
基于零代码ETL平台的订单利润分流数据加工实验
技能层面:我熟练掌握了助睿零代码ETL平台的核心操作,学会了如何通过可视化拖拽和配置参数(而非编写SQL或代码)来完成复杂的数据集成任务。我对“表输入”、“记录集连接”、“字段选择”、“过滤记录”和“Excel输出”这五大组件的功能边界和配置细节有了深刻认识。逻辑层面:我深入理解了多表关联(左外连接)、数据去重清洗和条件分流在ETL流程中的设计思路。尤其是在遇到“排序需要”错误和“输出为空”的问题
一、实验背景
1.1 实验目的
本次实验旨在借助助睿数智(Uniplore)一站式数据科学实验平台,利用其零代码ETL数据集成工具,完成订单数据与产品信息的关联整合、清洗过滤及条件分流,为后续的订单利润分析与业务决策提供高质量的结构化数据。
通过本次实验,我期望掌握以下四项核心技能与任务:
-
熟练平台操作:掌握助睿平台中新建数据转换、拖拽配置组件、执行转换任务的全流程操作规范;
-
配置核心组件:熟练掌握“表输入”、“记录集连接”、“字段筛选”、“数据过滤”、“文件输出”等常用ETL组件的功能特性与配置要点;
-
理解业务逻辑:深刻理解多表关联、数据清洗、条件分流的设计逻辑,能够基于订单利润正负的实际业务需求设计合理的数据加工流程;
-
完成数据加工:独立完成订单数据的清洗、整合与分流处理,最终形成符合业务分析需求的盈利/亏损订单结构化数据。
1.2 实验环境
本次实验完全在浏览器端通过零代码拖拽操作完成,无需编写任何代码,具体环境如下:
-
实验平台:
-
平台全称:助睿数智(Uniplore)一站式数据科学实验平台
-
平台定位:覆盖数据接入、ETL处理、机器学习建模到可视化分析的全链路Agentic零代码数据智能【9†L8-L9】。
-
实验地址:https://lab.guilian.cn/
-
产品官网:https://www.uniplore.com/
-
-
数据存储环境:
-
业务数据表:存储在MySQL中的订单明细表(business_anaylsis.order_detail)。
-
