
零代码搞定学生考勤画像!K-Means 聚类实战:让 AI 自动识别「乖宝宝」和「刺头」
哈喽大家好!还在用 Excel 一行行筛选考勤异常学生吗?👀 今天这篇保姆级教程,带你用 K-Means 聚类算法 在 助睿数智(Uniplore) 平台上,全程零代码、拖拽式 完成学生考勤行为分群。不用写一行 Python,AI 自动帮你把学生分成「乖宝宝型」「偶尔摸鱼型」「重点关注型」,直接输出可解释的考勤画像!🚀
🛠️ 实验平台速览
本次实验的「主战车」是 助睿数智(Uniplore)一站式数据科学实验平台:
-
平台定位: 全链路 Agentic 零代码,从数据接入、ETL 清洗、AI 建模到 BI 可视化,一站式包圆!
-
实验平台地址: https://lab.guilan.cn/
-
核心模块: 数据集成平台(ETL)、人工智能平台(AI Studio)、助睿 BI 数据可视化探索平台
第一部分:实验背景与大盘逻辑
1.1 我们要做什么?(实验目的)
简单来说,就是基于已完成的 学生考勤主题标签表(student_attendance_stats),把里面记录的 迟到、早退、请假、校服违规 次数等核心指标丢给 K-Means 算法。让 AI 自动把学生分成几个群,生成可解释的考勤画像,存回数据库,为校园精细化管理提供精准数据支撑。
1.2 手里有什么牌?(实验数据大揭秘)
前置实验已经输出了一张干净、标准化的宽表,存放在团队私有 MySQL 数据库中。这张表共 16 个字段:
| 字段名 | 说明 | 类型 |
|---|---|---|
| id | 自增主键 | 整数 |
| student_id | 学生 ID | 整数 |
| student_name | 学生姓名 | 文本 |
| class_id/class_name | 班级信息 | 整数 / 文本 |
| grade | 年级 | 文本 |
| gender | 性别 | 二分类 |
| birth_date | 出生日期 | 日期 |
| political_status | 政治面貌 | 文本 |
| is_boarder | 是否住校 | 二分类 |
