
学生用户画像-利用ETL零代码构建考勤主题标签
在创建学生考勤主题标签表的“执行一个SQL脚本”组件中修改SQL脚本,重新创建student_attendance_stats 表和相关字段,然后再重新获取字段。5 实验总结本次实验以 “数智教育” 数据集为基础,在助睿零代码平台完成学生考勤主题标签构建全流程 ETL 实践。
1 实验说明
1.1 实验目的
依托 “数智教育” 大赛数据集搭建学生考勤 ETL 转换流,掌握 ETL 全流程,解决校园考勤统计低效、标准不一问题;优化空值处理,输出精准多维度考勤数据,支撑校园考勤管理。
1.2 实验环境
- 工具:助睿零代码在线实验平台(https://lab.guilian.cn/),为一站式数据科学零代码平台,适配教学与企业数据加工。
- 数据源:“数智教育” 大赛 7 张核心业务表。
- 设备:可运行平台、能连接数据库的计算机。
1.3 实验范围
完成 ETL 全流程配置,实现多表接入、关联、标签衍生、聚合统计与入库;校验数据关联与统计精度,优化配置完成实验。
2 数据与标签梳理
梳理数据源、标签维度及计算口径,适配 ETL 转换流逻辑。
2.1 源数据说明
实验所用 “数智教育” 数据集共 7 张表,筛选出考勤主表、考勤类型表、学生信息表3 张核心表,构成 “事实表 + 维度表 + 属性表” 的星型模型,分别记录考勤明细、标准化考勤类型、学生基础属性,明确了各表关键字段。
2.2 标签字段说明
考勤标签分为三类:
- 学生基础属性标签:取自学生、考勤表,含 ID、姓名、性别等,用于多维度考勤分析。
- 学生画像维度标签:由原始数据衍生,含年级、是否住校、校区类型,适配分层、针对性校园管理。
- 考勤行为统计标签:统计迟到、早退、请假、没穿校服次数,衡量学生考勤纪律与行为规范。
2.3 标签处理口径
统一标签处理规则,保障统计精准可比:
- 基础属性:直接读取关键字段,空值替换为 “未知”。
- 衍生维度:从班级名称提取年级、校区,映射住校状态,规范空值。
- 考勤指标:按考勤事件关键词统计异常考勤次数。
3 实验步骤
3.1 创建实验项目
进入“个人团队”,点击“新建项目”,输入项目名称“学生用户画像标签构建”,创建项目。
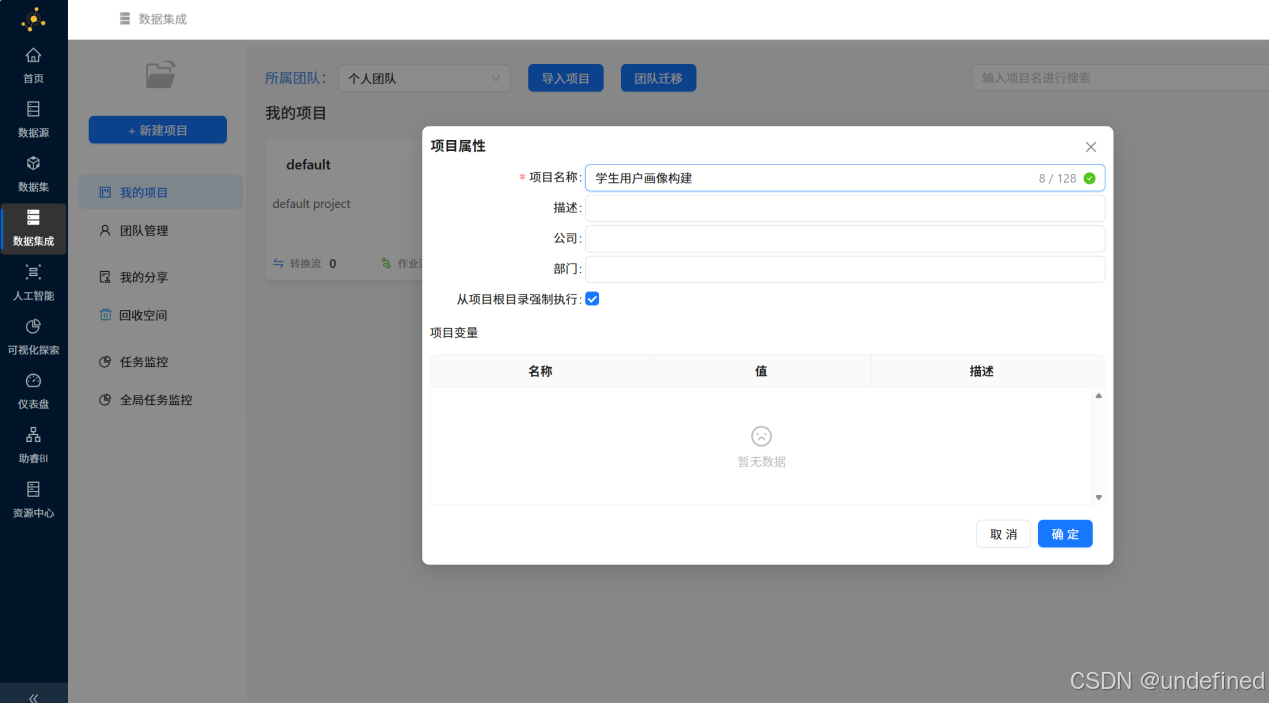
创建成功后进入新项目
3.2 数据资源获取
首先获取本次的实验数据集:点击“文件库”,右键根目录,点击“新建目录”
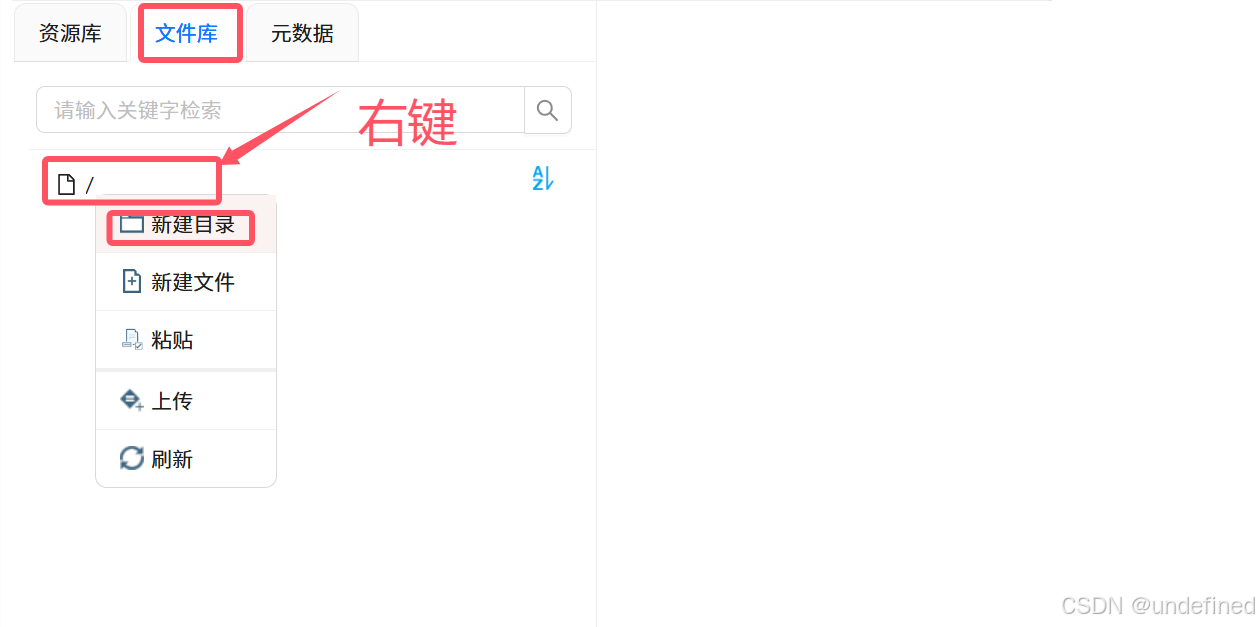
输入目录名称为“数智教育数据集”,点击“确定”
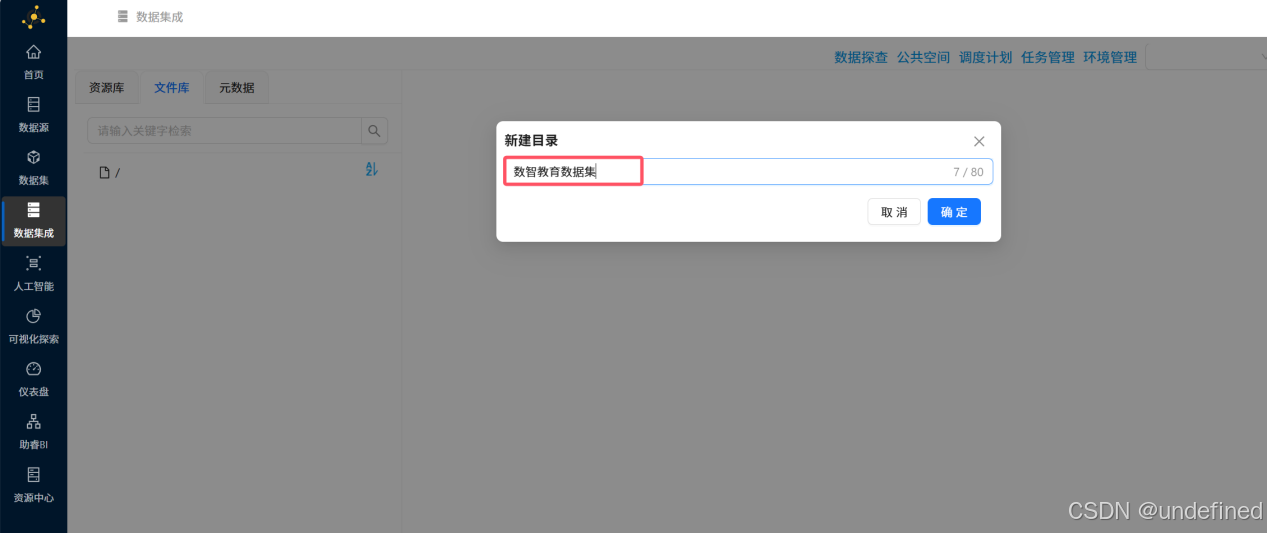
接下来我们将公共空间的数据资源导入到这个目录下
点击“公共空间”,然后点击“数据资源”
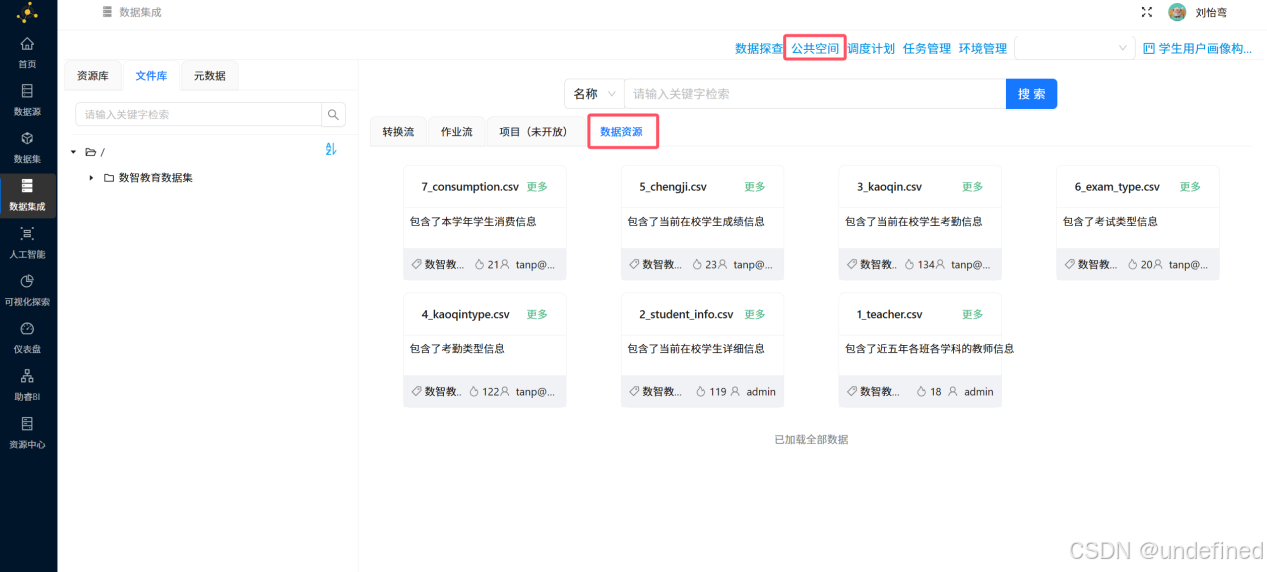
点击“3_kaoqin.csv”卡片右上角的“更多”,并点击“导出”
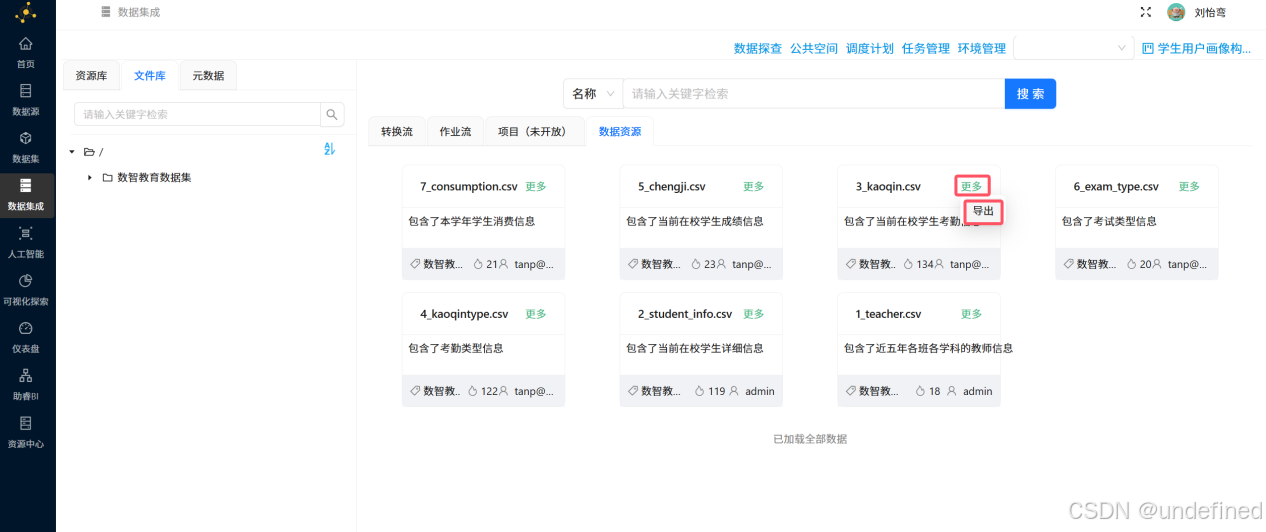
在弹出的窗口中选择导出到刚刚新创建的目录下
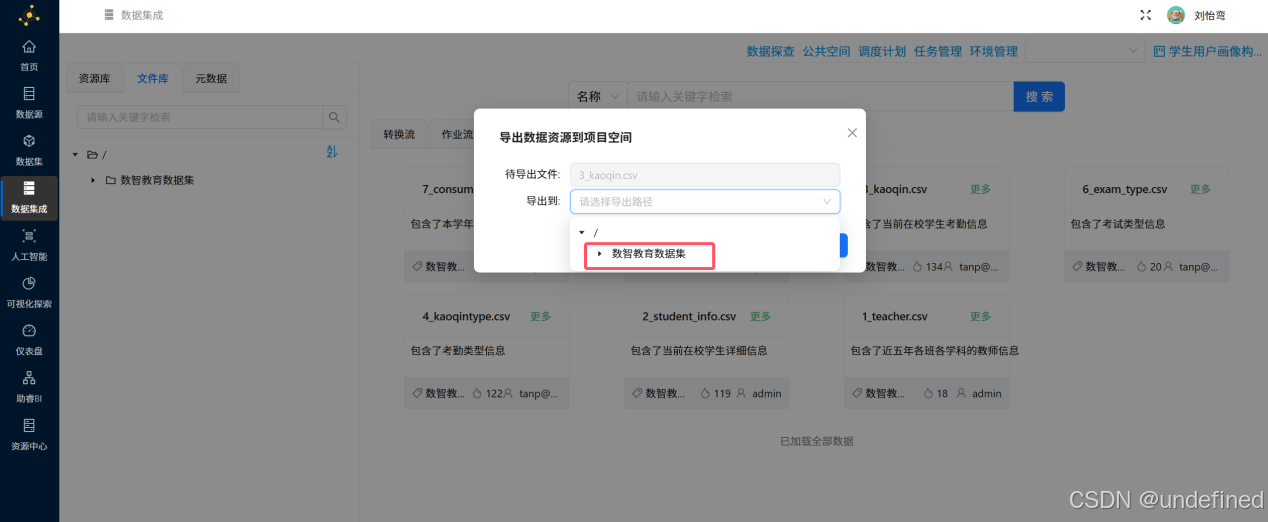
接下来重复以上导出操作,将本次实验用到的数据表 4_kaoqintype.csv 和 2_student_info.csv 都导出到“数智教育数据集”
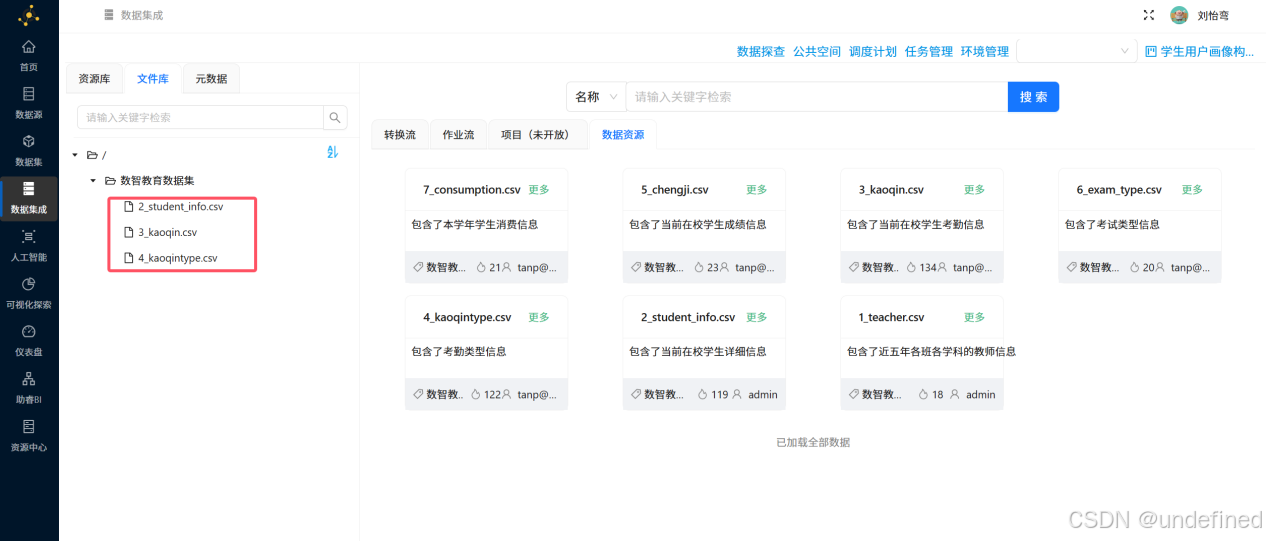
可以看到在数智教育数据集的目录下,新增了3个数据表
在元数据页面中,右键关系数据库打开菜单,选择“新建数据源”

弹出新建数据库连接窗口,连接类型选择“MySQL”,用户名和密码使用助教提供的账号和密码。服务器主机名使用助教提供的数据库连接地址“rm-2vc3qok06bag39a5n.mysql.cn-chengdu.rds.aliyuncs.com”,端口号为3306,数据库名为助教提供的数据库名称,驱动类型选择“MySQL 8+”,连接名称为“团队私有数据库”
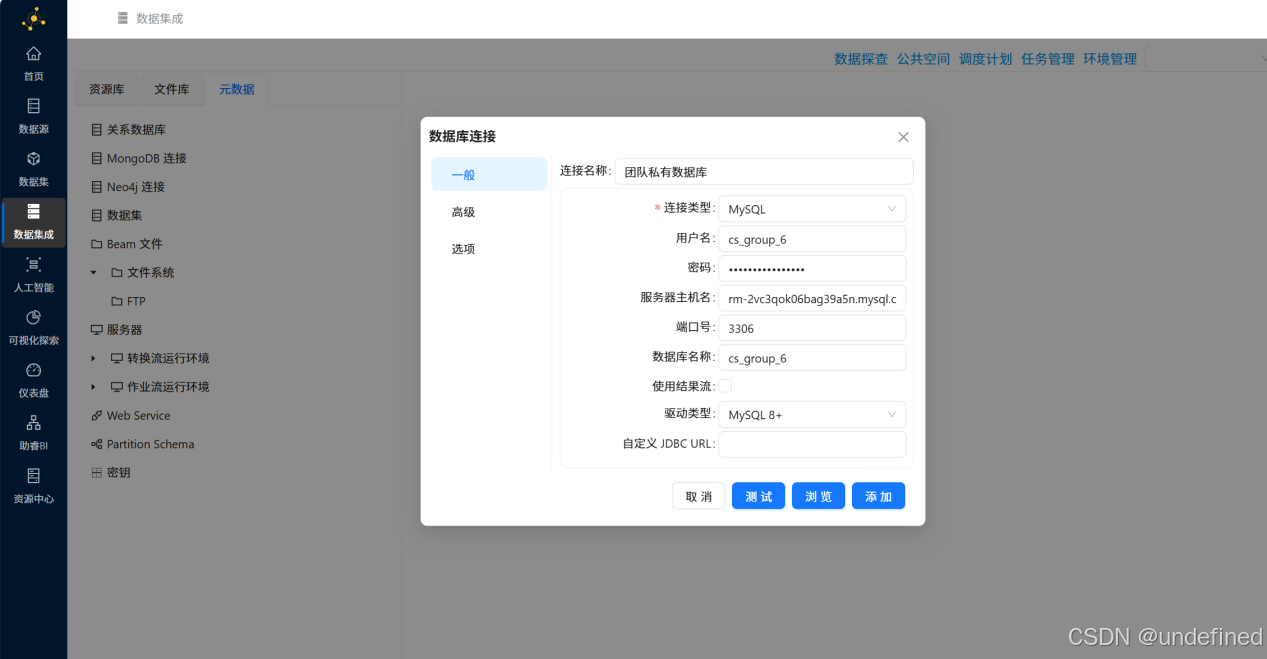
输入完成后,点击“添加”,添加成功后,关系数据库节点会增加一个子节点(团队私有数据库)。

3.3 创建原始_学生考勤表
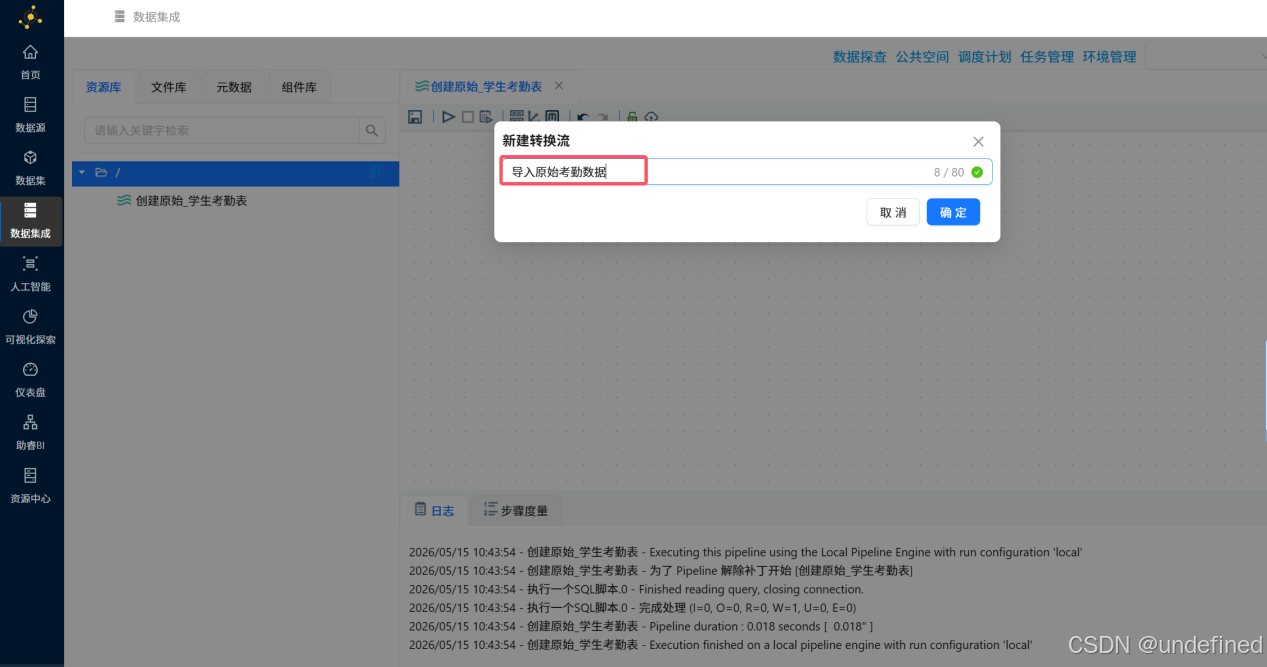