维表数据:存储在MySQL中的产品信息表(business_anaylsis.product)。
-
1.3 业务场景
在日常电商运营中,企业需要定期分析订单的利润情况,以识别哪些订单是盈利的、哪些是亏损的,从而为商品定价、促销策略和供应链优化提供数据支撑。本次实验模拟一个典型的业务需求:某零售企业拥有订单明细表(包含销售额、成本、利润等字段)和产品信息表(包含产品ID、产品名称、类别等字段),希望将两份数据关联整合后,根据利润金额的正负,将订单数据拆分为“盈利订单”和“亏损订单”两类,并分别导出为Excel文件,供后续财务分析和运营复盘使用。
该业务场景要求数据处理过程准确、可重复,且操作人员无需编写复杂代码。因此,我们使用助睿零代码ETL平台来快速搭建数据加工流程。
1.4 数据加工流程
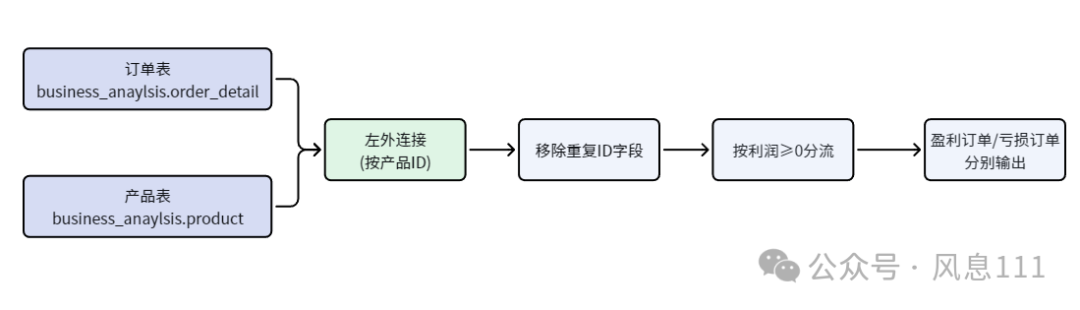
本次实验的数据加工整体逻辑相对清晰,是一个标准的ETL过程,我将其归纳为以下五个步骤:
-
数据抽取:从MySQL源数据库中分别读取“订单明细”与“产品信息”两张原始表。
-
数据关联:以“产品ID”为关联键,对上述两张表执行“左外连接”,实现订单数据与产品信息的横向整合。
-
数据清洗:移除关联过程中产生的重复“产品ID”字段,修正字段冗余问题,保证数据结构的规范性与整洁性。
-
条件分流:基于订单利润字段,设置过滤条件为“利润 ≥ 0”,将数据集划分为“盈利订单”与“亏损订单”两类。
-
数据加载:将分流后的两类数据,分别导出为独立的Excel文件,落地存储完成数据加工。
二、实验步骤
2.1 登录实验平台与数据源同步
首先,通过浏览器访问贵兰在线课程学习平台,在登录界面选择适合的方式登录(如账号密码或小程序扫码)。
登录成功后,我需要确保已进入指定的实验项目空间,准备开始数据同步工作。

2.2 创建实验项目
请选择数据集成/ETL,点击进入页面

点击团队管理,是小组任务请小组长负责创建小组,是个人任务请选择个人团队。
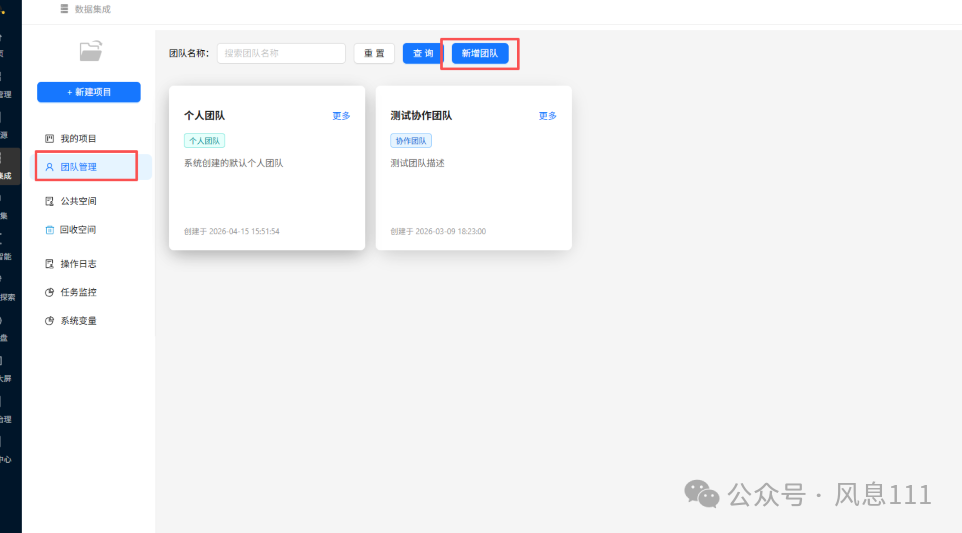
点击“新建项目”,即可完成新项目的创建。
