
C++项目推荐:eBPF+调度器性能分析框架
本项目实现了一个基于eBPF的性能分析框架,通过零代码侵入的方式追踪程序性能瓶颈。核心架构包含调度器、eBPF采集器和火焰图生成器三部分:调度器采用fork-exec和cgroup实现任务隔离,通过SIGSTOP/SIGCONT机制确保eBPF就绪后才启动目标程序;使用bpftrace脚本采集CPU栈采样、系统调用等数据,经符号解析和聚合生成可视化报告。支持分析IO密集型(如fsync阻塞)和CP
来源:程序员老廖的个人空间
想象一个场景:你写了一个程序,运行起来很慢,但你不知道慢在哪里。是 CPU 算得慢?还是等磁盘 IO?还是被锁卡住了?
传统的方法是加 printf 打时间戳,或者用 perf 采样。但这些方法要么侵入代码,要么输出晦涩难懂。
本项目提供了一个完整的解决方案:
你的程序 ──→ TaskScheduler 调度执行 ──→ eBPF 内核级追踪 ──→ 可读报告 + 火焰图整个过程零代码侵入——你不需要修改被分析的程序,调度器会自动在内核层面"透视"你的程序行为。
本教程将带你理解:
-
原理层:调度器如何管理进程?eBPF 如何在内核中采集数据?
-
实践层:如何运行实验、解读报告、定位瓶颈?
-
设计层:为什么 workload 要这样设计?编译选项为什么重要?
全景图:一条命令的完整旅程
下面用一条真实命令,追踪它从你敲下回车到最终生成报告的每一步,标注对应的源文件和代码行号。
你输入的命令:
sudo ./build/scheduler \
--cmd "./build/workload_io --rounds 3000" \
--enable-ebpf --ebpf-script-dir ./bpf --timeout 60这条命令触发的完整调用链如下(从上到下是时间顺序):
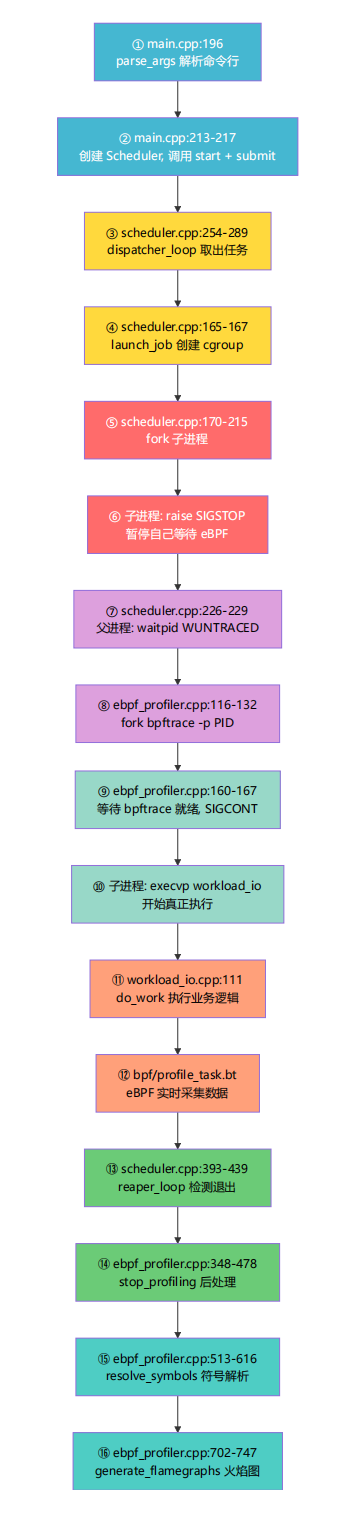
逐步详解:
阶段一:命令行解析与任务提交
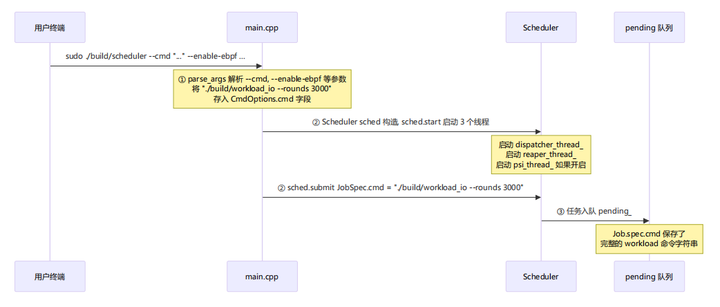
|
步骤 |
源文件:行号 |
做了什么 |
|---|---|---|
|
① |
main.cpp:196 |
parse_args 将 --cmd 后面的字符串存入 CmdOptions.cmd |
|
② |
main.cpp:213-217 |
创建 Scheduler 对象, start() 启动工作线程, submit() 提交任务 |
|
③ |
scheduler.cpp:47-57 |
submit 将 Job 放入 pending_ 队列, cv_.notify_all() 唤醒 |
阶段二:任务调度与进程创建
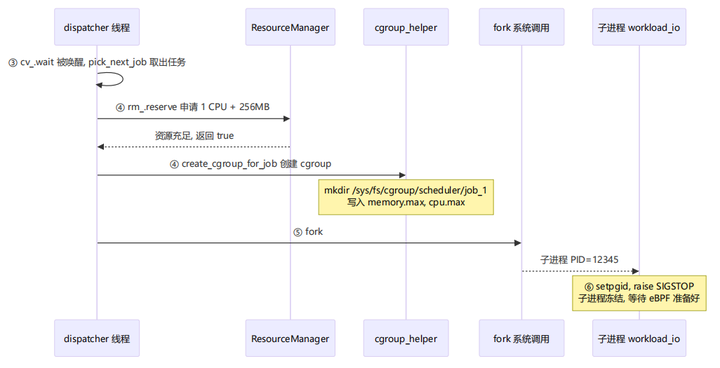
|
步骤 |
源文件:行号 |
做了什么 |
|---|---|---|
|
③ |
scheduler.cpp:258-274 |
dispatcher_loop 被 cv_.wait 唤醒,调用 pick_next_job |
|
④ |
scheduler.cpp:276-289 |
检查资源 → 创建 cgroup → 调用 launch_job |
|
⑤ |
scheduler.cpp:170 |
fork() 创建子进程 |
|
⑥ |
scheduler.cpp:173-177 |
子进程: setpgid(0,0) + raise(SIGSTOP) 暂停自己 |
阶段三:eBPF 附加与 workload 启动
这是最关键的阶段——workload_io 就是在这里被真正执行的。
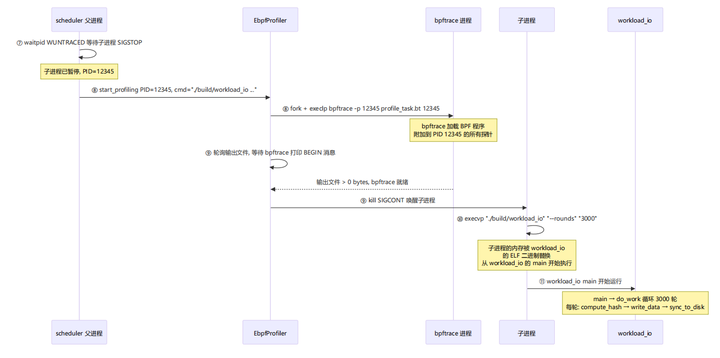
|
步骤 |
源文件:行号 |
做了什么 |
|---|---|---|
|
⑦ |
scheduler.cpp:225-226 |
父进程 waitpid(pid, &ws, WUNTRACED) 等子进程 SIGSTOP |
|
⑧ |
ebpf_profiler.cpp:116-132 |
start_profiling 内部再次 fork() , execlp("bpftrace",...) |
|
⑨ |
ebpf_profiler.cpp:139-167 |
轮询检查输出文件是否非空,就绪后 kill(target_pid, SIGCONT) |
|
⑩ |
scheduler.cpp:202-209 |
子进程收到 SIGCONT 后,调用 split_cmd 解析命令,然后execvp("./build/workload_io", ...) |
|
⑪ |
workload_io.cpp:110-111 |
workload_io 的 main() 开始执行 do_work(fd, rounds) |
核心要点: workload_io 是通过 execvp 被加载执行的,不是直接调用函数。 execvp 会将当前子进程的整个内存空间替换为 workload_io 的二进制代码,然后从 workload_io 的 main() 入口开始运行。
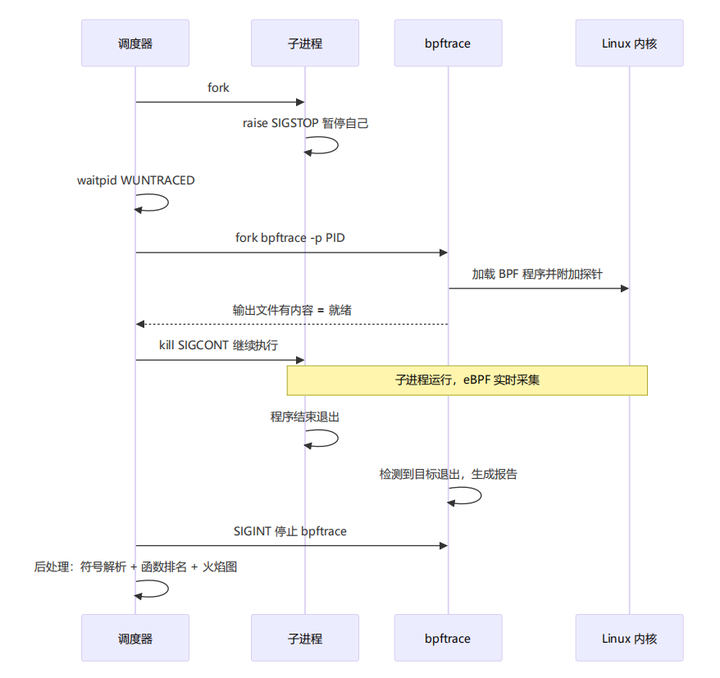
三进程协作时间线——下图展示 scheduler 父进程、子进程、bpftrace 三者在时间维度上的状态:
时间轴 ───────────────────────────────────────────────────────────────────►
scheduler 父进程:
┌─────────────────────────────────────────────────────────────────────────┐
