
【项目分享-知识讲解】C++标准库string类的模拟实现+KMP算法讲解+哈希思想了解
C++标准库string类作为STL的重要组成部分,我们了解他是必要的,而我们了解这个的最好方式就是亲自去实现它。let's go!!!!!我们实现了这么多的函数。利用了哈希思想,KMP算法等的手段,还发现了一些比较细节的点。但代码不止这些实现,我们还要在意安全性,例如我们利用const修饰不可改变的字符串,用assert排除显式的错误等等,这些也都是我们要注意的地方。希望这篇博客可以带给你们以帮

Gitee仓库:
目录
前言:
C++标准库string类作为STL的重要组成部分,我们了解他是必要的,而我们了解这个的最好方式就是亲自去实现它。接下来,让我们来看一下吧:
let's go!!!!!
Part1. 默认成员函数
默认成员函数作为类成员函数中必不可少的一环,自然是我们首当其冲就要实现的存在,我们来看代码:
public: string(const char* str="")//缺省构造函数 :_capacity(strlen(str))//初始化列表为_capacity,_size初始化 ,_size(strlen(str)) { _str=new char[strlen(str) + 1];//为其分配初始空间 strcpy(_str, str); _str[size()] = '\0';//一定要注意\0!! 要不然后续打印没有终止信号 会有乱码出现 } string(const string& s)//拷贝构造函数 { string tem(s._str);//下面结合图来解释 swap(tem); } ~string()//析构函数 { if (_str != nullptr)//当_str为nullptr不析构 { delete[] _str; _str = nullptr; _capacity = 0; _size = 0; } } void operator=(string s)//赋值重载函数 { swap(s);//下面结合图来解释 } void swap(string& s)//实现交换(可以认为为浅拷贝) { std::swap(_str, s._str); std::swap(_capacity, s._capacity); std::swap(_size, s._size); } private: char* _str=nullptr;//初始化为nullptr size_t _capacity; size_t _size; static const size_t npos=-1;//缺省值
上面的四个默认成员函数值得注意的就是拷贝构造和赋值重载函数,这两个函数都以较短的语句实现了应有的效果,但其的含义却很深,我们来结合图来看一下是怎么做到的吧:
Part1.1 拷贝构造函数
上面的图解释了拷贝构造的来龙去脉,以及为什么要初始化每个_str为nullptr的原因,关键还是在于我们复用了析构和构造函数的代码。接下来,让我们来看看赋值重载吧:
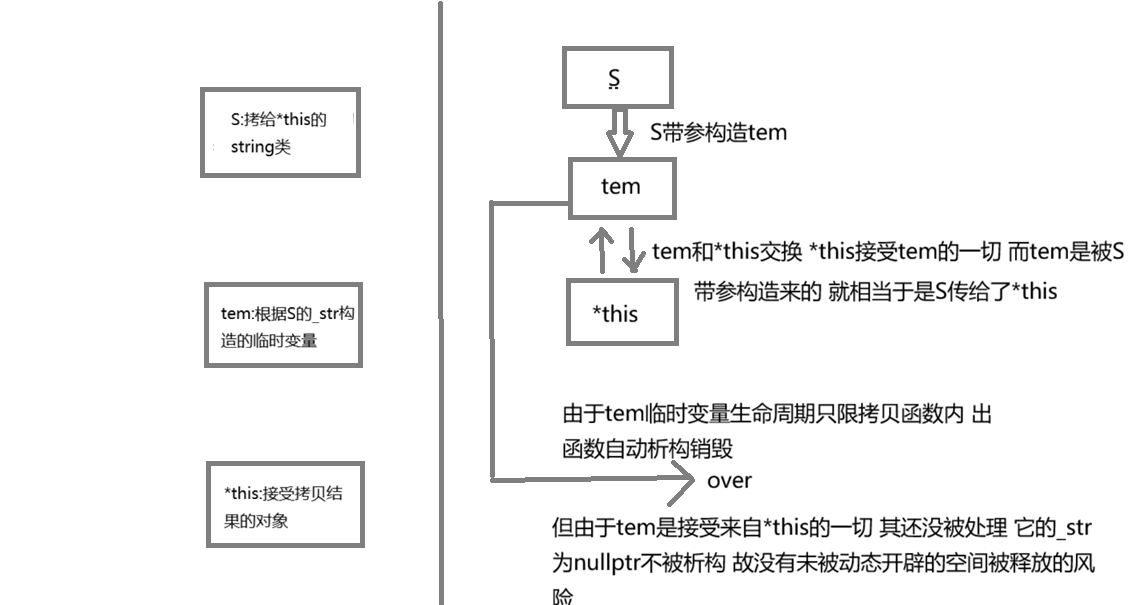
Part1.2 赋值重载函数
上面的图解释了赋值重载这样写的由来,关键还是与上面一样,就是代码的复用。
但这时候,可能会有人会疑惑。为什么上面拷贝构造不这样呢?因为拷贝构造只能传引用类型,不然会无穷递归,同时我们要保证我们的S(拷贝过去的对象)不被改变,就只能利用一个临时变量来承接了。
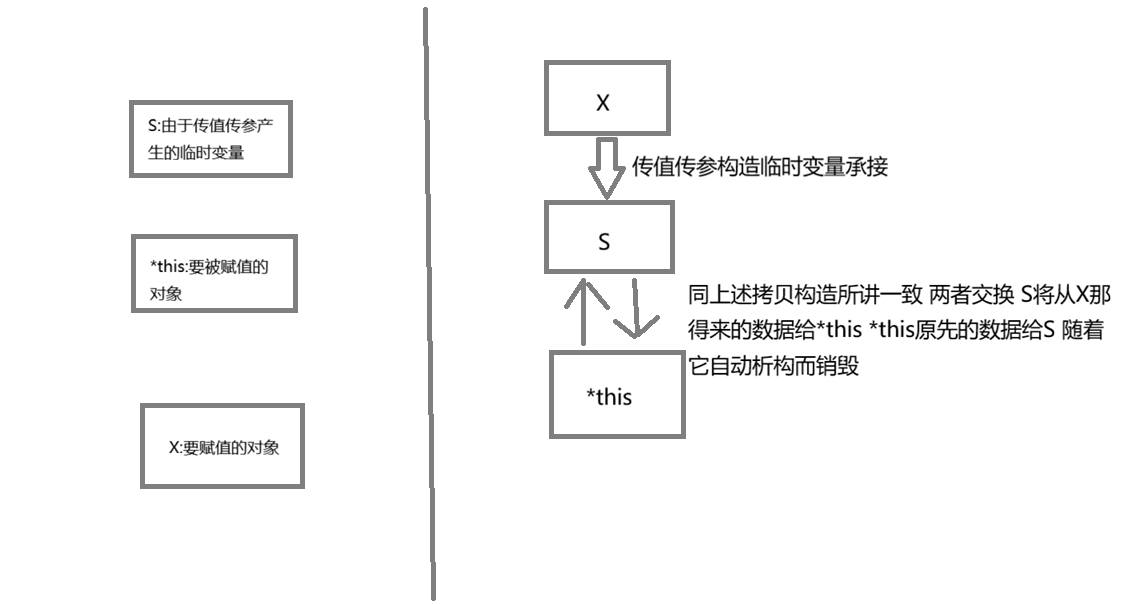
这样,我们就完成了默认成员函数的介绍。接下来,我们来看看string类简单函数的模拟实现吧:
Part2. 简单函数
简单函数,人如其名自然是实现比较简单的,我们来看代码:
public: typedef char* iterator;//迭代器的简单实现 把他认作char* typedef const char* const_iterator;//常性迭代器同理 size_t size()const//返回_size { return _size; } void swap(string& s)//交换 { std::swap(_str, s._str); std::swap(_capacity, s._capacity); std::swap(_size, s._size); } iterator begin()//返回迭代器的开始 { return _str; } iterator end()//返回结束 { return _str + size(); } const_iterator begin()const { return _str; } const_iterator end()const { return _str + size(); } void clear()//删光数据 不改容量(_capacity) { _str[0] = '\0'; _size = 0; }
上文的函数介绍就不需要了,关键在于我们为什么能用typedef来直接模拟迭代器?因为迭代器的一些作用与原生指针非常相似,在string类这里尤其是。因此我们可以用char*来简单模拟迭代器,为后面的范围for遍历做准备。
这样简单函数就实现了,这些都是为后面的一些较复杂的函数做准备的,我们来看看吧:
Part3. 复杂函数
复杂函数关键是要在意边界条件的控制,还有的函数(find)要利用我们自己实现的工具函数来辅助实现,我们来看:
public://函数声明 string& operator+=(char ch); string& operator+=(const char* str); void reserve(size_t n); void push_back(char ch); void append(const char* str); bool empty()const; void insert(size_t pos, char ch); void insert(size_t pos, const char* str); void erase(size_t pos,size_t len=npos); size_t find(char ch, size_t pos=0)const; size_t find(const char* str, size_t pos = 0)const; size_t find_first_of(const char* str,size_t pos=0)const; size_t find_not_of(const char* str, size_t pos = 0)const; void replace(size_t pos, const char* str,const size_t n = npos); char* c_str()const; string substr(size_t pos=0, size_t n=npos); //函数实现 string& string::operator+=(char ch)//+=运算符重载(用于单个字符) { assert(ch);//加上assert 代码健壮性 push_back(ch); return *this; } string& string::operator+=(const char* str)//+=运算符重载(用于字符串) { assert(str); append(str); return *this; } void string::reserve(size_t n)//开拓空间函数 { char* tem = new char[n];//利用临时变量承接 strcpy(tem, _str); std::swap(tem, _str); delete[] tem; _capacity = n; } void string::push_back(char ch)//往后放一个字符 { assert(ch); if (_size + 1 >= _capacity)//判断开多少空间 { 2 * _capacity > _size + 2 ? reserve(2 * _capacity) : reserve(_size + 2); } _str[_size] = ch; _size++; _str[_size] = '\0';//时刻注意\0 } void string::append(const char* str)//往后接一个字符串 { assert(str); if (str == "") { return; } if (_size + strlen(str) >= _capacity) { 2 * _capacity > _size + strlen(str) + 1 ? reserve(2 * _capacity) : reserve(_size + strlen(str) + 1); } for (size_t i = size(); i <= _size + strlen(str); i++)//放入数据 连带着\0也会拷贝过去 { _str[i] = str[i - size()]; } _size += strlen(str); } void string::insert(size_t pos, char ch)//在pos前插入单个字符 { assert(ch && pos >= 0 && pos <= size()); size_t i = 0; if (_size + 1 >= _capacity) { 2 * _capacity > _size + 2 ? reserve(2 * _capacity) : reserve(_size + 2); } for (i = size(); i > pos; i--)//移动原先字符串 为要来的字符挪开位置 { _str[i + 1] = _str[i]; } _str[i + 1] = _str[i];// <1> _str[pos] = ch; _size += 1; } void string::insert(size_t pos, const char* str)//与上面一致 { assert(str && pos >= 0 && pos <= size()); size_t i = 0; size_t len = strlen(str); if (_size + len >= _capacity) { 2 * _capacity > _size + len + 1 ? reserve(2 * _capacity) : reserve(_size + len + 1); } for (i = size(); i > pos; i--) { _str[i + len] = _str[i]; } _str[i + len] = _str[i]; for (i = pos; i < pos + len; i++) { _str[i] = str[i - pos]; } _size += len; } void string::erase(size_t pos, size_t len)//删除pos后len个字符 { assert(len >= 0 && pos >= 0 && pos < size()); if (len == 0) { return; } if (len == -1 || pos + len - 1 >= size())//如果len太大 修正一下 { len = size() - pos; } for (size_t i = pos + len; i <= size(); i++)//后面的数据往前覆盖 