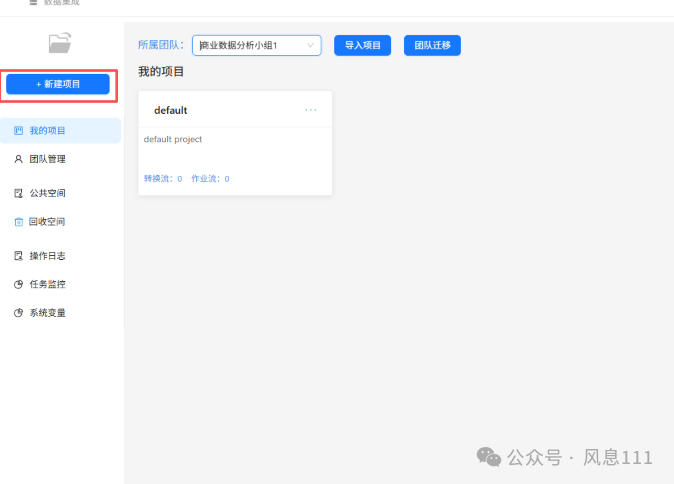
项目名称为“助睿ETL入门实验”,点击确定即可。
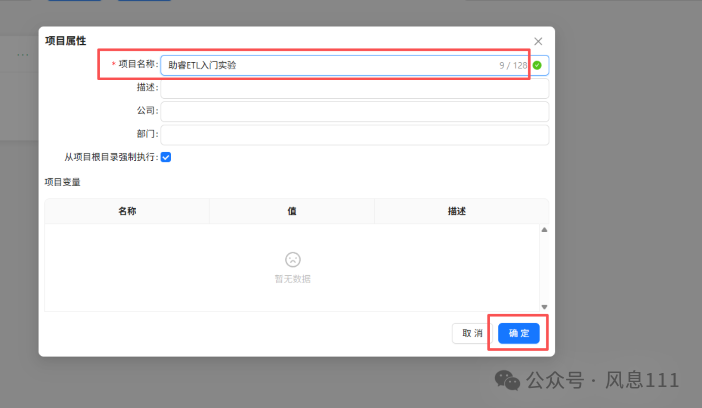
2.3 同步数据源
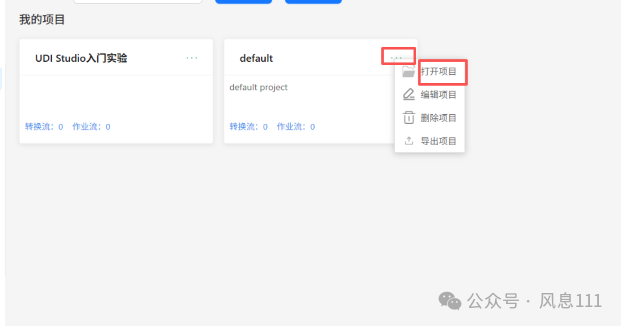
点击刚刚创建好的项目的右上角,再次点击“打开项目”
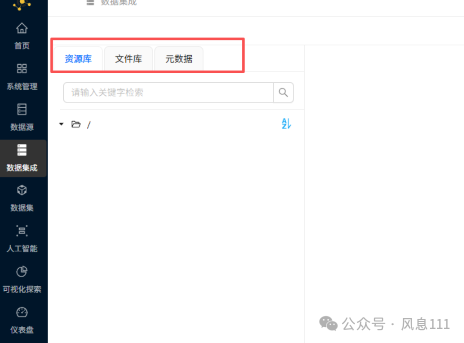
可以看到资源库、文件库、元数据三个选项。本次实验使用的是资源库和文件库。
-
资源库:用于管理数据处理流程的逻辑定义与作业设计,例如存储转换流(.hpl)、作业流(.hwf)等“工程图纸”类文件。它相当于项目的“设计室”,负责存放和编排整个ETL任务的构建蓝图。
-
文件库:用于存储数据处理过程中实际用到的输入文件与输出的结果文件,例如Excel、CSV、JSON等数据文件。它相当于项目的“仓库”,为资源库中的工作流提供真实的数据物料并保存最终产物。
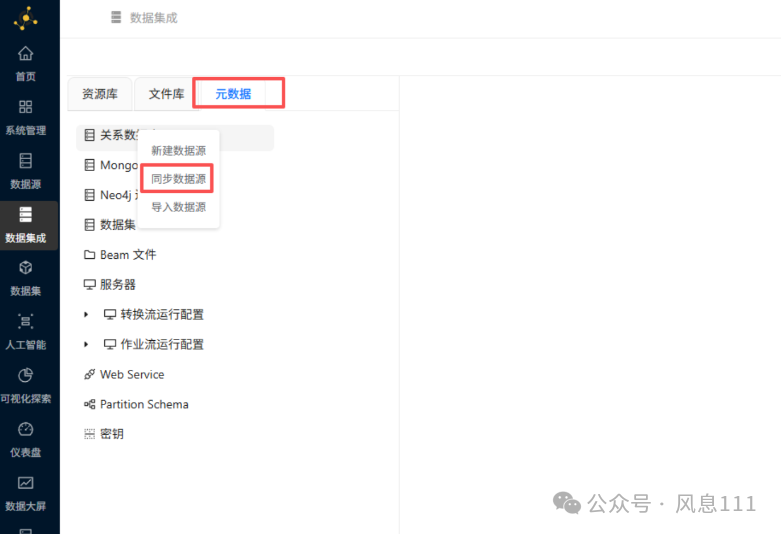
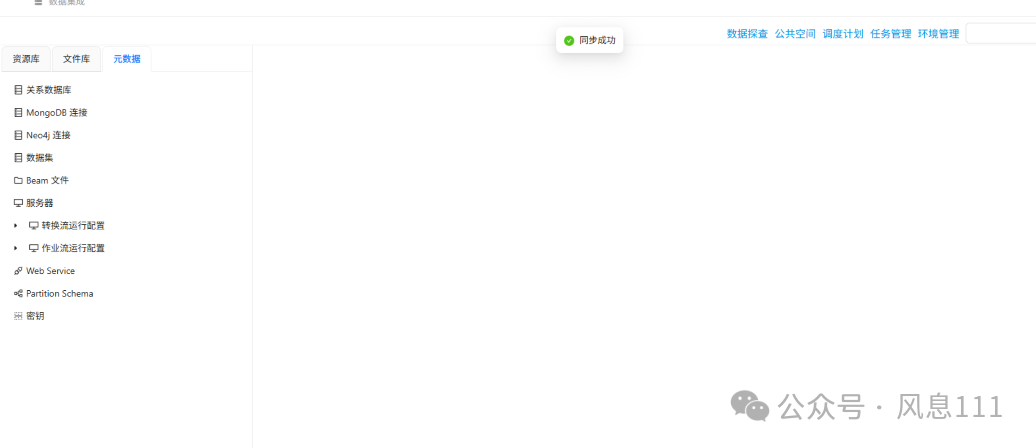
点击“元数据”,鼠标右键点击“关系数据库”,选择“同步数据源”
可以看到“同步成功”
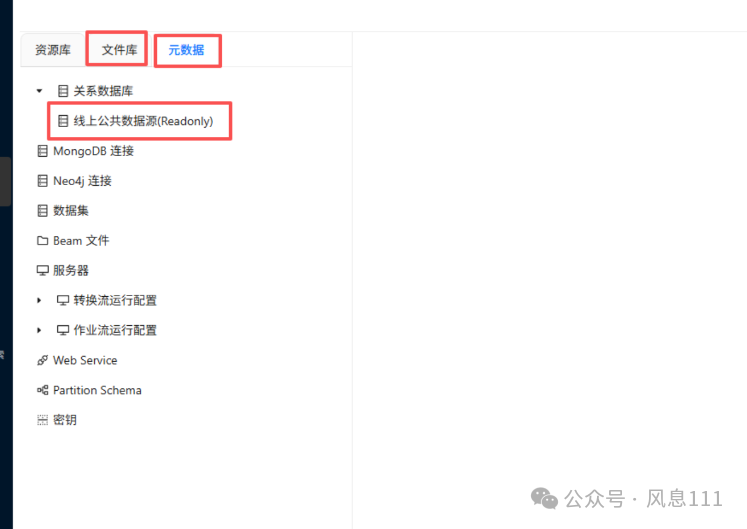
点击“文件库”再切换“元数据”,可以看到数据库“线上公共数据源(Readonly)”
2.4 新建数据流
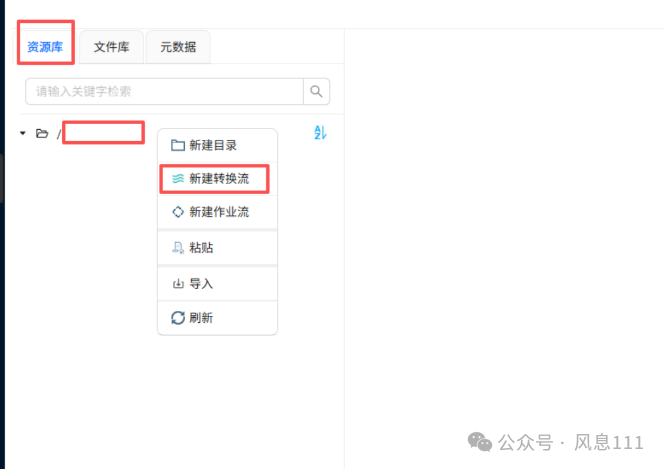
点击“资源库”,鼠标右键点击根目录,选择“新建数据流”
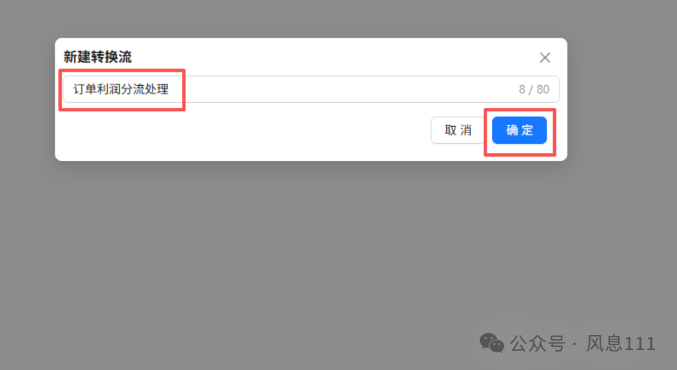
输入转换流名字“订单利润分流处理”,再点击“确定”
创建成功后进入转换流设计页面,点击🔒标识进行解锁
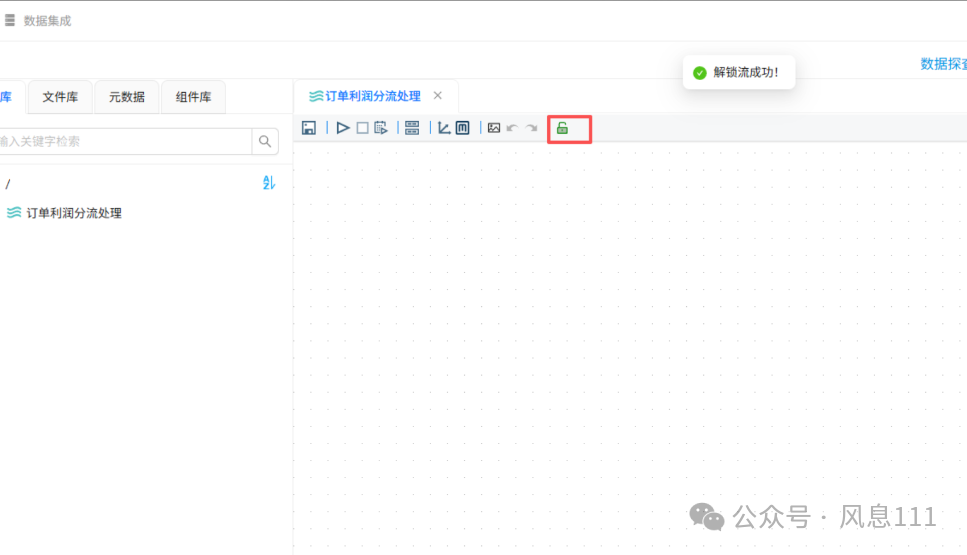
2.5 添加组件
