
保姆级教程!800万条行为日志揭秘浏览器市场,零代码构建商业大屏底层数据(附完整ETL全流程+踩坑详解)
大家好,我是你们的无情的数据打工人。 在商业数据分析中,做数据大屏(Dashboard)是展示分析成果最直观的方式。但很多人不知道,大屏光鲜亮丽的背后,是枯燥且复杂的ETL(数据提取、转换、加载)工作。 千万不要拿几百万条的原始明细表直接去连大屏组件,否则查询速度会教你做人!
今天这篇笔记,我将带大家完整走一遍:如何基于800万条真实用户行为日志,通过零代码平台加工出大屏所需的各项统计指标表。 我们要回答诸如“哪个浏览器用户最爱用?”、“核心用户的画像是什么?”等极具商业价值的问题。
第一部分:实验背景
1. 实验目的与业务框架
本次实验的目标很明确:基于“用户-日-浏览器-小时”的底层明细表,加工出供BI数据大屏直接调用的聚合统计表。我们要通过数据回答以下核心业务问题:
-
市场格局与趋势:谁是浏览器一哥?周活跃度是涨是跌?
-
用户习惯:工作日和周末的使用差异大吗?用户是轻度还是重度依赖?他们通常同时使用几个浏览器?
-
用户画像:核心用户的性别、年龄、学历、收入和地域分布是怎样的?
2. 实验环境与工具
-
实验平台:助睿在线实验平台
-
核心工具:助睿数智(Uniplore)一站式数据科学实验平台(覆盖从数据接入、ETL处理、机器学习建模到可视化分析的全链路Agentic零代码数据智能)。
-
操作模块:助睿 ETL 数据集成平台
3. 实验数据源
数据规模:1000个真实用户,超800万条行为记录,大小约825MB。
-
daily_browser_detail(由原始日志清洗而来的行为明细表)
-
demographic.csv(用户人口属性表)
4. 整体处理逻辑 (ETL架构图)
为了让大家更直观地理解数据流向,我画了一个整体的逻辑图:
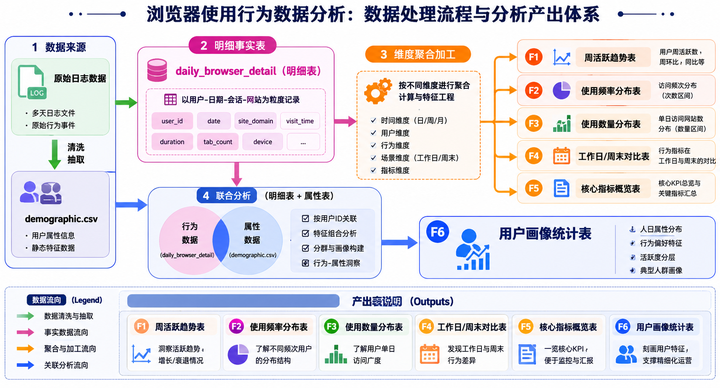
第二部分:实验步骤 (保姆级图文实操)
本次实验无需编写复杂的Python代码,我们主要使用助睿数智的拖拽式组件完成。
Step 1: 准备“用户-日-浏览器-小时”明细表
大屏需要聚合数据,不能直接查原始表。我们先建立并抽取一份基础明细表。
-
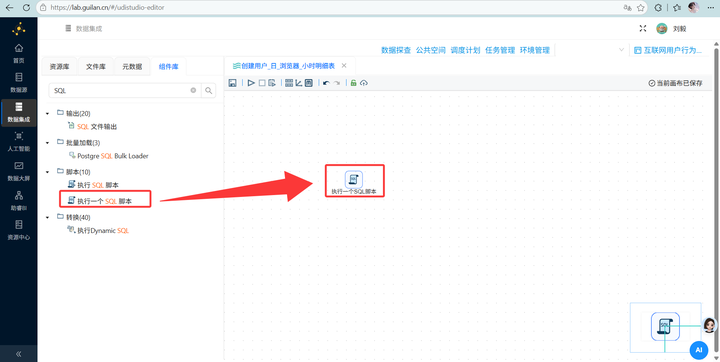
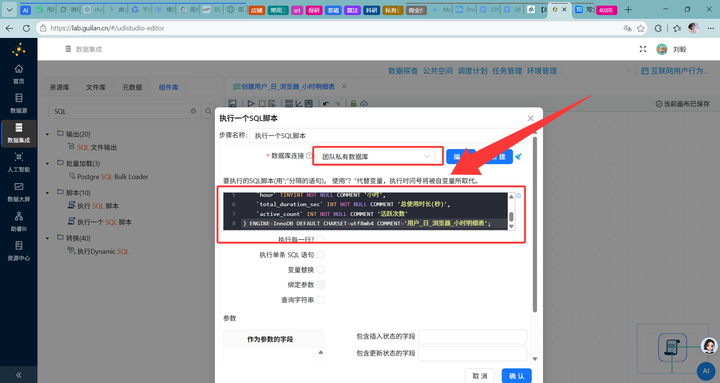
建表:新建转换流,拖入【执行一个SQL脚本】组件,连接“团队私有数据库”,输入SQL语句创建 daily_browser_detail 表。
CREATE TABLE IF NOT EXISTS `daily_browser_detail` (
`user_id` VARCHAR(50) NOT NULL COMMENT '用户ID',
`usage_date` DATE NOT NULL COMMENT '使用日期',
`browser_name` VARCHAR(50) NOT NULL COMMENT '浏览器名称',
`hour` TINYINT NOT NULL COMMENT '小时',
`total_duration_sec` INT NOT NULL COMMENT '总使用时长(秒)',
`active_count` INT NOT NULL COMMENT '活跃次数'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='用户_日_浏览器_小时明细表';
2. 复制转换流:复用上一个清洗实验的流,重命名为“输出用户日浏览器小时明细表”。
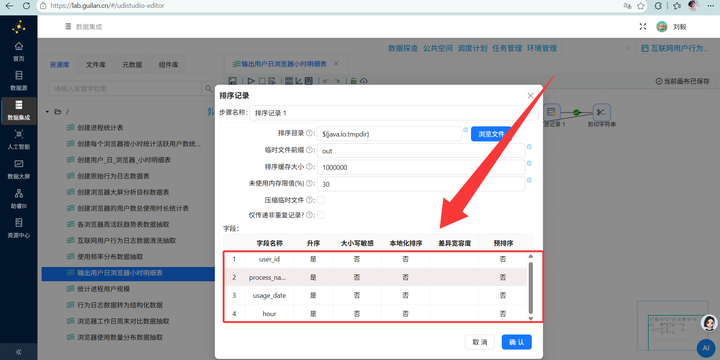
3. 修复排序与映射:这里是个大坑!原先的排序组件只按进程名排,但我们的分组字段有4个(user_id、usage_date等)。必须修改【排序记录】的字段与【分组】组件一致。
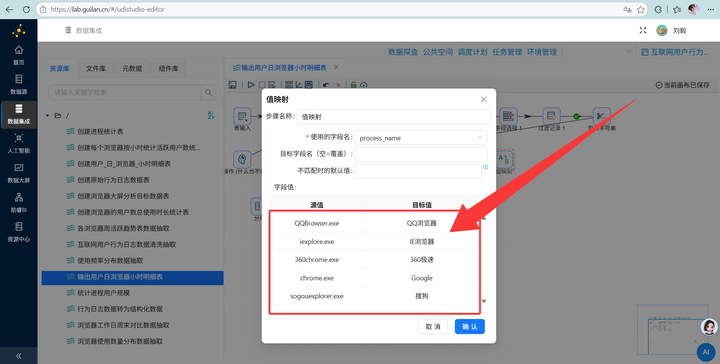
4. 值映射:拖入【值映射】组件,把晦涩的进程名(如 iexplore.exe)映射为人类可读的名称(如 IE浏览器)。注意过滤掉非浏览器进程。
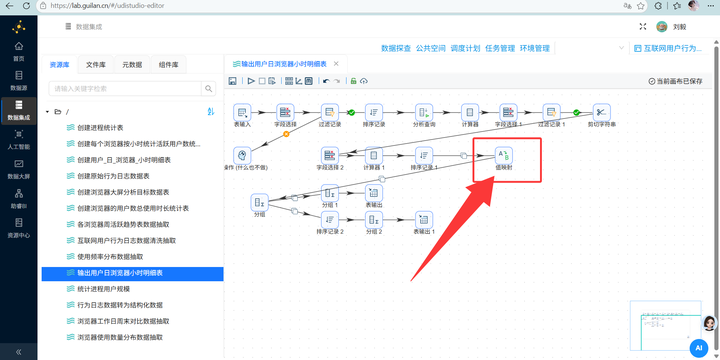
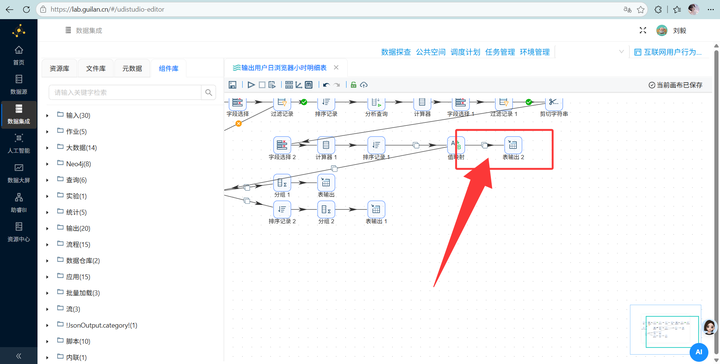
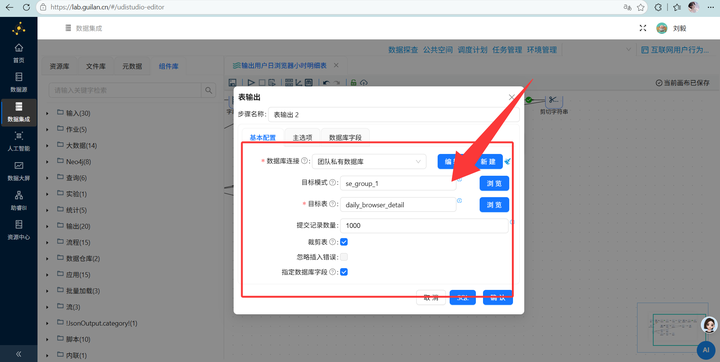
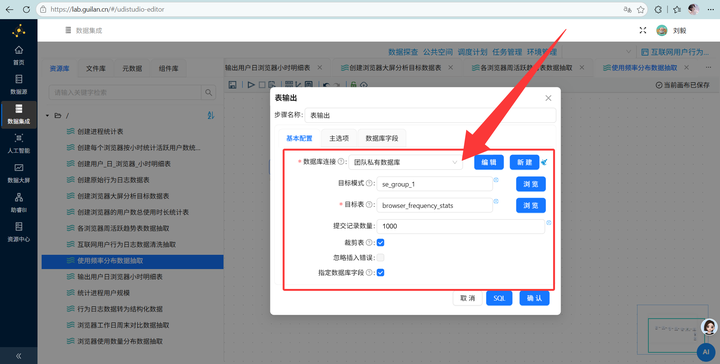
5. 输出入库:使用【表输出】组件,勾选“裁剪表”(清空旧数据),将数据写入 daily_browser_detail。运行转换流!
