
浏览器用户行为分析与流失预测-数据加工
1. 收获学会了使用助睿ETL平台对半结构化日志数据进行解析与转换的方法,掌握了获取文件名、Java代码解析、字段选择、过滤记录、计算停留时长、分组聚合等组件的实际应用。理解了从原始日志到结构化数据表的完整加工流程,能够独立完成浏览器覆盖率统计表和时段统计表的构建。2. 对平台的整体评价助睿平台覆盖了从数据接入、ETL处理到可视化分析的全链路功能,零代码操作降低了数据处理门槛,组件拖拽式配置灵活直
一、实验背景
1 实验目的
- 熟悉数据集构成与半结构化日志数据特点,掌握文本日志解析、字段拆分的实操方法
- 完成数据规整,将零散原始日志转化为标准结构化数据表
- 实现多维度数据聚合、字段衍生与跨表关联,搭建适配分析场景的指标体系
- 完成机器学习特征工程处理,产出可直接使用的预测建模数据集
2 实验环境
- 实验平台:助睿在线实验平台 https://lab.guilian.cn/
本次实验使用助睿数智(Uniplore)作为一站式数据科学平台。该平台覆盖从数据接入、ETL处理、机器学习建模到可视化展示的全链路零代码功能,适用于数据分析教学与企业数据加工场景。产品官网为 https://www.uniplore.com/
- 数据处理:助睿 ETL 数据集成平台
- 数据规模:1000 用户,800 万 + 条行为记录,约 825MB
3 实验数据
本实验基于首届中国互联网 数据挖掘 竞赛公开数据集开展,是非常典型的计算机用户行为半结构化日志数据,专门用于用户行为分析、习惯挖掘、活跃度预测与用户画像研究。
3.1 数据集整体构成
数据集包含三大核心部分:
- 用户基本信息表:
demographic.csv存储用户 ID、性别、年龄、职业、教育程度、收入等人口属性信息。 - 浏览器上网记录:日志中包含 URL、域名、访问时间等。
- 软件使用记录:日志中包含进程名、程序名、使用时长、窗口切换等。
数据总大小解压后约825MB,原始行为记录800 多万条,覆盖1000 名用户连续4 周的电脑使用行为(横跨 4 个月,每月抽取 1 周数据)。
- 第 1 周:2012-05-07 至 2012-05-13
- 第 2 周:2012-06-04 至 2012-06-10
- 第 3 周:2012-07-02 至 2012-07-08
- 第 4 周:2012-08-06 至 2012-08-12
3.2 数据文件结构
所有数据分为两部分:
behavior/文件夹:按日期归档,存放数万条 TXT 行为日志demographic.csv:用户属性表
两个数据通过用户 ID(user_id) 唯一关联。
3.3 日志文件命名规则
每个 TXT 文件 = 一个用户一次开机产生的行为日志文件名格式:用户ID_日期_开机时间.txt示例:0AB6BBBEDFF24EC8BAAC905F45AE314C_2012-05-07_21-22-38.txt
从文件名可直接解析出:
- user_id:用户唯一标识
- file_date:日志日期
- file_start_time:开机时间
3.4 日志文件内部格式
每个日志文件固定分为三部分:第 1 行:Last<=> 数字表示日志最后一条记录距离开机的秒数。
第 2 行:L_Start<=> 时间表示本次开机的绝对时间。
**第 3 行及以后:行为记录(核心数据)**格式示例:T<=>177[=]P<=>360se.exe[=]I<=>5572[=]W<=>30378[=]V<=>4,1,6,6[=]N<=>360安全浏览器[=]C<=> 360.cn
采用固定分隔符:
<=>:字段名与值分隔[=]:字段与字段之间分隔
3.5 字段含义必须掌握
|
字段 |
含义 |
|
T |
距离开机的秒数(行为发生时间) |
|
P |
进程名(如:360se.exe、QQ.exe) |
|
I |
进程 ID |
|
U |
浏览器访问 URL |
|
W |
非浏览器窗口句柄 |
|
V |
程序版本号 |
|
N |
程序名称(仅第一次出现) |
|
C |
开发公司名称(仅第一次出现) |
|
A/B |
浏览器窗口句柄 |
3.6 数据特点
- 属于半结构化数据,无固定行列,不能直接分析
- 数据量大、文件分散、格式统一、规则明确
二、 实验步骤
4.1 创建实验项目
点击“新建项目”
输入项目名称“互联网用户行为日志数据加工”,点击“确定”
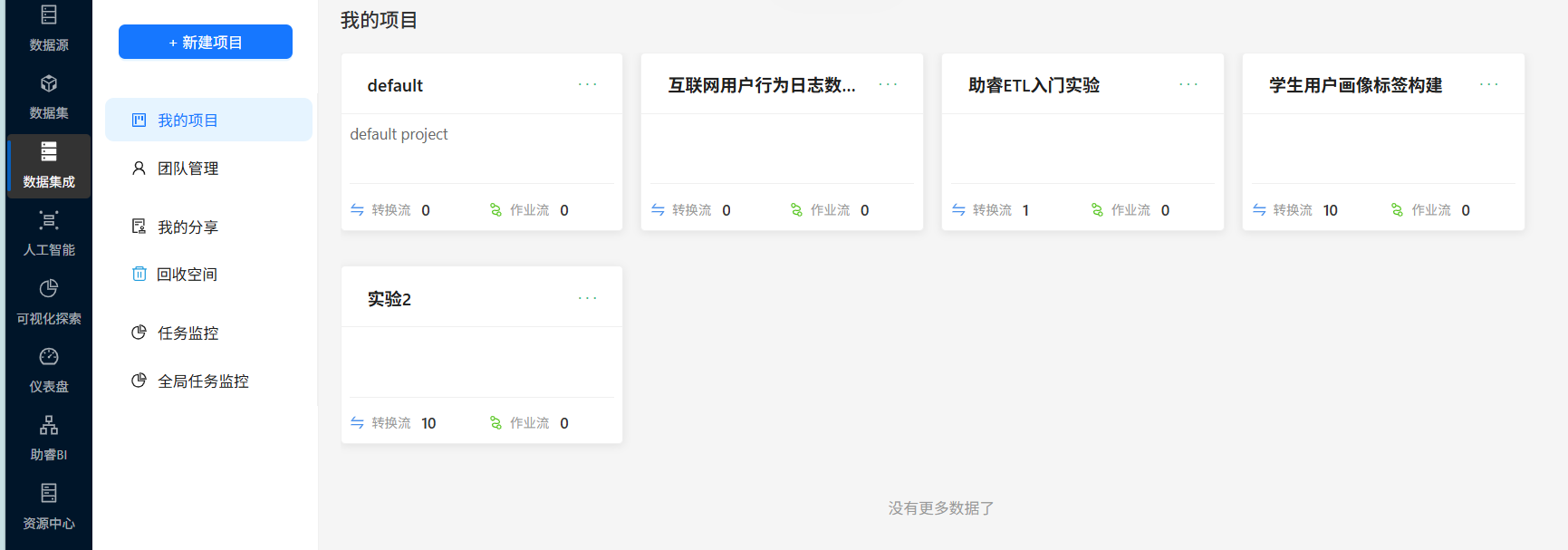
创建成功后即可在数据集成页面看到新创建的项目
4.2 日志数据结构化转换
4.2.1 数据资源获取
注意:由于本次实验的数据量过大,我们仅使用其中20个TXT数据来学习如何将半结构化数据转换为结构化数据
本实验的部分原始数据(20个TXT数据)已经上传公共空间,为方便后续的数据使用,我们可以将原始数据导入我们自己的文件目录下
项目创建成功后点击该项目右上角“…”,点击“打开项目”
在项目页面,可以看到左侧有3个菜单:资源库、文件、元数据
资源库用于对工作流的管理,包括新建、删除、修改、查看工作流的信息;导出导入工作空间;调度管理等操作
