
保姆级教程!别再用Excel盯考勤了,零代码+K-Means带你秒建学生考勤画像(附防坑指南)
本文完整复盘了基于助睿数智(Uniplore)零代码平台,利用 K-Means 聚类算法构建“学生考勤群体画像”的全链路实战。教程从底层考勤数据的 ETL 处理、AI Studio 拖拽式聚类建模,到助睿 BI 的多维散点图可视化洞察,最终将“自律模范”、“纪律高危”等画像标签完美回写至业务数据库,实现了从“离线分析”到“业务赋能”的闭环。全文不仅手把手拆解操作细节,更融入了“距离计算陷阱”、“最
哈喽大家好!还在盯着密密麻麻的考勤Excel表,一行行数谁迟到最多、谁没穿校服吗?传统的“人肉盯盘”不仅费眼,还找不出背后的规律。
今天,我们将用机器学习里的 K-Means 聚类算法,让 AI 自己去给学生打标签、做画像!重点是:全程零代码!点点鼠标就能完成全链路数据分析! 废话不多说,系好安全带,我们直接发车!🚀
🛠️ 课前小贴士:本次实验的神仙平台
在动手之前,先给大家安利一下这次实验的“主战车”——
-
平台全称: 助睿数智(Uniplore)一站式数据科学实验平台
-
平台定位: 主打一个“全链路 Agentic 零代码”,从数据接入、ETL清洗、AI建模到BI可视化,全包圆了!
-
实验平台地址: https://lab.guilian.cn/
第一部分:实验背景与大盘逻辑
1.1 我们要做什么?(实验目的)
简单来说,就是基于一份现成的“学生考勤统计表”,把里面记录的迟到、早退、请假、校服违规次数等数据丢给 K-Means 算法。让 AI 自动把学生分成几个群(比如:乖宝宝型、偶尔摸鱼型、刺头型),最后生成考勤画像,再存回数据库里,为后续的校园学生精细化管理提供精准的数据支撑。
1.2 手里有什么牌?(实验数据大揭秘)
这次我们不搞假数据,直接上硬核的业务宽表。我们前置准备好了一张干净、标准化的学生考勤主题标签表(student_attendance_stats),存放在团队私有的 MySQL 数据库中。
这张表里包含了 16 个字段,不仅有学生的“身份底牌”,还有他们的“行为战绩”:
-
基础信息(离散属性): 比如
student_id(学号)、gender(性别)、grade(年级)、is_boarder(是否住校)等。 -
考勤行为指标(连续型变量): 包括
late_count(迟到次数)、early_leave_count(早退次数)、leave_count(请假次数)、uniform_violate_count(没穿校服次数)。
1.3 建模思路大公开(为什么这么干?)
在把数据喂给 AI 之前,咱们得先盘盘逻辑,这也是数据分析师最核心的内功:
-
拒绝花里胡哨,直击核心维度: 数据维度很清晰,我们不需要搞复杂的降维操作。直接锁定“迟到、早退、请假、没穿校服”这 4 类行为。这四个指标之间相关性低、业务含义独立,丢进 K-Means 跑出来的结果解释性最强。
-
数据类型天然契合 K-Means: 考勤次数都是非负整数,属于纯纯的“连续型变量”。这意味着什么?意味着我们根本不需要做哑变量编码、二值化这些繁琐的预处理!直接原汁原味输入模型,稳得一批。
-
基础属性只围观,不参战: 敲黑板!像性别、年级这种“分类标签”是不参与聚类计算的(防止干扰模型距离计算),它们只作为辅助特征,等模型把人群分好类之后,再拿来做画像解释。
🧠 干货小课堂:为什么选 K-Means?
K-Means(K均值)属于机器学习中的无监督学习(Unsupervised Learning)算法。它的强大之处在于“不需要人工提前打标”(即不需要事先告诉机器谁是好学生)。它通过计算数据点在多维空间中的欧氏距离(Euclidean Distance),自动把特征相似的数据“聚”成一堆(即“物以类聚”)。这种算法特别适合用来做冷启动阶段的用户画像分群、RFM模型客户分层等场景。
1.4 一图看懂全流程
别被什么 ETL、BI、机器学习吓到,其实整个逻辑非常顺滑。我画了一张流程图,大家瞄一眼就能 get 到核心路径:
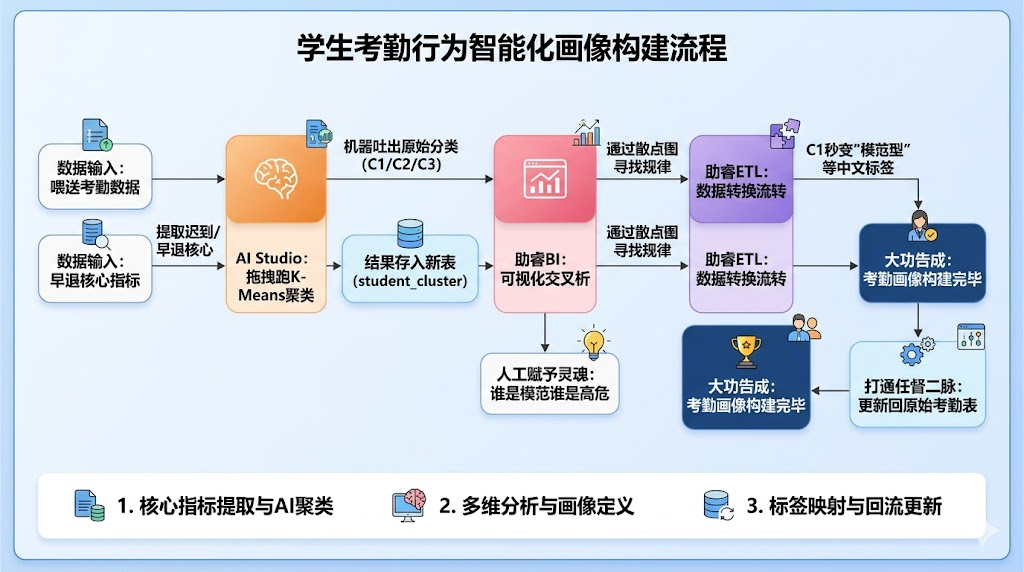
第二部分:实操步骤(手把手跟着做)
接下来的步骤大家可以直接“抄作业”,我会把细节全部拉满!
阶段一:AI Studio 聚类建模(让机器干活)
1. 新建工作流:开辟我们的主战场
-
操作说明: 登录平台后,直奔左侧菜单的“人工智能”(AI Studio 用户空间)。点左上角的“+”号,豪气地选择“新建工作流”。
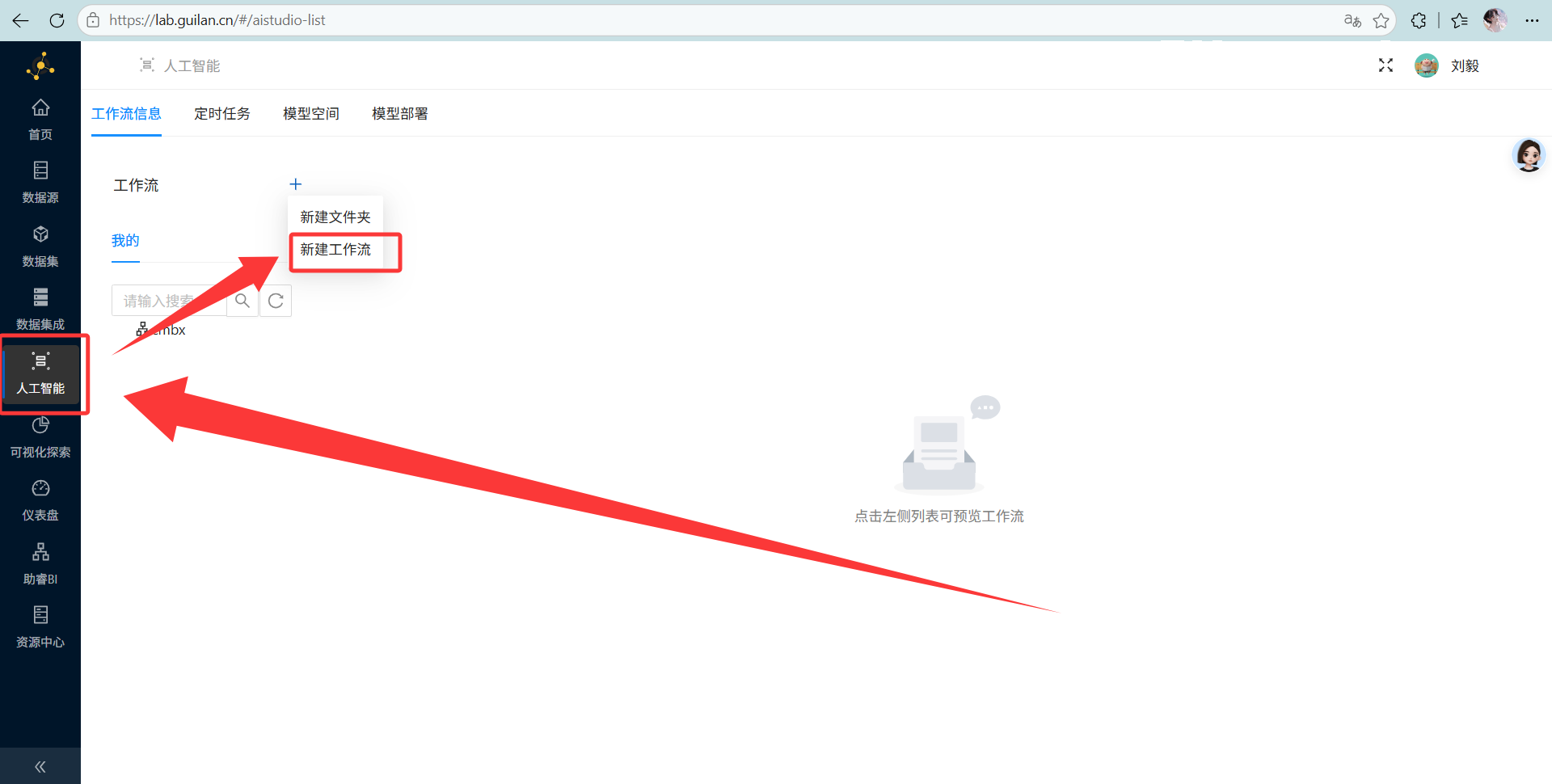
2. 数据导入与特征选择(敲黑板,重点来了!)
-
操作说明: 在左侧搜“数据库加载”,把它硬核拖拽到画布里。
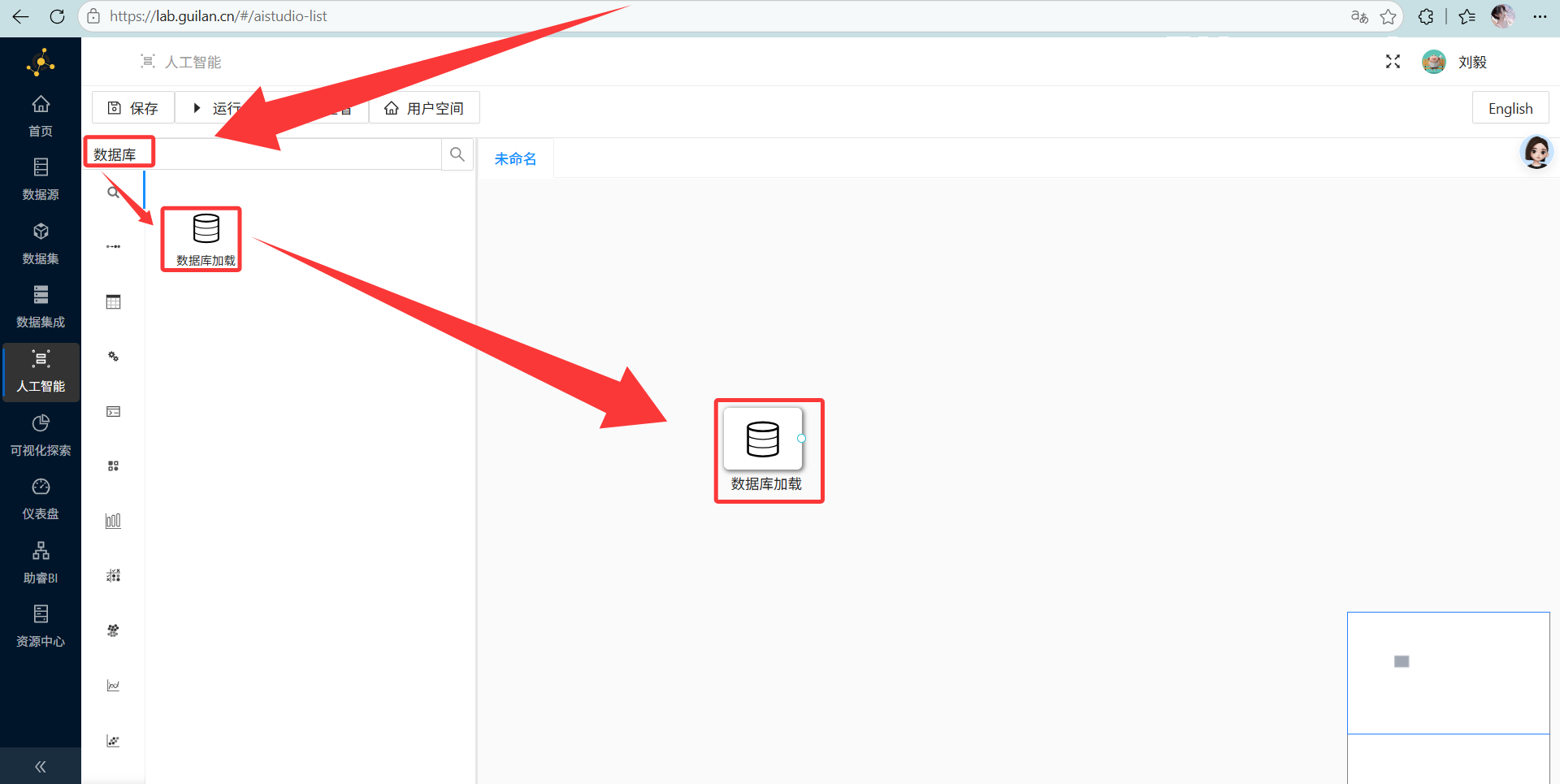 双击它,连上你们团队的 MySQL 数据库。
双击它,连上你们团队的 MySQL 数据库。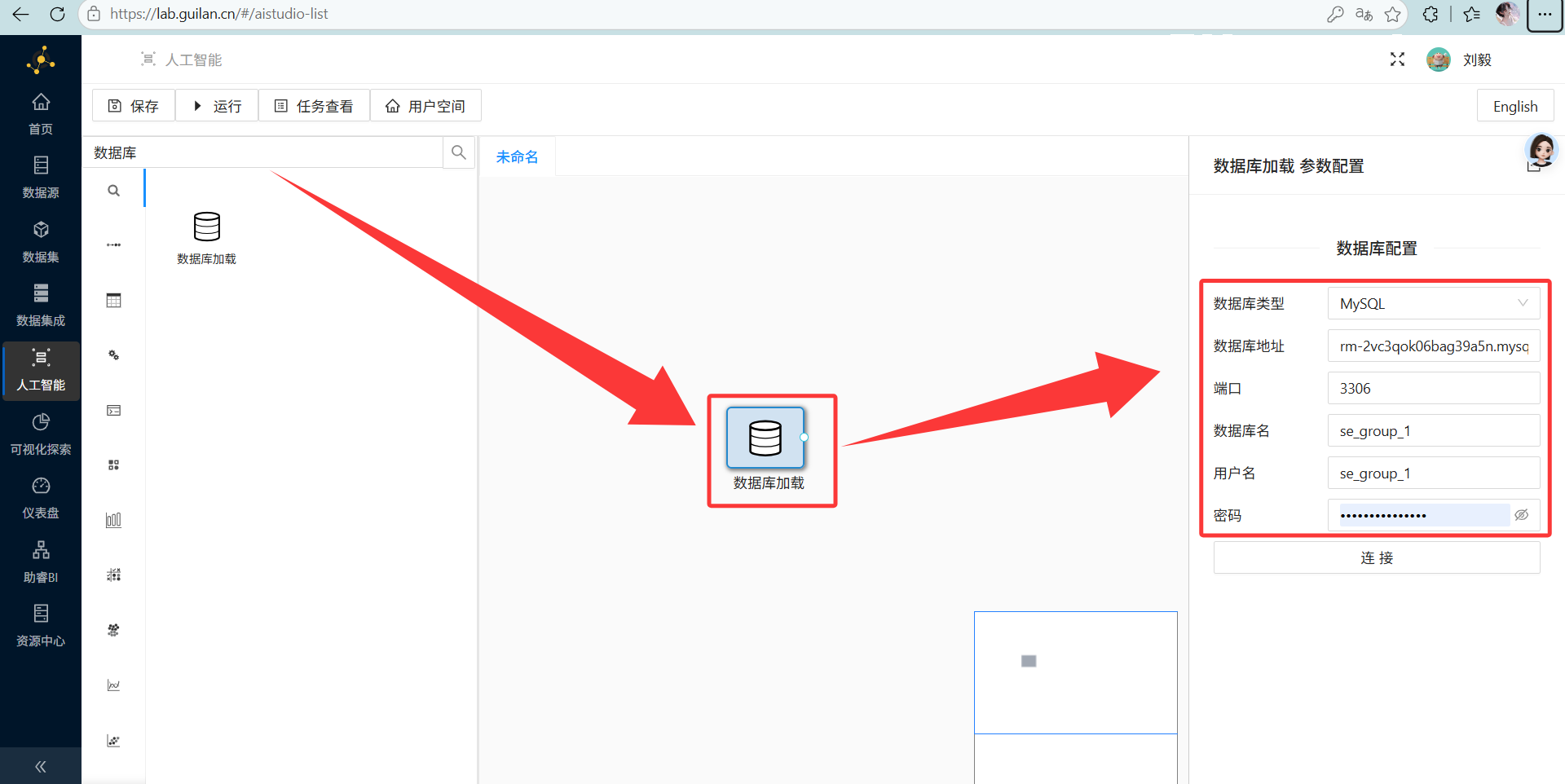
-
配置要点:
-
下拉选中我们的主角表
student_attendance_stats。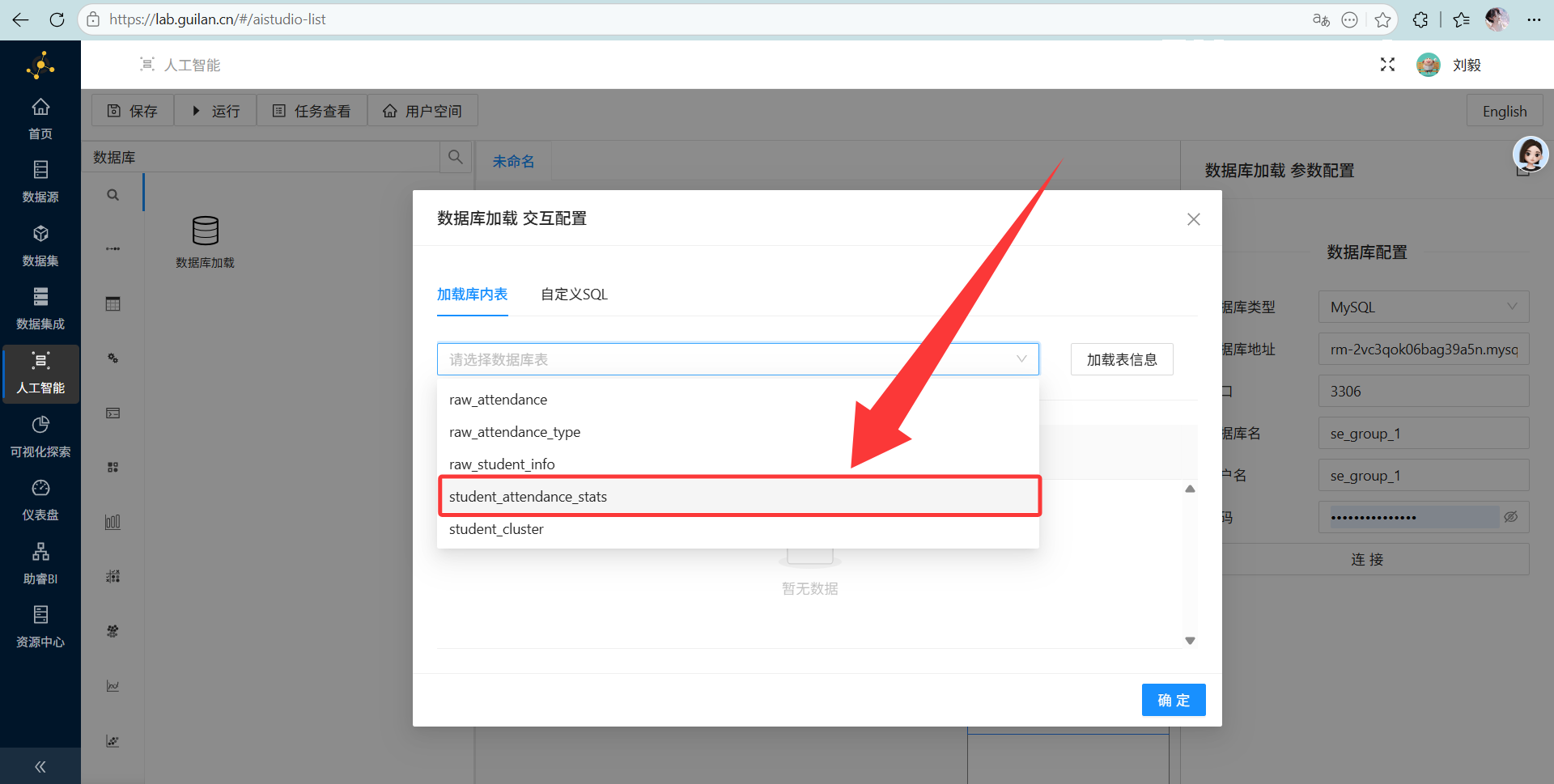
-
划重点: 我们只关心“异常行为”和“身份ID”,所以需要过滤字段!把
student_id、class_id选为categorical(类别型),把迟到、早退、请假、校服违规四个次数选为numeric(连续型),剩下的姓名、性别什么的通通选skip(跳过),别让冗余数据干扰 AI。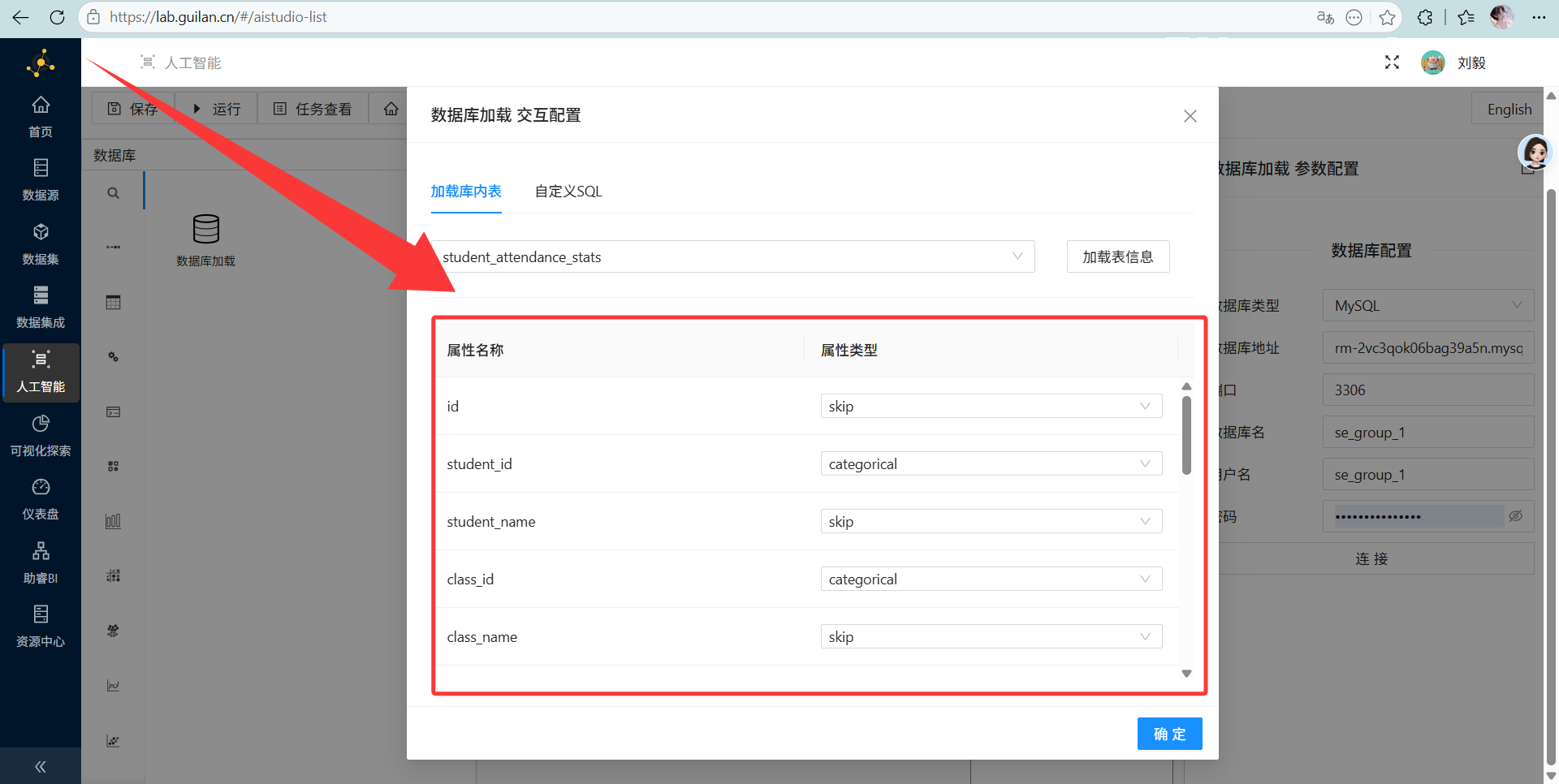
-
💡 避坑干货:K-Means 的“距离陷阱”
为什么连
student_id(学号)这种数字也要排除在计算之外(设为类别或跳过)?因为 K-Means 是算“距离”的。如果把学号强行当作连续数值参与建模,算法会觉得学号“1号”和“1000号”之间的物理距离非常远,从而误判他们差异极大。切记:凡是没有大小递进和量化关系的数据(如ID、手机号、分类代码),绝对不能作为连续型变量放进基于距离的聚类算法中!
