
学生用户画像-考勤主题扩展标签构建实验报告
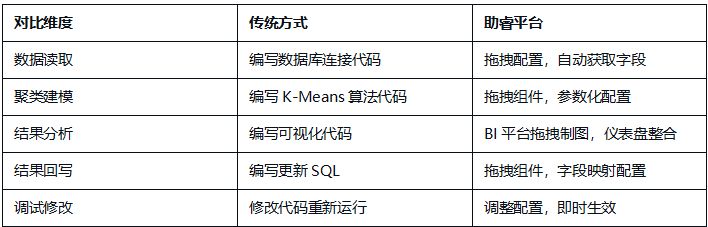
相比传统编写Python代码进行聚类分析的方式,助睿平台提供了完整的零代码解决方案:本实验为后续更复杂的机器学习场景(如分类预测、时序分析、异常检测等)奠定了良好的基础。附录K-Means聚类参数配置详情见3.1.3节值映射配置详情见3.3.4节更新组件配置详情见3.3.5节。
学生用户画像-考勤主题扩展标签构建实验报告
1 实验说明
1.1 实验目的
基于已完成的学生考勤主题标签表(student_attendance_stats),使用K-Means聚类算法对学生考勤行为进行自动分群。具体目标包括:
-
通过迟到、早退、请假、校服违规次数等核心指标,识别不同类型的考勤群体;
-
生成可解释的考勤画像,为校园学生管理、行为分析提供精准数据支撑;
-
掌握助睿AI平台零代码机器学习建模的全流程操作。
1.2 实验环境
-
工具平台:助睿数智(Uniplore)在线实验平台(访问地址:https://lab.guilian.cn/)
-
本次实验使用以下功能子平台:
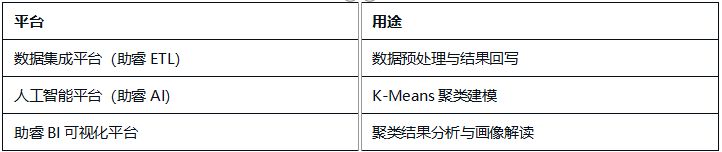
-
数据库:MySQL(团队私有数据库)
-
前置数据:学生考勤主题标签表(student_attendance_stats)
2 实验数据
2.1 数据构成
本次实验使用上一实验输出的学生考勤主题标签表,数据包含学生基础信息与考勤次数统计结果,为聚类建模提供干净、标准化的特征数据。
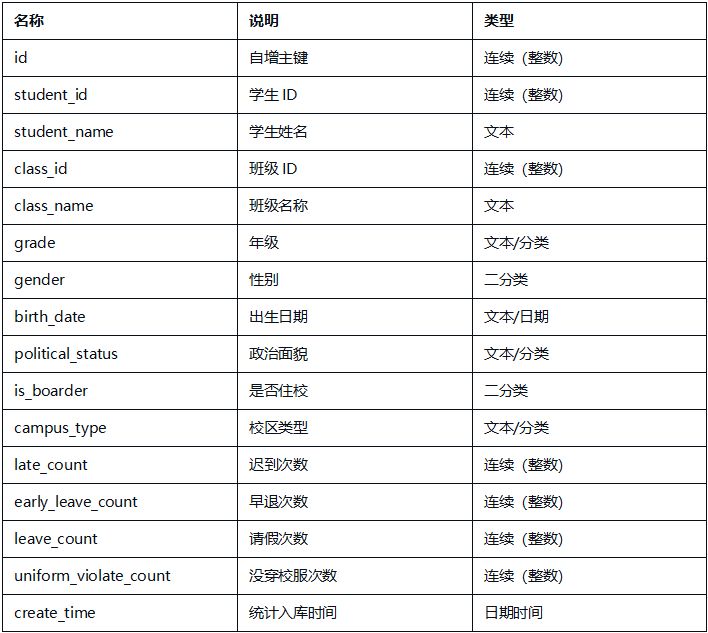
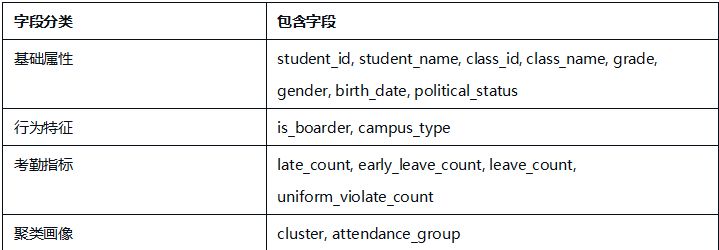
2.2 字段说明
2.3 建模思路
通过对数据的观察以及考勤分群的业务需求分析,确定本次建模思路如下:
2.3.1 变量选择聚焦考勤行为核心指标
基于考勤业务理解,将变量聚焦在四类行为维度:
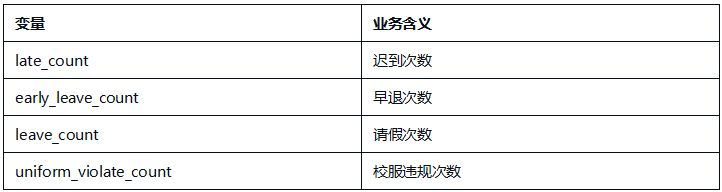
