
CSP-S 2025 提高级 第一轮(初赛) 题解
本文是CSP-S 2025提高级初赛的部分题解,包含9道单项选择题的详细解析。题目涉及组合数学(红蓝球不相邻排列)、算法基础(KMP的next数组)、数据结构(线段树结点访问、Trie树结点数)、图论(拓扑排序种类、最小生成树)、哈希表(线性探查法)、二叉树(后序转前序遍历)以及动态规划(0-1背包问题)等多个计算机科学知识点。每道题都给出了正确答案和详细的解题思路,包括数学推导、算法步骤和图示说
CSP-S 2025 提高级 第一轮(初赛) 题解
一、单项选择题
(共 15 题,每题 2 分,共计 30 分;每题有且仅有一个正确选项)
- 有 5 5 5 个红球和 5 5 5 个蓝球,它们除了颜色之外完全相同。将这 10 10 10 个球排成一排,要求任意两个蓝色球都不能相邻,有多少种不同的排列方法?
A. 25 25 25
B. 30 30 30
C. 6 6 6
D. 120 120 120
正确答案:C
首先将5个红球摆开,由于红球都相同,只有1种情况。红球两边以及红球之间的空隙都是可以放蓝球的位置,共有6个位置,由于蓝球不能相邻,每个位置最多放1个蓝球。因此需要在6个位置中选出5个位置放蓝球,由于蓝球之间相同,选出放蓝球的位置后也不需要进行排列,因此放蓝球的方案数是从6个位置中选出5个位置放蓝球的组合数,为 C 6 5 = C 6 1 = 6 C_6^5=C_6^1=6 C65=C61=6
- 在 K M P KMP KMP 算法中,对于模式串 P = "abacaba" P=\text{"abacaba"} P="abacaba",其 n e x t next next 数组( n e x t [ i ] next[i] next[i] 定义为模式串 P [ 0.. i ] P[0..i] P[0..i] 最长公共前后缀的长度,其数组下标从 0 0 0 开始)的值是什么?
A. { 0 , 0 , 1 , 0 , 1 , 2 , 3 } \{0,0,1,0,1,2,3\} {0,0,1,0,1,2,3}
B. { 0 , 1 , 2 , 3 , 4 , 5 , 6 } \{0,1,2,3,4,5,6\} {0,1,2,3,4,5,6}
C. { 0 , 0 , 1 , 1 , 2 , 2 , 3 } \{0,0,1,1,2,2,3\} {0,0,1,1,2,2,3}
D. { 0 , 0 , 0 , 0 , 1 , 2 , 3 } \{0,0,0,0,1,2,3\} {0,0,0,0,1,2,3}
正确答案:A
本题不需要执行KMP求 n e x t next next数组的算法,直接根据“最长相等前后缀”的定义,目视填出 n e x t next next数组每一项的值即可。
注意:KMP算法中“最长相等前后缀”,指的是“最长的相等的真前缀和真后缀”,该字符串自己不在讨论范围内。比如字符串"aba"的最长相等前后缀子串为"a",而不是自己"aba”。
求字符串 s s s最长相等前后缀的具体做法为: i i i从1开始。枚举该字符串的长为 i i i的前缀子串(前 i i i个字符构成的子串)和后缀子串(最后 i i i)个字符构成的子串,如果二者相同,再枚举该字符串长为 i + 1 i+1 i+1的前缀子串和后缀子串。。。直到发现某长度的前后缀子串不同,那么已经找到的长度最长的相同的前后缀子串的长度记为最长相等前后缀的长度。
取每个 p p p字符串的前缀子串,求出每个取出的子串的最长相等前后缀的长度,即为 n e x t next next数组。
i i i 字符串 p [ 0... i ] p[0...i] p[0...i] n e x t [ i ] next[i] next[i] 0 a 0 1 ab 0 2 aba 1 3 abac 0 4 abaca 1 5 abacab 2 6 abacaba 3 因此本题选A。
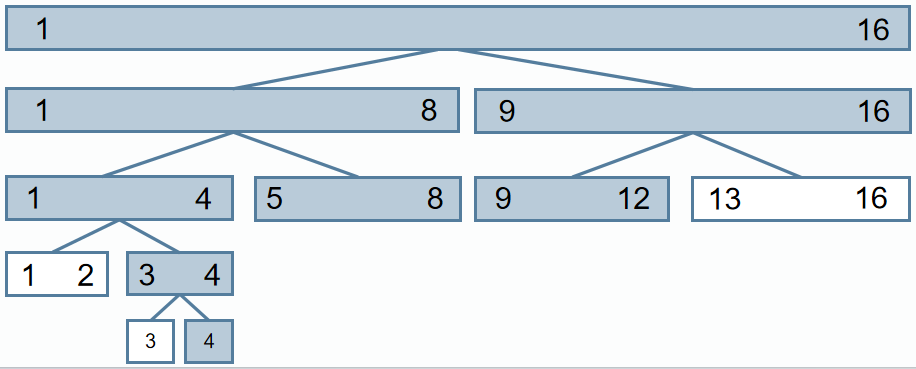
- 对一个大小为 16 16 16(下标 0 0 0– 15 15 15)的数组构建线段树,查询区间 [ 3 , 11 ] [3,\,11] [3,11] 时,最少需要访问多少个树结点(包括路径上的父结点和完全包含在查询区间内的结点)?