- 搞定后右键点击“运行该控件”,看看数据进来了没。
 运行成功后可右键点击“查看输出结果”
运行成功后可右键点击“查看输出结果”
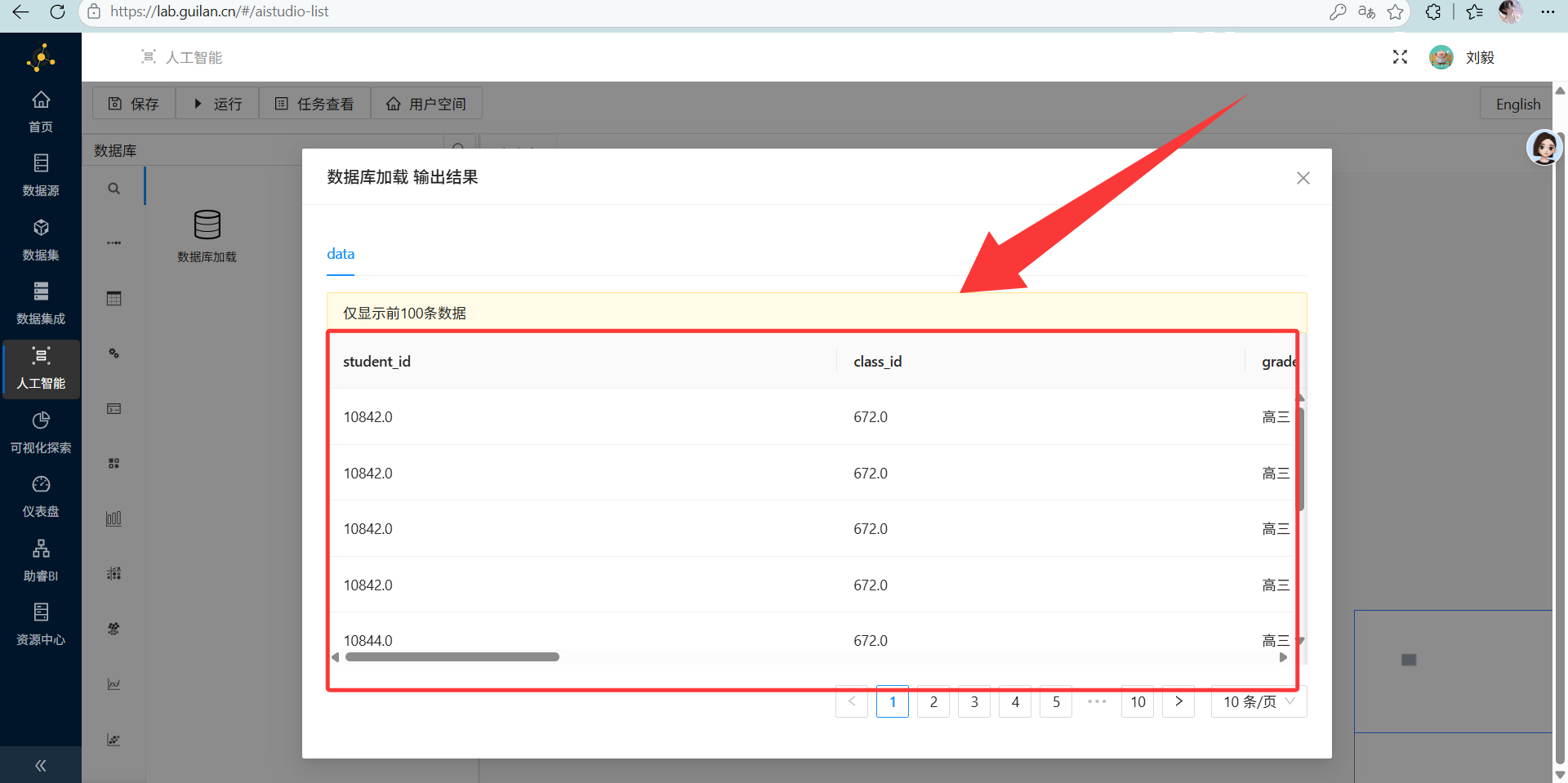
3. 拖拽出 K-Means 算法组件
-
操作说明: 继续在左边搜索“K-Means”,拖出来,跟前面的数据库组件拉一条线连起来。
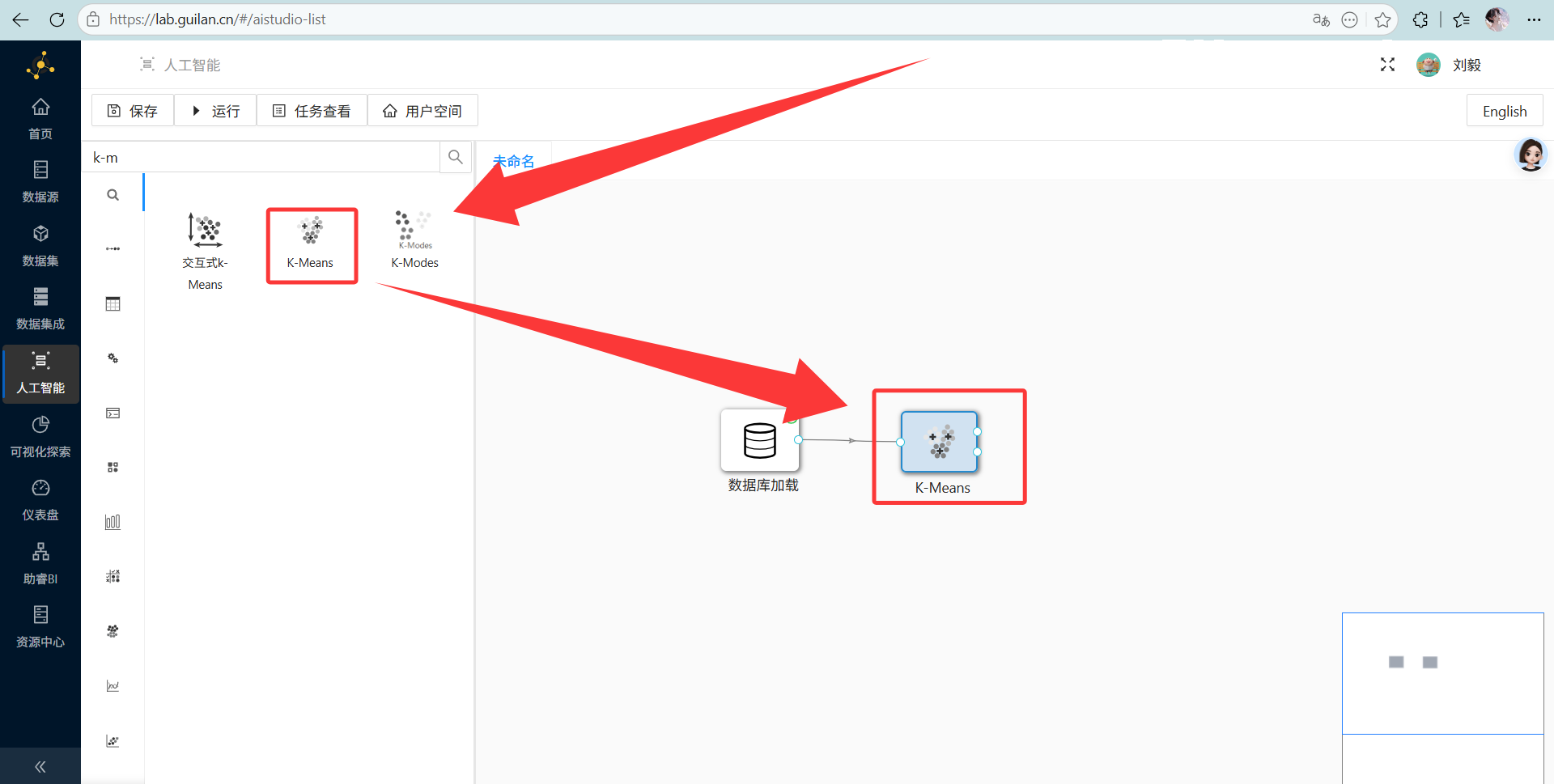
-
配置要点: 双击“K-Means”,我们今天就想把学生分成 3 拨人,所以把簇数量直接写死为 3,其他高深参数保持默认。
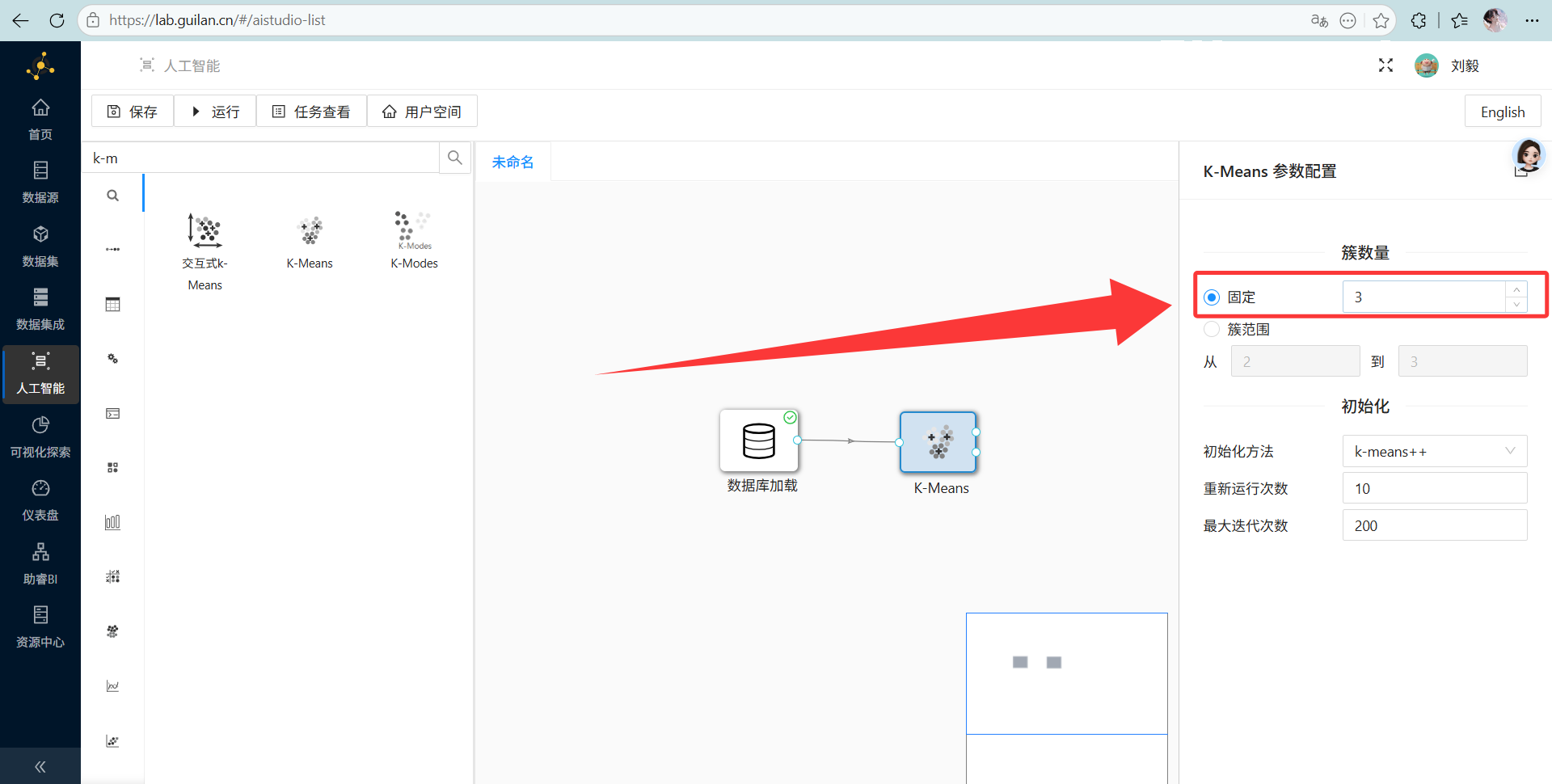 右键运行!跑完你就会发现,系统给每个学生打上了 C1、C2 或 C3 的神秘编号。
右键运行!跑完你就会发现,系统给每个学生打上了 C1、C2 或 C3 的神秘编号。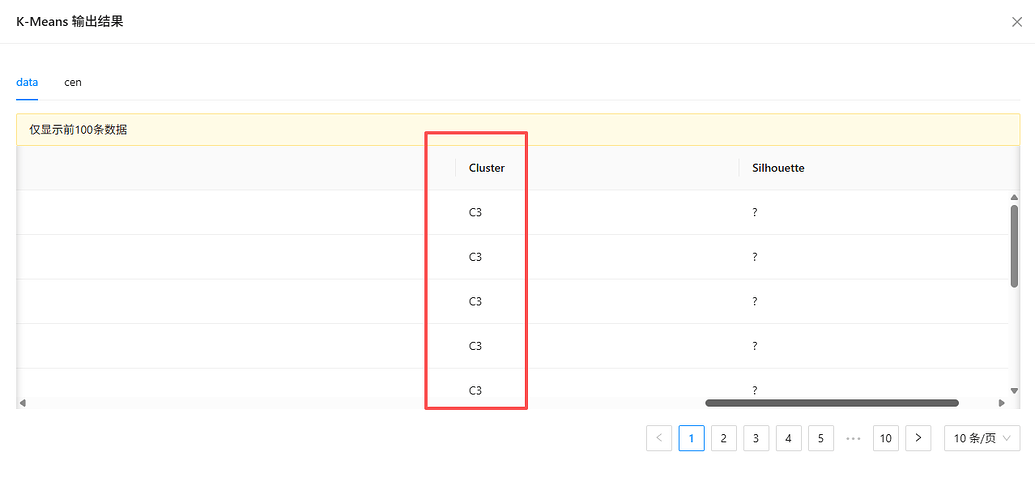
🧠 深度干货:K值(簇数量)怎么定才最科学?
教程里为了直奔主题直接写死了 K=3。但在真实的商业分析中,如果你不知道把用户分几类最合适,业界通用的做法是结合“手肘法(Elbow Method)”和“轮廓系数(Silhouette Coefficient)”。
-
手肘法: 看误差平方和(SSE)随K值的折线图,找到图形拐点(像胳膊肘一样的地方),通常就是最优K值。
-
轮廓系数: 衡量聚类的紧密度和分离度,值介于 [-1, 1] 之间,越接近1说明同类越紧密、异类越分明,聚类效果越好。
-
4. 结果入库保存
-
操作说明: 拖一个“数据入库”组件连在后面。
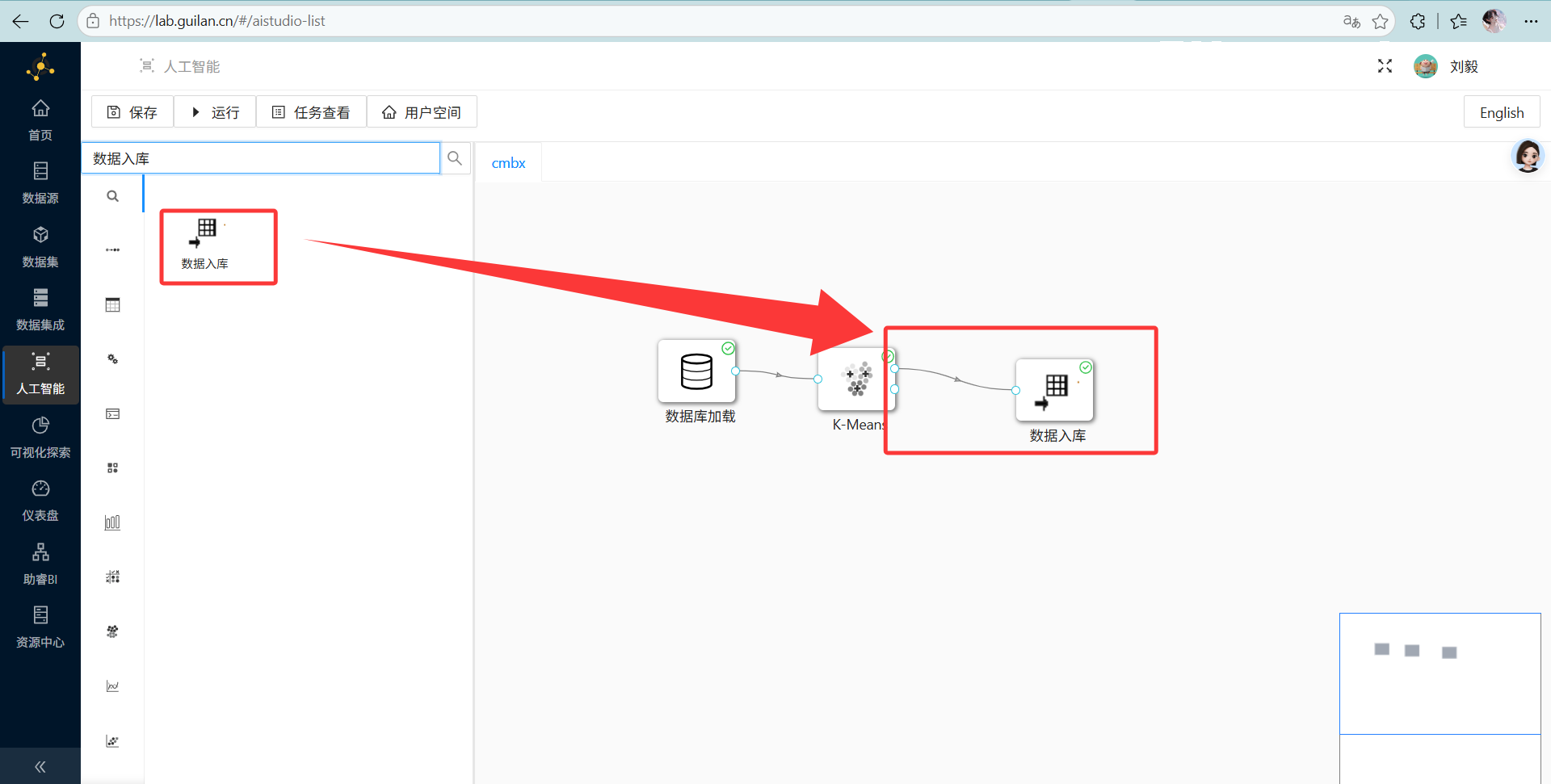
-
配置要点: 配置好数据库参数,选择“新建数据表”,名字就叫
student_cluster。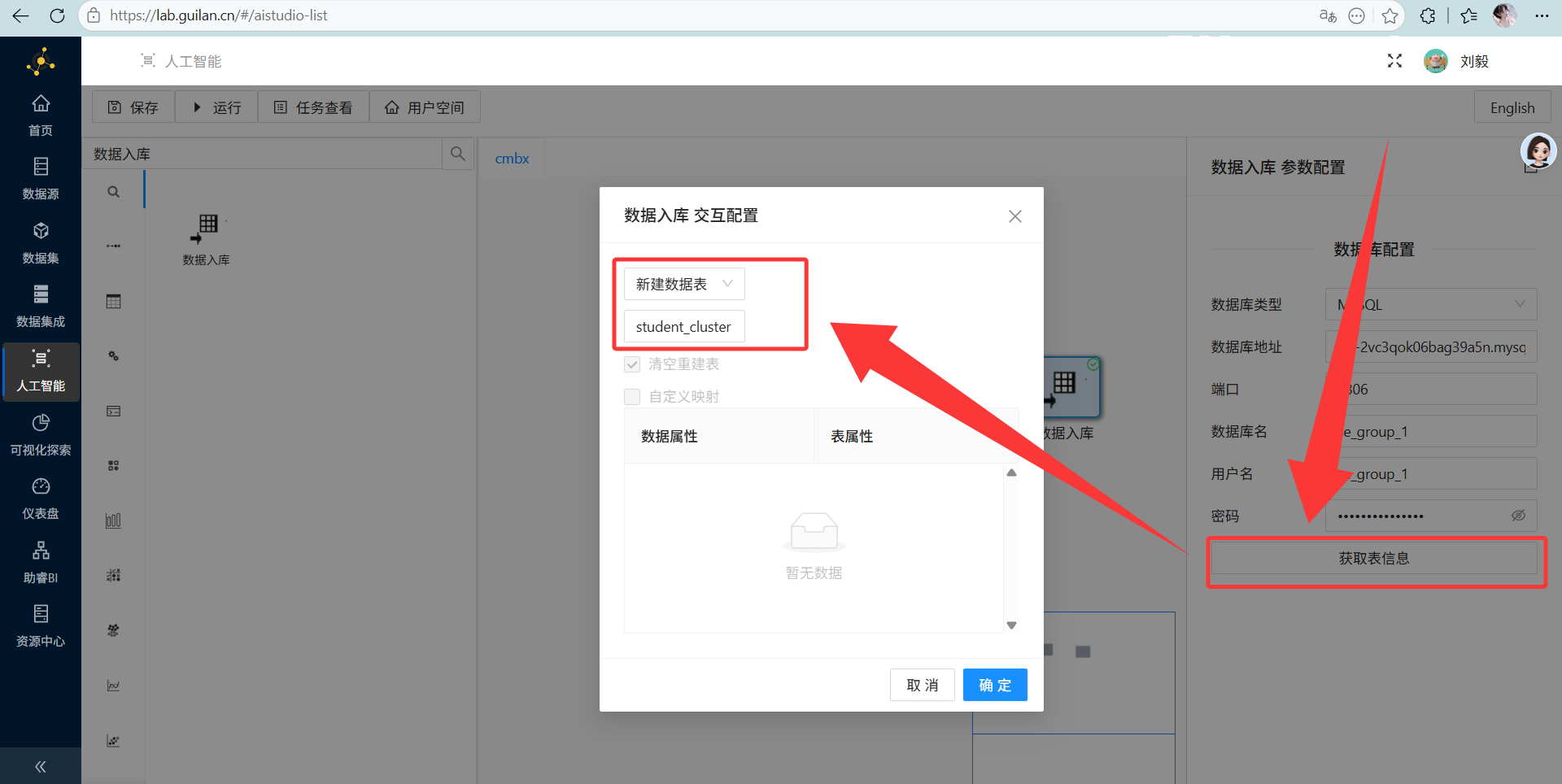 然后去画布顶端点大大的“运行”,看着绿勾勾一个个亮起,简直神清气爽。
