
基于 YOLO11 的三类可回收物视觉识别系统 | 用于智能回收柜、社区投放点监测、垃圾分类运营 | 附完整源码与效果演示
本项目基于YOLO11n与Streamlit,构建了一套面向社区智能回收柜与投放点的轻量化三类可回收物视觉识别系统。模型聚焦“金属、纸张、塑料”三类高价值可回收物,参数量仅2.6M,CPU即可实时推理,兼顾边缘部署的精度与效率。前端支持单图、批量、视频及摄像头四路输入,一键输出检测框、置信度与结构化报表,并内置类别分布图表与批量打包下载功能。系统通过配置文件实现业务话术与UI主题的零代码定制,将“
基于 YOLO11 的三类可回收物视觉识别系统:从模型到 Streamlit 全流程实战
关键词:YOLO11、可回收物识别、垃圾分类、智能回收柜、Streamlit、目标检测、Ultralytics
一、背景
1.1 行业痛点
「垃圾分类」喊了很多年,落到社区投放点、校园回收驿站和小区智能回收柜上,真正卡脖子的问题其实非常工程化:
- 居民投错率高:金属、纸张、塑料三类可回收物的形态千变万化(易拉罐、扁的金属盒、揉皱的纸团、泡沫塑料、PET 瓶、塑料袋…),靠人眼贴标签管理,错投比例长期在 20% 以上。
- 回收柜需要无人值守:智能回收柜、积分回收一体机要做到「投进去就给积分」,本质上需要一套能在低功耗终端上跑实时识别的视觉模型。
- 运营侧缺数据:哪类可回收物投放最多、哪个时段、哪个点位价值最高?没有视觉感知,运营完全是黑盒。
- 传统重模型部署难:把 YOLOv8x、Mask R-CNN 这类大模型塞进 ARM 边缘盒子或者 Jetson Nano,往往算力不够 / 帧率拉胯,最终落回「拍照上传云端识别」的笨办法。

把目标检测器轻量化到 YOLO11n 这一档(参数量约 2.6 M、CPU 也能实时),再封进一个开箱即用的 Streamlit 单页应用,就能让社区智能投放点、校园回收驿站、回收柜厂商用一份 yaml + 一份 best.pt 完成视觉识别能力的快速接入。本项目就是这条路线下的一份完整工程样板:基于 YOLO11n,识别金属、纸张、塑料三大类可回收物。
视频演示与源码下载
包含:
📦完整项目源码
📦预训练模型权重
🗂️数据集
1.2 项目运行效果
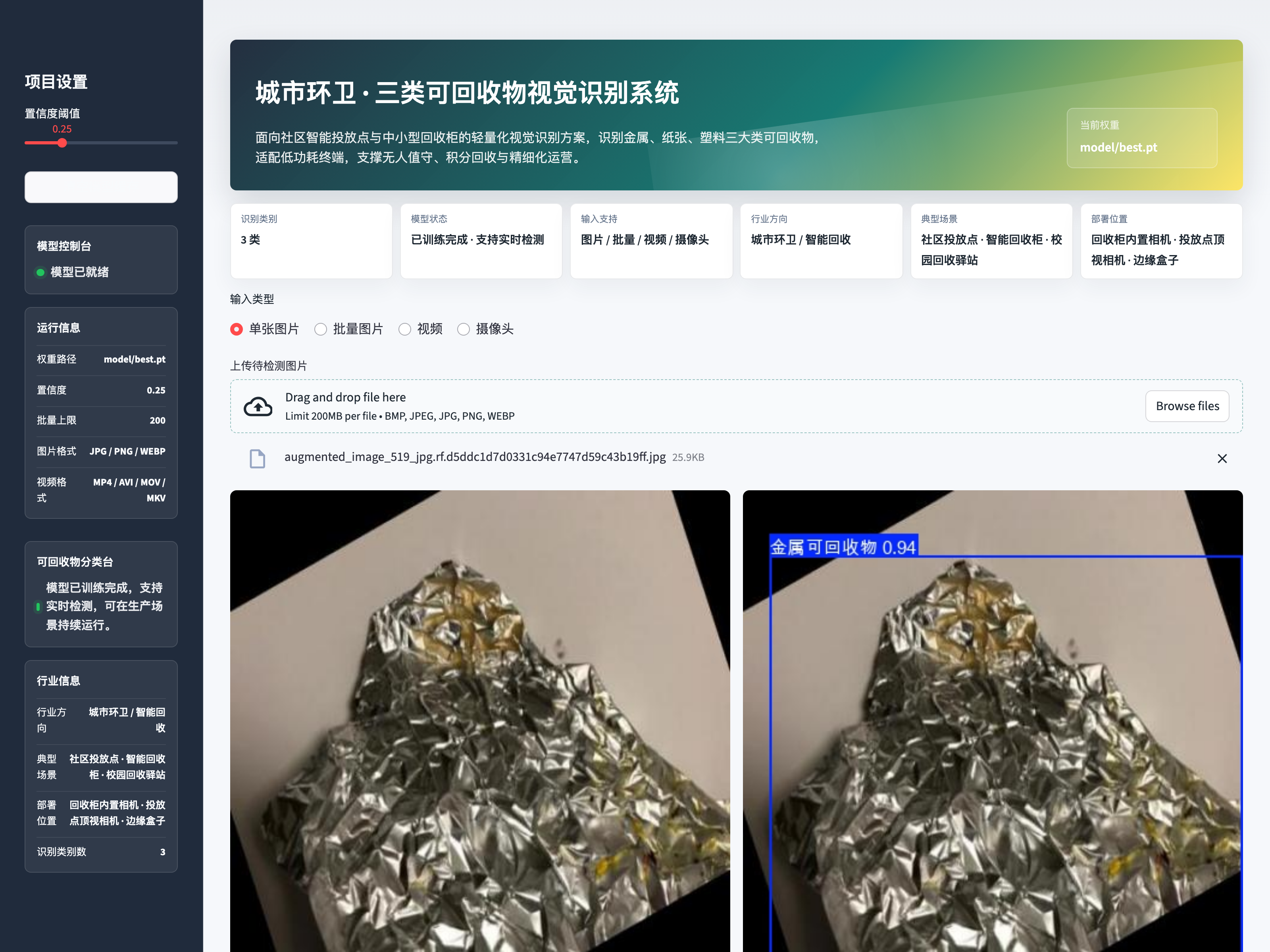
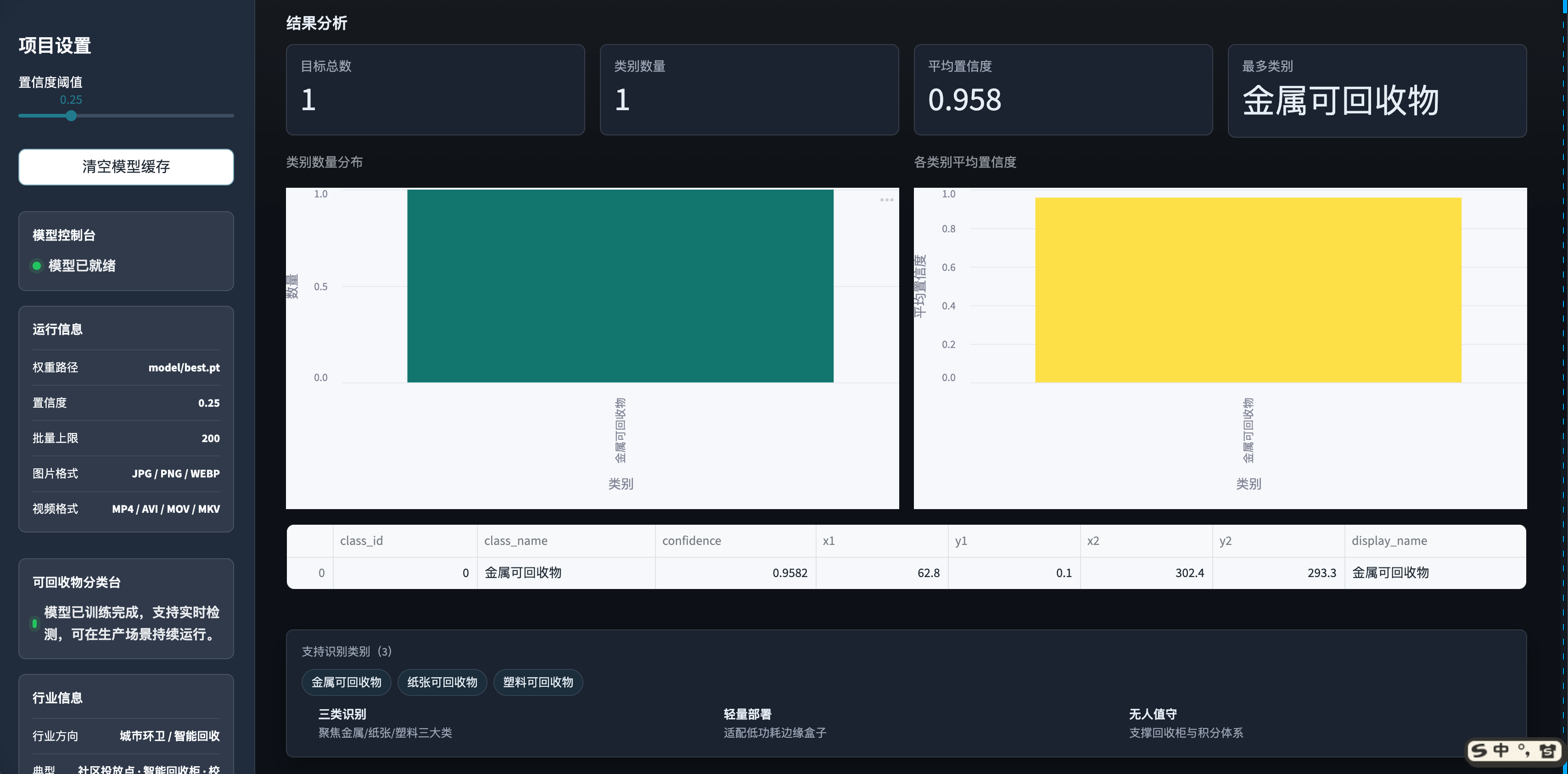
1.3 项目介绍
核心创新点:
| 维度 | 设计 |
|---|---|
| 类目设计 | 聚焦 金属 / 纸张 / 塑料 三类高价值可回收物,不做精细子类,降低误判压力 |
| 模型选型 | YOLO11n,参数量约 2.6 M,CPU 实时、边缘盒子(Jetson / RK3588)友好 |
| 部署形态 | Streamlit 单页应用 + 本地 best.pt,零数据库、零中间件,开箱即用 |
| 输入兼容 | 图片 / 批量图片(含 zip)/ 视频 / 摄像头 4 种输入复用同一推理引擎 |
