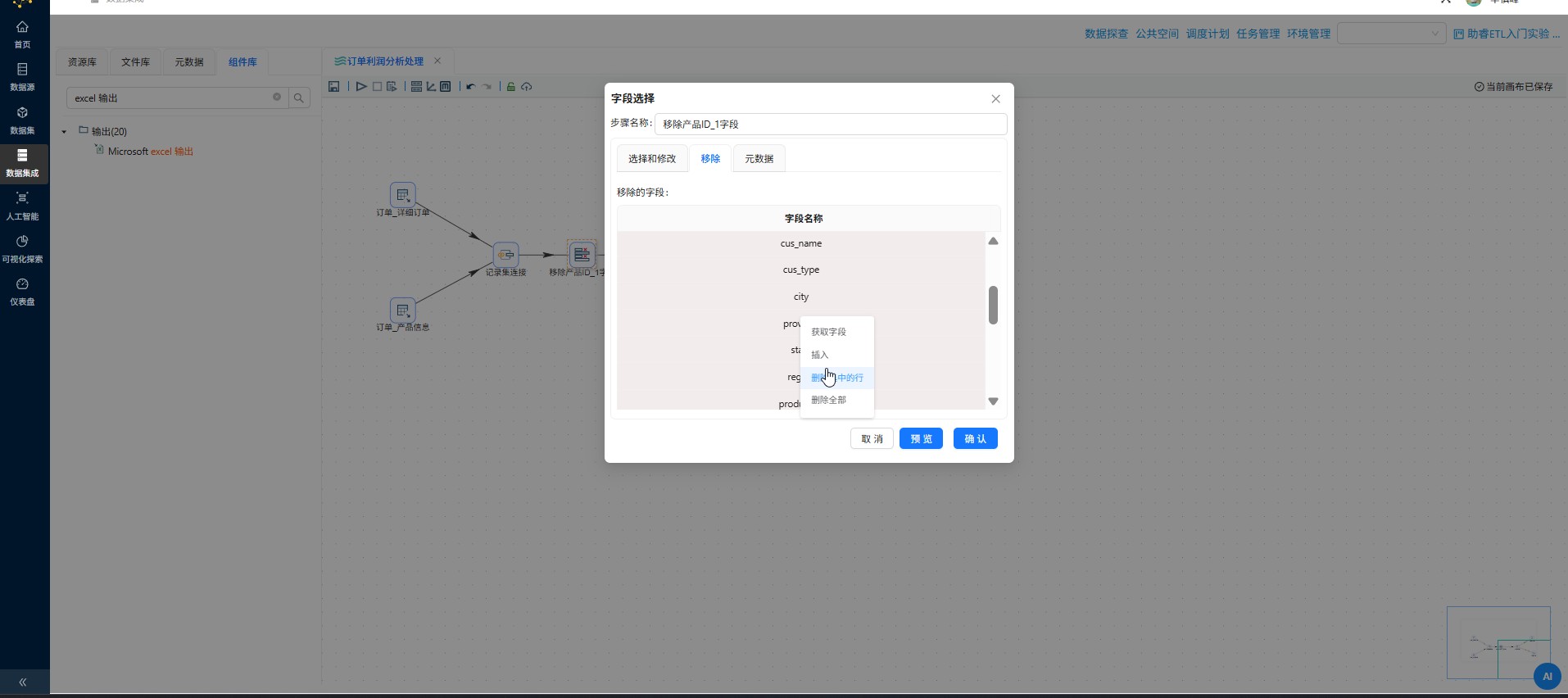
可以看到,字段"id"已被删除,点击"确认"
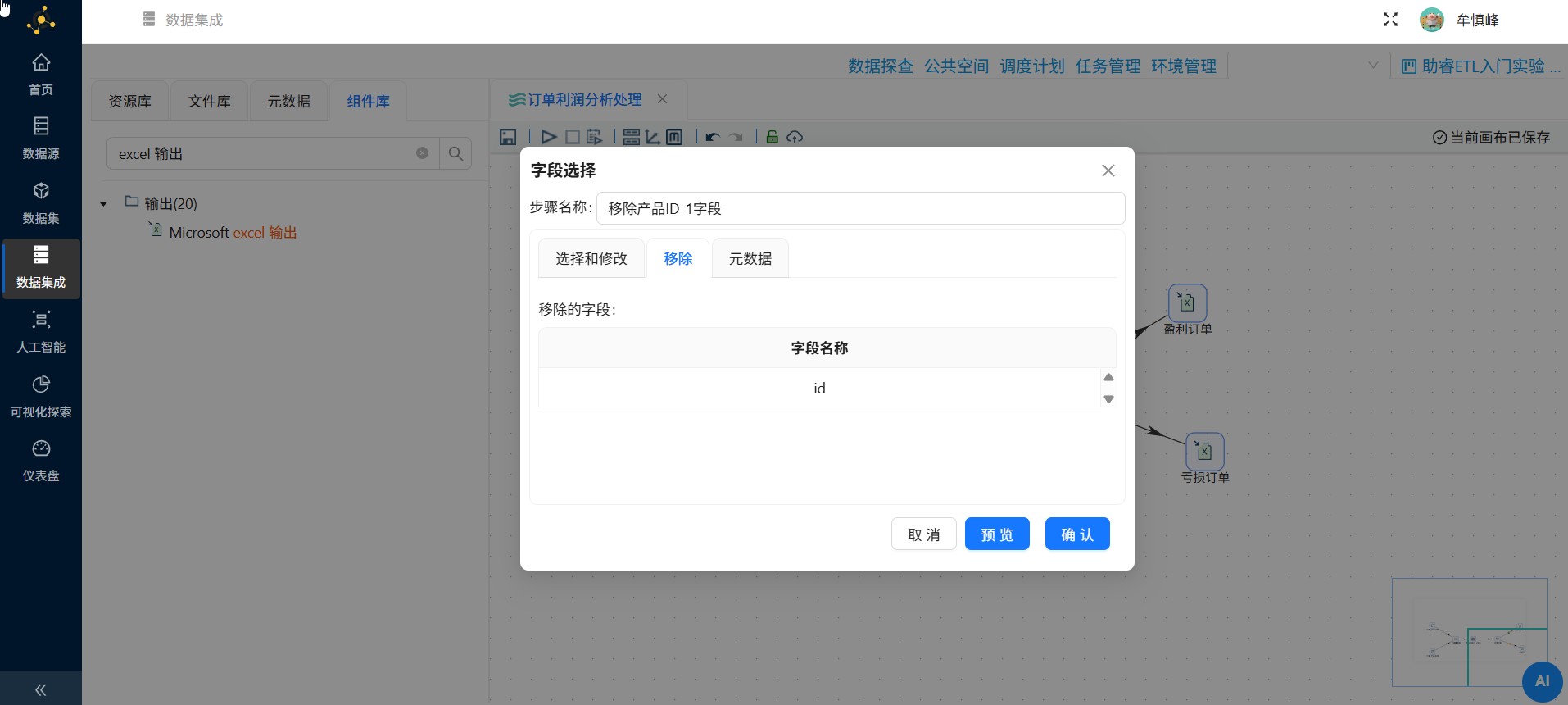
2.8.4 过滤记录组件配置
根据业务需求需要将盈利订单和亏损订单分开存储,两个订单可以使用字段利润来区分
双击"过滤记录"组件,在弹窗中的下拉列表中选择将结果发送给不同的后续处理步骤
选择字段利润(profit)来作为判断字段,选中"profit(Number)"后点击"确定"
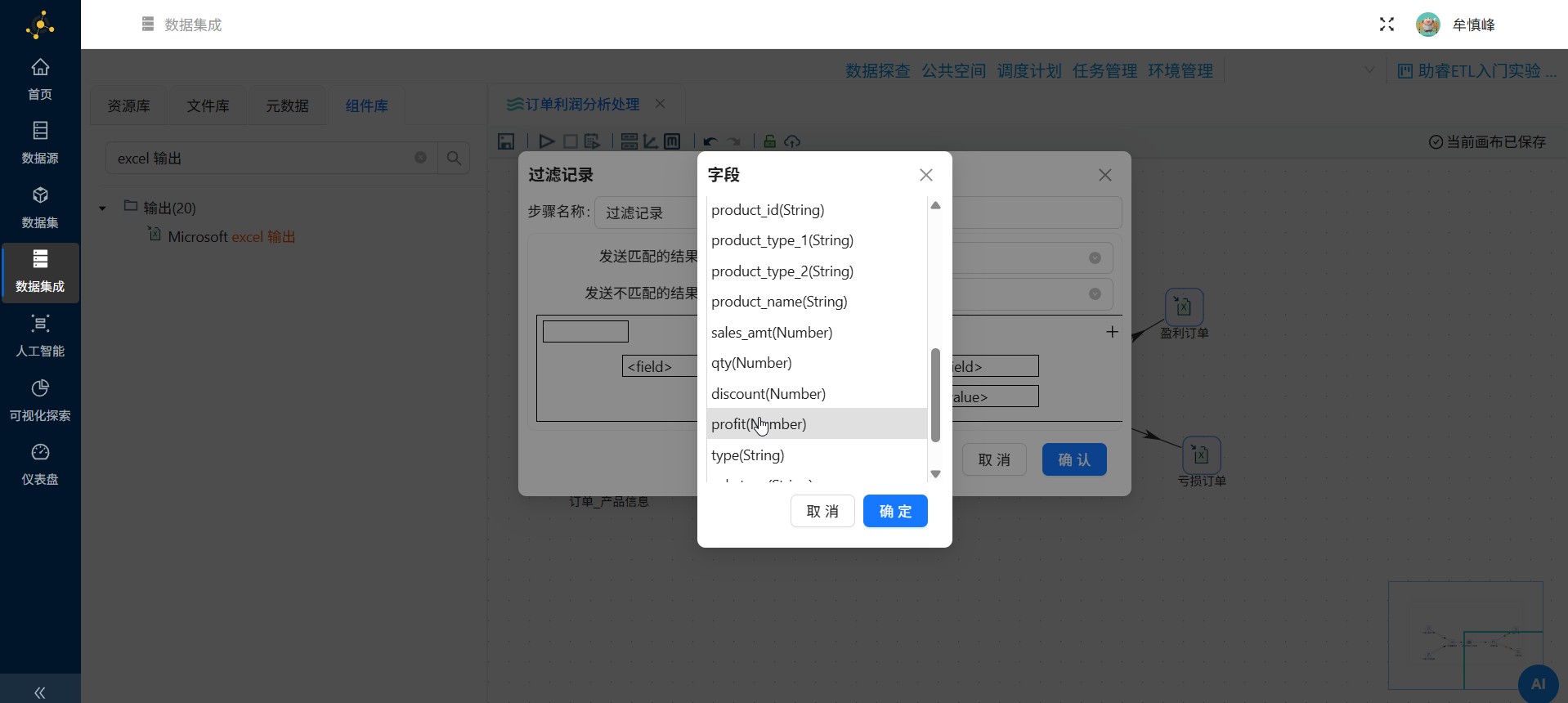
>=0 作为判断条件,点击"=",在函数中选择">="",点击"确定"
