
ETL进阶:教育数据分析,学生考勤画像标签构建全流程!(附组件配置详解与完整操作)
目录
一、实验背景与介绍
1.1 实验背景
在日常教学管理中,学生的考勤数据是评估学生行为习惯、支撑管理决策的重要依据。然而,原始考勤系统产出的数据往往分散在多个数据表中,格式不统一,维度信息缺失,难以直接用于分析。
本项目旨在构建一套标准化的学生考勤画像标签体系,将零散的打卡流水记录加工成结构化的宽表,输出每位学生的考勤行为全景画像,为后续的年级对比、校区分析、住校生管理等场景提供数据支撑。
核心任务拆解:
整合三张源表:考勤流水表、考勤类型字典表、学生基础信息表
自动识别四类异常行为:迟到、早退、请假、校服违规
衍生三个画像维度:年级、校区类型、住校状态
输出一张标准化标签宽表
1.2实验平台
本次实验继续在助睿数智(Uniplore)一站式数据科学实验平台上完成,实验地址为 https://lab.guilian.cn/ ,平台官网为 https://www.uniplore.com/ 。这是第二次进行ETL实验,上次完成了“订单利润分流数据加工”的任务(ETL入门教程零代码ETL入门:轻松搞定商业数据分析,实现订单利润分流),对平台的基本操作和常用组件已有初步了解。本次实验在此基础上进一步探索更复杂的多表关联、行为标签衍生和维度字段加工场景,加深对ETL工具在数据集成与标签构建方面实际应用的理解。
实验数据来源于“数智教育”大赛数据集,本次聚焦考勤主题,使用其中3张表:学生考勤流水表(3_kaoqin)、考勤类型字典表(4_kaoqintype)和学生基础信息表(2_student_info)。目标是将这三张分散的源表加工成一张结构化的学生考勤画像标签宽表。
| 数据源表 | 核心作用 | 关键字段 |
|---|---|---|
| 考勤主表(3_kaoqin) | 存储学生每日原始打卡记录、考勤行为明细 | 学生ID、班级ID、学期(qj_term)、打卡时间(DataDateTime)、考勤类型ID(ControllerID)、考勤描述(controler_name) |
| 考勤类型码表(4_kaoqintype) | 标准化考勤事件名称,区分正常与异常考勤类型 | 考勤类型ID(controller_id)、考勤事件名称(control_task_name) |
