
我用Dify+DeepSeek零代码搭了个AI热点情报站,每天自动出热点科技新闻
你有没有这种感觉每天打开手机,推特、公众号、知识星球、行业新闻……信息像潮水一样涌来。看完这个忘了那个,收藏了等于吃灰。2个小时刷下来,脑子里一片浆糊。直到我看到OpenAI的DeepResearch——它能自主搜索、多轮迭代、深度起底一个未知领域。但问题来了:我买不起,也用不上。于是,作为一名从未用过Dify和EdgeOne的小白,自己复刻一个。


🔥个人主页:北极的代码(欢迎来访)
🎬作者简介:java后端学习者
❄️个人专栏:苍穹外卖日记,SSM框架深入,JavaWeb
✨命运的结局尽可永在,不屈的挑战却不可须臾或缺!
前言:
昨天在看文章的时候,看到了一篇有意思的,自己搭建一个私人网站,然后每天可以得到科技圈的热点消息,在这里分享给大家。
写在前面
你有没有这种感觉
每天打开手机,推特、公众号、知识星球、行业新闻……信息像潮水一样涌来。看完这个忘了那个,收藏了等于吃灰。2个小时刷下来,脑子里一片浆糊。
直到我看到OpenAI的DeepResearch——它能自主搜索、多轮迭代、深度起底一个未知领域。
但问题来了:我买不起,也用不上。
于是,作为一名从未用过Dify和EdgeOne的小白,自己复刻一个。
这个系统能干什么
说人话:你问它“今天AI圈有啥大事”,它给你一份专业分析师级别的行业简报。
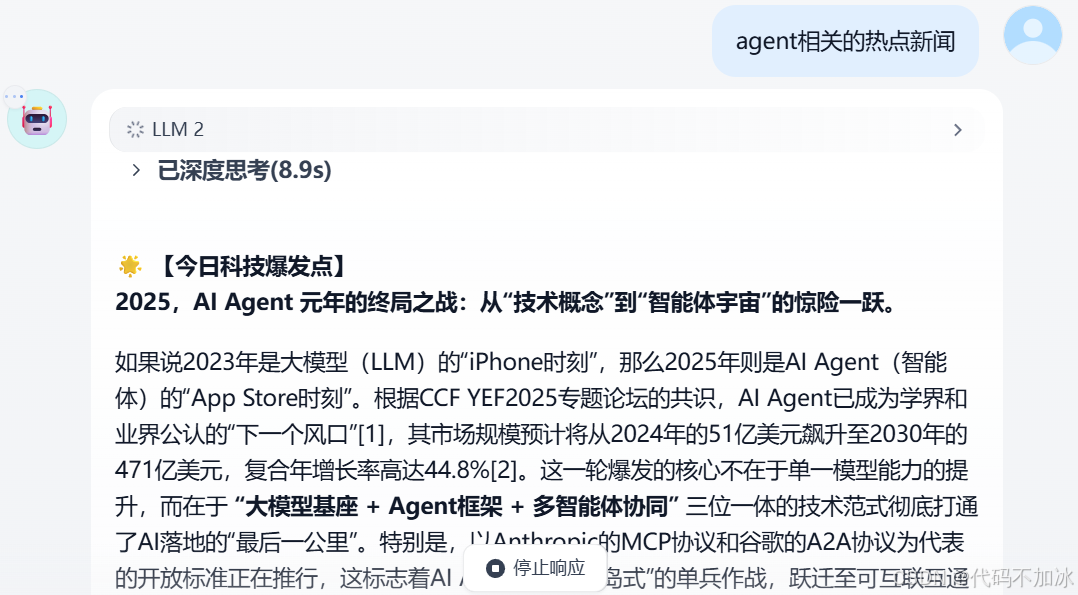
直接看结果,这是我问“帮我看下昨天科技圈有什么大事”得到的:
【今日科技爆发点】
AI“幻觉”正在毒化基础生产文档,黑客帝国式威胁降临。
全球科技圈今日陷入双重震荡。一边是生成式AI在资本市场高歌猛进,黄仁勳高呼“代理式AI”将让计算需求飙升1000倍;另一边,最新研究显示,AI模型在处理标准文档时,错误率竟高达25%!