│ fork ──→ waitpid(WUNTRACED) ──→ start_profiling ──→ 轮询等待 │
│ 等子进程暂停 fork bpftrace bpftrace就绪 │
│ │ │
│ reaper_loop: │ │
│ waitpid(WNOHANG) 轮询 │ │
│ ────→ 检测到子进程退出 │ │
│ ────→ stop_profiling │ │
│ ────→ 符号解析+火焰图 │ │
└─────────────────────────────────────────────────────────────────────────┘
子进程 → workload:
┌─────────────────────────────────────────────────────────────────────────┐
│ fork ──→ raise(SIGSTOP) ──→ [冻结] ──→ SIGCONT ──→ execvp │
│ 暂停自己 被唤醒 加载workload │
│ │ │
│ workload_io 运行中: │
│ do_work 循环 3000 轮 │
│ compute_hash │
│ write_data │
│ sync_to_disk │
│ ───────→ 正常退出 │
└─────────────────────────────────────────────────────────────────────────┘
bpftrace 进程:
┌─────────────────────────────────────────────────────────────────────────┐
│ fork ──→ 加载 BPF 程序 ──→ 附加探针 ──→ BEGIN 输出 │
│ 编译 profile_task.bt "eBPF 启动" │
│ │ │
│ 实时采集 workload 数据: │
│ profile:hz:99 CPU 栈采样 │
│ sys_enter/exit 系统调用跟踪 │
│ ───────→ 目标退出 │
│ ───────→ 收到 SIGINT │
│ ───────→ END 块: 生成报告 │
└─────────────────────────────────────────────────────────────────────────┘关键同步点:
-
同步点 A:子进程 raise(SIGSTOP) → 父进程 waitpid(WUNTRACED) 返回
-
同步点 B:bpftrace BEGIN 输出 → 父进程轮询发现文件非空 → kill(SIGCONT) 唤醒子进程
-
同步点 C:子进程退出 → bpftrace 检测到目标消失 → reaper waitpid 回收
阶段四:运行中 eBPF 数据采集
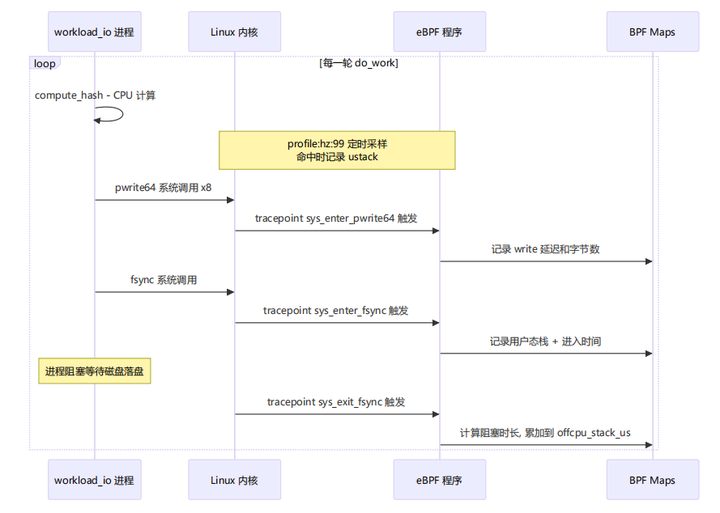
|
探针 |
源文件:行号 |
采集内容 |
|---|---|---|
|
profile:hz:99 |
profile_task.bt:218-224 |
CPU 上的用户态栈 + 采样计数 |
|
sys_enter_fsync |
profile_task.bt:181-185 |
用户态栈 + 进入时间戳 |
|
sys_exit_fsync |
profile_task.bt:186-194 |
阻塞时长,按栈聚合 |
|
raw_syscalls:sys_enter |
profile_task.bt:28-34 |
syscall 编号分布 |
阶段五:收割与报告生成
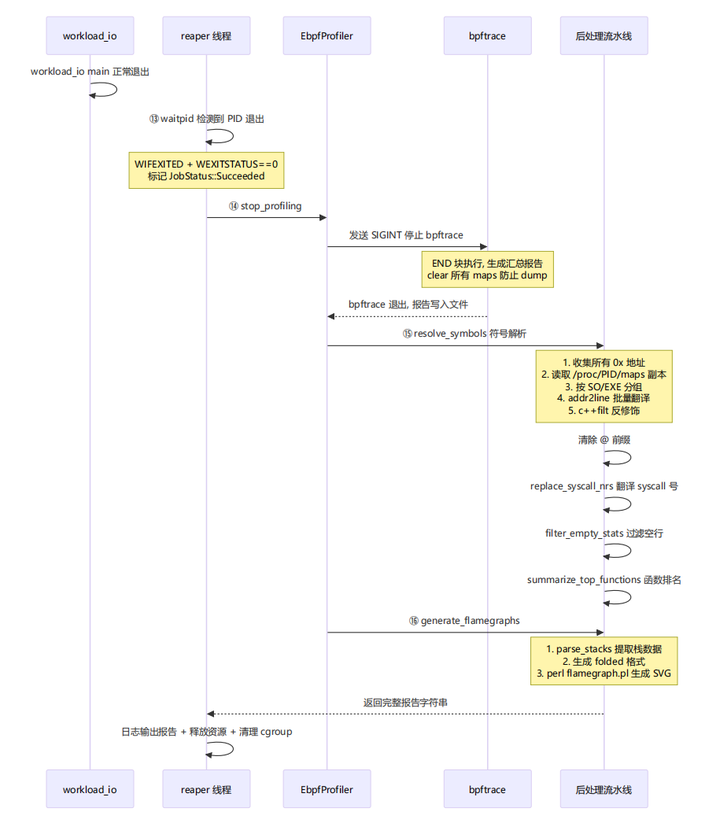
|
步骤 |
源文件:行号 |
做了什么 |
|---|---|---|
|
⑬ |
scheduler.cpp:393-401 |
reaper_loop 中 waitpid 检测到进程退出 |
|
⑭ |
scheduler.cpp:428-439 |
调用 profiler->stop_profiling() 收集报告 |
|
⑮ |
ebpf_profiler.cpp:513-616 |
resolve_symbols : 地址→函数名翻译 |
|
⑯ |
ebpf_profiler.cpp:702-747 |
generate_flamegraphs : 生成 On-CPU + Off-CPU SVG |
报告后处理流水线
stop_profiling 内部将 bpftrace 的原始输出经过 6 步流水线处理,最终变成人类可读的报告。每一步对应源码中 的一个函数:
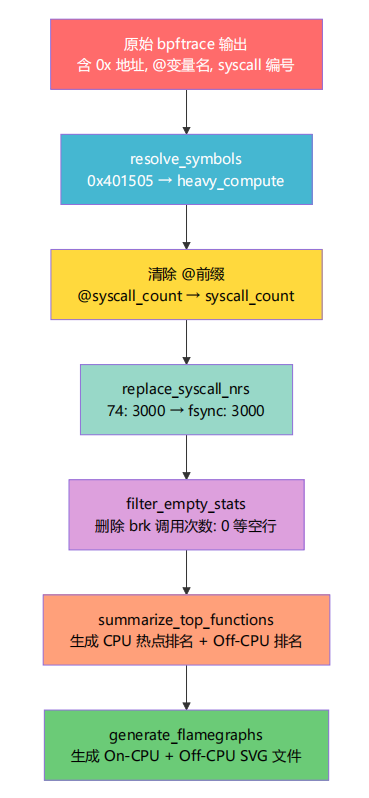
数据变化示例——以一段栈采样为例
第 1 步 原始数据: @cpu_stack_samples[\n 0x401505\n 0x4015d7\n]: 42
第 2 步 符号解析: cpu_stack_samples[\n heavy_compute\n do_work\n]: 42
第 3 步 清除 @ 前缀: [\n heavy_compute\n do_work\n]: 42
第 6 步 函数排名: >>> CPU 热点函数排名:
60.0% heavy_compute (42 samples)
第 7 步 火焰图 folded: do_work;heavy_compute 42
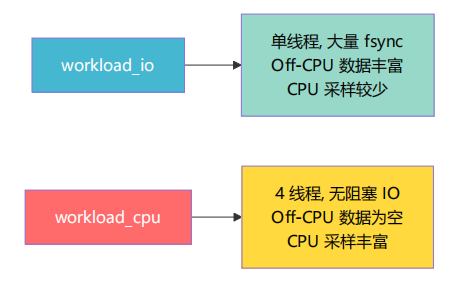
→ perl flamegraph.pl → .svg 文件workload_cpu 的执行路径有何不同?
