
C++数据结构--串操作
与BF算法一样,KMP算法同样解决的是字符串匹配问题,其相当于BF算法的优化,相较与BF算法O(m*n)的时间复杂度,其将时间复杂度稳定在O(m+n),效率更高。KMP算法的匹配逻辑可以拆解为两个核心阶段:预处理阶段(构建 next 数组)和正式匹配阶段(双指针遍历)。预处理阶段:构建 next 数组,记录了模式串中每个位置之前的子串,最长相等前后缀的长度。正式匹配阶段:利用next数组避免BF算
一.BF算法
1.什么是BF算法
BF算法,通常被称为暴力匹配算法或朴素模式匹配算法。
核心思想:拿着“模式串”(要找的短字符串)去和“主串”(被搜索的字符串)逐个字符进行比对。如果字符相等就继续往后比,如果不相等,就把模式串往后挪一位,从头开始重新比。
BF算法的匹配逻辑
1.假设主串为 S,模式串为 T,我们使用两个指针 i(指向主串)和 j(指向模式串)来进行匹配:
字符相等:如果 S[i] == T[j],说明当前字符匹配成功,两个指针同时后移(i++, j++),继续比对下一个字符。
2.字符不等:如果 S[i] != T[j],说明这一轮匹配失败。此时需要回溯:主串指针 i 退回到“这一轮起始位置的下一个位置”(即 i = i - j + 1)。模式串指针 j 重置为 0。
3.匹配成功:当 j 走完了整个模式串(即 j == 模式串长度),说明找到了匹配的子串,返回起始位置 i - j。
4.匹配失败:如果主串遍历完了还没匹配成功,则返回 -1。
时间复杂度:
时间复杂度:O(n*m)。
空间复杂度:O(1)。
2.代码实现
int main()
{
string s = "ABCDCABDEFG";
string t = "ABD";
size_t j = 0;
size_t i = 0;
while (i < s.length() && j < t.length())
{
if (s[i] == t[j]) {
i++;
j++;
}
else
{
i = i - j + 1;
j = 0;
}
}
if (j == t.length())
{
cout << i-j << endl;
}
else
{
cout << -1 << endl;
}
}二.KMP算法
1.什么是KMP算法
与BF算法一样,KMP算法同样解决的是字符串匹配问题,其相当于BF算法的优化,相较与BF算法O(m*n)的时间复杂度,其将时间复杂度稳定在O(m+n),效率更高。
KMP算法的匹配逻辑可以拆解为两个核心阶段:预处理阶段(构建 next 数组)和正式匹配阶段(双指针遍历)。
预处理阶段:构建 next 数组,记录了模式串中每个位置之前的子串,最长相等前后缀的长度。
正式匹配阶段:利用next数组避免BF算法匹配失败回退到起始位置的情况。
2.代码实现
int* getNext(string str)
{
int* next = new int[str.size()];
int j = 0;
int k = -1;
next[j] = k;
while (j < str.size() - 1)
{
if (k==-1||str[k] == str[j])
{
j++;
k++;
if (str[k] == str[j])
{
next[j] = next[k];
}
else
{
next[j] = k;
}
}
else
{
k = next[k];
}
}
return next;
}
int KMP(string s, string t)
{
int j = 0;
int i = 0;
int* next = getNext(t);
unique_ptr<int[]>ptr(next);
int size1 = s.length();
int size2 = t.length();
while ( i < size1 && j <size2)
{
if (j == -1||s[i] == t[j]) {
i++;
j++;
}
else
{
j = next[j];
}
}
if (j == t.length())
{
return i - j;
}
else
{
return -1;
}
}
三.Tire字典树(前缀树)
1.什么是Tire字典树
基本性质:
1.根节点不包含字符,除根节点外每一个节点都只包含一个字符
2.从根节点到某一结点,路径上经过的字符连接起来,为该节点对应的字符串
3.每个节点的所有子节点包含的字符都不相同
其核心就是利用字符串的公共前缀来减少查找时间
如图,我们利用字典树存储单词:tea,ten,ted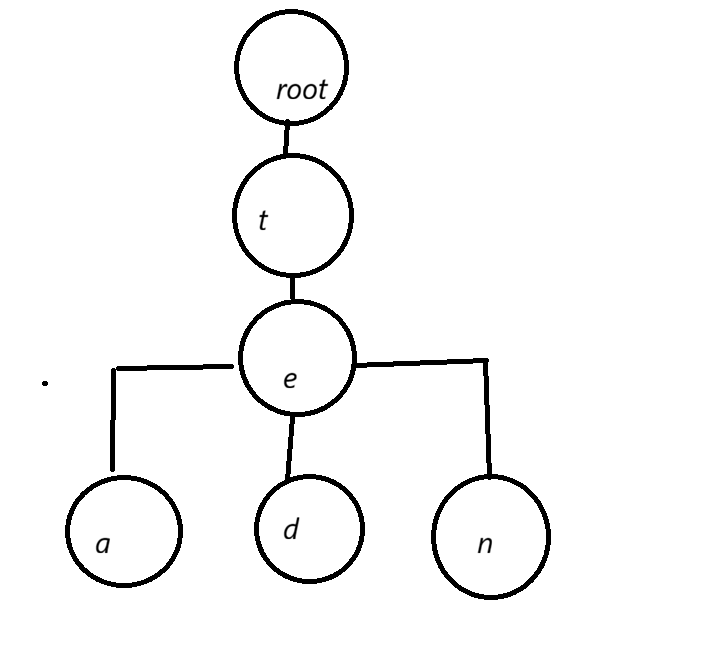
2.代码实现
class TireTree
{
public:
TireTree()
{
root = new TireNode('\0', 0);
}
~TireTree()
{
queue<TireNode*>que;
que.push(root);
while (!que.empty())
{
auto p = que.front();
que.pop();
for (auto& pair : p->mp)
{
que.push(pair.second);
}
delete p;
}
}
public:
//添加操作
void add(const string& str)
{
add(root, str);
}
//输出操作
void remove(const string& str)
{
remove(root, str);
}
//查询操作
int query(const string& str)
{
return query(root, str);