点击"value",值类型选择"Integer",值输入"0"点击"确定"
至此,过滤条件已配置完成,点击"确认"
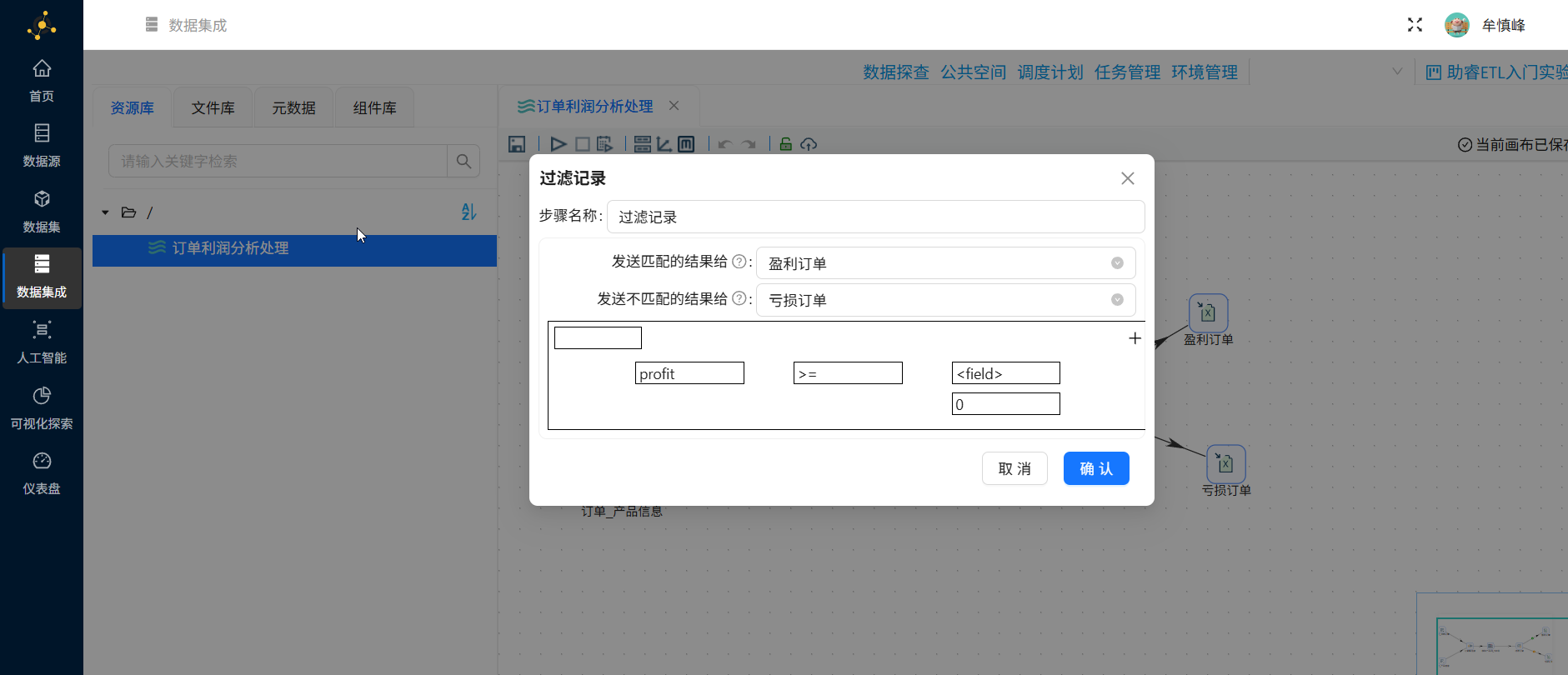
2.8.5 Excel 输出组件配置
将接收到的结果写入到Excel表中,双击"盈利订单"excel表输出组件,在配置弹窗中,文件名修改为"盈利订单",选择文件拓展名"xlsx [Excel 2007 and above]"
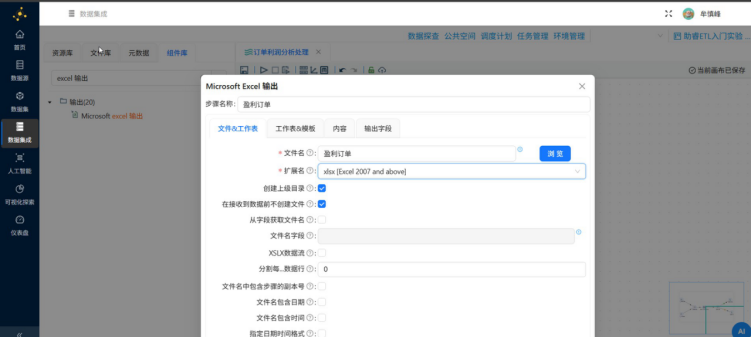
在配置弹窗中点击"输出字段",在空白表格处右键点击"获取字段"
字段获取后,点击"确认"