workload_cpu 的执行路径与 workload_io 完全相同——区别只在 execvp 的参数不同
# IO workload:
execvp("./build/workload_io", ["./build/workload_io", "--rounds", "3000"])
# CPU workload:
execvp("./build/workload_cpu", ["./build/workload_cpu", "--threads", "4", "--iterations",
"200000000"])对调度器而言,它只是执行了 --cmd 参数里的命令字符串,不关心具体执行的是哪个程序。这就是设计的关键——调度器是通用的。
两种 workload 被 eBPF 追踪时的行为差异:
项目源码领取:C++校招简历上只写WebServer太卷了?我撸了一个eBPF+调度器性能分析框架
第一章:项目架构与核心原理
1.1 整体架构
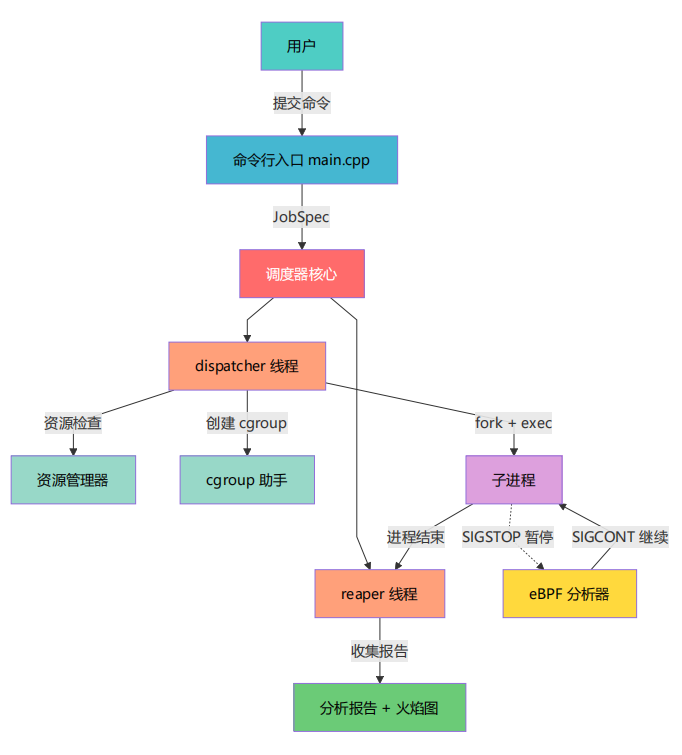
TaskScheduler 是一个 C++20 单机任务调度器,核心功能是接收用户提交的命令、以独立进程执行、并通过 eBPF 实时分析性能瓶颈。
关键设计决策:
|
技术选择 |
为什么 |
备选方案 |
|---|---|---|
|
fork/exec |
进程级隔离,独立地址空间 |
线程池(隔离性差) |
|
cgroup v2 |
内核级资源限制,不可绕过 |
nice / ulimit (粗粒度) |
|
bpftrace -p |
内核态追踪,零侵入 |
perf (需后处理)、 strace (高开销) |
|
先 SIGSTOP 再 SIGCONT |
保证 bpftrace 就绪后才开始执行 |
延迟启动(可能丢失初始事件) |
1.2 调度器工作原理
调度器内部有三个核心线程协同工作:

dispatcher 线程是"发令枪":
-
从 pending 队列取出任务
-
向 ResourceManager 申请 CPU + 内存资源
-
创建 cgroup 并 fork 子进程
-
如果启用了 eBPF,子进程会先 raise(SIGSTOP) 暂停自己
reaper 线程是"收割者":
-
循环 waitpid(WNOHANG) 检查子进程状态
-
检测超时并分级发送 SIGTERM → SIGKILL
-
子进程退出后,收集 eBPF 报告、释放资源、清理 cgroup
psi 线程是"压力传感器":
-
定期读取 /sys/fs/cgroup/memory.pressure 和 cpu.pressure
-
如果系统压力过高,设置背压标志
-
dispatcher 发现背压后暂停调度,等压力缓解
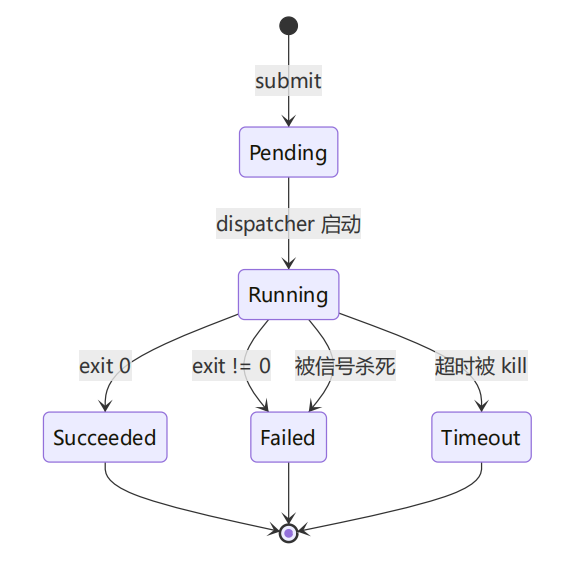
任务生命周期
1.3 cgroup v2 资源隔离
cgroup v2 是 Linux 内核提供的资源控制组机制。调度器利用它来限制每个任务可使用的资源:
/sys/fs/cgroup/scheduler/ # 调度器的 cgroup 根目录
├── job_1/ # 任务 1 的 cgroup
│ ├── cgroup.procs # 写入 PID 即将进程加入此组
│ ├── memory.max # 内存上限,如 "268435456"(256MB)
│ └── cpu.max # CPU 配额,如 "100000 100000"(1 核)
├── job_2/
│ └── ...工作流程:
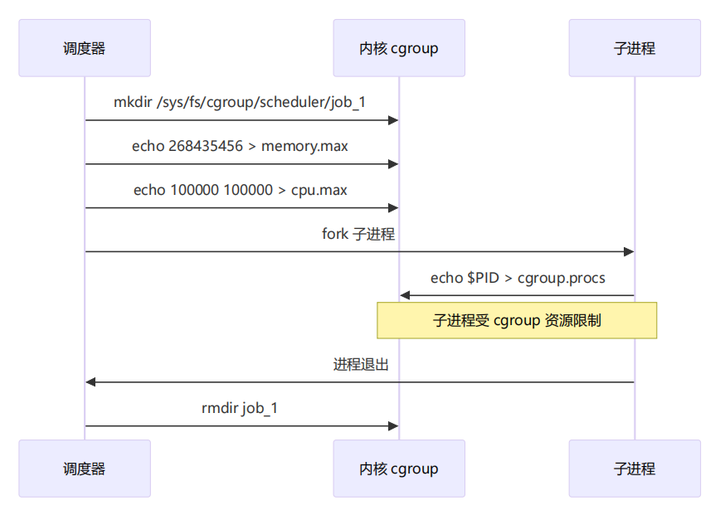
cpu.max 格式解读: "$QUOTA $PERIOD" — 在每个 $PERIOD 微秒内,允许使用 $QUOTA 微秒的 CPU。例如 "200000 100000" 表示"100ms 周期内可用 200ms CPU"= 2 个核心。
1.4 PSI 背压机制
PSI(Pressure Stall Information)是 Linux 内核的资源压力指标。当系统 CPU 或内存紧张时,PSI 会报告压力百分比。
# /sys/fs/cgroup/scheduler/memory.pressure
some avg10=0.50 avg60=0.30 avg300=0.10 total=12345