| campus_type | 校区类型 | 文本 |
| late_count | 迟到次数 | 整数 |
| early_leave_count | 早退次数 | 整数 |
| leave_count | 请假次数 | 整数 |
| uniform_violate_count | 没穿校服次数 | 整数 |
| create_time | 统计入库时间 | 日期时间 |
核心特征: 我们真正用来建模的,就是后面带 ⭐ 的 4 个连续型考勤次数指标。
1.3 建模思路大公开(为什么这么干?)
在把数据喂给 AI 之前,先盘盘逻辑,这也是数据分析师最核心的内功:
-
拒绝花里胡哨,直击核心维度: 数据维度清晰,变量数量适中。直接锁定「迟到、早退、请假、校服违规」这 4 类行为维度。它们业务含义独立、相关性低,丢进 K-Means 跑出来的结果解释性最强,无需复杂降维。
-
数据类型天然契合 K-Means: 考勤次数均为非负整数,属于纯纯的「连续型变量」。这意味着 根本不需要做哑变量编码、二值化或特殊转换,直接原汁原味输入模型,简化预处理流程,保证聚类结果稳定可靠。
-
基础属性只围观,不参战: 敲黑板!像
gender、grade、is_boarder这类离散属性 不参与聚类建模(防止干扰距离计算),只作为后续画像标签的辅助解释变量。
🧠 干货小课堂:为什么选 K-Means?
K-Means(K 均值)属于机器学习中的 无监督学习(Unsupervised Learning) 算法。它的强大之处在于「不需要人工提前打标」,通过计算数据点在多维空间中的 欧氏距离(Euclidean Distance),自动把特征相似的数据「聚」成一堆(即「物以类聚」)。特别适合做冷启动阶段的用户画像分群、RFM 模型客户分层等场景。
第二部分:实操步骤(手把手跟着做)
阶段一:AI Studio 聚类建模(让机器干活)
Step 1:新建工作流 —— 开辟主战场
-
操作路径: 登录实验平台 → 左侧菜单「人工智能」→ 进入 AI Studio 用户空间 → 点击左上角「+」→ 选择「新建工作流」。