然后去画布顶端点大大的“运行”,看着绿勾勾一个个亮起,简直神清气爽。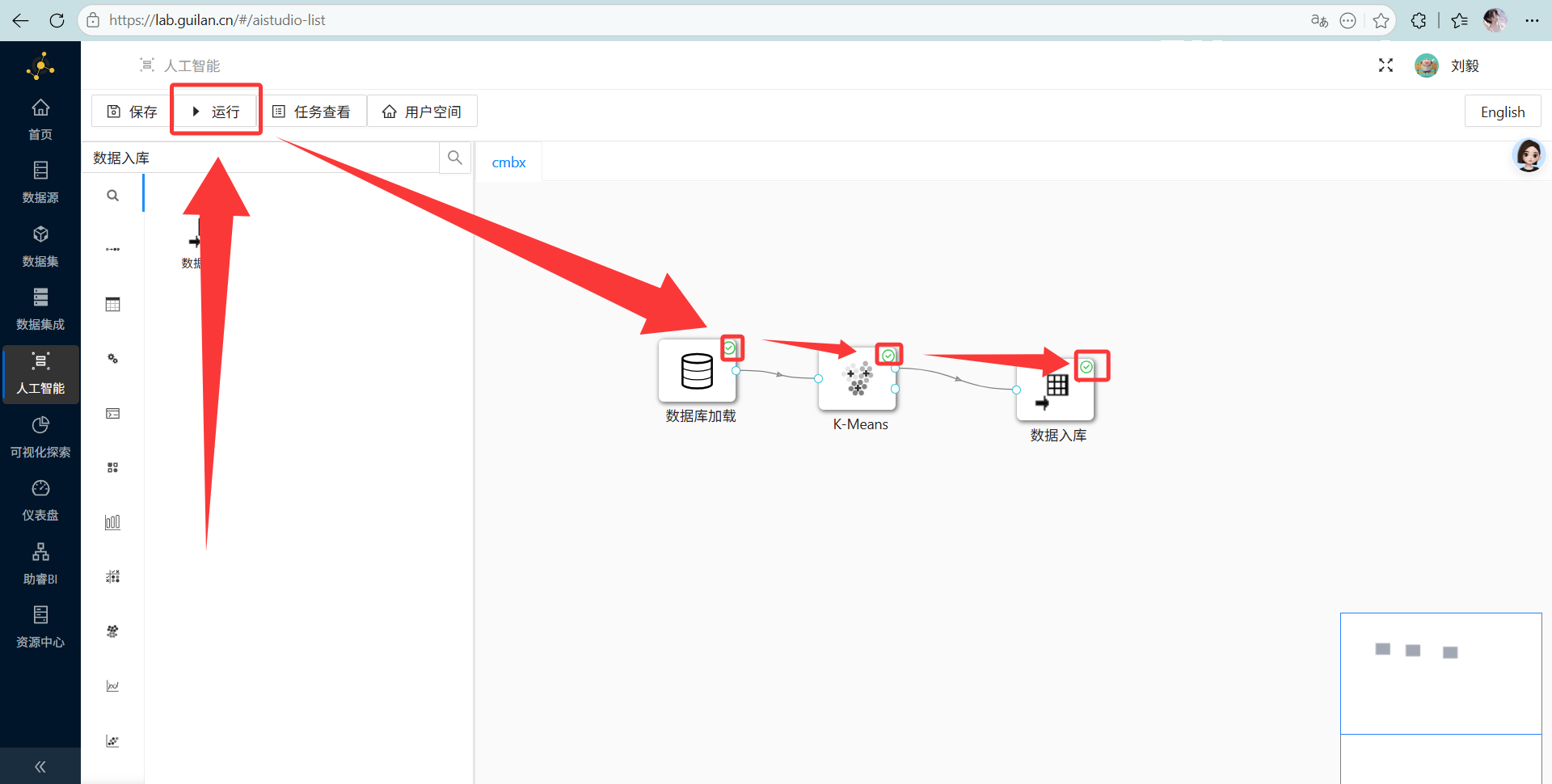
阶段二:助睿 BI 探索分析(给 C1/C2/C3 赋予灵魂)
光有 C1/C2/C3 没用啊,得知道它们到底代表啥样的学生。这时候就需要 BI 平台出马了。
1. 连接数据源与构建数据集
-
操作说明: 切换到左侧菜单的“助睿 BI”模块。
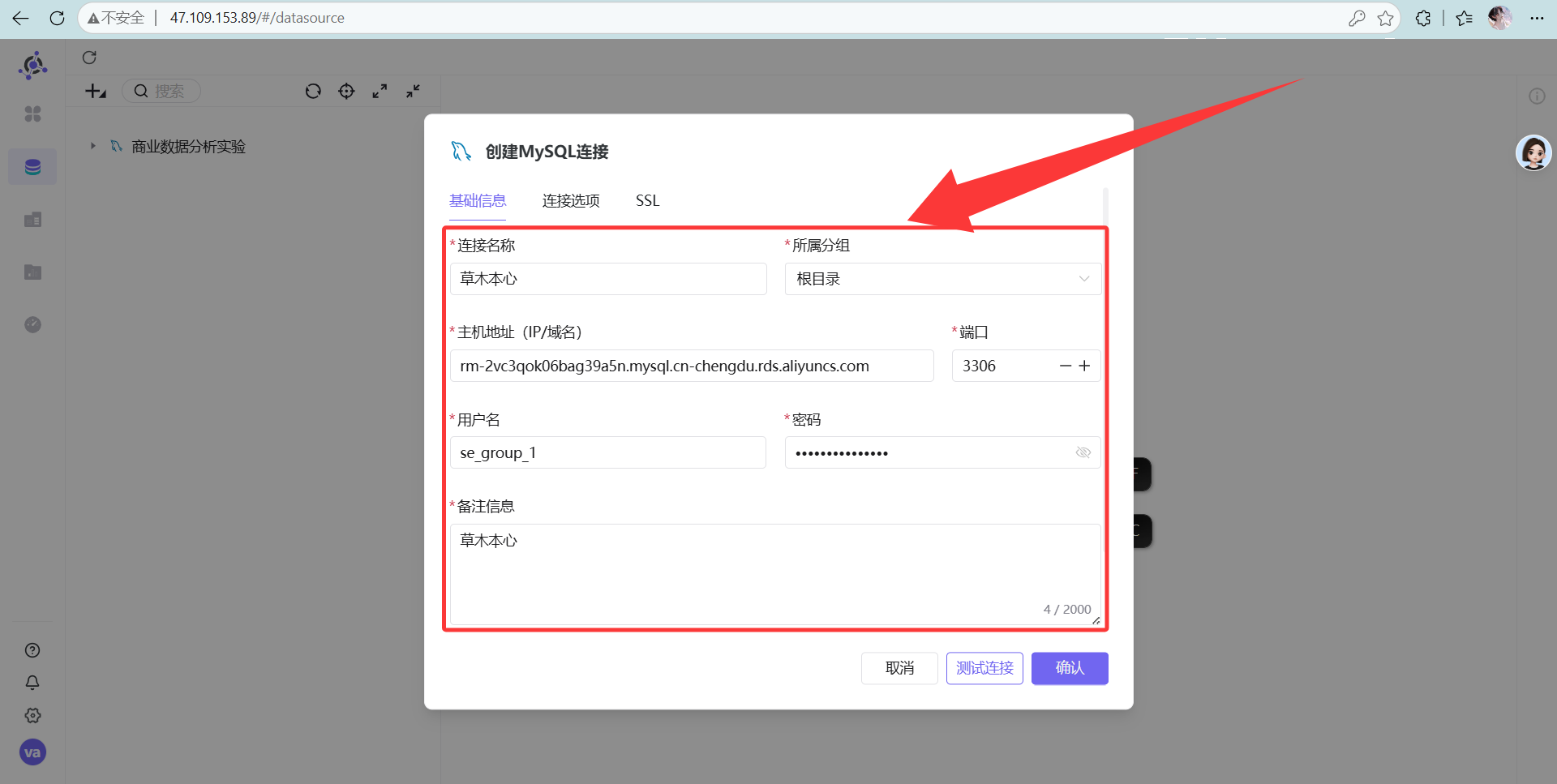
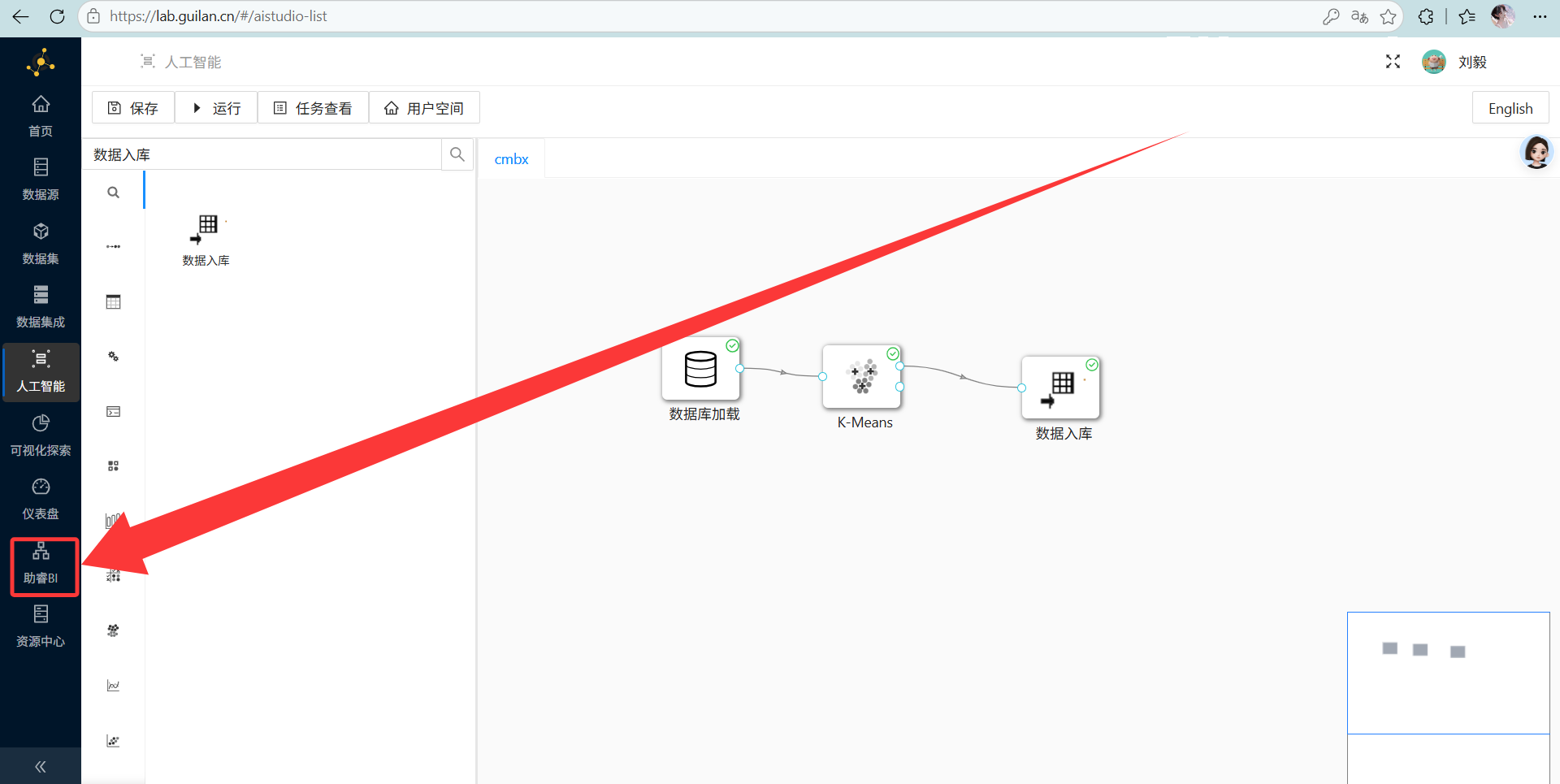 先去建个 MySQL 数据连接,搞定后进入“数据集”新建一个。
先去建个 MySQL 数据连接,搞定后进入“数据集”新建一个。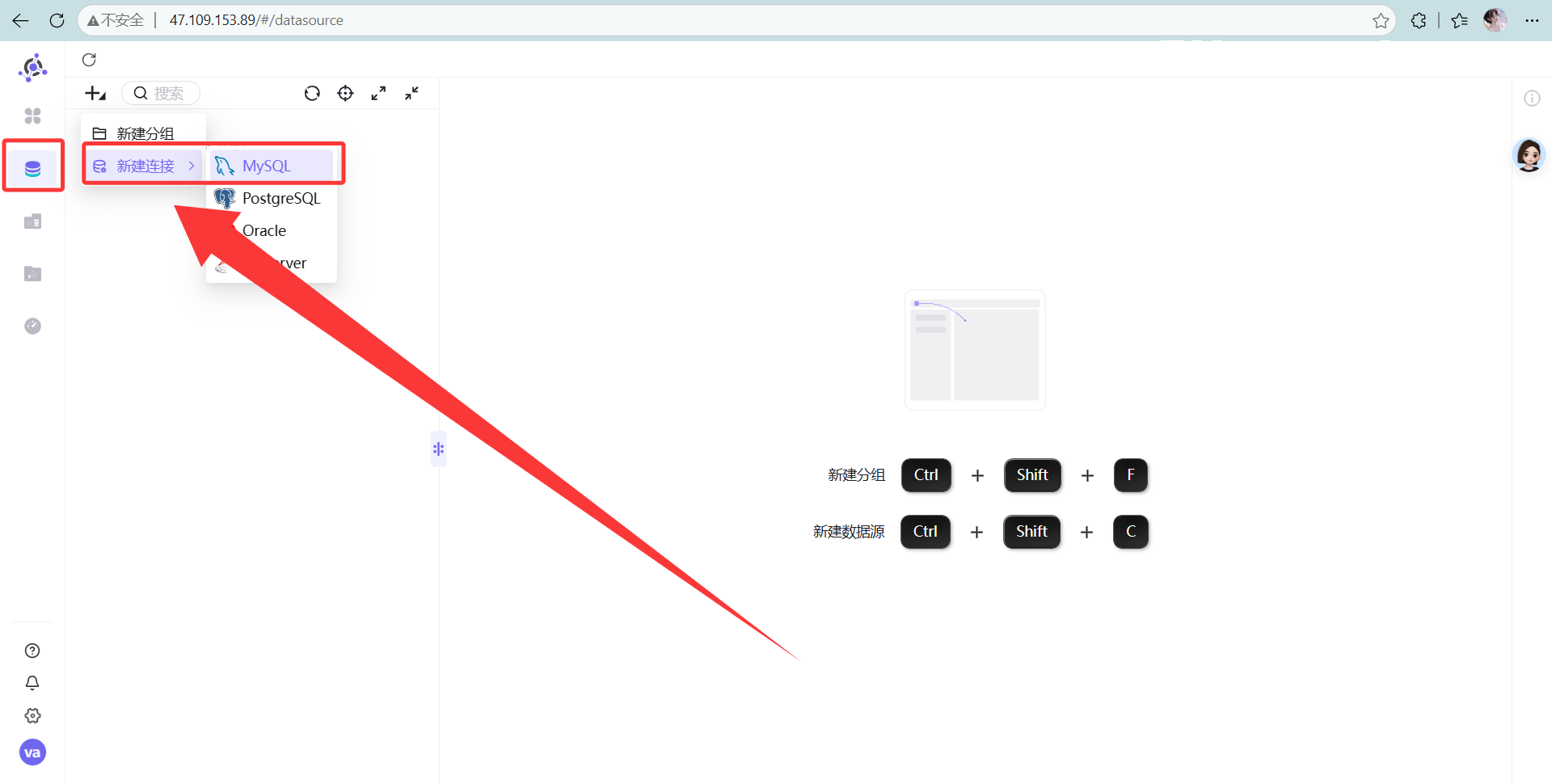
 点击新建的数据库目录,可以看到本次实验所用的学生考勤主题标签表
点击新建的数据库目录,可以看到本次实验所用的学生考勤主题标签表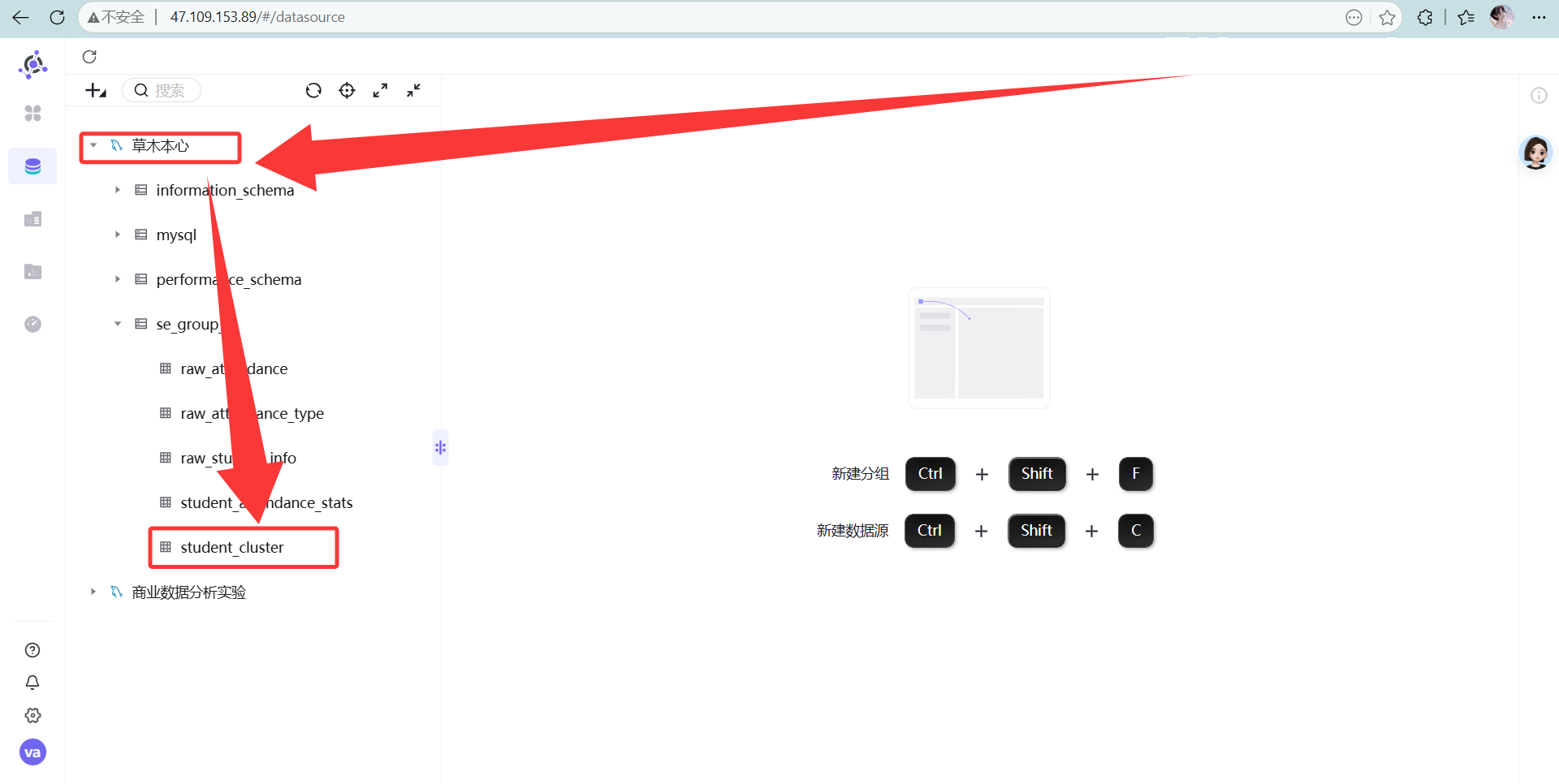 新建数据集
新建数据集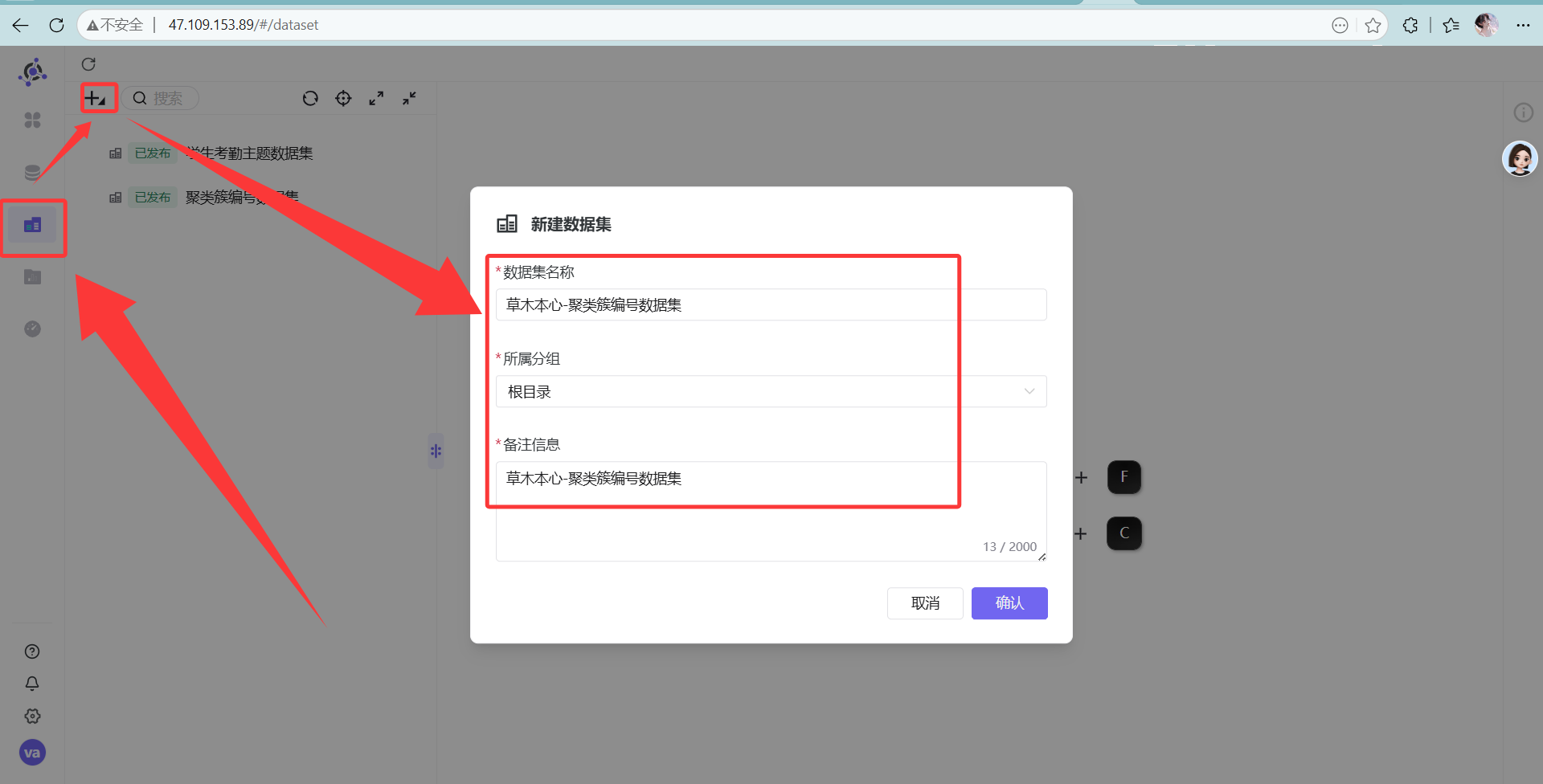 数据源的第一个选项选择我们刚刚新建的数据源,第二个选项则选择student_cluster 所在的目录
数据源的第一个选项选择我们刚刚新建的数据源,第二个选项则选择student_cluster 所在的目录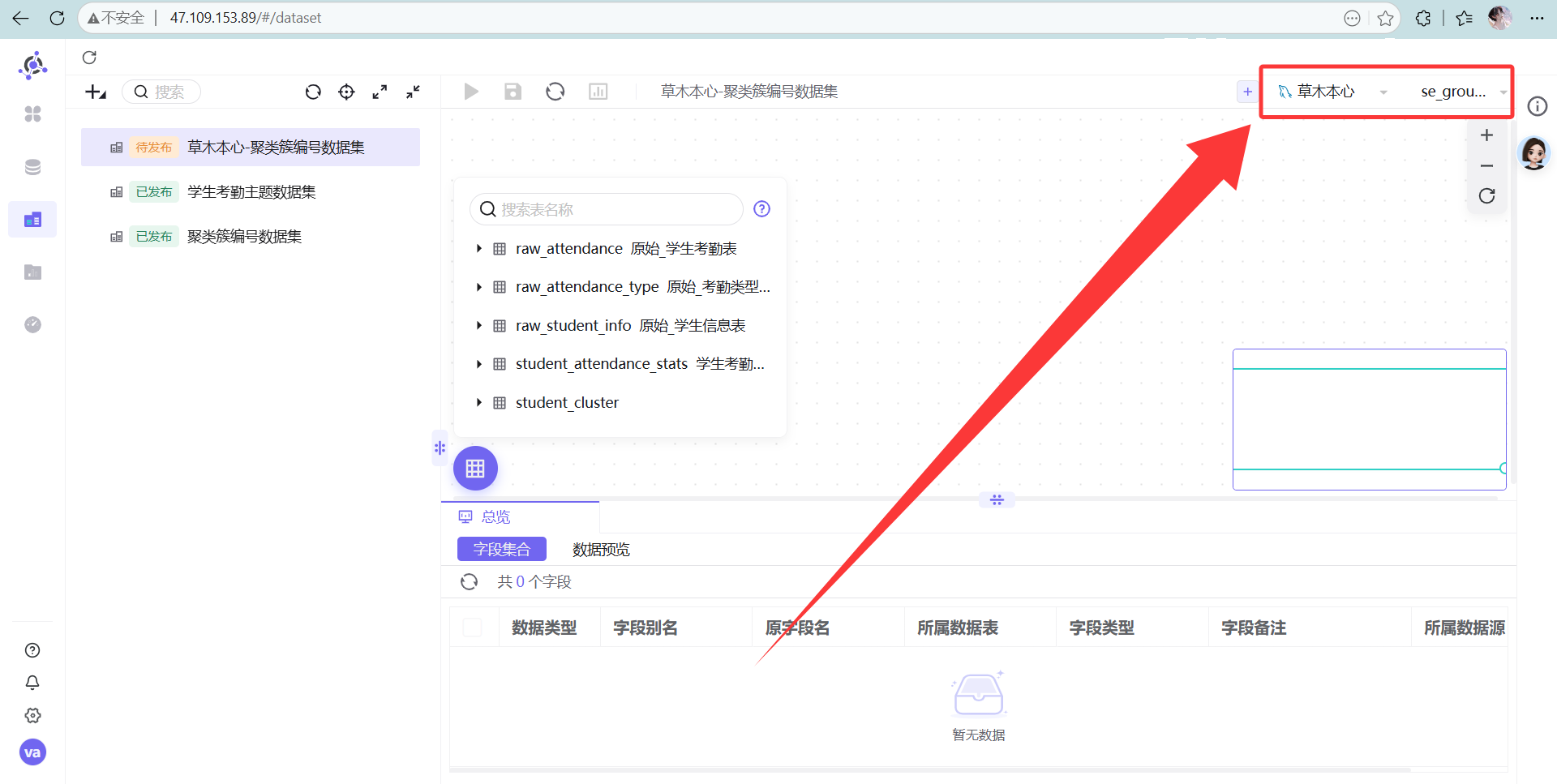
-
配置要点: 把我们刚生成的
student_cluster表拖进画布。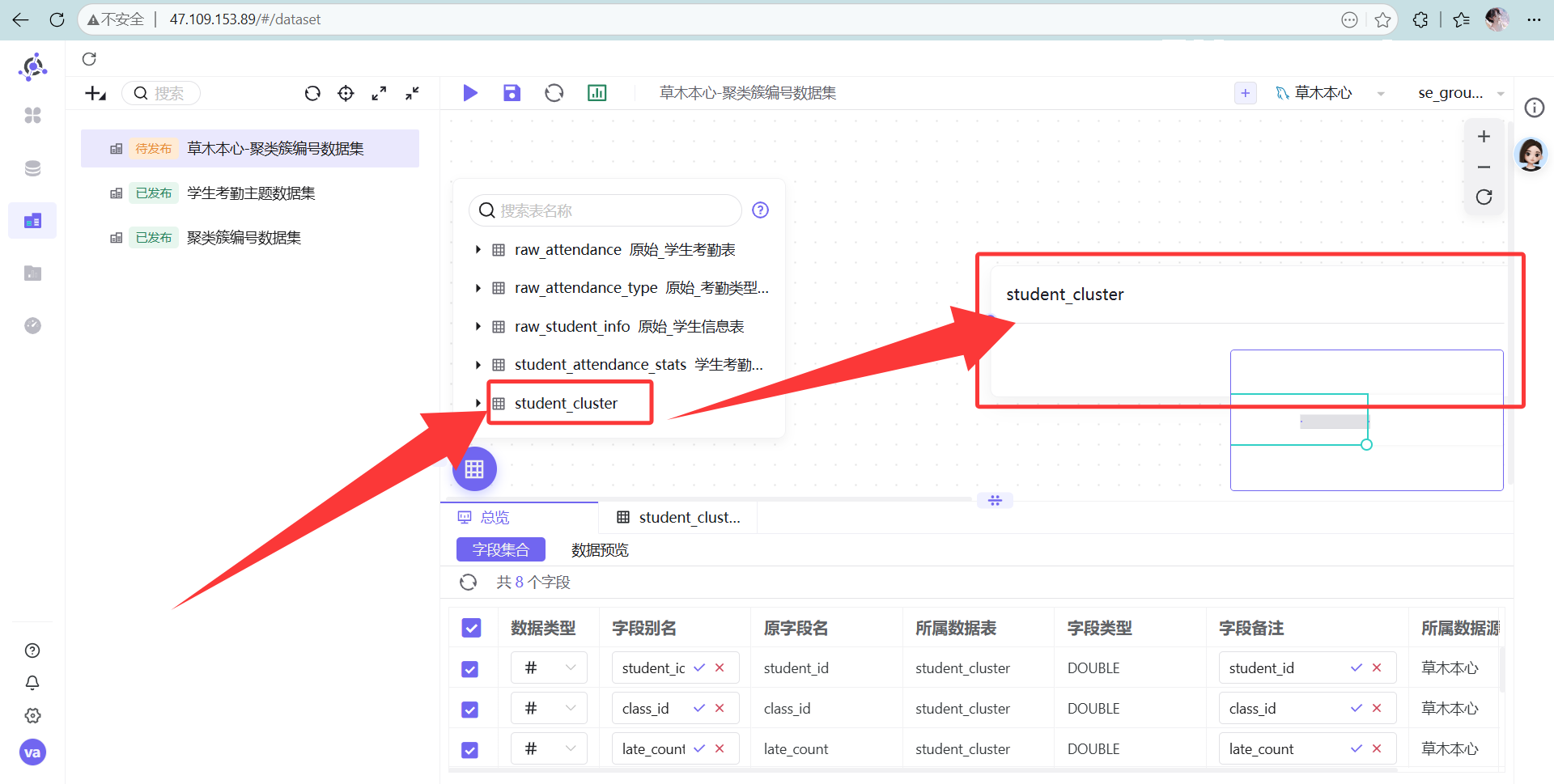 为了后续图表好看,务必把字段名改成中文(比如
为了后续图表好看,务必把字段名改成中文(比如 late_count改为“迟到次数”)。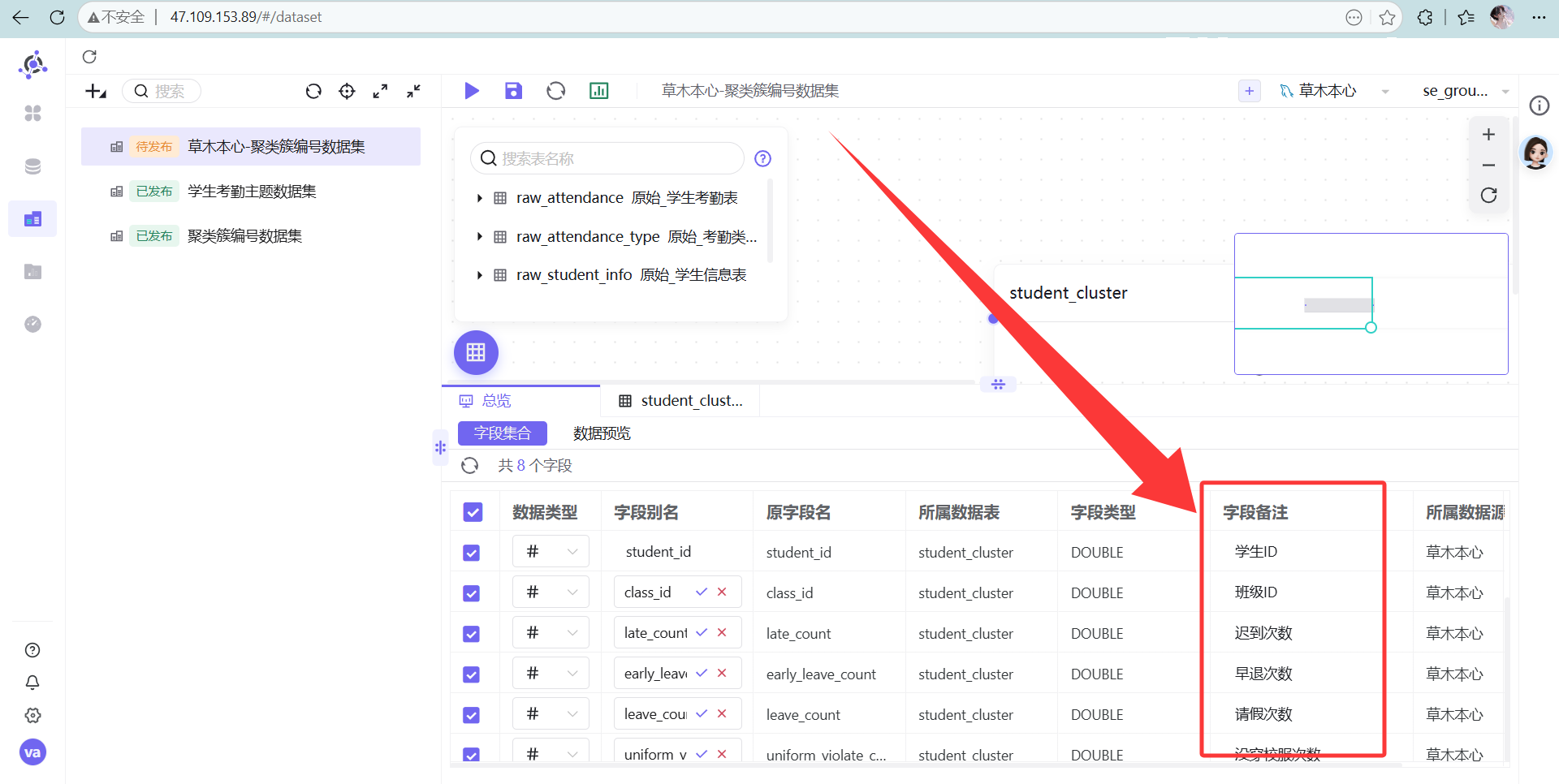 接着点右上角“保存并发布”!
