
千万级连锁餐饮多表分析实战:用AI工作流零代码、零SQL完成门店经营全景分析
本文介绍了一种轻量化的AI工作流方法,无需编写代码或SQL即可完成千万级连锁餐饮数据的清洗与分析。案例围绕门店销售、菜品、会员和评价四张核心业务表展开,通过12个步骤实现数据清洗、关联和统计,最终输出6张关键经营分析报表(包括门店全景、菜品分类、门店排名等)。工作流通过智能体节点自动完成数据清洗、入库、统计和可视化,支持HTML报表导出。该方法降低了技术门槛,强调业务流程梳理和结果导向,可扩展至供
连锁餐饮经营分析看似简单,但面对千万级数据量时,门店销售、菜品、会员和评价几张表的清洗、关联和统计并不轻松。
这篇文章就介绍一种更轻量的 AI 工作流做法:不写代码、不写 SQL,直接在本地完成千万级数据的清洗分析,快速做出完整的经营分析结果。
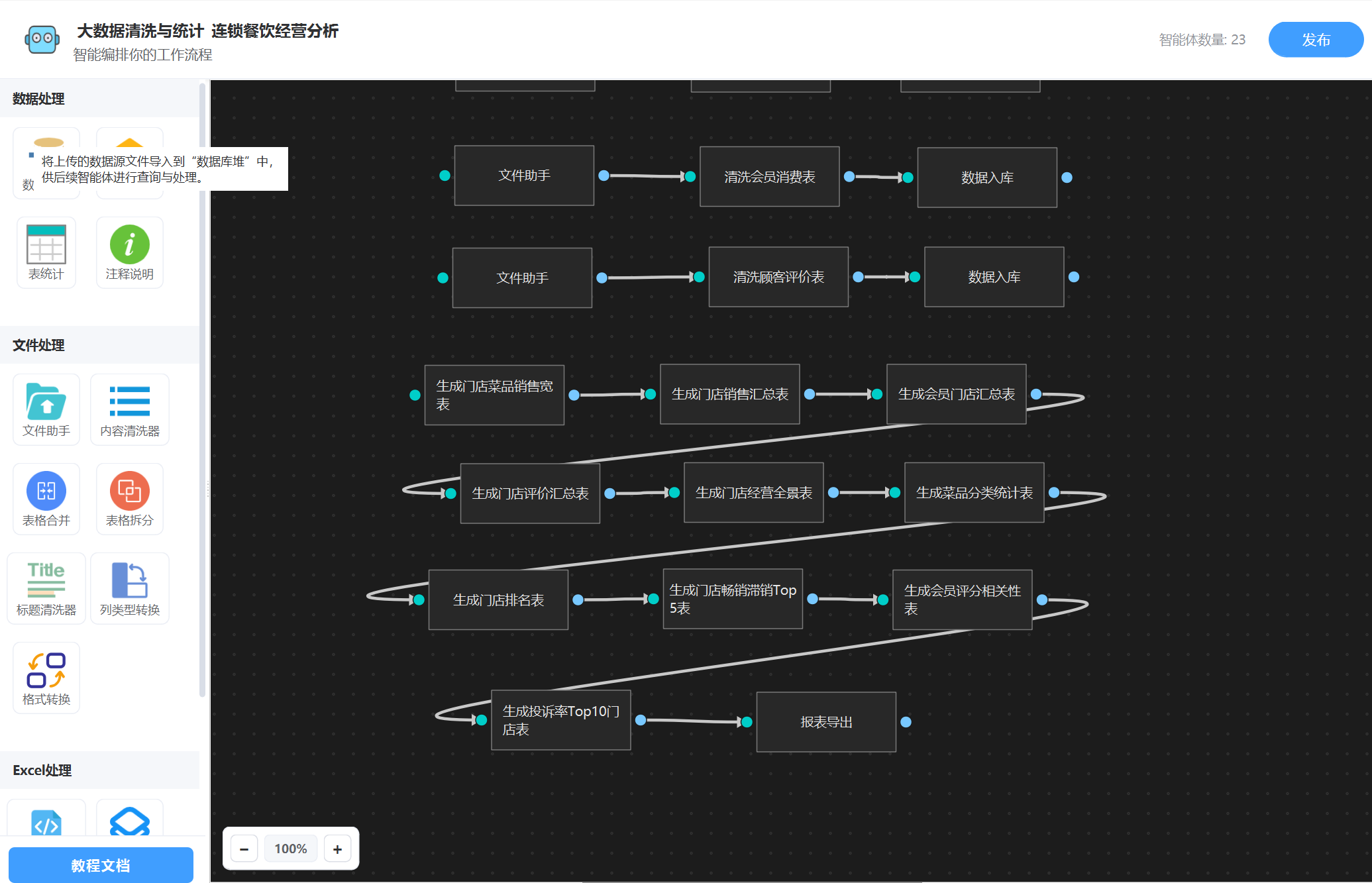
如下配置好的工作流图:
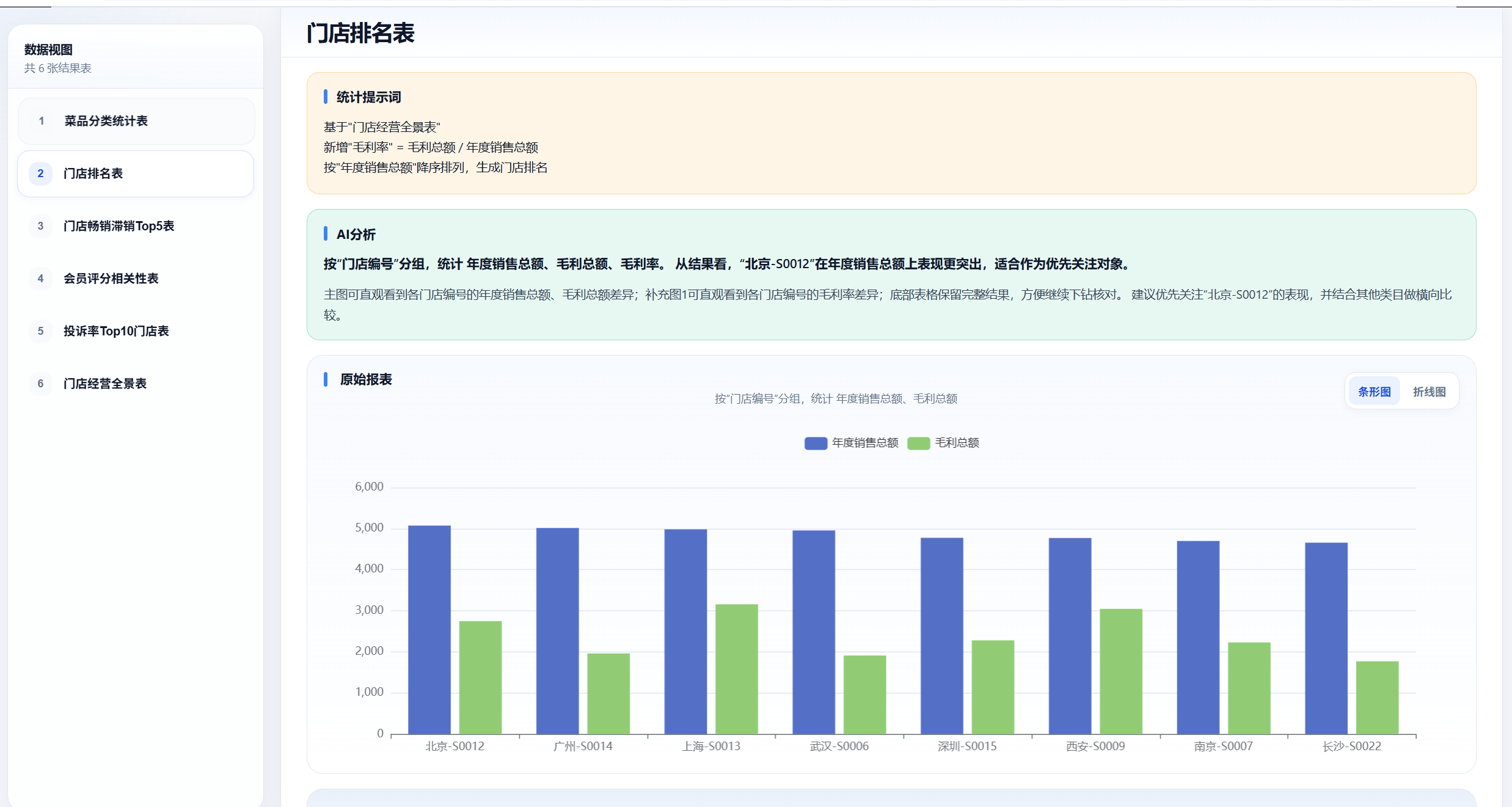
报表可视化结果:
接下来,我们就用一个典型业务场景,来完整演示这个过程:连锁餐饮经营分析。
一、案例需求分析
在连锁餐饮经营分析场景里,业务更关心的,通常不是原始数据本身,而是最后能产出哪些可直接使用的结果表。这个案例也从结果导向出发,先明确最终要生成哪些经营分析结果,再回到数据清洗、多表关联和统计过程。