A. 7
B. 8
C. 9
D. 10
正确答案:B
线段树中每个结点表示一个区间,如果当前结点表示的区间为 [ l , r ] [l, r] [l,r],设 m = ⌊ l + r 2 ⌋ m=\lfloor \frac{l+r}{2}\rfloor m=⌊2l+r⌋,那么左孩子表示的区间为 [ l , m ] [l,m] [l,m],右孩子表示的区间为 [ l + 1 , r ] [l+1,r] [l+1,r]。
如果待查询区间只在当前结点左孩子表示的区间中,那么只访问左孩子。
如果待查询区间只在当前结点右孩子表示的区间中,那么只访问右孩子。
如果待查询的区间既包括左孩子区间中的元素,也包含右孩子区间中的元素,那么先访问左孩子,再访问右孩子。
递归访问执行上述过程,如果当前结点表示的区间完全被待查询区间包含,那么返回当前结点表示的区间的值(比如区间和)。
下标 [ 0 , 15 ] [0,15] [0,15],转为下标从1开始的数组,下标范围为 [ 1 , 16 ] [1,16] [1,16],那么查询的区间变为 [ 4 , 12 ] [4,12] [4,12]
下图每个区间都表示一个线段树中的结点,进行区间查询会访问的结点对应的是下图中有颜色的区间,共访问8个结点,选B。
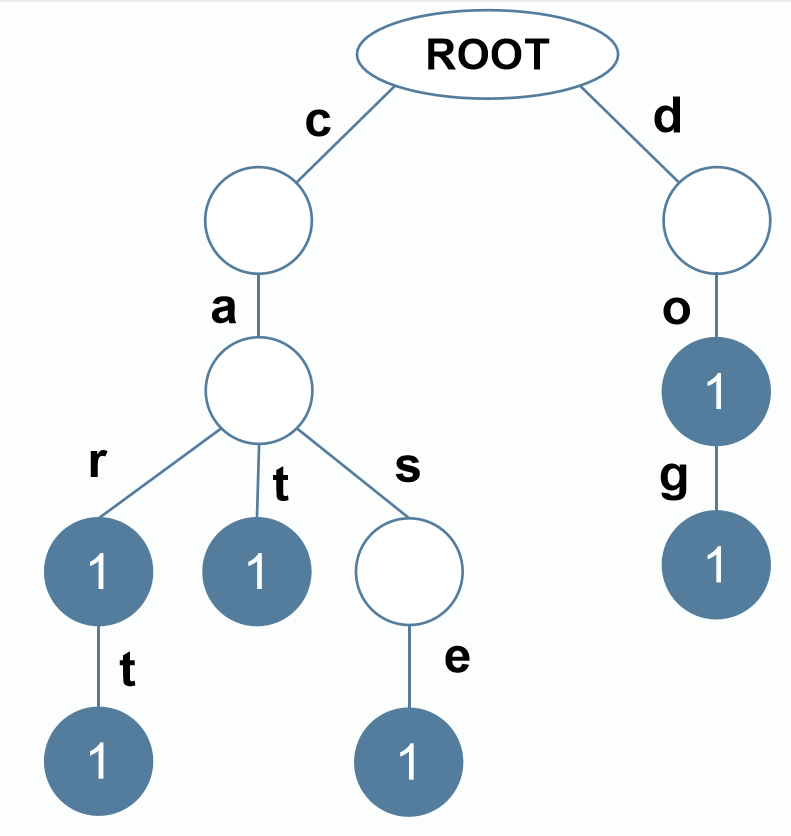
- 将字符串 “cat”、“car”、“cart”、“case”、“dog”、“do” 插入一个空的 Trie 树(前缀树)中,构建完成 Trie 树(包括根节点)共有多少个结点?
A. 8
B. 9
C. 10
D. 11
正确答案:D
Trie树也叫做字典树,有一个空的根结点,每条边表示一个字符,结点包含标记end表示是否存在字符串以该结点为结尾。向字典树插入字符串的方法为:从根出发,遍历字符串,每访问到一个字符,就从当前结点通过该字符对应的边走到孩子。如果当前结点没有该字符对应的边,就通过这条边到达一个新创建的子结点。如果遍历到了字符串的末尾字符,当前结点增加标记end。
构造形成的字典树如下:
共11个结点,选D
- 对于一个包含 n n n 个结点和 m m m 条边的有向无环图( D A G DAG DAG),其拓扑排序的结果有多少种可能?