接着点右上角“保存并发布”!
2. 制作散点图探索器(视觉冲击力极强)
-
操作说明: 为了方便管理,我们将本次制作的工作表集中存放在一个目录下,点击左上角的“+” - “新建分组”
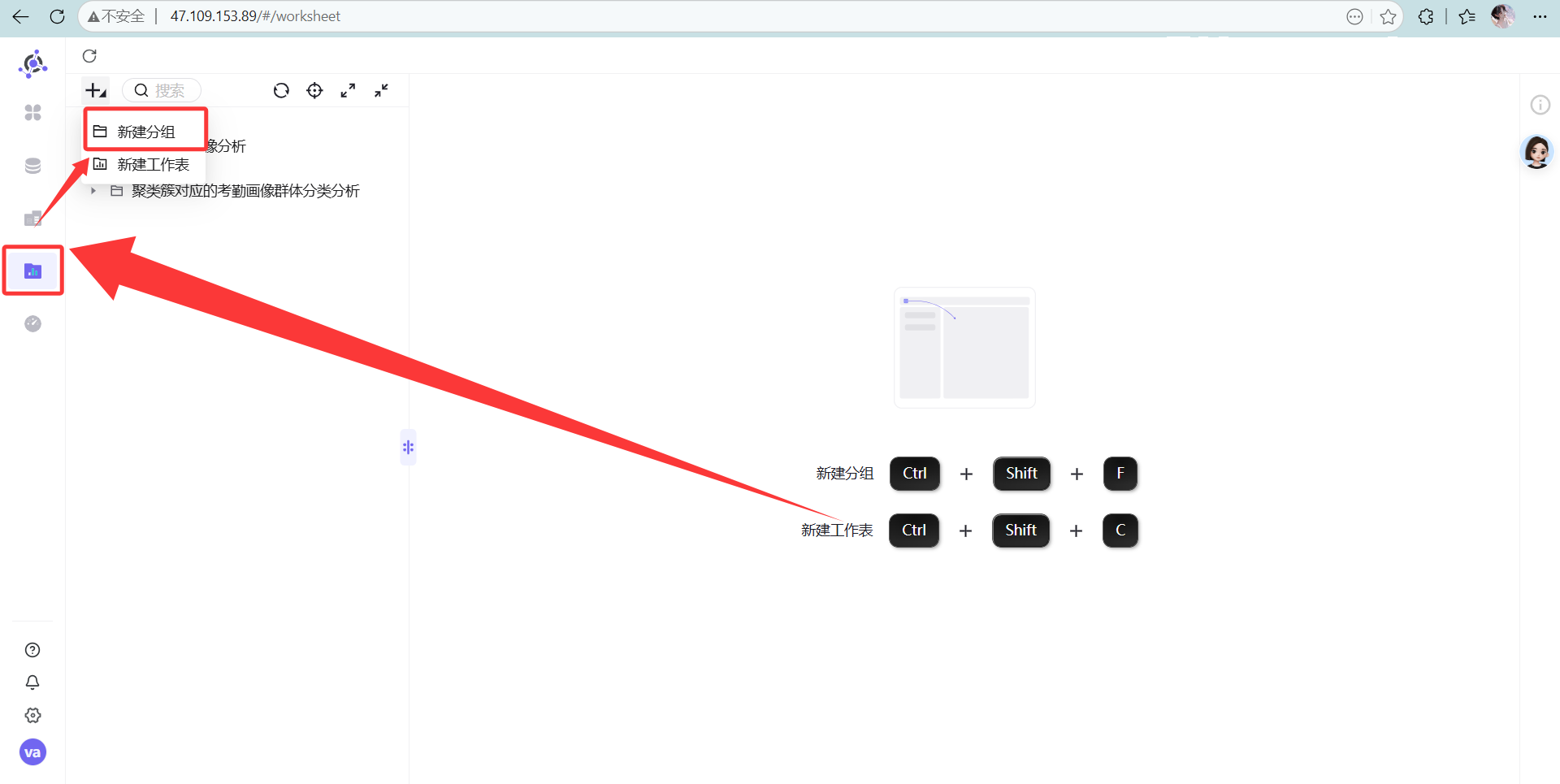
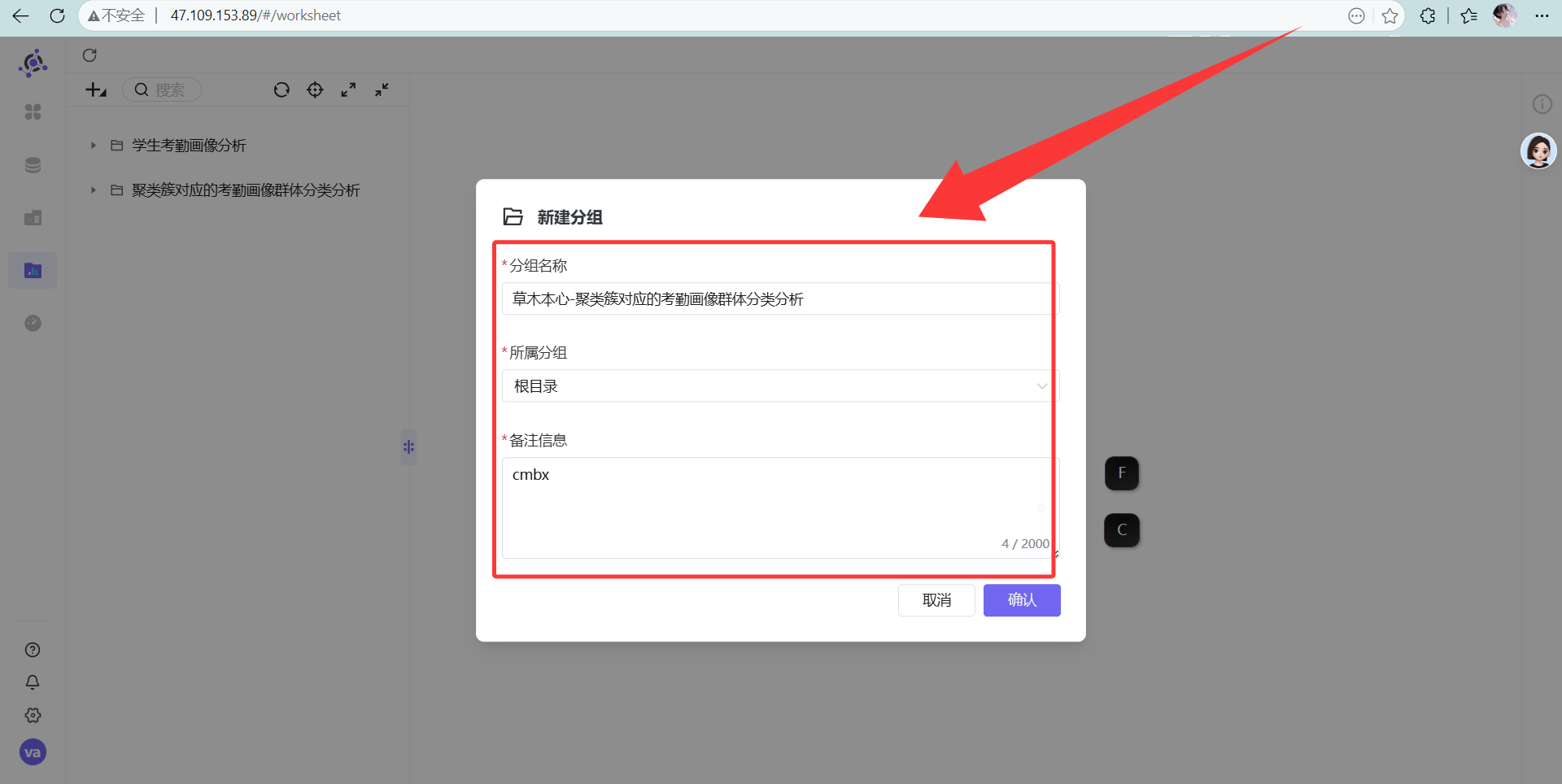 右键新建一个叫“迟到早退次数的聚类簇分析”的表
右键新建一个叫“迟到早退次数的聚类簇分析”的表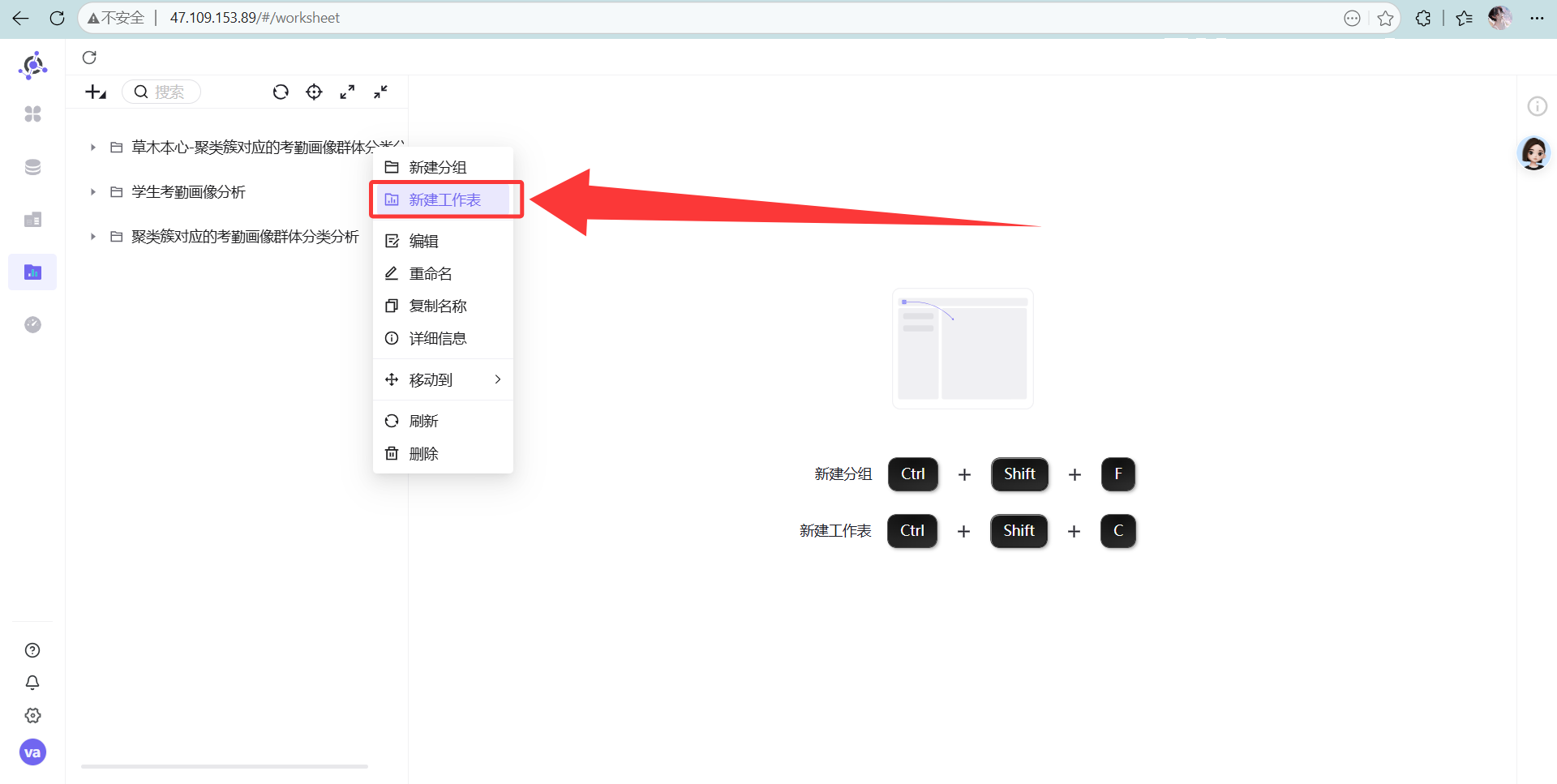
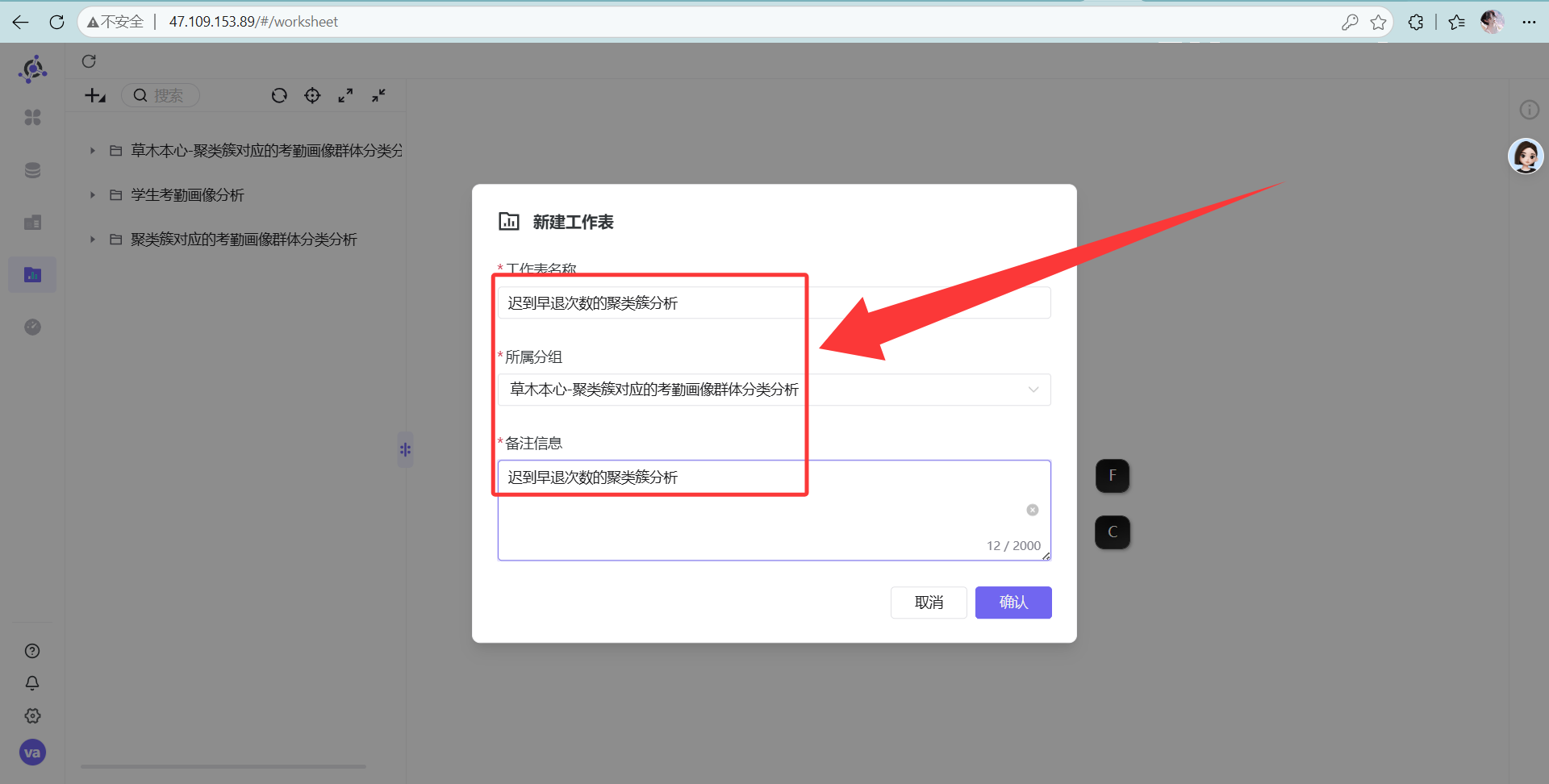 图表类型果断选“探索器”。
图表类型果断选“探索器”。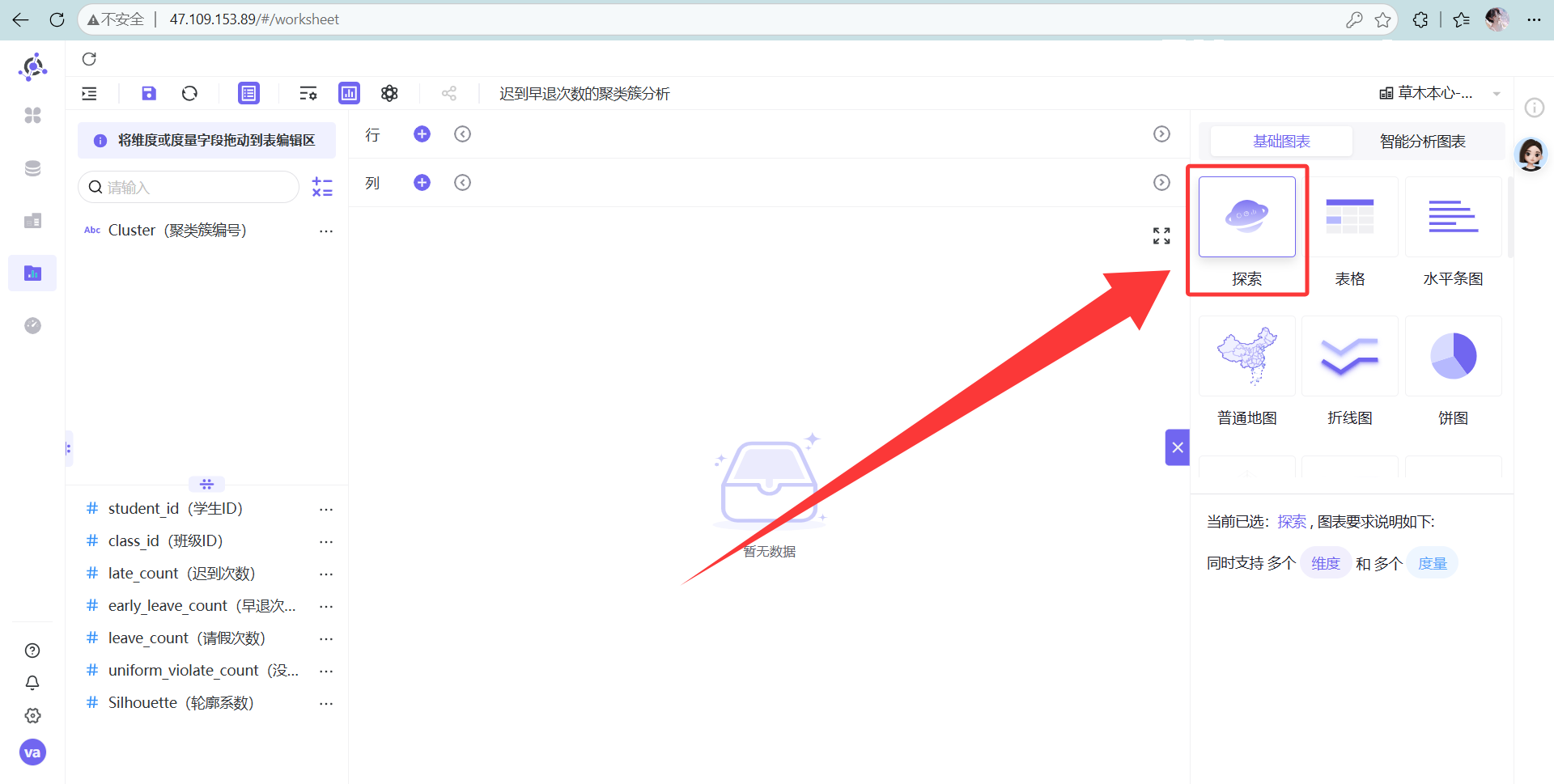
-
配置要点(防坑警告⚠️):
-
X轴放“迟到次数”,Y轴放“早退次数”。
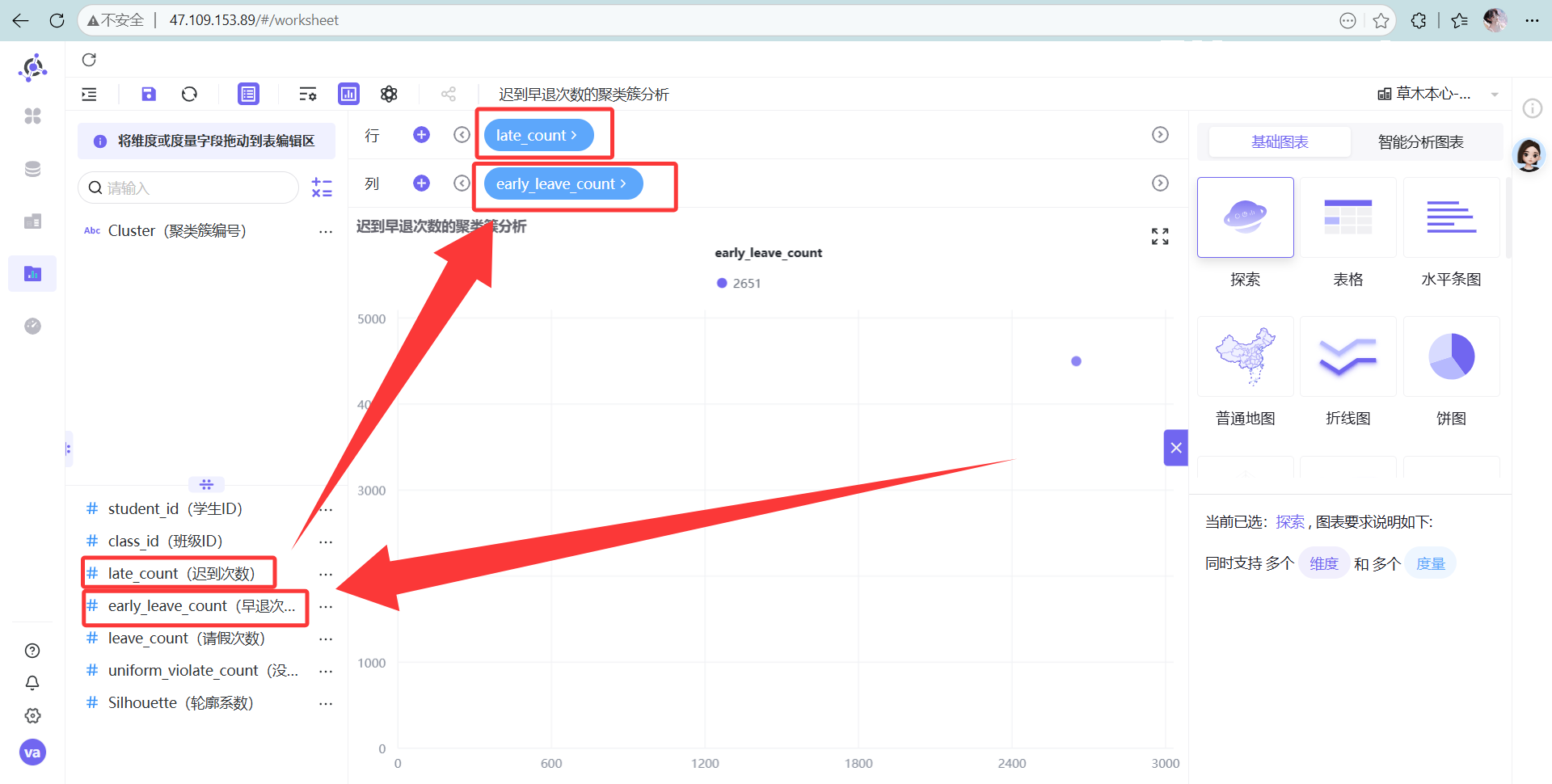
-
点击图形设置,颜色选“Cluster(聚类簇编号)”