文件库用于保存工作流中需要用到的文件和工作流产生的文件
元数据管理是助睿ETL的重要基石,可以为工作流定义“运行配置”、“数据库”、“flink集群”等配置
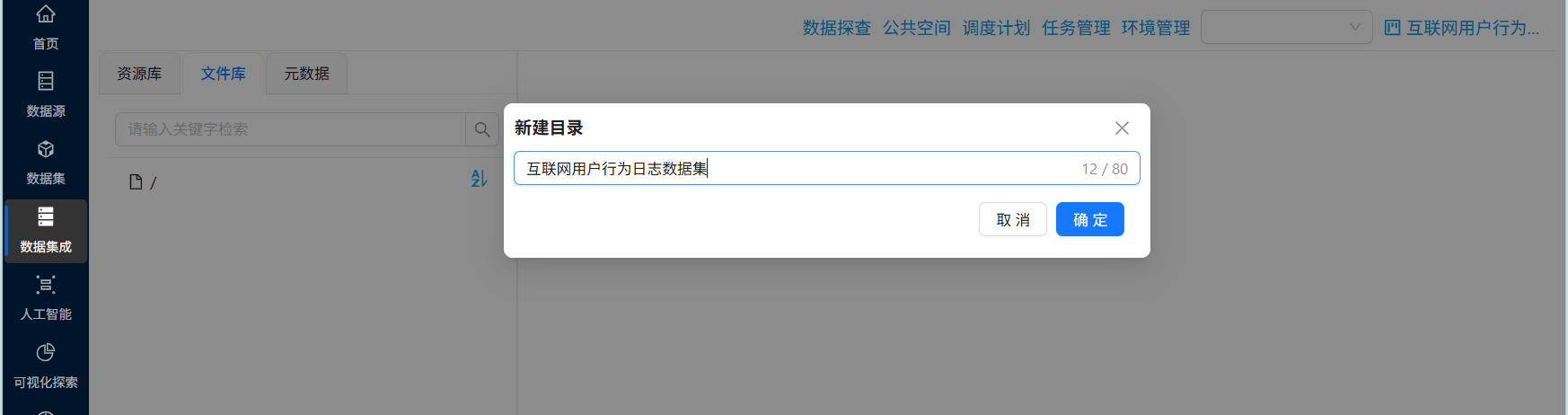
首先获取本次的实验数据集:点击“文件库”,右键根目录,点击“新建目录”
输入目录名称为“互联网用户行为日志数据集”,点击“确定”
接下来我们将公共空间的数据资源导入到这个目录下
点击公共空间
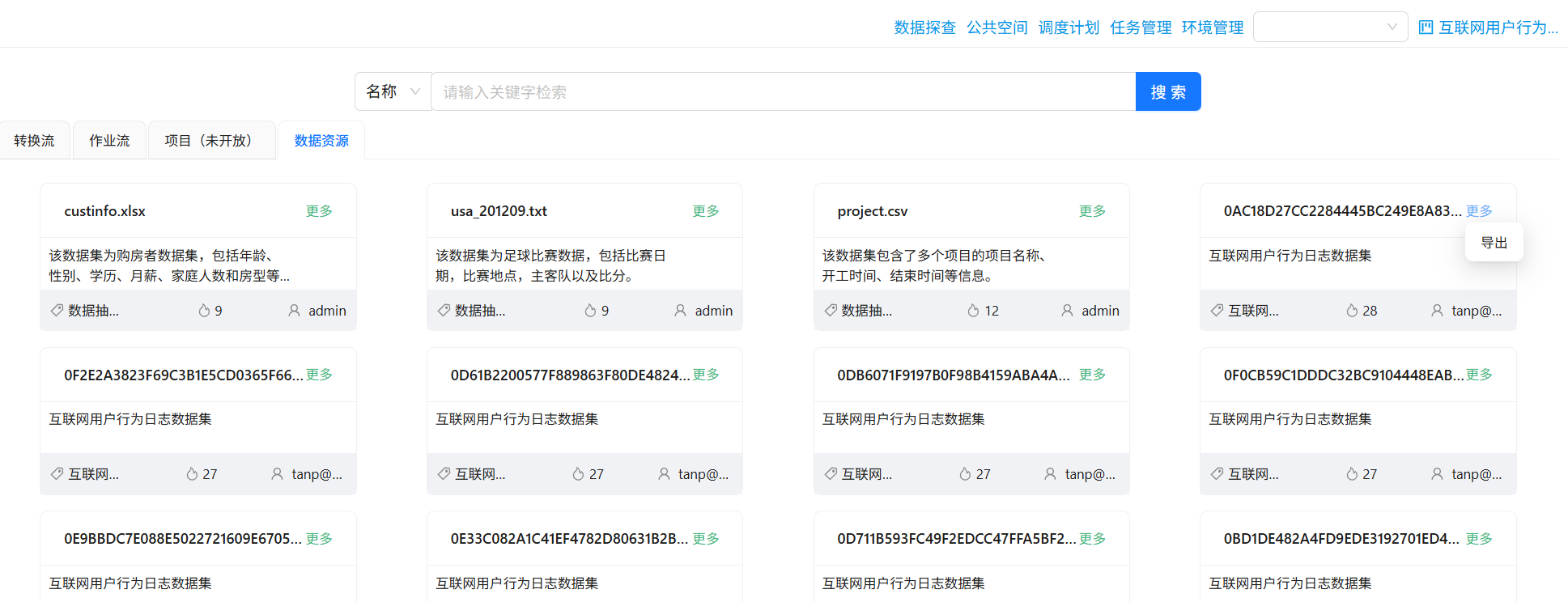
点击“数据资源”
点击属于“互联网用户行为日志数据集”下的数据卡片右上角的“更多”,并点击“导出”
在弹出的窗口中选择导出到刚刚新创建的目录下
点击“确定”
可以看到在互联网用户行为日志数据集的目录下,新增了数据文件
接下来重复以上导出操作,将本次实验用到的20个数据都导出到“互联网用户行为日志数据集”
4.2.2 建立数据源连接
在之前的实验《学生用户画像-考勤主题标签构建》中,我们已经创建了团队私有数据库的连接,无需再建立数据源连接

如果还未创建的,可以参考《学生用户画像-考勤主题标签构建》的 4.2.2 建立数据源连接 小节的内容下创建连接。
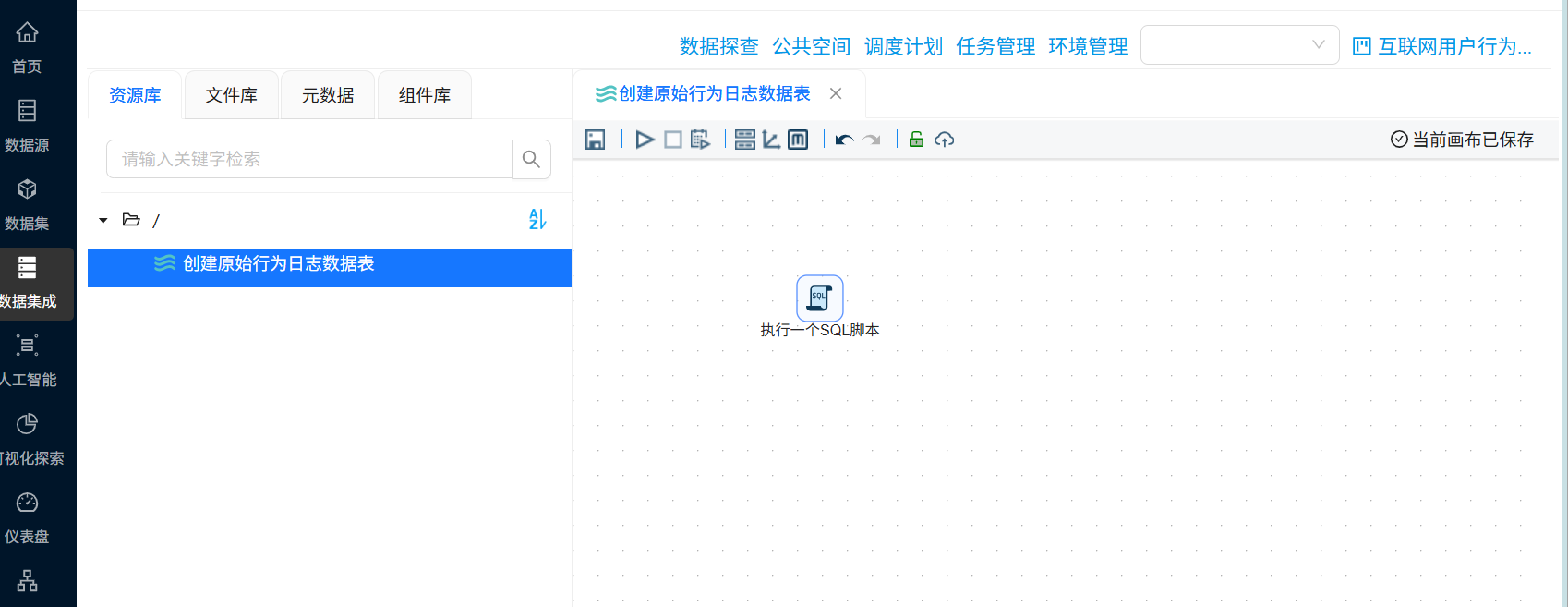
4.2.3 创建原始用户行为日志表
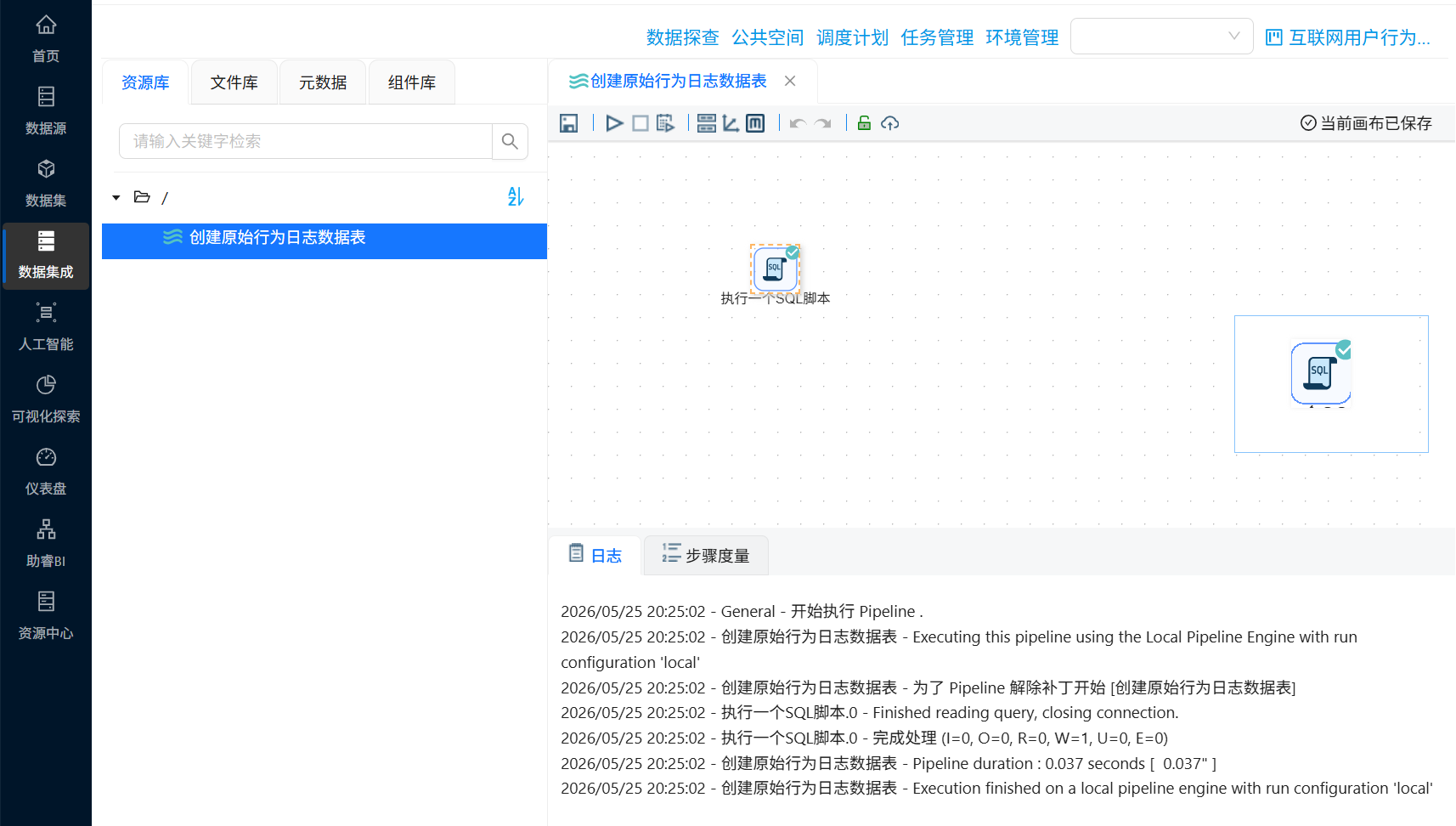
新建转换工作流,并命名为“创建原始行为日志数据表”,在该工作流中拖拽“执行一个SQL脚本”组件,通过执行SQL脚本来创建一个标签表。整个转换流如下所示:
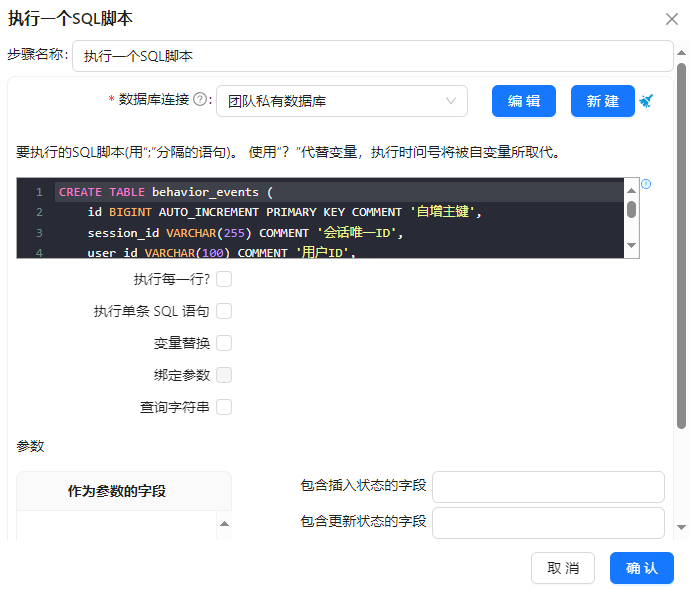
配置说明:在组件中填写SQL脚本,选择目标数据库连接“团队私有数据库”,确保脚本执行权限;
SQL脚本如下:

其他参数使用默认选项,完成后组件配置如下
完成后运行转换流,运行过程会定时刷新组件状态,并画布下面显示执行日志。
由于原始的数据是半结构化的数据,无法直接通过文件输入组件获取数据,所以需要换一种思路:
通过 “获取文件名” 组件批量读取并定位日志文件,再交由 “Java 代码” 组件完成半结构化日志的解析(含字段拆分),接着通过 “字段选择” 组件筛选并规整有效字段,最终输出为标准结构化数据表,实现原始文本日志到可分析数据的标准化转换。
4.2.4 获取文件名:日志文件批量采集
新建转换工作流,并命名为“行为日志数据转为结构化数据”,在该工作流中拖拽“获取文件名”组件
双击“获取文件名”组件,在配置窗口中,点击文件或目录后后的“浏览文件”按钮,在弹出的窗口中选择我们上面创建的目录“互联网用户行为日志数据集”,再点击“确定”
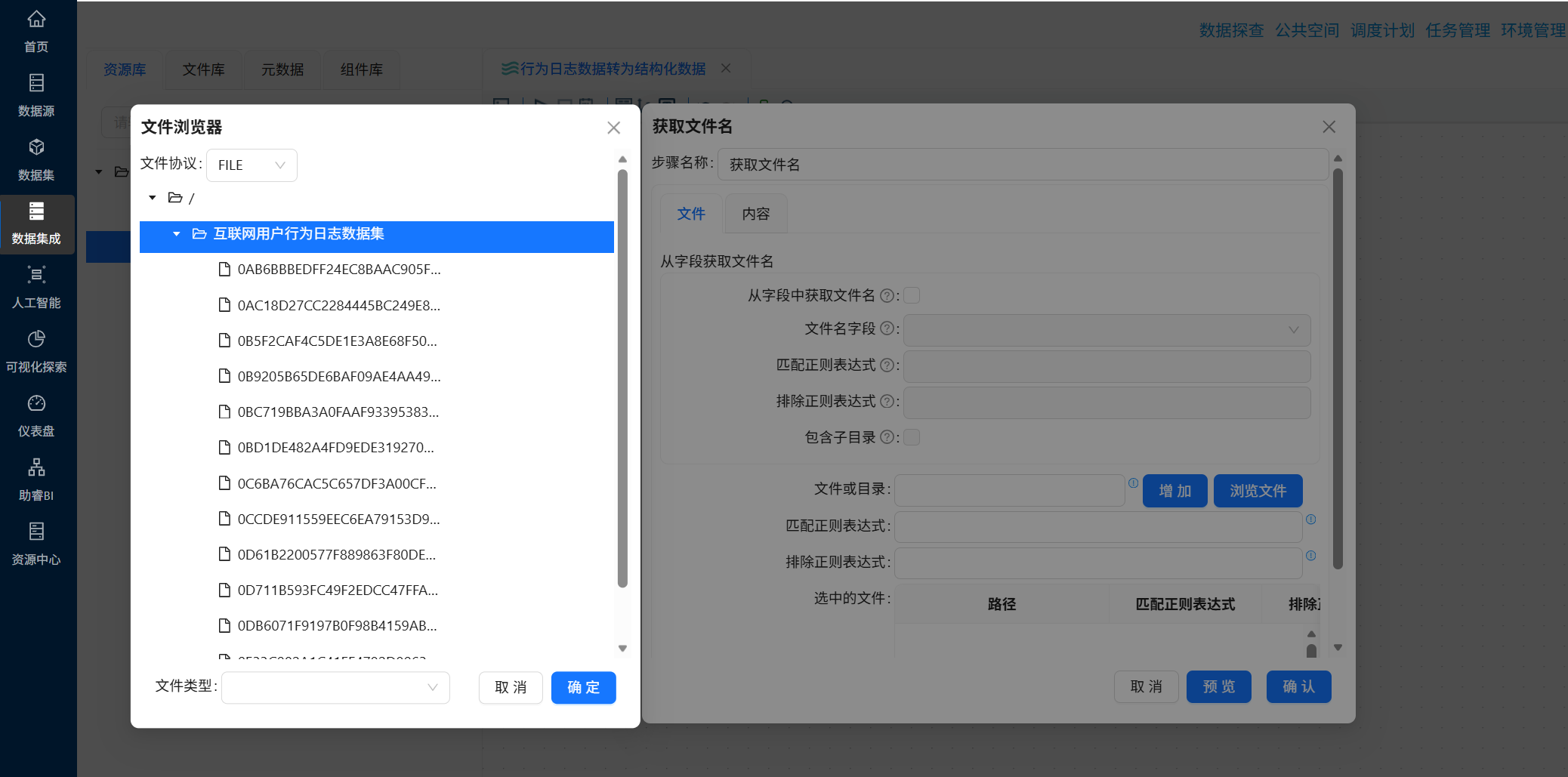
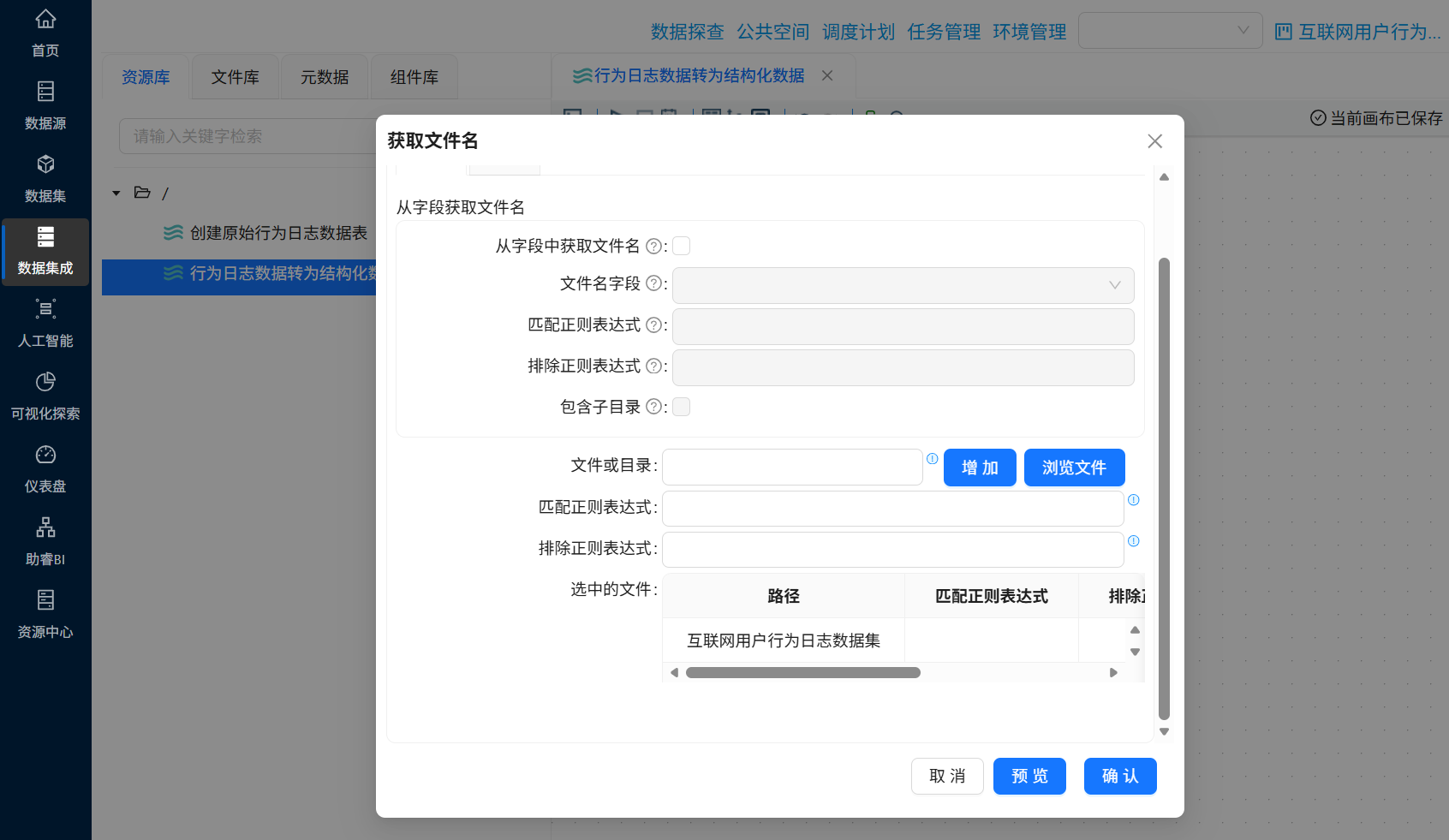
选择目录后,点击“增加”
选择的目录出现在下方的路径中,点击“确认”
4.2.5 Java 代码:日志解析与结构化转换
根据实验数据说明,我们可以通过 java 代码来 读取日志文件、解析文件名、提取用户与开机信息、跳过文件头部、按分隔符拆分半结构化行为记录,将原始 TXT 日志中的 T、P、I、U、V、W、N、C 等关键字段逐一解析提取,最终输出包含会话 ID、用户信息、行为详情的标准结构化数据,完成从半结构化数据到结构化数据的转换。
拖拽一个“Java 代码” 组件到画布中,并创建“获取文件名”组件到“Java 代码” 组件的连线,连接线类型选择“主输出步骤”
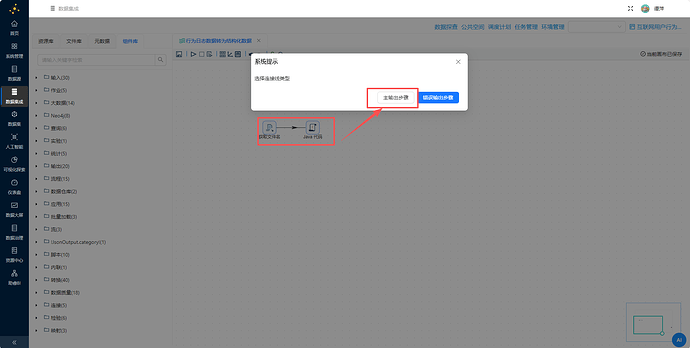
双击“Java 代码” 组件,输入以下代码:
// 全局变量定义
String pathField;
String shortFilenameField;
public boolean processRow() throws HopException {
if (first) {
pathField = "filename";
shortFilenameField = "short_filename";
first = false;
}
Object[] r = getRow();
if (r == null) {
setOutputDone();
return false;
}
String path = get(Fields.In, pathField).getString(r);
String short_filename = get(Fields.In, shortFilenameField).getString(r);
String user_id = "";
String l_start = "";
if (short_filename != null) {
String name = short_filename.replace(".txt", "");
String[] parts = name.split("_");