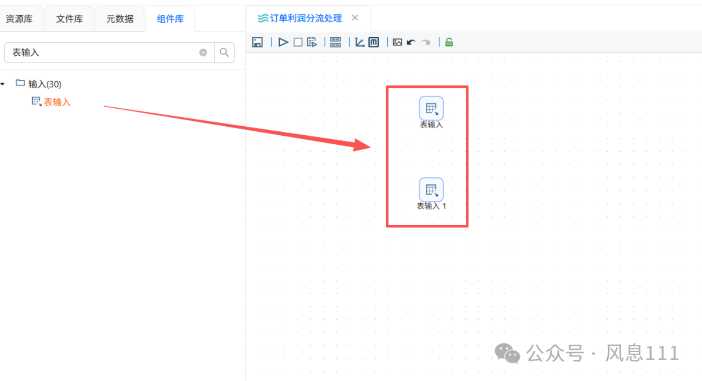
本次实验需要将两类数据进行合并计算,所以需要添加2个表输入组件,读取2个不同表的数据。
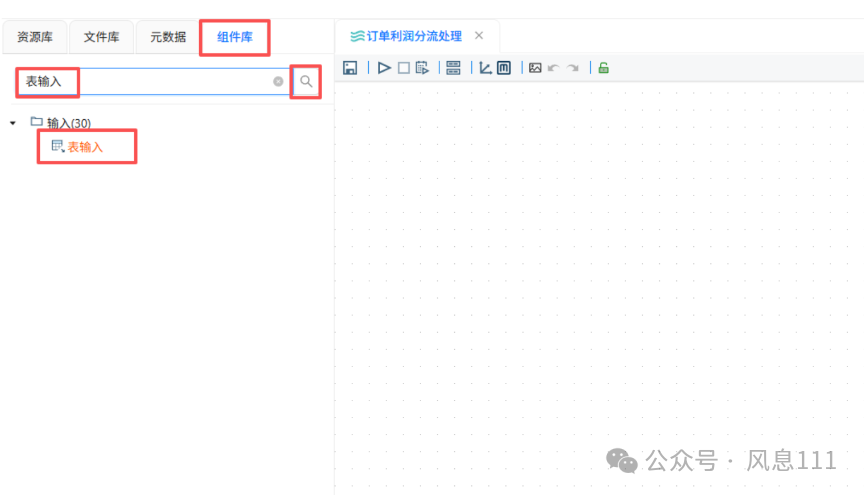
首先添加“表输入”
点击“组件库”,在搜索栏输入“表输入”,点击“表输入”,同时将“表输入”拖至画布中,需要两个
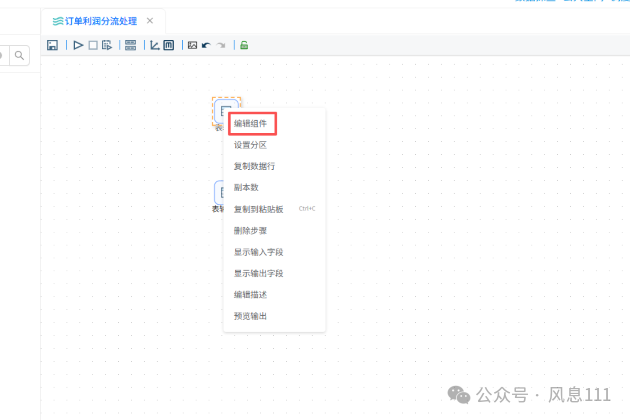
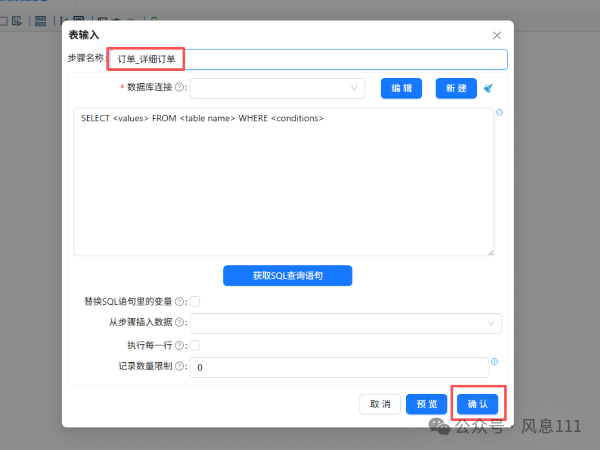
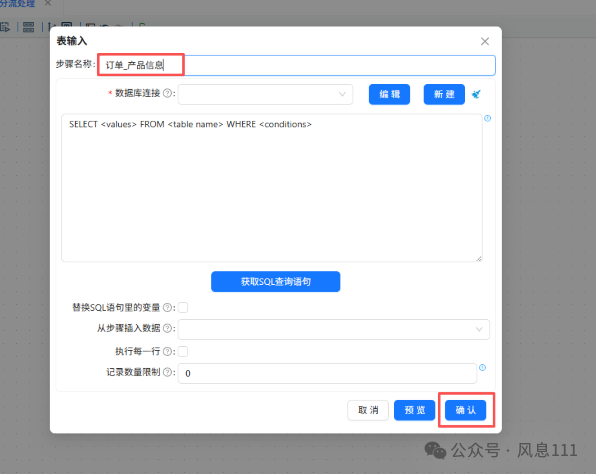
鼠标右键组件,选择“编辑组件”,修改步骤名称中“为订单_详细订单”,点击“确认”;修改第二个“表输入”组件的步骤名称为“订单_产品信息”,点击“确认”
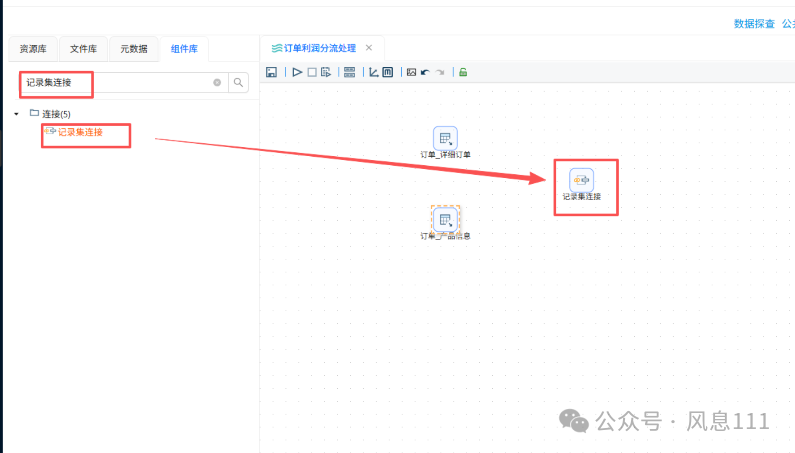
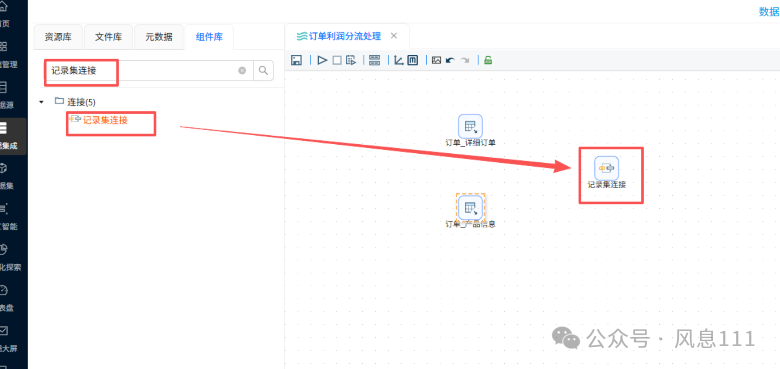
同样的方法将“记录集连接”拖至画布中
将两个表与记录集连接相连
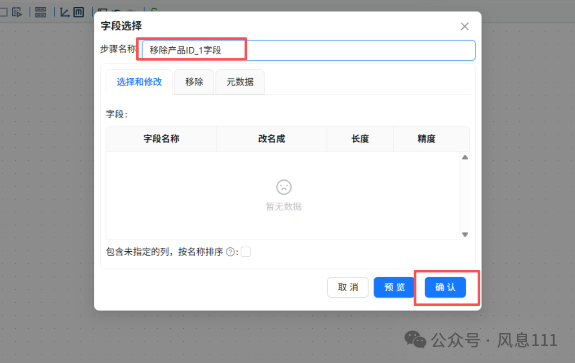
同样的方法将“字段选择”拖至画布中,修改步骤名称为“移除产品ID_1字段”
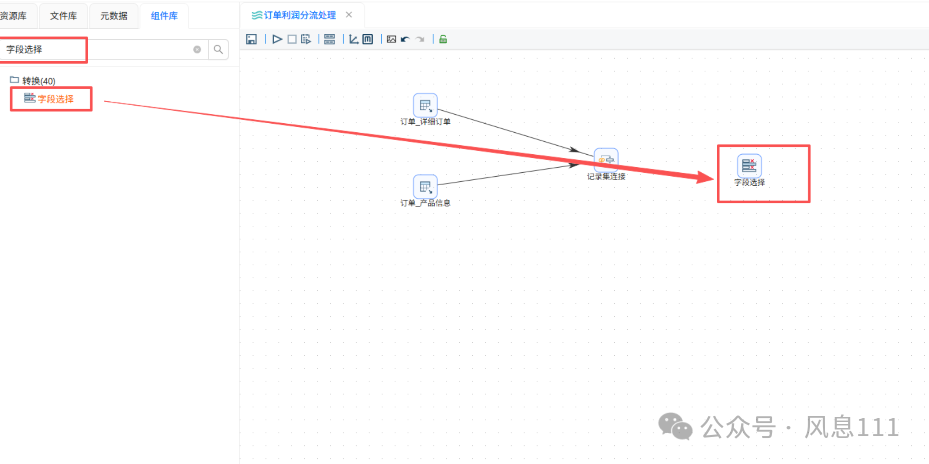
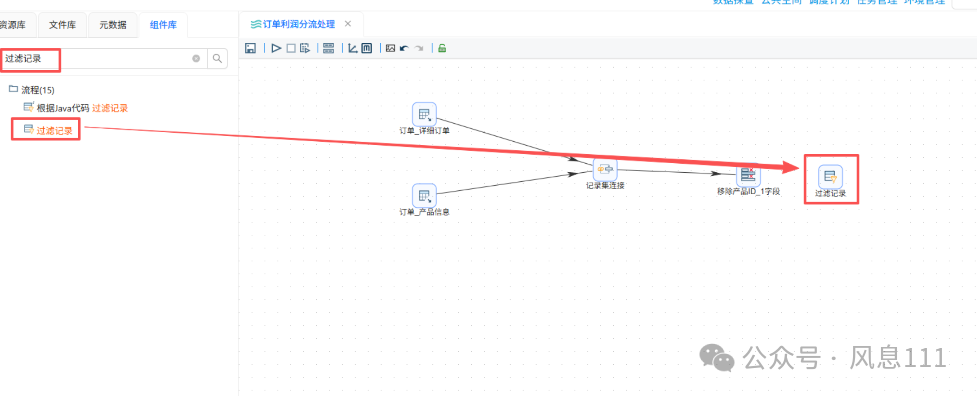
同样的方法将“过滤记录”拖至画布中,并创建如图的连线,选择“主输出步骤”
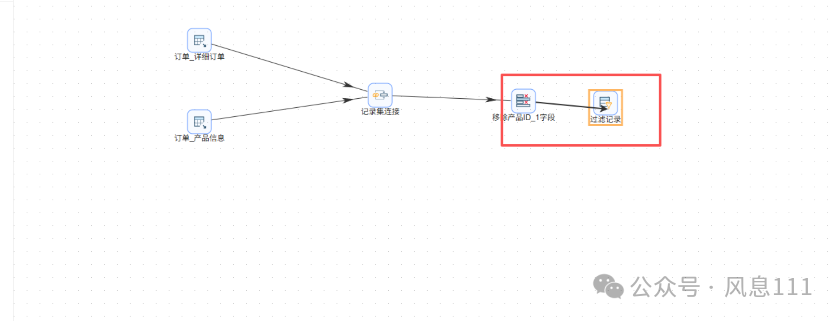
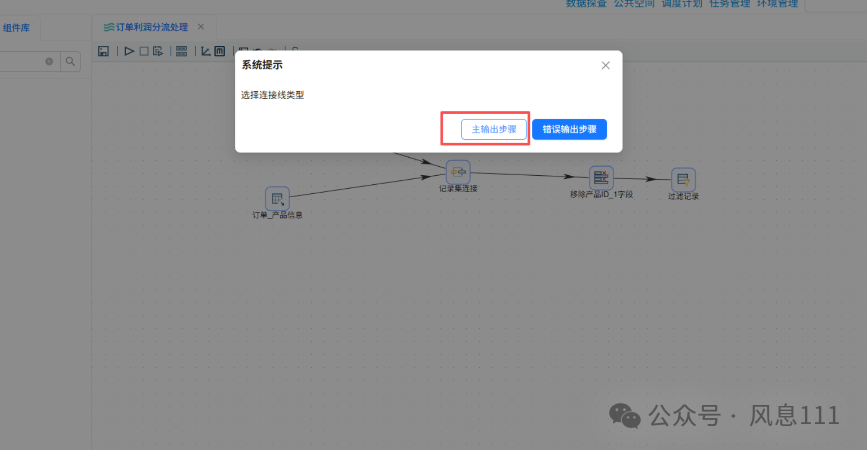
同样的方法将“excel输出”拖至画布中,需要两个,将步骤名称分别改为“盈利订单”和“亏损订单”,创建如图的连线时,“True输出”表示满足过滤条件的记录输出,对应盈利订单表,“False输出”则对应亏损订单表
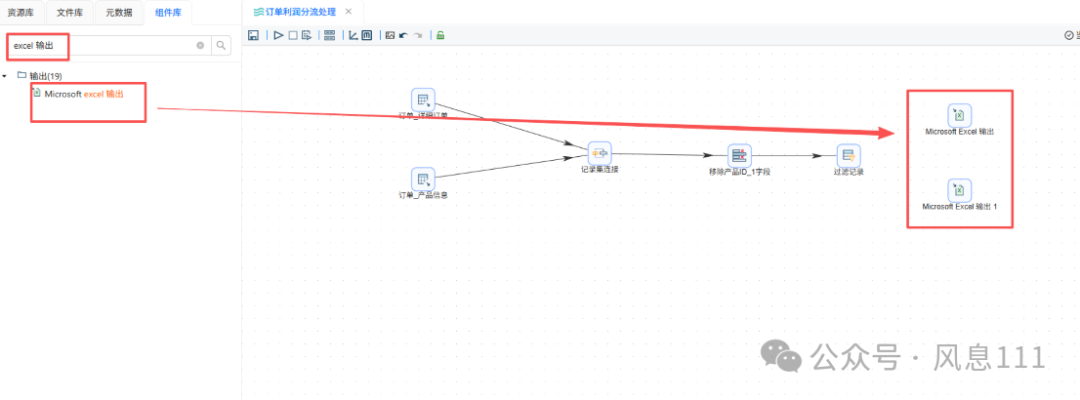
