
零代码ETL实战:手把手教你构建学生考勤多维度画像(助睿Uniplore平台踩坑全记录)
一、实验背景与目标
1.1 实验目的
本次实验基于"数智教育"大赛数据集,设计并实现学生多维度考勤统计ETL转换流。核心目标包括:
-
掌握ETL数据处理全流程(数据接入 → 关联 → 衍生 → 聚合 → 落地)
-
解决校园考勤人工统计效率低、口径不统一的痛点
-
结合实际数据中的空值、脏数据情况,优化处理逻辑
-
输出精准的多维度考勤统计结果(迟到、早退、请假、校服违规等),为校园考勤管理提供数据支撑
1.2 实验环境
| 项目 | 说明 |
|---|---|
| 平台 | 助睿数智(Uniplore)AI 驱动一站式数据科学平台 |
| 实验地址 | https://lab.guilian.cn/ |
| 数据源 | "数智教育" 大赛数据集(聚焦 3 张核心表:3_kaoqin.csv、4_kaoqintype.csv、2_student_info.csv) |
| 数据库 | MySQL 8+(团队私有数据库) |
| 设备 | 个人计算机(浏览器访问即可) |
1.3 核心处理逻辑
整个ETL转换流替代了传统人工Excel统计,实现从原始打卡到标准化结果的自动化闭环:
考勤主表(3_kaoqin) ──┐
考勤类型码表(4_kaoqintype) ──┼→ 多表关联整合 → 行为标签衍生 → 多维度聚合统计 → 基础属性补充 → 结果落地
学生信息表(2_student_info) ──┘二、数据与标签梳理(磨刀不误砍柴工)
在动手配置ETL之前,必须先搞清楚要用哪些表、取哪些字段、统计口径是什么。这是避免后期反复返工的关键!
2.1 源数据说明
原始数据集共7张表,但本次聚焦考勤主题,核心只需3张表形成星型模型:
| 数据源表 | 核心作用 | 关键字段 |
|---|---|---|
考勤主表 3_kaoqin |
事实表,存储每次考勤行为明细 | 学生 ID、班级 ID、学期 (qj_term)、打卡时间 (DataDateTime)、考勤类型 ID (ControllerID)、考勤描述 (controler_name) |
考勤类型码表 4_kaoqintype |
维度表,标准化考勤事件名称 | 考勤类型 ID (controller_id)、考勤事件名称 (control_task_name) |
学生信息表 2_student_info |