if (parts.length >= 3) {
user_id = parts[0];
l_start = parts[1] + " " + parts[2].replace("-", ":");
}
}
String session_id = user_id + "_" + l_start;
java.io.BufferedReader br = null;
try {
br = new java.io.BufferedReader(new java.io.FileReader(path));
String line = "";
// 跳过前两行(Last和L_Start)
br.readLine();
br.readLine();
while ((line = br.readLine()) != null) {
if (line.trim().isEmpty()) {
continue;
}
// 解析键值对
String[] kvPairs = line.split("\\[=\\]");
String t = "";
String p = "";
String i = "";
String u = "";
String a = "";
String b = "";
String v = "";
String w = "";
String n = "";
String c = "";
for (String kv : kvPairs) {
int sepIdx = kv.indexOf("<=>");
if (sepIdx == -1) {
continue;
}
String key = kv.substring(0, sepIdx).trim();
String val = kv.substring(sepIdx + 3);
if ("T".equals(key)) {
t = val;
} else if ("P".equals(key)) {
p = val;
} else if ("I".equals(key)) {
i = val;
} else if ("U".equals(key)) {
u = val;
} else if ("A".equals(key)) {
a = val;
} else if ("B".equals(key)) {
b = val;
} else if ("V".equals(key)) {
v = val;
} else if ("W".equals(key)) {
w = val;
} else if ("N".equals(key)) {
n = val;
} else if ("C".equals(key)) {
c = val;
}
}
// 创建输出行
Object[] outRow = createOutputRow(r, data.outputRowMeta.size());
get(Fields.Out, "session_id").setValue(outRow, session_id);
get(Fields.Out, "user_id").setValue(outRow, user_id);
get(Fields.Out, "l_start").setValue(outRow, l_start);
get(Fields.Out, "t").setValue(outRow, t);
get(Fields.Out, "p").setValue(outRow, p);
get(Fields.Out, "i").setValue(outRow, i);
get(Fields.Out, "u").setValue(outRow, u);
get(Fields.Out, "a").setValue(outRow, a);
get(Fields.Out, "b").setValue(outRow, b);
get(Fields.Out, "v").setValue(outRow, v);
get(Fields.Out, "w").setValue(outRow, w);
get(Fields.Out, "n").setValue(outRow, n);
get(Fields.Out, "c").setValue(outRow, c);
get(Fields.Out, "source_file").setValue(outRow, short_filename);
putRow(data.outputRowMeta, outRow);
}
} catch (Exception e) {
logError(e.getMessage(), e);
} finally {
try {
if (br != null) {
br.close();
}
} catch (Exception e) {
// ignore
}
}
return true;
}在字段空白表格处右键点击“插入”
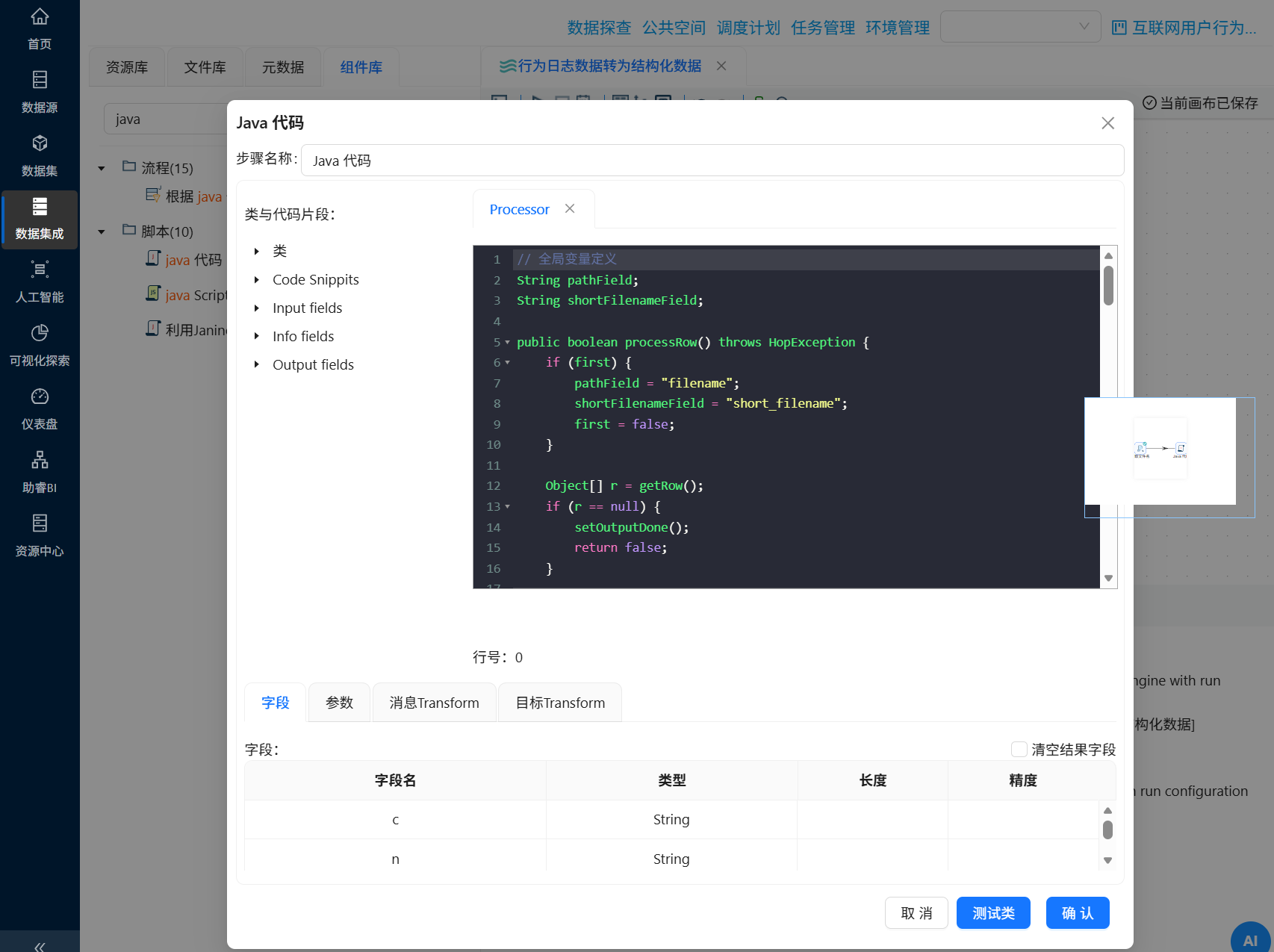
双击插入的行,字段名输入“session_id”,类型选择“String”