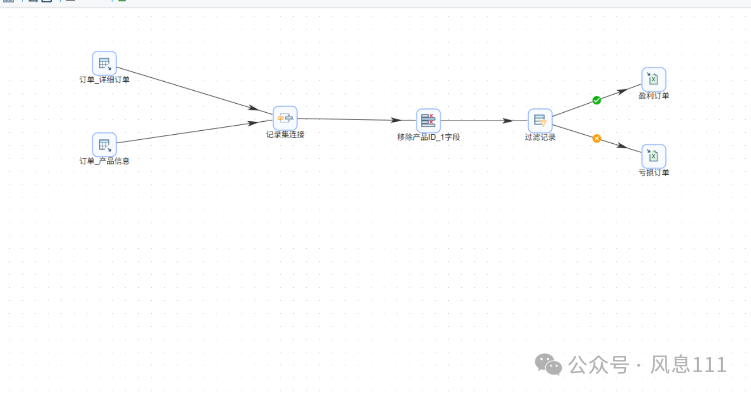
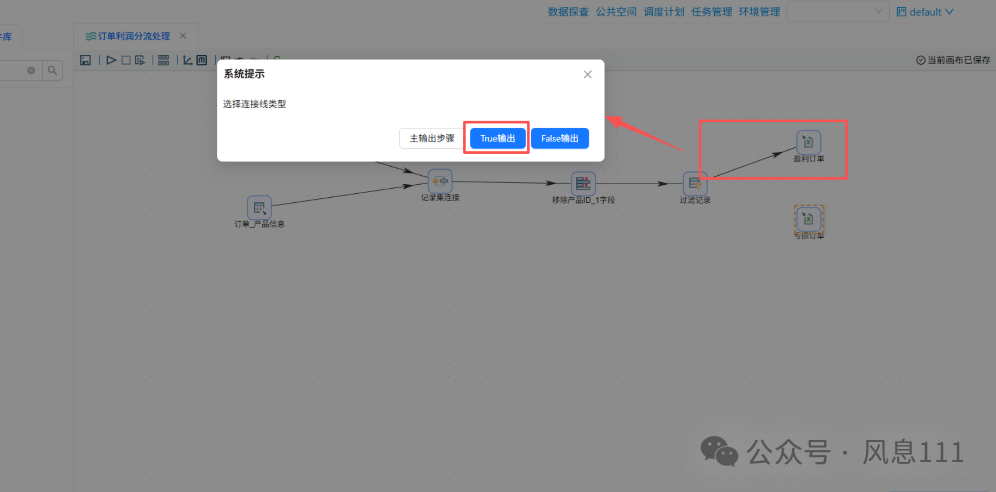
2.6 配置组件信息
2.6.1 表输入组件配置
双击“订单_详细订单”表输入组件,在数据库连接下拉框中选择“线上公共数据源(Readonly)”,点击“获取SQL查询语句”,自动生成SQL查询语句。
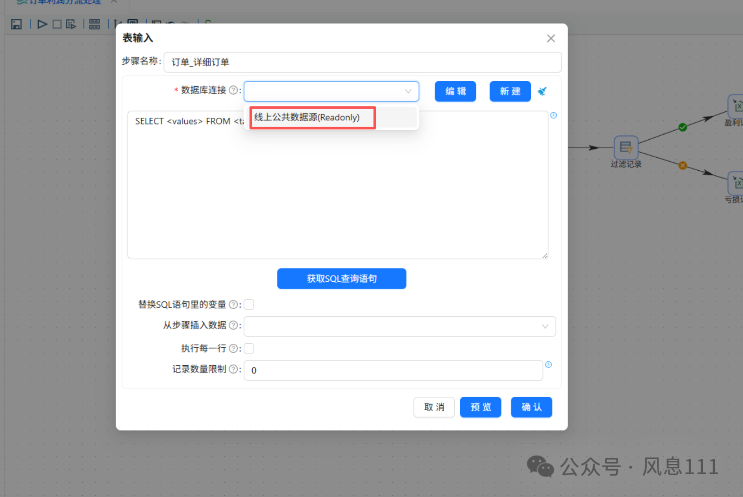
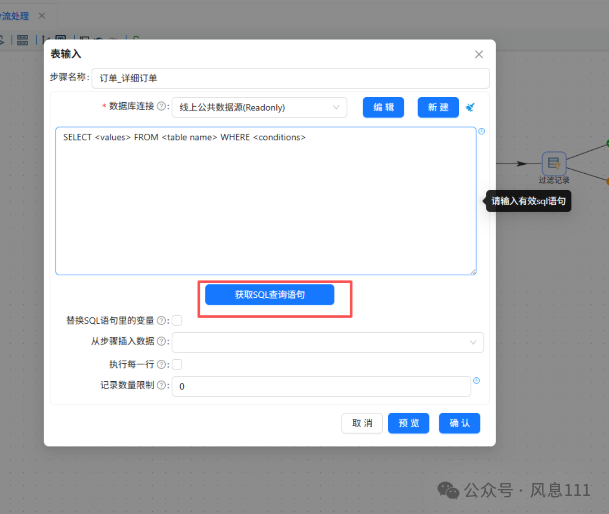
点开“线上公共数据源(Readonly)”-“表”目录,找到“business_anaylsis.order_detail”并点击它,再点击“确定”,再点击“确认”
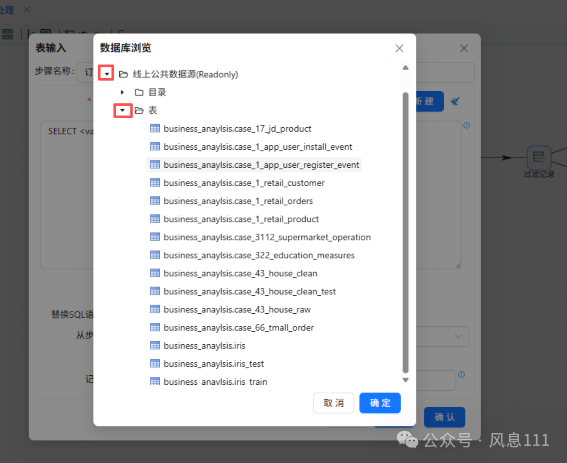
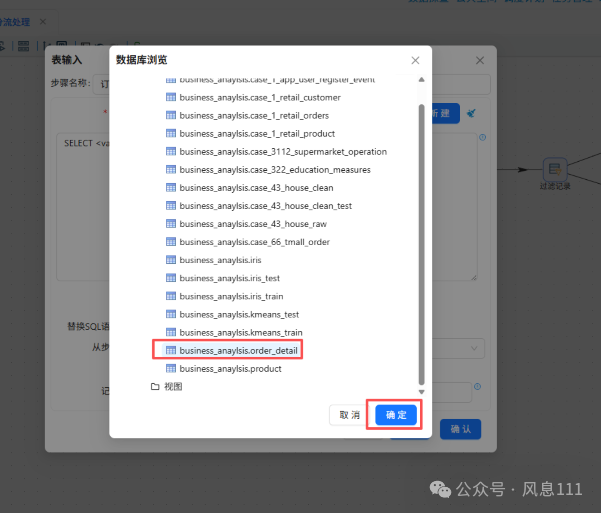
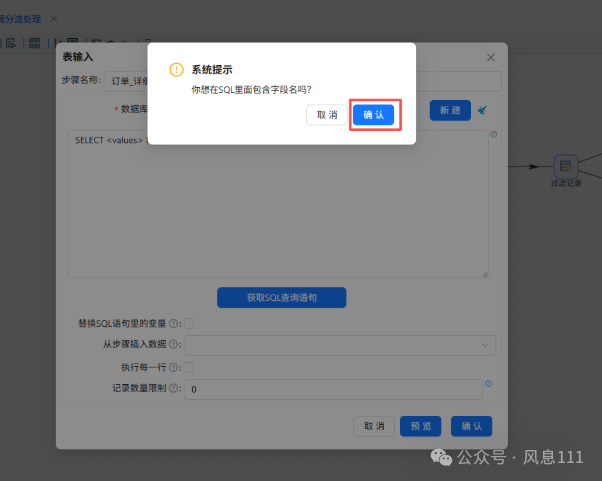
再次点击“确认”
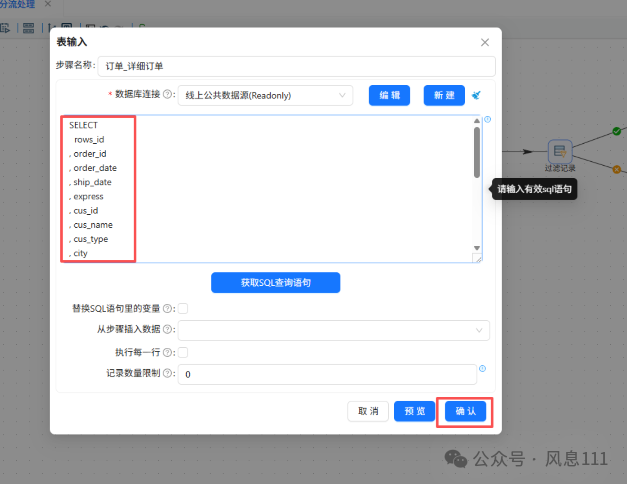
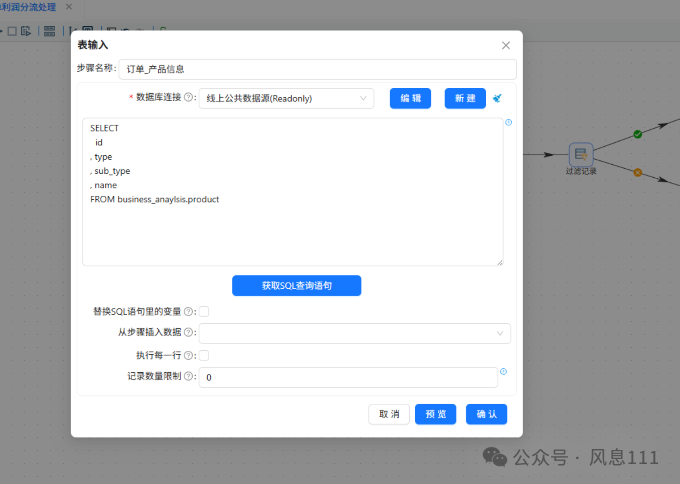
另一个订单_产品信息表按同样的方法,这里不再赘述。
2.6.2 记录集连接组件配置
双击“记录集连接”组件,如图操作
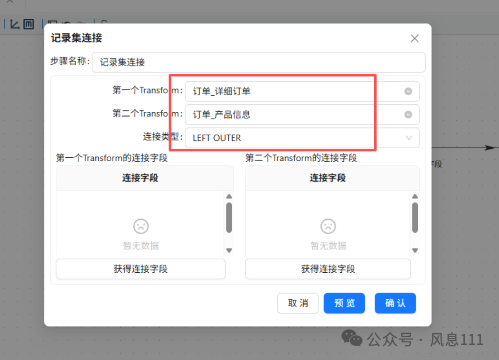
点击第一个Transform的连接字段中的“获得连接字段”,同样的方法用于第二个Transform
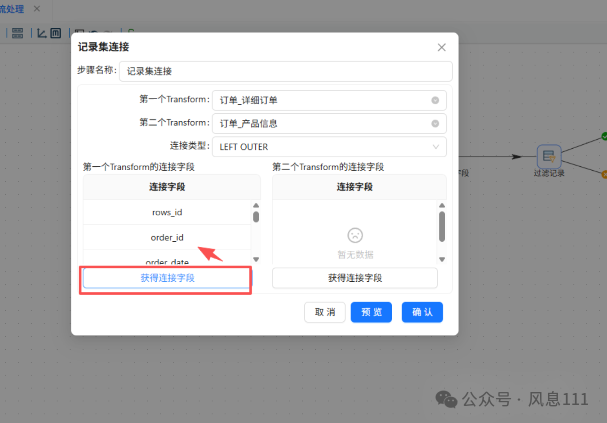
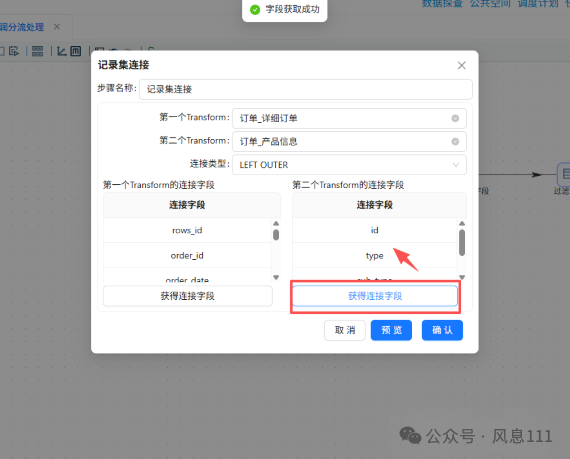
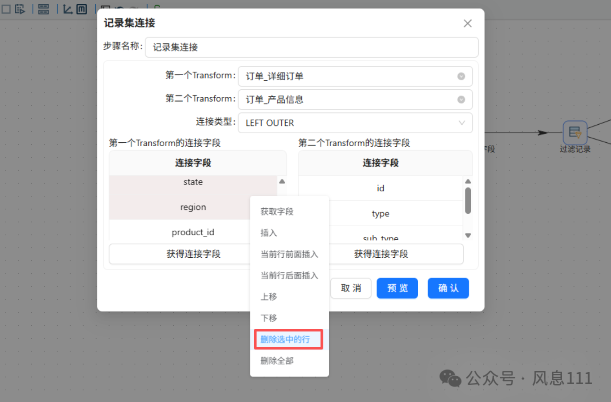
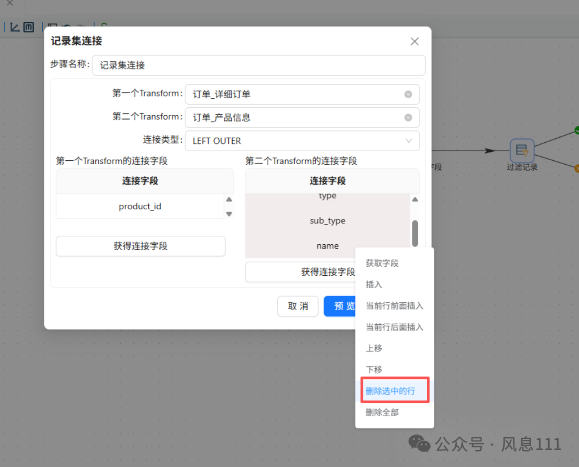
第一个字段保留produc_id,第二个字段保留id,其余右键选中删除