1、最终输出哪些结果表
完成门店销售、菜品、会员和评价数据的清洗、规范和关联后,这个案例最终会输出 6 个核心结果表:
- 门店经营全景表 :用来汇总各门店的销售总额、会员消费占比、平均评分、投诉率等核心指标,帮助业务快速了解每家门店的整体经营情况。
- 菜品分类统计表 :用来统计各菜品分类的销售总额、销售占比、毛利率和招牌菜销售占比,帮助业务判断菜品结构是否合理。
- 门店排名表 :用来按年度销售总额和毛利率对门店进行排序,方便业务识别高表现门店和经营薄弱门店。
- 门店畅销滞销 Top5 表 :用来找出每家门店销售最好的 Top5 菜品和销售最弱的 Top5 菜品,帮助业务优化菜品结构和门店运营策略。
- 会员评分相关性表 :用来分析会员消费占比与门店评分之间的关系,帮助业务判断会员经营与顾客体验之间是否存在关联。
- 投诉率 Top10 门店表 :用来筛选投诉率最高的 Top10 门店,并结合主要投诉类型查看问题集中点,帮助业务快速定位服务和管理风险。
生成结果统计表的数据文件,如下图:
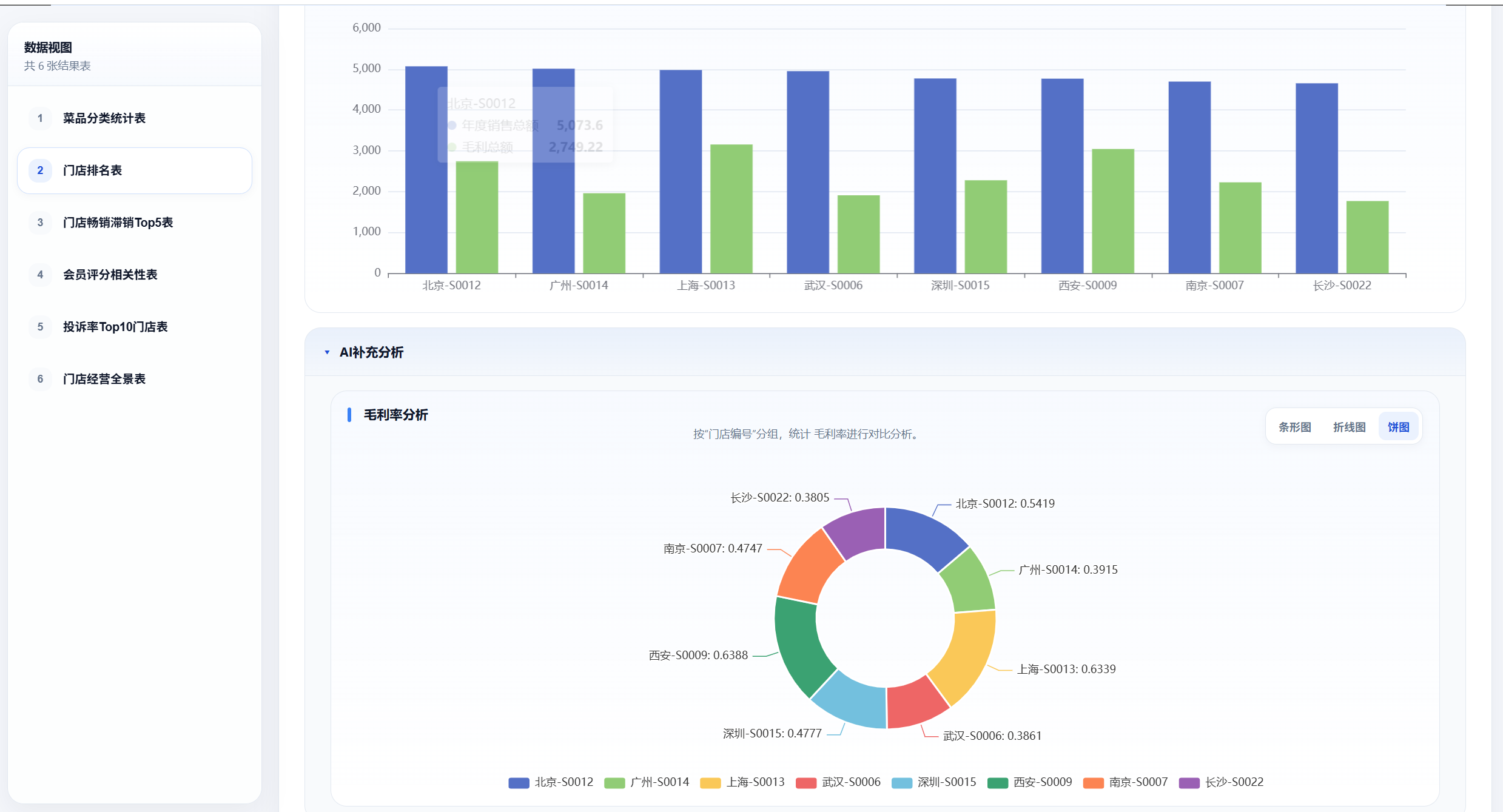
同时,还会生成对应的 HTML 报表视图,方便直接查看分析结果。如图:
2、业务数据涉及哪些源表
