
爆肝整理!保姆级教程:零代码搞定高校考勤画像可视化分析(K-Means聚类 + 双重对照组设计+ 炫酷BI大屏)
数据不只是用来看的,更是用来驱动决策的(DDDM)!基于精准的用户画像洞察,本报告彻底抛弃了“大锅饭”式的传统管理,为校方量身定制了针对高年级男生、老校区通勤优化以及特定薄弱班级的“网格化精准滴灌”干预策略。无论你是想拿下高分的数据分析小白,还是想提升业务思维的职场人,这篇实战总结都将为你彻底打通数据可视化的任督二脉!
同样是做学生考勤管理,为什么有的人只能每天对着Excel里的“迟到/早退”记录头疼,而有的人却能用一张炫酷的BI数据大屏,直接揪出背后的“纪律高危人群”,甚至精准定位到具体班级和群体特征?
今天,我将带大家硬核上手,基于真实的脱敏考勤数据,用全程零代码的方式,完成一次堪比专业数据分析师的“考勤画像可视化分析”。小白也能轻松复现,建议先收藏再看,以防找不到!
第一部分:实验背景(我们在解决什么问题?)
1. 实验目的:精准“捕获”纪律高危群体
基于前期已经完成 K-Means 聚类打标的学生数据,本次实验我们将拿着放大镜,专门盯住“纪律高危型”这个群体。 他们高频违纪、多维异常叠加,是校园管理的“定时炸弹”。我们要通过可视化的手段,把这群人的性别倾向、年级分布、校区差异、班级聚集度扒得一干二净,用数据教他们做人(划掉),为学校的精准干预提供铁证!
2. 实验环境与工具
-
神仙平台:助睿数智(Uniplore)一站式数据科学实验平台。这里强烈安利,它把数据接入、ETL、机器学习到可视化全包了,纯小白也能靠“拖拉拽”起飞。
-
平台传送门:https://lab.guilian.cn/
-
产品官网:https://www.uniplore.com/
-
弹药库(数据源):student_attendance_stats (学生考勤主题标签表,内含上万条多维脱敏数据)。
3. 实验数据(我们手里到底有什么牌?)
本次实验的核心“弹药”是存放在团队私有数据库中的 student_attendance_stats(学生考勤主题标签表)。这张表不仅包含了学生的脱敏基础信息,还汇总了他们各个维度的考勤指标,以及前期算法打上的“考勤群体分类”标签。总数据量过万条。
1️⃣ 核心数据表结构:
|
字段名 |
字段类型 |
中文释义 |
|---|---|---|
|
id |
int |
自增主键 |
|
student_id |
int |
学生ID |
|
student_name |
varchar(50) |
学生姓名(已脱敏) |
|
class_name |
varchar(50) |
班级名称 |
|
grade |
varchar(10) |
年级(如高一、高二) |
|
gender |
varchar(10) |
性别 |
|
campus_type |
varchar(10) |
校区类型(老校区/新校区) |
|
late_count |
int |
迟到次数 |
|
early_leave_count |
int |
早退次数 |
|
leave_count |
int |
请假次数 |
|
uniform_violate_count |
int |
没穿校服次数 |
|
cluster |
varchar(10) |
聚类簇编号(前期机器学算法产出) |
|
attendance_group |
varchar(30) |
考勤群体分类(本次分析的核心靶点) |
2️⃣ 真实脱敏数据长什么样?(样例瞥一眼):
|
id |
student_id |
student_name |
class_name |
grade |
gender |
campus_type |
late_count |
leave_count |
cluster |
attendance_group |
|---|---|---|---|---|---|---|---|---|---|---|
|
1 |
10842 |
马某某 |
高三(09) |
高三 |
未知 |
老校区 |
1 |
3 |
C3 |
纪律高危型 |
|
2 |
10844 |
叶某某 |
高三(09) |
高三 |
未知 |
老校区 |
0 |
5 |
C3 |
纪律高危型 |
|
3 |
10845 |
孙某某 |
高三(09) |
高三 |
未知 |
老校区 |
3 |
0 |
C3 |
纪律高危型 |
📌 点评:有了这些多维度的特征数据,我们就能像捏泥人一样,在 BI 平台里把高危群体的画像精准捏出来!
4. 处理流程(全局视野,不迷路)
在动手之前,先给大家上个干货满满的全局架构图。跟着这张图走,逻辑绝对清晰:
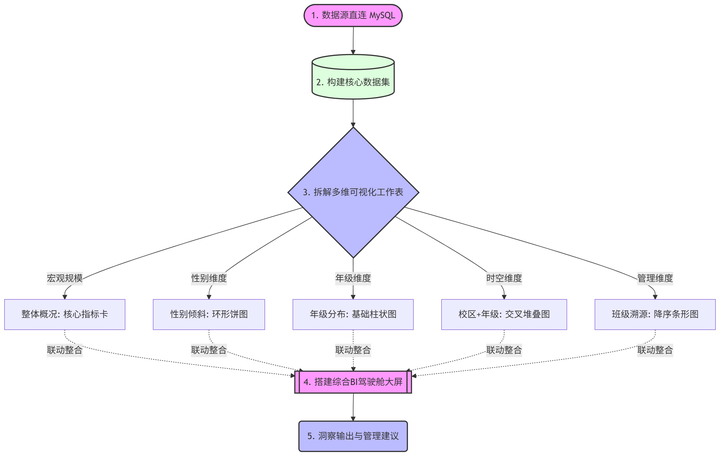
第二部分:保姆级实验步骤(跟着做,必成!)