2.6.3 字段选择组件配置
双击“移除产品ID_1字段”字段选择组件,点击“移除”,鼠标右键点击“获取字段”
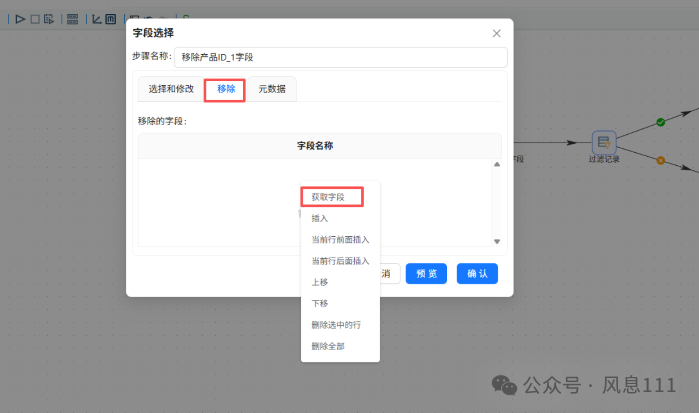
只保留id字段
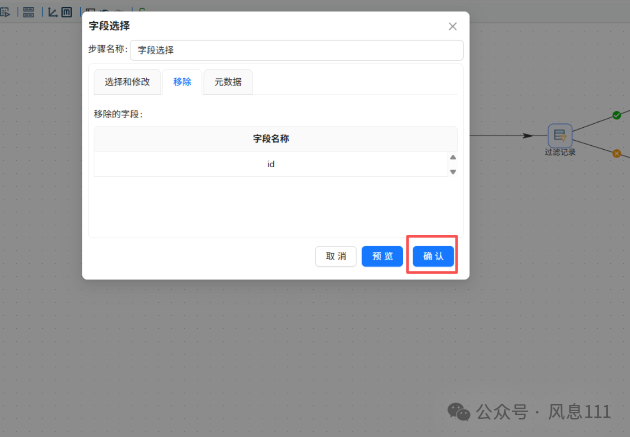
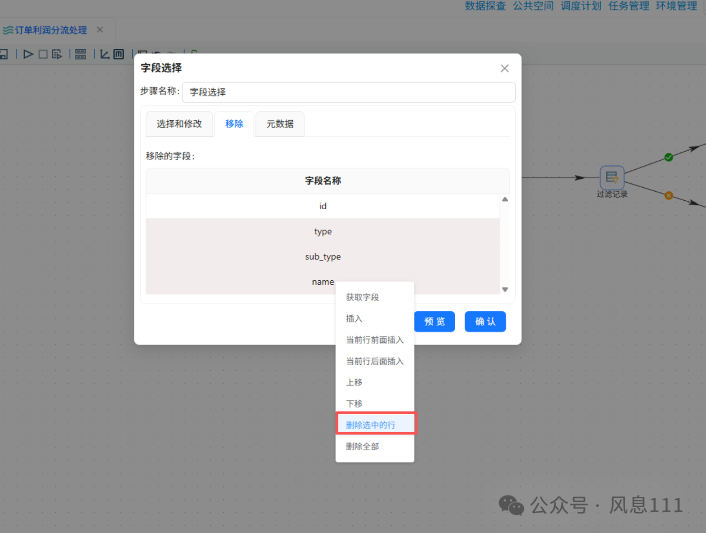
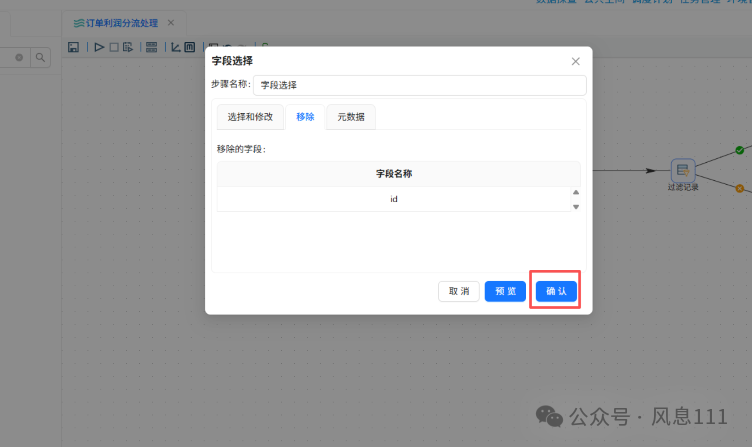
2.6.4 过滤记录组件配置
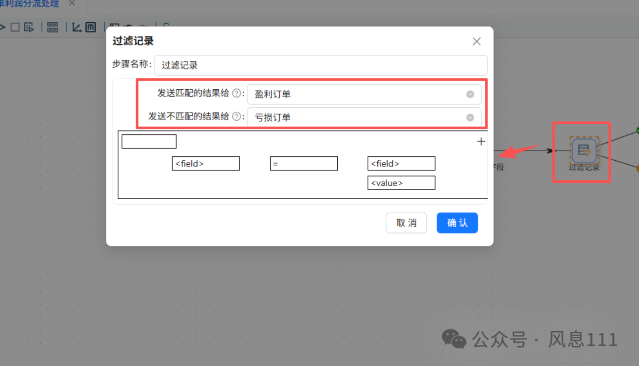
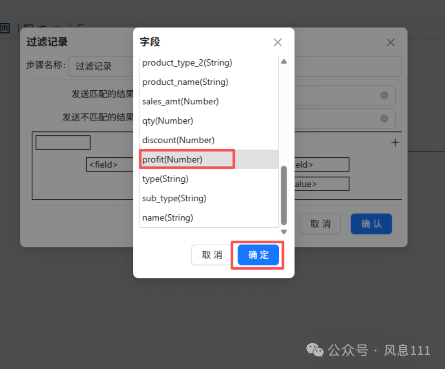
双击“过滤记录”组件,如图选择不同的订单,再点击<field>,选择“profit(Number)”点击“确定”
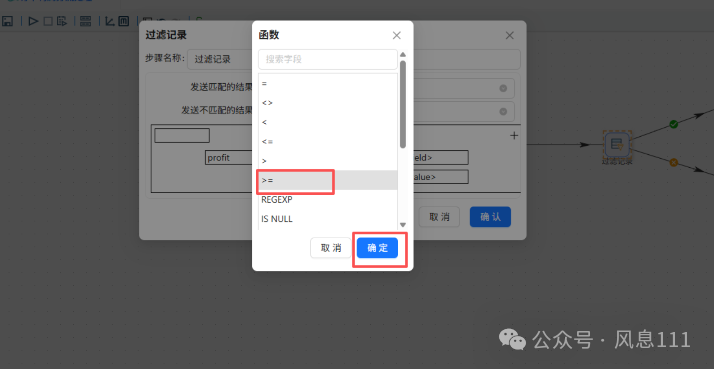
如图选择>=0,点击“=”,在函数中选择“>=”,点击确定,点击“value”,值类型选择“Integer”,值输入“0”点击“确定”
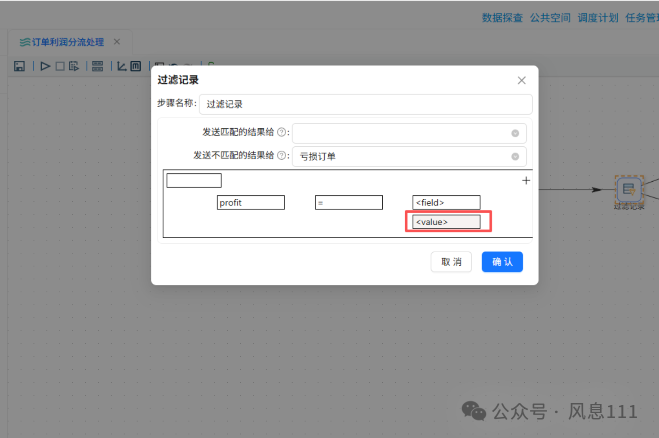
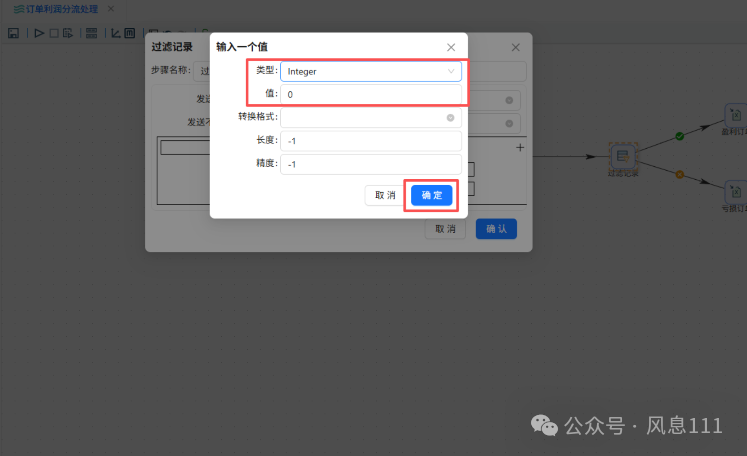
已配置完成,点击“确认”
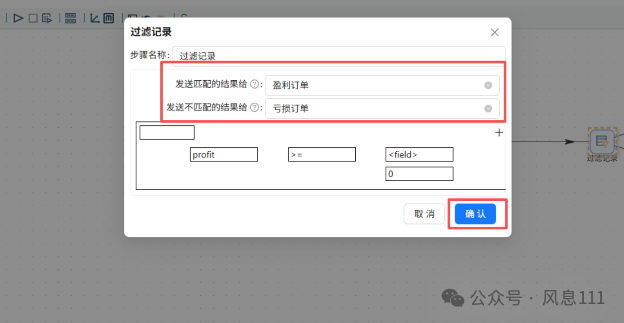
2.6.5 Excel 输出组件配置
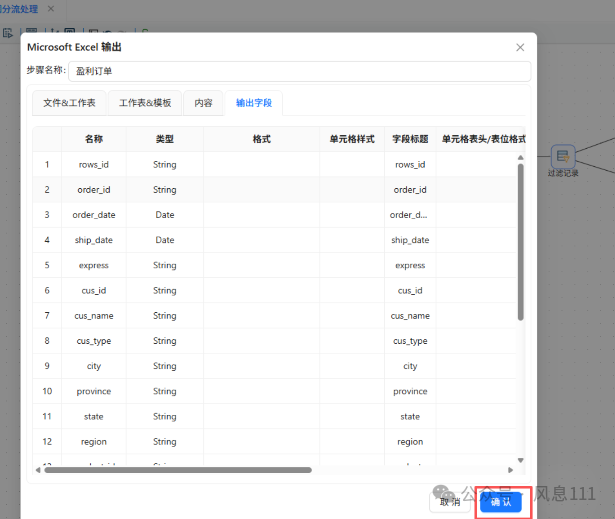
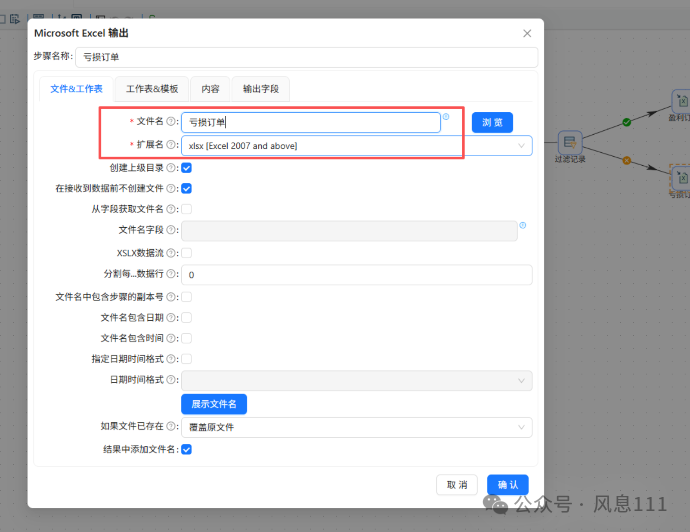
双击“盈利订单”excel表输出组件,在配置弹窗中,将文件名修改为“盈利订单”,选择拓展名“xlsx [Excel 2007 and above]”
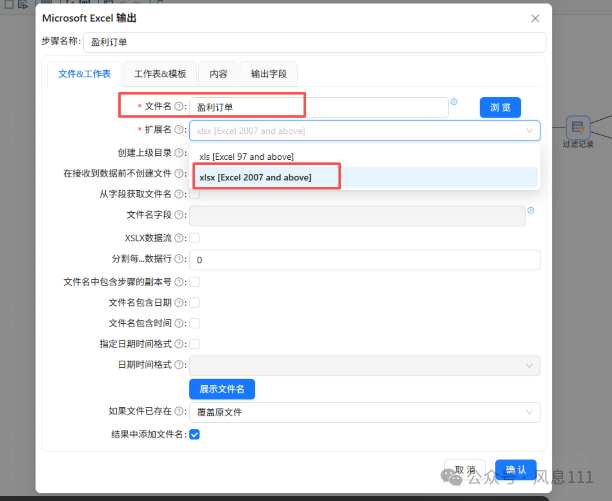
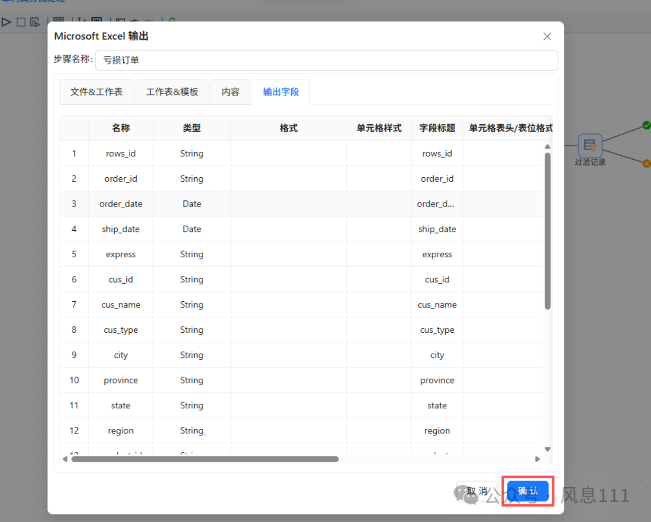