| 学生信息表(2_student_info) | 提供学生基础属性,支撑多维度学生画像 | 学生ID(bf_StudentID)、班级ID(cla_id)、学生姓名(bf_Name)、性别(bf_sex)、出生日期(bf_BornDate)、政治面貌(bf_policy)、是否住校(bf_zhusu) |
1.3流程介绍
本次实验的数据处理遵循“数据接入 → 多表关联 → 行为标记 → 指标聚合 → 属性补全 → 标准化处理 → 结果输出”的主线逻辑。整个转换流共使用16个组件,按数据流向编排如下:
数据接入(3个表输入组件读取源表)
→ 排序预处理(对关联键排序,保证连接正确)
→ 第一次关联(考勤表连接类型字典表,补全行为名称)
→ 行为标记(JavaScript脚本根据名称关键词生成4个0/1标记)
→ 指标聚合(分组组件按学生维度汇总行为次数)
→ 第二次关联(聚合结果连接学生信息表,补全性别、住校等属性)
→ 字段精简(移除连接过程中产生的冗余字段)
→ 空值处理(将NULL统一替换为“未知”)
→ 编码翻译(住校状态从0/1映射为否/是)
→ 维度衍生(从班级名提取年级、判定校区类型)
→ 结果入库(写入目标标签表)
二、实验步骤与内容
2.1 创建项目与数据准备
在助睿平台的数据集成部分点击“新建项目”,命名为“学生考勤画像标签构建”。创建完成后进入项目。
将公共空间的数据导入到数据集中,并在元数据里新建数据库连接,正确填写名称密码即可。
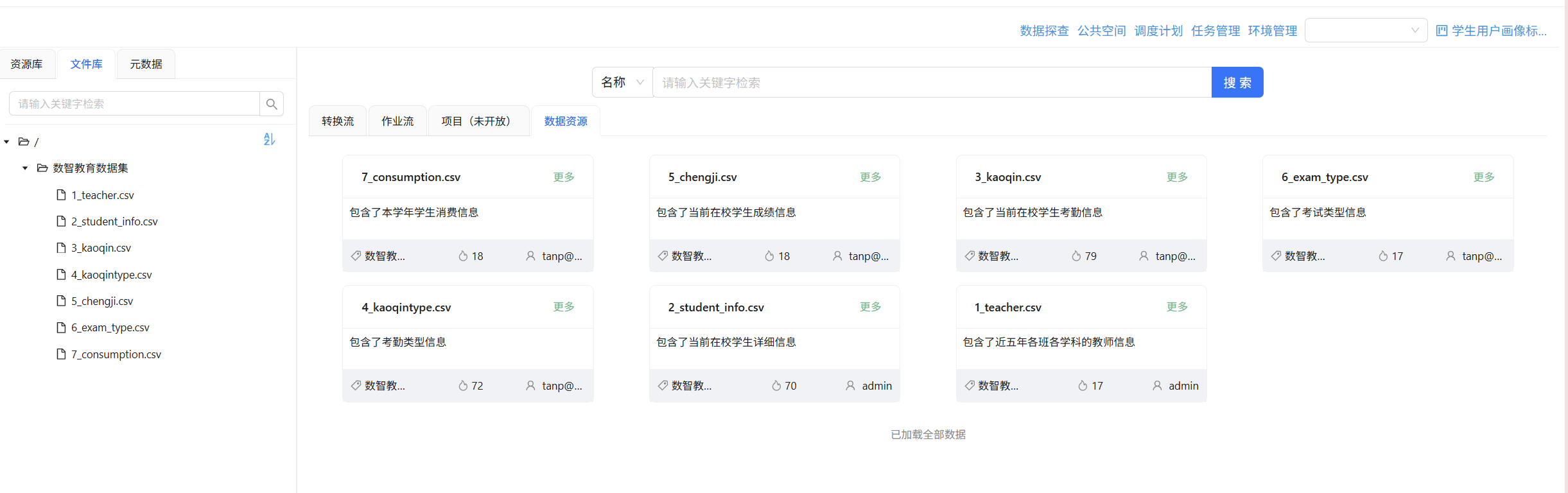
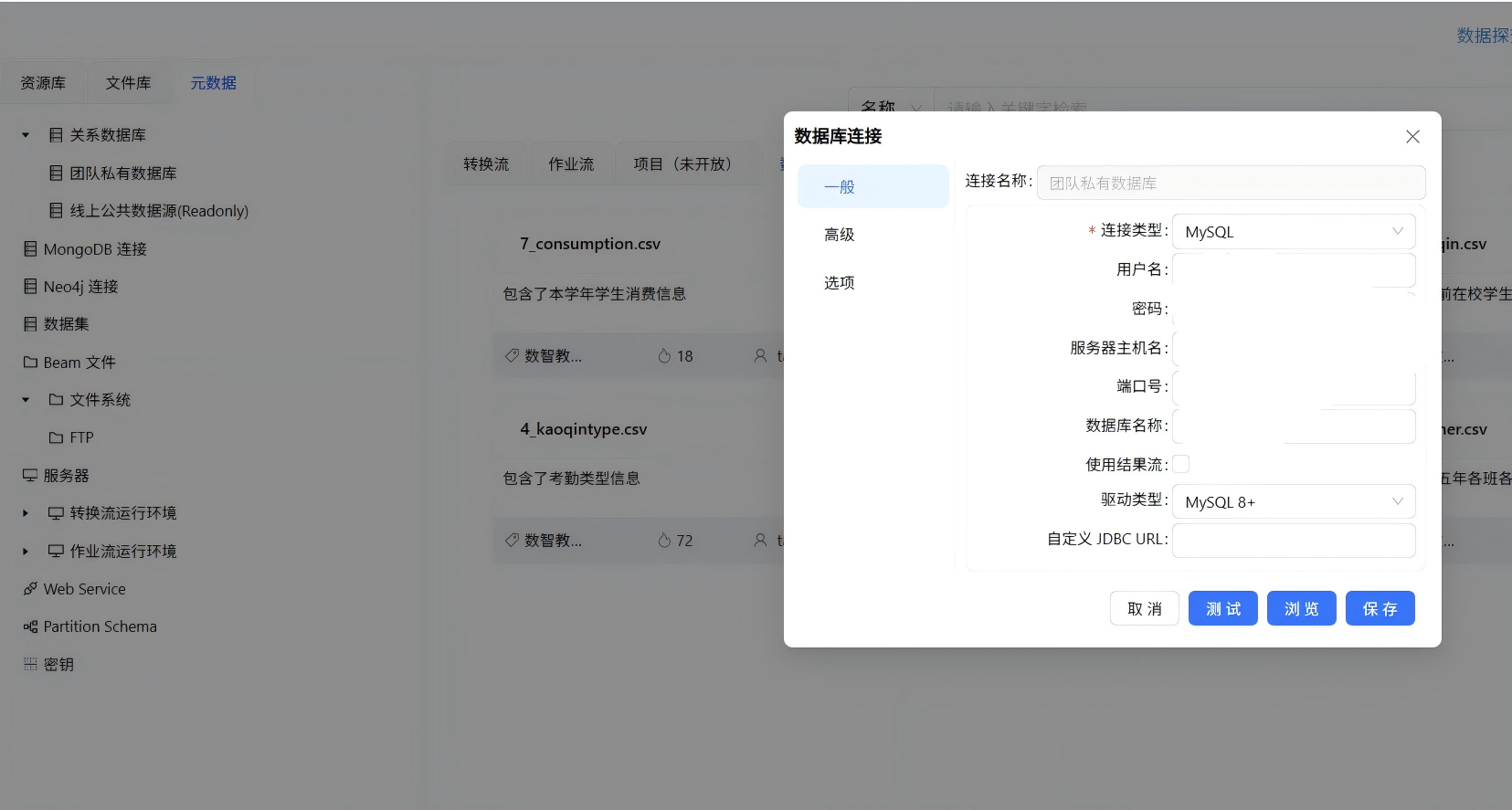
原始CSV文件需先导入团队私有数据库。我通过”执行SQL脚本“组件创建了三张原始数据表(raw_attendance、raw_attendance_type、raw_student_info)以及最终输出的目标标签表student_attendance_stats。建表SQL通过平台内置的数据库连接工具执行。
以原始考勤表为例,创建好转换流,添加SQL脚本组件,将建表语句输入运行即可。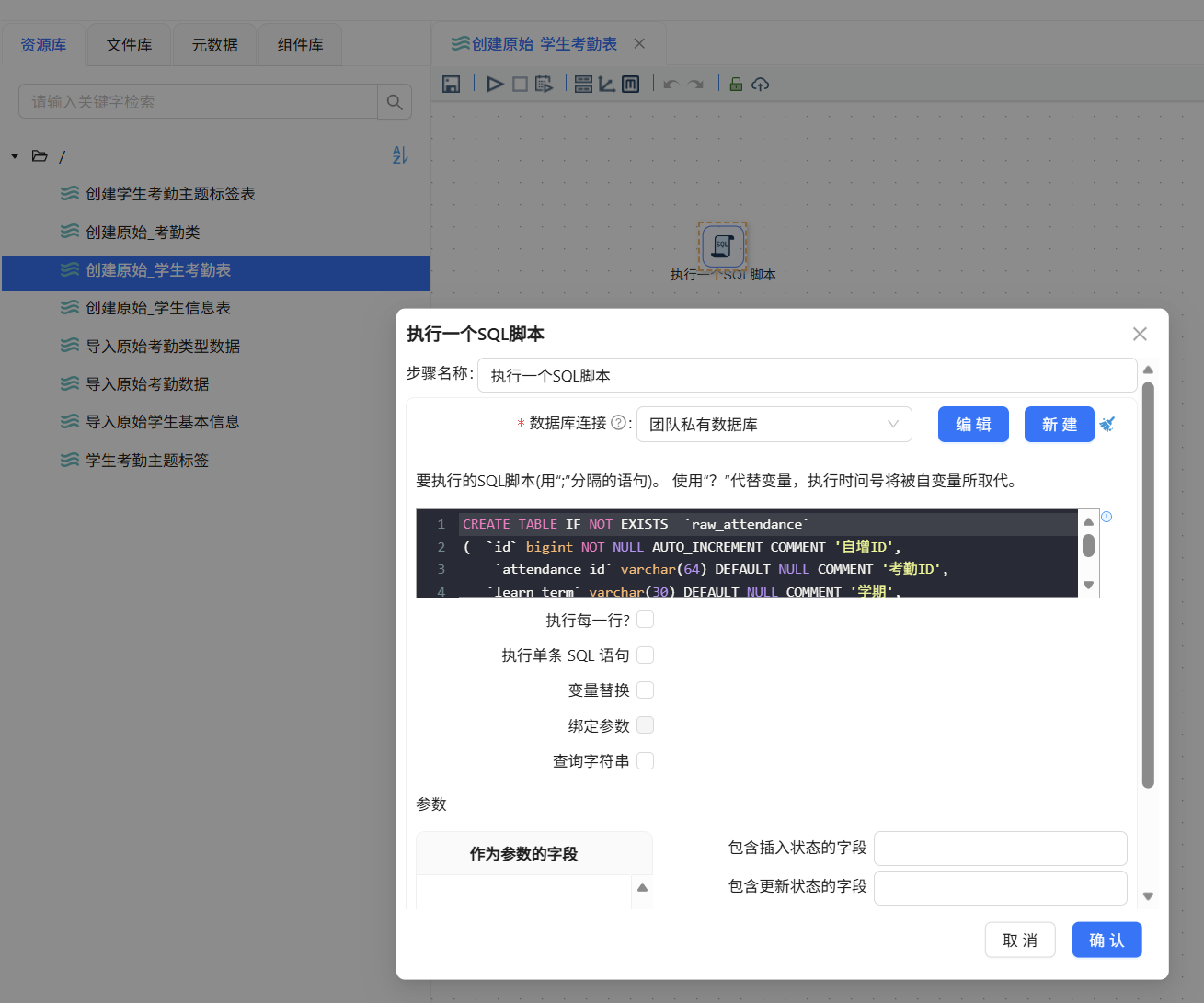
2.2 学生考勤标签表构建
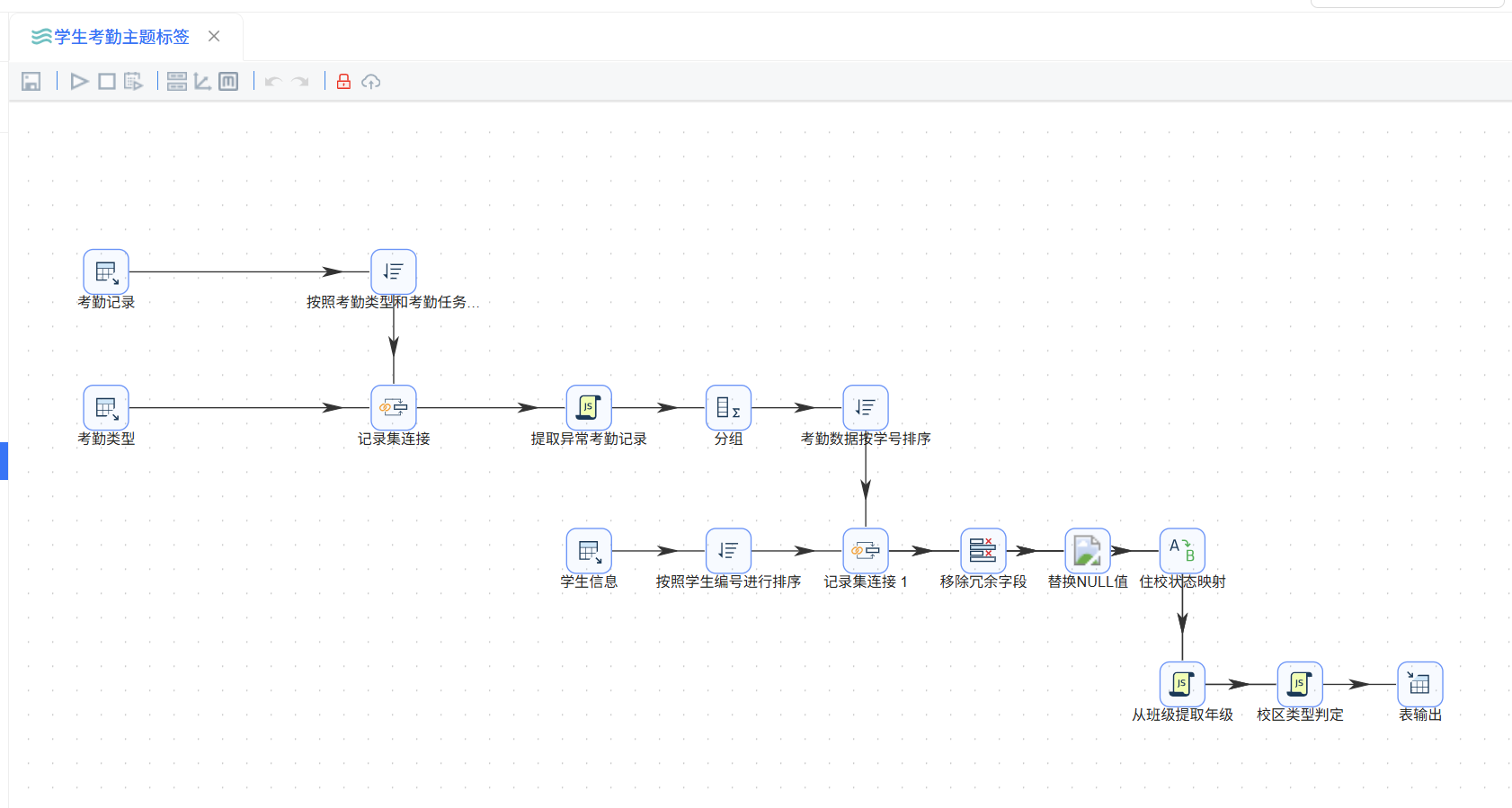