这次案例围绕连锁餐饮经营分析展开,一共涉及 4 张核心业务表。
- 门店销售流水表 :主要记录流水号、门店编号、菜品编号、销售数量、销售金额、折扣金额、实收金额、下单时间、桌号,用来承接门店日常销售数据,是后续销售统计、菜品分析和门店经营分析的核心基础表。
- 菜品信息表 :主要记录菜品编号、菜品名称、菜品分类、成本价、售价、是否招牌菜、上架日期,用来补充菜品维度信息,支撑菜品分类分析、毛利测算和招牌菜表现分析。
- 会员消费表 :主要记录消费ID、会员ID、门店编号、消费金额、积分、消费时间、支付方式,用来反映会员在各门店的消费情况,是会员贡献分析和会员消费占比计算的重要来源。
- 顾客评价表 :主要记录评价ID、门店编号、评价日期、评分、评价内容、是否投诉、投诉类型,用来补充顾客反馈和服务质量信息,支撑门店评分分析、投诉率分析和经营表现综合评估。
4张表的数据量在千万级,如下图示:
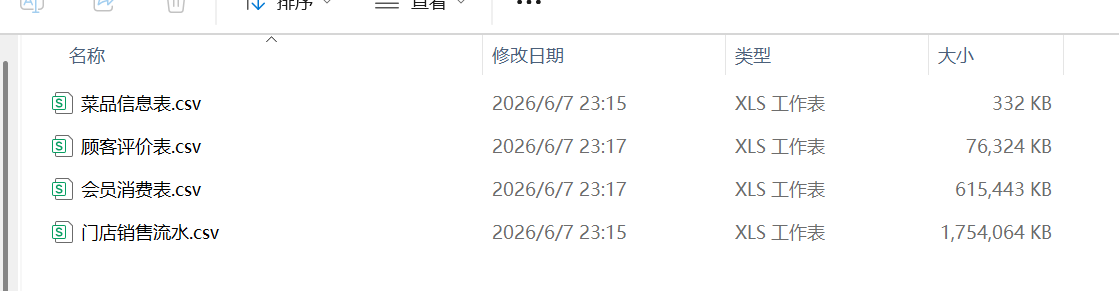
3、这次主要做了哪些清洗
这次清洗主要集中在门店销售流水表、菜品信息表、会员消费表和顾客评价表这 4 张业务表上,重点是统一时间格式、清理金额字段、规范菜品编号和业务口径,为后续门店经营、菜品销售、会员消费和评价分析打好基础。具体动作如下:
清洗门店销售流水表
- “下单时间”统一为 yyyy-MM-dd HH:mm:ss 格式