继续插入行,依次将java代码中输出的字段进行配置,参考如下:
|
字段名 |
类型 |
|
session_id |
String |
|
user_id |
String |
|
l_start |
String |
|
t |
String |
|
p |
String |
|
i |
String |
|
u |
String |
|
a |
String |
|
b |
String |
|
v |
String |
|
w |
String |
|
n |
String |
|
c |
String |
|
source_file |
String |
配置完成后点击“确认”
4.2.6 字段选择:有效字段筛选与规整
右键“java 代码”组件点击“预览输出字段”,可以看到有很多字段是我们不需要也不属于原始数据字段的,需要移除
拖拽“字段选择”组件到画布中,并创建“Java 代码”组件到“字段选择”组件的连线,连接线类型选择“主输出步骤”
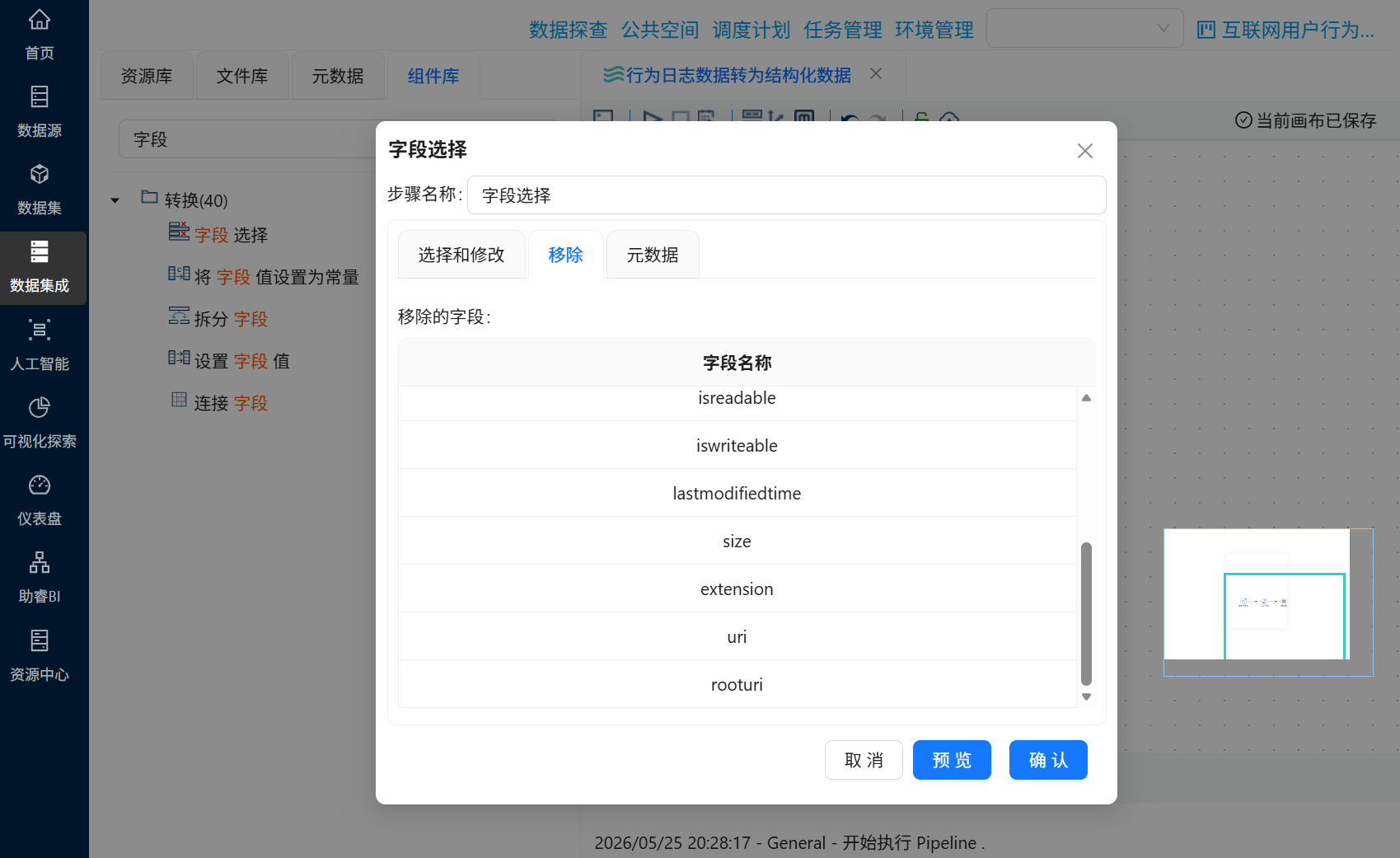
双击“字段选择”组件,点击tab选项“移除”,并在字段名称下方空白处右键点击“获取字段”
选中上一步骤中的Java代码输出的字段后,右键点击“删除选中的行”
最后剩下多余的字段即可点击“确认”
4.2.7 表输出:结构化数据表落地
接下来,我们将已经转换为结构化的数据输出到数据库中,以便后续使用
拖拽“表输出”组件到画布中,并创建“字段选择”组件到“表输出”组件的连线,连接线类型选择“主输出步骤”
双击“表输出”组件,选择“团队私有数据库”连接
勾选“裁剪表”,这样表输出组件在插入数据前会清空原始表数据,避免重复插入
勾选“指定数据库字段”,建立工作流字段与数据库表字段的映射关系。勾选后会激活“数据库字段”tab页,在数据库字段tab页,右键选择“获取字段”
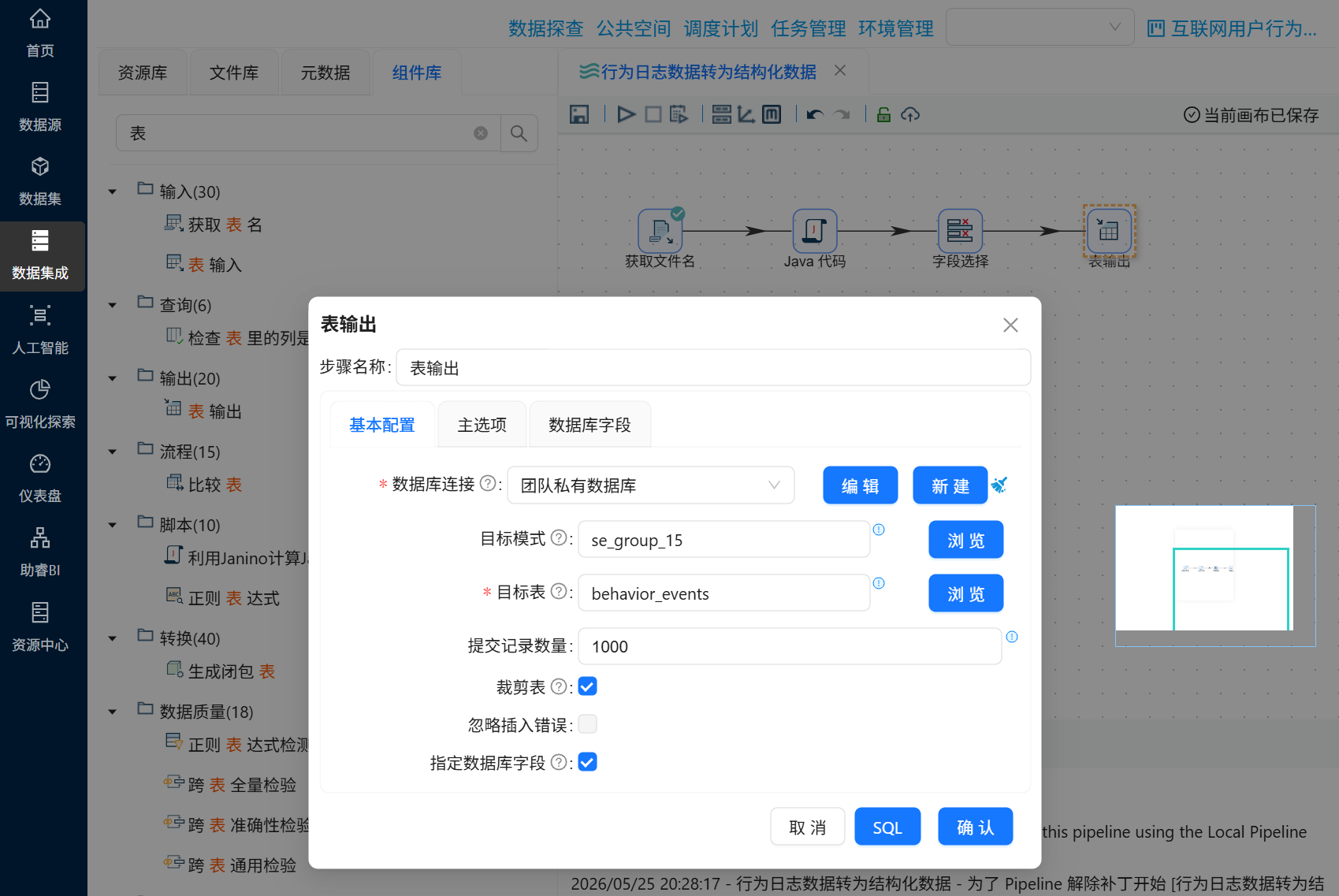
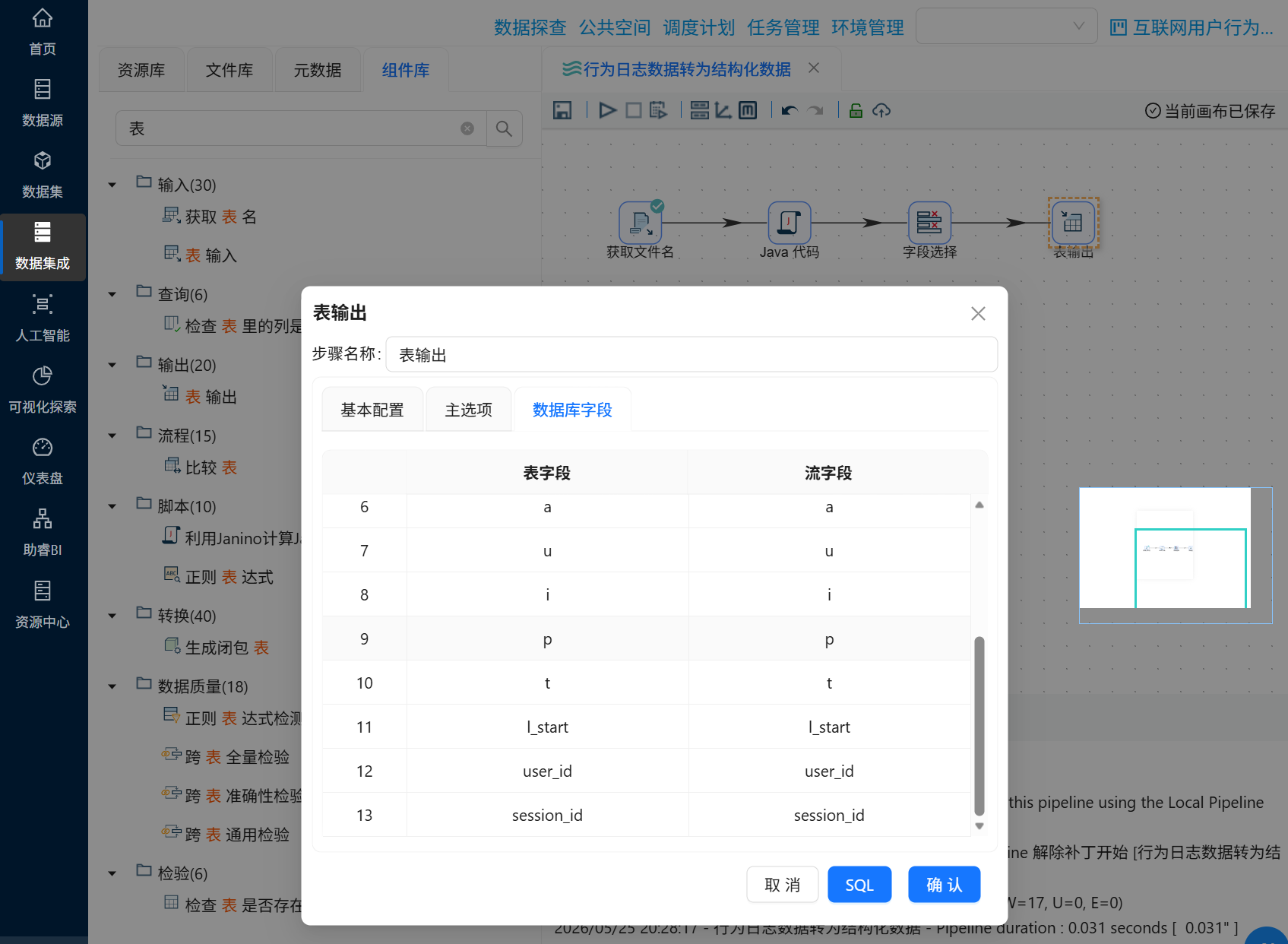
我们在4.2.3小节中创建的表字段与流字段是不一样的,双击表字段,在下拉框中选择正确的表字段
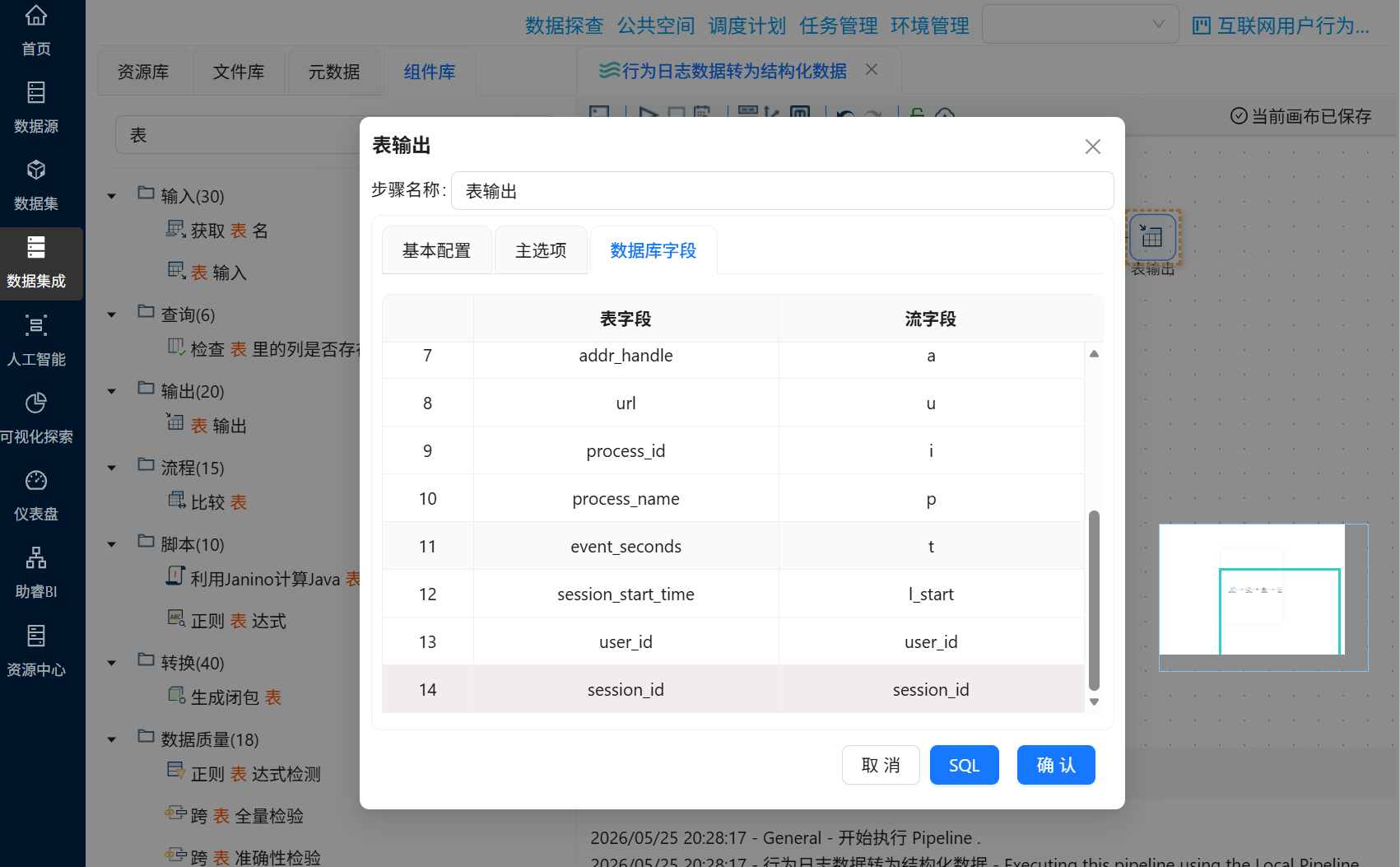
设置完成后点击“确认”
4.2.8 执行转换流
执行转换流,点击工具栏中的“执行”按钮
在弹出执行配置窗口中,选择默认配置,然后点击“启动”按钮,启动工作流
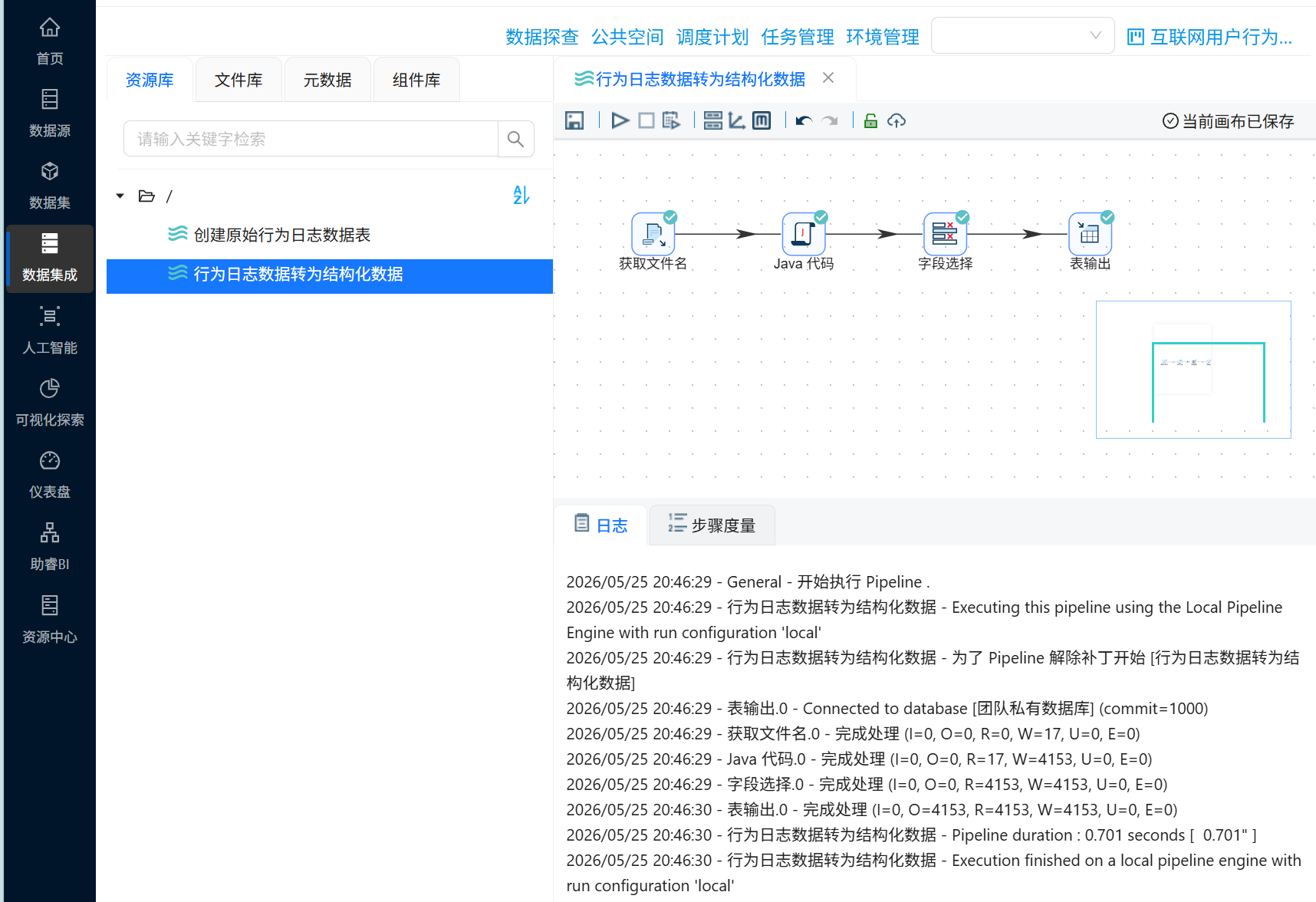
查看日志,工作流执行后会打开日志页面,定期刷新工作流日志数据。
查看数据库结果
打开“元数据”tab页,在“团队私有数据库”连接上右键选择“加载元数据”
然后进入数据探查页面,展开“团队私有数据库”
双击目标表“behavior_events”,在右侧页面选择“查询”tab标签
查看数据库表数据是否符合预期
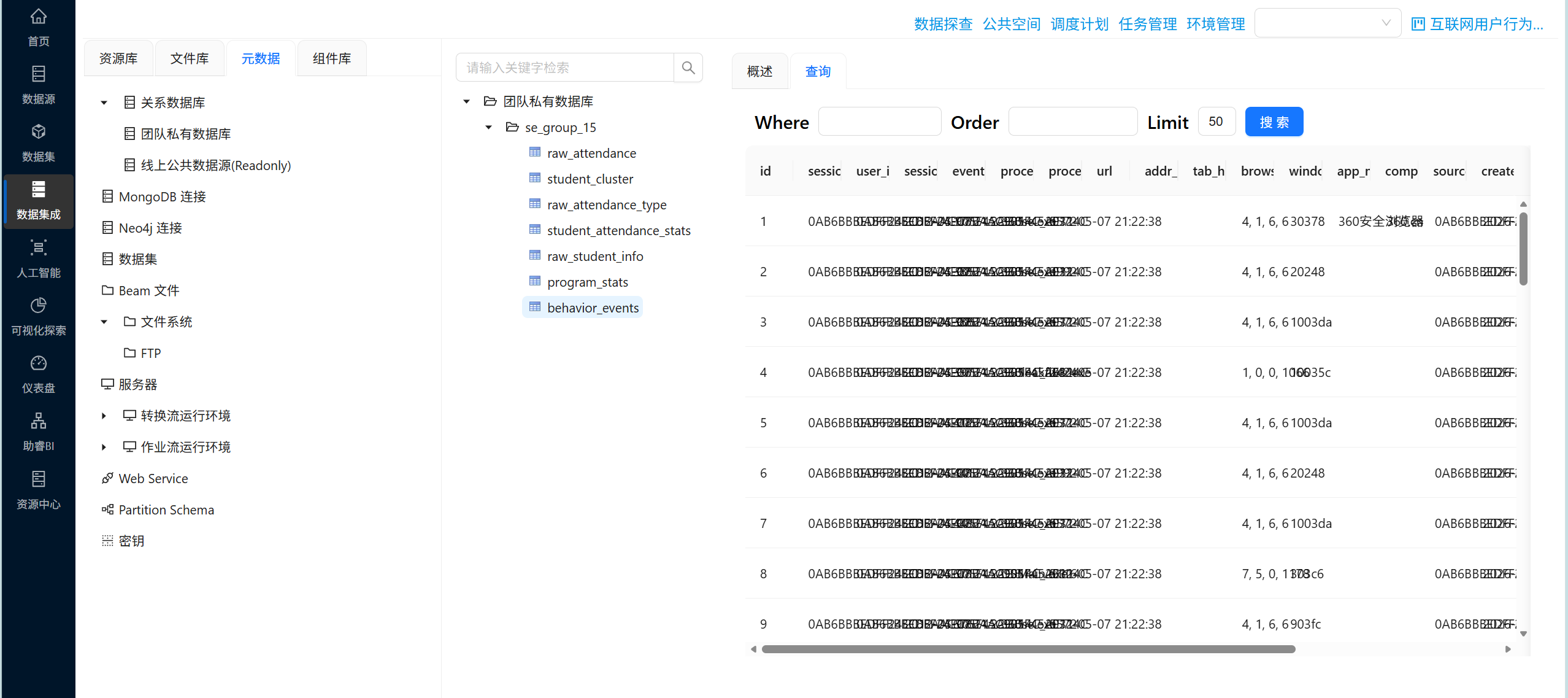
4.3 数据分析方向确定
得到 behavior_events 后,我们需要决定分析什么。对 behavior_events 按进程名 process_name 统计使用人数,可以快速看出哪些程序覆盖的用户最广。这个统计的价值在于:它能帮我们从九百多万条杂乱记录中,迅速锁定最值得分析的候选对象。
4.3.1 创建进程统计表
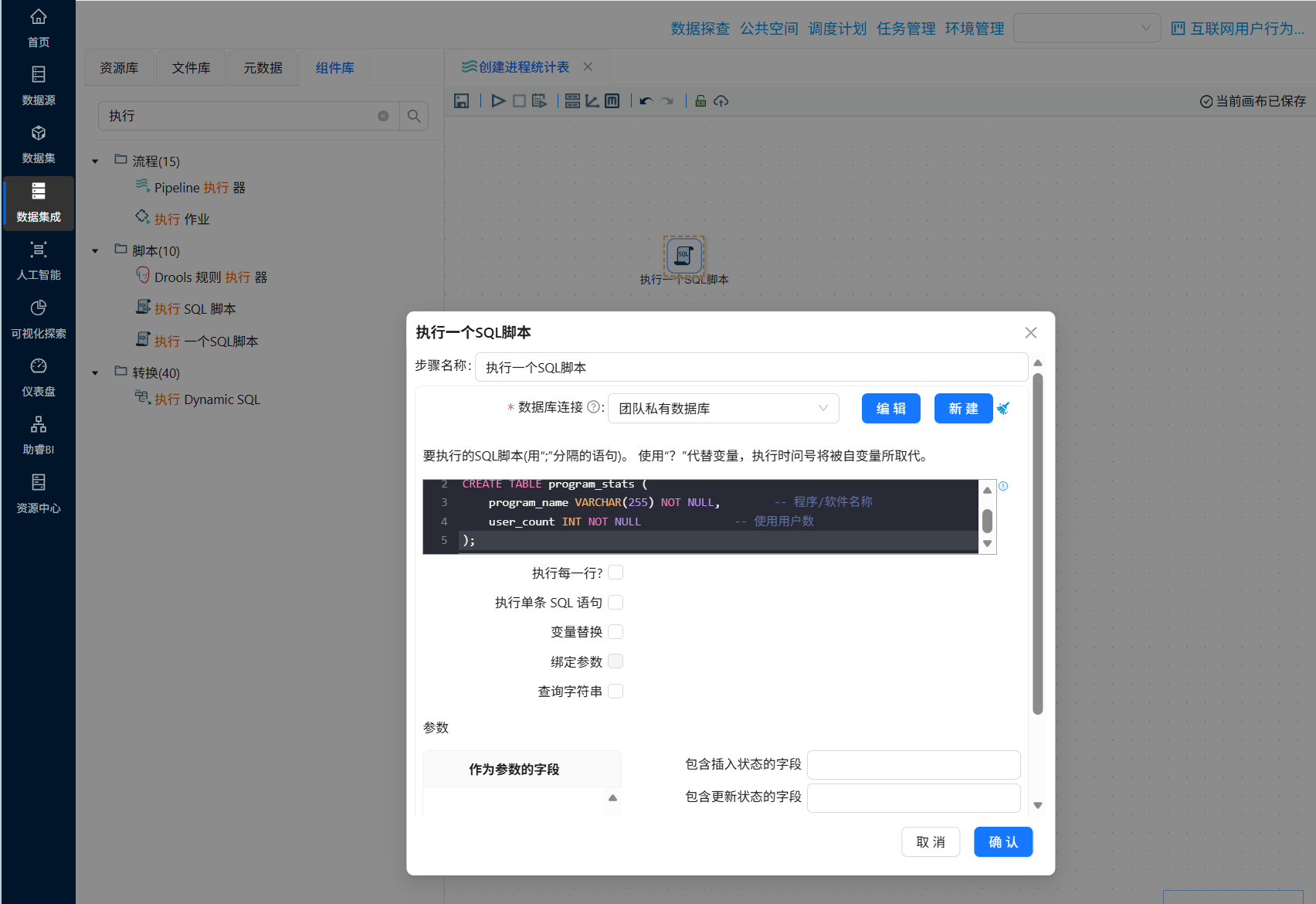
新建转换工作流,并命名为“创建进程统计表”,在该工作流中拖拽“执行一个SQL脚本”组件,通过执行SQL脚本来创建一个标签表。整个转换流如下所示:
配置说明:在组件中填写SQL脚本,选择目标数据库连接“团队私有数据库”,确保脚本执行权限;
SQL脚本如下:
-- 创建程序/软件统计表CREATE TABLE program_stats (
program_name VARCHAR(255) NOT NULL, -- 程序/软件名称
user_count INTNOT NULL-- 使用用户数
);其他参数使用默认选项,完成后组件配置如下:
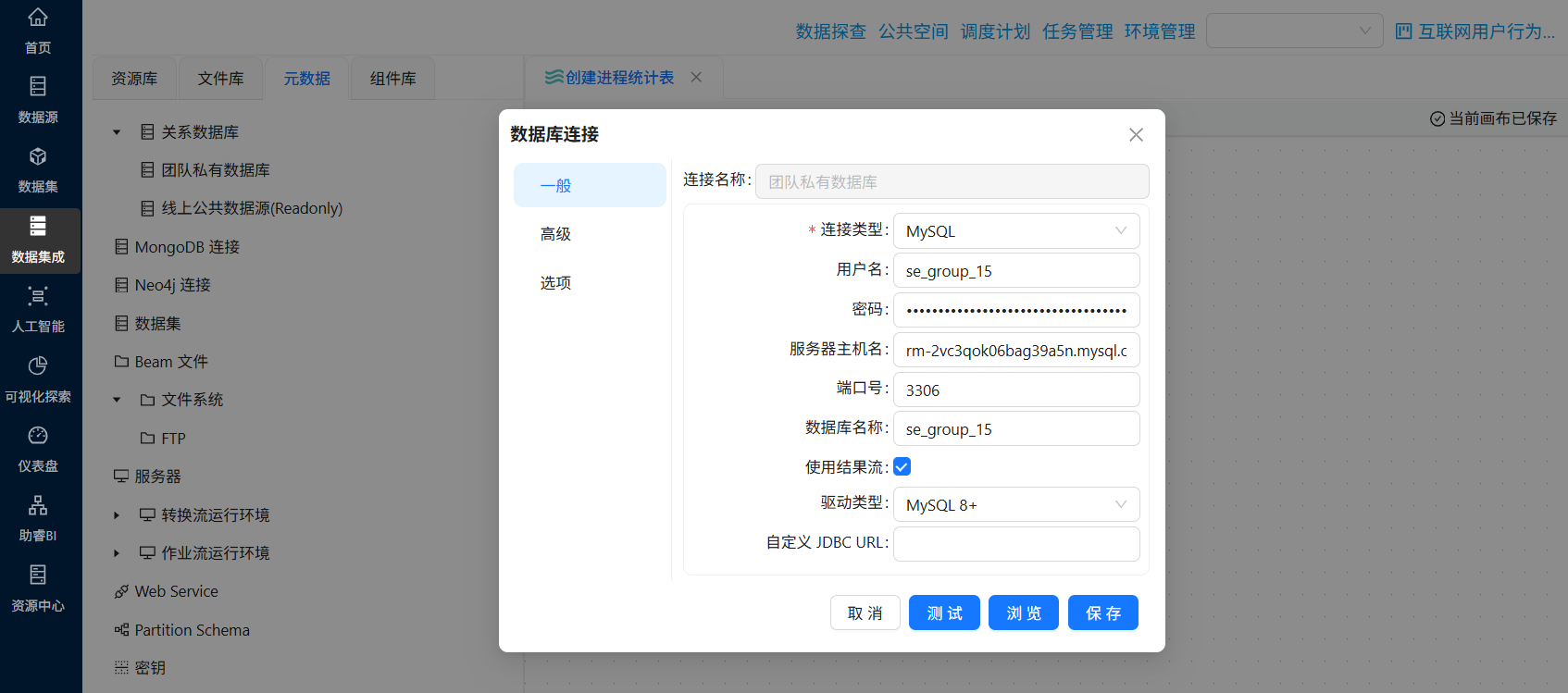
由于数据量较大,为了顺利运行转换流,我们点开“元数据”,双击“团队私有数据库”,勾选“使用结果流”
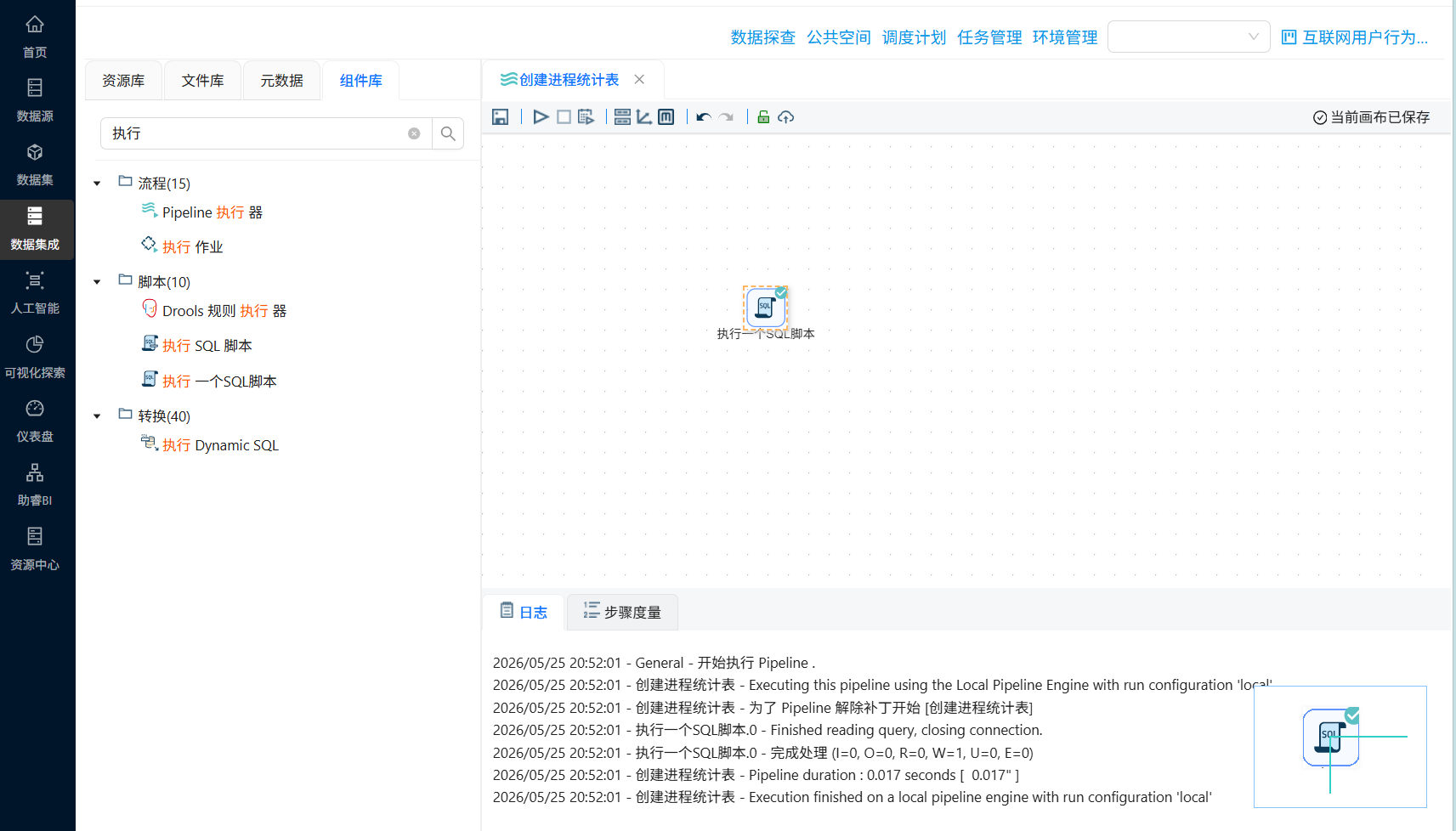
完成后运行转换流,运行过程会定时刷新组件状态,并画布下面显示执行日志。
4.3.2 统计进程用户规模
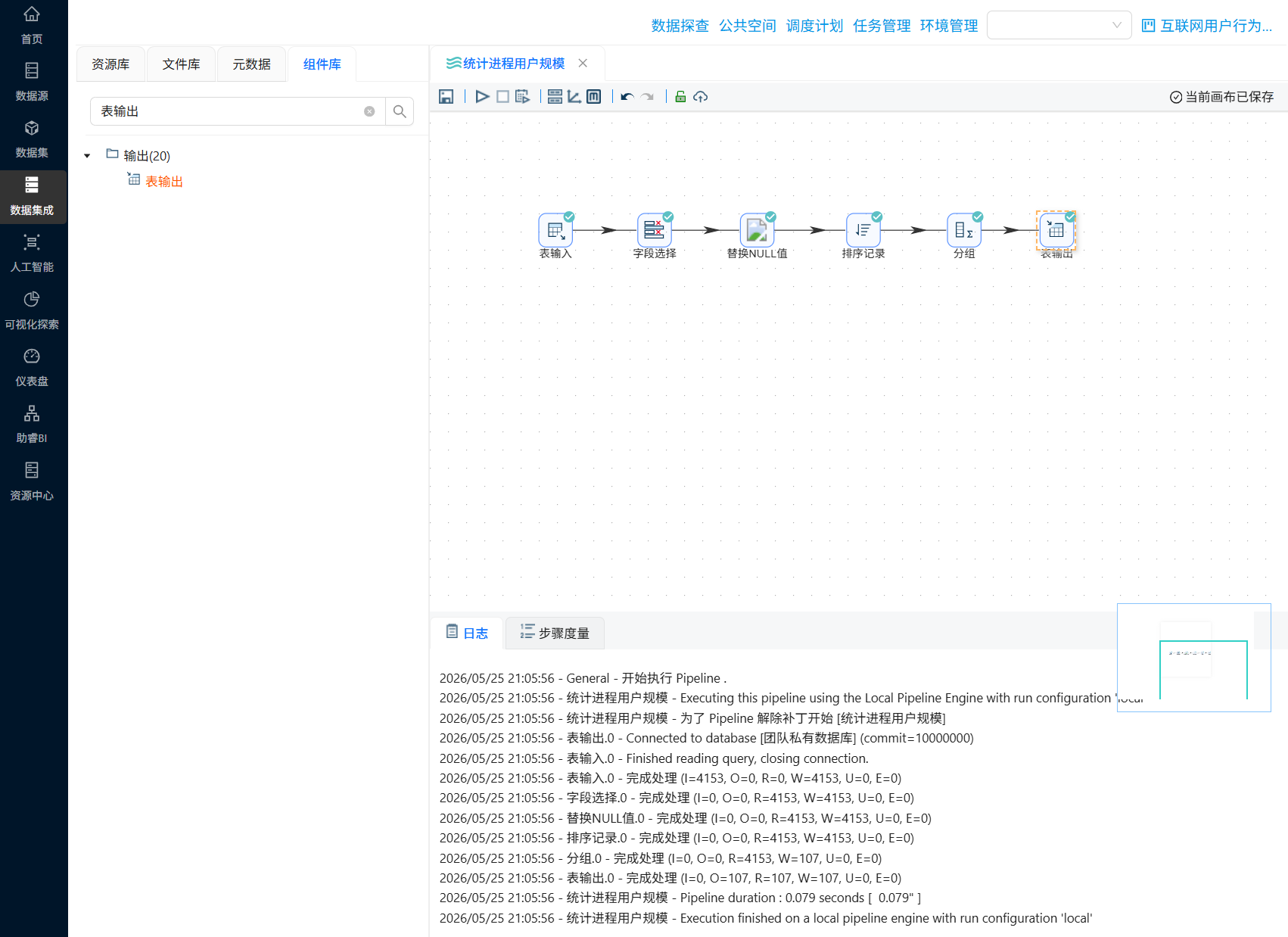
每个进程得用户规模即用户数量 = 每个进程名称得用户ID计数
新建转换流“统计进程用户规模”,拖拽“表输入”组件到画布中,数据库连接选择“团队私有数据库”,并获取 behavior_events 得所有SQL查询语句
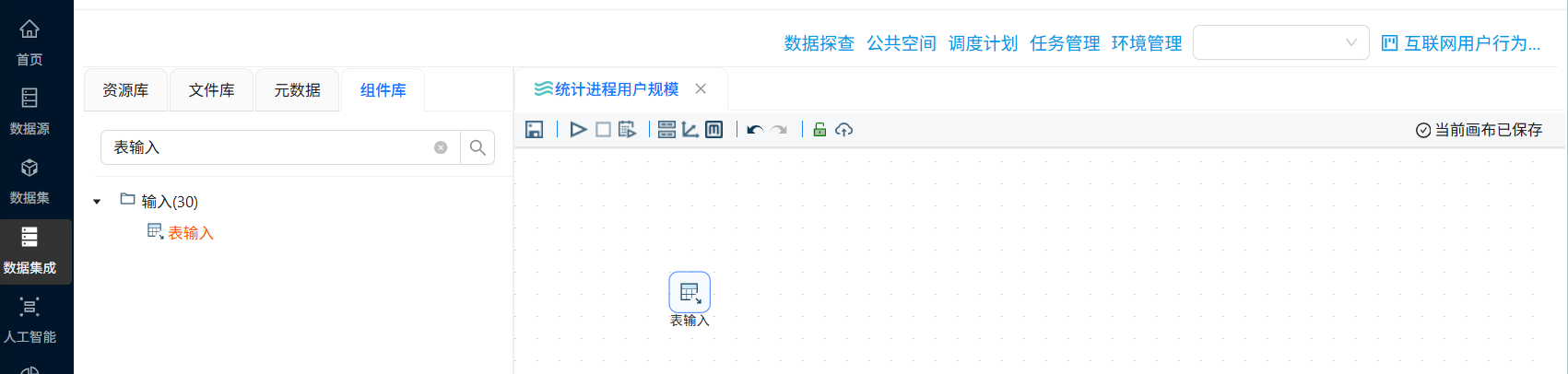
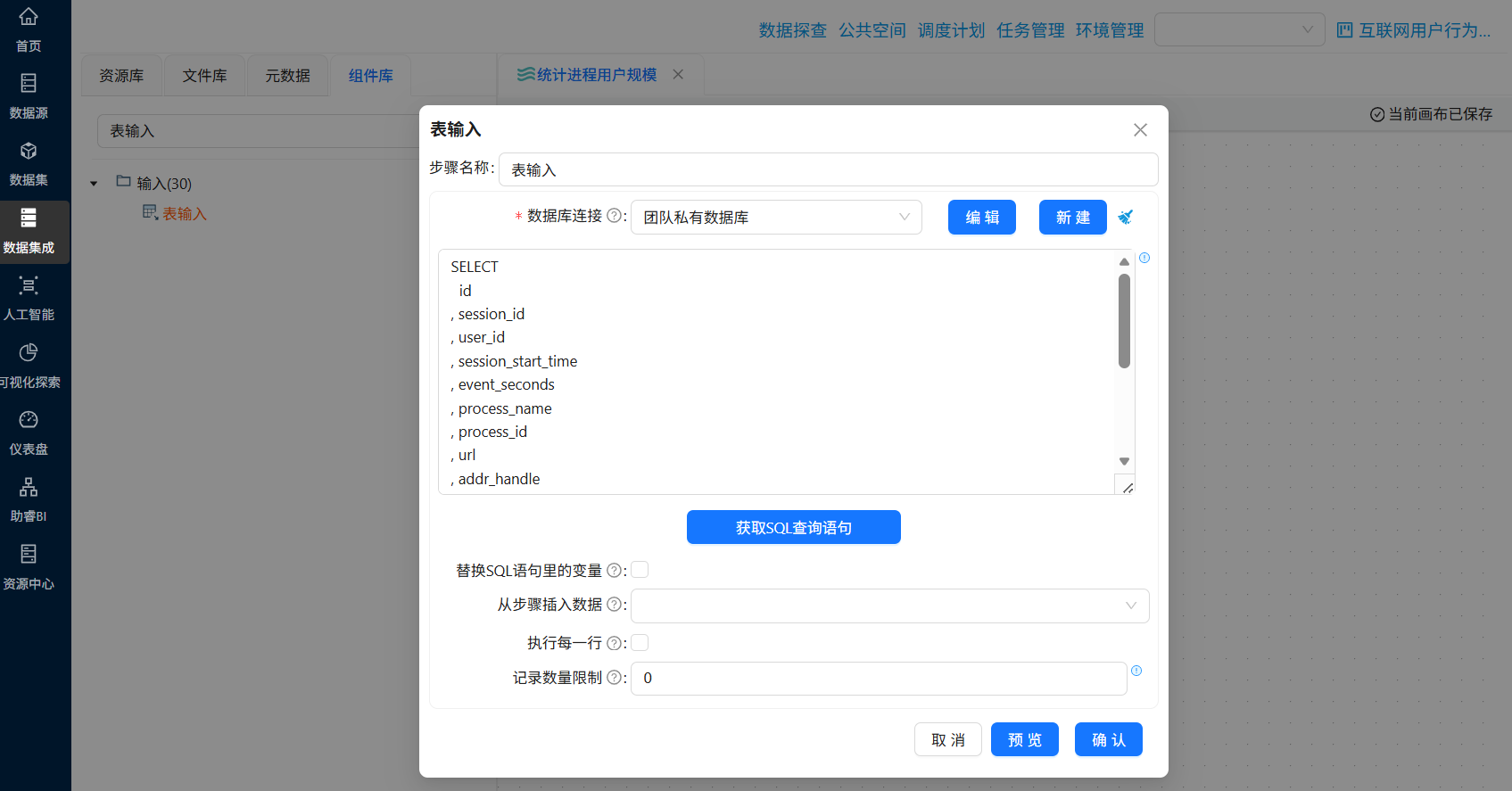
