
【实验5-1实战】浏览器市场与用户画像分析:零代码打通 800 万日志 ETL 加工链路(附排雷记录)
平台全称:助睿数智(Uniplore)一站式数据科学实验平台•平台定位:覆盖数据接入、ETL处理、机器学习建模到可视化分析的全链路Agentic零代码数据智能•产品官网:https://www.uniplore.com/•实验平台地址:https://lab.guilian.cn/
作为一名数据分析师,我们在做数据可视化大屏前,往往面临一个灵魂拷问:几百万条的原始日志数据,能直接接到大屏上吗?答案显然是不能。大屏加载需要的是轻量级的聚合指标,而不是海量明细。 今天,我将以一份包含 1000 位用户、800万条行为记录(约 825MB)的浏览器行为日志为例,手把手教大家如何利用零代码平台,将庞杂的 用户-日-浏览器-小时 明细数据,精细加工成大屏所需的7张业务统计表。
- 实验背景:为什么要做这次数据加工?
1. 实验目的
本次实验的核心目的,是基于上一步清洗好的底层行为明细表(daily_browser_detail)和人口属性表(demographic.csv),完成数据大屏所需的各项高阶业务统计加工。我们需要构建并输出多张目标表,如浏览器周活跃趋势、使用频率分布(轻/中/重度)、竞品重叠度、工作日周末对比,以及多维度的用户画像统计,为后续的大屏可视化铺平道路。
- 实验环境与工具
实验平台:助睿数智(Uniplore)在线实验平台(https://lab.guilian.cn/ ),这是一款覆盖数据接入、ETL、AI建模到可视化全链路的一站式零代码平台。官网为 https://www.uniplore.com/
核心模块:主要依赖助睿的数据集成平台(ETL组件)。
数据规模:底层明细数据量达 800万+ 条记录。
3. 整体分析框架(以终为始的数据推演)
在动手写逻辑前,我梳理了以下业务框架,反向推导需要产出哪些目标表: 回答“用户活跃趋势” 需加工 browser_weekly_active(周活跃表) 回答“用户粘性与重度依赖” 需加工 browser_frequency_stats(使用频率表) 回答“竞品多开情况” 需加工 browser_multi_usage(使用数量分布表) 回答“工作日/周末场景差异” 需加工 browser_weekday_weekend(对比表) 回答“核心用户长什么样” 需加工 user_profile_stats(多维画像表)