维度表,提供学生基础属性 | 学生 ID (bf_StudentID)、班级 ID (cla_id)、姓名 (bf_Name)、性别 (bf_sex)、出生日期 (bf_BornDate)、政治面貌 (bf_policy)、是否住校 (bf_zhusu) |
2.2 标签体系设计
本次构建的标签分为三大类:
① 学生基础属性标签(直接读取)
| 标签字段 | 数据来源 | 处理方式 |
|---|---|---|
| 学生 ID | 考勤主表 / 学生信息表 | 直接读取 |
| 学生姓名 | 考勤主表 / 学生信息表 | 直接读取 |
| 班级 ID | 考勤主表 / 学生信息表 | 直接读取 |
| 班级名称 | 考勤主表 | 直接读取 |
| 性别 | 学生信息表 | 空值替换为 "未知" |
| 出生日期 | 学生信息表 | 空值替换为 "未知" |
| 政治面貌 | 学生信息表 | 空值替换为 "未知" |
② 学生画像维度标签(衍生加工)
| 标签字段 | 衍生逻辑 | 口径说明 |
|---|---|---|
| 年级 | 从cla_name中提取 |
包含 "高一"→高一,"高二"→高二,"高三"→高三,其他→未知 |
| 是否住校 | 映射bf_zhusu字段 |
1→"是",0→"否",空值→"未知" |
| 校区类型 | 从cla_name判断 |
以 "白 -" 或 "东 -" 开头→新校区,其他→老校区 |
③ 考勤行为统计标签(核心指标)
| 指标 | 统计逻辑 | 口径说明 |
|---|---|---|
| 迟到次数 | COUNT (包含 "迟到"/"晚到" AND 非请假) | 排除请假记录,避免重复计数 |
| 早退次数 | COUNT (包含 "早退" AND 非请假) | 排除请假记录 |
| 请假次数 | COUNT (包含 "请假") | 包含事假、病假等各类请假,全覆盖统计 |
| 没穿校服次数 | COUNT (包含 "校服") | 根据数据说明,"校服 [移动考勤]" 即未穿校服 |
💡 口径设计理由:请假属于正常缺勤,不应计入迟到/早退的违规统计;"校服"关键词能唯一识别校服违规记录。
三、实验步骤全流程记录
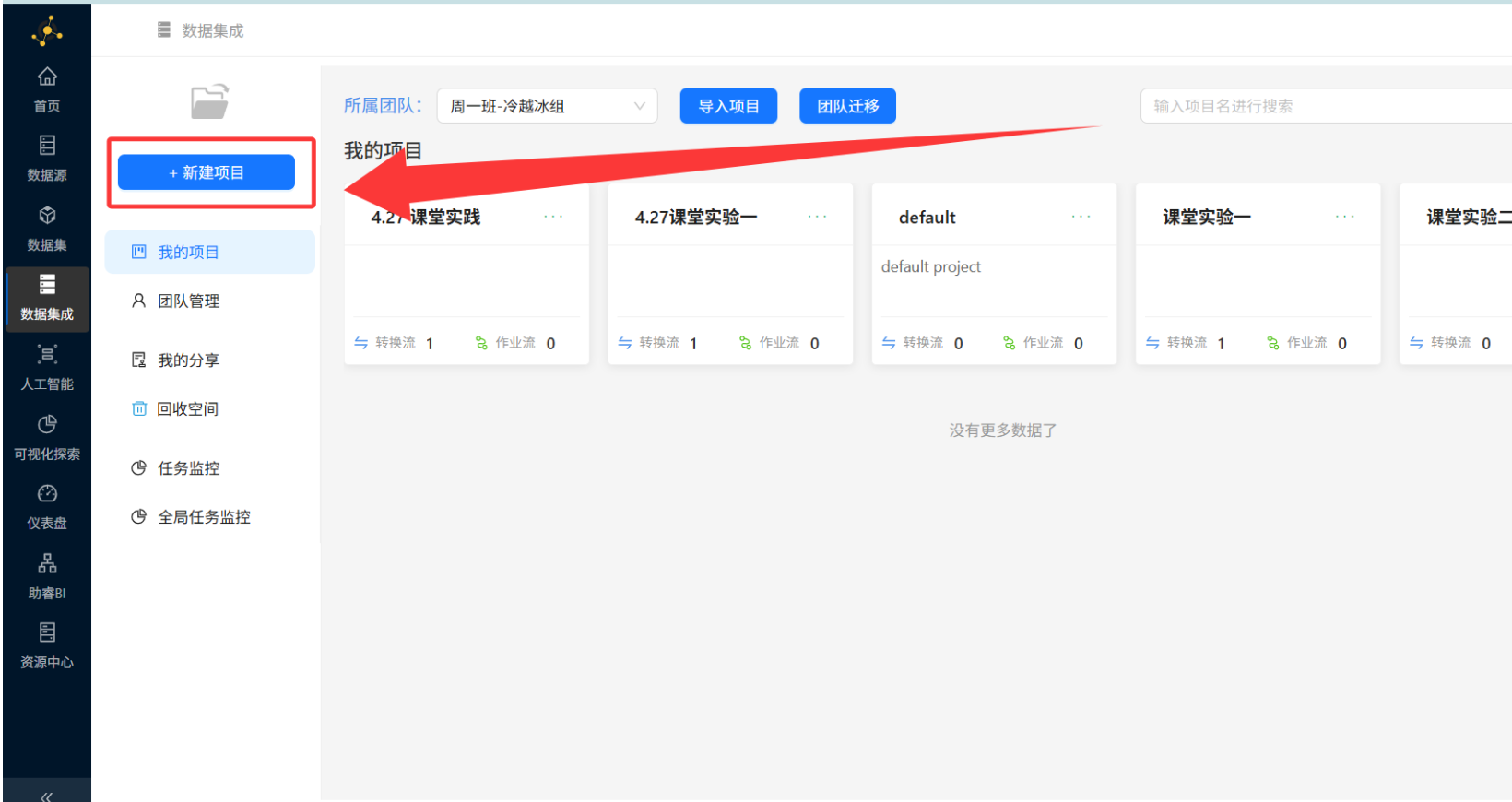
步骤一:创建实验项目
操作路径:登录平台 → 数据集成 → 新建项目
-
点击左侧"+ 新建项目"
-
输入项目名称:"学生用户画像标签构建"
-
点击"确定",创建成功后即可在数据集成页面看到新项目
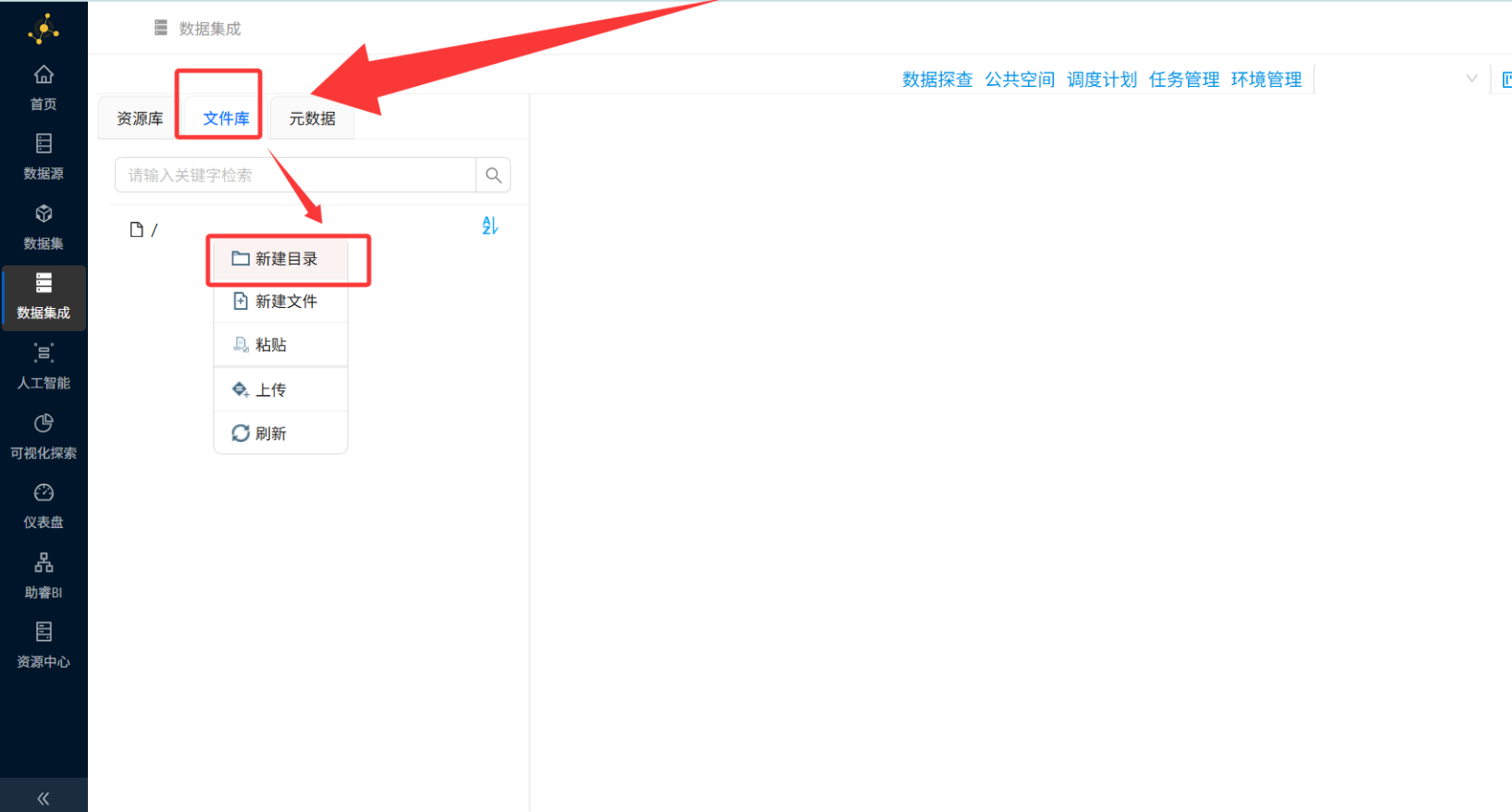
