
基于助睿平台的学生用户画像考勤主题标签构建
本次实验让我掌握了助睿平台的全流程数据处理能力,从项目创建、多数据源接入,到数据关联、清洗衍生、聚合统计与结果输出,成功完成了将原始数据转换为标准化学生考勤标签。我理解并掌握了空值处理、字段映射、关键词匹配等数据清洗技巧,同时建立了从校园考勤业务需求出发,通过数据手段解决人工统计效率低、口径不统一问题的工程思维,为后续数据科学项目奠定了基础。助睿平台凭借零代码可视化操作,大幅降低了ETL学习门槛,
基于助睿平台的学生用户画像考勤主题标签构建
实验背景
1.1 实验目的
本次实验旨在设计并实现一个学生多维度考勤统计的助睿ETL转换流。通过该实验,掌握以下技能并完成以下任务:
-
掌握ETL数据处理全流程:包括数据接入、多表关联、衍生字段生成、聚合统计及结果输出。
-
解决实际问题:替代人工Excel统计,统一考勤统计口径,提升效率,避免统计口径不一致的问题。
-
优化空值处理逻辑:结合实际数据情况,设计合理的空值替换策略,确保转换流可稳定运行。
-
输出精准统计结果:生成多维度考勤指标,为校园考勤管理提供数据支撑。
1.2 实验环境
-
实验平台:助睿数智(Uniplore)一站式数据科学实验平台
-
登录地址:https://lab.guilian.cn/
-
平台官网:https://www.uniplore.com/
-
数据库:MySQL
-
实验数据:“数智教育”大赛数据集,共包含7张核心业务表,本次实验聚焦考勤记录表(3_kaoqin.csv)、考勤类型表(4_kaoqintype.csv)、学生基本信息表(2_student_info.csv)
1.3 处理流程简述
-
数据接入。将考勤记录表(3_kaoqin)、考勤类型表(4_kaoqintype)、学生基本信息表(2_student_info)三张核心表接入助睿ETL平台。
-
多表关联。对考勤记录表与考勤类型表按考勤类型ID进行左外连接,补充考勤事件标准化名称;再将结果与、学生基本信息表按学生ID进行左外连接,补充学生基础属性信息。
-
标签衍生。从班级名称中提取年级、判断校区类型;映射是否住校字段。
-
指标计算。按学生维度聚合,统计迟到次数、早退次数、请假次数、没穿校服次数。
-
字段整理。移除连接后产生的重复字段,保留学生ID、姓名、班级、性别、出生日期、政治面貌等基础属性,以及四项考勤行为统计指标。
-
结果输出。将多维度考勤统计结果输出到目标表或Excel文件中。
实验步骤
2.1创建实验项目
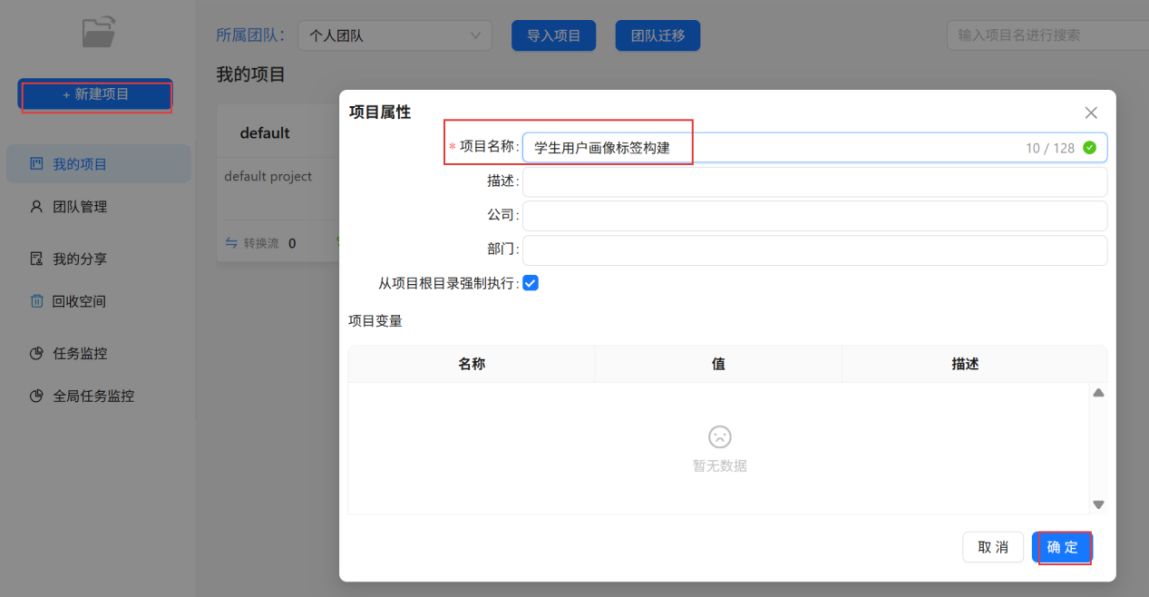
点击“+新建项目”,输入项目名称“学生用户画像标签构建”,点击“确定”。
2.2 数据资源获取
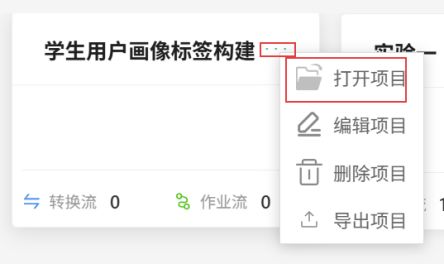
点击该项目右上角“…”,点击“打开项目”。
2.2.1获取实验数据集
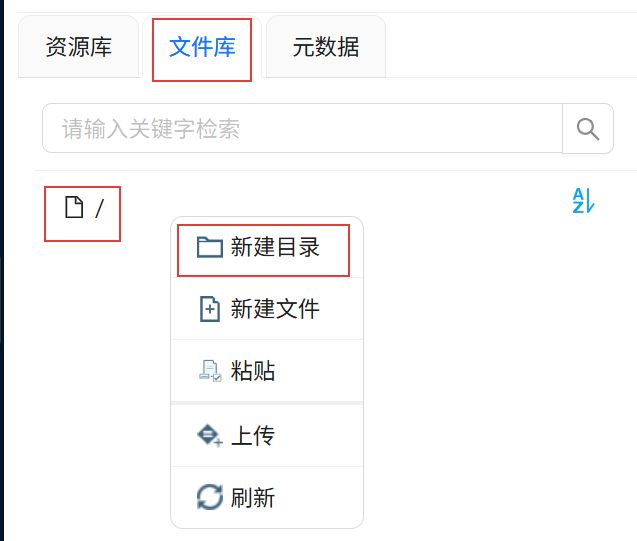
点击“文件库”,右键根目录,点击“新建目录”。
输入目录名称为“数智教育数据集”,点击“确定”。

点击“公共空间”。

点击“数据资源”,点击“3_kaoqin.csv”卡片右上角的“更多”,并点击“导出”。
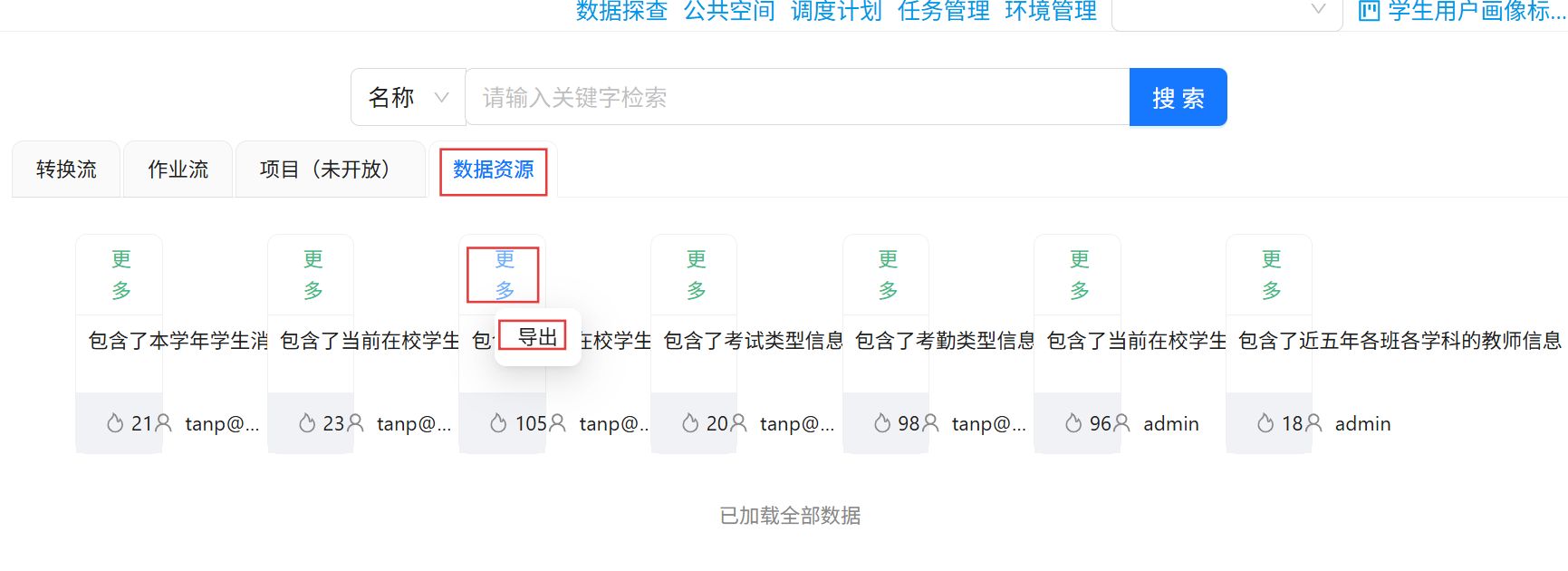
在弹出的窗口中选择导出到刚刚新创建的目录下。
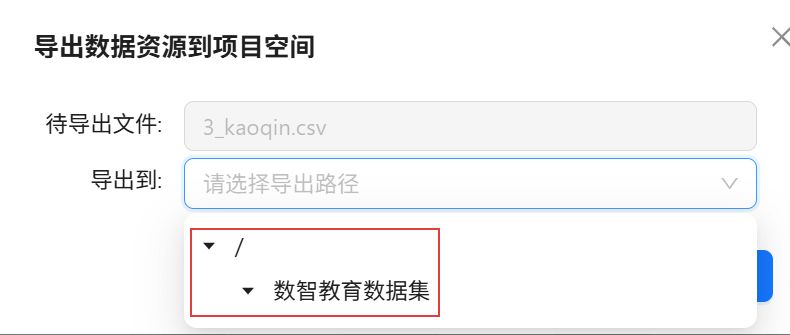
点击“确定”。
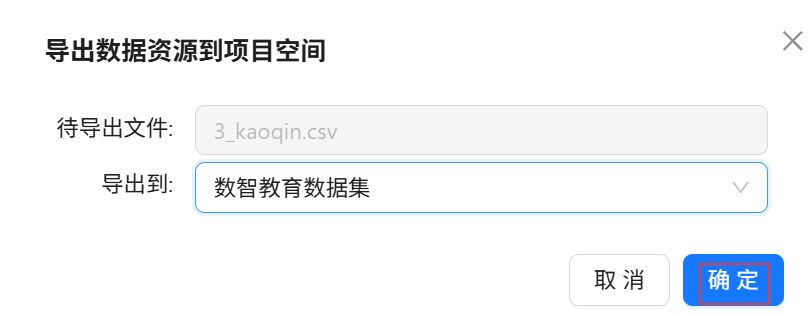
重复以上操作,将本次实验用到的数据表4_kaoqintype.csv和 2_student_info.csv都导出到“数智教育数据集”。
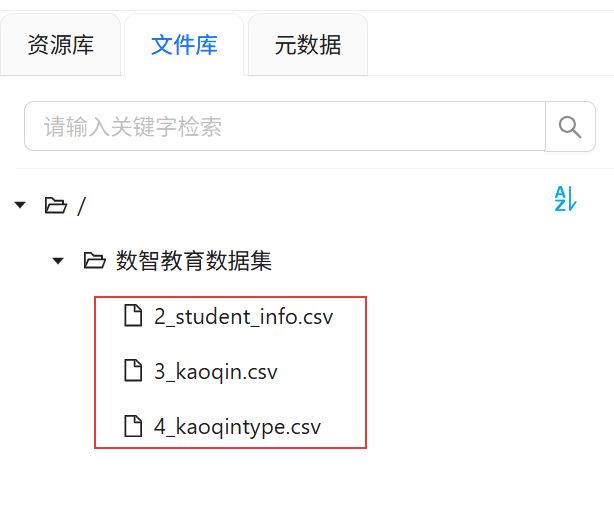
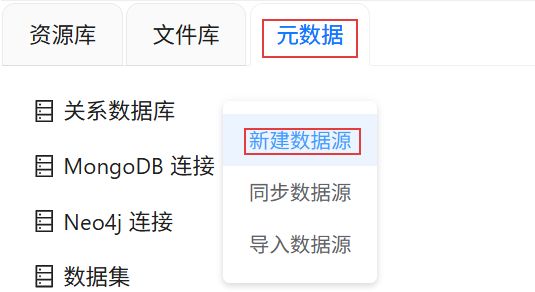
2.2.2建立数据源连接
点击“元数据”,右键关系数据库右键,点击“新建数据源”。
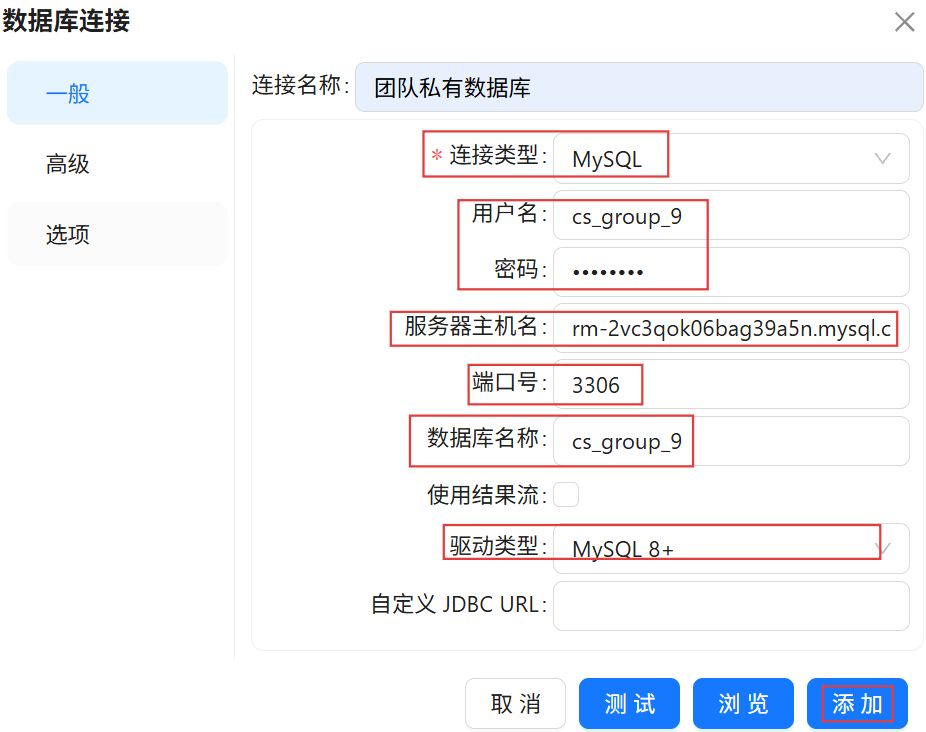
连接类型选择“MySQL”,填入用户名和密码。服务器主机名使用“rm-2vc3qok06bag39a5n.mysql.cn-chengdu.rds.aliyuncs.com”,端口号为3306,数据库名为“cs_group_9”,驱动类型选择“MySQL 8+”,连接名称为“团队私有数据库”。最后点击“添加”。
2.2.3原始考勤记录表数据导入
点击“资源库”,右键根目录,点击“新建转换流”。
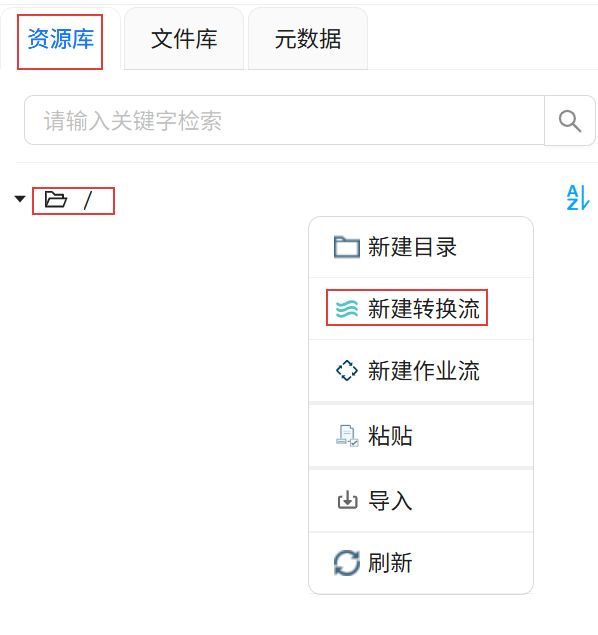
输入转换流名称“创建原始_学生考勤表”,点击“确定”。

点击锁形图标解锁画布。
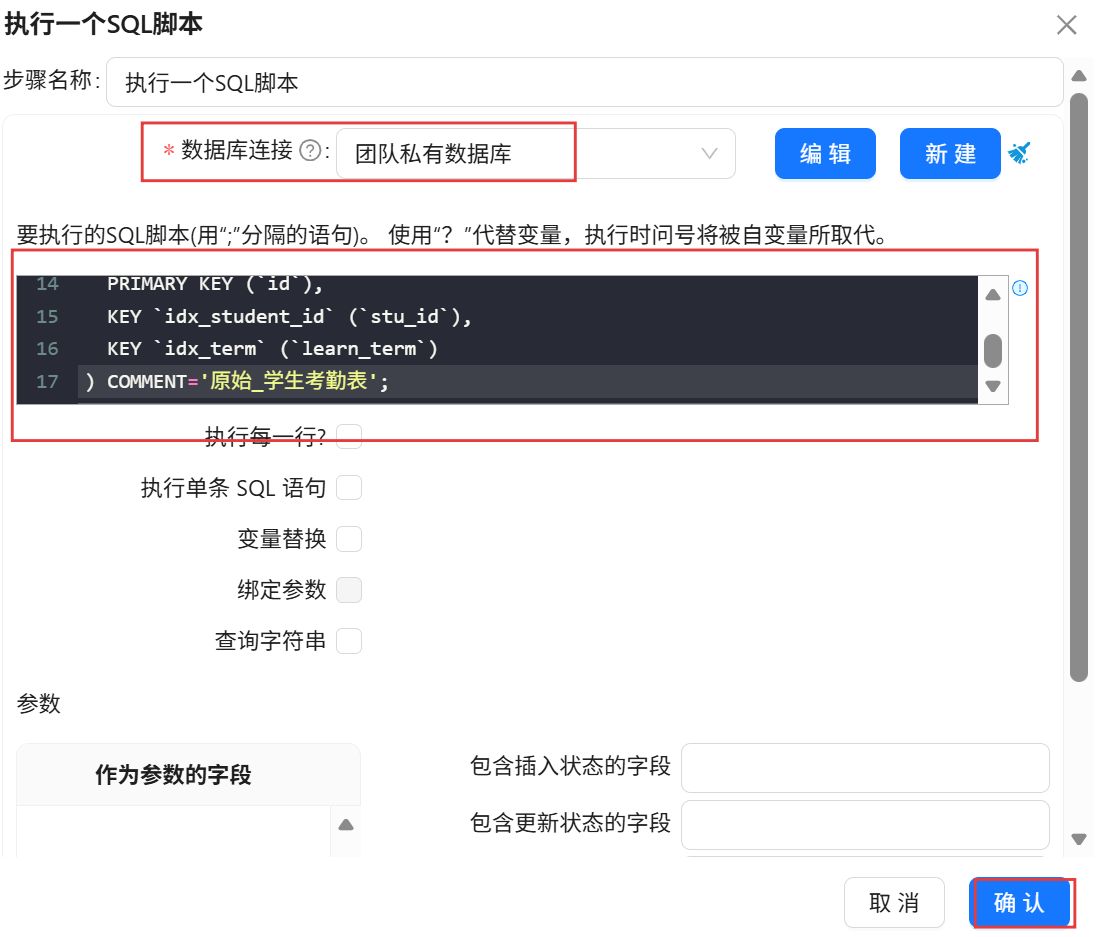
点击“组件库”,搜索“执行一个SQL脚本”,将其拖入右侧画布。
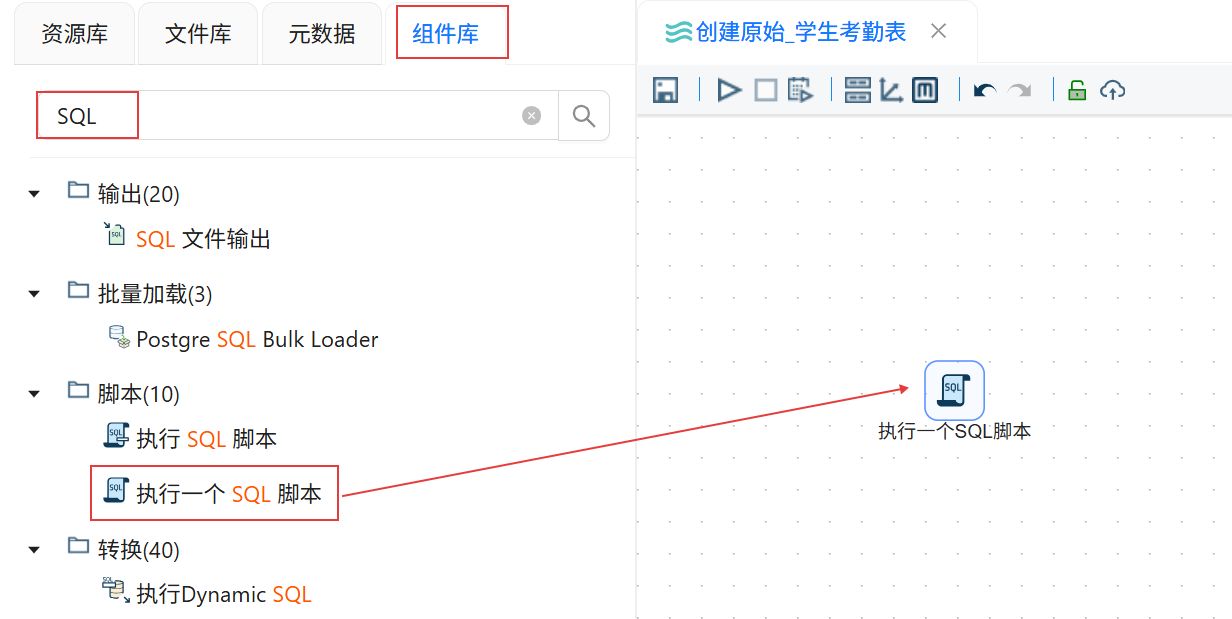
数据库连接选择“团队私有数据库”,在组件中填写SQL脚本,点击“确认”。
点击三角形图标,运行转换流。
点击“启动”。
运行过程会定时刷新组件状态,并显示执行日志。
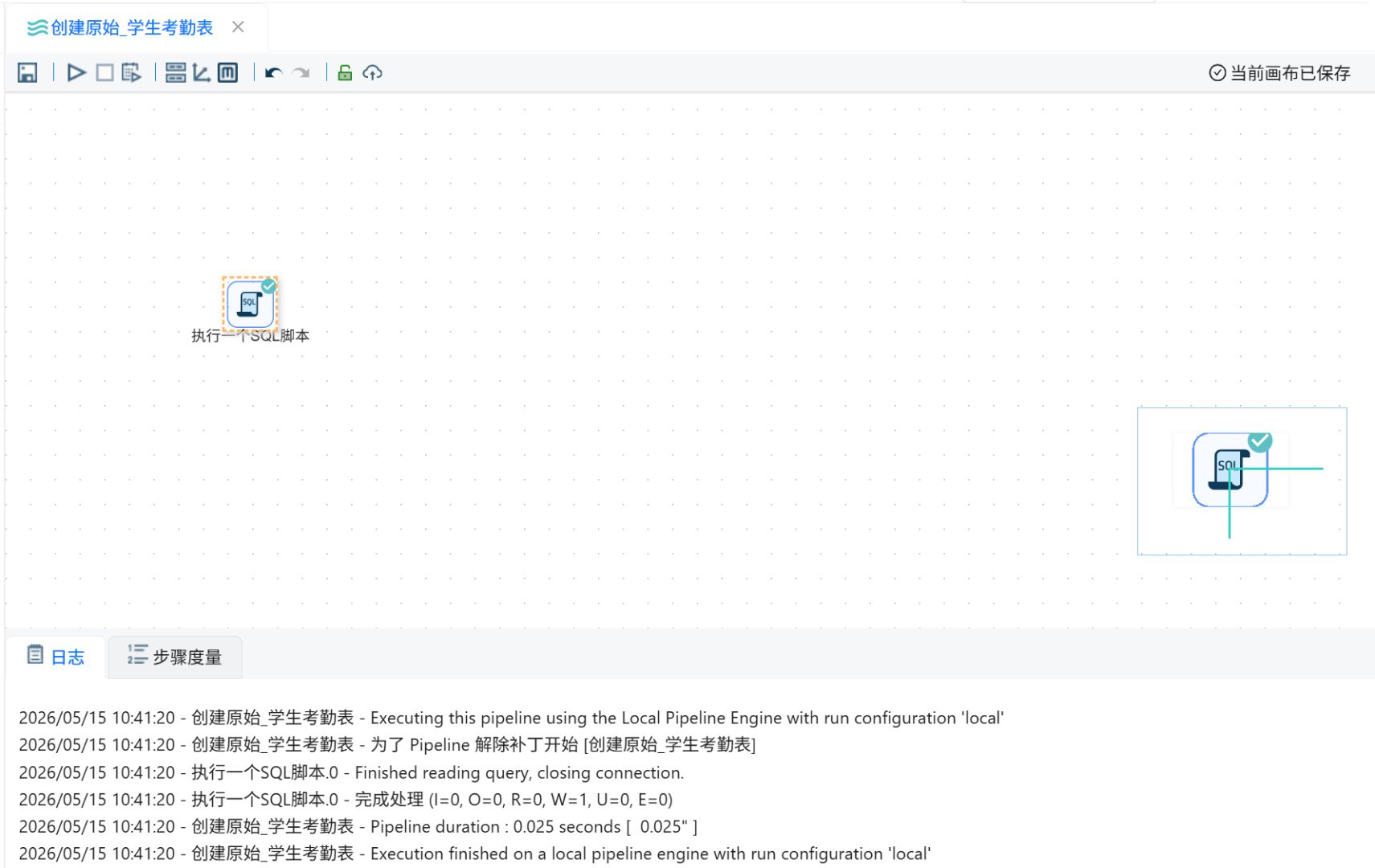
点击“资源库”,右键根目录,点击“新建转换流”。
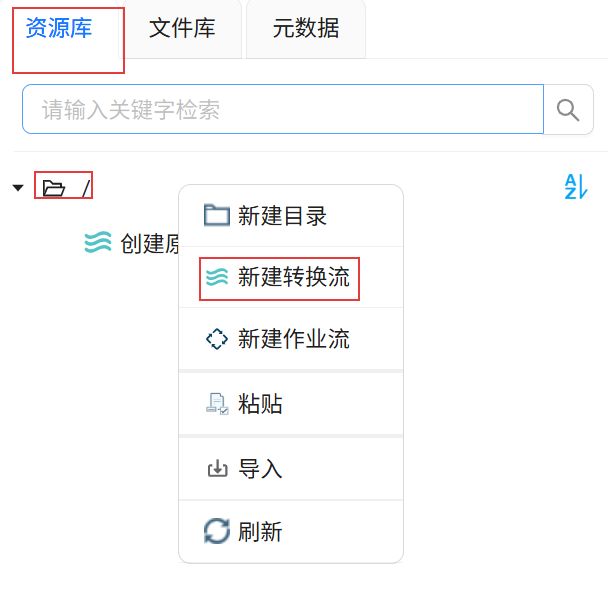
输入转换流名称“导入原始考勤数据”。点击“确认”。