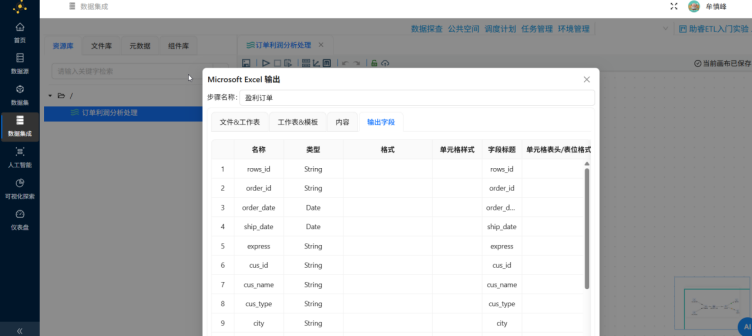
"亏损订单"的excel组件也进行同样的设置
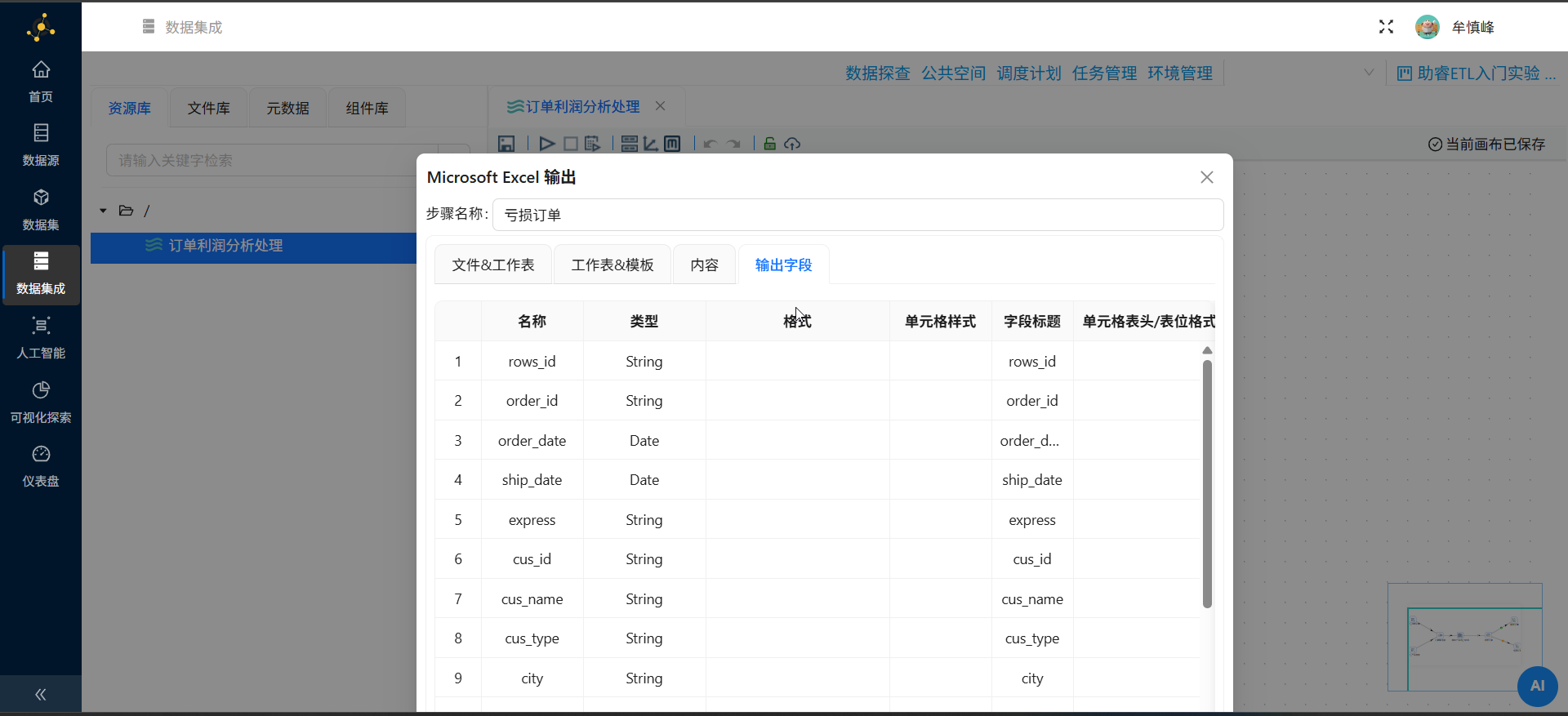
2.9 执行转换
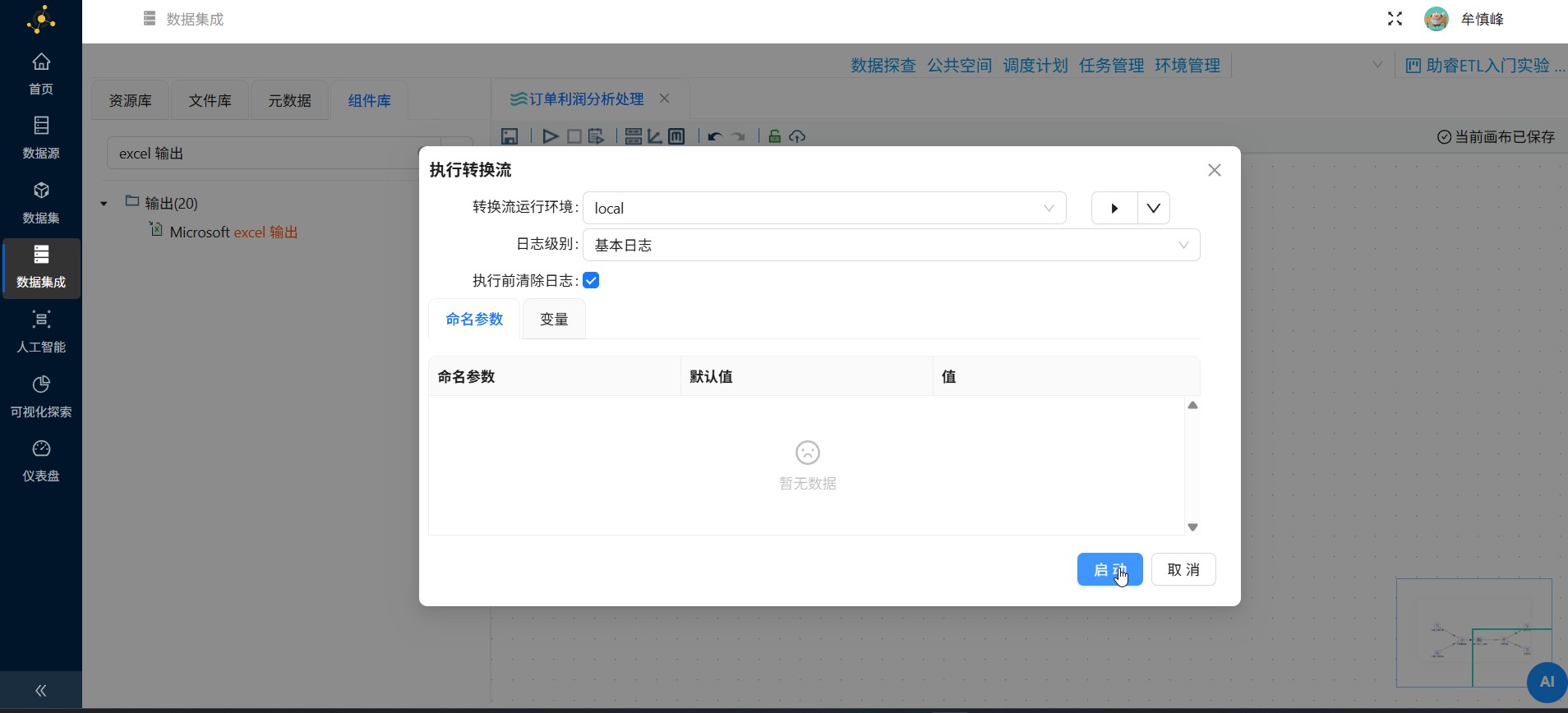
组件配置完成后,可执行转换任务,点击启动按钮
在弹出的窗口中点击"启动"
执行成功
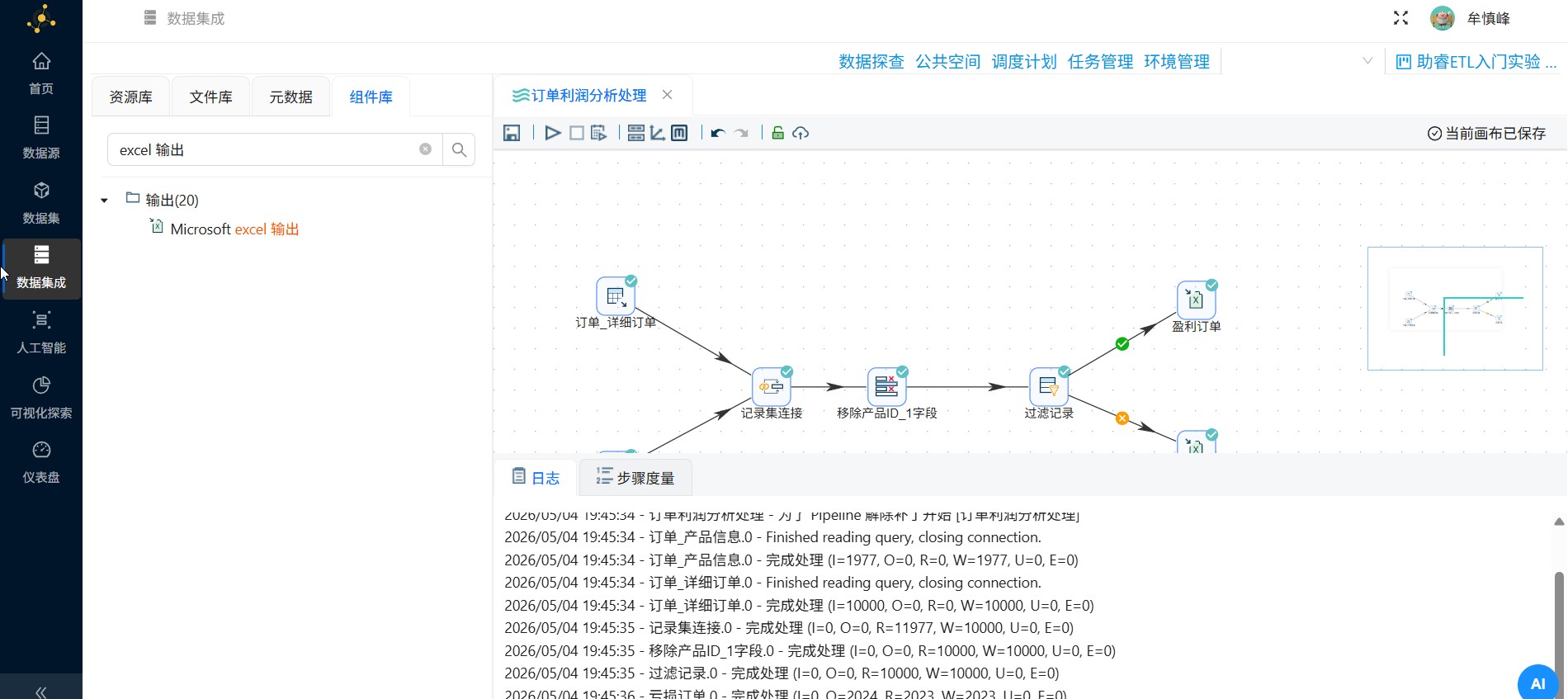
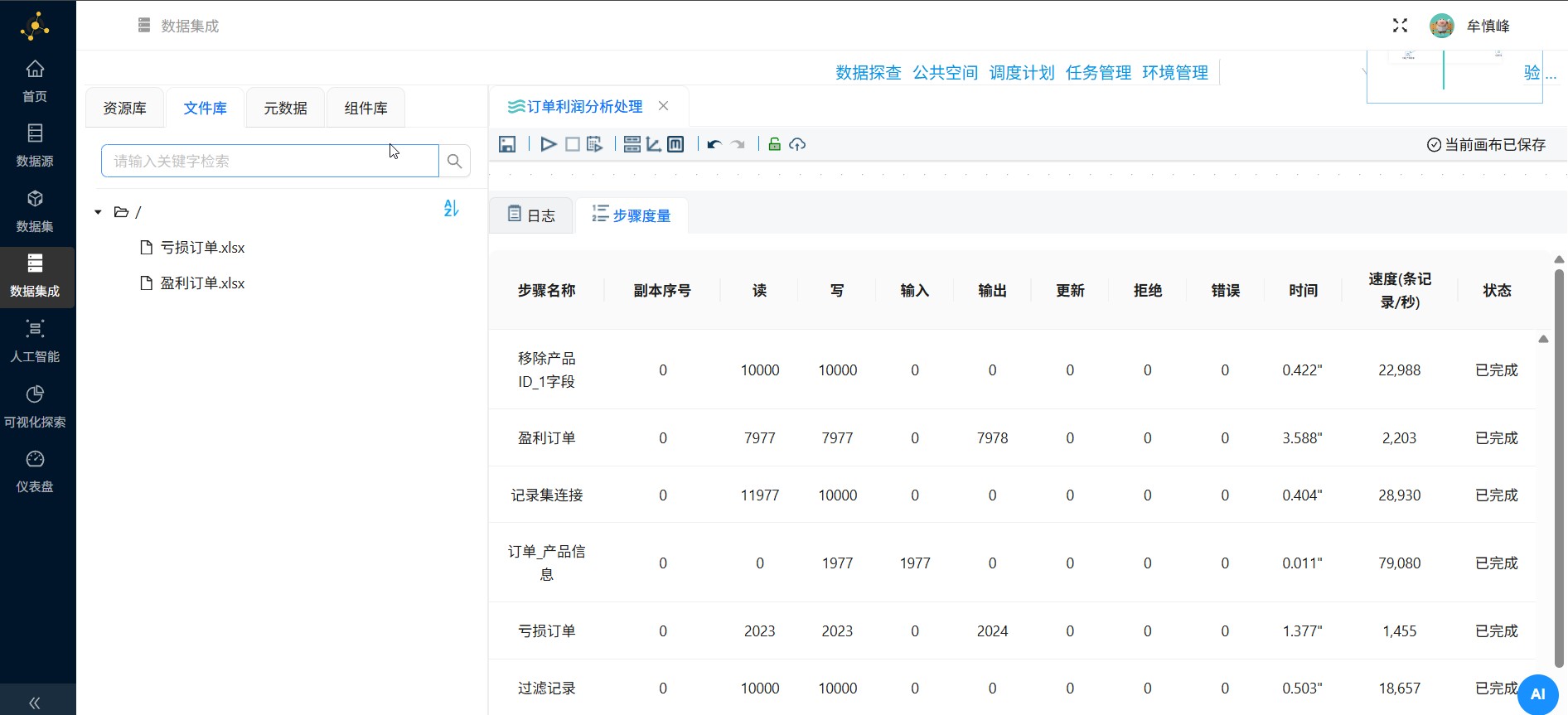
2.10 查看执行日志
任务执行过程中,会将相关操作记录到日志中,任务执行完毕后,可查看执行结果及日志