首先在目录下创建名为“创建学生考勤主题标签表”的转换工作流,并添加组件,本次转换流使用的全部组件汇总如下,整个流程共使用7种组件类型、16个组件实例:
| 组件类型 | 使用数量 | 组件实例名称 | 在流程中的作用 |
|---|---|---|---|
| 表输入 | 3 | 考勤记录、考勤类型、学生信息 | 从数据库中读取三张源表,作为数据管道的起点 |
| 排序记录 | 3 | 按考勤类型和任务类型排序、按学生编号排序 | 对数据流按关联键排序,保证记录集连接的准确性 |
| 记录集连接 | 2 | 记录集连接、记录集连接 1 | 实现两表LEFT JOIN,分别补全考勤行为名称和学生属性 |
| JavaScript代码 | 3 | 提取异常考勤记录、从班级提取年级、校区类型判定 | 执行自定义逻辑:行为标记、年级提取、校区判定 |
| 分组 | 1 | 分组 | 按学生维度聚合,将明细标记转为行为次数汇总 |
| 字段选择 | 1 | 移除冗余字段 | 删除多表关联产生的多余字段,精简数据结构 |
| 替换NULL值 | 1 | 替换NULL值 | 将关键字段的空值统一替换为“未知” |
| 值映射 | 1 | 住校状态映射 | 将住校编码0/1转换为可读文本否/是 |
| 表输出 | 1 | 表输出 | 将最终结果写入目标数据库表 |
从组件类型的分布可以看出,本次实验的核心操作集中在三个环节:数据关联(排序记录+记录集连接,共4个组件)、逻辑加工(JavaScript代码,共3个组件)和数据标准化(字段选择+替换NULL+值映射,共3个组件)。三者构成了从“原始流水”到“标准化标签”的数据加工主线。
2.3 数据接入:配置三个表输入组件
从组件库中搜索“表输入”,拖入画布三次,分别命名为“考勤记录”“考勤类型”“学生信息”。
每个表输入组件需要选择数据库连接为“团队私有数据库”,然后通过SQL语句读取对应源表(raw_attendance,raw_attendance_type,raw_student_info),三个组件配置方式相同,区别仅在于指向的表不同,以考勤记录为例,配置如下: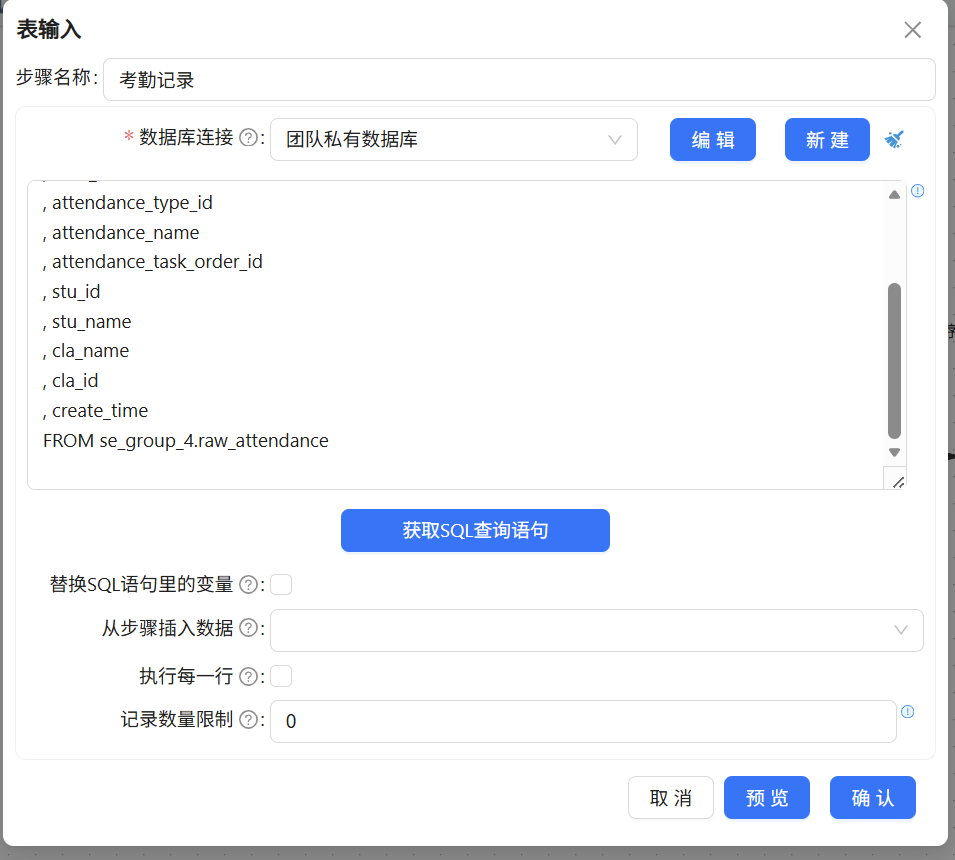
这三个组件是数据管道的起点,分别输出三条独立的数据流,后续通过排序和连接组件进行交汇。