拖拽“字段选择”组件到画布中,并创建“表输入”组件到“字段选择”组件得连线,双击“字段选择”组件,点击tab选项“移除”,然后再字段名称下方空白处右键点击“获取字段”
统计每个进程得用户数量只需用到 user_id、process_name 两个字段,所以需要移除其他字段
选中user_id、process_name 两个字段,右键点击“删除选中的行”
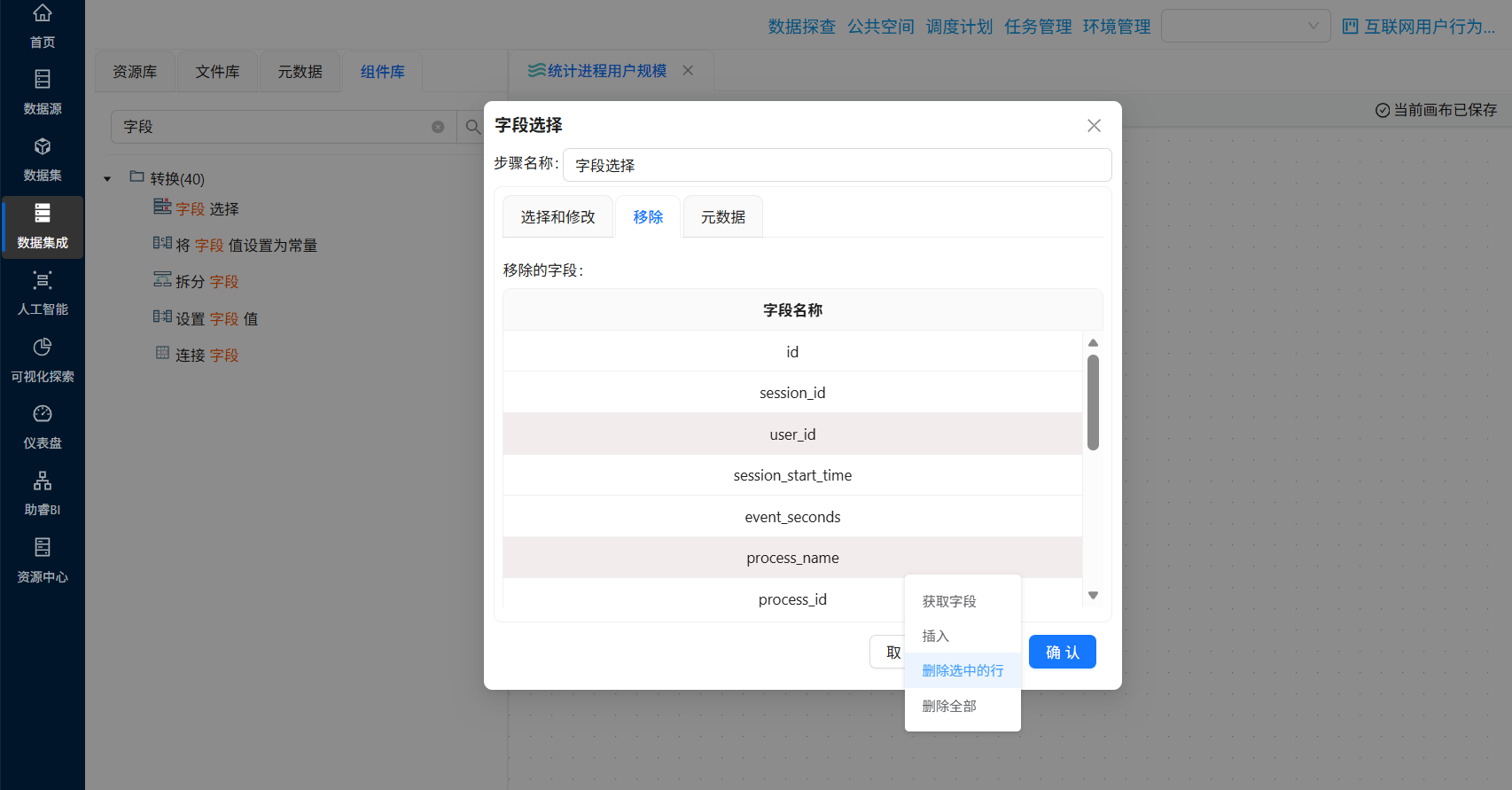
删除后点击“确认”
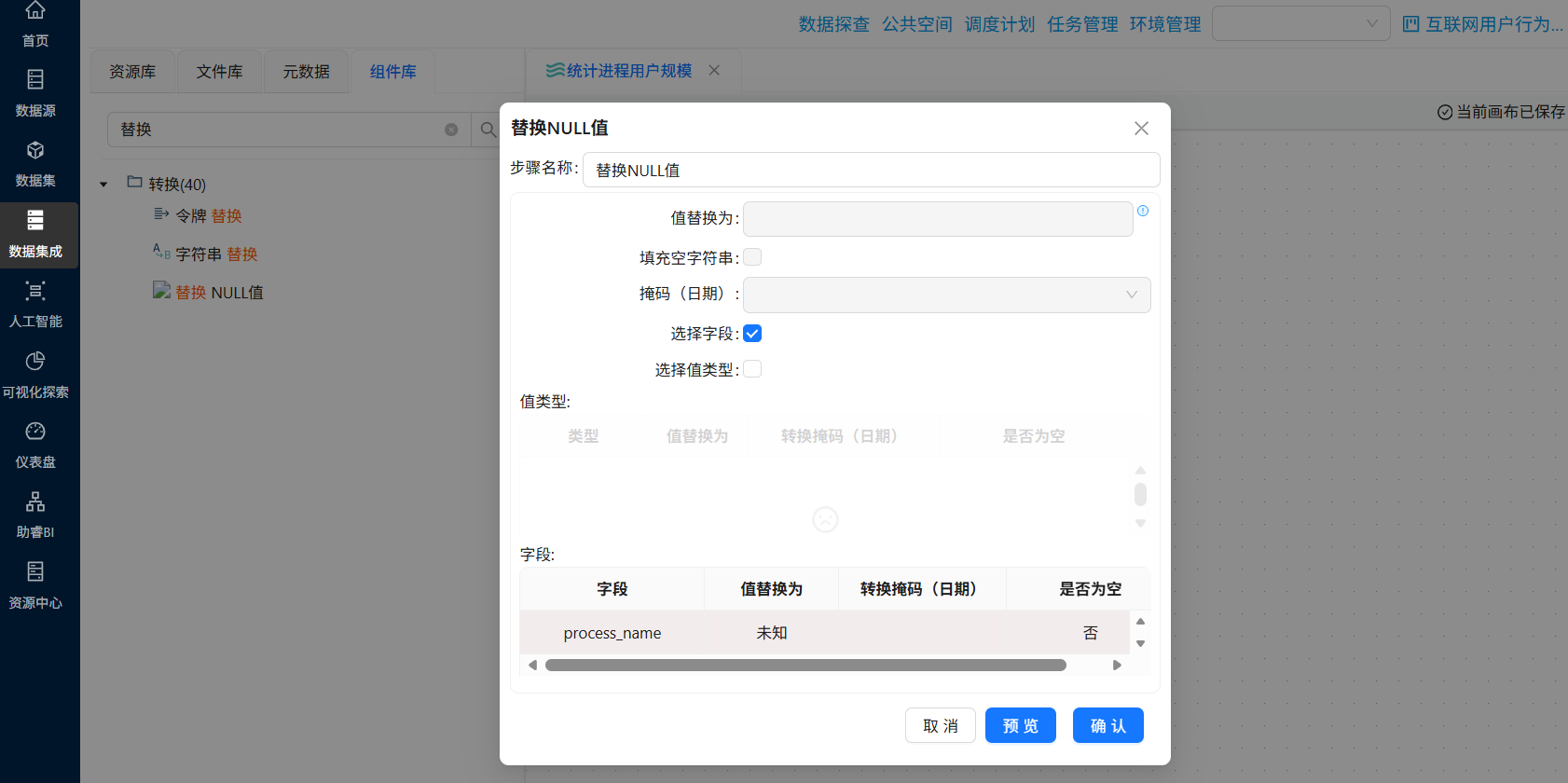
字段 process_name 可能存在空值,为避免后续操作错误,需要将空值替换为“未知”。拖拽“替换NULL值”组件到画布中,并创建“字段选择”组件到“替换NULL值”组件的连线,连接线类型选中“主输出步骤”
双击“替换NULL值”组件,勾选“选择字段”,在下方字段表格中插入一行,并输入:
- 字段:process_name
- 值替换为:未知
- 是否为空:否
分组聚合之前需要对数据进行排序,否则分组计算结果可能出错。拖拽“排序字段”组件到画布中,创建“替换NULL值”组件到“排序记录”组件的连线,连接线类型选中“主输出步骤”
双击“替换NULL值”组件,将数据按照“process_name”字段升序排序
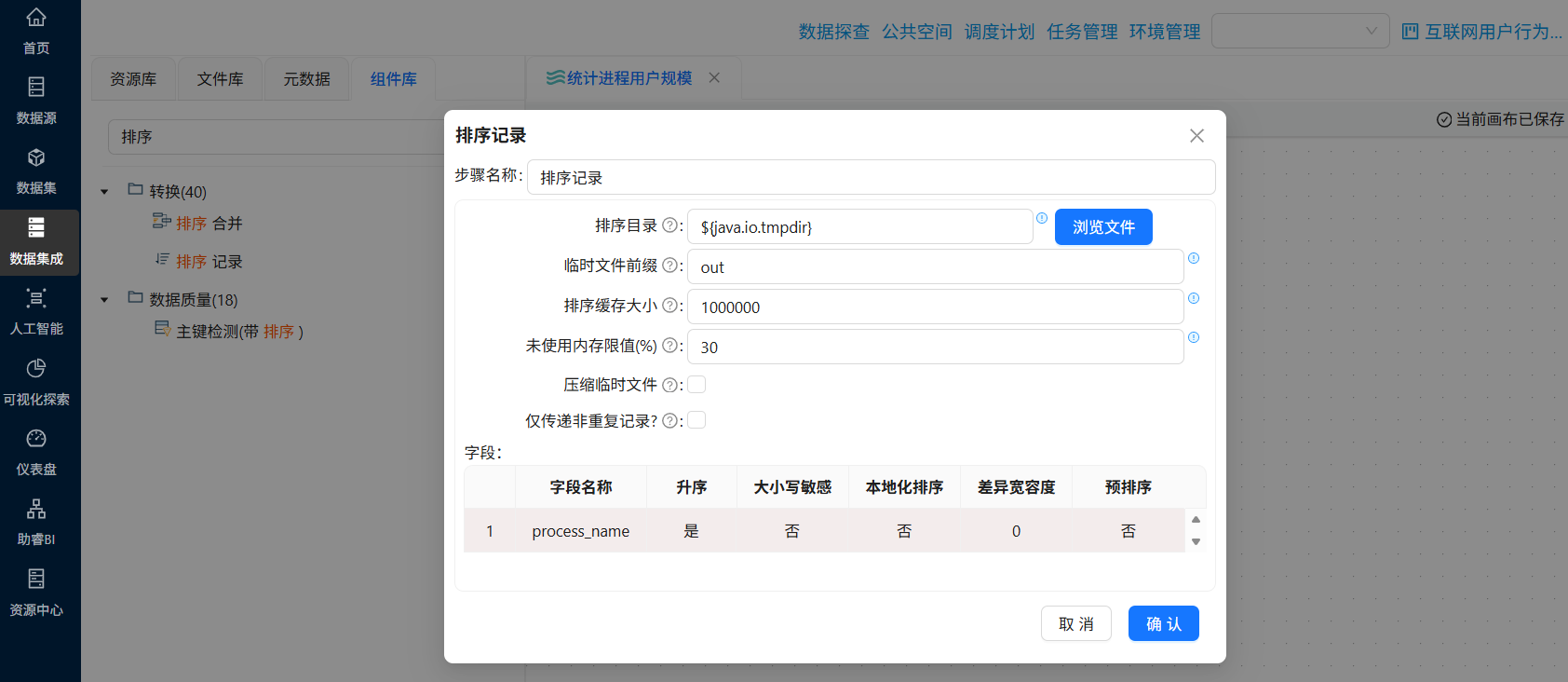
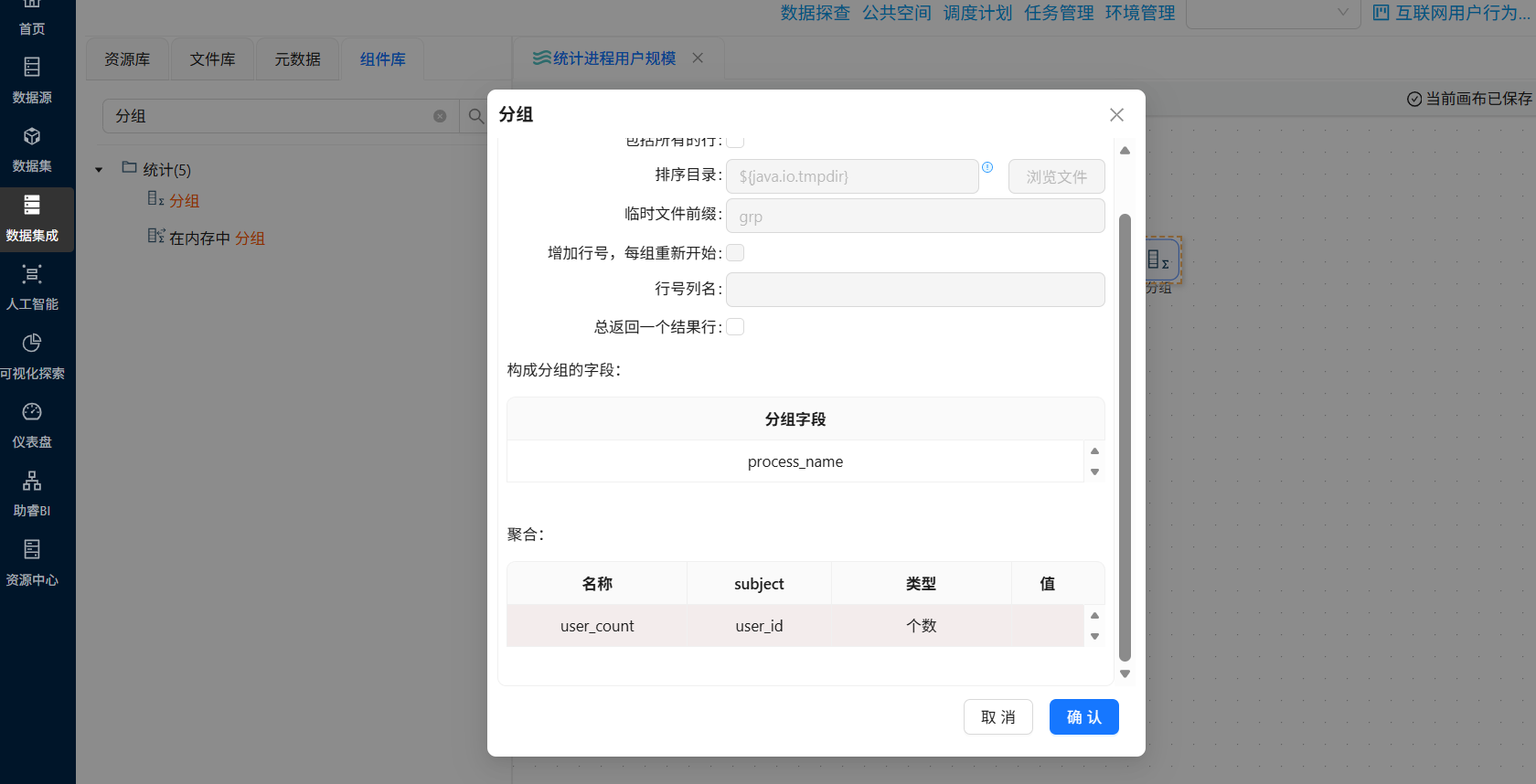
接下来就可以对排序后的数据进行分组聚合统计了,拖拽“分组”组件到画布中,创建“排序记录”组件到“分组”组件的连线,
双击“分组”组件,在分组字段空白处获取字段后,仅保留“process_name”
在聚合表格空白处右键点击“插入”
双击插入的空白行,名称输入“user_count”,subject选择“user_id”,类型选择“个数”,最后点击“确认”
分组聚合后的数据我们需要输出到4.3.1小节创建的统计表中,拖拽“表输出”组件,创建“分组”组件到“表输出”组件的连线
双击“表输出”组件,选择“团队私有数据库”连接,勾选“裁剪表”,这样表输出组件在插入数据前会清空原始表数据,避免重复插入
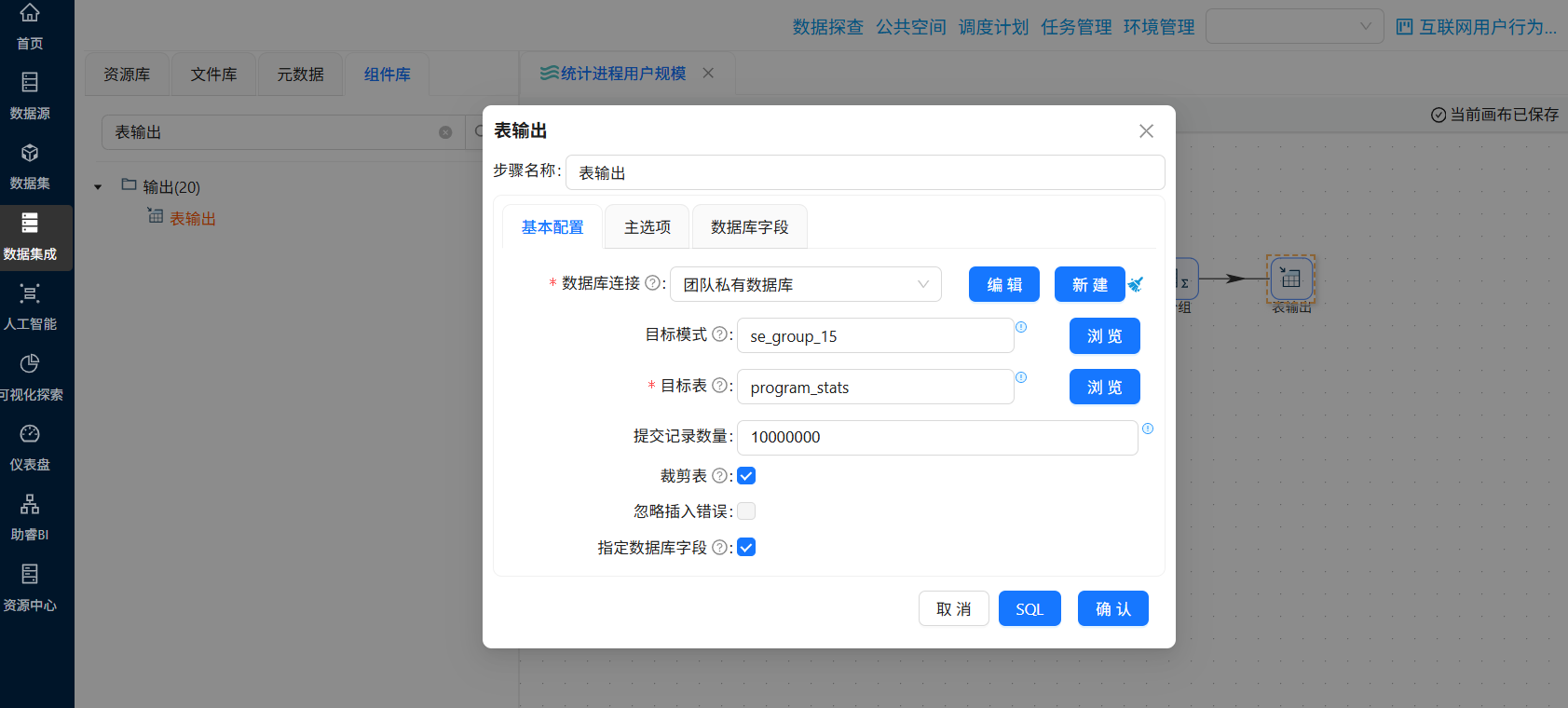
勾选“指定数据库字段”,建立工作流字段与数据库表字段的映射关系。勾选后会激活“数据库字段”tab页,在数据库字段tab页,右键选择“获取字段”
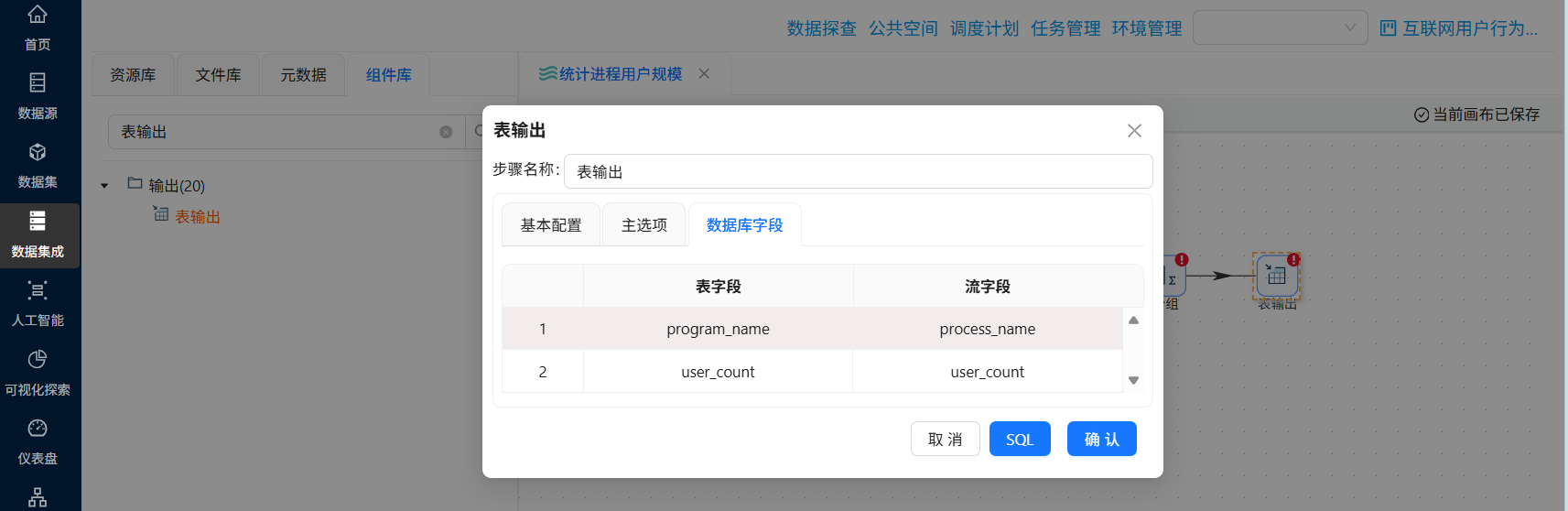
最后执行转换流即可
4.3.3 观察数据确定分析方向
为了确定覆盖用户最广的进程/软件,我们使用助睿BI来观察数据
点击实验平台左边菜单“助睿BI”,进入助睿BI首页
由于之前的实验已经创建了团队私有数据库的数据源连接,本次实验无需再创建数据源连接,可直接创建数据集
点击“数据集”菜单
在数据集页面点击“+” - “新建数据集”
数据集名称和备注信息都输入“进程用户数据统计”,点击“确认”
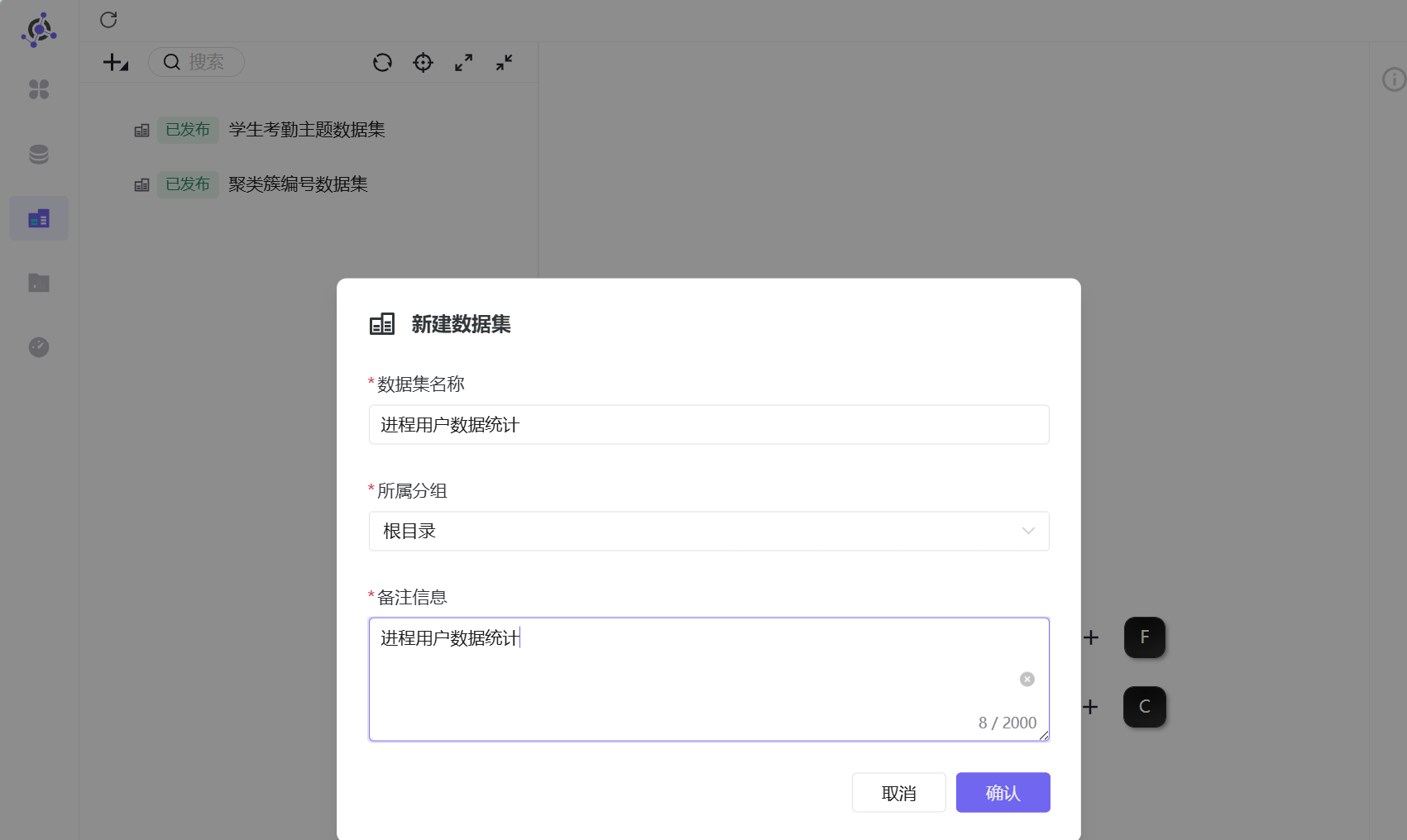
右上角数据源选择进程统计表 program_stats 所在的“商业数据分析” - “labs”
将 program_stats 拖拽至画布中
可以看到 program_stats 的数据结果,为了方便观察,可以将字段备注修改为中文
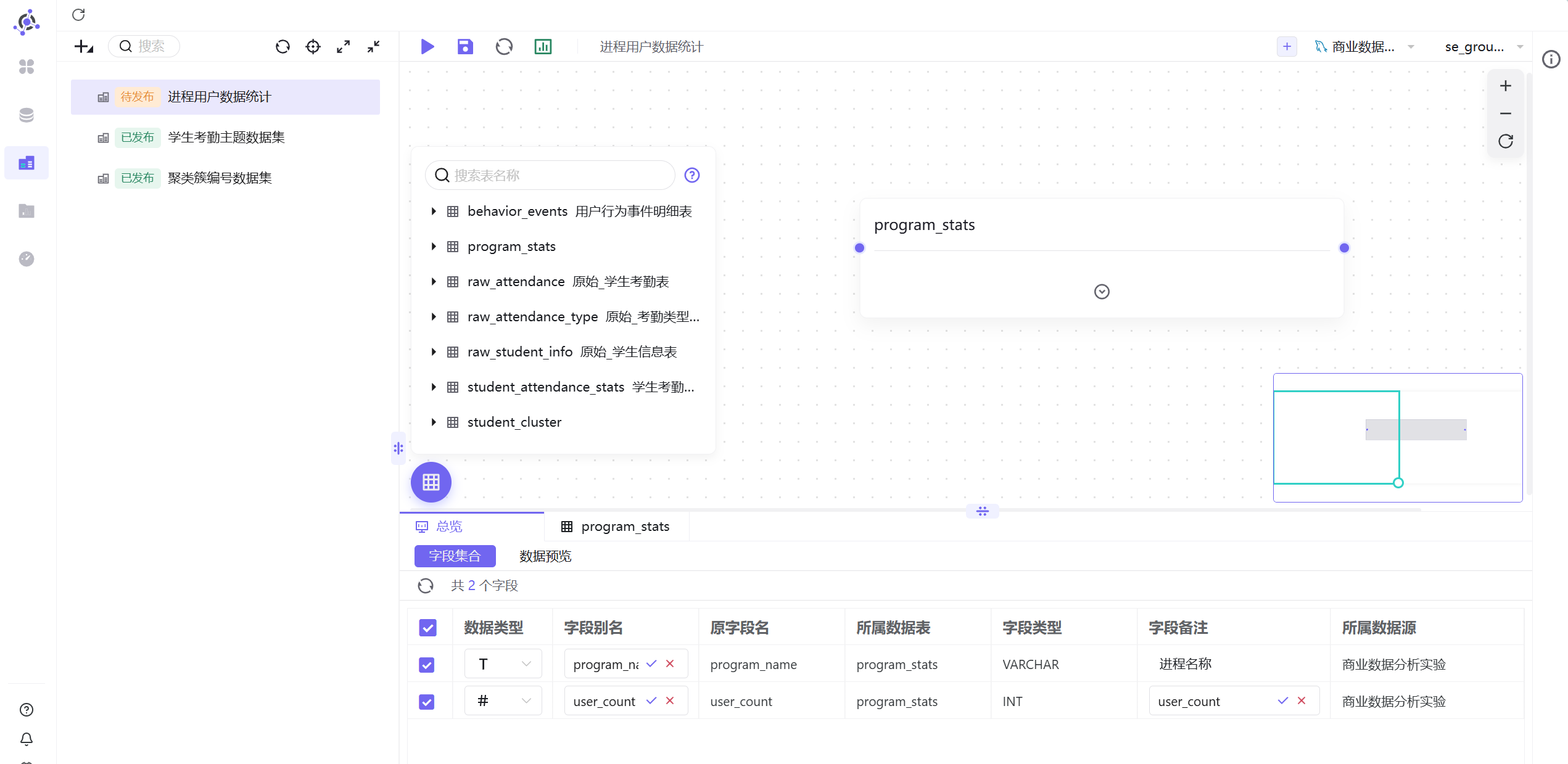
修改完成后点击“保存”,保存并发布数据集
点击“工作表”
进入工作表页面后,点击“+” - “新建工作表”
输入工作表名称和备注信息后点击“确认”
数据集选择刚刚创建的数据集“进程用户数据统计”,图表类型选择“水平条图”
将字段“program_name”拖拽至Y轴,“user_count”拖拽至X轴,并将“user_count”按照降序排序
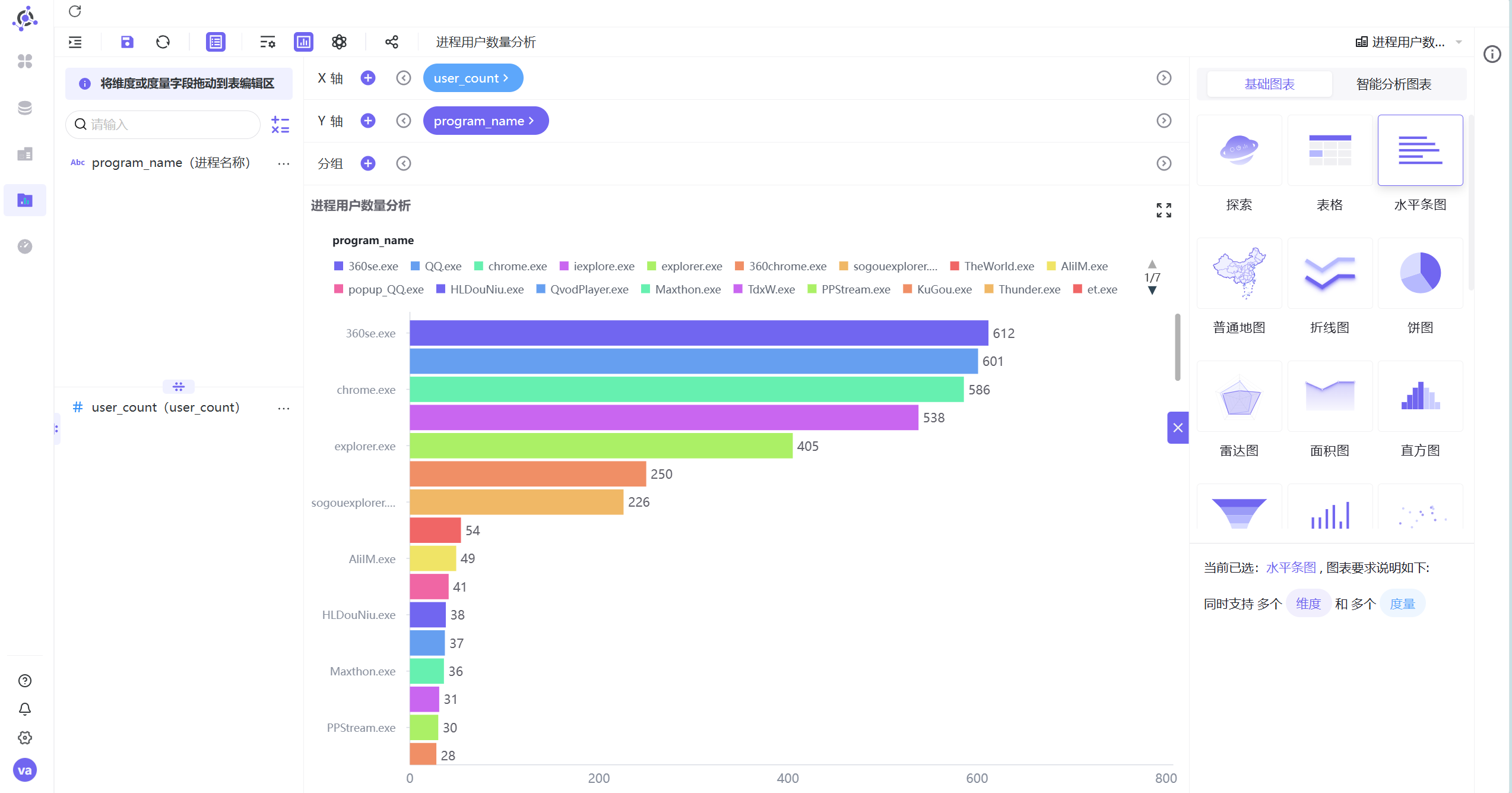
由此,我们可以看到,浏览器类进程(chrome.exe、360chrome.exe、sogouexplorer.exe、QQBrowser.exe)的用户数明显高于其他软件(如 QQ.exe、EXCEL.EXE、WINWORD.EXE)。这表明浏览器是覆盖面最广的应用,样本充足;同时浏览器记录包含 url,可进一步分析网站偏好。因此,确定浏览器为分析对象。
4.4 分析方案设计与数据确定
根据 4.3 节的统计结果,我们发现浏览器类进程的用户覆盖率远高于其他软件,且浏览器记录包含 url 字段,可以挖掘用户网站偏好。因此,我们将分析对象锁定为浏览器,并围绕以下业务问题展开分析:
- 浏览器市场格局:哪些浏览器用户最多、使用时长最长?
- 用户画像:不同浏览器的用户在年龄、职业上有何差异?
- 使用习惯:用户集中在什么时段使用浏览器?
- 竞争迁移:用户是否会从一款浏览器切换到另一款?
- 流失预测:哪些用户可能停止使用 iexplore.exe 浏览器?
- 个性化推荐:根据用户的网站访问历史,可以推荐哪些网站?