在配置弹窗中选择“输出字段”,在空白表格处鼠标右键点击“获取字段”,获取后点击“确认”
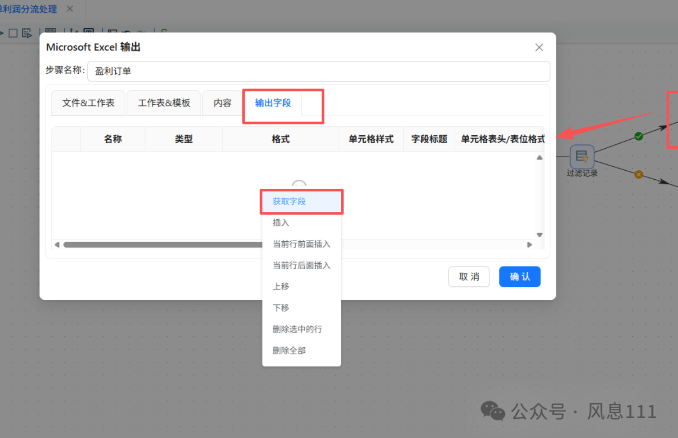
“亏损订单”使用同样的方法,这里不再赘述
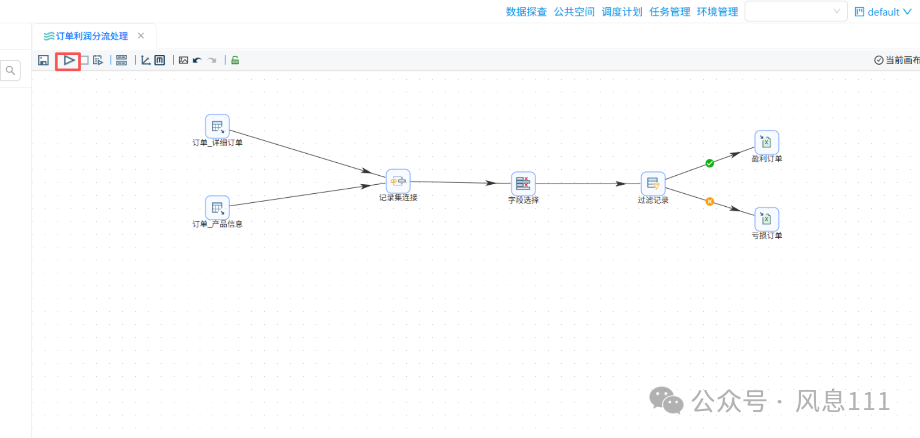
2.7 执行转换
组件配置完成后,可执行转换任务,点击启动按钮,点击“启动”
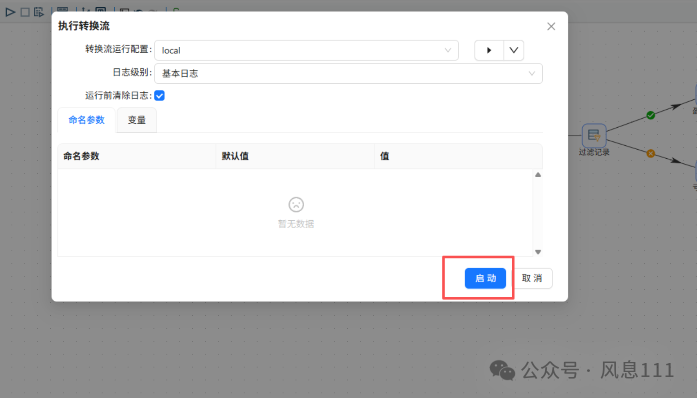
执行成功,如图
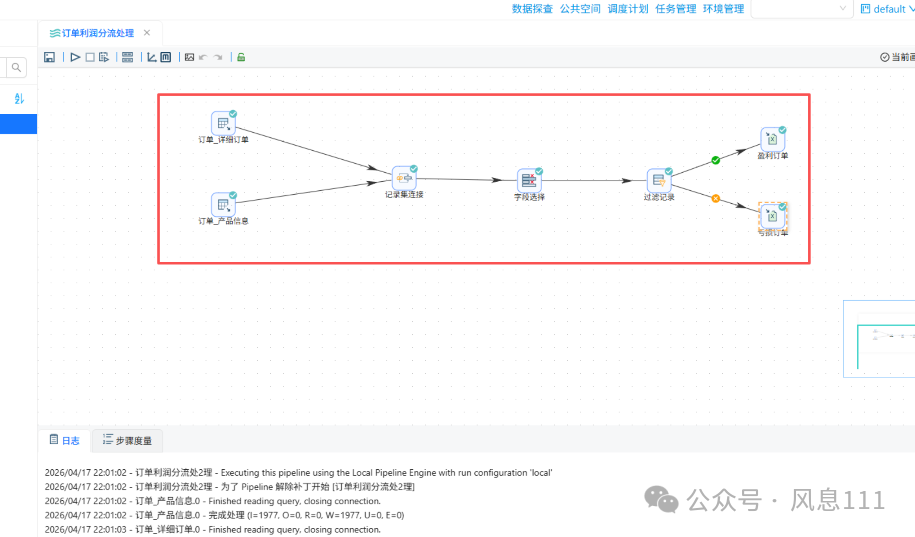
2.8 查看执行日志
任务执行完毕后,可查看执行结果和日志,如图
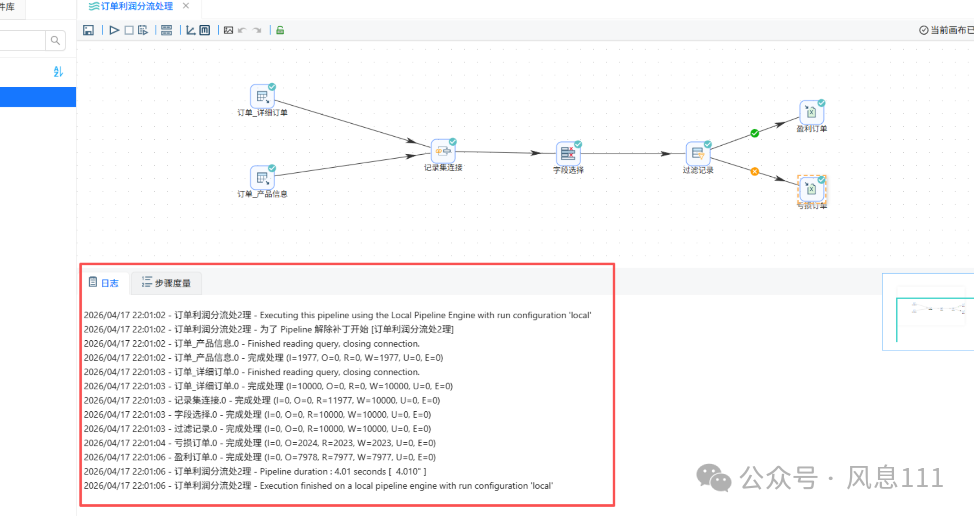
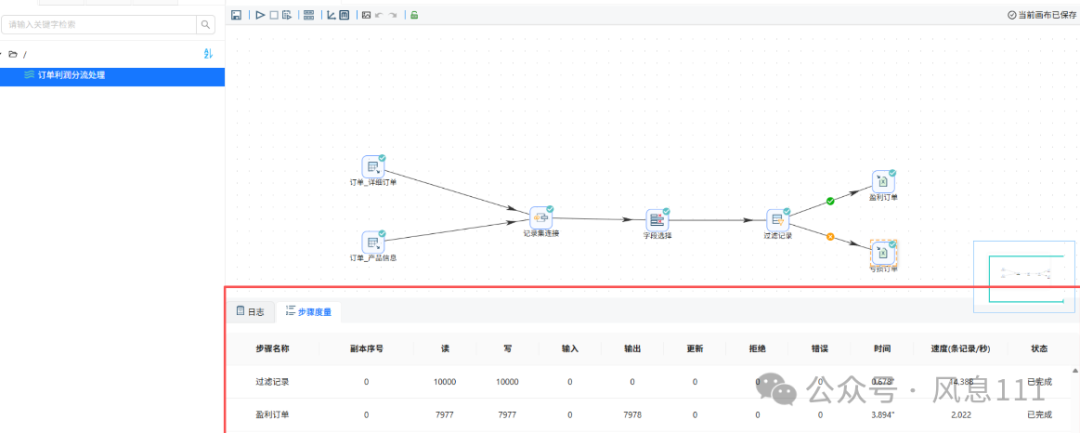
2.9 查看结果
点击“文件库”,右键刷新,可以看到转换任务的输出结果
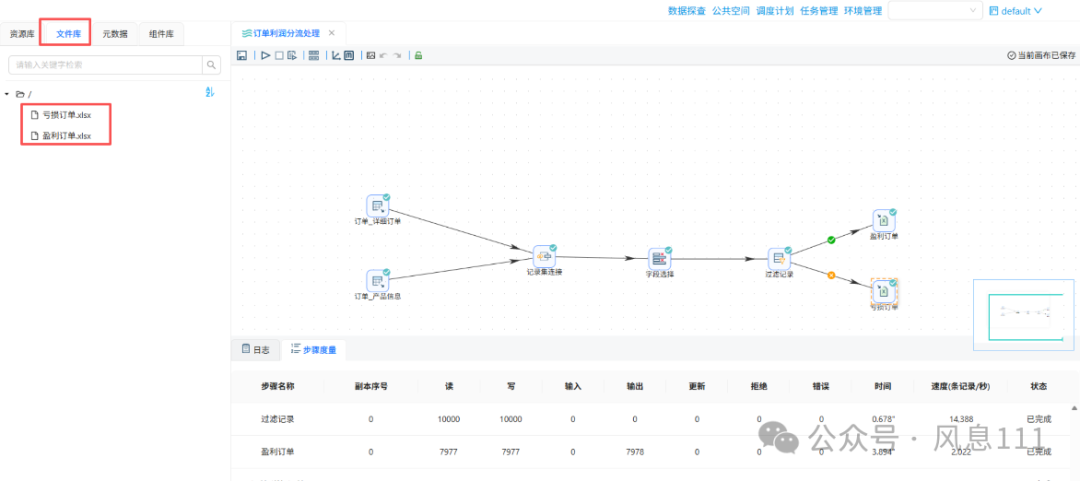
三、实验结果
|
输出文件 |
内容 |
说明 |
|---|---|---|
|
盈利订单.xlsx |
profit ≥ 0 的订单 |
可进一步分析高利润产品 |
|
亏损订单.xlsx |
profit < 0 的订单 |
可用于亏损原因追踪 |
四、问题与解决
在实验过程中,我遇到了一些意料之外的问题,但也正是这些排查和解决的过程,让我对ETL工具和数据流控制的理解更加深刻。
问题一:记录集连接组件弹出“排序需要”警告
-
问题现象:在给两个“表输入”组件向“记录集连接”组件建立连线时,平台弹出了一个红色或黄色的警告框,提示“排序需要”或“数据需要按关联键排序”。
-
问题原因:通过查阅“记录集连接”组件的说明文档,我了解到该组件的底层数据处理机制依赖于数据流的顺序。如果进入连接器的两个数据流没有严格按照关联键(此处为“产品ID”)进行排序,平台无法保证关联结果的准确性,可能出现数据错配或遗漏。
-