2.4 关联预处理:配置排序记录组件
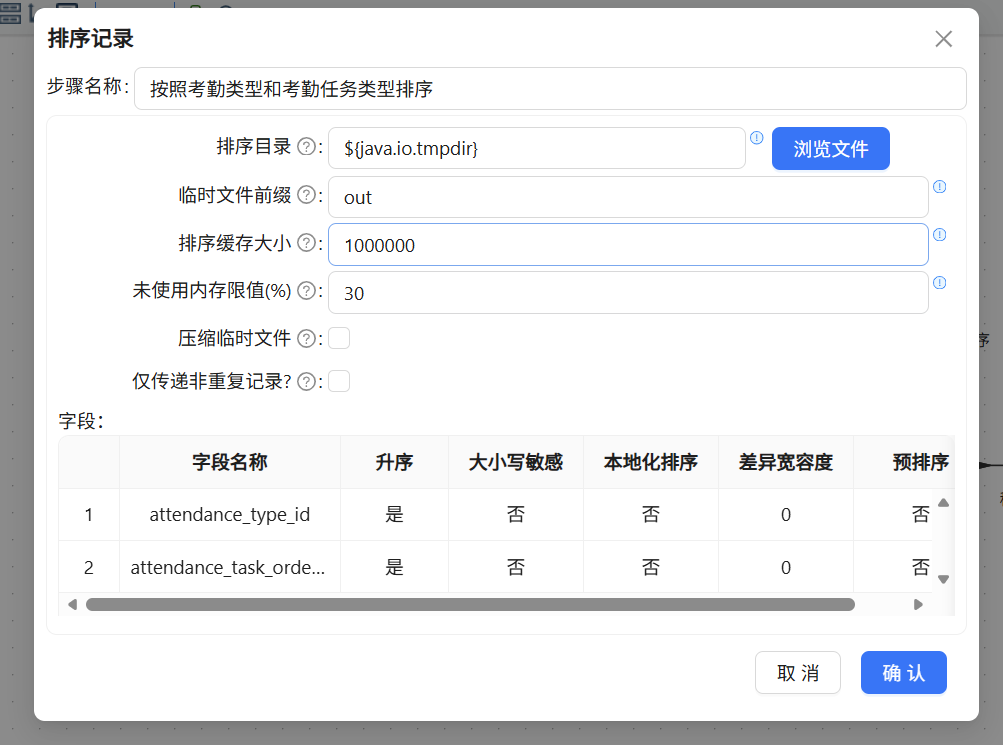
因为记录集连接组件按接收顺序逐条匹配,如果数据未按关联键排序,连接结果可能出问题,所以需要在“考勤记录”表输入与“记录集连接”之间插入一个“排序记录”组件,命名为“按照考勤类型和考勤任务类型排序”。
通过“获取字段”拉取全部字段,只保留attendance_type_id和attendance_task_order_id两个关联键,按它们升序排列即可。
2.5 第一次数据关联:考勤记录连接考勤类型
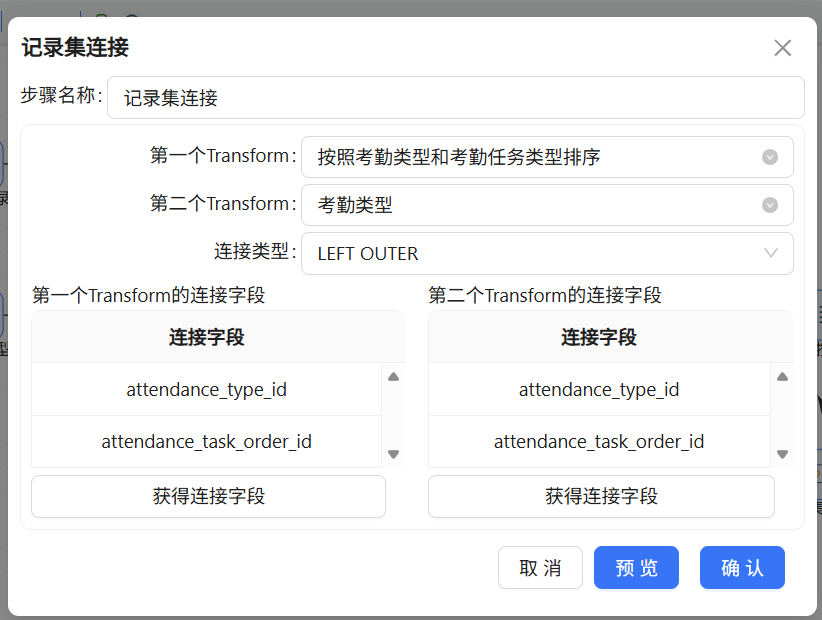
拖入“记录集连接”组件,分别选择考勤记录流和考勤类型表,类型设为LEFT OUTER。这一步的目的是把考勤记录中的数字编码翻译成可读的行为名称,补全attendance_type_name和attendance_task_name。
连接字段为attendance_type_id和attendance_task_order_id
2.6 行为标记:JavaScript脚本生成异常标签
在记录集连接后添加“JavaScript代码”组件,命名为“提取异常考勤记录”,通过关键词匹配给每条记录打上4个0/1标记:isLate(迟到)、isEarly(早退)、isLeave(请假)、isNoUniform(校服违规)
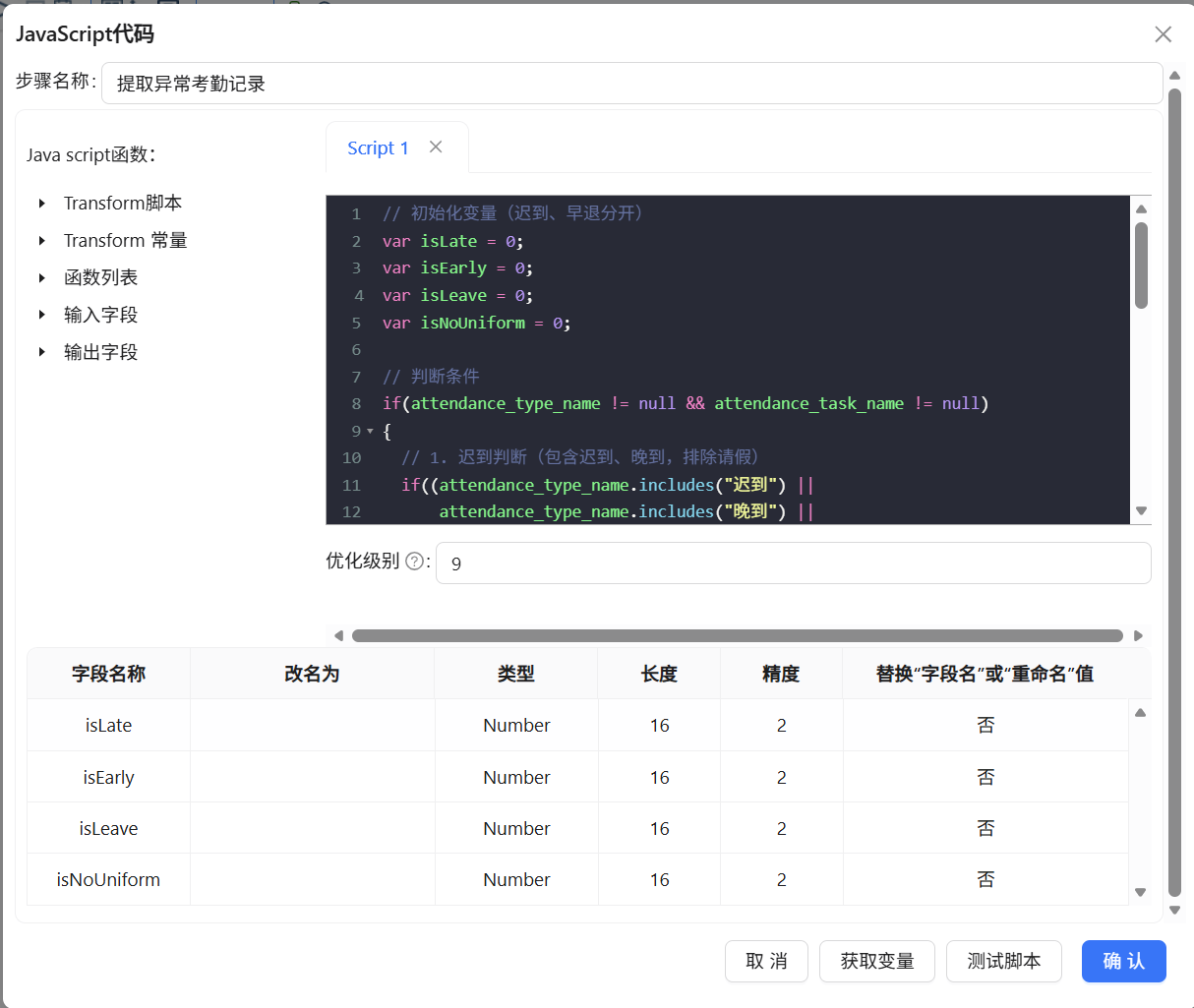
具体代码脚本如下:
// 初始化变量(迟到、早退分开)
var isLate = 0;
var isEarly = 0;
var isLeave = 0;
var isNoUniform = 0;
// 判断条件
if(attendance_type_name != null && attendance_task_name != null)
{
// 1. 迟到判断(包含迟到、晚到,排除请假)
if((attendance_type_name.includes("迟到") ||
attendance_type_name.includes("晚到") ||
attendance_task_name.includes("迟到") ||