2.11 查看结果
点击"文件库",右键根目录刷新,可以看到转换任务的输出结果:盈利订单和亏损订单,可以右键下载查看
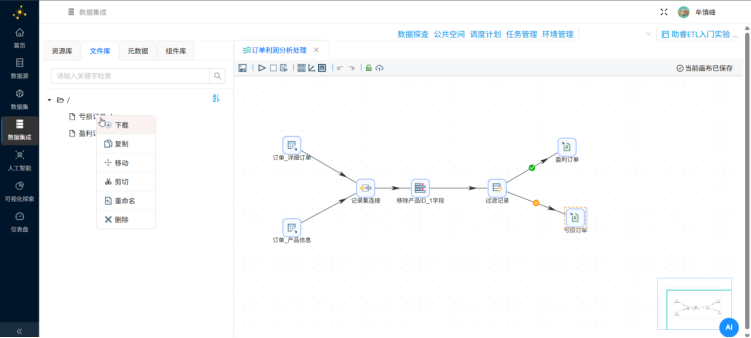
三、实验结果
|
输出文件 |
内容 |
说明 |
|
盈利订单.xlsx |
profit >= 0 的订单 |
可进一步分析高利润产品 |
|
亏损订单.xlsx |
profit < 0 的订单 |
可用于亏损原因追踪 |
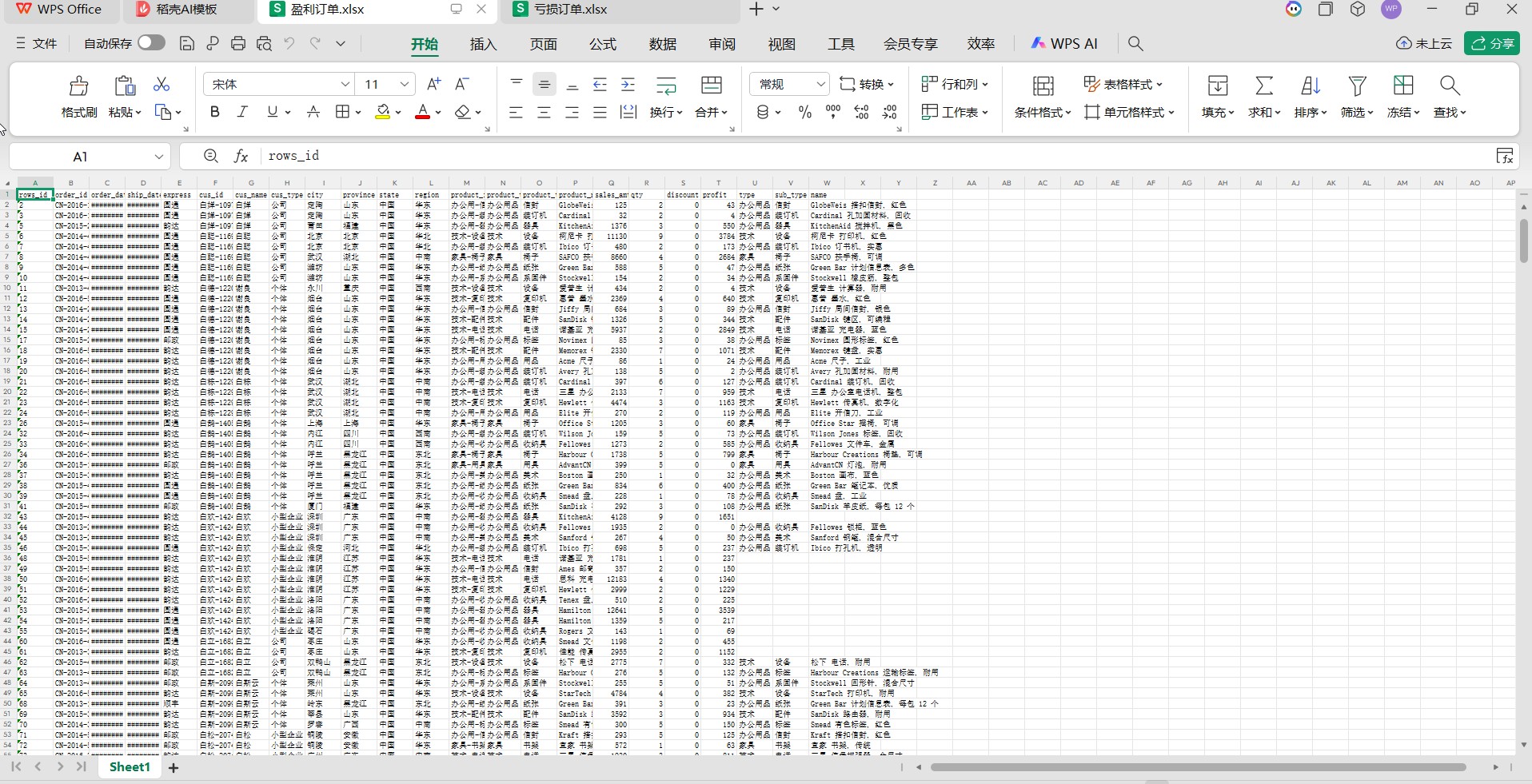
盈利订单.xlsx:
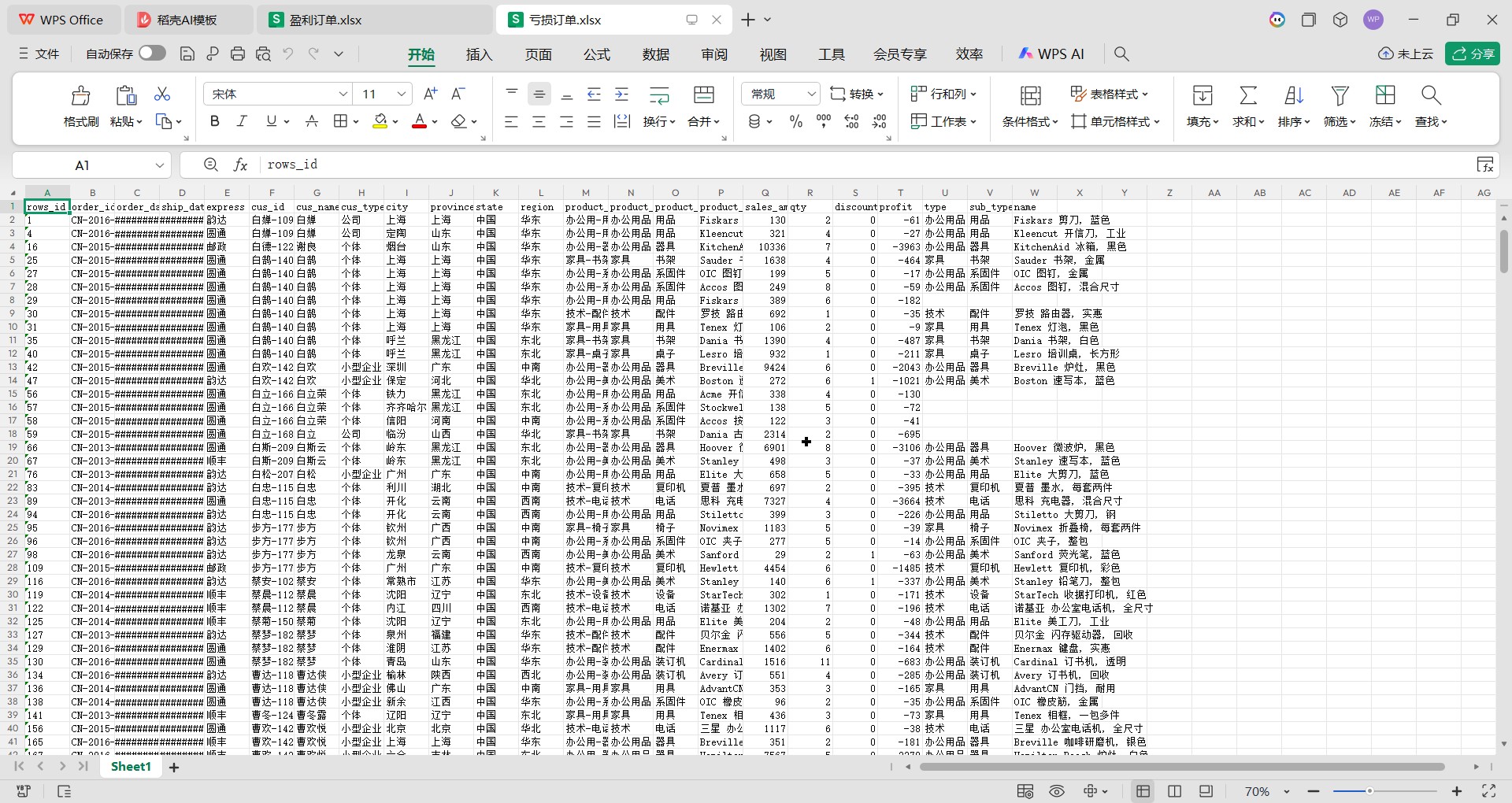
亏损订单.xlsx:
实验成功实现了订单数据的关联与分流处理,为后续的盈利分析提供了规范的数据基础。
四、核心组件说明
|
组件 |
作用 |
本实验配置要点 |
|
表输入 |
从数据库读取数据 |
配置数据源连接,选择表自动生成SQL |
|
记录集连接 |
执行表Join操作 |
LEFT OUTER JOIN,用produc_id关联id |
|
字段选择 |
字段筛选与重命名 |
移除Join后重复的id字段 |
|
过滤记录 |
条件路由/数据分流 |
设置profit >= 0条件,分True/False两路输出 |
|
Excel输出 |
导出处理结果 |
配置文件名,获取输出字段 |
五、问题与解决
做实验的时候踩了几个坑,记录一下避免下次再犯。
问题1:Excel输出获取不到字段
配置Excel输出的时候点「获取字段」没反应,字段列表是空的。我查了好久才发现,Hop的类型选错了。从过滤记录连到Excel输出时,盈利订单应该连「True输出」,亏损订单应该连「False输出」。我一开始都连成了「主输出步骤」,导致数据流不对,字段也获取不到。重新连线后就正常了。
这个问题说明ETL平台的Hop是有语义的,不能乱连。每个组件的输出端口都有特定含义,要理解数据流图的结构。
问题2:文件名冲突导致执行报错
配置完两个Excel输出组件后执行Pipeline,直接报错了。我一看日志,说是文件名冲突。原来两个Excel输出组件默认文件名都是「file」,我没改。平台无法区分两个输出文件,就报错了。改成「盈利订单」和「亏损订单」后再执行就成功了。