| 主题封装 | 暖青 + 亮黄主色调,呼应"环卫 / 回收"行业视觉,一份 project.yaml 统一品牌 |
功能概览:
- ♻️ 单图检测:拖拽上传 → 实时返回带框图 + 类别 / 置信度 / 坐标明细
- 📚 批量检测:单次最多 200 张,输出汇总表 + 类别分布柱状图 + zip 打包下载
- 🎬 视频检测:mp4 / avi / mov / mkv,逐帧推理后落盘新视频,便于回收柜监控录像离线复盘
- 📷 摄像头实时检测:可对接回收柜内置相机 / 投放点顶视相机,做实时投放感知
3 类可回收物:金属可回收物 🥫、纸张可回收物 📦、塑料可回收物 🧴。
技术栈:
| 层 | 选型 |
|---|---|
| 模型框架 | Ultralytics 8.3 + PyTorch |
| 视觉算法 | YOLO11n(Anchor-Free,C2f Backbone,Decoupled Head + DFL) |
| Web 前端 | Streamlit 1.35 + 自定义 HTML 主题(暖青 #0f766e + 亮黄 #fde047) |
| 视频 / 图像 | OpenCV、imageio-ffmpeg |
| 数据可视化 | Plotly / Streamlit 原生 chart |
| 配置管理 | 单一 configs/project.yaml,行业话术 / UI / 推理阈值统一收口 |
二、设计框架
2.1 系统架构
┌──────────────────────────────────────────┐
│ Streamlit Web 前端(单页 SPA) │
│ · 三类图鉴 / 单图 / 批量 / 视频 / 摄像头 │
│ · 侧栏 · 阈值 · 类别筛选 · 模型缓存 │
└────────────────────┬─────────────────────┘
│ Python 调用
▼
┌──────────────────────────────────────────┐
│ 推理服务层(infer_image_path 等) │
│ · bytes / Path / frame → tensor │
│ · 推理结果 → 标注图 + DataFrame │
└────────────────────┬─────────────────────┘
│
▼
┌──────────────────────────────────────────┐
│ YOLO11n 推理引擎(model/best.pt) │
│ Backbone (C2f+SPPF) → Neck (FPN/PAN) │
│ → Decoupled Head(DFL + cls × 3) │
└──────────────────────────────────────────┘
2.2 YOLO11 网络结构
输入 640×640×3
│
▼
[Backbone]
Conv → C2f → Conv → C2f → Conv → C2f → Conv → C2f → SPPF
│
▼
[Neck] FPN 上采样 + PAN 下采样:P3 / P4 / P5 三级金字塔