full avg10=0.00 avg60=0.00 avg300=0.00 total=0
# /sys/fs/cgroup/scheduler/cpu.pressure
some avg10=25.30 avg60=15.00 avg300=8.00 total=98765调度器的背压策略:
|
指标 |
阈值 |
含义 |
|---|---|---|
|
memory.some avg10 |
> 0.5 |
有进程在等内存 |
|
memory.full avg10 |
> 0.1 |
所有进程都在等内存 |
|
cpu.some avg10 |
> 0.8 |
有进程在等 CPU |
任一指标超阈值 → 暂停调度新任务,直到压力缓解。
1.5 代码调用关系详解
本节用源码级别的调用图展示各模块之间的函数调用关系,帮助你在阅读源码时快速定位。
1.5.1 源文件之间的依赖关系
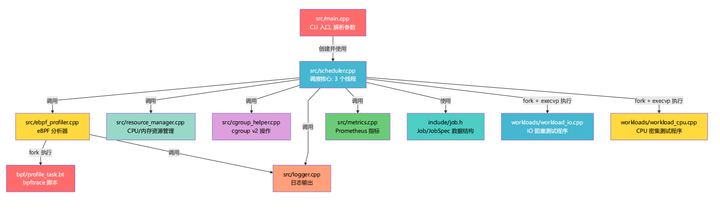
1.5.2 scheduler.cpp 内部函数调用关系
scheduler.cpp 是调度器的核心。以下是它内部的函数调用链:
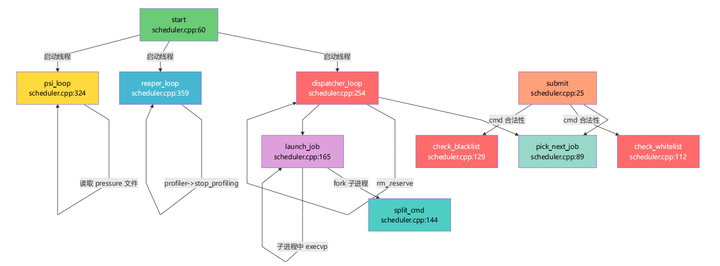
1.5.3 launch_job 内部的 fork 分支详解
launch_job 是整个项目最关键的函数——它决定了 workload 如何被执行。
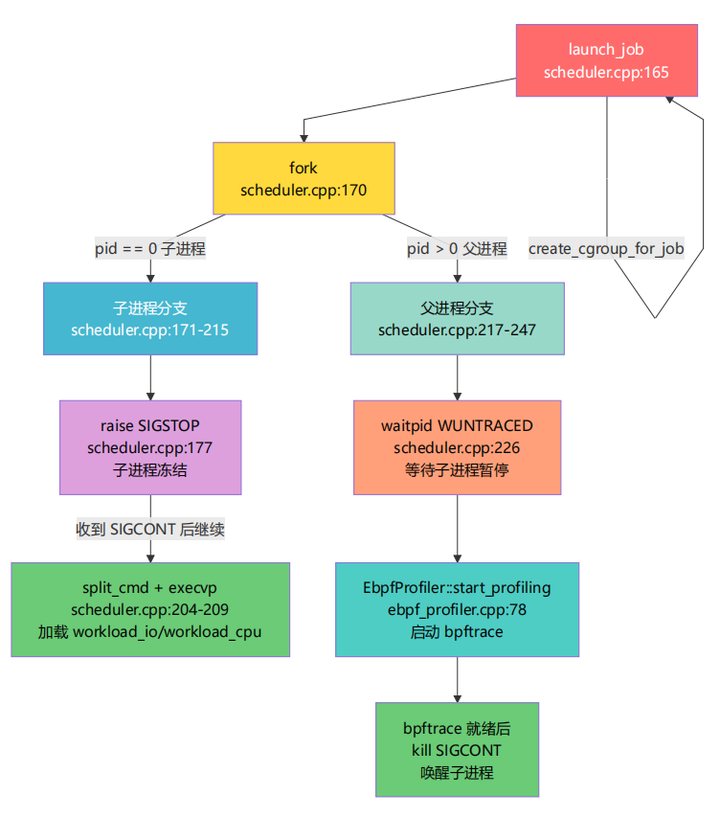
关键理解: fork() 之后,代码分成两条路径同时执行:
|
路径 |
PID |
代码位置 |
做了什么 |
|---|---|---|---|
|
子进程 |
新 PID |
scheduler.cpp:171-215 |
SIGSTOP → 等 eBPF → execvp workload |
|
父进程 |
原 PID |
scheduler.cpp:217-247 |
waitpid → 启动 bpftrace → SIGCONT |
execvp 的效果是用 workload 的二进制代码完全替换子进程的内存。执行 execvp 之后,子进程已经不再是 scheduler 的代码了,它变成了 workload_io 或 workload_cpu 。
1.5.4 ebpf_profiler.cpp 内部函数调用关系
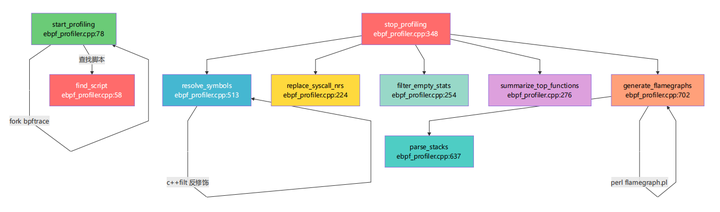
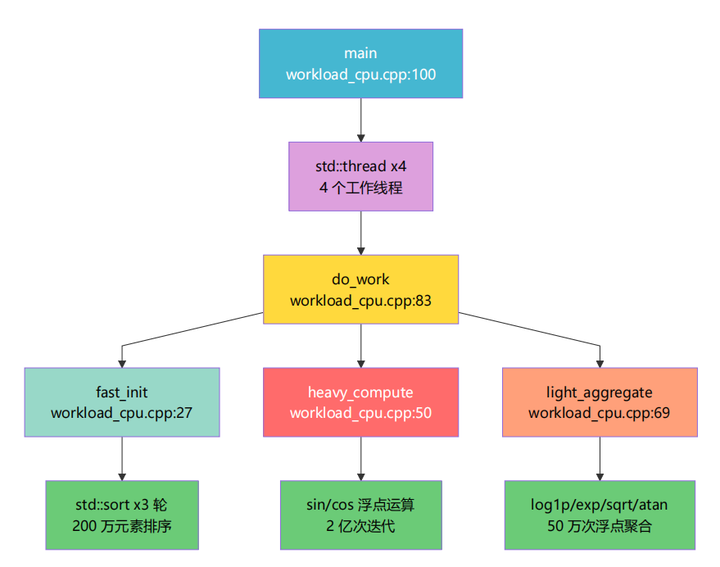
1.5.5 workload 内部函数调用关系
workload_io.cpp:
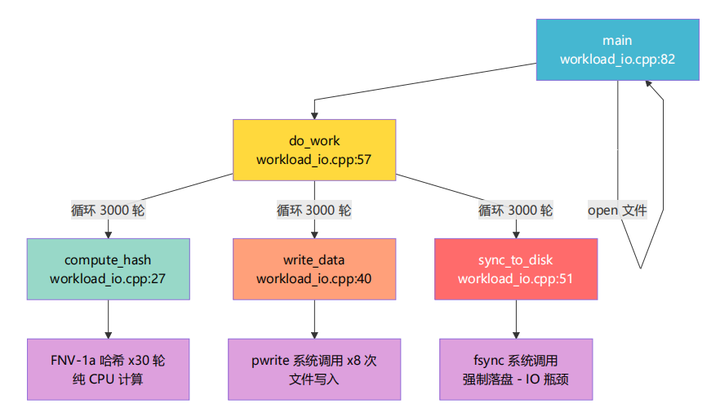
workload_cpu.cpp:
第二章:eBPF 分析原理
2.1 什么是 eBPF
eBPF(Extended Berkeley Packet Filter)是 Linux 内核中的一个可编程虚拟机。它允许你在不修改内核源码、不重启系统的前提下,将小段程序注入内核的特定位置执行。
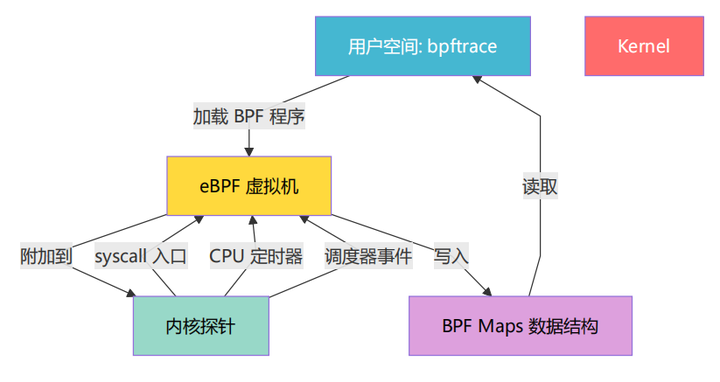
类比理解:如果内核是一条高速公路,eBPF 就是在公路边设置的测速摄像头——不影响车辆通行,但能准确记录每辆车的速度。
传统性能分析工具的对比:
|
工具 |
工作层级 |
侵入性 |
开销 |
精度 |
|---|---|---|---|---|
|
printf 调试 |
用户代码 |
高(修改源码) |
中 |
手动控制 |
|
strace |
系统调用 |
低(ptrace) |
非常高(30-100x) |
syscall 级 |
|
perf record |
内核+用户 |
低 |
低 |
采样级 |
|
eBPF/bpftrace |
内核 |
零 |
极低 |
事件级/采样级 |
2.2 bpftrace 工具链
bpftrace 是 eBPF 的高级前端,提供类 awk 的脚本语言,大幅降低 eBPF 编程门槛。
本项目使用 bpftrace -p <PID> 模式——附加到一个正在运行的进程。整个工作流如下:
为什么要先 SIGSTOP 再 SIGCONT?