这个错误提示还算清晰,不过我觉得平台应该在配置时做个校验,当两个输出目标文件名重复的时候给出警告。
六、实验总结
这次实验算是把助睿平台的ETL功能过了一遍,从创建项目、同步数据源,到新建Pipeline、添加配置组件、执行再到看结果,整个流程都跑通了。表输入、Join、字段选择、过滤、输出这些常用组件的配置也都掌握了。
从软件工程的角度看,助睿平台这种零代码拖拽的方式,本质上是把传统代码化的ETL任务可视化、图形化了。Pipeline其实就是数据流图,每个Transform算子都是数据流上的一个节点,Hop定义了节点之间的依赖关系。这种设计让数据处理逻辑变得直观,调试起来也方便——数据流向一目了然,出了问题容易定位。
跟手写SQL比起来,可视化平台的优势是降低了学习门槛。特别是对非技术背景的用户,拖拽组件比写代码容易多了。但我觉得这种模式也有局限性,复杂的数据转换逻辑可能还是写代码更灵活。不过作为入门和常规数据处理场景,零代码平台确实挺实用的。
整体来说,这次实验让我对ETL有了更直观的理解,对数据流图、管道-过滤器这些软件工程模式也有了实际体验。
#助睿数智 #商业数据分析 #ETL数据加工 #数据实验

一站式 AI 云服务平台
更多推荐



 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)