步骤二:数据资源准备(文件库管理)
进入项目后,左侧有三个核心菜单:
-
资源库:管理工作流(转换流、作业流)
-
文件库:保存工作流用到的文件
-
元数据:定义数据库连接、运行环境等配置
2.1 创建数据集目录
-
点击"文件库" → 右键根目录 → "新建目录"
-
输入目录名:"数智教育数据集" → 确定
2.2 从公共空间导入数据
-
点击顶部"公共空间" → "数据资源"
-
找到
3_kaoqin.csv,点击卡片右上角"更多" → "导出"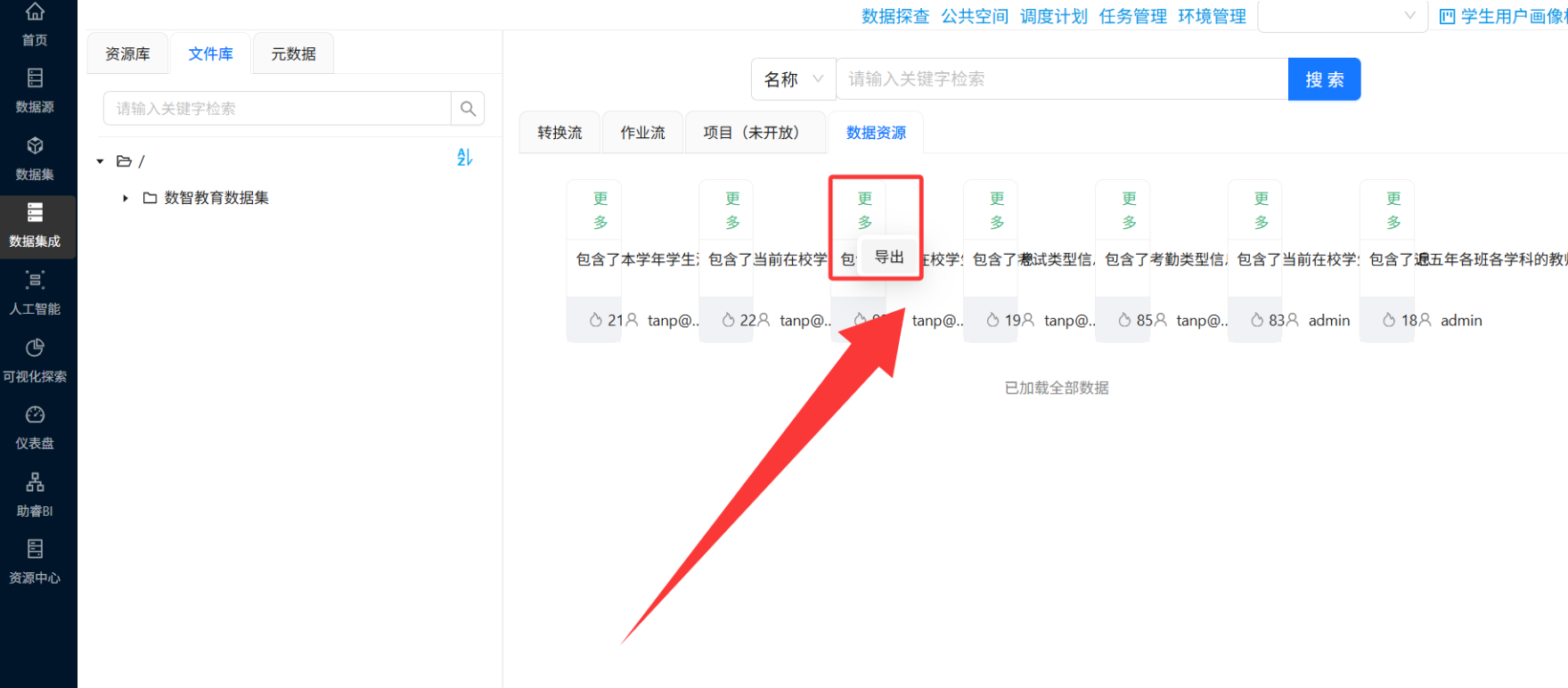
-
在弹出窗口中选择导出到刚刚创建的"数智教育数据集"目录
-
重复上述操作,将
4_kaoqintype.csv和2_student_info.csv一并导出
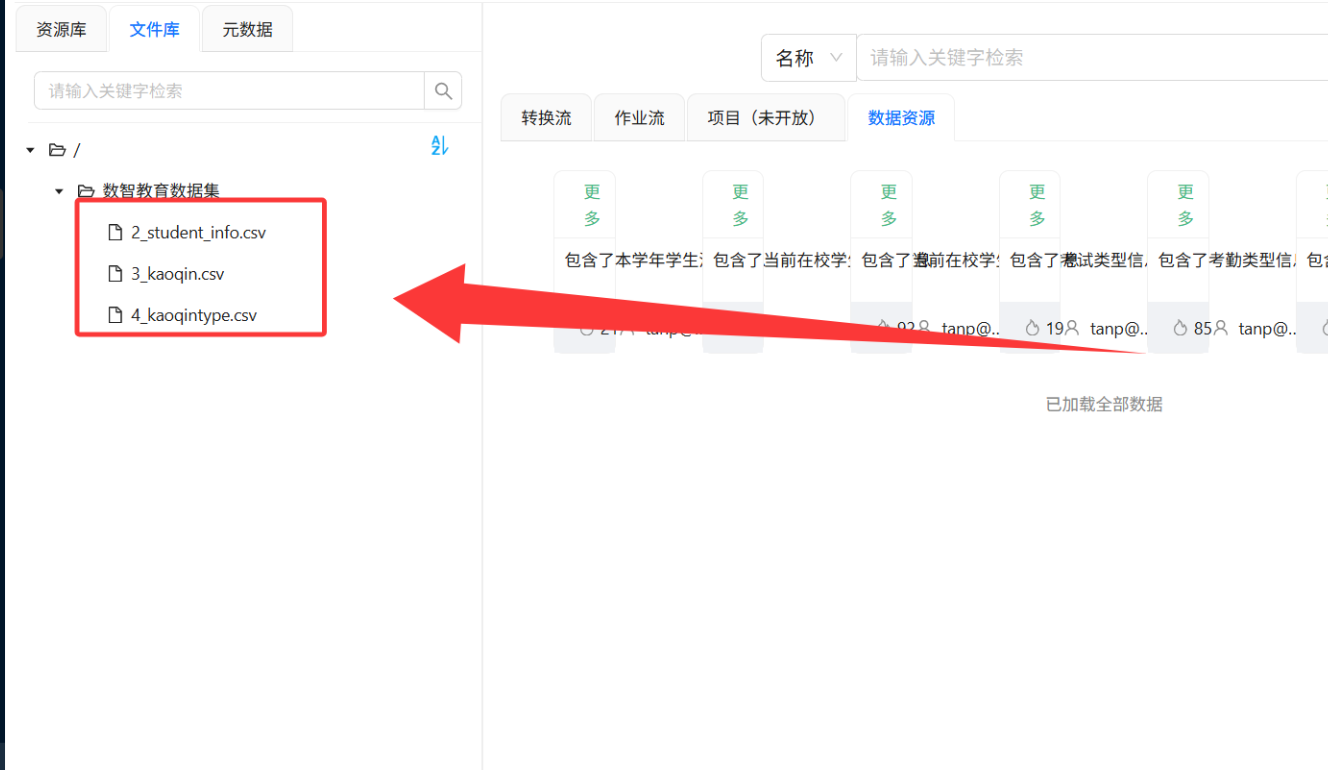
完成后,你的文件库目录下应该有3个文件:
-
2_student_info.csv -
3_kaoqin.csv -
4_kaoqintype.csv
步骤三:建立数据源连接(元数据配置)
在正式ETL之前,必须先配置好团队私有数据库的连接,后续所有结果表都要落地到这里。
操作路径:元数据 → 关系数据库 → 右键 → 新建数据源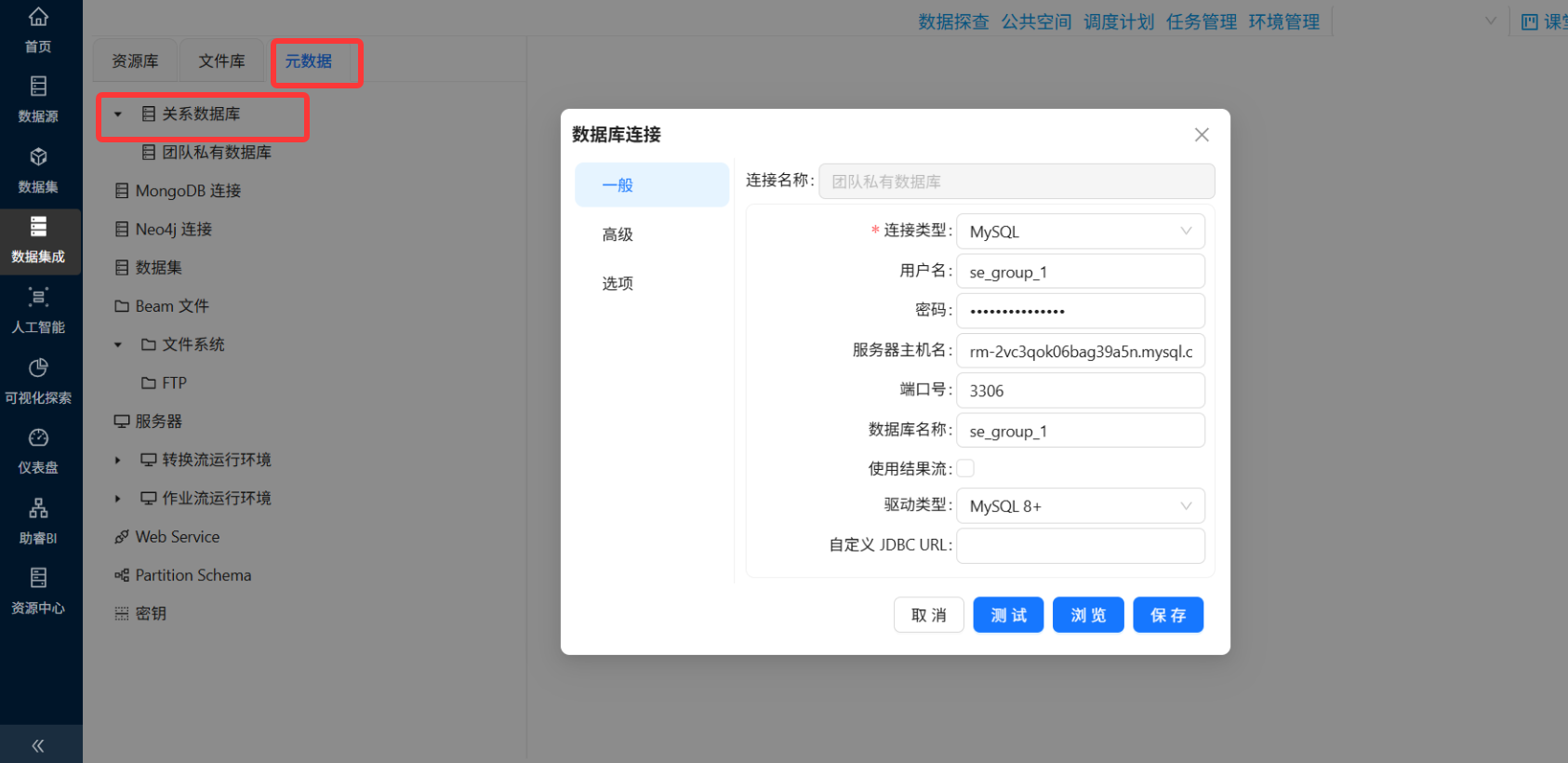
| 配置项 | 填写内容 |
|---|---|
| 连接名称 | 团队私有数据库 |
| 连接类型 | MySQL |
| 用户名 / 密码 | 助教提供的账号密码 |
| 服务器主机名 | rm-2vc3qok06bag39a5n.mysql.cn-chengdu.rds.aliyuncs.com |
| 端口号 | 3306 |
| 数据库名 | 助教提供的数据库名(如 labs) |
| 驱动类型 | MySQL 8+ |
填写完毕后,务必点击"测试"按钮验证连接。看到"数据库连接成功"的提示后,再点击"添加"。
步骤四:创建目标表(执行SQL脚本)
在导入原始数据之前,我们需要先在MySQL中创建好原始考勤记录表,用于后续ETL流程的落地。
操作路径:资源库 → 新建转换工作流 → 命名为"创建原始_学生考勤表"
-
从组件库拖拽"执行一个SQL脚本"组件到画布
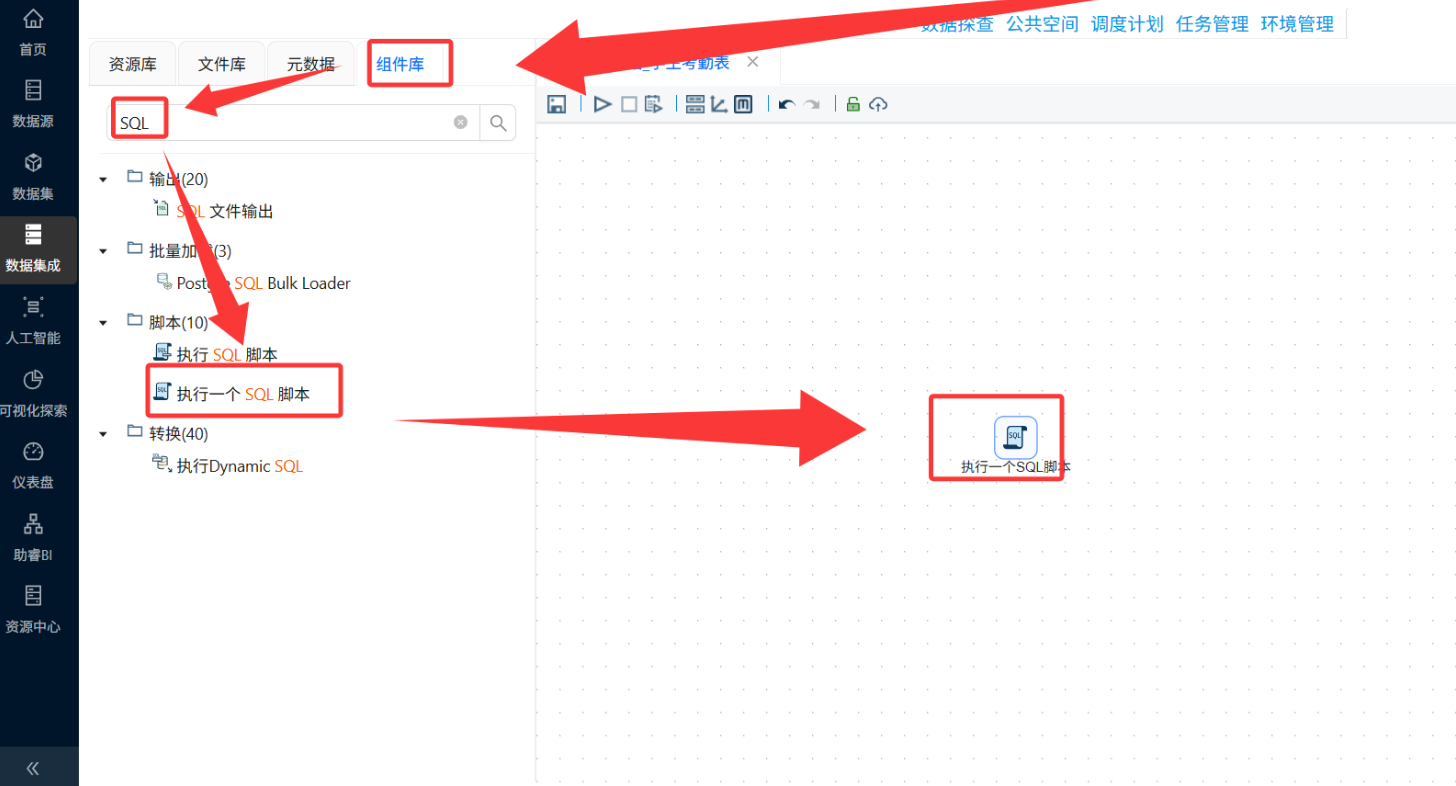
-
配置数据库连接为"团队私有数据库"