│
▼
[Head] Decoupled Head(cls 头 / reg 头解耦)
回归头采用 DFL(Distribution Focal Loss)
Anchor-Free,输出 (cx, cy, w, h, cls × 3)
│
▼
[NMS] iou=0.7, conf=0.25 → 最终检测框
2.3 检测流程
投放点 / 回收柜相机帧
│
▼
Letterbox 640×640 + RGB
│
▼
YOLO11n forward
│
▼
Detect Head 输出 (cls × 3)
│
▼
conf 过滤 + NMS
│
▼
result.plot() 画框 + 类别 + 置信度
│
▼
Streamlit 双列展示 + DataFrame + 类别分布图
三、代码结构(核心 50 行 + 解析)
项目目录:
三类可回收物识别/
├── app/streamlit_app.py # Web 入口
├── configs/project.yaml # 行业话术 / UI / 训练 / 推理参数
├── model/best.pt # 训练好的 YOLO11n 权重
├── scripts/ # train / validate / export 等
├── data/dataset/ # 训练 / 验证 / 测试集
└── 三类可回收垃圾检测数据集/ # 原始数据集(含训练 / 验证 / 测试切分)
最核心的 50 行——模型加载 + 单图推理 + Streamlit 单图 Tab:
# === 1. 模型加载(带 streamlit 资源缓存,避免每次刷新重载)=============
@st.cache_resource(show_spinner=False)
def load_model(model_path: str) -> YOLO:
return YOLO(model_path)
# === 2. 单图推理:路径 → 标注图 + 检测明细 DataFrame ===================
def infer_image_path(model: YOLO, image_path: Path, conf: float):
result = model.predict(str(image_path), conf=conf, verbose=False)[0]
annotated = result.plot() # BGR ndarray,已画框
rows = []
if result.boxes is not None:
for box in result.boxes:
cls_id = int(box.cls.item())
x1, y1, x2, y2 = [float(v) for v in box.xyxy[0].tolist()]
rows.append({
"class_id": cls_id,
"class_name": result.names[cls_id], # eg. "金属可回收物"
"confidence": round(float(box.conf.item()), 4),