准备好了吗?我们要开始“大闹”数据源了!👇
🛠️ 步骤 1:突入助睿BI大本营
登录助睿实验平台后,目光锁定左侧菜单栏,点击“助睿BI”。
在首页,你可以像指挥官一样俯瞰当前账户的数据资产和处理流程。
🛠️ 步骤 2:秒连数据源
得益于我们在上一个实验(上次实验的链接)中已经打通了团队私有 MySQL 数据库的连接,student_attendance_stats 这张表已经就位。这一步我们直接白嫖之前的数据源,免去了繁琐的配置。
🛠️ 步骤 3:构建专属数据集
要想让图表听话,得先给数据立规矩,也就是构建“数据集”。
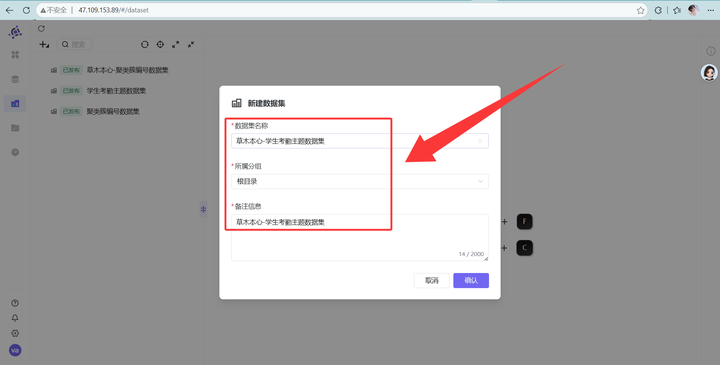
1. 点击左侧“数据集” -> 点击左上角 “+ 新建数据集”。
2. 给它起个响亮的名字(比如:学生考勤主题数据集),选好分组,点击确认。
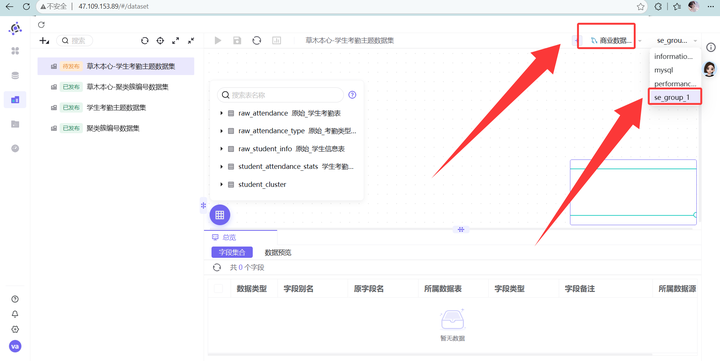
3. 划重点:在配置页面,第一个下拉框选中我们的私有数据源,第二个选择 se_group_1 目录。
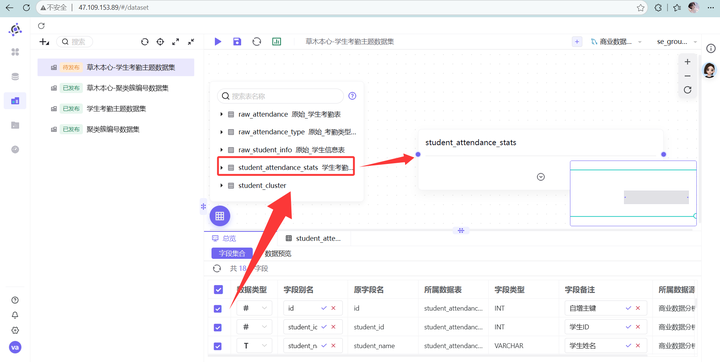
4. 将左侧栏里的 student_attendance_stats 表,优雅地拖拽到中间画布。
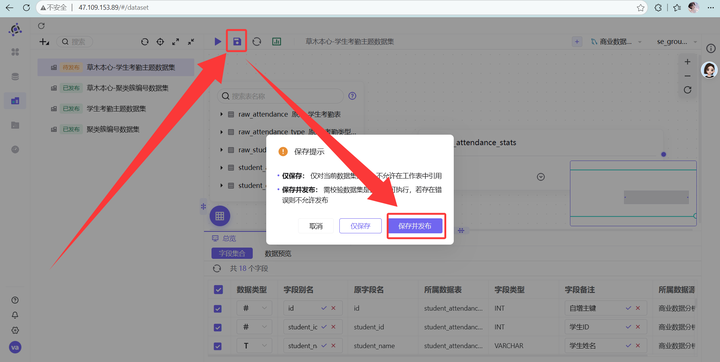
5. 点击左上角“保存” -> “保存并发布”。搞定!
🛠️ 步骤 4:爆肝制作可视化图表(前方高能 🚀)
这是最硬核的部分,我们要通过5个维度,把高危群体彻底剥析!建议先建个分组叫“学生考勤主题分析”。
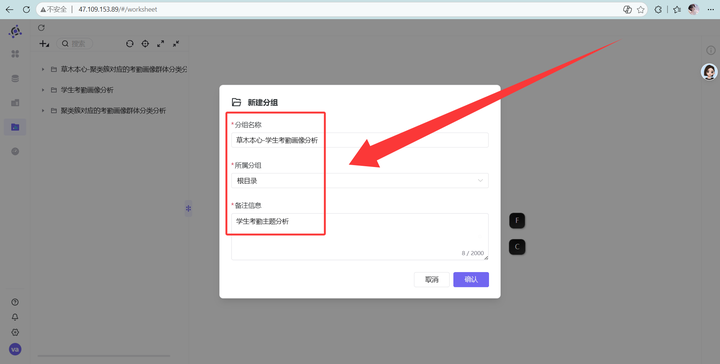
⚔️ 维度一:整体概况(他们到底有多少人?)
我们需要做4张高颜值的指标卡,瞬间摸清敌情。
-
新建工作表,命名“自律模范型人数”
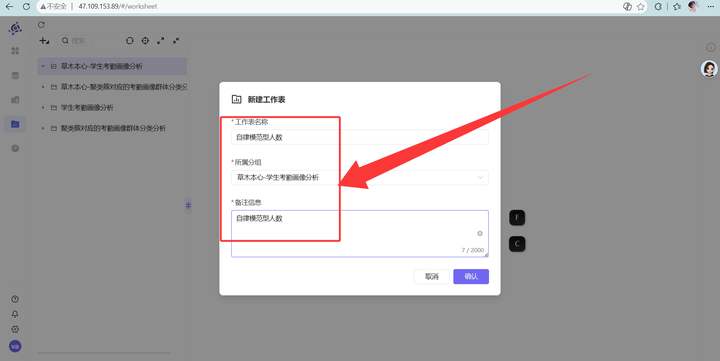
选好刚才发布的数据集。
2. 图表类型选择“指标卡”。
3. 把 student_id 拖到“值”区域,聚合类型毫不犹豫地改为“去重计数”(保证人数不重复)。
4. 灵魂操作(过滤器):在过滤器处点击“+”,选择 attendance_group(考勤群体分类)
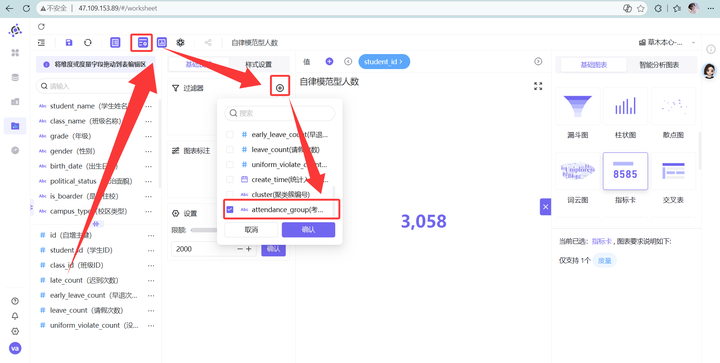
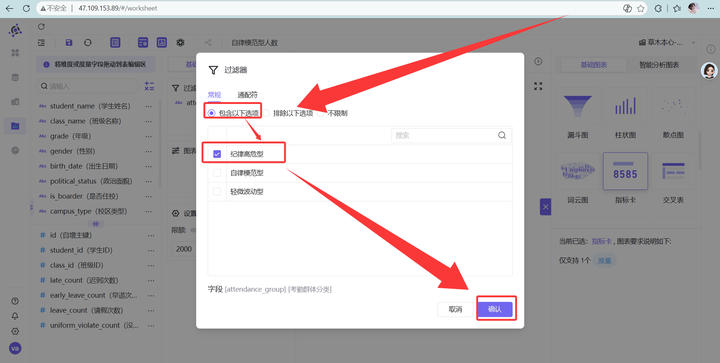
设为“包含: 纪律高危型”(同理也可看自律模范型)。
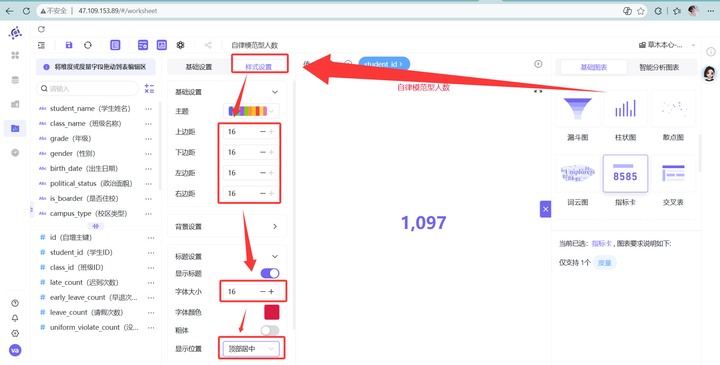
5. 颜值即正义:进入“样式设置”,边距拉满到16,标题调成红色/16号/顶部居中,数值调成红色/30号/加粗。霸气侧漏!