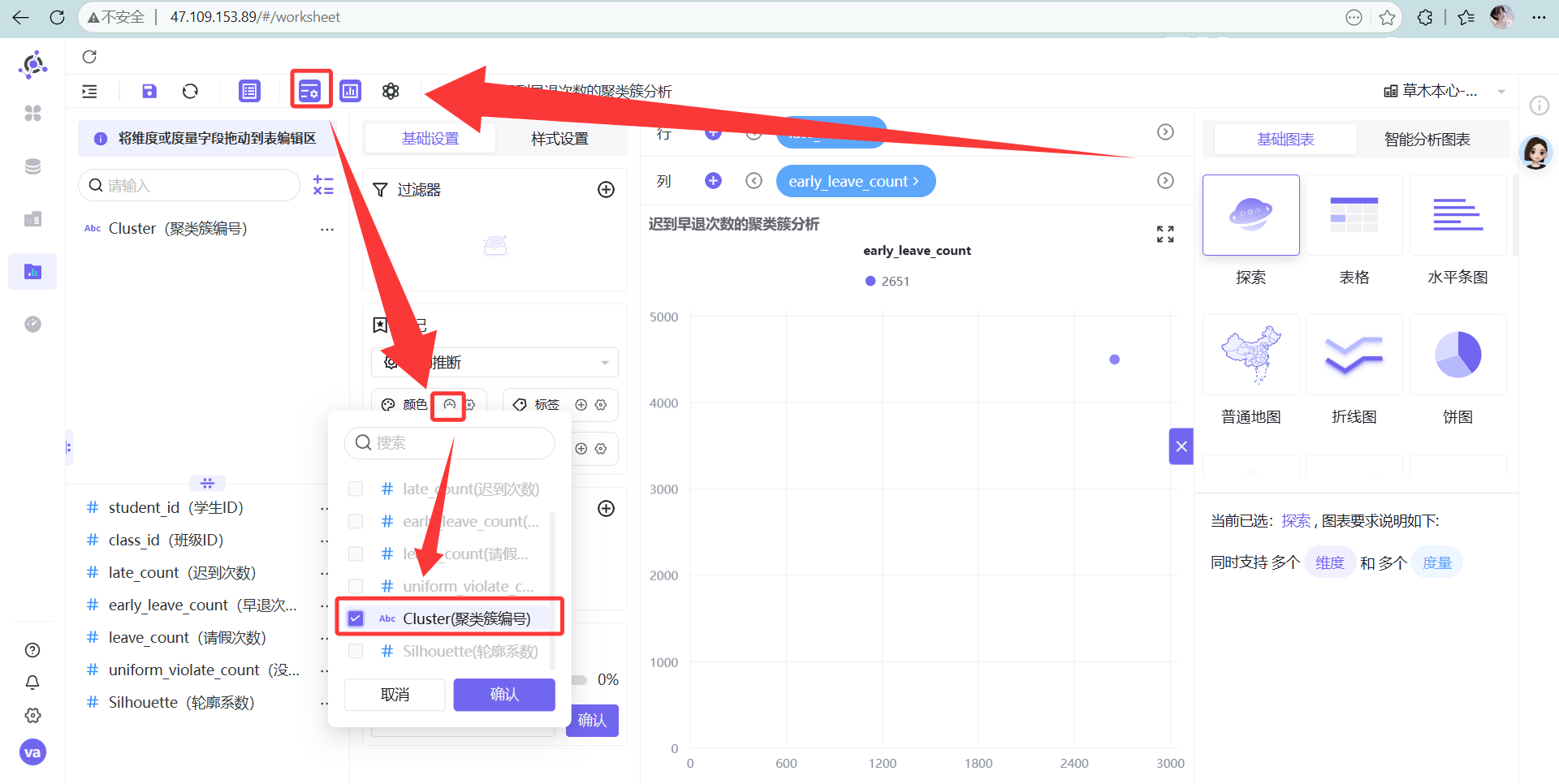 信息选“student_id(学生ID,设为维度)”。
信息选“student_id(学生ID,设为维度)”。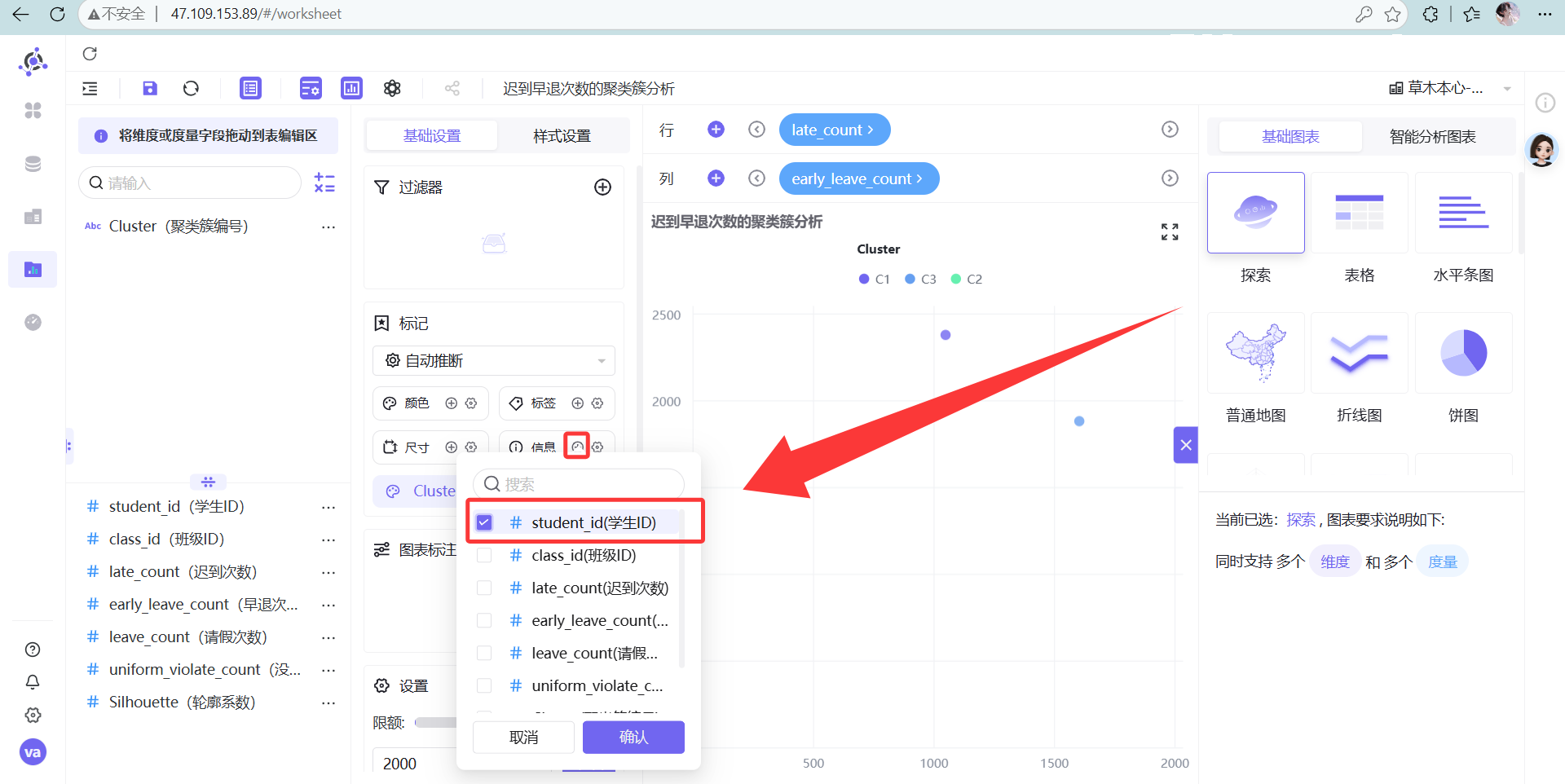
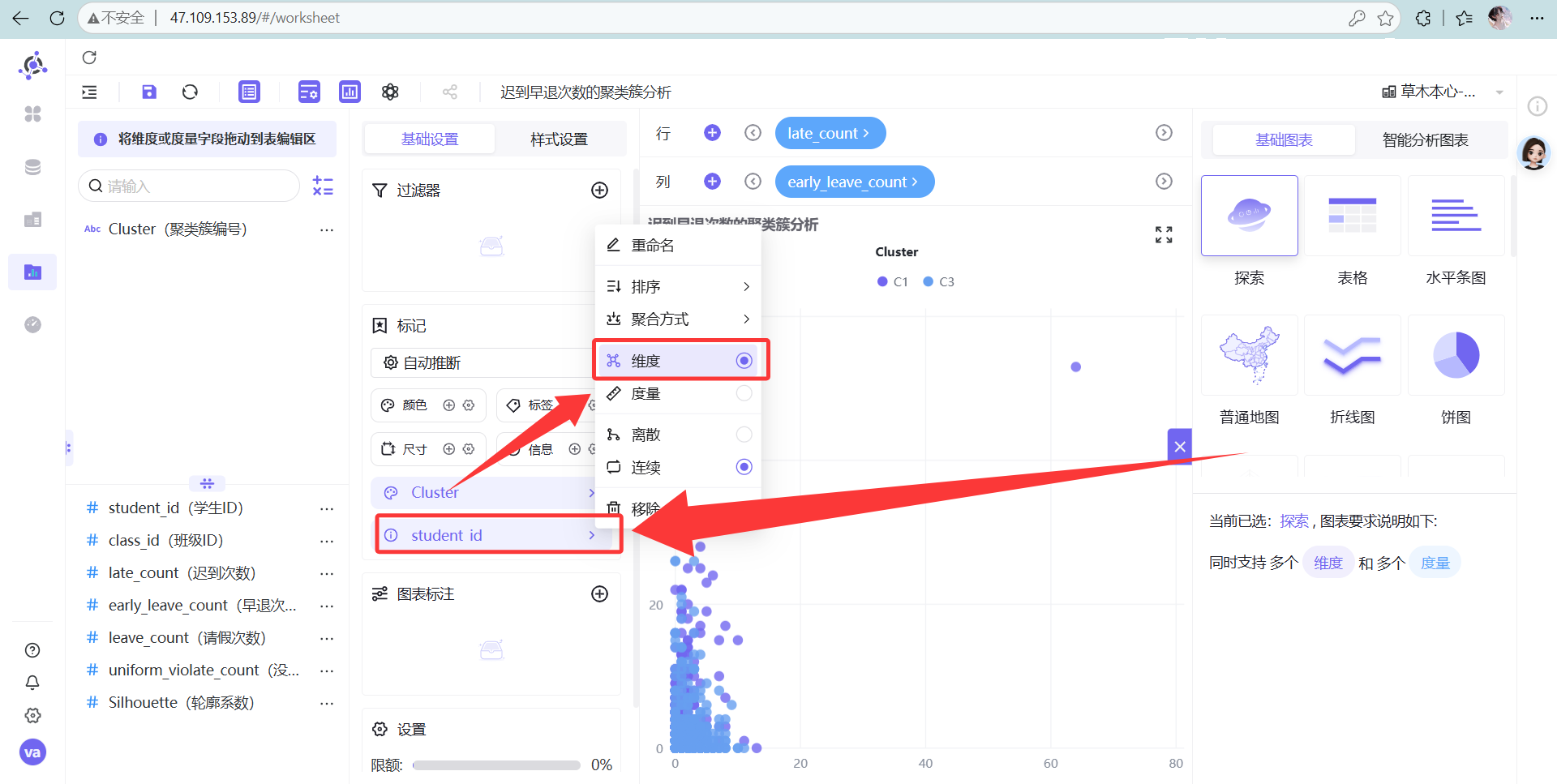
-
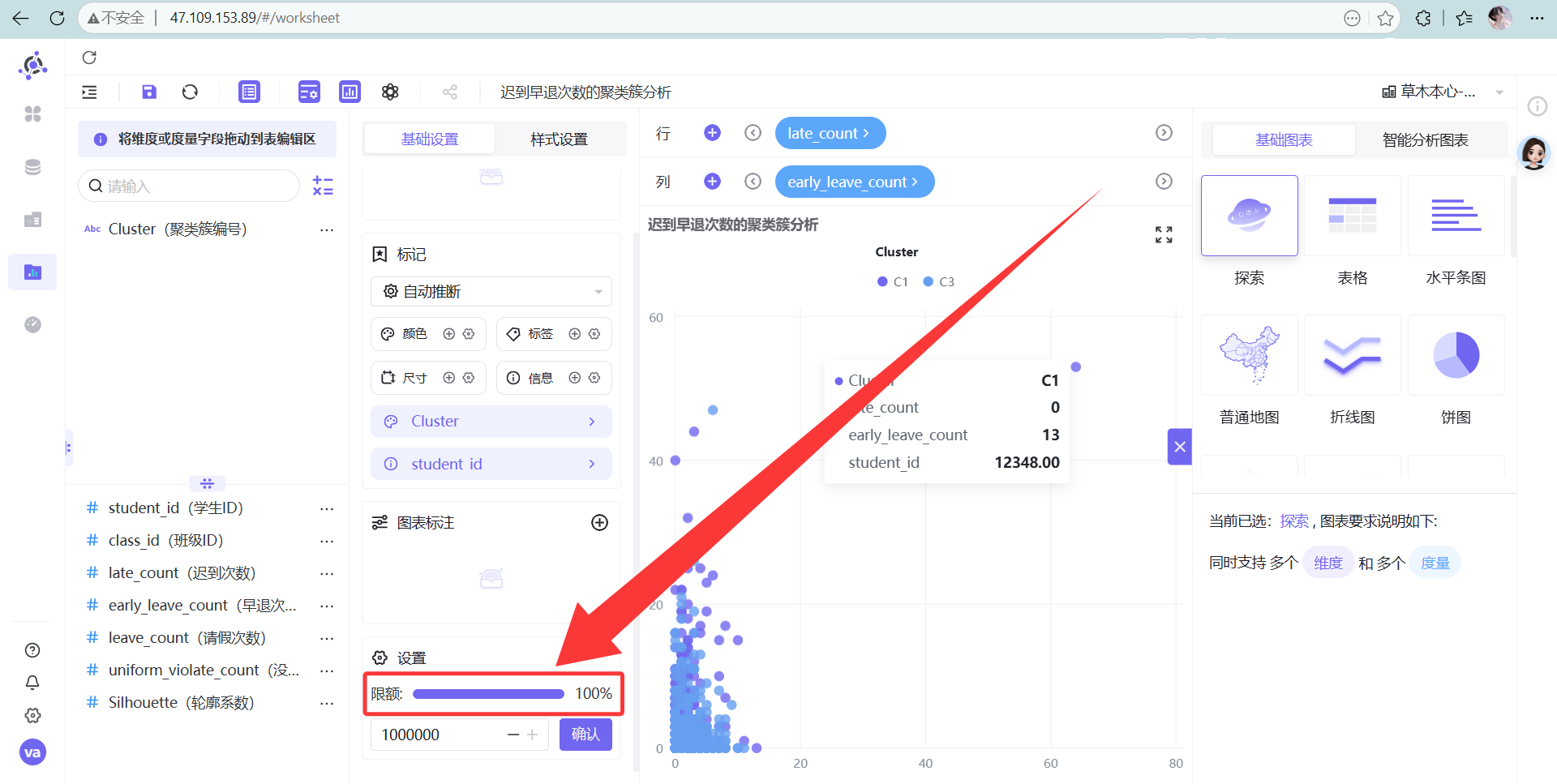
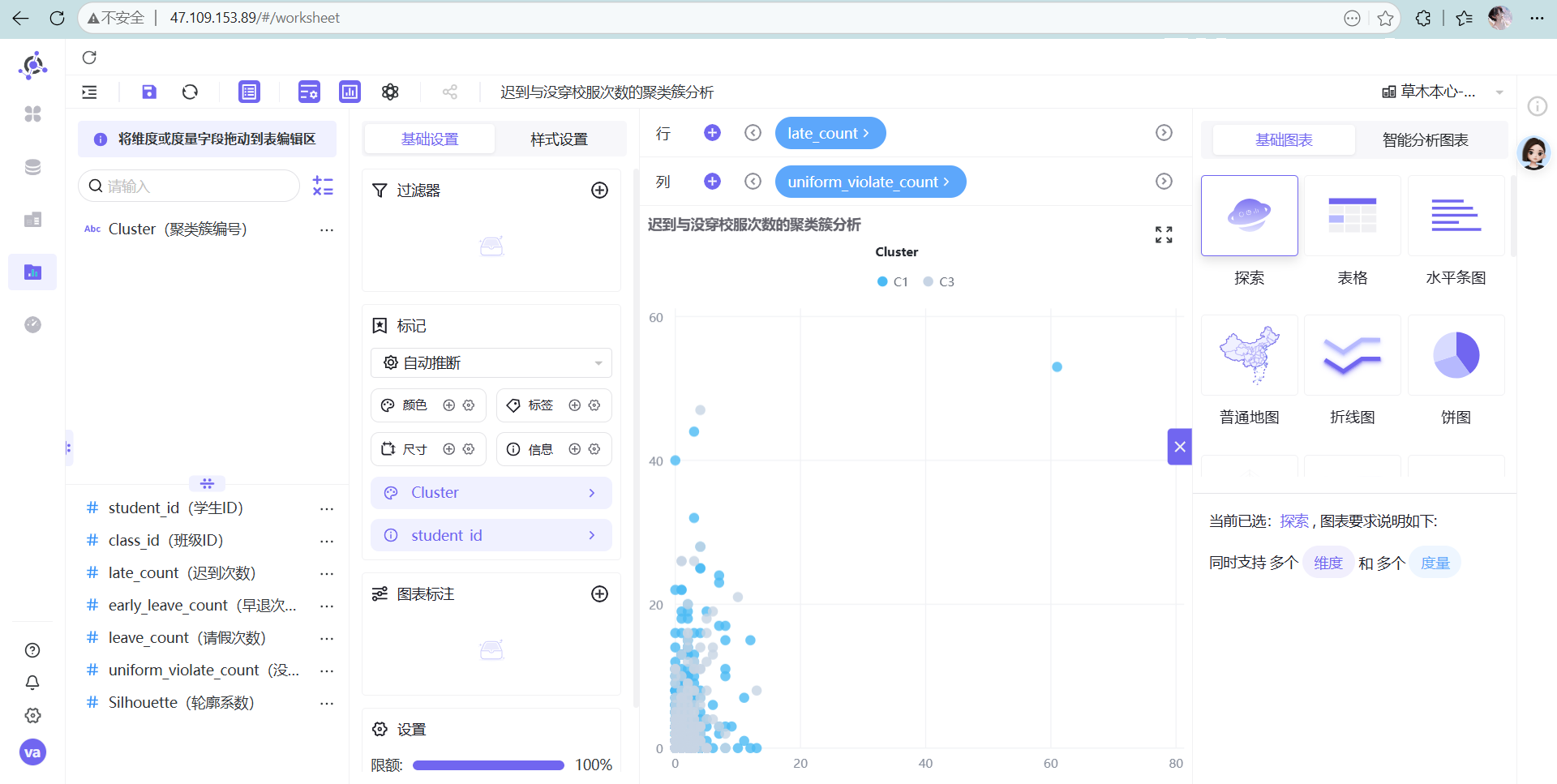
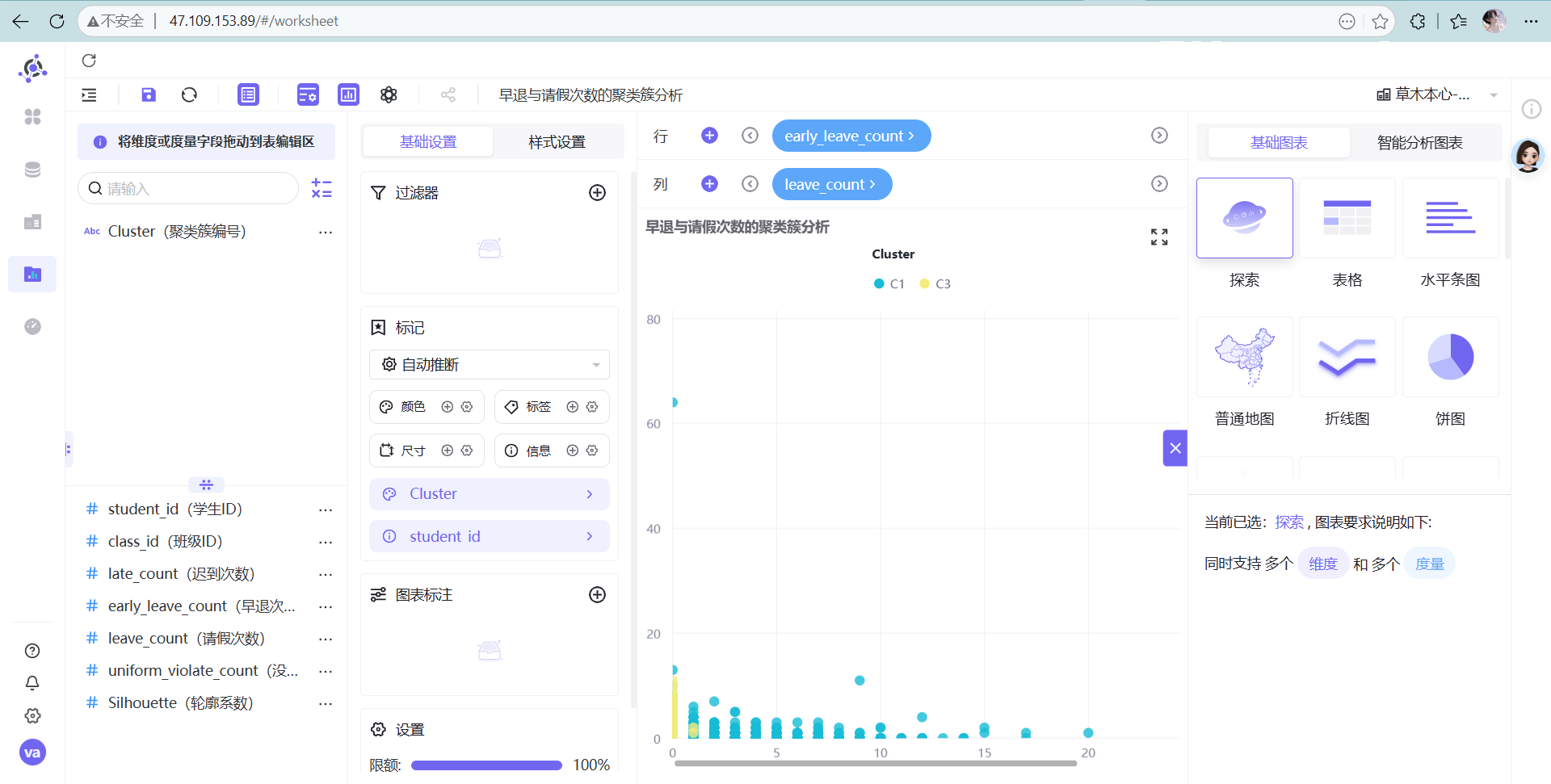
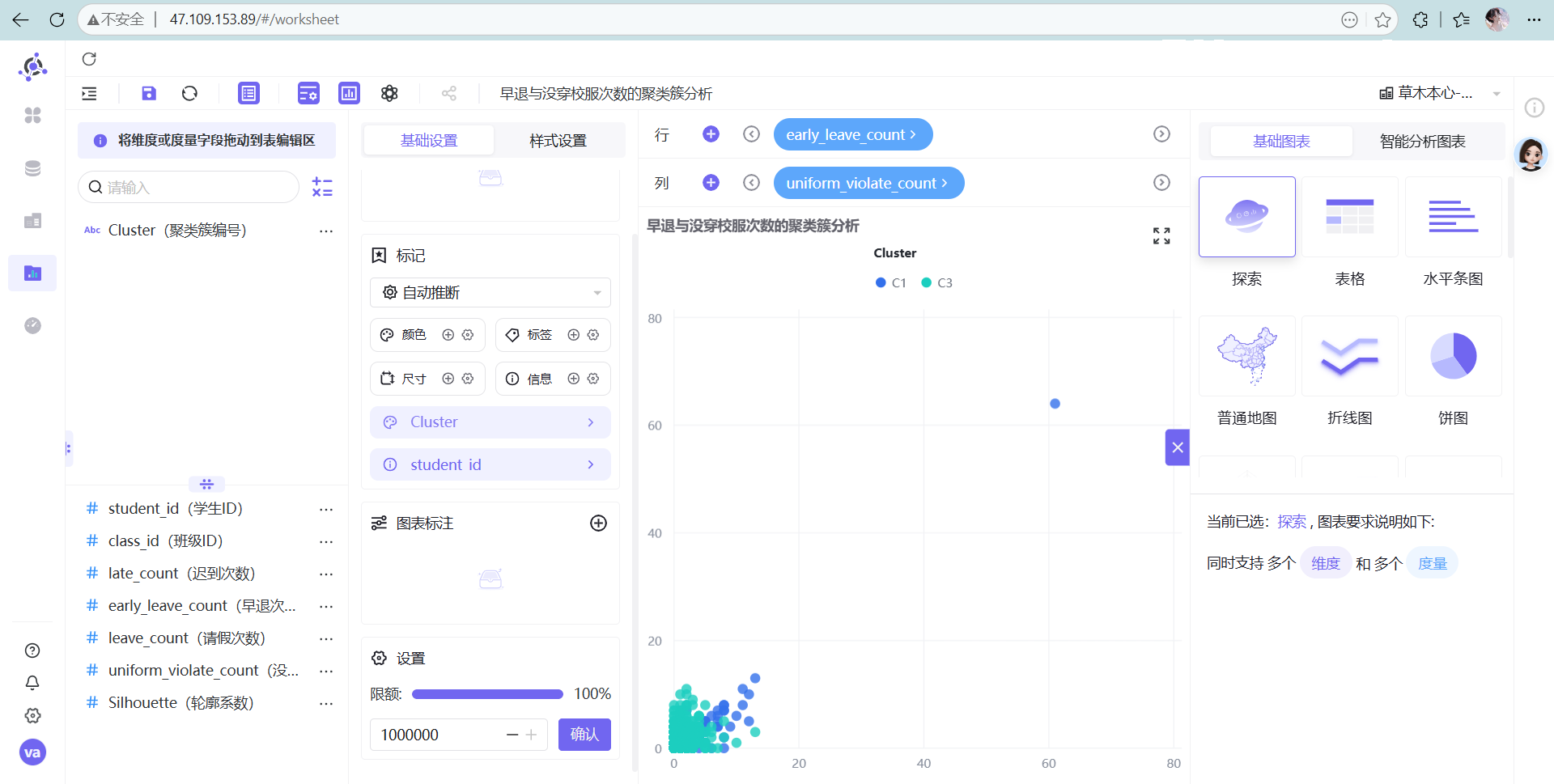
高能预警: 系统默认最多展示 2000 条数据,一定要去右下角把限额改成 100%,不然数据看不全!
-
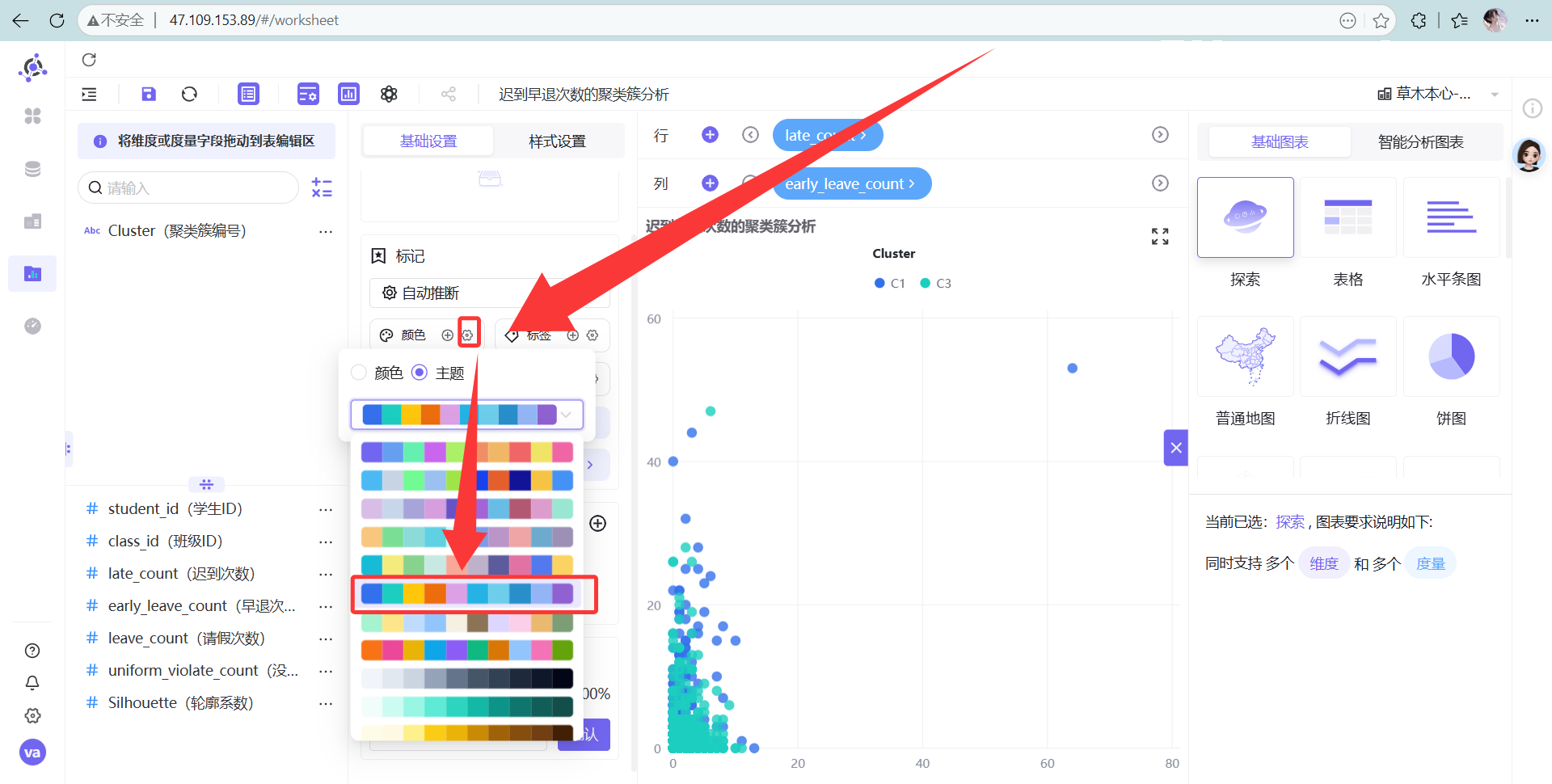
颜色尽量选个反差大的主题。
-
📊 洞察干货:为什么用“散点图”来解释聚类?