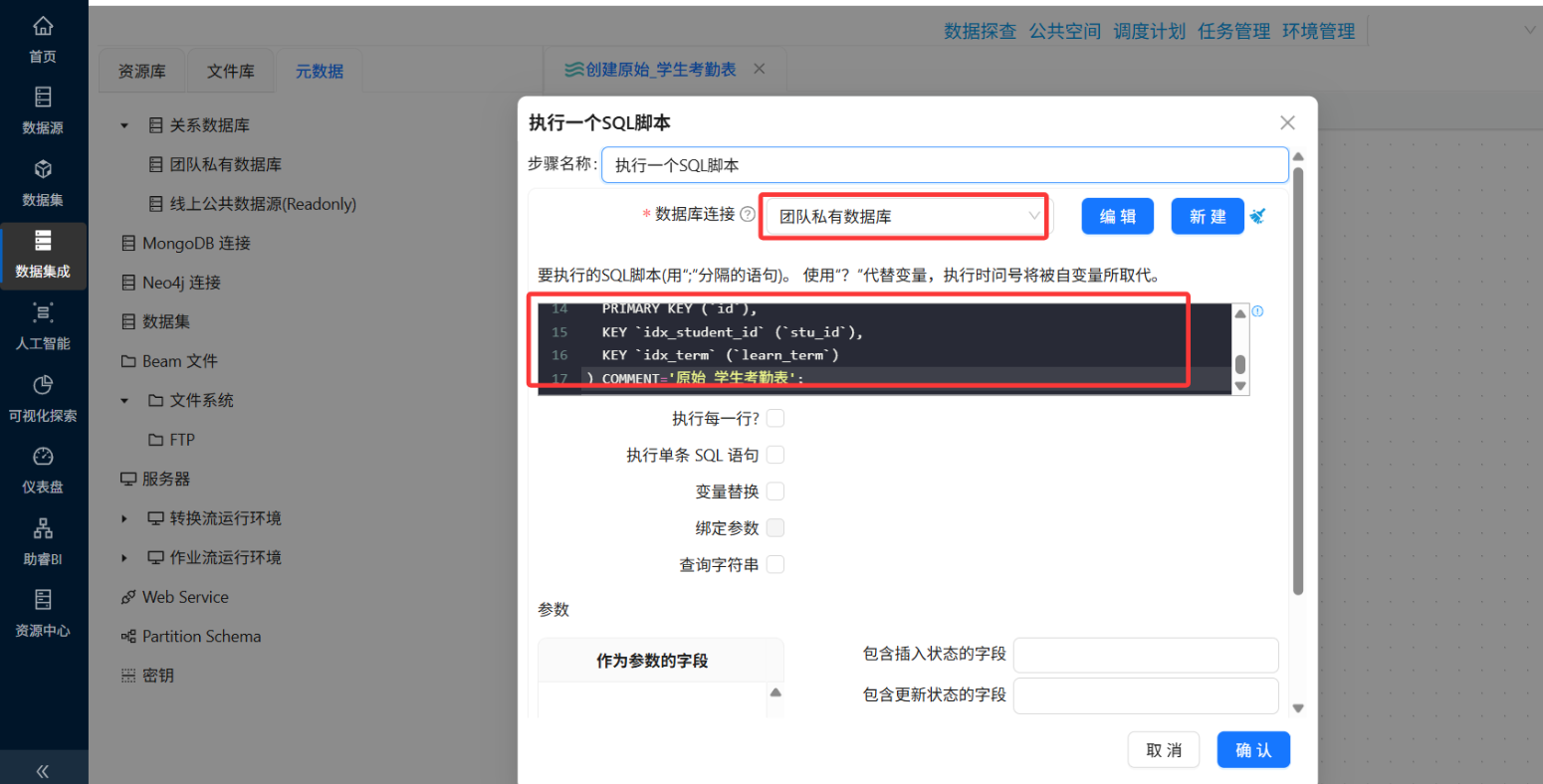
-
粘贴以下建表SQL:
CREATE TABLE IF NOT EXISTS `raw_attendance` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '自增ID',
`attendance_id` varchar(64) DEFAULT NULL COMMENT '考勤ID',
`learn_term` varchar(30) DEFAULT NULL COMMENT '学期',
`data_datetime` varchar(50) DEFAULT NULL COMMENT '时间和日期',
`attendance_type_id` varchar(64) DEFAULT NULL COMMENT '考勤类型ID',
`attendance_name` varchar(100) DEFAULT NULL COMMENT '考勤名称',
`attendance_task_order_id` varchar(64) DEFAULT NULL COMMENT '考勤事件ID',
`stu_id` varchar(64) DEFAULT NULL COMMENT '学生ID',
`stu_name` varchar(100) DEFAULT NULL COMMENT '学生姓名',
`cla_name` varchar(100) DEFAULT NULL COMMENT '班级名',
`cla_id` varchar(64) DEFAULT NULL COMMENT '班级ID',
`create_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '入库时间',
PRIMARY KEY (`id`),
KEY `idx_student_id` (`stu_id`),
KEY `idx_term` (`learn_term`)
) COMMENT='原始_学生考勤表';-
其他参数保持默认,点击"确认"保存组件配置
-
运行该转换流,验证表是否创建成功
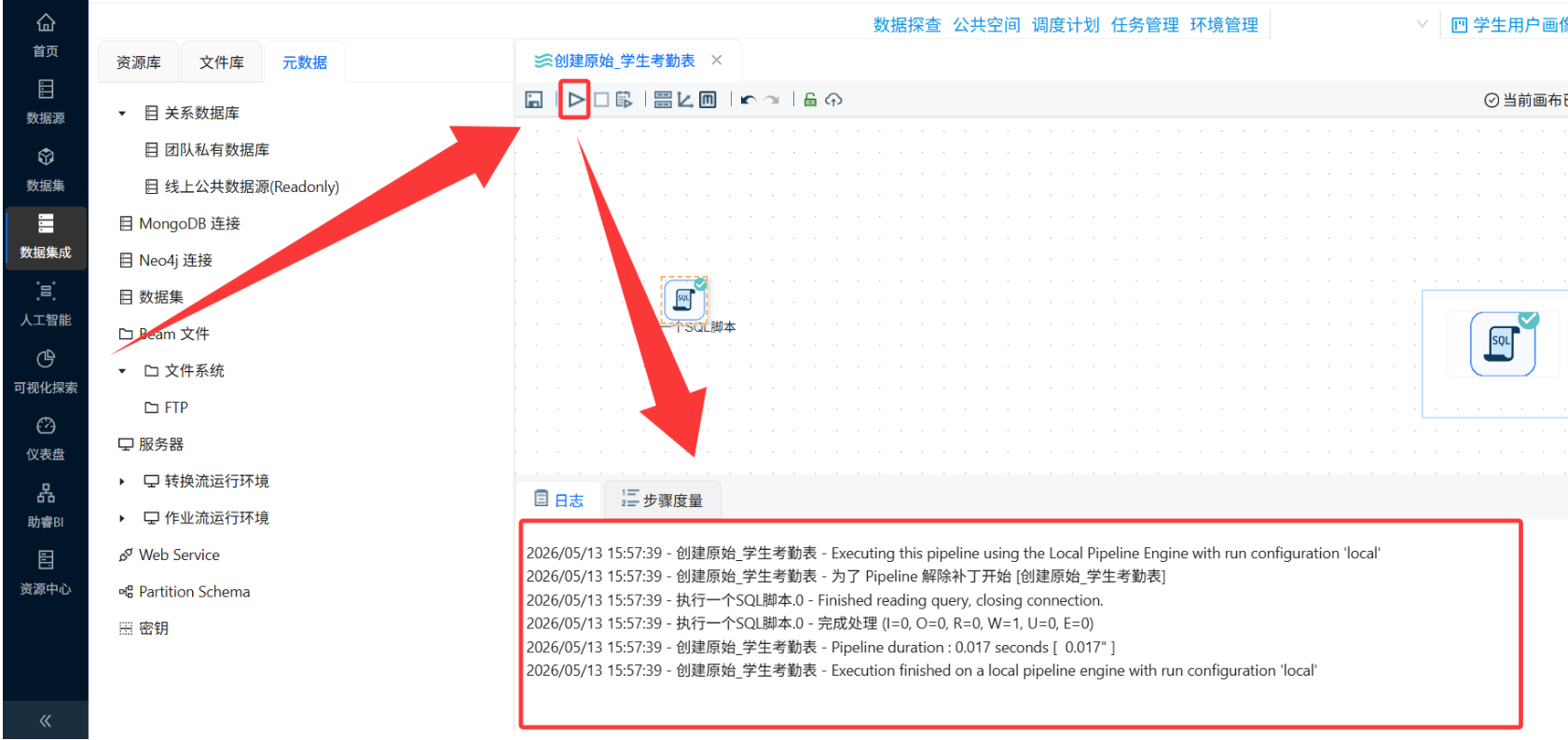
⚠️ 踩坑记录①:这里一定要确认数据库连接权限足够。如果SQL执行报错"权限不足",需要联系助教确认账号是否有
CREATE TABLE权限。
步骤五:原始数据入库(CSV → MySQL)