如果子进程直接运行,bpftrace 还没准备好,前几毫秒的事件就丢失了。通过SIGSTOP/SIGCONT 协调,保证从第一条指令开始就被追踪。
2.3 探针类型与数据采集
profile_task.bt 脚本使用了以下探针类型:
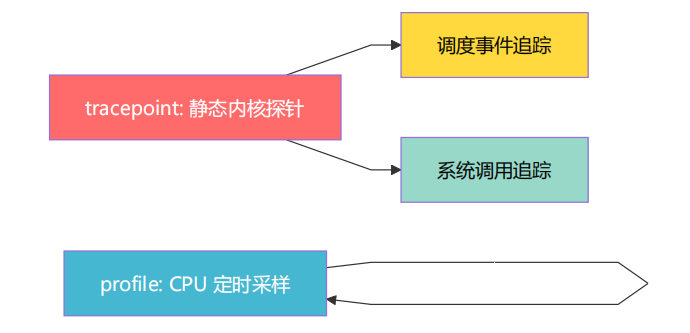
|
探针 |
触发时机 |
采集内容 |
用途 |
|---|---|---|---|
|
tracepoint:raw_syscalls:sys_enter |
每次系统调用入口 |
syscall 编号、时间戳 |
统计 syscall 分布 |
|
tracepoint:raw_syscalls:sys_exit |
每次系统调用返回 |
延迟 |
计算 syscall 耗时 |
|
tracepoint:syscalls:sys_enter_fsync |
调用 fsync 时 |
用户态调用栈 |
Off-CPU 阻塞栈 |
|
tracepoint:syscalls:sys_exit_fsync |
fsync 返回时 |
阻塞时长 |
Off-CPU 耗时统计 |
|
tracepoint:sched:sched_switch |
CPU 切换进程时 |
上下文切换信息 |
调度延迟分析 |
|
profile:hz:99 |
每秒 99 次 |
用户态调用栈 |
CPU 热点采样 |
2.4 On-CPU 采样原理
On-CPU 采样的核心思想:以固定频率打断 CPU,记录当前正在执行的函数。
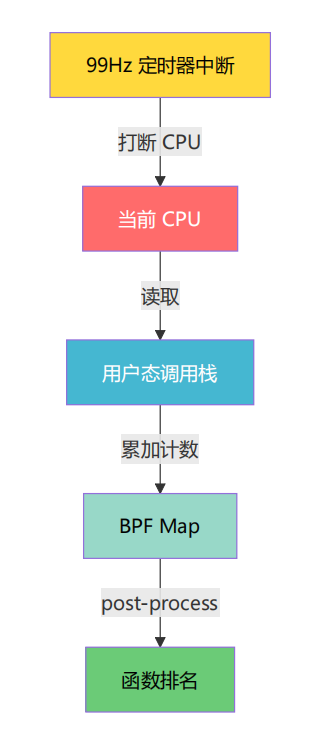
举个例子:如果程序运行 10 秒,99Hz 采样就会产生约 990 个样本。假设:
-
600 个样本的栈顶是 heavy_compute → 60% CPU 时间
-
200 个样本的栈顶涉及 std::sort → 20% CPU 时间(来自 fast_init )
-
190 个样本的栈顶涉及 sin/cos/log1p → 19% CPU 时间(来自 light_aggregate )
这就得出了函数级 CPU 热点排名。
为什么选 99Hz 而不是 100Hz?
避免与系统其他定时器(通常是 100Hz/250Hz)产生锁步效应(lock-step),导致总是采样到相同位置。99 是质数,能更均匀地分散采样点。
栈采样深度:
本项目的 BPF 脚本使用 ustack(16) 来采集用户态栈,最多可获取 16 层栈信息。这样可以确保捕获到完整的函数调用链,包括 main 函数内部调用的 func_a 、 func_b 、 func_c 等函数。
2.5 Off-CPU 分析原理
On-CPU 采样能找到"CPU 上在忙什么",但如果程序大部分时间在等待 IO,CPU 采样反而抓不到它——因为等待时进程不占 CPU。
Off-CPU 分析解决的问题是:程序不在 CPU 上的时间,到底在等什么?
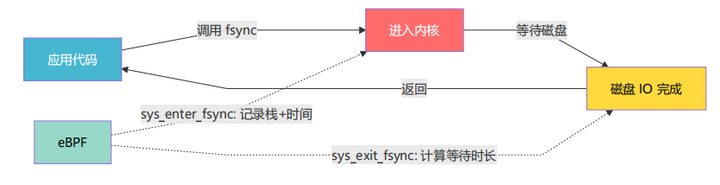
本项目的 Off-CPU 分析策略:
-
在 sys_enter_fsync 时刻,记录用户态调用栈 + 进入时间
-
在 sys_exit_fsync 时刻,计算 阻塞时长 = 返回时间 - 进入时间
-
将阻塞时长按调用栈分组累加
为什么在 syscall 入口记录栈,而不是在内核态?
因为 libc 的 fsync() 实现可能不保留帧指针,导致从内核态回溯栈时断裂。在 syscall 入口记录用户态栈,能保证看到完整的应用层调用链。
2.6 符号解析流水线
bpftrace 输出的原始栈帧可能是地址(如 0x401505 ),用户看不懂。需要将地址翻译成函数名。
详细步骤:
-
收集 /proc/<pid>/maps :记录进程的内存映射,知道每个地址范围属于哪个可执行文件/共享库
-
分组地址:将地址按所属 EXE/SO 分组
-
计算文件偏移: file_offset = virtual_addr - segment_start + segment_offset
-
调用 addr2line: addr2line -f -s -e /path/to/binary 0x... 获取函数名
-
C++ 反修饰: c++filt _ZN5heavy7computeEyy → heavy_compute
为什么 workload 要用 -no-pie 编译?
PIE(Position-Independent Executable)会让可执行文件每次加载到随机地址。对于可执行文件本身的符号,非 PIE 模式下地址是固定的(如 0x401xxx ), addr2line 可以直接解析。PIE 模式则需要额外计算 ASLR 偏移。
第三章:工作负载设计哲学
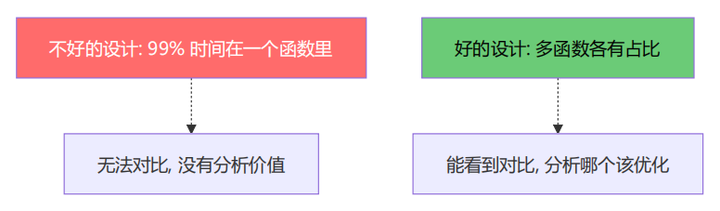
3.1 为什么需要精心设计的 workload
一个好的性能分析教学 workload 需要满足:
-
清晰的函数调用层次:能在栈中看到调用关系
-
多个可辨识的热点:不是只有一个函数占 99%,而是多个函数有不同占比
-
可被 eBPF 观测:函数不能被编译器内联、栈帧不能丢失
-
运行时间适中:太短采样不够,太长等待太久
3.2 IO 阻塞型负载设计
workload_io.cpp 模拟一个典型的日志写入/数据持久化场景:
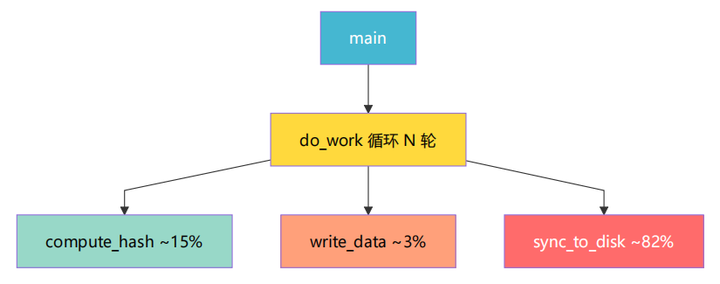
每个函数的设计意图:
|
函数 |
做什么 |
CPU 开销 |
IO 开销 |
设计意图 |
|---|---|---|---|---|
|
compute_hash |
FNV-1a 哈希 30 轮 |
中等 |
无 |
在 CPU 采样中可见 |
|
write_data |
pwrite 写 8 次 |
低 |
中 |
在 IO 统计中可见 |
|
sync_to_disk |
fsync 强制落盘 |
极低 |
极高 |
主瓶颈,Off-CPU 分析靶标 |
关键代码片段与编译器对抗:
// __attribute__((noinline)) 防止编译器将函数内联到 do_work 中
// 如果被内联,eBPF 栈采样就看不到独立的函数名
__attribute__((noinline))
int sync_to_disk(int fd) {
// volatile 防止编译器将 fsync 优化为尾调用
// 尾调用会复用调用者的栈帧,导致栈回溯时看不到 sync_to_disk
volatile int rc = fsync(fd);
return rc;
}3.3 CPU 密集型负载设计
workload_cpu.cpp 模拟一个数据处理管线:初始化 → 计算 → 聚合。
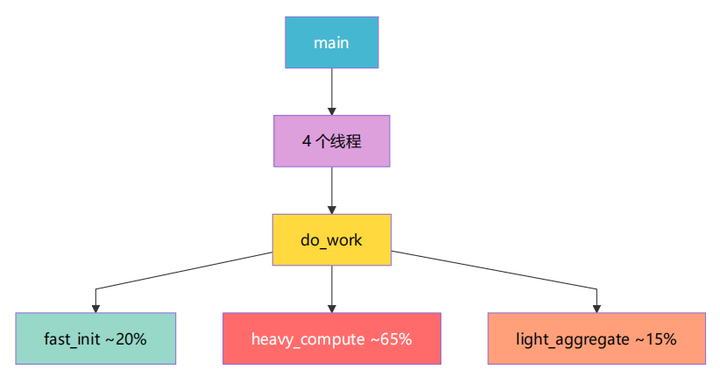
每个函数的设计意图:
|
函数 |
算法 |
特征 |
设计意图 |
|---|---|---|---|
|
fast_init |
3 轮 200 万元素排序 + XOR 混淆 |
内存密集 + CPU |
展示排序类热点 |
|
heavy_compute |
2 亿次位运算 + 周期性 sin/cos |
纯 CPU 密集 |
主热点 |
|
light_aggregate |
50 万次 log1p/exp/sqrt/sin/cos |
浮点密集 |
展示数学库热点 |
多线程的好处:4 个线程会让 CPU 采样数据更丰富,可以观察到:
-