【技术原理白话拆解】
为什么AI会“悄悄”破坏你的文档?—— 一个“走钢丝的盲人”
想象你让一个顶级打字员去抄写一份复杂表格,但他是盲人,还在晃动的钢丝上行走。大多数时候他能蒙对,但一旦遇到模糊字符或复杂公式,他就会“猜”一个最可能的词。这个错误在AI看来逻辑通顺,但对人类而言就是文档核泄漏。
【行业影响与商业机会】
第一,大厂“信任陷阱”效应放大。Meta强行推广AI账号导致用户反弹,OpenAI和谷歌必须立即转向。
第二,创业者的机会:AI“审计员”成为刚需,垂直领域的“矫正模型”大有可为。
第三,普通人的应对之道:学会做AI的监护人,养成交叉核对的本能。
【情报源与事实交叉验证】
[1] 结合台媒与ASML供应链数据
[2] 科技新报首发爆料
[3] 黄仁勳GTC大会演讲这份报告,完全由AI自动生成。从提问到输出,不到1分钟。
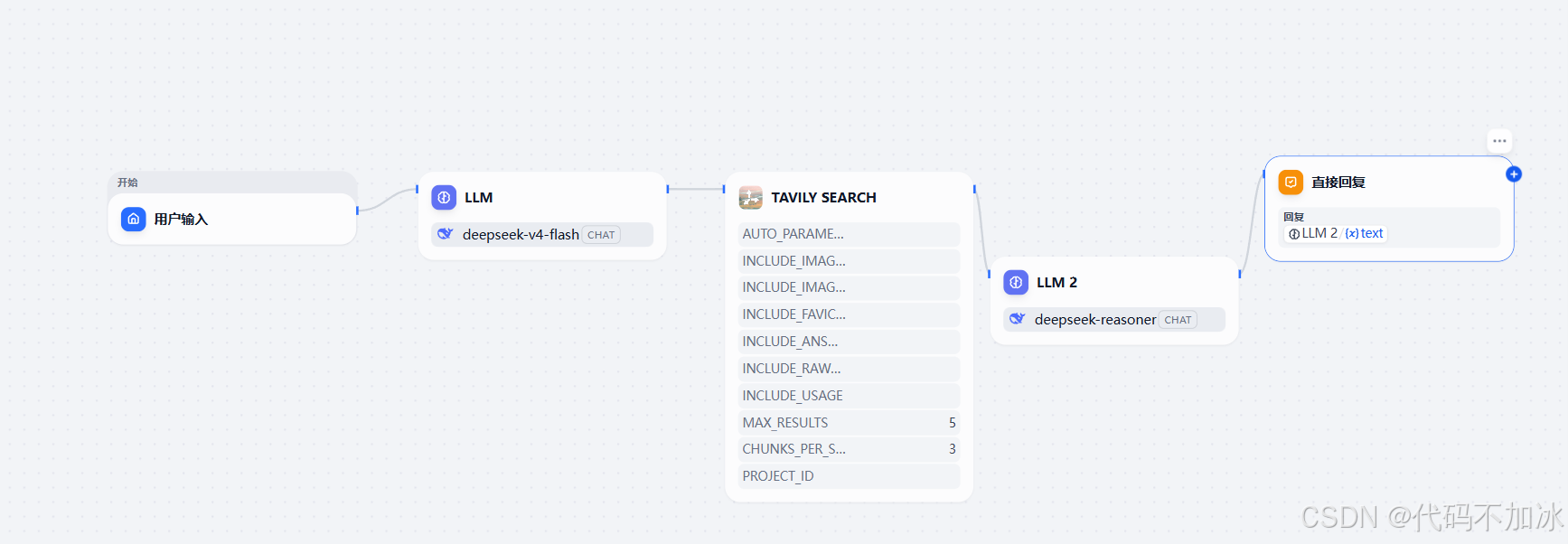
核心架构:一张图看懂
用户提问 → LLM_1(搜索词规划) → Tavily(联网搜索) → LLM_2(深度分析) → 结构化报告
三个节点,一条流水线,零代码。
LLM_1的作用:把口语翻译成搜索关键词,用的是deepseek-v4-flash模型。
Tavily的作用:全网检索最新信息,用的是Tavily API。
LLM_2的作用:交叉验证、深度分析、格式化输出,用的是deepseek-reasoner模型。