每个维度直接反映一类考勤特征,变量间业务含义独立、相关性低,可直接用于K-Means聚类建模,避免变量冗余导致模型解释困难。
2.3.2 数据类型适配算法要求
本次建模采用次数类连续变量,均为非负整数,满足K-Means对数据类型的要求,无需进行哑变量编码或特殊转换,可直接输入模型,简化预处理流程。
2.3.3 辅助变量不参与聚类
学生基础离散属性(性别、年级、住校状态等)不参与聚类建模,仅作为后续画像标签的辅助解释变量。
3 实验步骤
3.1 AI Studio聚类建模
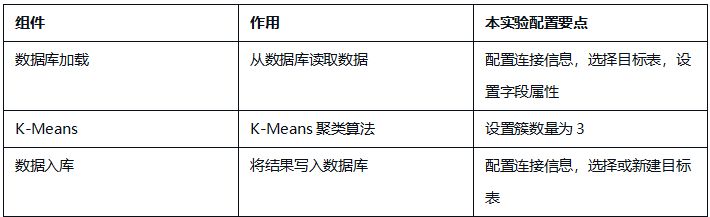
人工智能平台(AI Studio)是一站式大数据智能应用平台,以零代码拖拽的方式简化机器学习全流程,提供从数据加载、预处理、特征工程到模型训练与评估的完整解决方案。
3.1.1 新建工作流
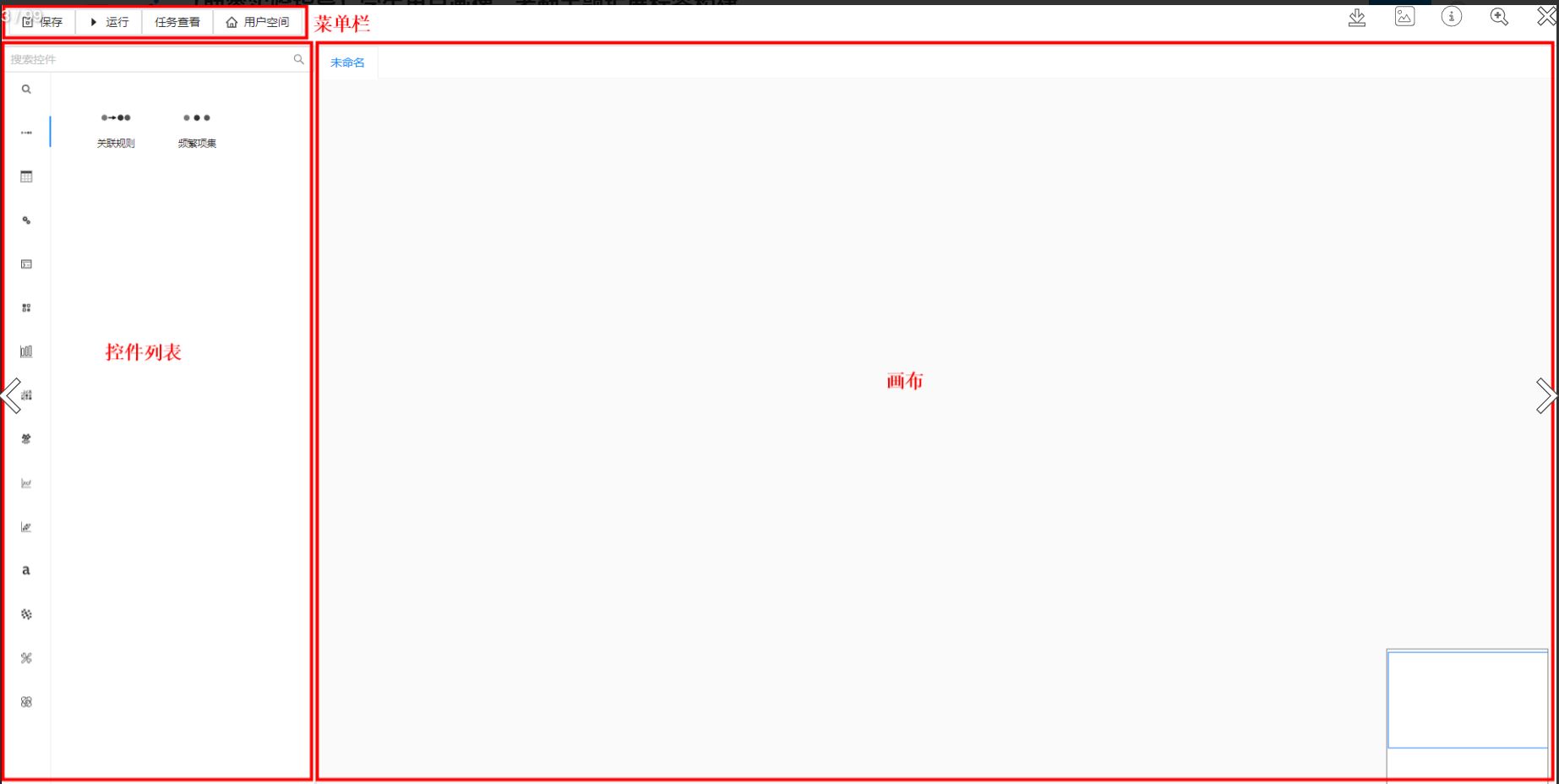
进入人工智能平台(AI Studio),点击【+】→【新建工作流】。
AI Studio页面主要包含三个模块:菜单栏、控件列表以及画布(用于工作流构建)。
3.1.2 数据导入
步骤1:拖拽“数据库加载”控件
搜索“数据库加载”控件,拖拽至画布。
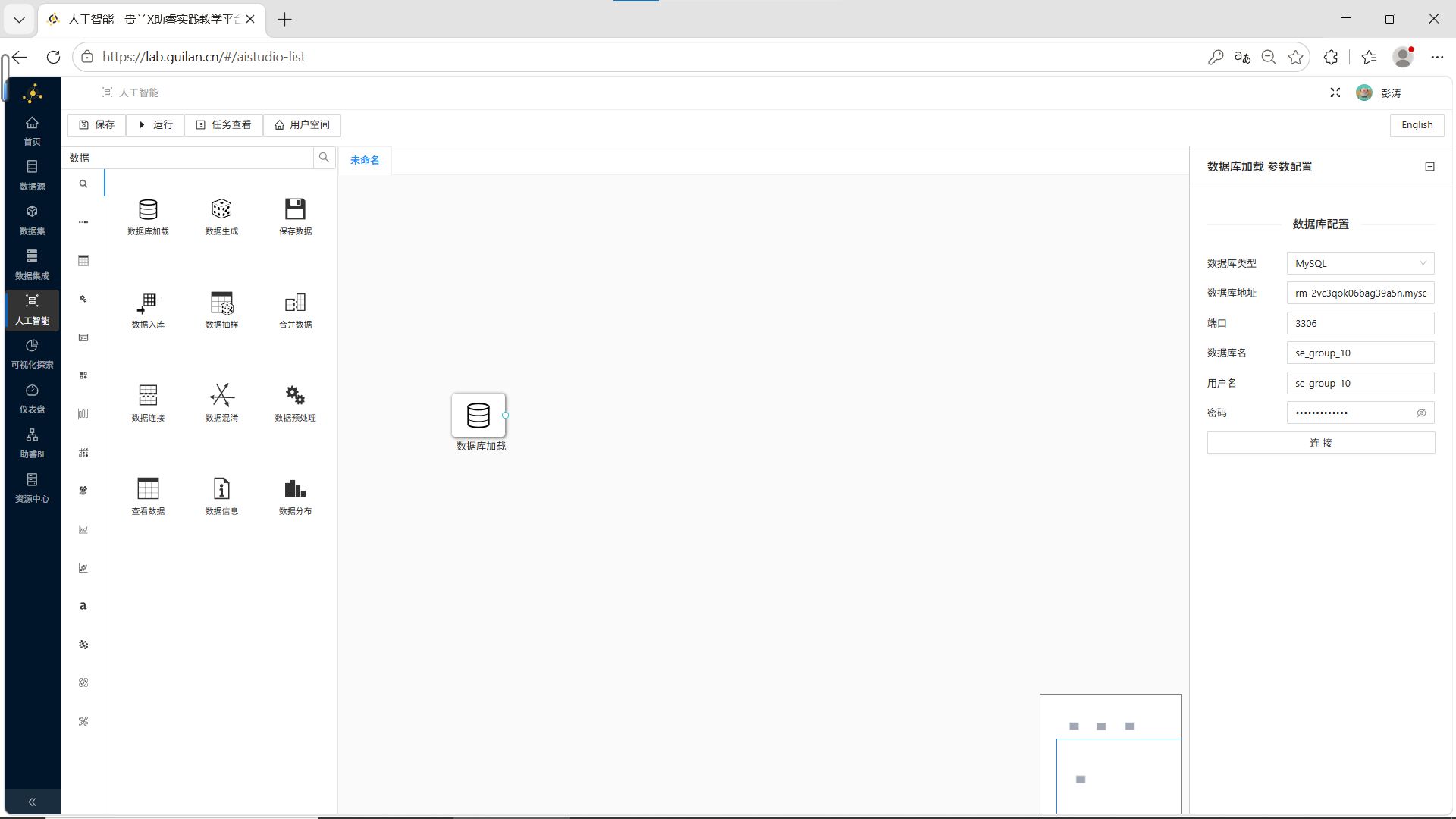
步骤2:配置数据库连接
双击控件,在右侧配置窗口中填写团队私有数据库连接信息,点击【连接】。
步骤3:选择数据表
在弹出的窗口中,选择 student_attendance_stats 表。
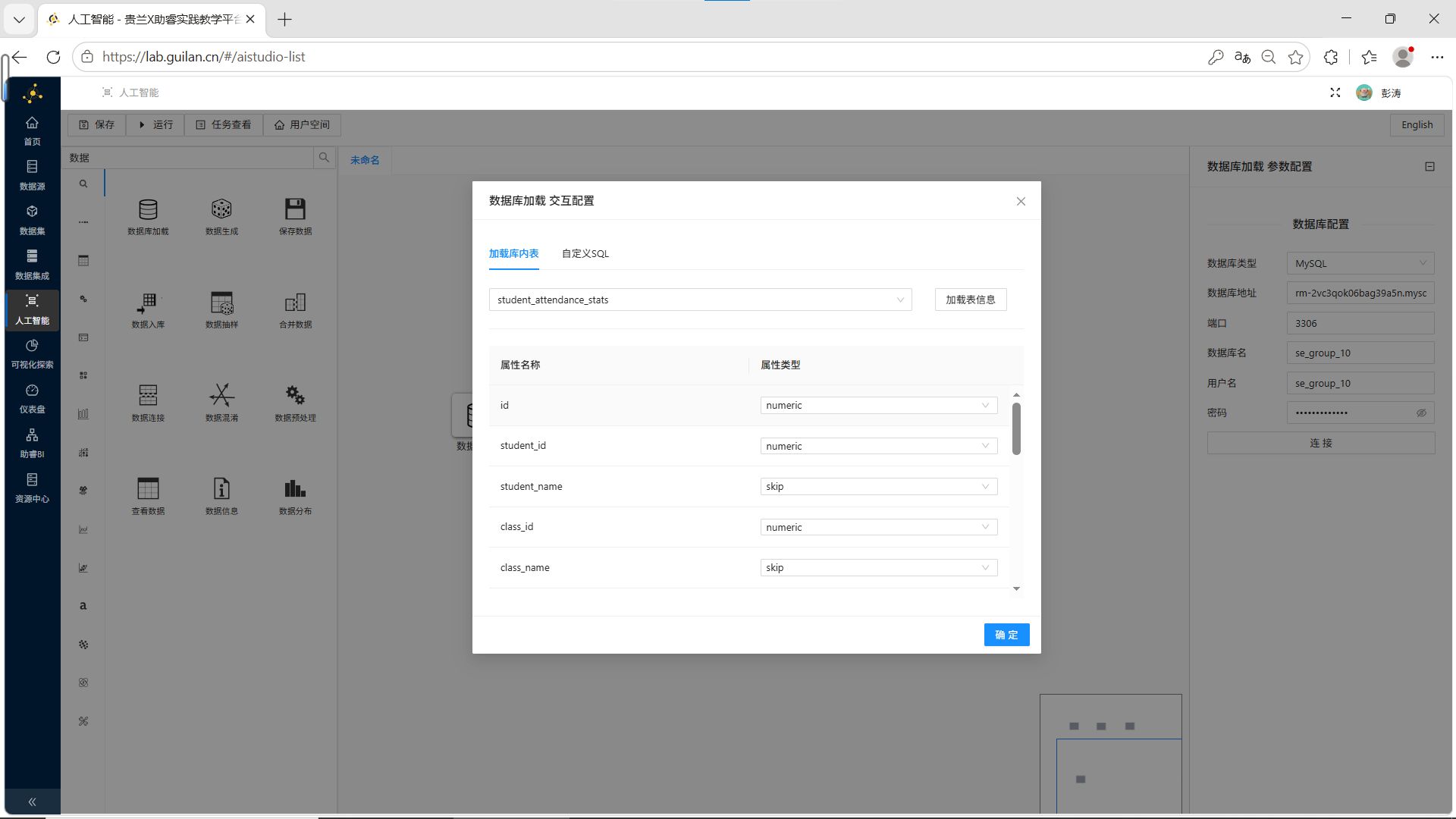
步骤4:字段选择与属性配置
选择后自动加载表信息。本实验主要分析各类异常考勤特征,字段配置如下:
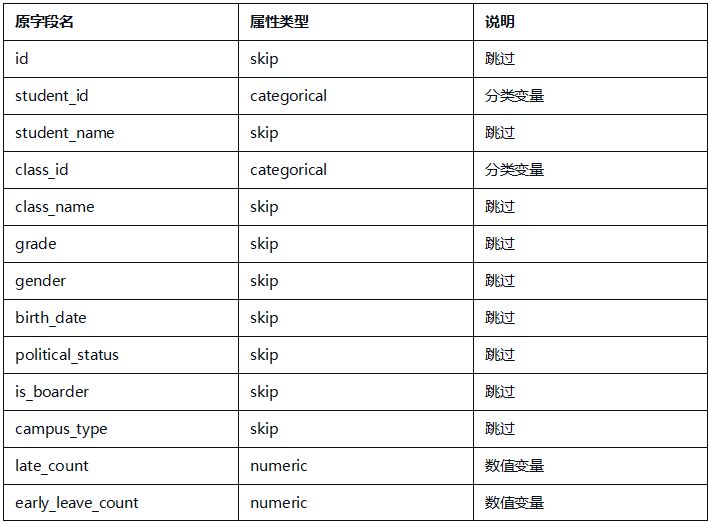

步骤5:运行并查看结果
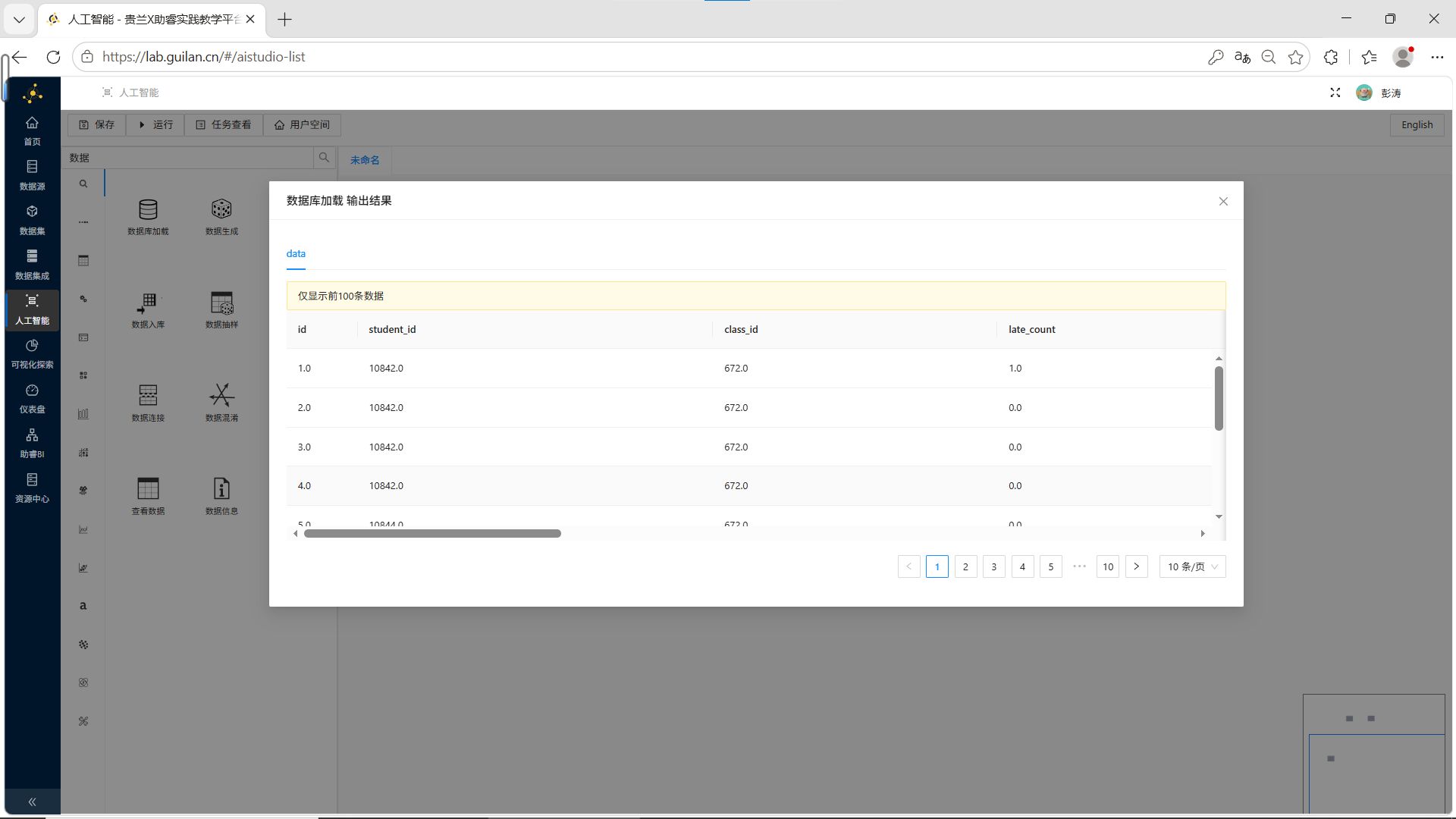
右键点击“数据库加载”控件,选择【运行该控件】。运行成功后,右键【查看输出结果】。
3.1.3 K-Means聚类建模
步骤1:添加K-Means组件
拖拽“K-Means”组件到画布,创建从数据库加载组件到K-Means组件的连线。