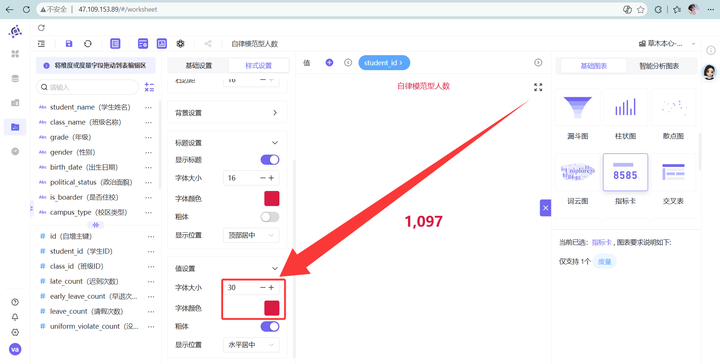
6. 选择保存->保存并发布
7. 举一反三(制作另外3张细分指标卡):有了总人数,我们再如法炮制另外三张。分别新建工作表“高危型男生人数”、“高危型女生人数”、“高危型未知性别人数”。唯一的区别是:在图表的过滤器中,再多加一层对 gender(性别)字段的筛选,分别勾选对应的“男”、“女”或“未知”即可轻松搞定!
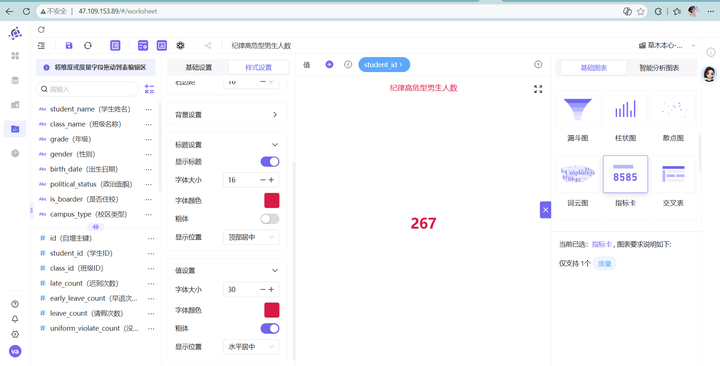
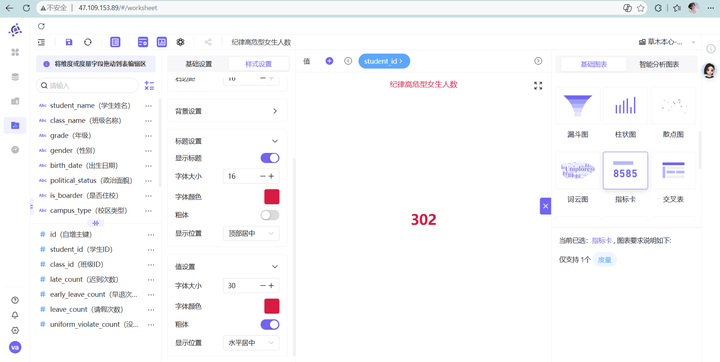
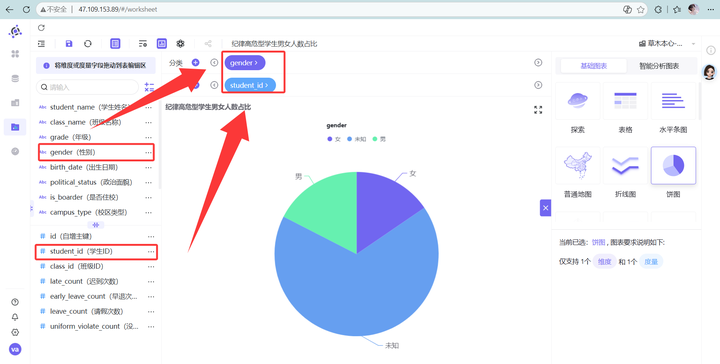
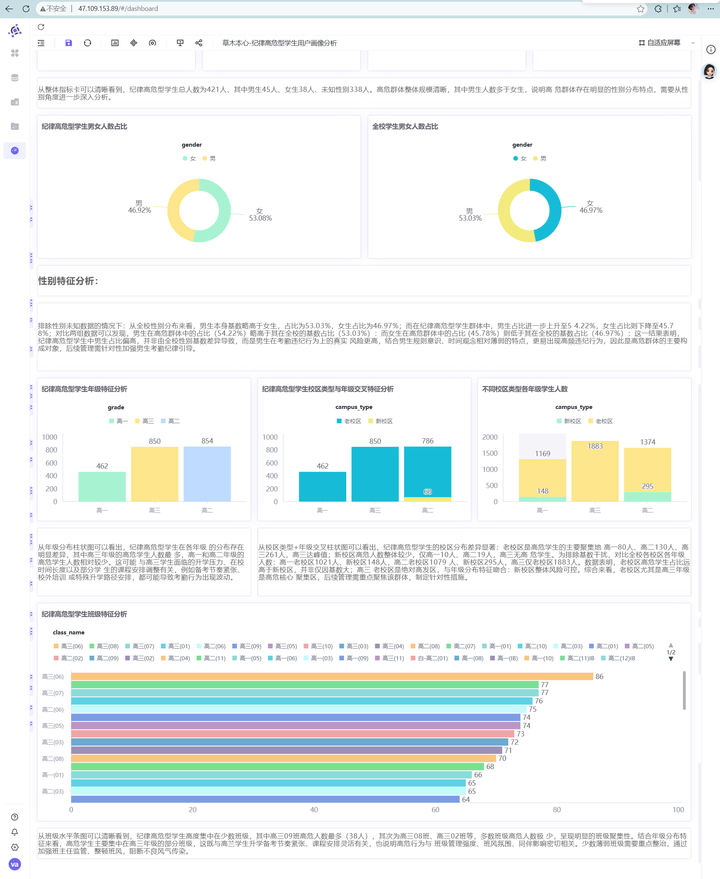
💡 维度一数据深度洞察(宏观基本盘): 从这四张高亮指标卡中,我们能一眼看清战场全貌: 全校纪律高危型学生总人数为 421 人。虽然占万名总人数的比例可控,但这 421 人的高频、多维考勤违纪行为会严重侵蚀正常的班学风。 在已知性别的学生中,男生为 45 人,女生为 38 人。 初步业务洞察:在已知性别的纪律高危学生中,男生人数明显多于女生。这初步勾勒出了高危人群的性别倾斜轮廓。但是,这真的是因为“男生更容易考勤违纪”吗?还是说仅仅是因为这所学校里男生本来就特别多,基数大导致的?我们必须引入“对照组饼图”,进行无情地求证!