按照下图的提示新建转化流
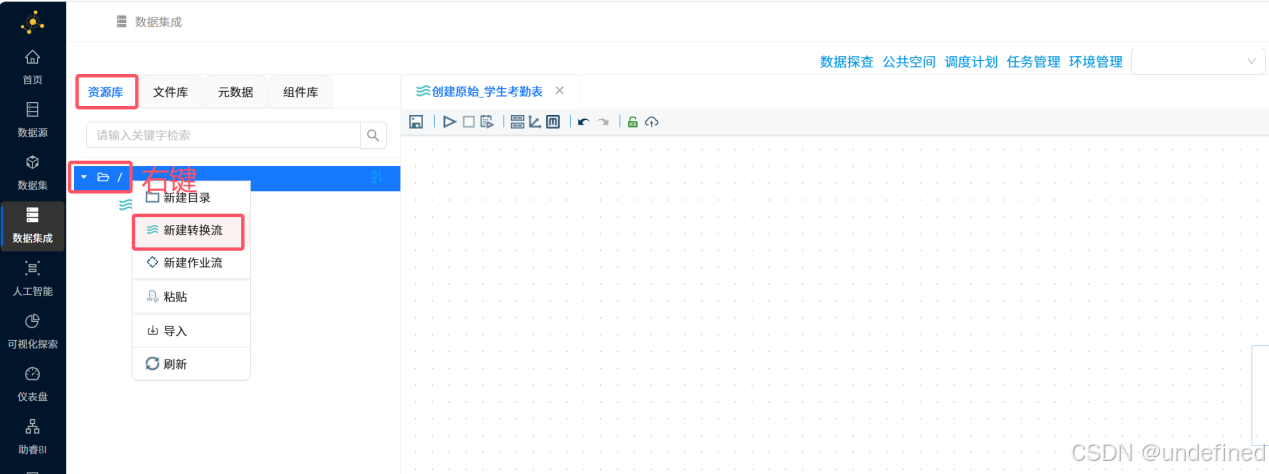
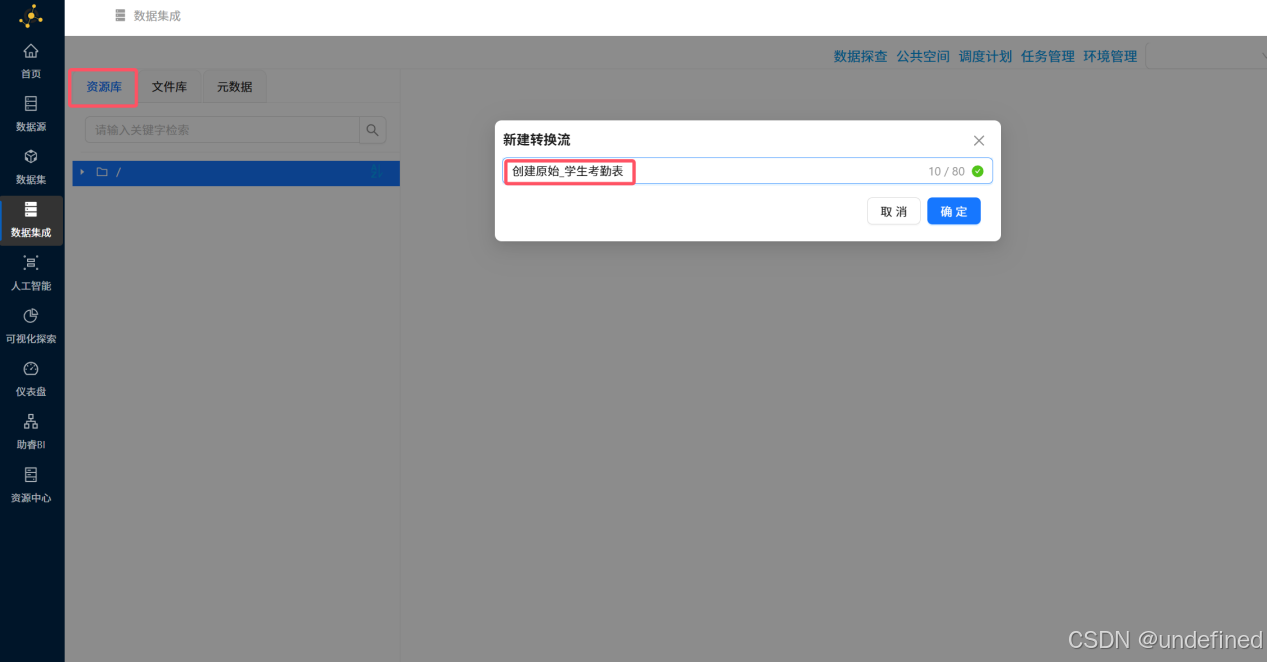
命名为“创建原始_学生考勤表”
在该工作流中拖拽“执行一个SQL脚本”组件,通过执行SQL脚本来创建一个标签表。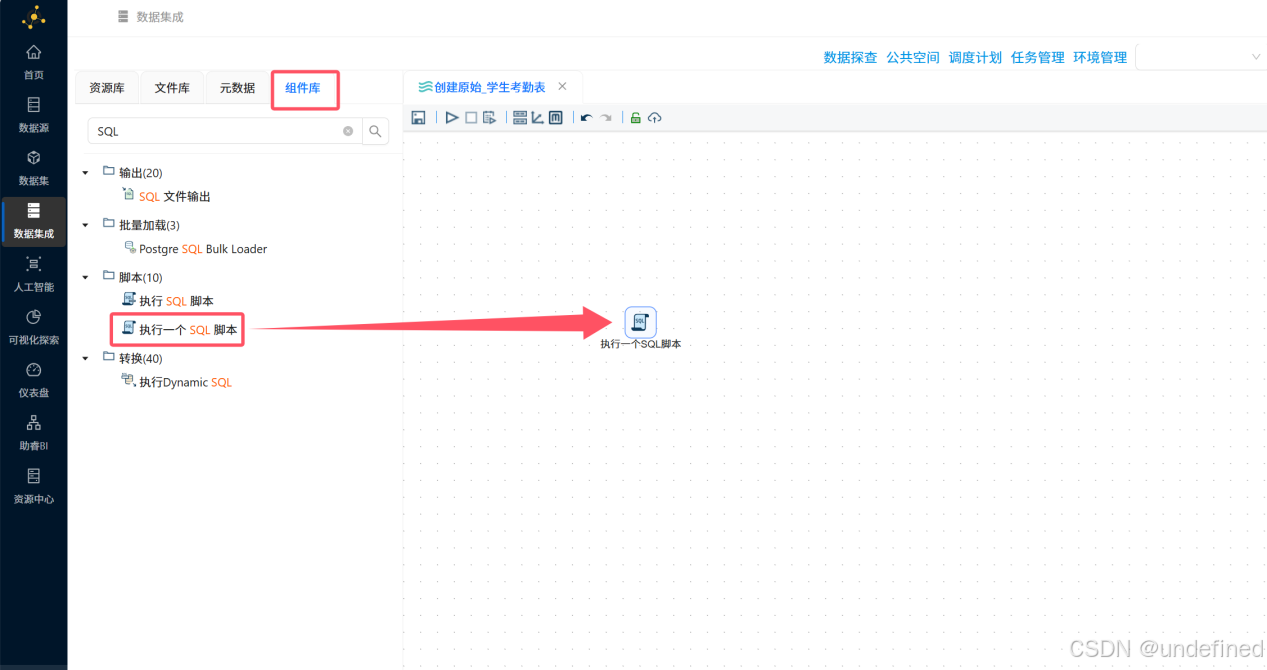
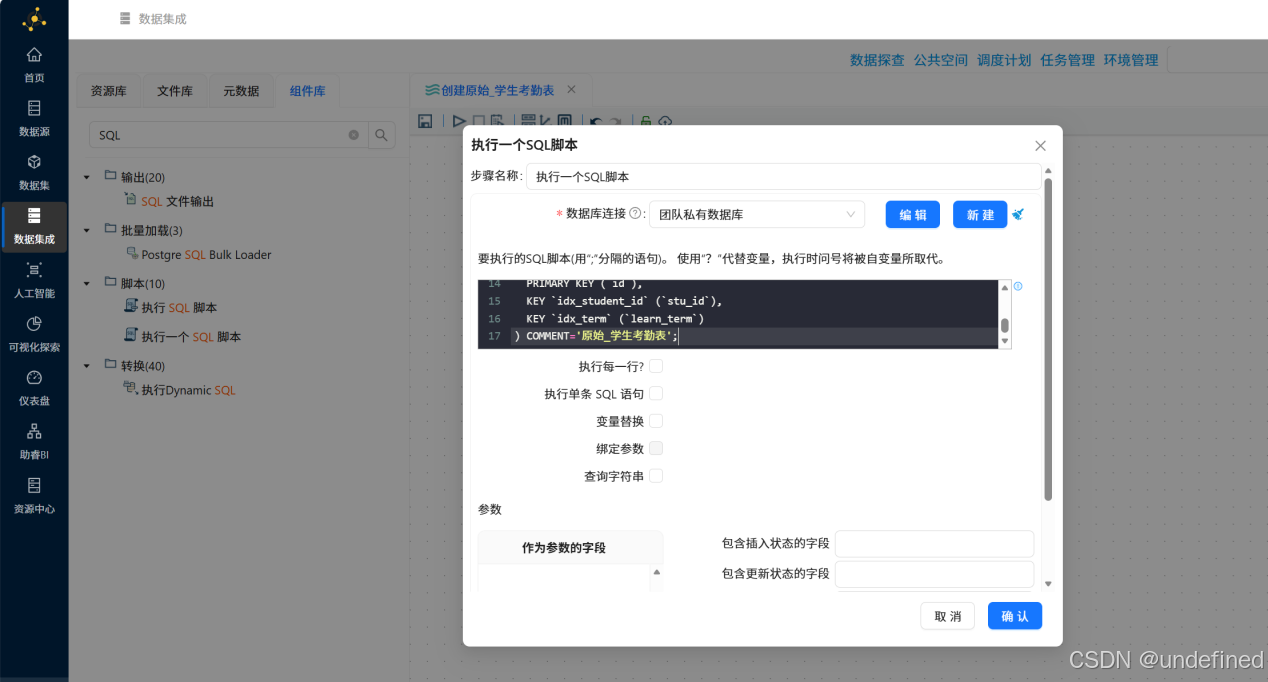
配置说明:在组件中填写SQL脚本,选择目标数据库连接“团队私有数据库”,确保脚本执行权限;
SQL脚本如下:
CREATE TABLE IF NOT EXISTS `raw_attendance` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '自增ID',
`attendance_id` varchar(64) DEFAULT NULL COMMENT '考勤ID',
`learn_term` varchar(30) DEFAULT NULL COMMENT '学期',
`data_datetime` varchar(50) DEFAULT NULL COMMENT '时间和日期',
`attendance_type_id` varchar(64) DEFAULT NULL COMMENT '考勤类型ID',
`attendance_name` varchar(100) DEFAULT NULL COMMENT '考勤名称',
`attendance_task_order_id` varchar(64) DEFAULT NULL COMMENT '考勤事件ID',
`stu_id` varchar(64) DEFAULT NULL COMMENT '学生ID',
`stu_name` varchar(100) DEFAULT NULL COMMENT '学生姓名',
`cla_name` varchar(100) DEFAULT NULL COMMENT '班级名',
`cla_id` varchar(64) DEFAULT NULL COMMENT '班级ID',
`create_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '入库时间',
PRIMARY KEY (`id`),
KEY `idx_student_id` (`stu_id`),
KEY `idx_term` (`learn_term`)
) COMMENT='原始_学生考勤表';其他参数使用默认选项,完成后组件配置如下,然后点击“确定”。
完成后运行转换流,运行过程会定时刷新组件状态,并画布下面显示执行日志。
3.4 导入原始考勤数据
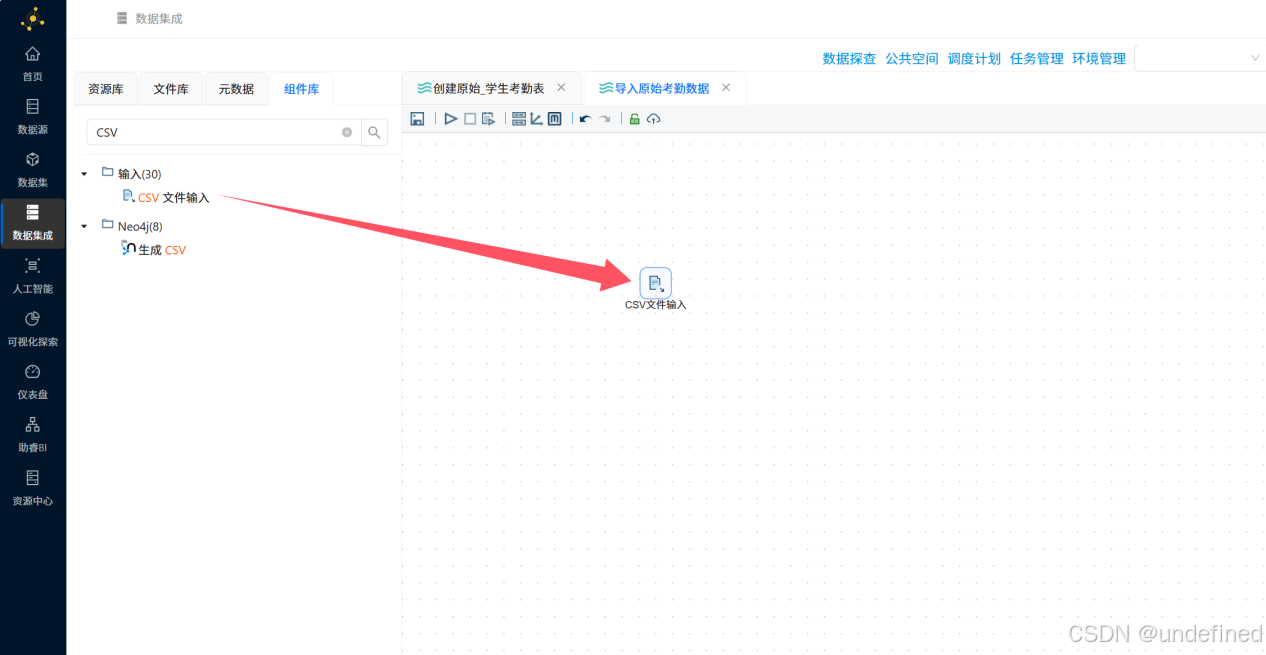
按照上一步创建转换工作流的操作,新建转换工作流,并命名为“导入原始考勤数据”
在该工作流中拖拽一个“CSV文件输入”组件到画布
双击CSV文件输入组件,在步骤名称中输入“考勤记录”
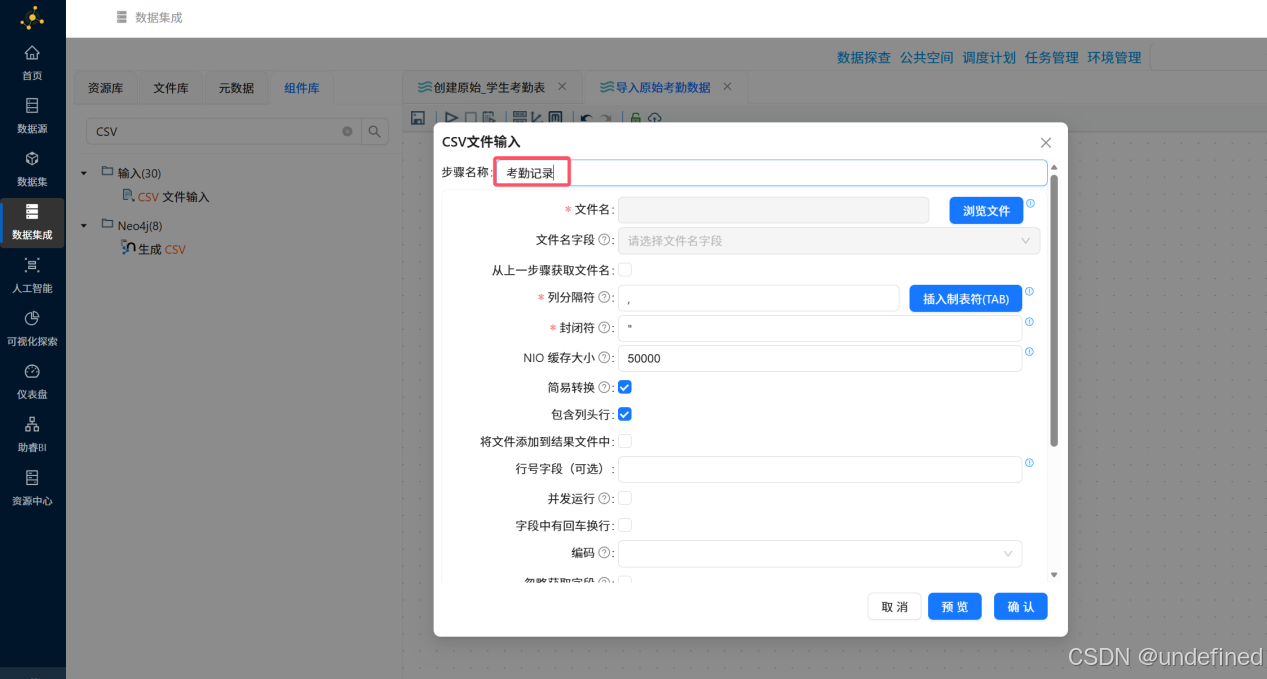
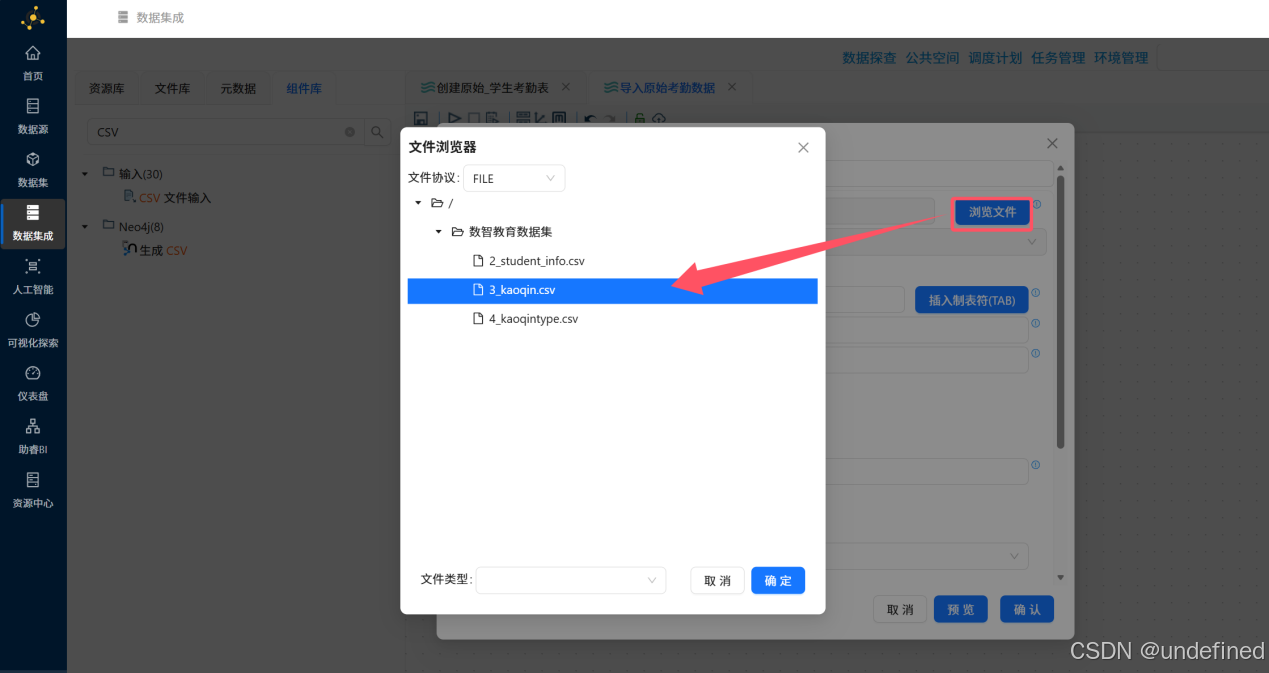
点击文件名后的“浏览文件”按钮,在弹出的窗口中选择“3_kaoqin.csv”,点击“确定”
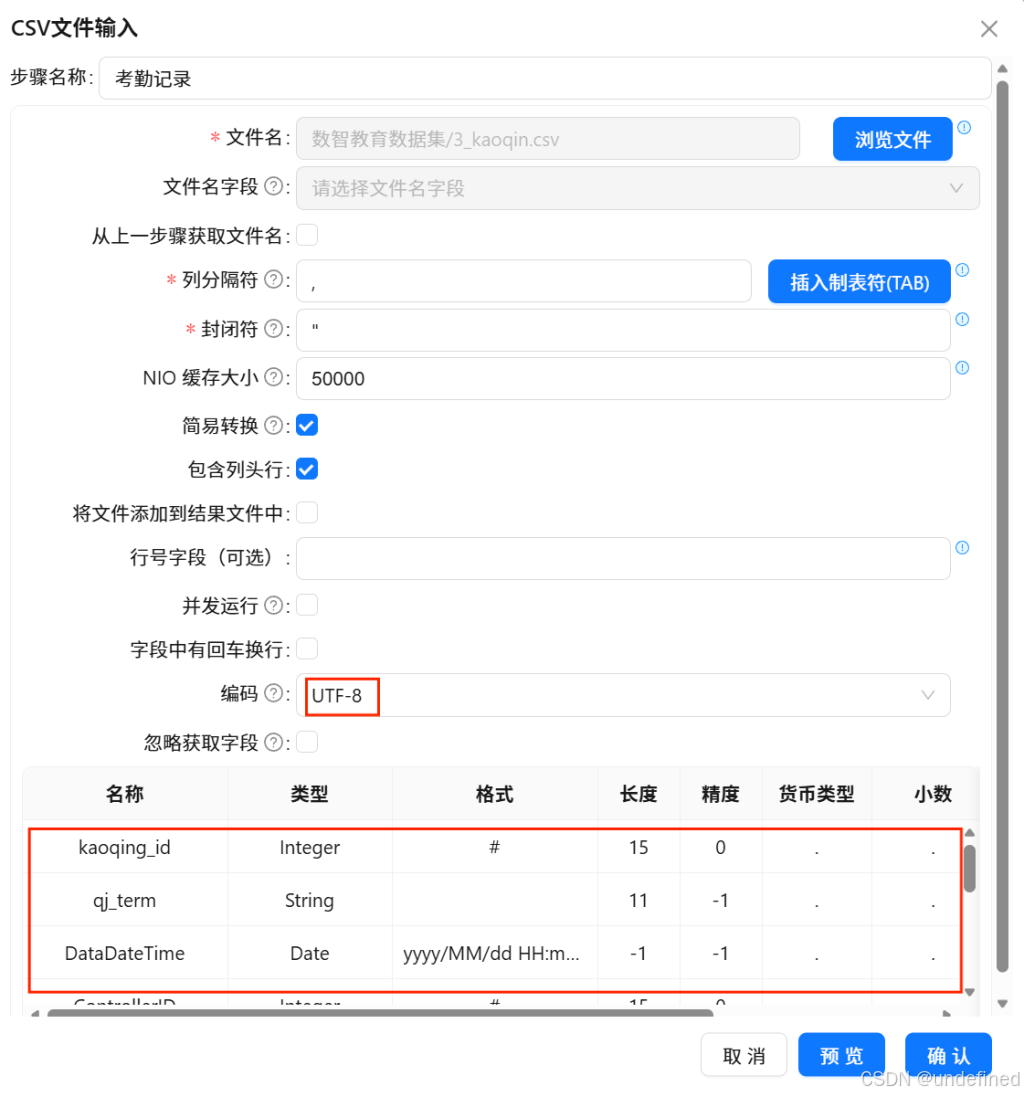
列分隔符和封闭符使用默认参数,注意列分隔符是一个英文逗号“,”,编码选择“UTF-8”,继续下滑在字段表格中空白处右键点击“获取字段”,获取下方图片中的相关字段。然后点击确定。
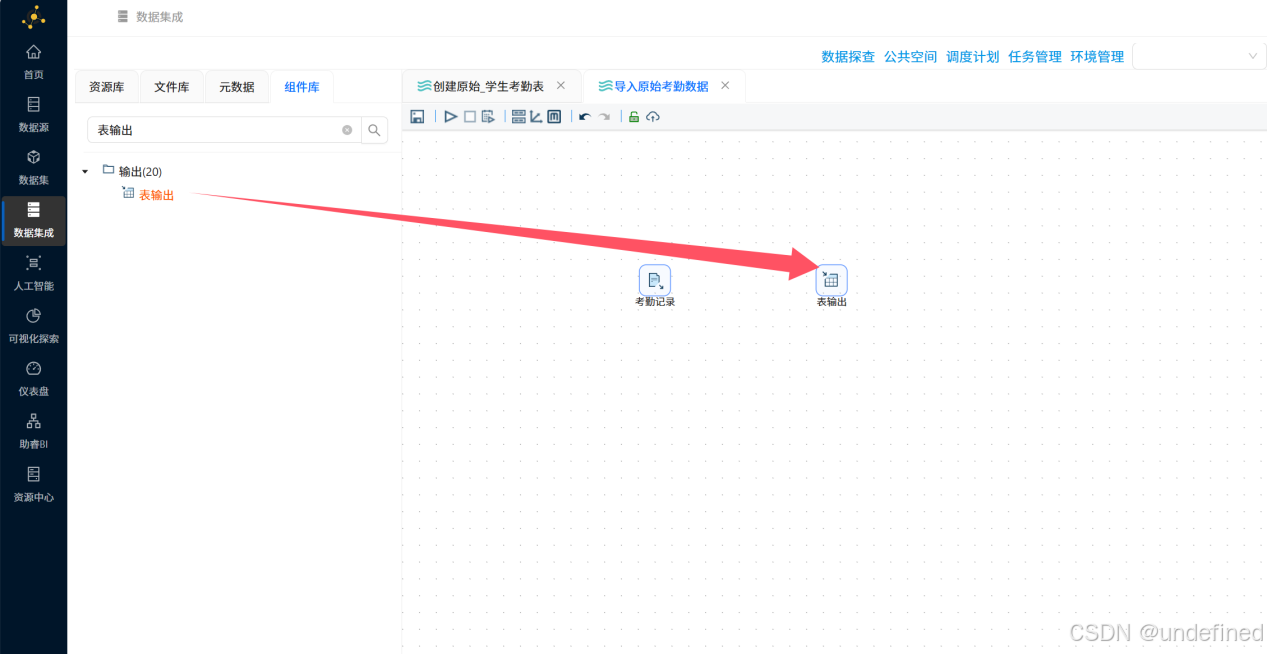
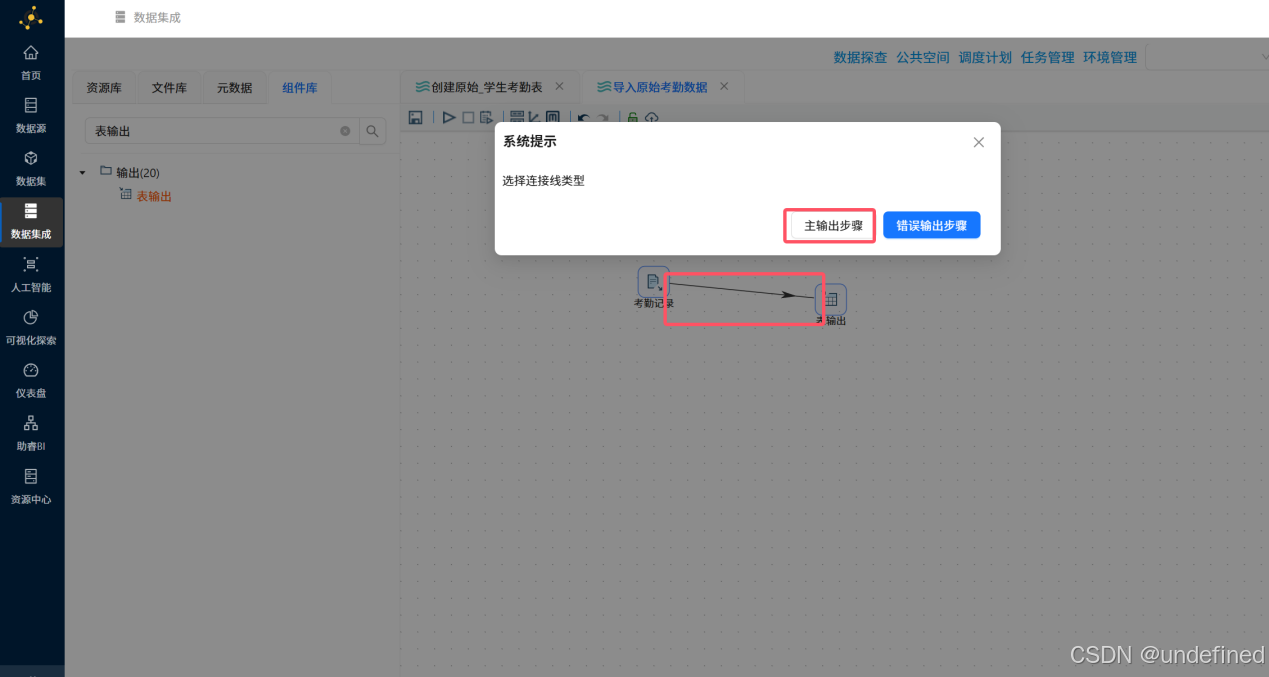
接下来拖拽一个“表输出”组件到画布,并创建“考勤记录”CSV文件输入组件到“表输出”组件的连线,连线类型选择“主输出步骤”
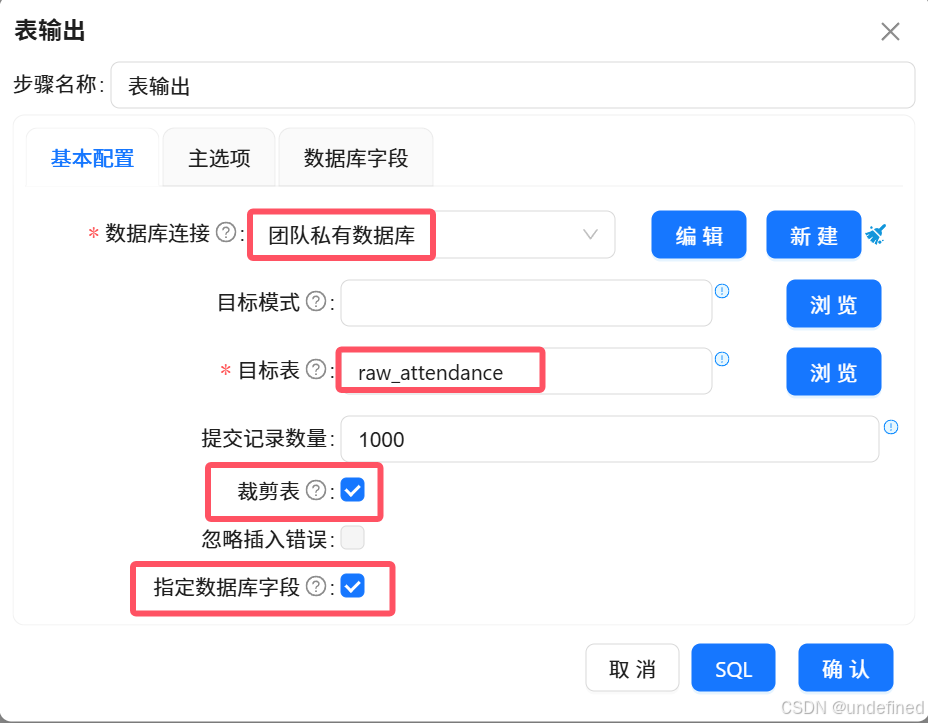
双击“表输出”组件,基本配置中,数据库连接选择“团队私有数据库”,目标表输入使用SQL组件创建的“raw_attendance”,具体配置如下:
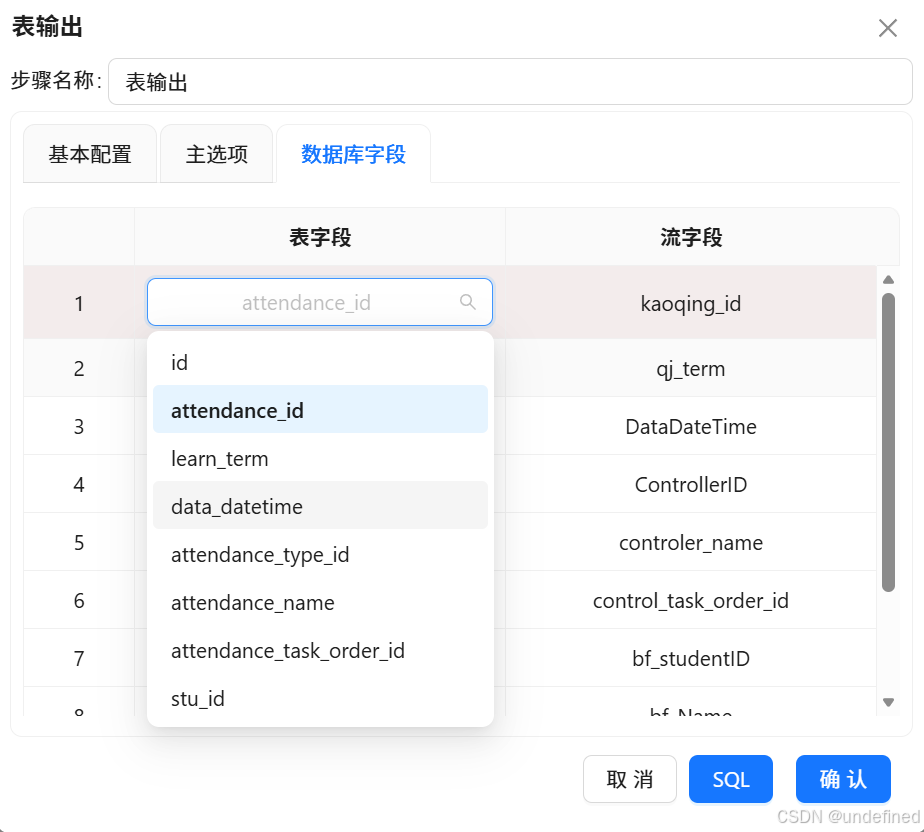
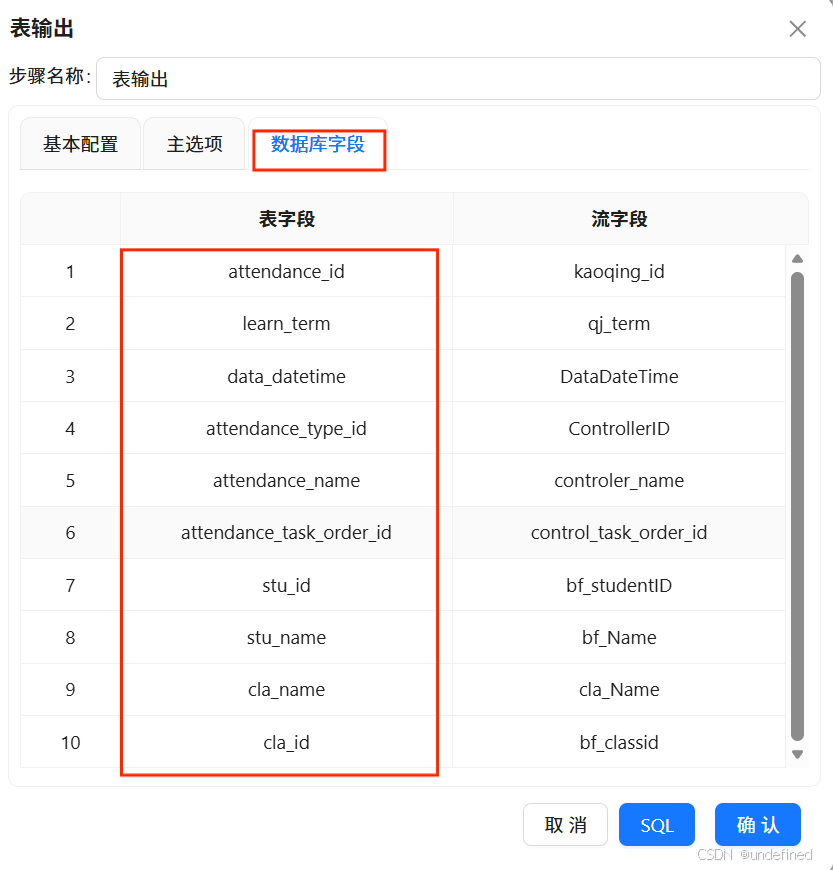
点击“数据库字段”,在空白处右键“获取字段”,将表字段修改为建表语句中对应的字段,
双击表字段就可以在下拉列表中选择相关字段,如下图所示,所有表字段修改完成之后,点击“确定”。
完成后运行转换流,运行过程会定时刷新组件状态,并画布下面显示执行日志。
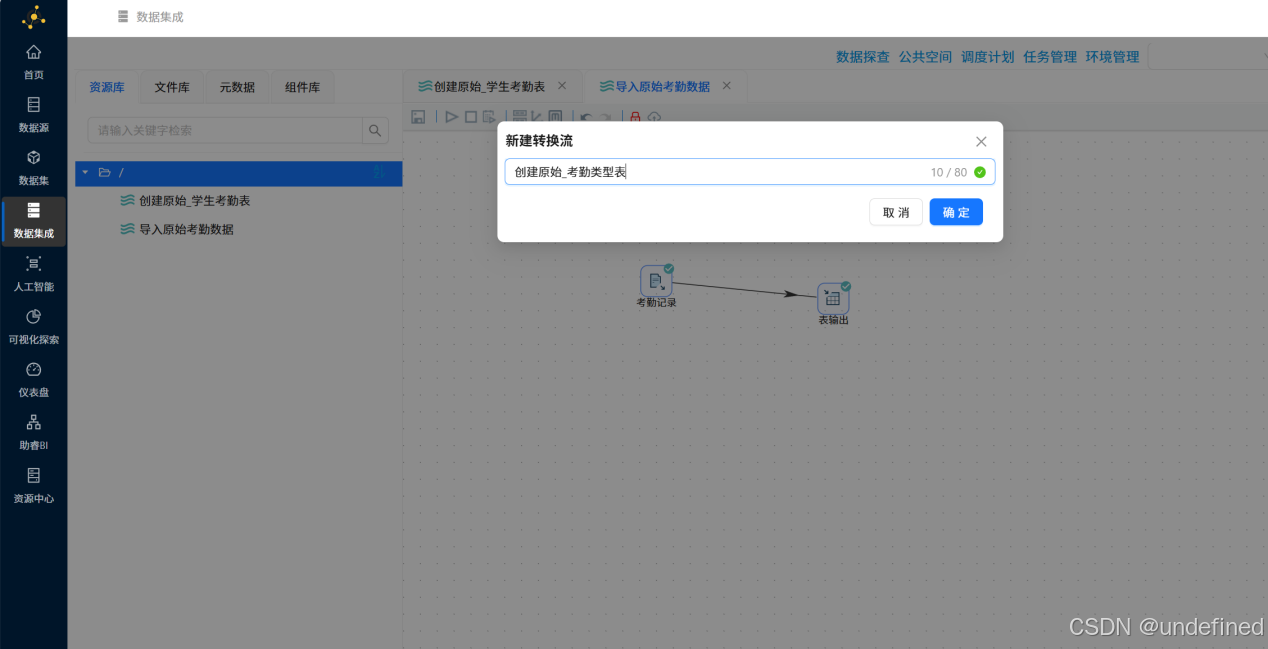
3.5 创建原始_考勤类型表
首先新建转化工作流,命名为“创建原始_考勤类型表”
然后拖拽“执行一个SQL脚本”组件到画布中
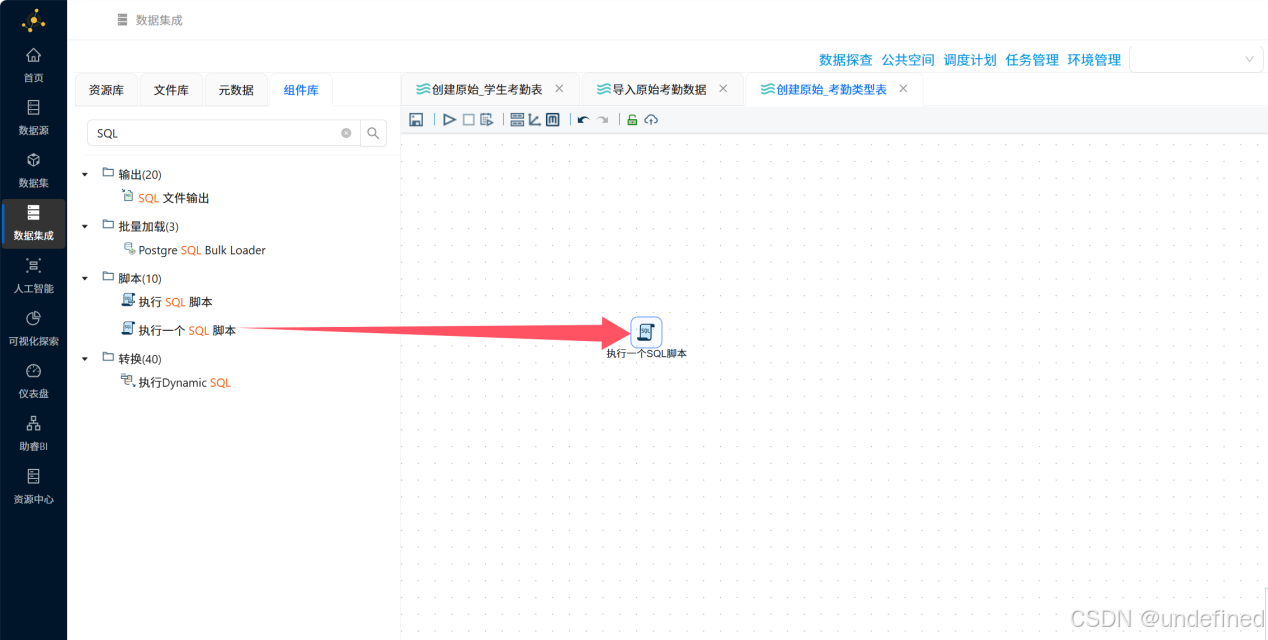
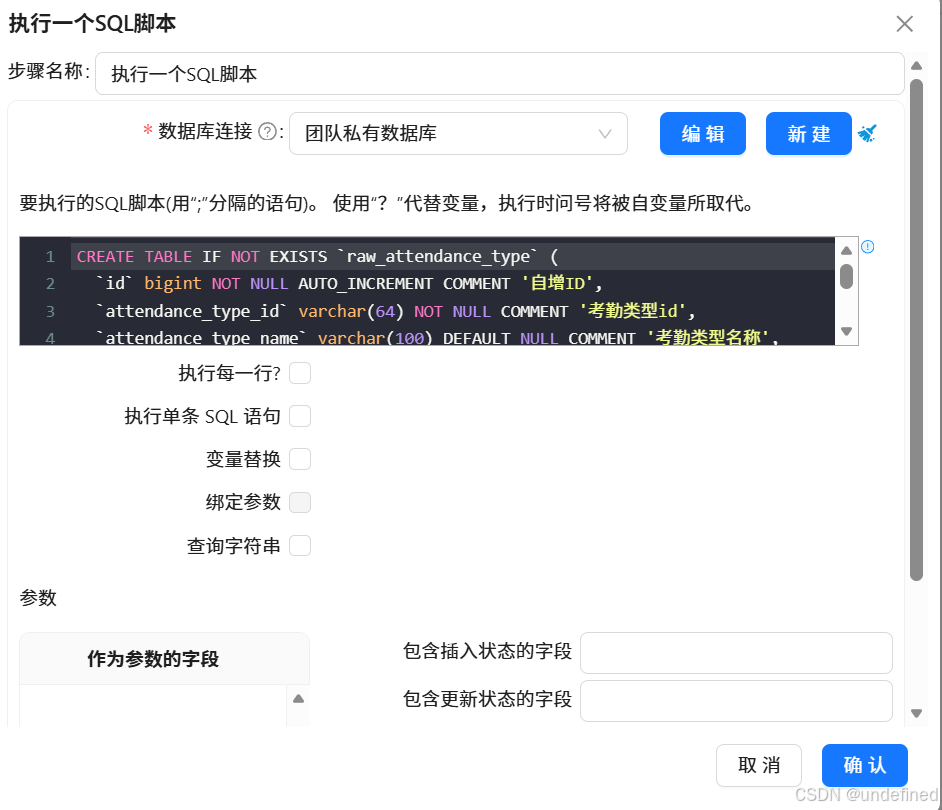
双击“执行一个SQL脚本”,建表SQL为:
CREATE TABLE IF NOT EXISTS `raw_attendance_type` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '自增ID',
`attendance_type_id` varchar(64) NOT NULL COMMENT '考勤类型id',
`attendance_type_name` varchar(100) DEFAULT NULL COMMENT '考勤类型名称',
`attendance_task_order_id` varchar(64) DEFAULT NULL COMMENT '考勤事件id',
`attendance_task_name` varchar(100) DEFAULT NULL COMMENT '考勤事件名',
`create_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '入库时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_attendance_type_id` (`attendance_task_order_id`)
)COMMENT='原始_考勤类型表';如下图,然后点击确定
执行创建原始_考勤类型表转换流:
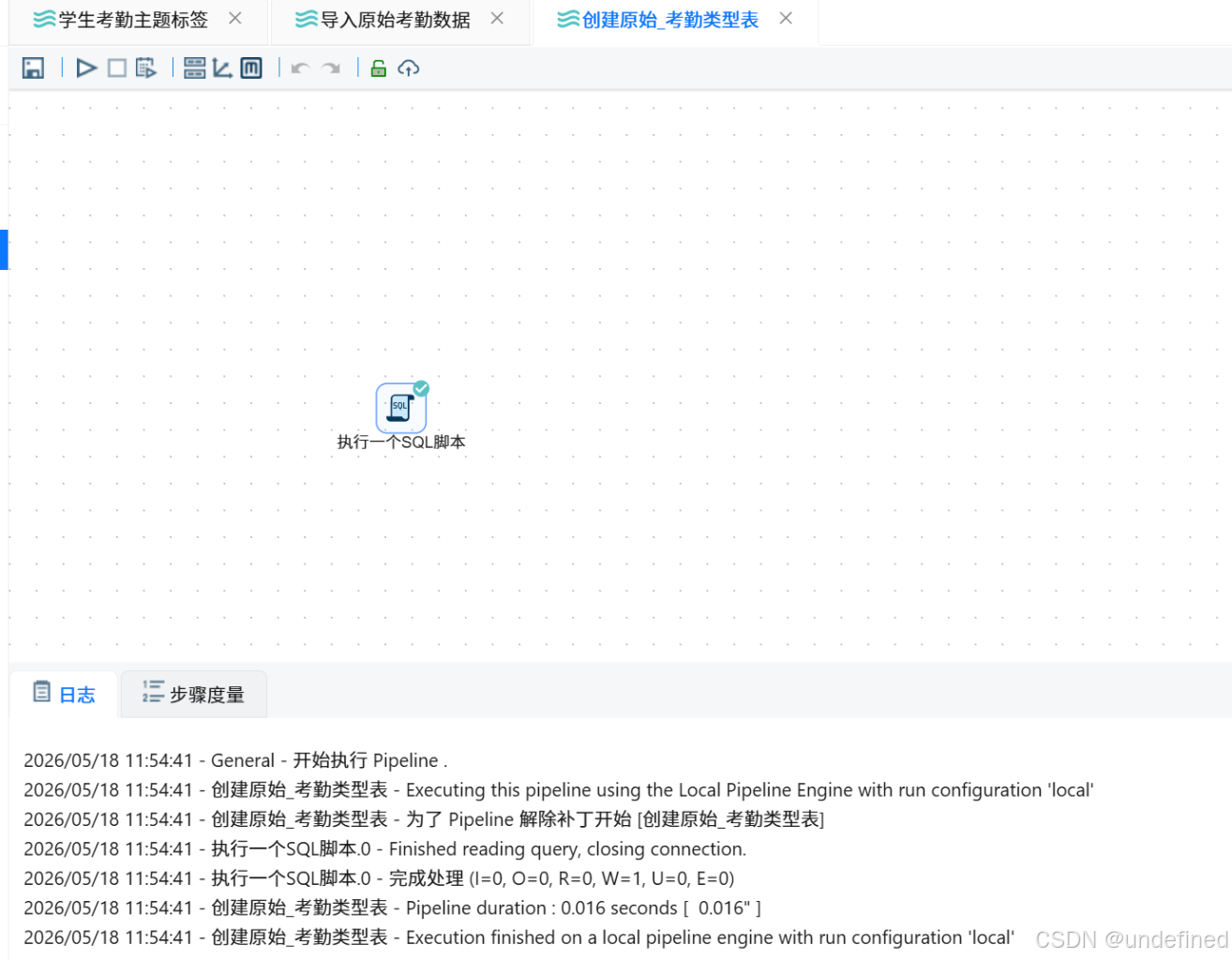
-
3.6 导入原始考勤类型表数据
将如下图所示的“CSV文件输入”组件和“表输出”组件拖拽到画布中,连接两个组件,连线类型同样选择“主输出步骤”。
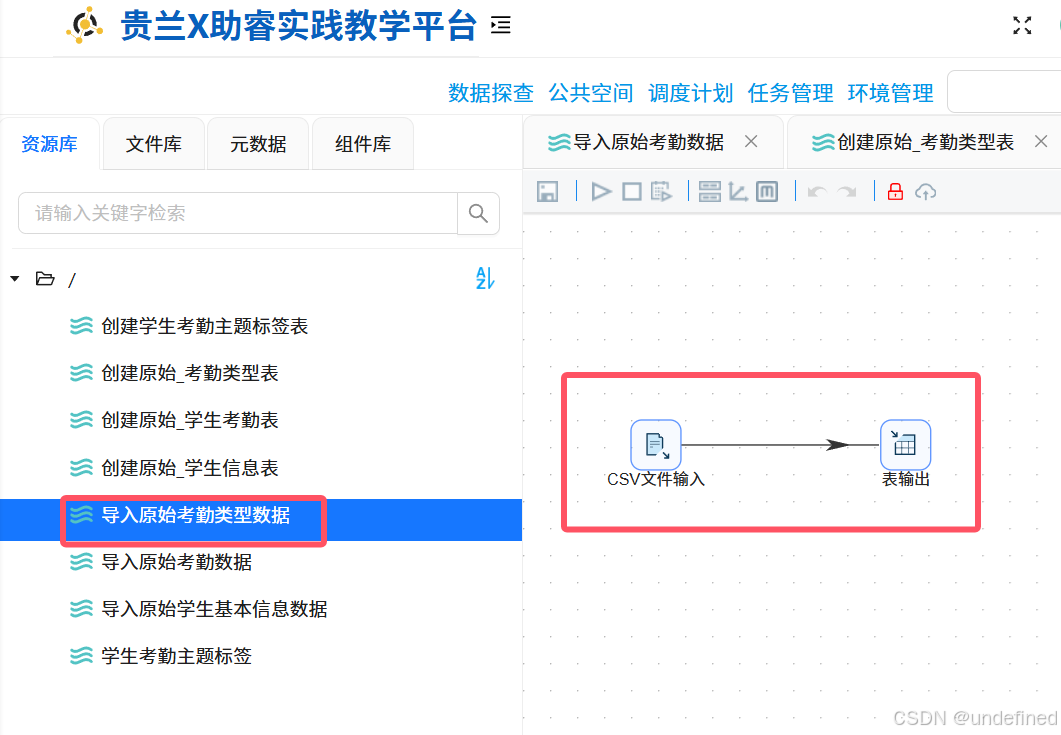
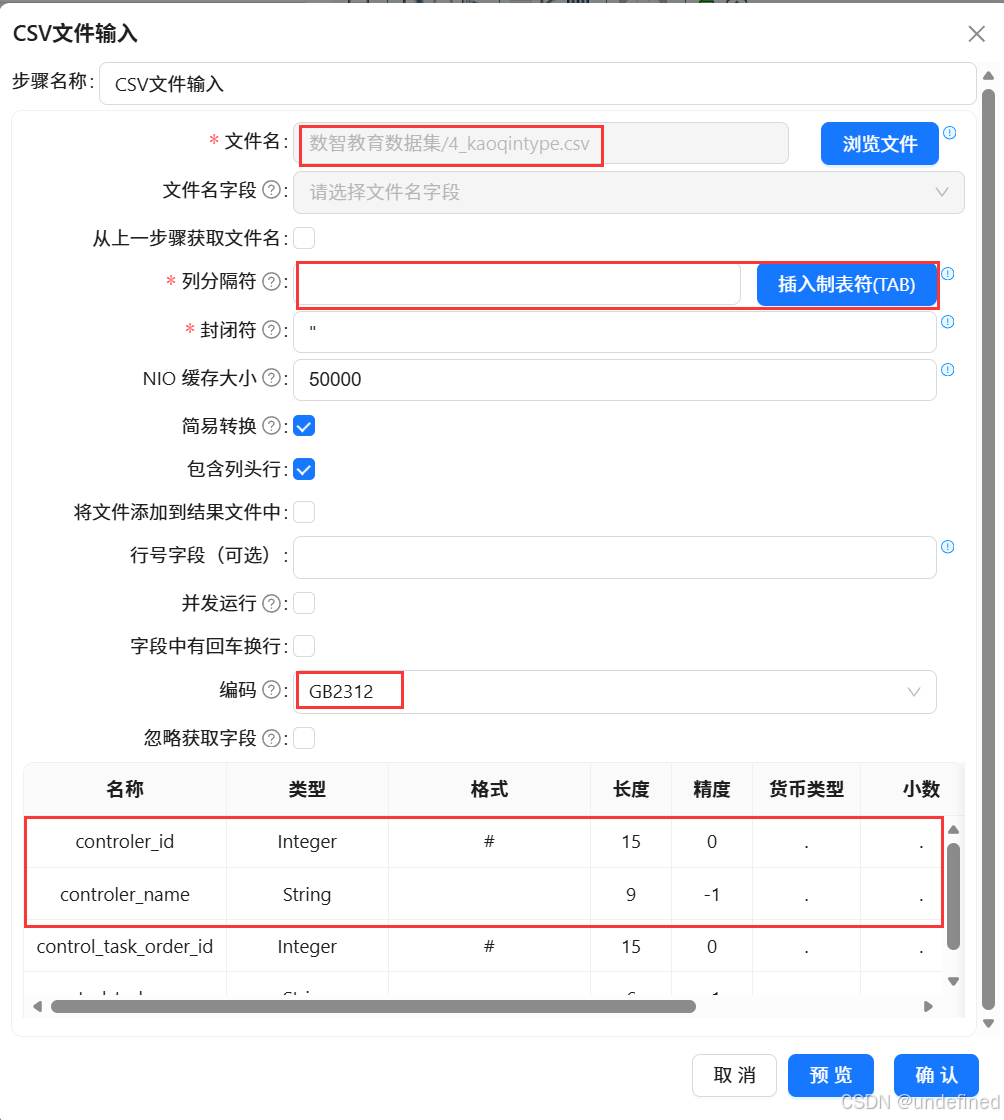
双击“CSV文件输入”组件,配置列分隔符为“插入制表符(TAB)”、编码为“GB2312”,
同样右键获取字段,获取的部分字段如下图所示:
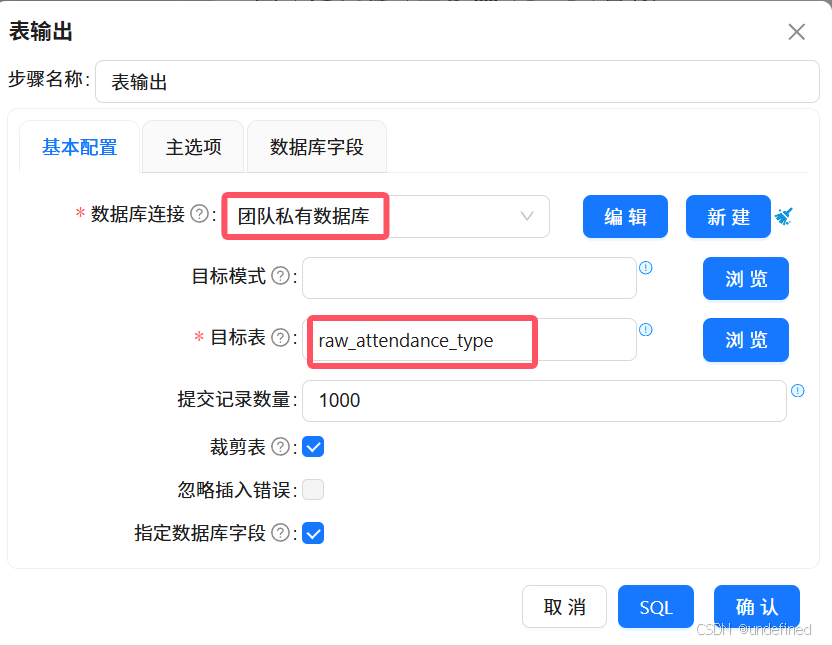
双击“表输出”组件,配置表输出如下图所示:
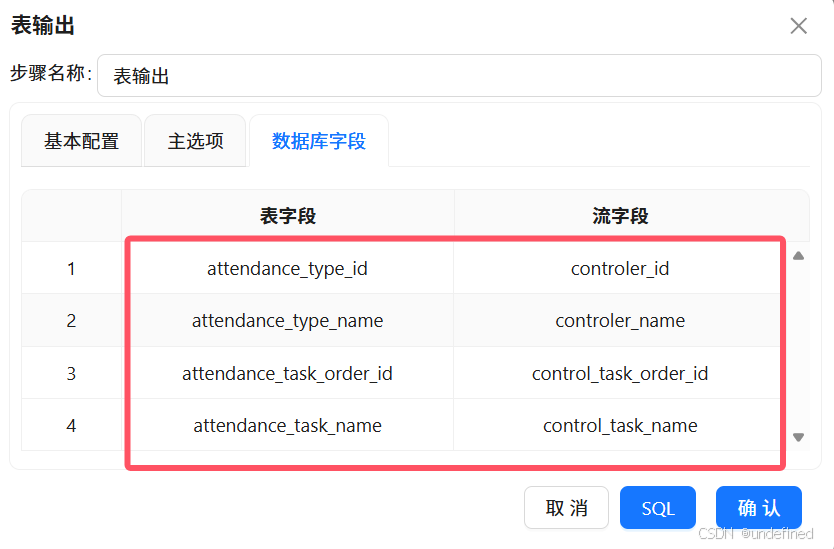
注意表字段要和下图的字段名称相同
配置完成后执行转换流,运行过程会定时刷新组件状态,并画布下面显示执行日志
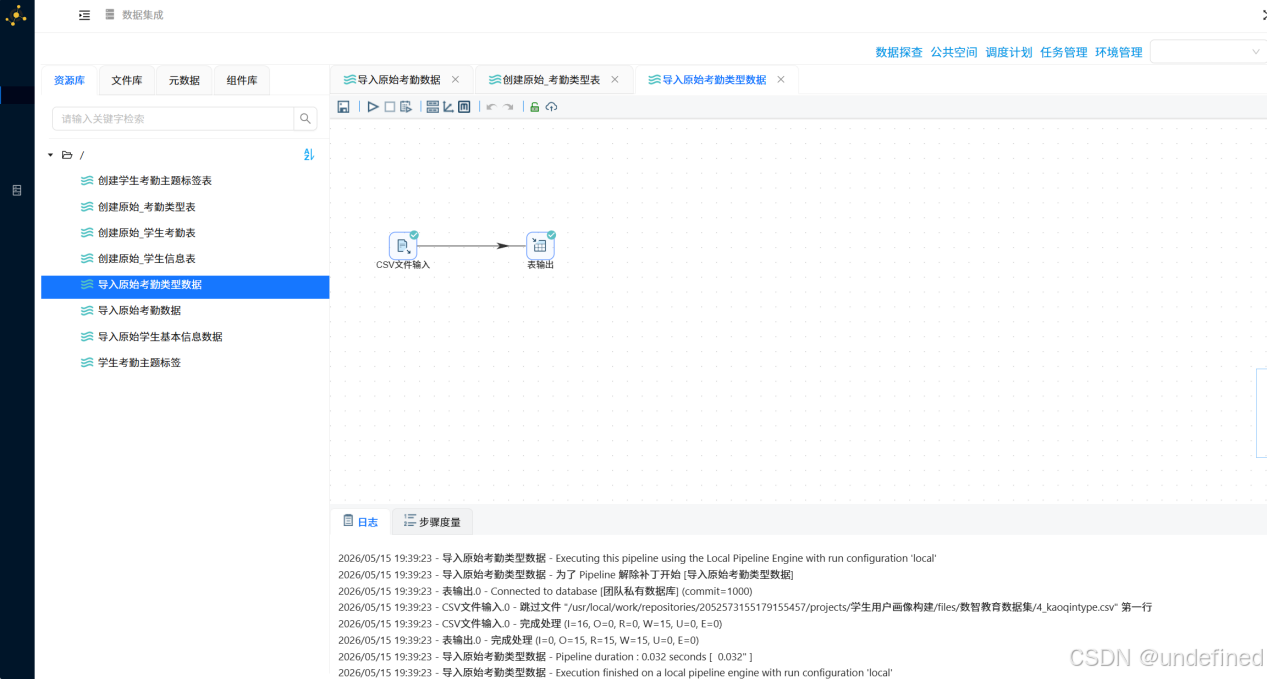
-
3.7 创建原始_学生信息表
首先新建一个名为“创建原始_学生信息表”的转化流,把“执行一个SQL脚本”拖拽到画布中。
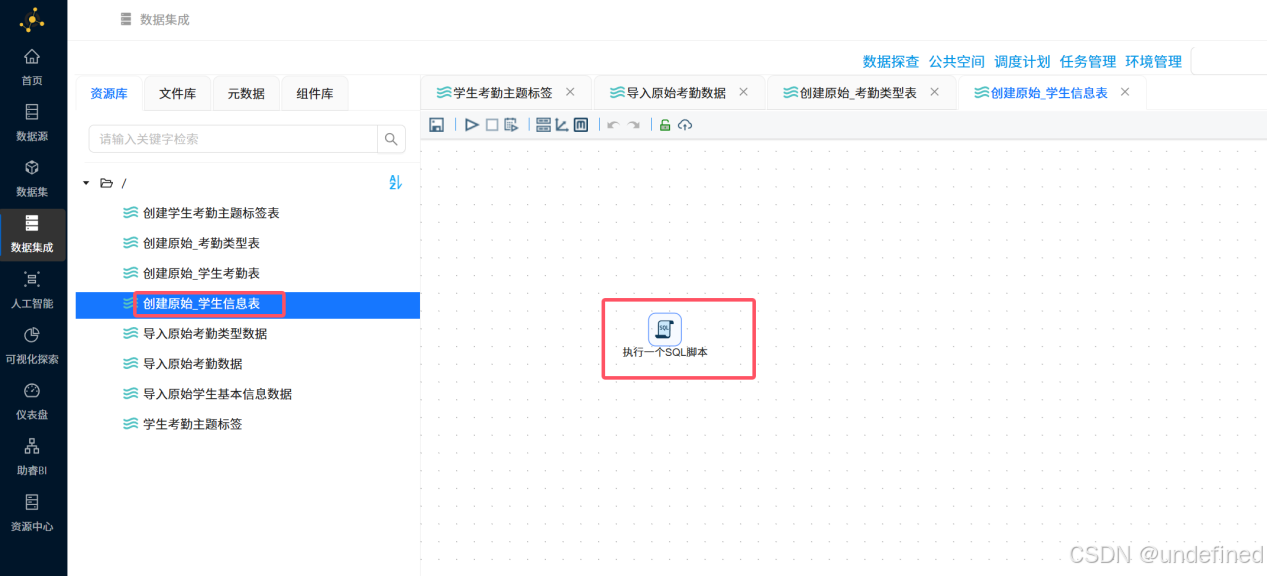
双击组件,其中的建表SQL语句为:
CREATE TABLE IF NOT EXISTS `raw_student_info` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '自增ID',
`stu_id` varchar(64) NOT NULL COMMENT '学生ID',
`stu_name` varchar(100) DEFAULT NULL COMMENT '学生姓名',
`stu_sex` varchar(10) DEFAULT NULL COMMENT '性别',
`stu_nation` varchar(50) DEFAULT NULL COMMENT '民族',