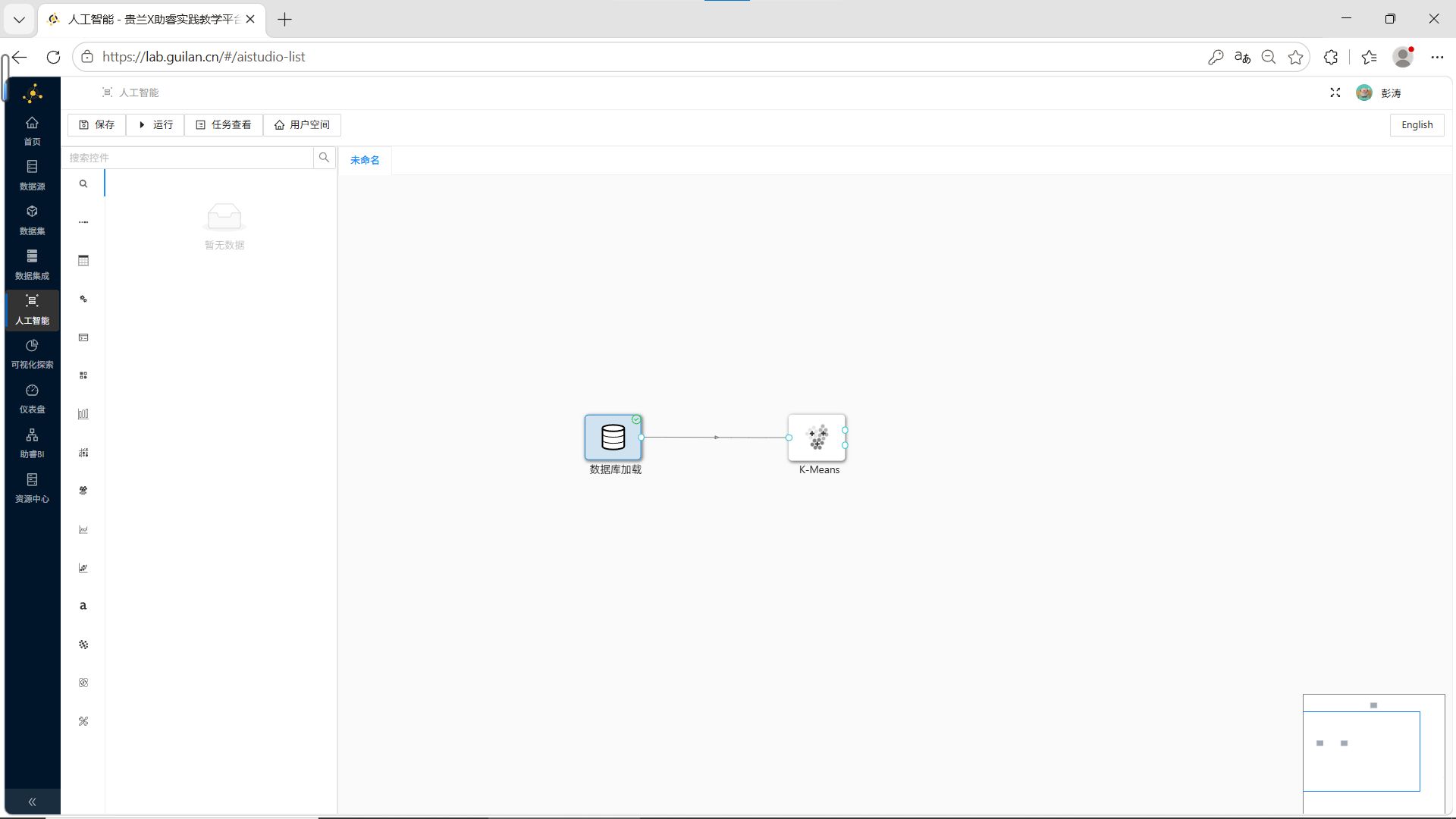
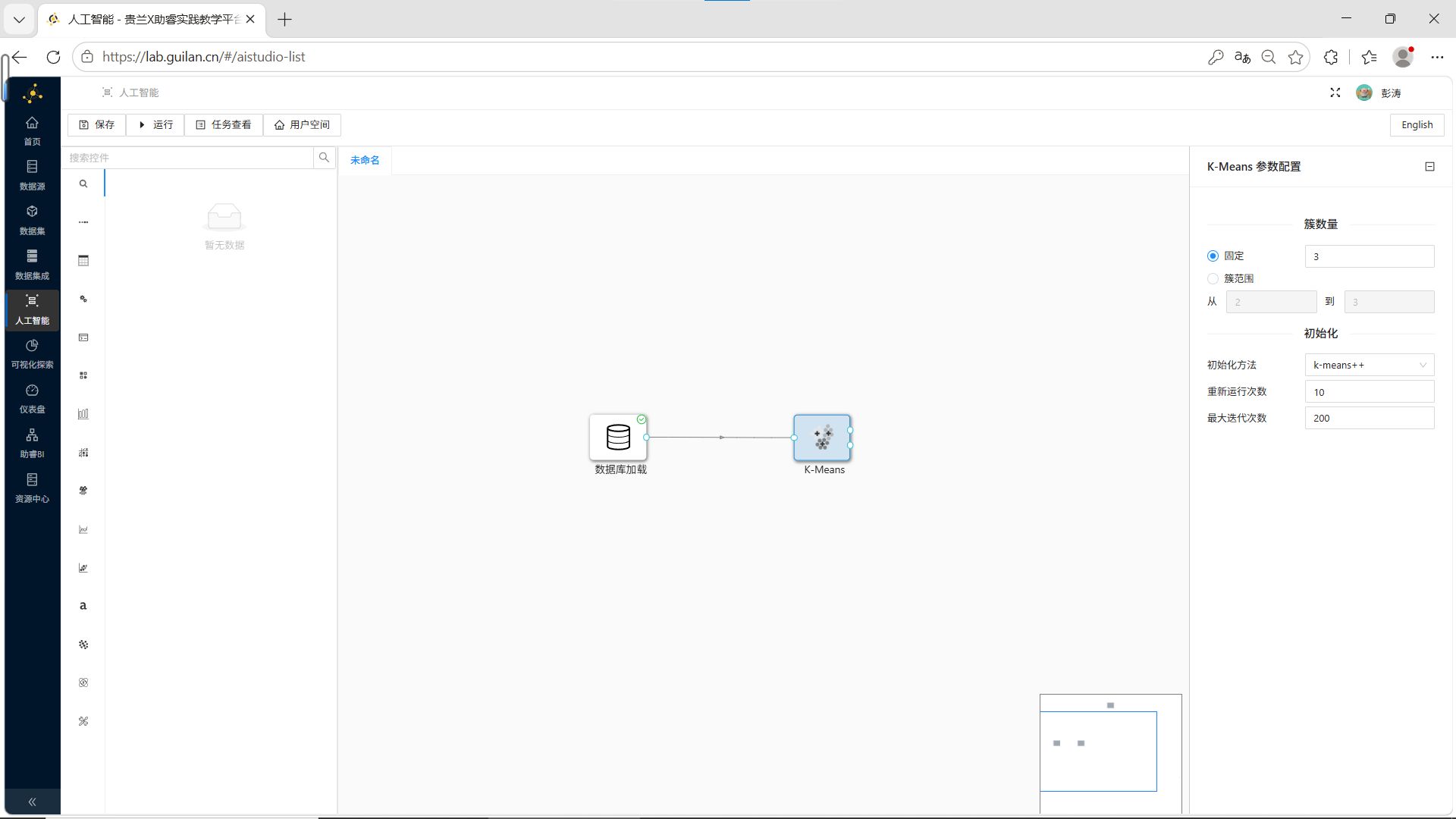
步骤2:配置K-Means参数
双击K-Means组件,在配置窗口中:
-
簇数量:选择固定为3个
-
其他参数保持默认
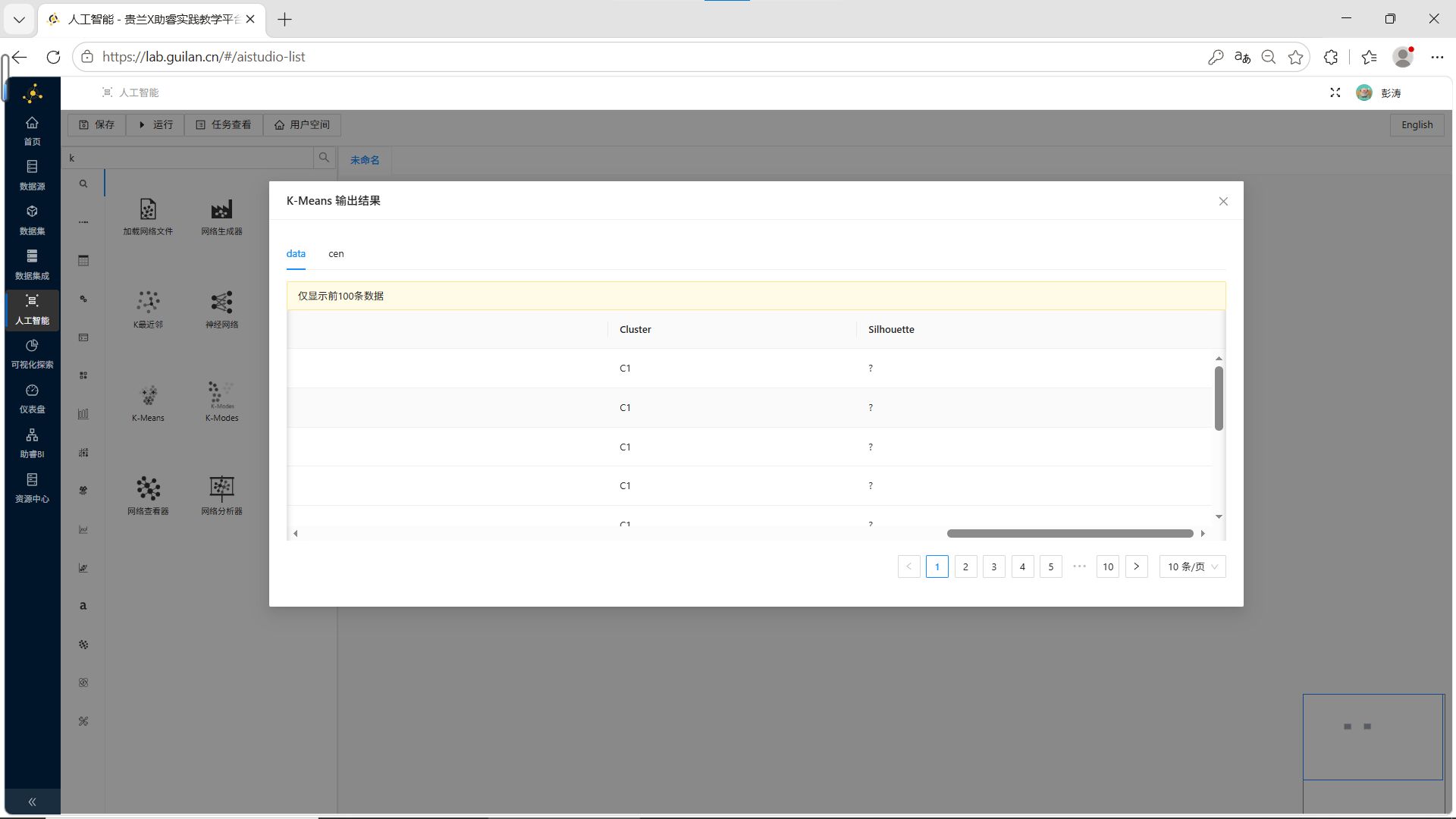
步骤3:运行并查看结果
右键运行该控件,查看输出结果,可以看到每个学生分别被标记了对应的簇类C1/C2/C3。
3.1.4 结果输出与保存
步骤1:添加数据入库组件
拖拽“数据入库”组件到画布,创建K-Means组件到数据入库组件的连线。
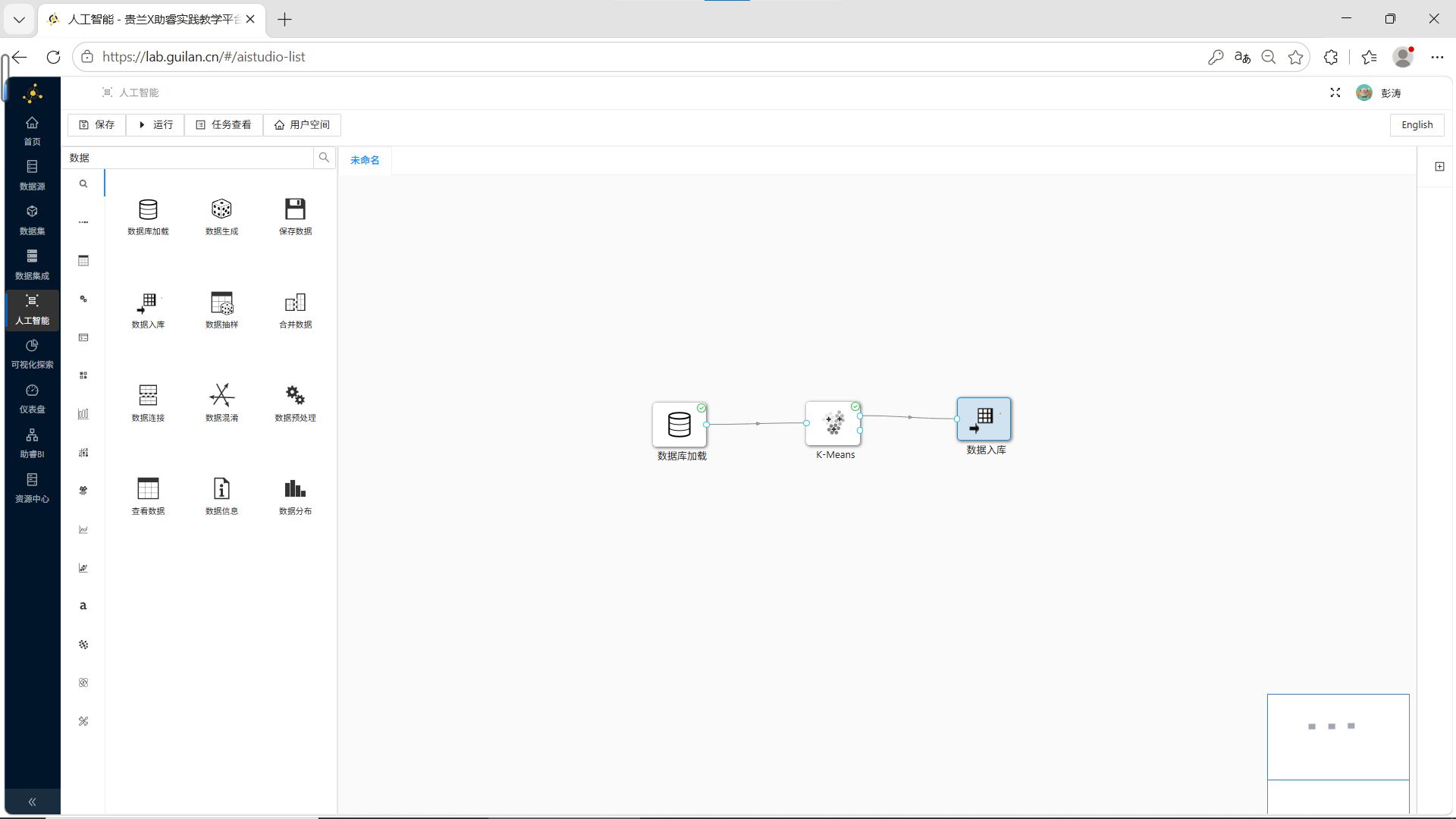
步骤2:配置入库参数
双击数据入库组件,填写团队私有数据库连接信息,点击【获取表信息】。
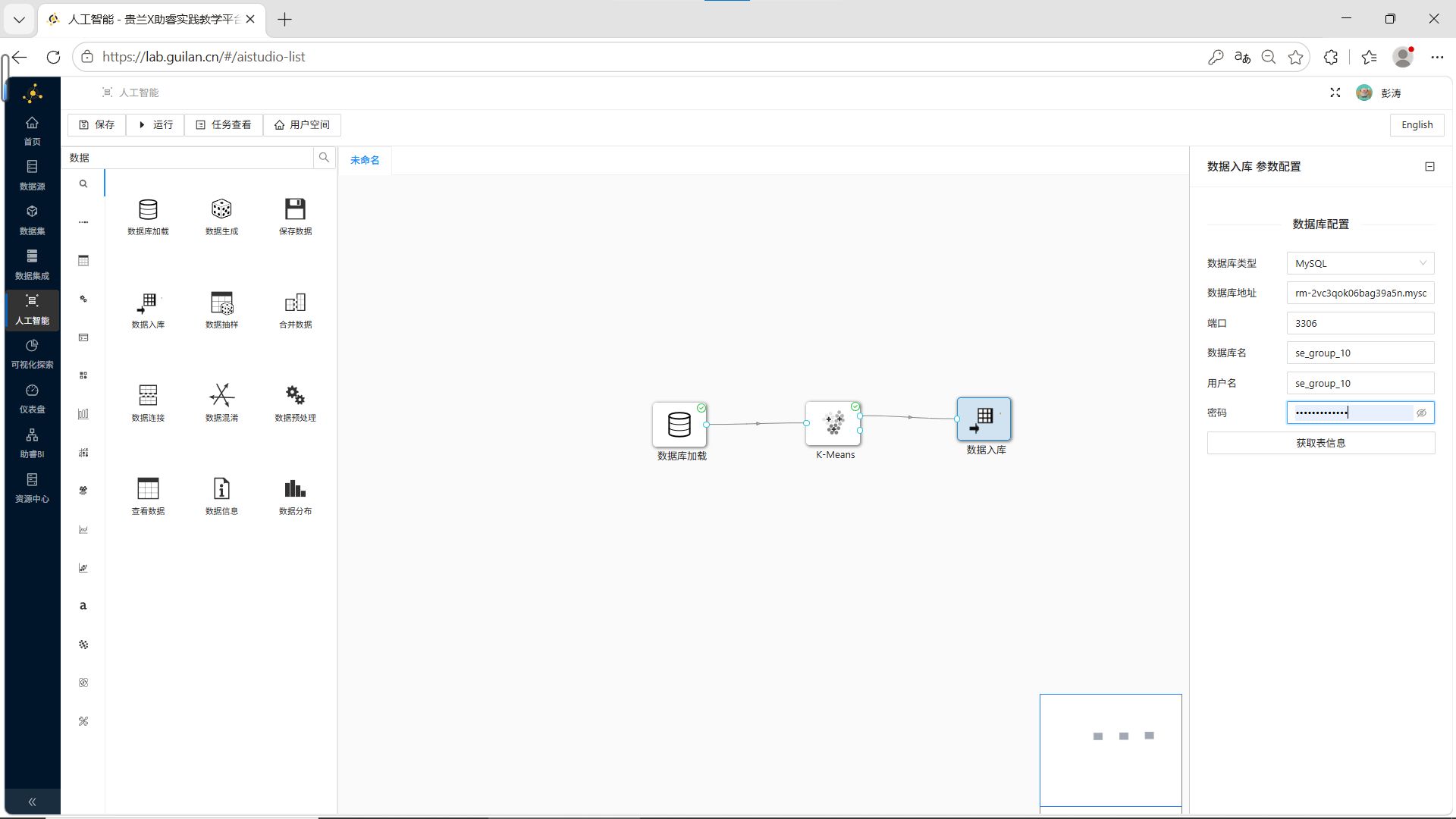
步骤3:新建目标表
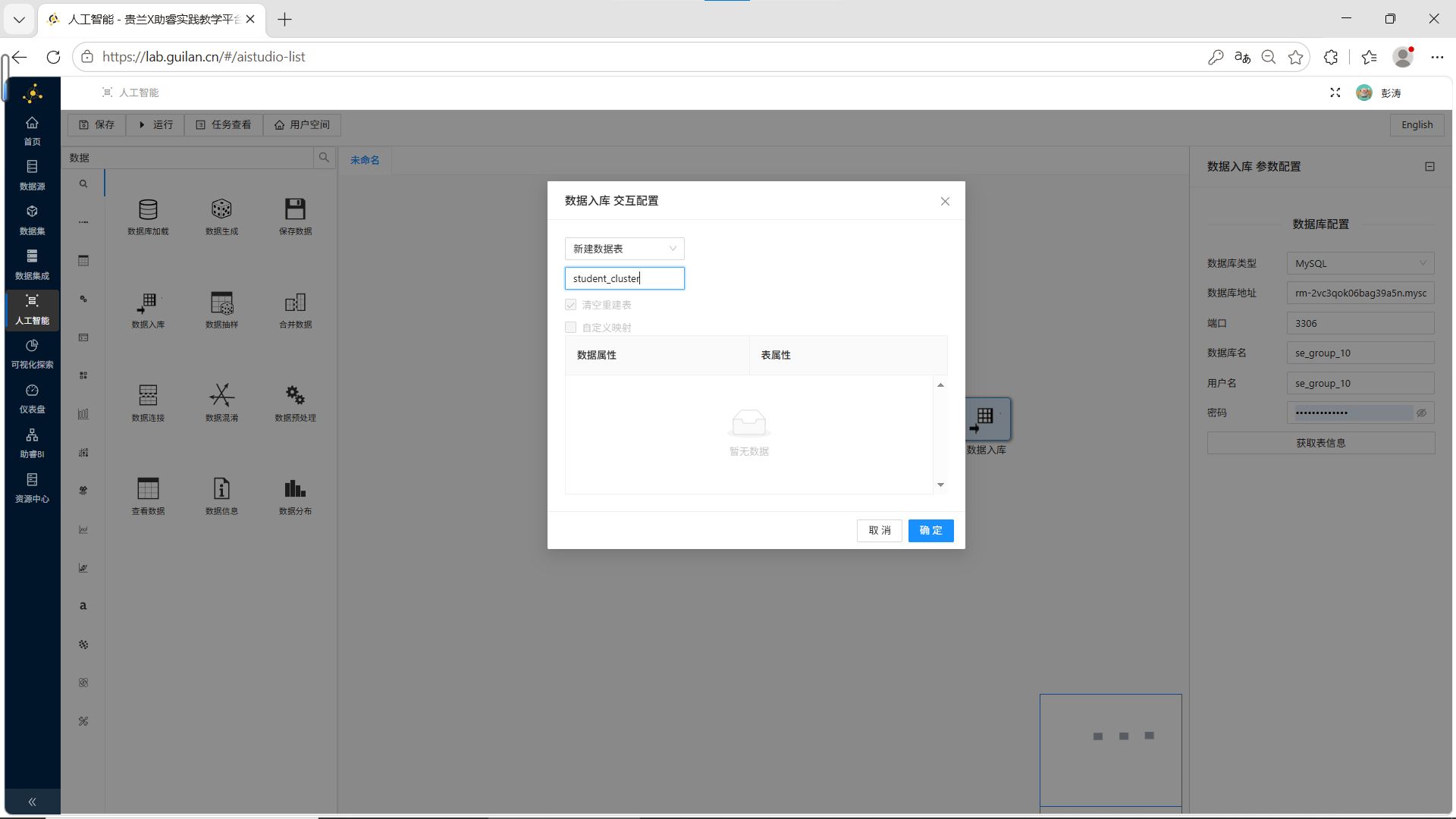
在弹出的窗口中,选择“新建数据表”,表名称修改为 student_cluster,点击【确定】。
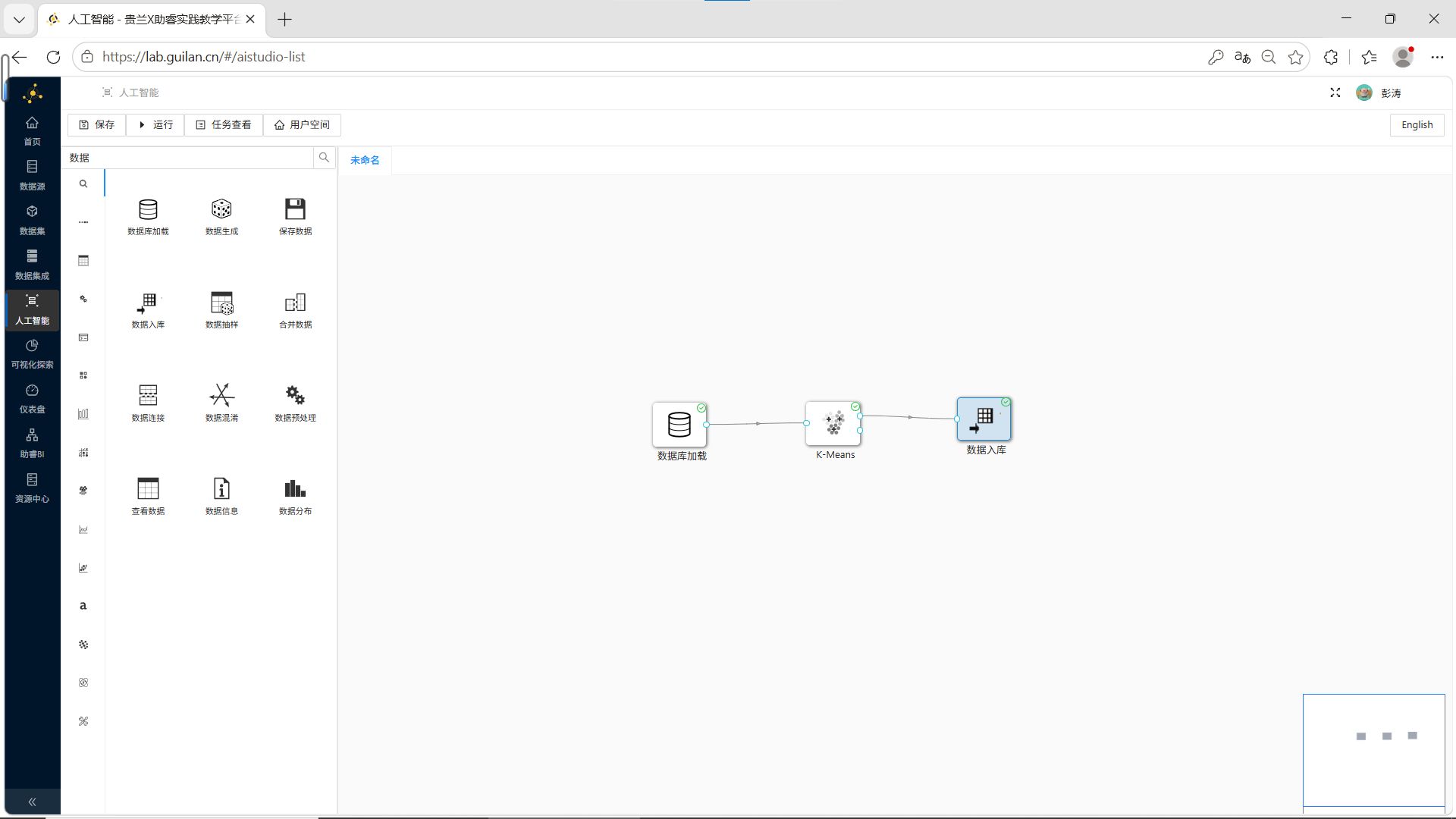
步骤4:执行工作流
点击运行,各控件均运行成功则工作流执行完成。
3.2 分析聚类簇编号对应的考勤群体分类
上一步骤输出的聚类簇编号无法直接确定对应的考勤群体分类,需要通过助睿BI可视化分析来解读。
点击实验平台左边菜单【助睿BI】,进入可视化分析平台。
3.2.1 连接数据源
步骤1:新建数据源连接
点击左边菜单【数据源】→ 左上角【+】→【新建连接】→【MySQL】。
步骤2:配置连接信息
输入团队私有数据库的连接信息,点击【测试连接】,显示“测试连接成功”后点击【确认】。
步骤3:验证数据表
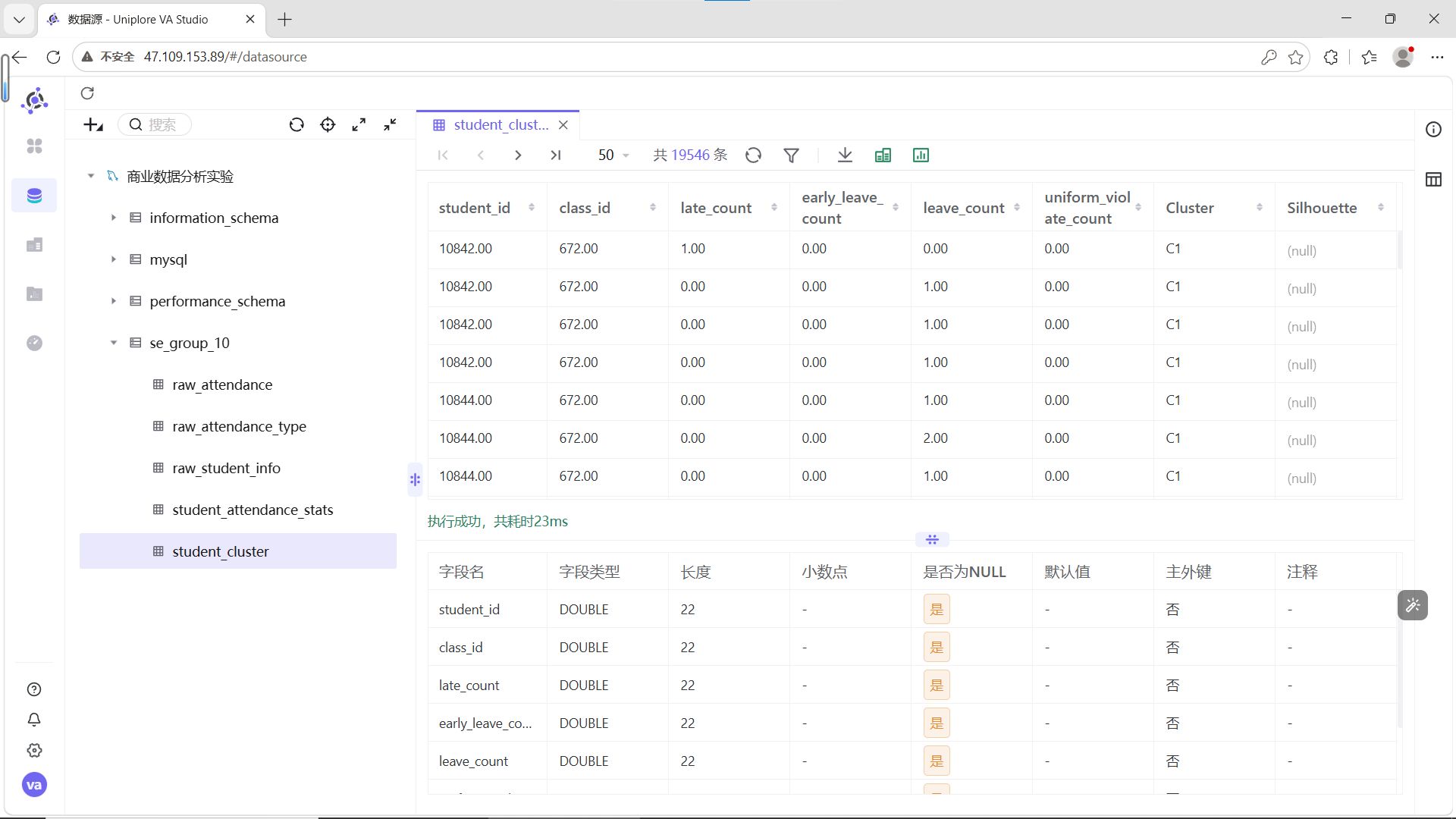
点击新建的数据库目录,可以看到 student_cluster 表,右键可预览数据。