A. 只有 1 1 1 种
B. 最多 n n n 种
C. 等于 n − m n-m n−m 种
D. 以上都不对
正确答案:D
如果这 n n n个顶点形成一条链,那么拓扑排序的结果只有一种。
如 n = 3 n=3 n=3,有向边为 < 1 , 2 > , < 2 , 3 > <1,2>,<2,3> <1,2>,<2,3>,拓扑排序的结果只能为 1 , 2 , 3 1,2,3 1,2,3
当图中有 n n n个顶点但没有边时,拓扑排序的结果为这 n n n个顶点的全排列,为 n ! n! n!种。每增加一条有向边,就限制了拓扑排序中两顶点之间的先后关系,会使得拓扑排序的数量减少。
因此 n n n个顶点 m m m条边的有向无环图的拓扑排序的结果最少有1种,最多有 n ! n! n!种,ABC选项描述都不正确,选D。
- 在一个大小为 13 13 13 的哈希表中,使用闭散列法的线性探查来解决冲突。哈希函数为 H ( key ) = key m o d 13 H(\text{key})=\text{key}\bmod 13 H(key)=keymod13。依次插入关键字 18 , 26 , 35 , 9 , 68 , 74 18,\,26,\,35,\,9,\,68,\,74 18,26,35,9,68,74,插入 74 74 74 后,它最终被放置在哪个索引位置?
A. 5
B. 7
C. 8
D. 11
正确答案:D
闭散列就是开放地址法。每次对关键字求哈希值,如果在表中以哈希值为下标的位置已经被占用了,那么就需要按照探测下一个位置的规则不断探测,直到找到一个可以使用的位置,在该位置存储关键字。
线性探查法:为如果当前位置已经被占用,那么就让探测位置加1,看新的位置是否已被占用。如果探测位置已经达到表的末尾,则让探测位置指向表的第一个元素。
依次保存各个元素:
H ( 18 ) = 18 m o d 13 = 5 H(18) = 18 \bmod 13 = 5 H(18)=18mod13=5,18存储在下标5位置。
H ( 26 ) = 26 m o d 13 = 0 H(26) = 26 \bmod 13 = 0 H(26)=26mod13=0,26存储在下标0位置。
H ( 35 ) = 35 m o d 13 = 9 H(35) = 35 \bmod 13 = 9 H(35)=35mod13=9,35存储在下标9位置。
H ( 9 ) = 9 m o d 13 = 9 H(9) = 9 \bmod 13 = 9 H(9)=9mod13=9,9准备存储在下标9位置,但第9位置已被占用,则看第10位置,第10位置未被占用,将9存储在下标10位置。
H ( 68 ) = 68 m o d 13 = 3 H(68) = 68 \bmod 13 = 3 H(68)=68mod13=3,68存储在下标3位置。
H ( 74 ) = 74 m o d 13 = 9 H(74) = 74 \bmod 13 = 9 H(74)=74mod13=9,74准备存储在下标9位置,但下标9位置已被占用,向后探测,下标10位置也已被占用,向后探测,下标11位置未被占用,将 74 74 74存储在下标 11 11 11位置。
因此本题选D。
- 一个包含 8 8 8 个顶点的完全图(顶点的编号为 1 1 1 到 8 8 8),在每两个点之间的边权重等于两顶点编号的绝对值。例如,顶点 3 3 3 和 7 7 7 之间的边权重为 ∣ 7 − 3 ∣ = 4 |7-3|=4 ∣7−3∣=4。该图的最小生成树的权重是多少?
A. 7
B. 8
C. 9
D. 10
正确答案:A
使用Kruskal算法,每次在图中选择边权最小的与已选择的边不形成环的边,执行 n − 1 n-1 n−1次( n n n为图中顶点总数)即可得到最小生成树。
该图中边权最小的边长度为1,为 ( 1 , 2 ) , ( 2 , 3 ) , ( 3 , 4 ) , ( 4 , 5 ) , ( 5 , 6 ) , ( 6 , 7 ) , ( 7 , 8 ) (1,2),(2,3),(3,4),(4,5),(5,6),(6,7),(7,8) (1,2),(2,3),(3,4),(4,5),(5,6),(6,7),(7,8),这7条边的权值都为1,而且选择这 7 7 7条边不形成环。依次选择这7条边,图中一共有8个顶点,选择7条边即可构成一棵树,这棵树就是该图的最小生成树,该树上边的总权值为7。本题选A。
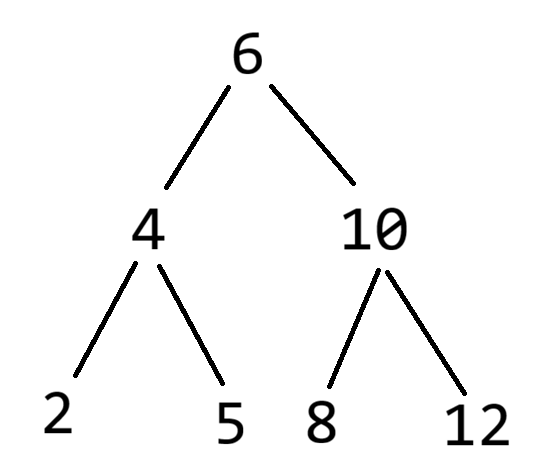
- 如果一棵二叉搜索树的后序遍历序列是 2 , 5 , 4 , 8 , 12 , 10 , 6 2,\,5,\,4,\,8,\,12,\,10,\,6 2,5,4,8,12,10,6,那么该树的前序遍历是什么?