`born_date` varchar(10) DEFAULT NULL COMMENT '出生日期(年)',
`cla_name` varchar(100) DEFAULT NULL COMMENT '班级名',
`native_place` varchar(200) DEFAULT NULL COMMENT '家庭住址',
`residence_type` varchar(50) DEFAULT NULL COMMENT '家庭类型',
`policy` varchar(50) DEFAULT NULL COMMENT '政治面貌',
`cla_id` varchar(64) DEFAULT NULL COMMENT '班级ID',
`cla_term` varchar(30) DEFAULT NULL COMMENT '班级学期',
`live_on_campus` varchar(10) DEFAULT NULL COMMENT '是否住校',
`leave_school` varchar(10) DEFAULT NULL COMMENT '是否退学',
`dormitory_no` varchar(50) DEFAULT NULL COMMENT '宿舍号',
`create_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '入库时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_student_id` (`stu_id`),
KEY `idx_cla_id` (`cla_id`)
) COMMENT='原始_学生信息表';如下图所示,然后点击确定。
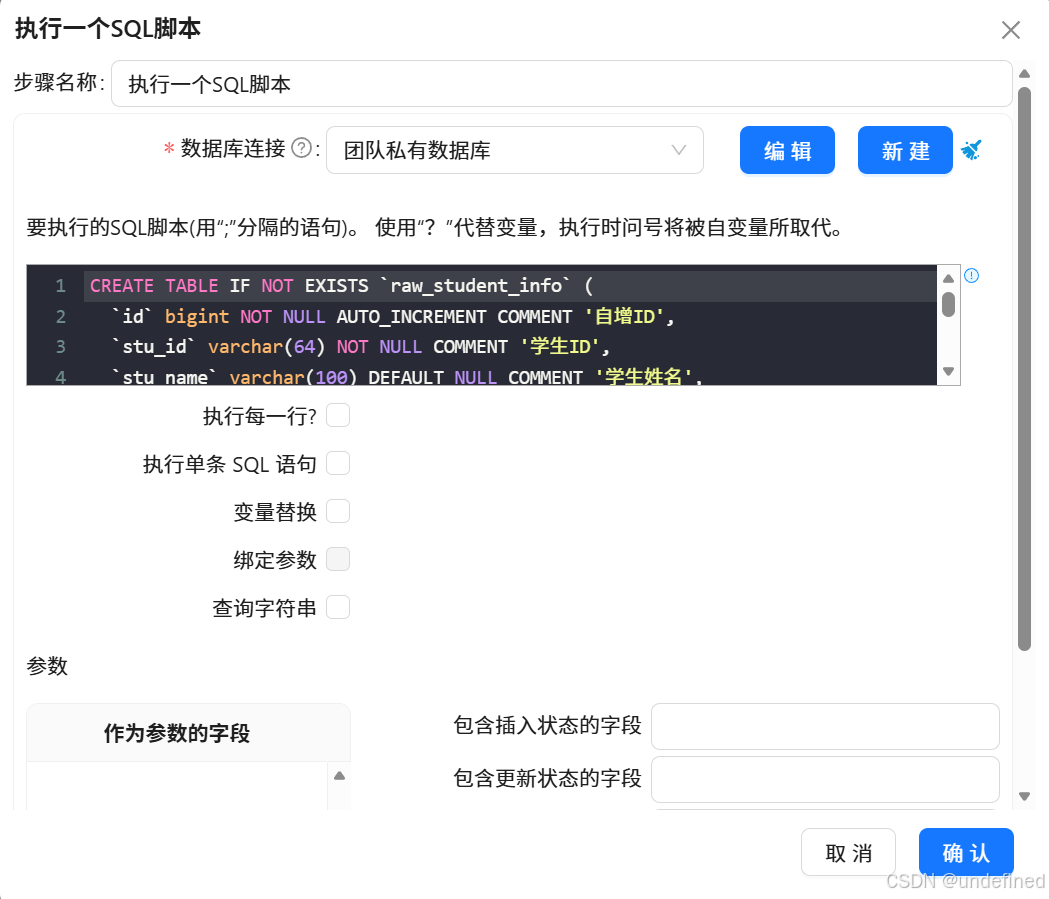
执行创建原始_学生信息表转换流:
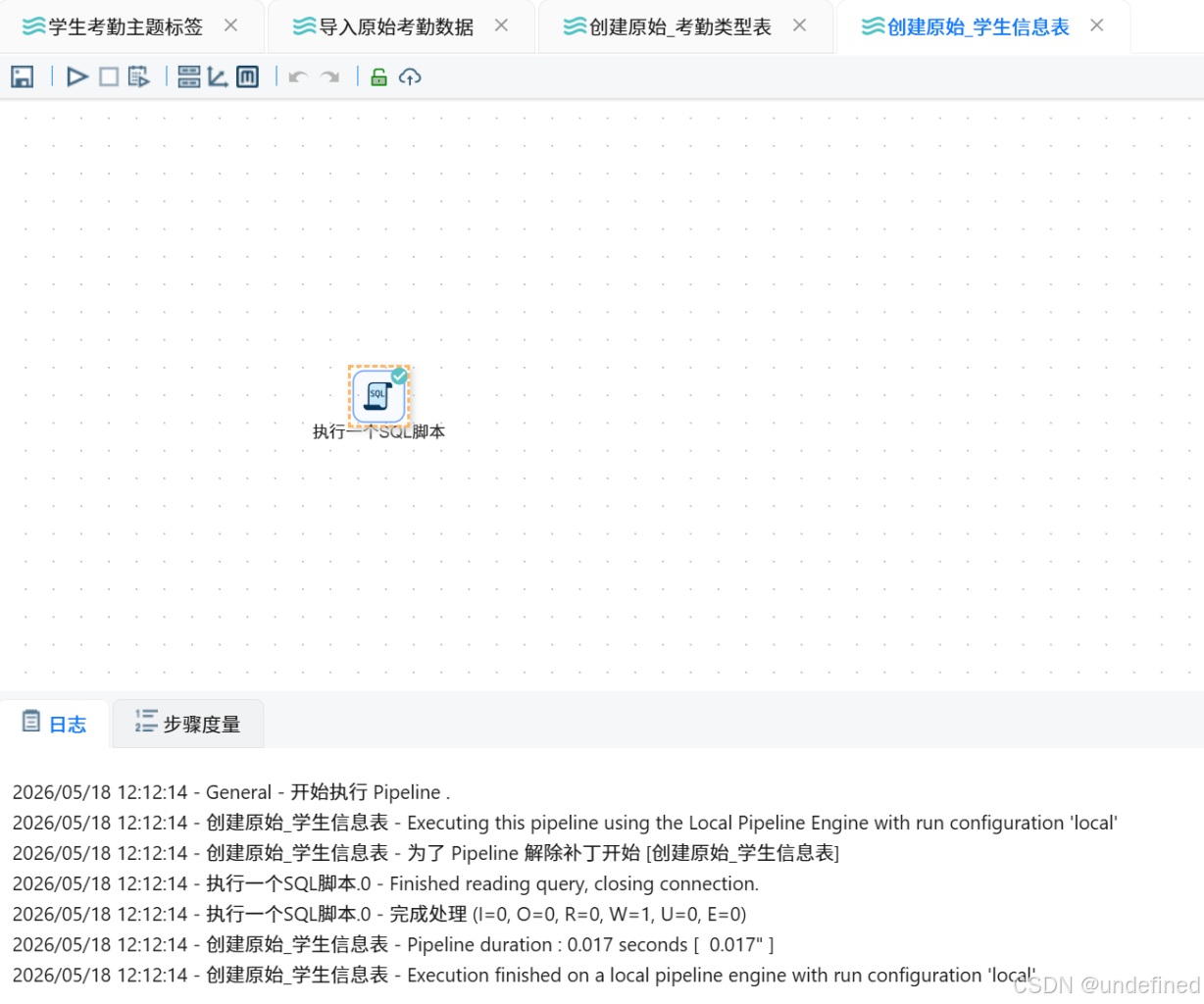
-
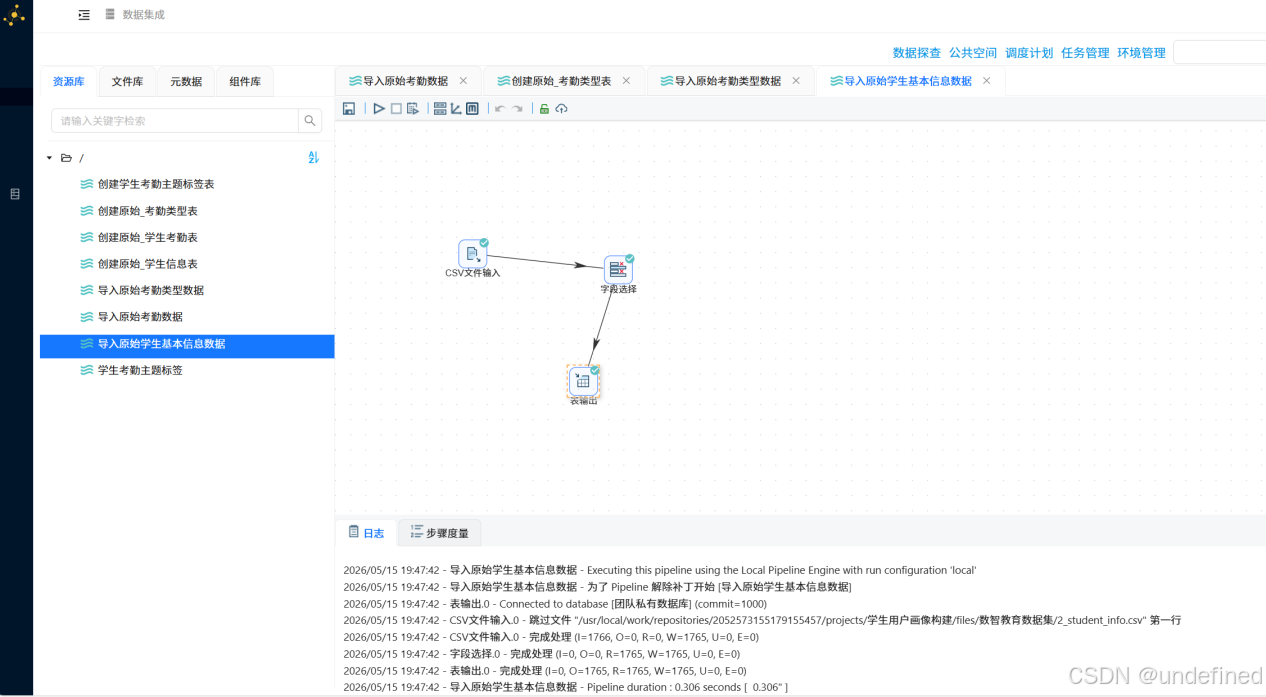
3.8 导入原始学生基本信息数据
新建名为“导入原始学生基本信息数据”的转化流,并拖拽下图所示的三个组件进入画布。
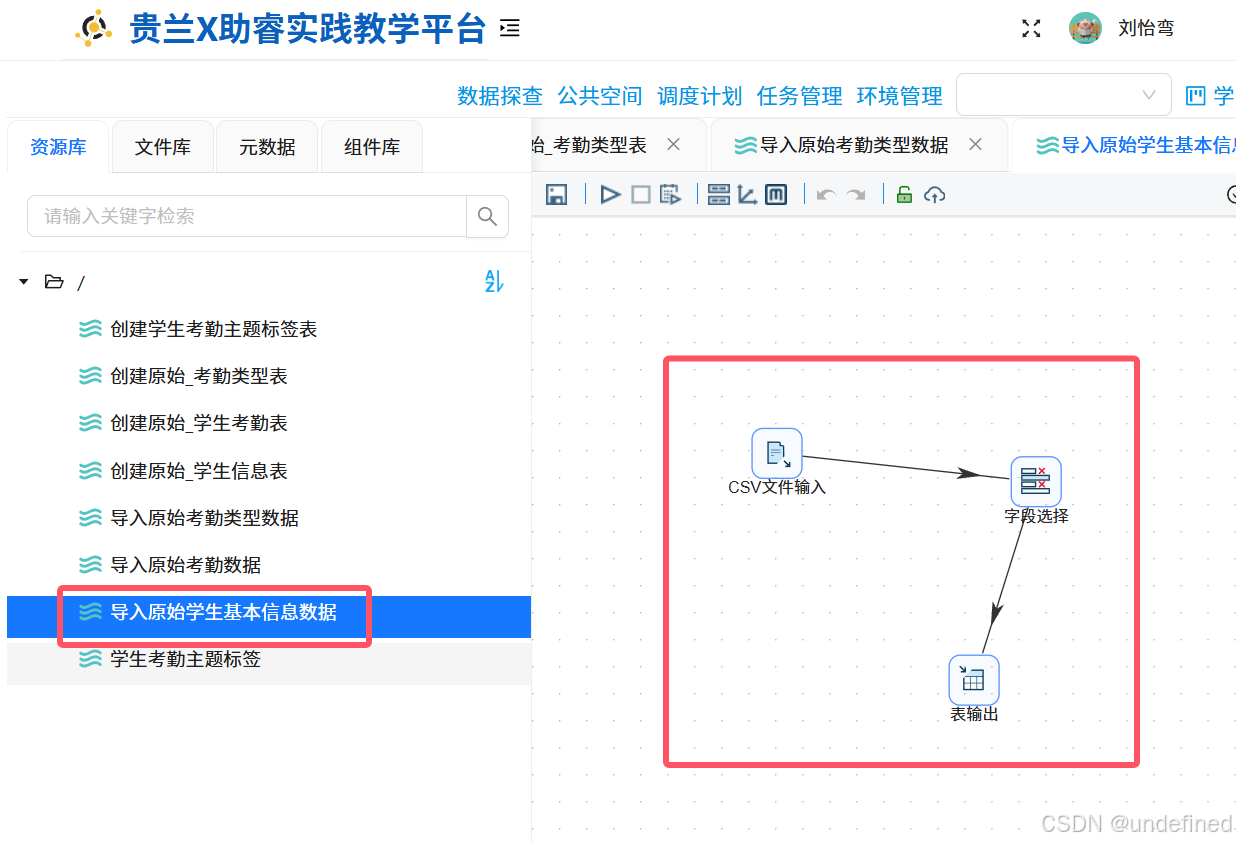
使用“CSV文件输入”组件输入“2_student_info.csv”数据。
获取字段时,需要将“bf_leaveSchool”的字段类型修改为“String”
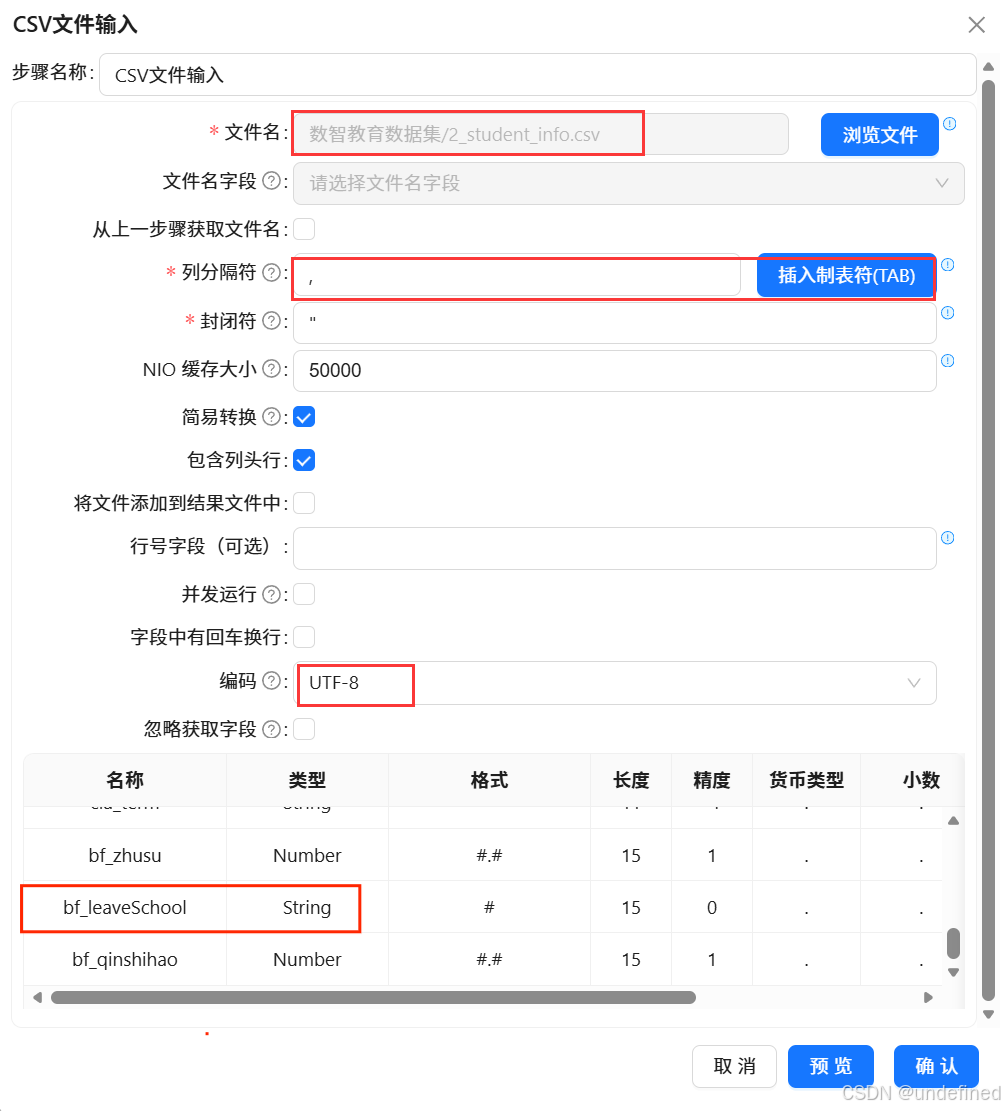
特别说明:bf_zhusu、bf_qinshihao 这2个字段是Integer,为避免出现小数,需要使用“字段选择”组件来固化并规范
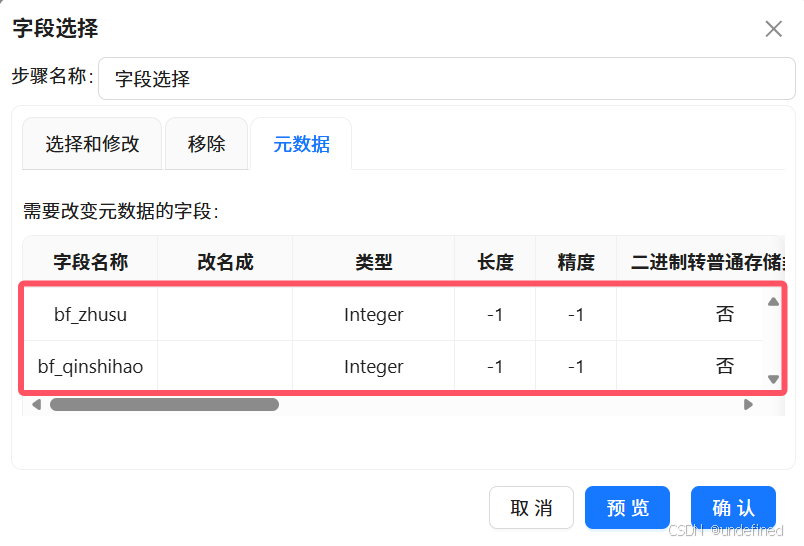
双击“字段选择”组件,在配置窗口中,点击“元数据”,并在空白处插入2行,将“bf_zhusu”、“bf_qinshihao”字段的元数据设置如下:
使用“表输出”组件将“2_student_info.csv”数据输出到团队私有数据库的“raw_student_info”中
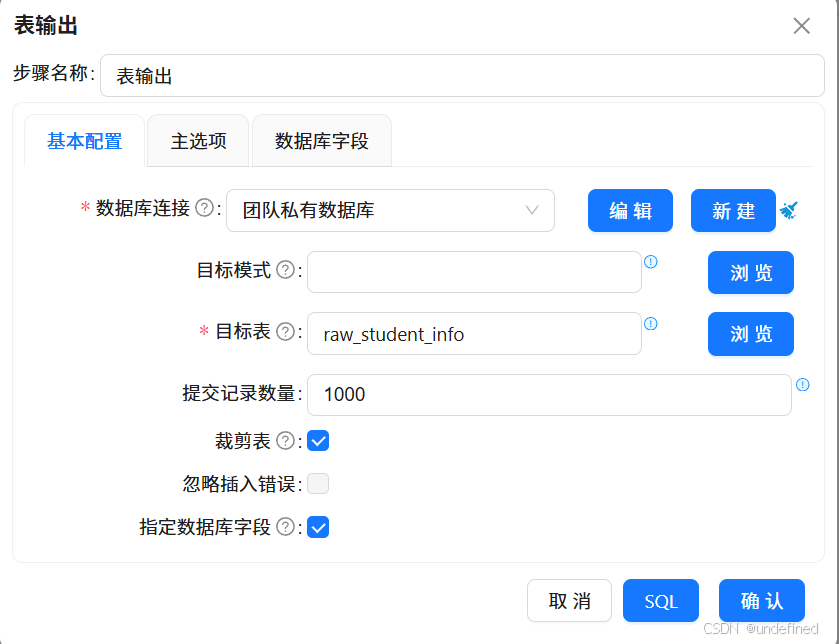
注意数据库字段的表字段也需要通过双击修改为和下图一样的字段:
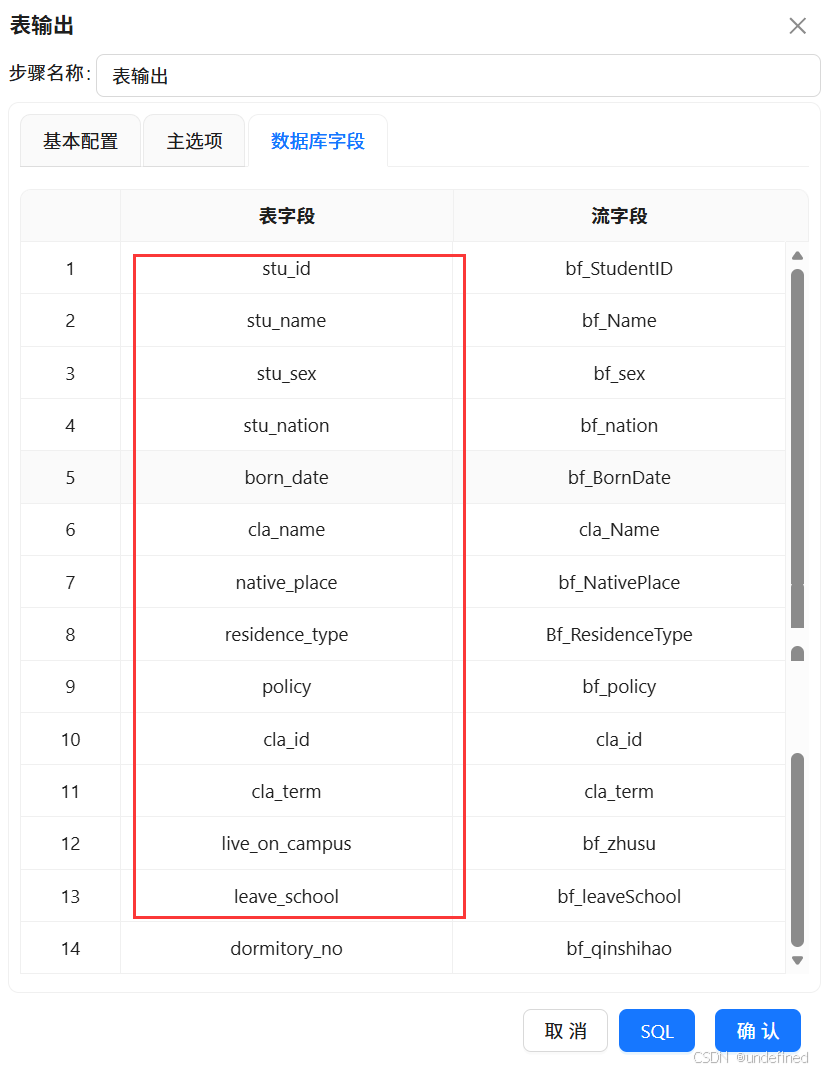
执行转化流:
-
3.9 创建学生考勤主题标签表
新建转换工作流,并命名为“创建学生考勤主题标签表”,在该工作流中拖拽“执行一个SQL脚本”组件,通过执行SQL脚本来创建一个标签表
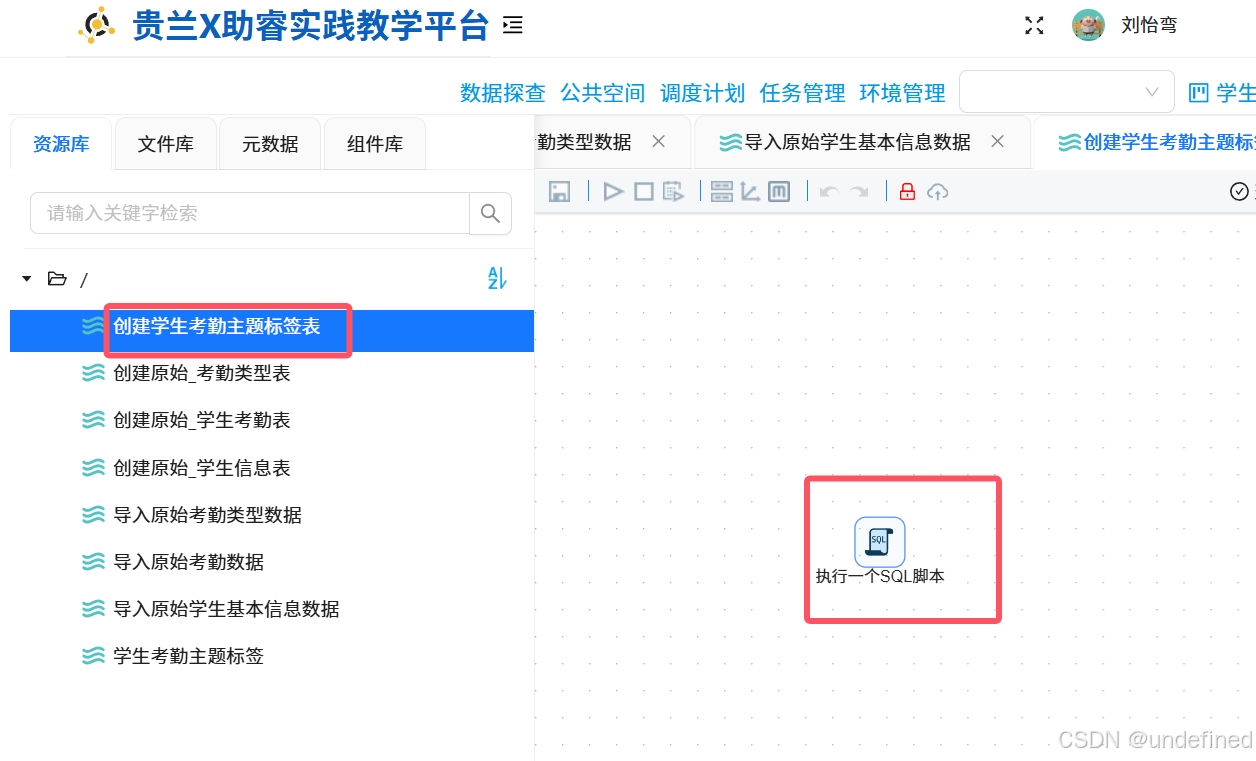
配置说明:在组件中填写SQL脚本,选择目标数据库连接“团队私有数据库”,确保脚本执行权限;
SQL脚本如下:
CREATE TABLE IF NOT EXISTS student_attendance_stats (
id INT PRIMARY KEY AUTO_INCREMENT COMMENT '自增主键',
student_id INT NOT NULL COMMENT '学生ID',
student_name VARCHAR(50) NOT NULL COMMENT '学生姓名',
class_id INT NOT NULL COMMENT '班级ID',