每个线程的采样是否均匀分布(通过 各线程 CPU 采样分布 段)
-
多线程对 std::sort 等函数的竞争
3.4 编译器对抗:防内联与帧指针
eBPF 栈采样依赖完整的调用栈。编译器优化会破坏这一点:
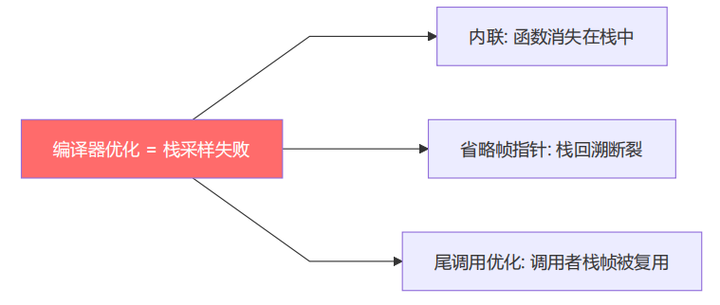
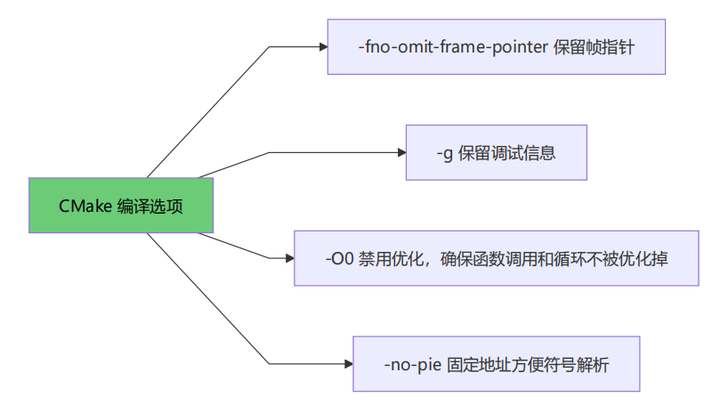
CMakeLists.txt 中的关键配置:
set(WORKLOAD_FLAGS -fno-omit-frame-pointer -g -O0 -no-pie)
target_compile_options(workload_io PRIVATE ${WORKLOAD_FLAGS})
target_link_options(workload_io PRIVATE -no-pie)|
选项 |
作用 |
不加会怎样 |
|---|---|---|
|
-fno-omit-frame-pointer |
保留 RBP 帧指针寄存器 |
栈回溯断裂,只能看到最外层函数 |
|
-g |
生成 DWARF 调试信息 |
addr2line 无法解析函数名 |
|
-O0 |
禁用优化,确保函数调用和循环不被优化掉 |
函数调用可能被内联,循环可能被优化掉,导致栈采样不完整 |
|
-no-pie |
禁用地址随机化 |
地址→符号映射需要额外计算 ASLR 偏移 |
__attribute__((noinline)) 是函数级的防内联指令。即使在 -O2 下,标记了 noinline 的函数也不会被内联。
第四章:环境搭建与编译
4.1 系统依赖安装
操作系统要求:Linux 内核 5.x+,推荐 Ubuntu 22.04 / 24.04 LTS。
# 基础编译工具
sudo apt update
sudo apt install -y build-essential cmake g++
# eBPF 工具链
sudo apt install -y bpftrace linux-headers-$(uname -r)
# 符号解析工具
sudo apt install -y binutils # 提供 addr2line 和 c++filt
# 火焰图工具(Brendan Gregg 的 FlameGraph)
git clone https://github.com/brendangregg/FlameGraph.git /tmp/FlameGraph
sudo cp /tmp/FlameGraph/flamegraph.pl /usr/local/bin/
sudo chmod +x /usr/local/bin/flamegraph.pl
# 或者放到项目的 tools/ 目录
mkdir -p tools
cp /tmp/FlameGraph/flamegraph.pl tools/
chmod +x tools/flamegraph.pl验证依赖是否就绪:
# 检查 bpftrace
bpftrace --version
# 应输出 bpftrace v0.17+
# 检查 BTF 支持(eBPF 类型格式)
ls /sys/kernel/btf/vmlinux
# 应存在该文件
# 检查 addr2line
addr2line --version
# 检查是否有 root 权限(eBPF 需要 root)
sudo whoami
# 应输出 root4.2 项目编译
# 克隆项目
git clone <项目地址> TaskScheduler
cd TaskScheduler
# 创建构建目录
mkdir -p build && cd build
# 配置
cmake .. -DCMAKE_BUILD_TYPE=RelWithDebInfo
# 编译(使用所有 CPU 核心)
make -j$(nproc)编译成功后, build/ 目录下会生成三个可执行文件:
build/
├── scheduler # 调度器主程序
├── workload_io # IO 阻塞型测试程序
└── workload_cpu # CPU 密集型测试程序4.3 验证安装
# 1. 测试调度器基本功能(不需要 root)
./build/scheduler --cmd "echo hello" --timeout 5
# 应看到 "hello" 输出和 job 完成日志
# 2. 单独运行 workload,确认它们能正常执行
./build/workload_io --rounds 10
# 应看到 elapsed_ms 输出
./build/workload_cpu --threads 2 --iterations 10000000
# 应看到 elapsed_ms 和 checksum 输出
# 3. 测试 eBPF 功能(需要 root)
sudo ./build/scheduler \
--cmd "./build/workload_io --rounds 100" \
--enable-ebpf \
--ebpf-script-dir ./bpf \
--timeout 30
# 应看到 eBPF 性能分析报告输出如果第 3 步报 "not available",请检查:
-
是否以 root 运行
-
bpftrace 是否安装
-
/sys/kernel/btf/vmlinux 是否存在
第五章:实验操作指南
5.1 实验一:IO 阻塞分析
目标:分析一个以 fsync 为瓶颈的 IO 密集程序,学会识别阻塞热点。
运行命令:
sudo ./build/scheduler \
--cmd "./build/workload_io --rounds 3000" \
--enable-ebpf \
--ebpf-script-dir ./bpf \
--timeout 60参数说明:
|
参数 |
值 |
含义 |
|---|---|---|
|
--cmd |
"./build/workload_io --rounds 3000" |
执行 IO workload,循环 3000 轮 |
|
--enable-ebpf |
(标志) |
启用 eBPF 分析 |
|
--ebpf-script-dir |
./bpf |
bpftrace 脚本所在目录 |
|
--timeout |
60 |
超时 60 秒自动终止 |
预期运行时间:约 3-5 秒。
预期结果:
-
CPU 热点排名: __GI_fsync 占 ~82%, compute_hash 占约 ~15%, __libc_pwrite64 占 ~3%
-
Off-CPU 阻塞排名: __GI_fsync 占 100%(约 2.2 秒)
-
生成 On-CPU 和 Off-CPU 火焰图 SVG 文件
输出文件位置:
taskscheduler_ebpf/
├── job_1_pid_<PID>.txt # 完整的文本分析报告
├── job_1_pid_<PID>_oncpu.svg # On-CPU 火焰图(红色主题)
├── job_1_pid_<PID>_offcpu.svg # Off-CPU 火焰图(蓝色主题)
└── job_1_maps.txt # 进程内存映射备份(用于符号解析)你可以用浏览器打开 SVG 文件查看交互式火焰图:
firefox taskscheduler_ebpf/job_1_pid_*_oncpu.svg思考题:
1. 为什么 fsync 在 CPU 热点中占比也很高?