A. 6 , 4 , 2 , 5 , 10 , 8 , 12 6,\,4,\,2,\,5,\,10,\,8,\,12 6,4,2,5,10,8,12
B. 6 , 4 , 5 , 2 , 10 , 12 , 8 6,\,4,\,5,\,2,\,10,\,12,\,8 6,4,5,2,10,12,8
C. 6 , 2 , 4 , 5 , 8 , 10 , 12 6,\,2,\,4,\,5,\,8,\,10,\,12 6,2,4,5,8,10,12
D. 6 , 2 , 5 , 4 , 10 , 8 , 12 6,\,2,\,5,\,4,\,10,\,8,\,12 6,2,5,4,10,8,12
正确答案:A
二叉搜索树的中序遍历序列为有序序列,默认情况为升序序列。那么该二叉树的中序遍历序列为 2 , 4 , 5 , 6 , 8 , 10 , 12 2,\,4,\,5,\,6,\,8,\,10,\,12 2,4,5,6,8,10,12。
那么这就是一个已知二叉树后序、中序建树,而后求先序遍历的问题。
每次先取后续遍历序列的最后一个元素,为根结点的值。而后在中序遍历序列中查找到根结点的值的位置。中序遍历序列中根结点值左侧的子段为左子树的中序遍历序列,右侧的子段为右子树的中序遍历序列。
而后根据左子树中序遍历序列的长度,确定后序遍历序列中的左子树的后序遍历序列和右子树的后序遍历序列。
递归上述过程,根据左子树的后序、中序遍历序列构建左子树,根据右子树的后序、中序遍历序列构建右子树。
根据上述方法构建得到的二叉搜索树为:
对该树的先序遍历序列为:6 4 2 5 10 8 12,选A。
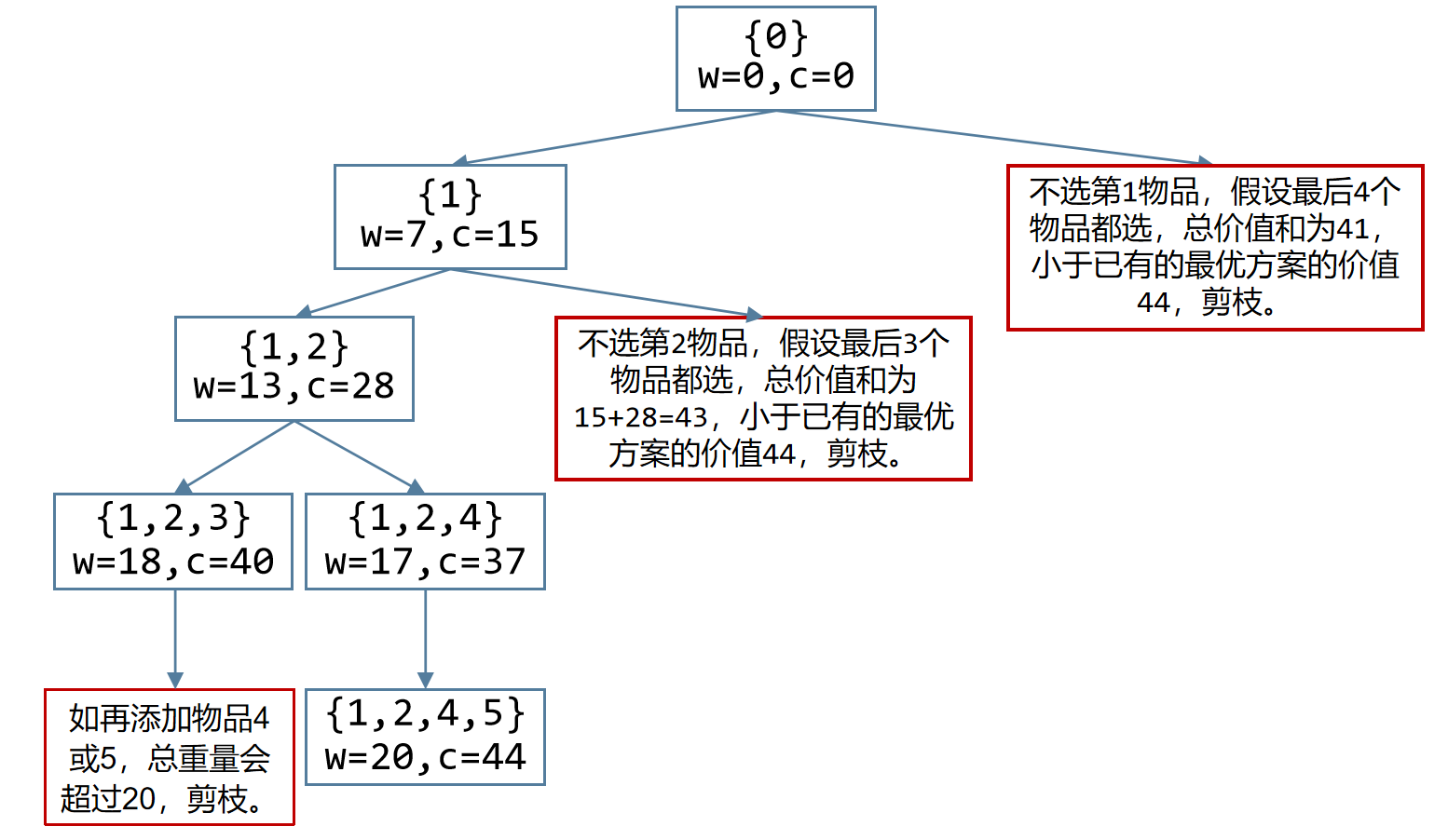
- 一个 0 0 0- 1 1 1 背包问题,背包容量为 20 20 20。现有 5 5 5 个物品,重量和价值分别为 7 , 5 , 4 , 3 , 6 7,\,5,\,4,\,3,\,6 7,5,4,3,6 和 15 , 12 , 9 , 7 , 13 15,\,12,\,9,\,7,\,13 15,12,9,7,13。装入背包的物品能获得的最大总价值是多少?