点击锁形图标解锁画布。
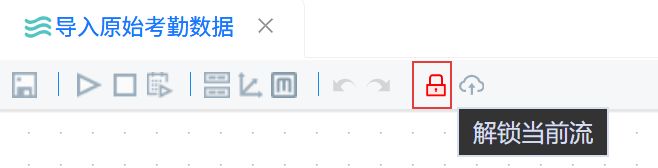
点击“组件库”,搜索“CSV文件输入”,将其拖入右侧画布。
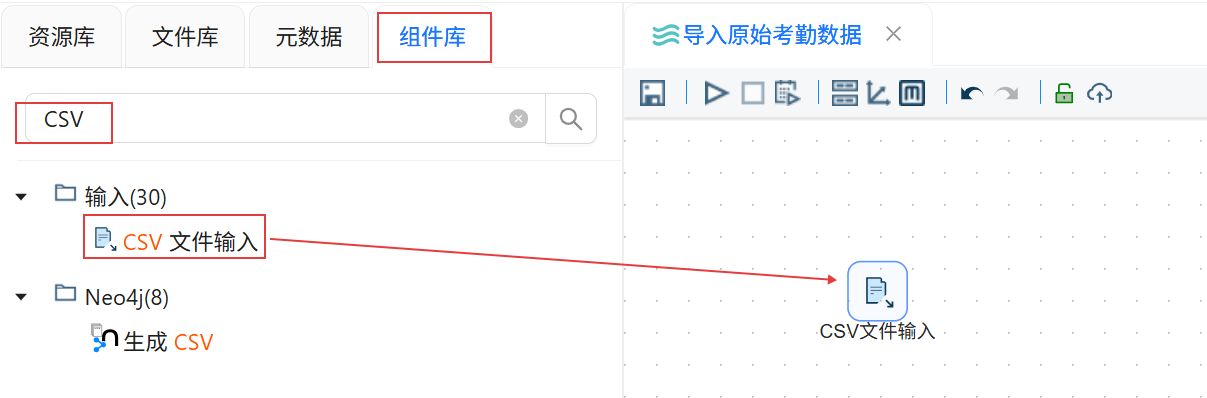
双击CSV文件输入组件,在步骤名称中输入“考勤记录”。编码选择“UTF-8”。点击“浏览文件”。
选择“3_kaoqin.csv”,点击“确定”。
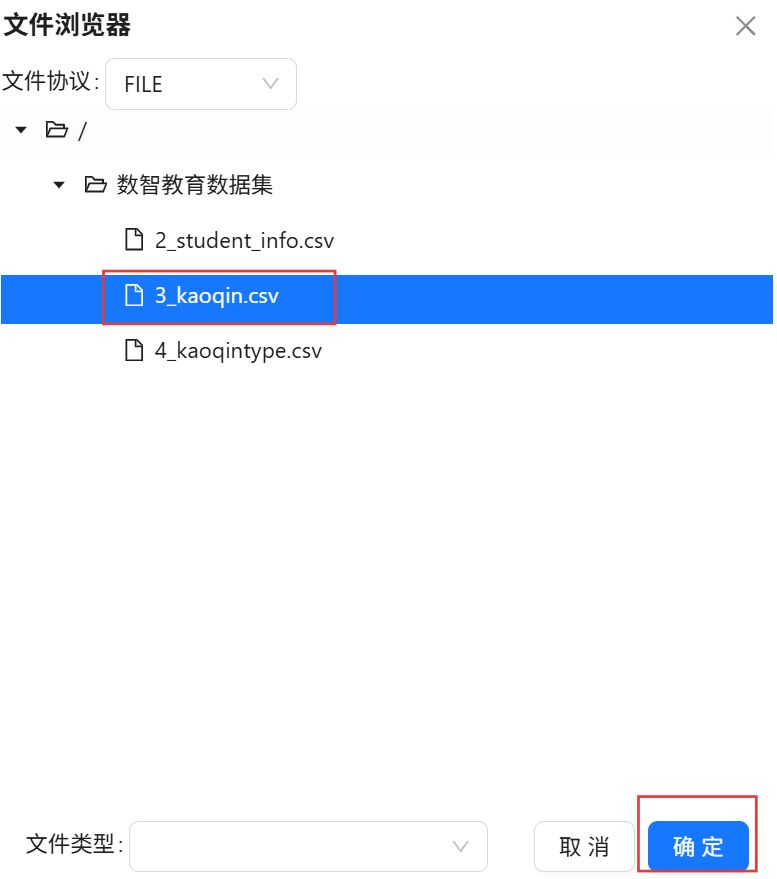
在字段表格中空白处右键点击“获取字段”。最后点击“确认”。
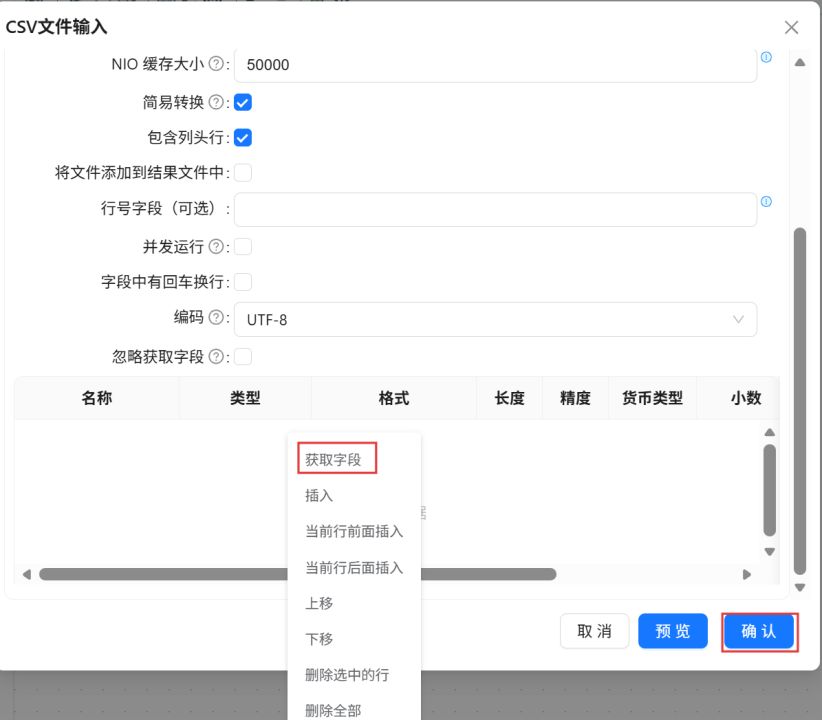
点击“组件库”,搜索“表输出”,将其拖入右侧画布。
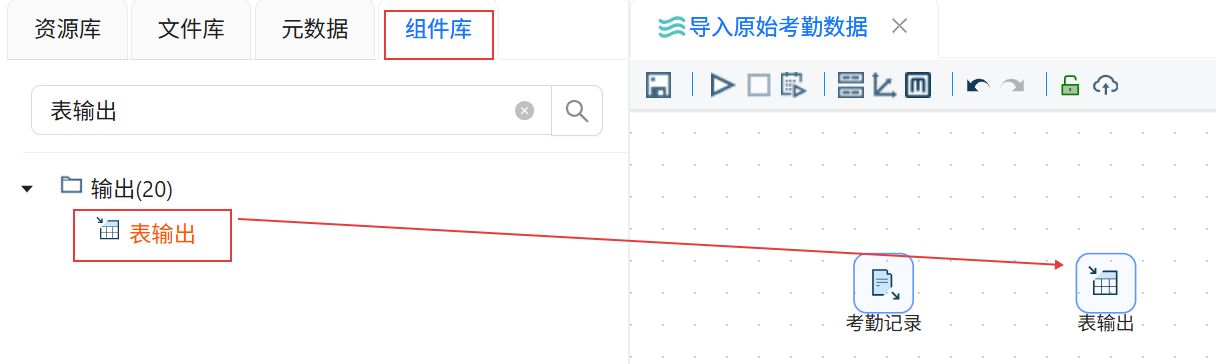
创建“考勤记录”CSV文件输入组件到“表输出”组件的连线。
连线类型选择“主输出步骤”。

双击“表输出”组件,数据库连接选择“团队私有数据库”,目标表输入我们使用SQL组件创建的“raw_attendance”。勾选“裁剪表”和“指定数据库字段”。
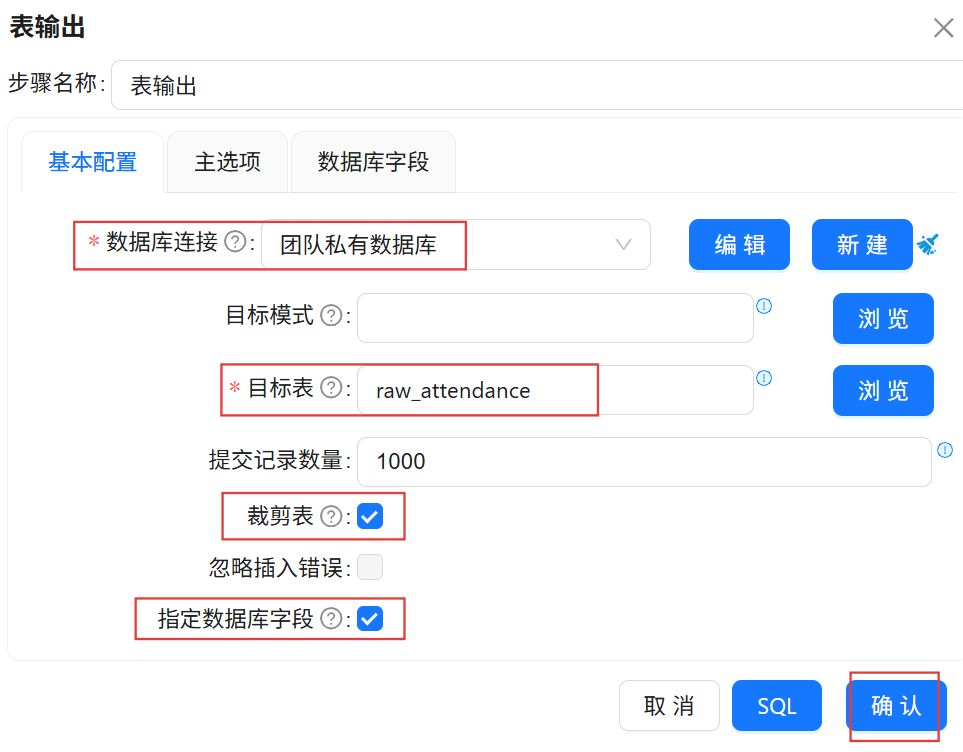
点击“数据库字段”,在空白处右键“获取字段”
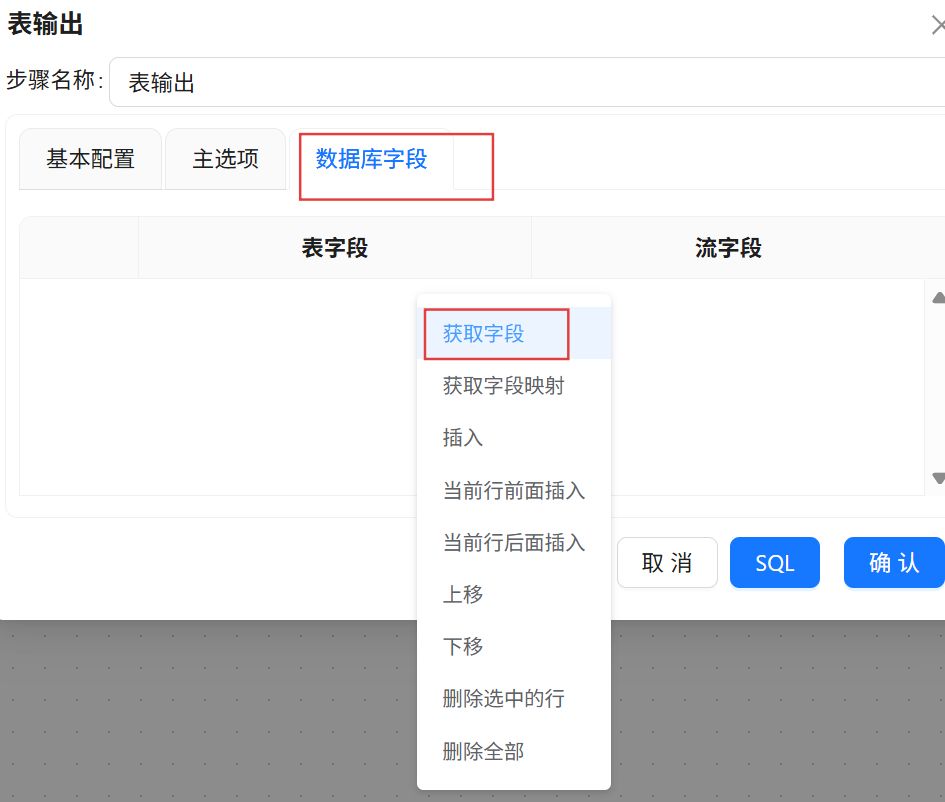
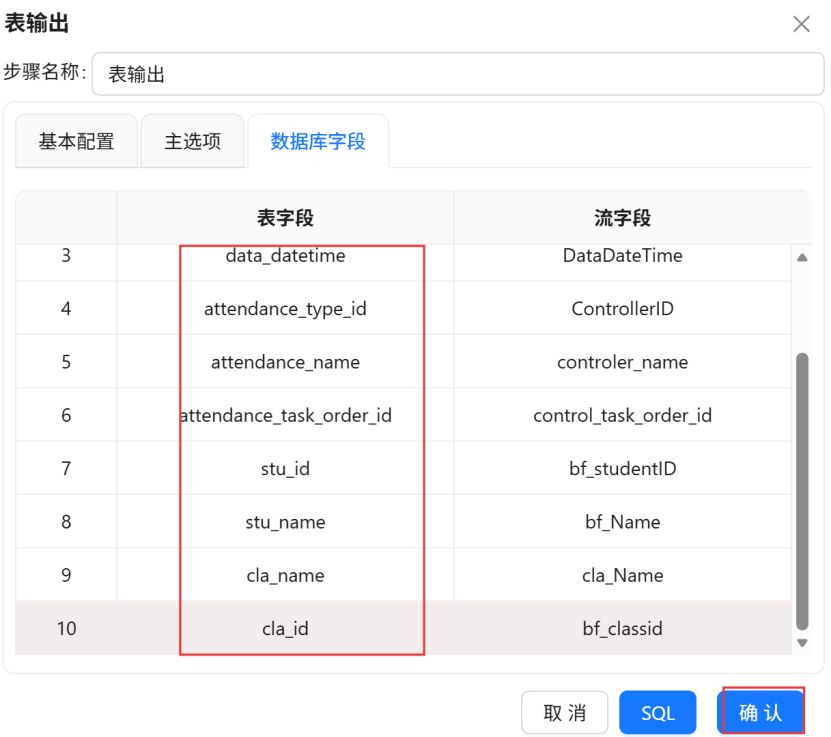
将表字段修改为建表语句中对应的字段,点击“确认”
点击三角形图标,运行转换流。
点击“启动”。
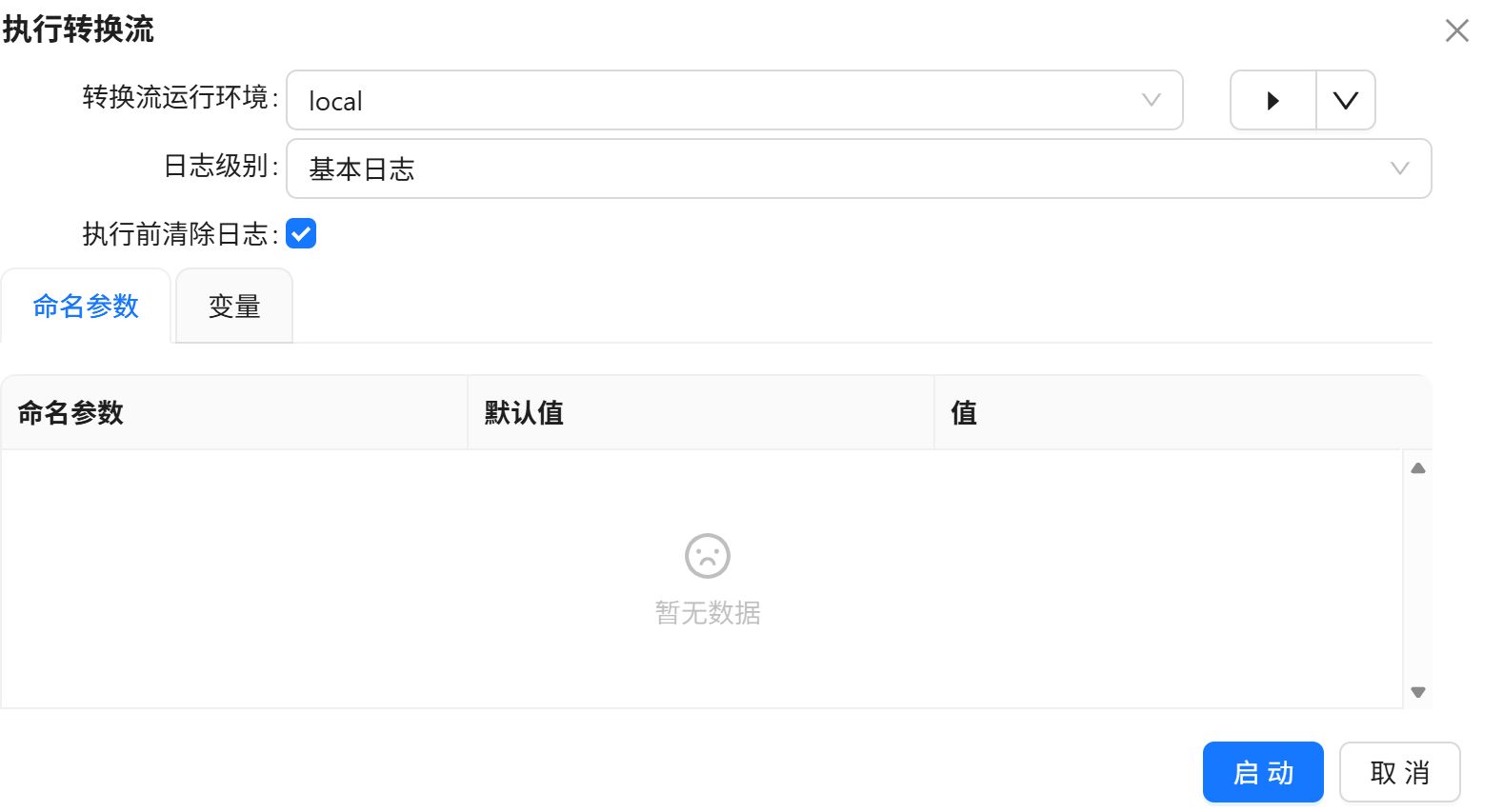
运行过程会定时刷新组件状态,并显示执行日志。
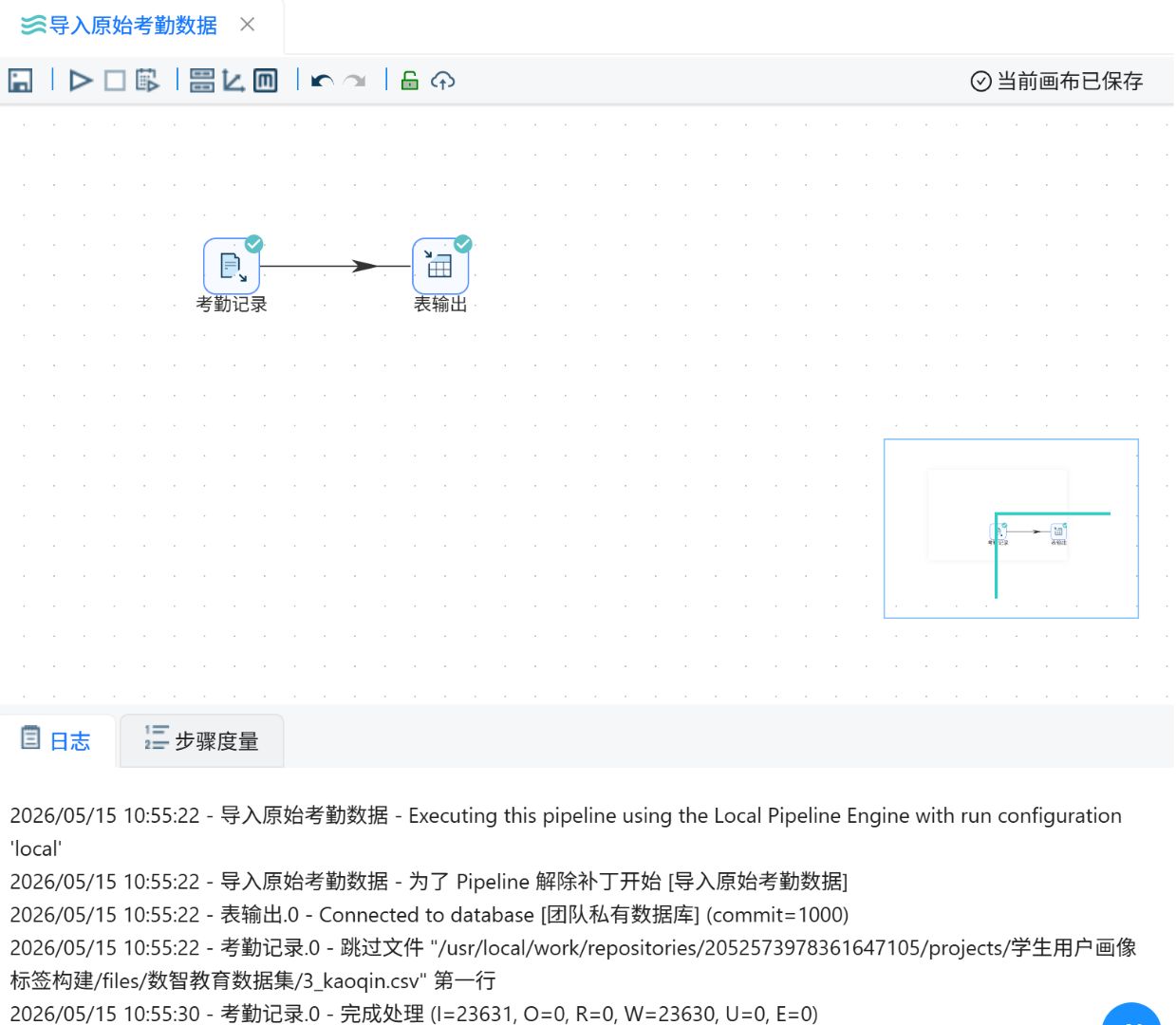
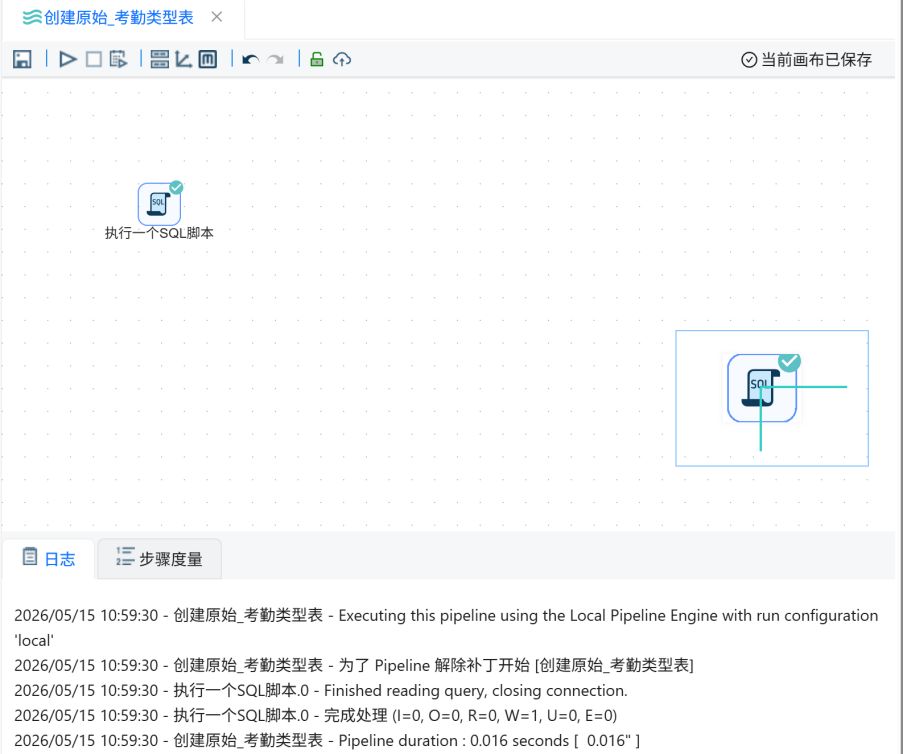
2.2.4原始考勤类型表数据导入
点击“资源库”,右键根目录,点击“新建转换流”。
输入转换流名称“创建原始_考勤类型表”,点击“确定”。