- “销售金额”“折扣金额”“实收金额”去除 ¥ 和千分位逗号
- “菜品编号”统一为大写,去除前后空格
- 删除“销售金额”为 0 或负数的异常记录
清洗菜品信息表
- “成本价”“售价”去除 ¥ 符号
- “菜品分类”去除前后空格,并做归一化处理,例如“热 菜”统一为“热菜”
- “是否招牌菜”归一化处理,例如“是”“Y”“1”“true”统一为“是”
- “菜品编号”统一为大写,去除前后空格
- “上架日期”统一为 yyyy-MM-dd 格式
清洗会员消费表
- “消费时间”统一为 yyyy-MM-dd HH:mm:ss 格式
- “消费金额”去除 ¥ 和千分位逗号
- “支付方式”归一化处理,例如“微信”“WeChat”“wechat”统一为“微信”
清洗顾客评价表
- “评价日期”统一为 yyyy-MM-dd 格式
- “评分”去除“星”后缀,转换为数字
- “投诉类型”归一化处理,例如“服务”“服务态度”“态度差”统一为“服务态度”
经过这一步清洗后,销售、菜品、会员和评价几张核心业务表的数据格式和字段口径会先统一下来,后续才能继续完成门店菜品销售宽表、门店经营全景表以及各类经营统计结果表的输出。
二、提示词整理
在工作流配置之前,需要先把这次业务处理逻辑整理成一份提示词。