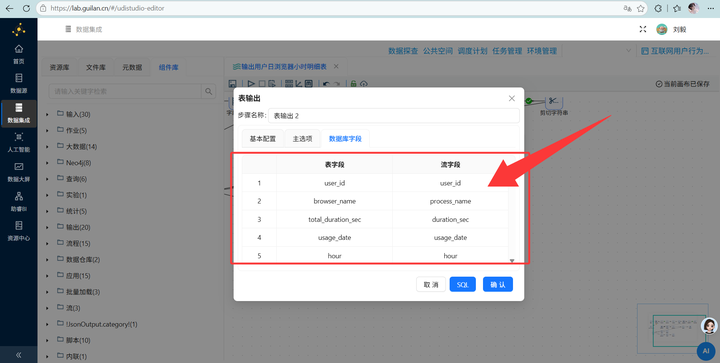
Step 2: 批量创建大屏目标数据表
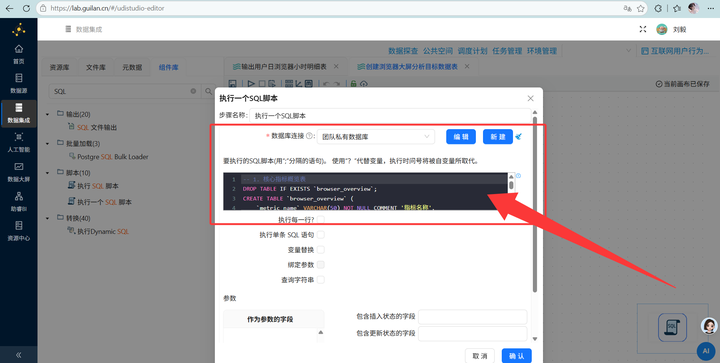
为了存放后续算好的聚合数据,我们要预先建表。新建转换流,执行以下SQL脚本批量创建6张表(这里使用了 DROP TABLE IF EXISTS,好习惯,重跑不会报错):
-- 1. 核心指标概览表
DROP TABLE IF EXISTS `browser_overview`;
CREATE TABLE `browser_overview` (
`metric_name` VARCHAR(50) NOT NULL COMMENT '指标名称',
`metric_value` DECIMAL(12,2) NOT NULL COMMENT '指标值'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='核心指标概览表';
-- 2. 各浏览器周活跃趋势表
DROP TABLE IF EXISTS browser_weekly_active;
CREATE TABLE `browser_weekly_active` (
`browser_name` VARCHAR(50) NOT NULL COMMENT '浏览器名称',
`week_range` VARCHAR(20) NOT NULL COMMENT '周日期范围',
`active_user_count` INT NOT NULL COMMENT '活跃用户数'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='各浏览器周活跃趋势表';
-- 3. 浏览器使用频率分布表
DROP TABLE IF EXISTS browser_frequency_stats;
CREATE TABLE `browser_frequency_stats` (
`browser_name` VARCHAR(50) NOT NULL COMMENT '浏览器名称',
`usage_level` VARCHAR(10) NOT NULL COMMENT '使用等级',
`user_count` INT NOT NULL COMMENT '用户数'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='浏览器使用频率分布表';
-- 4. 用户使用浏览器数量分布表
DROP TABLE IF EXISTS browser_multi_usage;
CREATE TABLE `browser_multi_usage` (
`browser_count` VARCHAR(10) NOT NULL COMMENT '使用浏览器数量',
`user_count` DECIMAL(5,2) NOT NULL COMMENT '用户数量'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='用户使用浏览器数量分布表';
-- 5. 浏览器工作日周末对比表
DROP TABLE IF EXISTS browser_weekday_weekend;
CREATE TABLE `browser_weekday_weekend` (
`browser_name` VARCHAR(50) NOT NULL COMMENT '浏览器名称',
`day_type` VARCHAR(10) NOT NULL COMMENT '工作日/周末',
`avg_duration_sec` INT NOT NULL COMMENT '人均使用时长(秒)',
`total_duration_hour` BIGINT NOT NULL COMMENT '总使用时长(小时)',
`user_count` INT NOT NULL COMMENT '用户数'
) COMMENT '浏览器工作日周末对比表';
-- 6. 用户画像统计表
DROP TABLE IF EXISTS `user_profile_stats`;
CREATE TABLE `user_profile_stats` (
`browser_name` VARCHAR(50) NOT NULL COMMENT '浏览器名称',
`gender` VARCHAR(10) COMMENT '性别',