点击锁形图标解锁画布。
点击“组件库”,搜索“执行一个SQL脚本”,将其拖入右侧画布。
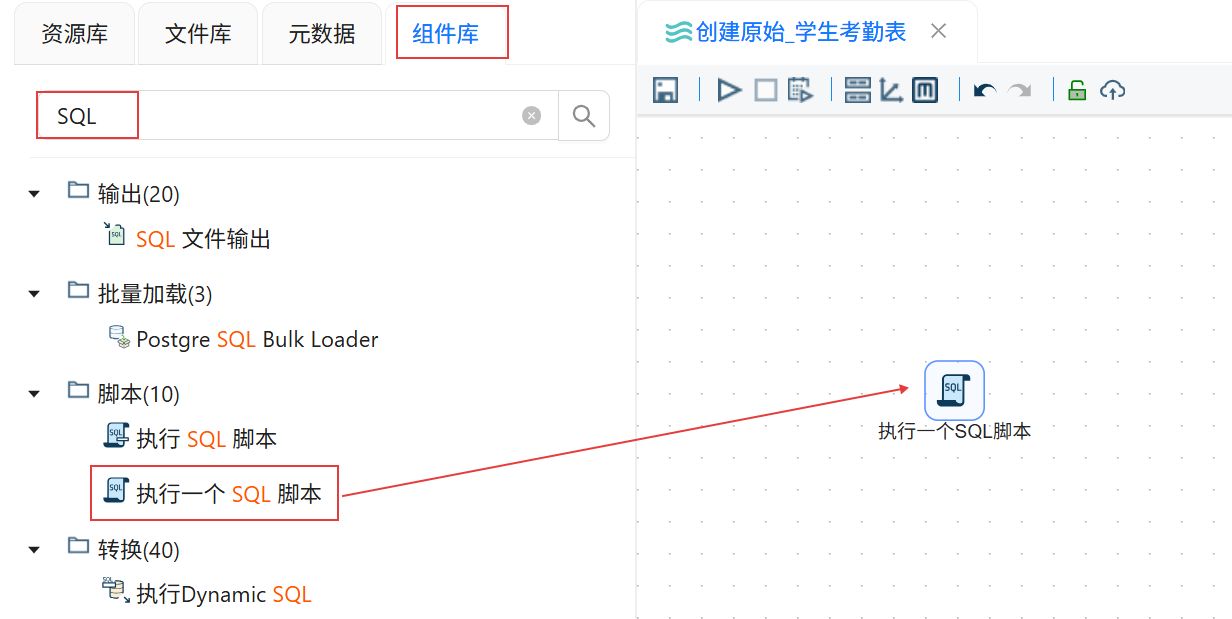
数据库连接选择“团队私有数据库”,在组件中填写SQL脚本,点击“确认”。
点击三角形图标,运行转换流。
点击“启动”。
运行过程会定时刷新组件状态,并显示执行日志。
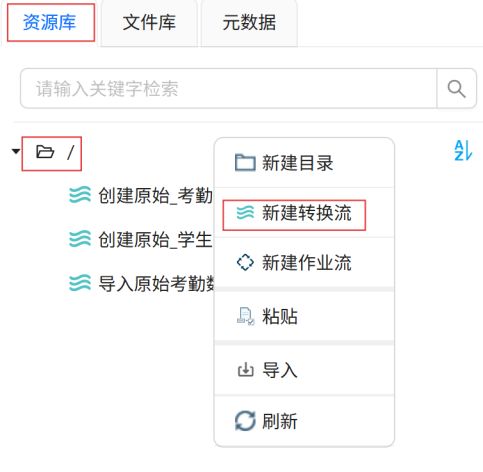
点击“资源库”,右键根目录,点击“新建转换流”。
输入转换流名称“导入原始考勤类型数据”。点击“确认”。

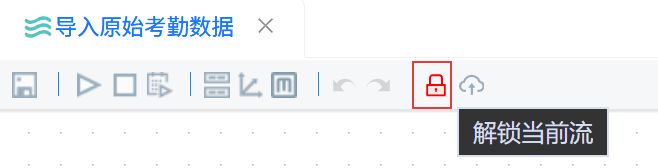
点击锁形图标解锁画布。
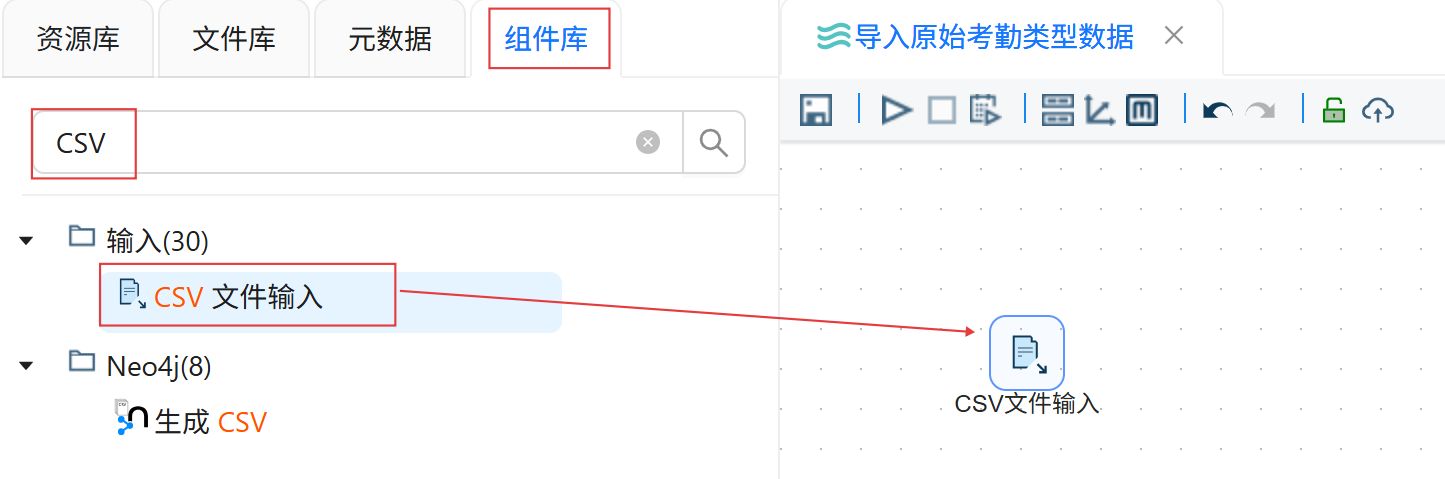
点击“组件库”,搜索“CSV文件输入”,将其拖入右侧画布。
双击CSV文件输入组件,列分隔符为“插入制表符(TAB)”。编码选择“GB2312”。点击“浏览文件”。
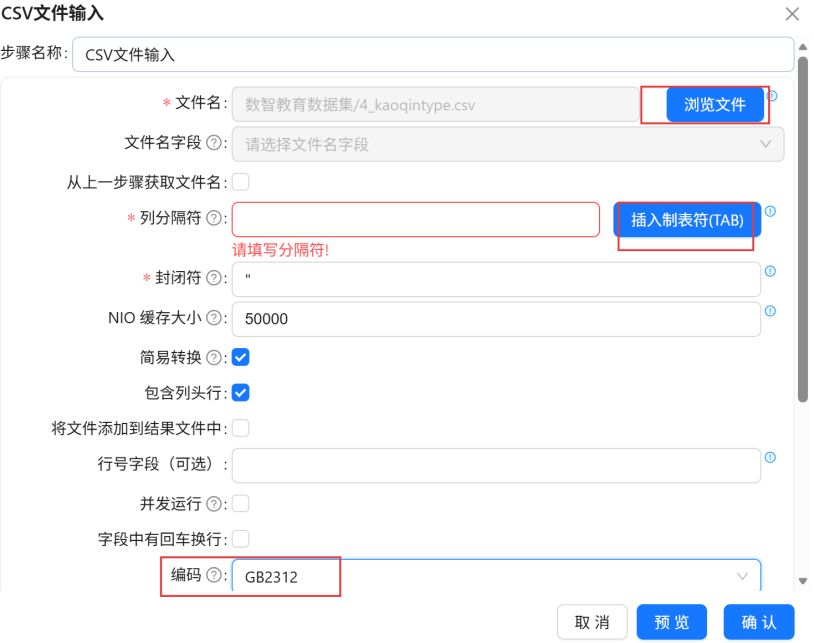
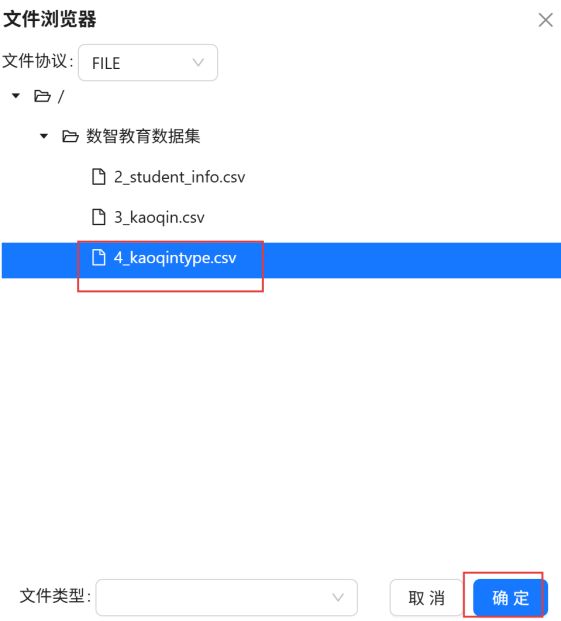
选择“4_kaoqintype.csv”,点击“确定”。
在字段表格中空白处右键点击“获取字段”。最后点击“确认”。
点击“组件库”,搜索“表输出”,将其拖入右侧画布。
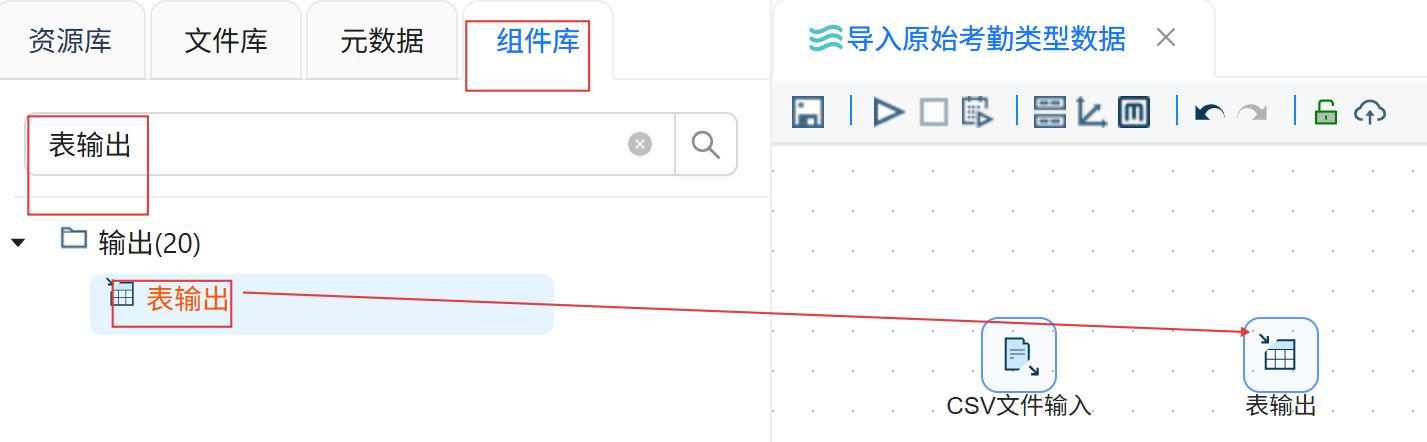
创建CSV文件输入组件到“表输出”组件的连线。
连线类型选择“主输出步骤”。

双击“表输出”组件,数据库连接选择“团队私有数据库”,目标表输入我们使用SQL组件创建的“raw_attendance_type”。勾选“裁剪表”和“指定数据库字段”。
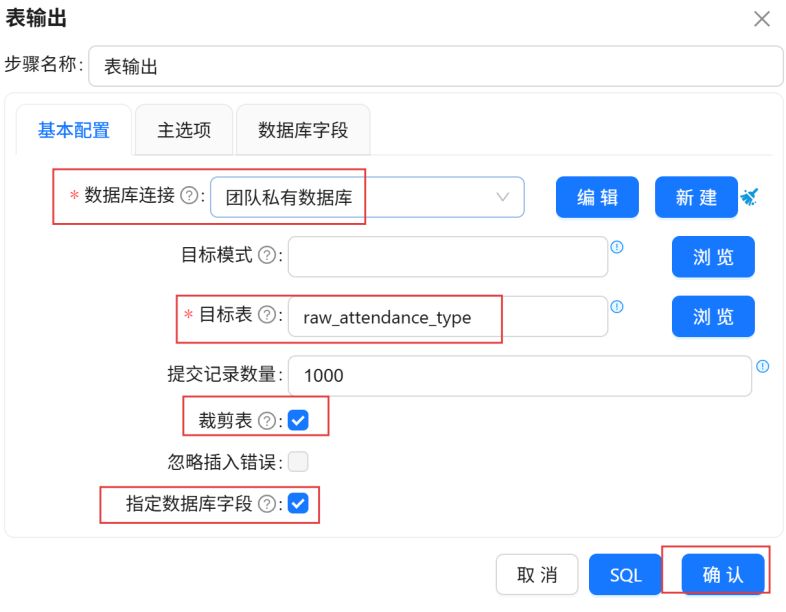
点击“数据库字段”,在空白处右键“获取字段”
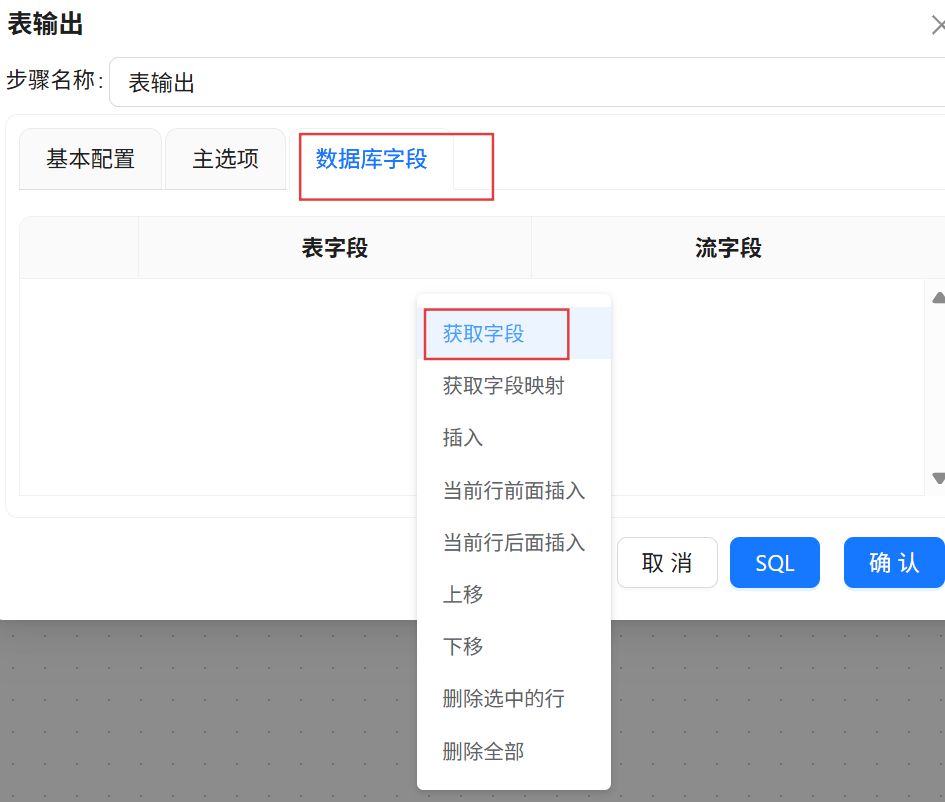
将表字段修改为建表语句中对应的字段,点击“确认”

点击三角形图标,运行转换流。
点击“启动”。
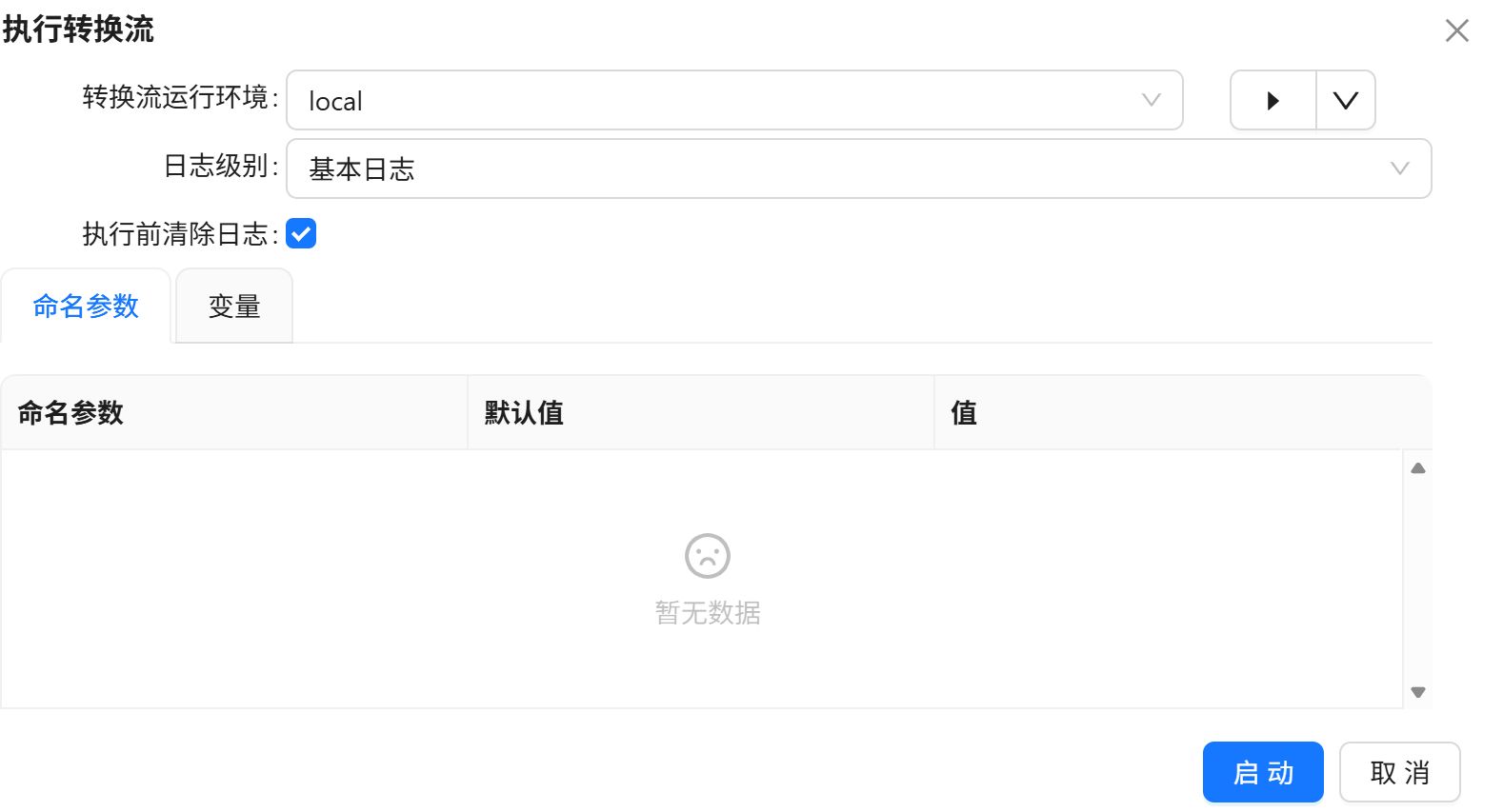
运行过程会定时刷新组件状态,并显示执行日志。
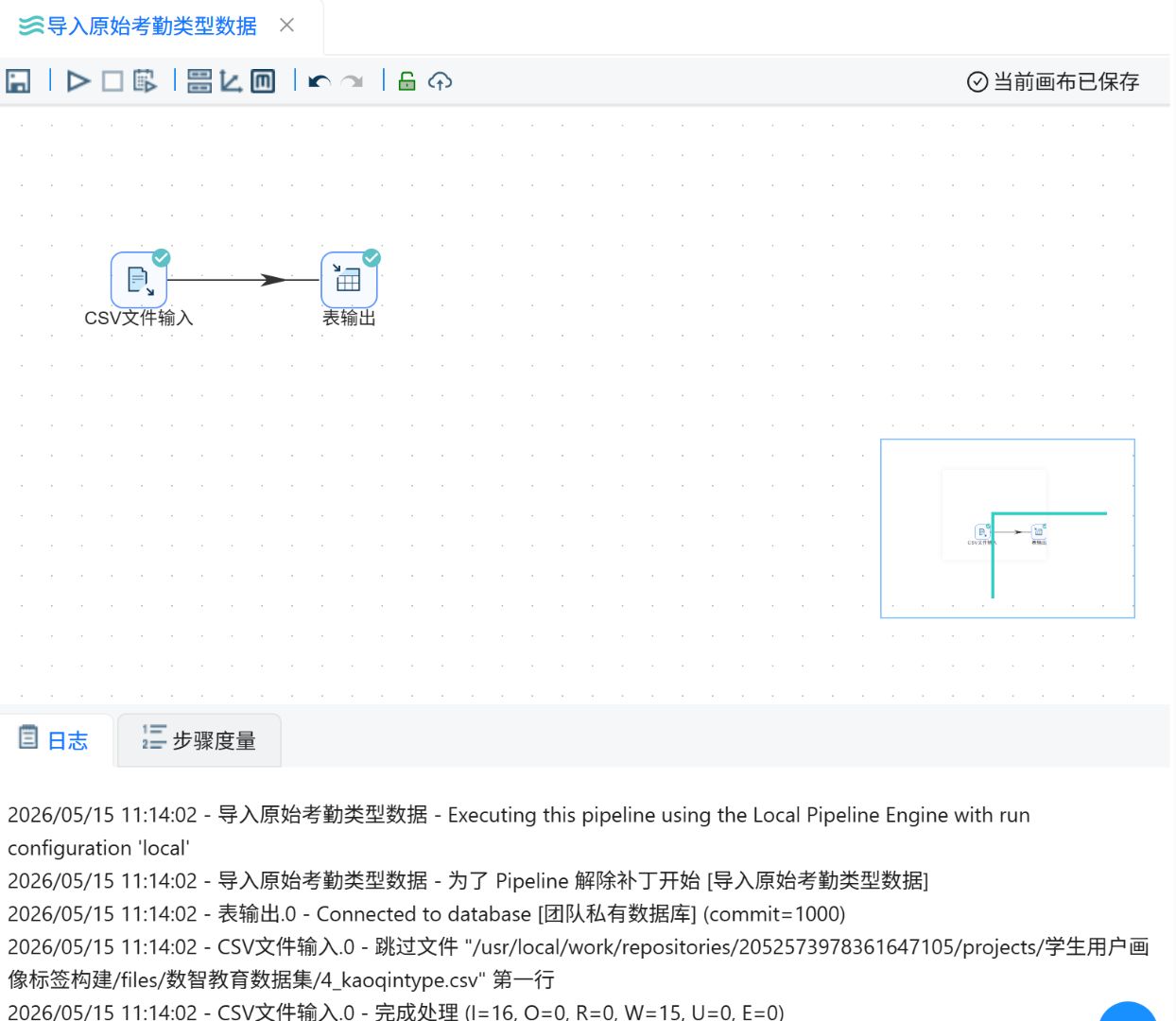
2.2.5原始学生基本信息表数据导入
点击“资源库”,右键根目录,点击“新建转换流”。
输入转换流名称“创建原始_学生信息表”,点击“确定”。