- 实验步骤:化繁为简的零代码 ETL 实战
在助睿平台上,我通过创建多个转换流(Transformations)完成了上述任务,以下是核心步骤的拆解:
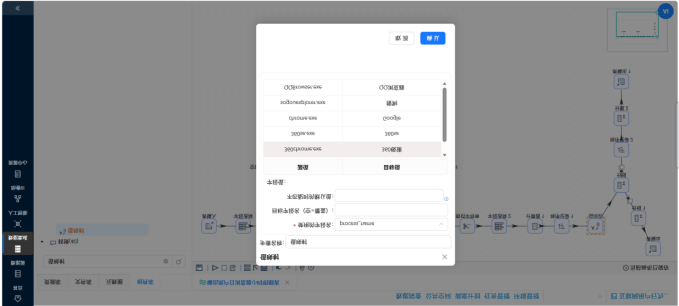
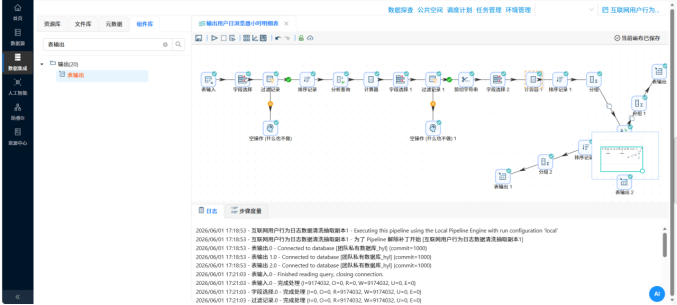
�� 步骤 1:底层“地基”搭建 —— 产出标准化日明细表 操作说明:首先,通过执行 SQL 脚本在私有数据库中建立 daily_browser_detail 明细表作为地基。随后,复制上一个实验的数据清洗流,补充“值映射”组件将系统进程名(如 iexplore.exe)规范化为业务名(如 IE浏览器),并将数据落地到数据库中。
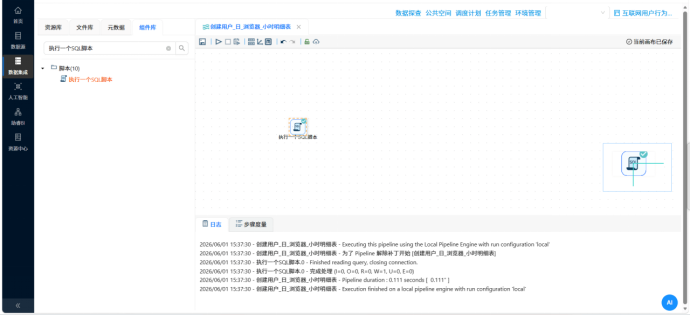
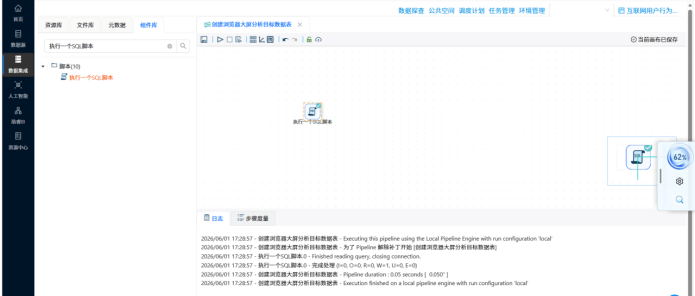
�� 步骤 2:建表造库 —— 批量创建大屏目标表 操作说明:为了存放后续跑出来的指标,新建一个转换流,利用“执行一个SQL脚本”组件,通过执行多条 CREATE TABLE 语句,一次性在数据库中建好大屏需要的全部 7 张目标表。
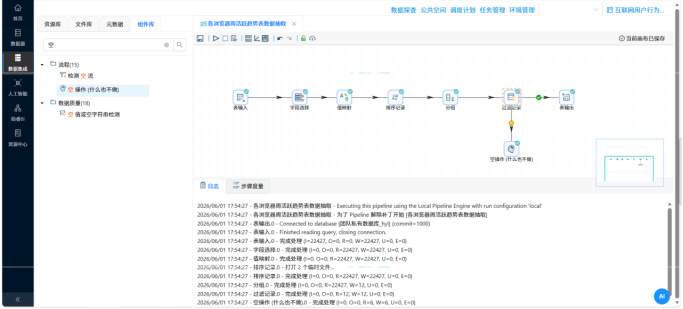
�� 步骤 3:高阶指标加工 —— 衍生与聚合的艺术
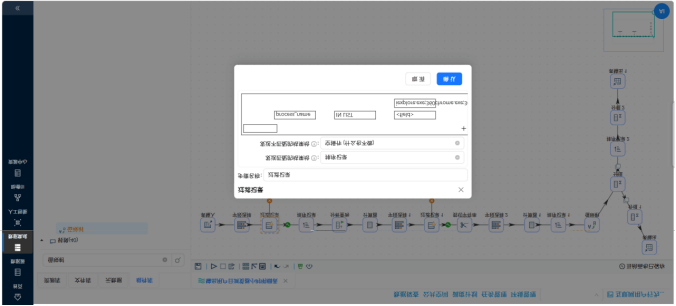
这部分我分别创建了多个独立的转换流,利用丰富的数据处理组件实现了复杂的业务口径提取: 周活跃趋势抽取:利用“字段选择”组件转换日期格式,配合“值映射”组件,将散乱的日级日期(usage_date)映射归并为标准的周区间(week_range),再进行分组求和计算。 时段偏好与工作日切分:引入“JavaScript代码”组件,通过 usage_date.getDay() 函数提取星期几,巧妙判定并衍生出“工作日”和“周末”的文本标签(day_type),再按照浏览器名称和日期类型进行双重分组(Group By)。 使用频率分级(轻/中/重度):先通过“增加常量”和“计算器”组件将总秒数转换为小时。再次利用 JS 脚本配置业务条件判断规则(如时长<3h 为轻度,>10h 为重度),生成业务标签后进行分组计数。