3.2.2 构建数据集
步骤1:新建数据集
点击左边菜单【数据集】→ 左上角【+】→【新建数据集】。
输入数据集名称(如“聚类簇编号数据集”)、选择所属分组,点击【确认】。
步骤2:选择数据源
数据集创建成功后自动跳转到配置页面。选择数据源为刚才创建的MySQL连接,目录选择 labs。
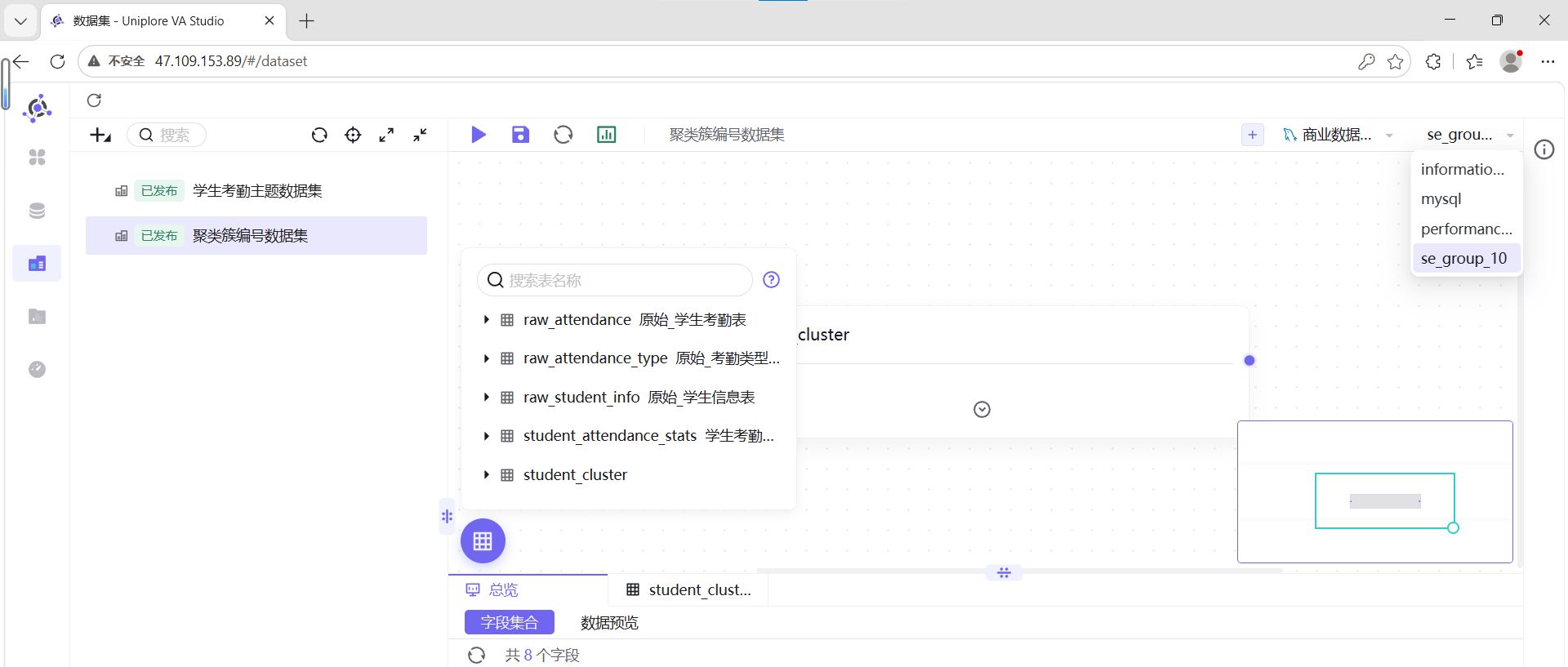
步骤3:拖拽数据表
将 student_cluster 表拖拽至画布中。
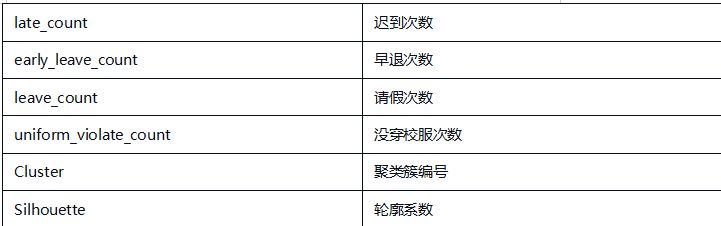
步骤4:修改字段备注
将字段备注修改为中文,便于识别:

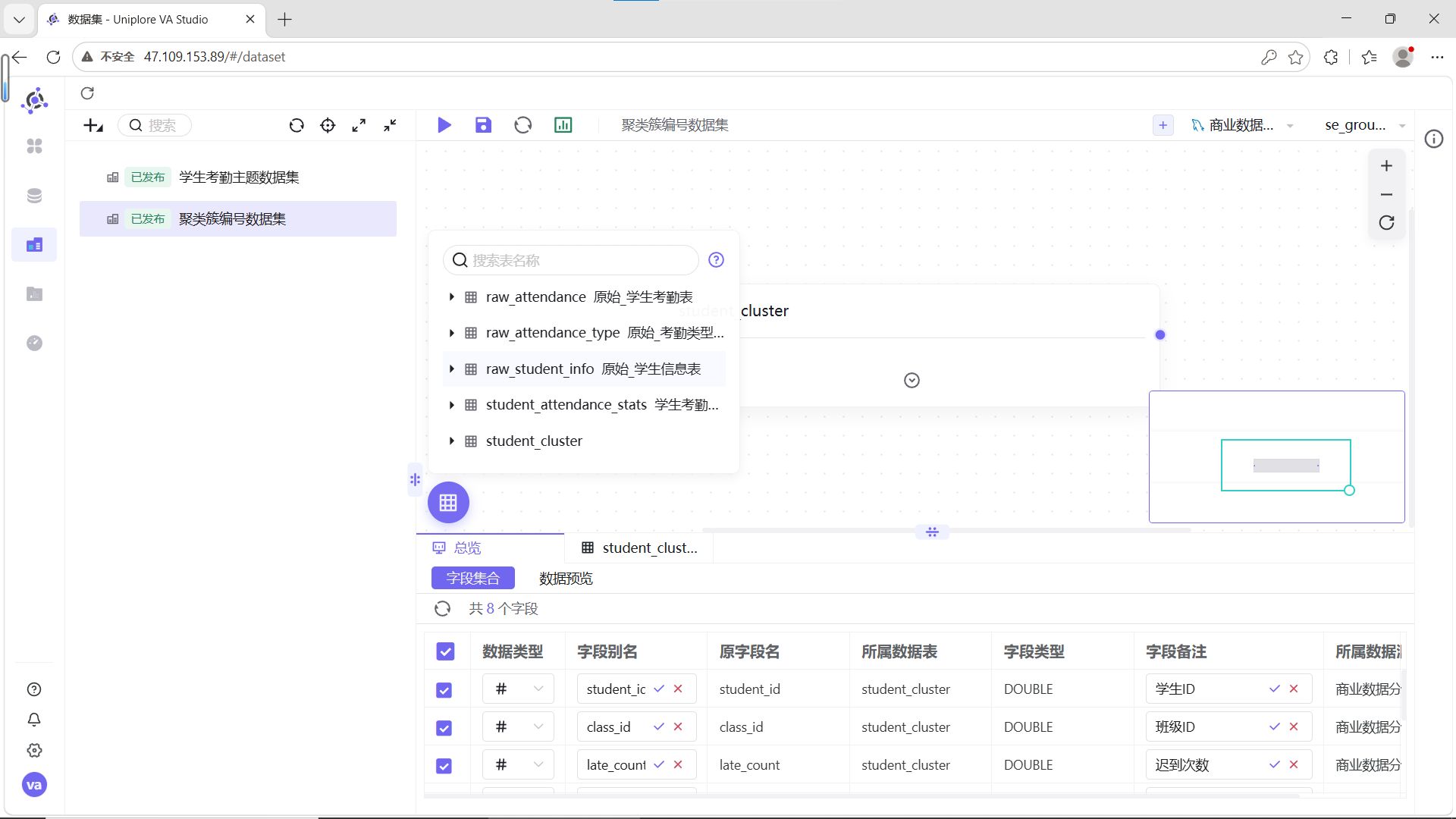
步骤5:保存并发布
点击画布左上角【保存】,在提示中选择【保存并发布】。只有发布后的数据集才能在工作表中引用。
3.2.3 制作工作表
工作表是助睿BI平台中用于承载可视化图表、完成数据探索与分析的核心单元。
3.2.3.1 创建分组
点击左边菜单【工作表】→ 左上角【+】→【新建分组】,创建“聚类簇考勤画像分析”分组。
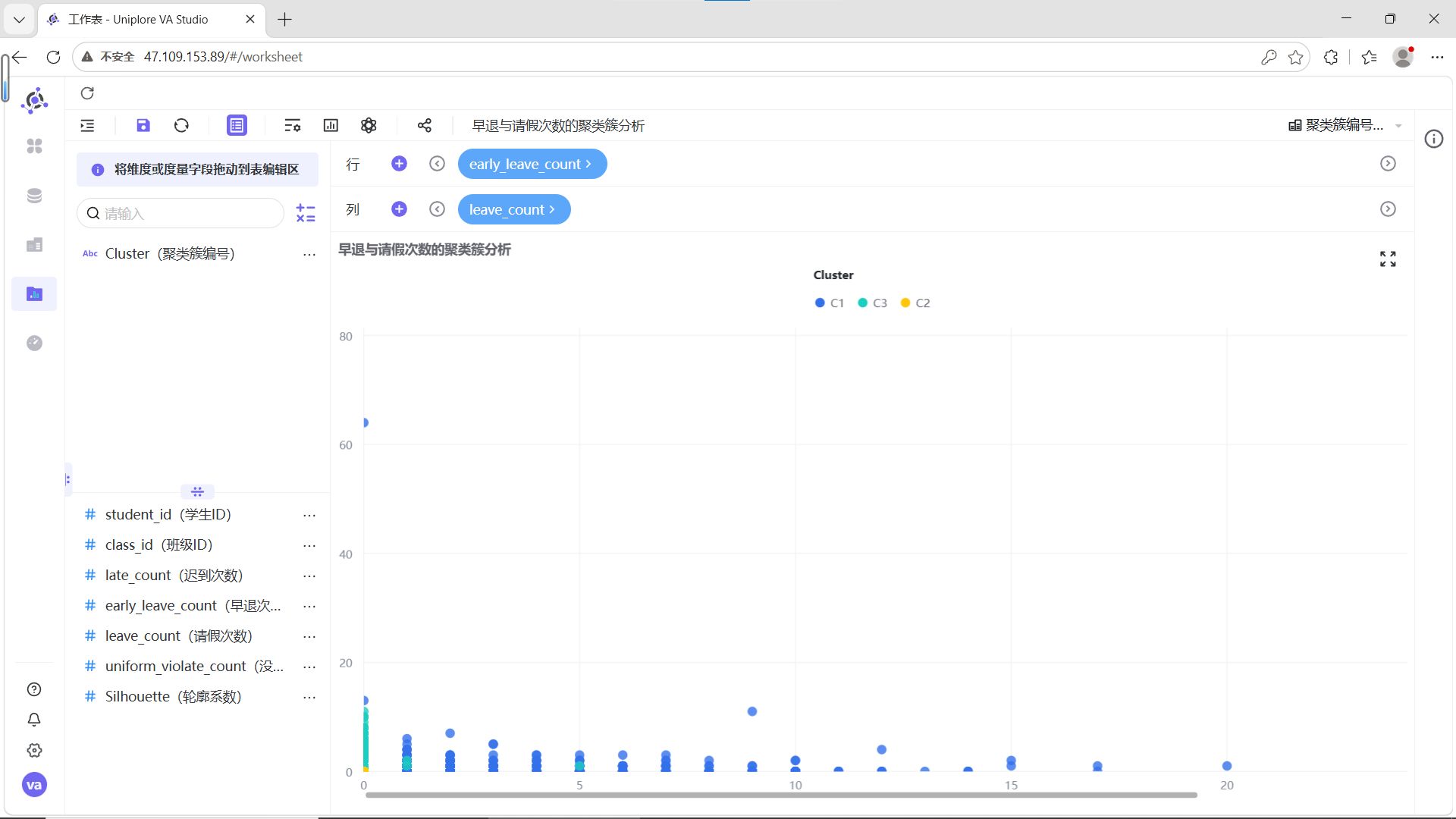
3.2.3.2 制作迟到与早退次数组间分析
步骤1:新建工作表
右键分组名称,选择【新建工作表】,命名为“迟到早退次数的聚类簇分析”。
步骤2:选择数据集
在数据集选择框中,选择刚刚创建的“聚类簇编号数据集”。
步骤3:配置图表
-
图表类型选择“探索器”
-
X轴:late_count(迟到次数)
-
Y轴:early_leave_count(早退次数)
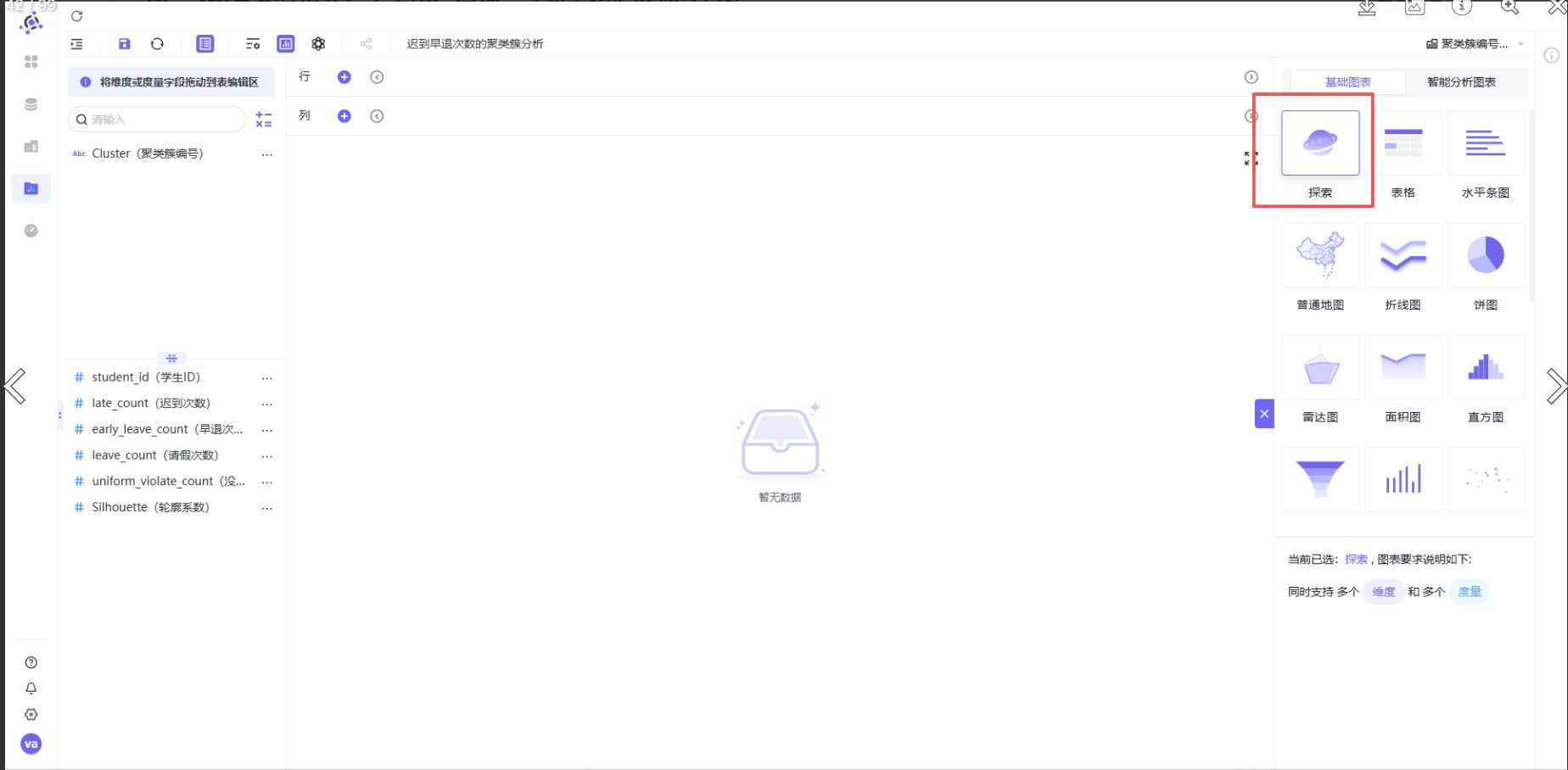
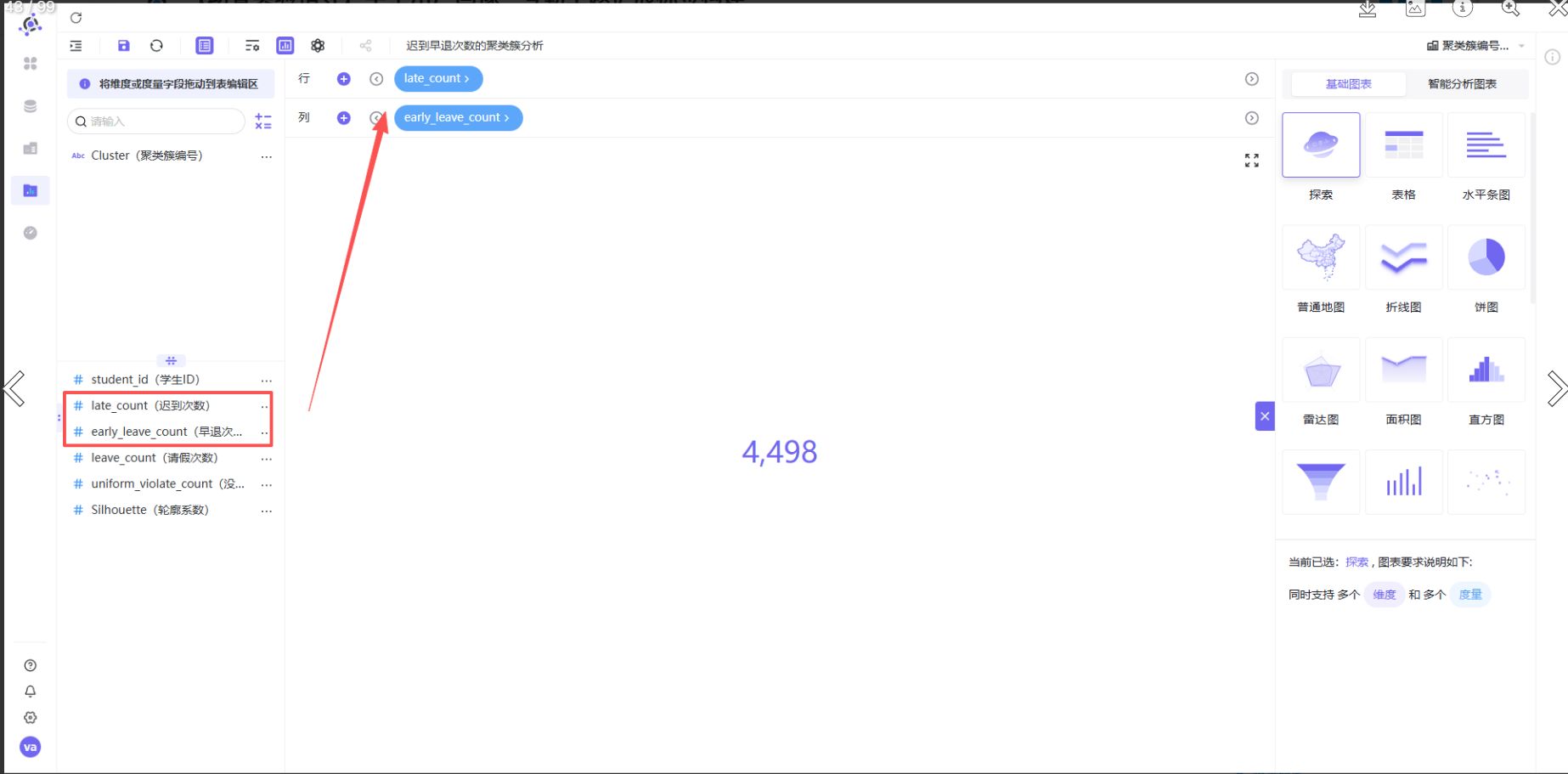
步骤4:设置颜色分组
点击图形设置按钮,在颜色区域点击【+】,选择“Cluster(聚类簇编号)”。
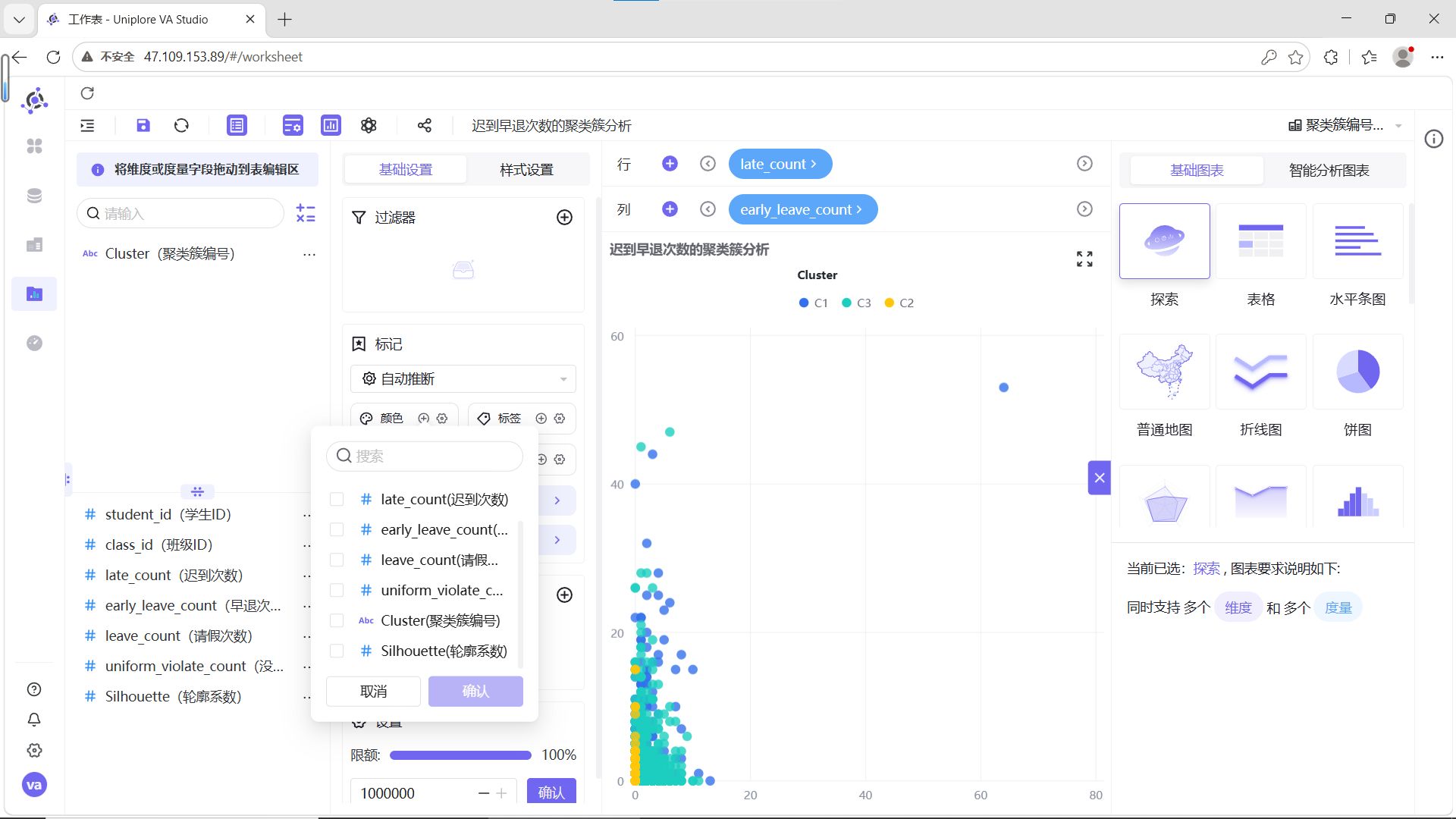
步骤5:设置信息标签
点击信息区域【+】,选择“student_id(学生ID)”,并将student_id设置为“维度”。