提示:fsync 虽然是 IO 操作,但 CPU 需要切换到内核态、构建 IO 请求、等待返回。这段时间如果恰好被 99Hz 采样命中,就会被计入。
2. compute_hash 的 30 轮哈希,如果改成 3 轮,它还能在 CPU 采样中看到吗?
提示:如果计算时间太短(远小于采样间隔 ~10ms),被采样命中的概率就极低。
5.2 实验二:CPU 热点分析
目标:分析一个单线程 CPU 密集程序,学会从采样数据中识别函数级热点。
运行命令:
sudo ./build/scheduler \
--cmd "./build/workload_cpu" \
--enable-ebpf \
--ebpf-script-dir ./bpf \
--timeout 60参数说明:
|
参数 |
值 |
含义 |
|---|---|---|
|
--cmd |
"./build/workload_cpu" |
执行 CPU workload,单线程循环执行 |
|
--enable-ebpf |
(标志) |
启用 eBPF 分析 |
|
--ebpf-script-dir |
./bpf |
bpftrace 脚本所在目录 |
|
--timeout |
60 |
超时时间 60 秒 |
预期运行时间:约 1-3 秒。
预期结果:
|
函数 |
预期占比 |
来源 |
|---|---|---|
|
func_c |
~35% |
直接热点(35 个单位的计算) |
|
main |
~30% |
循环调度开销(30 个单位的计算) |
|
func_b |
~20% |
直接热点(20 个单位的计算) |
|
func_a |
~10% |
直接热点(10 个单位的计算) |
|
func_d |
~5% |
直接热点(5 个单位的计算) |
输出文件位置:与实验一相同,在 taskscheduler_ebpf/ 目录下。CPU workload 通常只生成 On-CPU 火焰图 (Off-CPU 火焰图可能为空或很小,因为没有阻塞 IO)。
思考题:
1. 为什么 func_c 的采样占比最高?
提示: func_c 包含了最多的计算量(35 个单位),因此被采样命中的概率最高。
2. 火焰图中能看到完整的调用链吗?
提示:火焰图会将所有栈帧展开,你可以看到 main → func_a → func_d 的完整路径。
5.3 实验三:自定义程序分析
你可以分析任何自己的程序。只需要两个条件:
1. 编译时保留帧指针: -fno-omit-frame-pointer -g
2. 用调度器运行:
sudo ./build/scheduler \
--cmd "/path/to/your/program args..." \
--enable-ebpf \
--ebpf-script-dir ./bpf \
--timeout 300小贴士:
-
如果程序运行太快(< 1 秒),CPU 采样可能不够。增加工作量或循环次数。
-
如果看不到函数名,检查是否用 -g 编译,或尝试加 -no-pie 。
-
火焰图 SVG 在 taskscheduler_ebpf/ 目录下。
第六章:报告解读指南
eBPF 分析报告是整个项目的核心产出。本章逐段解读报告中的每一个部分。
6.1 报告整体结构
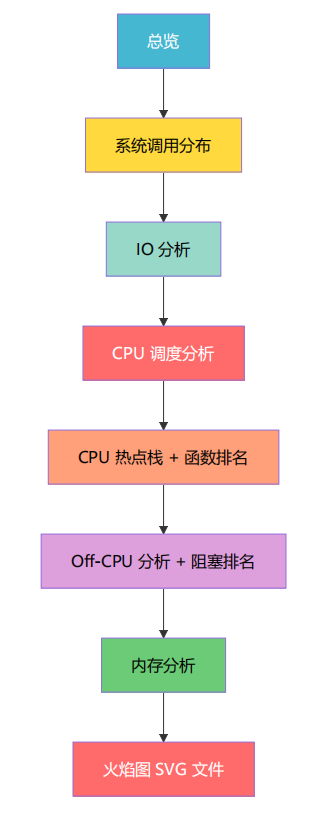
6.2 总览区解读
==================================================
eBPF 性能分析报告
==================================================
分析时长: 4961 ms
┌───────────────────────────────────────────────┐
│ 总览 │
├───────────────────────────────────────────────┤
│ 系统调用总次数: 24880
│ 慢系统调用(>1ms): 438
│ 上下文切换: 5258
│ - 自愿切换: 5256
│ - 非自愿切换: 2
│ CPU 采样次数: 121
│ 线程创建次数: 0
└───────────────────────────────────────────────┘逐行解读:
|
指标 |
本例值 |
含义 |
分析 |
|---|---|---|---|
|
分析时长 |
4961ms |
程序从开始到结束的总时间 |
— |
|
系统调用总次数 |
24880 |
程序调用了多少次内核服务 |
IO 型程序通常很高(pwrite×8 + fsync 每轮) |
|
慢系统调用>1ms |
438 |
超过 1ms 的系统调用次数 |
部分 fsync 超过 1ms |
|
上下文切换 |
5258 |
CPU 切换执行上下文的次数 |
— |
|
自愿切换 |
5256 |
程序主动让出 CPU(如等IO) |
≈ rounds 数 × ~1.75 → 每轮 fsync 让出 |
|
非自愿切换 |
2 |
被调度器抢占 |
几乎没有 → IO 主导,不是 CPU 竞争 |
|
CPU 采样次数 |
121 |
99Hz 采样命中目标进程的次数 |
5s × 99Hz ≈ 495,但多数时间在睡眠 |
|
线程创建次数 |
0 |
clone/clone3 调用次数 |
IO workload 单线程 |
诊断规则:
-
自愿切换 >> 非自愿切换 → 程序以 IO 等待为主
-
非自愿切换 >> 自愿切换 → CPU 密集,被抢占
-
CPU 采样次数 << 理论值 → 程序大部分时间不在 CPU 上(Off-CPU)
6.3 系统调用分布解读
┌────────────────────────────────────────────────────────────┐
│ 系统调用分布 (按 syscall nr) │
└────────────────────────────────────────────────────────────┘
close: 1
write: 1
unlink: 1
exit_group: 1
fsync: 2764
pwrite64: 22112后处理器已将系统调用号翻译为人类可读的名称。分析要点:
|
syscall |
次数 |
分析 |
|---|---|---|
|
pwrite64 |
22112 |
≈ rounds × 8(每轮 write_data 写 8 次),部分 fsync 采样时段未覆盖 |
|
fsync |
2764 |
≈ rounds(每轮调一次 fsync) |
|
write |
1 |
标准输出的打印 |
|
unlink |
1 |
临时文件清理 |
诊断技巧:用 syscall 次数反推代码行为。 pwrite64 / fsync ≈ 8 ,说明 write_data 函数每轮写 8 遍,与代码中 write_count=8 一致。
注意:实际采集到的 syscall 次数可能略少于理论值。因为 bpftrace 在 BEGIN 就绪和 SIGCONT 之间有微小时 间差,前几轮的 syscall 可能未被追踪到。
6.4 IO 分析区解读
┌──────────────────────────────────────────────────────────┐
│ IO 分析 │
├──────────────────────────────────────────────────────────┤
│ Write 调用次数: 22057
│ Write 总字节: 90341632
│ fsync 调用次数: 2757
│ fsync 总耗时(us): 2181503
└──────────────────────────────────────────────────────────┘关键计算:
-
Write 总字节 = 90,341,632 bytes ≈ 86 MB
-
每次 Write 大小 = 90341632 / 22057 ≈ 4096 bytes = BUF_SIZE,符合预期
-
fsync 总耗时 = 2,181,503 us ≈ 2.2 秒 — 全程 5 秒中 44% 在 fsync
-
fsync 平均耗时 = 2181503 / 2757 ≈ 791 us ≈ 0.8 ms
--- fsync 延迟分布 (us) ---
[128, 256) 174 |@@@@ |
[256, 512) 53 |@ |
[512, 1K) 2111 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[1K, 2K) 378 |@@@@@@@@@ |
[2K, 4K) 37 | |
[4K, 8K) 2 | |
[8K, 16K) 1 | |
[16K, 32K) 1 | |直方图读法:横向柱状图,左边是延迟区间,右边是次数和柱形。
解读:绝大多数 fsync(2111 次)延迟在 512us~1ms 之间。少部分(174 次)在 128~256us 很快完成。有极少量尾部延迟到 32ms,可能是磁盘写合并或操作系统调度抖动。
6.5 CPU 热点函数排名解读
这是最有价值的分析段落,直接告诉你哪个函数消耗了最多 CPU 时间。
>>> CPU 热点函数排名(栈顶采样合并):
81.8% __GI_fsync (99 samples)
14.9% compute_hash (18 samples)
3.3% __libc_pwrite64 (4 samples)解读方式:

|
排名 |
函数 |
采样数 |
占比 |
解读 |
|---|---|---|---|---|
|
1 |
__GI_fsync |
99 |
81.8% |
glibc 的 fsync 实现,即 sync_to_disk |
|
2 |
compute_hash |
18 |
14.9% |
哈希计算的 CPU 开销 |
|
3 |
__libc_pwrite64 |
4 |
3.3% |
pwrite 系统调用的 CPU 开销 |
为什么看到的是 __GI_fsync 而不是 sync_to_disk ?