解决方法:针对这个问题,我在两个“表输入”组件之后、连接至“记录集连接”之前,分别添加了一个“排序记录”组件。在每个“排序记录”组件中,我将“排序字段”配置为“产品ID”,并选择“升序”排列。重新执行后,警告消除,数据关联结果也符合预期。
问题二:输出Excel文件为空
-
问题现象:第一次执行转换任务时,任务显示“执行成功”,但我在文件库中找到的
盈利订单.xlsx和亏损订单.xlsx文件打开后是空白的,只有表头没有数据行。 -
问题原因:经过排查,我发现问题根源在于“过滤记录”组件配置。在配置分流条件时,我只输入了“利润 >= 0”,但忘记勾选“发送True数据到‘步骤’”和“发送False数据到‘步骤’”这两个选项。这导致分流逻辑虽然执行了,但两条分支路径并没有实际接收到数据流。
-
解决方法:我重新打开“过滤记录”组件的配置窗口,在分流条件设置下方,勾选了“发送True数据到‘步骤’(下游盈利)”和“发送False数据到‘步骤’(下游亏损)”,并确保下游步骤名称与后续组件匹配。保存配置后重新运行任务,文件成功写入了数据。
五、实验总结
通过本次实验,我有了很多新的收获:
-
技能层面:我熟练掌握了助睿零代码ETL平台的核心操作,学会了如何通过可视化拖拽和配置参数(而非编写SQL或代码)来完成复杂的数据集成任务。我对“表输入”、“记录集连接”、“字段选择”、“过滤记录”和“Excel输出”这五大组件的功能边界和配置细节有了深刻认识。
-
逻辑层面:我深入理解了多表关联(左外连接)、数据去重清洗和条件分流在ETL流程中的设计思路。尤其是在遇到“排序需要”错误和“输出为空”的问题时,通过排查和解决,我对数据流的有序性和分流路径配置有了从理论到实践的认知提升。
-
思维层面:从“业务场景”出发构建数据处理流程的思维方式得到了锻炼。我学会了如何将“我要对订单利润进行分析”这样一个模糊的业务需求,拆解为“数据抽取 -> 关联 -> 清洗 -> 分流 -> 落地”这样清晰、可执行的数据加工流水线。

一站式 AI 云服务平台
更多推荐


 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)