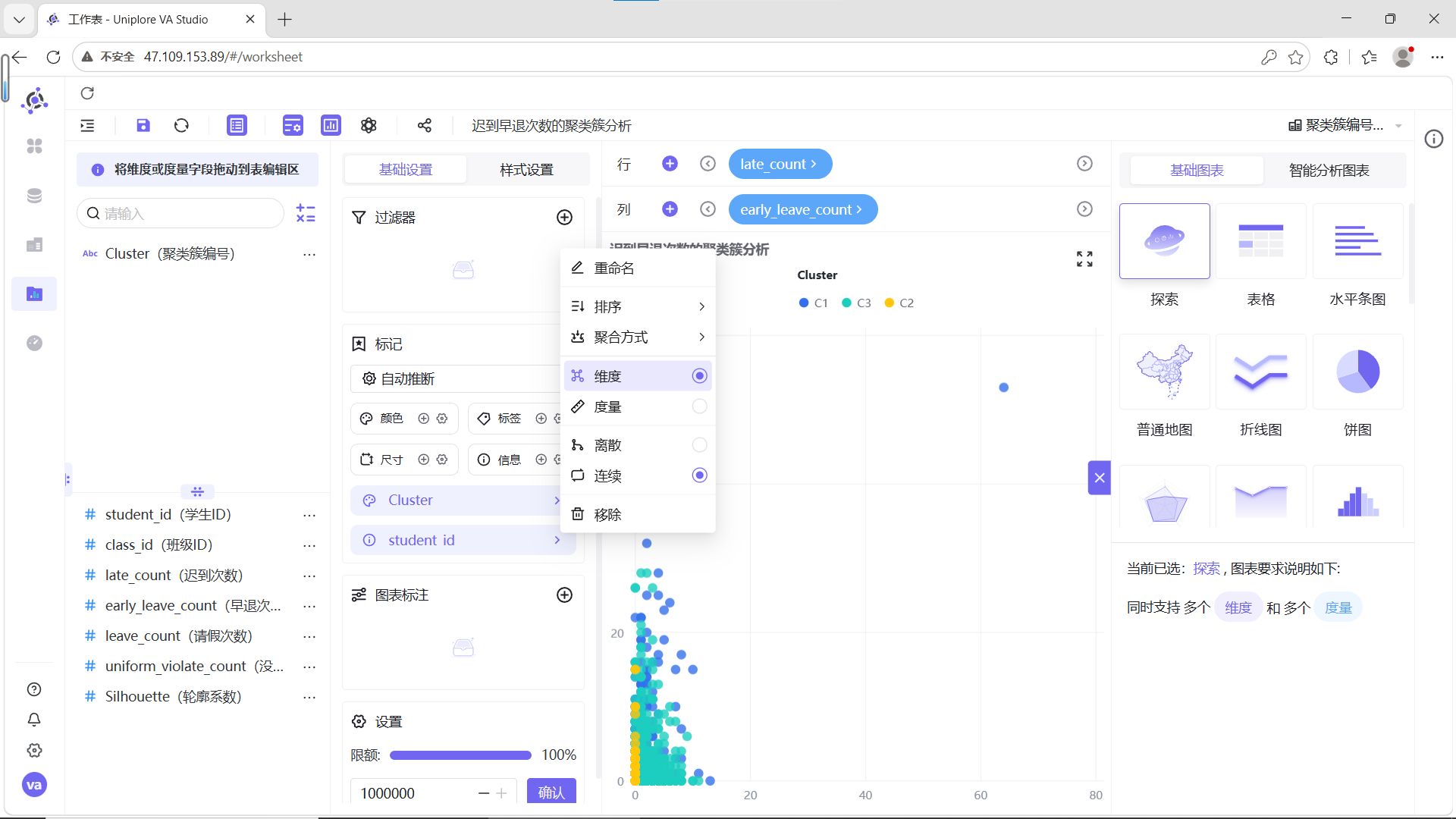
步骤6:调整显示限额
系统默认限额2000条数据,将限额设置为100%以确保显示全部数据。
步骤7:设置配色方案
点击颜色区域的设置按钮,选择对比强烈的主题。
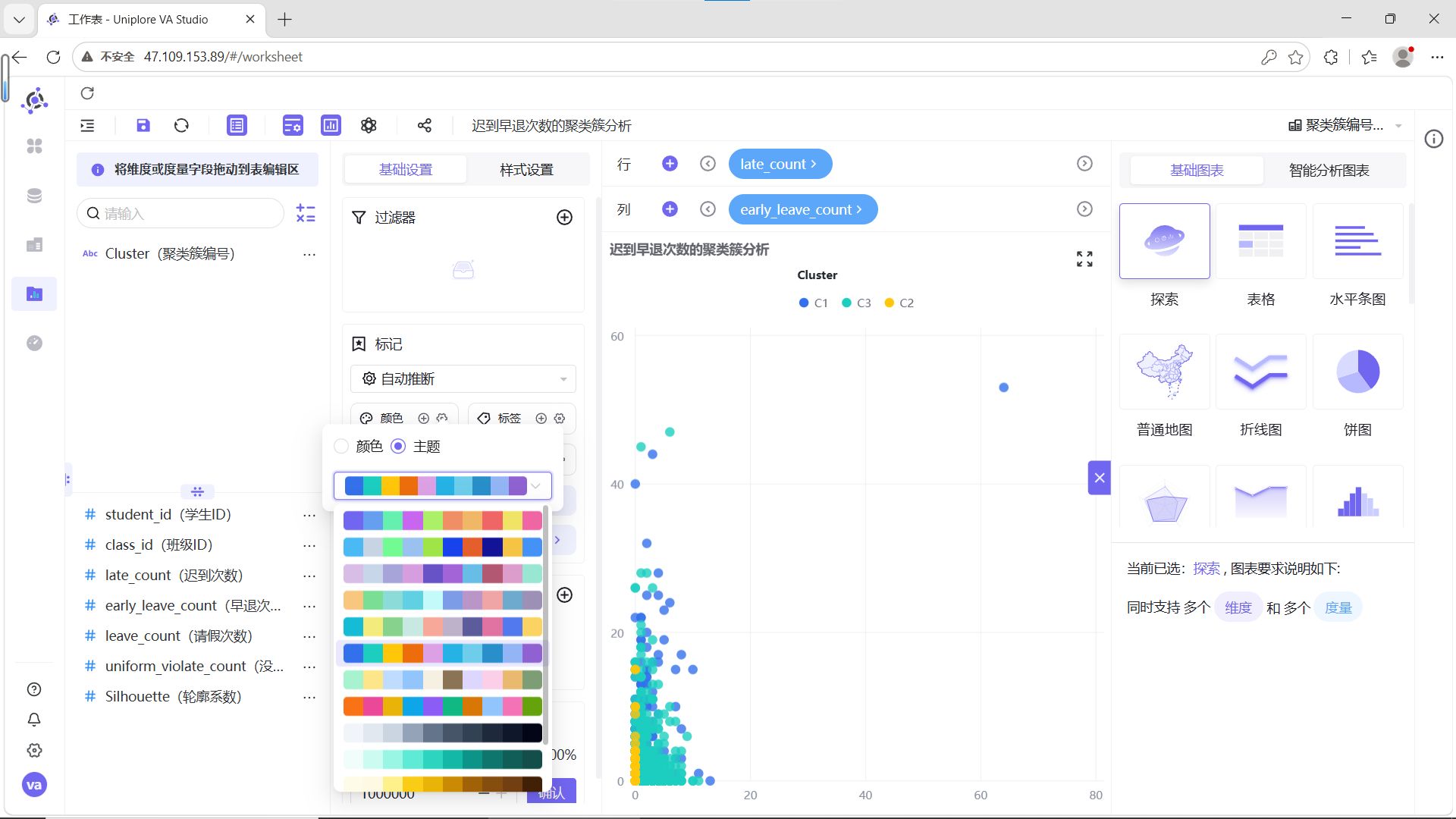
步骤8:保存工作表
点击保存按钮,保存并发布工作表。
3.2.3.3 制作其他组合分析工作表
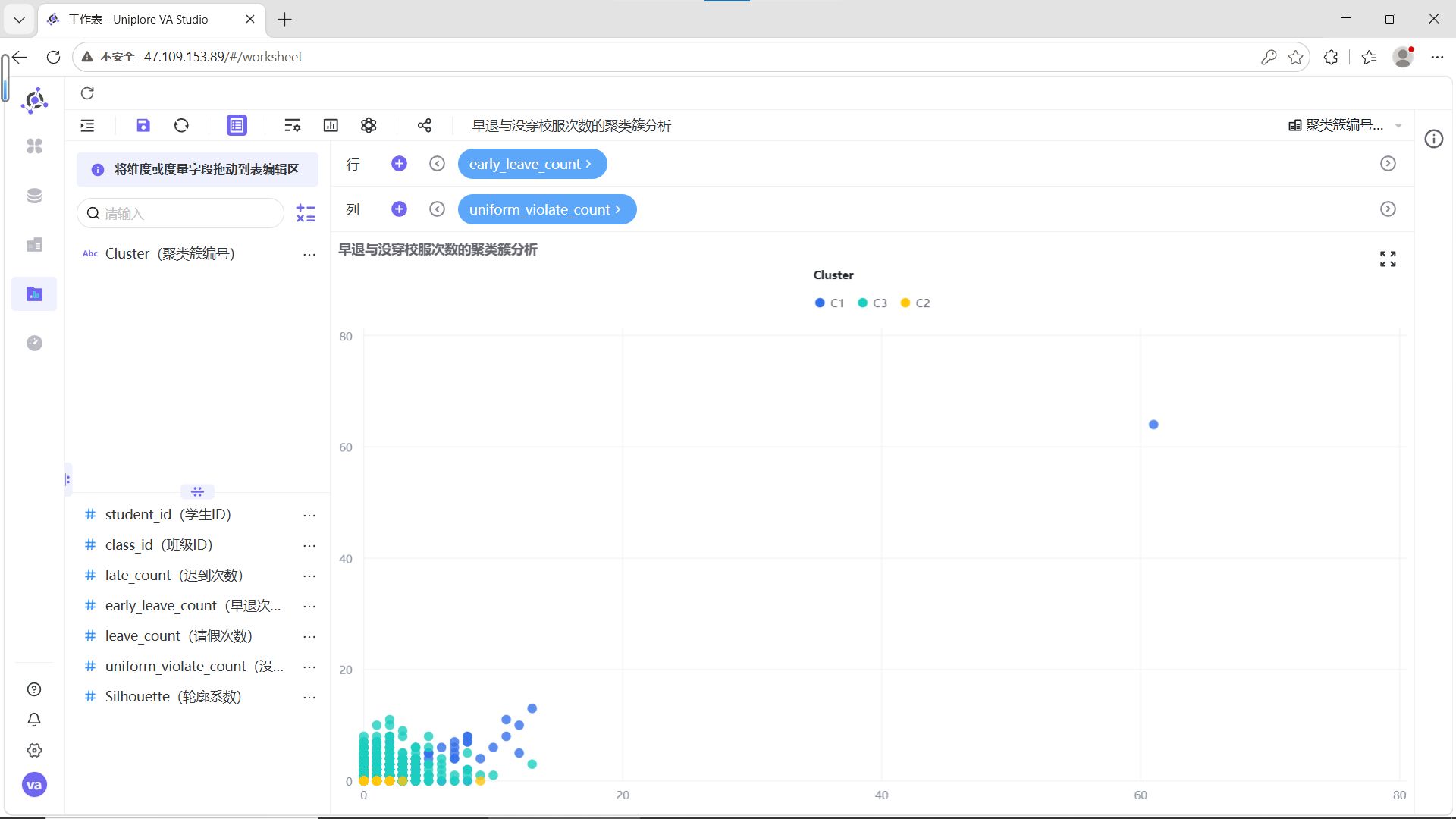
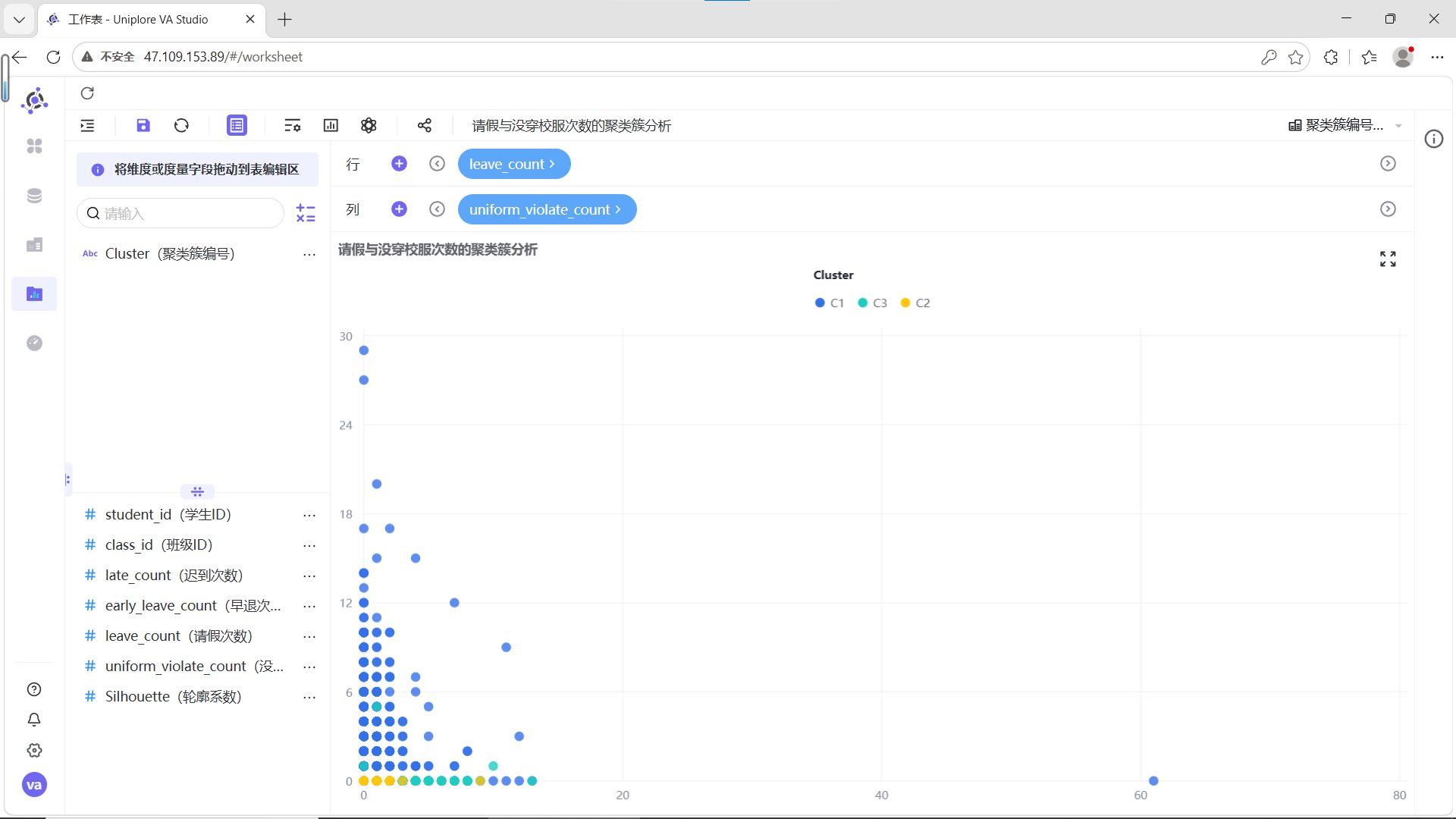
按照相同步骤,依次制作以下工作表:

3.2.4 搭建仪表盘
为了便于综合分析,将制作的6个工作表集中展示在一个仪表盘中。
步骤1:新建仪表盘
点击左边菜单【仪表盘】→ 左上角【+】→【新建仪表盘】,输入名称“聚类簇分析”。
步骤2:添加标题文本
在右侧组件区域,拖拽一个“文本”组件到画布,输入“聚类簇分析”,设置字体颜色、大小、加粗、居中。
步骤3:调整组件布局
鼠标移至组件右下角可拖动调整大小,点击右上角图钉图标可固定位置。
步骤4:添加工作表组件
切换到【工作表】标签,将3.2.3节制作的6个工作表拖拽至画布中。
步骤5:调整仪表盘布局
按住图表顶部中间位置可拖动,使用鼠标调整图表大小和布局,达到预期效果。
步骤6:保存仪表盘
点击保存按钮,保存并发布仪表盘。
3.2.5 聚类群体画像解读
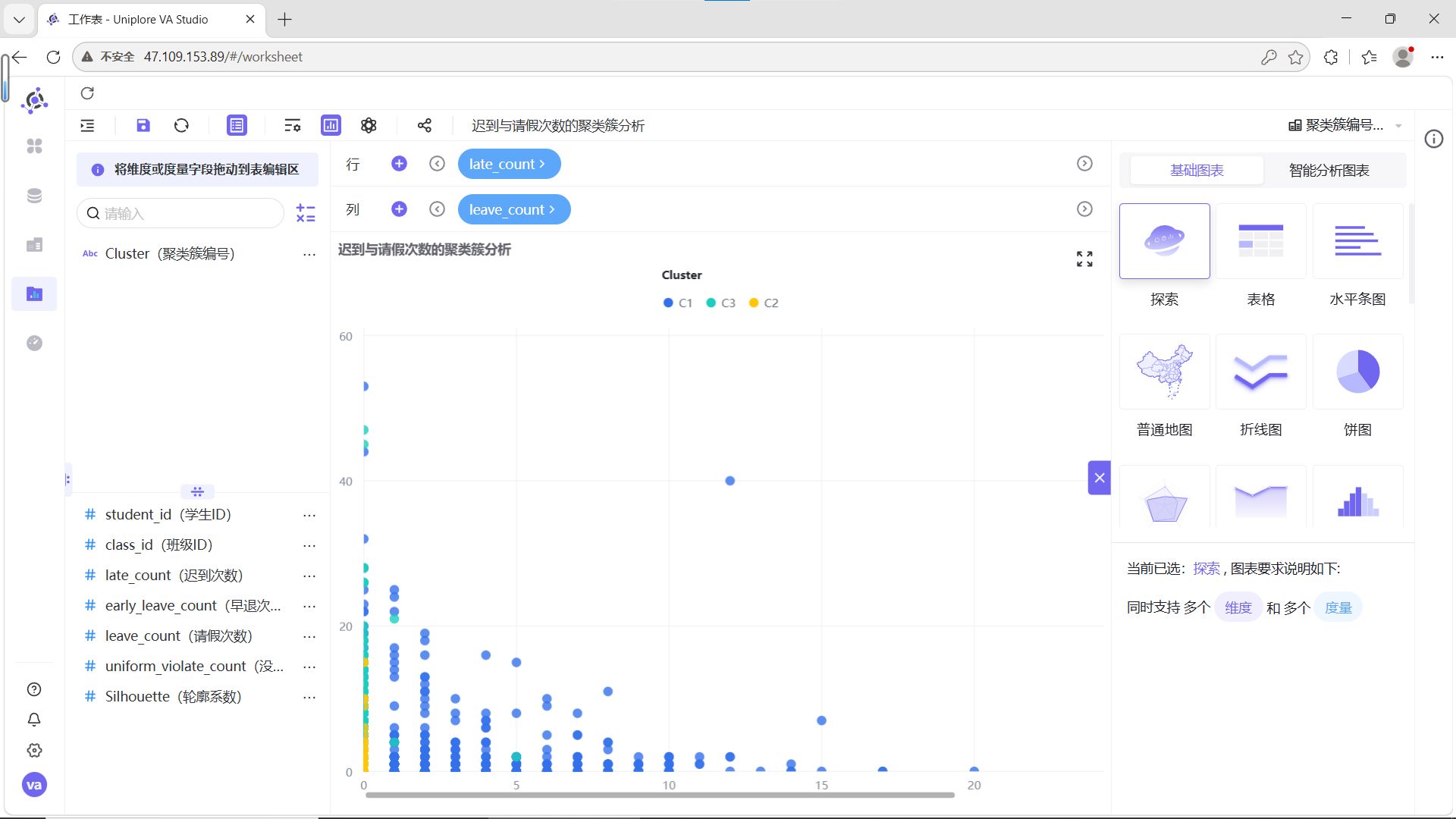
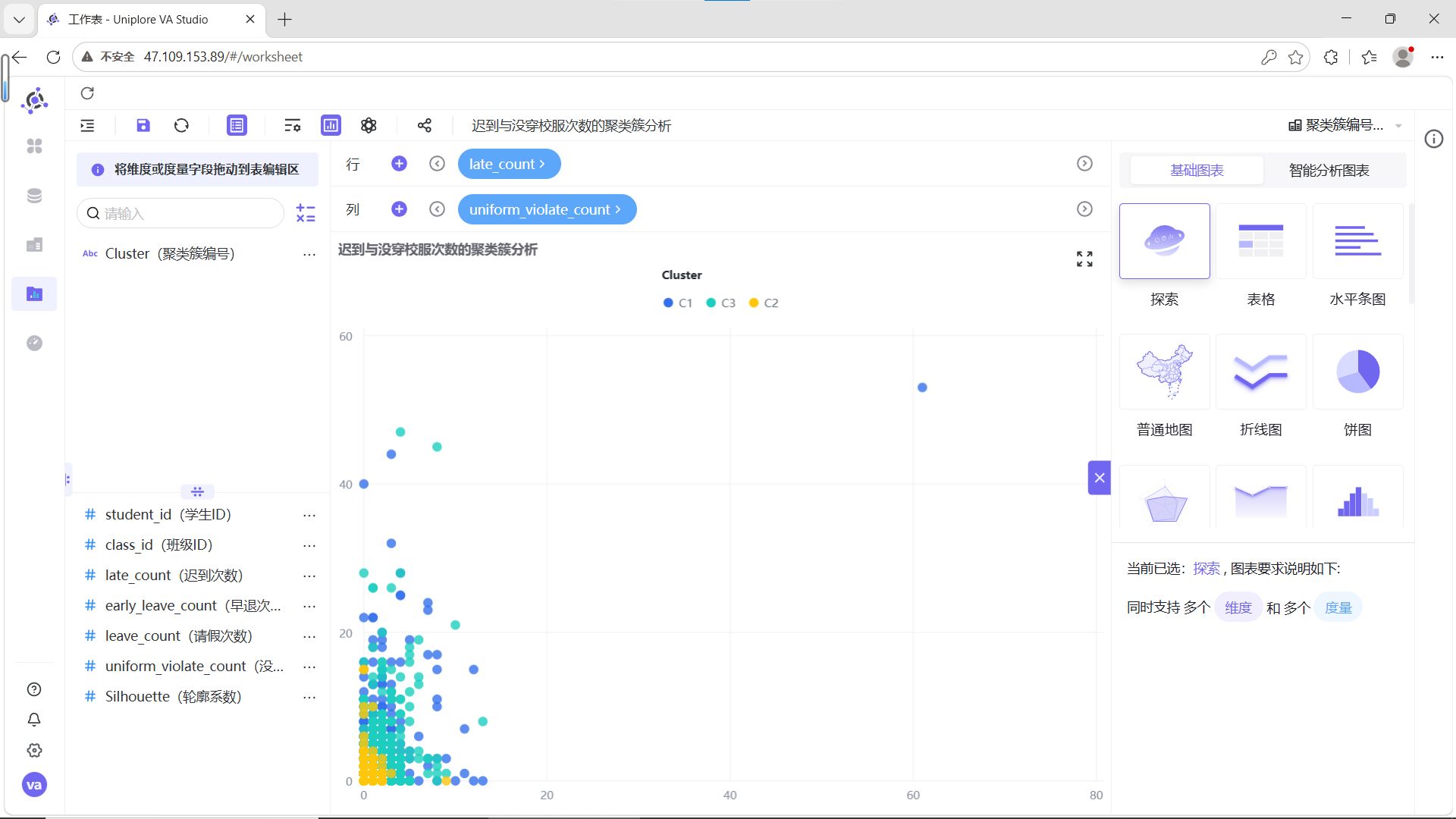
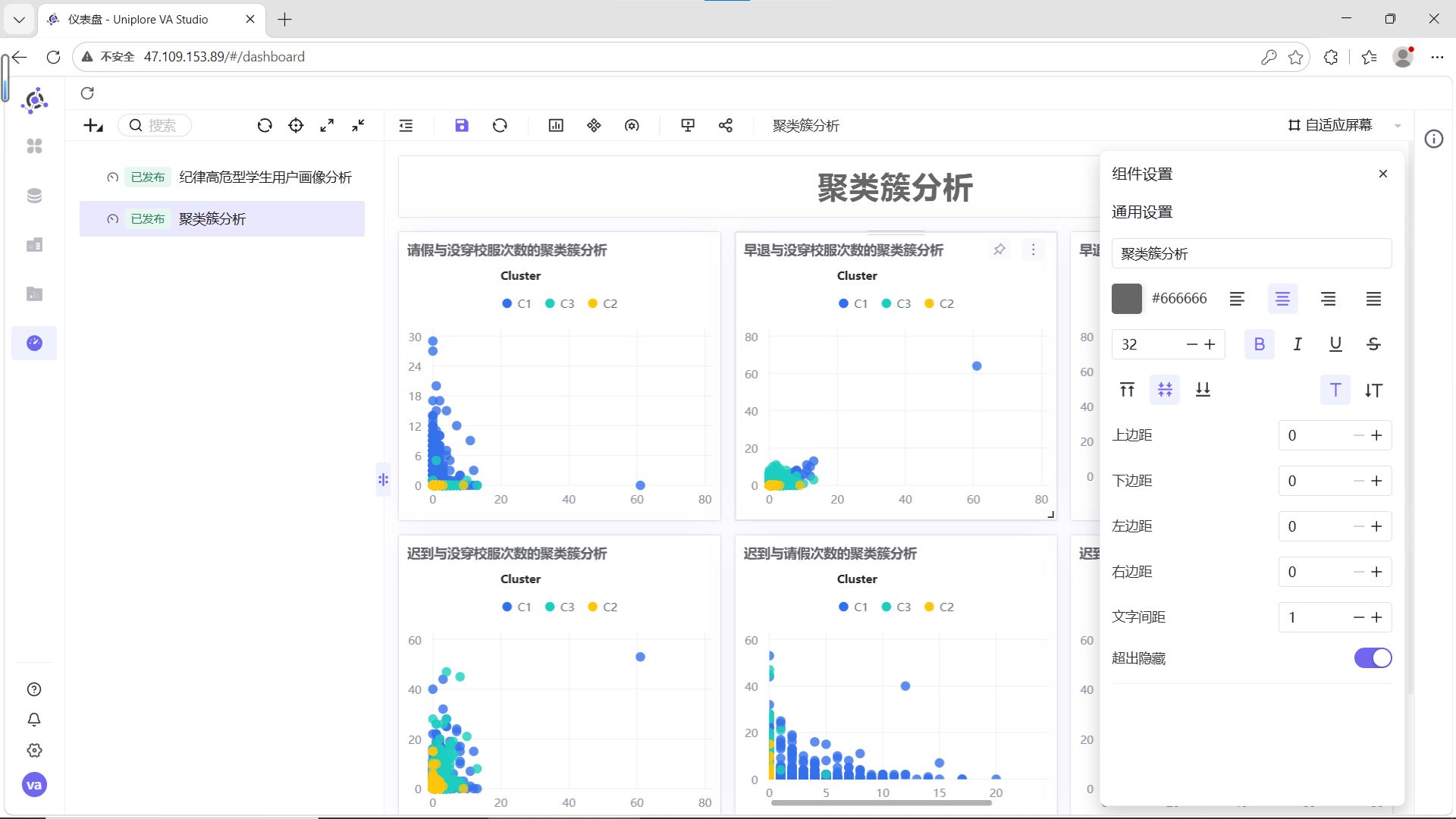
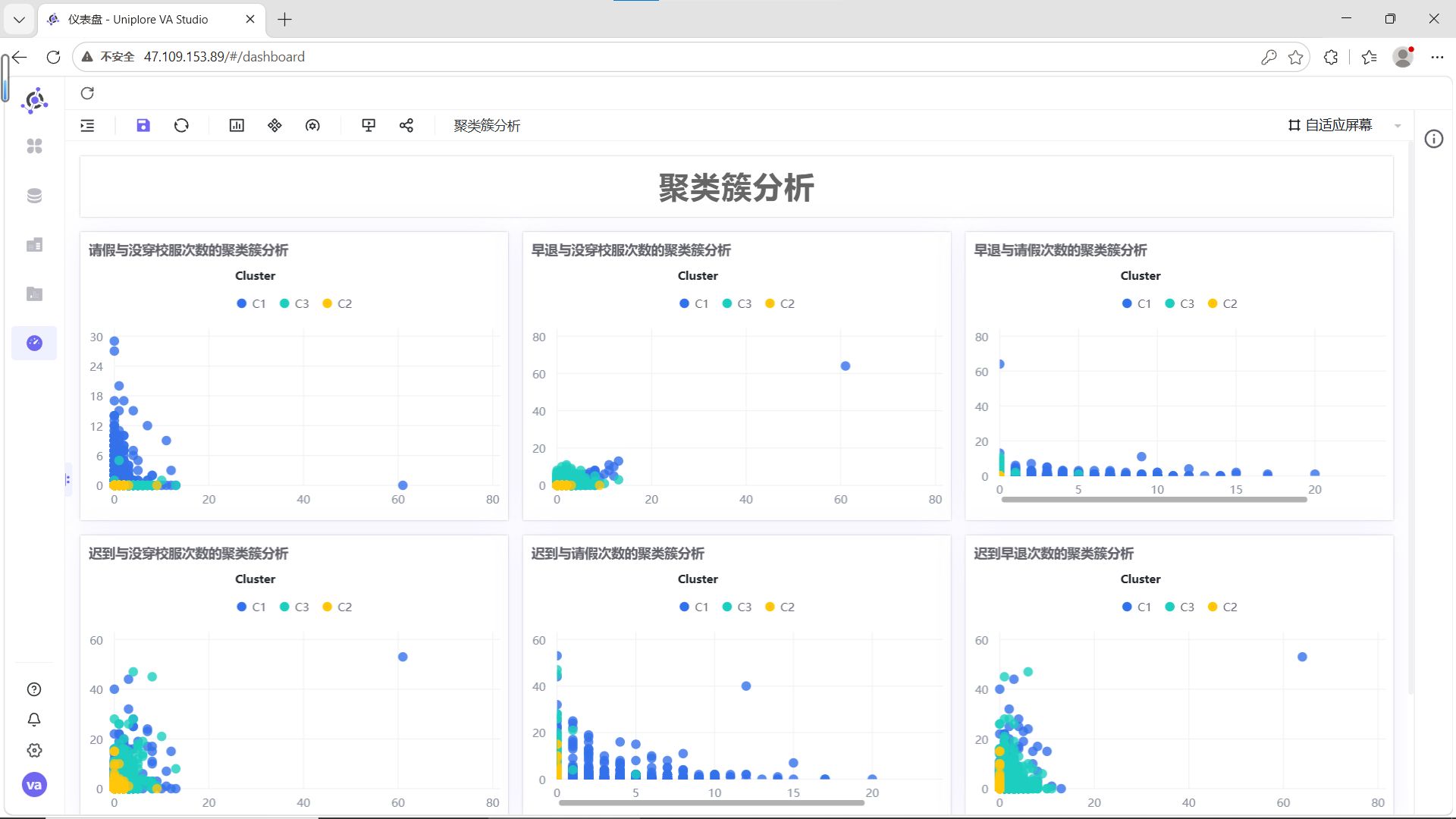
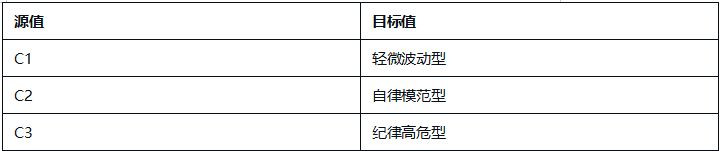
结合6组两两指标散点图的分布特征,为C1、C2、C3三类聚类簇赋予清晰的业务含义:

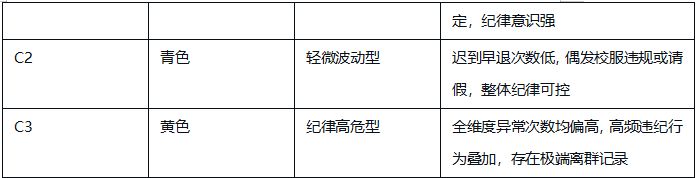