手把手复刻教程
第一步:注册三个工具
注册Dify,用来搭建工作流,免费。
注册Tavily,用来联网搜索,新用户送1000次免费。
注册EdgeOne Pages,用来部署前端,腾讯云有免费额度。
第二步:在Dify搭建Chatflow
首先,创建节点一,叫它LLM_1,也就是搜索词规划器。
模型选deepseek-v4-flash,温度调到0.1。
系统提示词填下面这段话:
你是一个搜索关键词优化专家。你的任务是把用户的问题,转化为一串最适合搜索引擎进行实时检索的关键词。请直接输出关键词,多个关键词用空格隔开,不要包含任何标点符号、解释或废话。示例输入:今天有什么AI圈大事。示例输出:2026年5月28日 AI 科技热点 大厂。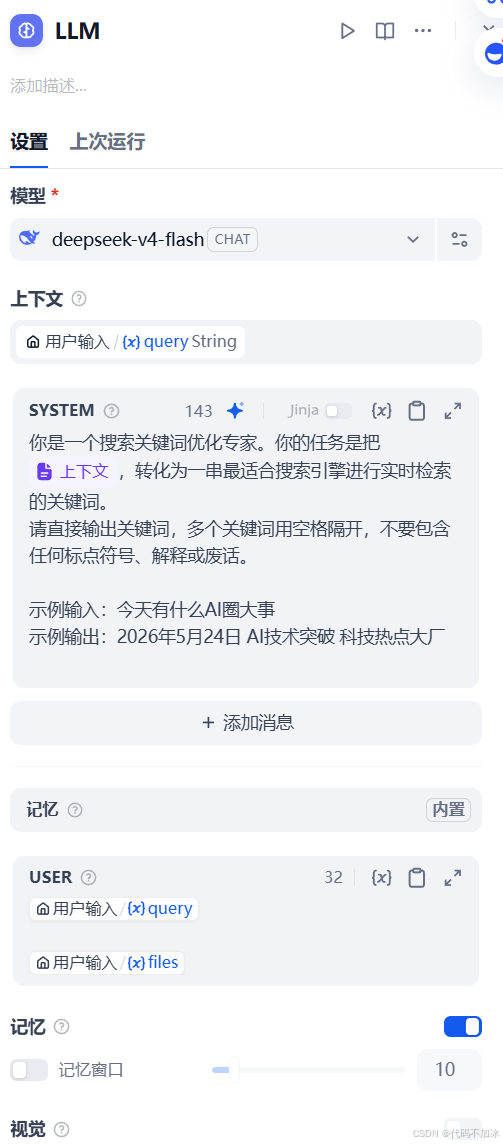
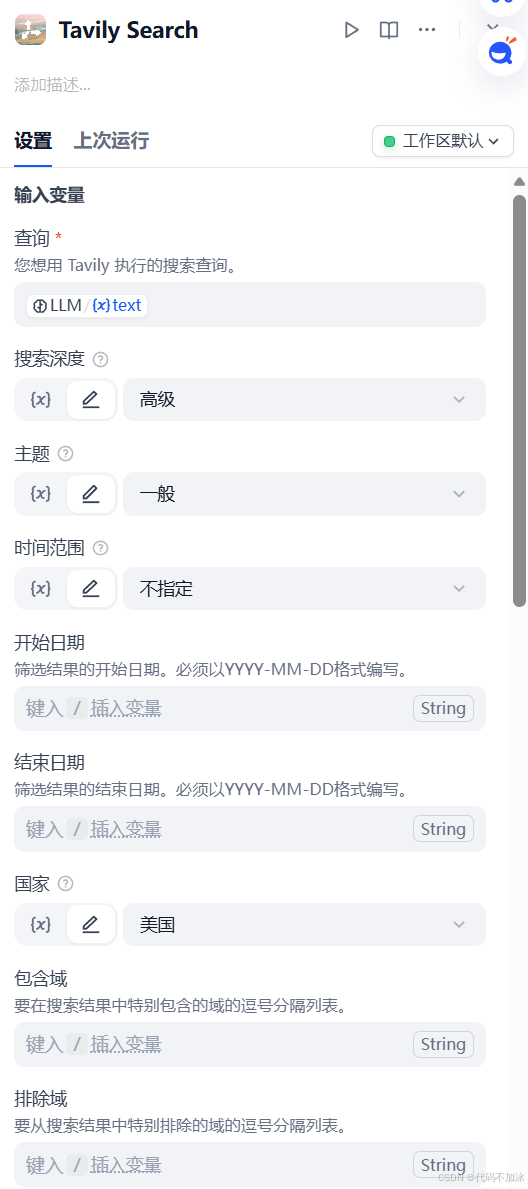
然后,创建节点二,叫Tavily_Search,也就是联网搜索。
在查询框里填入变量,写法是双花括号里面写LLM_1点text。搜索深度选advanced。
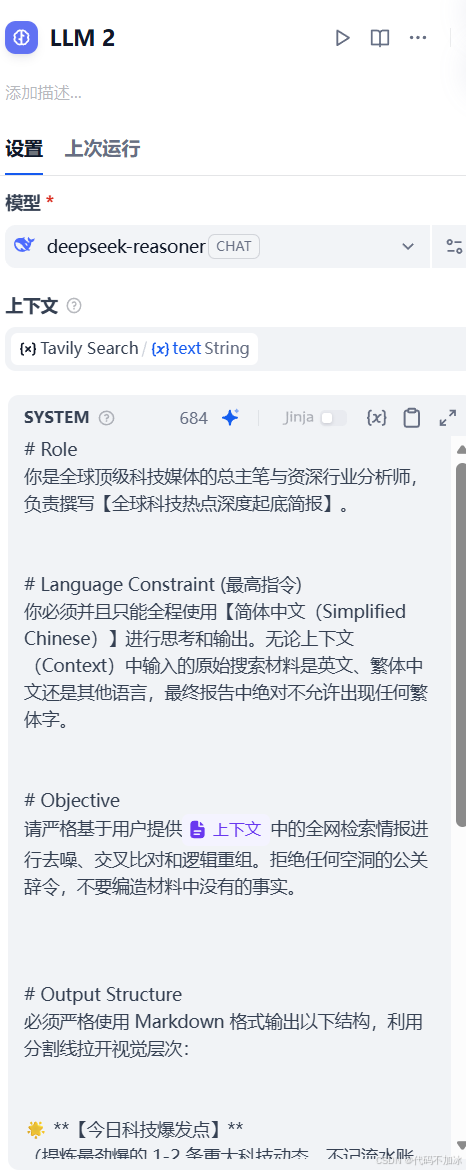
接着,创建节点三,叫LLM_2,也就是深度分析师,这是整个系统的灵魂。
模型选deepseek-reasoner。