因为 CPU 采样命中时,CPU 正在 glibc 的 fsync() 内部执行。 sync_to_disk 虽然是调用者,但采样记录的是当前最内层函数(栈顶)。火焰图中可以看到完整的调用链。
6.6 Off-CPU 阻塞函数排名解读
┌────────────────────────────────────────────────────────┐
│ Off-CPU 分析 (阻塞等待热点栈) │
├────────────────────────────────────────────────────────┤
│ 阻塞切换次数: 2746
│ 阻塞总耗时(us): 2176269
└────────────────────────────────────────────────────────┘
>>> Off-CPU 阻塞函数排名(耗时合并):
100.0% __GI_fsync (2.18 s)解读:
-
阻塞切换次数 2746 ≈ fsync 调用 2757 次(几乎每次 fsync 都触发了阻塞切换)
-
2.18 秒全部花在 fsync 等待磁盘上
-
如果有其他阻塞函数(如 pthread_mutex_lock ),也会出现在排名中
CPU 型 workload 的 Off-CPU 情况:
对于 workload_cpu ,Off-CPU 数据通常为空或极少,因为纯 CPU 计算不产生阻塞。这本身就是有意义的信息 ——"程序不存在 IO 瓶颈"。
6.7 两种 workload 报告核心指标对比
下表将 IO workload 和 CPU workload 的报告关键指标并排对比,帮助你快速判断一个程序的瓶颈类型:
|
指标 |
IO workload |
CPU workload |
怎么判断瓶颈类型 |
|---|---|---|---|
|
CPU 采样次数 |
121(理论 495) |
337(理论 396) |
IO 型 << 理论值;CPU 型 ≈ 理论值 |
|
自愿切换 |
5256 |
3 |
IO 型极高(每次 fsync 都让出 CPU) |
|
非自愿切换 |
2 |
0 |
两者都不高,但 IO 型更低 |
|
慢 syscall>1ms |
438 |
4 |
IO 型很多(fsync 延迟);CPU 型几乎没有 |
|
fsync 调用 |
2757 |
0 |
IO 型核心指标 |
|
Off-CPU 总耗时 |
2.18 s |
0 |
IO 型阻塞明显;CPU 型无阻塞 |
|
CPU 热点Top1 |
__GI_fsync 82% |
heavy_compute 21% |
IO 型 = IO 函数占顶;CPU 型 = 计算函数占顶 |
|
火焰图形态 |
Off-CPU 图丰富 |
On-CPU 图丰富 |
看哪个火焰图更"丰满" |
快速判断口诀:
-
自愿切换多 + Off-CPU 有数据 + CPU 采样少 → IO 瓶颈
-
非自愿切换多 + Off-CPU 为空 + CPU 采样满 → CPU 瓶颈
6.8 直方图读法
报告中多处出现 bpftrace 的 hist() 直方图,格式如下:
[区间下界, 区间上界) 次数 |@@@@@@@@@@@@@@@@@@@@@@@|关键点:
-
区间使用2 的幂次(对数刻度): [1K, 2K) 表示 1024~2047
-
@ 符号的长度代表相对比例
-
单位取决于上下文:syscall 延迟用 ns ,IO 延迟用 us
快速判断模式:
-
柱形集中在低区间 → 正常,延迟低
-
柱形分散到多个区间 → 延迟波动大,可能有尾部延迟问题
-
高区间有孤立柱形 → 偶发高延迟(如 GC、页面换入、磁盘抖动)
第七章:火焰图解读
7.1 什么是火焰图
火焰图(Flame Graph)是 Brendan Gregg 发明的性能分析可视化方法。它将栈采样数据以堆叠柱形展示,像一簇火焰。
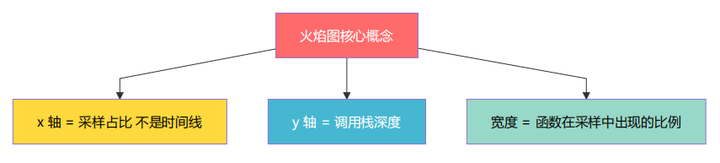
火焰图阅读三原则:
-
越宽的色块,占用时间越多(宽度 = 采样占比)
-
上层函数被下层函数调用(从下往上读 = 从调用者到被调用者)
-
x 轴的顺序无意义(仅按字母排序,不代表时间先后)
7.2 On-CPU 火焰图解读
代码已经改成了一个更简单的on-cpu火焰图,实际函数以代码为准
On-CPU 火焰图(文件名: *_oncpu.svg )显示 CPU 上在执行什么。
IO Workload 的 On-CPU 火焰图示意:
┌──────────────────────────────────────────────┐
│ main │ ← 底层
├──────────────────────────────────────────────┤
│ do_work │
├──────────────┬──────────────┬────────────────┤
│ sync_to_disk │ compute_hash │ write_data │
│ __GI_fsync │ │ libc_pwrite64 │
│ █████████ │ ██████ │ ██ │
│ 82% │ 15% │ 3% │
└──────────────┴──────────────┴────────────────┘你能看到的信息:
-
sync_to_disk → __GI_fsync 占据了最宽的色块 → 主要 CPU 占用
-
compute_hash 有独立色块 → CPU 计算清晰可见
-
write_data → __libc_pwrite64 很窄 → 写入操作 CPU 开销小
CPU Workload 的 On-CPU 火焰图示意:
┌───────────────────────────────────────────────────────────────┐
│ main │
├───────────────────────────────────────────────────────────────┤
│ std::thread::invoke │
├───────────────────────────────────────────────────────────────┤
│ do_work │
├─────────────┬──────────────────────────┬──────────────────────┤
│ fast_init │ heavy_compute │ light_aggregate │
│ std::sort │ ┌───────────┬──────────┐ │ ┌─────┬──────┬──────┐│
│ ██████ │ │ heavy_comp│ do_sin │ │ │ log │ sqrt │ sin ││
│ 20% │ │ ████████ ─│ ████████ │ │ │████ │████ │████ ││
│ │ │ 27% │ 25% │ │ │ 5% │ 4% │ 4% ││
└─────────────┴─┴───────────┴──────────┴─┴─┴─────┴──────┴──────┴┘你能看到的信息:
-
heavy_compute 虽然在函数排名中只占 27%,但加上它调用的 do_sin (25%),整体占约 52%
-
fast_init → std::sort 路径清晰可见,约 20%
-
light_aggregate 下面分叉为 log1p 、 sqrt 、 sin 等数学库函数
火焰图的优势就在这里:报告中 heavy_compute 和 do_sin 是分开的两行,但火焰图中它们是上下堆叠的,一眼看出 heavy_compute 的真实开销 = 自身 + 调用链。
7.3 Off-CPU 火焰图解读
Off-CPU 火焰图(文件名: *_offcpu.svg ,蓝色主题)显示 程序在等什么。
IO Workload 的 Off-CPU 火焰图示意:
┌─────────────────────────────────────────────────────┐
│ main │
├─────────────────────────────────────────────────────┤
│ do_work │
├─────────────────────────────────────────────────────┤
│ sync_to_disk │
├─────────────────────────────────────────────────────┤
│ __GI_fsync │
│ ████████████████████████████████████████████████ │
│ 100% │
└─────────────────────────────────────────────────────┘解读:蓝色火焰图中只有一根"柱子",从 main → do_work → sync_to_disk → __GI_fsync ,说明所有阻塞时间 都花在同一条调用路径上。
如果有多种阻塞原因(比如既有 fsync 又有 mutex_lock),火焰图会分叉成多根"柱子"。
7.4 火焰图分析技巧
技巧一:从最宽的色块开始看
最宽的色块就是性能瓶颈所在。如果 __GI_fsync 占了 82%,优化方向就是减少 fsync 调用(如批量写入后再 sync)。
技巧二:关注"平顶"
如果火焰图上有一个"平顶"(没有子函数的宽色块),说明该函数本身消耗大量 CPU,而不是调用其他函数。这种函数通常是优化的直接目标。
┌──────────────────────────────────────────┐
│ heavy_compute │ ← 平顶 = 函数本身在消耗 CPU
│ █████████████████████████████████████ │
└──────────────────────────────────────────┘技巧三:对比 On-CPU 和 Off-CPU 火焰图
|
场景 |
On-CPU 火焰图 |
Off-CPU 火焰图 |
结论 |
|---|---|---|---|
|
CPU 密集 |
丰富的多层调用 |
几乎为空 |
优化算法 |
|
IO 密集 |
fsync/read/write 很宽 |
fsync 占满 |
优化 IO 模式 |
|
锁竞争 |
正常分布 |
mutex_lock 很宽 |
减少锁粒度 |
技巧四:在浏览器中使用
SVG 火焰图是交互式的!用浏览器打开后:
-
点击色块可以放大查看子调用
-
悬停显示函数名和采样占比
-
搜索功能可以高亮特定函数名
# 在浏览器中打开火焰图
firefox taskscheduler_ebpf/job_1_pid_12345_oncpu.svg
一站式 AI 云服务平台
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)