`age_group` VARCHAR(10) COMMENT '年龄段',
`edu` VARCHAR(50) COMMENT '学历',
`job` VARCHAR(50) COMMENT '职业',
`income` VARCHAR(50) COMMENT '收入',
`city_type` VARCHAR(10) COMMENT '居住地类型',
`province` VARCHAR(50) COMMENT '省份',
`user_count` INT NOT NULL COMMENT '用户数'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='用户画像统计表';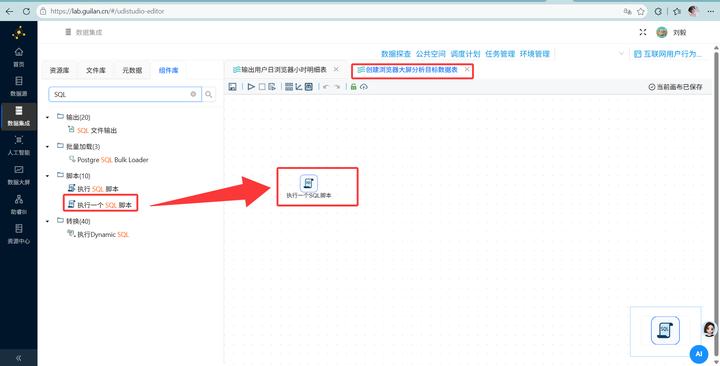
Step 3: 各浏览器周活跃趋势加工
业务目的:看活跃度是在增长还是衰退。
-
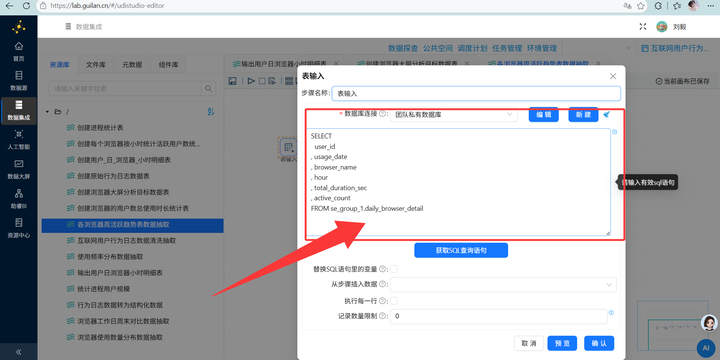
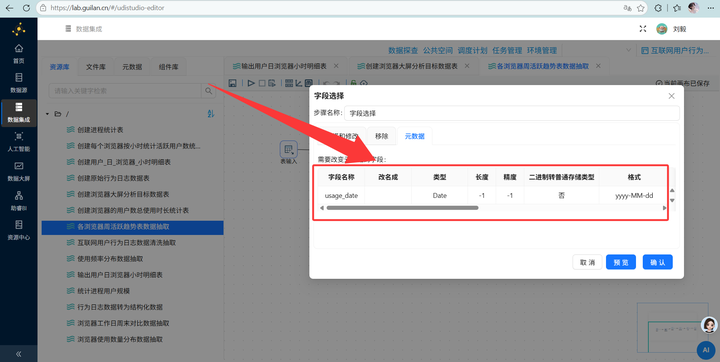
日期格式化:用【表输入】读取明细表后,接【字段选择】组件,把 usage_date 类型设为 Date,格式 yyyy-MM-dd。
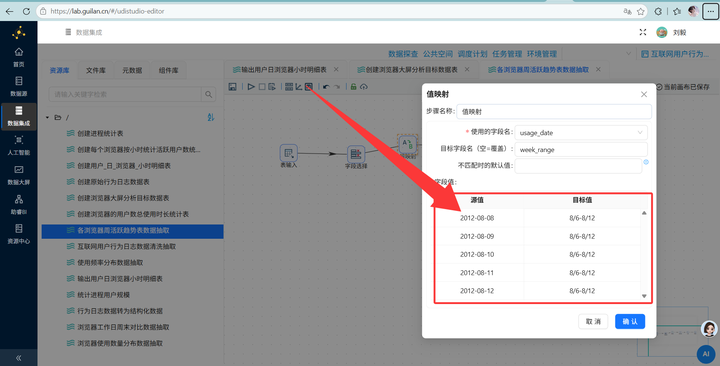
2. 周区间映射:接【值映射】组件,将具体的日期映射为周区间(如 5/7-5/13),新字段命名为 week_range。
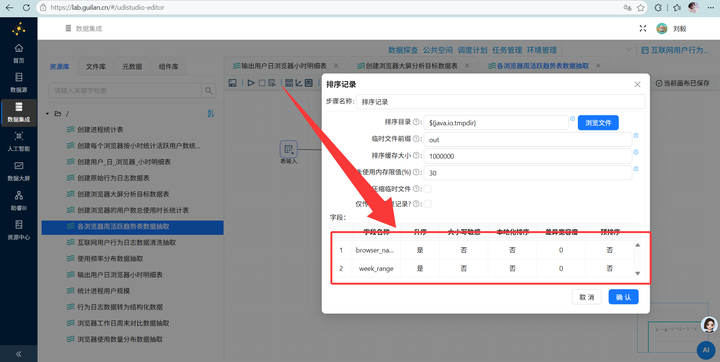
3. 分组聚合:先用【排序记录】按 browser_name 和 week_range 升序排,再接【分组】组件,对 user_id 进行“统计不同值的数量(N)”操作(去重计数)。
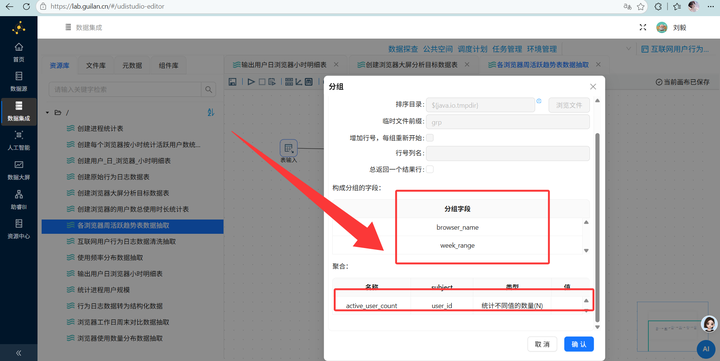
4. 输出:写入 browser_weekly_active 表。
Step 4: 用户使用频率分布加工 (轻/中/重度)
业务目的:区分核心用户和边缘用户。
-
计算总秒数:【表输入】后,按用户和浏览器【排序】,再【分组】求和,得到每个人用各个浏览器的总秒数。
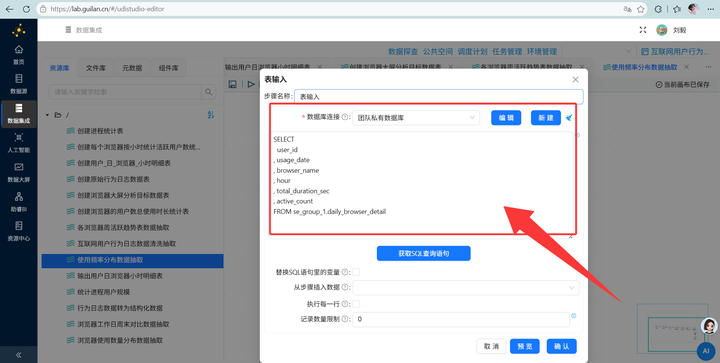
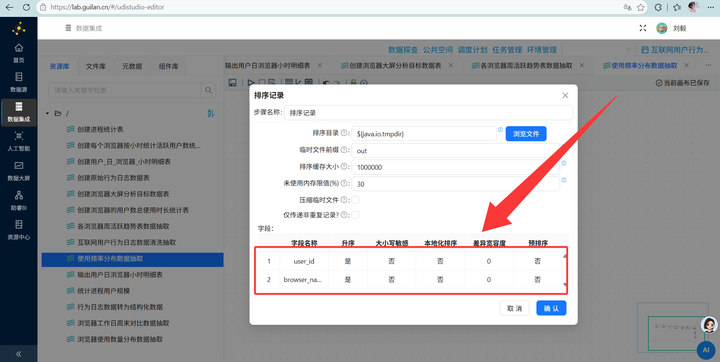
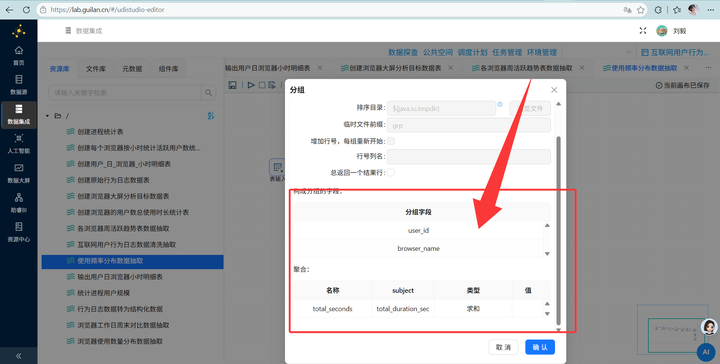
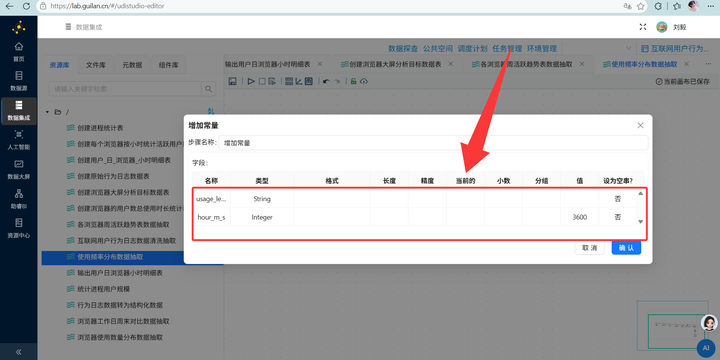
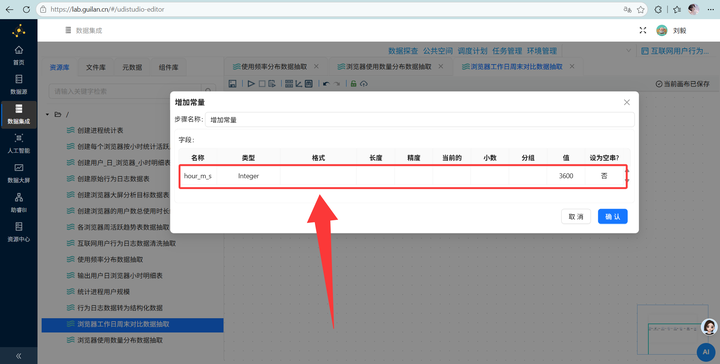
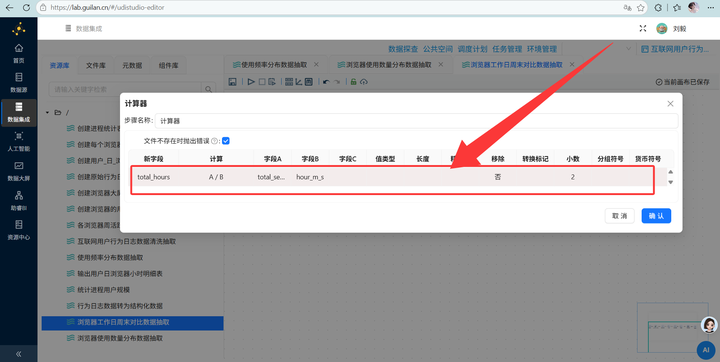
2. 秒转小时:单位是秒太难看了,我们要转小时。接【增加常量】组件增加一个值为 3600 的字段,再接【计算器】组件,用总秒数除以3600,保留2位小数。
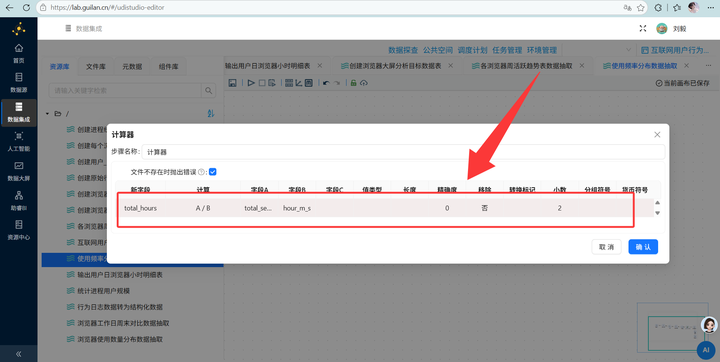
3. 打标签(JS高光时刻):拖入【JavaScript代码】组件,写一段简单的逻辑给用户打标签:
var total_hours = total_hours;
var usage_level = '';
if (total_hours < 3) {
usage_level = '轻度';
} else if (total_hours >= 3 && total_hours < 10) {
usage_level = '中度';
} else {
usage_level = '重度';
}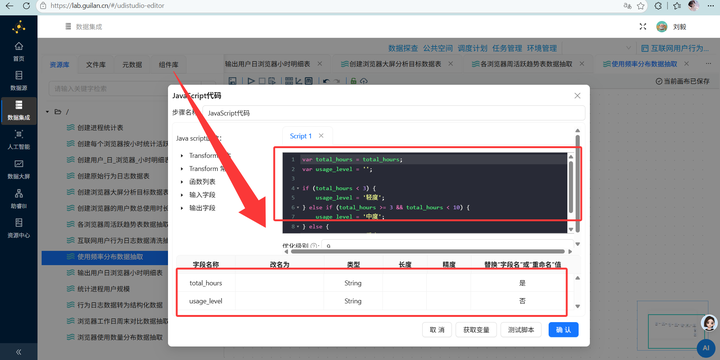
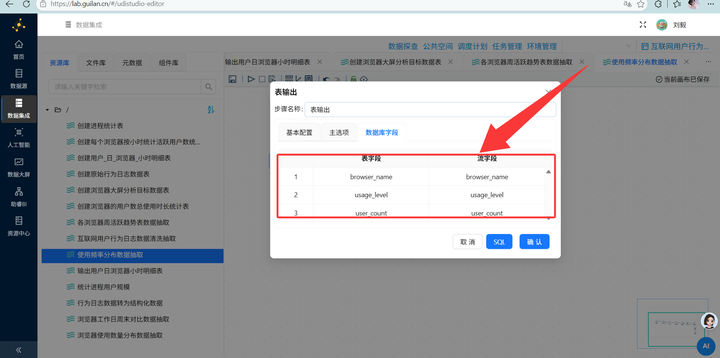
4. 最终聚合:按 usage_level 再次【排序】和【分组】统计人数,输出到 browser_frequency_stats。
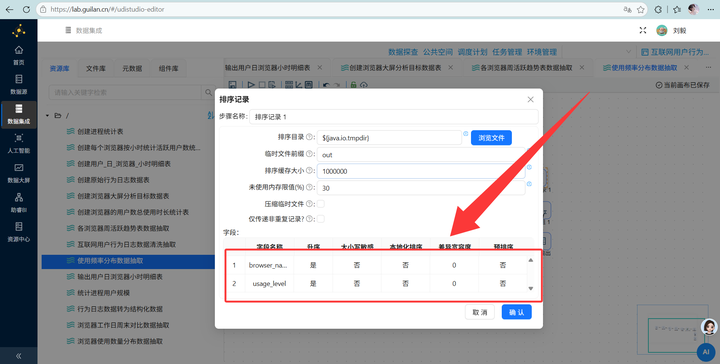
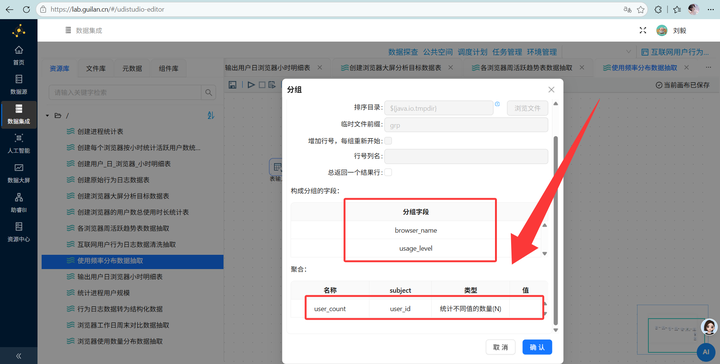
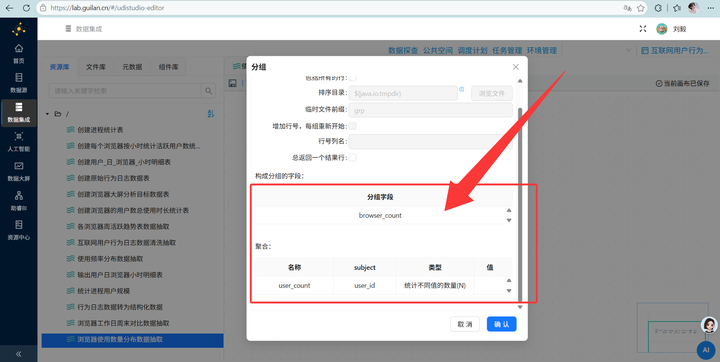
Step 5: 浏览器使用数量分布加工
业务目的:判断用户的品牌忠诚度(专一还是海王?)