class_name VARCHAR(50) NOT NULL COMMENT '班级名称',
grade VARCHAR(10) NOT NULL COMMENT '年级',
gender VARCHAR(10) NOT NULL COMMENT '性别',
birth_date VARCHAR(10) NOT NULL COMMENT '出生日期',
political_status VARCHAR(20) NOT NULL COMMENT '政治面貌',
is_boarder VARCHAR(10) NOT NULL COMMENT '是否住校',
campus_type VARCHAR(10) NOT NULL COMMENT '校区类型',
late_count INT NOT NULL DEFAULT 0 COMMENT '迟到次数',
early_leave_count INT NOT NULL DEFAULT 0 COMMENT '早退次数',
leave_count INT NOT NULL DEFAULT 0 COMMENT '请假次数',
uniform_violate_count INT NOT NULL DEFAULT 0 COMMENT '没穿校服次数',
create_time DATETIME DEFAULT CURRENT_TIMESTAMP COMMENT '统计入库时间',
INDEX idx_student (student_id),
INDEX idx_class (class_id),
INDEX idx_grade (grade)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='学生考勤主题标签表';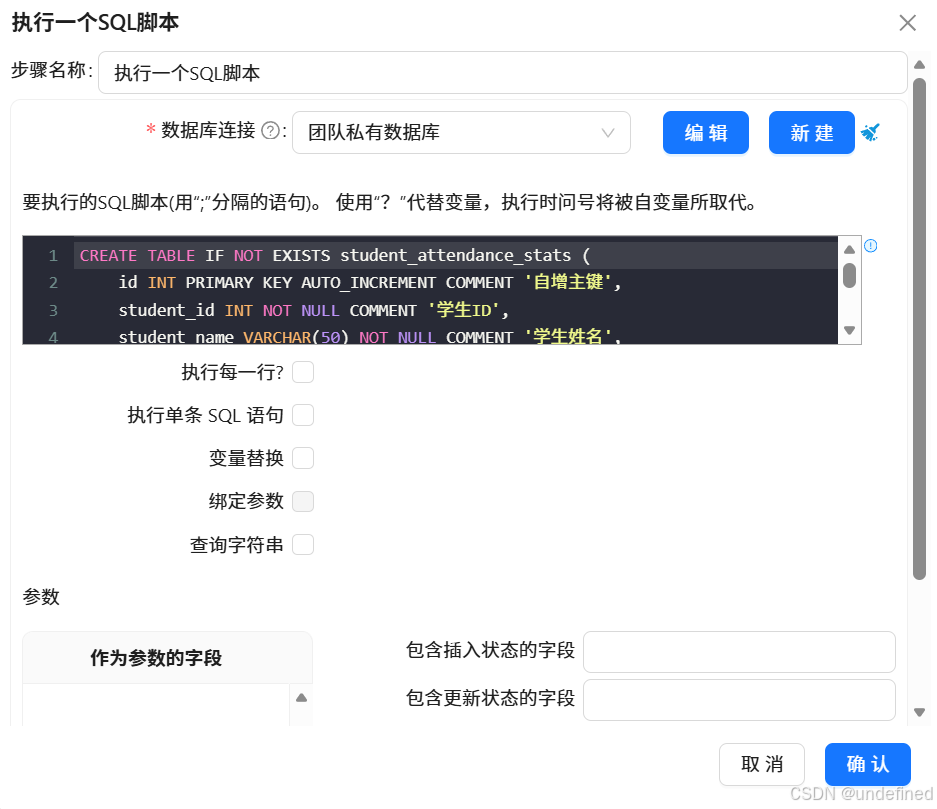
完成后运行转换流,运行过程会定时刷新组件状态,并在画布下面显示执行日志。
4 学生考勤主题标签构建
4.1 数据接入:获取考勤记录、考勤类型数据、学生信息数据
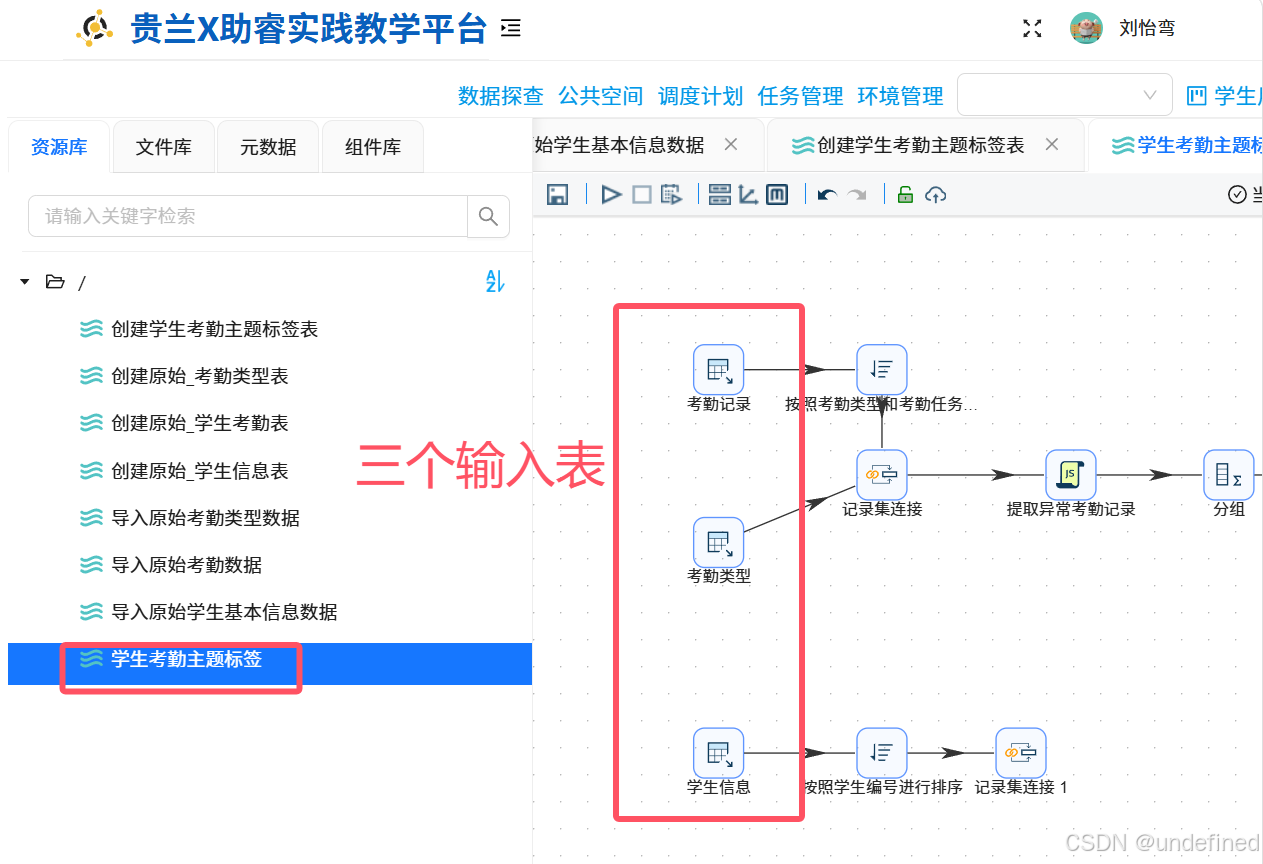
新建名为“学生考勤主题标签”转化流,拖拽三个“输入流”组件进入画布,并分别命名为“考勤记录”“考勤类型”和“学生信息”,如下图所示:
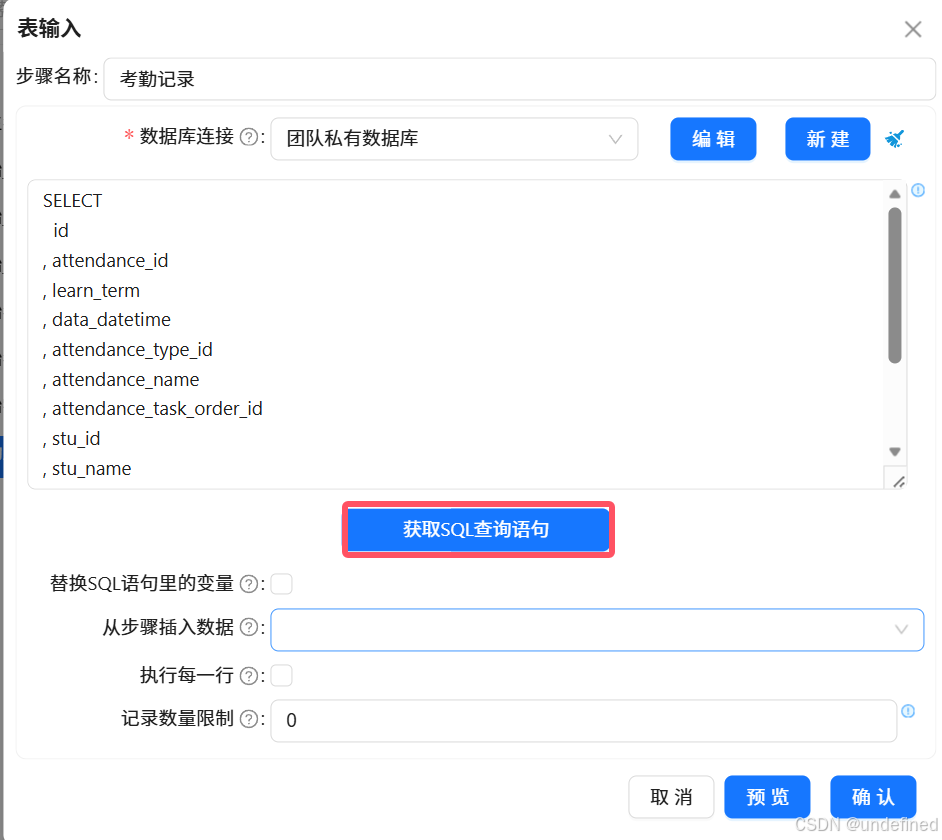
双击“考勤记录”表输入组件,在配置窗口中,数据库连接选择“团队私有数据库”,并点击“获取SQL查询语句”
在数据库中选择“raw_attendance”原始_学生考勤表
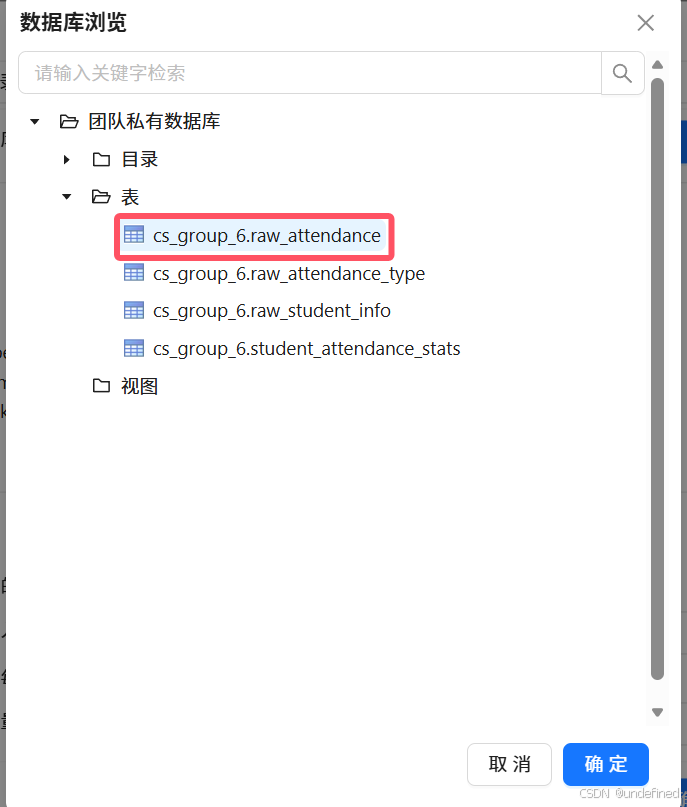
系统提示弹窗中点击“确认”,获取“raw_attendance”考勤记录表的所有字段
获取SQL查询语句后,点击“确认”
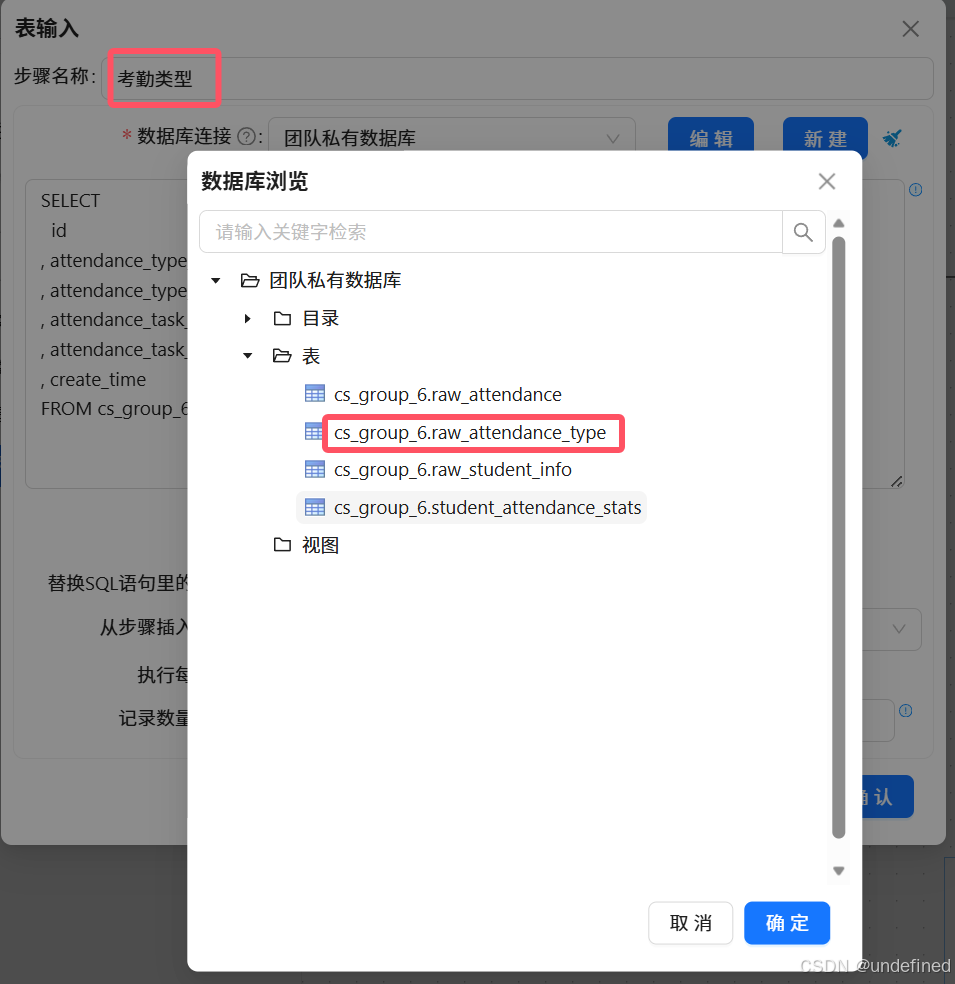
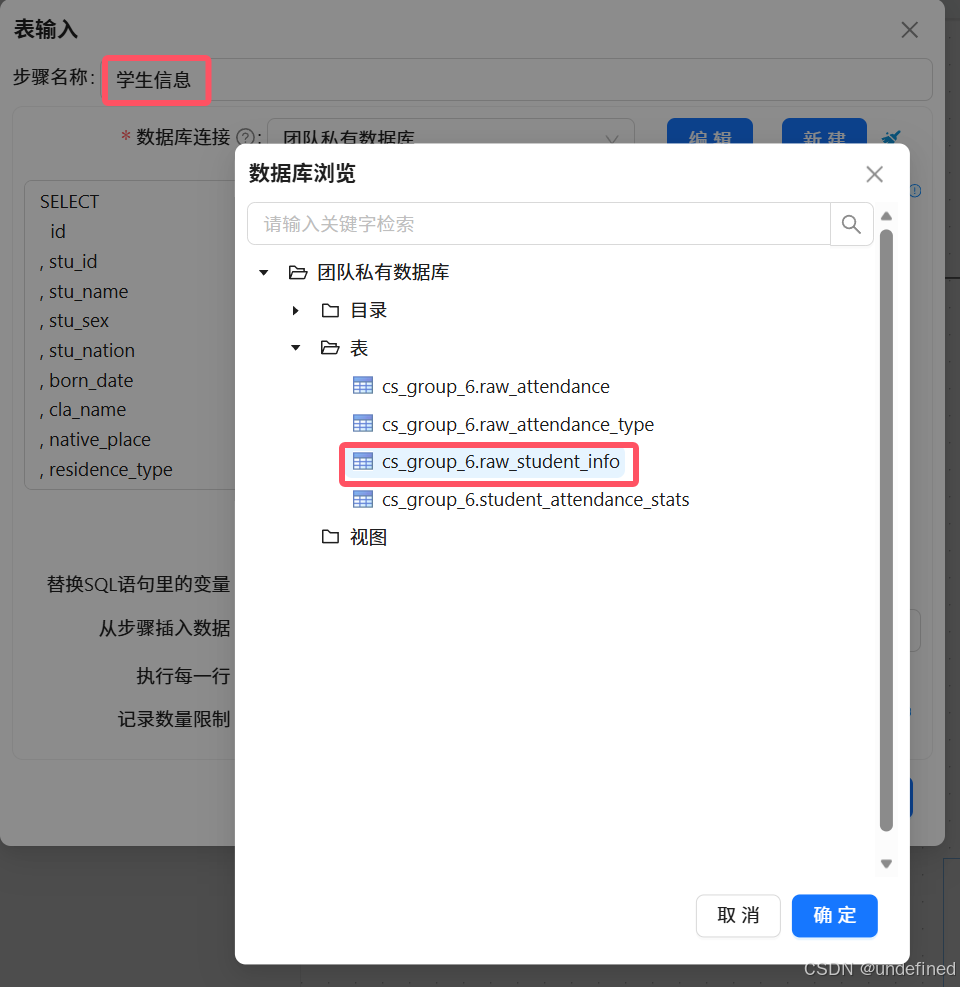
同样的,参考以上步骤,将“考勤类型”和“学生信息”组件,分别获取“raw_attendance_type”考原始_考勤类型表和“raw_student_info”原始_学生信息表所有字段数据
4.2 数据关联:关联考勤记录+考勤类型
为避免因为排序问题造成连接结果出错,拖拽“排序记录”组件进入画布中,连接“考勤记录”
双击“排序记录”组件,通过“获取字段”功能获取字段列表,然后删除多余字段,只保留“attendance_type_id”、“attendance_task_order_id”字段。因为下一步连接是使用这两个字段进行连接,所以采用这两个字段对记录进行排序。最后设置步骤名称为“按照考勤类型和考勤任务类型排序”
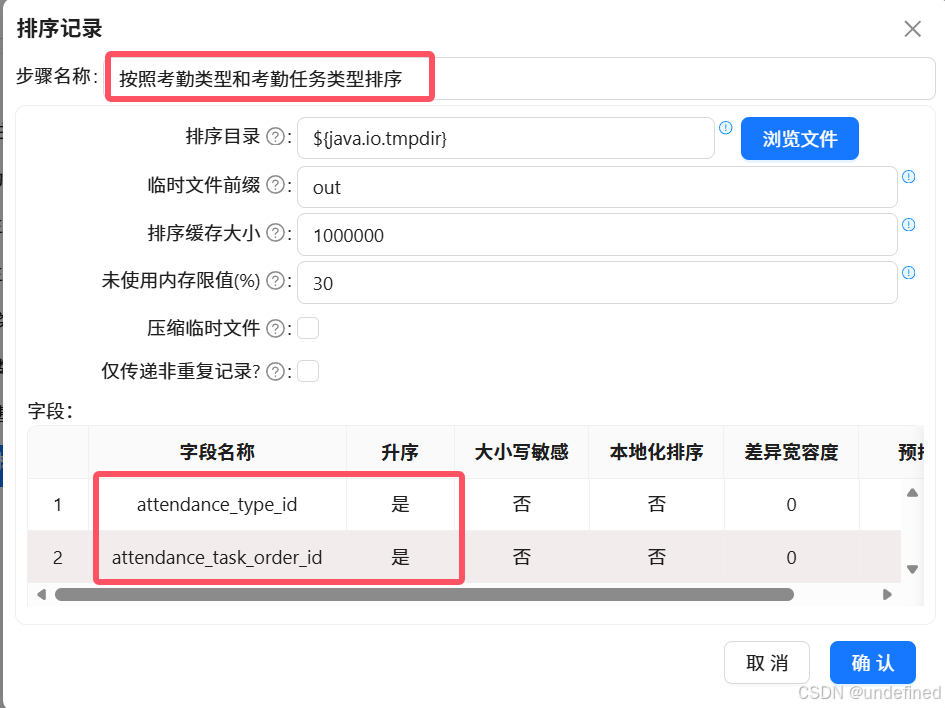
拖拽“记录集连接”组件进入画布中,连接“考勤类型”组件。由于“考勤类型”组件的记录默认是按“attendance_type_id”、“attendance_task_order_id”这两个字段升序记录的,所以无需再次排序。
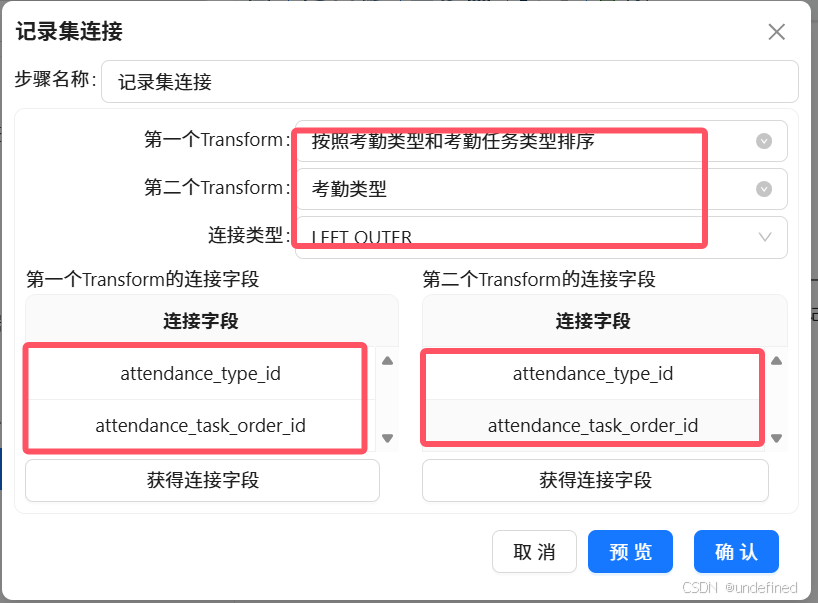
双击“记录集连接”,修改配置为下图所示:
4.3 行为标签衍生:统计学生异常考勤次数