attendance_task_name.includes("晚到")) &&
!attendance_task_name.includes("请假")){
isLate = 1;
}
// 2. 早退判断(排除请假)
if((attendance_type_name.includes("早退") ||
attendance_task_name.includes("早退")) &&
!attendance_task_name.includes("请假")){
isEarly = 1;
}
// 3. 没穿校服标记 ← 这里原来少了右括号
if(attendance_type_name.includes("校服") ||
attendance_task_name.includes("校服")){ // ← 补上了 )
isNoUniform = 1;
}
}
// 4. 请假标记
if(attendance_task_name != null){
if(attendance_task_name.includes("请假")){
isLeave = 1;
}
}2.7 指标聚合:分组组件汇总行为次数
上一步输出的还是逐条打卡记录,接下来用“分组”组件按学生维度聚合,把明细数据压缩成每人一条的汇总。分组字段用stu_id、stu_name、cla_id、cla_name,聚合函数统一用SUM,把isLate、isEarly、isLeave、isNoUniform四个标记字段各自求和,得到每位学生的迟到次数、早退次数、请假次数和未穿校服次数。
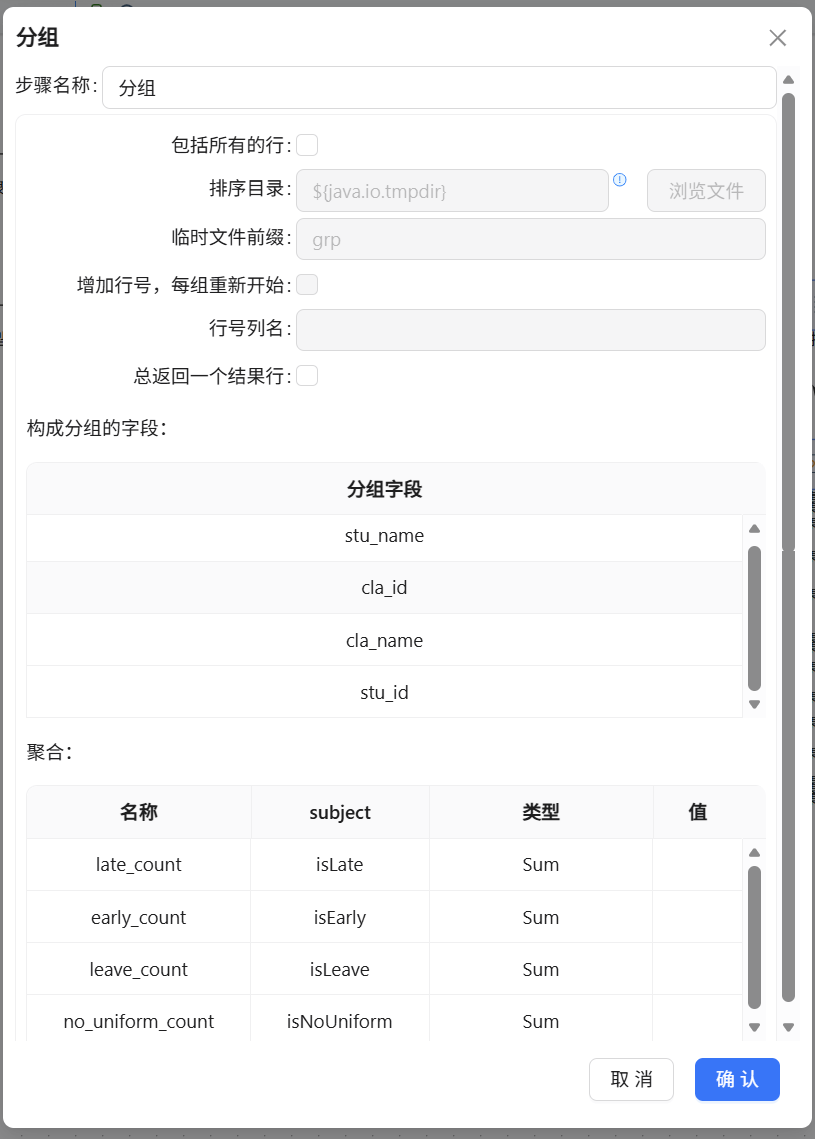
2.8 第二次数据关联:连接学生信息表
分组聚合后只有学生ID和班级信息,还缺性别、出生日期、政治面貌、住校状态这些属性,需要关联学生信息表补全。在“学生信息”表输入后面先加一个排序记录组件,按stu_id升序排列,然后用第二个记录集连接组件,左表是聚合结果,右表是排序后的学生信息,同样LEFT OUTER连接,关联键用一个stu_id就行

(两个排序记录配置都是一样的,这里以“考勤数据按学号排序”配置为例)
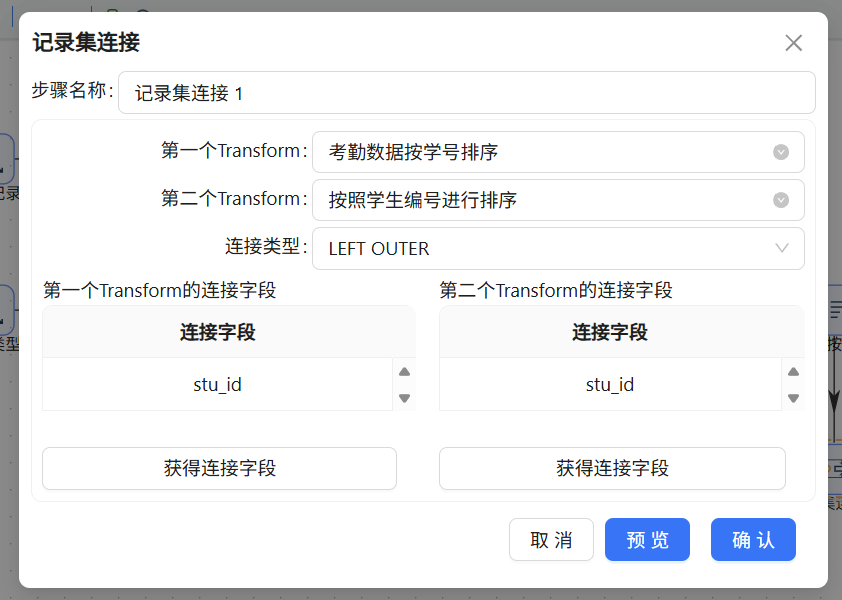
2.9 字段精简:移除冗余字段