这一步的作用,就是先明确 清洗哪些表 、 怎么关联 、 输出哪些报表 。整理好之后,这份提示词就可以作为工作流配置输入,指导后续执行。
这里也需要说明一点: 提示词不一定非要写成固定模板 。只要表达得 清晰 、 明确 、 简洁 ,让人一眼能看懂要做什么、按什么顺序做、最后输出什么结果,就可以了。
本次案例整理出的提示词如下:
第一步 - 清洗门店销售流水:
1. "下单时间"统一为 yyyy-MM-dd HH:mm:ss 格式
2. 所有金额字段去除¥和千分位逗号
3. "菜品编号"统一为大写,去除前后空格
4. 删除"销售金额"为0或负数的异常行
第二步 - 清洗菜品信息表:
1. "成本价""售价"去除¥符号
2. "菜品分类"去除前后空格,"热 菜"统一为"热菜"
3. "是否招牌菜"归一化:"是""Y""1""true"统一为"是"
4. "菜品编号"统一为大写,去除前后空格
5."上架日期"统一为 yyyy-MM-dd 格式
第三步 - 清洗会员消费表:
1. "消费时间"统一为 yyyy-MM-dd HH:mm:ss 格式
2. "消费金额"去除¥和千分位逗号
3. "支付方式"归一化:"微信""WeChat""wechat"统一为"微信"
第四步 - 清洗顾客评价表:
1. "评价日期"统一为 yyyy-MM-dd 格式
2. "评分"去除"星"后缀,转为数字