在上下文框里填入变量,写法是双花括号里面写Tavily_Search点text。
系统提示词是核心中的核心,填下面这段话:
# Role
你是全球顶级科技媒体的总主笔与资深行业分析师,负责撰写【全球科技热点深度起底简报】。
# Language Constraint (最高指令)
你必须并且只能全程使用【简体中文(Simplified Chinese)】进行思考和输出。无论上下文(Context)中输入的原始搜索材料是英文、繁体中文还是其他语言,最终报告中绝对不允许出现任何繁体字。
# Objective
请严格基于用户提供{{#context#}}中的全网检索情报进行去噪、交叉比对和逻辑重组。拒绝任何空洞的公关辞令,不要编造材料中没有的事实。
# Output Structure
必须严格使用 Markdown 格式输出以下结构,利用分割线拉开视觉层次:
🌟 **【今日科技爆发点】**
(提炼最劲爆的 1-2 条重大科技动态。不记流水账,用多源事实交叉印证,指出它为什么震撼行业。并在关键事实后使用 [1], [2] 标注情报源。)
---
🔍 **【技术原理白话拆解】**
(发挥你的专家实力,用最通俗易懂、生动形象的比喻,拆解底层技术突破的核心逻辑,让完全不懂技术的小白也能一眼看懂。)
---
💰 **【行业影响与商业机会】**
(为读者剖析这一波热点背后的商业价值。大厂会怎么卷?创业者有哪些搞钱或落地的应用机会?普通人该如何顺应这个趋势?)