-
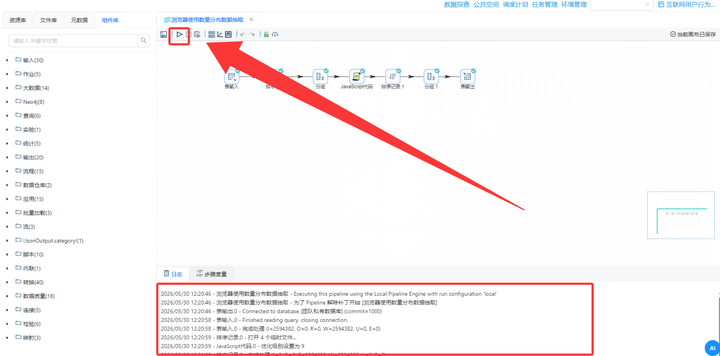
新建转换流与读取数据:新建转换流“浏览器使用数量分布数据抽取”,拖拽【表输入】组件,数据库连接选择“团队私有数据库”,读取 daily_browser_detail 表的所有数据。
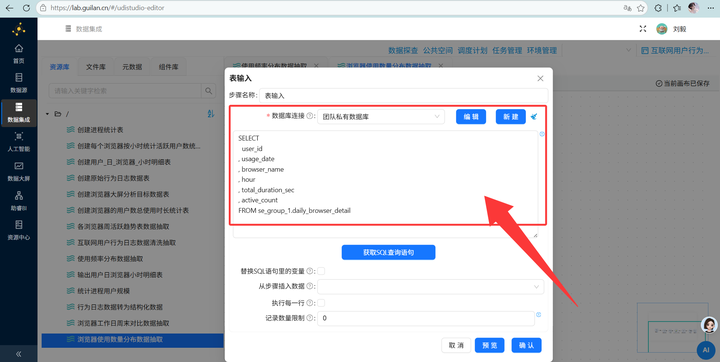
2. 按用户统计浏览器种类数:先拖拽【排序记录】组件按 user_id 升序排序,接着用【分组】组件对每个 user_id 使用的浏览器名称进行“去重计数”。
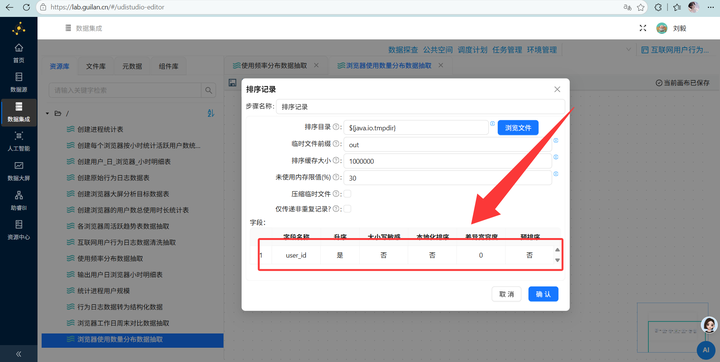
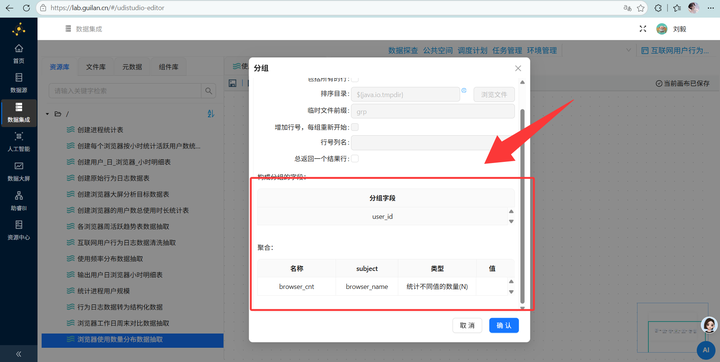
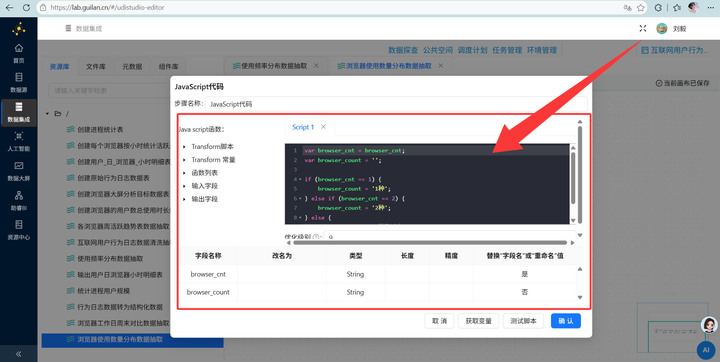
3. JS打标签分类:拖入【JavaScript代码】组件,利用以下代码将使用的种类数量分为“1种”、“2种”、“3种及以上”:
var browser_cnt = browser_cnt;
var browser_count = '';
if (browser_cnt == 1) {
browser_count = '1种';
} else if (browser_cnt == 2) {
browser_count = '2种';
} else {
browser_count = '3种及以上';
}
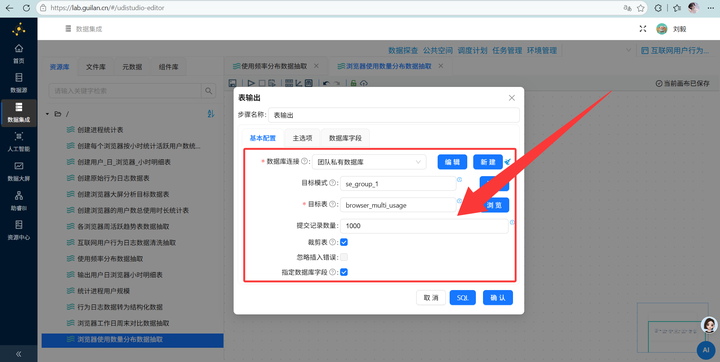
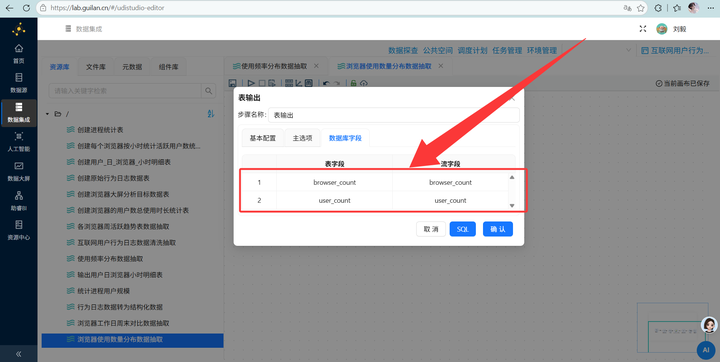
4. 最终聚合输出:拖入【排序记录】组件将数据按照 browser_count 升序排序,再接【分组】组件统计各分类人数,最后拖拽【表输出】组件写入 browser_multi_usage。
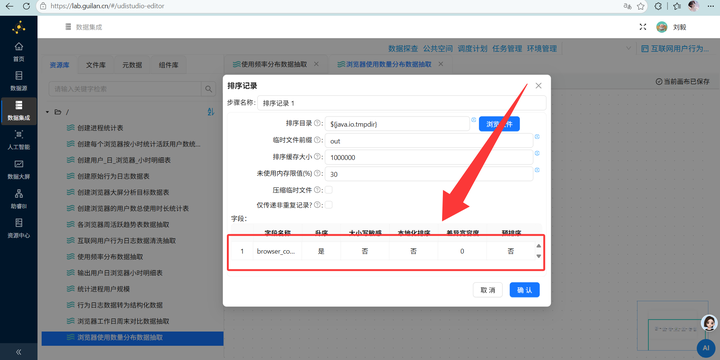
Step 6: 工作日 vs 周末 习惯对比
业务目的:区分办公与娱乐场景。
-
新建转换流与读取数据:新建转换流“浏览器工作日周末对比数据抽取”,拖拽【表输入】组件读取 daily_browser_detail 表。
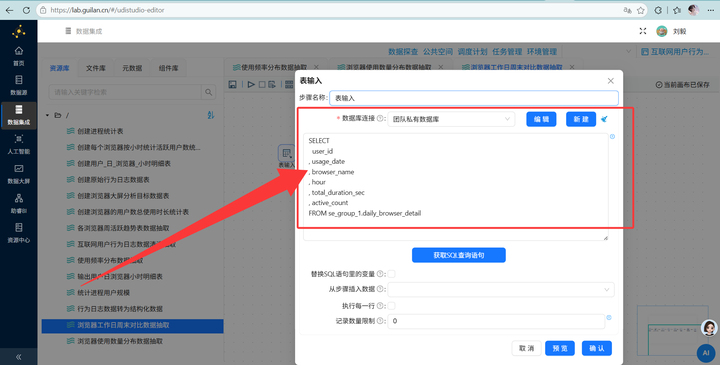
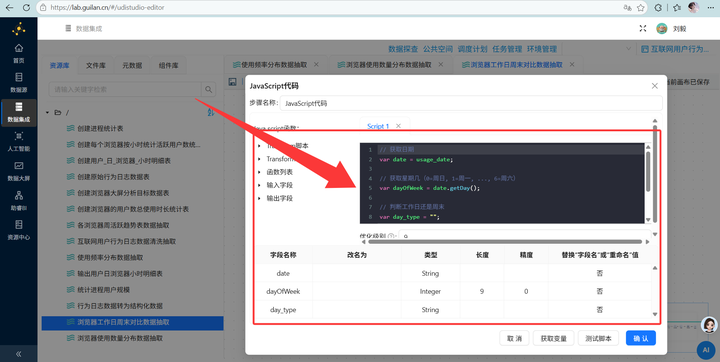