散点图(Scatter Plot)是解释 K-Means 结果最完美的图表语言。K-Means 的核心是寻找高维空间中的“质心”,而在二维散点图中,我们可以用 X轴/Y轴 观察任意两个维度的交叉情况,直观地看到每个簇(Cluster)的分布密度和边界。如果图上不同颜色的点泾渭分明,说明聚类效果极佳;如果全部糊成一团,说明你选的指标没有区分度。
- 点击保存按钮,保存并发布工作表
- 照葫芦画瓢,把四个异常指标两两组合,总共做出 6 张图。
- 迟到与请假次数的聚类簇分析
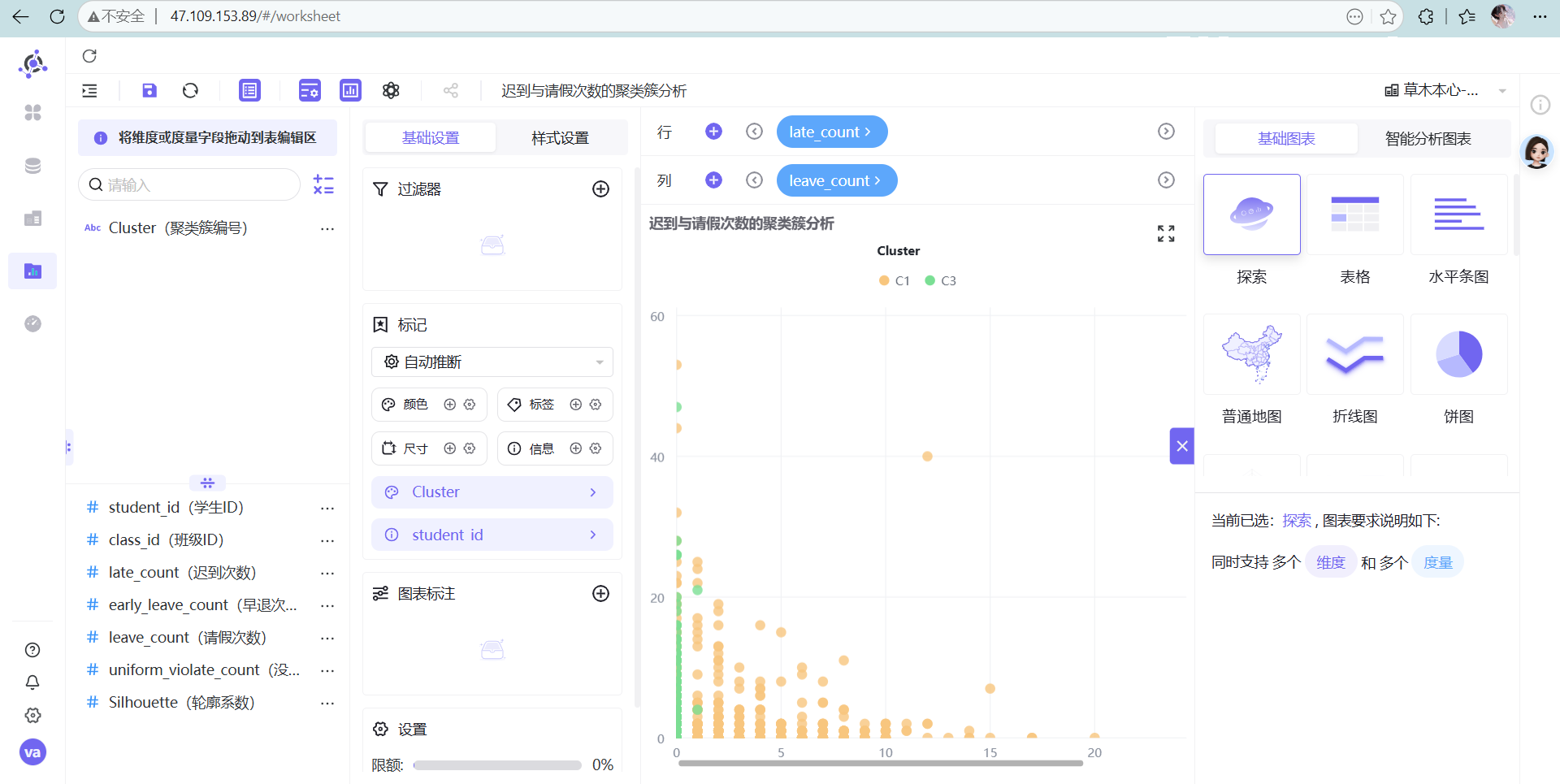
- 迟到与没穿校服次数的聚类簇分析
- 早退与请假次数的聚类簇分析
- 早退与没穿校服次数的聚类簇分析
- 请假与没穿校服次数的聚类簇分析
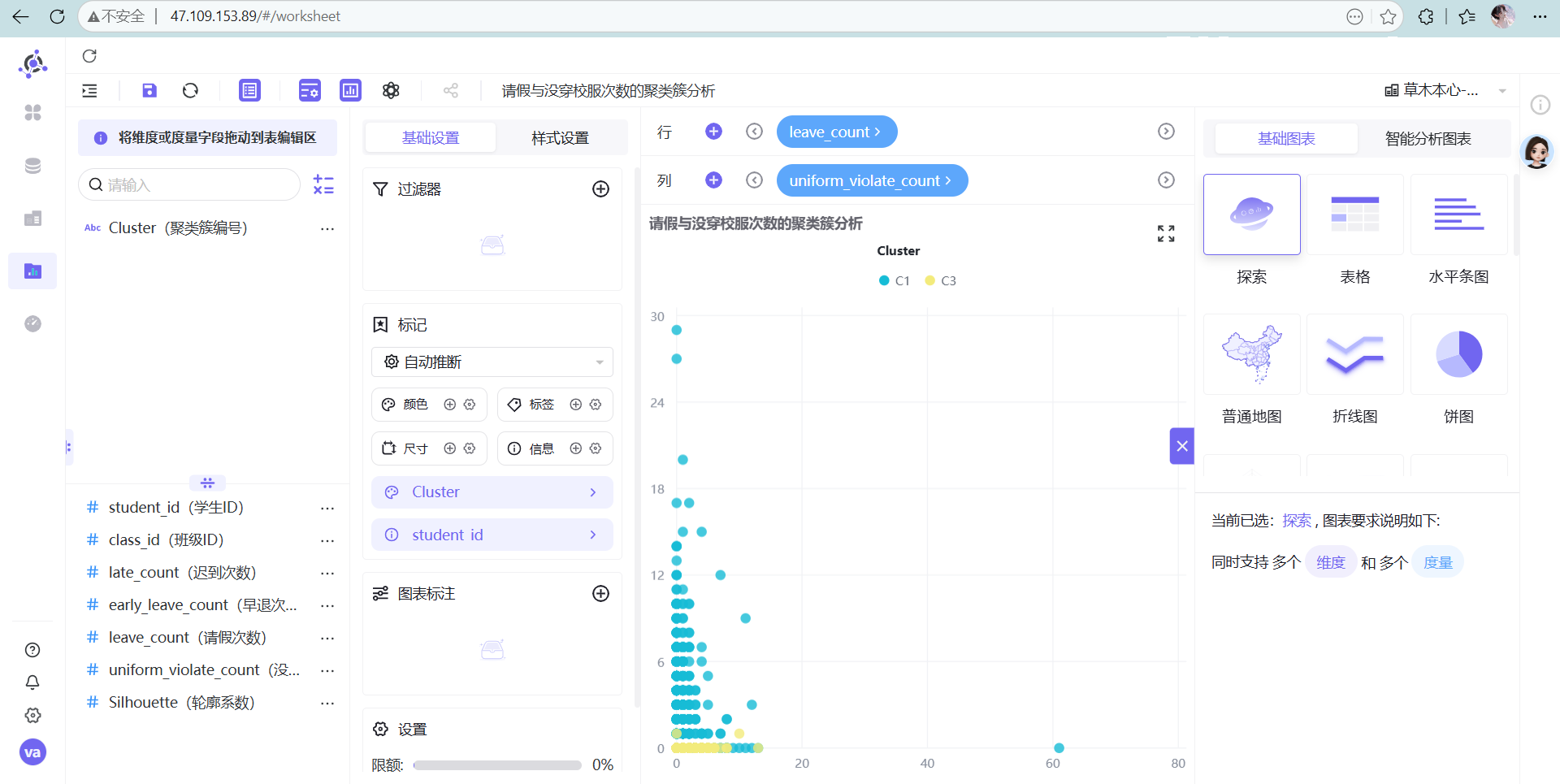
- 迟到与请假次数的聚类簇分析
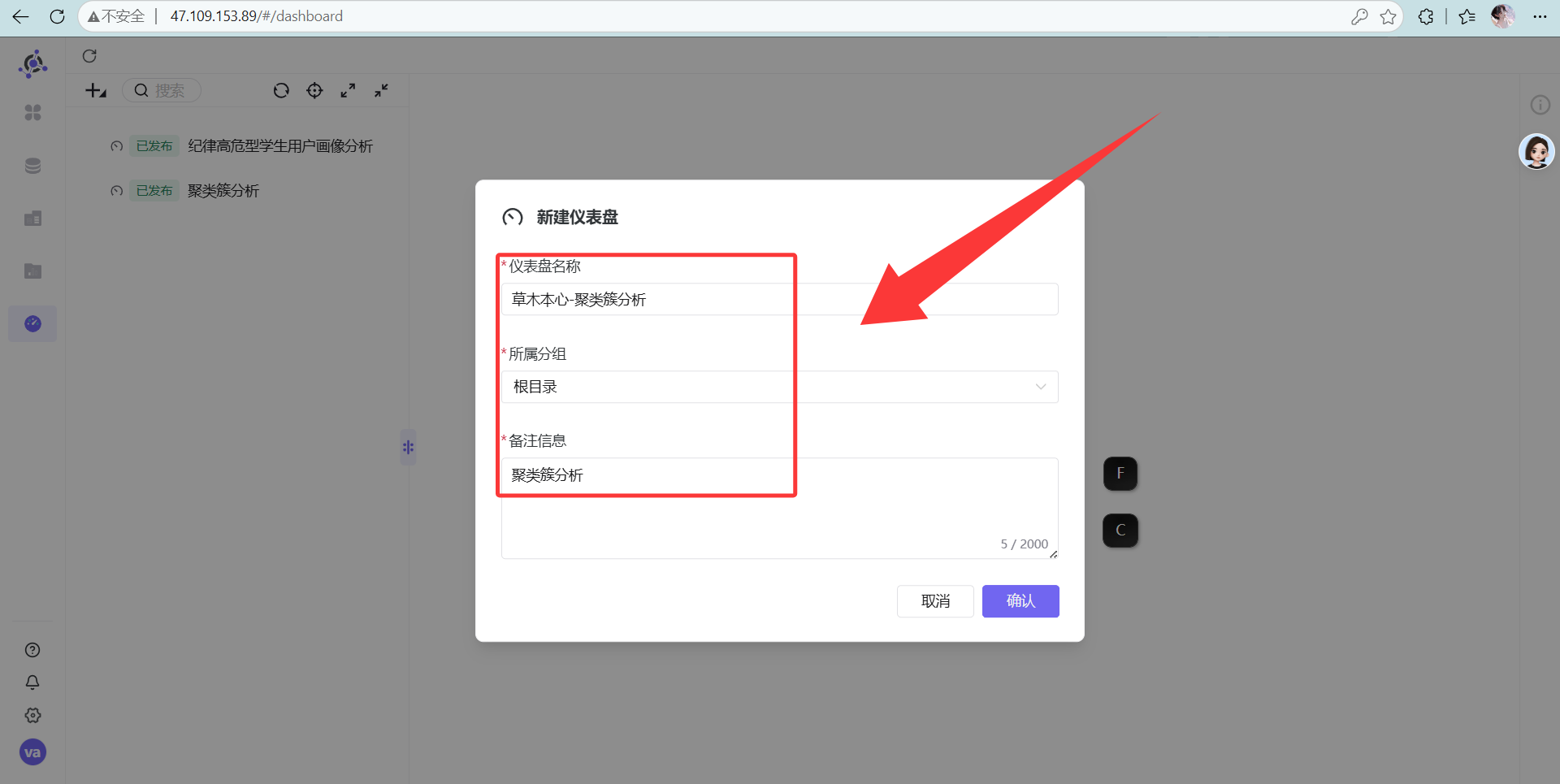
3. 组装“高大上”的仪表盘
-
操作说明: 去“仪表盘”菜单新建一个仪表盘,名字输入“草木本心-聚类簇分析”,备注信息输入“聚类簇分析”,点击“确认”
 拖个文本组件当标题,并设置字体颜色、字体大小、加粗、居中
拖个文本组件当标题,并设置字体颜色、字体大小、加粗、居中
 组件右下角可以拖动跳转组件大小,调整为下图的样式:
组件右下角可以拖动跳转组件大小,调整为下图的样式: 然后把刚才做的 6 张图一股脑拖进来排好版
然后把刚才做的 6 张图一股脑拖进来排好版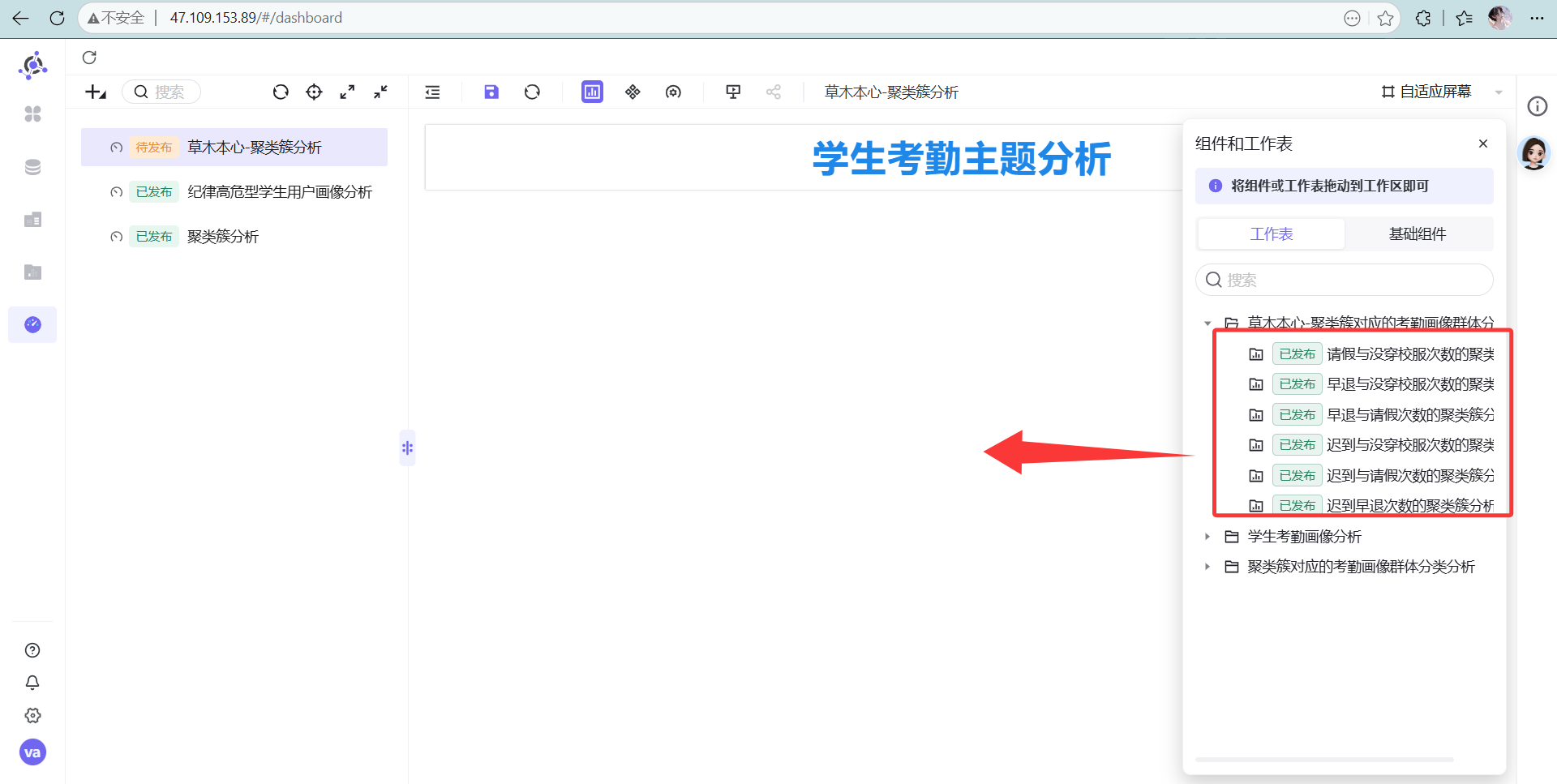 点击图钉钉死位置。最终效果如下,老板看了都得给你加鸡腿!
点击图钉钉死位置。最终效果如下,老板看了都得给你加鸡腿!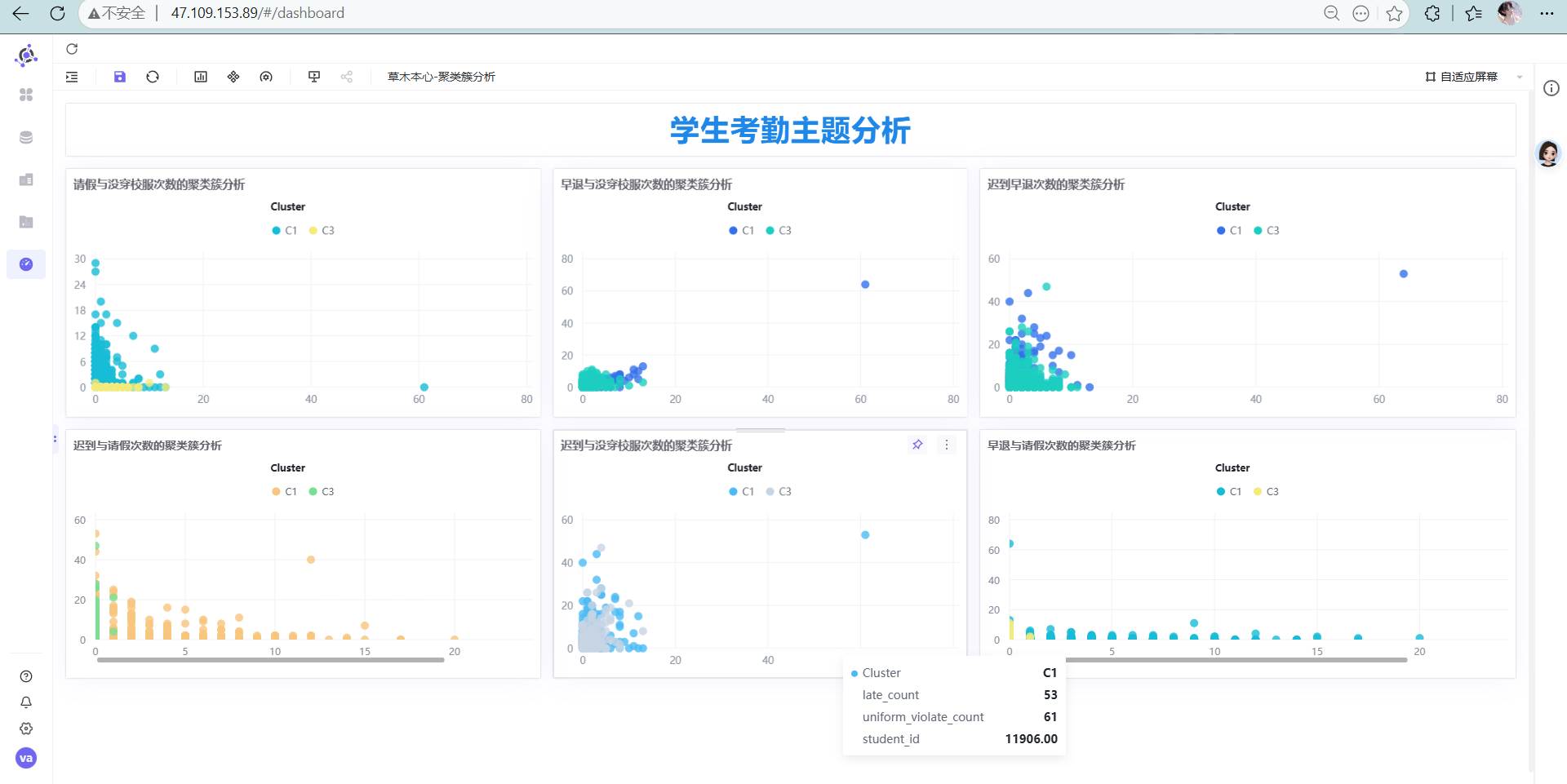 最后别忘了点击保存按钮,保存并发布仪表盘
最后别忘了点击保存按钮,保存并发布仪表盘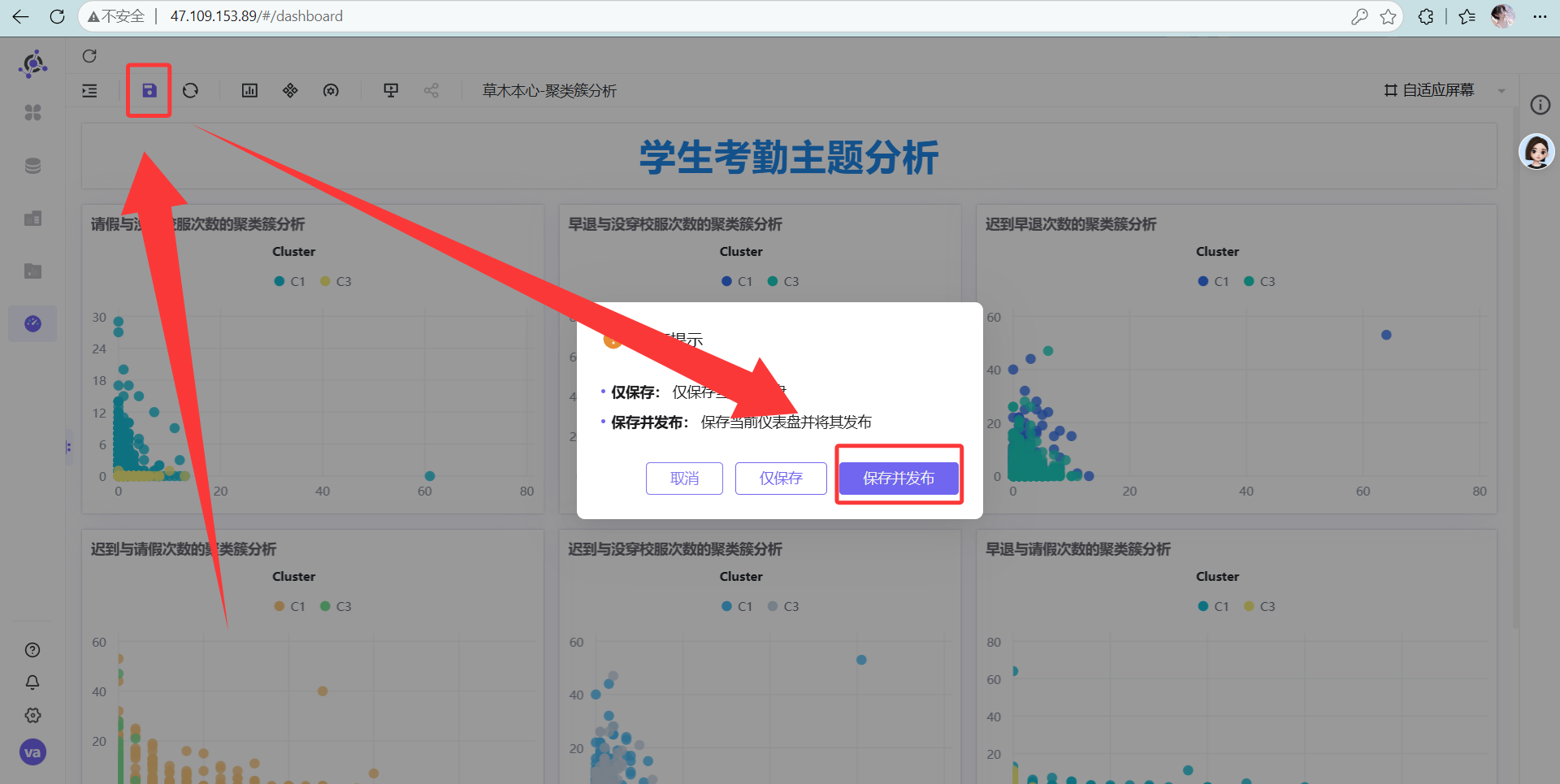
阶段三:助睿 ETL 回写画像标签(闭环才是王道)
业务含义我们搞清楚了,最后一步,用 ETL 把这些标签写回原始数据库里!
⚙️ 架构干货:数据分析的尽头是 ETL 闭环
ETL(Extract-Transform-Load,即抽取、转换、加载)是现代数据工程的基石。很多初级数据分析师只负责在 Notebook 里跑算法,产出一堆图表或 CSV 就宣告结束。但真正有商业价值的分析,必须把产出的高价值标签(如这里的画像归属)打通(Load)回业务系统的数据库中,这就是所谓的“数据闭环”。没有这一步,你的标签就永远无法被其他业务系统调用!