"x1": round(x1, 1), "y1": round(y1, 1),
"x2": round(x2, 1), "y2": round(y2, 1),
})
# BGR → RGB 给 Streamlit;rows 转 DataFrame 给表格组件
return annotated[:, :, ::-1], pd.DataFrame(rows)
# === 3. bytes → 临时文件 → 复用同一函数 ================================
def run_image_inference(model: YOLO, image_bytes: bytes, conf: float, suffix=".jpg"):
with tempfile.NamedTemporaryFile(delete=False, suffix=suffix) as f:
f.write(image_bytes); tmp = Path(f.name)
try:
return infer_image_path(model, tmp, conf)
finally:
tmp.unlink(missing_ok=True)
# === 4. Streamlit 单图 Tab:上传 → 推理 → 双列展示 =====================
model = load_model(str(MODEL_PATH))
uploaded = st.file_uploader("上传一张包含可回收物的图片", type=IMAGE_UPLOAD_TYPES)
conf = st.sidebar.slider("置信度阈值", 0.05, 0.95, DEFAULT_CONF, 0.01)
if uploaded is not None:
annotated, df = run_image_inference(model, uploaded.getvalue(), conf,
suffix=Path(uploaded.name).suffix)
col1, col2 = st.columns(2)
col1.image(uploaded, caption="原图")
col2.image(annotated, caption="检测结果(带类别标签)")
st.dataframe(detections_to_display(df))
render_detection_analysis(df)
5 段解析:
@st.cache_resource把YOLO(model_path)的耗时锁在第一次访问,之后所有 session 共享同一份模型实例,避免每次切换 Tab 都重载(这对回收柜内置相机长时间运行尤其友好——一次加载、长期使用)。result.plot()直接返回带颜色框 + 类别 + 置信度的BGR ndarray,自动按class_id上色,金属 / 纸张 / 塑料三类一目了然,方便在投放点屏幕上直接展示给居民。- 把每个