建表完成后,需要将3个CSV文件的数据导入到MySQL中。在助睿平台中,通常使用"CSV文件输入" + "表输出"组件组合完成。
转换流设计:
CSV文件输入(3_kaoqin.csv) → 字段清洗/类型转换 → 表输出(raw_attendance)关键配置点:
-
CSV文件输入:选择文件库中的
3_kaoqin.csv,注意分隔符是否为逗号,文本编码是否为UTF-8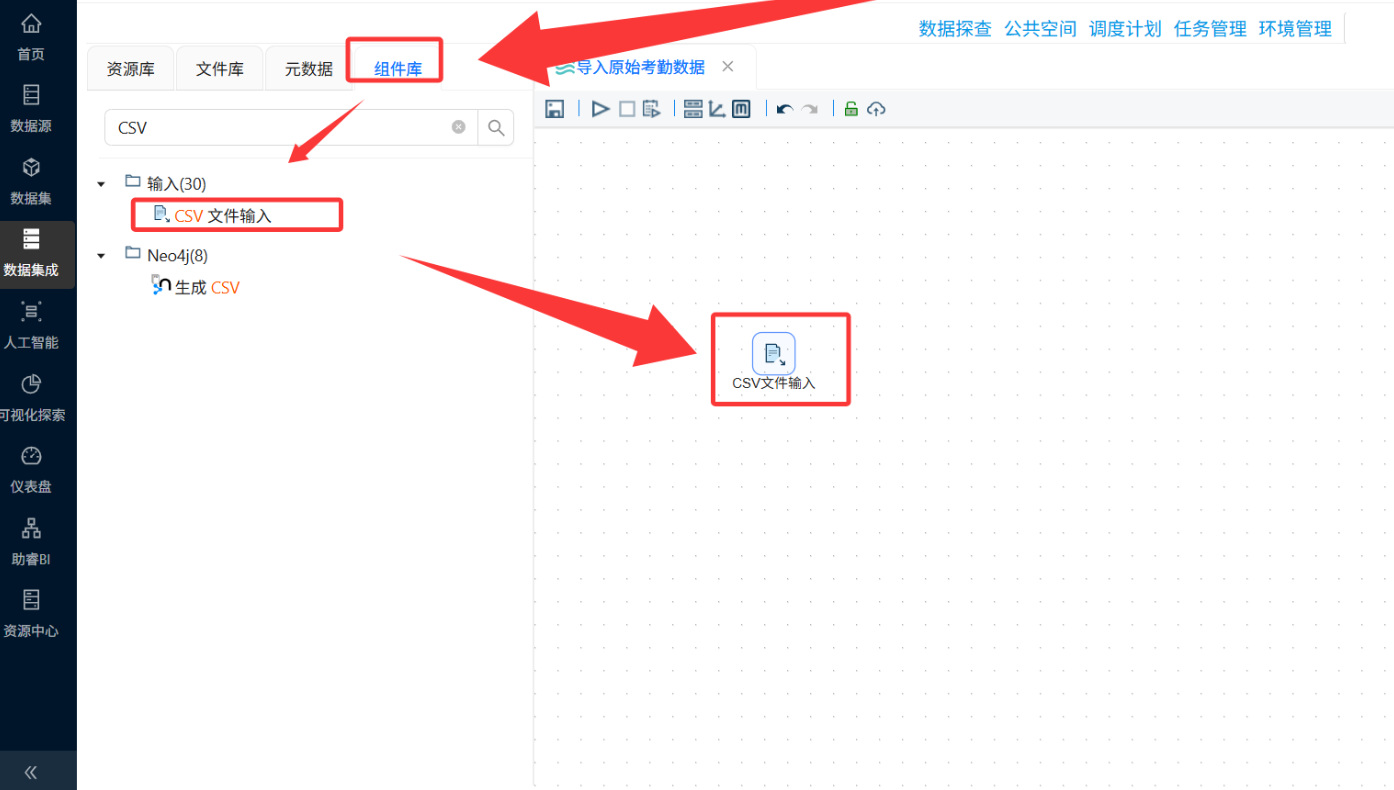
-
字段映射:确保CSV列与
raw_attendance表字段一一对应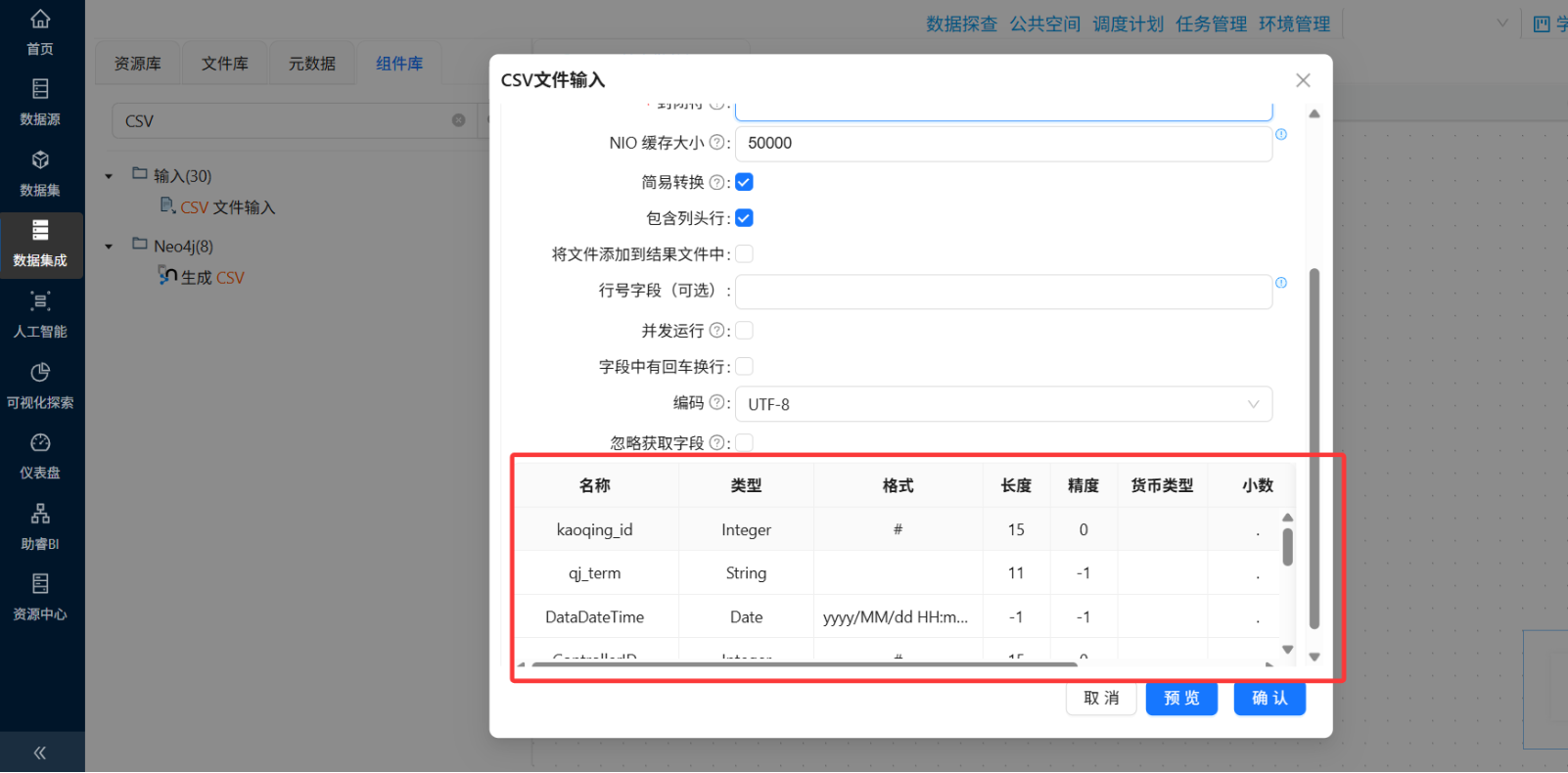
-
表输出:选择"团队私有数据库",目标表填写
raw_attendance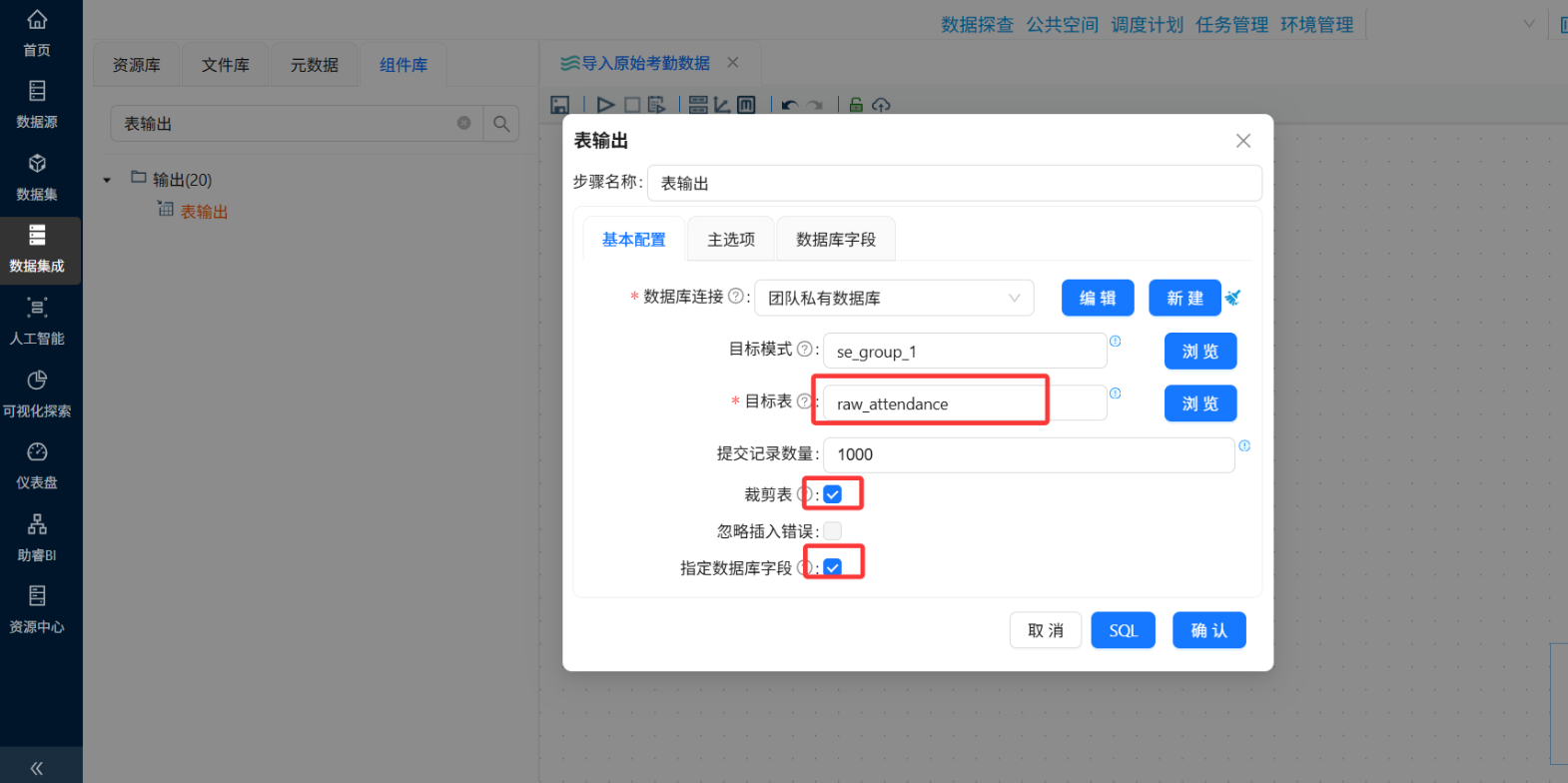
⚠️ 踩坑记录②:
3_kaoqin.csv中的DataDateTime字段是字符串格式,直接入库没问题,但后续做时间计算时可能需要转换。建议在建表时先用varchar接收,后续ETL步骤中再用函数转换。⚠️ 踩坑记录③:学生信息表
2_student_info.csv中存在空值(如性别、出生日期为空),导入时不要急于在源头过滤,先全量入库,后续用ETL组件统一处理空值替换,这样更符合"先接入后治理"的ETL理念。
对 4_kaoqintype.csv 和 2_student_info.csv 重复上述导入操作,分别创建:
-
raw_kaoqin_type(原始考勤类型表) -
raw_student_info(原始学生信息表)
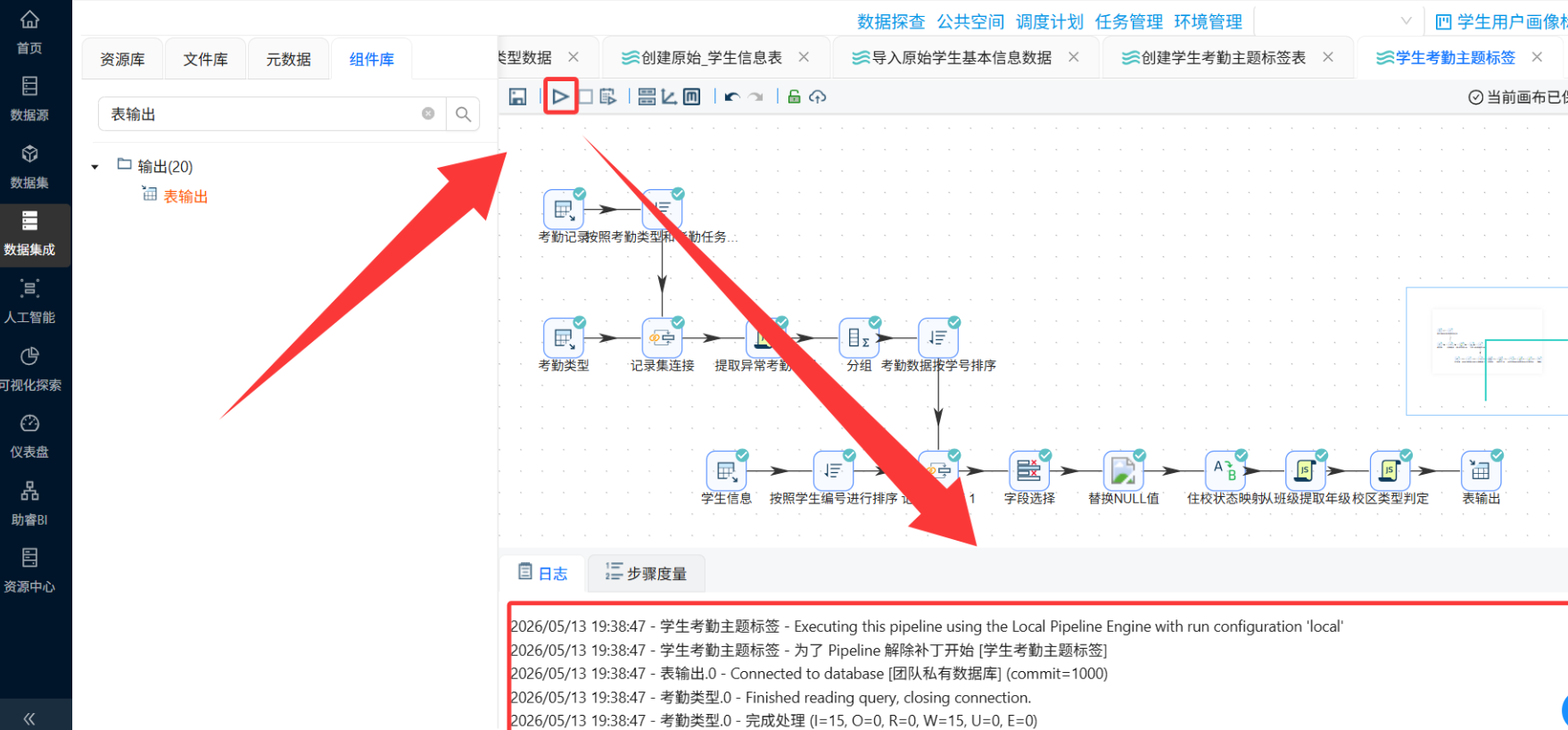
步骤六:核心ETL转换流设计(重头戏)
这是整个实验最核心的部分。我们需要设计一个完整的转换流,实现:多表关联 → 行为标签衍生 → 聚合统计 → 属性补充 → 结果落地。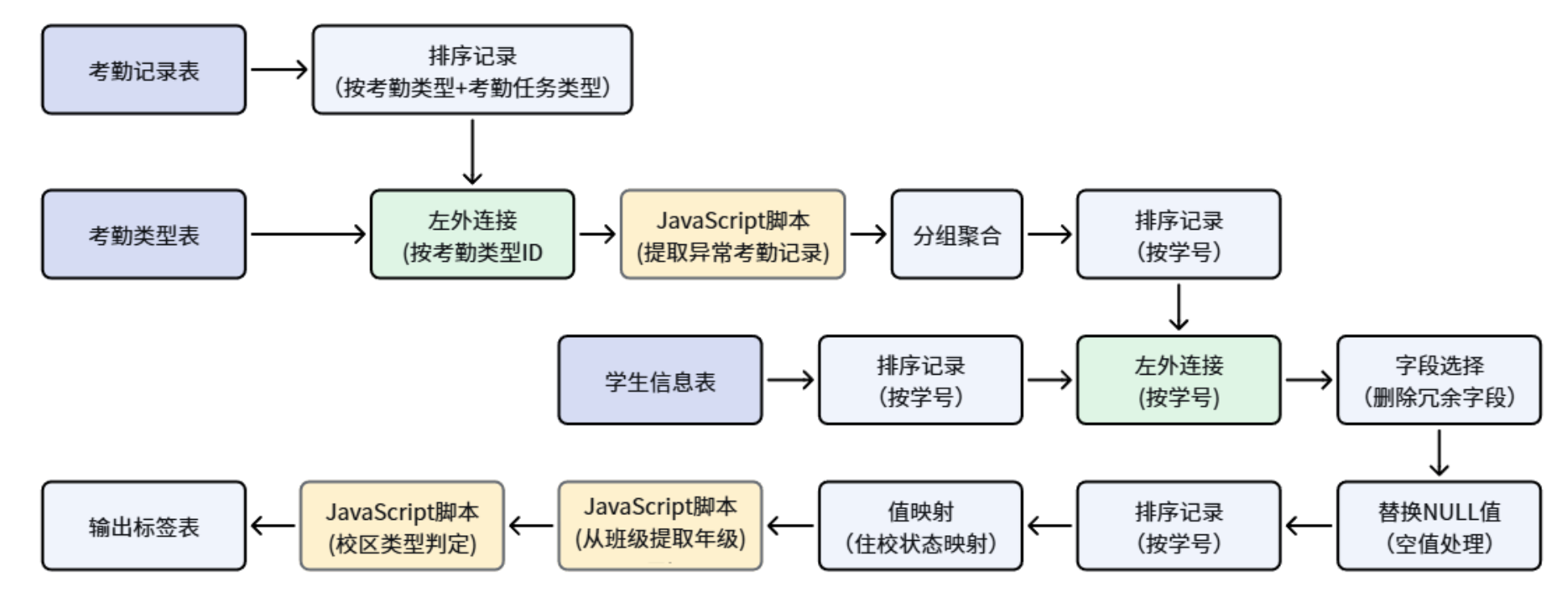
6.1 转换流整体架构
建议将转换流拆分为多个子流程或在一个大画布中按区域组织:
| 区域 | 组件组合 | 说明 |
|---|---|---|
| 数据接入区 | 表输入 × 3 | 从 MySQL 读取 3 张原始表 |
| 关联整合区 | 记录集连接 / 合并连接 | 考勤主表左连接考勤类型码表、学生信息表 |
| 标签衍生区 | JS 脚本 / 字段计算 | 提取年级、校区类型、是否住校;标记迟到 / 早退 / 请假 / 校服 |