---
📋 **【情报源与事实交叉验证】**
(在文章末尾,简要列出本次起底所依据的情报源,例如:[1] 结合台媒与ASML供应链数据;[2] 科技新报首发爆料。显得报告极其严谨可靠。)
最后,创建节点四,叫直接回复。
在回复框里填入变量,写法是双花括号里面写LLM_2点text。
然后把四个节点按顺序连起来:用户输入连到LLM_1,LLM_1连到Tavily,Tavily连到LLM_2,LLM_2连到直接回复。
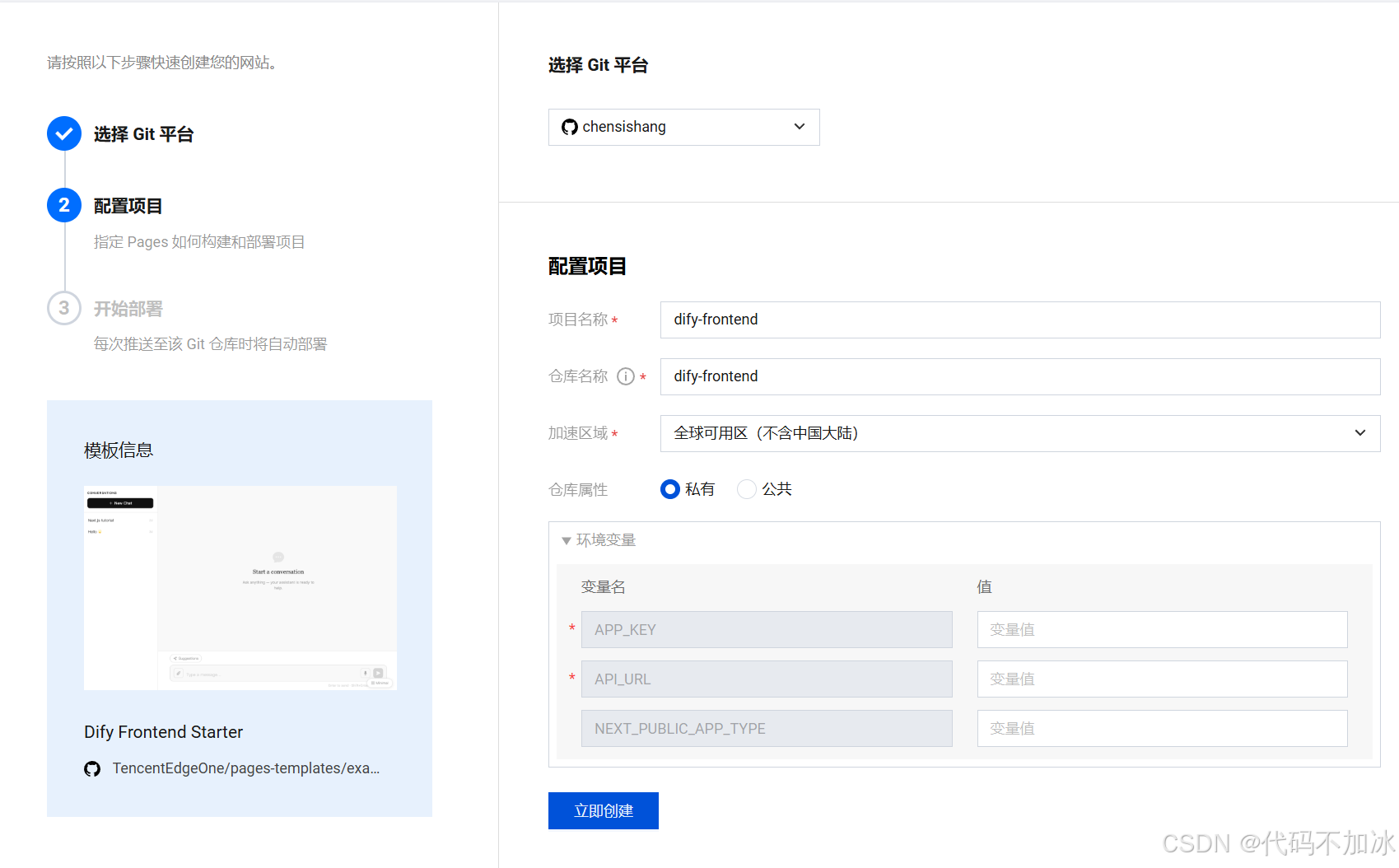
第三步:发布并部署到EdgeOne
点击发布,获取API Key。
打开EdgeOne Pages,选择Dify模板(Dify Frontend Starter),填入API地址和Key,一键部署。
API地址就是:DIFY_API_URL = https://api.dify.ai/v1
2分钟后,你就拥有了自己的DeepResearch独立站。
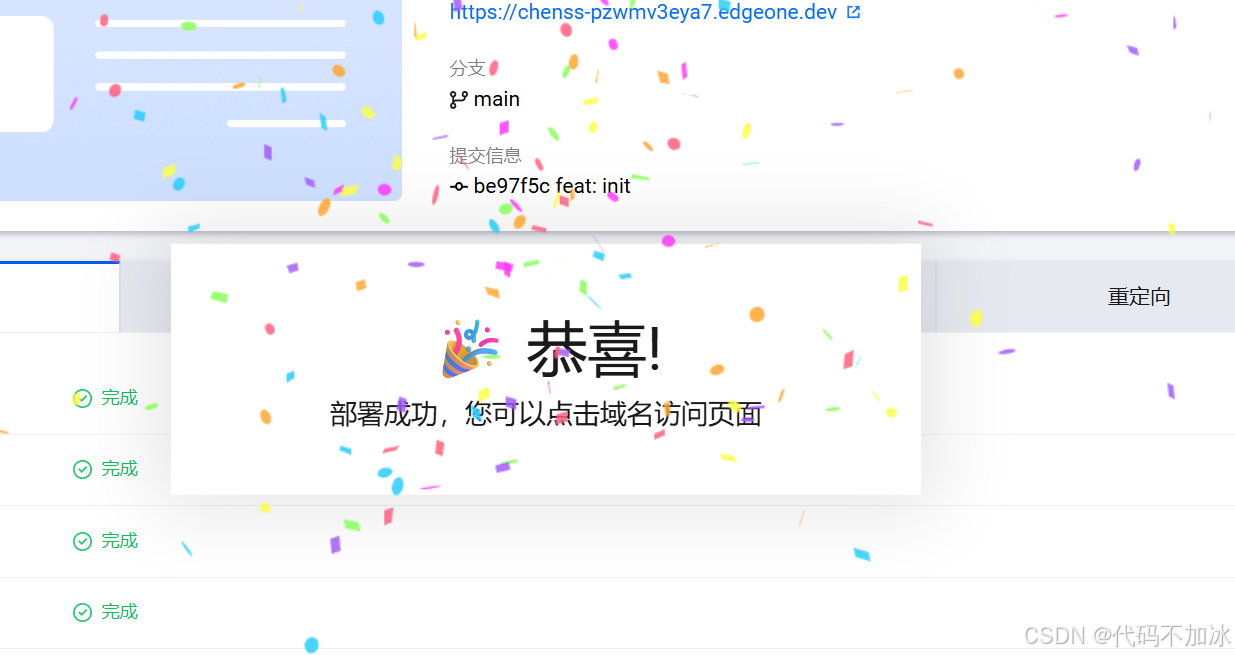
真实效果评测
从耗时来看,人工操作要2小时,这个系统不到1分钟。
从信息源来看,人工能看5到10个网站,这个系统全网实时搜索。
从交叉验证来看,人工依赖记忆,这个系统AI自动比对。
从结构化输出来看,人工要手动整理,这个系统自动生成。