两轮关联下来数据流里夹带了不少中间字段,用“字段选择”组件做一次清理。切换到“移除”标签页,把不需要的字段勾选,删除stu_id、stu_name、cla_id、cla_name、late_count、early_count、leave_count、no_uniform_count、stu_sex、born_date、policy、live_on_campus这13个核心字段。
注意:配置中删除的字段是处理后会保留的,配置中存在的字段是处理中会被删除的(有点绕,但是不要删错了)
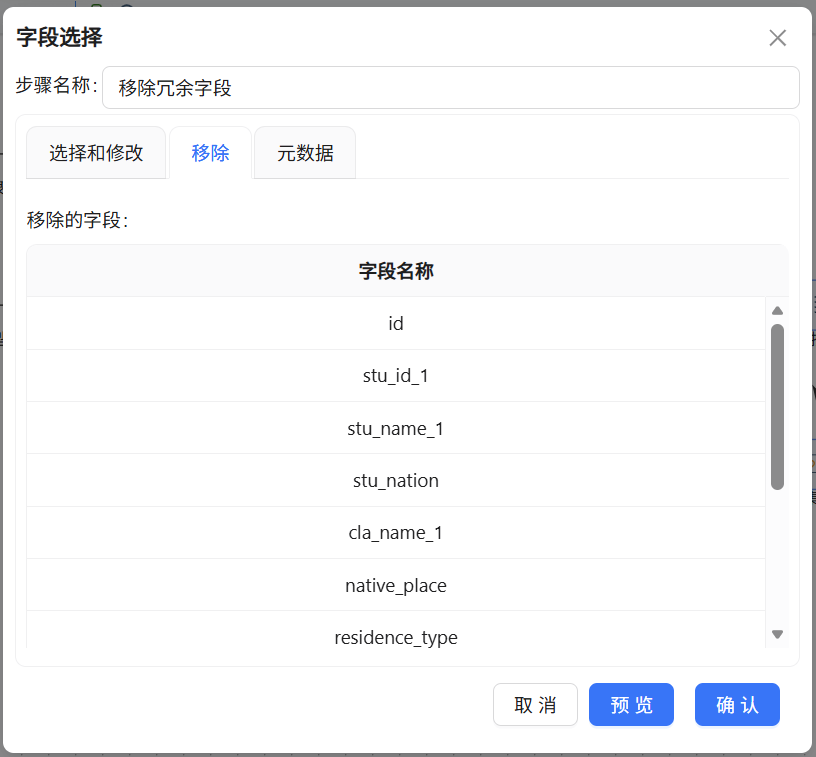
2.10 空值处理:替换NULL值
检查中间数据时发现学生信息表里部分字段存在缺失,比如政治面貌没填、住校状态为空。这些NULL如果不处理,后面做值映射和维度衍生可能会出问题。拖入“替换NULL值”组件,把stu_sex、born_date、policy、live_on_campus四个字段的空值统一替换成“未知”——既保留了“信息缺失”的语义,也保证了后续流程不会因为空值报错。
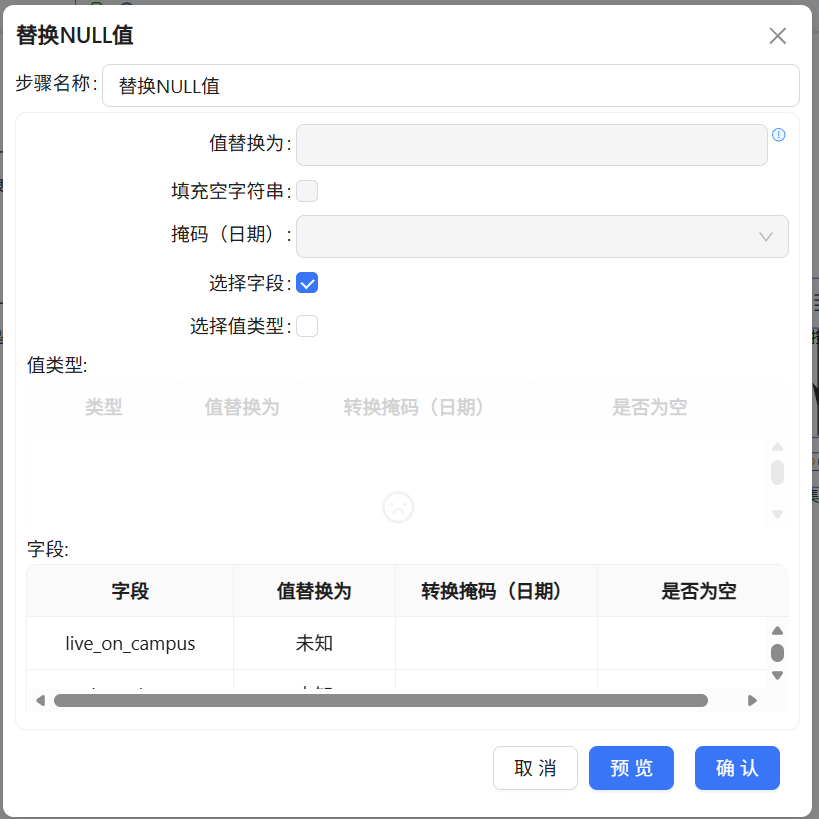
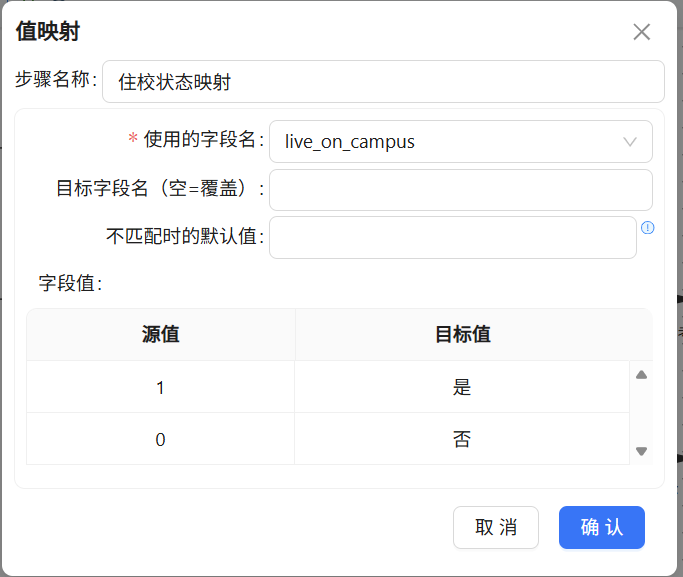
2.11 编码翻译:住校状态值映射
live_on_campus字段在原始数据里存的是0和1,可读性较差,这里用“值映射”组件做转换:0映射为“否”,1映射为“是”。
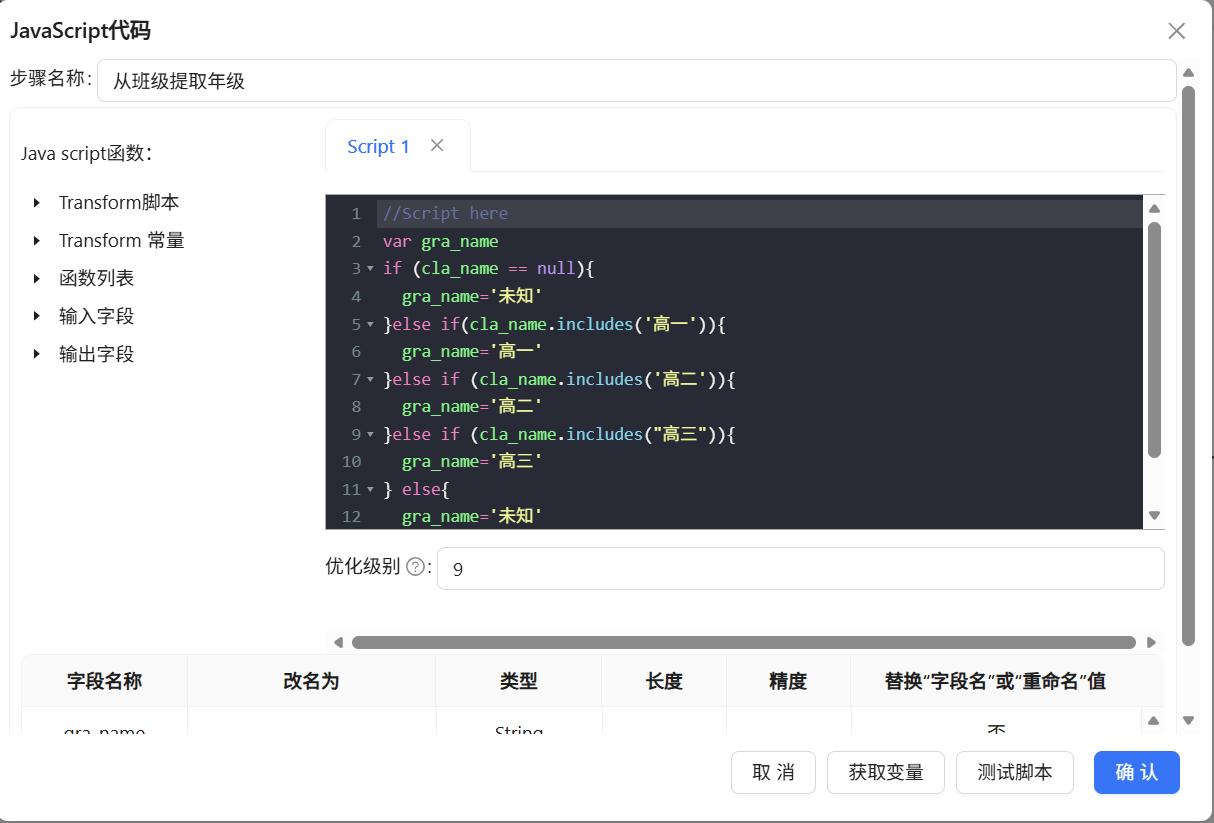
2.12 维度衍生一:从班级名提取年级
原始数据没有独立的年级字段,但按年级统计考勤是常见需求。我观察了班级名称的规律,发现所有班级名都包含“高一”“高二”或“高三”(比如“高一(03)班”“白-高二(01)”),于是用JavaScript组件做字符串匹配提取。依次判断cla_name中包含哪个年级关键词
//Script here
var gra_name
if (cla_name == null){
gra_name='未知'
}else if(cla_name.includes('高一')){
gra_name='高一'
}else if (cla_name.includes('高二')){
gra_name='高二'
}else if (cla_name.includes("高三")){