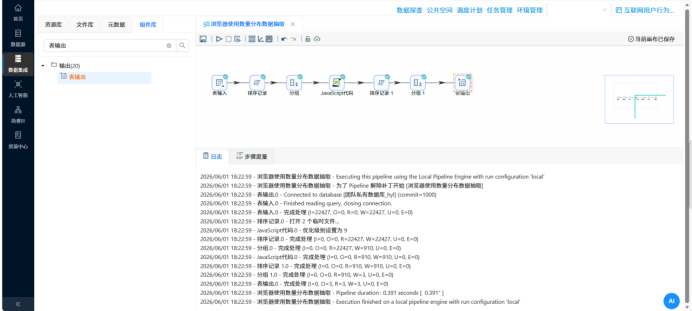
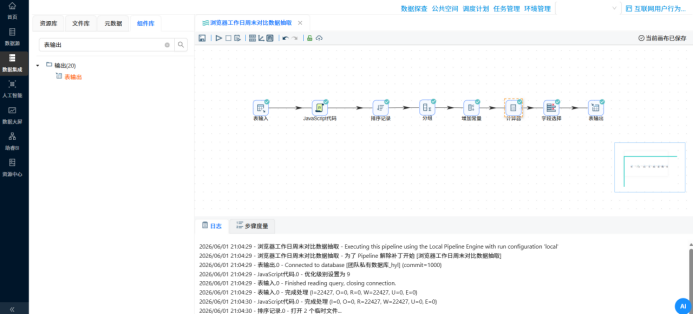
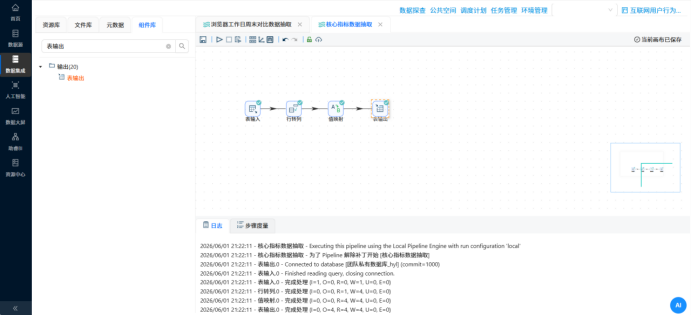
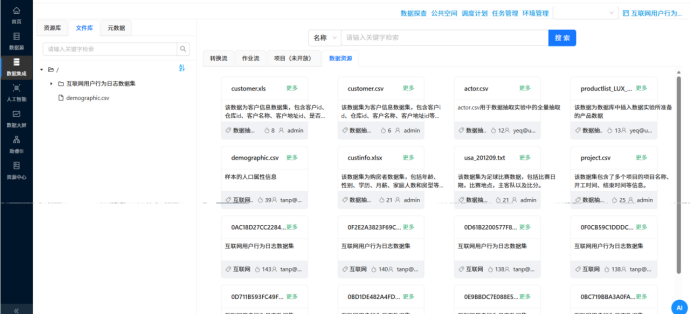
�� 步骤 4:多表关联大熔炉 —— 用户画像表加工 操作说明:为了透视用户属性,需要将业务日志(明细表)和人口库(CSV文件)揉在一起。 配置要点: 用“CSV文件输入”读取人口库,先用“计算器”组件算出年龄(2012 - 出生年份),再用 JS 脚本给年龄分段(如 18-25、26-35等)。 用“表输入”读取日志明细。 分别将两路数据按照 user_id 进行排序后,送入“记录集连接”组件执行 LEFT OUTER JOIN 操作。 关联完成后,按照性别、年龄段、学历、居住地等8个维度进行超级大分组,并用“表输出”组件入库。
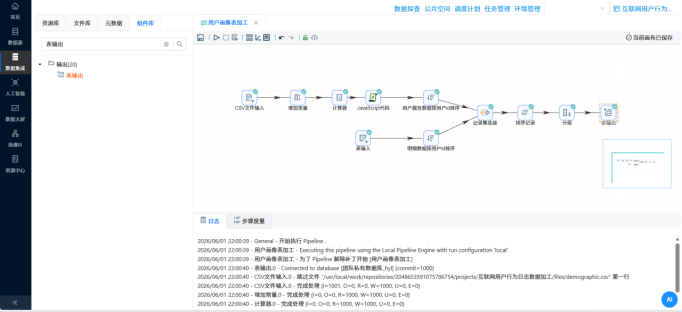
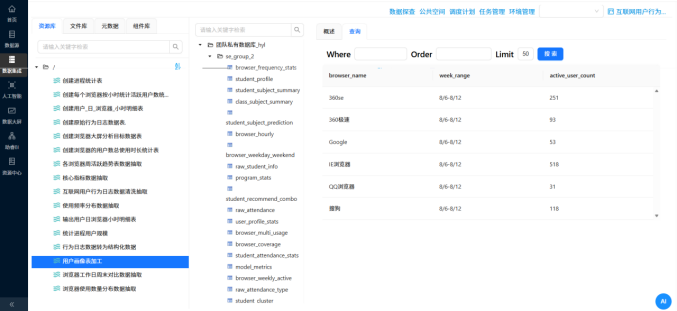
- 实验结果:大屏弹药库准备就绪
所有的转换流执行完毕后,我们点开助睿的“元数据探查”面板,可以清晰地看到最初 800 万条的“流水账”日志,已经被浓缩成了结构极其清晰的业务报表: 数据结果:私有数据库中成功生成了 browser_overview、browser_frequency_stats、user_profile_stats 等7张聚合统计表。 结果验证:抽查结果发现,原本只能按天统计的粗颗粒度数据,现在被完美拆解。比如在工作日与周末的对比表中,可以直接直观看出某些浏览器在周末的人均使用时长(avg_duration_sec)出现了显著断崖,同时用户画像表也成功补齐了海量日志背后的“男女老少”属性。至此,数据大屏所需的全部“口粮”已准备完毕!