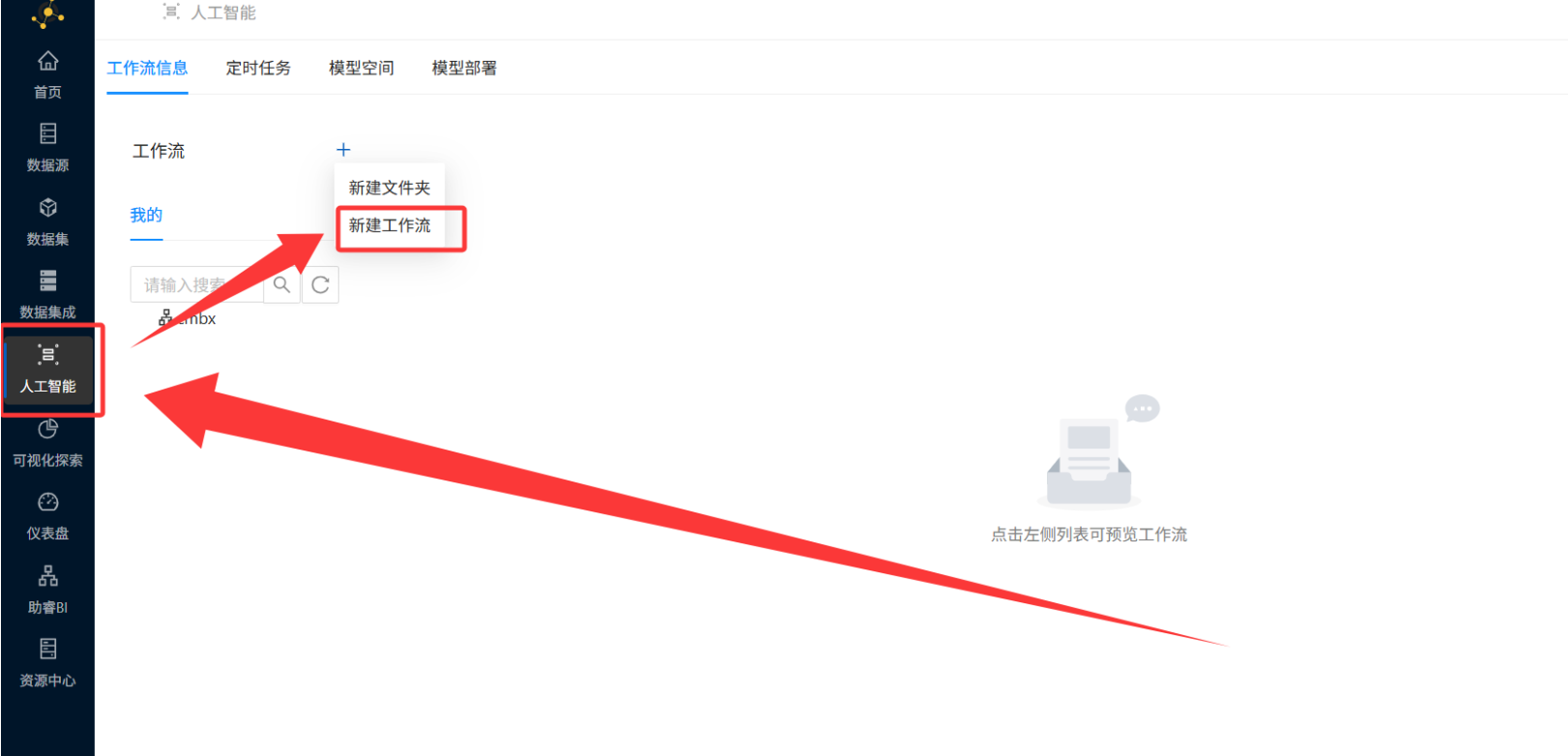
AI Studio 是集构建、运行、编辑、查看于一体的工作区域,包含菜单栏、控件列表和画布三大模块。在这里,我们将搭建从数据加载到聚类建模、结果输出的完整流程。
Step 2:数据导入 —— 把考勤数据请进来
-
操作路径: 在左侧控件列表搜索「数据库加载」→ 硬核拖拽到画布中 → 双击控件进行参数配置。
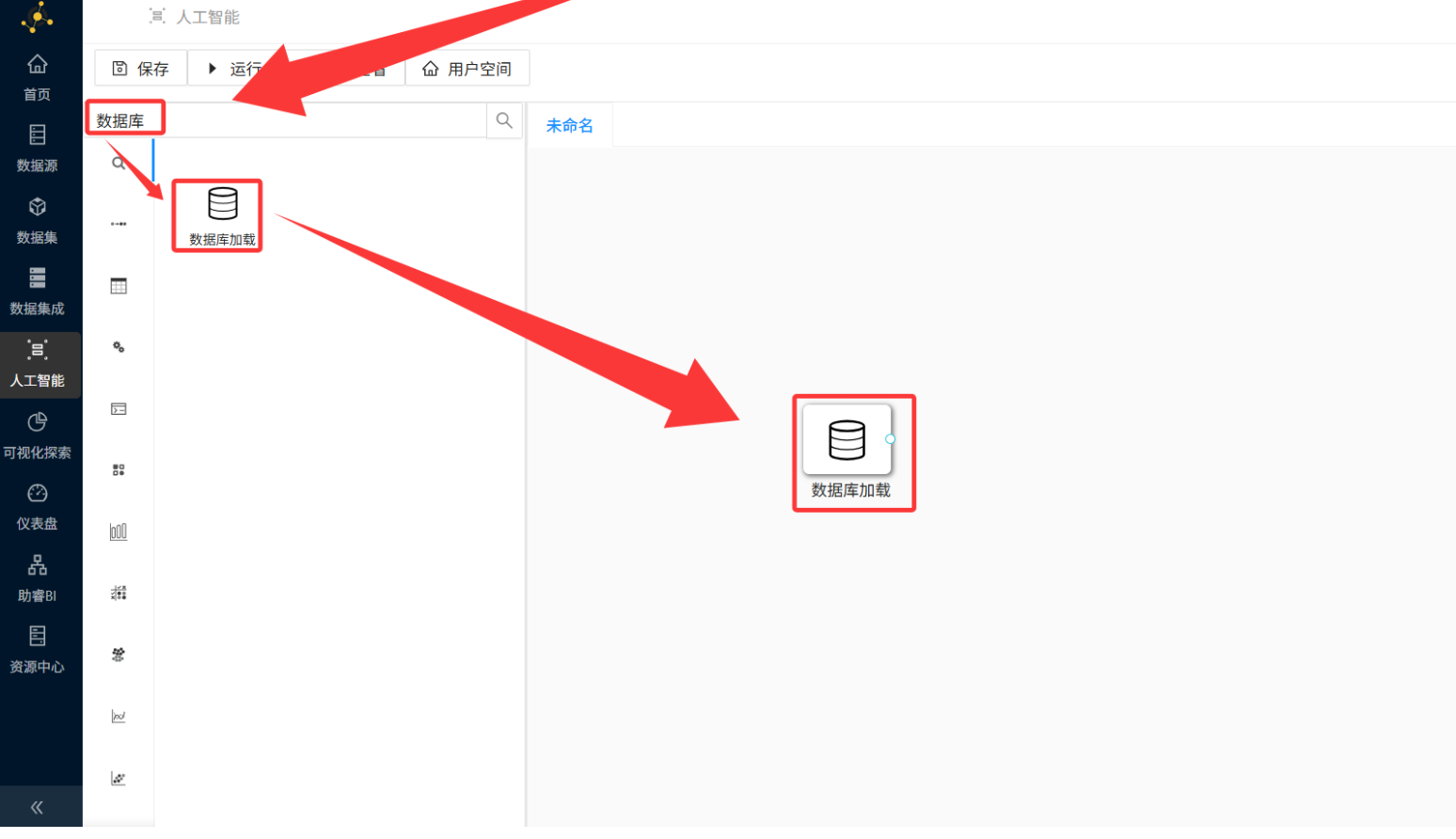
配置要点:
-
数据库类型选择 MySQL,填入团队私有数据库的连接地址、端口(3306)、库名、用户名和密码,点击「连接」。
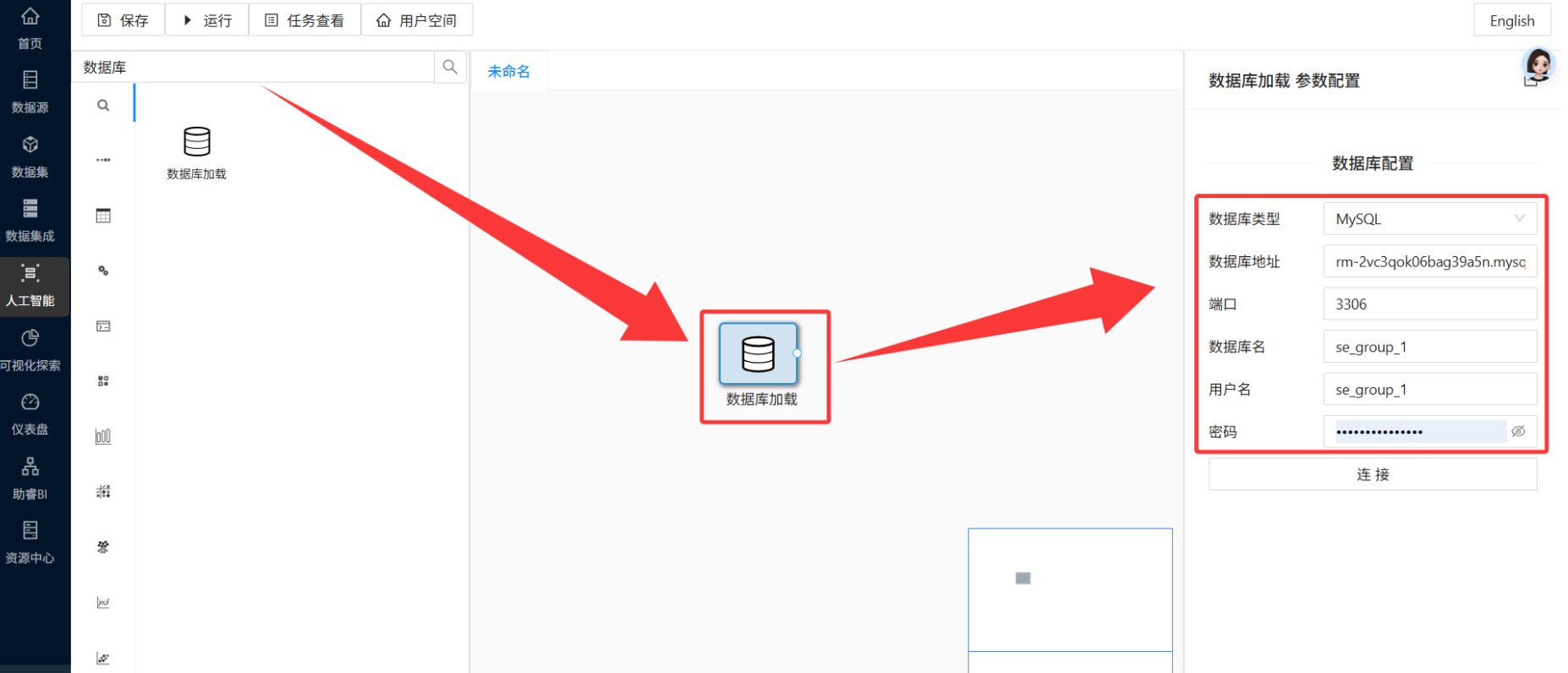
-
在弹出的交互配置窗口中,下拉选中我们的主角表
student_attendance_stats。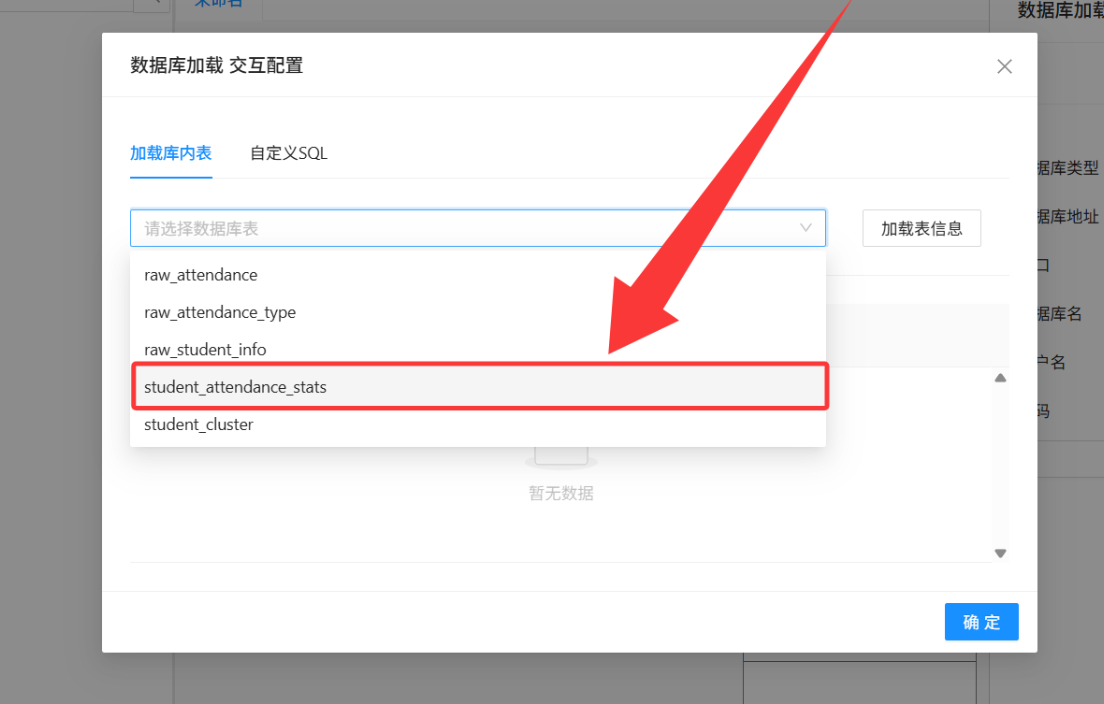
-
字段筛选(重点!): 为保留的字段选择对应属性类型,其余字段选择 skip(跳过)。
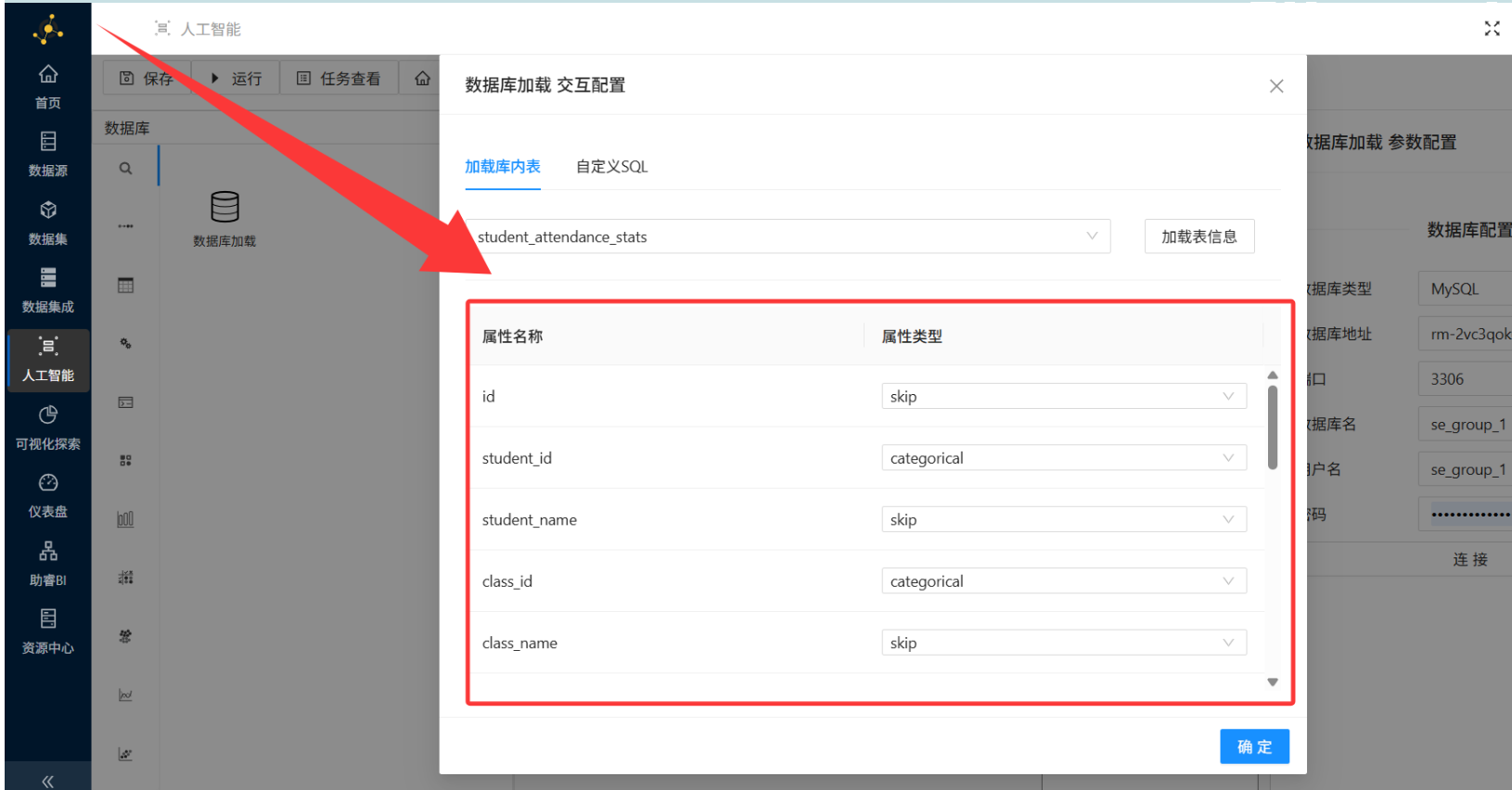
| 属性名称 | 属性类型 | 属性名称 | 属性类型 |
|---|---|---|---|
| id | skip | political_status | skip |
| student_id | categorical | is_boarder | skip |
| student_name | skip | campus_type | skip |
| class_id | categorical | late_count | numeric |
| class_name | skip | early_leave_count | numeric |
| grade | skip | leave_count | numeric |
| gender | skip | uniform_violate_count | numeric |
| birth_date | skip | create_time | skip |