A. 43
B. 41
C. 45
D. 44
正确答案:D
01背包的状态定义为: d p i , j dp_{i,j} dpi,j:前 i i i个物品中选择物品放入容量为 j j j的背包能获得的最大价值。
第 i i i物品的重量为 w i w_i wi,价值为 c i c_i ci。
状态转移方程为: d p i , j = { d p i − 1 , j w i > j m a x ( d p i − 1 , j , d p i − 1 , j − w i + c i ) w i ≤ j dp_{i,j} = \begin{cases} dp_{i-1,j} & w_i > j \\ max(dp_{i-1,j}, dp_{i-1,j-w_i}+c_i) & w_i\le j \end{cases} dpi,j={dpi−1,jmax(dpi−1,j,dpi−1,j−wi+ci)wi>jwi≤j
初始状态: d p 0 , j = d p i , 0 = 0 dp_{0,j}=dp_{i,0}=0 dp0,j=dpi,0=0
本题所求的结果为 d p 5 , 20 dp_{5,20} dp5,20。
如果在草纸上列表,使用递推的思路一直推出本题所求的 d p 5 , 20 dp_{5,20} dp5,20,需要填 5 5 5行 20 20 20列的表,共有 5 ∗ 20 = 100 5*20=100 5∗20=100项,不是不能做,但在考场上做这样大量的计算有些浪费时间。也可以考虑使用记忆化递归的思路。
由于数据量很少,可以使用深搜枚举物品集合的所有子集,求满足条件的物品子集中价值最大的子集的价值。
可以考虑的剪枝有:
- 优化搜索顺序:按照物品重量从大到小的顺序依次确定是否选择该物品。
- 可行性剪枝:如果物品总重量大于了背包容量,则结束搜索。
- 最优性剪枝:求出剩下几个物品能获得的最大价值。如果当前已选物品的价值加上剩下所有物品价值的总和还小于已经求出的最大价值,那么可以结束搜索。
将物品按重量从大到小排序,得:
属性\编号 i i i 1 2 3 4 5 重量 w i w_i wi 7 6 5 4 3 价值 c i c_i ci 15 13 12 9 7 取价值数组 c i c_i ci的后缀和,用于最优性剪枝:
最后1个物品的价值和为 7 7 7
最后2个物品的价值和为 16 16 16
最后3个物品的价值和为 28 28 28
最后4个物品的价值和为 41 41 41
最后5个物品的价值为 56 56 56每个结点表示一个状态“{}”中为当前已选择的物品编号, w w w表示当前已选择物品的总重量, c c c表示当前已选择物品的总价值。按顺序遍历每个物品,对于每个物品都有“选择或不选择”两种情况,产生两个后继状态。如果满足剪枝条件,则不再看后面的物品。这会形成一个树形结构。在各满足条件的状态中,找到物品总价值最大的状态,该状态的价值即为问题的结果。观察下图可知,当选择物品 1 , 2 , 4 , 5 1,2,4,5 1,2,4,5时,能获得最大价值,为44,本题选D。
- 在一棵以结点 1 1 1 为根的树中,结点 12 12 12 和结点 18 18 18 的最近公共祖先( L C A LCA LCA)是结点 4 4 4。那么下列哪个结点的 L C A LCA LCA 组合是不可出现的?