⚔️ 维度二:性别特征(男生更皮,还是女生更野?)
1️⃣ 纪律高危型学生男女人数占比(高危靶点)
-
新建工作表“纪律高危型学生男女人数占比”
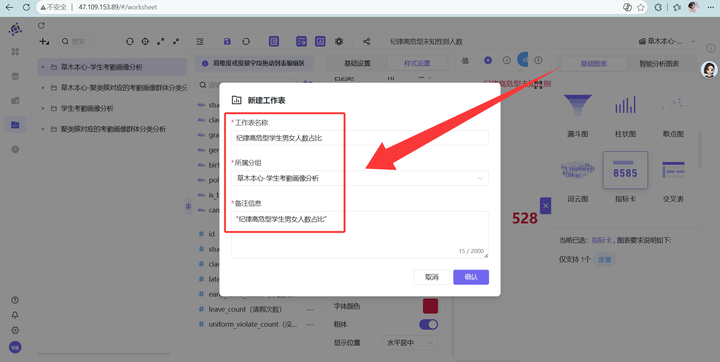
选“饼图”。
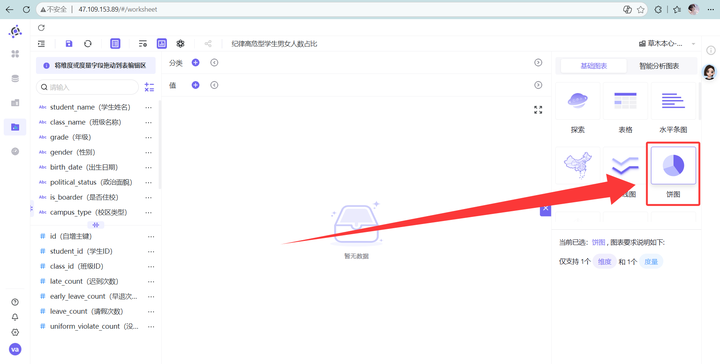
2. student_id (去重计数) 拖入值,gender 拖入分类。
3. 避坑指南:记得在过滤器里,排除 gender 为“未知”的数据
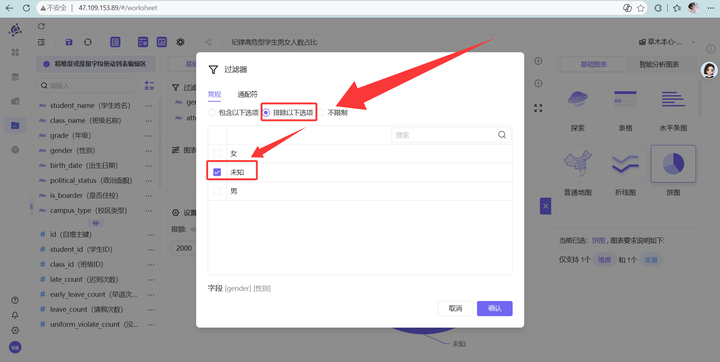
并锁定群体为“纪律高危型”,否则比例会严重失真!
4. 进入图表元素设置,开启“百分比标签”
内环大小设为 50%
并设置一个好看的主题色,一个极具现代感的环形饼图就诞生了。
5. 点击“保存”按钮,“保存并发布”工作表
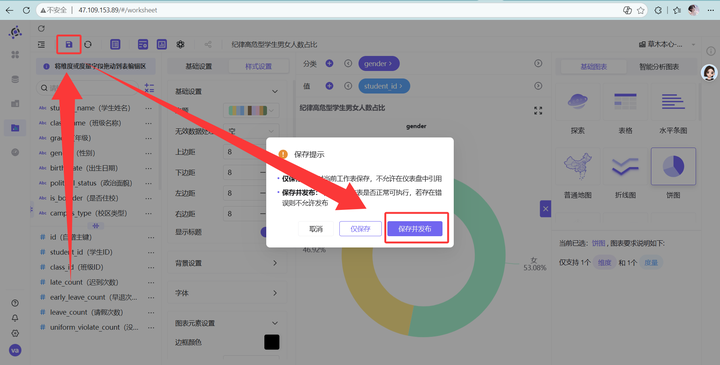
2️⃣ 全校学生男女人数占比(全校大盘对照组) 我们需要看清全校真实的“人口底色”:
-
新建工作表,命名为“全校学生男女人数占比”,同样选择“饼图”。
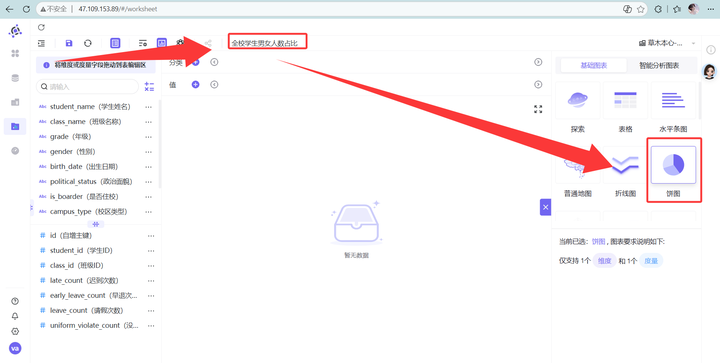
2. student_id (去重计数) 拖入值,gender 拖入分类。
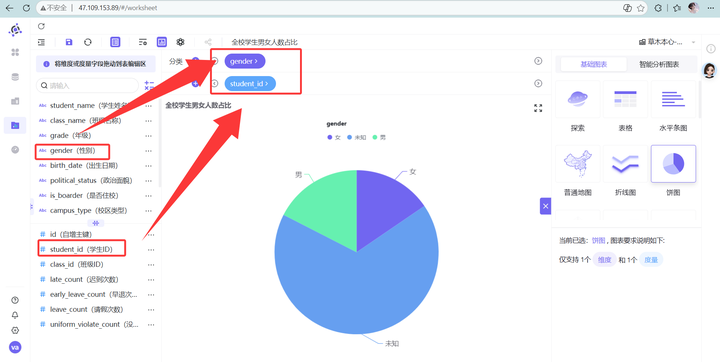
3. 关键差异:这次我们过滤器里只保留排除 gender “未知” 的条件,绝对不要添加 attendance_group 的过滤条件!