1. 数据库新增扩展字段
-
操作说明: 去“数据集成”(助睿 ETL)新建转换流,拖入“执行一个SQL脚本”组件。
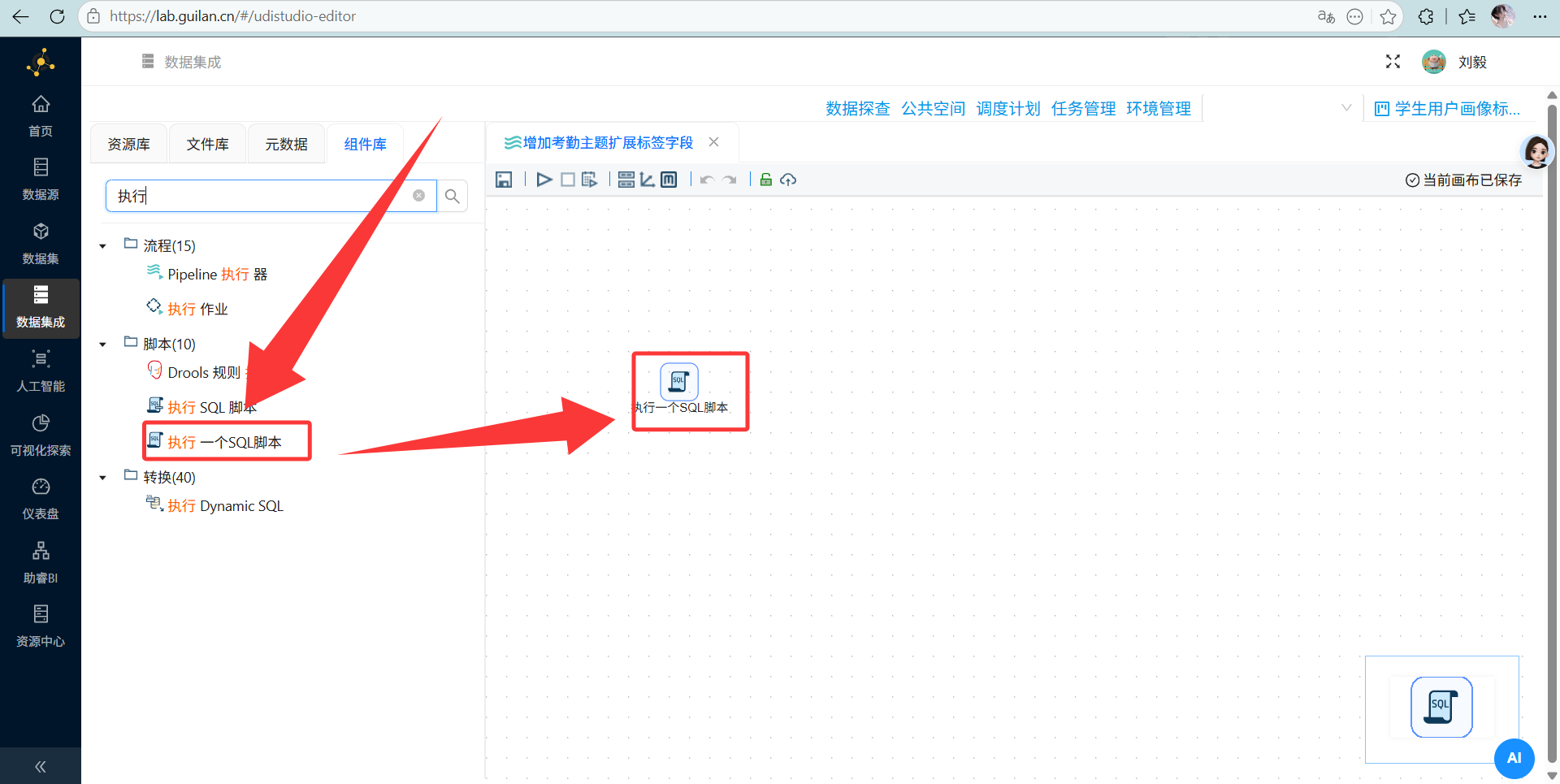
-
配置要点: 输入 SQL 语句,给原表
student_attendance_stats加两个空槽位:cluster和attendance_group -
-- 为学生考勤统计表添加聚类结果字段 ALTER TABLE student_attendance_stats ADD COLUMN cluster VARCHAR(10) NULL DEFAULT NULL COMMENT '聚类簇编号', ADD COLUMN attendance_group VARCHAR(30) NULL DEFAULT NULL COMMENT '考勤群体分类';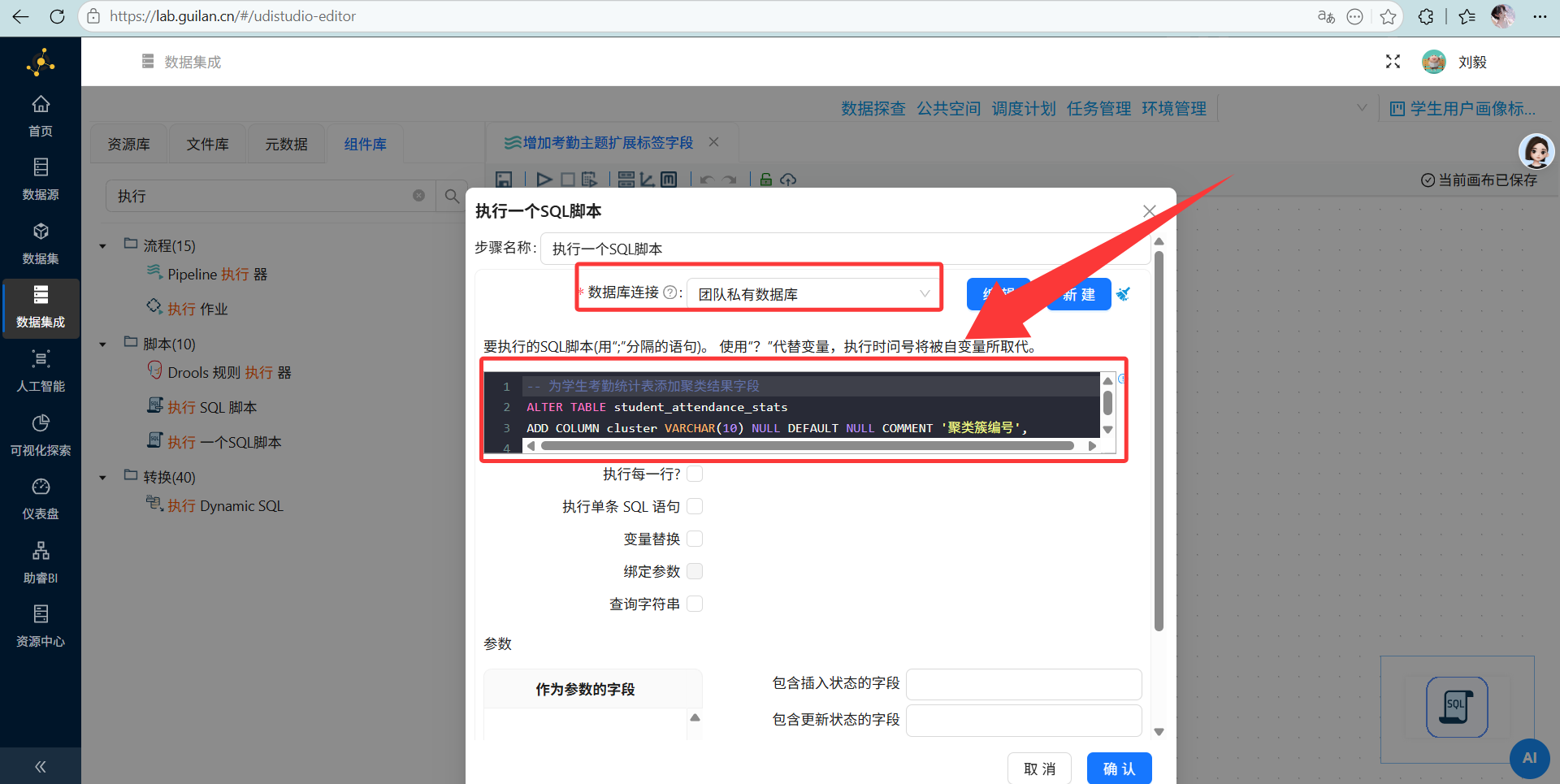 执行转换流
执行转换流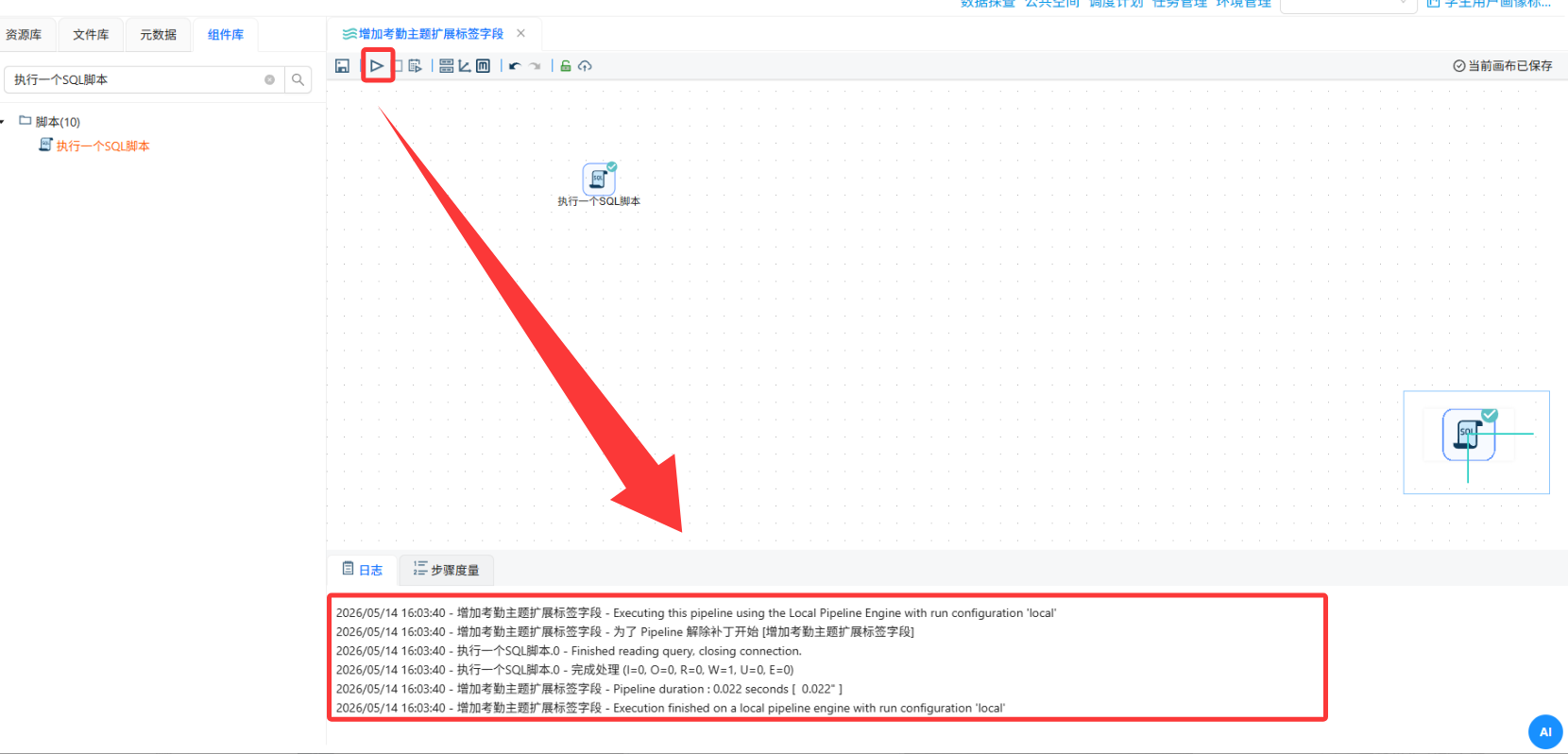
2. 获取结果并进行字段类型转换
-
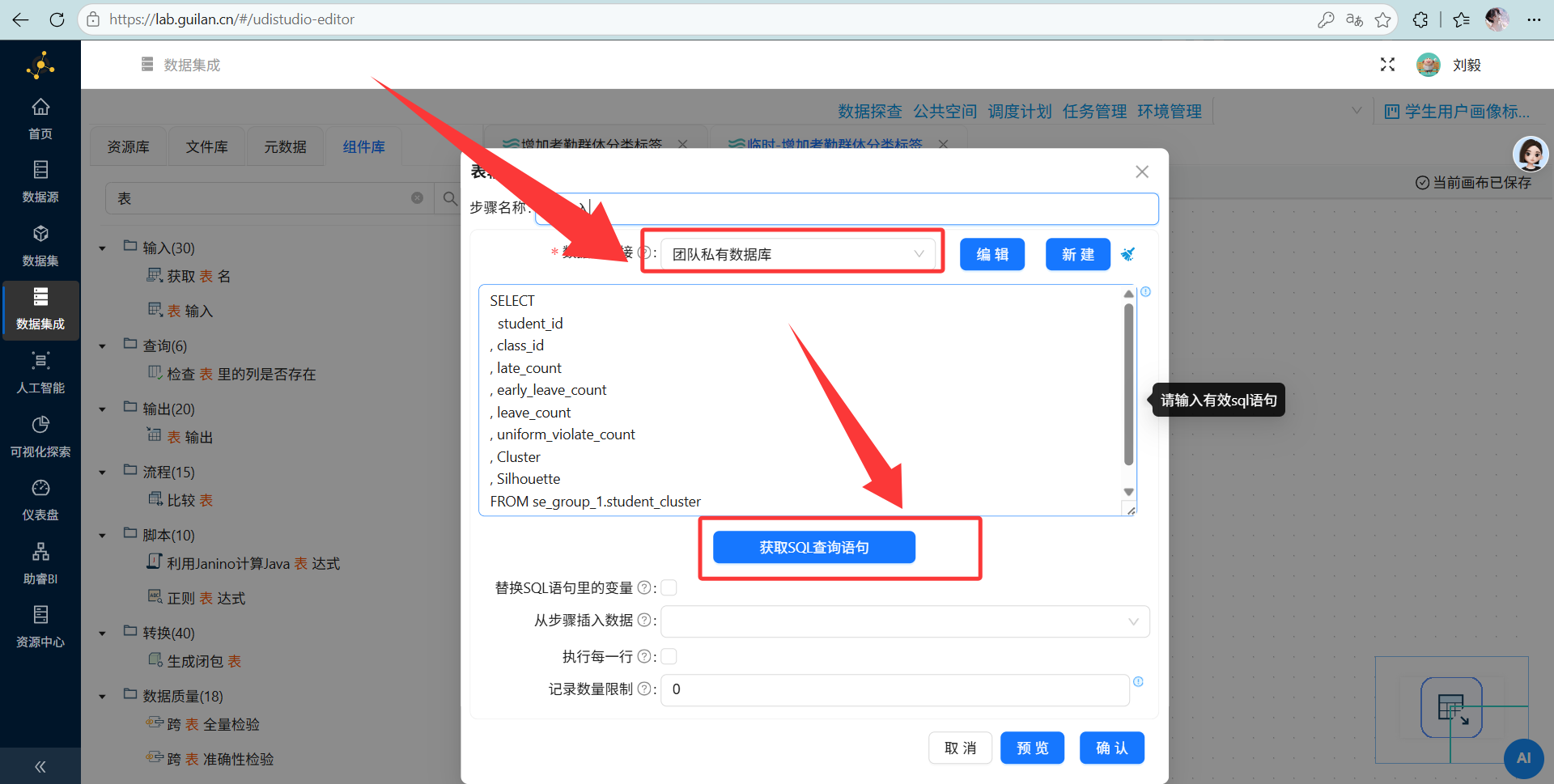
操作说明: 另建一个转换流,用“表输入”查出
student_cluster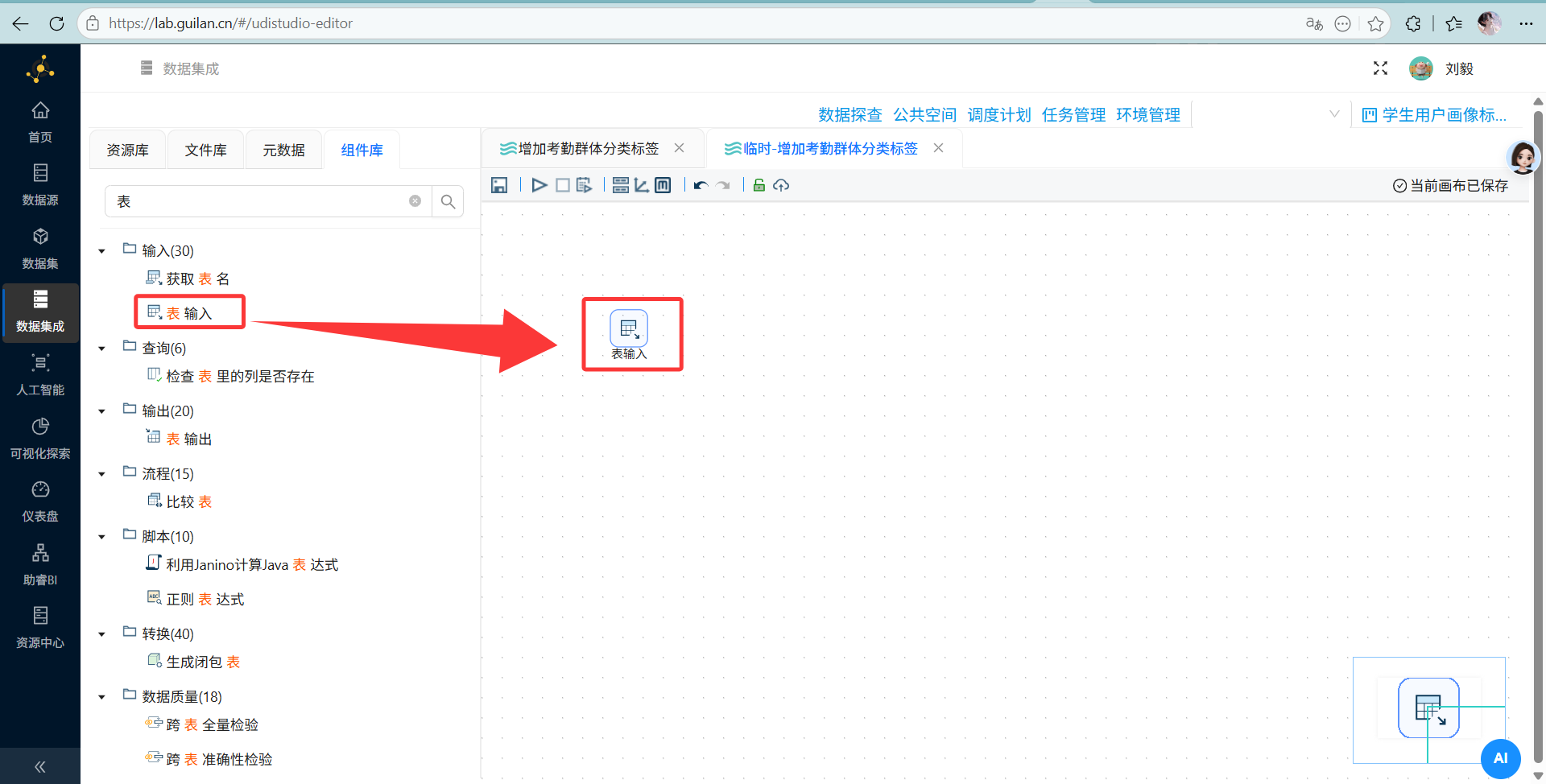
 连上“字段选择”组件。
连上“字段选择”组件。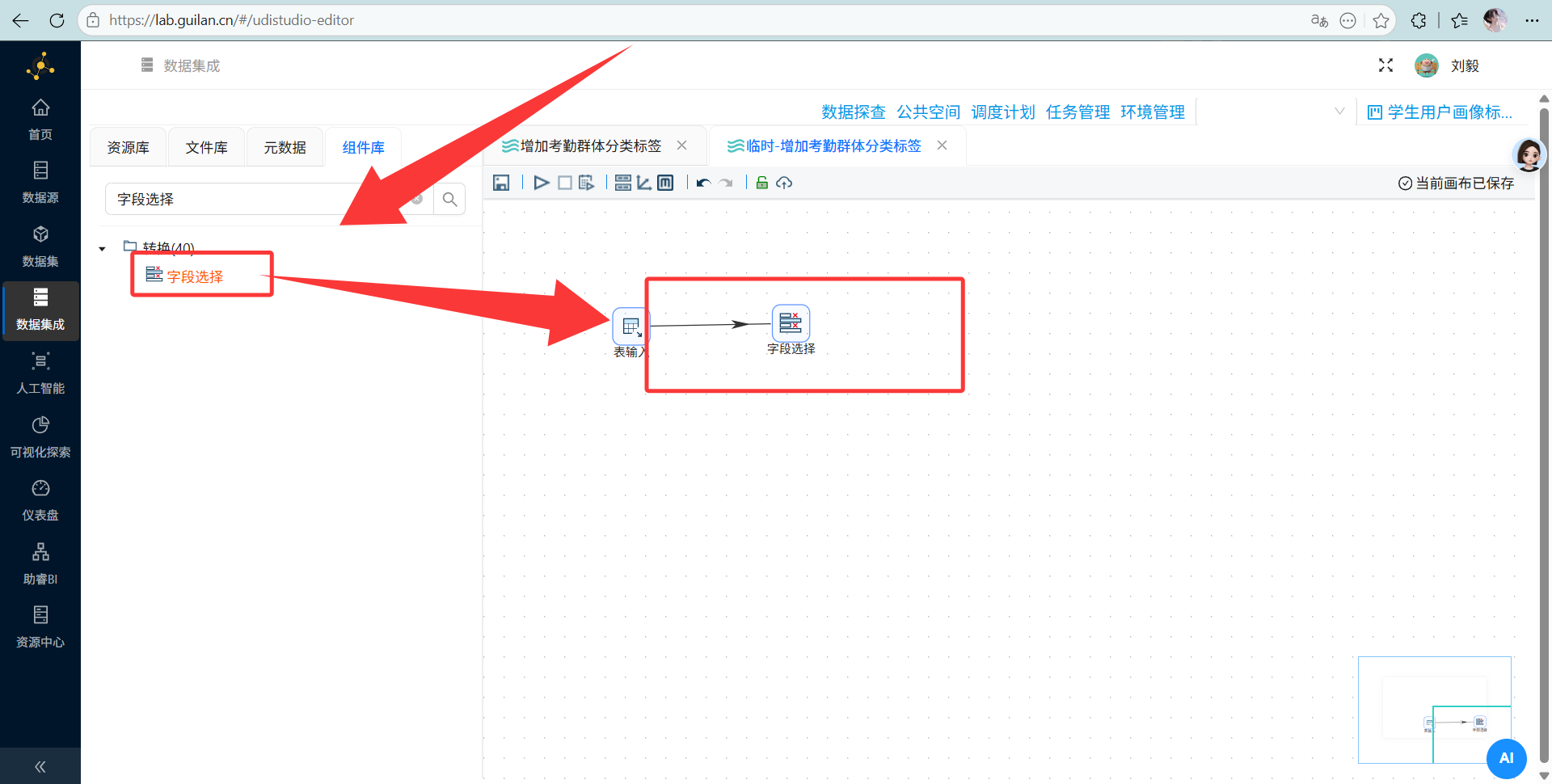
-
配置要点: 删掉无用字段
student_id、class_id和Cluster。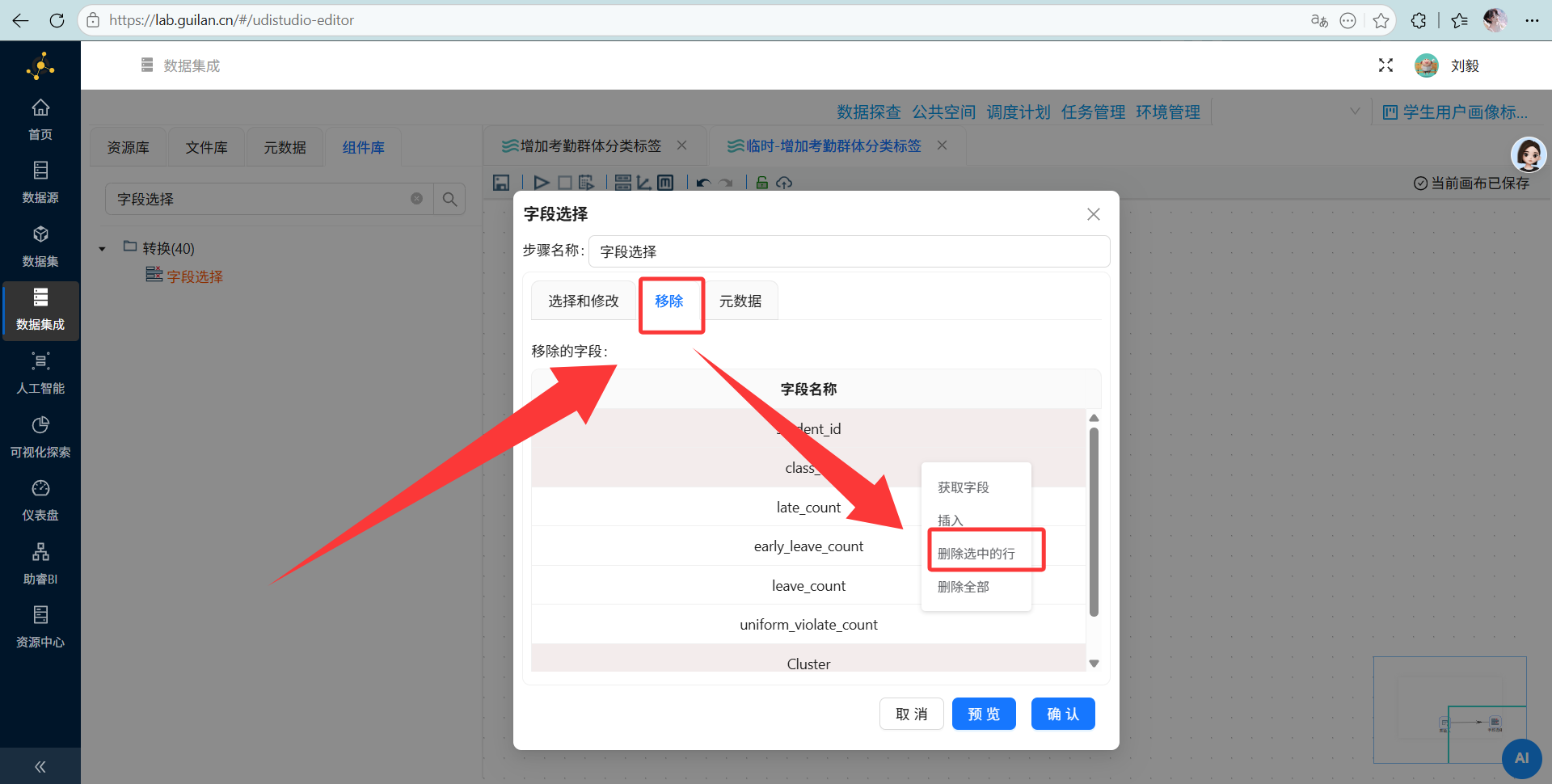 重点来了:为了保持和 student_attendance_stats 表中字段类型一致,不影响后续数据更新到 student_attendance_stats,需要将 student_id、class_id 的类型修改为Integer,点击元数据选项,插入2行, student_id、class_id 的配置如下:
重点来了:为了保持和 student_attendance_stats 表中字段类型一致,不影响后续数据更新到 student_attendance_stats,需要将 student_id、class_id 的类型修改为Integer,点击元数据选项,插入2行, student_id、class_id 的配置如下: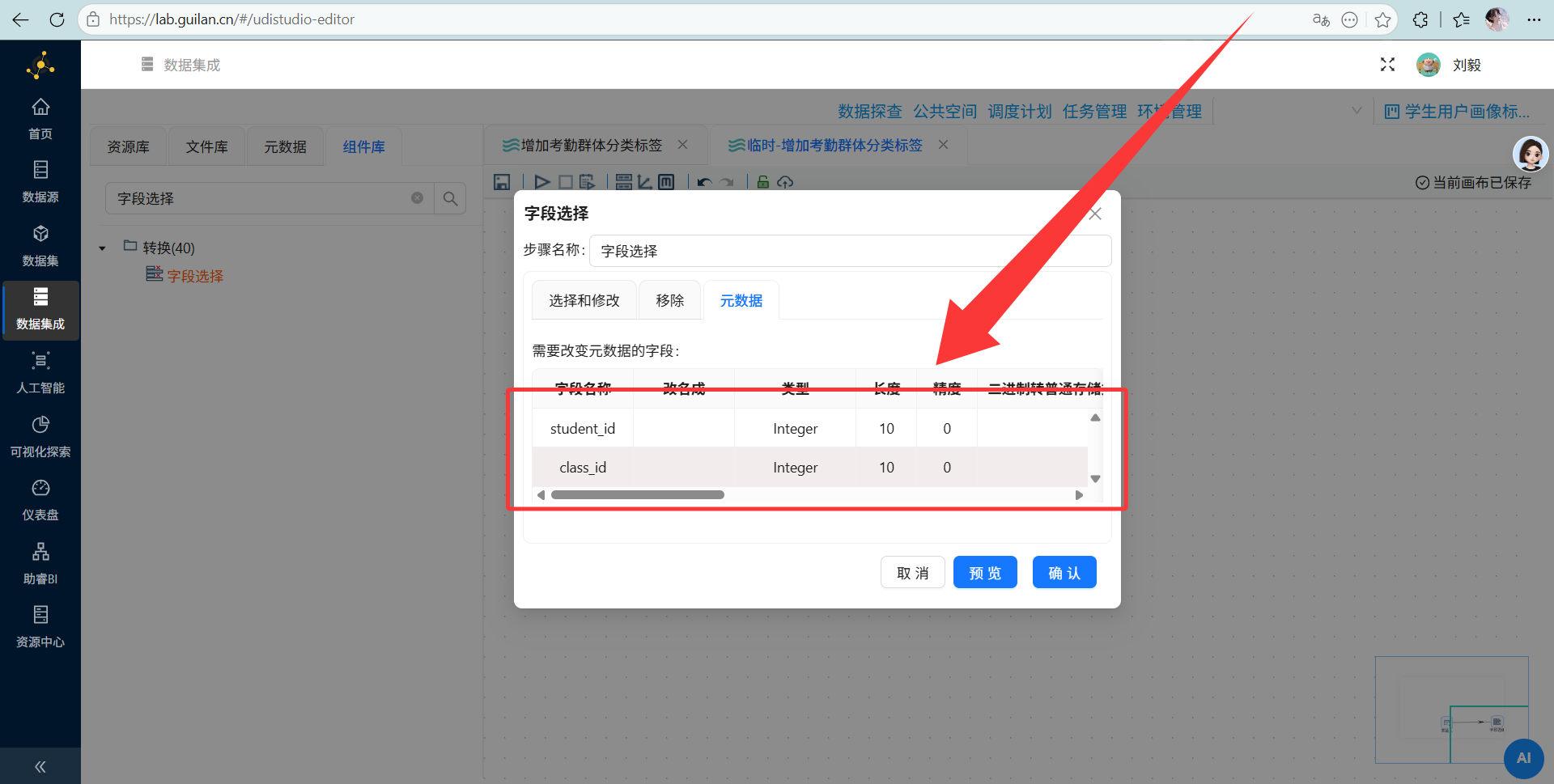
3. 值映射与最终更新
-
操作说明: 拖入“值映射”组件给标签贴中文名,最后接上“更新”组件写回数据库。
-
配置要点:
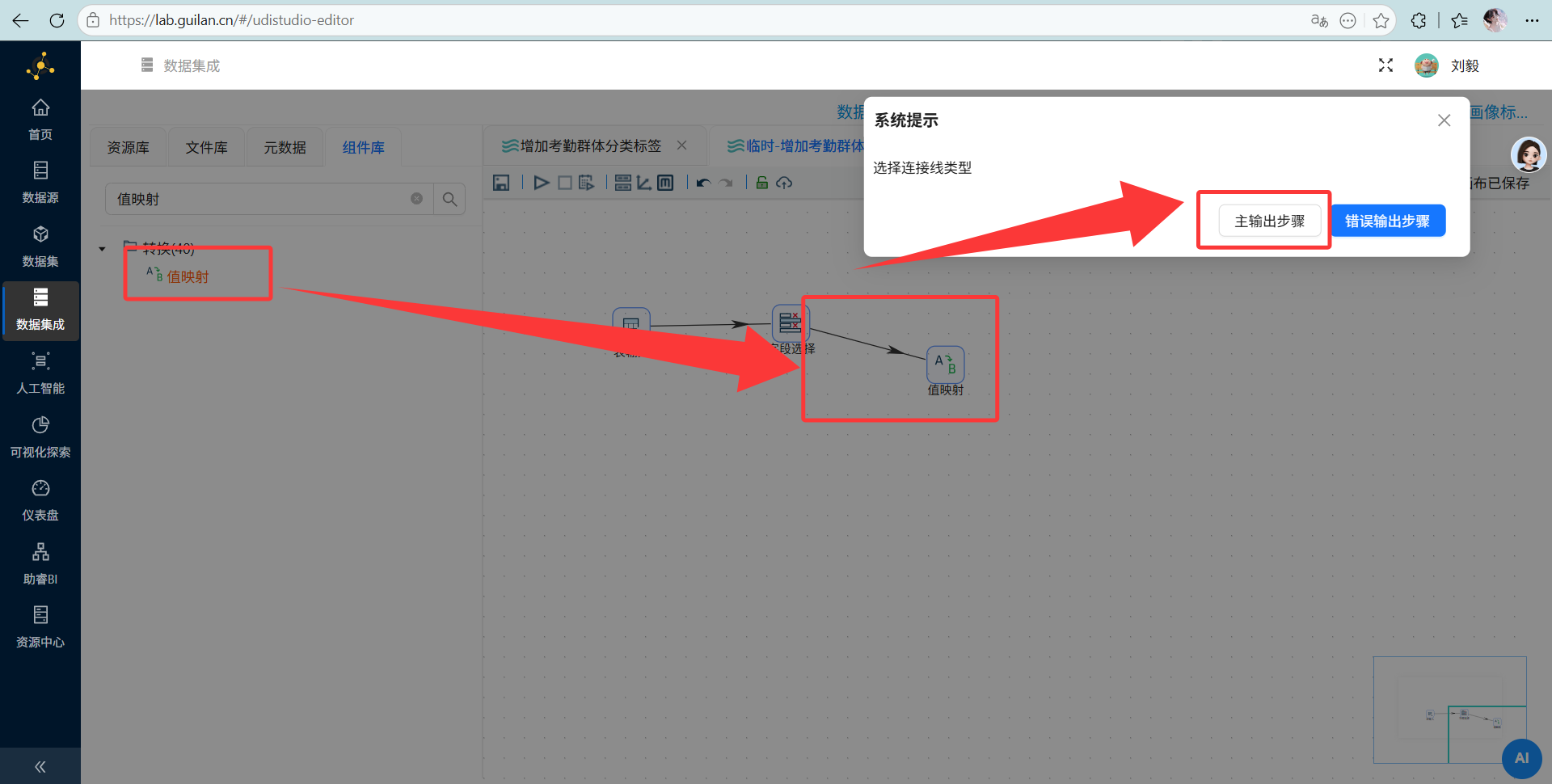
-
值映射: 映射字段填
Cluster,目标字段填attendance_group。源值输入 C1、C2、C3,目标值根据图表规律映射(比如我这里 C1 是轻微波动,C2 是模范,C3 是高危,具体看大家跑出来的散点图哦!)。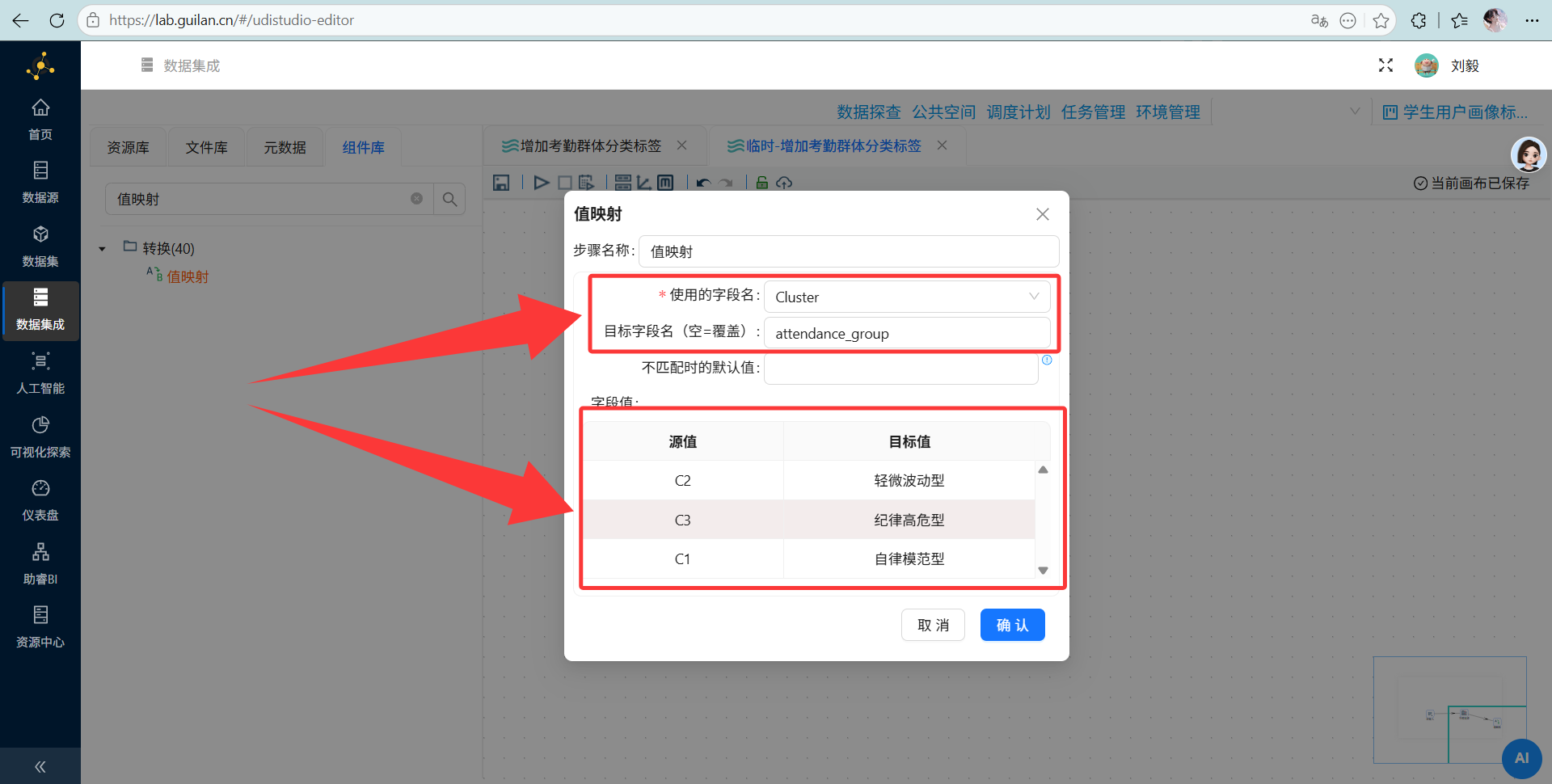
-
更新:
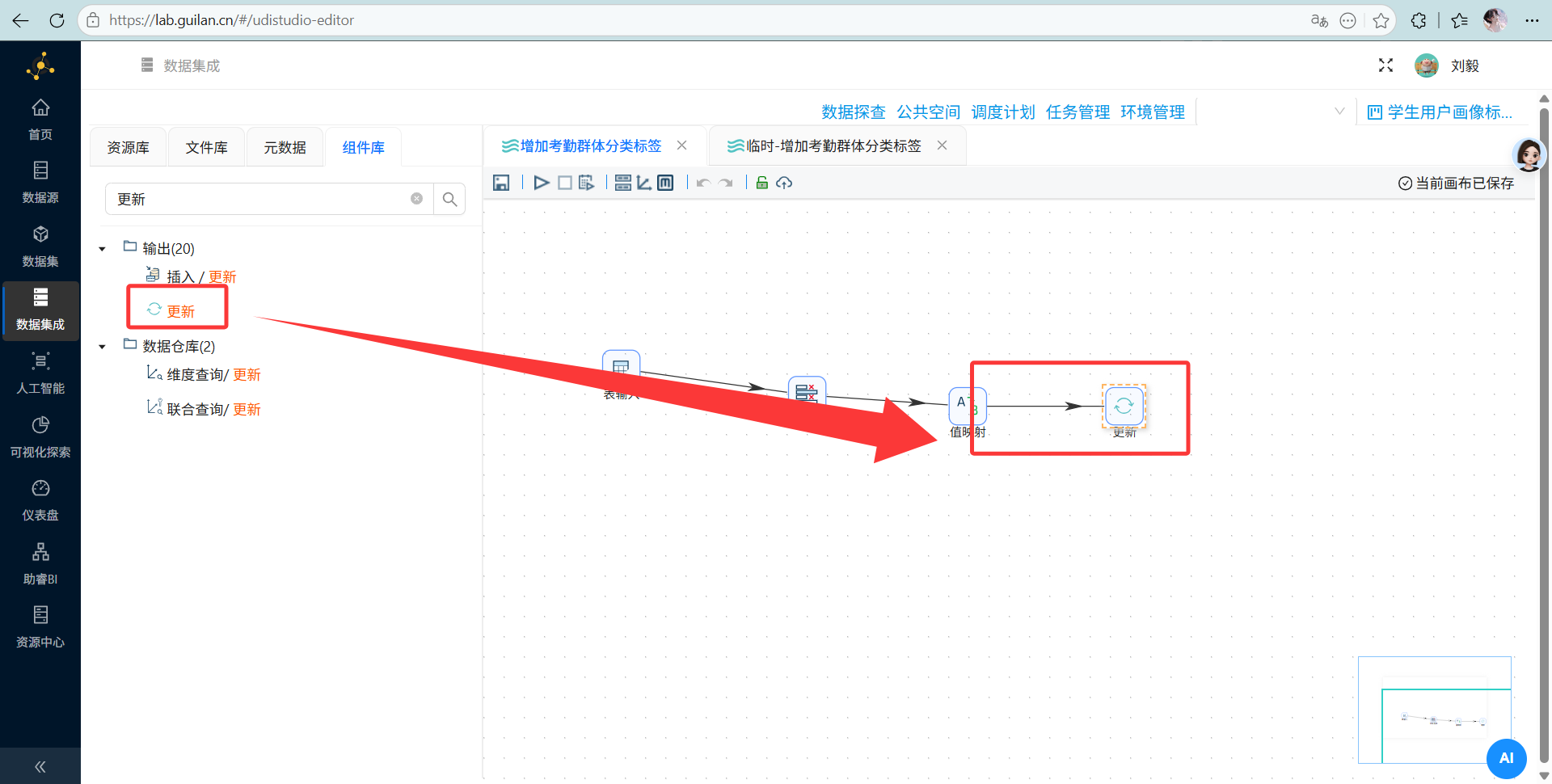 目标表选
目标表选 student_attendance_stats。查询关键字是student_id匹配,把流里的数据塞给表里的新字段。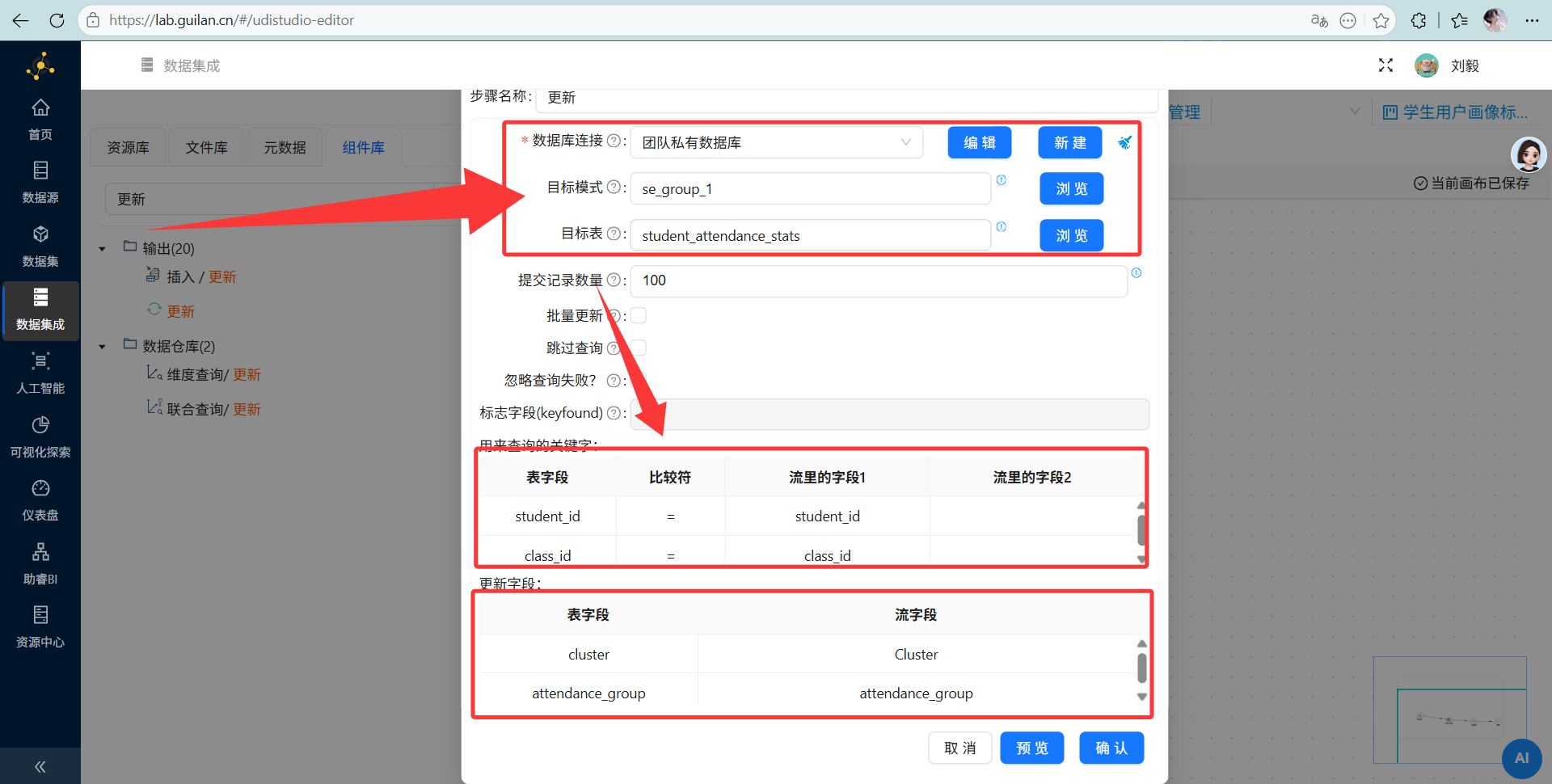 跑起来!
跑起来!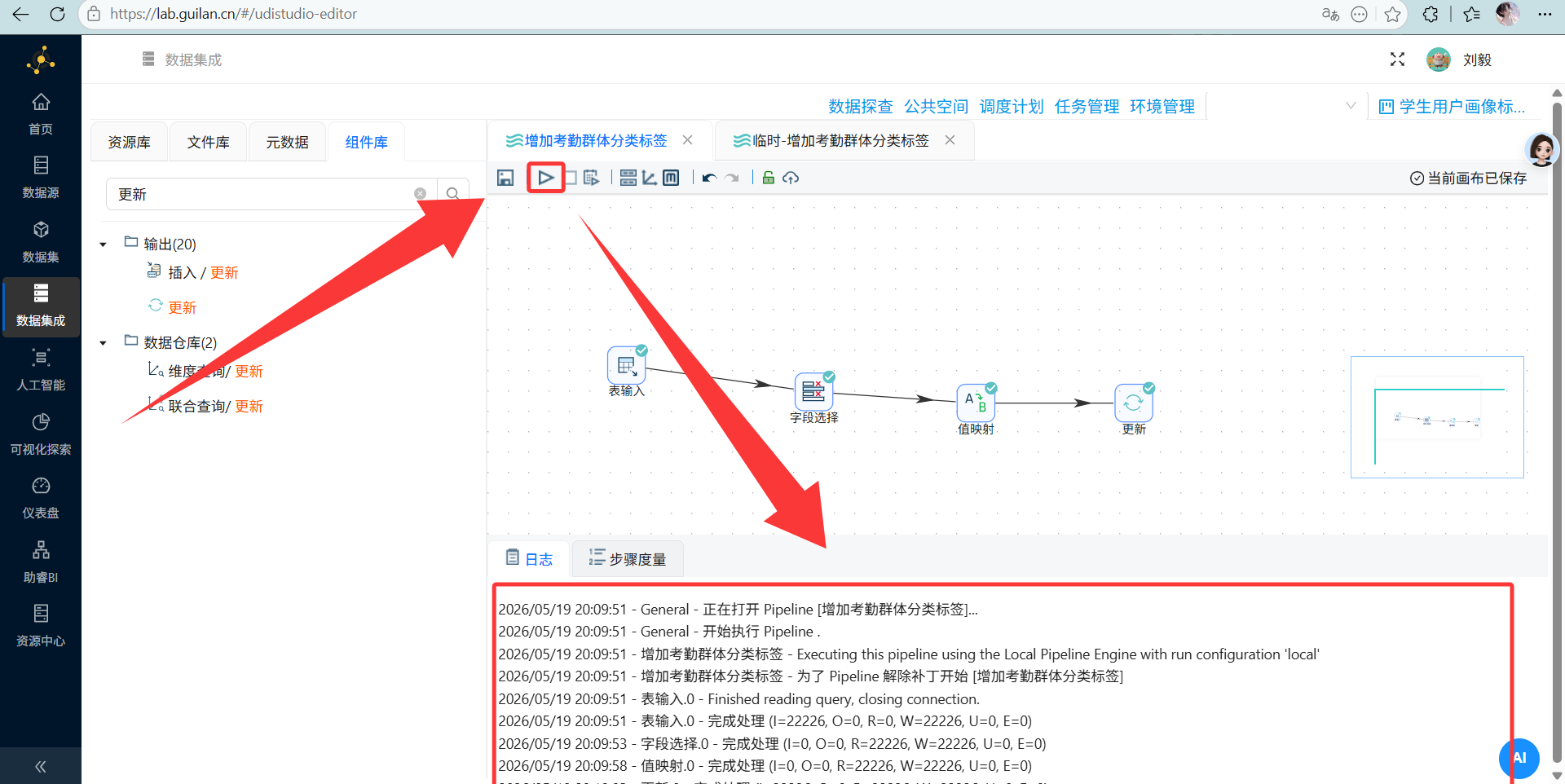
-
第三部分:实验结果
行云流水一番操作后,来看看我们的战果:
1. 人人都能看懂的聚类画像(BI洞察结果) 基于那 6 张炫酷的散点图,三类人群彻底原形毕露:
|
神秘代号 |
代表色 |
标签命名 |
画像特征(一看就懂) |
|---|---|---|---|
|
C1 |
青色 |
👑 自律模范型 |
数据全贴在地板上!不迟到不早退,纪律委员本员,校园里的正面标杆。 |
|
C2 |
蓝色 |
🌬️ 轻微波动型 |