A. L C A ( 12 , 4 ) = 4 LCA(12,\,4)=4 LCA(12,4)=4
B. L C A ( 18 , 4 ) = 4 LCA(18,\,4)=4 LCA(18,4)=4
C. L C A ( 12 , 18 , 4 ) = 4 LCA(12,\,18,\,4)=4 LCA(12,18,4)=4
D. L C A ( 12 , 1 ) = 4 LCA(12,\,1)=4 LCA(12,1)=4
正确答案:D
L C A ( 12 , 18 ) = 4 LCA(12,18)=4 LCA(12,18)=4,那么 4 4 4既是 12 12 12的祖先,也是 18 18 18的祖先。根据:如果 a a a是 b b b的祖先,有 L C A ( a , b ) = a LCA(a,b)=a LCA(a,b)=a,那么有 L C A ( 12 , 4 ) = 4 LCA(12,\,4)=4 LCA(12,4)=4, L C A ( 18 , 4 ) = 4 LCA(18,\,4)=4 LCA(18,4)=4。 12 , 18 , 4 12,18,4 12,18,4三者的最近公共祖先也是 4 4 4, L C A ( 12 , 18 , 4 ) = 4 LCA(12,\,18,\,4)=4 LCA(12,18,4)=4。
根结点 1 1 1是树中所有结点的祖先, 1 1 1是 12 12 12的祖先, 12 12 12和 1 1 1的最近公共祖先应该为根结点 1 1 1,不是 4 4 4。D选项错误,本题选D。
- 递归关系式 T ( n ) = 2 T ( n / 2 ) + O ( n 2 ) T(n)=2T(n/2)+O(n^{2}) T(n)=2T(n/2)+O(n2) 描述了某个分治算法的时间复杂度。请问该算法的时间复杂度是多少?
A. O ( n ) O(n) O(n)
B. O ( n log n ) O(n\log n) O(nlogn)
C. O ( n 2 ) O(n^{2}) O(n2)
D. O ( n 2 log n ) O(n^{2}\log n) O(n2logn)
正确答案:C
设算法该时间频度的递推式形式为 T ( n ) = a T ( n b ) + f ( n ) T(n)=aT(\frac{n}{b})+f(n) T(n)=aT(bn)+f(n)。
则 a = 2 , b = 2 a=2, b=2 a=2,b=2, n log b a = n log 2 2 = n , O ( n log b a ) = O ( n ) n^{\log_ba}=n^{\log_22}=n, O(n^{\log_ba})=O(n) nlogba=nlog22=n,O(nlogba)=O(n)
f ( n ) = O ( n 2 ) , O ( f ( n ) ) = O ( n 2 ) f(n)=O(n^2),O(f(n)) = O(n^2) f(n)=O(n2),O(f(n))=O(n2)
所以 O ( n log b a ) < O ( f ( n ) ) O(n^{\log_ba})<O(f(n)) O(nlogba)<O(f(n))
根据主定理可知,该算法的时间复杂度为 O ( f ( n ) ) = O ( n 2 ) O(f(n))=O(n^2) O(f(n))=O(n2),选C。
- 在一个初始为空的最小堆(min-heap)中,依次插入元素 20 , 12 , 15 , 8 , 10 , 5 20,\,12,\,15,\,8,\,10,\,5 20,12,15,8,10,5。然后连续执行两次“删除最小值(delete-min)”操作。请问此时堆顶元素是什么?
A. 10
B. 12
C. 15
D. 20
正确答案:A
最小堆的堆顶始终为集合中共的最小值。插入这些元素后,连续两次删除最小值,会删掉集合中的 5 、 8 5、8 5、8,集合中剩下的元素为 10 , 12 , 15 , 20 10,12,15,20 10,12,15,20,此时堆顶为该集合中的最小值 10 10 10,选A。
- 1 1 1 到 1000 1000 1000 之间,不能被 2 2 2、 3 3 3、 5 5 5 中任意一个整除的整数有多少个?
A. 266
B. 267
C. 333
D. 734
正确答案:A
[ 1 , 1000 ] [1,1000] [1,1000]共1000个数构成全集 S S S,能被 2 2 2或 3 3 3或 5 5 5整除的数构成集合 P P P,设能被 2 2 2整除的数构成的集合为 A A A,能被 3 3 3整除的数构成的集合为 B B B,能被 5 5 5整除的数构成的集合为 C C C。能被 2 2 2或 3 3 3或 5 5 5整除的数构成集合 P P P为 A 、 B 、 C A、B、C A、B、C的并集。
记 ∣ P ∣ |P| ∣P∣表示集合 P P P中元素的个数。根据容斥原理,有: ∣ P ∣ = ∣ A ∪ B ∪ C ∣ = ∣ A ∣ + ∣ B ∣ + ∣ C ∣ − ∣ A ∩ B ∣ − ∣ A ∩ C ∣ − ∣ B ∩ C ∣ + ∣ A ∩ B ∩ C ∣ |P|=|A\cup B\cup C| = |A|+|B|+|C|-|A\cap B|-|A\cap C|-|B\cap C|+|A\cap B\cap C| ∣P∣=∣A∪B∪C∣=∣A∣+∣B∣+∣C∣−∣A∩B∣−∣A∩C∣−∣B∩C∣+∣A∩B∩C∣。