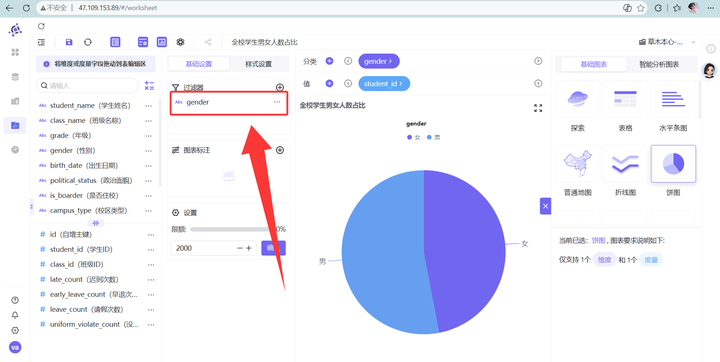
4. 样式设置与高危型饼图保持一致,保持视觉美观。
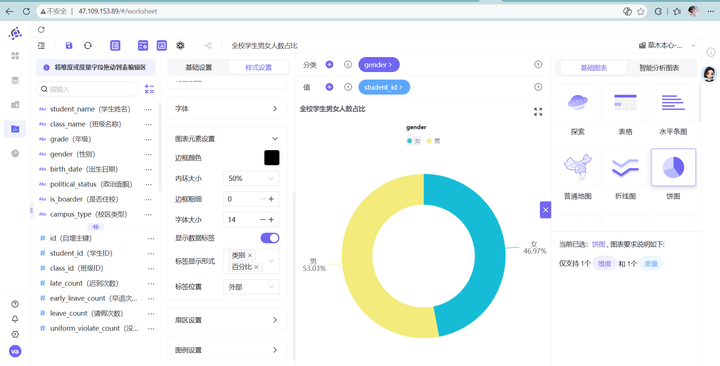
💡 维度二数据深度洞察(性别特征剖析): 让我们把这两张精美的环形图放在一起,进行硬核的数据“对线”: 深入分析:对比发现,男生在高危群体中的占比(54.22%),明显高于其在全校的基数占比(53.03%),高出了近 1.2 个百分点;相反,女生在高危群体中的占比(45.78%),则低于其在全校的基数大盘比例(46.97%)。 结论:这一实锤的数据对比表明,高危群体中男生偏多绝对不是因为全校男生人多,而是因为在真实的考勤场景下,男生的违纪风险确实显著高于女生!男生在时间观念、规则意识、学校规章制度的自我约束上相对较弱,后续学校的纪律引导课,必须针对男生进行定点突破。
⚔️ 维度三:年级特征(哪个年级最难管?)
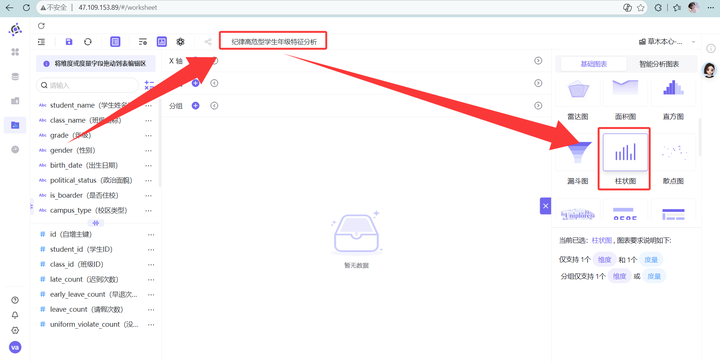
-
新建工作表“纪律高危型学生年级特征分析”,选“柱状图”。
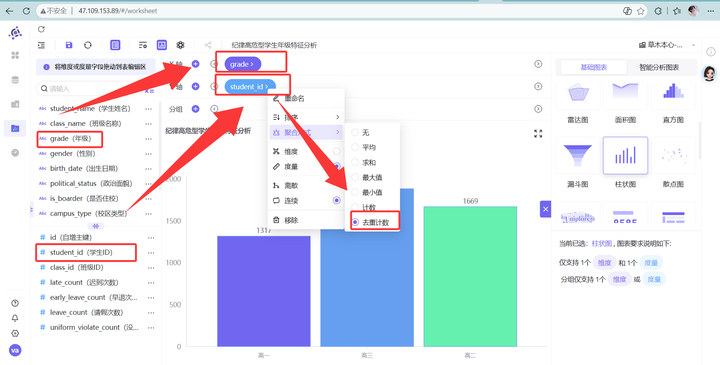
2. X轴放 grade,Y轴放 student_id (去重计数)。
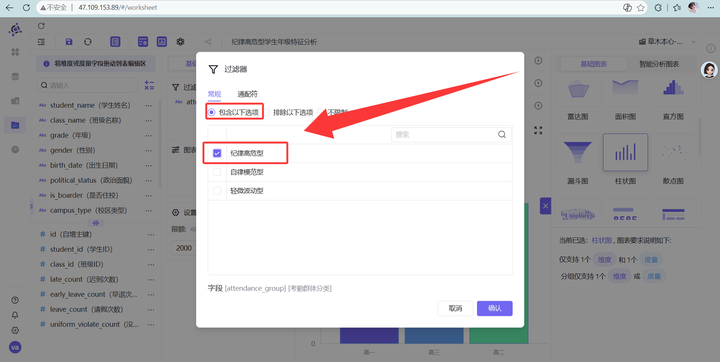
3. 过滤器同样死死锁住“纪律高危型”。
4. 一键去除边框,统一UI色调,保存发布。
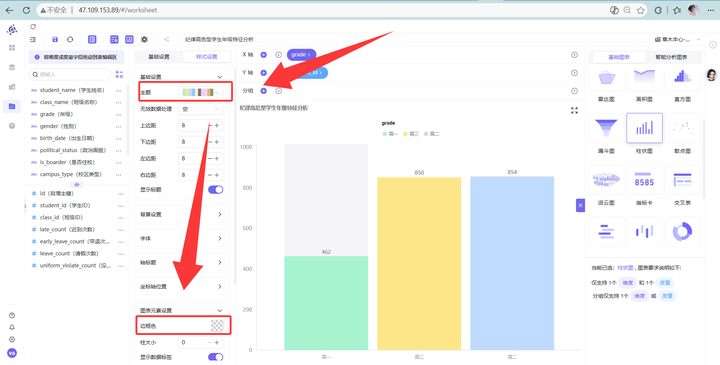
💡 维度三数据深度洞察: 柱状图呈现极其强烈的“长尾特征”:高三年级的高危学生人数呈断层式遥遥领先,而高一、高二年级的高危人数则极少,甚至可以说是“岁月静好”。 结论:高危考勤违纪行为在年级维度上呈现“越往高年级,违纪风险越高”的惊人规律。这与我们日常的直觉相符——高三学生由于面临着极为严苛的备考压力,备考节奏极其紧张。部分学生可能存在校外特殊培训、特殊升学路径调整、甚至是因为升学无望而产生浮躁、摆烂等心态,导致考勤行为在最后一年出现大面积脱轨。管理层应当对高三考勤给予针对性弹性和精准监控。
⚔️ 维度四:时空交叉(新校区 vs 老校区)
单一维度看腻了?我们来个降维打击——交叉分析。
-
新建工作表“纪律高危型学生校区类型与年级交叉特征分析”并选择柱状图