没大毛病,就是偶尔迟个到、忘穿个校服,属于“敲打敲打就行”的普通玩家。 |
|
C3 |
黄色 |
🚨 纪律高危型 |
图表右上角疯狂乱窜的离群点就是他们!多重违纪叠加,班主任重点“盯防”对象。 |
2. 标签完美落库(ETL回写结果) 打开数据探查看看原始考勤表,见证奇迹的时刻——每个学生后面都整整齐齐地加上了 cluster 和 attendance_group,数据一分不差,业务完美闭环!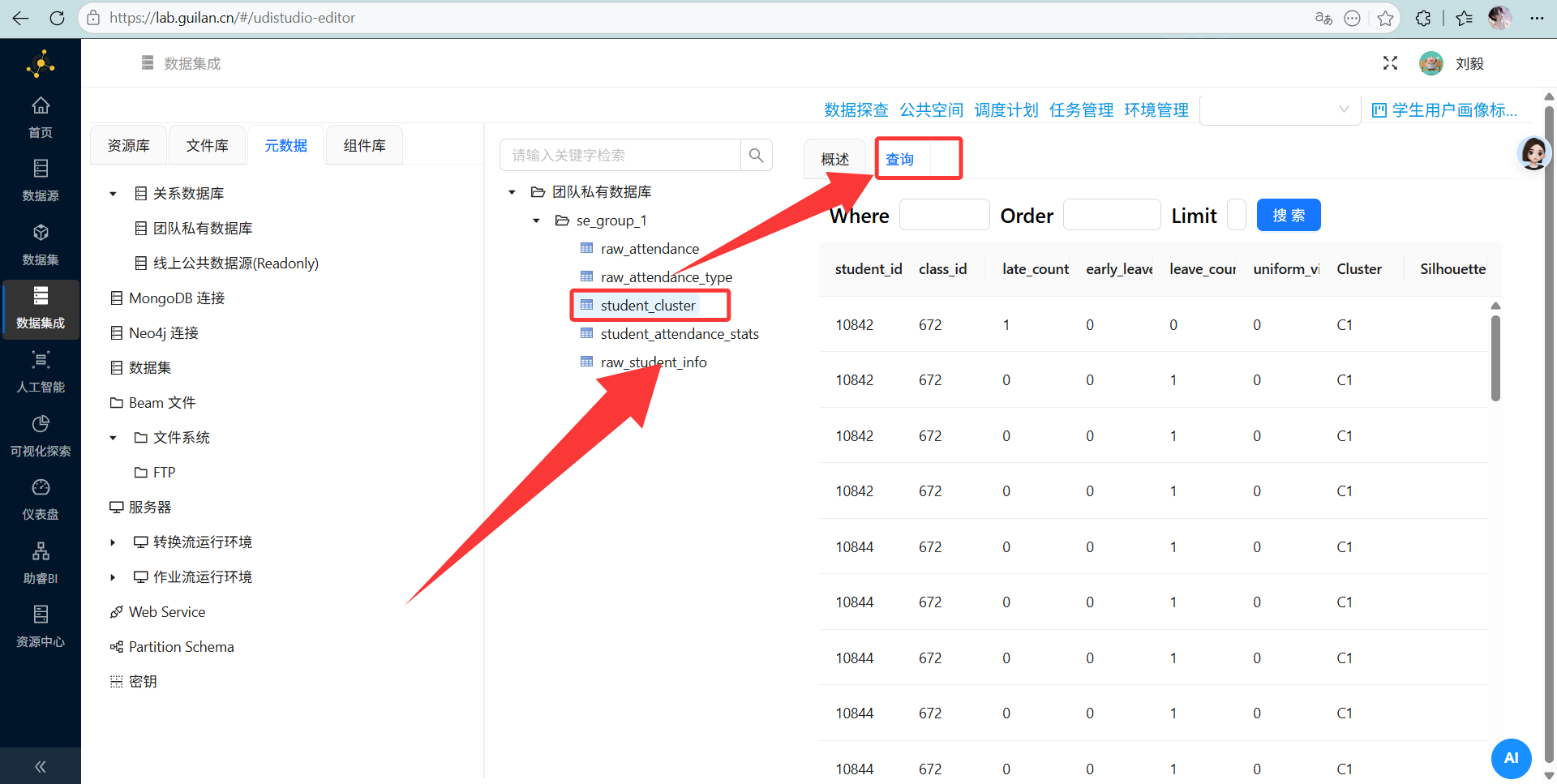
有了这张带标签的新表,我们就能解决实际问题:
-
大屏监控: 这些打好标签的数据可以直接对接校长办公室的数据大屏,各年级、各班的“高危预警人数”占比一目了然。
-
精准施策: 班主任可以一键导出自己班的“轻微波动型”名单,把问题扼杀在摇篮里;对于“自律模范型”则可以作为学期末评优评先的数据佐证,彻底告别“凭感觉管理”。
第四部分:踩坑必看(血泪防坑指南)
常在河边走哪有不湿鞋,操作过程中遇到了两个巨坑,帮大家排个雷:
坑一:BI 散点图里“刺头学生”竟然隐身了?
-
问题现象: 画 C3(纪律高危型)散点图时,发现那些极端离群点居然不显示!
-
问题原因: 助睿 BI 默认的展示限额是 2000 条,为了防卡顿,超出部分被悄悄截断了。
-
解决方法: 在图表右下角找到“限额”配置,果断把“2000”改成“100%”,消失的高危点瞬间全部显形。
坑二:ETL 回写数据时疯狂报错“类型不匹配”?
-
问题现象: 在最后一步做“更新”组件写回数据库时,点击运行后日志里飘红,提示
student_id无法关联或更新失败。 -
问题原因: K-Means 跑出来的结果表里,
student_id会被系统默认为浮点型(Float)或者字符串,但咱们最开始的 MySQL 原表里,student_id是整数型(Integer)。类型不同,数据库自然拒绝相认! -
解决方法: 在 ETL 连线中,必须加一个“字段选择”组件。点开它的“元数据”页签,手动把
student_id的类型强制转成Integer。这步千万不能省,血泪教训!
坑三:K-Means 跑出来的结果完全无规律?
-
问题现象: AI Studio 里点击运行 K-Means 后模型是跑通了,但去 BI 里看散点图,发现簇跟簇之间完全混在一起,毫无区分度。
-
问题原因: 这是新手最容易踩的坑——把学号、班级ID甚至学生姓名当成数值喂给模型了!K-Means 是靠算“距离”来分类的,如果你把“学号 202301”和“学号 202302”的差值当成考勤差距,模型当场就得“精神分裂”。
-
解决方法: 倒车回到“数据库加载”组件!一定要把非考勤特征的字段无情过滤掉,把学号和班级设为
categorical(类别型)或者skip,只留下四个考勤次数为numeric(数值型)。干干净净的数据,才能喂出好模型!
第五部分:实验总结
1. 满载而归的收获
这次实验真的是打通了我的任督二脉:
-
AI原来可以这么简单: 以前觉得跑 K-Means 要写一堆 Python 和 Pandas 代码,现在发现通过合理的零代码拖拽,数据降维分群也是分分钟的事。
-
业务Sense的建立: 懂得了机器吐出的冰冷代号(C1/C2)是没有价值的,必须结合 BI 散点图把它们翻译成“人话”(自律型/高危型),才是数据分析师的真正价值。
-
工程闭环思维: 跑完模型不算完,得把结果通过 ETL 变回业务字段存进数据库里,这叫“让数据回流业务”,太实用了!
2. 对平台的真香评价
必须吹一波 助睿数智(Uniplore) 这个平台,体验极其丝滑! 把 AI 建模、BI 报表和 ETL 清洗三大金刚完美柔和在了一个系统里。不用搞什么本地环境配置,也不用在多个软件之间倒腾数据导入导出。作为数据分析人员,我们可以把 90% 的脑容量用来思考“业务逻辑怎么建”,剩下的脏活累活全交给平台的“零代码”去跑就行了,极大地降低了数据科学的门槛,这波真的是闭眼入、疯狂点赞!
全文完,整理不易,如果你觉得有帮助,别忘了点赞收藏哦~

一站式 AI 云服务平台
更多推荐

 1
1 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)