各群体详细解读:
-
C1(蓝色,自律模范型):在迟到、早退、请假、校服违规次数的所有组合中,数据点高度集中在低频次区间,无明显离群值。这类学生出勤稳定、纪律意识强,是校园考勤行为的正面典型。
-
C2(青色,轻微波动型):整体数据点同样集中在低频次区间,但相比C1分布略散,少量记录存在轻微的校服违规或请假行为,迟到、早退次数始终保持低位。这类学生整体纪律可控,属于需要日常提醒的群体。
-
C3(黄色,纪律高危型):数据点呈现明显的“离群特征”,在迟到次数与其他指标的组合图中,出现了大量高频迟到记录,且伴随不同程度的早退、请假或校服违规行为,是唯一存在多维度叠加违纪的群体,需要重点关注和干预。
3.3 将映射结果加入学生考勤主题标签表
需要将聚类群体分类数据回写到上一实验输出的 student_attendance_stats 表中。
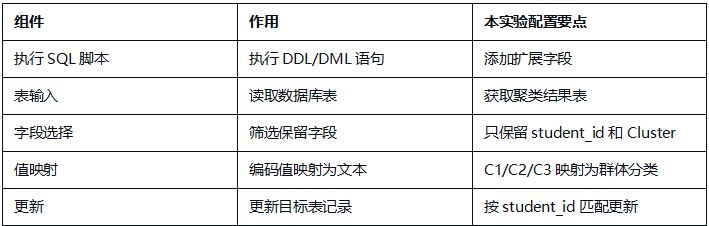
3.3.1 新增扩展字段
student_attendance_stats 表中没有考勤群体分类字段,需要先增加两个字段:

操作步骤:
进入数据集成平台,在上一实验创建的项目中新建转换流“增加考勤主题扩展标签字段”,拖拽“执行一个SQL脚本”组件。
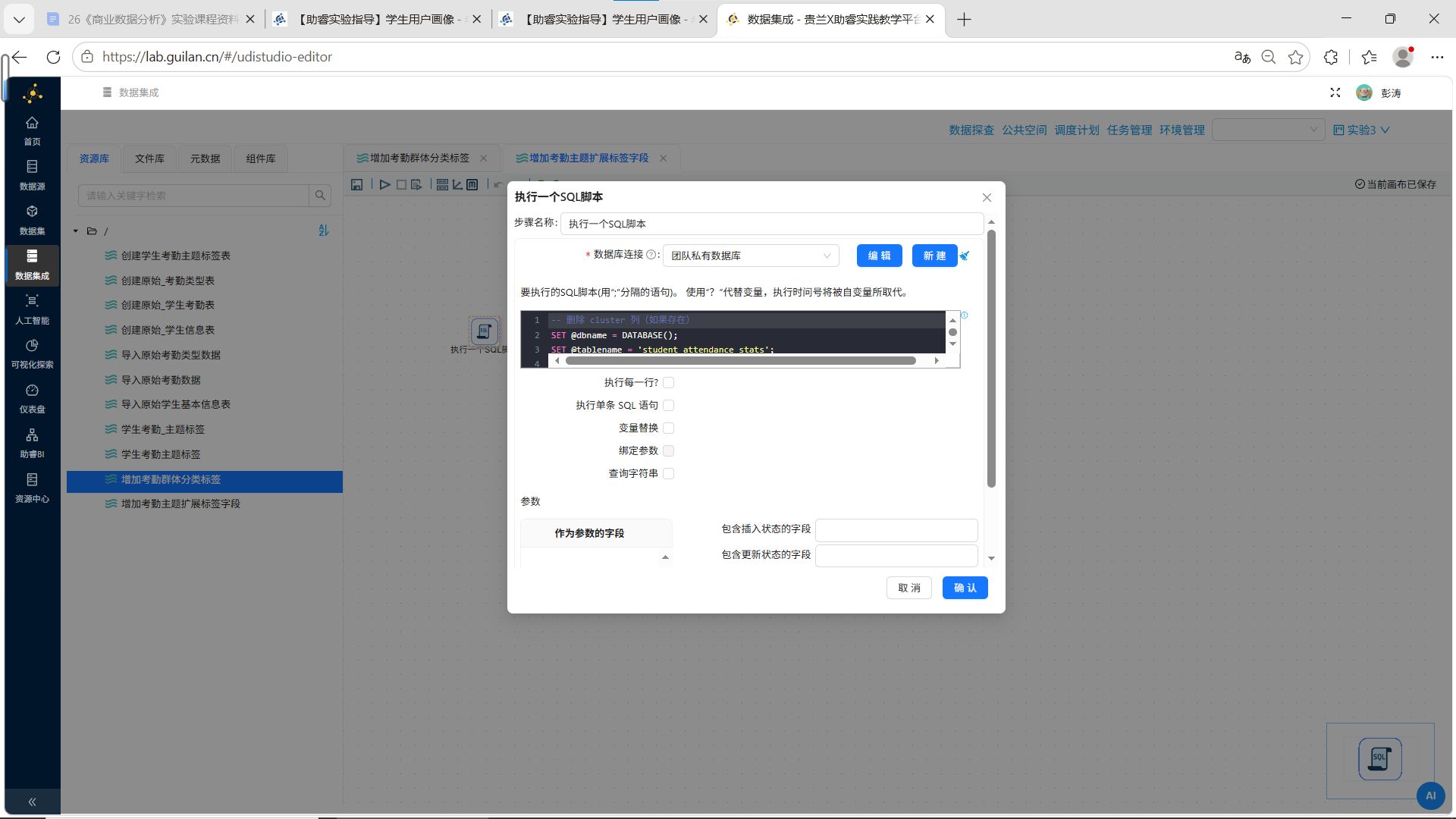
配置SQL脚本:
-
ALTER TABLE student_attendance_stats
-
ADD COLUMN cluster VARCHAR(10) NULL DEFAULT NULL COMMENT '聚类簇编号',
-
ADD COLUMN attendance_group VARCHAR(30) NULL DEFAULT NULL COMMENT '考勤群体分类';
执行转换流。
3.3.2 聚类簇编号数据获取
新建转换流“增加考勤群体分类标签”,拖拽“表输入”组件,从团队私有数据库获取 student_cluster 表的所有数据。
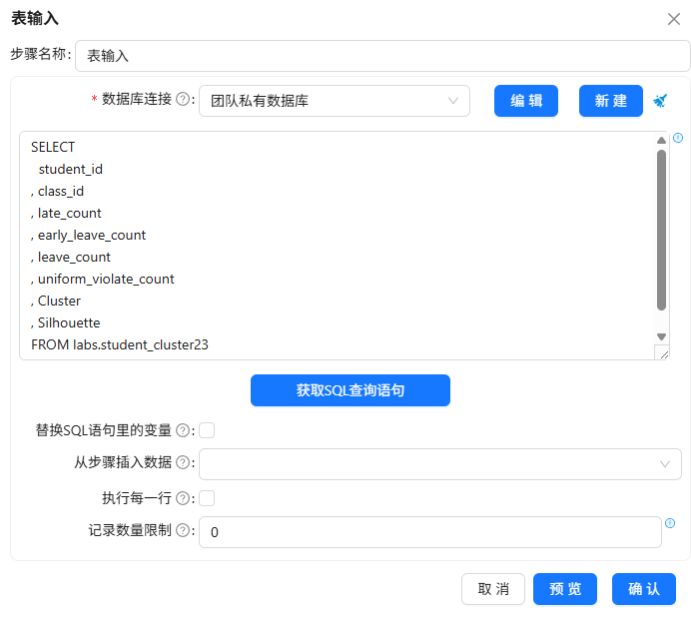
3.3.3 字段选择