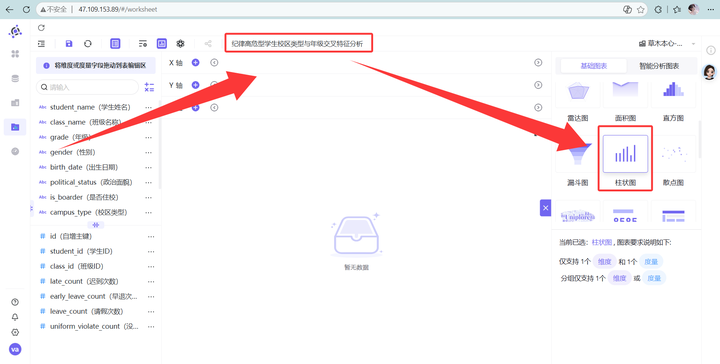
2. 参考“纪律高危型学生年级特征分析”的步骤,先完成纪律高危型学生年级分布柱状图
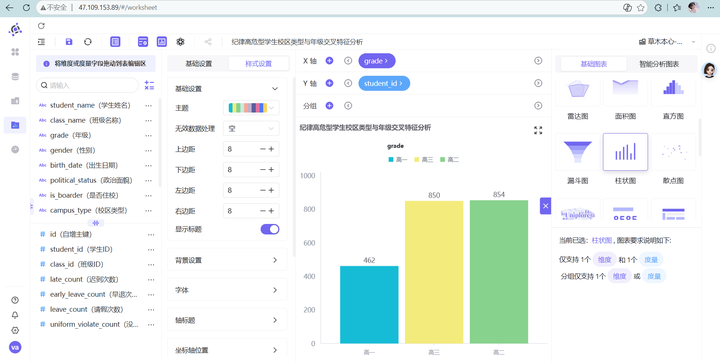
3. 接下来把 campus_type(校区类型)拖拽到“分组”槽位。见证奇迹的时刻:普通的柱状图瞬间变成了信息量爆棚的堆叠柱状图。老校区和新校区的差距一览无余!
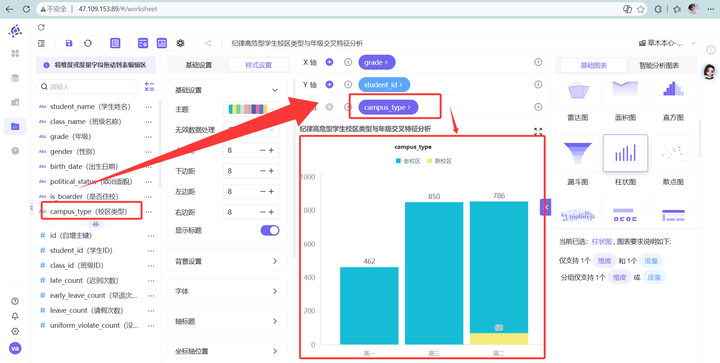
4. 点击“保存”按钮,“保存并发布”工作表
不同校区类型各年级学生人数工作表(全校大盘对照组)
为了彻底查明老校区违纪学生多,究竟是因为“老校区本身人满为患”,还是因为“老校区的管理氛围更容易出问题”,我们需要做全校大盘的时空堆叠对照图!
-
新建工作表,命名为 “不同校区类型各年级学生人数”。图表类型同样选择“柱状图”。
2. 数据配置:X轴拖入 grade,Y轴拖入 student_id(去重计数),分组拖入 campus_type。
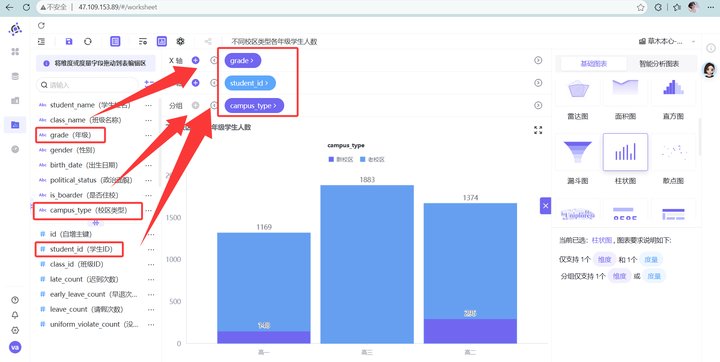
3. 对照核心点:不添加任何过滤器字段!让全校各个班级、所有类型学生的时空分布在大盘图上原形毕露。
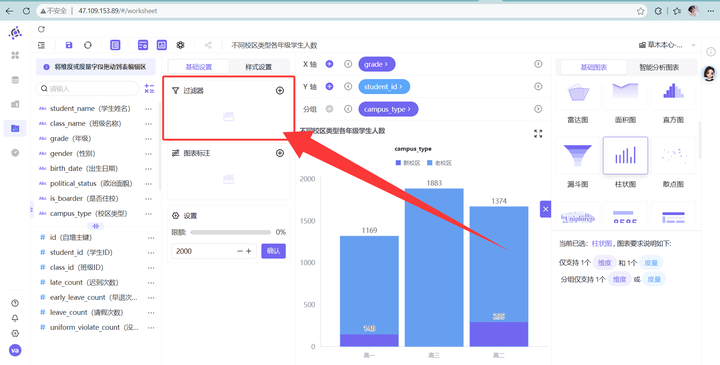
4. 样式设置选一个好看的~~
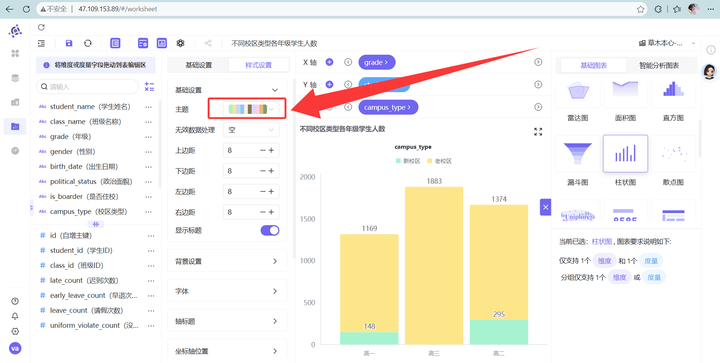
5. 保存并发布。
💡 维度四数据深度洞察(时空双向对碰): 让我们来做一次教科书般精细的数据对碰分析: 高一:全校大盘中老校区 1021 人,新校区 148 人(老校区是新校区的 6.9 倍)。而在高危群体中,老校区高一 80 人,新校区 10 人(比例为 8 倍)。老校区略高,基本符合人口比例。 高二:全校大盘中老校区 1079 人,新校区 295 人(老校区是新校区的 3.6 倍)。但在高危群体中,老校区高二 130 人,新校区 19 人(比例飙升至 6.8 倍!)。这证明老校区高二学生的实际违纪风险已经开始偏轨。 高三:全校大盘中老校区 1883 人,新校区为 0 人(高三全部集中在老校区)。对应的高危人数也全部堆积在老校区,高达 261 人! 结论:新校区整体风险极度受控,这可能得益于新校区更具现代化的封闭式管理、更便利的校内住宿通勤和崭新的治学氛围。而老校区是考勤违纪的绝对高危温床。由于老校区可能存在通勤堵车、周边娱乐设施较多、老旧设施干扰等问题,叠加高三毕业班焦虑,导致高三老校区成为高危违纪的重灾区。管理力量和打卡硬件应当重点向老校区倾斜!