拖拽“JavaScript 代码”组件进入画布中,对接“记录集连接”组件的输出,通过关键词匹配,生成二进制判断标签(1=是,0=否),用于后续指标聚合:
双击“JavaScript代码”组件,命名为“提取异常考勤记录”,在Script1中输入JavaScript脚本
脚本代码如下:
// 初始化变量
var isLate = 0;
var isEarly = 0;
var isLeave = 0;
var isNoUniform = 0;
// 核心判断逻辑
if(attendance_type_name != null && attendance_task_name != null){
// 迟到判断(排除请假)
if((attendance_type_name.includes("迟到") ||
attendance_type_name.includes("晚到") ||
attendance_task_name.includes("迟到") ||
attendance_task_name.includes("晚到")) &&
!attendance_task_name.includes("请假")){
isLate = 1;
}
// 早退判断(排除请假)
if((attendance_type_name.includes("早退") ||
attendance_task_name.includes("早退")) &&
!attendance_task_name.includes("请假")){
isEarly = 1;
}
// 校服违规:只要包含“校服”就标记违规
if(attendance_type_name.includes("校服") || attendance_task_name.includes("校服")){
isNoUniform = 1;
}
}
// 请假判断
if(attendance_task_name != null){
if(attendance_task_name.includes("请假")){
isLeave = 1;
}
}使用“获取变量”获取输出字段,系统将自动解析脚本中变量定义代码,生成字段数据
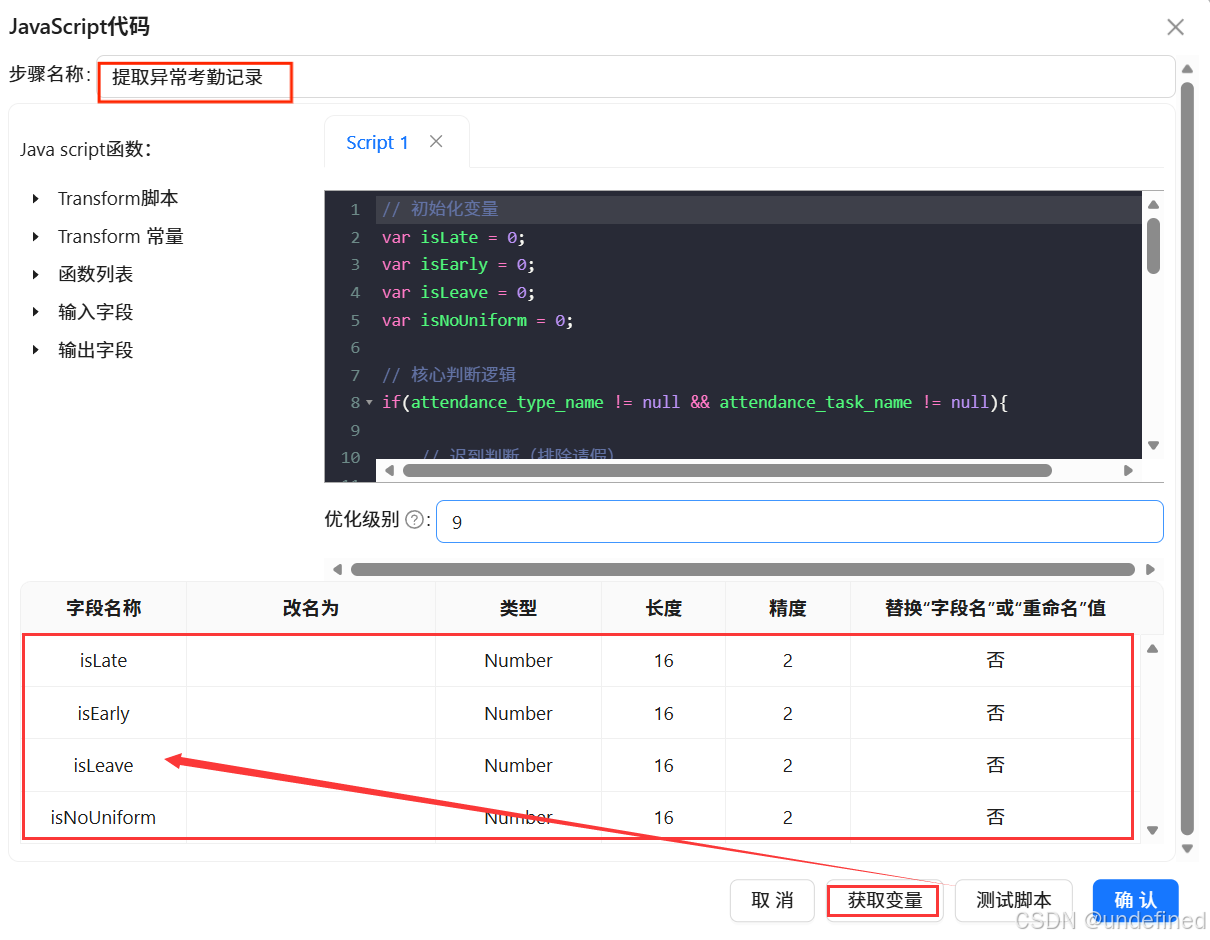
点击“JavaScript脚本”组件的“测试脚本”按钮,确认标记字段(is_late_early、is_leave等)仅存在1和0两个值,标签判断准确(如迟到记录对应is_late_early=1,正常出勤对应is_compliant=1),无异常。
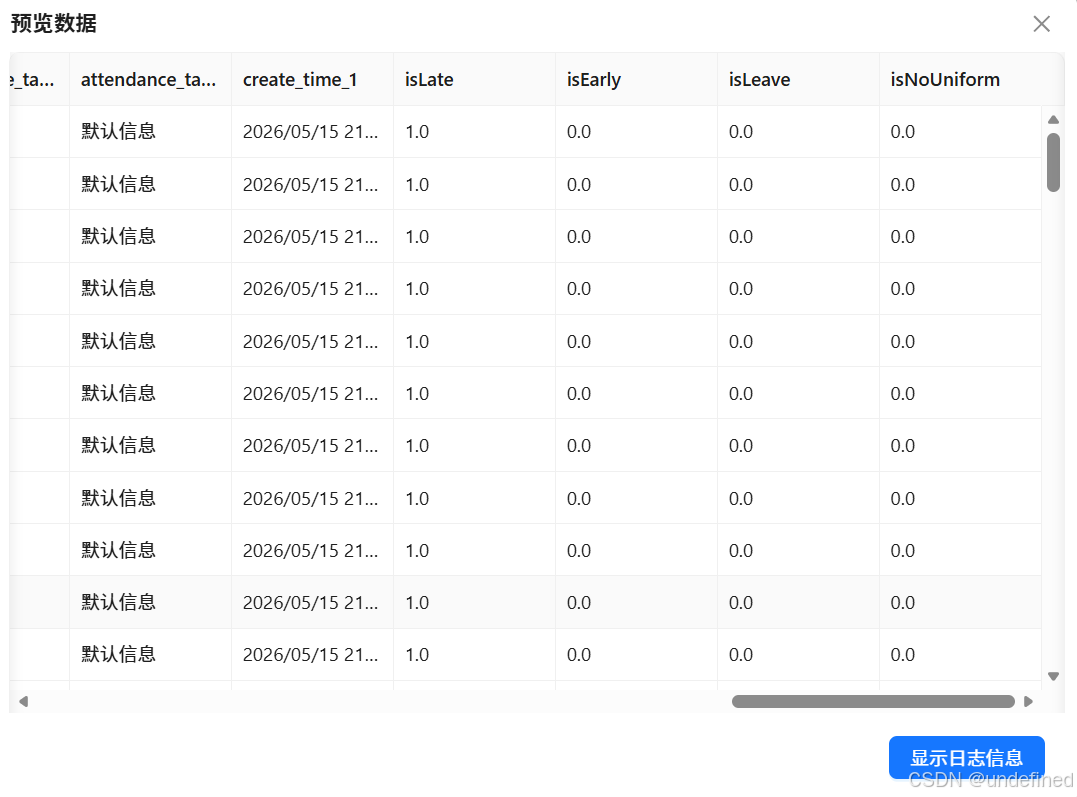
4.4 多维度分组聚合统计
拖拽“分组”组件进入画布,连接“提取异常考勤记录”
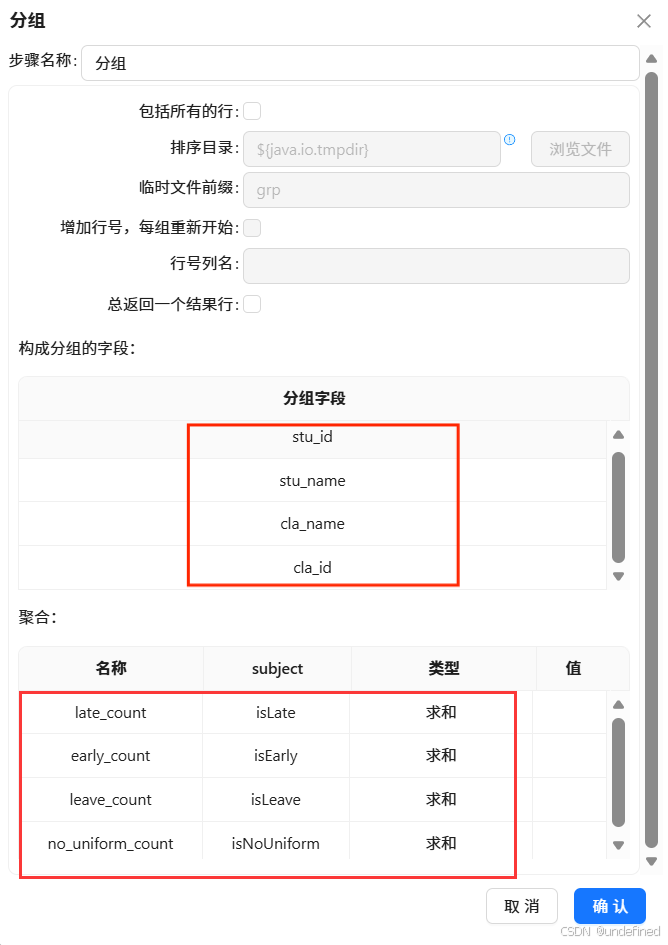
对“分组”组件进行如下配置:
4.5 关联学生信息
由于“学生信息”数据表中的学号不是升序记录的,所以在进行记录关联前,也需要对数据进行排序。拖拽“排序记录”组件进入画布,并建立“学生信息”表输入组件到“排序记录”组件的连接线
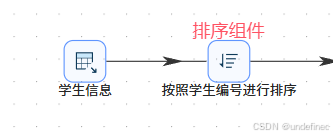
双击“排序记录”组件,通过“获取字段”功能获取字段列表,然后删除多余字段,只保留“stu_id”字段。因为下一步连接是使用这个字段进行连接,所以采用这个字段对记录进行排序。最后设置步骤名称为“按照学生编号进行排序”
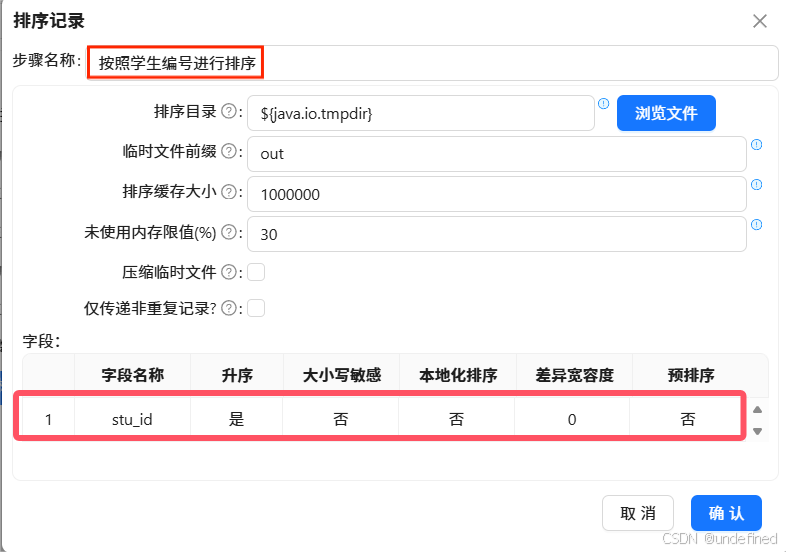
拖拽“记录集连接”组件至画布中,创建“按照学生编号进行排序”排序记录组件到“记录集连接 1”组件的连接线
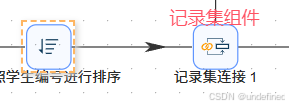
由于考勤记录数据不是按“学号”升序记录的,所以在进行记录关联前,也需要对数据进行排序。再次添加“排序记录”,并建立“记录集连接”组件到“排序记录”组件的连接线
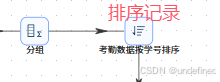
双击“排序记录”组件,按下图进行配置,步骤名称设置为“考勤数据按学号排序”,排序字段为“stu_id”
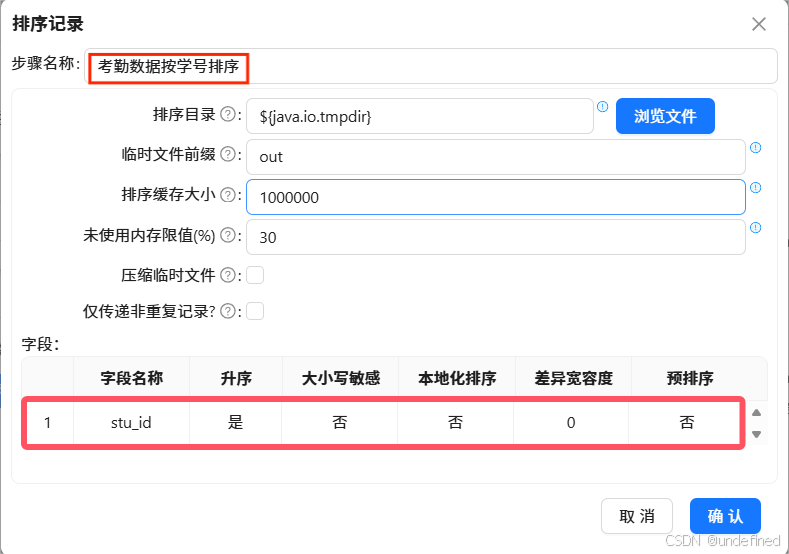
创建“考勤数据按学号排序”记录排序组件到记录集连接 1组件的连线,关联学生信息和考勤记录信息