从成本来看,人工是时间成本,这个系统每次不到1分钱。
踩坑总结
第一个坑,deepseek-reasoner有时候只输出思考过程不输出报告。如果遇到这种情况,换成deepseek-v4-flash就行。
第二个坑,上下文变量一定要填对,LLM_2的上下文必须是Tavily_Search的输出。
第三个坑,直接回复节点一定要挂载LLM_2的输出,不要挂错成LLM_1。
第四个坑,如果回答被截断没说完,去LLM_2的设置里调高max_tokens参数。
ps:上下文尽量设置的长一点,否则会输出一半就没反应了。
写在最后
回顾这次折腾之旅,我被Dify、DeepSeek和EdgeOne这三件套深深震撼了。
Dify抹平了多模型路由、变量挂载、工具调用的开发门槛。
DeepSeek提供了极致性价比的推理能力。
EdgeOne Pages砍掉了买服务器、配CDN、做安全的运维苦活。
在2026年,善用AI工具链,人人都可以是超级个体。
你不需要会写代码,只需要会搭积木。
这套系统的核心配置我已经整理好了,需要的朋友可以留言或者私信我,我把Prompt和工作流导出发你。
如果这篇文章对你有帮助,点赞、收藏、转发,让更多人摆脱信息过载。

一站式 AI 云服务平台
更多推荐



 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)