}
//排序应用:字典序打印存储的所有字符串
//前序遍历:VLR
void Preorder()
{
string word;
vector<string>vec;
Preorder(root, word,vec);
for (auto v : vec)
{
cout << v << endl;
}
cout << endl;
}
//前缀搜索
void queryPrefix(const string& prefix)
{
vector<string>str;
string word;
queryPrefix(root, prefix, str);
for (auto s : str)
{
cout << s << endl;
}
cout << endl;
}
private:
struct TireNode
{
TireNode(char data, int freq)
:m_data(data)
, m_freq(freq)
{
}
char m_data;
int m_freq;
map<char, TireNode*>mp;
};
TireNode* root;
void add(TireNode* node, const string& str)
{
TireNode* p = node;
for (size_t i = 0; i < str.length(); i++)
{
auto childit = p->mp.find(str[i]);
if (childit == p->mp.end())
{
TireNode* childNode = new TireNode(str[i], 0);
p->mp.insert({ str[i], childNode });
p = childNode;
}
else
{
p = childit->second;
}
}
p->m_freq++;
}
int query(TireNode* node, const string& str)
{
TireNode* p = node;
for (size_t i = 0; i < str.length(); i++)
{
auto childit = p->mp.find(str[i]);
if (childit != p->mp.end())
{
p = childit->second;
}
else
{
return 0;
}
}
return p->m_freq;
}
void Preorder(TireNode* node, string word, vector<string>&vec)
{
TireNode* p = node;
if (p != nullptr)
{
word.push_back(p->m_data);
}
if (p->m_freq > 0)
{
vec.push_back(word);
}
for (auto s : p->mp)
{
Preorder(s.second, word,vec);
}
}
void queryPrefix(TireNode* node, string prefix, vector<string>& str)
{
TireNode* p = node;
for (size_t i = 0; i < prefix.length(); i++)
{
auto childit = p->mp.find(prefix[i]);
if (childit == p->mp.end())
{
return;
}
else
{
p = childit->second;
}
}
Preorder(p, prefix.substr(0, prefix.length() - 1), str);
}
void remove(TireNode* node, const string& str)
{
TireNode* p = node;
TireNode* del = node;
char delch=str[0];
for (size_t i = 0; i < str.length(); i++)
{
auto childit = p->mp.find(str[i]);
if (childit == p->mp.end())
{
return;
}
if (p->m_freq > 0 || p->mp.size() > 1)
{
del = p;
delch = str[i];
}
p = childit->second;
}
if (p->mp.empty())
{
queue<TireNode*>que;
auto child = del->mp[delch];
del->mp.erase(delch);
que.push(child);
while (!que.empty())
{
auto pn = que.front();
que.pop();
for (auto& pair : pn->mp)
{
que.push(pair.second);
}
delete pn;
}
}
else
{
p->m_freq = 0;
}
}
};四.跳跃表
1.什么是跳跃表
我们都知道,普通的有序链表虽然插入和删除很方便,但查找效率极低,时间复杂度是 O(n)(必须从头遍历)。而数组虽然可以用二分查找实现 O(log n) 的极速查找,但插入和删除时又需要移动大量元素。
跳跃表的出现,就是为了完美融合两者的优点:既保留链表插入删除的灵活性,又能像二分查找一样实现 O(log n) 的高效查找。
2.代码实现
class SkipList
{
public:
SkipList()
{