点击锁形图标解锁画布。
点击“组件库”,搜索“执行一个SQL脚本”,将其拖入右侧画布。
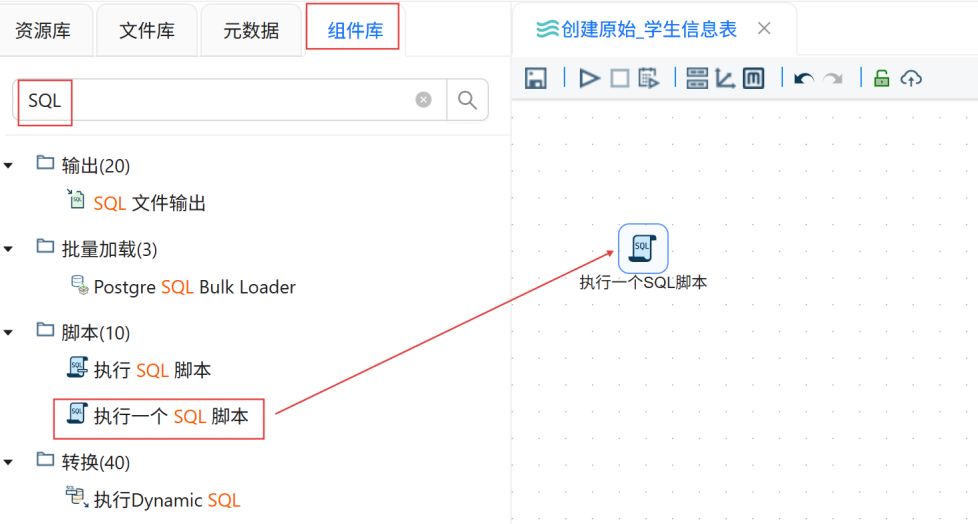
数据库连接选择“团队私有数据库”,在组件中填写SQL脚本,点击“确认”。
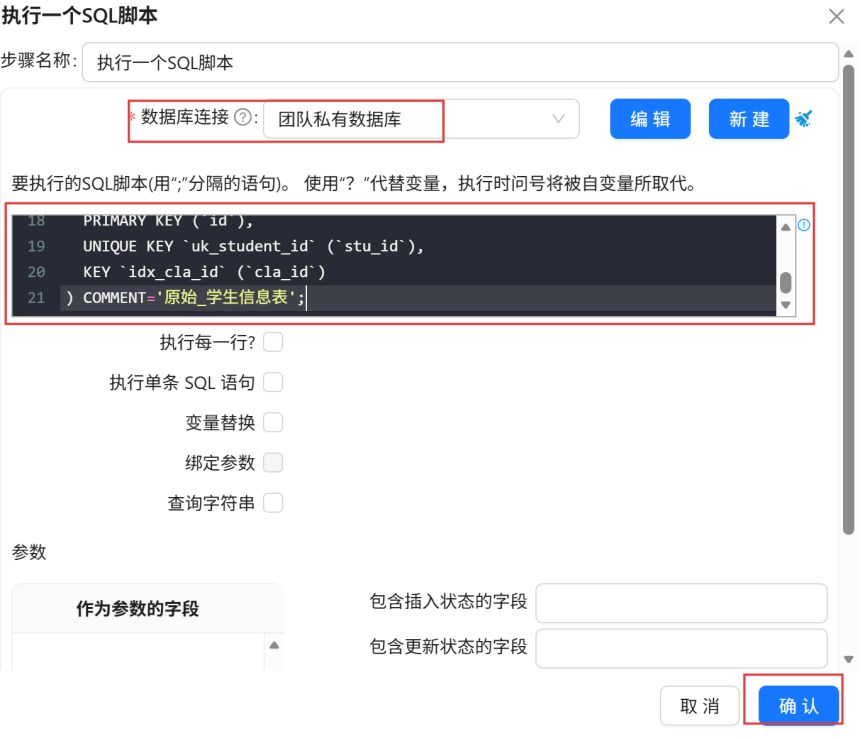
点击三角形图标,运行转换流。
点击“启动”。
运行过程会定时刷新组件状态,并显示执行日志。
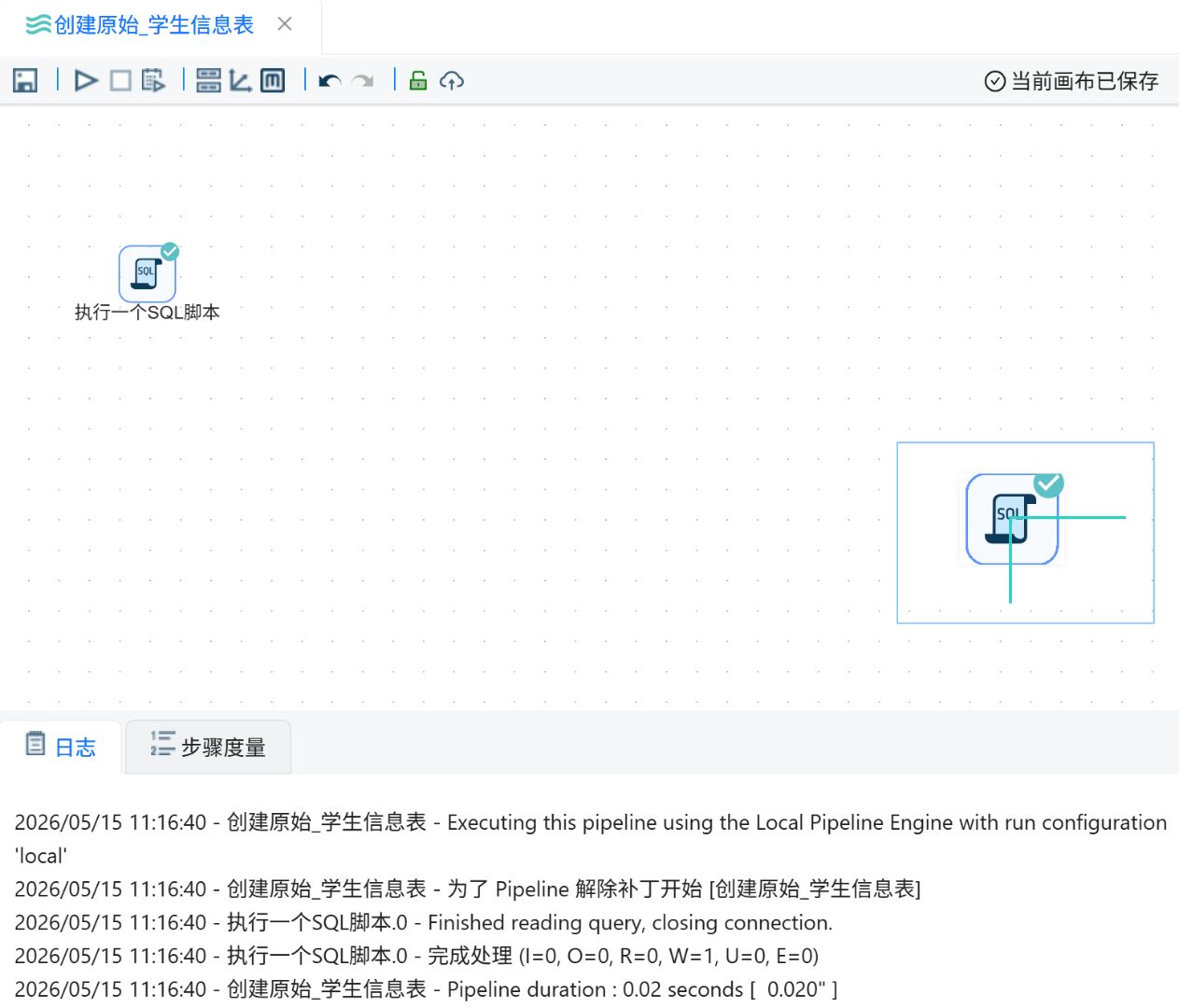
点击“资源库”,右键根目录,点击“新建转换流”。
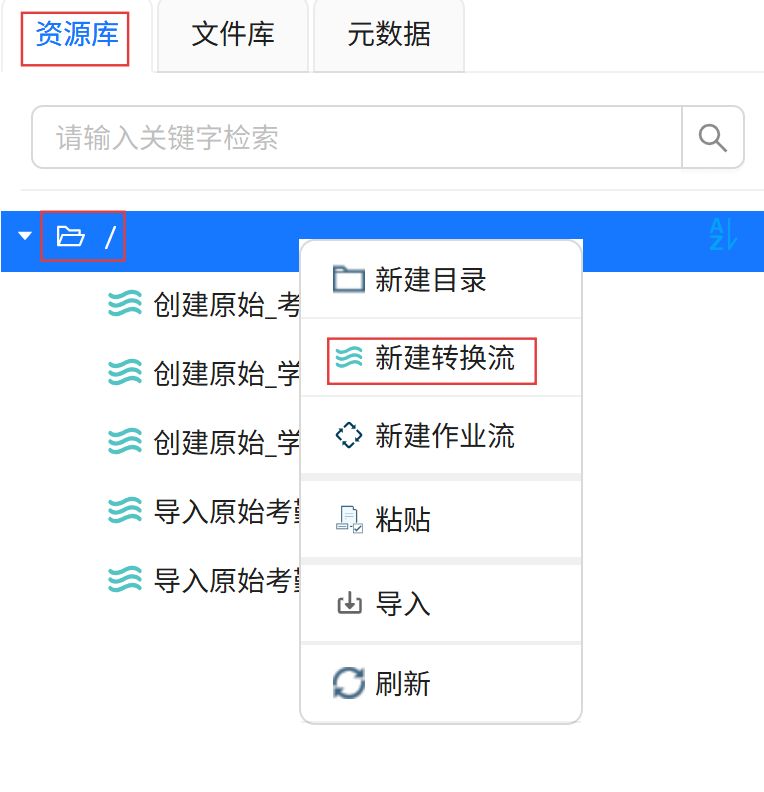
输入转换流名称“导入学生基本信息数据”。点击“确认”。

点击锁形图标解锁画布。
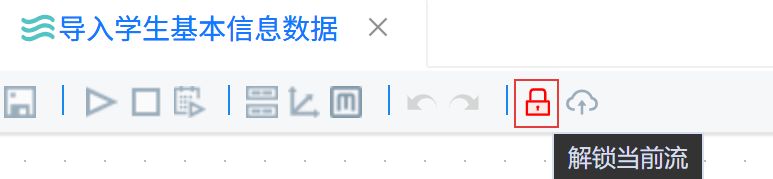
点击“组件库”,搜索“CSV文件输入”,将其拖入右侧画布。
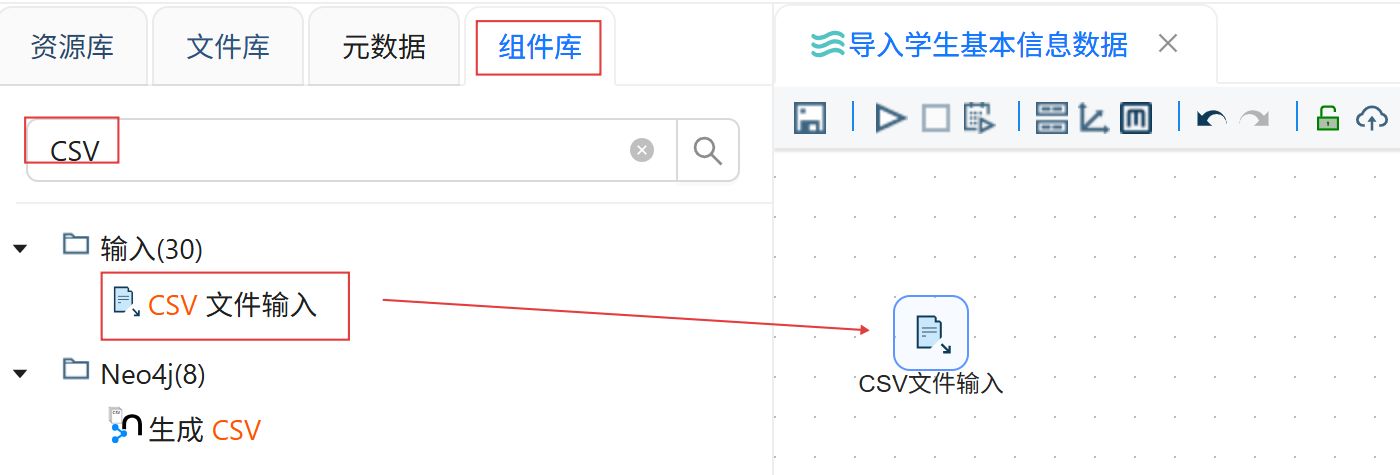
双击CSV文件输入组件。编码选择“UTF-8”。点击“浏览文件”。
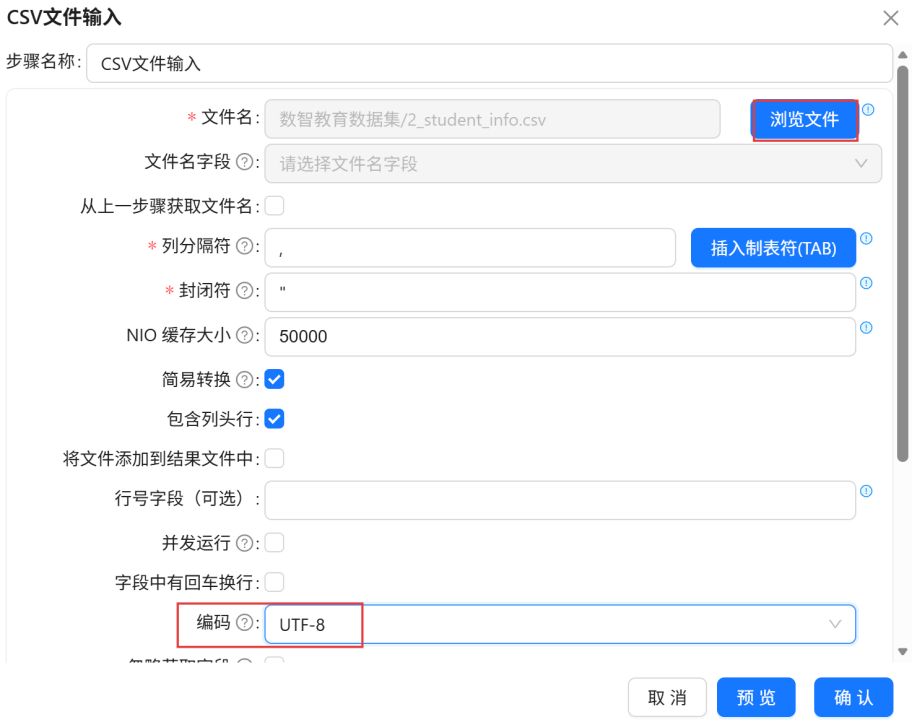
选择“2_student_info.csv”,点击“确定”。
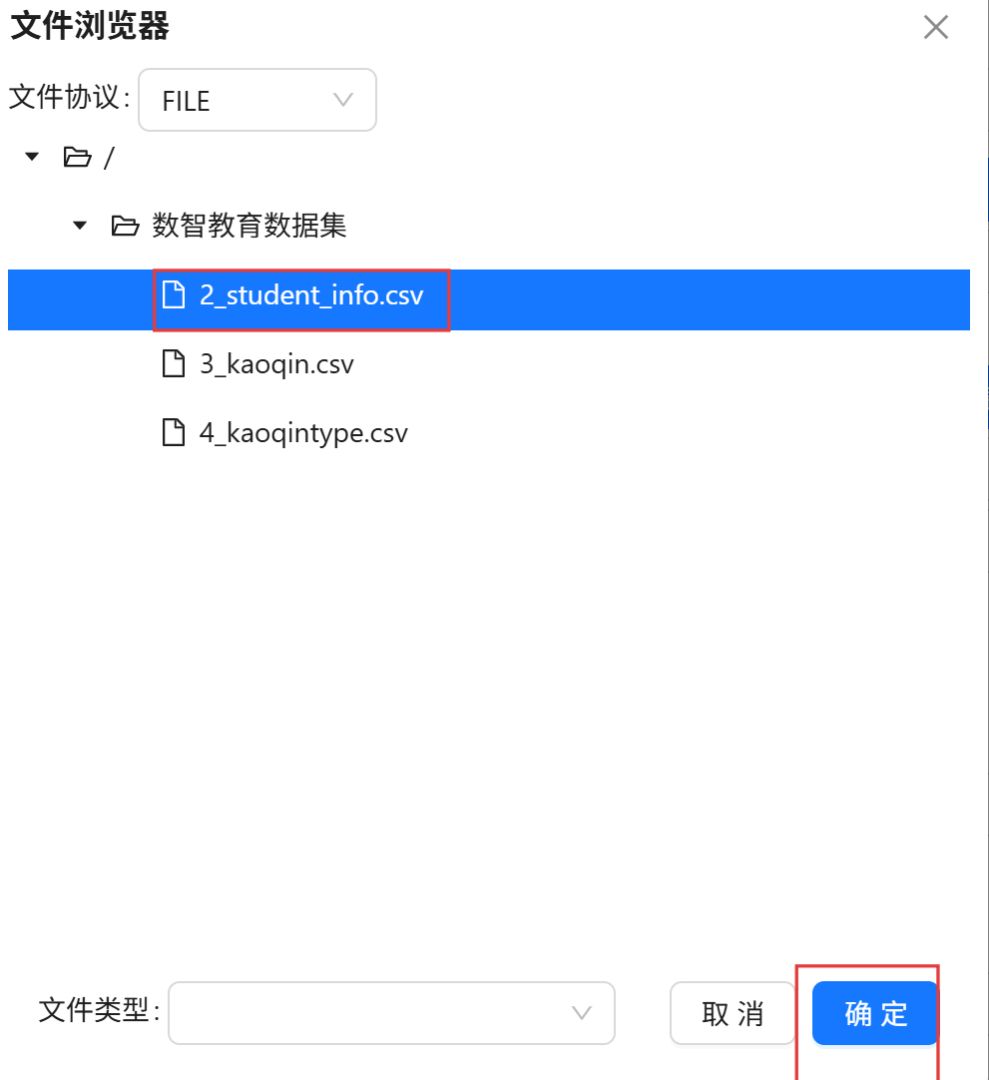
在字段表格中空白处右键点击“获取字段”。
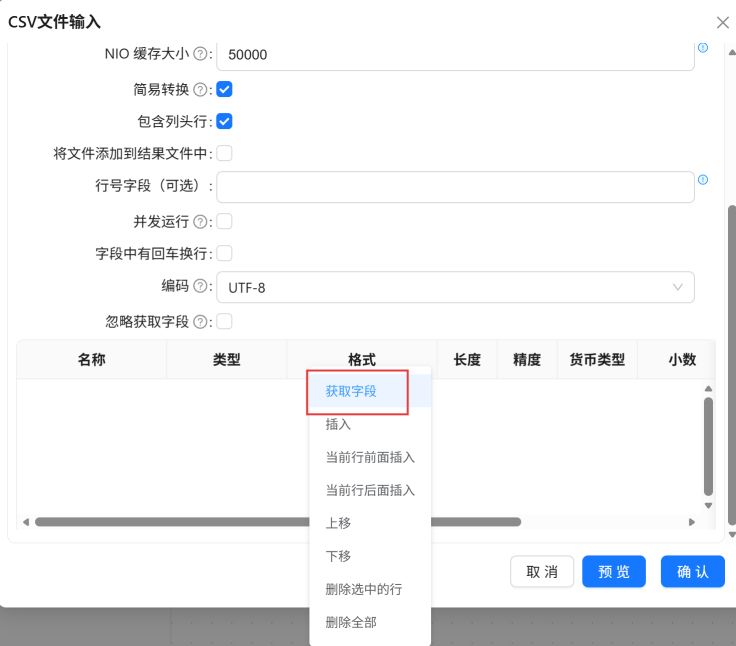
将“bf_leaveSchool”的字段类型修改为“String”。最后点击“确认”。
点击“组件库”,搜索“字段选择”,将其拖入右侧画布。
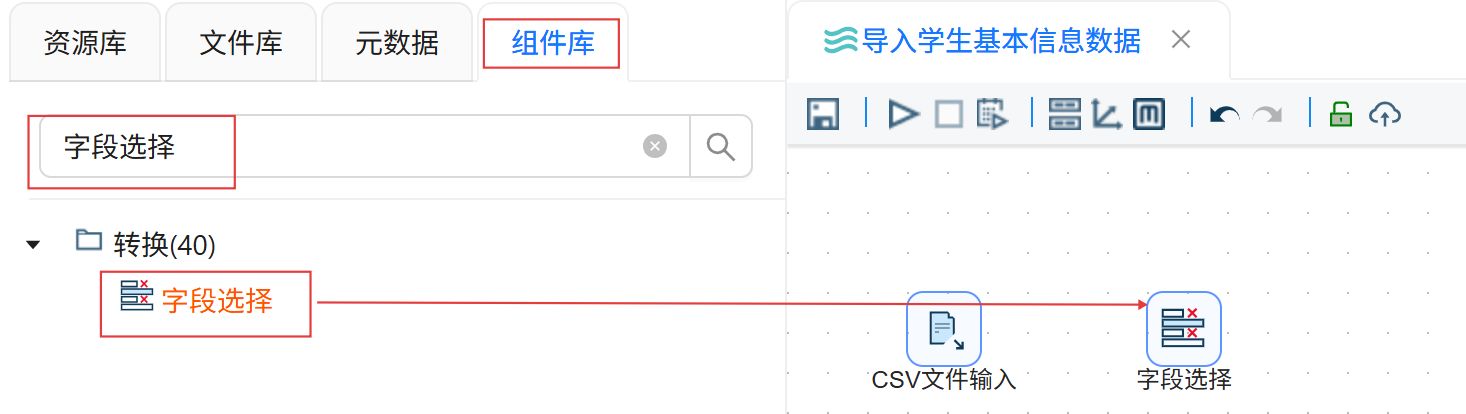
创建CSV文件输入组件到“字段选择”组件的连线。
连线类型选择“主输出步骤”。

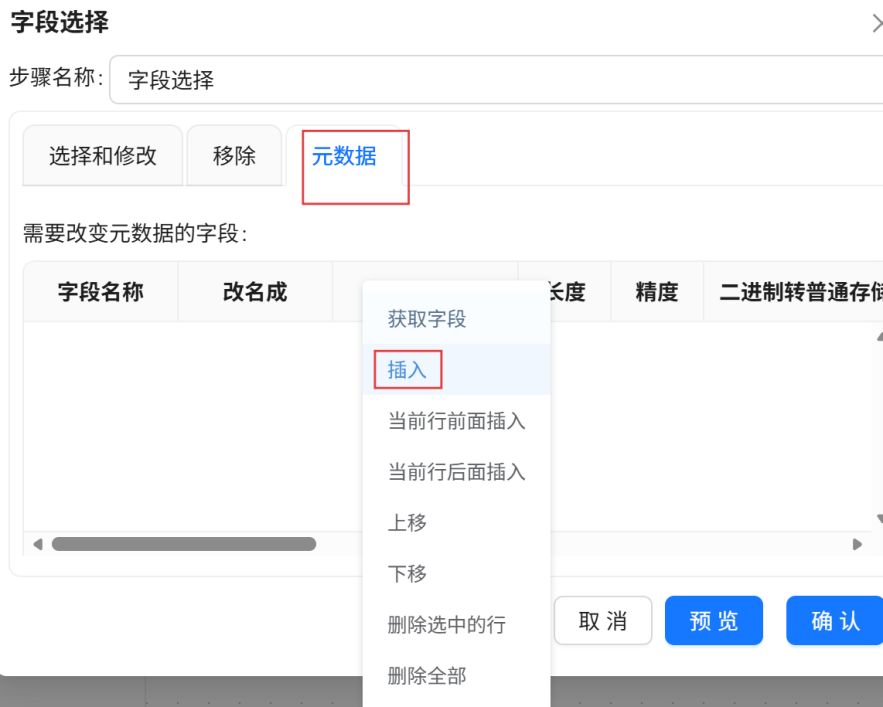
双击“字段选择”组件,点击“元数据”,并在空白处插入2行。
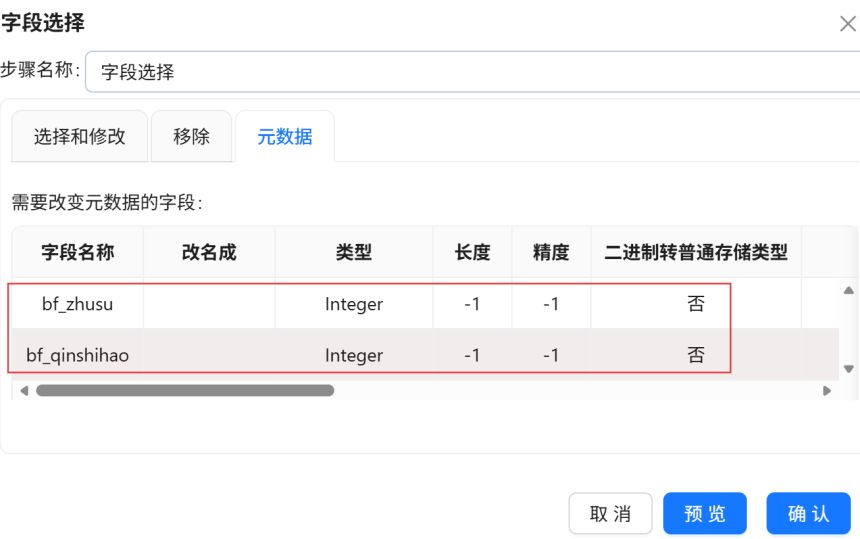
设置“bf_zhusu”、“bf_qinshihao”字段的元数据。最后点击“确认”。
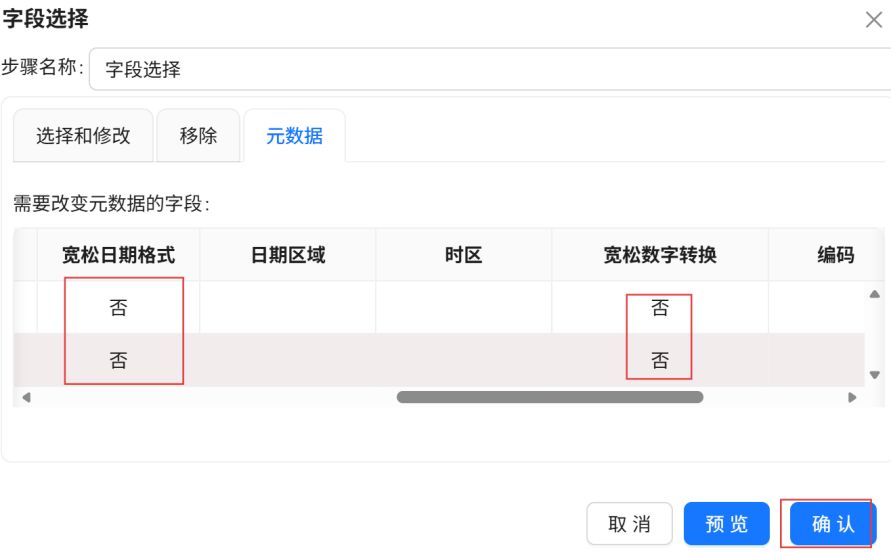
点击“组件库”,搜索“表输出”,将其拖入右侧画布。
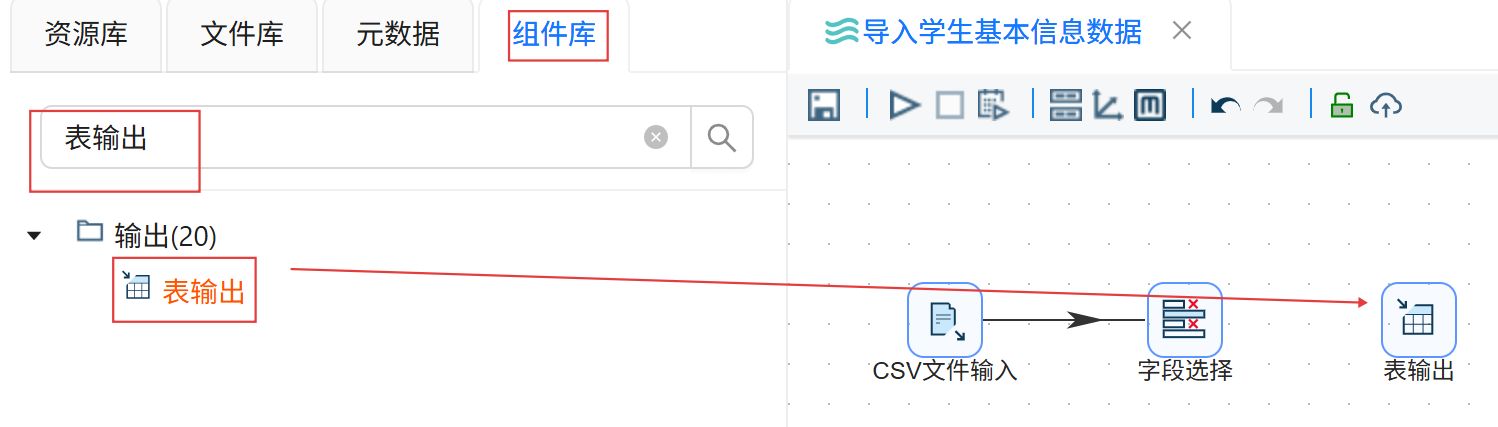
创建“字段选择”组件到“表输出”组件的连线。