[ 1 , n ] [1,n] [1,n]中能被 i i i整除的数有 i , 2 i , . . . , m ⋅ i i,2i,...,m\cdot i i,2i,...,m⋅i,其中 m m m为满足 m ⋅ i ≤ n m\cdot i\le n m⋅i≤n的最大整数,即 m ≤ n i m\le \frac{n}{i} m≤in, m m m能取到的最大值为 ⌊ n i ⌋ \lfloor \frac{n}{i} \rfloor ⌊in⌋,因此 [ 1 , n ] [1,n] [1,n]中能被 i i i整除的数的数量为 ⌊ n i ⌋ \lfloor \frac{n}{i} \rfloor ⌊in⌋。
[ 1 , 1000 ] [1,1000] [1,1000]中能被 2 2 2整除的数的个数 ∣ A ∣ = ⌊ 1000 2 ⌋ = 500 |A|=\lfloor \frac{1000}{2} \rfloor = 500 ∣A∣=⌊21000⌋=500
[ 1 , 1000 ] [1,1000] [1,1000]中能被 3 3 3整除的数的个数有 ∣ B ∣ = ⌊ 1000 3 ⌋ = 333 |B|=\lfloor \frac{1000}{3} \rfloor = 333 ∣B∣=⌊31000⌋=333
[ 1 , 1000 ] [1,1000] [1,1000]中能被 2 2 2整除的数的个数有 ∣ C ∣ = ⌊ 1000 5 ⌋ = 200 |C|=\lfloor \frac{1000}{5} \rfloor = 200 ∣C∣=⌊51000⌋=200
[ 1 , 1000 ] [1,1000] [1,1000]中能同时被 2 、 3 2、3 2、3整除即能被 6 6 6整除的数的个数 ∣ A ∩ B ∣ = ⌊ 1000 6 ⌋ = 166 |A\cap B|=\lfloor \frac{1000}{6} \rfloor = 166 ∣A∩B∣=⌊61000⌋=166
[ 1 , 1000 ] [1,1000] [1,1000]中能同时被 3 、 5 3、5 3、5整除即能被 15 15 15整除的数的个数 ∣ B ∩ C ∣ = ⌊ 1000 15 ⌋ = 66 |B\cap C|=\lfloor \frac{1000}{15} \rfloor = 66 ∣B∩C∣=⌊151000⌋=66
[ 1 , 1000 ] [1,1000] [1,1000]中能同时被 2 、 5 2、5 2、5整除即能被 10 10 10整除的数的个数 ∣ A ∩ C ∣ = ⌊ 1000 10 ⌋ = 100 |A\cap C|=\lfloor \frac{1000}{10} \rfloor = 100 ∣A∩C∣=⌊101000⌋=100
[ 1 , 1000 ] [1,1000] [1,1000]中能同时被 2 、 3 、 5 2、3、5 2、3、5整除即能被 30 30 30整除的数的个数 ∣ A ∩ B ∩ C ∣ = ⌊ 1000 30 ⌋ = 33 |A\cap B\cap C|=\lfloor \frac{1000}{30} \rfloor = 33 ∣A∩B∩C∣=⌊301000⌋=33
因此 ∣ P ∣ = ∣ A ∪ B ∪ C ∣ = ∣ A ∣ + ∣ B ∣ + ∣ C ∣ − ∣ A ∩ B ∣ − ∣ A ∩ C ∣ − ∣ B ∩ C ∣ + ∣ A ∩ B ∩ C ∣ = 500 + 333 + 200 − 166 − 100 − 66 + 33 = 734 |P|=|A\cup B\cup C| = |A|+|B|+|C|-|A\cap B|-|A\cap C|-|B\cap C|+|A\cap B\cap C|\\ =500+333+200-166-100-66+33=734 ∣P∣=∣A∪B∪C∣=∣A∣+∣B∣+∣C∣−∣A∩B∣−∣A∩C∣−∣B∩C∣+∣A∩B∩C∣=500+333+200−166−100−66+33=734。
那么不能被 2 、 3 、 5 2、3、5 2、3、5任意一个数整除的数构成的集合为 P P P关于 S S S的补集,其元素个数为 ∣ S − P ∣ = ∣ S ∣ − ∣ P ∣ = 1000 − 734 = 266 |S-P|=|S|-|P|=1000-734=266 ∣S−P∣=∣S∣−∣P∣=1000−734=266,本题选A。
- 斐波那契数列的定义为 F ( 0 ) = 0 , F ( 1 ) = 1 , F ( n ) = F ( n − 1 ) + F ( n − 2 ) F(0)=0,\ F(1)=1,\ F(n)=F(n-1)+F(n-2) F(0)=0, F(1)=1, F(n)=F(n−1)+F(n−2)。使用朴素递归方法计算 F ( n ) F(n) F(n) 的时间复杂度是指数级的,而使用动态规划(或迭代)方法的时间复杂度是线性的。造成这两种巨大差异的根本原因是?