添加“字段选择”组件,只保留 student_id、Cluster 两个字段。
为确保数据类型一致,在【元数据】选项中将 student_id 类型修改为Integer。
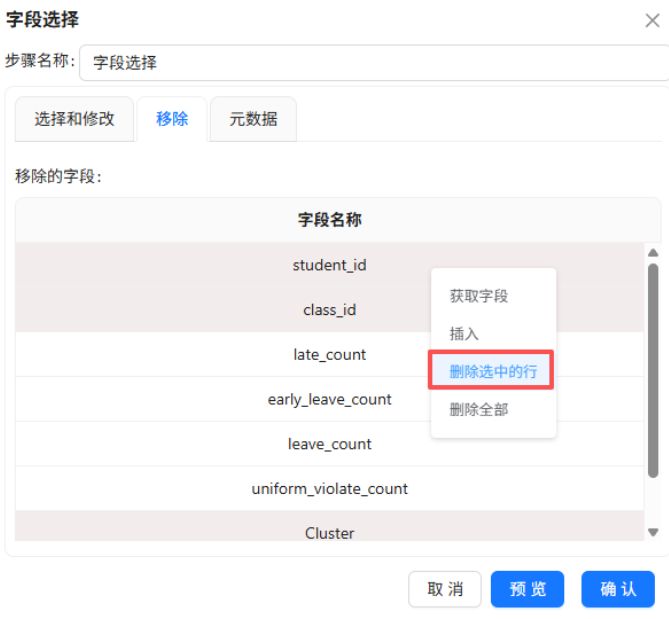
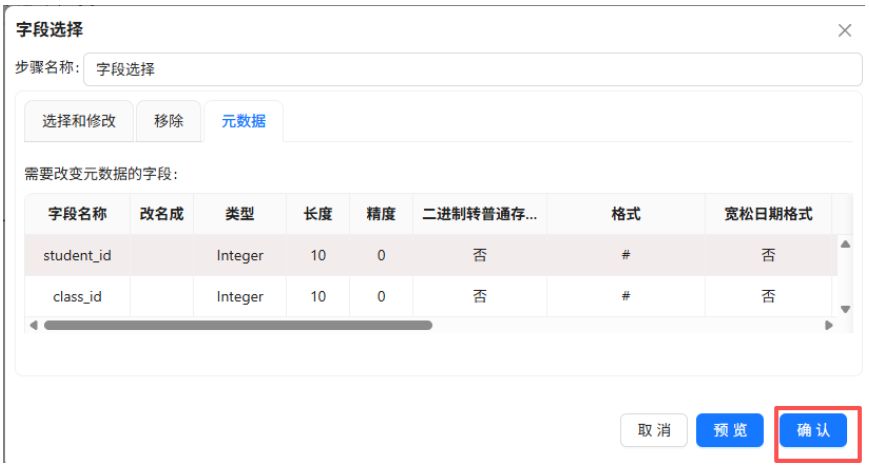
3.3.4 聚类簇编号映射
添加“值映射”组件,将聚类簇编号映射为中文群体分类:
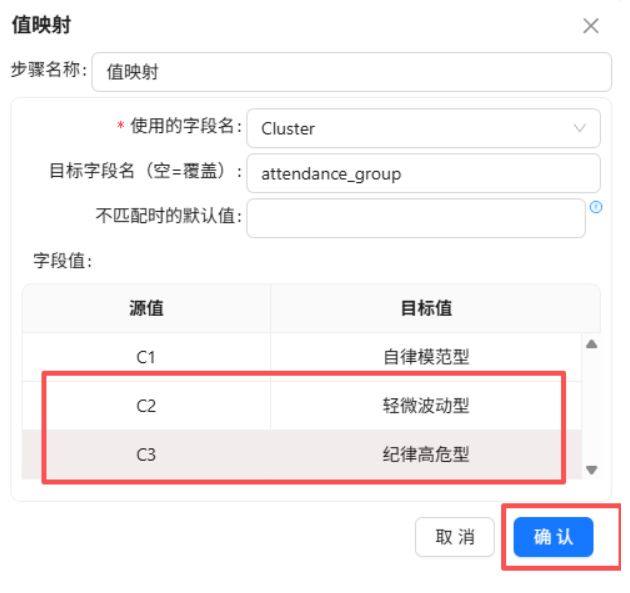
3.3.5 更新学生考勤主题标签表
添加“更新”组件,配置如下:
-
数据库连接:团队私有数据库
-
目标模式:labs
-
目标表:student_attendance_stats
更新条件(关键字):使用 student_id 作为匹配字段
更新字段映射:

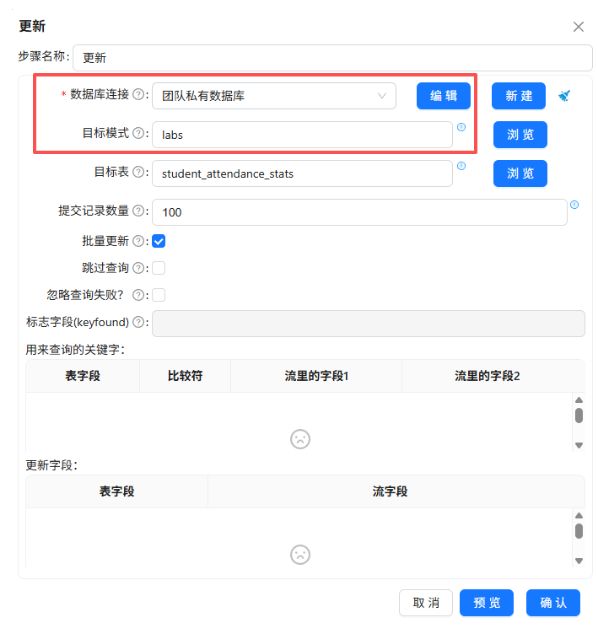
3.3.6 运行转换流
点击运行按钮,执行转换流。

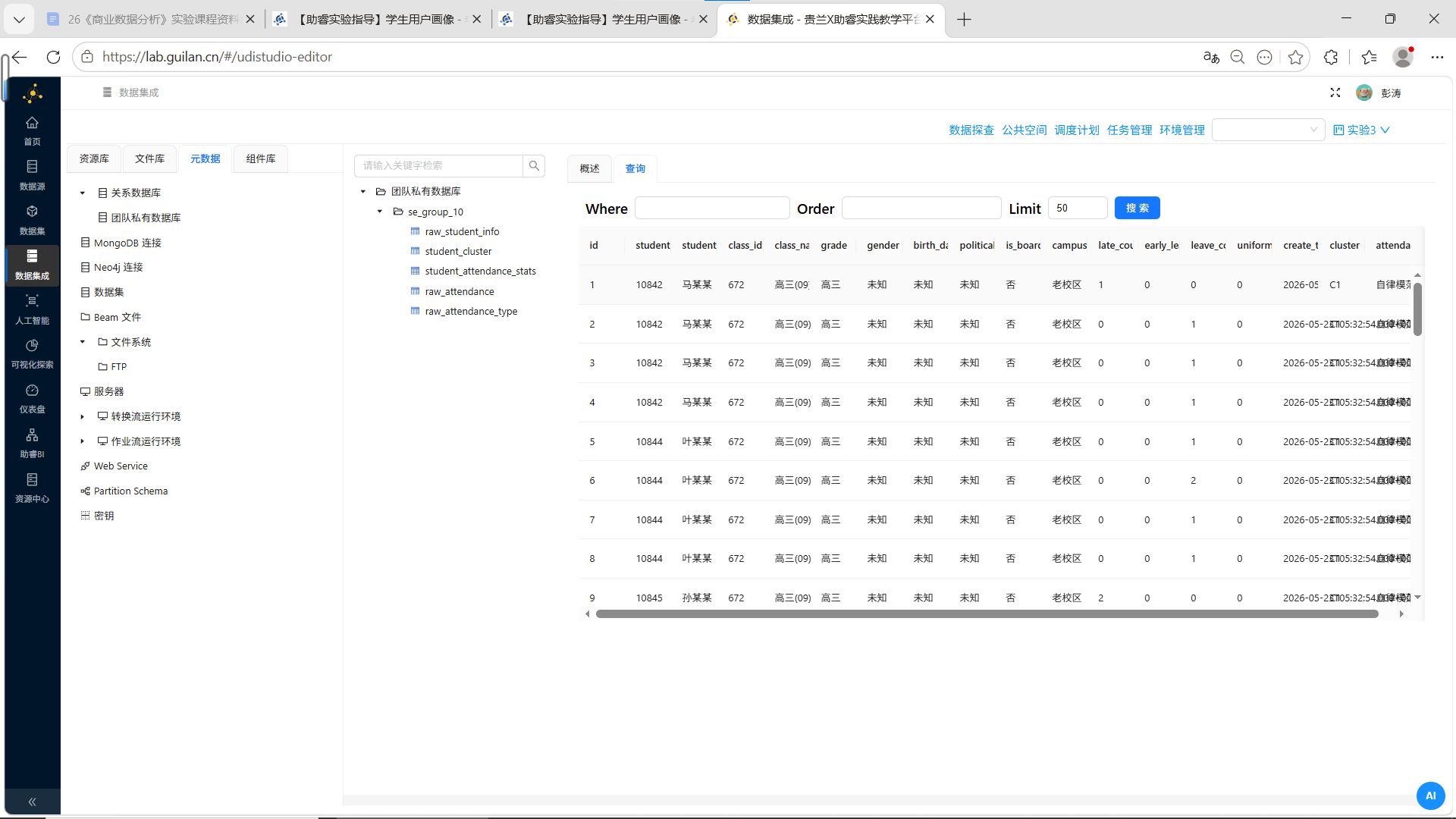
3.3.7 查看结果
-
切换至【元数据】选项,右键“团队私有数据库”,点击【加载元数据】
-
点击【数据探查】,进入数据探查页面
-
点击 student_attendance_stats 表,选择【查询】标签页
可以看到 cluster、attendance_group 字段已成功更新。
4 实验结果
4.1 聚类模型结果

4.2 最终学生考勤主题标签表
student_attendance_stats 表现在包含完整的考勤统计与聚类画像字段:
5 核心组件说明
5.1 AI Studio组件
5.2 助睿BI组件

5.3 数据集成组件
6 常见问题与解决
问题1:K-Means聚类结果无法直接解读
现象:K-Means输出的聚类簇编号为C1、C2、C3,无法直接对应具体的考勤群体类型。
解决方法:通过助睿BI制作6组两两指标散点图,观察各聚类簇在不同指标组合下的分布特征,结合业务经验为每个簇赋予明确的业务含义(自律模范型、轻微波动型、纪律高危型)。
问题2:数据类型不一致导致更新失败