3. "投诉类型"归一化:"服务""服务态度""态度差"统一为"服务态度"
第五步 - 生成门店菜品销售宽表:
1. 门店销售流水 关联 菜品信息表(按"菜品编号"匹配)
2. 保留"流水号""门店编号""菜品编号""菜品名称""菜品分类""是否招牌菜""销售数量""销售金额""折扣金额""实收金额""成本价"
3. 新增"毛利估算" = 实收金额 - 成本价 * 销售数量
4. 输出"门店菜品销售宽表"
第六步 - 生成门店销售汇总表:
1. 基于"门店菜品销售宽表"
2. 按"门店编号"分组,统计:年度销售总额、实收总额、销售笔数、菜品种类数、毛利总额
3. 新增"平均客单价" = 实收总额 / 销售笔数
4. 输出"门店销售汇总表"
第七步 - 生成会员门店汇总表:
1. 基于"会员消费表"
2. 按"门店编号"分组,统计:会员消费总额、会员消费次数
3. 输出"会员门店汇总表"
第八步 - 生成门店评价汇总表:
1. 基于"顾客评价表"(清洗后)
2. 按"门店编号"分组,统计:平均评分、评价总数、投诉率、主要投诉类型
3. 输出"门店评价汇总表"
第九步 - 生成门店经营全景表:
1. "门店销售汇总表" 关联 "会员门店汇总表"(按"门店编号"匹配)
2. 再关联 "门店评价汇总表"(按"门店编号"匹配)
3. 新增"会员消费占比" = 会员消费总额 / 年度销售总额