2. 判断工作日还是周末:接入【JavaScript代码】组件,利用 getDay() 函数判断日期类型:
// 获取日期
var date = usage_date;
// 获取星期几(0=周日, 1=周一, ..., 6=周六)
var dayOfWeek = date.getDay();
// 判断工作日还是周末
var day_type = "";
if (dayOfWeek >= 1 && dayOfWeek <= 5) {
day_type = "工作日";
} else {
day_type = "周末";
}
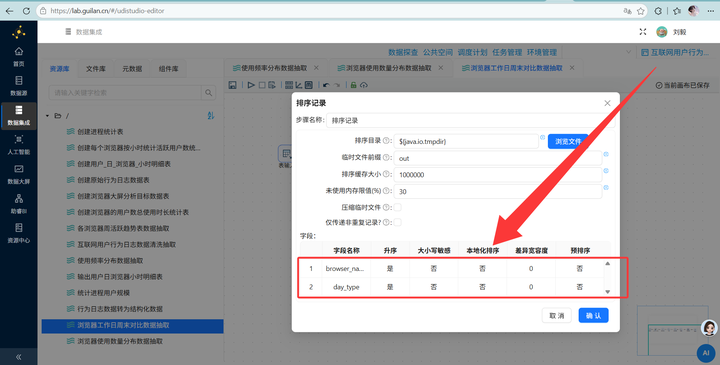
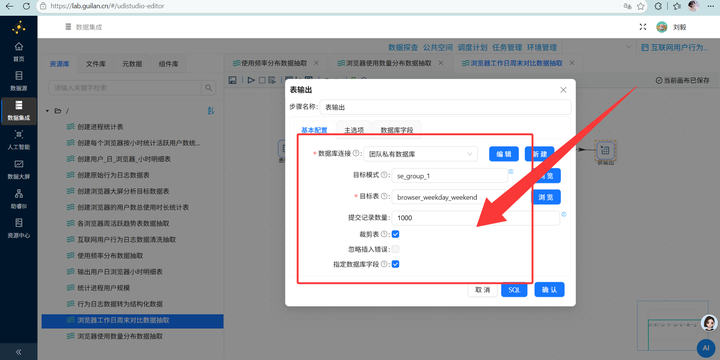
3. 排序与分组聚合:先拖入【排序记录】组件按浏览器和 day_type 【升序排序】,然后接入【分组】组件,计算平均时长、总时长和人数。
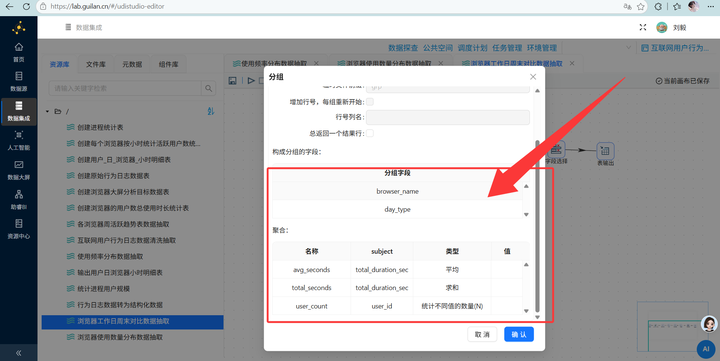
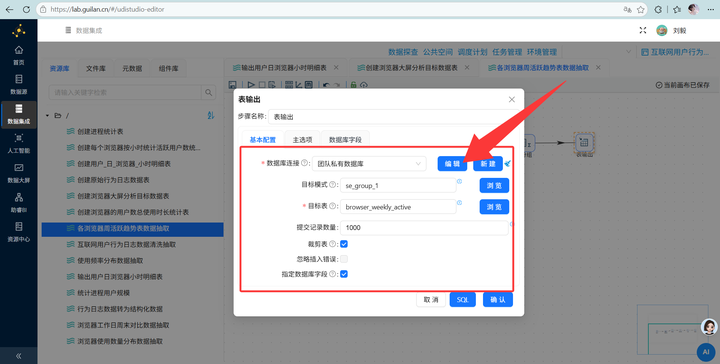
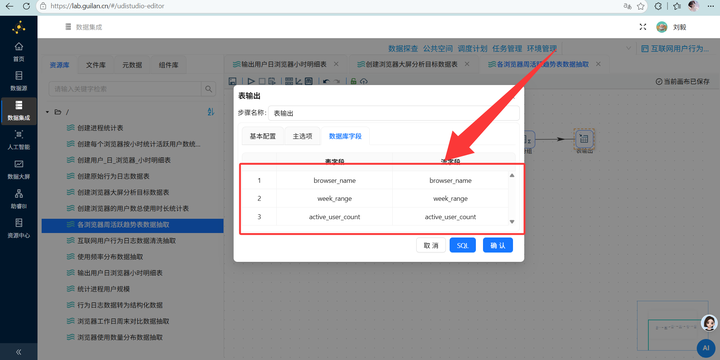
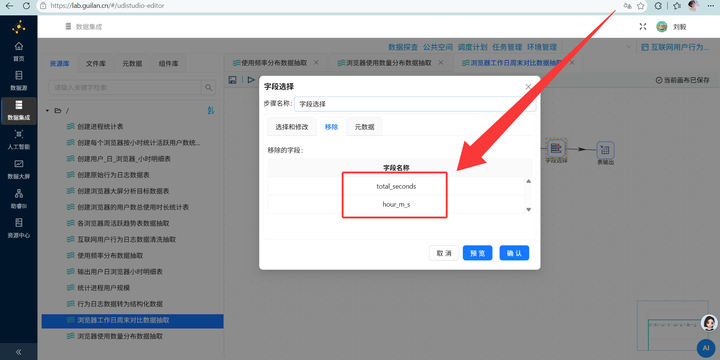
4. 单位转换与输出:复用之前学过的技巧,通过【增加常量】和【计算器】组件将总时长(秒)转换为(小时),最后用【字段选择】删掉多余的中间字段,通过【表输出】写入 browser_weekday_weekend。
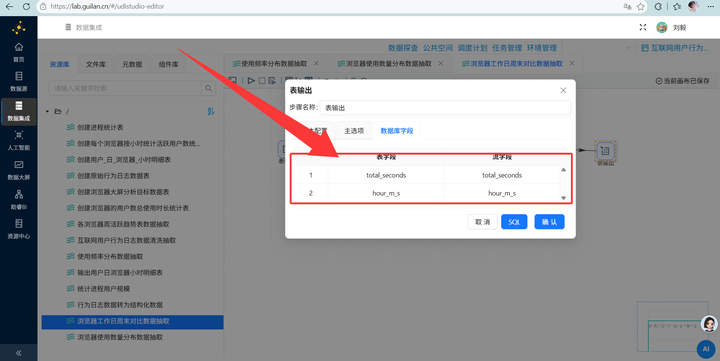
Step 7: 核心指标概览表提取
业务目的:大屏顶部的四个关键数字(总时长、人均时长、活跃率、重度率)。 为了避免各浏览器间的用户重叠导致全局数据算错,这里最快的方法是直接写SQL。
-
新建转换流与执行SQL:新建转换流,使用【表输入】执行包含聚合子查询的复杂SQL,一次性算出所有指标:
SELECT
ROUND(SUM(total_duration_sec) / 3600, 2) AS total_hours,
ROUND(SUM(total_duration_sec) / 3600 / COUNT(DISTINCT user_id), 2) AS avg_hours,
ROUND(
(SELECT COUNT(DISTINCT user_id) FROM daily_browser_detail