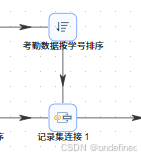
双击“记录集连接”组件,对组件进行如下配置:
点击第一个Transform的连接字段中的“获得连接字段”按钮,即可获取考勤记录和考勤类型关联后的字段。同样的,获取第二个Transform的连接字段。第一个Transform字段保留“stu_id”,第二个Transform字段保留“stu_id”。
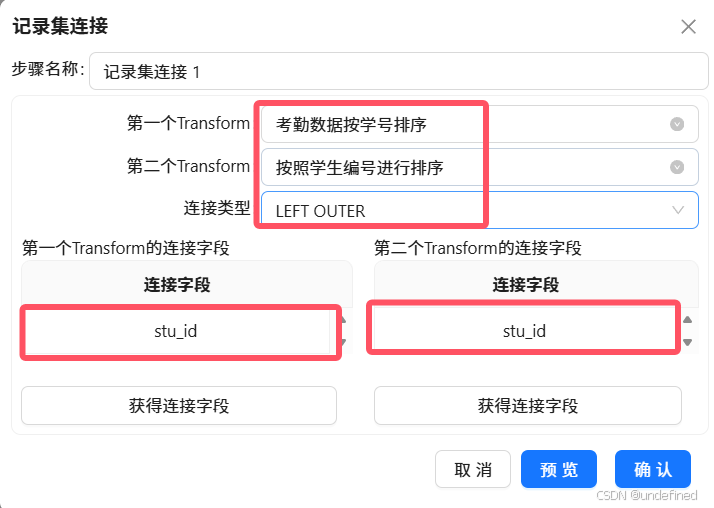
4.6 字段选择:移除冗余字段
经过多表关联和前期接入,数据中会包含大量与考勤统计无关的字段(如学生信息表中的非必要属性),需要对关联后的数据进行冗余字段移除,因为这些冗余字段不仅会增加数据处理的负担,还可能导致后续聚合、计算出现干扰,只有移除冗余字段,保留核心有用字段,才能提升处理效率,确保统计逻辑清晰。
首先拖拽“字段选择”组件至画布中,创建“记录集连接 1”组件到字段选择组件的连接线
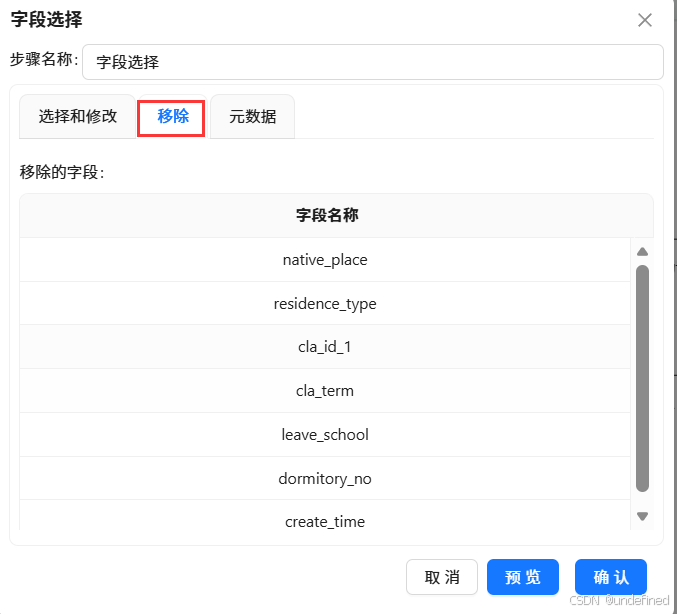
双击字段选择组件,在配置弹窗中,步骤名称输入“移除冗余字段”,点击“移除”标签,右键空白处并点击“获取字段”
在获取的字段中,删除以下核心字段外,其他字段保留,为后续时间维度拆解和行为标签衍生奠定基础:
学生 ID(stu_id)
学生姓名(stu_name)
班级 ID(cla_id)
班级名称(cla_name)
迟到次数(late_count);
早退次数(early_count);
请假次数(leave_count);
没穿校服次数(no_uniform_count)
性别(stu_sex)
出生日期(born_date)
政治面貌(policy)
是否住校(live_on_campus)
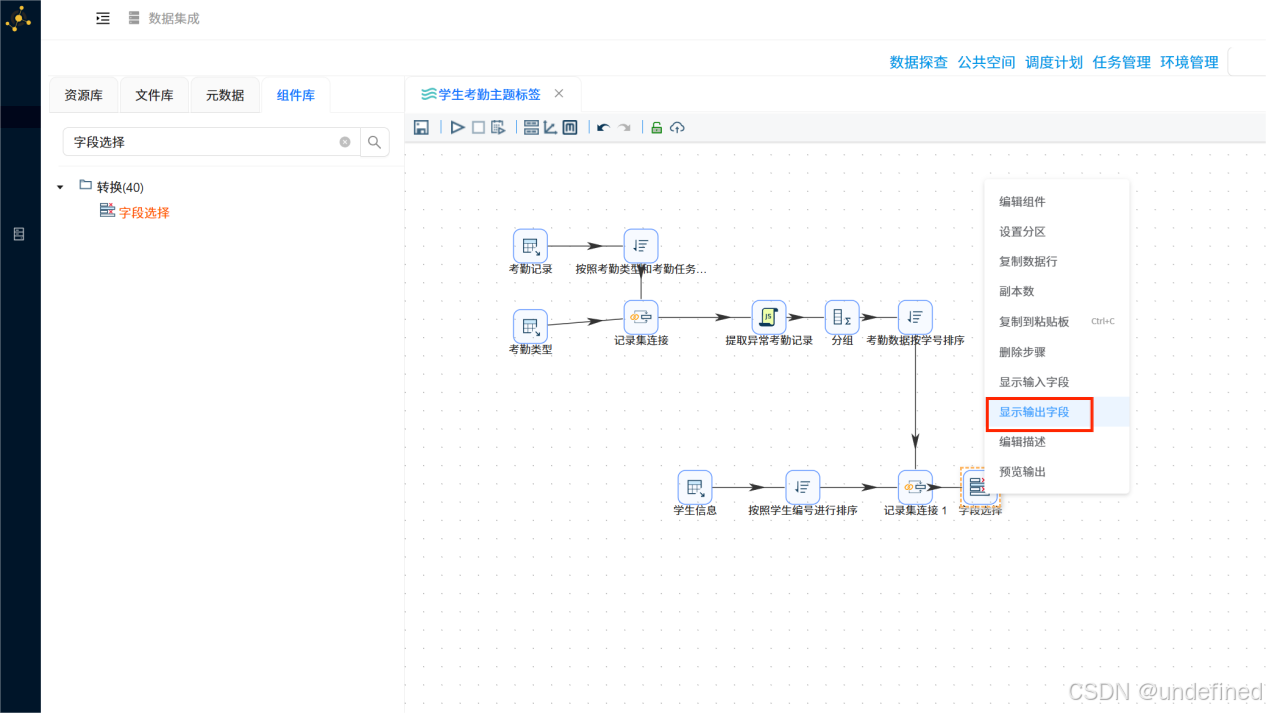
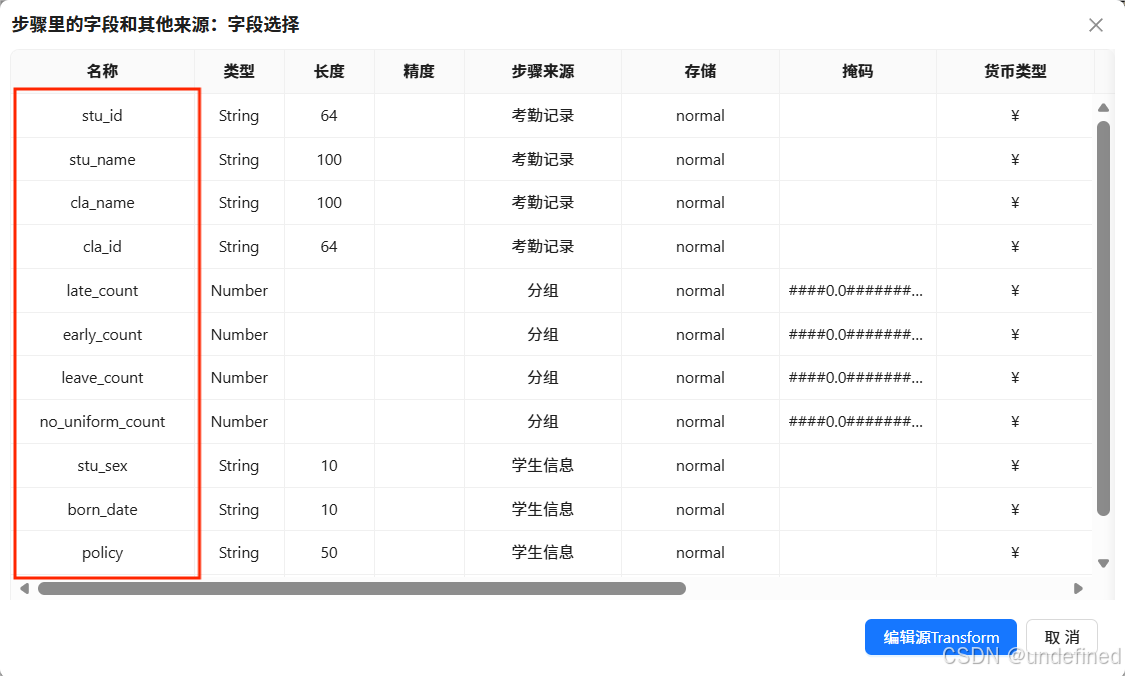
在字段选择组件鼠标右键弹出菜单,点击“显示输出字段”,查看输出字段是否正确
4.7 空值处理
3个数据表关联后,字段“stu_sex”、“born_date”、“policy”、“live_on_campus”存在空值,需要对这么空值进行处理。
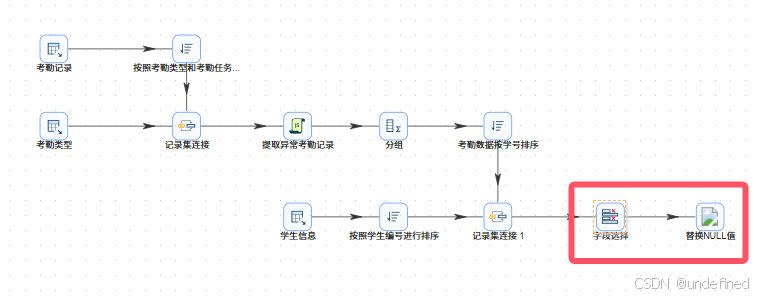
拖拽“替换NULL值”组件至画布,创建“移除冗余字段”字段选择组件到“替换NULL值”组件的连线,连线类型选择“主输出步骤”
双击“替换NULL值”组件,勾选“选择字段”,并在字段空白表格中右键。点击“插入”
双击插入的行,字段名称选择“stu_sex”,继续插入行,将“born_date”、“policy”、“live_on_campus”的空值均替换为“未知”
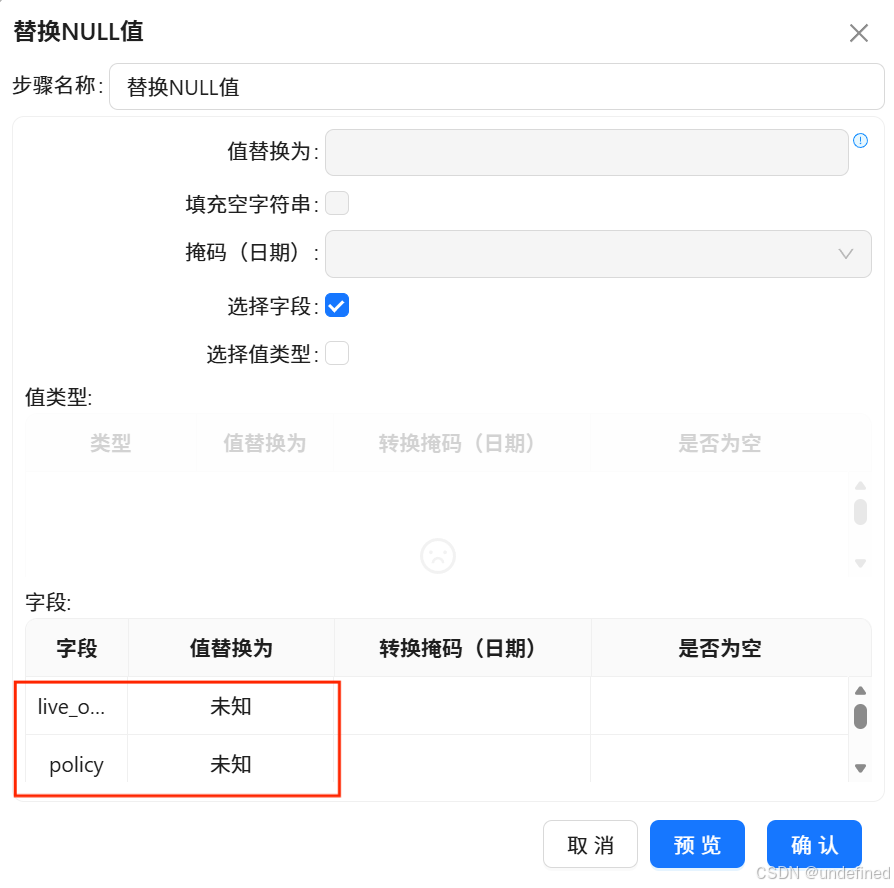
4.8 学生基础属性标准化处理
经过多表关联与字段筛选后,原始数据中住校状态为编码值,且缺少年级、校区类型等画像分析必需字段,无法直接用于学生考勤标签输出与后续用户画像分析。因此需要对学生基础属性进行标准化映射、缺失字段衍生,统一数据格式、补齐分析维度,保证标签表规范可用。
拖拽“值映射”组件到画布中,并创建替换NULL值组件到值映射组件的连线,并选择“主输出步骤”
双击“值映射”组件,步骤名称改为“住校状态映射”,使用的字段名为“live_on_campus”,不匹配时的默认值为“否”。然后在下方字段值表格空白处右键,点击“插入”
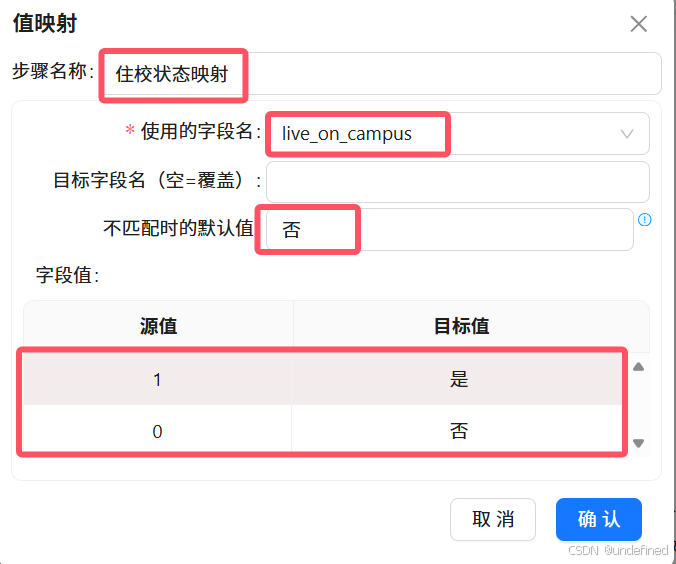
原始数据无独立年级字段,无法按年级做考勤统计与画像分群,通过从班级名称中提取年级信息,补齐年级维度,支撑年级层面的考勤分析。
拖拽“JavaScript代码”组件至画布中,创建住校状态映射组件到JavaScript代码组件的连线
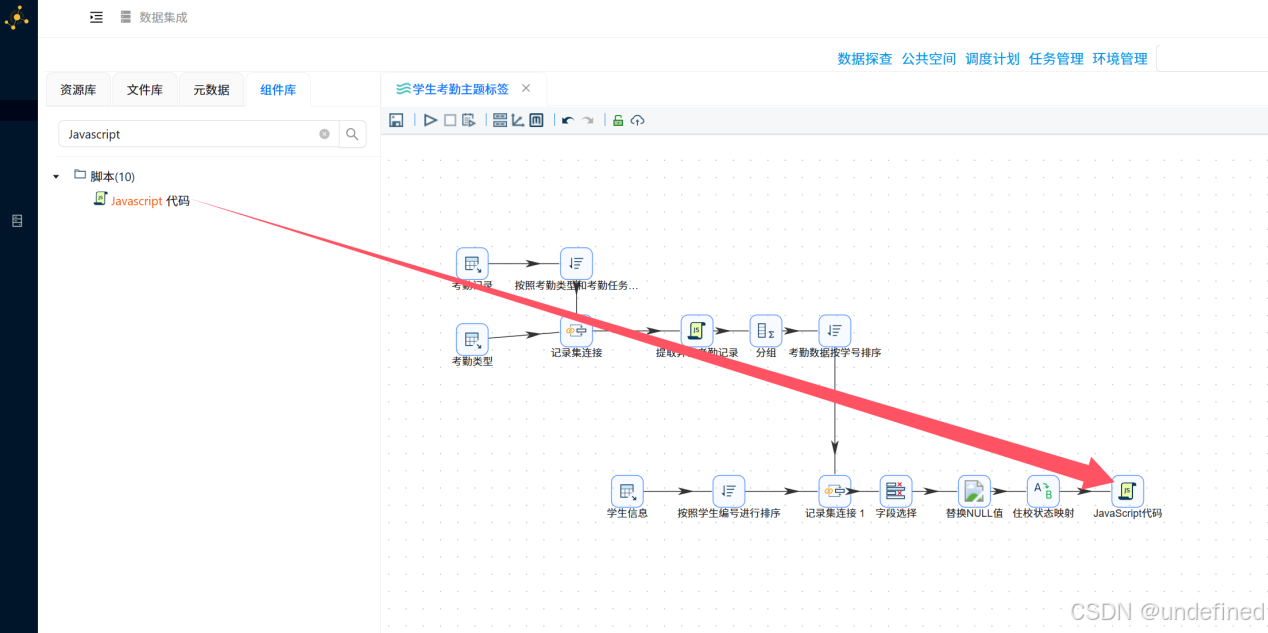
双击“JavaScript代码”组件,步骤名称改为“从班级提取年级”,并输入以下代码:
var gra_name
if (cla_name == null){
gra_name='未知'
}else if(cla_name.includes('高一')){
gra_name='高一'
}else if (cla_name.includes('高二')){