连线类型选择“主输出步骤”。

双击“表输出”组件,数据库连接选择“团队私有数据库”,目标表输入我们使用SQL组件创建的“raw_student_info”。勾选“裁剪表”和“指定数据库字段”。
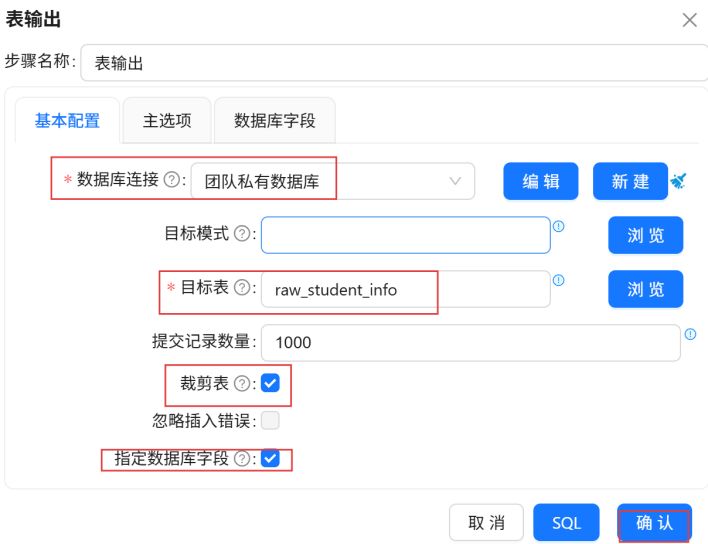
点击“数据库字段”,在空白处右键“获取字段”
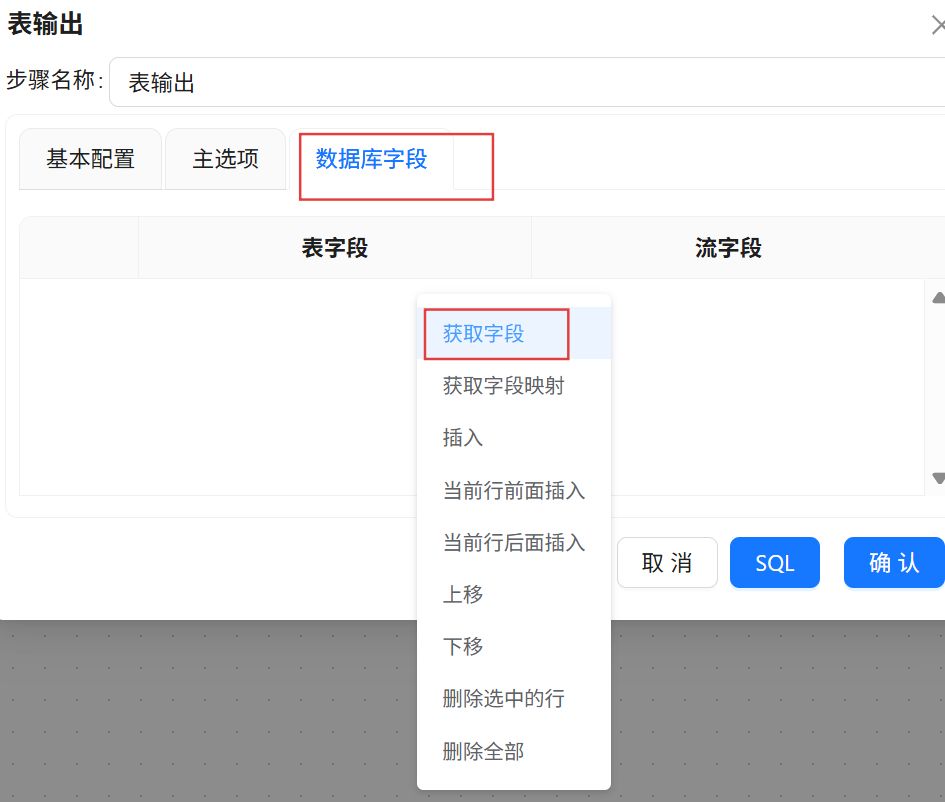
将表字段修改为建表语句中对应的字段,点击“确认”
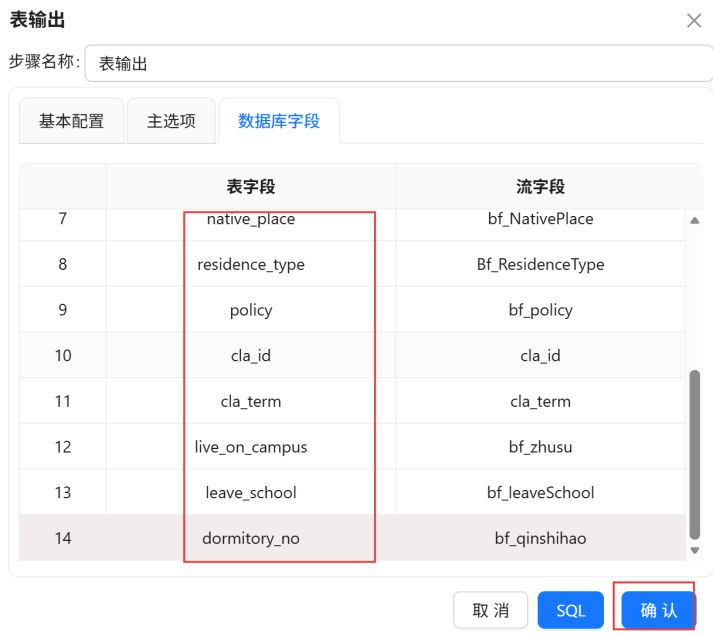
点击三角形图标,运行转换流。
点击“启动”。
运行过程会定时刷新组件状态,并显示执行日志。
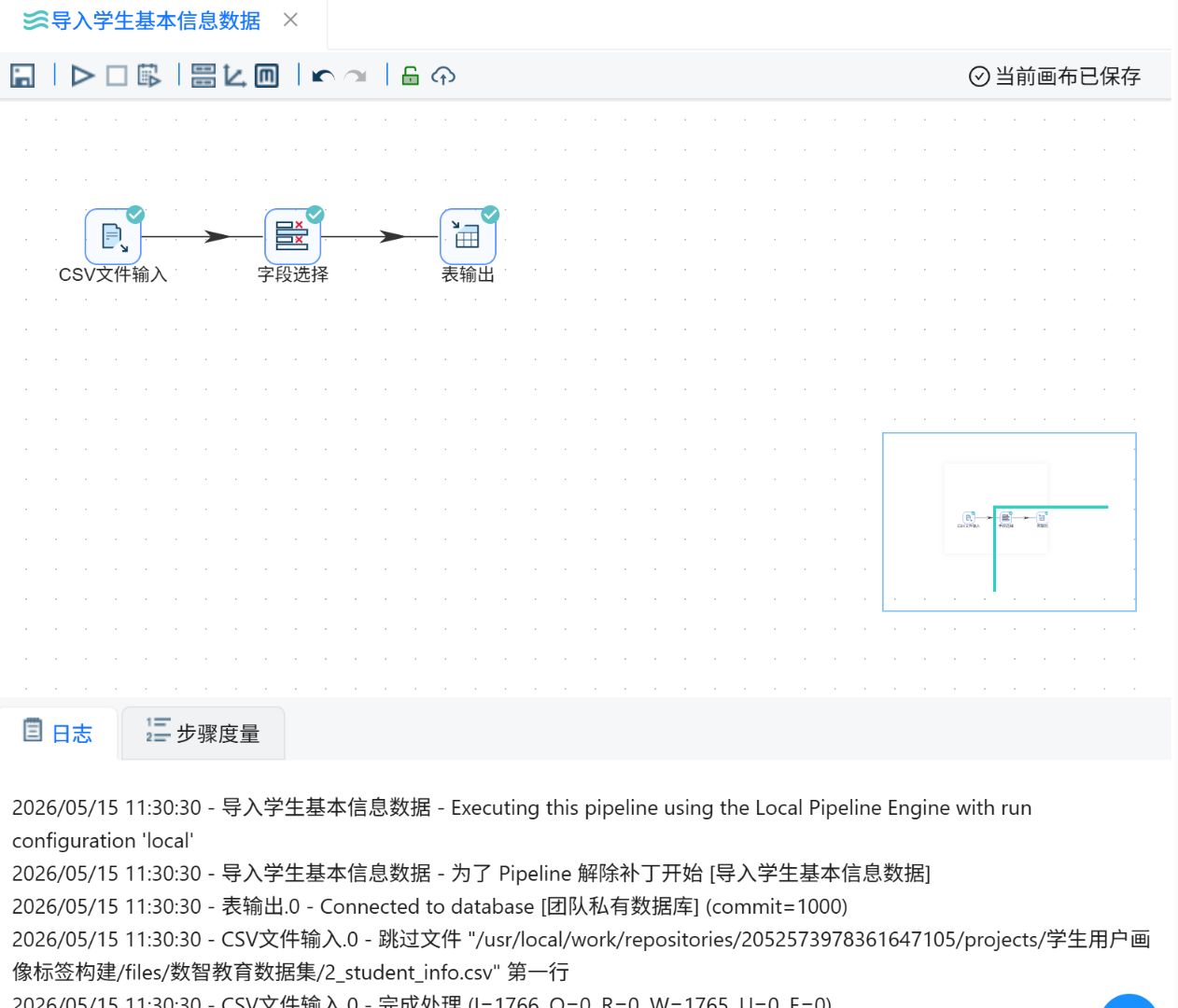
2.2.6创建学生考勤主题标签表
点击“资源库”,右键根目录,点击“新建转换流”。
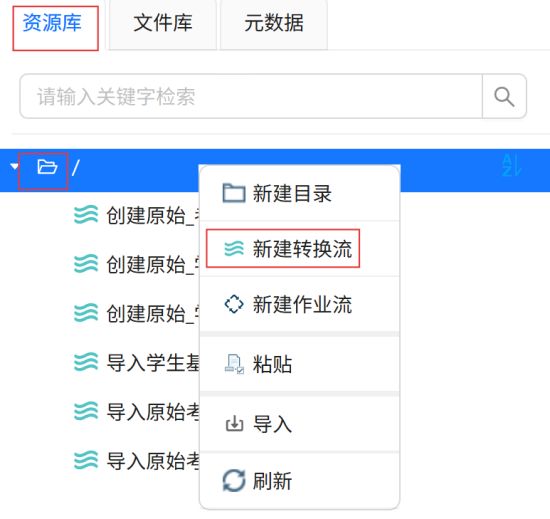
输入转换流名称“创建学生考勤主题标签表”,点击“确定”。