包括\0 { _str[i - len] = _str[i]; } _size -= len; } size_t string::find(char ch, size_t pos)const//找单个字符 找到返回其位置 { assert(ch && pos >= 0); for (int i = 0; i < size(); i++) { if (_str[i] == ch) { return i; } } return npos; } size_t string::find(const char* str, size_t pos)const//找字符串 找到返回其首位置 { assert(str); return all::tool::kmp_find(_str, str);// <2> } size_t string::find_first_of(const char* str, size_t pos)const//若找到任意的存在于_str中的字符返回其位置 { assert(str&&pos>=0); short buf[256] = { 0 };// <3> size_t n = strlen(str); for (int i = 0; i < n; i++) { buf[str[i]] = -1; } for (int i = 0; i < _size; i++) { if (buf[_str[i]] == -1) { return i; } } return -1; } size_t string::find_not_of(const char* str, size_t pos)const//若找到任意的不存在于_str中的字符返回其位置 { assert(str && pos >= 0); short buf[256] = { 0 }; size_t n = strlen(str); for (int i = 0; i < n; i++) { buf[str[i]] = -1; } for (int i = 0; i < _size; i++) { if (buf[_str[i]] != -1) { return i; } } return -1; } bool string::empty()const//判空 { return (_size == 0); } void string::replace(size_t pos, const char* str, const size_t n )//将pos位置开始的n个字符取代为str { assert(pos >= 0 && pos < size() && n >= 0 && str); erase(pos, n); insert(pos, str); } char* string::c_str()const//返回_str指针 { return _str; } string string::substr(size_t pos, size_t n)//将pos位置开始的n个字符转化为string类的形式返回 { assert(pos >= 0 && pos < size() && n >= 0); if (pos + n - 1 >= size()) { n = size() - pos; } string tem; tem.reserve(n); for (int i = 0; i < n; i++) { tem += _str[i + pos]; } return tem; }
上面我们通过代码的注释基本了解了这几个复杂函数,但仍有部分问题没有解决(上面注释标<1><2><3>的地方)。接下来,我们来逐一攻破一下吧:
Part3.1 C语言隐弊之隐式类型转换
for (i = size(); i >= pos; i--)
我们来看上面的这个代码,当 i > pos时循环就会继续进行。当pos=0时,这个i要到 -1 才可以结束循环,但是我们这个 i 是size_t(无符号整型),它不存在负数这个概念,当它为负数的时候会自动转化为最大的整形,从而导致循环无法结束。
这时候我们可能会想到一个方法:那就是我们把这个 i 类型改为 int 不就好了。但是坑的点就在这里,当 int 和 size_t 进行比较时,会进行隐式类型转换,将 int 转化为 size_t 从而解决不了问题。因此我们采用了这个方法:
for (i = size(); i > pos; i--) { _str[i + 1] = _str[i]; } _str[i + 1] = _str[i];//将最后一步单拿出来进行 而不在循环之中
这样我们就解决了这个问题,这个问题属于是C语言留给C++的“坑”了。
Part3.2 KMP算法实现
KMP算法相信大家或多或少的都听说过,作为秒杀暴力字符串匹配算法的存在,我们有必要来理解一下其深邃的思想,我们来看一下吧:
size_t tool::kmp_find(const char* _str, const char* str)//由于和string类没什么关联 故放到tool命名空间里面 { int* next = new int[strlen(str) + 1];//定义移动表 made_next(str, next);//填充 int _p = 0;//主字符移动指针 int p = 0;//要匹配的字符移动指针 while (_p < strlen(_str))//开始匹配 { if (_str[_p] == str[p]) { _p++; p++; if (p == strlen(str))//匹配成功 返回第一个匹配成功的字符的位置 { delete[] next; return _p - strlen(str); } } else { p = next[p];//失败则回溯匹配 if (p == -1)//若回溯到开头的位置 就从头开始匹配 { p = 0; _p++; } } } delete[] next; return -1;//没找到 } void tool::made_next(const char* str, int* next) { next[0] = -1;//第一个固定为-1 int left = -1;//left作用:给next[right] 同时失败时回溯 int right = 0;//right作用:不断前进 给所在位置的next赋值 while (right < strlen(str)) { if (left == -1 || str[left] == str[right])//当left==-1或者匹配成功了left和right分别++ 并且赋值 { left++; right++; next[right] = left; } else { left = next[left];//回溯 } } }
光看这个代码和注释估计是不好完全理解的,我们来结合图来看一下:
我们来看上图:假如这是一个字符串,且A区和C区完全相等,假如我们用这个来匹配,且这时候D处没匹配成功,这时候怎么办?我们可以让指针到E来,因为A与C完全相等,我们前面匹配完了C区域,这时候相当于是让A取代已经匹配过的位置,减少匹配次数
这时候我们就知道了next表中的数字的含义:
“对于next表中x位置的值,其指代的是从0到x-1位置最多对称的字符的数目”
所谓的填充next表的过程就是不断找对称的过程,包括回溯也是,我们来看:
假如我们D与E匹配失败,这时候其实是延续A与C这两个大块的对称,现在不行了,我们就要找下一个对称,我们访问E的next值,找到它前面的对称(F前面),这时候相当于是将D与F前面的那个字符比较,延续F的对称了。(因为A=C -> G=H 又因为F=G -> F=H依旧对称)
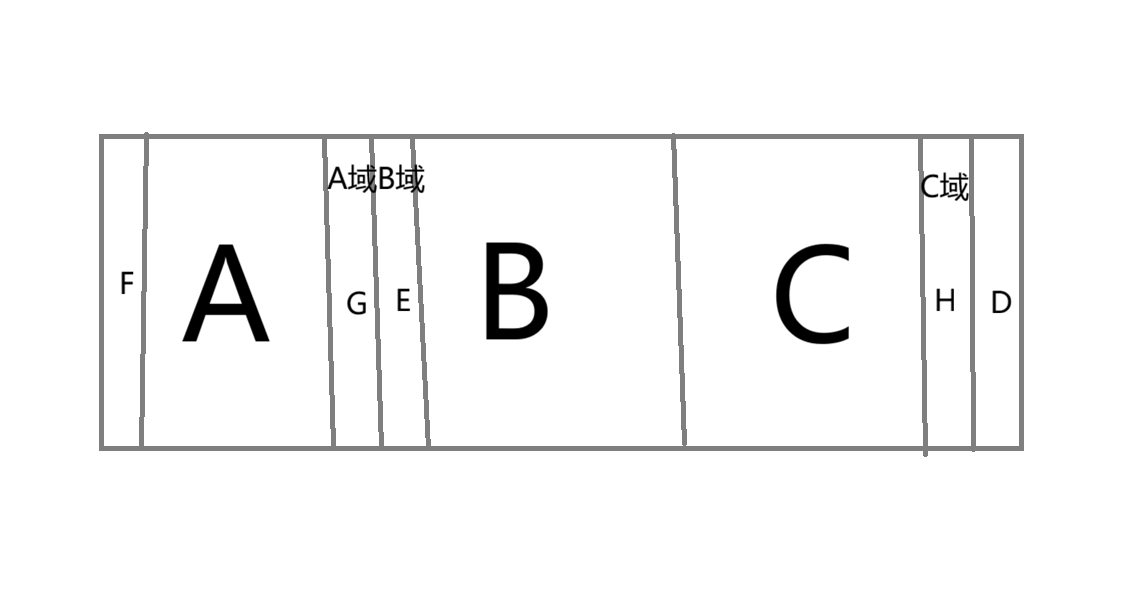
这样我们就了解了KMP算法,接下来自己实践一下,彻底掌握吧!
Part3.3 哈希思想的应用
这里说这个哈希,大家估计很陌生,但要讲计数排序大家估计就会有一点熟悉,这个是利用数组下标天然有序的性质,将值映射下标。具体的可以看我另一个博客:
八种常见排序的详细介绍和测试比较适用范围(总集篇)-CSDN博客
我们这里利用的是字符的ASCII码值,例如‘a’的ASCII码值为97,我们就在创建的数组的第97位标记一下,标为-1啥的都行,代表这个位置的字符有过。
这就是哈希思想,它将查找从O(N)降到了O(1)的级别,是一项伟大的突破。它在一些算法题也常有体现,是非常重要的思想。
Part4. 运算符重载相关函数
运算符重载函数还是比较特别的。由于C++类函数第一个参数必须为隐式的*this,限制了左操作的类型,这就导致一些运算符重载必须要“游离”在成员函数之外,成为独立的存在。我们来看一下吧:
//函数声明 std::ostream& operator<<(std::ostream& out, const string& s); std::istream& operator>>(std::istream& in, string& s); bool operator>(const string& s1, const string& s2); bool operator>=(const string& s1, const string& s2); bool operator<(const string& s1, const string& s2); bool operator<=(const string& s1, const string& s2); bool operator==(const string& s1, const string& s2); bool operator!=(const string& s1, const string& s2); //函数实现 std::ostream& operator<<(std::ostream& out, const string& s)//打印 { for (auto ch : s)//范围for 包装迭代器 { out << ch; } return out; } std::istream& operator>>(std::istream& in, string& s)//输入 { s.clear(); char ch; ch = in.get();//获得单个字符 不可用<< 这个遇到‘ ’和‘\n’会直接跳过 而不终止 const int n = 256; char buf[n];//利用一个可以存256字符的数组 等到其满了再输入进_str 避免多次扩容带来的时间消耗 int i = 0; while (ch != ' ' && ch != '\n') { buf[i++] = ch; if (i == n - 1) { buf[i] = '\0'; s += buf; i = 0; } ch = in.get(); } if (i != 0)//补充残余 { buf[i] = '\0';//记得\0 s += buf; } return in; } bool operator>(const string& s1, const string& s2) { return strcmp(s1.c_str(), s2.c_str())>0; } bool operator>=(const string& s1, const string& s2) { return s1 > s2 || s1 == s2; } bool operator<(const string& s1, const string& s2) { return !(s1 >= s2); } bool operator<=(const string& s1, const string& s2) { return !(s1 > s2); } bool operator==(const string& s1, const string& s2) { return strcmp(s1.c_str(), s2.c_str())== 0; } bool operator!=(const string& s1, const string& s2) { return !(s1 == s2); }