gra_name='高三'
} else{
gra_name='未知'
}
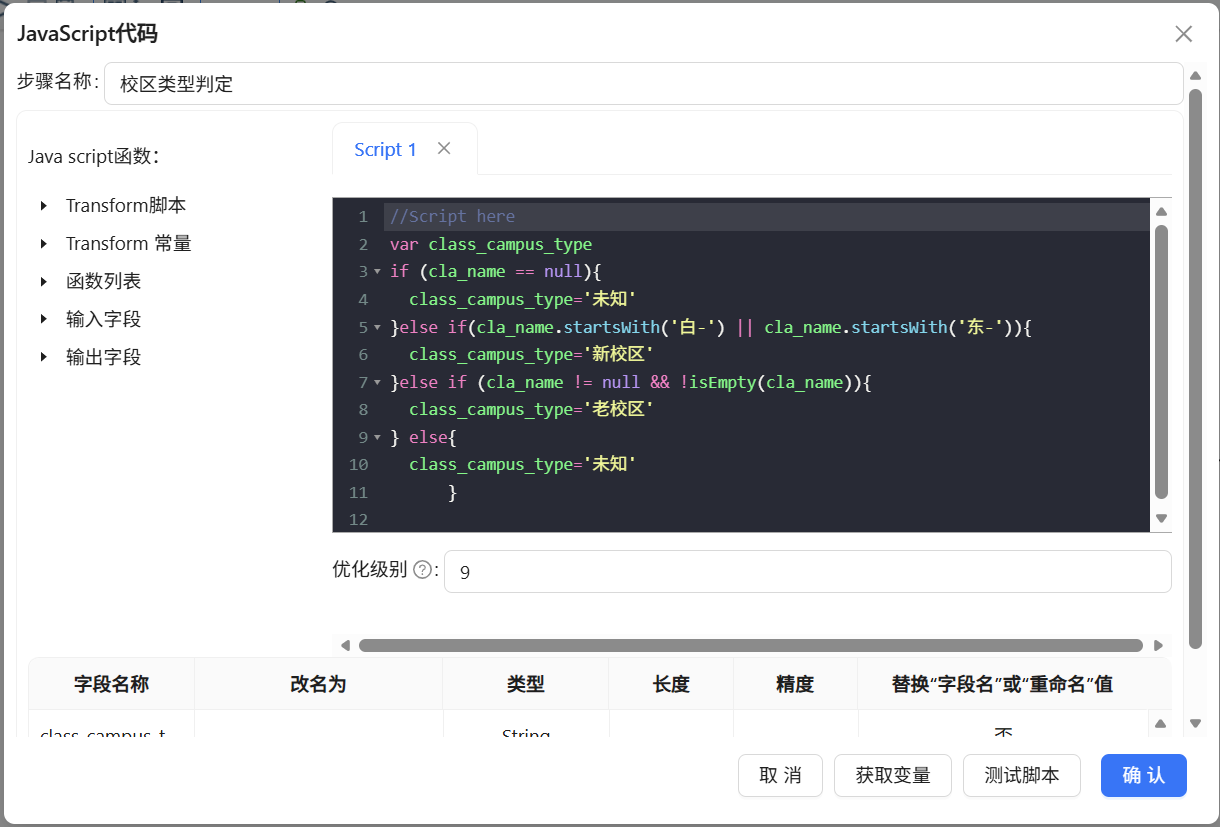
2.13 维度衍生二:校区类型判定
第三个JavaScript组件用来判定校区。根据数据说明,该校新校区的班级名以“白-”或“东-”开头(如“白-高二(01)”),老校区没有这个前缀。用startsWith方法判断前缀即可:匹配上“白-”或“东-”就是新校区,班级名不为空但不符合前缀规则就是老校区
//Script here
var class_campus_type
if (cla_name == null){
class_campus_type='未知'
}else if(cla_name.startsWith('白-') || cla_name.startsWith('东-')){
class_campus_type='新校区'
}else if (cla_name != null && !isEmpty(cla_name)){
class_campus_type='老校区'
} else{
class_campus_type='未知'
}
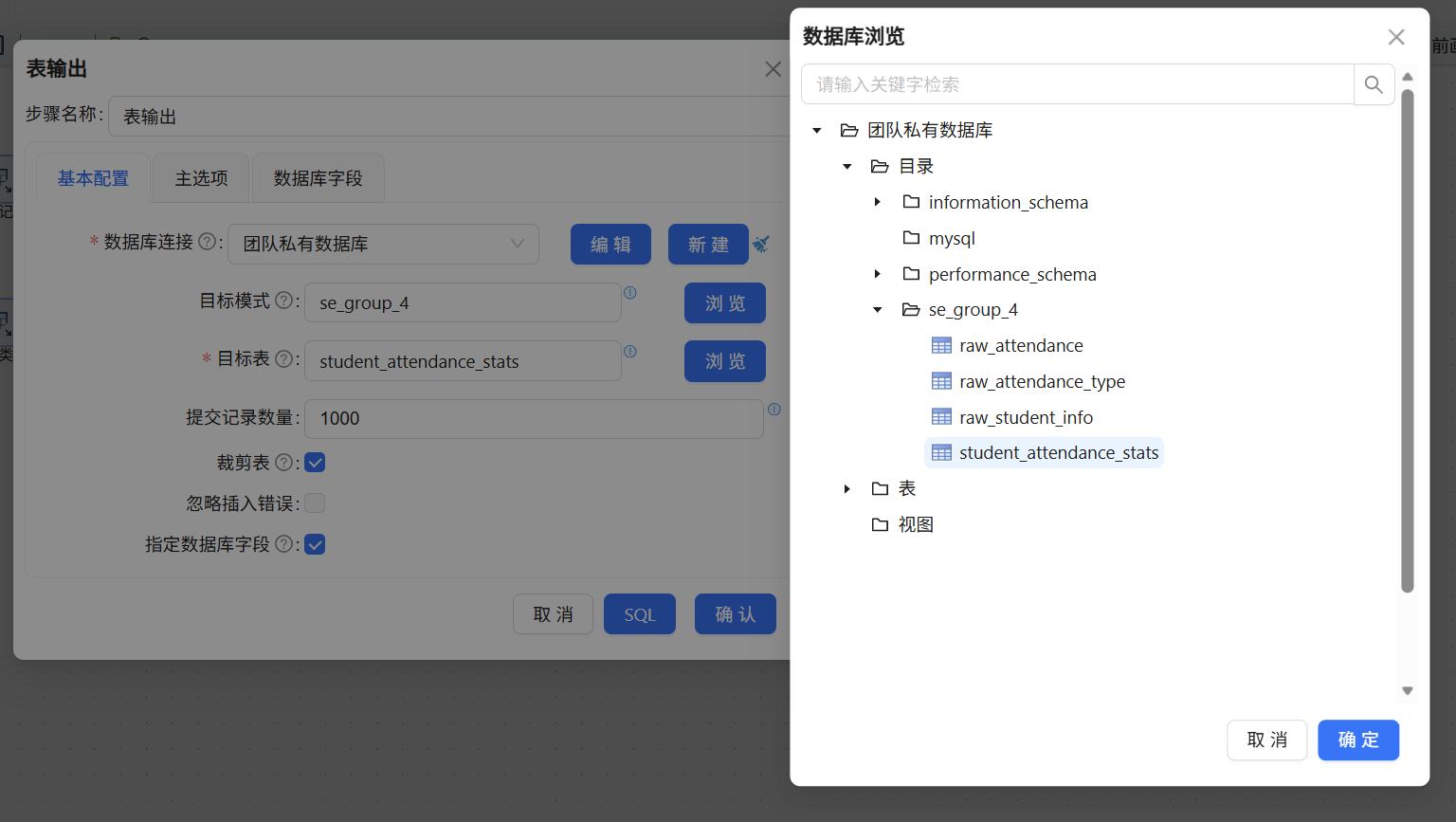
2.14 结果入库:表输出配置
最后一个环节,用“表输出”组件把处理完的数据流写入前期建好的student_attendance_stats表。勾选“裁剪表”确保每次执行前清空旧数据,勾选“指定数据库字段”后还需手动核对流字段与表字段的映射关系,确认每个字段都对上号
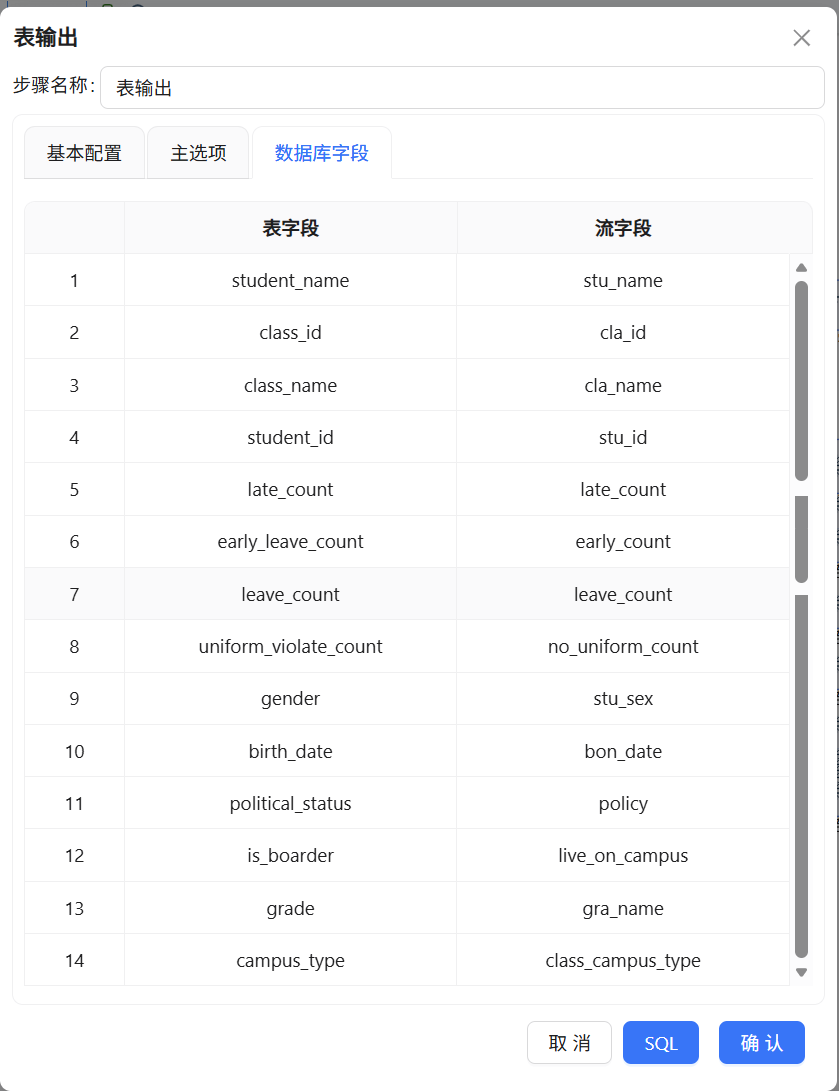
2.15 执行工作流与结果验证
所有组件配置完成后,点击工具栏的“执行”按钮运行整个转换流。平台会实时显示各组件状态,画布下方输出执行日志。
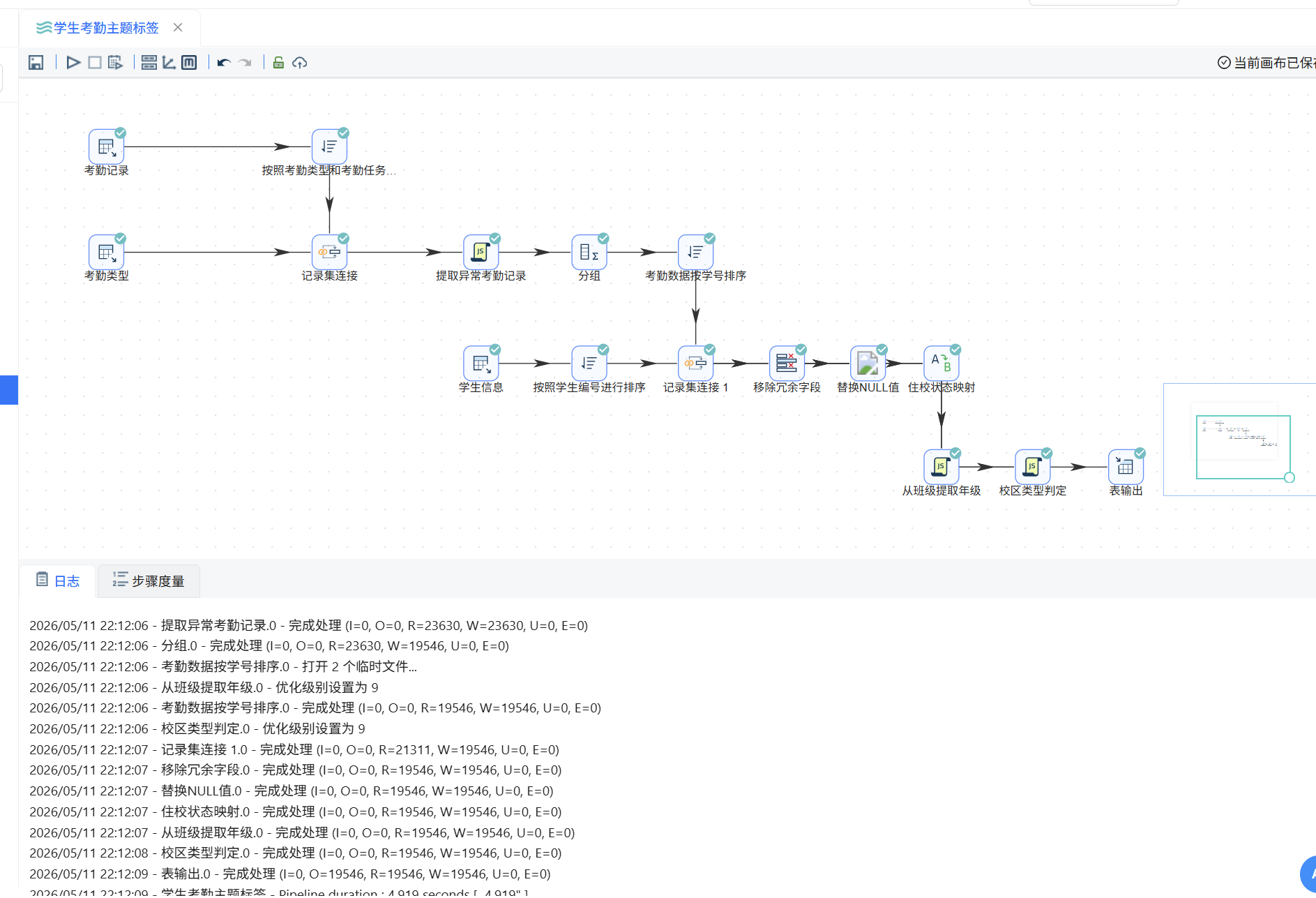
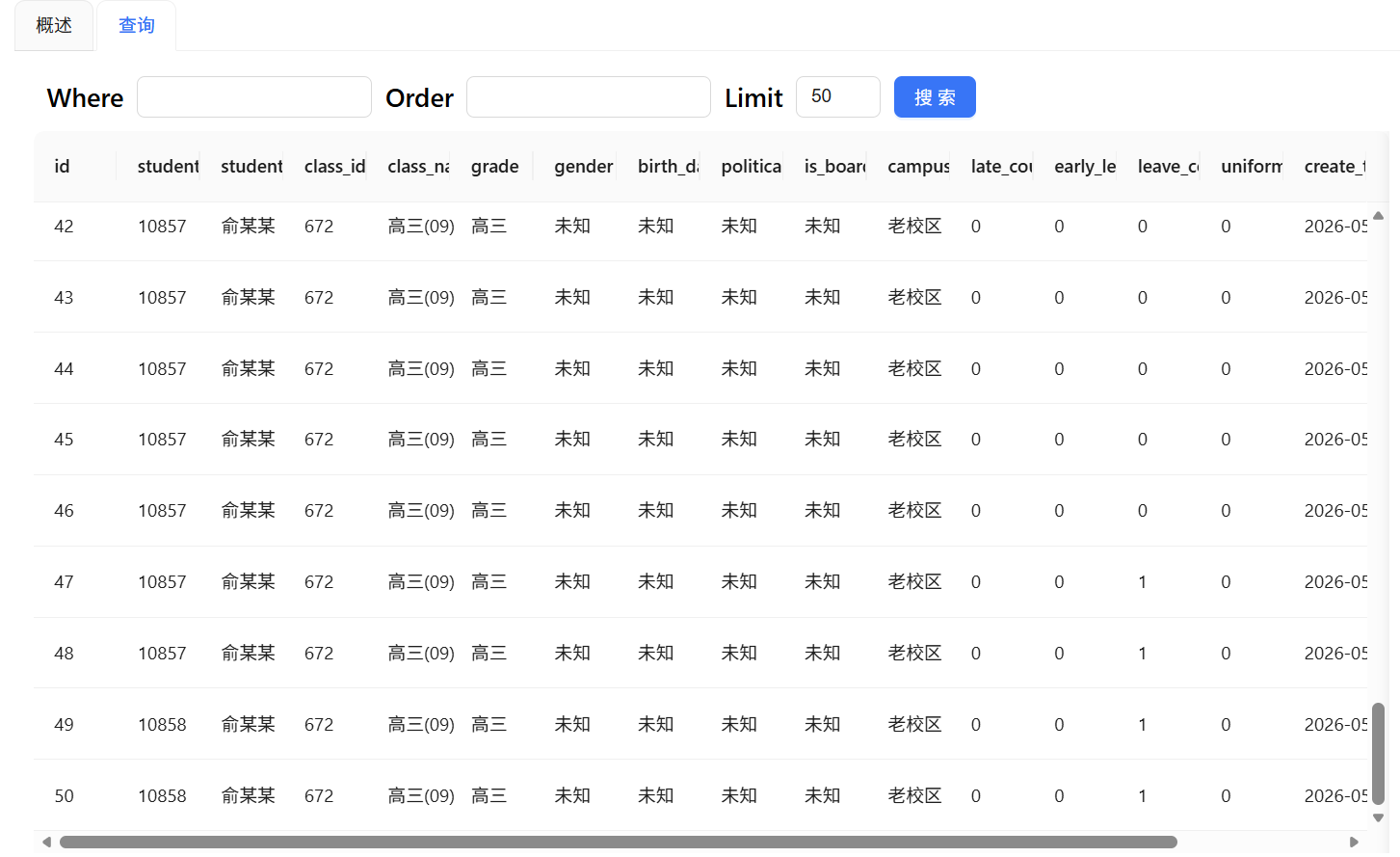
在数据探查中可以看到处理后获得的数据表结构和内容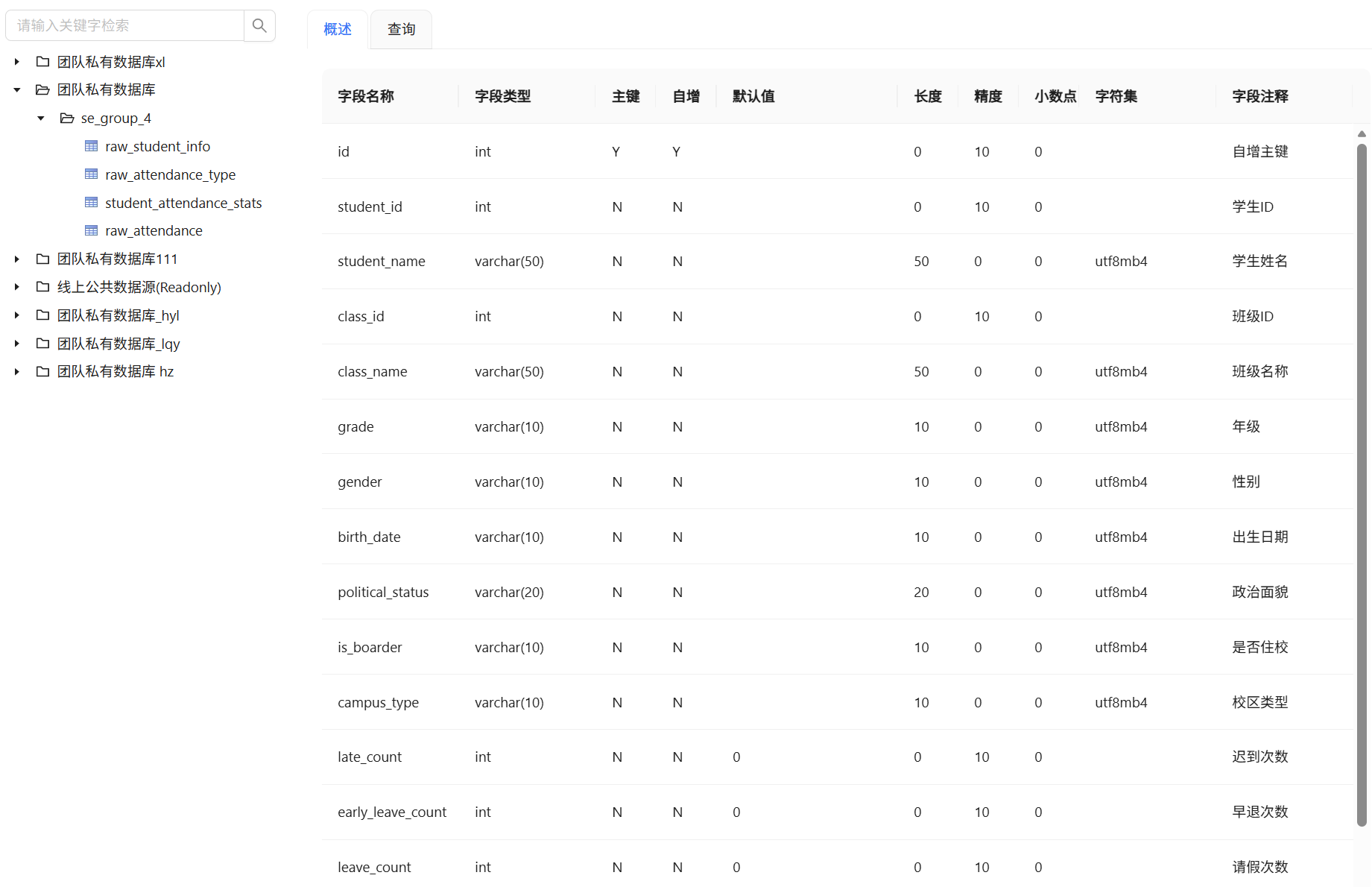
三、问题与解决
问题1:JavaScript组件输出字段未手动添加导致丢失,运行JavaScript组件后,下游组件无法识别isLate、isEarly等标记字段,数据流中找不到这些字段。