⚔️ 维度五:班级溯源(擒贼先擒王)
到底哪个班是“重灾区”?
-
新建工作表“纪律高危型学生班级特征分析”,选“水平条图”。
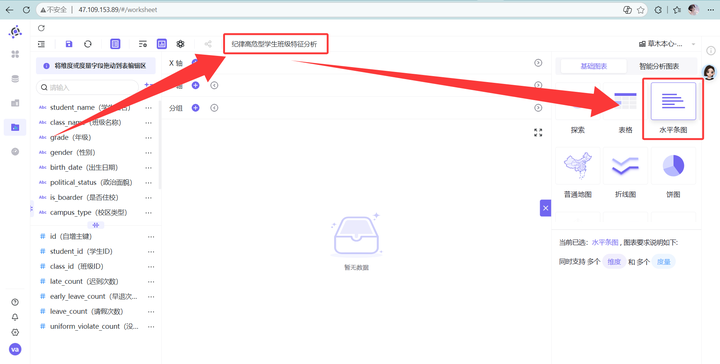
2. Y轴 class_name,X轴 student_id (去重计数)。
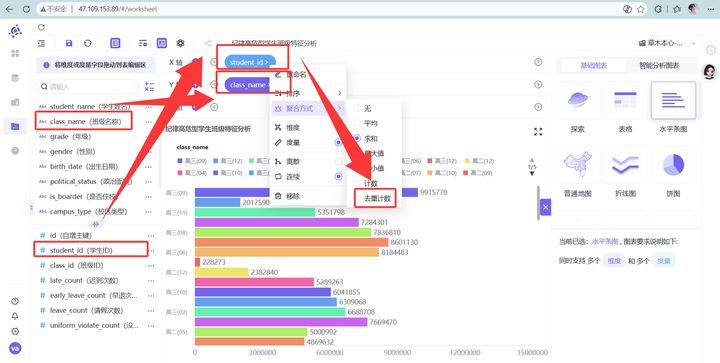
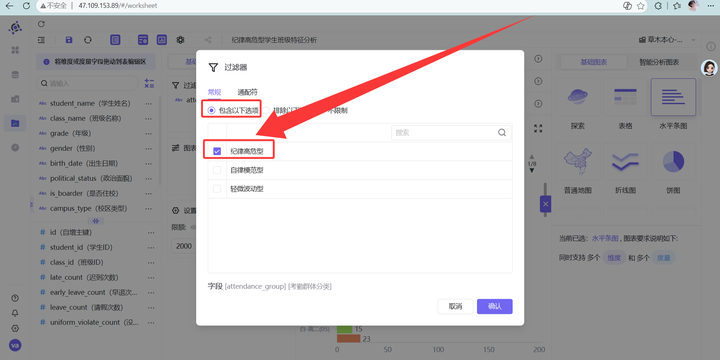
过滤“纪律高危型”。
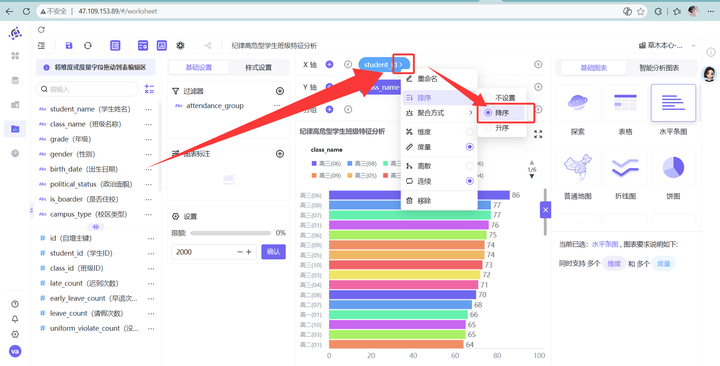
3. 关键一步:对人数进行降序排列。排在最上面的那几个班,班主任可能要被请喝茶了。
4. 点击样式设置,将主题色设置为一个好看的~
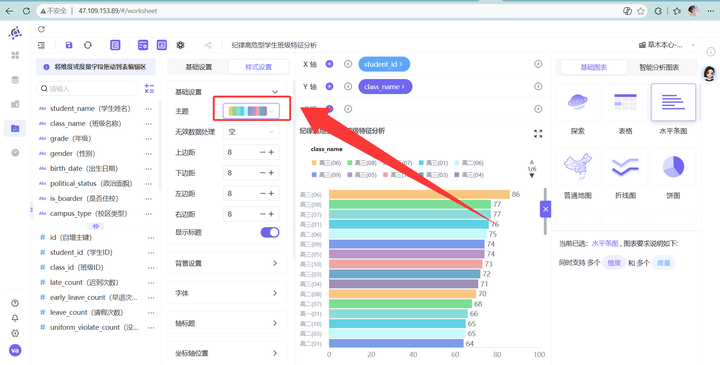
💡 维度五数据深度洞察(班级特征剖析): 极其强烈的聚集性(羊群效应):从条形图中我们可以震惊地发现,违纪高危学生并不是在全校各个班级零星、均匀散布的,而是高度、极度聚集在极少数薄弱班级中! 具体数据:高三(09)班独占 38 名高危学生,位列全校第一;紧随其后的是高三(08)班、高三(02)班等。而学校绝大多数班级的高危人数仅为零星几人甚至为零。 结论:这一特征证实了校园违纪行为存在极强的“同伴效应”与班级传染*。当一个班级班风开始松懈、班主任监管缺失时,不良风气会迅速蔓延,导致群体性脱轨。抓班风、盯班主任、阻断不良风气的传染,是消灭高危人群成本最低、成效最快的策略。
🛠️ 步骤 5:终极大招——搭建BI驾驶舱
零散的图表就像一盘散沙,我们要把它们组装成一台“数据超跑”。
-
进入左侧“仪表盘”,“+ 新建仪表盘”,命名“纪律高危型学生用户画像分析”。
2. 拽一个“文本组件”当大屏的炫酷Title,字号拉大,加粗居中。
3. 从“工作表”列表里,把刚才做的图表一个个拖进画布。
4. 化身UI设计师:调整大小,合理排版。可以在旁边再加几个文本组件写上你的分析结论。
5. 发布后可以点击分享,分享给其他人查看,准备迎接他们的膝盖吧!