WHERE usage_date BETWEEN '2012-08-06' AND '2012-08-12'
) * 100.0 / COUNT(DISTINCT user_id), 2
) AS active_ratio,
ROUND(
(SELECT COUNT(*) FROM (
SELECT user_id FROM daily_browser_detail
WHERE usage_date BETWEEN '2012-05-07' AND '2012-07-08'
GROUP BY user_id
HAVING SUM(total_duration_sec) / 3600 > 30
) t) * 100.0 / COUNT(DISTINCT user_id), 2
) AS heavy_ratio
FROM daily_browser_detail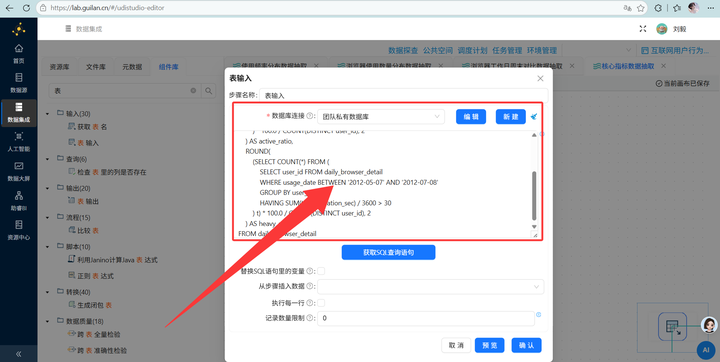
2. 行列转换与映射:使用【列转行】组件,把1行4列的数据,变成4行(指标名 - 指标值键值对)。然后使用【值映射】将英文字段名转为中文。
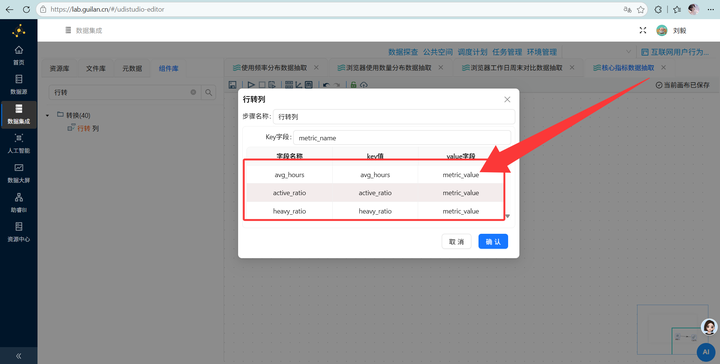
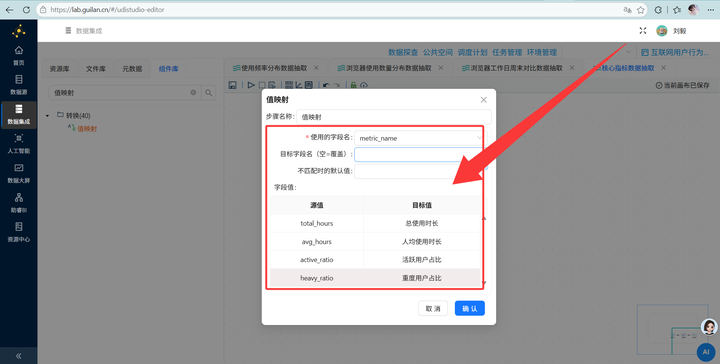
3. 表输出:通过【表输出】组件写入 browser_overview 表。
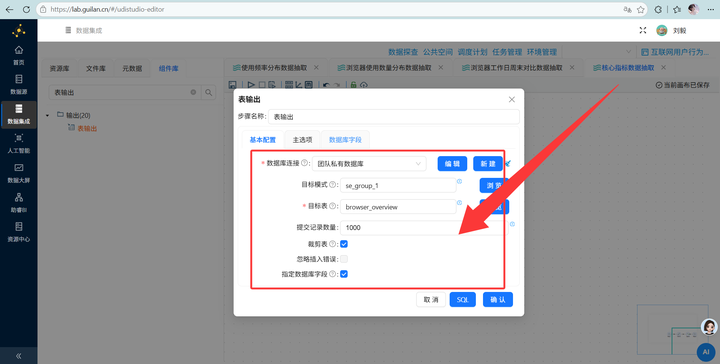
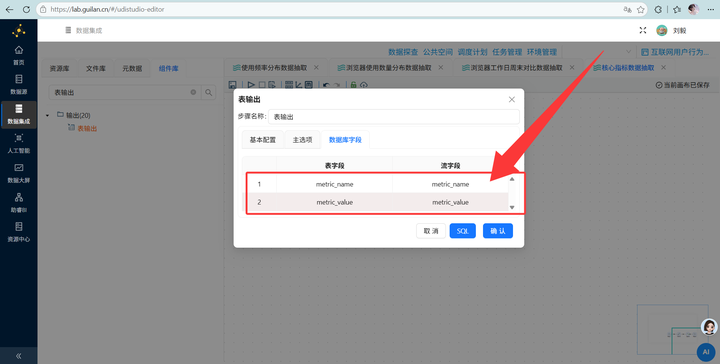
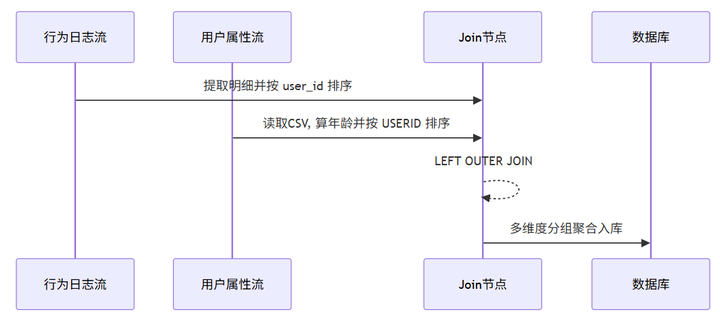
Step 8: 重头戏!用户画像表加工 (Join操作)
业务目的:知道我们的用户到底是谁?(这步涉及到跨表连接)
-
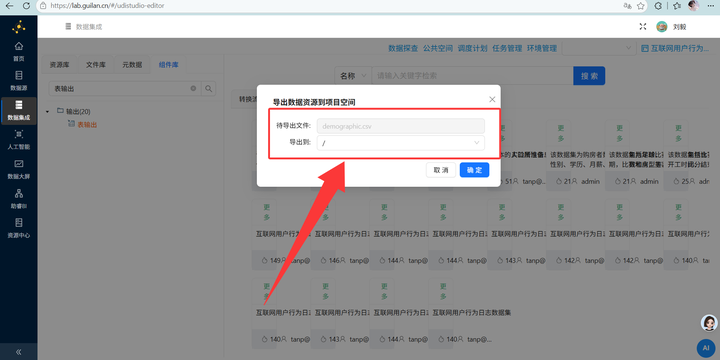
获取属性表:从公共空间数据资源导出 demographic.csv,存放到个人文件目录。
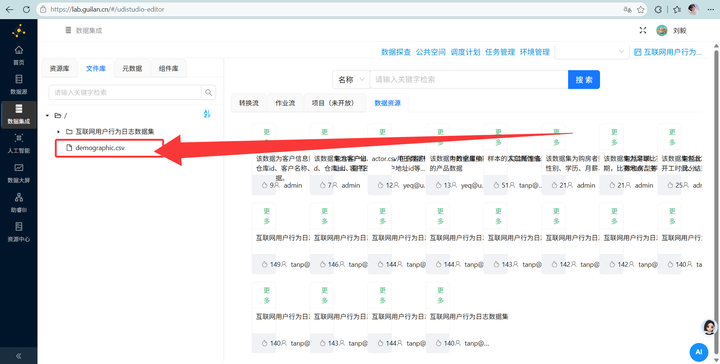
2. 算年龄 (CSV流):新建转换流“用户画像表加工”,拖拽【CSV文件输入】组件读取数据,通过【增加常量】(2012年)和【计算器】算出年龄,再用【JS代码】划分年龄段:
var age_group = '';
if (age < 18) {