- 实战踩坑局:排雷手记
在处理复杂的日期衍生和多表联接时,我踩了几个经典的“坑”,特此复盘:
�� 踩坑 1:分组排序报错,导致大量数据重复 问题现象:在提取周活跃数据和使用频率分布时,跑出来的指标数异常膨胀,分组聚合并没有生效,产生了大量冗余数据行。
问题原因:这是 ETL 初学者经常忽略的问题。助睿平台的“分组”组件本质上是一种基于排序的数据流扫面机制,它的前提是输入的数据流必须是按分组字段排好序的!
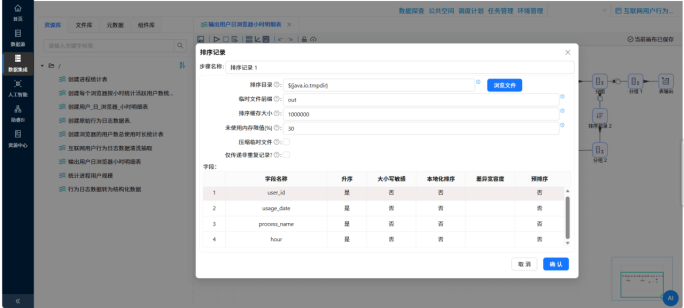
解决方法:在所有的“分组”组件之前,强制插入一个“排序记录”组件,并且确保排序字段的顺序和名称,必须与后续分组组件里的分组字段一模一样。加上这道保险后,聚合计算恢复正常。
�� 踩坑 2:日志表和属性表关联时,数据“乱点鸳鸯谱” 问题现象:在最后加工用户画像表时,使用“记录集连接”将日志明细表和 Demographic 人口属性表关联,发现最终输出的表中,职业、学历等人口字段出现了大面积乱码和错配。
问题原因:与分组组件的原理类似,助睿的“记录集连接”组件也是依赖有序数据流进行匹配的。两张表在进入连接器之前,如果没有按相同的关联键排序,就会导致错位匹配。 解决方法:在连接之前,分别为两条数据分支加上了“排序记录”组件。
注意细节:明细表按照 user_id 升序排,属性表按照大写的 USERID 升序排。排好序的“双规”列车再驶入记录集连接器,完美解决了属性串台的问题。
- 实验总结:数据工程的底座魅力
1. 实验收获
通过本次近乎“实战级”的数据加工演练,我对数据处理有了更立体的认知。一方面,我掌握了如何通过 JavaScript 和计算器组件,在 ETL 流程中灵活植入复杂的业务判断逻辑(如定义何为重度用户、工作日划分等)。另一方面,我深刻意识到,数据开发绝不仅仅是“跑通就行”,合理的流程拆分、冗余字段的及时剔除、以及在连接和分组前严谨的排序意识,才是保证数据质量和效率的关键。
2. 对平台的整体评价
本次加工涉及的数据量高达千万级,逻辑跳转也非常频繁。但助睿数智(Uniplore) 平台依然展现出了极其稳定的承载力。它的零代码可视化画布,让我可以像“搭积木”一样梳理复杂的业务推导逻辑。特别是它内置的字段追踪和分步骤日志查看功能,极大地降低了查错成本,让我能够将主要精力集中在“业务口径的设计”上,而不是在底层代码里大海捞针。非常期待用这批处理好的数据去搭建炫酷的可视化大屏!
平台全称:助睿数智(Uniplore)一站式数据科学实验平台
• 平台定位:覆盖数据接入、ETL处理、机器学习建模到可视化分析的全链路Agentic零代码数据智能
• 产品官网:https://www.uniplore.com/
• 实验平台地址:https://lab.guilian.cn/

一站式 AI 云服务平台
更多推荐


 3
3 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)