问题原因: 在JavaScript组件中写完脚本后,只定义了变量,但没有在组件配置界面下方的表格中手动添加输出字段信息。平台不会自动将脚本中的变量注册为输出字段,需要手动配置字段名称、类型、长度、精度等属性。
解决方法: 在JavaScript组件配置窗口下方的表格中右键“插入”,逐一手动添加字段。
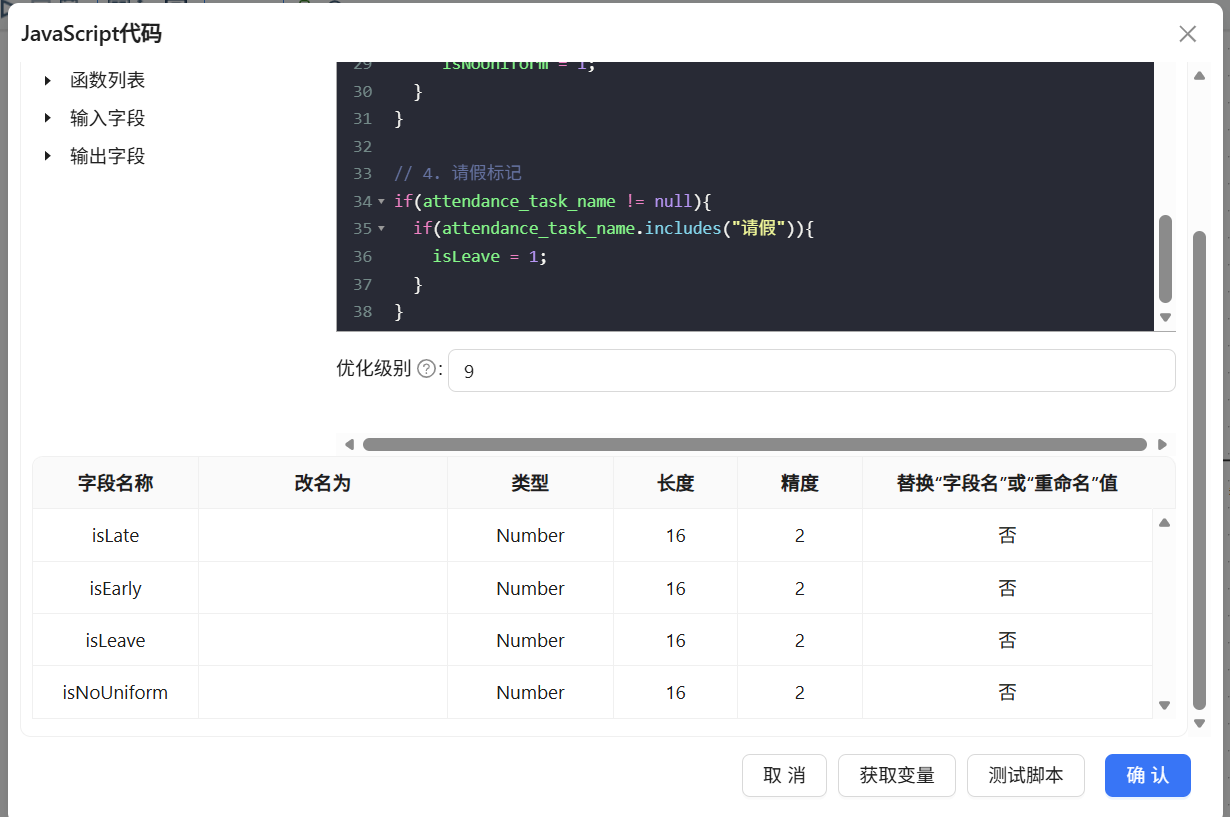
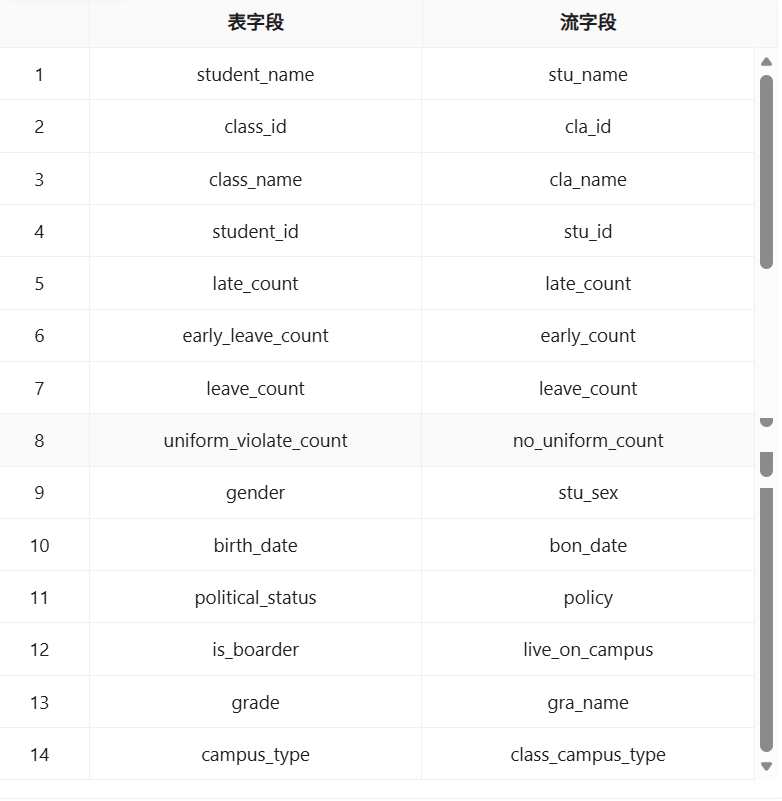
问题2:表输出字段映射未手工核对导致数据结构不符, 表输出组件执行后,查询目标表发现部分字段值为空或字段对应关系错位。
问题原因: 表输出组件勾选“指定数据库字段”后,我用“获取字段”自动拉取了流字段和表字段,但没有逐一核对每个字段的对应关系。平台自动匹配时可能因为字段排列顺序不一致而导致映射错位。
解决方法: 在“数据库字段”标签页中,逐行双击表字段名称,在下拉框中手动选择正确的目标字段,确保流字段与表字段一一对应。
四、实验总结
本次实验完成了学生考勤画像标签的构建,将考勤流水表、考勤类型字典表和学生信息表三张原始数据,加工为一张包含年级、校区、住校状态等画像维度以及迟到、早退、请假、校服违规四类行为次数指标的标准化标签宽表。
整个转换流使用了9种组件类型共15个组件,核心环节包括:通过两次记录集连接分别补全考勤行为名称和学生属性,通过JavaScript脚本的关键词匹配实现异常行为自动标记,通过分组聚合将明细记录汇总为主体级指标,以及通过解析班级名称衍生年级和校区两个分析维度。
相较于上一次的订单利润分流实验,本次实验的流程更长、组件组合更复杂,依然是在助睿数智(Uniplore)一站式数据科学实验平台(https://lab.guilian.cn/)上完成,我也对平台的ETL能力有了比较完整的认识。
后续我会继续学习,采用ETL平台来实现更加多维深入的数据分析,届时也会更新对应的进阶教程,欢迎关注!
如果对你有帮助的话,请点赞收藏转发哦!
关注我,共同进步!

一站式 AI 云服务平台
更多推荐

 32
32 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)