age_group = '<18';
} else if (age <= 25) {
age_group = '18-25';
} else if (age <= 35) {
age_group = '26-35';
} else {
age_group = '>35';
}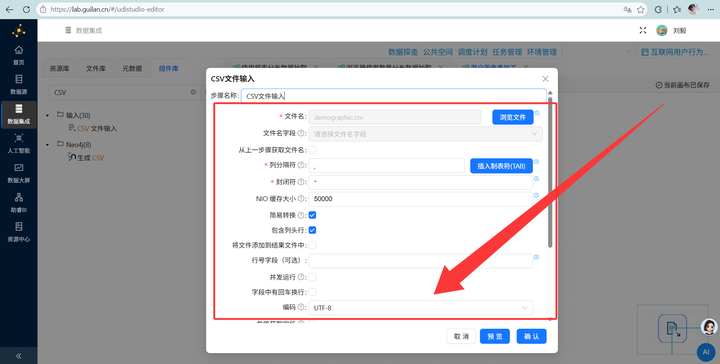
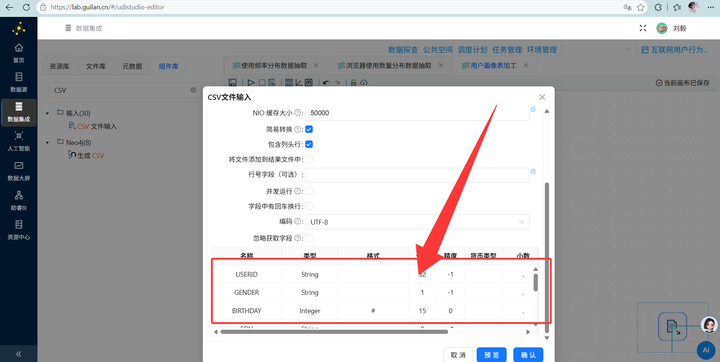
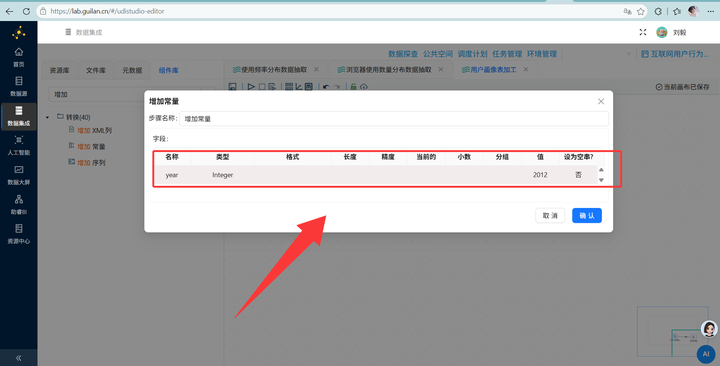
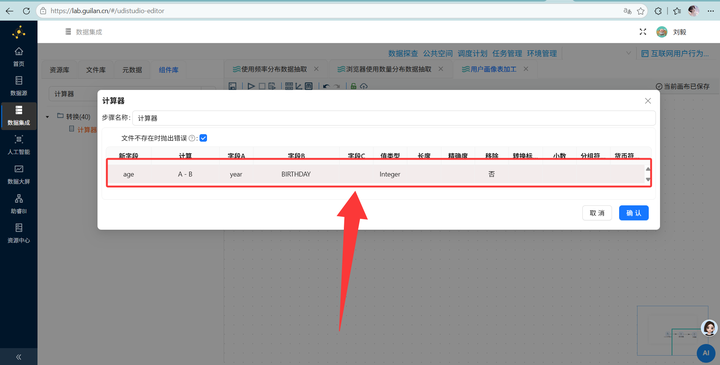
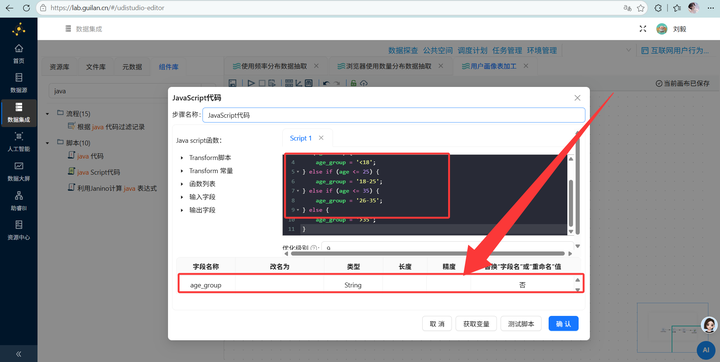
3. 读取明细数据 (SQL流):在同一个画布中,拖入【表输入】组件,读取用户明细表 daily_browser_detail。
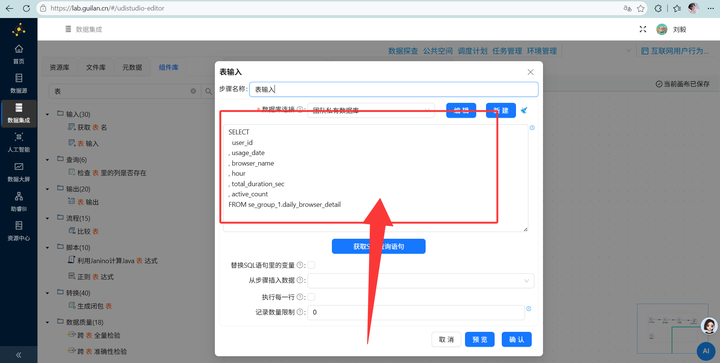
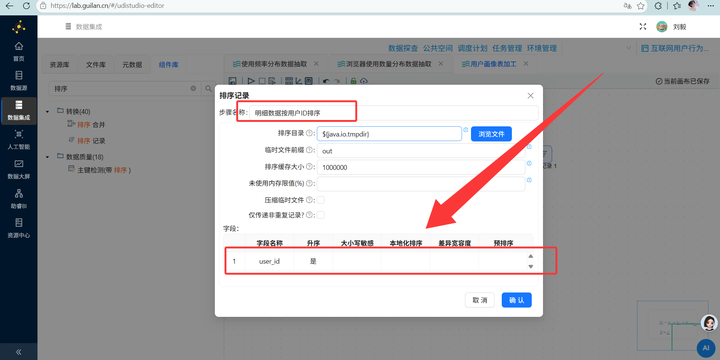
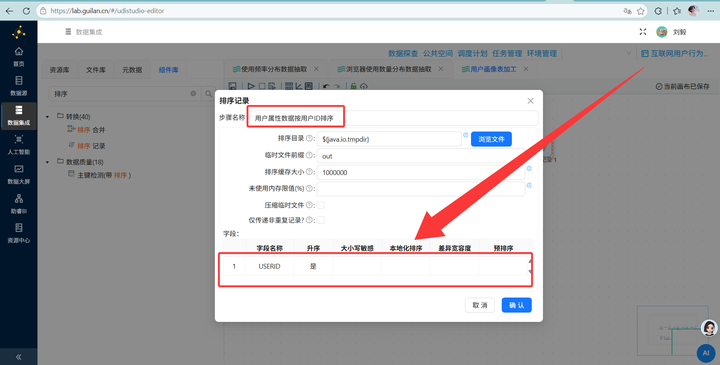
4. 双流各自排序:连接前必须双双排序! 左边的 SQL 流接【排序记录】组件按 user_id 升序排,右边的 CSV 属性流接另一个【排序记录】组件按 USERID 升序排。
5. 记录集连接:拖入【记录集连接】组件,将两股排序好的数据流接入,连接类型选择 LEFT OUTER(左外连接),配置好两侧的关联字段。
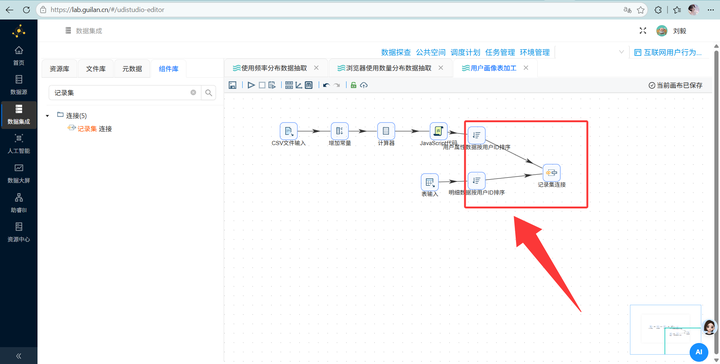
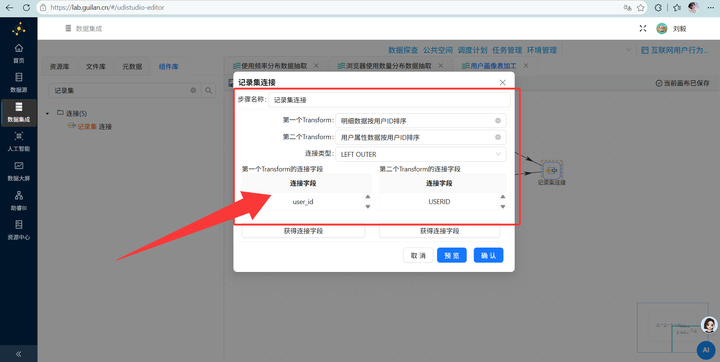
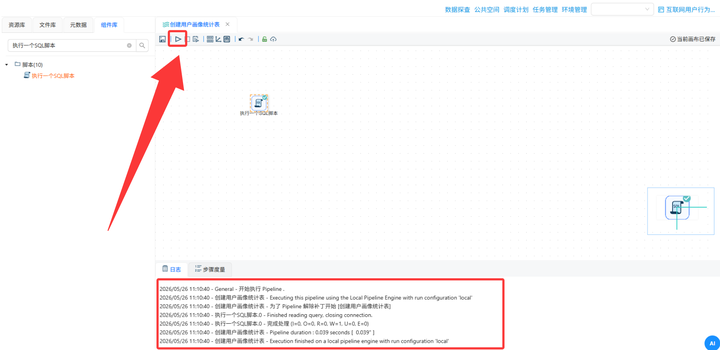
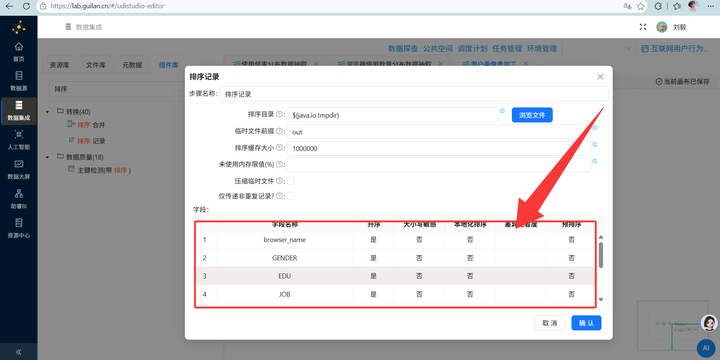
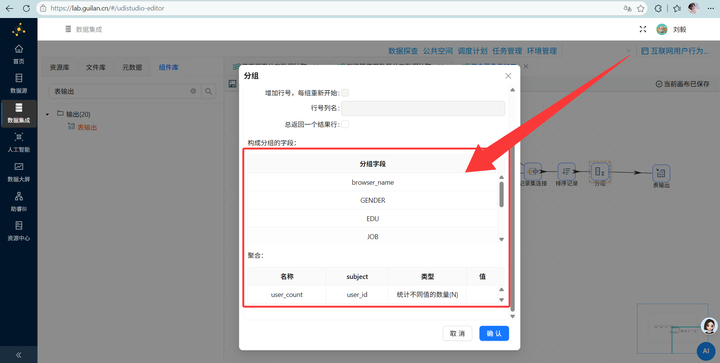
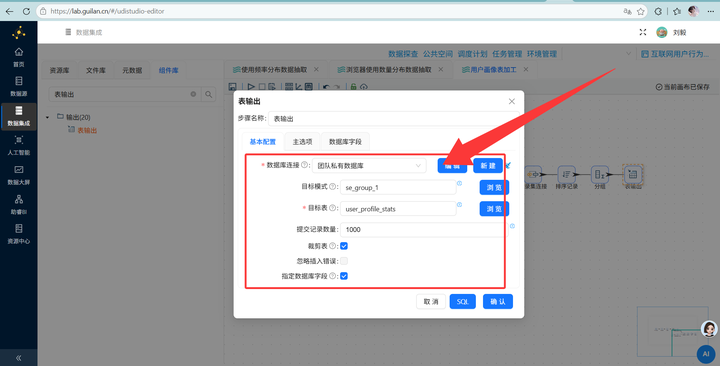
6. 多维分组输出:关联完数据后,先接一个【排序记录】组件按需要分组的所有维度字段排序,再接入【分组】组件按浏览器、性别、学历、职业、收入、城市类型、年龄段进行终极大统计,最后【表输出】写入 user_profile_stats。大功告成!