点击锁形图标解锁画布。
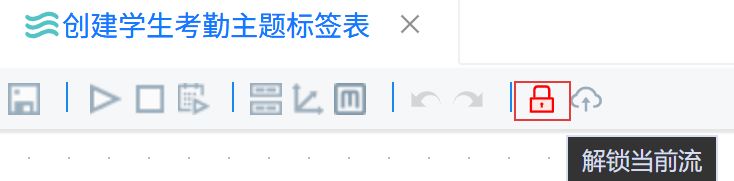
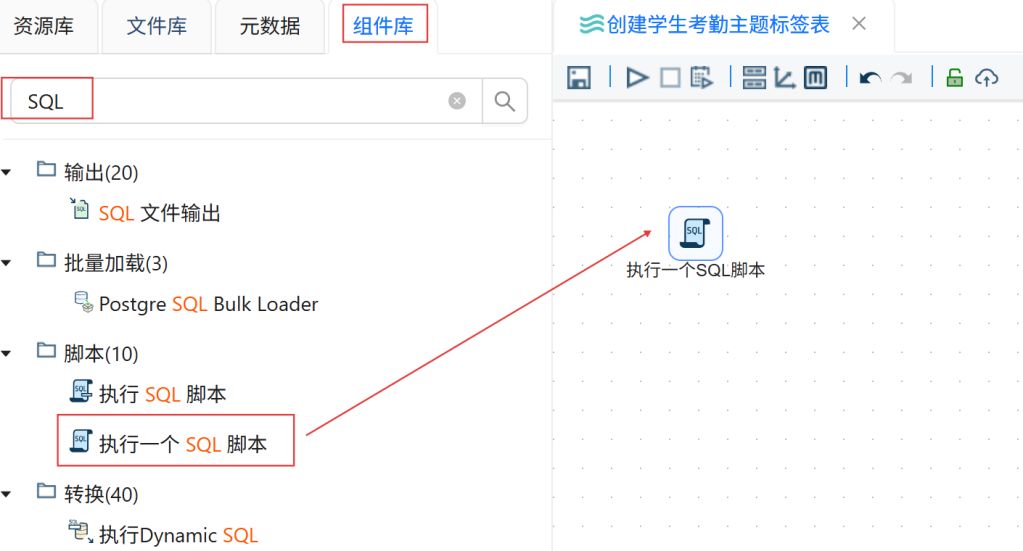
点击“组件库”,搜索“执行一个SQL脚本”,将其拖入右侧画布。
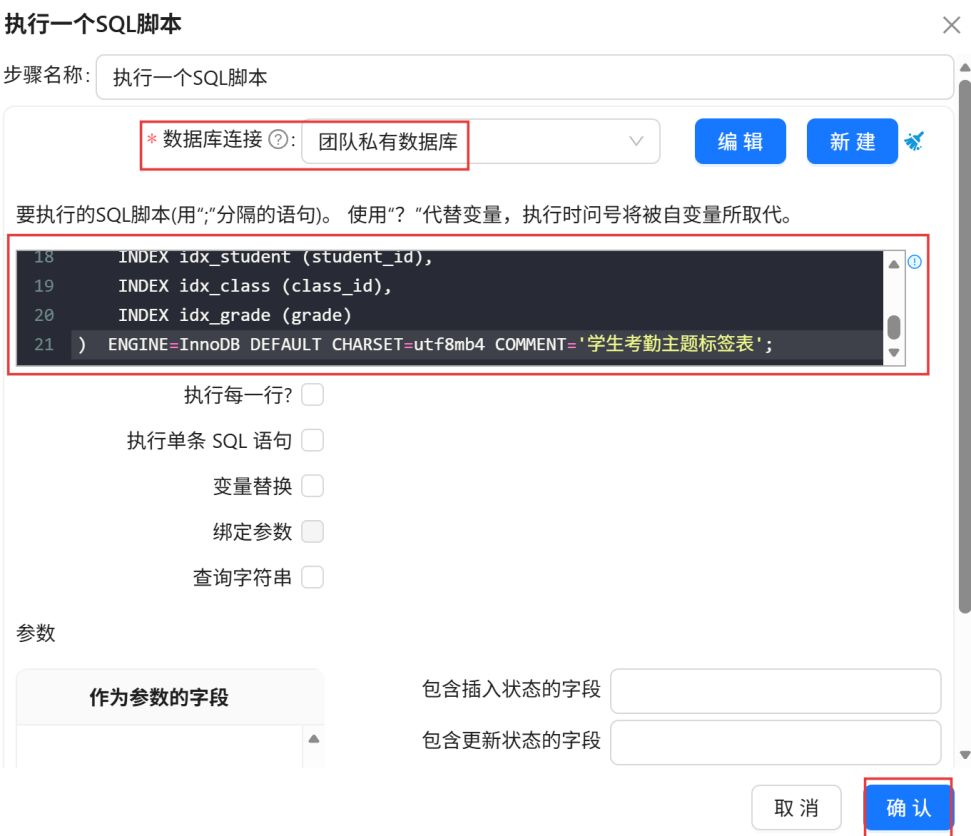
数据库连接选择“团队私有数据库”,在组件中填写SQL脚本,点击“确认”。
点击三角形图标,运行转换流。
点击“启动”。
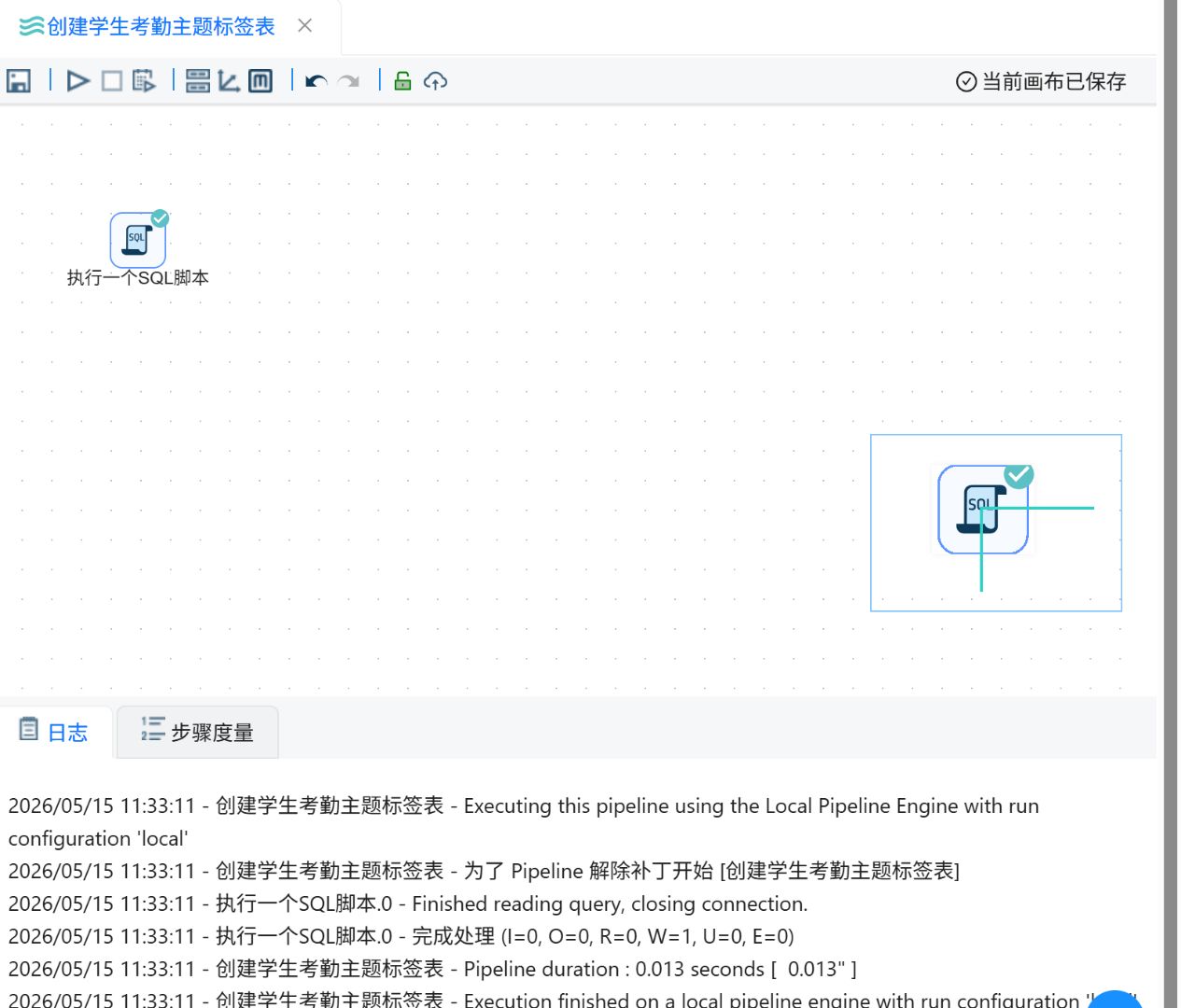
运行过程会定时刷新组件状态,并显示执行日志。
2.3 学生考勤主题标签构建
2.3.1数据接入:获取考勤记录、考勤类型数据、学生信息数据
点击“资源库”,右键根目录,点击“新建转换流”。
输入转换流名称“学生考勤主题标签”,点击“确定”。
点击锁形图标解锁画布。
点击“组件库”,搜索“表输入”,拖拽3个表输入组件至画布中。
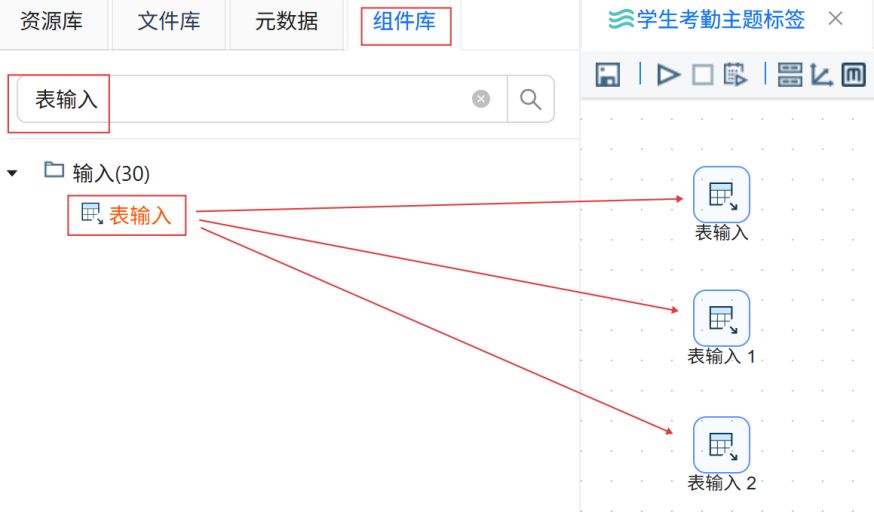
双击第一个表输入组件,步骤名称修改为“考勤记录”,数据库连接选择“团队私有数据库”,并点击“获取SQL查询语句”。
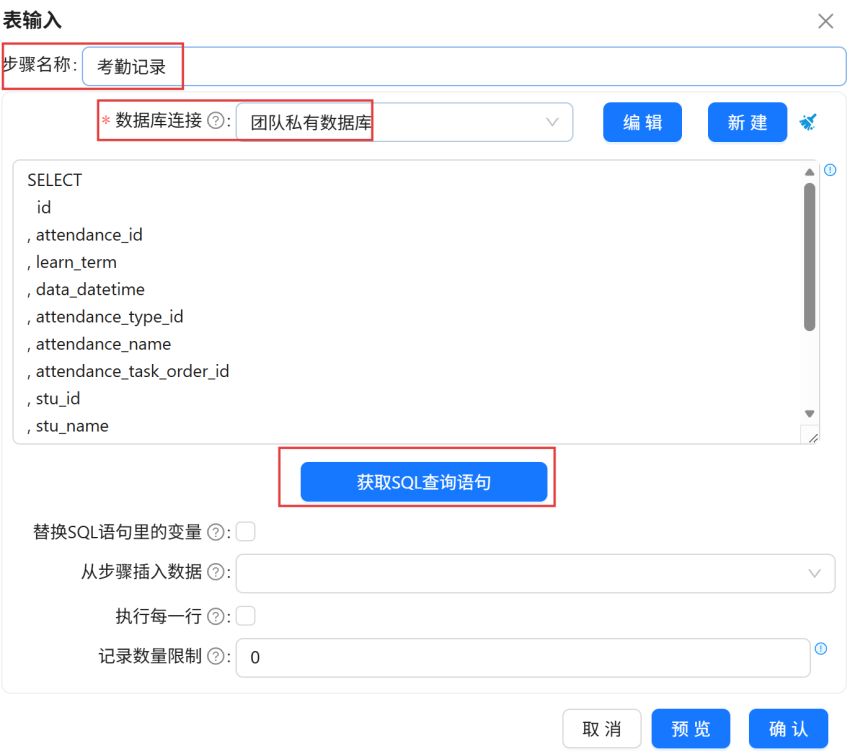
在数据库中选择“raw_attendance”原始_学生考勤表。点击“确定”。
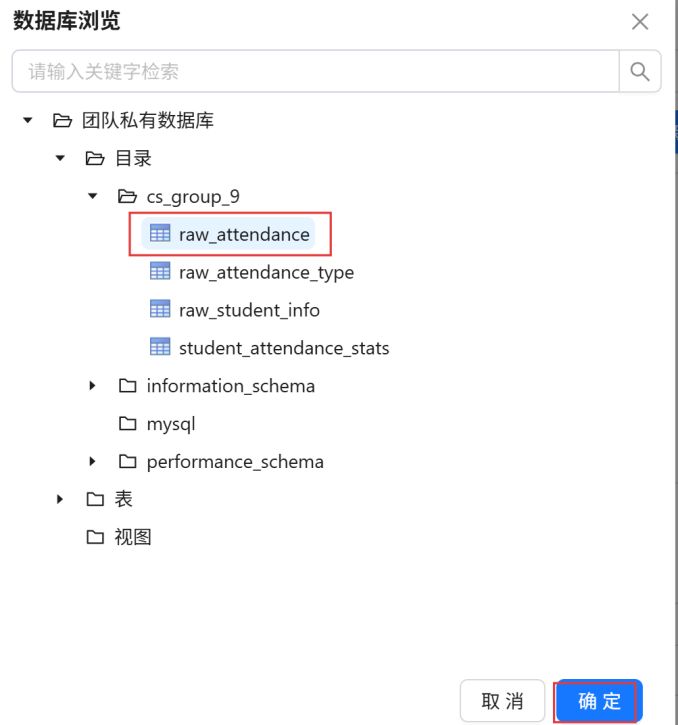
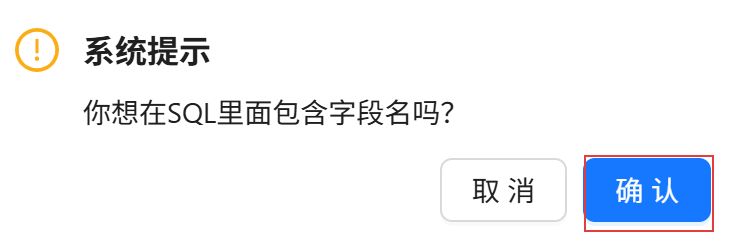
在系统提示弹窗中点击“确认”。
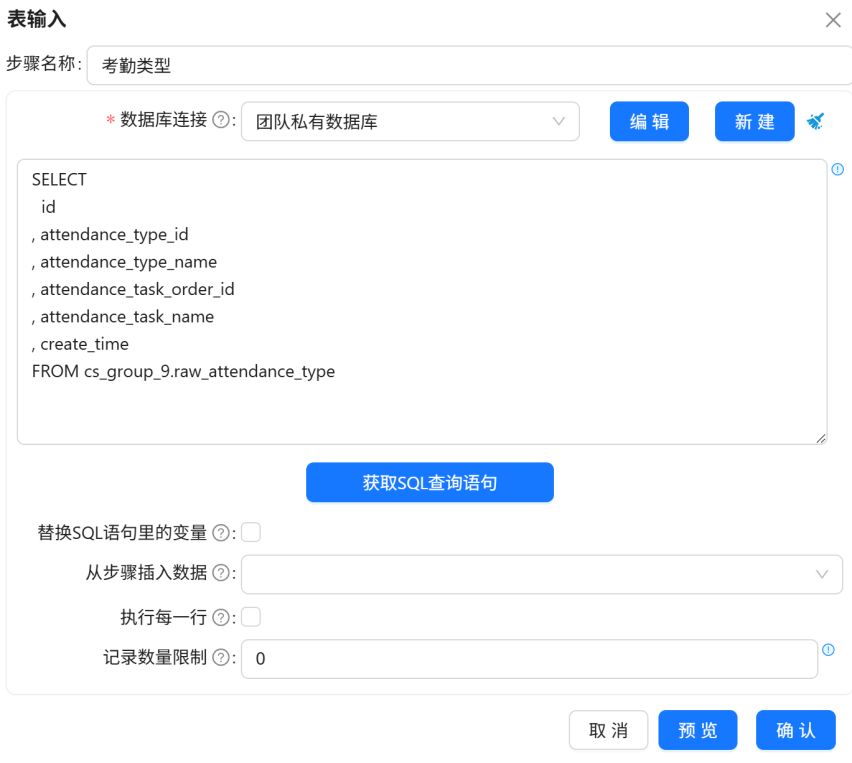
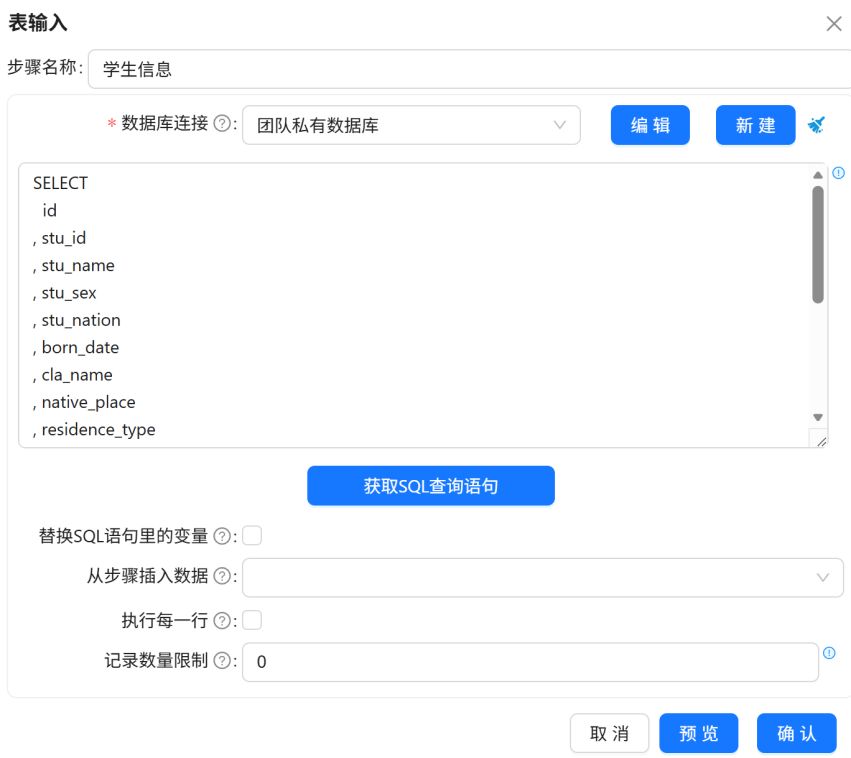
按以上步骤,将“表输入 1”和“表输入 2”组件分别命名为“考勤类型”和“学生信息”,分别获取考原始_考勤类型表(raw_attendance_type)和原始_学生信息表(raw_student_info)所有字段数据。
2.3.2数据关联:关联考勤记录+考勤类型
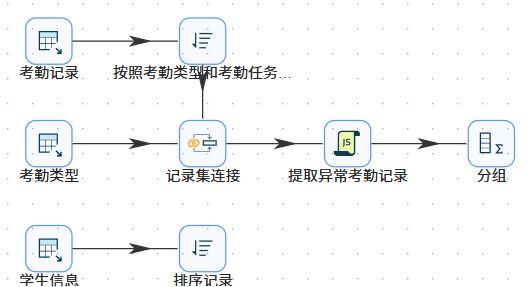
点击“组件库”,搜索“排序记录”,将其拖入右侧画布。
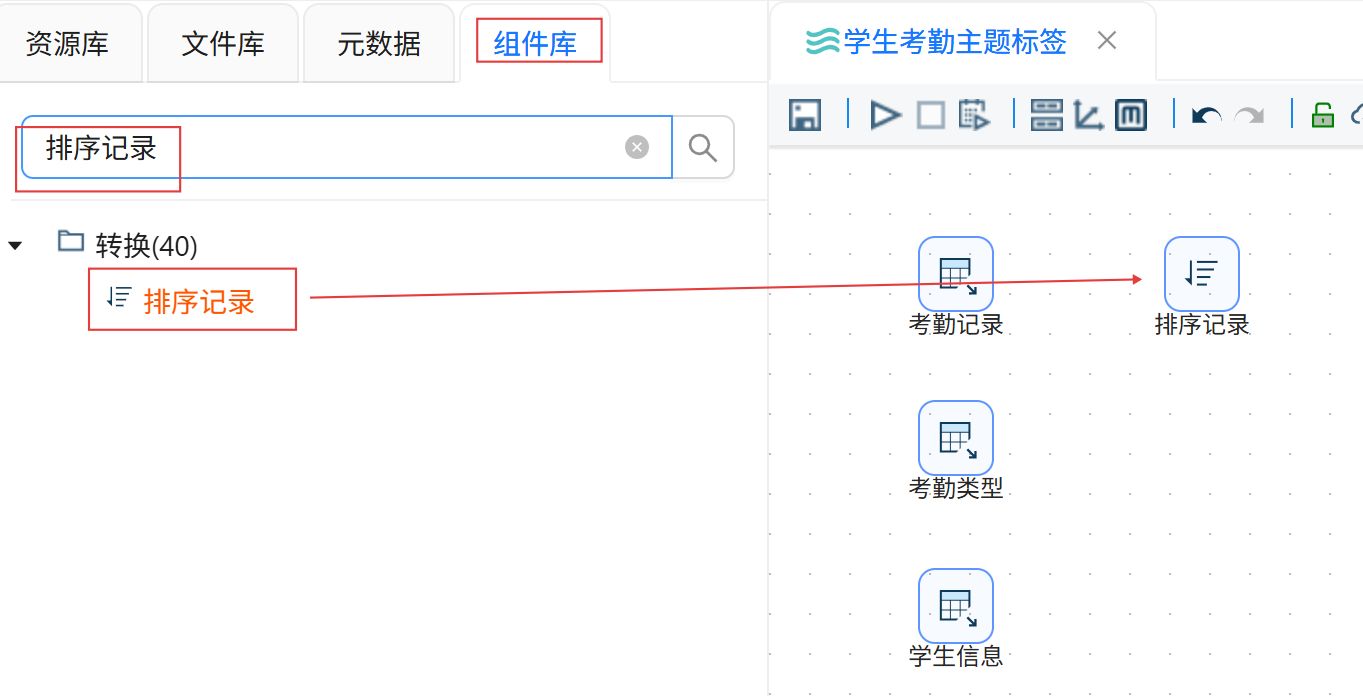
创建“考勤记录”CSV文件输入组件到“排序记录”组件的连接线。
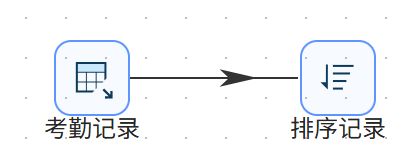
双击“排序记录”组件,在字段表格中空白处右键点击“获取字段”。
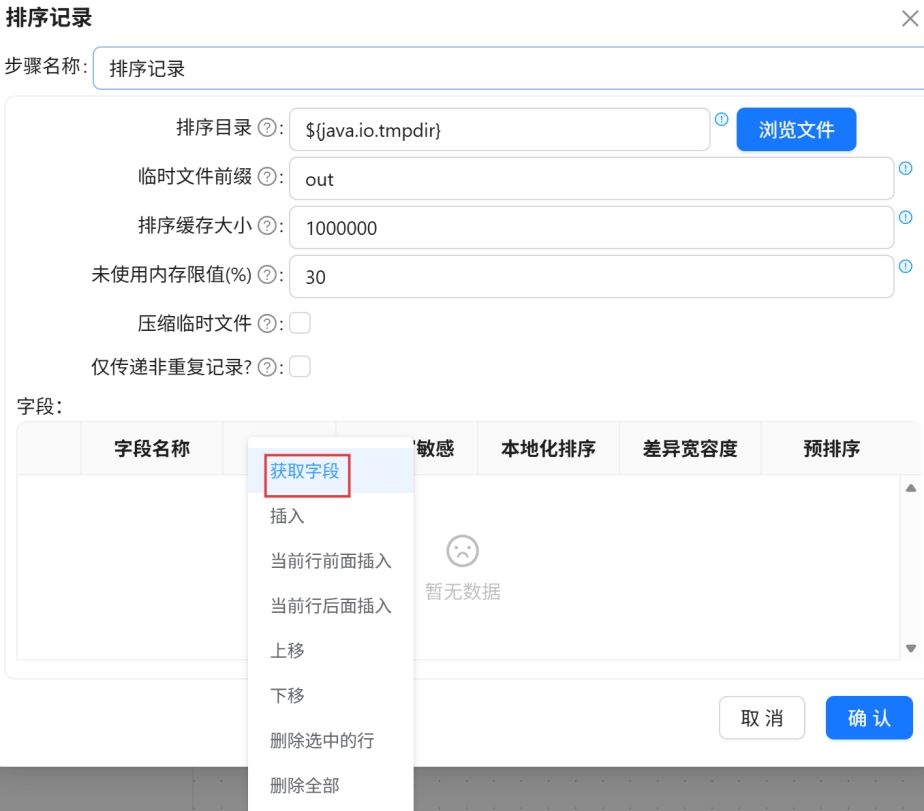
选中多余字段,删除多余字段。
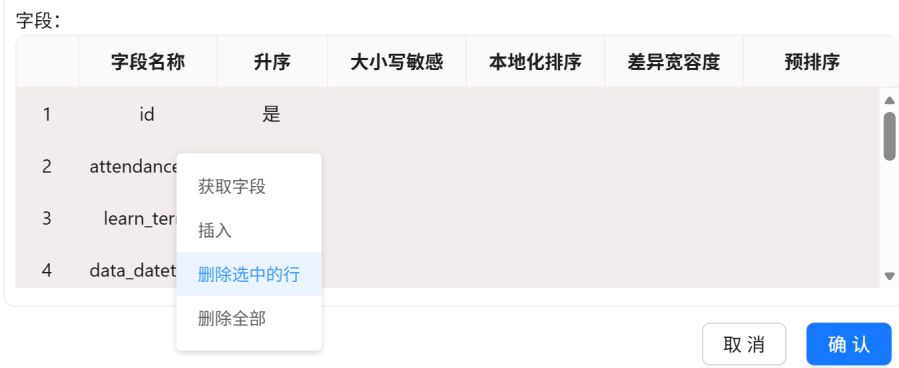
只保留“attendance_type_id”、“attendance_task_order_id”字段。最后设置步骤名称为“按照考勤类型和考勤任务类型排序”,点击“确认”。
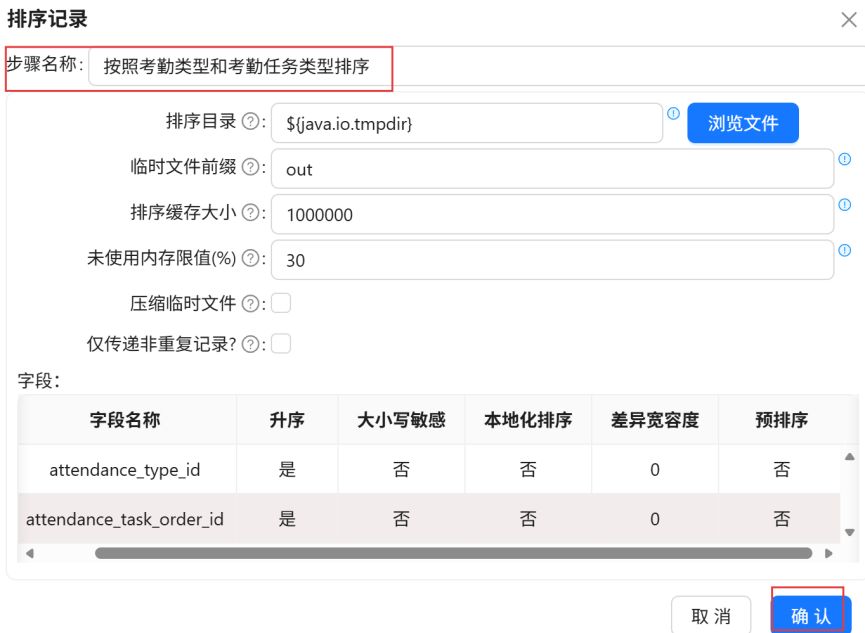
点击“组件库”,搜索“记录集连接”,将其拖入右侧画布。
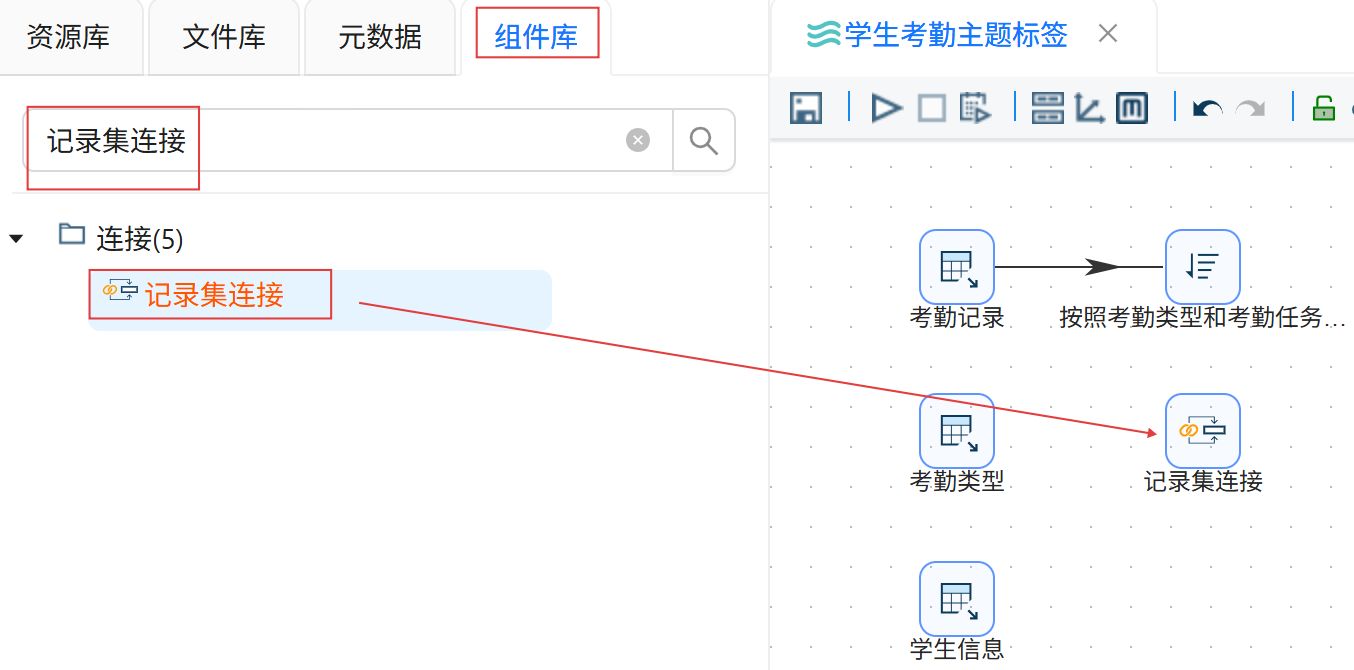
创建排序记录组件到记录集连接组件的连接线。创建“考勤类型”表输入组件到记录集连接组件的连接线。
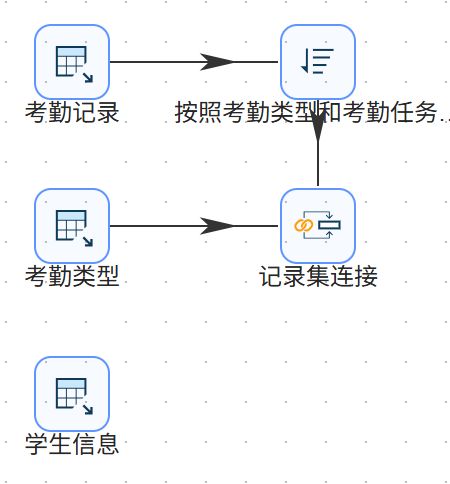
双击记录集连接组件,第一个Transform选择“按照考勤类型和考勤任务类型排序”,第二个Transform选择“考勤类型”,连接类型选择LEFT OUTER。

点击“获得连接字段”,选中多余字段,删除多余字段。

2个Transform字段中仅保留“attendance_type_id”、“attendance_task_order_id”字段。最后点击“确认”。

2.3.3行为标签衍生:统计学生异常考勤次数
点击“组件库”,搜索“Java Script代码”,将其拖入右侧画布。
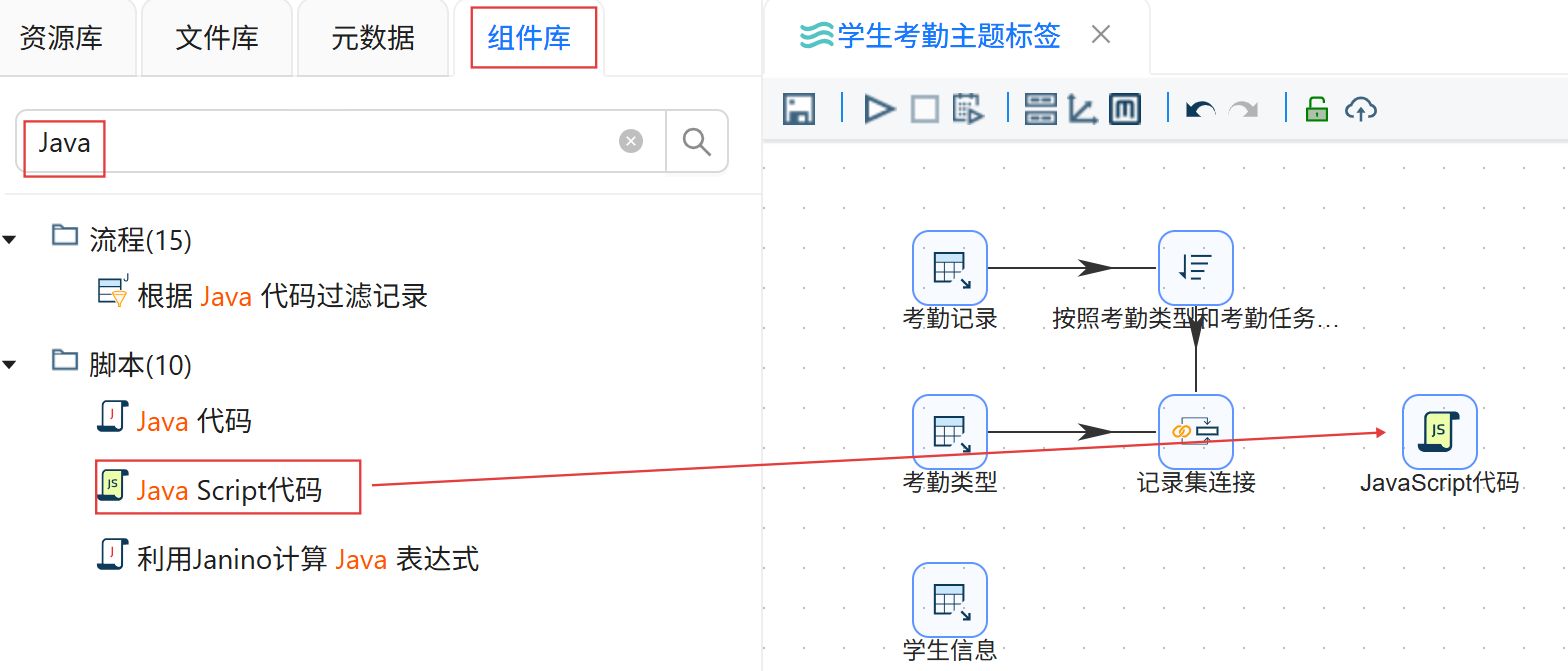
创建记录集组件到“Java Script代码”组件的连接线。
双击“JavaScript代码”组件,命名为“提取异常考勤记录”,在Script1中输入JavaScript脚本。点击“获取变量”。最后点击“确认”。
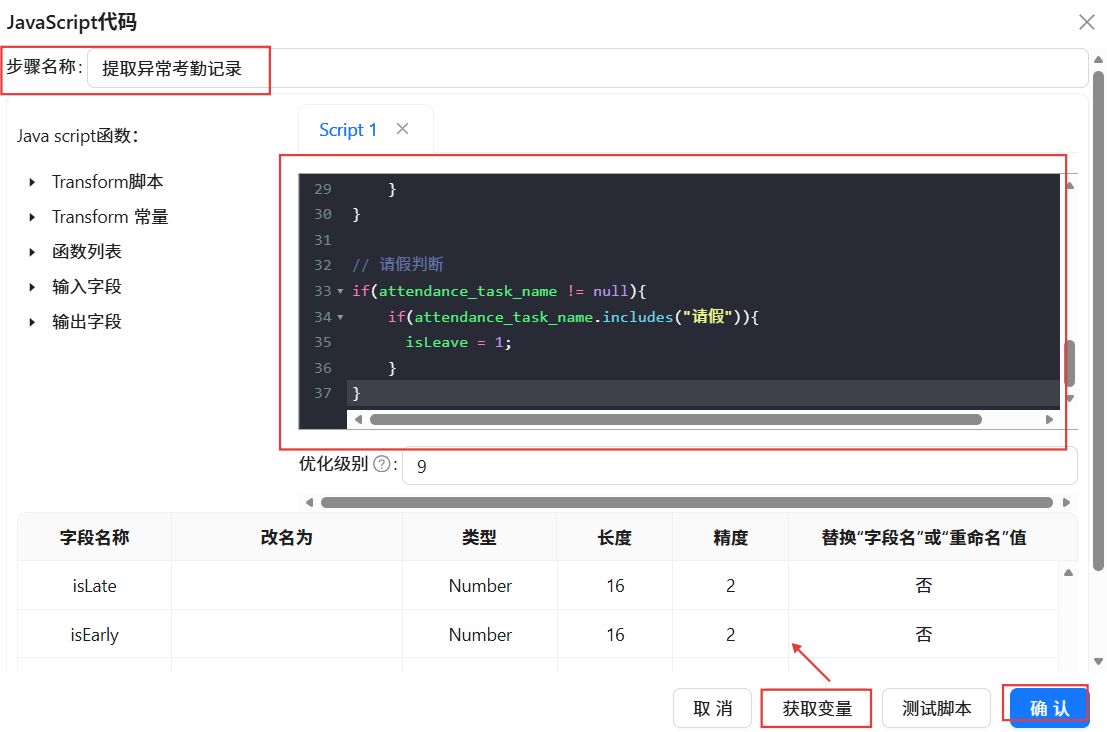
2.3.4多维度分组聚合统计
点击“组件库”,搜索“分组”,将其拖入右侧画布。
创建“提取异常考勤记录”组件到分组组件的连线。
连线选择“主输出步骤”。