-
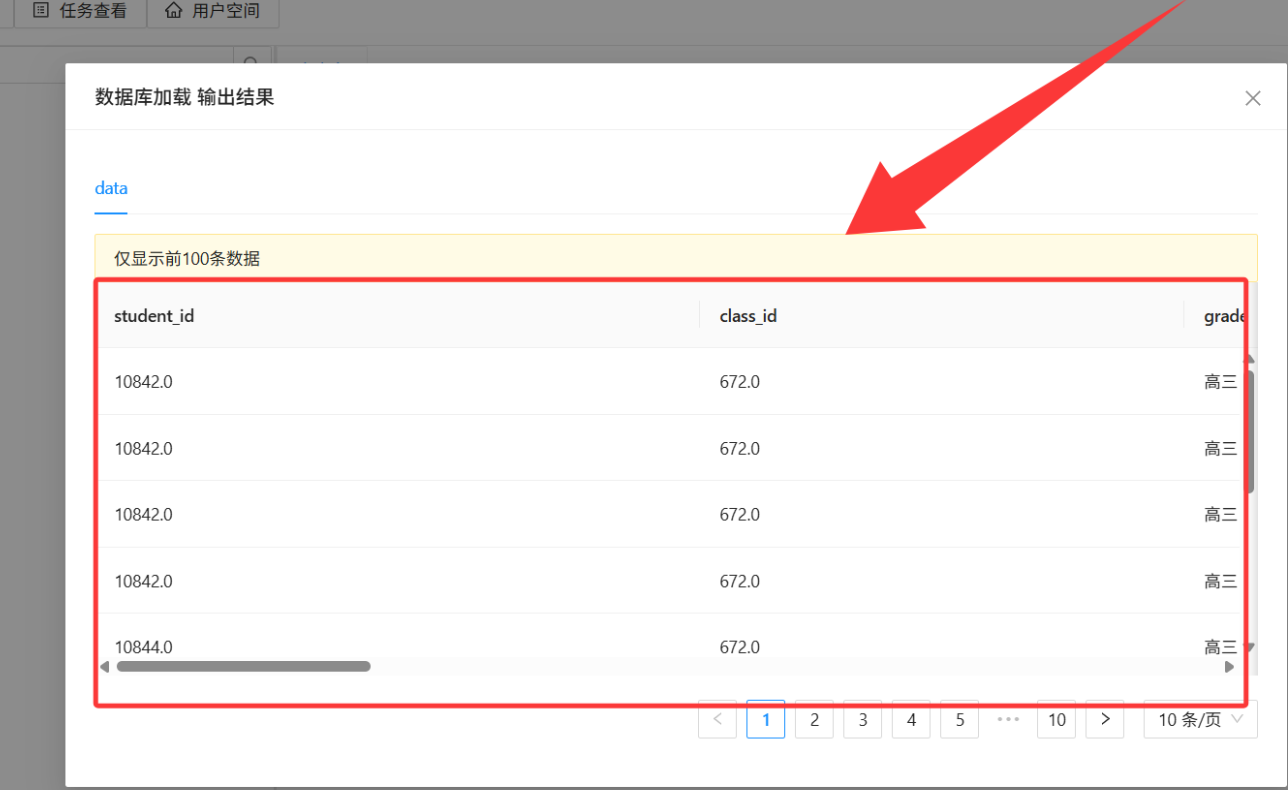
点击「确定」保存配置。右键该控件 →「运行该控件」→ 运行成功后右键「查看输出结果」,确认数据已正确加载。
Step 3:K-Means 聚类 —— 让 AI 自动分群
-
操作路径: 在控件列表搜索「K-Means」→ 拖拽到画布 → 创建从「数据库加载」到「K-Means」的连线。
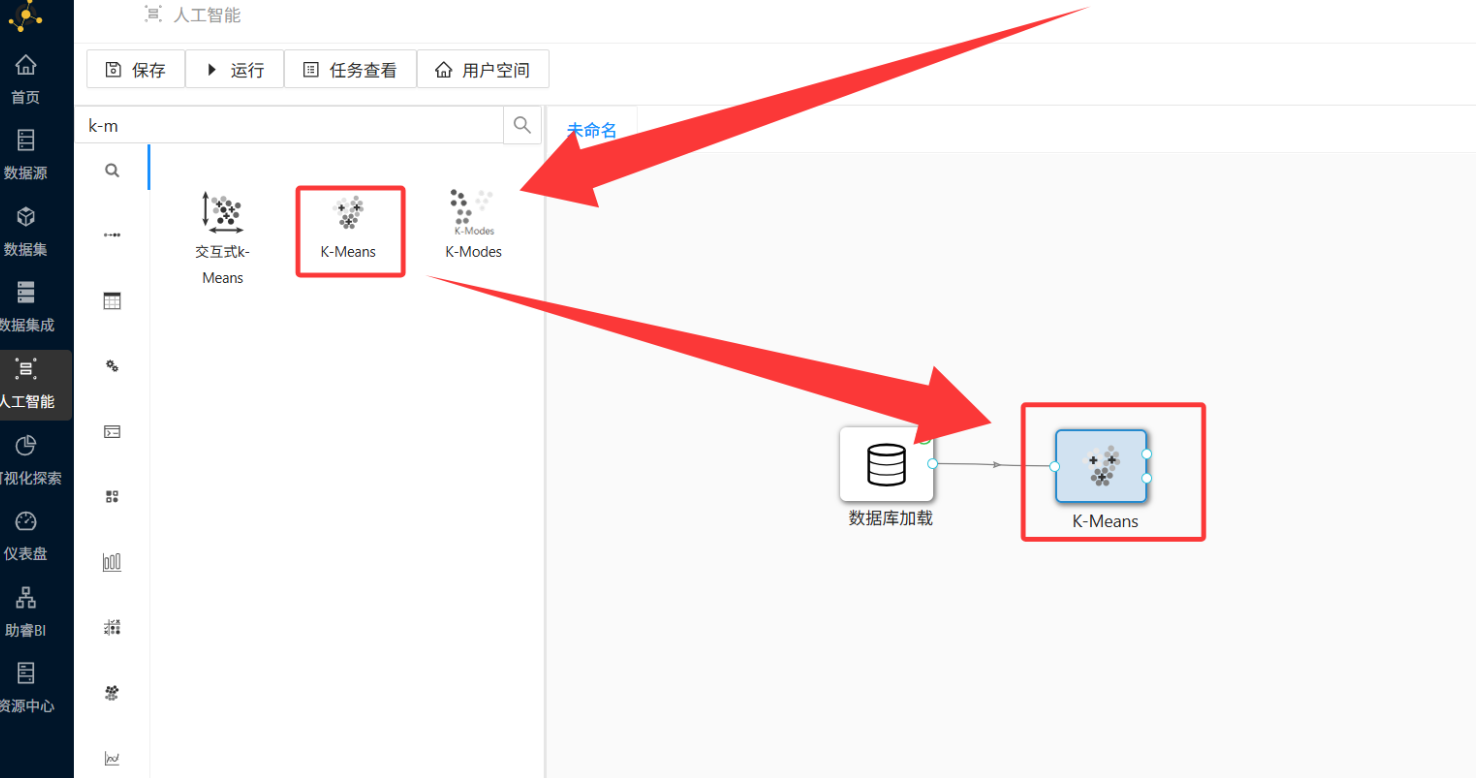
双击「K-Means」控件,配置窗口中:
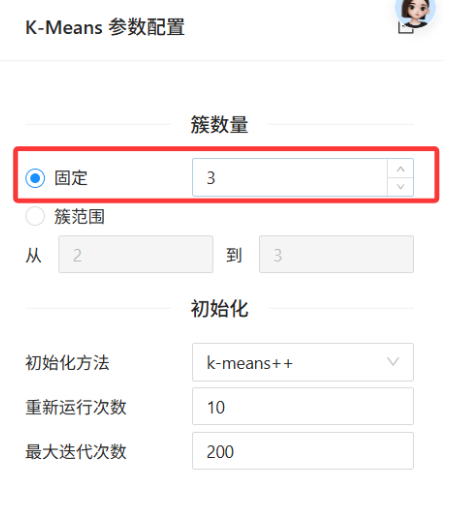
-
簇数量: 选择「固定」,填入 3(即把学生分为 3 类)。
-
初始化方法:
k-means++(默认,更优的初始中心点选择策略)。 -
重新运行次数: 10(避免局部最优)。
-
最大迭代次数: 200。
其他参数保持默认,点击确定。右键运行该控件,查看输出结果,可以看到每个学生都被标记了对应的簇类 C1 / C2 / C3,以及对应的轮廓系数(Silhouette)。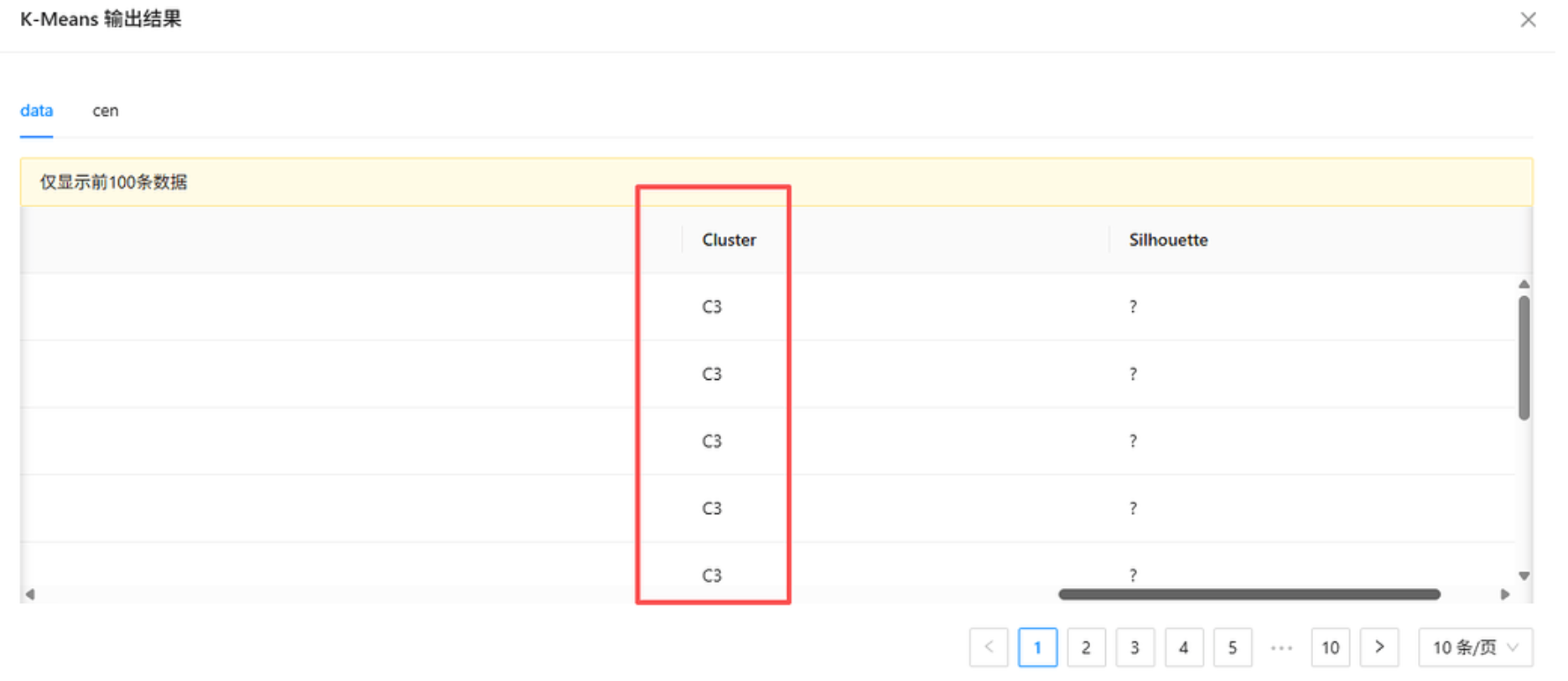
Step 4:结果输出与保存 —— 把聚类结果落库
聚类后的数据需要保存到数据库中,以便后续在 BI 平台做可视化分析。
-
操作路径: 搜索「数据入库」控件 → 拖拽到画布 → 创建从「K-Means」到「数据入库」的连线 → 双击配置。
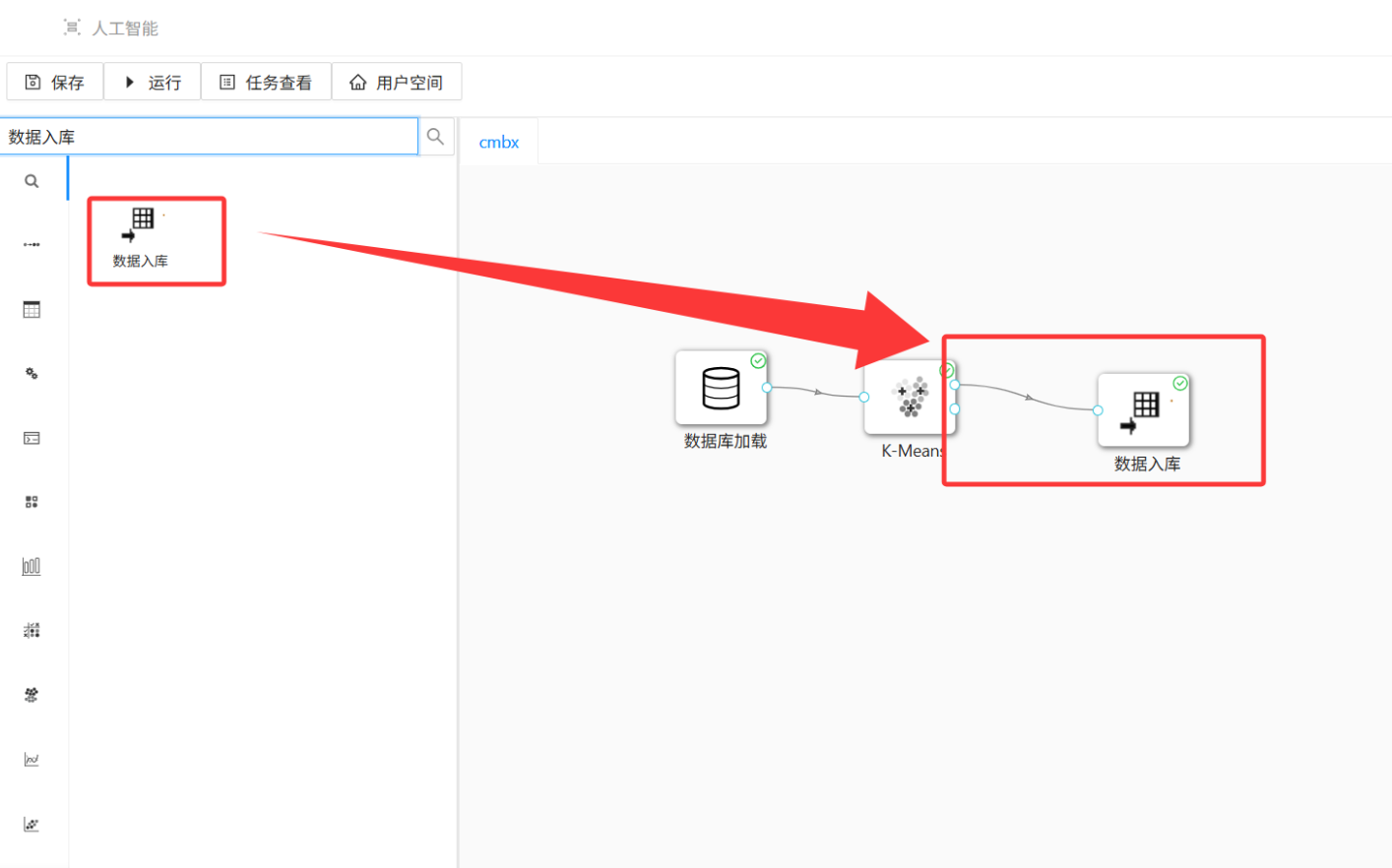
配置要点:
-
数据库配置中再次输入团队私有数据库的参数,点击「获取表信息」。
-
在交互配置窗口中,选择「新建数据表」,表名称修改为
student_cluster,勾选「清空重建表」(如有需要),点击「确定」。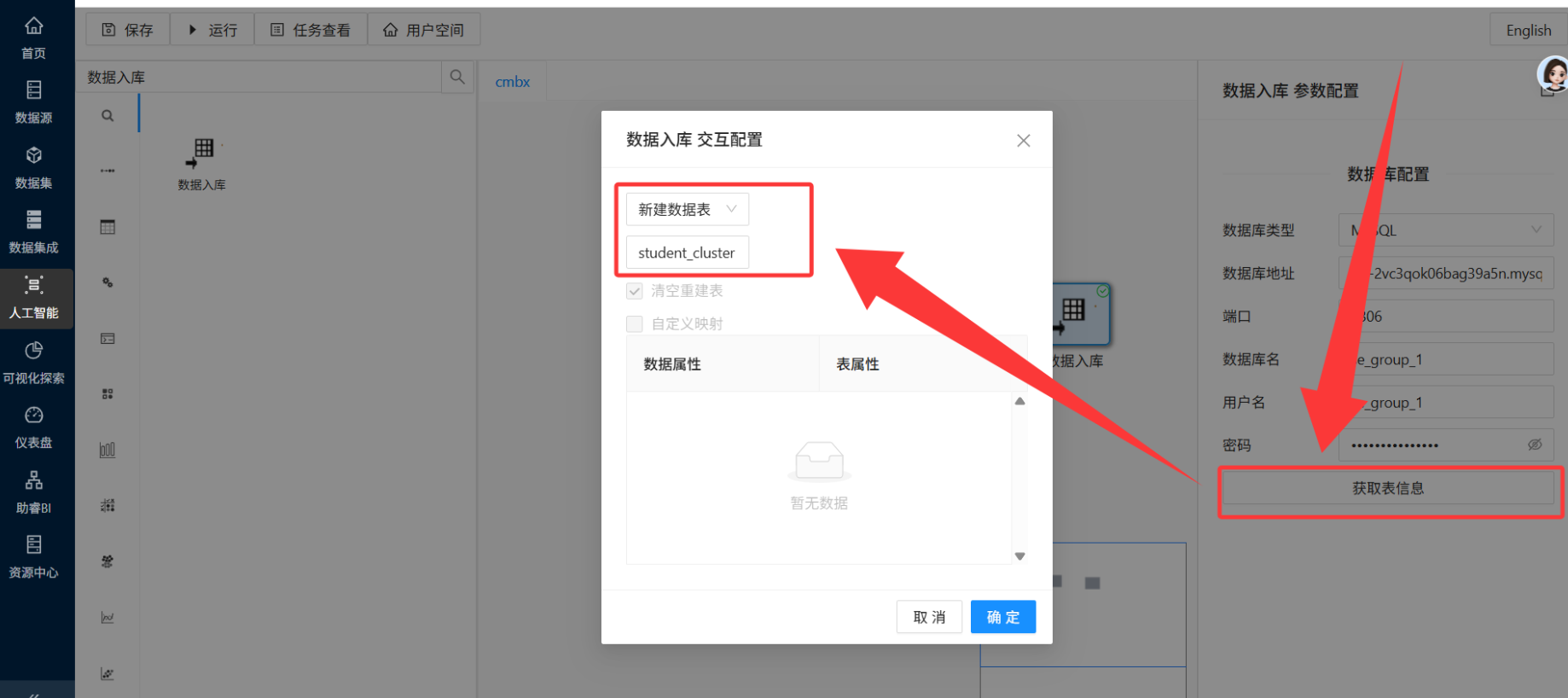
-
点击顶部菜单栏的「运行」按钮,运行整个工作流。当所有控件右上角都出现绿色对勾 ✅,表示工作流运行成功,聚类结果已写入