gra_name='高二'
}else if (cla_name.includes("高三")){
gra_name='高三'
} else{
gra_name='未知'
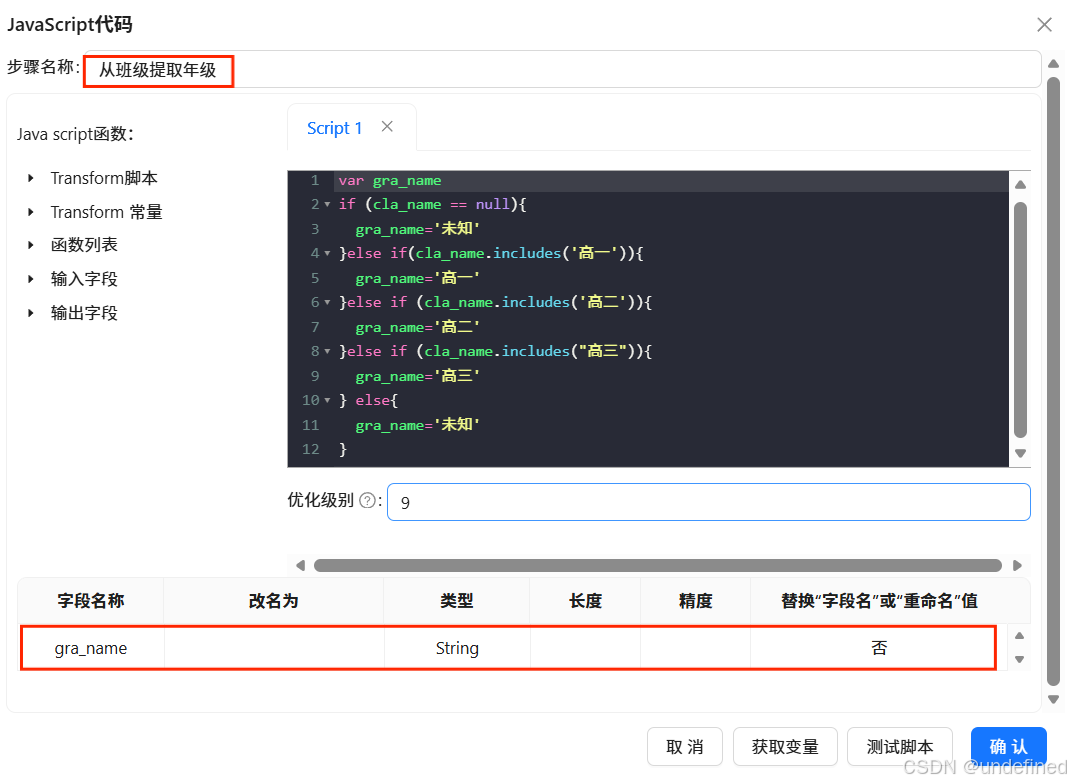
}接下需要设置“gra_name”字段类型,在配置窗口的下方空白表格处右键,点击“插入”,字段名称输入“gra_name”,类型为“String”,替换“字段名”或“重命名”值选择“否”,设置完成后点击“确认”
原始数据无校区类型字段,不同校区管理口径与考勤规则存在差异,通过班级名称规则判定老校区/新校区,增加校区分析维度,使考勤标签更贴合校园实际管理场景。
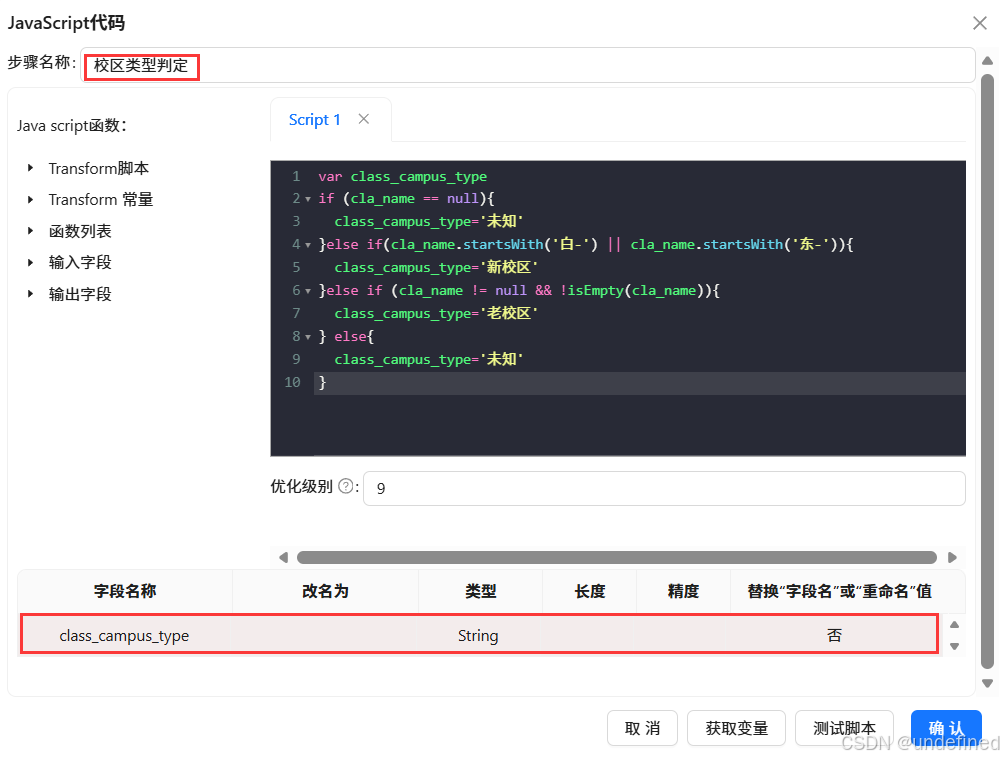
添加“JavaScript代码”组件,“JavaScript代码”组件命名为“校区类型判定”,输入的代码如下:
var class_campus_type
if (cla_name == null){
class_campus_type='未知'
}else if(cla_name.startsWith('白-') || cla_name.startsWith('东-')){
class_campus_type='新校区'
}else if (cla_name != null && !isEmpty(cla_name)){
class_campus_type='老校区'
} else{
class_campus_type='未知'
}
字段名称“class_campus_type”,类型为“String”,替换“字段名”或“重命名”值选择“否”
4.9 结果入库
拖拽“表输出”到画布中,并连接“校区类型判定组件”
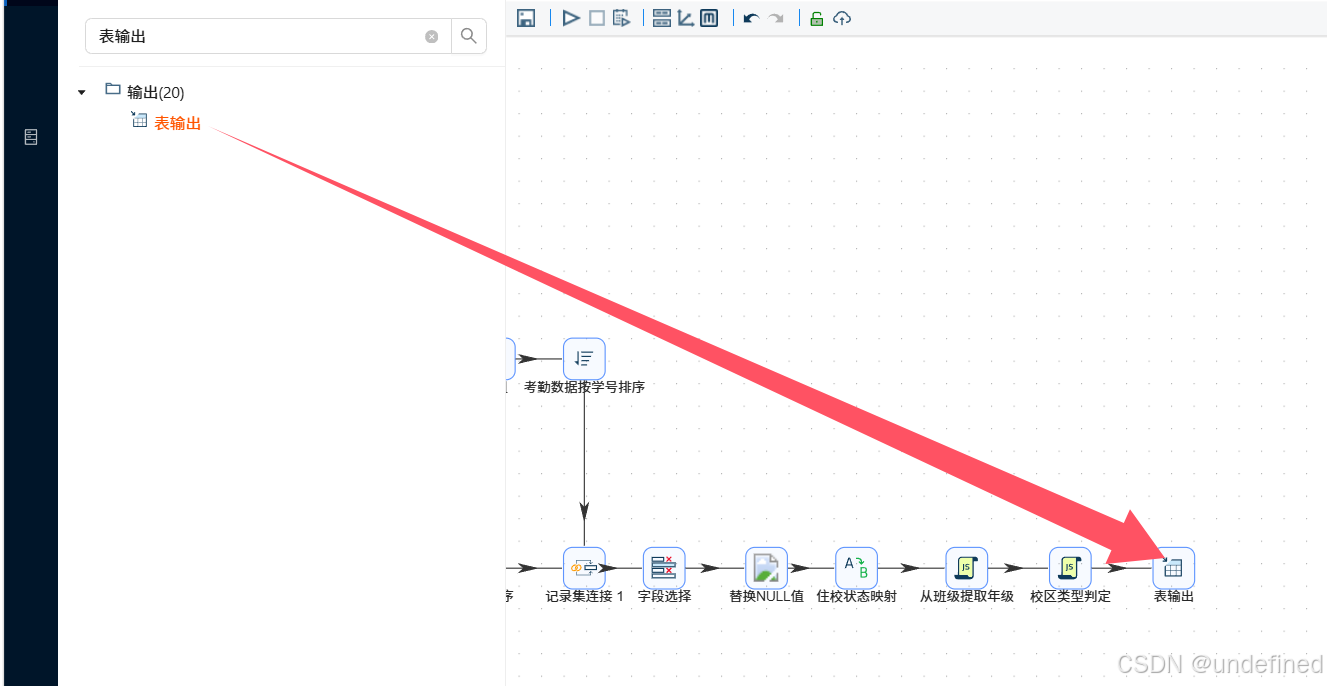
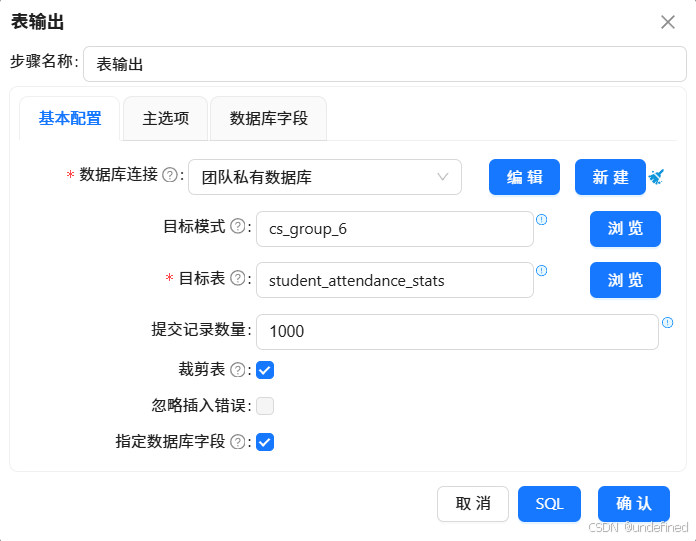
按照下述图片对组件进行配置,注意目标表的输入需要点击“浏览”选择对应的表
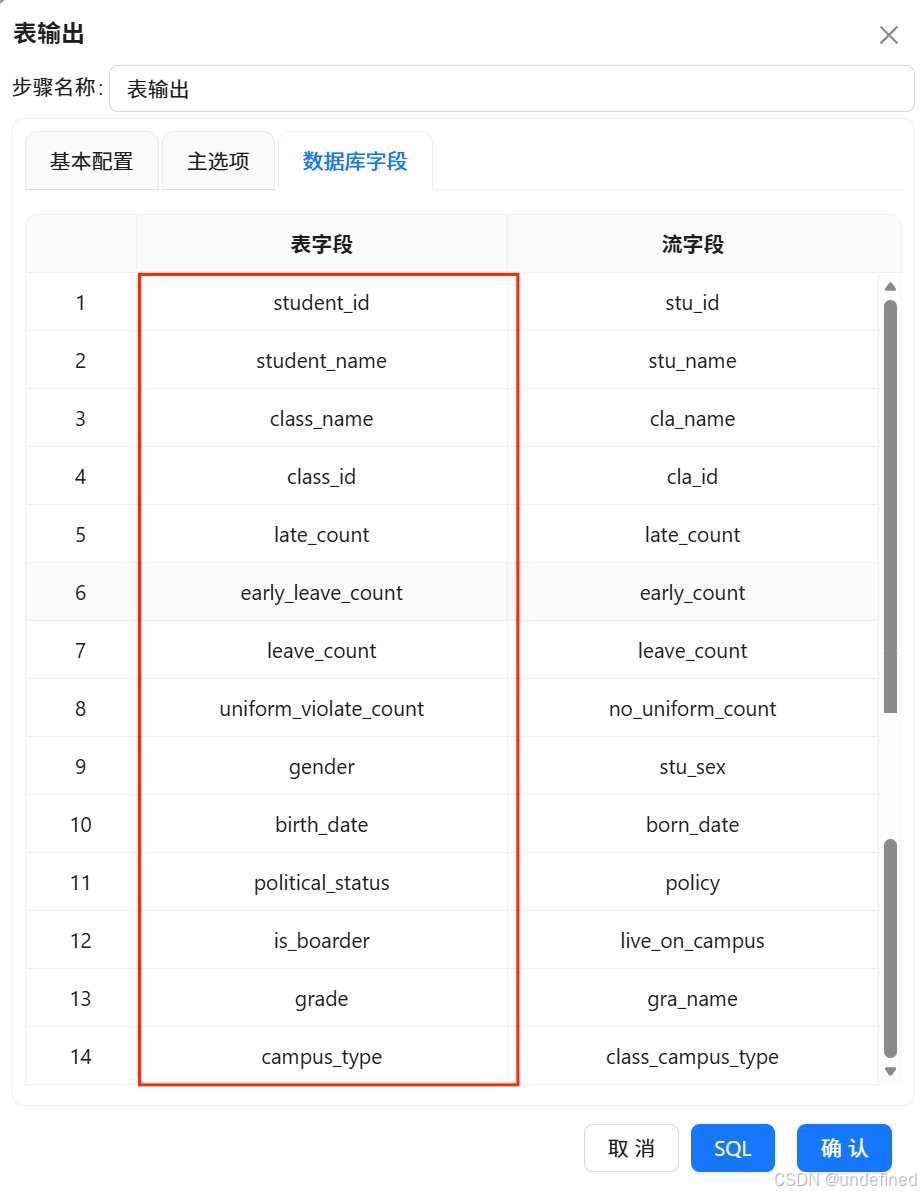
点击“数据库字段”,右键“获取字段”,双击表字段中的字段名称,在下拉框中选择正确的对应字段
执行转换流,点击工具栏中的“执行”按钮。查看日志,工作流执行后会打开日志页面,定期刷新工作流日志数据。
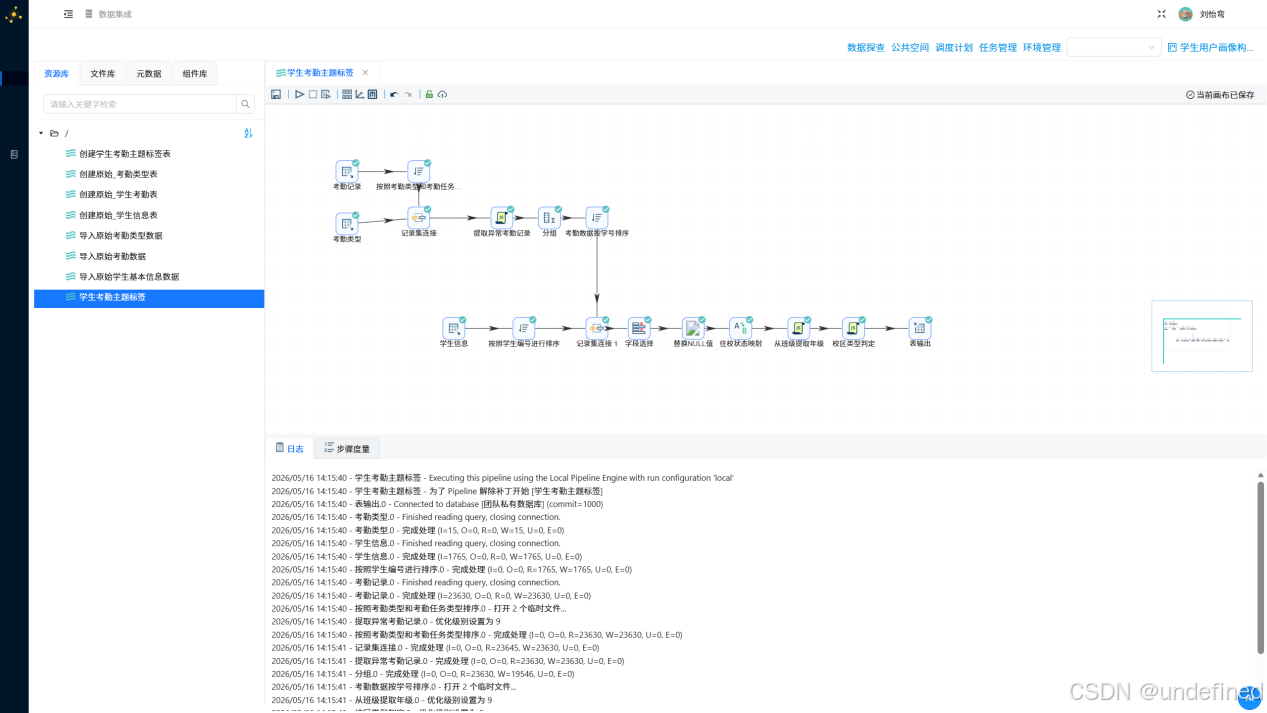
打开“元数据”tab页,在“团队私有数据库”连接上右键选择“加载元数据”
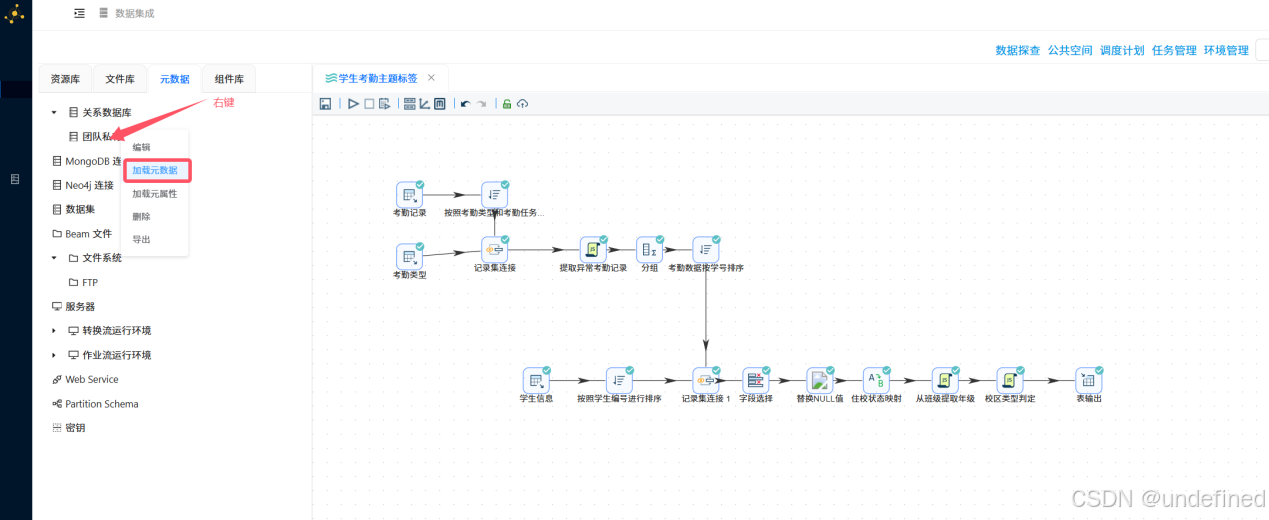
然后进入数据探查页面,展开“团队私有数据库”
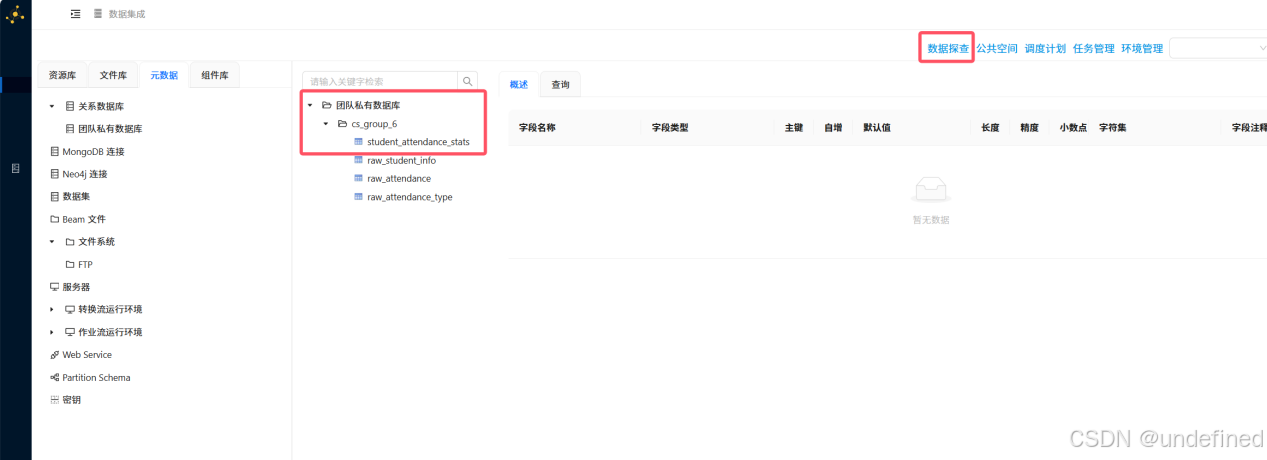
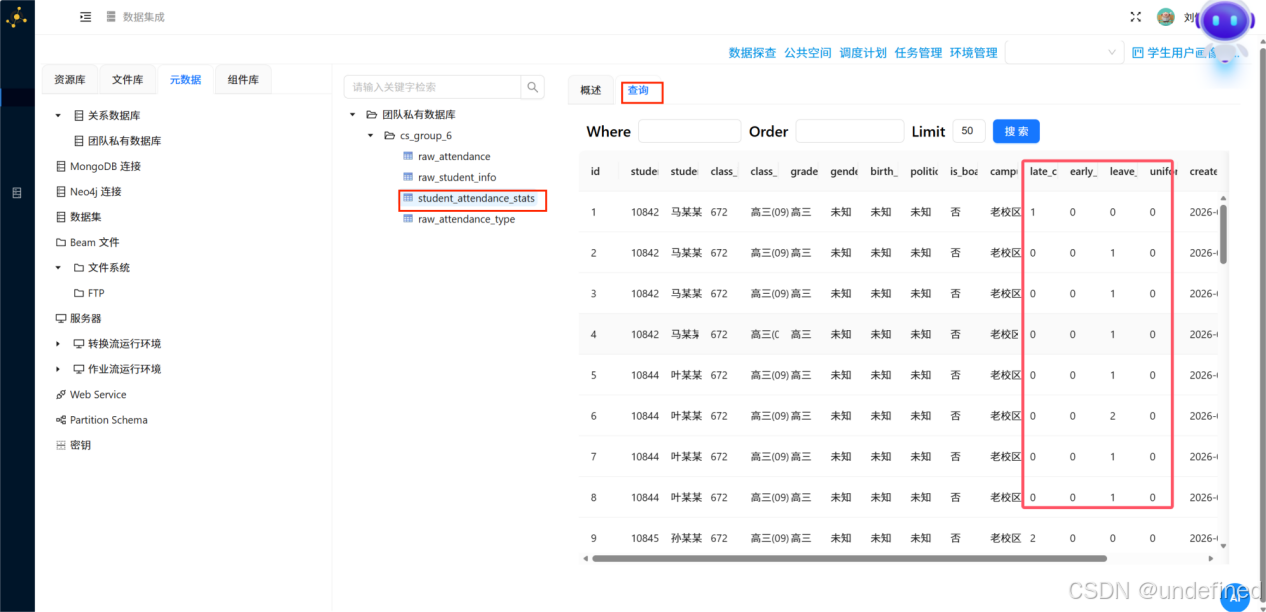
双击目标表“student_attendance_stats”,在右侧页面选择“查询”tab标签,可以看到结果符合预期
4 问题与解决
问题一:第一次在Javascript组件点测试脚本没有报错,但后面再次点击时会出现报错
解决方案:是后续组件配置不正确引起的,测试脚本会执行整个工作流。删除后续添加的组件再点击测试脚本。
问题二:在最后的表输出组件中,数据库字段的表字段的下拉列表中没有出现相对应的表字段
解决方案:在创建学生考勤主题标签表的“执行一个SQL脚本”组件中修改SQL脚本,重新创建student_attendance_stats 表和相关字段,然后再重新获取字段。
5 实验总结
本次实验以 “数智教育” 数据集为基础,在助睿零代码平台完成学生考勤主题标签构建全流程 ETL 实践。通过创建原始考勤、考勤类型、学生信息三张核心表,完成数据导入、多表关联、异常考勤识别、分组统计与属性标准化处理,最终生成包含学生基础信息、住校状态、年级校区及迟到 / 早退 / 请假 / 校服违规等维度的考勤标签表,有效解决校园考勤统计低效、标准不统一的问题。实验过程中掌握了数据接入、清洗、关联、衍生、聚合与入库的完整操作,熟悉空值处理、字段映射与脚本判断等关键技巧,提升了零代码数据加工与学生用户画像构建的实践能力。

一站式 AI 云服务平台
更多推荐

 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)