双击“分组”组件,设置分组字段为“stu_id”、“stu_name”、“cla_id”、“cla_name”。
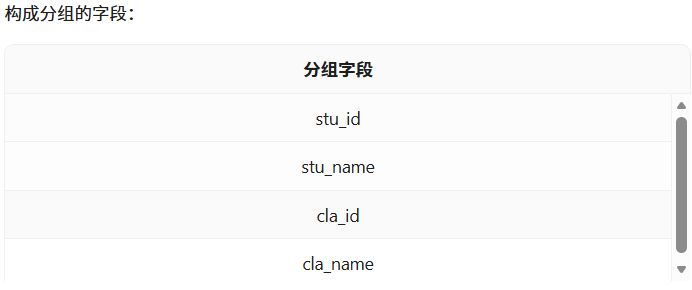
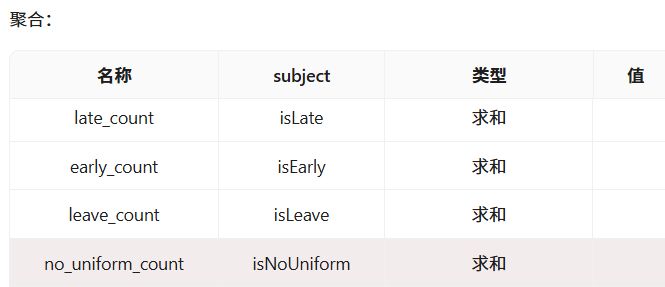
设置聚合字段为“late_count”、“early_count”、“leave_count”、“no_uniform_count”。
2.3.5关联学生信息
点击“组件库”,搜索“排序记录”,将其拖入右侧画布。
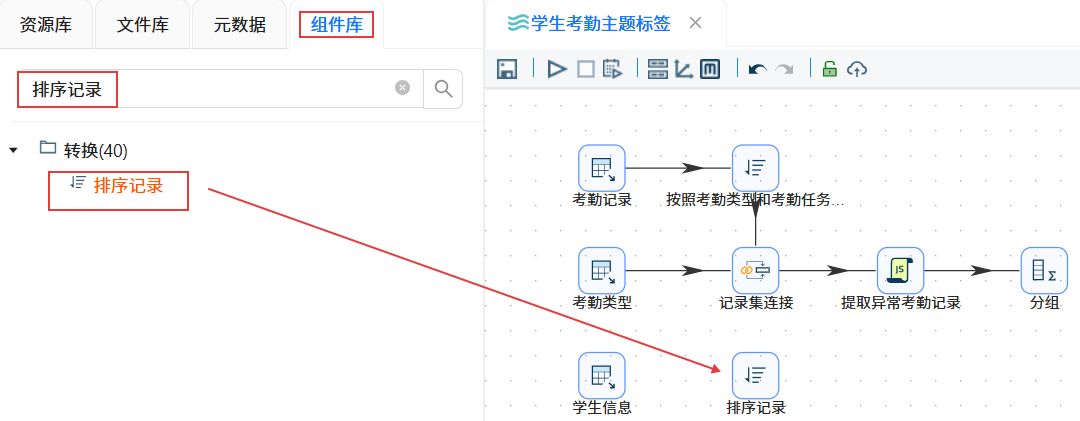
建立“学生信息”表输入组件到“排序记录”组件的连接线。
双击“排序记录”组件,通过“获取字段”功能获取字段列表,然后删除多余字段,只保留“stu_id”字段。最后设置步骤名称为“按照学生编号进行排序”,点击“确认”。
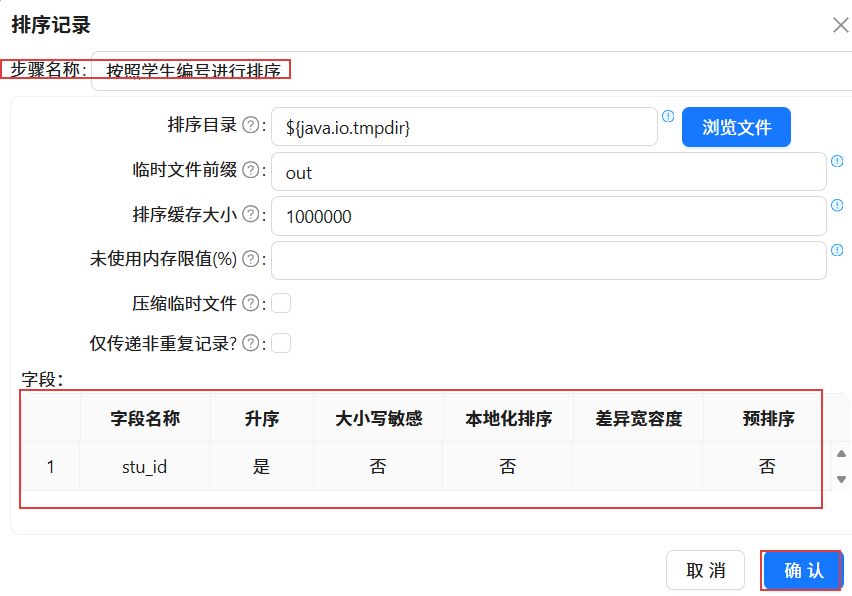
拖拽“记录集连接”组件至画布中,创建“按照学生编号进行排序”排序记录组件到“记录集连接 1”组件的连接线。
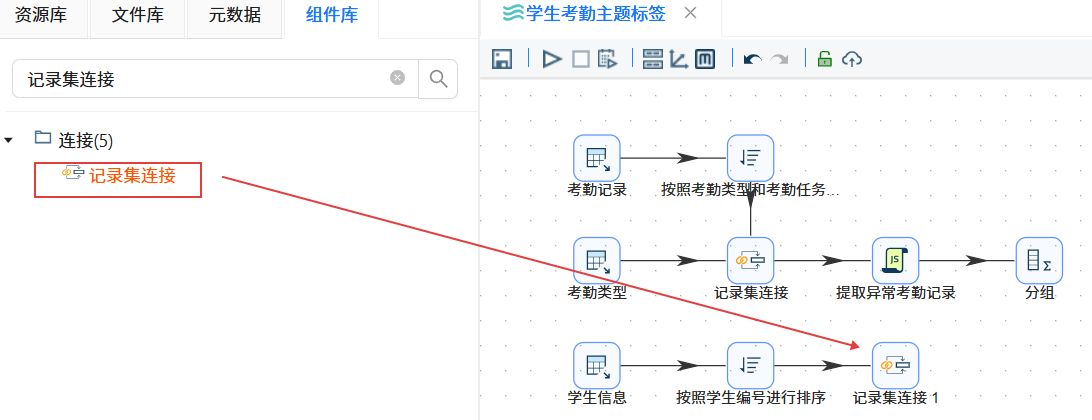
拖拽“排序记录”组件至画布中,创建“分组”组件到“排序记录”组件的连接线。
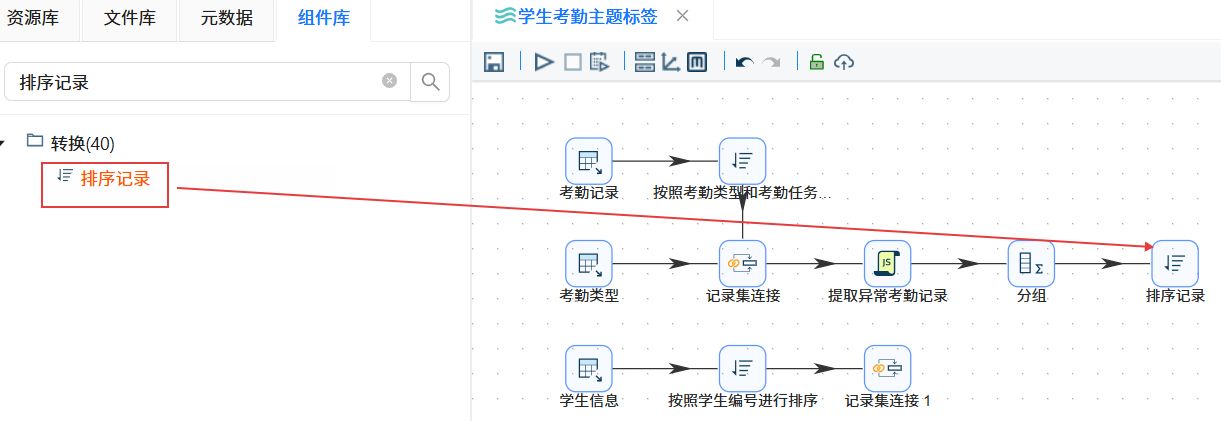
双击“排序记录”组件,通过“获取字段”功能获取字段列表,然后删除多余字段,只保留“stu_id”字段。最后设置步骤名称为“按照学生编号进行排序”,点击“确认”。
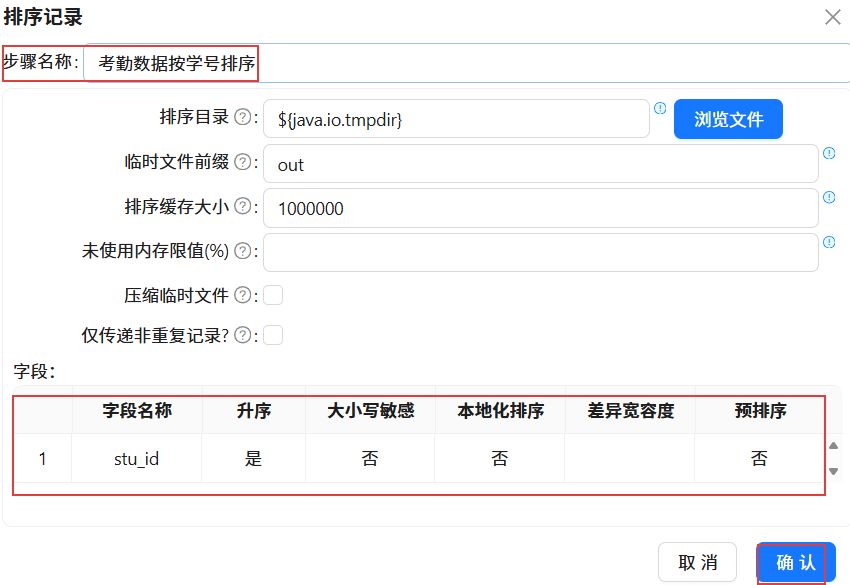
创建“考勤记录按学号排序”组件到“记录集连接 1”组件的连接线。创建“按照学生编号进行排序”组件到“记录集连接 1”组件的连接线。
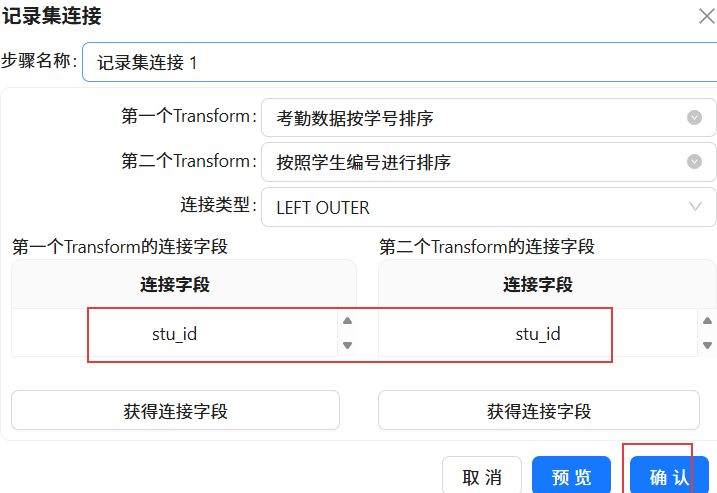
双击记录集连接 1组件,第一个Transform选择“考勤数据按学号排序”,第二个Transform选择“按照学生编号进行排序”,连接类型选择LEFT OUTER。

点击“获得连接字段”,删除多余字段,只留下“stu_id”。点击“确认”。
2.3.6字段选择:移除冗余字段
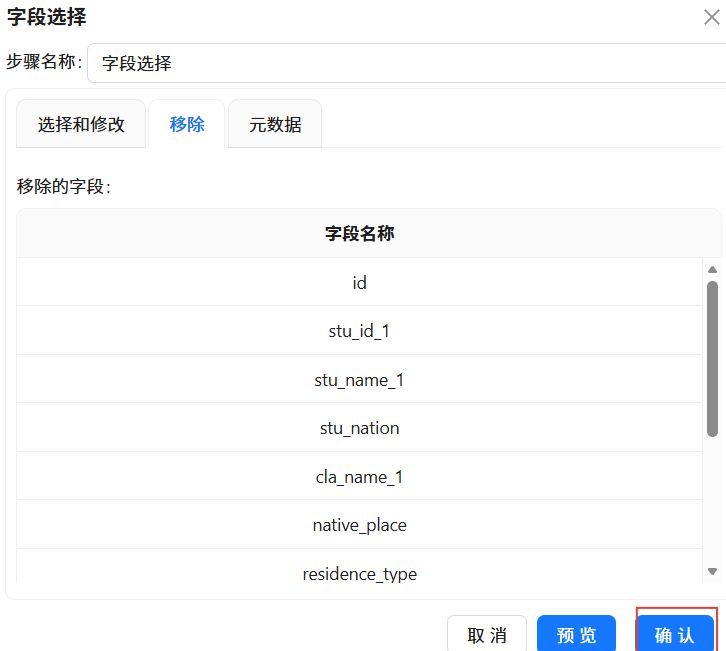
拖拽“字段选择”至画布中,创建“记录集连接 1”组件到字段选择组件的连接线。
双击“字段选择”组件,点击“移除”,点击“获取字段”。
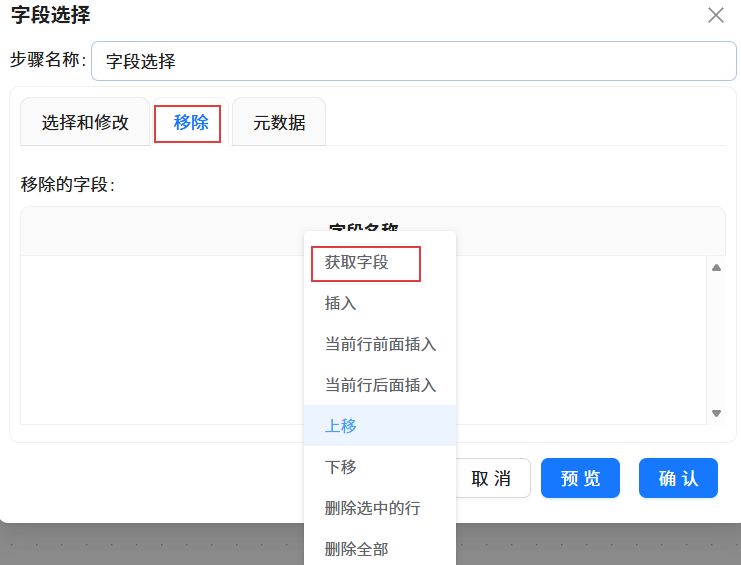
删除“stu_id”、“stu_name”、“cla_id”、“cla_name”、“late_count”、“early_count”、“leave_count”、“no_uniform_count”、“stu_sex”、“born_date”、“policy”、“live_on_campus”字段,点击“确认”。
2.3.7空值处理
拖拽“替换NULL值”组件至画布,创建“移除冗余字段”字段选择组件到“替换NULL值”组件的连线。
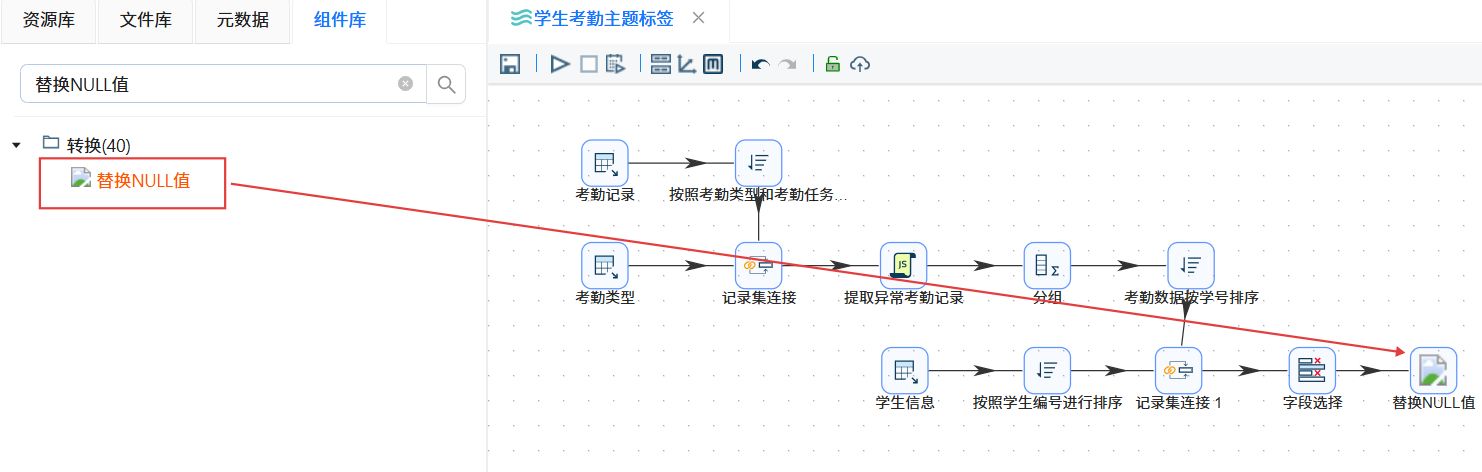
连线类型选择“主输出步骤”。

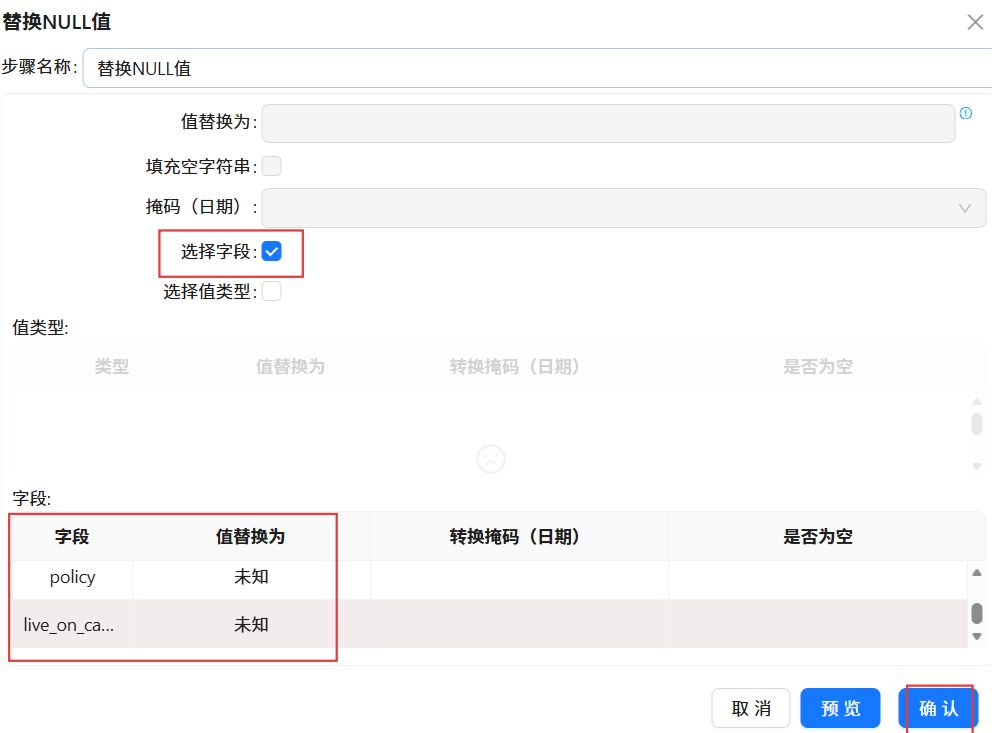
双击“替换NULL值”组件,勾选“选择字段”,插入“stu_sex”、“born_date”、“policy”、“live_on_campus”字段,将其空值均替换为“未知”。点击“确认”。
2.3.8住校状态映射
拖拽“值映射”组件到画布中,并创建替换NULL值组件到值映射组件的连线。
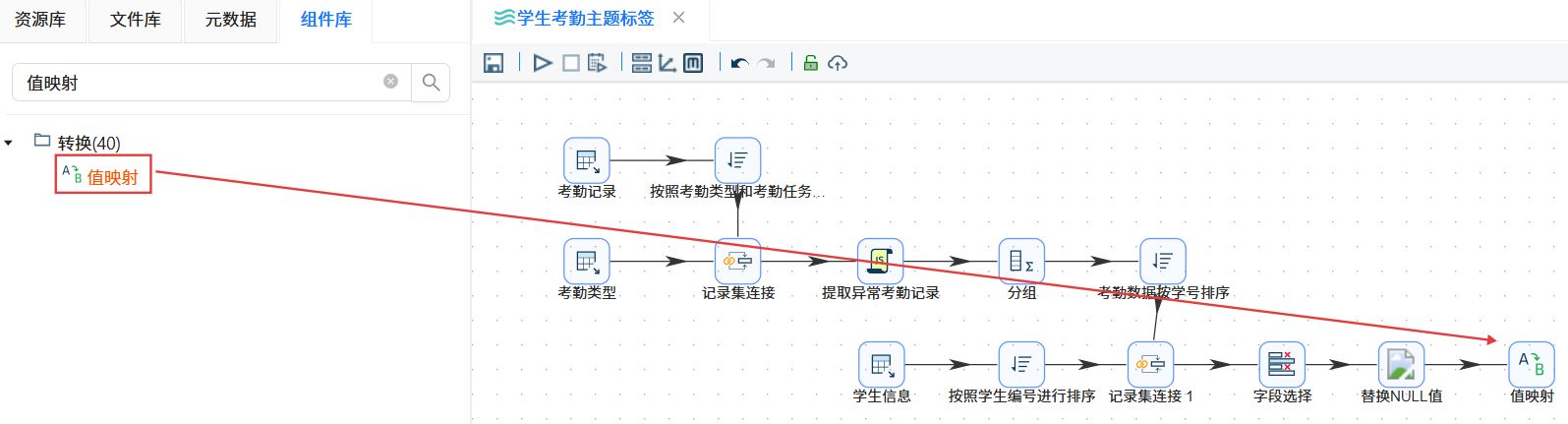
连线选择“主输出步骤”。

双击“值映射”组件,步骤名称改为“住校状态映射”,使用的字段名为“live_on_campus”,不匹配时的默认值为“否”。
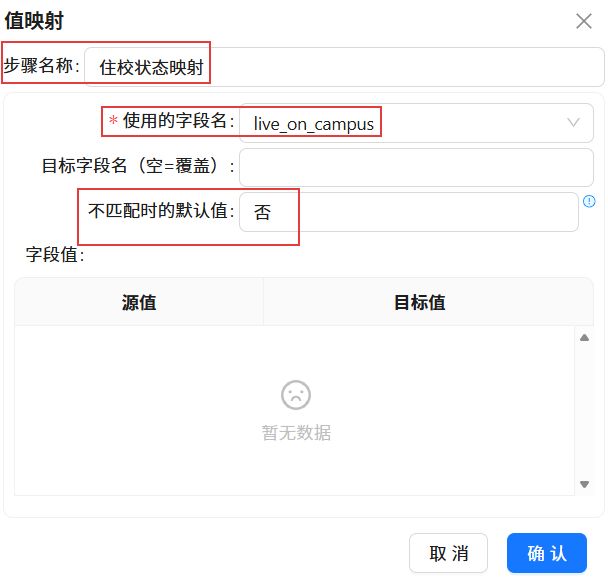
插入两行,一行在源值中输入“0”,目标值输入“否”。一行在源值中输入“1”,目标值输入“是”。点击“确认”。
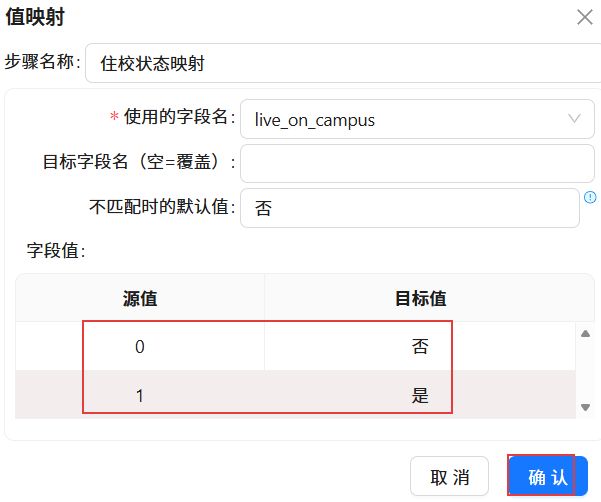
2.3.9从班级名提取年级
拖拽“JavaScript代码”组件至画布中,创建住校状态映射组件到JavaScript代码组件的连线。
连线选择“主输出步骤”。