student_cluster表。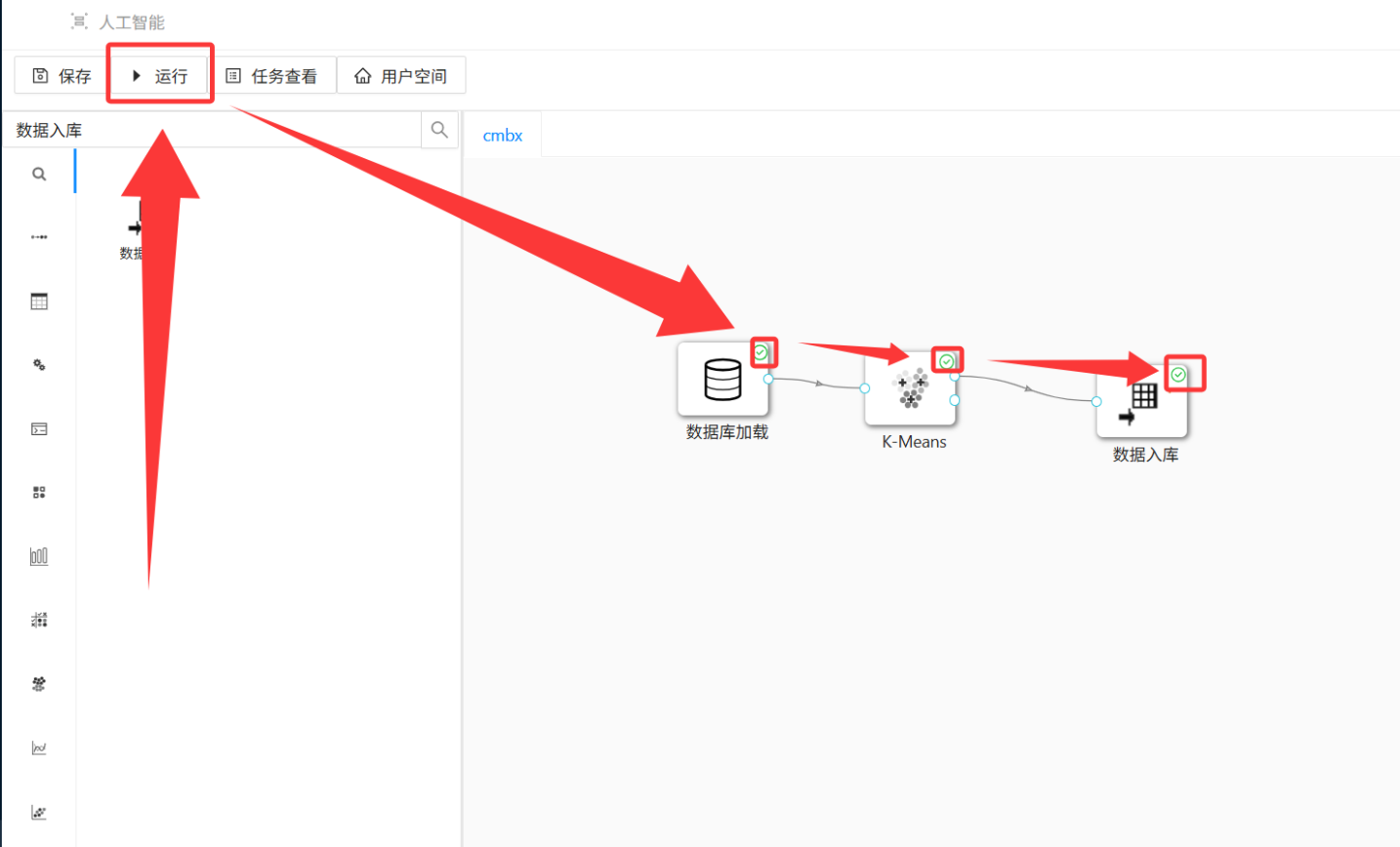
阶段二:助睿 BI 可视化分析(给聚类结果赋予业务含义)
上一步输出的聚类簇编号(C1/C2/C3)只是机器视角的分类,接下来要通过 助睿 BI 的可视化分析,确定每个簇对应的真实考勤群体分类(比如「全勤乖宝宝」「偶尔迟到型」「重点关注型」)。
Step 1:进入助睿 BI 平台
-
操作路径: 点击实验平台左侧菜单「助睿 BI」→ 进入助睿 BI 平台首页。
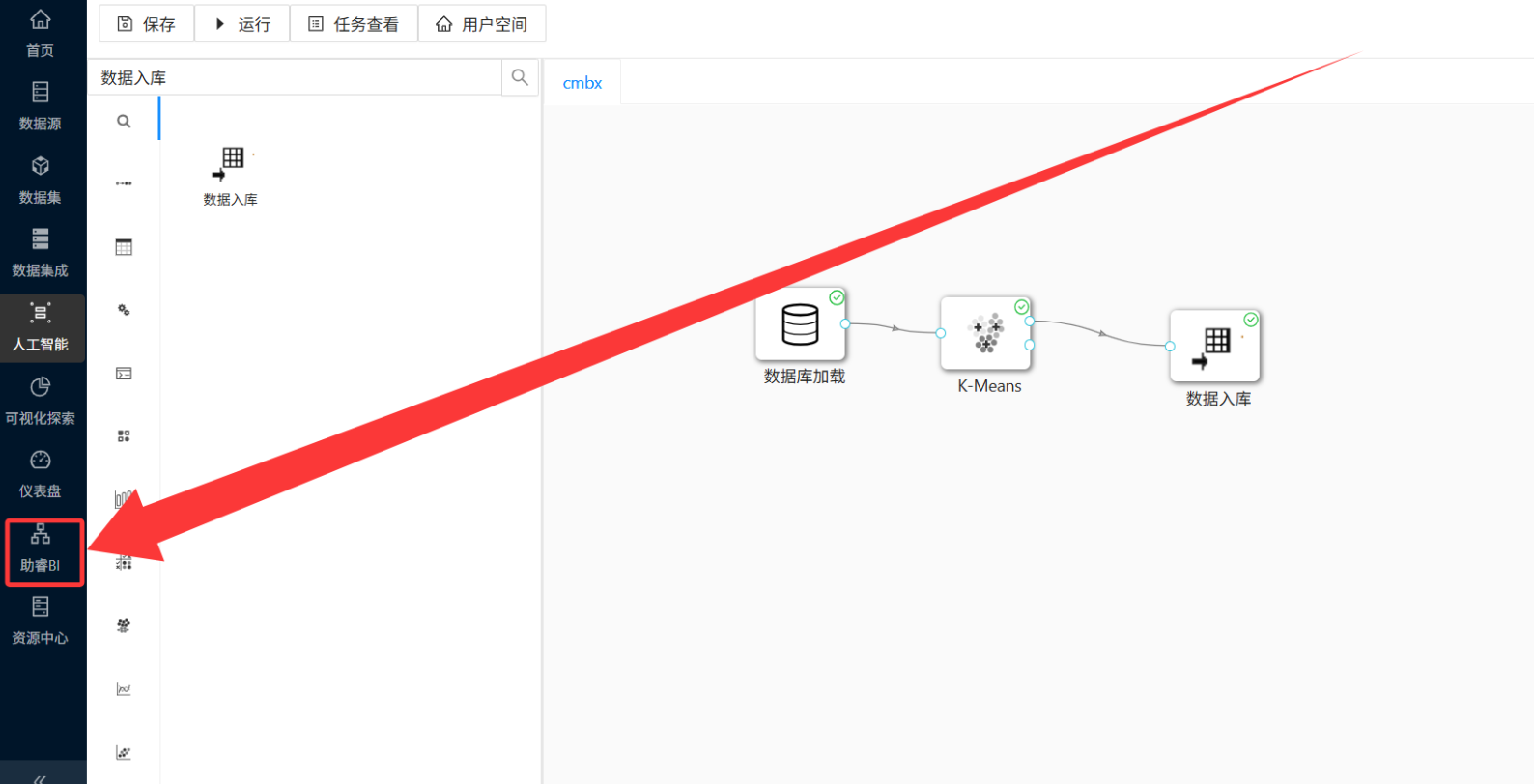
💡 避坑提示: 如果进入的是登录页面,直接关闭后重新从实验平台点击进入即可。
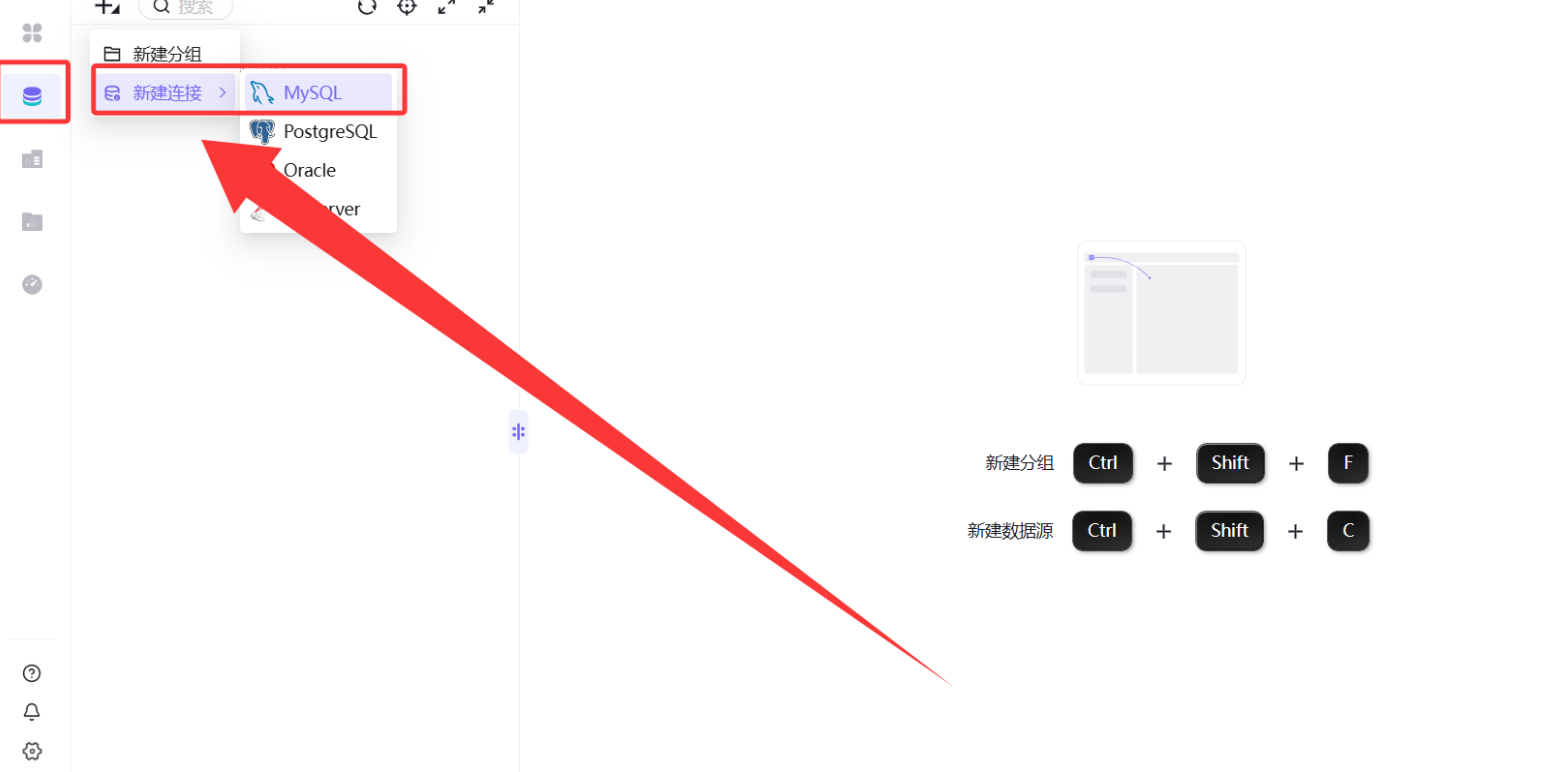
Step 2:连接数据源 —— 让 BI 认识你的数据库
student_cluster 表存放在团队私有数据库中,需要先在 BI 平台创建数据库连接。
-
操作路径: 左侧菜单「数据源」→ 左上角「+」→「新建连接」→ 选择 MySQL。
-
在弹出的窗口中输入数据库连接信息(主机地址、端口 3306、用户名、密码等),点击「测试连接」。
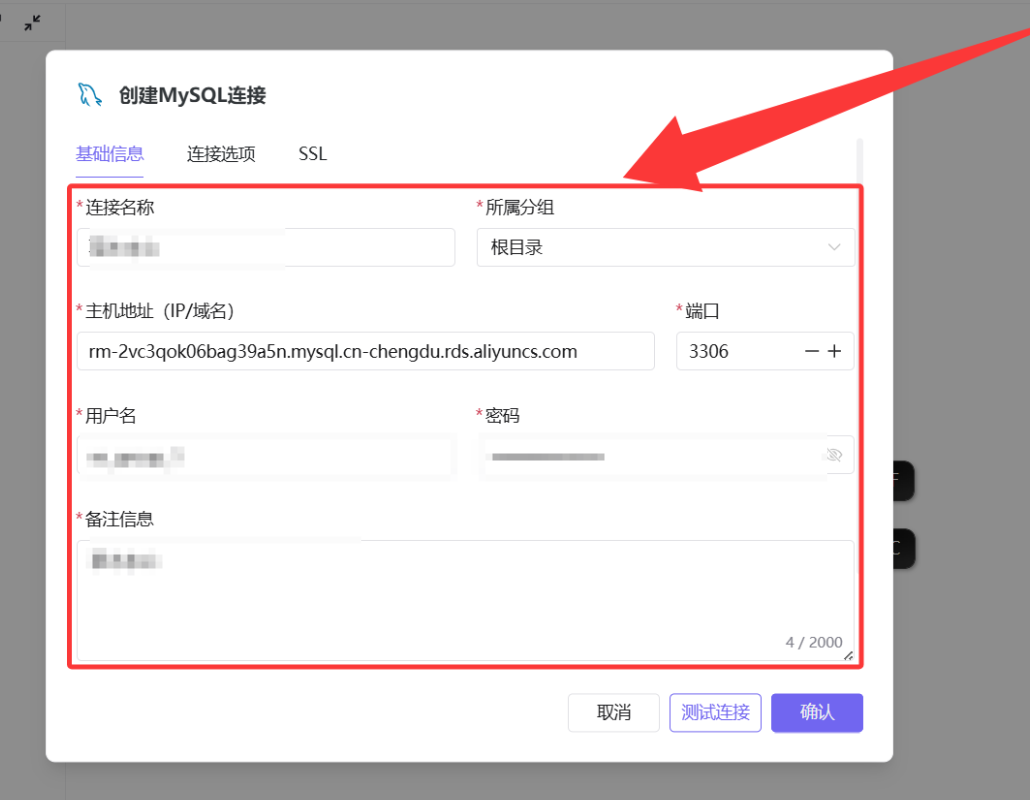
-
出现「测试连接成功」提示后,点击「确认」。
-
展开新建的数据源目录,可以看到
student_cluster表已出现在列表中。右键点击该表 →「查看表数据」,可预览聚类结果。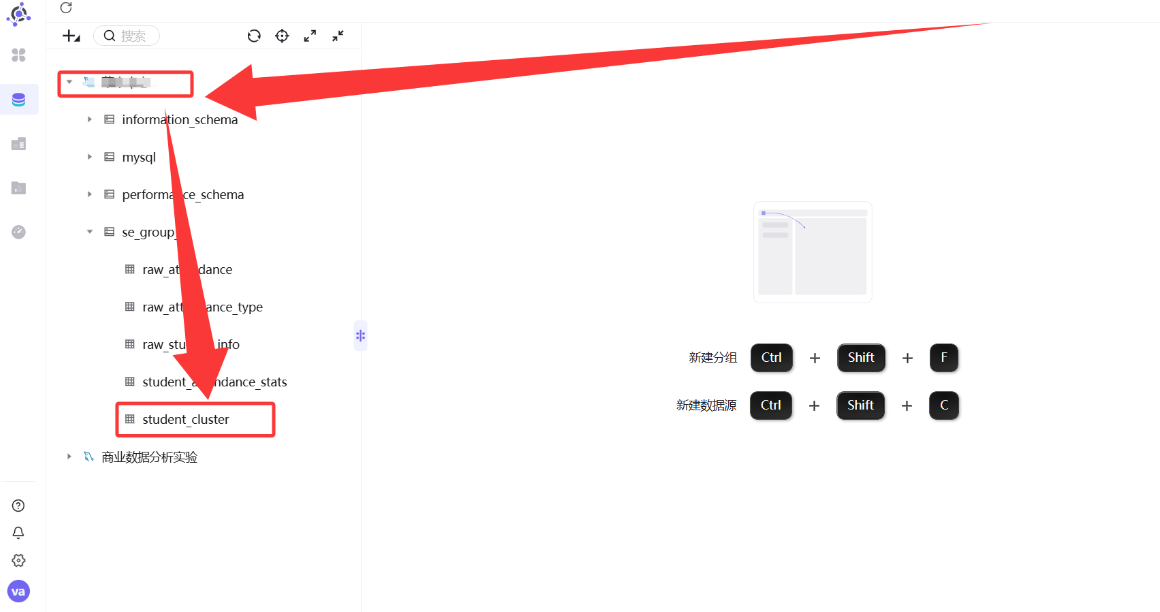
Step 3:构建数据集 —— 为可视化做准备
数据源连接成功后,需要将分析所需的数据表构建为数据集。
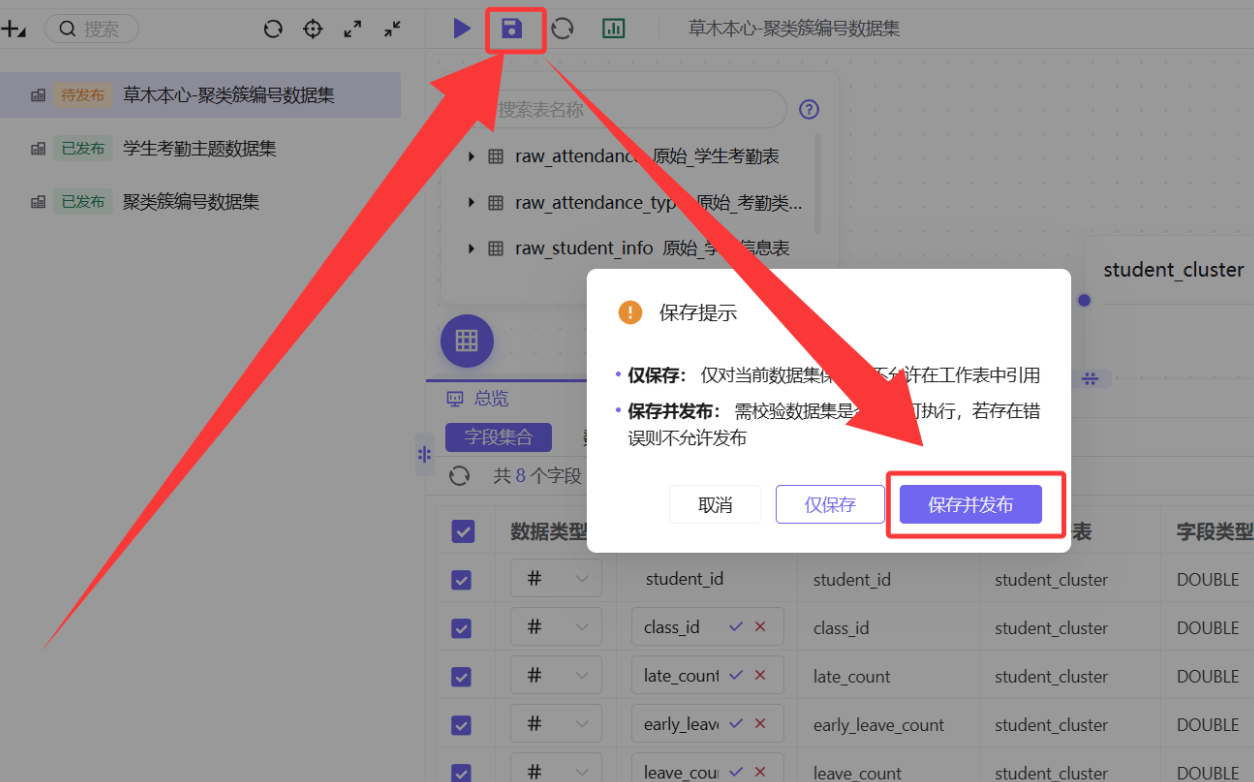 数据集创建成功后,会进入数据集详情页,显示字段列表和数据预览。此时我们的数据准备工作已经完成,接下来进入真正的可视化分析环节!
数据集创建成功后,会进入数据集详情页,显示字段列表和数据预览。此时我们的数据准备工作已经完成,接下来进入真正的可视化分析环节!