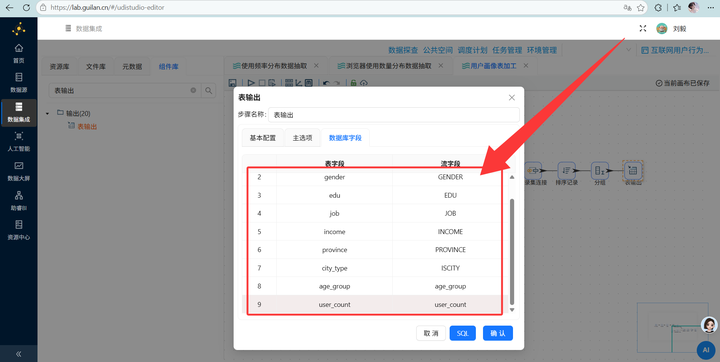
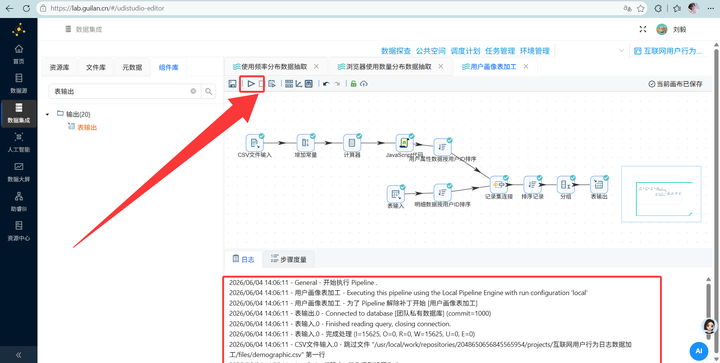
第三部分:实验结果验证
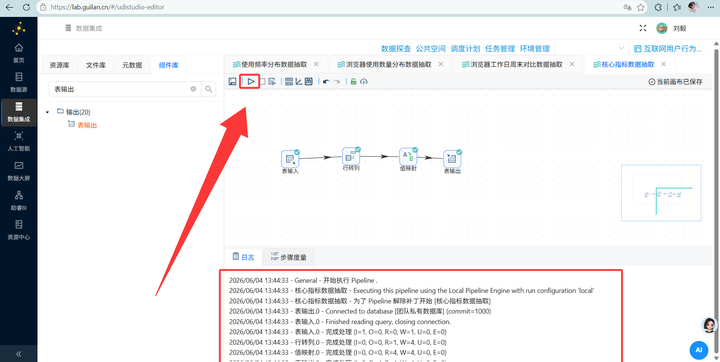
经过这一通操作,我们的团队私有数据库中已经成功生成了7张供大屏调用的统计表。 进入平台的“数据探查”模块查看:
-
可以看到数据已经完美按照维度聚合好,没有任何原始用户的敏感信息(符合数据安全规范)。
-
随便拿 browser_frequency_stats 看一眼,就能直接得出“XX浏览器重度用户占比极高”的商业结论,这可以直接指导后续的市场投放策略。

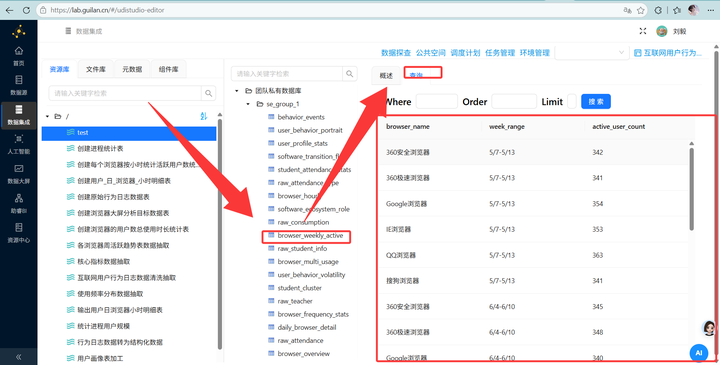
第四部分:防坑指南(问题与解决)
做数据工程有一句名言:“常在河边走,哪有不湿鞋”。在处理这800万条真实日志时,我也是踩了好几个暗坑,差点把服务器跑到冒烟。为了让大家少走弯路,我把这几个典型的“大无语事件”整理出来了,绝对干货,建议反复阅读!
踩坑现象 1:数据越聚合越多?遭遇“数据发散”刺客!
-
惨痛经历:在加工明细表(6.1步)时,我本来以为直接复用上个实验的流就万事大吉了。结果一跑出来,输出的数据行数比预期多了一大截,出现了大量极其诡异的碎片化重复记录!
-
深度剖析:我在复制流的时候偷了个懒,完全忘记去改【排序记录】组件的排序字段! 原先的排序只按 process_name 单个字段排,但紧接着的【分组】组件我却设置了 4 个分组字段(user_id、usage_date 等)。敲黑板划重点!在绝大多数 ETL 工具(包括底层引擎)中,如果不按所有的分组字段进行全量前置排序,分组器一旦遇到不连续的数据,就会顺理成章地把它当成一个“新组”! 这就导致同一个用户同一天的数据被切成了无数个小碎块,直接引发灾难级的数据发散。
-
满分自救:老老实实把【排序记录】的字段修改为 user_id、usage_date、process_name、hour,保证它与后面的分组字段 100% 完全对应。千万别在数据排序上偷懒,它真的会教你做人!
踩坑现象 2:Join 完数据全丢了?“沉默的隐形杀手”!
-
惨痛经历:在做最复杂的第八步“用户画像联合分析”时,我满怀期待地把明细表和 CSV 属性表给 Left Join 在了一起。组件连线没报错,全程绿灯亮起,结果去数据库一看——关联出来的用户属性全为空!数据居然凭空丢了一大半!
-
深度剖析:这是无数 ETL 新手(甚至是写代码的老油条)最容易栽跟头的地方——在执行记录集连接(Join)之前,没有对两股输入的数据流按“连接键(Key)”进行排序! 平台底层引擎使用的是归并排序连接算法(Merge Join),这种算法的硬性前提就是“两边的数据必须已经是有序的”。如果数据乱序,指针一旦错位,它就会认为没有匹配项直接跳过,导致大量匹配失败,而且系统完全不会弹红框报错!这种“无声的 bug”排查起来最让人抓狂。
-
满分自救:在连接组件之前,强行给左流和右流各加一个【排序记录】组件! 左表按 user_id 升序,右表按 USERID 升序。记住这句咒语:“排序保平安,Join 前必排!”
踩坑现象 3:无限重跑失败之“Table Already Exists”
-
惨痛经历:在调试 ETL 转换流的时候,难免需要反复点击运行来验证逻辑。结果第二次点“运行”时,流直接全线爆红,控制台无情嘲讽:“Table browser_overview already exists”。
-
深度剖析:我在建表组件的 SQL 脚本里只写了 CREATE TABLE。在严谨的 ETL 管道设计中,有一个极其重要的概念叫做“幂等性”(Idempotence),也就是说,你设计的这个数据流,无论跑一次还是跑一万次,结果和初始状态都应该是一致的,绝对不能因为跑过一次就再也跑不通了。
-
满分自救:火速修改所有建表 SQL,在 CREATE 前面加上一句护身符:DROP TABLE IF EXISTS xxx;。这样每次跑数据之前都会自动“清理历史遗留战场”,保证丝般顺滑。
踩坑现象 4:JS节点空指针异常,可怕的“数据黑洞”
-
惨痛经历:在写 JavaScript 代码给用户打标签(比如时长分类)时,偶尔会报出某一行脚本执行失败。
-
深度剖析:大家一定要认清一个残酷的现实——真实的业务数据一定充满了“脏数据”!有的用户可能只有一条登录日志没有登出日志,导致底层的 total_hours 算出来直接是 NULL。而在 JS 脚本里如果你盲目地用 < 3 去判断一个 NULL 值,不仅逻辑会错乱,还容易引发不可预知的运行时异常。
-
满分自救:在编写任何 JS 代码的开头,都要加上“防御性编程”的判空逻辑:if (total_hours == null) { usage_level = '未知'; }。永远不要相信原始数据是完美的!
第五部分:实验总结与心得
经过这一整套行云流水(磕磕绊绊)的操作,我终于看着数据库里那 7 张整整齐齐的聚合表长舒了一口气。这次实验不仅是一次简单的作业实操,更是一场对商业数据分析底层逻辑的“降维打击”式认知升级!总结下来,我有三个极其深刻的感悟:
1. 核心技能栈的“任督二脉”彻底被打通了 以前看别人做花里胡哨的数据大屏,总觉得就是拽拽图表、配配颜色。现在实操一遍才深刻领悟到业界那句扎心的名言:“数据分析师 80% 的时间都在做数据清洗和 ETL 准备,剩下 20% 的时间在抱怨数据太脏。” 通过这次从 0 到 1 的实战,我彻底搞懂了从海量杂乱无章的数据明细,到提炼出多维高阶聚合指标的完整架构逻辑。我算是把 ETL 处理中的一套“万能高频套路”给玩明白了: 👉 第一步清洗格式化 -> 第二步映射加工(借助 JS/常量/计算器灵活打标) -> 第三步双重强制排序 -> 第四步高阶分组聚合 -> 第五步列转行 -> 最终目标表安全入库。 尤其是异构数据源(数据库海量事实表 + 业务线 CSV 维度表)的 Left Join 实战,让我以后再遇到类似跨部门的数据打通需求时,底气足了不止一星半点!
2. 拥抱“Agentic零代码”工具的终极真香时刻 实不相瞒,作为一个平时习惯敲代码的数据分析师,起初我对所谓的“可视化零代码工具”是带着一丝丝偏见和轻视的。但这次,助睿数智 (Uniplore) 平台真的给我上了一课。 大家试想一下,如果不用这个平台,面对这 800 万条、将近 1 个 G 的日志数据量,我得干嘛?我得默默掏出我的 Jupyter Notebook,查文档写上几百行 PySpark 或者 Pandas 代码,还得小心翼翼地切分块读取(Chunking)防止内存直接爆满溢出(OOM 报错),最后还要手动配置一堆恶心的连接池,才能往 MySQL 里慢慢插数据。折腾小半天,可能环境依赖就先报红报错了。 但是现在呢?在助睿的拖拽式画布上,整条数据流的血缘关系(Data Lineage)一目了然,数据的上下游流向清晰到连毫无技术背景的产品经理都能看懂!哪个节点跑成功了亮绿灯,哪个卡住了直接双击看底层日志。特别是平台里内置的 JavaScript 脚本节点,既完美保留了硬编码的灵活性,又极大降低了整体工程的开发门槛。这简直是对数据打工人生产力的极大解放!“零代码构建企业级数据管道”,这一次我信了,而且直呼真香!
3. 写在最后的话 大数据的真正魅力就在于,你永远不知道那一堆看似杂乱无章、毫无意义的英文字母和枯燥的时间戳里,究竟藏着怎样惊人的商业增长秘密。今天我们通过几套转换流,找出了浏览器的“重度依赖用户群体”和他们的“清晰画像”;明天,这同一套底层的方法论,就可以无缝迁移到电商的“高价值 VIP 会员挖掘”,或者是游戏行业的“濒临流失大 R 玩家提前干预预测”中!数据的价值,永远取决于你如何去加工它。
🔗 相关干货传送门(拿走不谢): 想要体验降维打击的数据处理?产品官网指路:Uniplore iDIS-大数据智能全流程服务平台-BI数据可视化工具 纸上得来终觉浅,立即上手体验同款环境:https://lab.guilian.cn/
🔥 如果你觉得这篇超长、超硬核的保姆级排坑教程对你有哪怕一点点启发,求一个素质三连(点赞、收藏、转发)!👍 码字、画图、排版不易,你们的支持就是我持续爆肝更新的最大动力!各位同行或者同学,大家在实际跑数据流的时候,还遇到过什么让人抓狂的“奇葩坑”或者“大无语事件”?欢迎在评论区激情留言吐槽,让我们互相取暖,咱们评论区见!👇

一站式 AI 云服务平台
更多推荐

 8
8 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)