为了回答这些问题,我们可以预先设计一套可视化方案(将在下一实验完成)。下表列出了每张图表对应的业务问题、所需数据字段以及最终输出的数据表名,后续数据加工将围绕它们展开。
|
输出表名 |
内容 |
粒度 |
|
browser_coverage.csv |
每个浏览器的用户数、总使用时长 |
每个浏览器一行 |
|
browser_hourly.csv |
每个浏览器按小时统计活跃用户数 |
浏览器 × 小时 |
|
browser_demographic.csv |
每个浏览器按年龄分段、职业的用户分布 |
浏览器 × 年龄组 × 职业 |
|
browser_retention.csv |
每个浏览器从第3周到第4周的留存率 |
每个浏览器一行 |
|
browser_migration.csv |
用户从第3周主用浏览器切换到第4周主用浏览器的迁移对及人数 |
源浏览器 → 目标浏览器 |
|
churn_features.csv |
每个用户前三周的 Chrome 行为特征及标签 |
每个用户一行 |
|
churn_probability.csv |
每个用户的流失概率(AI Studio 输出) |
每个用户一行 |
|
feature_importance.csv |
流失预测模型的特征重要性 |
每个特征一行 |
|
high_risk_users.csv |
流失概率最高的 20% 用户及其关键特征 |
每用户一行(约200行) |
本次实验我们先完成前2个数据的加工,首先需要在团队私有数据库中先创建这2个数据表
创建两个转换流“创建浏览器的用户数总使用时长统计表”、“创建每个浏览器按小时统计活跃用户数统计表”
两个转换流都拖拽“执行一个SQL脚本”组件到画布中,分别输入以下SQL:
- 创建浏览器的用户数总使用时长统计表的“执行一个SQL脚本”组件配置如下:
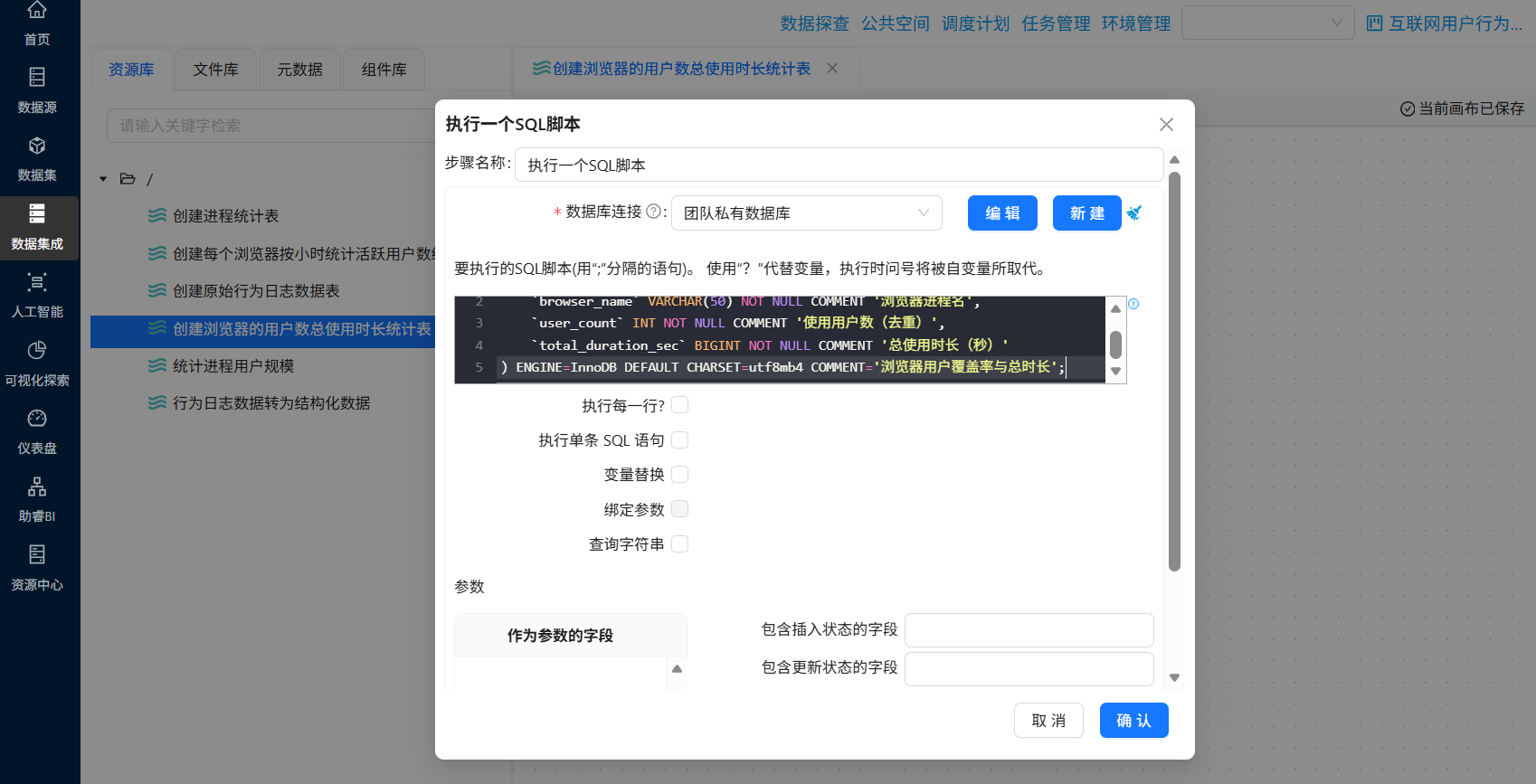
SQL:
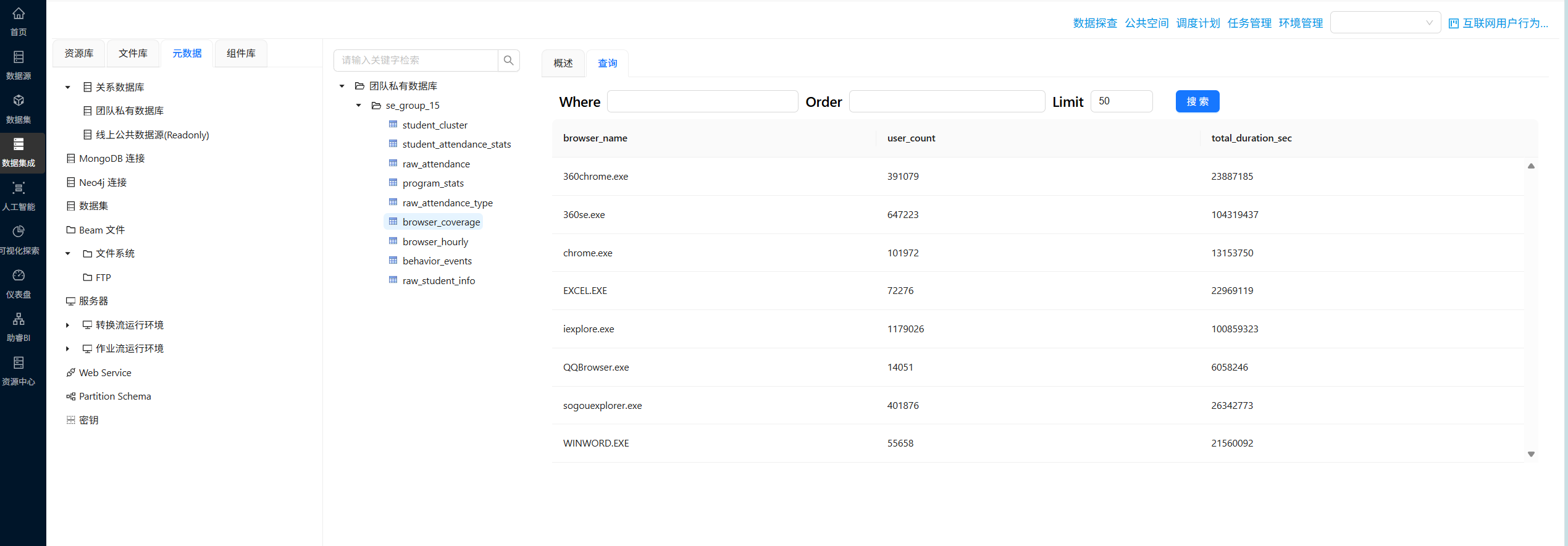
CREATE TABLE `browser_coverage` (
`browser_name` VARCHAR(50) NOT NULL COMMENT '浏览器进程名',
`user_count` INT NOT NULL COMMENT '使用用户数(去重)',
`total_duration_sec` BIGINT NOT NULL COMMENT '总使用时长(秒)'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='浏览器用户覆盖率与总时长';- 创建每个浏览器按小时统计活跃用户数统计表的“执行一个SQL脚本”组件配置如下:
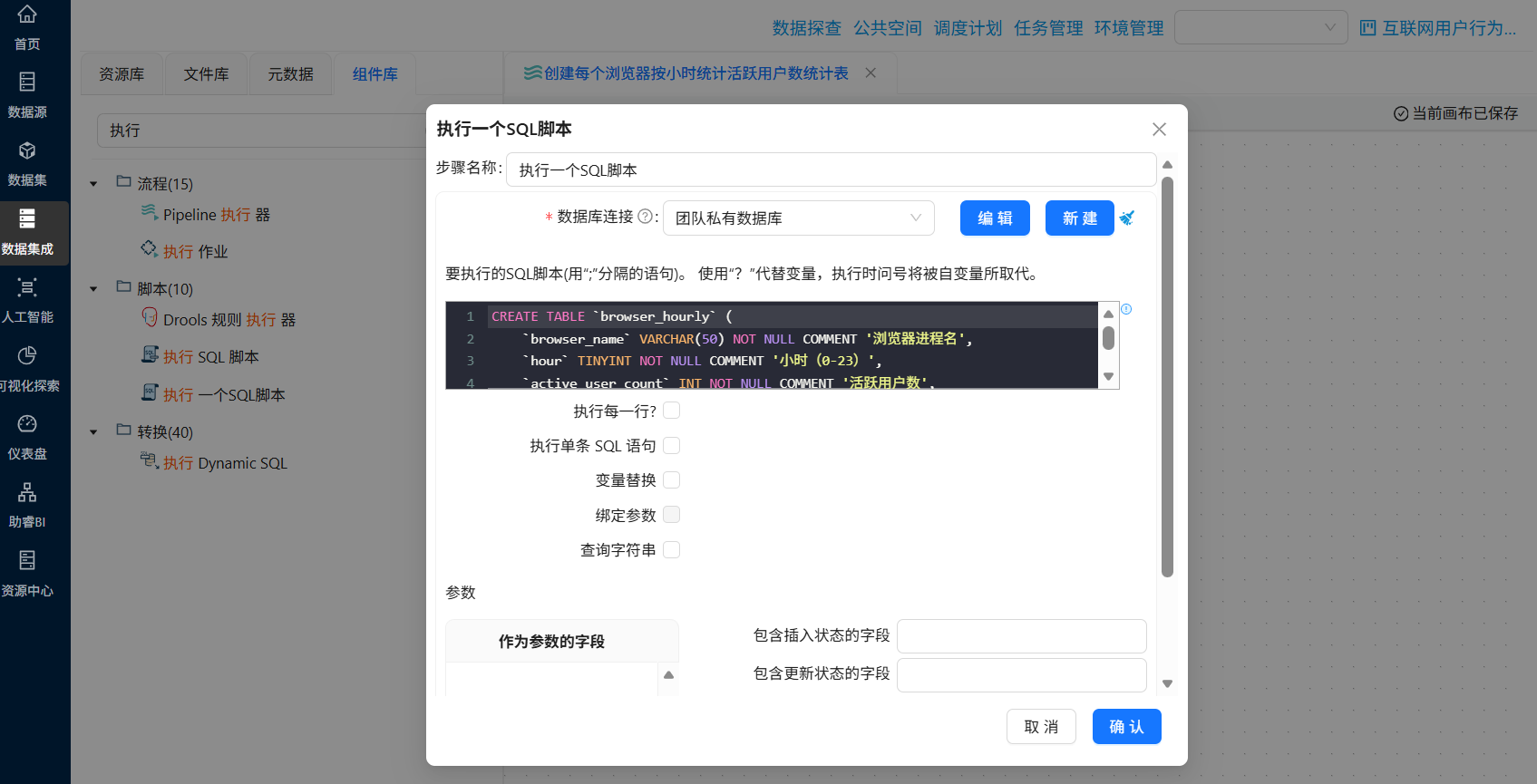
SQL
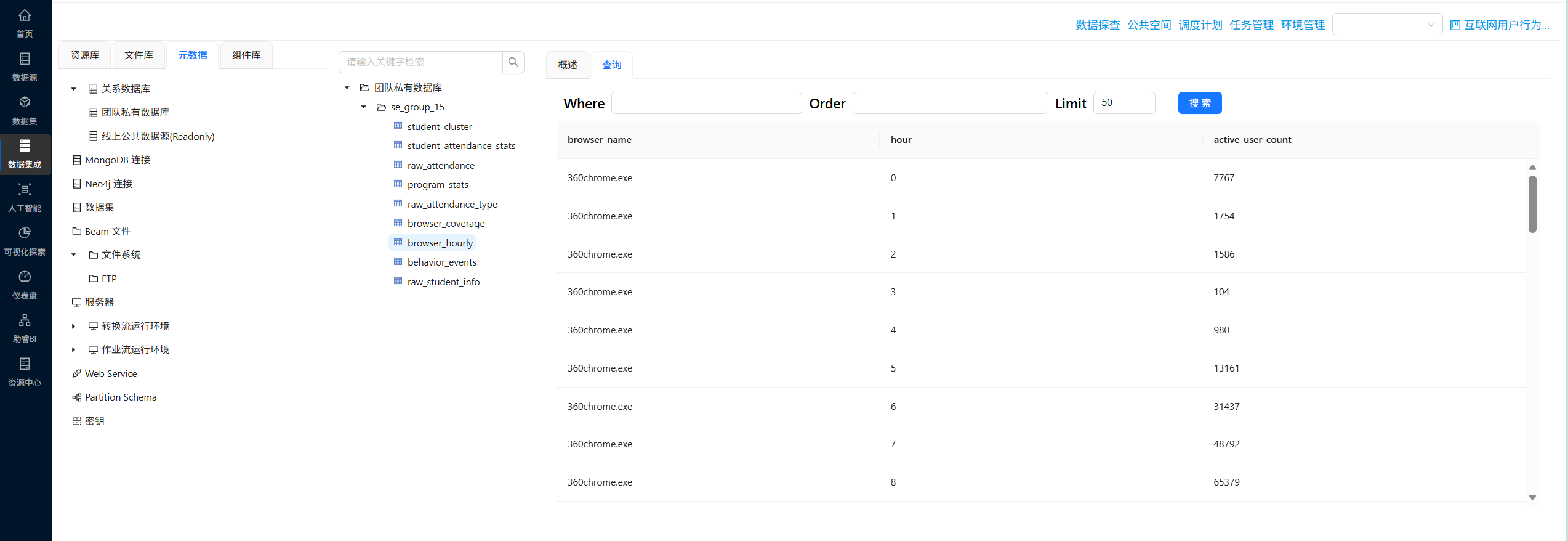
CREATE TABLE `browser_hourly` (
`browser_name` VARCHAR(50) NOT NULL COMMENT '浏览器进程名',
`hour` TINYINT NOT NULL COMMENT '小时(0-23)',
`active_user_count` INT NOT NULL COMMENT '活跃用户数',
PRIMARY KEY (`browser_name`, `hour`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='浏览器按小时活跃用户数';最后分别执行两个转换流即可
4.5 数据清洗、聚合与关联加工
在4.1章节转换后得到明细结构化数据,单条记录仅反映单次电脑操作行为,无法直观体现用户整体使用习惯,因此开展清洗、聚合与关联加工,提炼核心统计指标,并结合用户基础属性信息,形成具备分析价值的整合数据集。
解析完成的behavior_events行为明细表,同时引入demographic.csv用户人口属性数据表,依靠用户唯一编号完成两份数据联动处理。
注:包含全部数据的 behavior_events 行为明细表已经存放在线上公共数据库中,可以直接使用
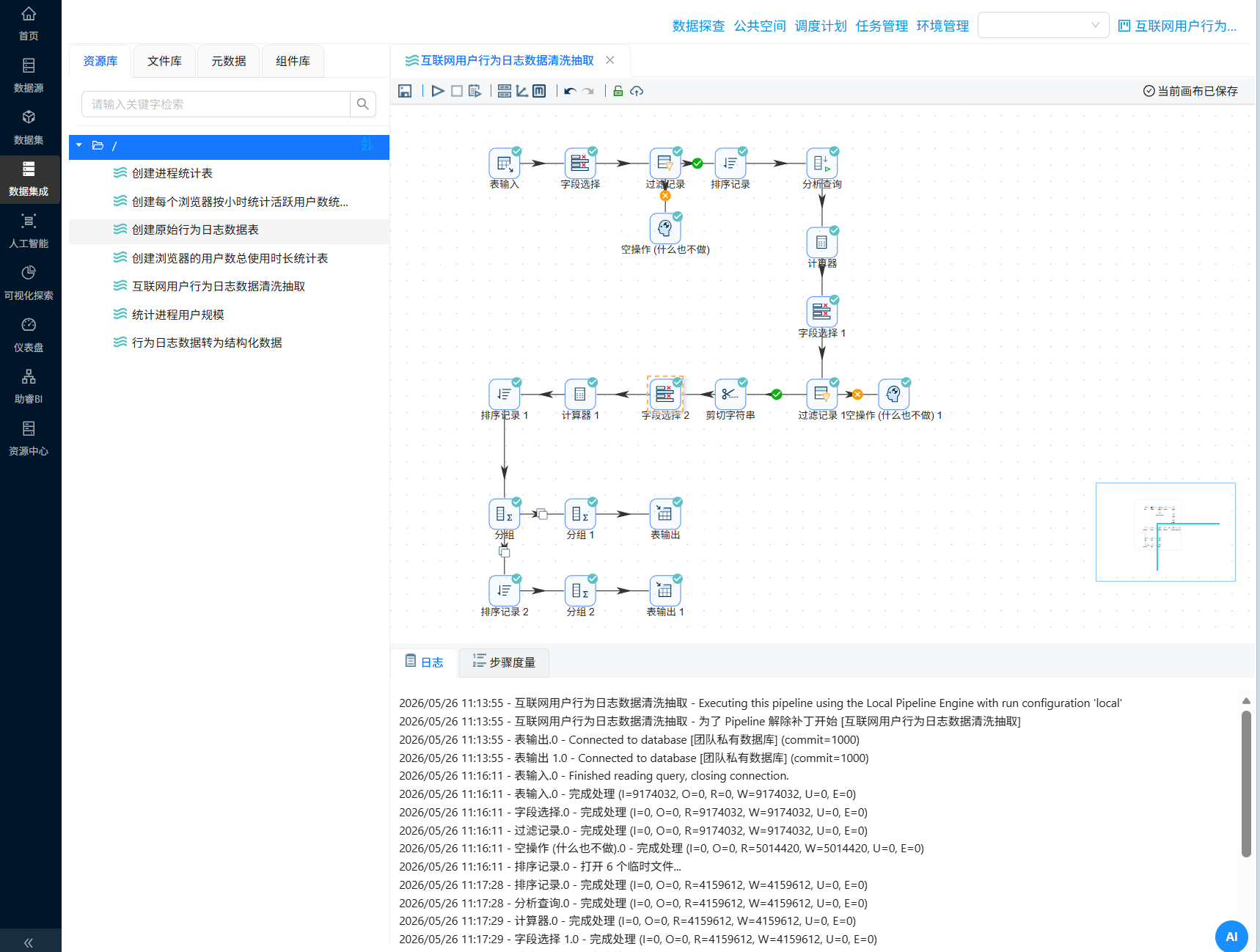
新建转换流“互联网用户行为日志数据清洗抽取”
4.5.1 表输入:读取行为日志数据
拖入“表输入”组件到画布中
连接线上公共 数据源,获取 behavior_events 的所有SQL查询语句
4.5.2 字段选择:删除冗余字段
拖拽“字段选择”组件到画布中,创建“表输入”组件到“字段选择”组件的连线
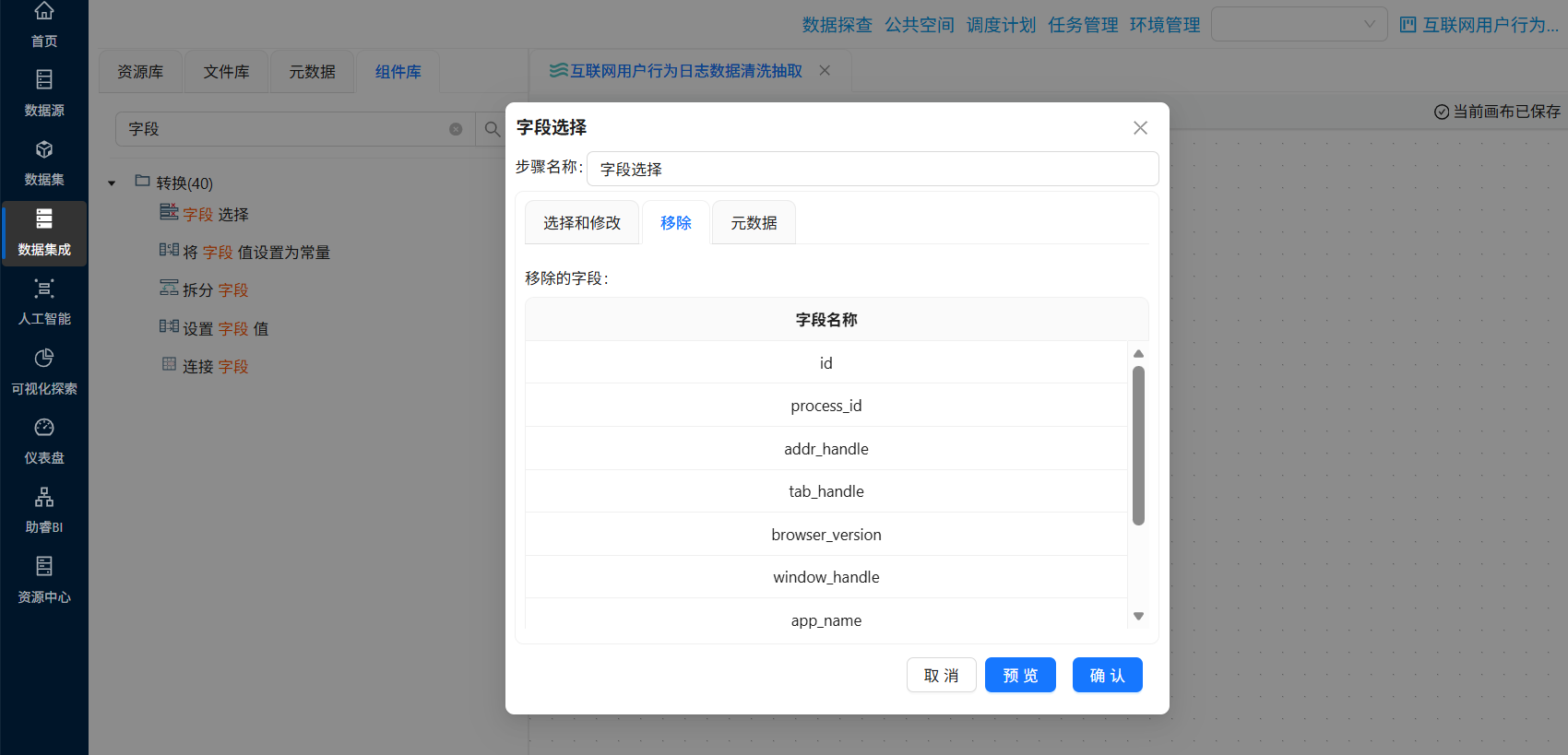
双击“字段选择”组件,点击“移除”tab选项,在字段名称下方空白处右键点击“获取字段”
选中 session_id, user_id, session_start_time, process_name, url, event_seconds 后删除选中的行,保留下来的字段就是要移除的字段,点击“确认”
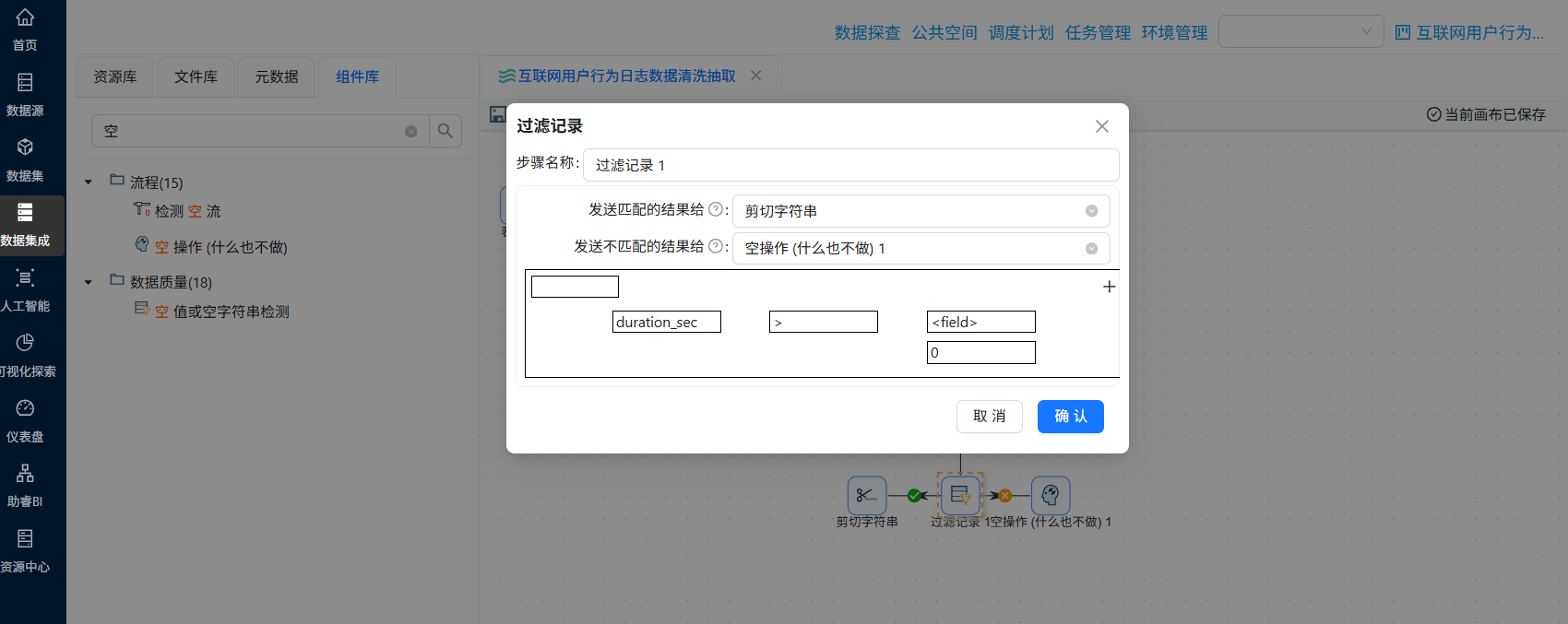
4.5.3 过滤记录:筛选进程为主要浏览器的数据
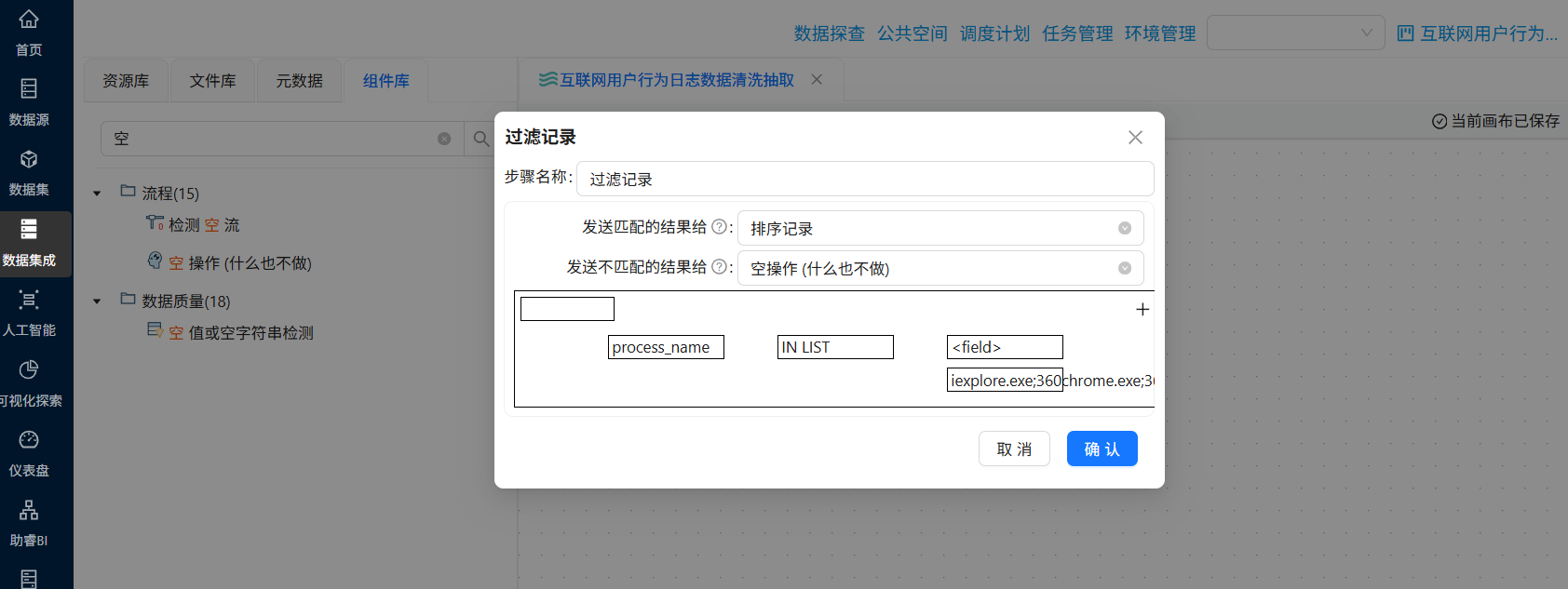