-
操作路径: 左侧菜单「数据集」→ 左上角「+」→「新建数据集」→ 选择刚才连接的数据源及
student_cluster表 → 按向导完成数据集构建。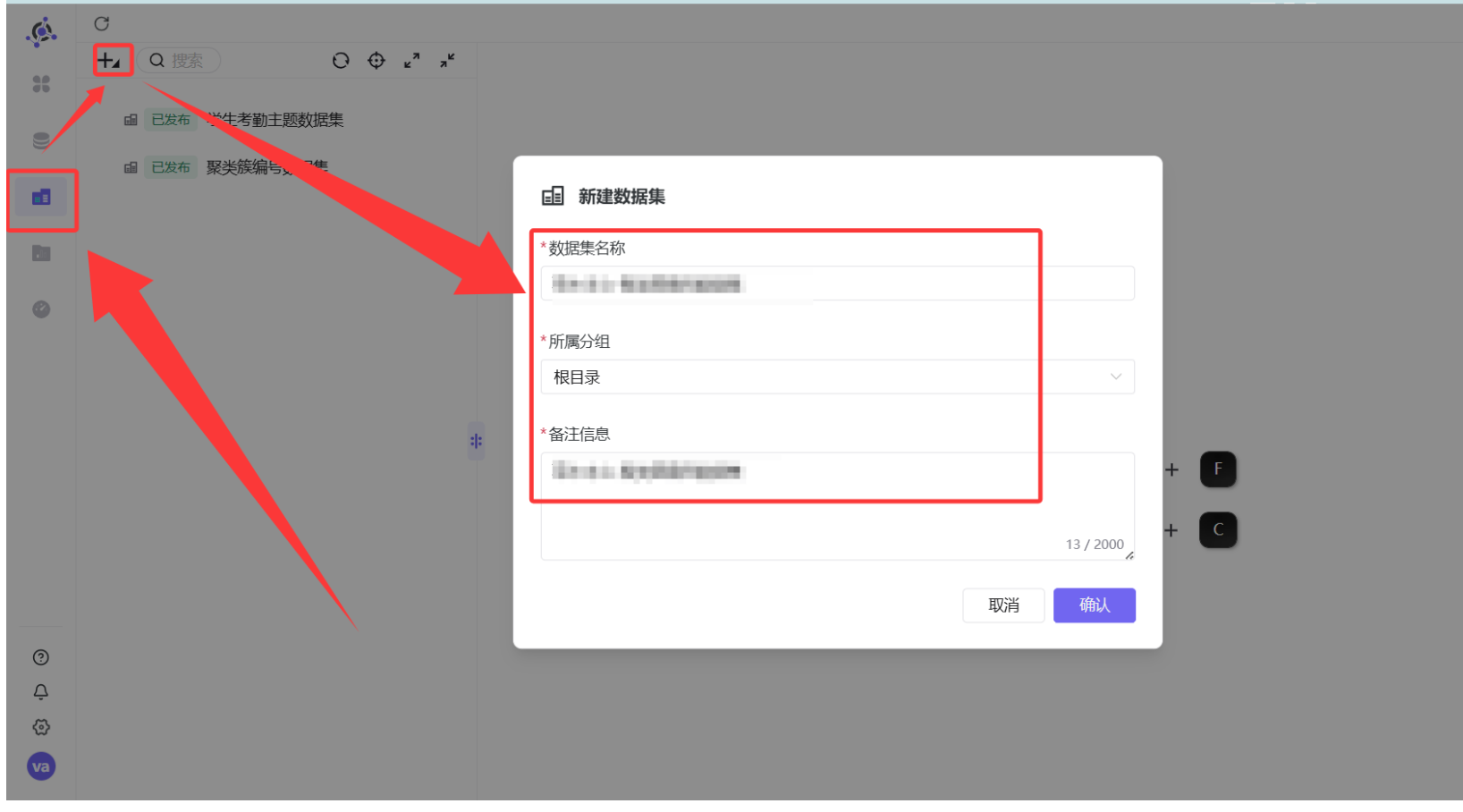
阶段三:可视化探索——让聚类结果"开口说话"
数据集构建完成后,我们要通过可视化图表来分析三个簇(C1/C2/C3)的考勤特征差异,从而给每个簇赋予业务含义(比如"全勤乖宝宝""偶尔迟到型""重点关注型")。
Step 4:创建可视化工作表
操作路径: 左侧菜单「工作表」→ 左上角「+」→「新建工作表」→ 选择刚才创建的 student_cluster 数据集。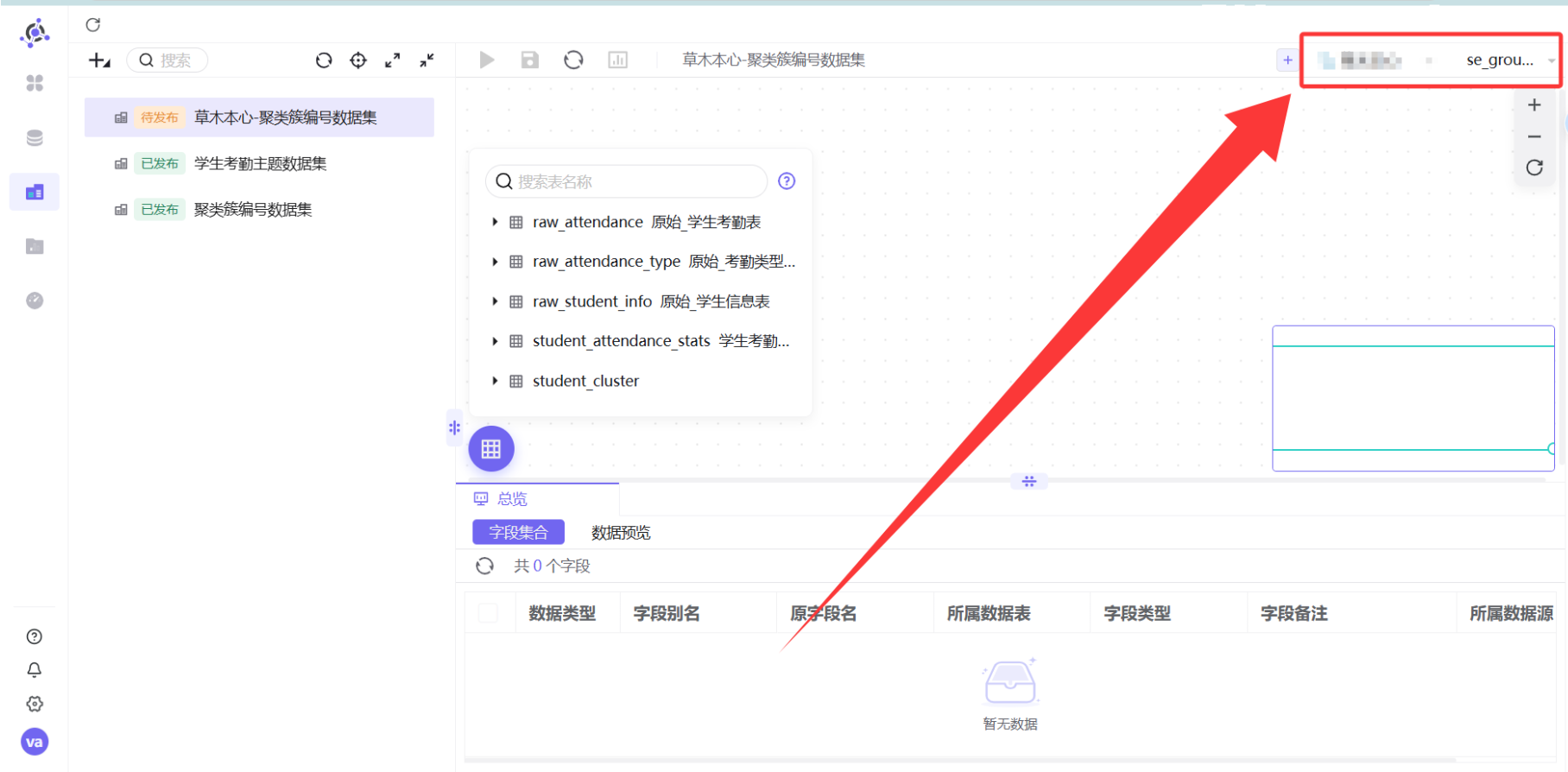
进入工作表编辑界面后,你会看到左侧是维度和度量面板,右侧是画布区域。接下来我们要制作几张核心图表:
-
操作路径:
-
左侧「维度」面板找到
Cluster字段,拖拽到「列」区域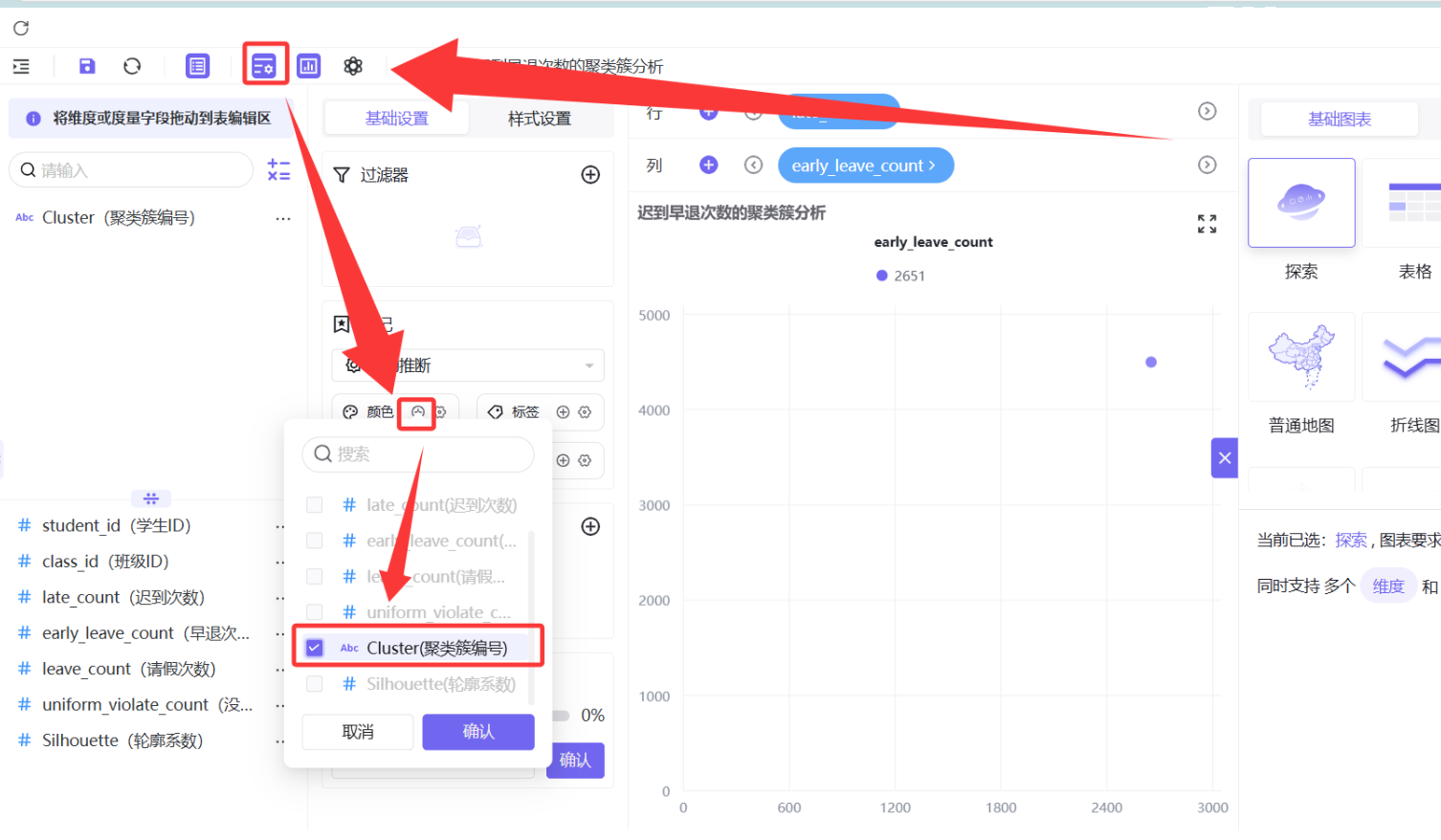
-
左侧「度量」面板依次将
late_count、early_leave_count、leave_count、uniform_violate_count拖拽到「行」区域,并都设置为「平均值」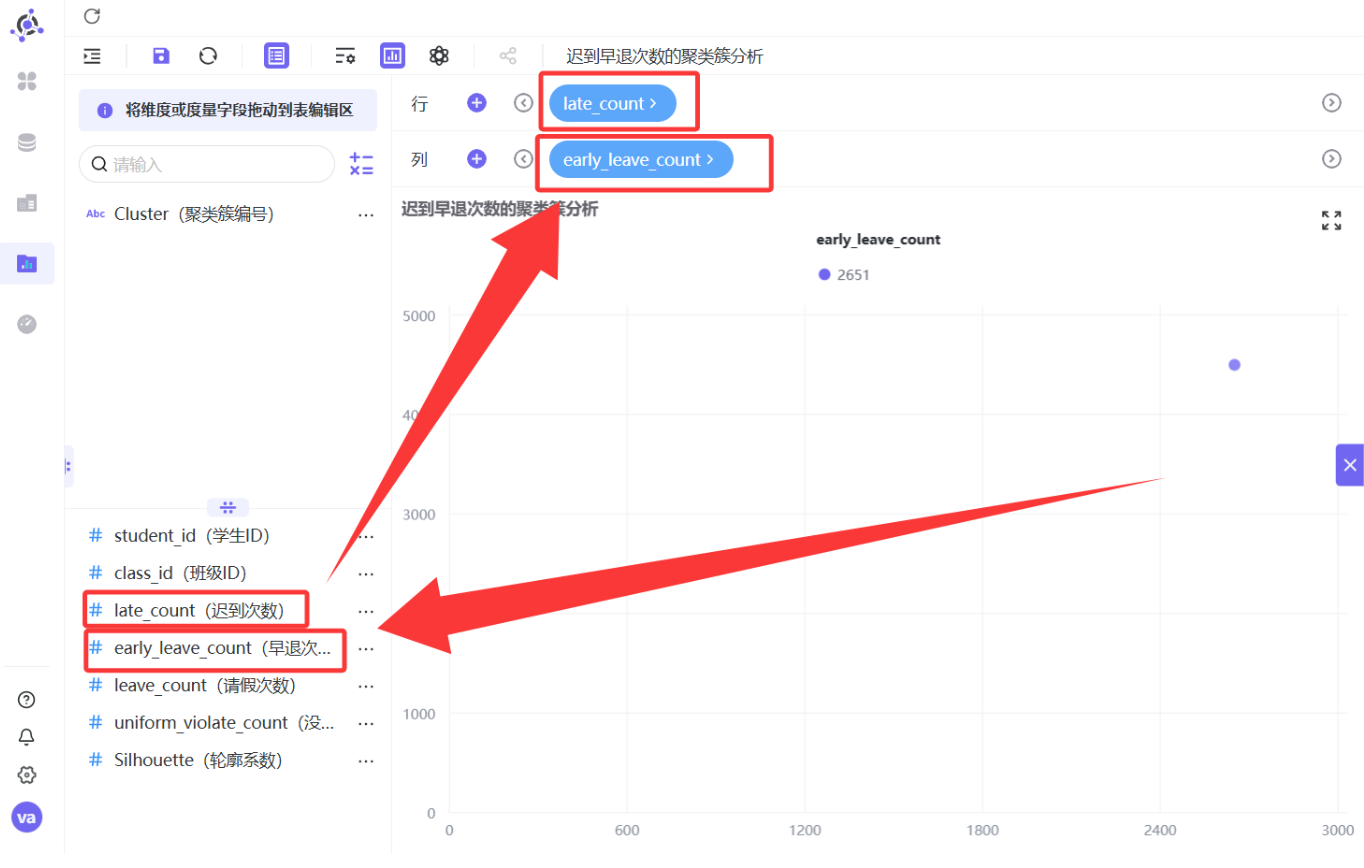
-
顶部图表类型选择
-
🔥 核心洞察示例:
C1: 四项指标均为0或接近0 → 「全勤乖宝宝」
C2:
late_count和uniform_violate_count轻度偏高,其他为0 → 「偶尔摸鱼型」C3:
late_count、early_leave_count、leave_count均显著偏高 → 「重点关注型」
阶段四:画像命名与标签生成——给机器结果赋予灵魂
通过上面的可视化分析,我们现在可以明确每个簇的业务含义了。这一步是从"技术语言"到"业务语言"的翻译,也是整个实验最有价值的部分!