m_head = new HeadNode(1);
}
~SkipList()
{
for (size_t i = 0; i < m_head->m_level; i++)
{
Node* cur = m_head->next;
while (cur != nullptr)
{
Node* temp = cur->next;
delete cur;
cur = temp;
}
cur = m_head;
m_head = static_cast<HeadNode*>(cur->down);
delete cur;
}
}
public:
//搜索操作
bool find(int val)
{
Node* cur = m_head->next;
Node* pre = m_head;
while (1)
{
if (cur != nullptr)
{
if (cur->m_data < val)
{
pre = cur;
cur = pre->next;
continue;
}
else if (cur->m_data == val)
{
return true;
}
}
if (pre->down == nullptr)
{
break;
}
pre = pre->down;
cur = pre->next;
}
return false;
}
//插入操作
void add(int val)
{
if (find(val))
{
return;
}
int level = getLevel();
if (level > m_head->m_level)
{
level = m_head->m_level + 1;
HeadNode* hhead = new HeadNode(level);
hhead->down = m_head;
m_head = hhead;
}
Node** nodelist = new Node*[level];
for (size_t i = 0; i < level; i++) // 修正循环范围,初始化所有 nodelist 元素
{
nodelist[i] = new Node(val);
if (i > 0)
{
nodelist[i]->down = nodelist[i - 1];
}
}
Node* head = m_head;
for (size_t i = m_head->m_level; i > level; i--)
{
head = head->down;
}
Node* pre = head;
Node* cur = pre->next;
for (size_t i = 0; i < level; i++)
{
while (cur != nullptr && val > cur->m_data) {
pre = cur;
cur = cur->next;
}
nodelist[level - i - 1]->next = cur; // 修正下标,防止越界
pre->next = nodelist[level - i - 1];
pre = pre->down;
if (pre != nullptr)
{
cur = pre->next;
}
}
delete[] nodelist;
}
//打印操作
void show()const
{
Node* h = m_head;
while (h!=nullptr)
{
Node* node = h->next;
while (node!=nullptr)
{
cout << node->m_data << " ";
node = node->next;
}
cout << endl;
h = h->down;
}
cout << endl;
}
//删除操作
void remove(int val)
{
Node* cur = m_head->next;
Node* pre = m_head;
while (1)
{
if (cur != nullptr)
{
if (cur->m_data < val)
{
pre = cur;
cur = pre->next;
continue;
}
else if (cur->m_data == val)
{
while (cur != nullptr)
{
pre->next = cur->next;
cur = cur->down;
}
}
}
if (pre->down == nullptr)
{
break;
}
pre = pre->down;
cur = pre->next;
}
return ;
}
private:
int getLevel()
{
int level = 1;
while (rand()%2==1)
{
level++;
}
return level;
}
private:
struct Node
{
Node(int data = int())
:m_data(data)
, next(nullptr)
, down(nullptr)
{
}
int m_data;
Node* next;
Node* down;
};
struct HeadNode :public Node
{
HeadNode(int level)
:m_level(level)
{
}
int m_level;
};
HeadNode* m_head;
};五.倒排索引
倒排索引是搜索引擎和许多推荐系统底层的核心数据结构。
它的核心思想非常直白:建立从“词”到“文档”的映射,从而实现毫秒级的全文检索。

一站式 AI 云服务平台
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)