A. 递归函数调用栈开销过大
B. 操作系统对递归深度有限制
C. 朴素递归中存在大量的重复子问题未被重复利用
D. 动态规划使用了更少的数据存储空间
正确答案:C
A. 递归函数调用是有一定开销,但如果递归调用次数不多,递归调用造成的开销可以忽略。递归求斐波那契数列时间复杂度高,主要原因是递归调用次数过多,原因不在递归函数调用的开销。
B. 如果操作系统对递归调用的深度有限制,那么会导致使用递归算法求斐波那契数列时,无法完成求解,或由于栈区太小,限制了递归调用的层数,递归调用层数过多时发生栈溢出,产生运行时错误。这与该算法的时间复杂度无关。
D. 动规算法大多情况下会比直接递归使用更多的存储空间。
求斐波那契数列时,会需要解决大量重复的子问题。如求 F ( 5 ) F(5) F(5)时需要先求 F ( 4 ) F(4) F(4)与 F ( 3 ) F(3) F(3),求 F ( 4 ) F(4) F(4)时需要先求 F ( 3 ) F(3) F(3)与 F ( 2 ) F(2) F(2),可以看到 F ( 3 ) F(3) F(3)这个子问题会被重复求解。朴素递归算法遇到子问题都会重复求解,因此时间复杂度较高。动态规划算法会用一个表记录子问题的结果,遇到重复子问题时直接在表中查询结果,可以避免对子问题进行重复求解,提高算法效率。具体实现时,可以使用递推或记忆化递归实现动态规划算法。因此C选项描述正确。
- 5 5 5 个独立的、不可抢占的任务 A 1 , A 2 , A 3 , A 4 , A 5 A_1, A_2, A_3, A_4, A_5 A1,A2,A3,A4,A5 需要在一台计算机上执行(从时间 0 0 0 开始执行),每个任务都有对应的处理时长和截止时刻,按顺序分别为 3 , 4 , 2 , 5 , 1 3,\,4,\,2,\,5,\,1 3,4,2,5,1 和 5 , 10 , 3 , 15 , 11 5,\,10,\,3,\,15,\,11 5,10,3,15,11。如果某一个任务超时,相应的惩罚等于其处理时长。为了最小化总惩罚,应该优先执行哪个任务?
A. 处理时间最短的任务 A 5 A_5 A5
B. 截止时间最早的任务 A 3 A_3 A3
C. 处理时间最长的任务 A 4 A_4 A4
D. 任选一个任务都可以
正确答案:B
设第 i i i个任务的处理时长为 l i l_i li,截止时刻为 t i t_i ti。
属性\编号 1 2 3 4 5 处理时长 l i l_i li 3 4 2 5 1 截止时刻 t i t_i ti 5 10 3 15 11 可以依次按照题目各选项指出的方法,来选择任务。
A. 如果每次都选处理时长最短的任务,那么执行任务的顺序是: 5 , 3 , 1 , 2 , 4 5,3,1,2,4 5,3,1,2,4。
执行 A 5 A_5 A5,占用时段 [ 1 , 1 ] [1,1] [1,1],未超时。
执行 A 3 A_3 A3,占用时段 [ 2 , 3 ] [2,3] [2,3],未超时。
执行 A 1 A_1 A1,占用时段 [ 4 , 6 ] [4,6] [4,6],超时,惩罚3。
执行 A 2 A_2 A2,占用时段 [ 7 , 10 ] [7,10] [7,10],未超时。
执行 A 4 A_4 A4,占用时段 [ 11 , 15 ] [11,15] [11,15],未超时。
总惩罚为 3 3 3。
B. 如果每次都选截止时刻最早的任务,那么执行任务的顺序是: 3 , 1 , 2 , 5 , 4 3,1,2,5,4 3,1,2,5,4。
执行 A 3 A_3 A3,占用时段 [ 1 , 2 ] [1,2] [1,2],未超时。
执行 A 1 A_1 A1,占用时段 [ 3 , 5 ] [3,5] [3,5],未超时。
执行 A 2 A_2 A2,占用时段 [ 6 , 9 ] [6,9] [6,9],未超时。
执行 A 5 A_5 A5,占用时段 [ 10 , 10 ] [10,10] [10,10],未超时。
执行 A 4 A_4 A4,占用时段 [ 11 , 15 ] [11,15] [11,15],未超时。
总惩罚为 0 0 0。
C. 如果每次都选处理时间最长的任务,那么执行任务的顺序为: 4 , 2 , 1 , 3 , 5 4,2,1,3,5 4,2,1,3,5
执行 A 4 A_4 A4,占用时段 [ 1 , 5 ] [1,5] [1,5],未超时。
执行 A 2 A_2 A2,占用时段 [ 6 , 9 ] [6,9] [6,9],未超时。
执行 A 1 A_1 A1,占用时段 [ 10 , 12 ] [10,12] [10,12],超时,惩罚3。
执行 A 3 A_3 A3,占用时段 [ 13 , 14 ] [13,14] [13,14],超时,惩罚2。
执行 A 5 A_5 A5,占用时段 [ 15 , 15 ] [15,15] [15,15],超时,惩罚1。
总惩罚为 6 6 6
D. 显然也不对。因此本题选B。
二、阅读程序
三、完善程序

一站式 AI 云服务平台
更多推荐



 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)