运算符重载函数还是比较easy的,除了<<要特别关注一下,要用in.get()外,其余都是洒洒水啦。
Part5. 代码分享
Part5.1 源1.cpp
#include"头.h" namespace all { std::ostream& operator<<(std::ostream& out, const string& s) { for (auto ch : s) { out << ch; } return out; } std::istream& operator>>(std::istream& in, string& s) { s.clear(); char ch; ch = in.get(); const int n = 256; char buf[n]; int i = 0; while (ch != ' ' && ch != '\n') { buf[i++] = ch; if (i == n - 1) { buf[i] = '\0'; s += buf; i = 0; } ch = in.get(); } if (i != 0) { buf[i] = '\0'; s += buf; } return in; } string& string::operator+=(char ch) { assert(ch); push_back(ch); return *this; } string& string::operator+=(const char* str) { assert(str); append(str); return *this; } void string::reserve(size_t n) { char* tem = new char[n]; strcpy(tem, _str); std::swap(tem, _str); delete[] tem; _capacity = n; } void string::push_back(char ch) { assert(ch); if (_size + 1 >= _capacity) { 2 * _capacity > _size + 2 ? reserve(2 * _capacity) : reserve(_size + 2); } _str[_size] = ch; _size++; _str[_size] = '\0'; } void string::append(const char* str) { assert(str); if (str == "") { return; } if (_size + strlen(str) >= _capacity) { 2 * _capacity > _size + strlen(str) + 1 ? reserve(2 * _capacity) : reserve(_size + strlen(str) + 1); } for (size_t i = size(); i <= _size + strlen(str); i++) { _str[i] = str[i - size()]; } _size += strlen(str); } void string::insert(size_t pos, char ch) { assert(ch && pos >= 0 && pos <= size()); size_t i = 0; if (_size + 1 >= _capacity) { 2 * _capacity > _size + 2 ? reserve(2 * _capacity) : reserve(_size + 2); } for (i = size(); i > pos; i--) { _str[i + 1] = _str[i]; } _str[i + 1] = _str[i]; _str[pos] = ch; _size += 1; } void string::insert(size_t pos, const char* str) { assert(str && pos >= 0 && pos <= size()); size_t i = 0; size_t len = strlen(str); if (_size + len >= _capacity) { 2 * _capacity > _size + len + 1 ? reserve(2 * _capacity) : reserve(_size + len + 1); } for (i = size(); i > pos; i--) { _str[i + len] = _str[i]; } _str[i + len] = _str[i]; for (i = pos; i < pos + len; i++) { _str[i] = str[i - pos]; } _size += len; } void string::erase(size_t pos, size_t len) { assert(len >= 0 && pos >= 0 && pos < size()); if (len == 0) { return; } if (len == -1 || pos + len - 1 >= size()) { len = size() - pos; } for (size_t i = pos + len; i <= size(); i++) { _str[i - len] = _str[i]; } _size -= len; } size_t string::find(char ch, size_t pos)const { assert(ch && pos >= 0); for (int i = 0; i < size(); i++) { if (_str[i] == ch) { return i; } } return npos; } size_t string::find(const char* str, size_t pos)const { assert(str); return all::tool::kmp_find(_str, str); } size_t tool::kmp_find(const char* _str, const char* str) { int* next = new int[strlen(str) + 1]; made_next(str, next); int _p = 0; int p = 0; while (_p < strlen(_str)) { if (_str[_p] == str[p]) { _p++; p++; if (p == strlen(str)) { delete[] next; return _p - strlen(str); } } else { p = next[p]; if (p == -1) { p = 0; _p++; } } } delete[] next; return -1; } void tool::made_next(const char* str, int* next) { next[0] = -1; int left = -1; int right = 0; while (right < strlen(str)) { if (left == -1 || str[left] == str[right]) { left++; right++; next[right] = left; } else { left = next[left]; } } } size_t string::find_first_of(const char* str, size_t pos)const { assert(str&&pos>=0); short buf[256] = { 0 }; size_t n = strlen(str); for (int i = 0; i < n; i++) { buf[str[i]] = -1; } for (int i = 0; i < _size; i++) { if (buf[_str[i]] == -1) { return i; } } return -1; } size_t string::find_not_of(const char* str, size_t pos)const { assert(str && pos >= 0); short buf[256] = { 0 }; size_t n = strlen(str); for (int i = 0; i < n; i++) { buf[str[i]] = -1; } for (int i = 0; i < _size; i++) { if (buf[_str[i]] != -1) { return i; } } return -1; } bool string::empty()const { return (_size == 0); } void string::replace(size_t pos, const char* str, const size_t n ) { assert(pos >= 0 && pos < size() && n >= 0 && str); erase(pos, n); insert(pos, str); } char* string::c_str()const { return _str; } string string::substr(size_t pos, size_t n) { assert(pos >= 0 && pos < size() && n >= 0); if (pos + n - 1 >= size()) { n = size() - pos; } string tem; tem.reserve(n); for (int i = 0; i < n; i++) { tem += _str[i + pos]; } return tem; } bool operator>(const string& s1, const string& s2) { return strcmp(s1.c_str(), s2.c_str())>0; } bool operator>=(const string& s1, const string& s2) { return s1 > s2 || s1 == s2; } bool operator<(const string& s1, const string& s2) { return !(s1 >= s2); } bool operator<=(const string& s1, const string& s2) { return !(s1 > s2); } bool operator==(const string& s1, const string& s2) { return strcmp(s1.c_str(), s2.c_str())== 0; } bool operator!=(const string& s1, const string& s2) { return !(s1 == s2); } }