box的cls / conf / xyxy拍成dict,再拼成DataFrame——后续表格、CSV 下载、类别分布柱状图、视频时间线全部复用同一份结构。运营侧拉数据时直接to_csv即可。 bytes → tempfile → infer_image_path这层薄壳让"前端上传"、“批量解 zip”、"视频抽帧"三种来源都复用同一个推理函数,新接一个数据源时不用重写推理逻辑。- Streamlit 的
cache_resource + file_uploader + dataframe组合,让一个产品级可回收物识别页面只需 11 行代码——这是 Streamlit 在 AI 应用快速出活的关键,特别适合给回收柜厂商做"内嵌大屏"或"管理后台"。
四、训练效果
模型在自建的「三类可回收垃圾检测数据集」(约 2800 张实拍图像,金属 / 纸张 / 塑料三类)上完成 YOLO11n 训练并保存 best.pt。在测试集上检测效果良好,可稳定识别金属、纸张、塑料三类典型可回收物,已能满足社区智能投放点、校园回收驿站、智能回收柜等场景的初筛 / 计数 / 引导投放等使用需要。
从单图检测样例(上文「项目运行效果」截图)可以看到:在不同光照、不同摆放姿态、不同颜色背景下,模型都能给出框 + 类别 + 置信度,配合 Streamlit 前端实时呈现给居民和运营方。
五、项目总结
做对了什么:
- 把可回收物识别收敛到金属/纸张/塑料三大类,避免了"几十个细分子类"带来的标注成本爆炸和类间混淆,更贴合社区投放点、回收柜的实际计费 / 计数颗粒度;
- 用 YOLO11n 这种轻量级 Anchor-Free 检测器作为底座,CPU 也能实时,算力预算压到回收柜内置 ARM 处理器一档;
- 用一份
project.yaml把"行业话术 / UI 主题色 / 类别映射 / 训练超参 / 推理阈值"全部收口,迁移到「四类可回收物」「六类生活垃圾」等场景只需替换数据集与重新训练; - 单图、批量、视频、摄像头四种输入复用同一个
infer_image_path,后期接 RTSP 投放点摄像头流时只需把"摄像头帧"喂进来即可。
还能怎么做:
- 在数据集层面持续补充强光 / 逆光 / 多物堆叠 / 透明塑料等难样本,把"塑料瓶 vs 玻璃瓶"、"金属罐 vs 喷漆纸罐"这类高度相似的样本判别力进一步拉开;
- 接入重量传感器 + 视觉识别双路投票,回收柜场景中能显著降低单路视觉的误判(视觉看到塑料 + 称重判断为玻璃 → 触发人工复核);
- 把检测结果 + 时间戳 + 点位 ID 推送到运营后台,做「点位画像」「时段画像」「品类增长曲线」,让回收业务真正变成数据驱动的精细化运营。
一句话总结:YOLO11 + Streamlit 让"社区可回收物视觉识别"从一个研究课题变成了"一份 yaml + 一份 best.pt + 一份 streamlit_app.py"的工程化标准动作,本文给出了一份可以直接 fork 落地的样板。

一站式 AI 云服务平台
更多推荐

 1
1 0
0- 0



 已为社区贡献106条内容
已为社区贡献106条内容

所有评论(0)