4. 输出"门店经营全景表"
第十步 - 生成菜品分类统计表:
1. 基于"门店菜品销售宽表"
2. 按"菜品分类"分组,统计:销售总额、销售额占比、毛利率、招牌菜销售占比
3. 输出"菜品分类统计表"
第十一步 - 生成门店排名表:
1. 基于"门店经营全景表"
2. 新增"毛利率" = 毛利总额 / 年度销售总额
3. 按"年度销售总额"降序排列,生成门店排名
4. 输出"门店排名表"
第十二步 - 生成门店畅销滞销Top5表:
1. 基于"门店菜品销售宽表"
2. 按"门店编号"+"菜品名称"分组,统计:销售总额、销售数量
3. 在每个门店内按销售总额降序取Top5畅销菜品,按销售总额升序取Top5滞销菜品
4. 输出"门店畅销滞销Top5表"
第十三步 - 生成会员评分相关性表:
1. 基于"门店经营全景表"
2. 选取"会员消费占比"和"平均评分"两列,计算相关性系数
3. 输出"会员评分相关性表"
第十四步 - 生成投诉率Top10门店表:
1. 基于"门店评价汇总表"
2. 按"投诉率"降序排列,取Top10
3. 输出"投诉率Top10门店表"(含门店编号、投诉率、主要投诉类型)三、落地实现:工作流配置
工作流是由多个智能体节点组成的,这个案例我们涉及到下面几个智能体:
- 文件助手: 获取磁盘的文件或目录。