Step 5:确定画像标签
根据各簇的考勤特征,建议采用如下命名规范:
| 簇编号 | 画像标签 | 标签定义 | 管理建议 |
|---|---|---|---|
| C1 | 全勤乖宝宝 | 四项考勤指标均为 0,无异常记录 | 公开表扬,树立榜样 |
| C2 | 偶尔摸鱼型 | 某 1 项指标轻度异常(如偶尔迟到≤2 次) | 口头提醒,关注趋势 |
| C3 | 重点关注型 | 多项指标显著偏高,或单一指标严重超标 | 班主任约谈,家校联动 |
📝 命名技巧:
避免负面词汇: 不用"差生""刺头",改用"需关注""偶发异常"等中性词
体现可干预性: 标签要暗示"这个群体可以通过管理措施改善"
保持简洁: 4-6个字最佳,方便后续在报表和通知中使用
阶段五:数据回写与资产沉淀
如果你希望将这些画像标签写回数据库,供其他系统(如班主任工作台、家长通知系统)调用,可以通过以下方式实现:
方案A:在BI中直接导出
-
操作路径: 工作表右上角「···」→「导出数据」→ 选择 CSV/Excel 格式
-
适用场景: 临时给班主任发邮件、制作PPT汇报材料
方案B:通过SQL将标签更新回原表(推荐)
在 MySQL 客户端或平台的 SQL 编辑器中执行:
-- 给 student_attendance_stats 表添加画像标签字段
ALTER TABLE student_attendance_stats
ADD COLUMN attendance_profile VARCHAR(20);
-- 根据聚类结果更新标签(示例,需根据你的实际Cluster含义调整)
UPDATE student_attendance_stats s
JOIN student_cluster c ON s.student_id = c.student_id
SET s.attendance_profile = CASE
WHEN c.Cluster = 'C1' THEN '模范守纪型'
WHEN c.Cluster = 'C2' THEN '偶发异常型'
WHEN c.Cluster = 'C3' THEN '高频违规型'
ELSE '未分类'
END;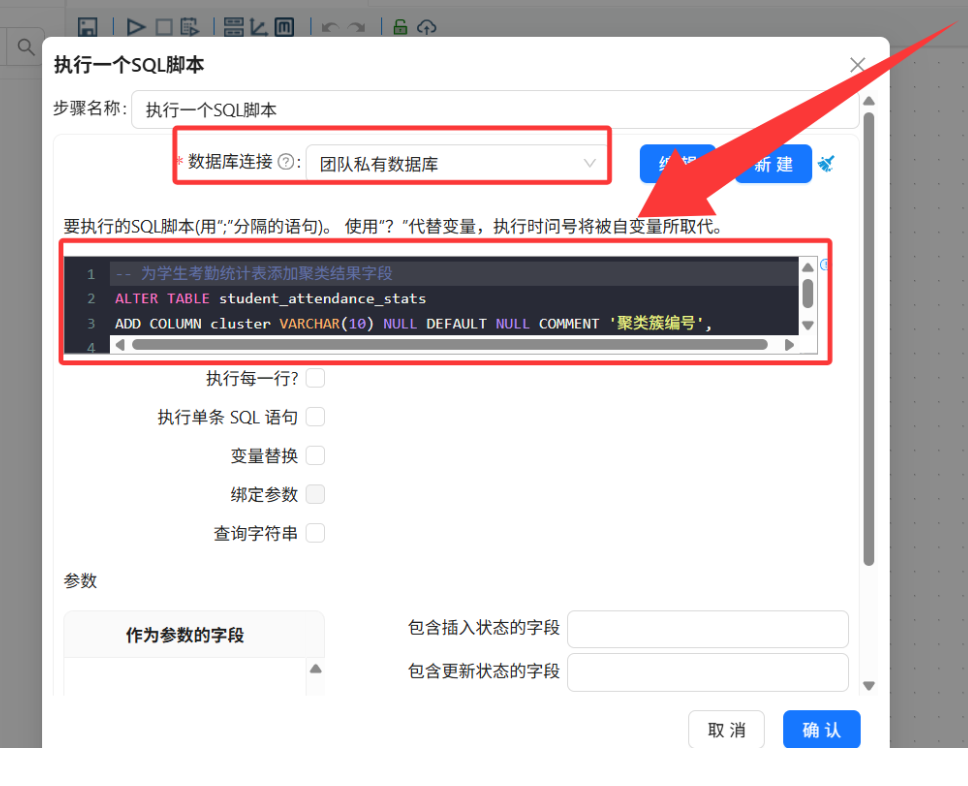
值映射与最终更新
-
操作说明: 拖入“值映射”组件给标签贴中文名,最后接上“更新”组件写回数据库。
-
配置要点:
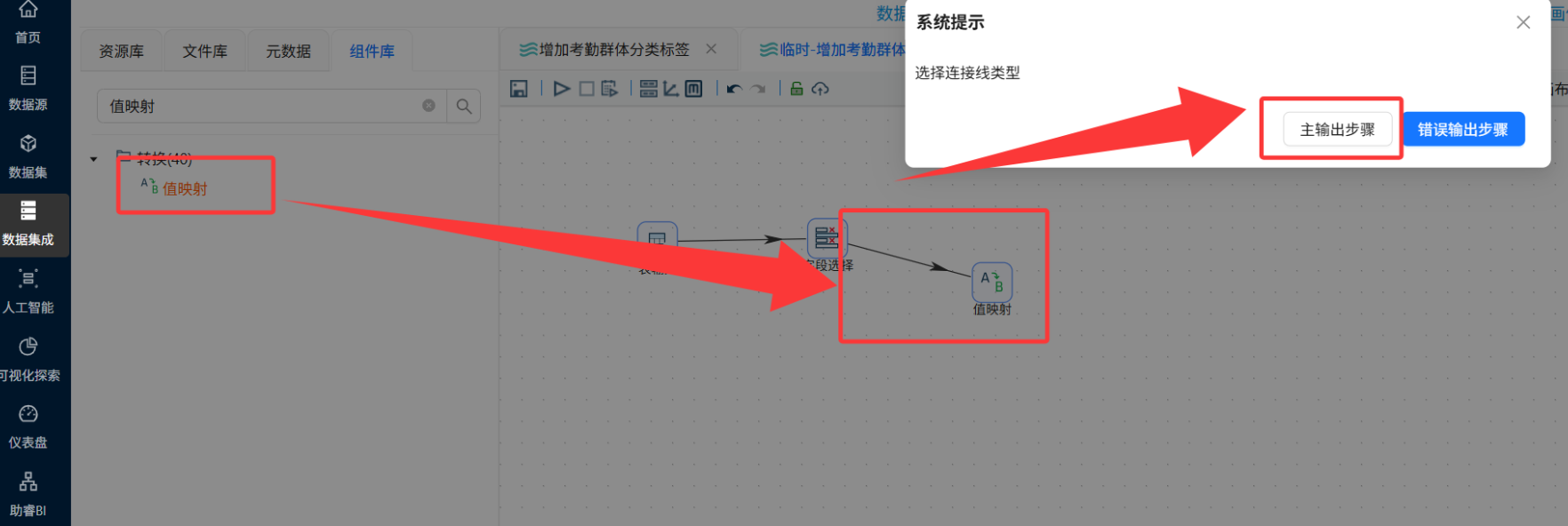
值映射: 映射字段填Cluster,目标字段填attendance_group。源值输入 C1、C2、C3,目标值根据图表规律映射。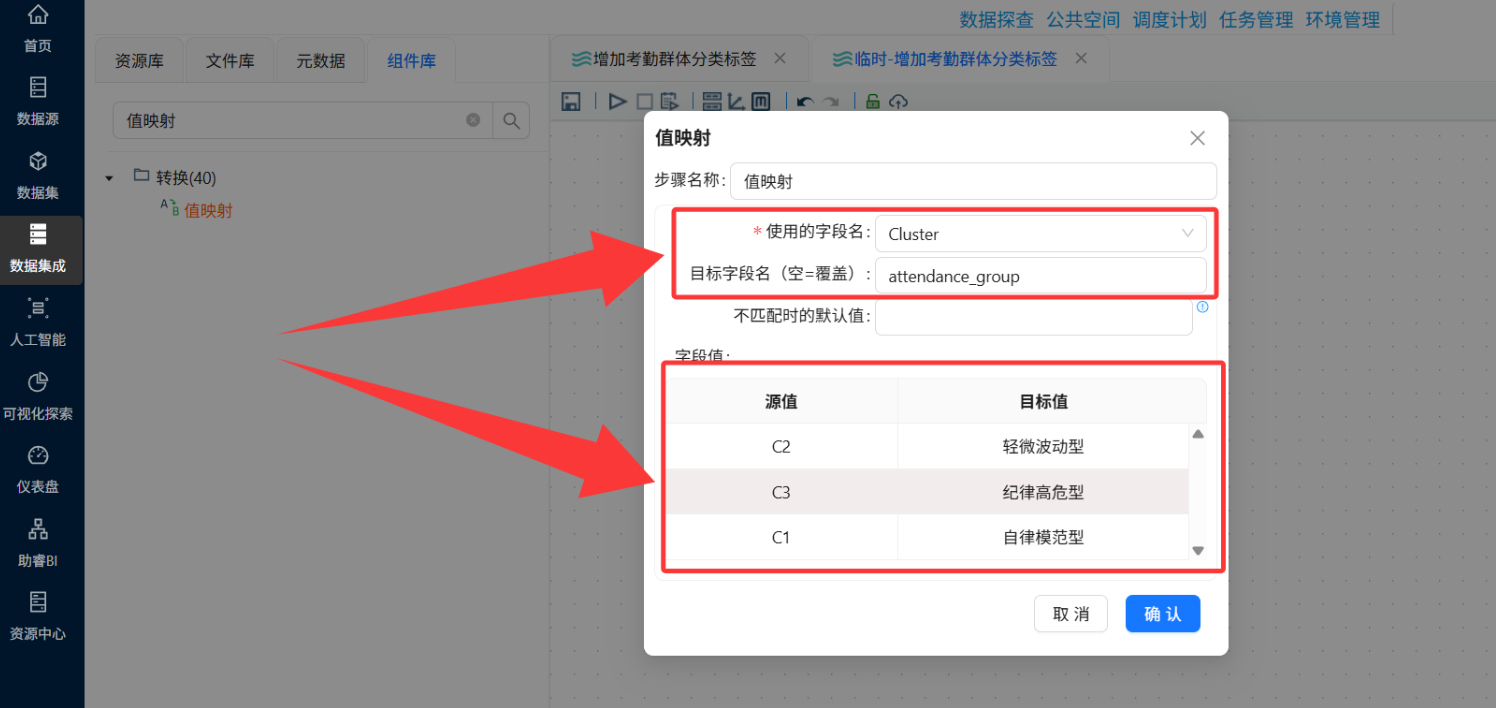