双击“JavaScript代码”组件,步骤名称改为“从班级提取年级”,在Script1中输入JavaScript脚本。空白表格处右键,点击“插入”,字段名称输入“gra_name”,类型为“String”,替换“字段名”或“重命名”值选择“否”,设置完成后点击“确认”。
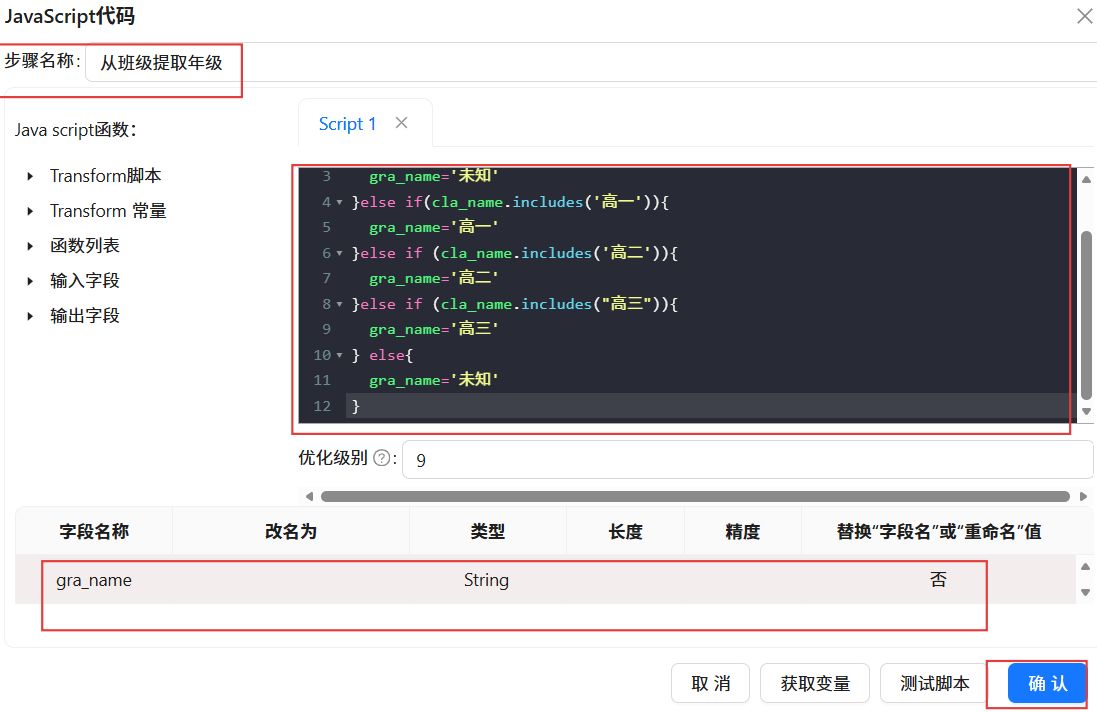
2.3.10校区类型判定
拖拽“JavaScript代码”组件至画布中,创建“从班级提取年级”组件到JavaScript代码组件的连线。
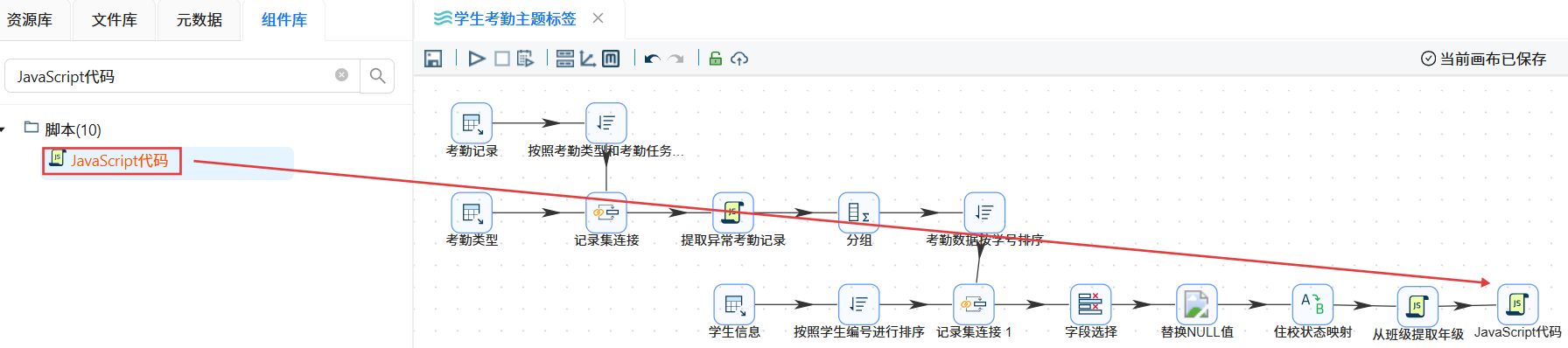
连线选择“主输出步骤”。

双击“JavaScript代码”组件,步骤名称改为“校区类型判定”,在Script1中输入JavaScript脚本。空白表格处右键,点击“插入”,字段名称输入“class_campus_type”,类型为“String”,替换“字段名”或“重命名”值选择“否”,设置完成后点击“确认”。
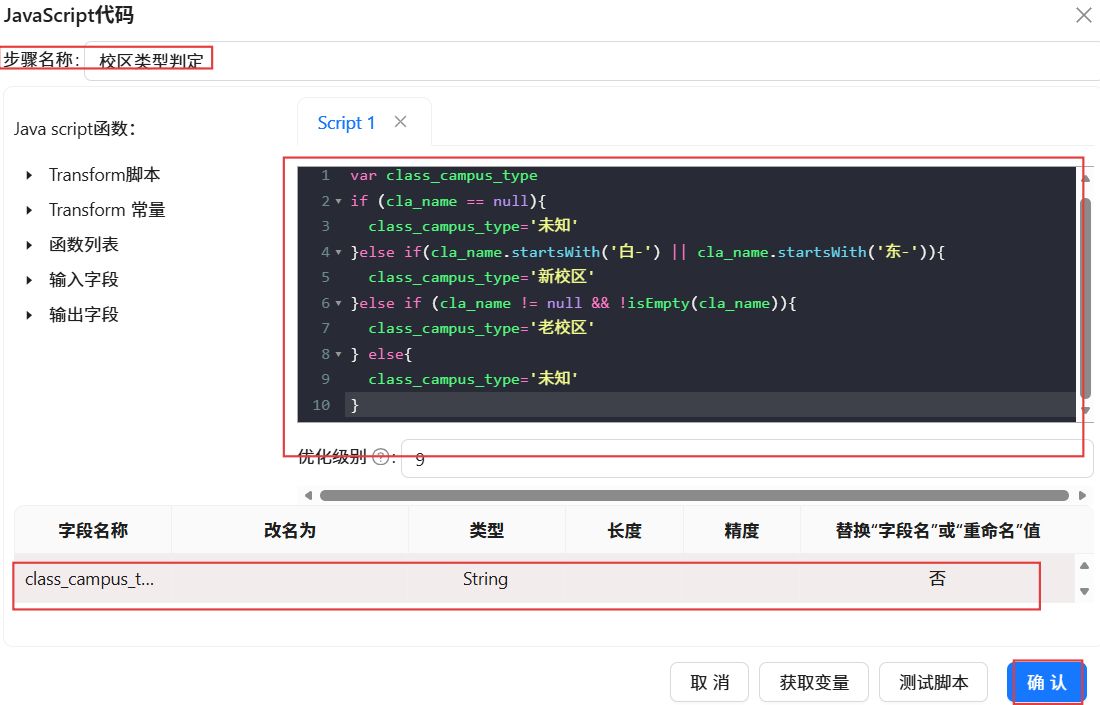
2.3.11结果入库
拖拽表输出组件至画布,并创建“校区类型判定”“JavaScript代码组件到表输出组件的连线。
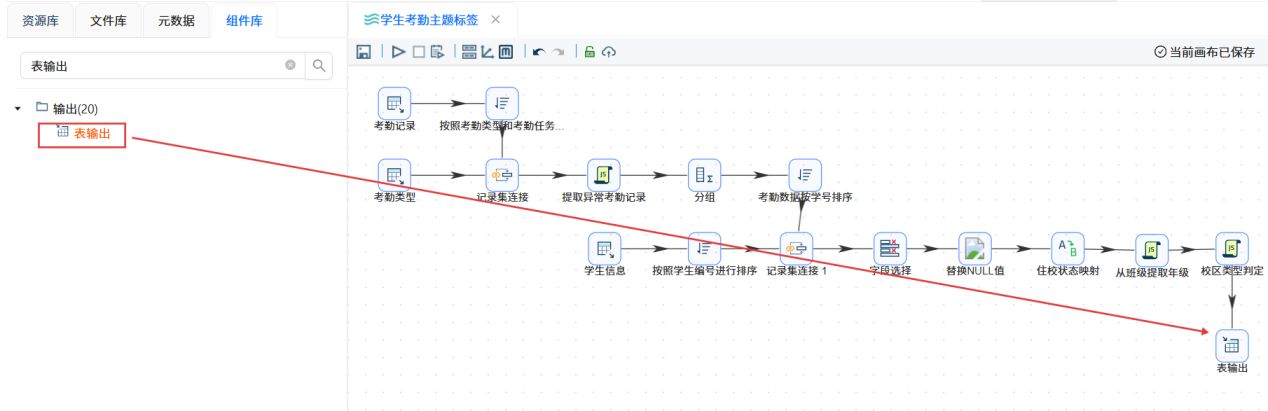
双击表输出组件,选择“团队私有数据库”连接,目标表选择“student_attendance_stats”,勾选裁剪表和指定数据库字段。
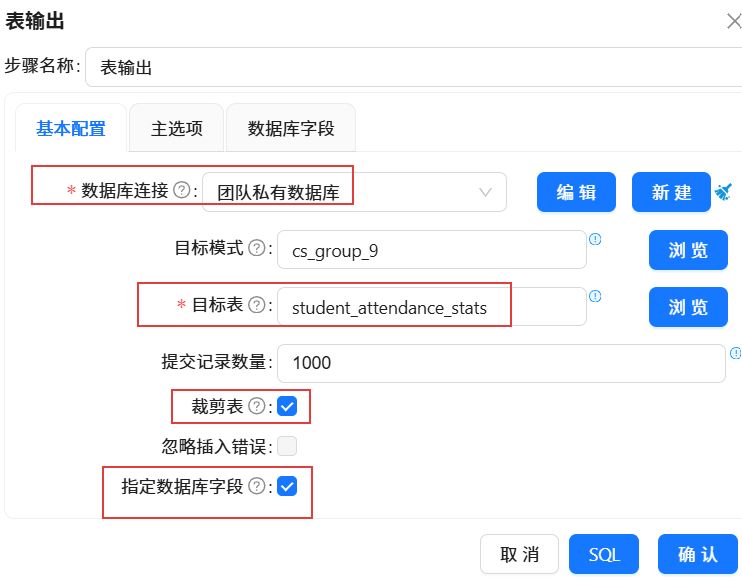
点击“数据库字段”,右键选择“获取字段”,双击表字段中的字段名称,在下拉框中选择正确的对应字段。
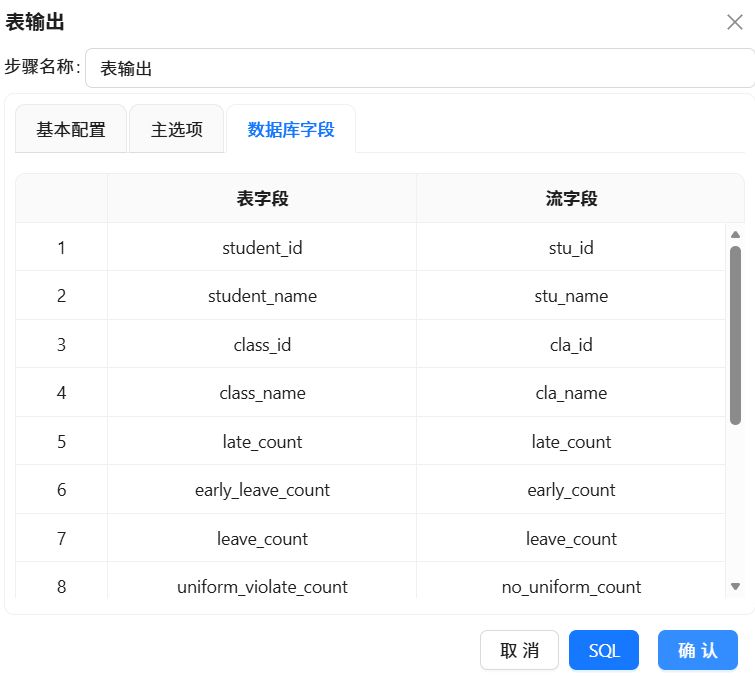
2.3.11执行工作流
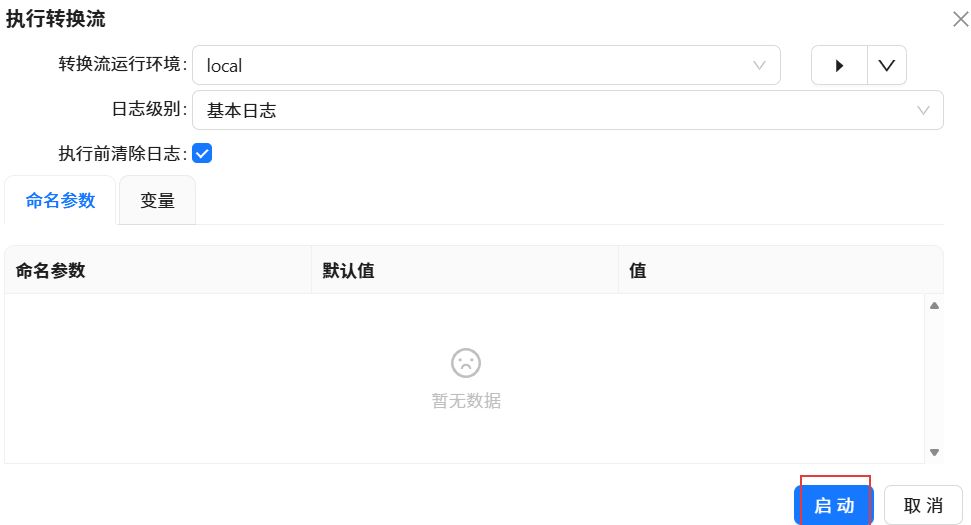
点击三角形图标,执行转换工作流。

点击“启动”。
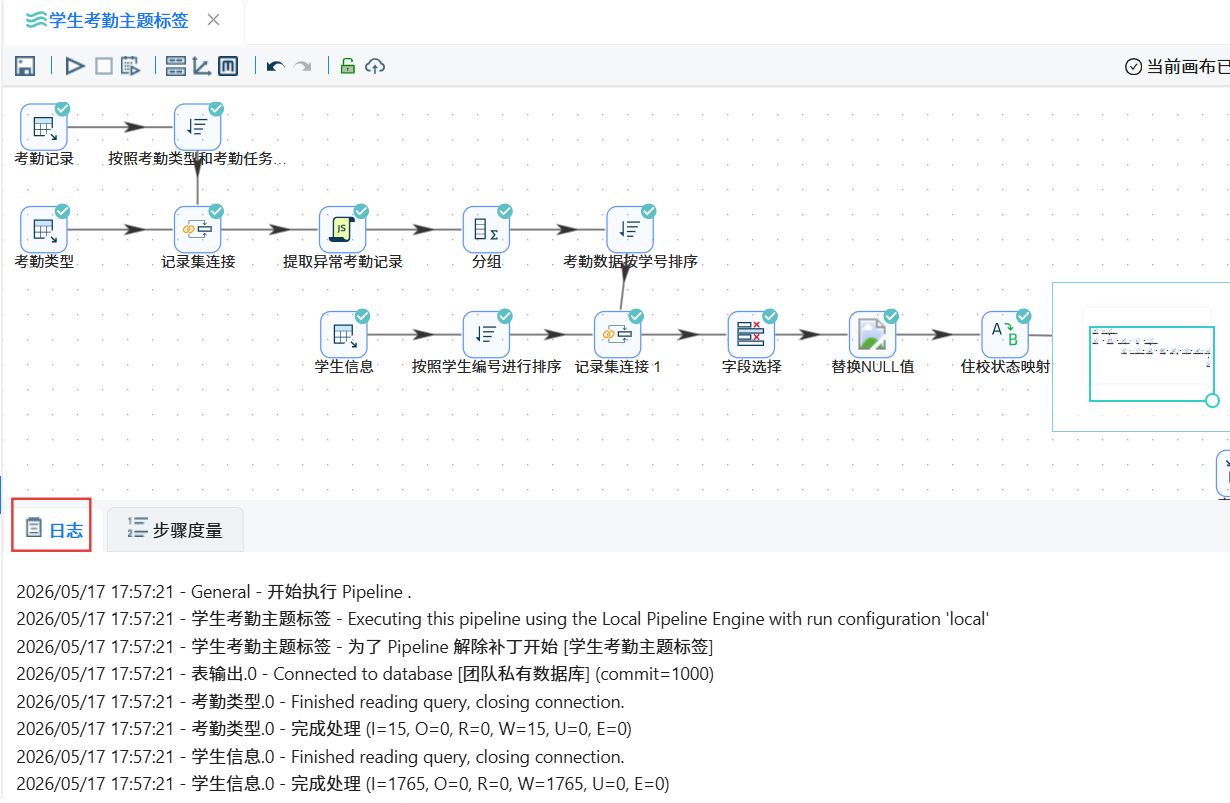
成功执行后可以查看日志界面。
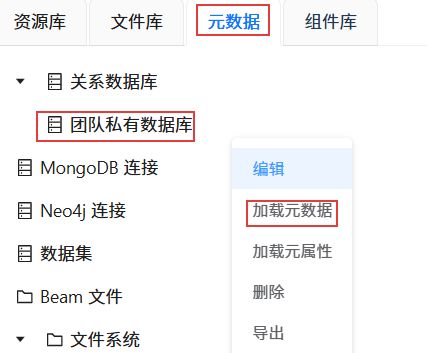
点击“元数据”,在“团队私有数据库”连接上右键选择“加载元数据”。
点击“数据探查”,展开“团队私有数据库”,双击目标表“student_attendance_stats”,在右侧页面点击“查询”,即可查看最终结果。
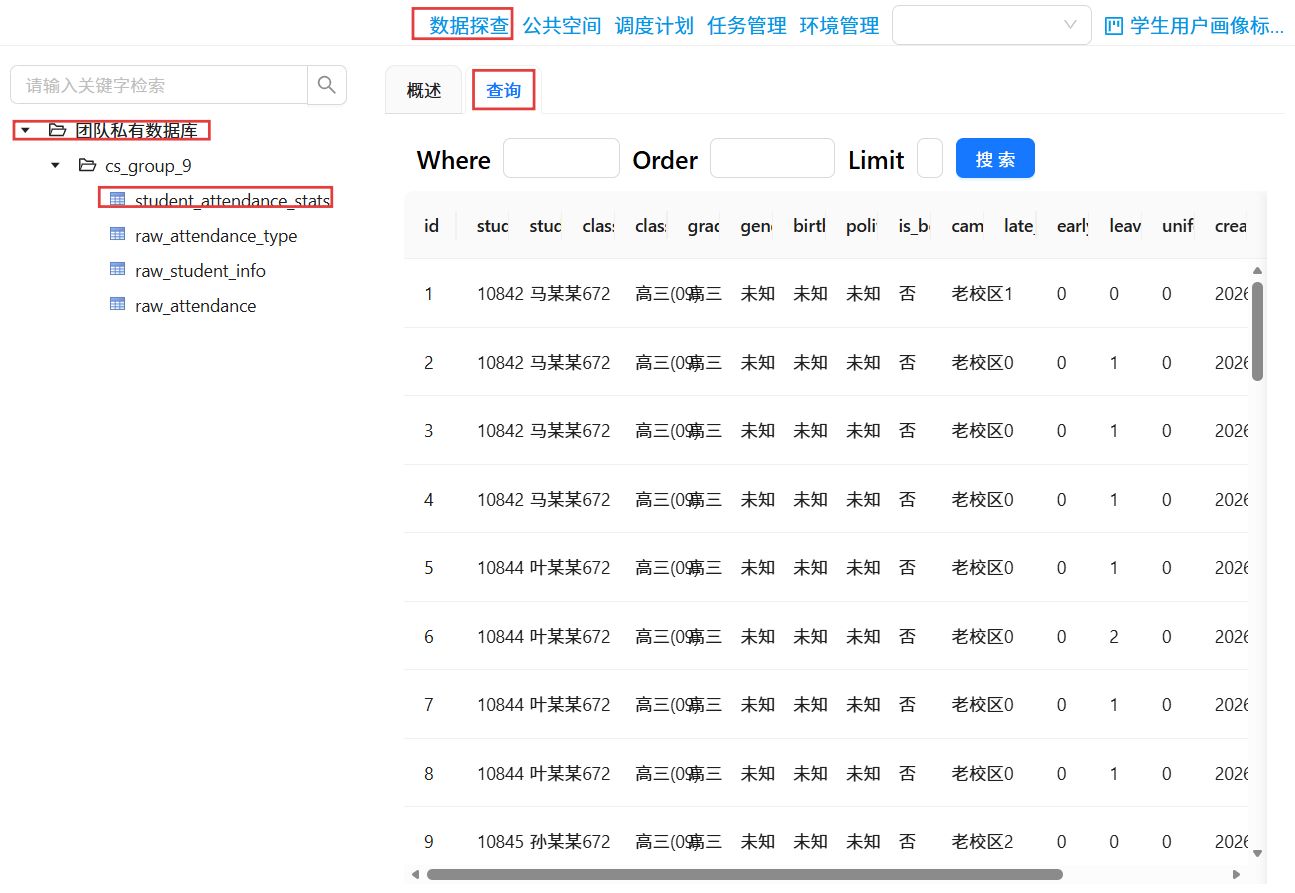
实验结果
3.1 输出数据展示
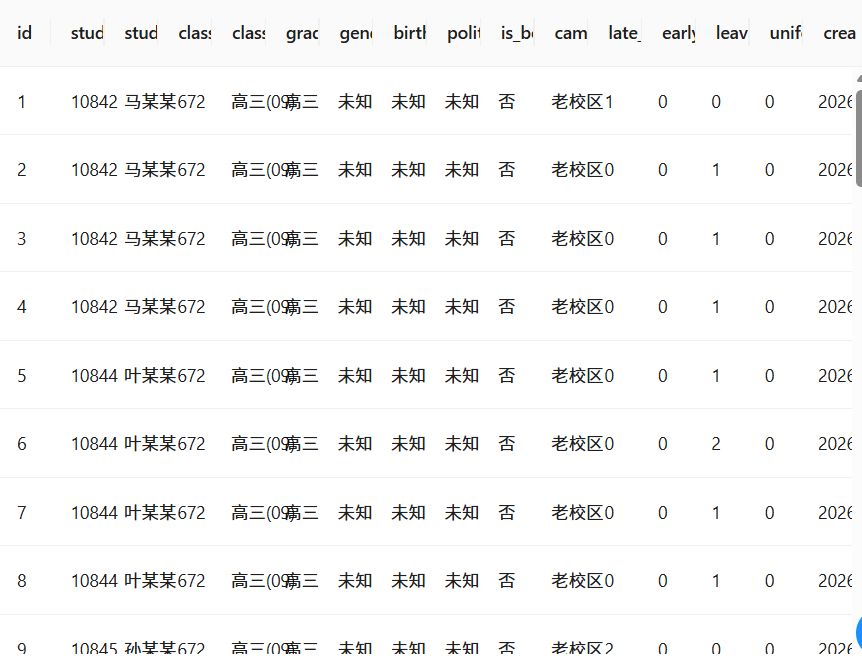
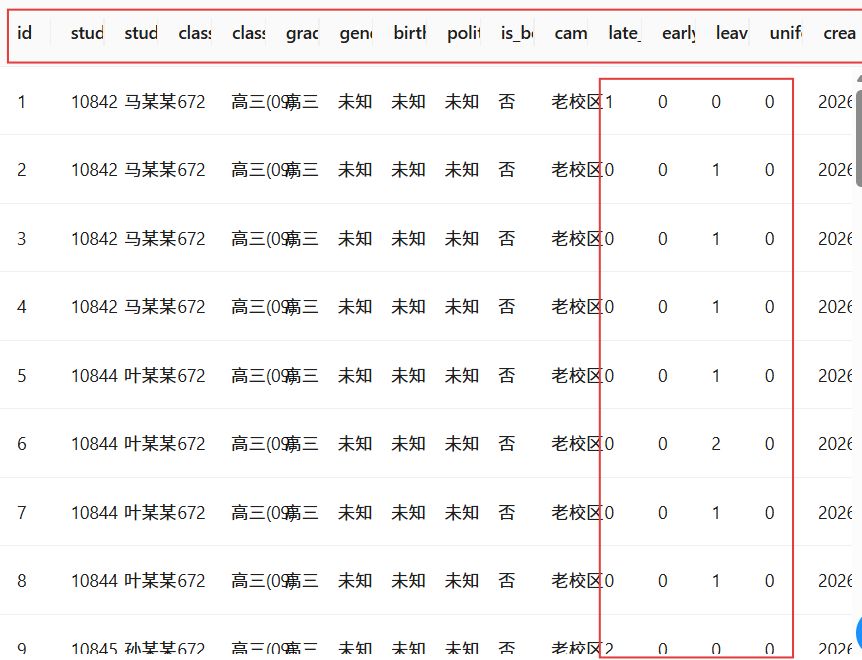
3.2结果分析与验证
本次实验成功生成学生考勤统计标签表,核心字段包括: student_id(学号)、student_name(姓名)、class(班级)、grade(年级)、campus_type(校区类型)、is_boarder(是否住校)、late_count(迟到次数)、early_count(早退次数)、leave_count(请假次数)、uniform_violation(未穿校服次数)。学生基础属性和考勤行为标签都成功完成了相应的标准化处理。
问题与解决
问题一:表输出的部分表字段和流字段不匹配
解决方法:在配置表输出组件时,要建立工作流字段与数据库表字段的映射关系,我在下拉框中选择了错误的对应字段。最后通过查看创建学生考勤主题表签表的SQL脚本,找到了正确的对应字段。
实验总结
本次实验让我掌握了助睿平台的全流程数据处理能力,从项目创建、多数据源接入,到数据关联、清洗衍生、聚合统计与结果输出,成功完成了将原始数据转换为标准化学生考勤标签。我理解并掌握了空值处理、字段映射、关键词匹配等数据清洗技巧,同时建立了从校园考勤业务需求出发,通过数据手段解决人工统计效率低、口径不统一问题的工程思维,为后续数据科学项目奠定了基础。
助睿平台凭借零代码可视化操作,大幅降低了ETL学习门槛,其全链路数据处理功能与教学友好的项目管理、日志查看机制,完美支撑了本次实验的开展。平台在易用性与稳定性上表现突出,能高效完成从数据到标签的转化

一站式 AI 云服务平台
更多推荐

 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)