现象:执行更新组件时,student_id 字段类型不匹配导致更新操作失败。
原因:聚类结果表中的 student_id 为String类型,而目标表中的 student_id 为Integer类型。
解决方法:在“字段选择”组件的【元数据】选项中,将 student_id 的类型修改为Integer,确保类型一致。
问题3:仪表盘图表数据显示不全
现象:仪表盘中部分图表只显示了部分数据点。
原因:系统默认限额为2000条数据,当数据量超过2000时会被截断。
解决方法:在工作表设置中,将显示限额设置为100%。
7 实验总结
本次实验完成了以下工作:
7.1 技术能力提升
-
AI Studio建模能力:掌握了从数据加载、K-Means聚类到结果入库的零代码机器学习全流程操作;
-
助睿BI可视化分析能力:学会了数据源连接、数据集构建、工作表制作、仪表盘搭建的可视化分析全流程;
-
ETL数据回写能力:掌握了通过字段选择、值映射、更新等组件完成聚类标签回写至原始表的操作。
7.2 业务价值实现
-
考勤群体自动划分:基于迟到、早退、请假、校服违规四个核心指标,利用K-Means算法完成学生考勤行为的自动分群;
-
可解释的画像构建:通过多维度可视化分析,为机器生成的聚类簇赋予明确的业务含义,形成三类可解释的考勤画像:
-
自律模范型:全维度异常次数极低
-
轻微波动型:偶发轻微违规,整体可控
-
纪律高危型:多维度违纪叠加,需重点关注
-
-
数据资产沉淀:将聚类结果回写至学生考勤主题标签表,完成考勤主题扩展标签构建,为后续精准管理、行为干预提供数据支撑。
7.3 平台优势总结
相比传统编写Python代码进行聚类分析的方式,助睿平台提供了完整的零代码解决方案:
本实验为后续更复杂的机器学习场景(如分类预测、时序分析、异常检测等)奠定了良好的基础。
附录:
-
K-Means聚类参数配置详情见3.1.3节
-
值映射配置详情见3.3.4节
-
更新组件配置详情见3.3.5节

一站式 AI 云服务平台
更多推荐
 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)