更新: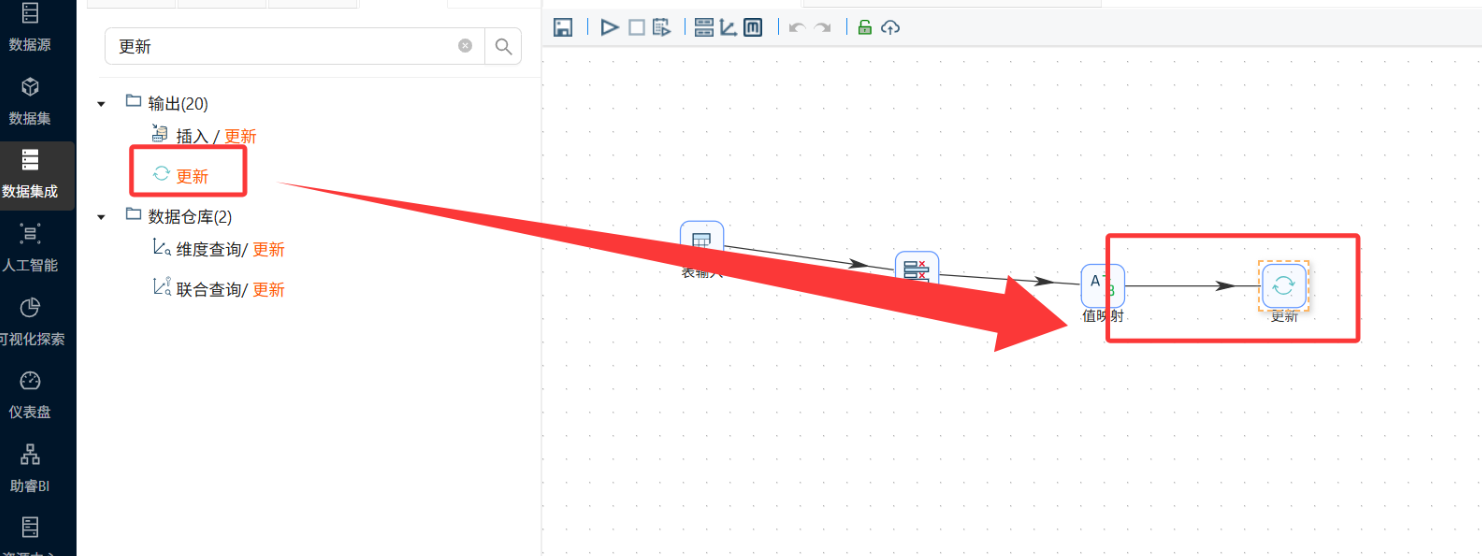
目标表选student_attendance_stats。查询关键字是student_id匹配,把流里的数据塞给表里的新字段。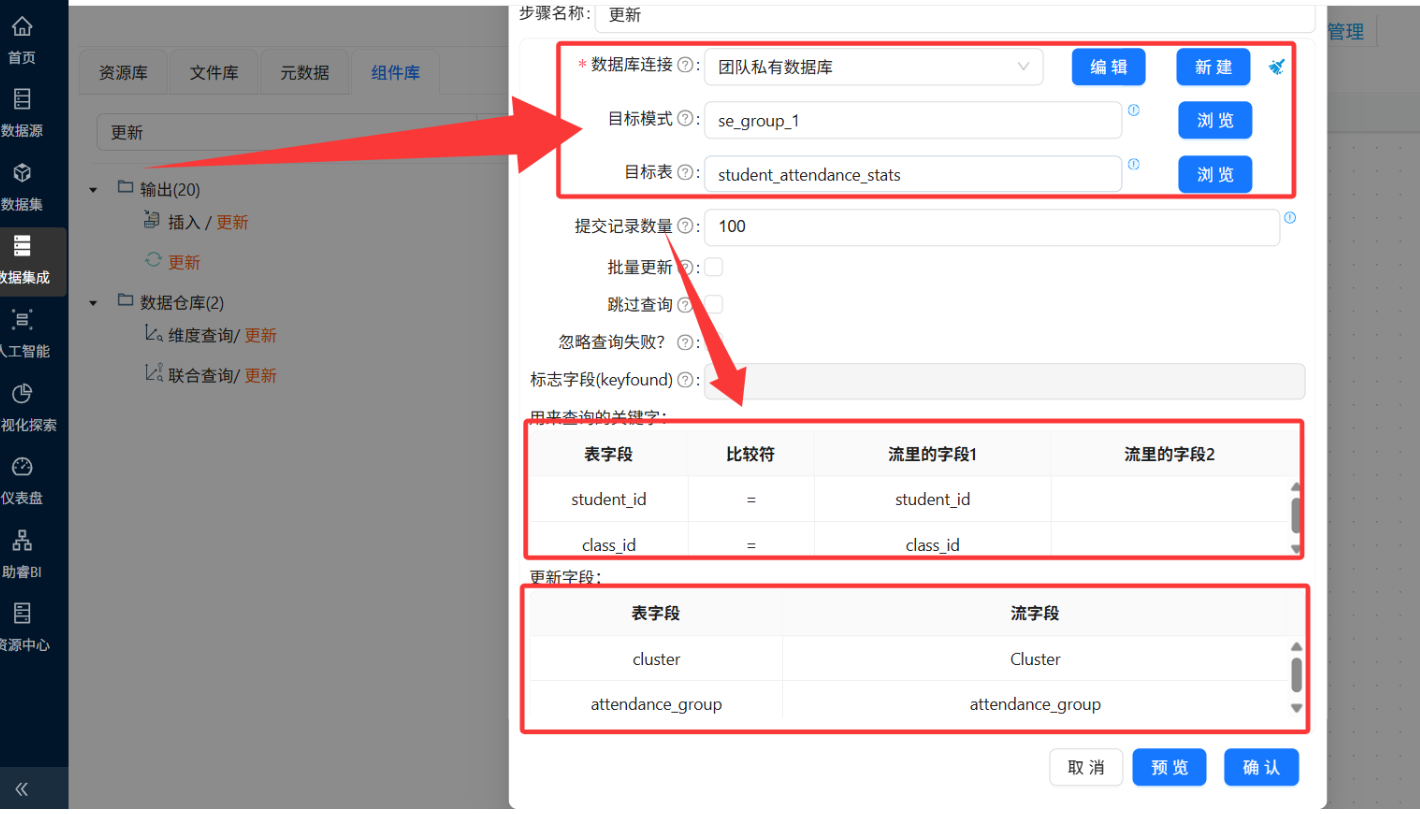
运行: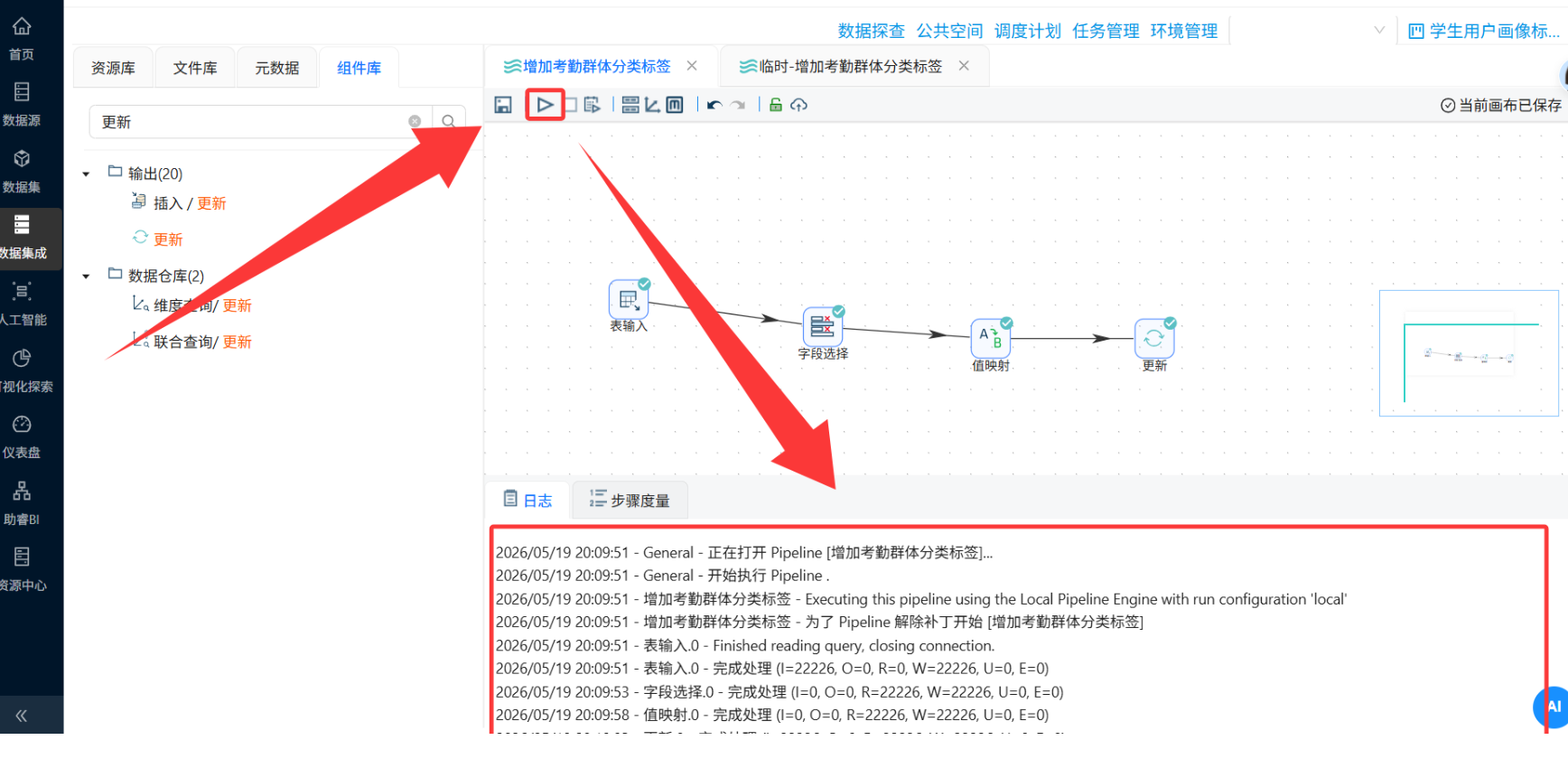
✅ 回写后的价值:
班主任在「学生管理系统」中直接看到每个学生的考勤画像标签
系统可根据标签自动触发不同的管理流程(如C3自动发送家长通知)
为后续的「消费主题」「学业主题」等用户画像扩展提供基础标签
🎯 避坑指南 & 常见问题
| 坑点 | 解决方案 |
|---|---|
| K-Means 簇数量怎么定? | 本实验业务场景明确(好 / 中 / 差三类),直接固定为 3。实际项目中可用肘部法则或轮廓系数辅助决策。 |
| 为什么性别、年级不参与聚类? | K-Means 基于欧氏距离计算,离散型分类变量直接参与会扭曲距离度量。这些属性留作分群后的画像解释即可。 |
| 数据入库时提示表已存在? | 勾选清空重建表选项,或手动修改表名。 |
| BI 平台进不去 / 显示登录页? | 关闭页面,从实验平台左侧菜单重新点击助睿 BI 进入,单点登录会自动带入身份。 |
| 聚类结果怎么看不懂? | 重点看 Cluster 簇编号和 Silhouette 轮廓系数,数值越接近 1 聚类效果越好。 |
| 聚类结果怎么看不懂? | 重点看 Cluster(簇编号)和 Silhouette(轮廓系数,越接近 1 表示聚类效果越好)。 |
📝 实验总结
通过本次实验,我们完整走通了 「数据加载 → 特征选择 → K-Means 聚类 → 结果入库 → BI 可视化解读」 的全链路:
-
✅ 在 AI Studio 中零代码搭建工作流,完成学生考勤行为的 K-Means 聚类建模;
-
✅ 将聚类结果保存至
student_cluster表,实现数据资产的沉淀; -
✅ 在助睿 BI 平台连接数据源、构建数据集,为后续的可视化分析和业务画像命名打下基础。
整个过程无需编写 Python/SQL 代码,通过拖拽组件和配置参数即可完成,真正实现了「让业务人员也能玩转机器学习」!
如果你也觉得这篇教程有帮助,别忘了点赞 👍 + 收藏 ⭐ + 关注! 后续还会更新更多 Uniplore 平台的数据挖掘实战案例,咱们下期再见!👋
实验平台: 助睿数智 Uniplore
实验入口: https://lab.guilan.cn/

一站式 AI 云服务平台
更多推荐


 12
12 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)