Part5.2 头.h
#define _CRT_SECURE_NO_WARNINGS 1 #pragma once #include<iostream> #include<algorithm> #include<assert.h> namespace all { namespace tool { size_t kmp_find(const char* _str, const char* str); void made_next(const char* str, int* next); } class string { public: typedef char* iterator; typedef const char* const_iterator; string(const char* str="") :_capacity(strlen(str)) ,_size(strlen(str)) { _str=new char[strlen(str) + 1]; strcpy(_str, str); _str[size()] = '\0'; } string(const string& s) { string tem(s._str); swap(tem); } ~string() { if (_str != nullptr) { delete[] _str; _str = nullptr; _capacity = 0; _size = 0; } } void operator=(string s) { swap(s); } size_t size()const { return _size; } void swap(string& s) { std::swap(_str, s._str); std::swap(_capacity, s._capacity); std::swap(_size, s._size); } iterator begin() { return _str; } iterator end() { return _str + size(); } const_iterator begin()const { return _str; } const_iterator end()const { return _str + size(); } void clear() { _str[0] = '\0'; _size = 0; } string& operator+=(char ch); string& operator+=(const char* str); void reserve(size_t n); void push_back(char ch); void append(const char* str); bool empty()const; void insert(size_t pos, char ch); void insert(size_t pos, const char* str); void erase(size_t pos,size_t len=npos); size_t find(char ch, size_t pos=0)const; size_t find(const char* str, size_t pos = 0)const; size_t find_first_of(const char* str,size_t pos=0)const; size_t find_not_of(const char* str, size_t pos = 0)const; void replace(size_t pos, const char* str,const size_t n = npos); char* c_str()const; string substr(size_t pos=0, size_t n=npos); private: char* _str=nullptr; size_t _capacity; size_t _size; static const size_t npos=-1; }; std::ostream& operator<<(std::ostream& out, const string& s); std::istream& operator>>(std::istream& in, string& s); bool operator>(const string& s1, const string& s2); bool operator>=(const string& s1, const string& s2); bool operator<(const string& s1, const string& s2); bool operator<=(const string& s1, const string& s2); bool operator==(const string& s1, const string& s2); bool operator!=(const string& s1, const string& s2); }
Part6. 结语
我们实现了这么多的函数。利用了哈希思想,KMP算法等的手段,还发现了一些比较细节的点。但代码不止这些实现,我们还要在意安全性,例如我们利用const修饰不可改变的字符串,用assert排除显式的错误等等,这些也都是我们要注意的地方。
希望这篇博客可以带给你们以帮助。
最后,祝大家可以:春风得意马蹄疾,一日看尽长安花!
最后的最后,要是觉得本文还可以的话,可以点点赞,关注小编一波,谢谢大家!~

一站式 AI 云服务平台
更多推荐

 26
26 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)