复制结果如下,读者可以点击连接查看仪表盘 访问地址:Uniplore VA Studio
第三部分:实验结果(数据不会撒谎)
经过一番猛如虎的操作,我们成功输出了这份价值连城的《纪律高危型学生画像仪表盘》。 结合全校大盘数据做交叉验证,我们得出了以下几个令管理层“心跳加速”的结论:
-
群体真容:高危总计 421 人。男生不仅绝对数量多,排除基数差异后,其真实违纪风险依然显著高于女生。
-
风暴中心(时空特征):高危人群呈现极端的聚集性,老校区的高三年级(高达 261 人)简直是风暴中心,反观新校区则非常岁月静好。
-
羊群效应(班级特征):违纪并不是均匀分布的,而是高度集中在高三09班(38人)、08班等极少数班级,说明班风的“传染性”极强。
第四部分:防坑指南(问题与解决)
在实战中我踩过的坑,都给你们填平了:
❌ 踩坑 1:性别饼图比例诡异,加起来不到 100%?
-
深层原因:脱敏数据中混入了大量 gender = "未知" 的记录,它们作为分母稀释了真实男女比例。
-
破局之法:玩转过滤器。在图表设置中新增 gender 过滤器,选择【排除以下选项】并勾选“未知”。数据瞬间恢复正常。
❌ 踩坑 2:高大上的仪表盘,文字备注被残忍截断?
-
深层原因:助睿BI的文本组件默认开启了防溢出的“超出隐藏”功能,导致多行文本无法换行。
-
破局之法:选中该文本组件,在右侧属性面板里,果断关闭“超出隐藏”开关,长篇大论立刻服服帖帖地自动换行。
第五部分:实验总结(升华时刻)
💡 1. 认知颠覆:从“看数据”到“用数据驱动决策 (DDDM)”
在做这个项目之前,面对一万多条学生考勤记录,我眼中的数据只是一堆冰冷的数字。但通过这一整套“K-Means 聚类打标 + 多维可视化大屏”的组合拳,我真正体会到了什么叫数据驱动决策(Data-Driven Decision Making)。机器学习算法产出的标签仅仅是一个“黑盒结论”,而 BI 可视化大屏则是把黑盒彻底打开,将其转化为校领导和班主任能够一眼看懂的“管理作战地图”。
🧠 2. 核心分析思维进阶:“对照组思维”与“多维切片”
通过这次爆肝实战,我彻底打通了数据分析的任督二脉:没有对比,数据就没有灵魂。
-
排除幸存者偏差:当我们看到高危人群中男生占 54% 时,如果直接得出“男生更坏”的结论是非常业余的。只有当我们引入“全校大盘底色”(男生基础占比仅 53%)进行硬核对碰,才能科学地论证溢出风险。
-
时空交叉切片:单一维度的分析往往会掩盖真相。我们利用“校区 + 年级”的双堆叠交叉降维打击,精准洗清了新校区的“嫌疑”,把真正的暴风眼(老校区高三年级)给揪了出来。这种严谨的分析逻辑,是通往资深商业数据分析师的必经之路!
🎯 3. 业务反哺:技术如何真正赋能“精细化管理”
商业数据分析的终极目的从来不是为了画几张好看的图表炫技,而是解决真实的业务痛点。 通过这块大屏,学校的考勤管理可以直接从传统的“一刀切、全校通报”升级为“精准网格化滴灌”:不搞大锅饭,不搞连坐,而是把有限的巡逻保安和德育老师,直接精准投放给老校区的高三年级;把防微杜渐的班风整顿会,直接精准开到高三(09)班、(08)班的班主任头上。建立高危学生的一对一帮扶台账。这就是数据分析创造的巨大商业(管理)价值!
🌟 4. 平台体验与工具论:释放生产力,回归“商业思考”
最后,必须要给这次立下汗马功劳的助睿数智(Uniplore)平台送上最高级别的安利! 过去我们要实现这样的分析,需要耗费大量时间去写 Python(Pandas清洗数据 + Matplotlib绘图代码),或者写长篇大论的 SQL 甚至还要手搓前端组件,单单是排查环境报错和 Bug 就能让人崩溃。 但在助睿 BI 里,我深刻体验到了什么是“数据平权(Data Democratization)”:
-
真正的全链路零代码:全程只靠鼠标拖拽、点选多重过滤器,就能极其丝滑地完成复杂的数据清洗和对照组拼接,所见即所得。
-
大厂级的视觉美学:图表之间的联动、内环百分比的展示、边框留白设计,非常符合现代商业驾驶舱的高级审美标准。
-
敏捷交付的效率神话:一键生成分享链接,极大地降低了团队协作与学术成果交付的门槛。 助睿这样的 Agile BI(敏捷BI)工具,把打工人和学生党从枯燥繁杂的代码中彻底解放了出来,让我们能把 80% 的精力花在业务思考和商业洞察上。强烈推荐每一个学习商业数据分析的朋友前去白嫖探索!
✍️ 写在最后: 爆肝排版、画图、写结论不易,如果这篇充满了“对照组商业思维”和“避坑干货”的保姆级教程帮到了你,别忘了点赞、收藏、关注三连支持一下!有任何问题我们在评论区不散,一起探讨数据之美!👇👇👇

一站式 AI 云服务平台
更多推荐
 1
1 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)