拖拽“过滤记录”组件到画布中,创建“字段选择”组件到“过滤记录”组件的连线,连接线类型选择“主输出步骤”
双击“过滤记录”组件,可以看到需要配置匹配和不匹配的结果的输出步骤
因此,我们先将后续的步骤的组件拖进来,拖拽“排序记录”组件到画布中,创建“过滤记录”组件到“排序记录”组件的连线,连接线类型选择“True输出”
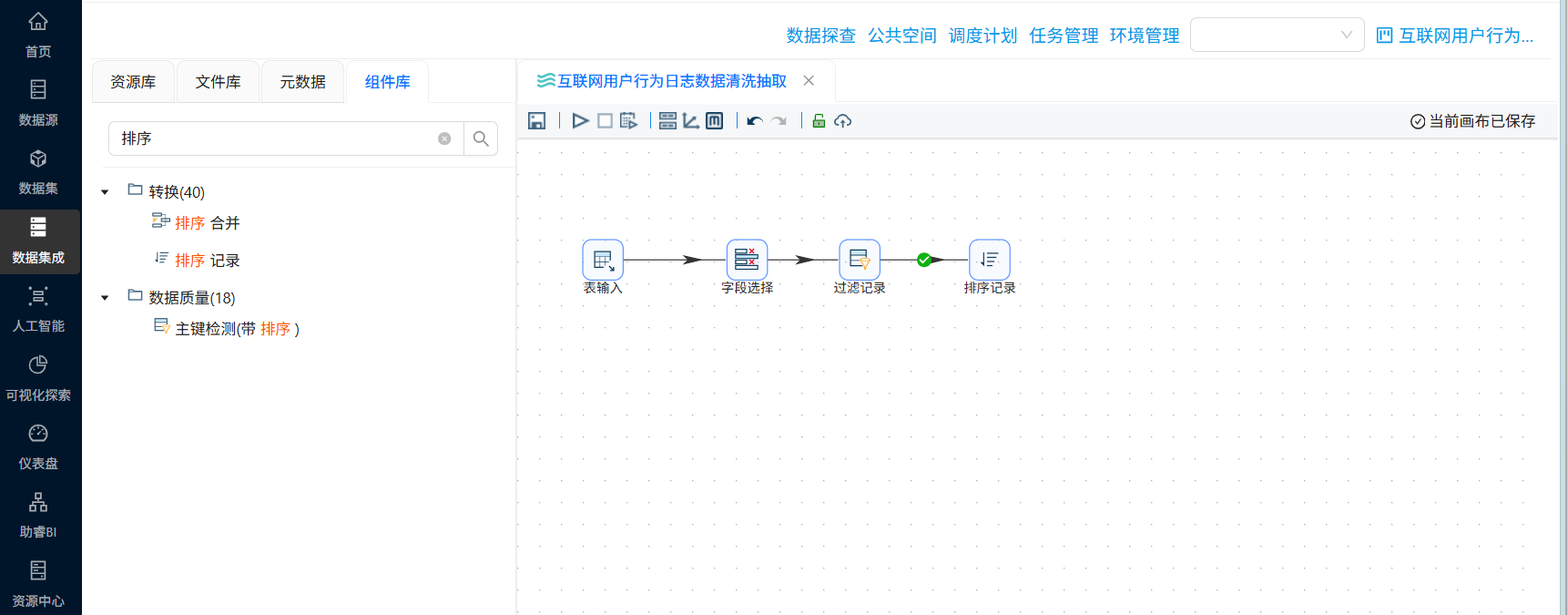
再拖一个“空操作 (什么也不做)”组件到画布中,创建“过滤记录”组件到“空操作 (什么也不做)”组件的连线,连接线类型选择“False输出”
再次双击“过滤记录”组件,发送匹配的结果给“排序记录”,发送不匹配的结果给“空操作 (什么也不做)”
接下来配置过滤条件,点击第一个“field”,选择“process_name”,表示过滤条件为process_name的值
点击函数符号,选择“IN LIST”
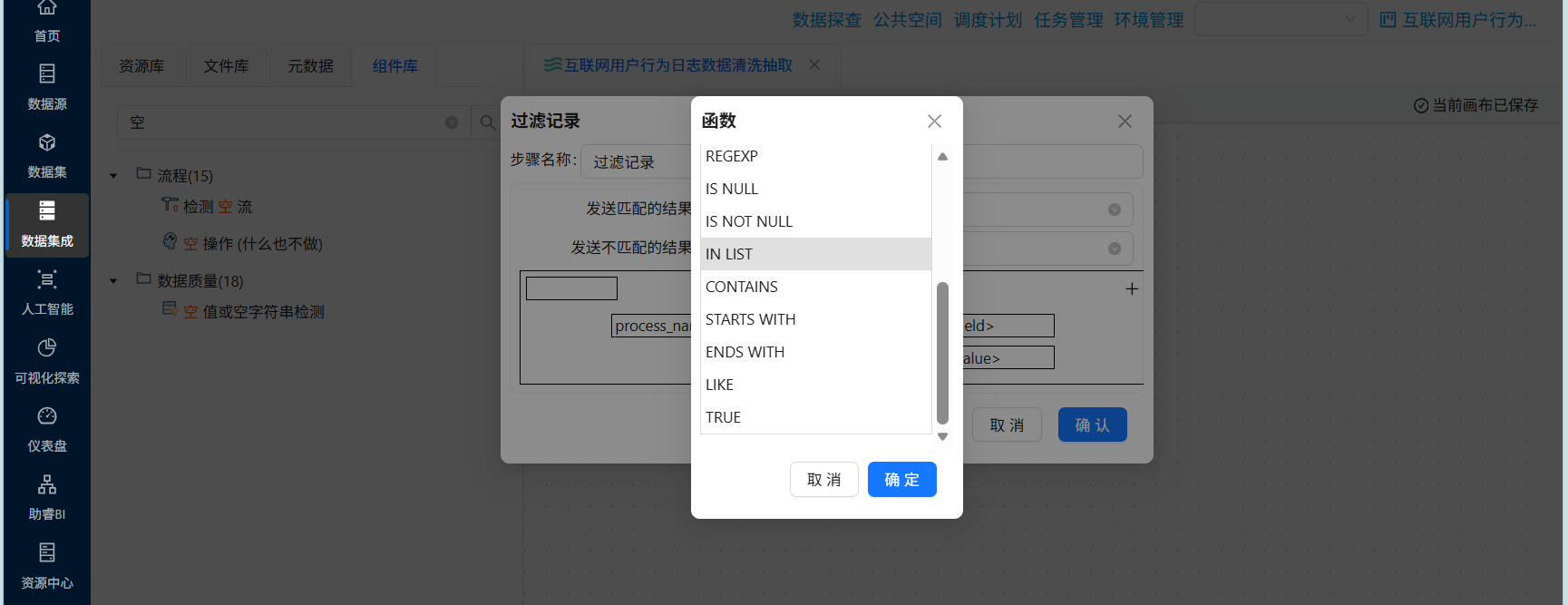
点击“value”
在弹出的窗口中,类型选择“String”,值为“iexplore.exe;360chrome.exe;360se.exe;chrome.exe;sogouexplorer.exe;EXCEL.EXE;WINWORD.EXE;AlilM.exe;QQBrowser.exe”,表示process_name的值在其中的记录则为True,否则为False
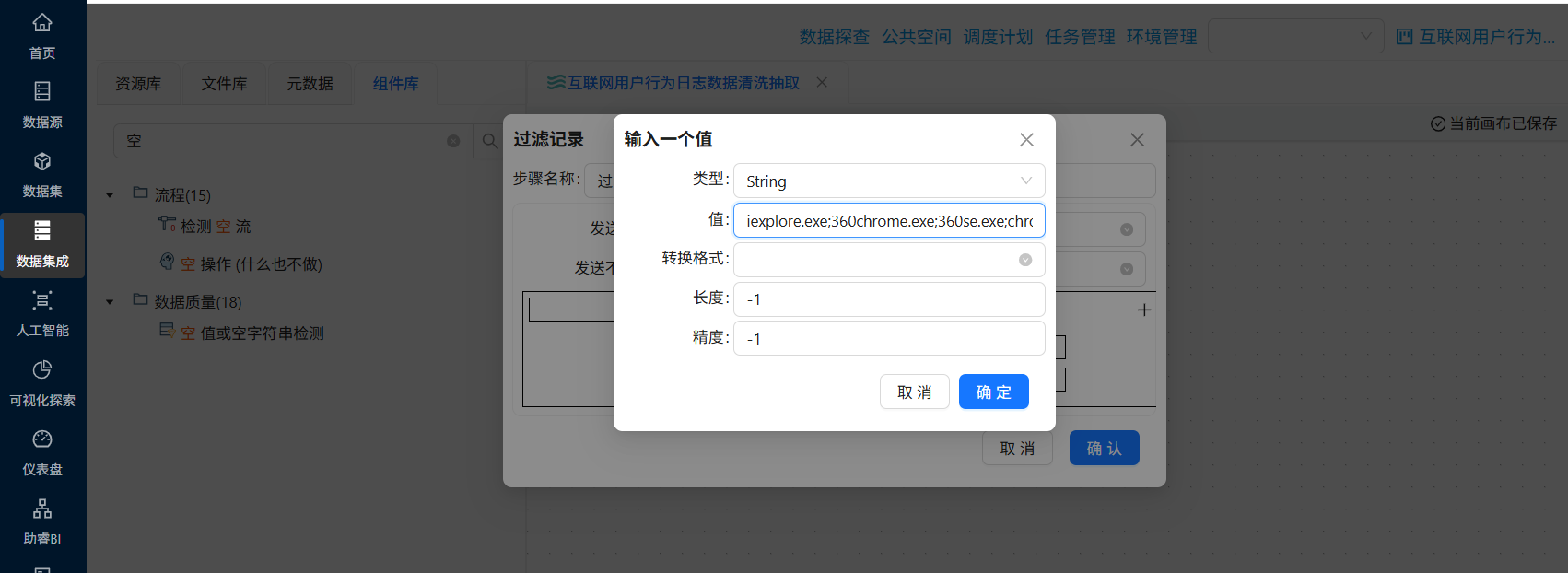
最后点击“确认”
4.5.4 计算停留时长
原始日志只记录了焦点切换的时刻,没有直接给出停留时长。但通过前后两条记录的 event_seconds 相减,就能算出用户在每个窗口上停留了多久。这个时长是后续聚合(总使用时长)的基础数据。
这一步骤需要用到3个组件:
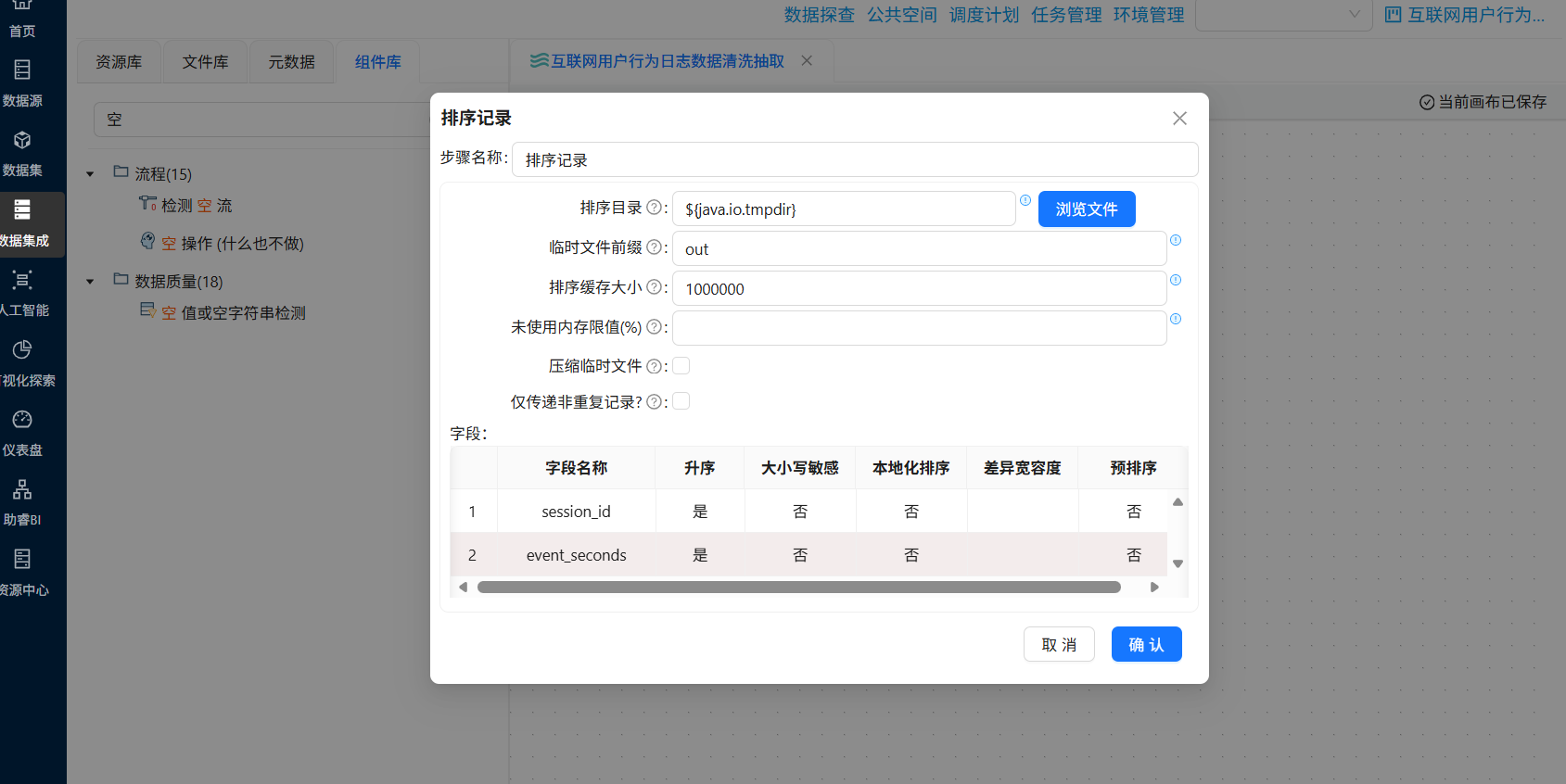
- 排序记录:按
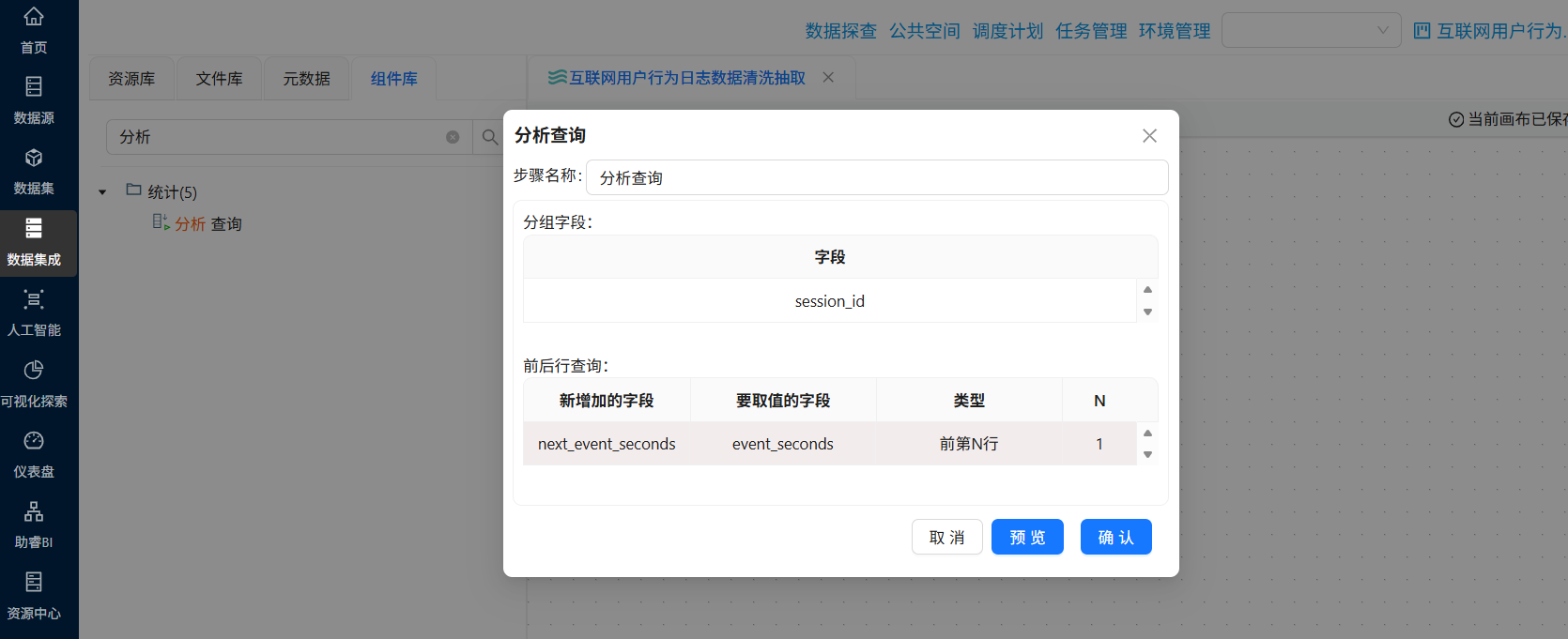
session_id和event_seconds升序排列,确保同一个会话内的行为按时间顺序处理 - 分析查询:获取同一会话内下一行的
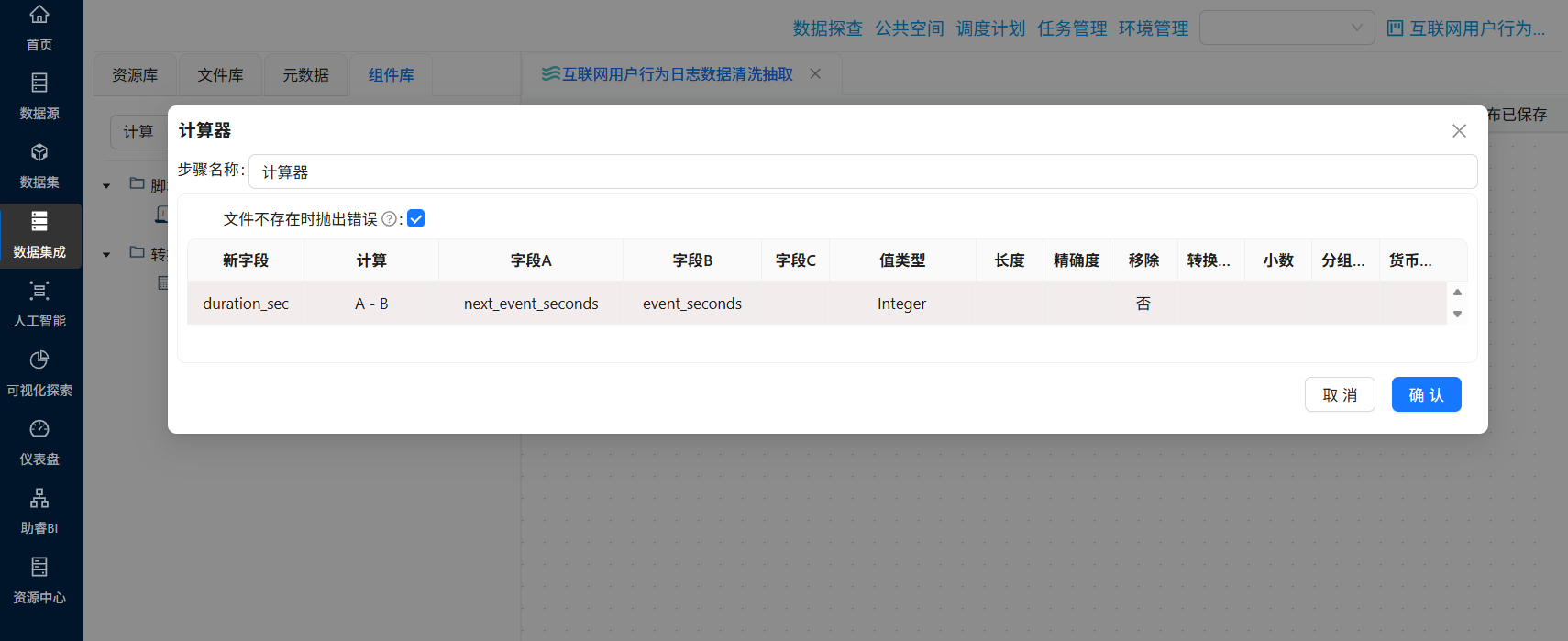
event_seconds值,存入新字段next_event_seconds - 计算器:计算
next_event_seconds - event_seconds得到停留时长duration_sec
首先,“排序记录”组件在上一步骤已经拖入了,双击“排序记录”组件,按 session_id 和 event_seconds 升序排列
拖拽“分析查询”组件到画布中,创建“排序记录”组件到“分析查询”组件的连线,
双击“分析查询”组件,分组字段为“session_id”,新增加的字段“next_event_seconds”,要取值的字段为“event_seconds”,类型“前第N行”,N为“1”,获取同一会话内下一行的 event_seconds 值,存入新字段 next_event_seconds
拖拽“计算器”组件到画布中,创建“分析查询”组件到“计算器”组件的连线
双击“计算器”组件,插入新字段行,新字段输入“duration_sec”,计算公式选择“A - B”,字段A选择“next_event_seconds”,字段B选择“event_seconds”,值类型为“Integer”
4.5.5 字段选择:保留必要字段
使用“字段选择”,只保留 user_id, process_name, session_start_time, url, duration_sec
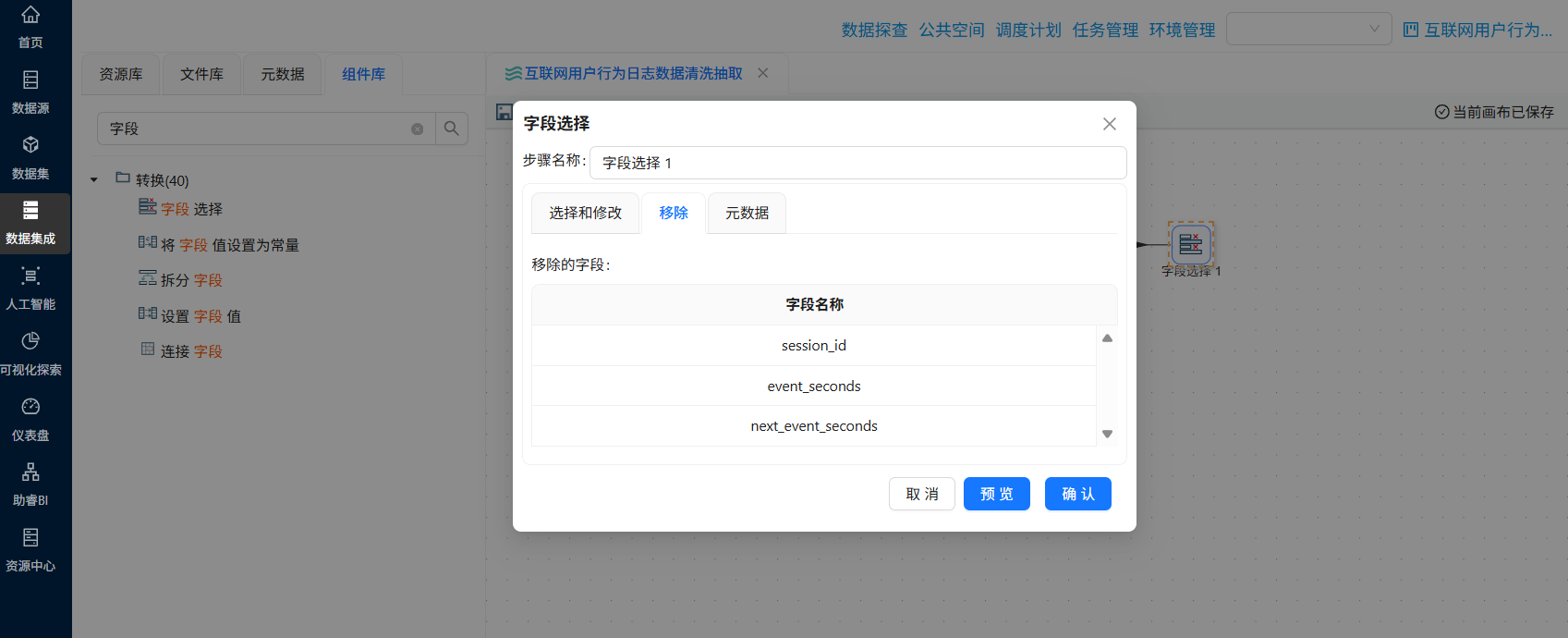
4.5.6 过滤记录:筛选停留时长>0的数据
使用“过滤记录”组件,过滤掉 duration_sec <= 0 的记录(最后一条记录没有下一条,时长无效,忽略)
4.5.7 剪切字符串:提取日期
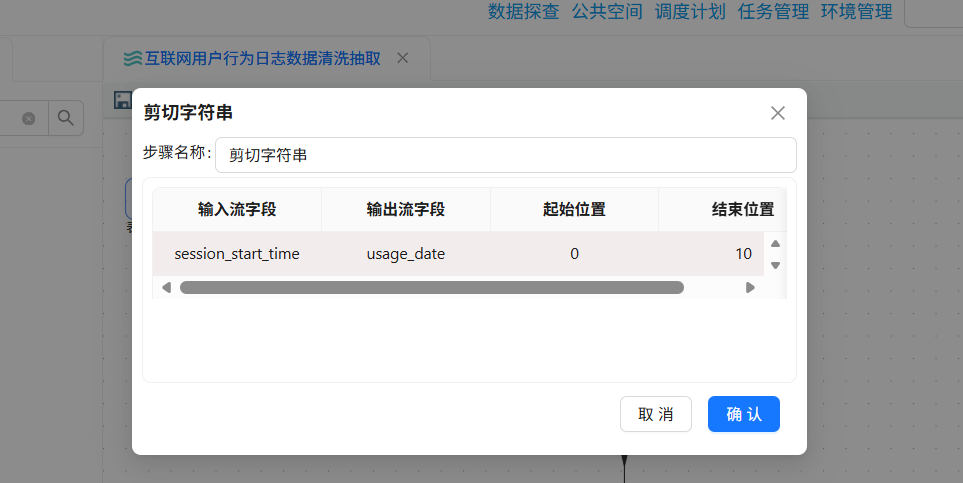
后续很多分析需要按天、按时段聚合(比如每日使用时长、时段热力图)。提前提取好日期和小时,后续分组时直接使用,避免重复解析。
session_start_time 的格式为:yyyy-MM-dd HH:mm:ss,通过剪切字符串组件可以直接获取yyyy-MM-dd
拖拽剪切字符串组件到画布中,创建过滤记录 1组件到拖拽剪切字符串组件的连线,连接线类型选择“Trur输出”,剪切字符串组件的配置如下:
4.5.8 字段选择:设置日期格式
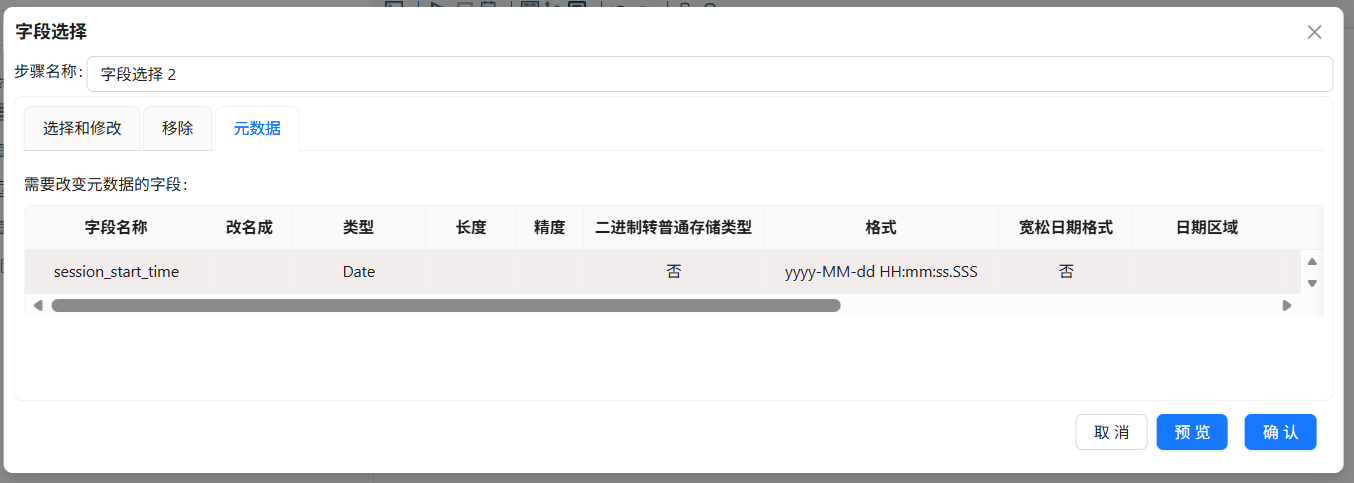
目前获取的数据中,session_start_time 的类型为String,为方便提前提取好小时,需要将session_start_time 的类型设置为Date
拖拽字段选择组件到画布中,创建剪切字符串组件到字符选择组件的连线,连接线类型选择“主输出步骤”,字段选择2组件的配置如下:
4.5.9 计算器:提取小时
通过计算器组件,我们可以提取 yyyy-MM-dd HH:mm:ss 中的HH,拖拽计算器组件到画布中,创建字符选择组件到计算器组件的连线,连接线类型选择“主输出步骤”,计算器 1组件的配置如下:
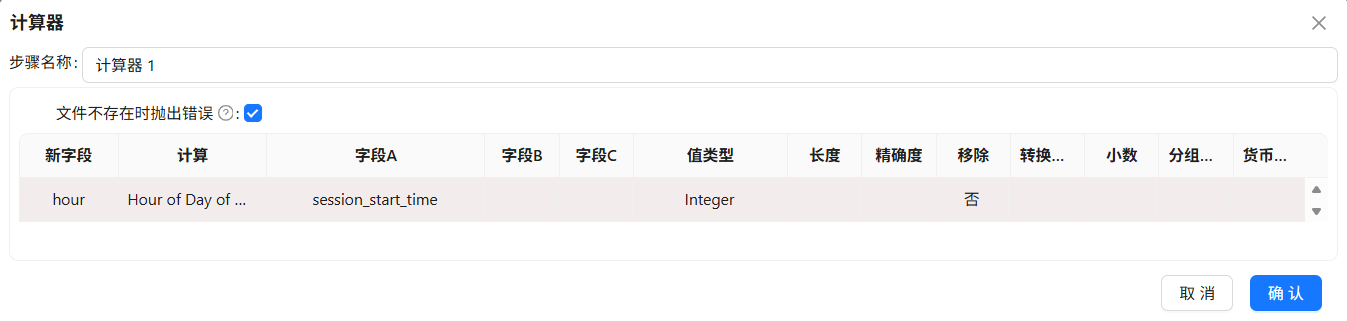
4.5.10 生成用户-日-浏览器-小时明细
原始数据是每条窗口切换记录,粒度太细。我们真正关心的是“每个用户每天每浏览器每小时用了多久、启动了几次”。这一步将数据压缩到合适的粒度,同时为后续所有统计表提供统一的基础数据。
接下来我们就可以分组聚合组件来统计用户每天使用浏览器的时段数据了,但在分组聚合前,先使用排序记录组件进行排序,避免分组聚合结果出错
拖拽排序记录组件到画布中,创建“计算器 1”组件到“排序记录 1”组件的连线,排序记录 1组件的配置如下:
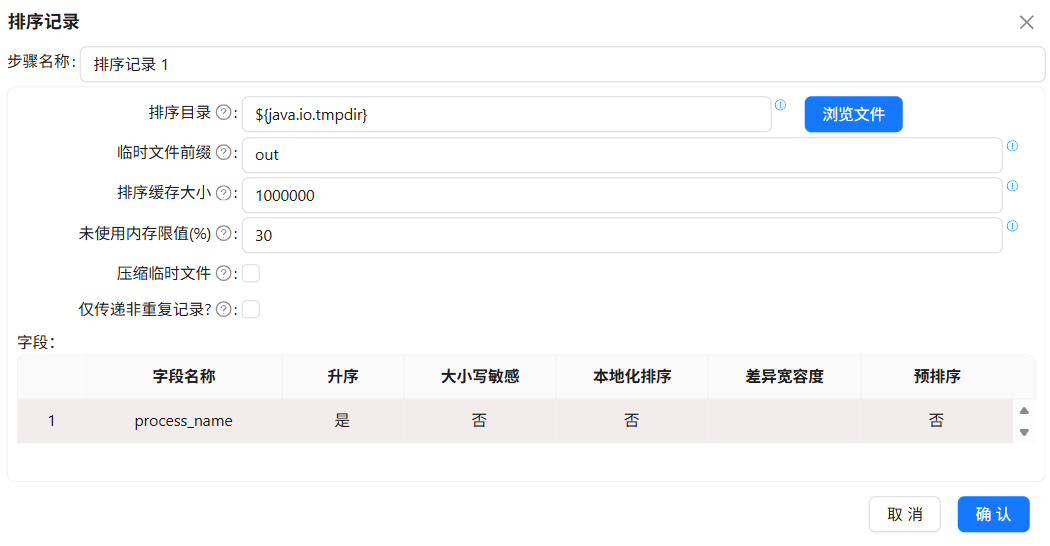
接下来,拖拽分组组件,创建“排序记录 1”组件到分组组件的连线,分组组件的配置如下:
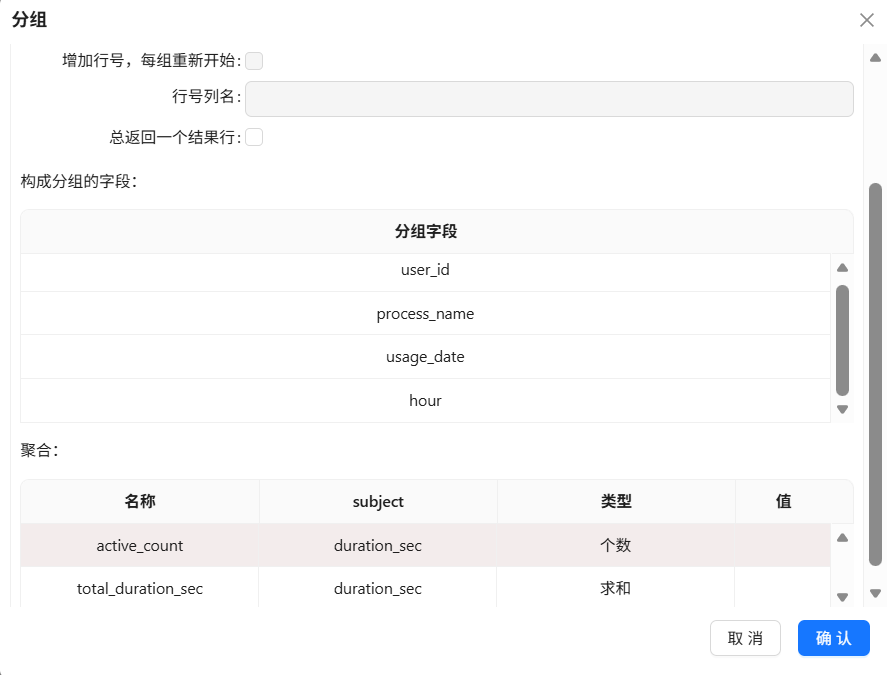
以上步骤获取的数据已经是比较合适颗粒度的数据了,可以以此为基础,抽取不同维度的数据,以便用来实现后续的可视化分析
4.5.11 分支A:生成市场格局表
目标:统计每个浏览器的总用户数和总使用时长
这两个指标直接回答“哪种浏览器覆盖最广、用得最久”。去重计数能避免同一用户被重复计算,总时长反映真实使用强度。
拖拽分组组件到画布中,创建“分组”组件到“分组 1”组件的连线
“分组 1”组件只按 process_name 分组
聚合:
user_count= COUNT(user_id) (有多少不同用户使用过该浏览器)total_duration= SUM(total_duration_sec) (所有用户的累计使用时长)
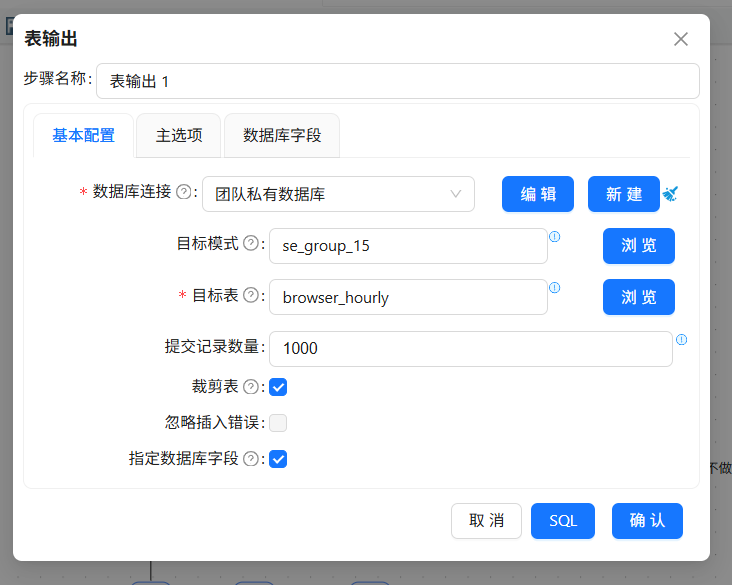
分组聚合的结果需要落地数据库,拖拽“表输出”组件到画布中,创建“分组 1”组件到“表输出 组件的连线”
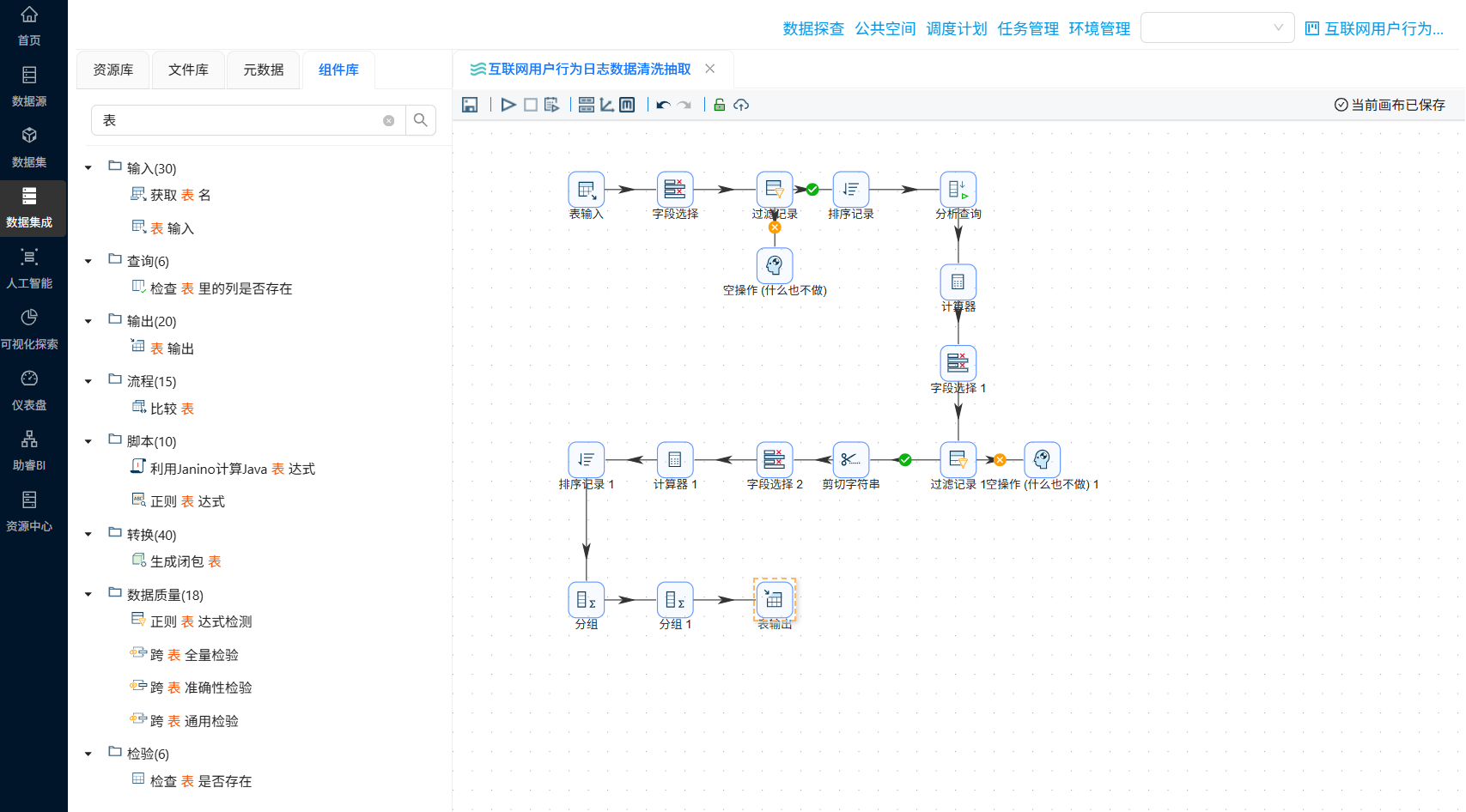
表输出组的配置如下:
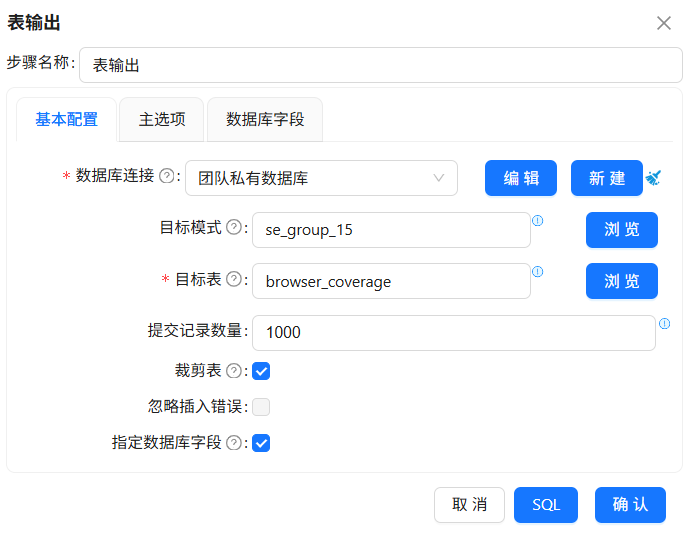
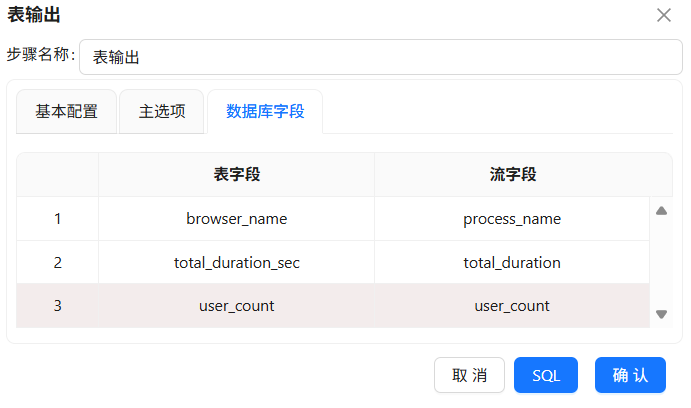
4.5.12 分支B:生成时段统计表
目标:统计每个浏览器在每个小时的使用情况,用于分析用户的时间段偏好
通过这张表可以绘制柱状图或折线图,展示不同浏览器的使用高峰时段。例如,白天工作时间 Chrome 使用量高,晚上娱乐时段 360 浏览器更活跃。按小时聚合已经足够,不需要更细的粒度
此分支的分组字段包含浏览器、小时,即process_name、hour,而前一个排序记录只对process_name排序,所以在这里需要按照process_name、hour升序排序
拖拽“排序记录”组件到画布中,创建“分组”组件到“排序记录 2”组件的连线,数据传输模式选择复制发送
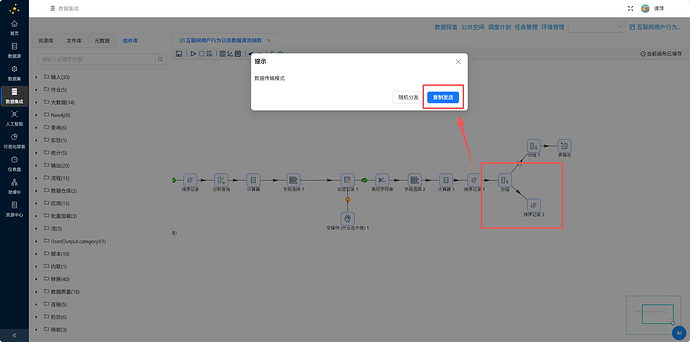
“排序记录 2”组件的配置如下:
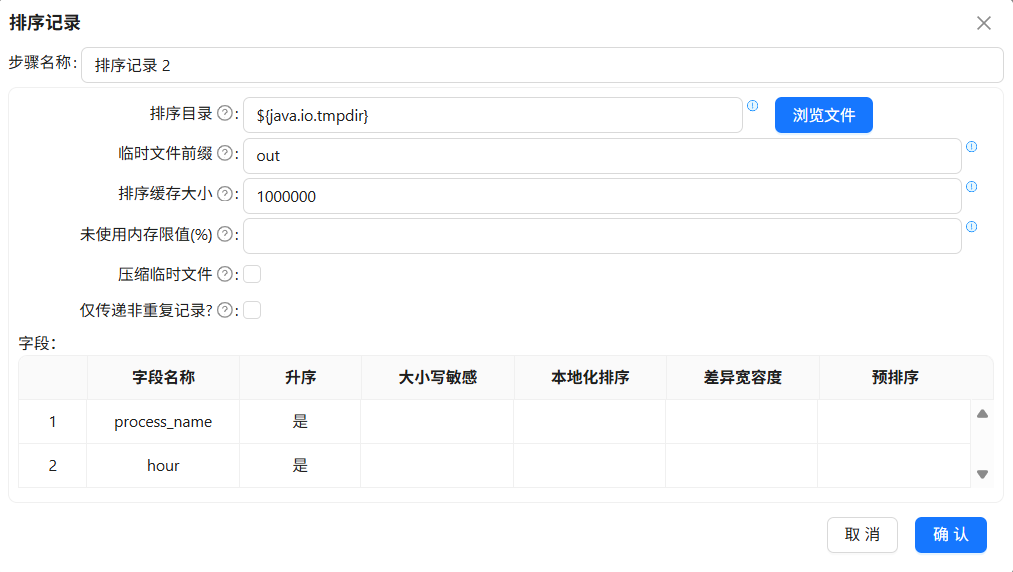
拖拽分组组件到画布中,创建“排序记录 2”组件到“分组 2”组件的连线
“分组 2”组件按 process_name、hour 分组
聚合:active_user_count =user_id个数
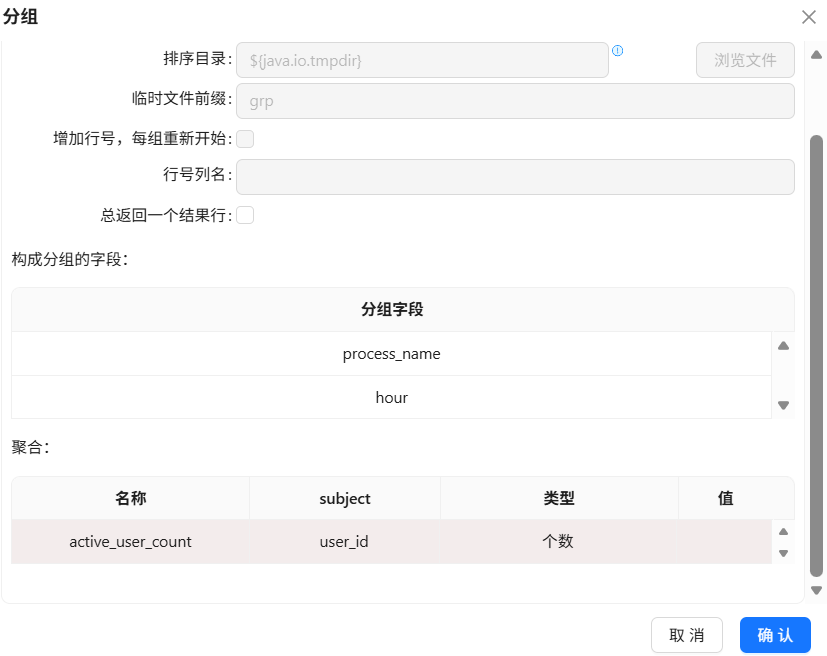
分组聚合的结果需要落地数据库,拖拽“表输出”组件到画布中,创建“分组 2”组件到“表输出 1组件的连线”
表输出组的配置如下:
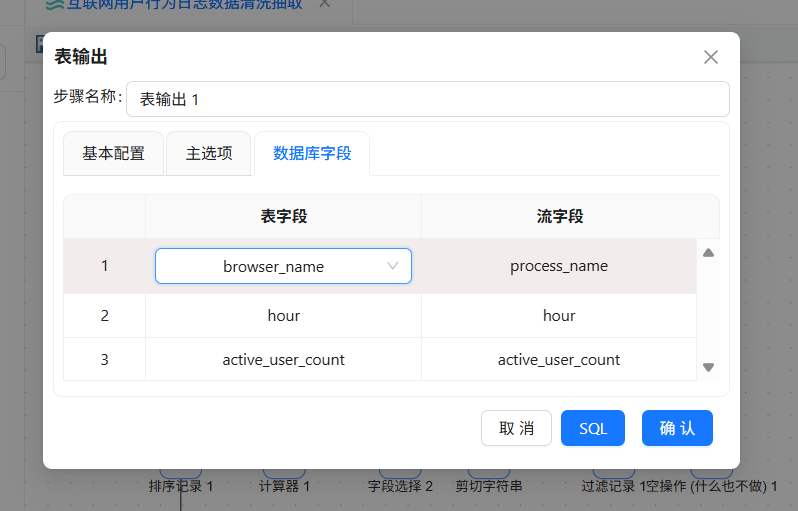
4.5.13 执行转换流
点击运行按钮
三、实验结果
4.5.14 查看结果
点击“元数据”tab选项,右键团队私有数据,并点击“加载元数据”
接着点击“数据探查”,可以看到团队私有数据库目录
点击 browser_coverage、browser_hourly 两个数据表,查询数据情况是否符合预期
四、问题与解决
问题1:日期格式转换错误
现象: 字段选择2组件报错,提示无法将字符串"2012-05-07 12:29:51"转换为日期类型。
原因: 程序设定的日期格式为"yyyy-MM-dd HH:mm:ss.SSS"(含毫秒),但实际数据格式为"yyyy-MM-dd HH:mm:ss"(不含毫秒)。
解决方案: 将字段选择2组件中session_start_time字段的日期格式改为"yyyy-MM-dd HH:mm:ss"。
五、实验总结
1. 收获
学会了使用助睿ETL平台对半结构化日志数据进行解析与转换的方法,掌握了获取文件名、Java代码解析、字段选择、过滤记录、计算停留时长、分组聚合等组件的实际应用。理解了从原始日志到结构化数据表的完整加工流程,能够独立完成浏览器覆盖率统计表和时段统计表的构建。
2. 对平台的整体评价
助睿平台覆盖了从数据接入、ETL处理到可视化分析的全链路功能,零代码操作降低了数据处理门槛,组件拖拽式配置灵活直观。日志实时反馈便于排查问题,与BI、AI Studio的无缝衔接提升了数据加工与分析效率。

一站式 AI 云服务平台
更多推荐
 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)