| 聚合统计区 | 分组聚合 | 按学生 ID 分组,统计各类考勤次数 |
| 属性补充区 | 记录集连接 | 将聚合结果与学生基础属性关联 |
| 结果落地区 | 表输出 | 写入最终统计表 |
6.2 关键节点详解
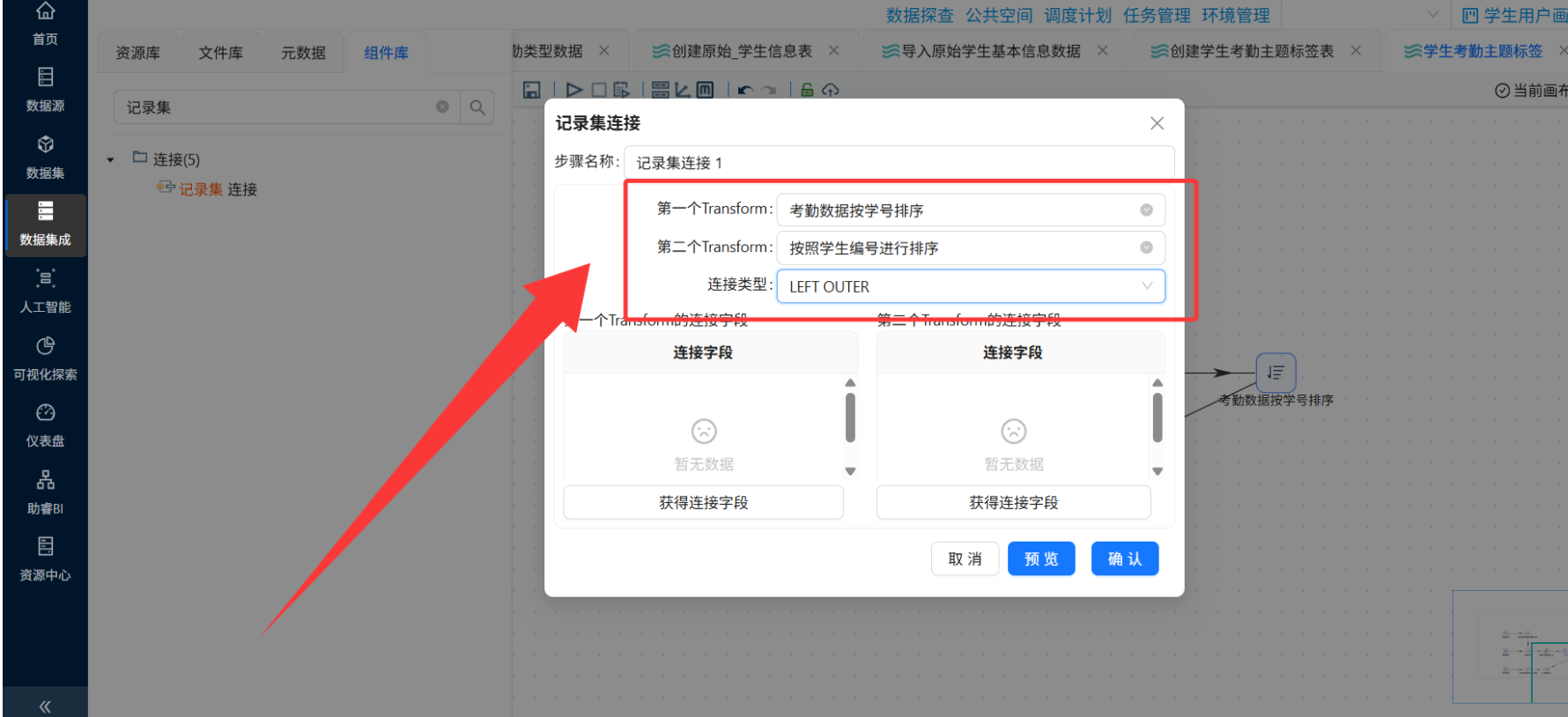
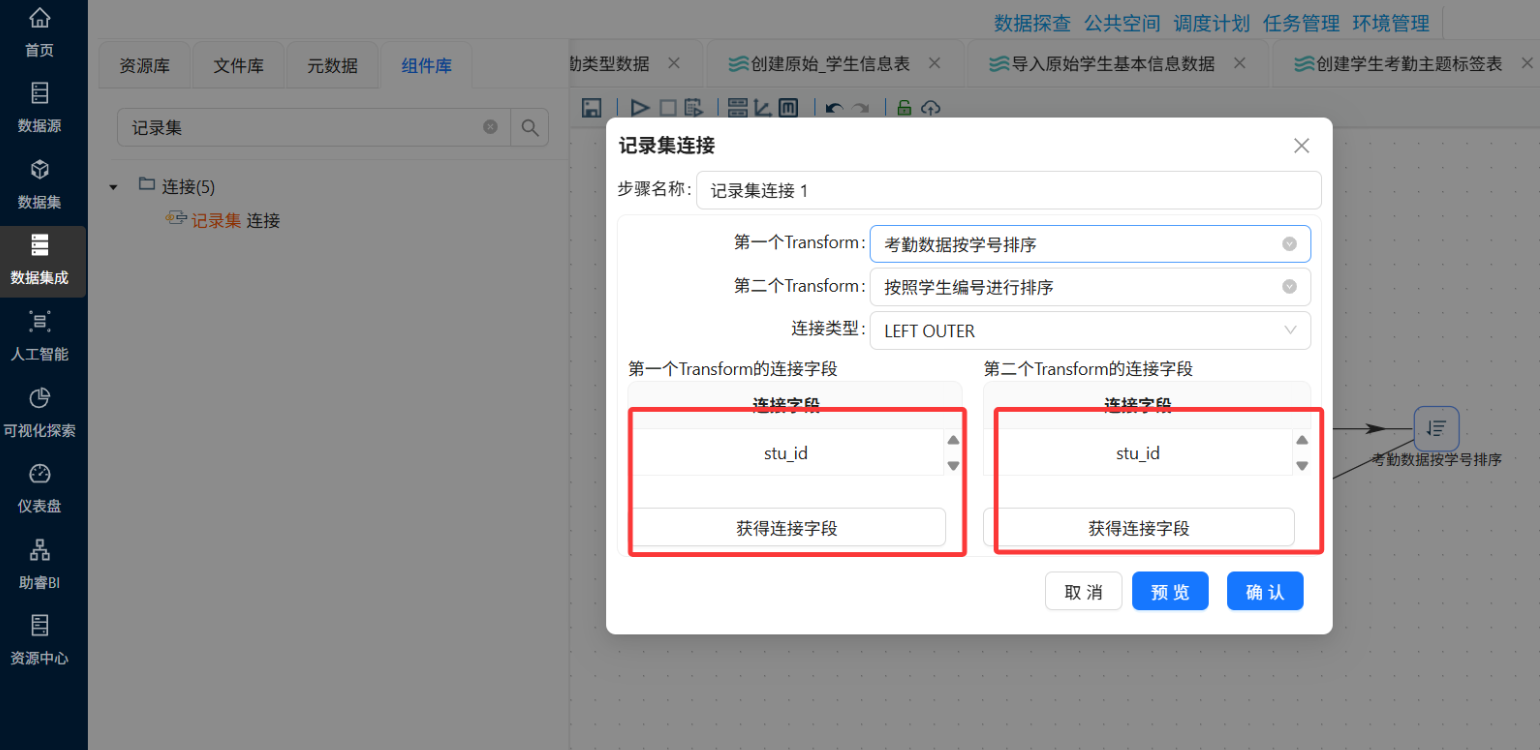
① 多表关联整合
-
以
raw_attendance为主表,左连接raw_kaoqin_type(关联字段:attendance_type_id=controller_id) -
再左连接
raw_student_info(关联字段:stu_id=bf_StudentID) -
注意:左连接是为了保留所有考勤记录,即使个别学生信息缺失也能继续处理
② 行为标签衍生(JS脚本)
使用"JavaScript代码"或"字段计算"组件,根据control_task_name(考勤事件名称)衍生行为标签: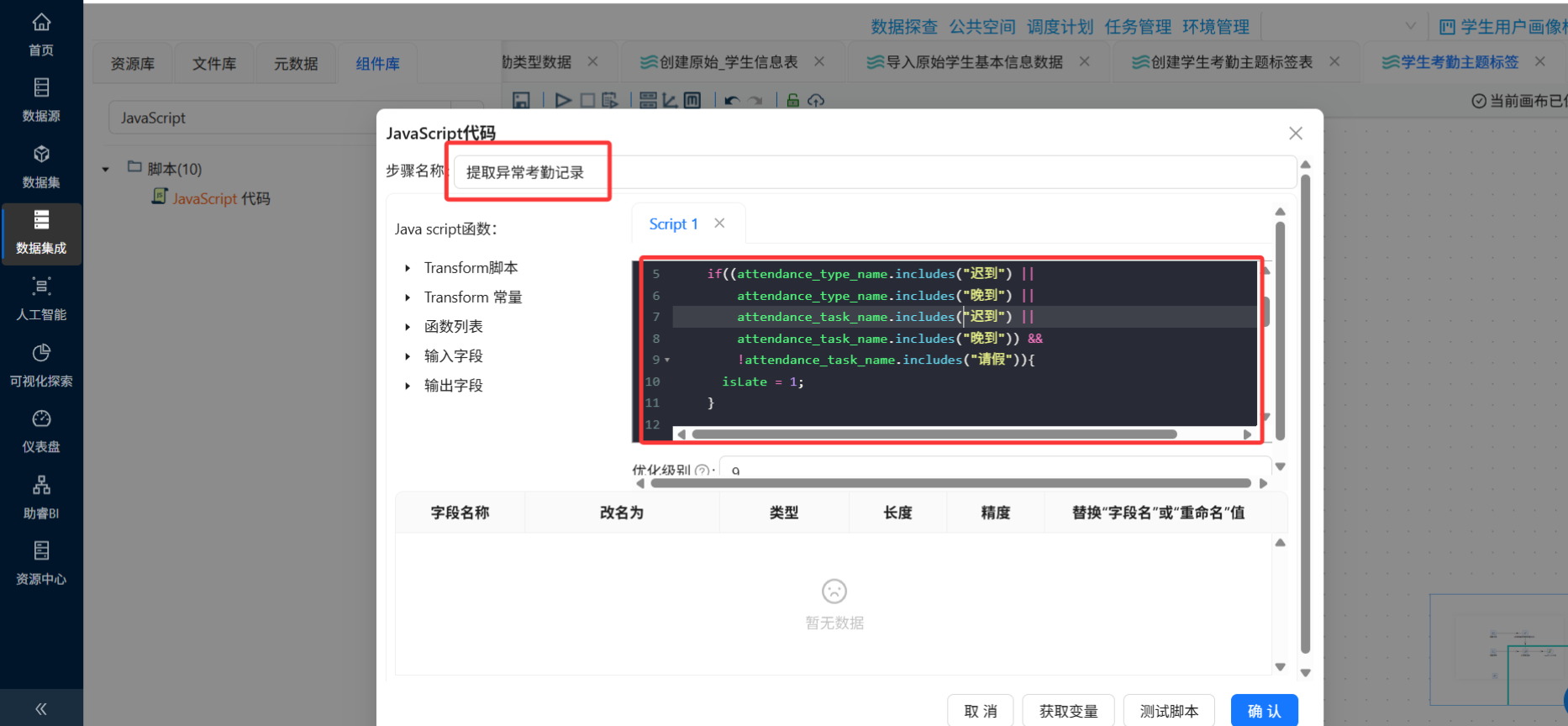
// 伪代码示例(助睿平台中可用类似逻辑)
var behavior_tag = "";
var is_late = 0;
var is_early_leave = 0;
var is_leave = 0;
var is_uniform_violation = 0;
if (control_task_name.indexOf("迟到") >= 0 || control_task_name.indexOf("晚到") >= 0) {
is_late = 1;
}
if (control_task_name.indexOf("早退") >= 0) {
is_early_leave = 1;
}
if (control_task_name.indexOf("请假") >= 0) {
is_leave = 1;
}
if (control_task_name.indexOf("校服") >= 0) {
is_uniform_violation = 1;
}③ 衍生维度加工
-
年级提取:从
cla_name中截取,如包含"高一"则标记为"高一"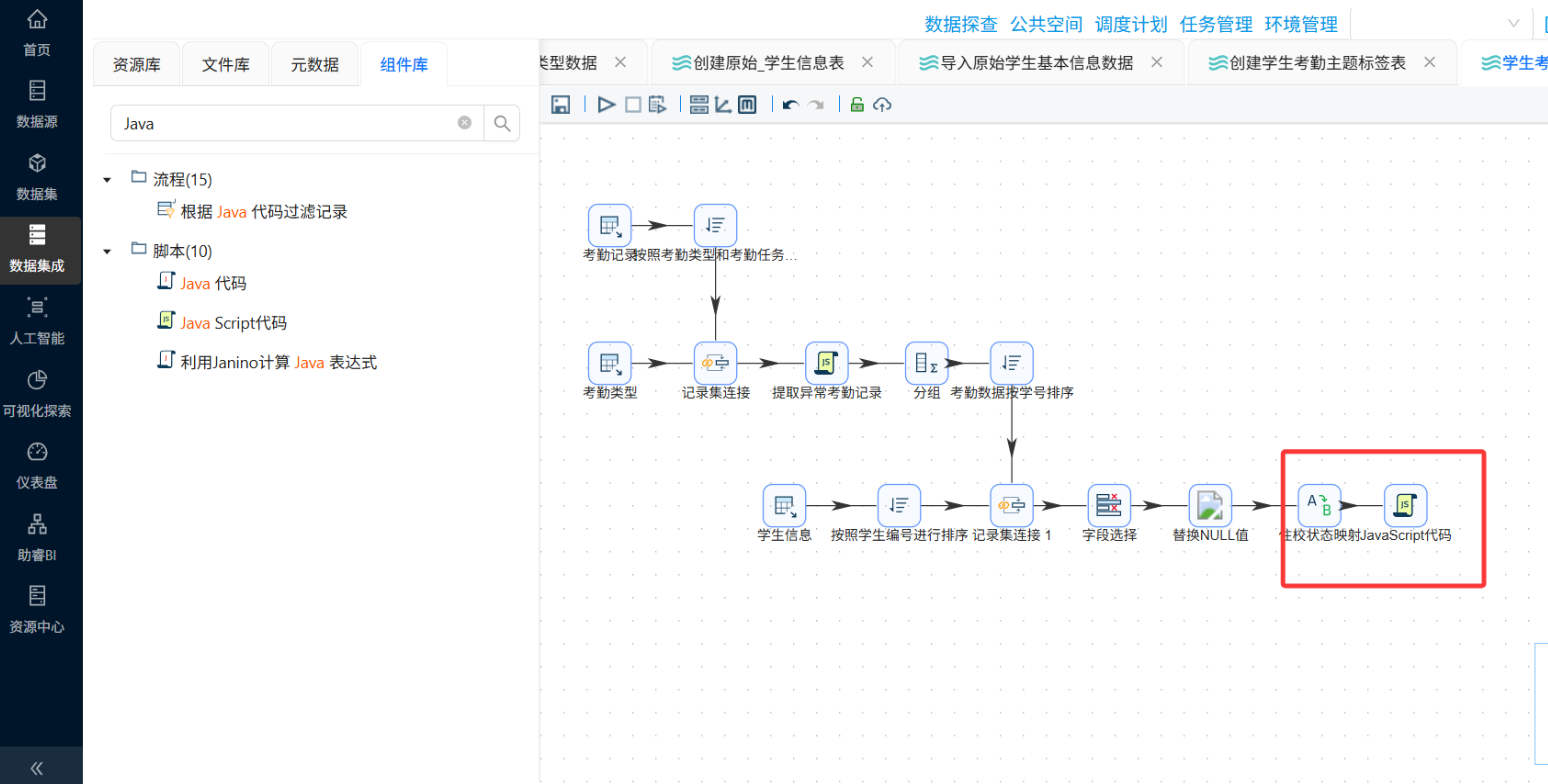
-
校区类型:
cla_name以"白-"或"东-"开头 → "新校区",否则 → "老校区"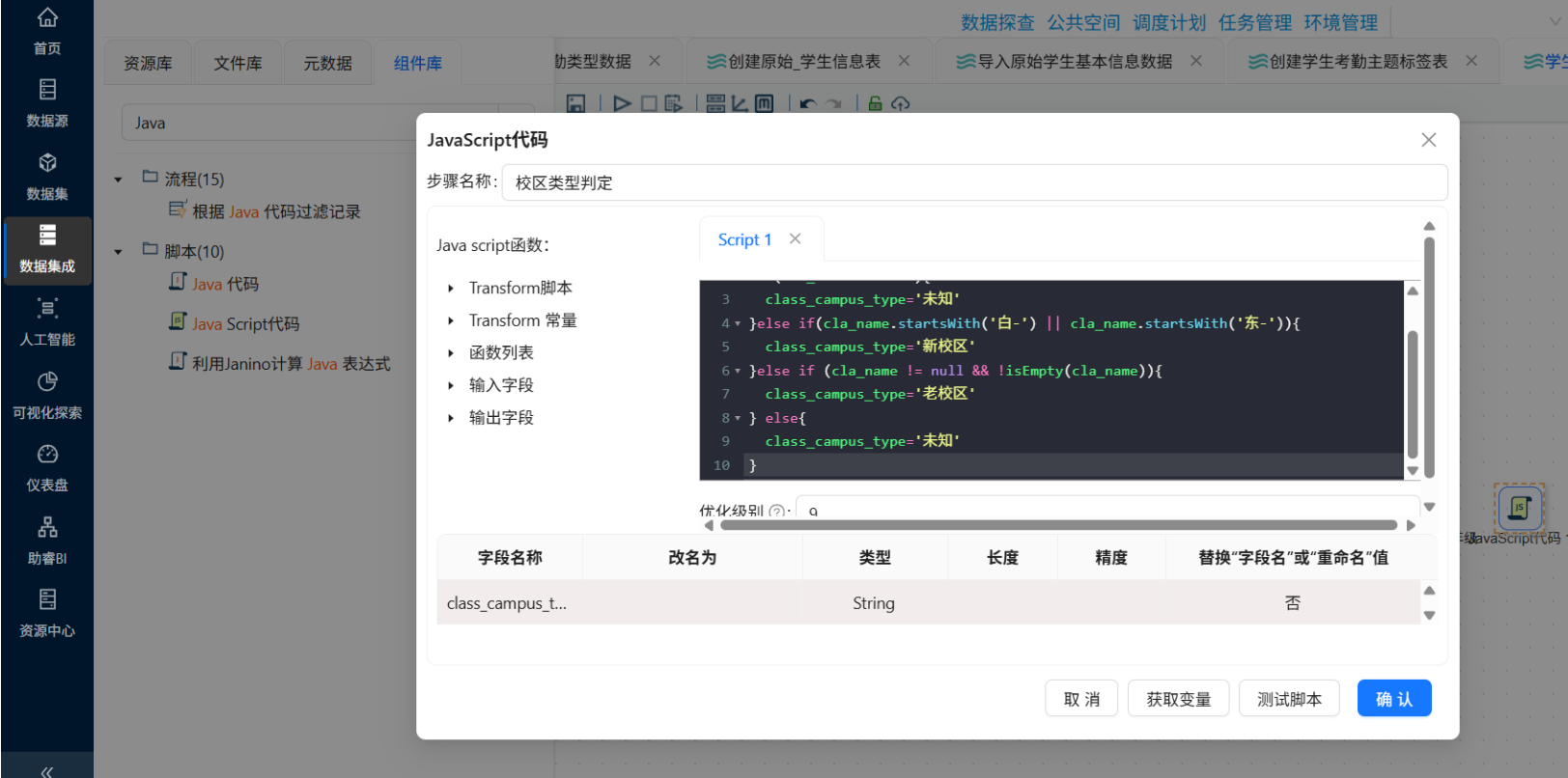
-
是否住校:
bf_zhusu= 1 → "是",0 → "否",空值 → "未知"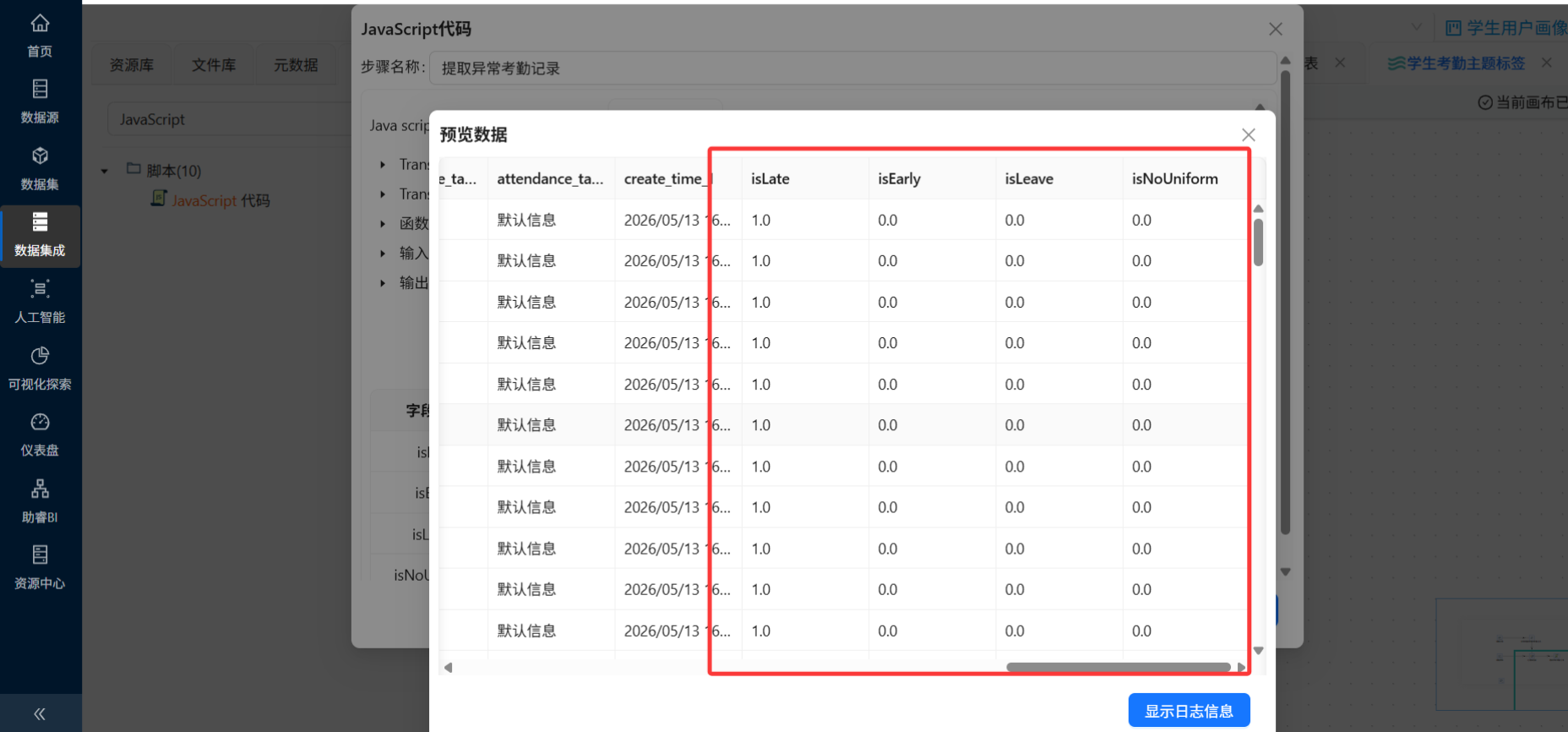
| 输出字段 | 聚合方式 |
|---|---|
late_count |
SUM(is_late),且需排除is_leave=1的记录 |
early_leave_count |
SUM(is_early_leave),且需排除is_leave=1的记录 |
leave_count |
SUM(is_leave) |
uniform_violation_count |
SUM(is_uniform_violation) |
⚠️ 踩坑记录⑤:迟到/早退必须排除请假记录! 这是最容易踩的口径坑。如果学生当天请了假,系统里可能同时有一条"请假"记录和一条"迟到"记录(打卡时间晚了),如果不排除,会把请假的人统计成迟到,导致结果严重失真。在聚合条件中务必加上过滤:
is_leave = 0。
⑤ 基础属性关联与空值处理
将聚合结果再次左连接raw_student_info,补充:
-
学生姓名(
bf_Name) -
性别(
bf_sex,空值替换为"未知") -
出生日期(
bf_BornDate,空值替换为"未知") -
政治面貌(
bf_policy,空值替换为"未知"
使用"空值替换"组件或JS脚本统一处理空值。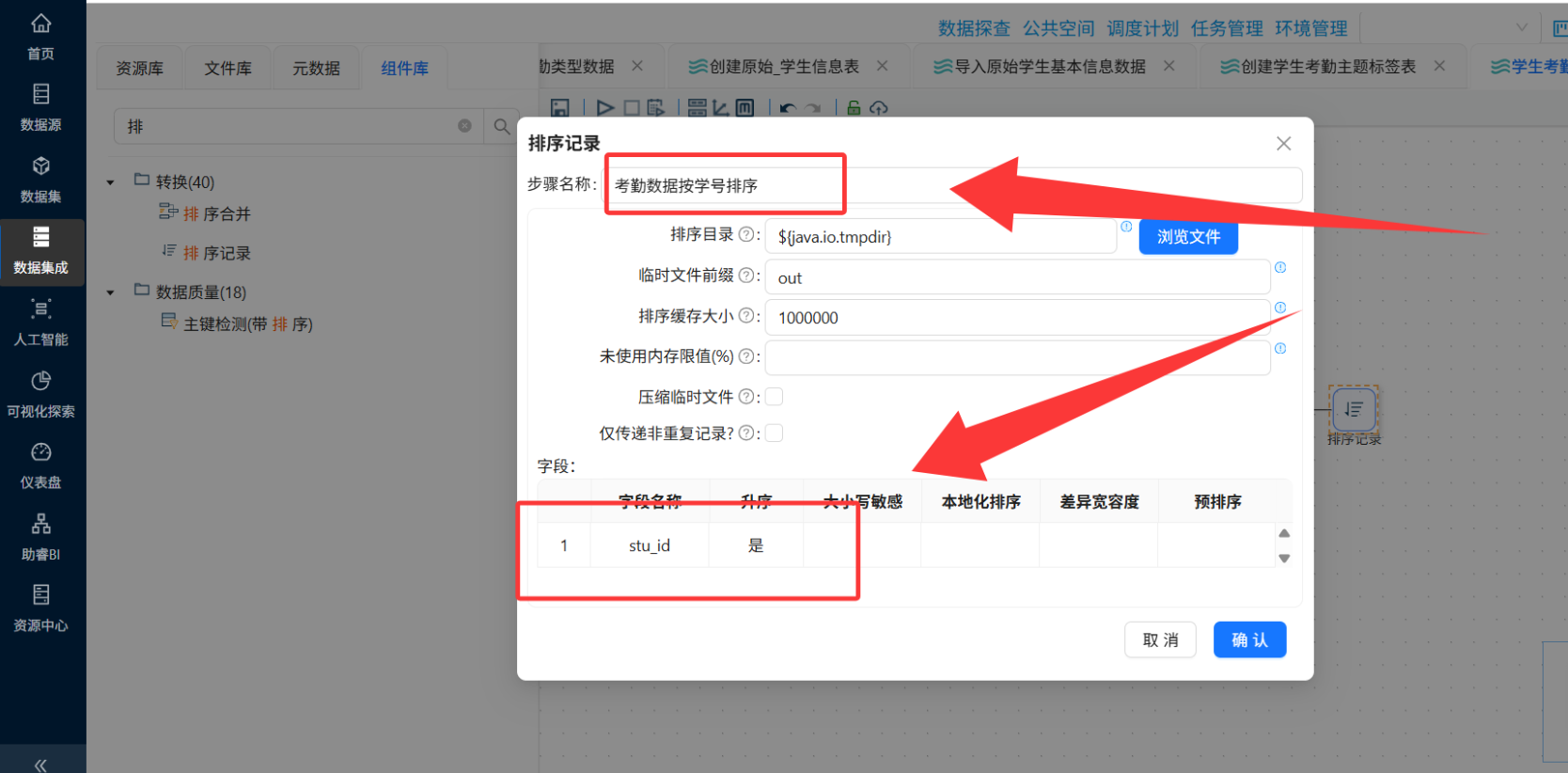
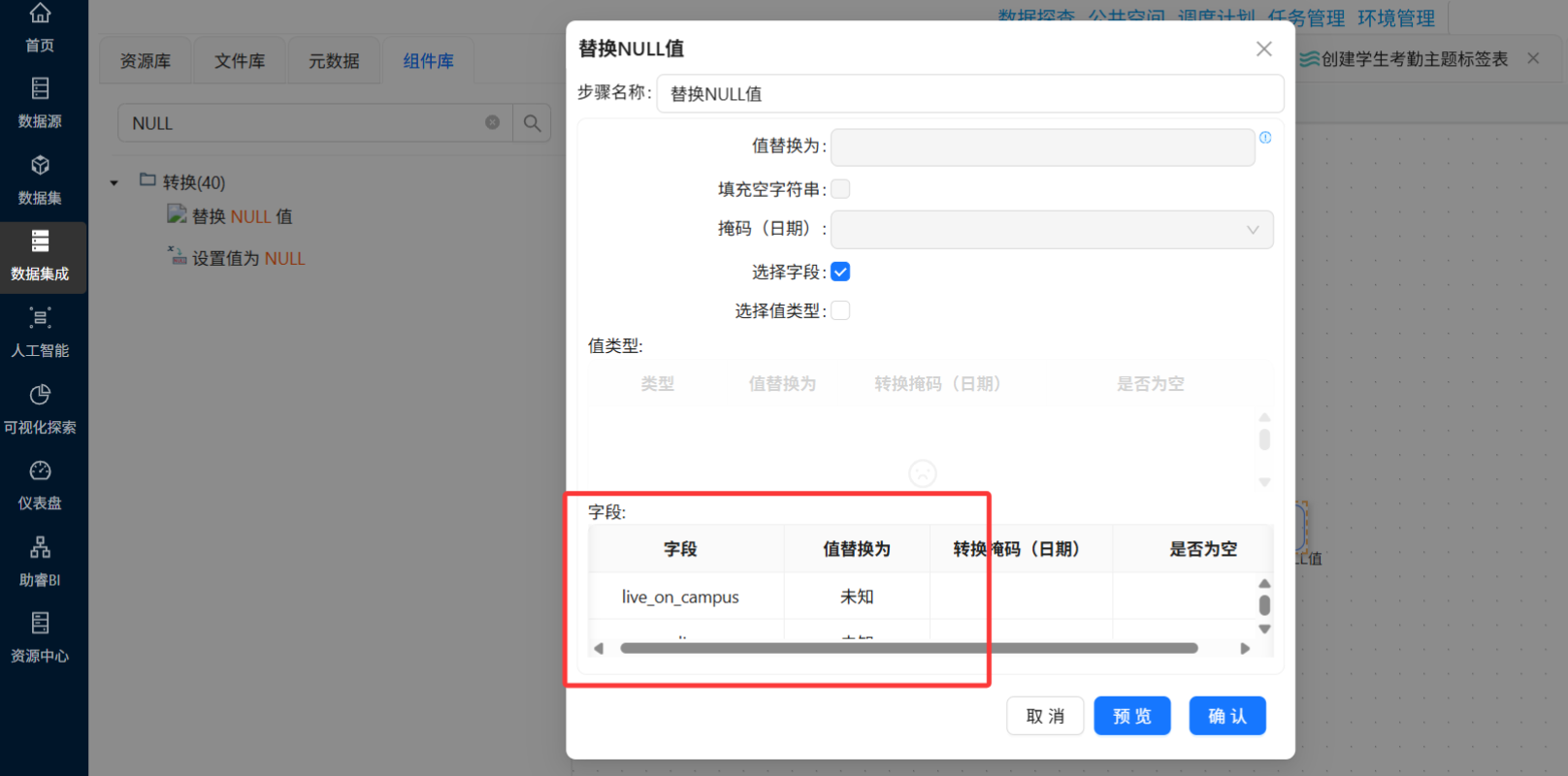
⑥ 结果落地
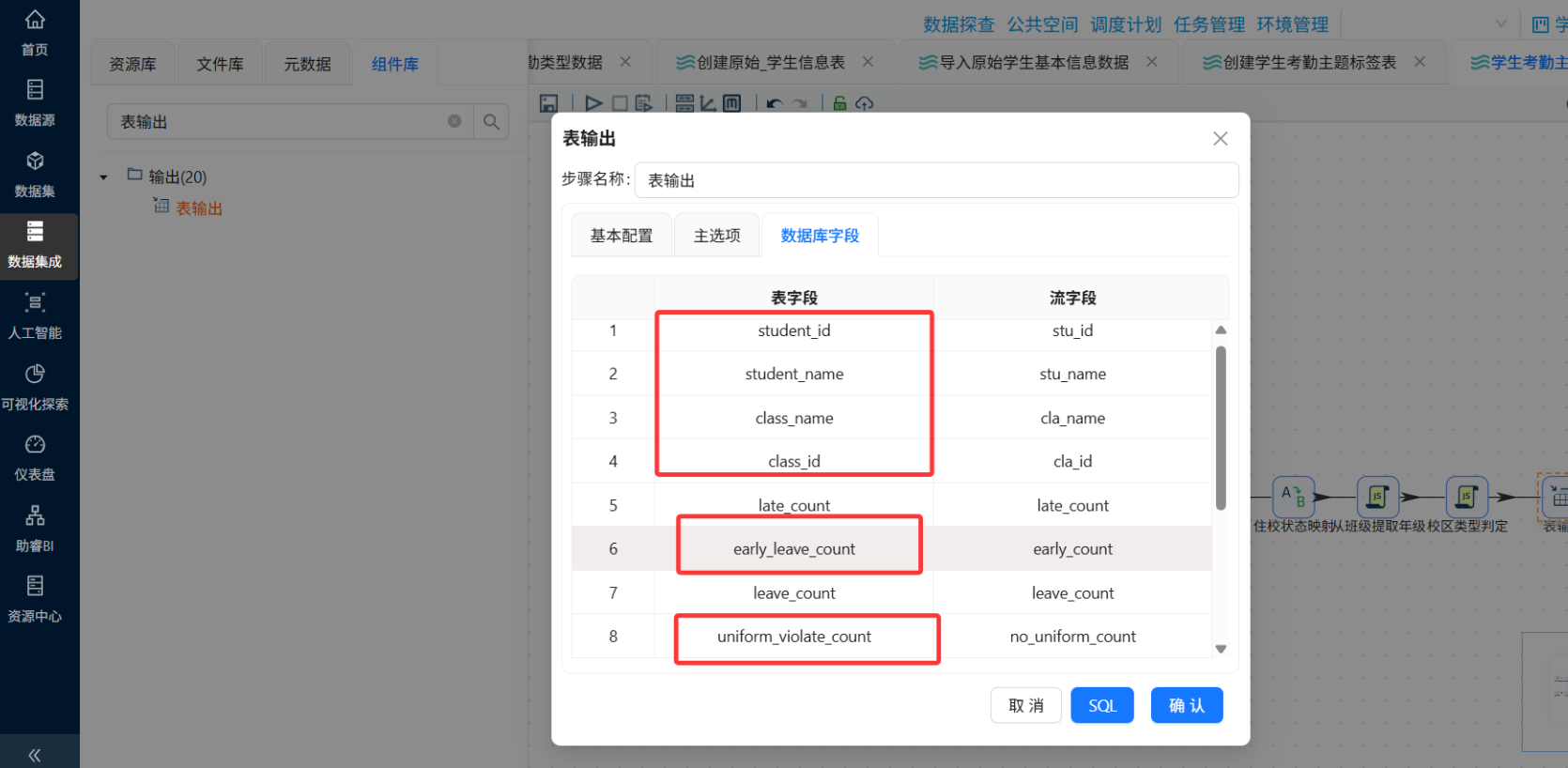
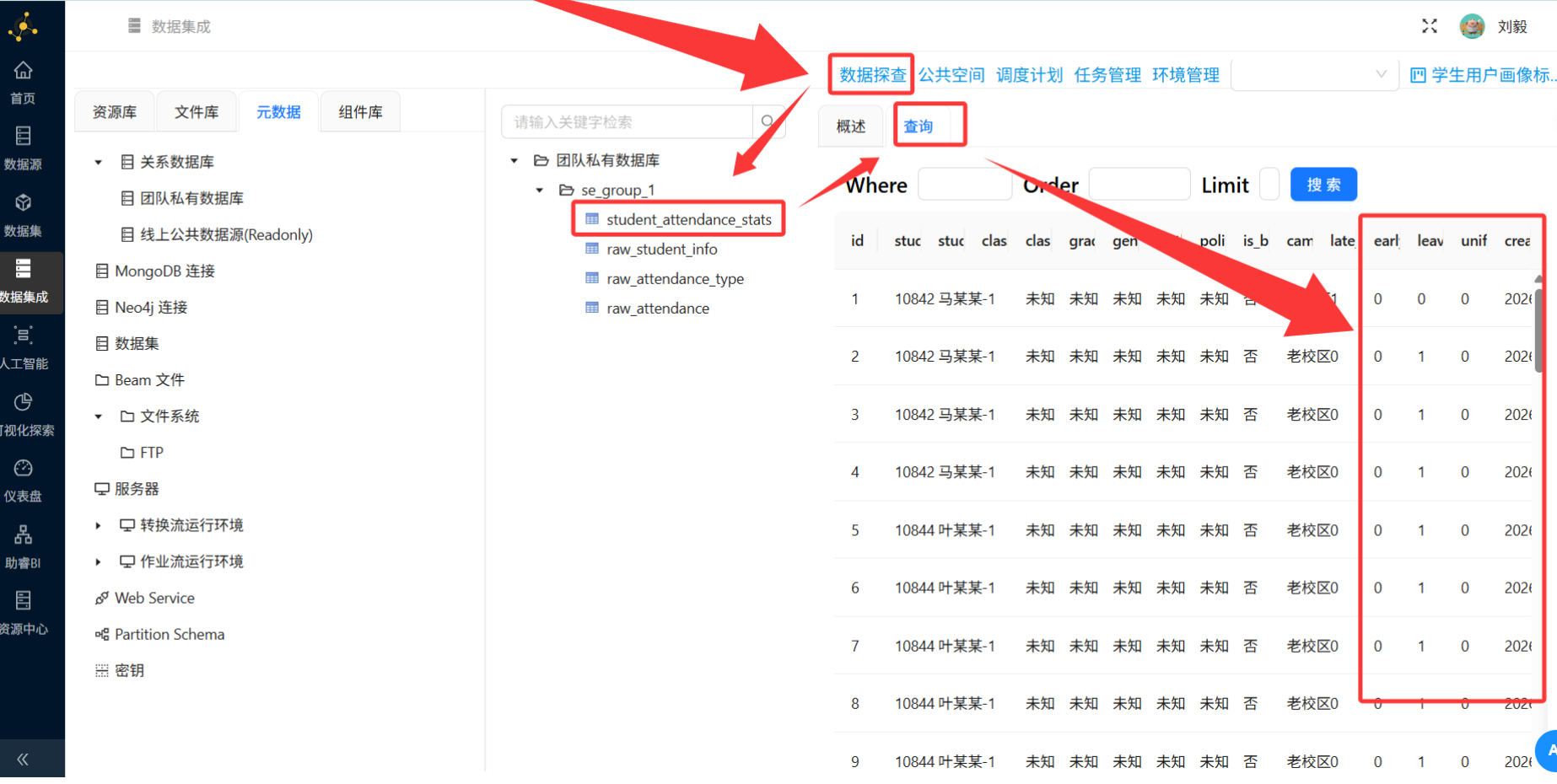
创建最终目标表(如student_attendance_stats),包含字段:
-
学生ID、姓名、班级ID、班级名称
-
年级、校区类型、是否住校、性别、出生日期、政治面貌
-
迟到次数、早退次数、请假次数、没穿校服次数
-
统计日期/入库时间
通过"表输出"组件写入,注意勾选"指定数据库字段"做好映射。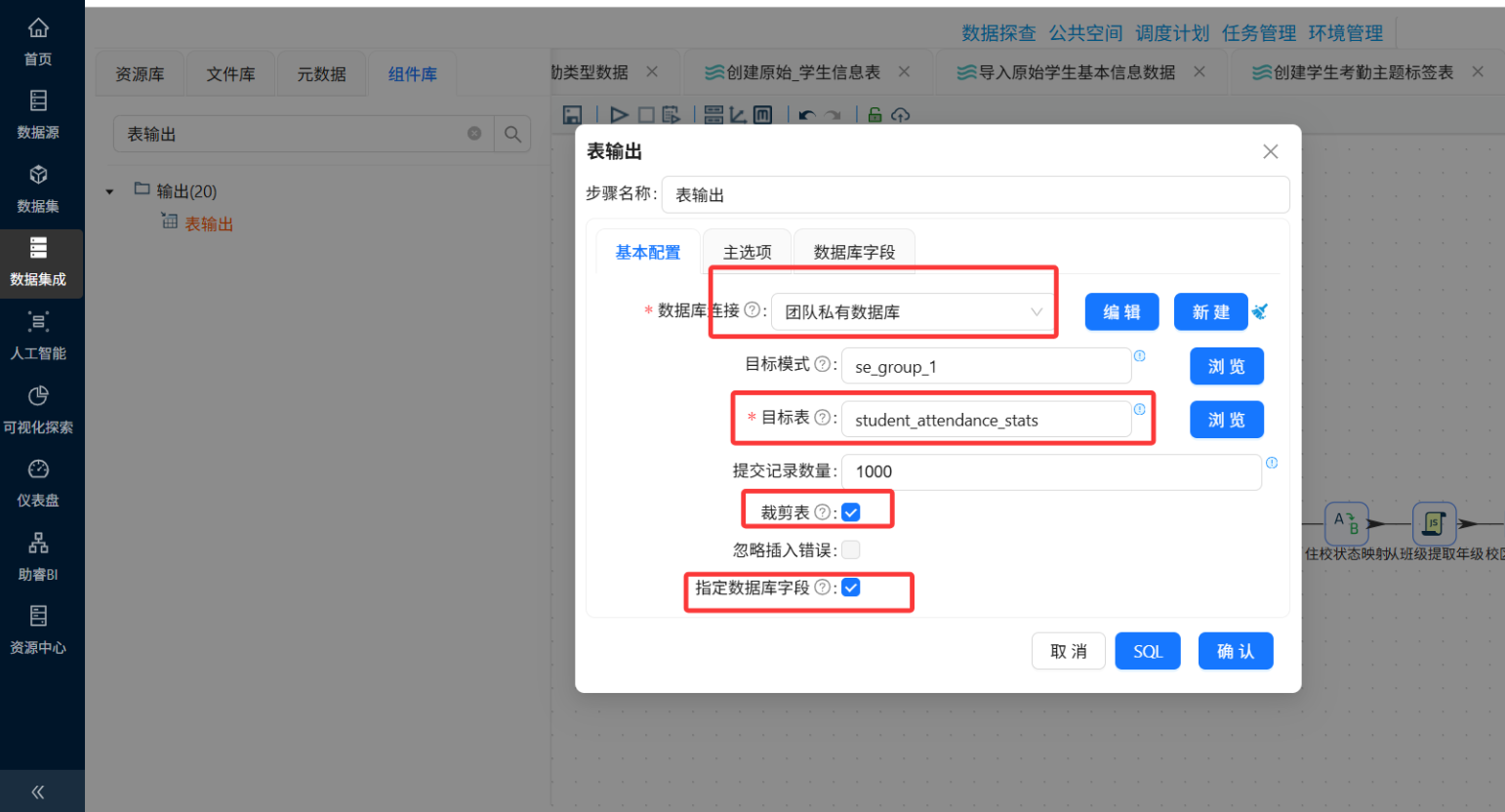
四、实验结果验证
转换流运行成功后,务必进行以下验证:
-
记录数核对:最终表记录数 = 去重后的学生数(应与
raw_student_info中的学生数基本一致) -
空值检查:查询
性别 = '未知'的记录数,评估空值占比 -
指标合理性抽查:
-
找几个已知经常迟到的学生,核对
late_count是否符合预期 -
随机抽10条记录,人工核对原始考勤明细与统计结果是否一致
-
-
口径交叉验证:总请假人数 + 总迟到人数(去重后)不应超过总学生数(避免同一人被重复统计的异常)
-- 验证SQL示例 SELECT COUNT(*) as total_students, SUM(CASE WHEN gender = '未知' THEN 1 ELSE 0 END) as unknown_gender, AVG(late_count) as avg_late, MAX(late_count) as max_late FROM student_attendance_stats;
 五、踩坑复盘与经验总结
五、踩坑复盘与经验总结坑位 现象 解决方案 ①数据库权限不足 SQL 脚本执行报错,无法建表 联系助教确认账号权限,或使用指定高权限账号 ②时间字段格式混乱 DataDateTime 格式不统一,时间计算报错 以字符格式接收数据,在数据流程内统一解析格式 ③空值处理时机错误 导入阶段过滤空值,造成原始数据缺失 先完整导入全部数据,后期统一清洗处理 ④班级名称格式不统一 符号字体杂乱,字段提取规则失效 提前预览样本数据,编写通用性提取规则 ⑤请假与迟到重复计数 请假记录被计入迟到数据,统计结果不准 统计时添加筛选条件,剔除请假相关数据 ⑥多表关联字段类型不匹配 关联字段数据类型不一致,表连接失败 关联数据前统一转换字段数据类型 ⑦目标表主键冲突 重复运行任务出现主键重复、数据重复录入 合理设置联合主键,使用插入更新模式写入数据 六、思考总结
通过这次实验,我完整走通了零代码ETL从数据接入到结果落地的全链路。最大的感受是:ETL工作看似是"体力活",实则是数据项目中最重要的"脑力活"。标签口径的定义、空值的处理策略、多表关联的顺序,每一个决策都会直接影响下游分析的准确性。
助睿(Uniplore)平台的可视化拖拽方式确实大大降低了ETL的技术门槛,让非SQL高手也能快速构建数据管道。但对于业务口径的理解和数据质量的把控,仍然是不可替代的核心能力。
如果你也在做类似的校园数据分析项目,希望这篇记录能帮你少走弯路。有问题欢迎在评论区交流!
本文原创,转载请注明出处。如果觉得有帮助,别忘了点赞 + 收藏支持一下! ⭐

一站式 AI 云服务平台
更多推荐

 24
24 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)