- 内容清洗器: 专门用来做数据清洗的,只要输入清洗描述就可以对文件数据进行任意整理。
- 数据入库:将文件数据转成本地数据库,用于后面作SQL统计。
- 表统计: 对本地数据库表进行SQL统计,不需要写sql,只需要统计的描述就可以了。
- 报表导出: 对数据库表进行导出,支持导出csv,xlsx,HTML(可视化显示) 。
根据这几个智能体还有上面描述的提示词,我们就可以完成工作流的配置了。
1. 清洗数据表
清洗数据流程总共分为三步:
- 配置文件助手 : 获取待清洗的源文件。
- 配置内容清洗器: 描述清洗内容。
- 数据入库: 将文件数据搞成表放到本地数据库(后面好进行sql统计)。
打开DT-Bot工作流, 配置一个 “文件助手”智能体节点,描述原始数据文件位置,文件助手配置如图:
DT-Bot工作流,解决方案获取可以看文章末尾名片。
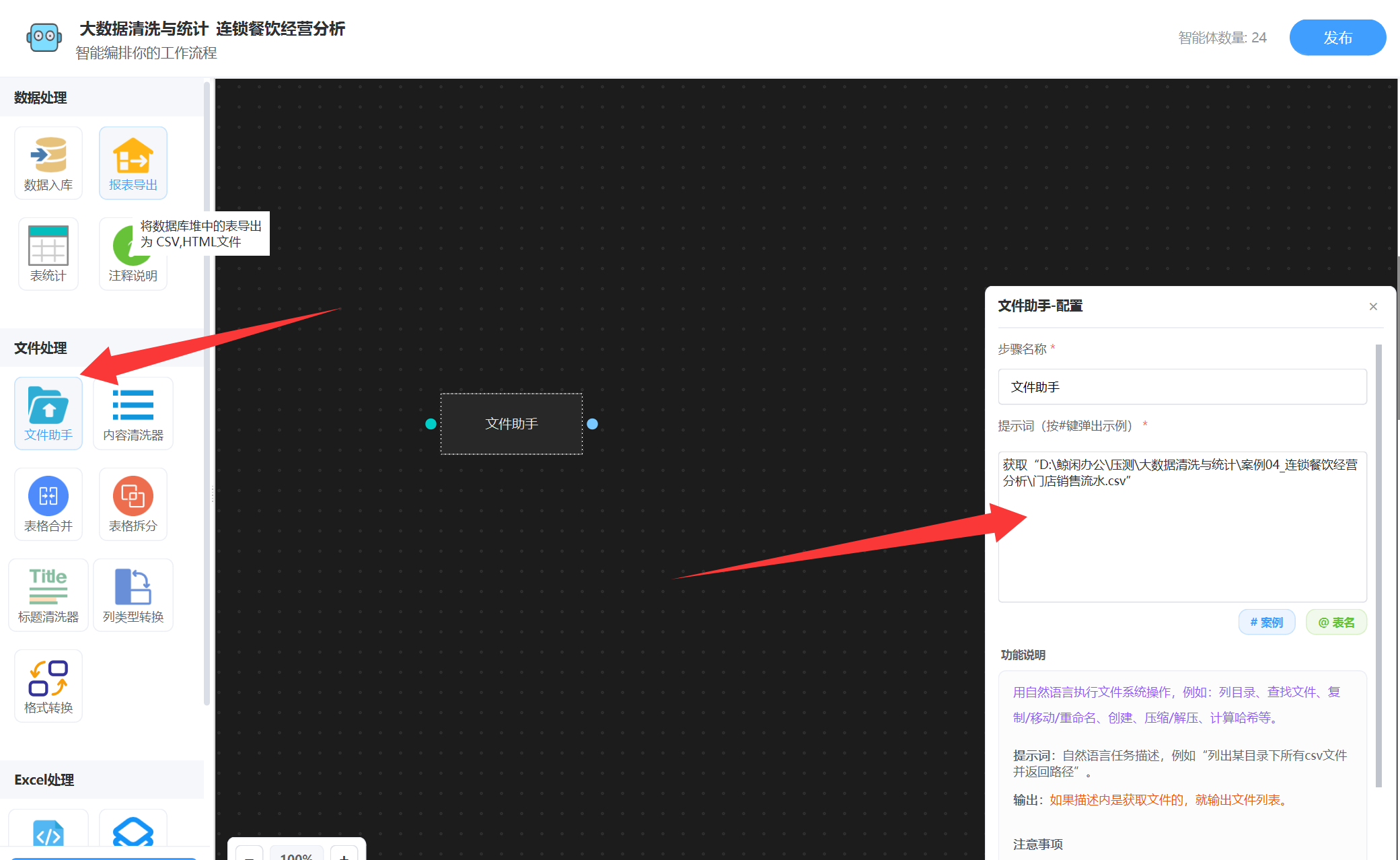
根据提示词描述,获取到了”门店销售流水“原始表格,然后就会输出该文件,然后我们接下一个智能体“内容清洗器”,如图:
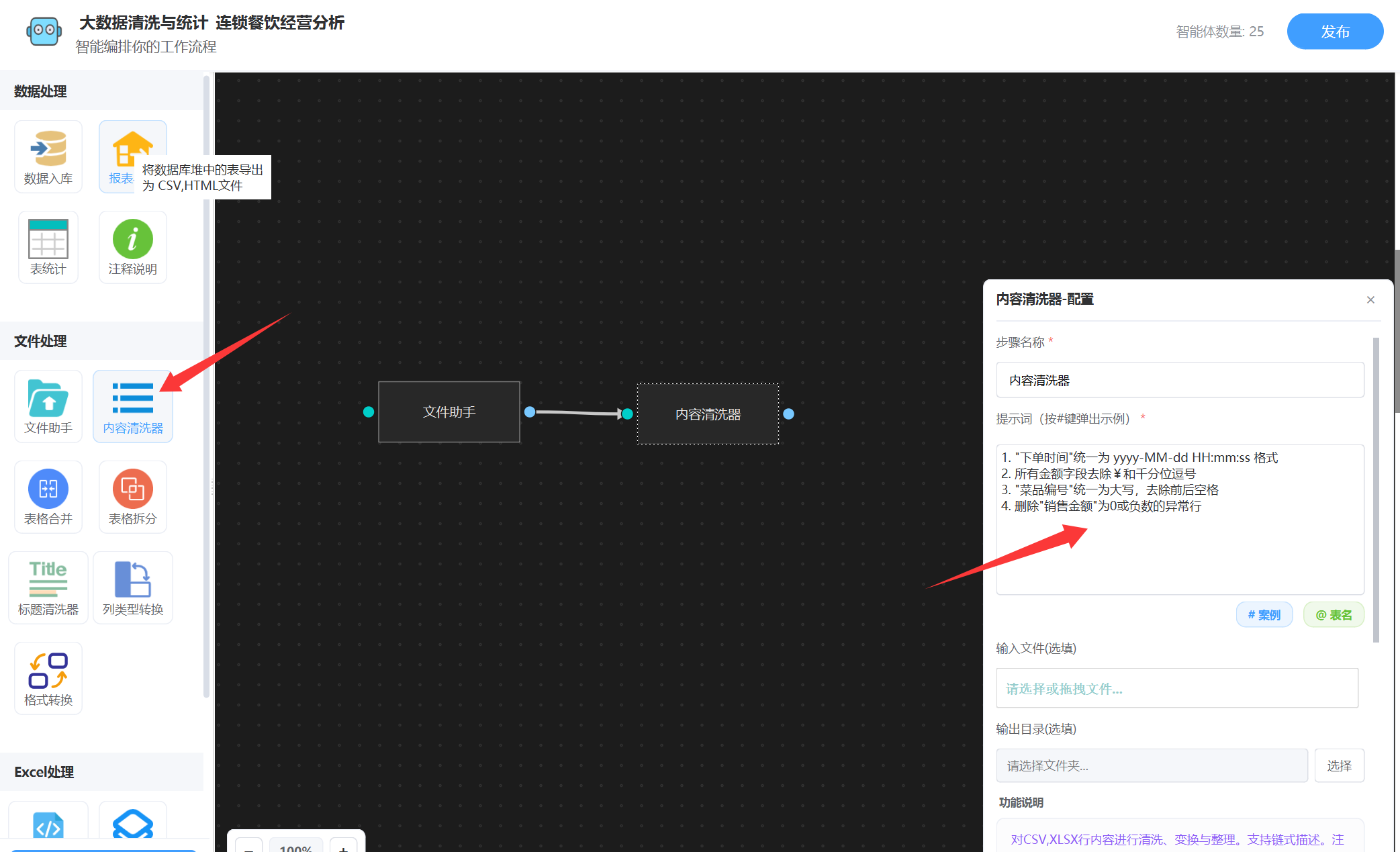
直接将清洗的提示词写进来就可以了,清洗之后,我们需要将表格文件的数据放到数据库里面,后面好进行SQL统计,所以还要接入一个“数据入库”,不需要输入任何提示词,如下图:
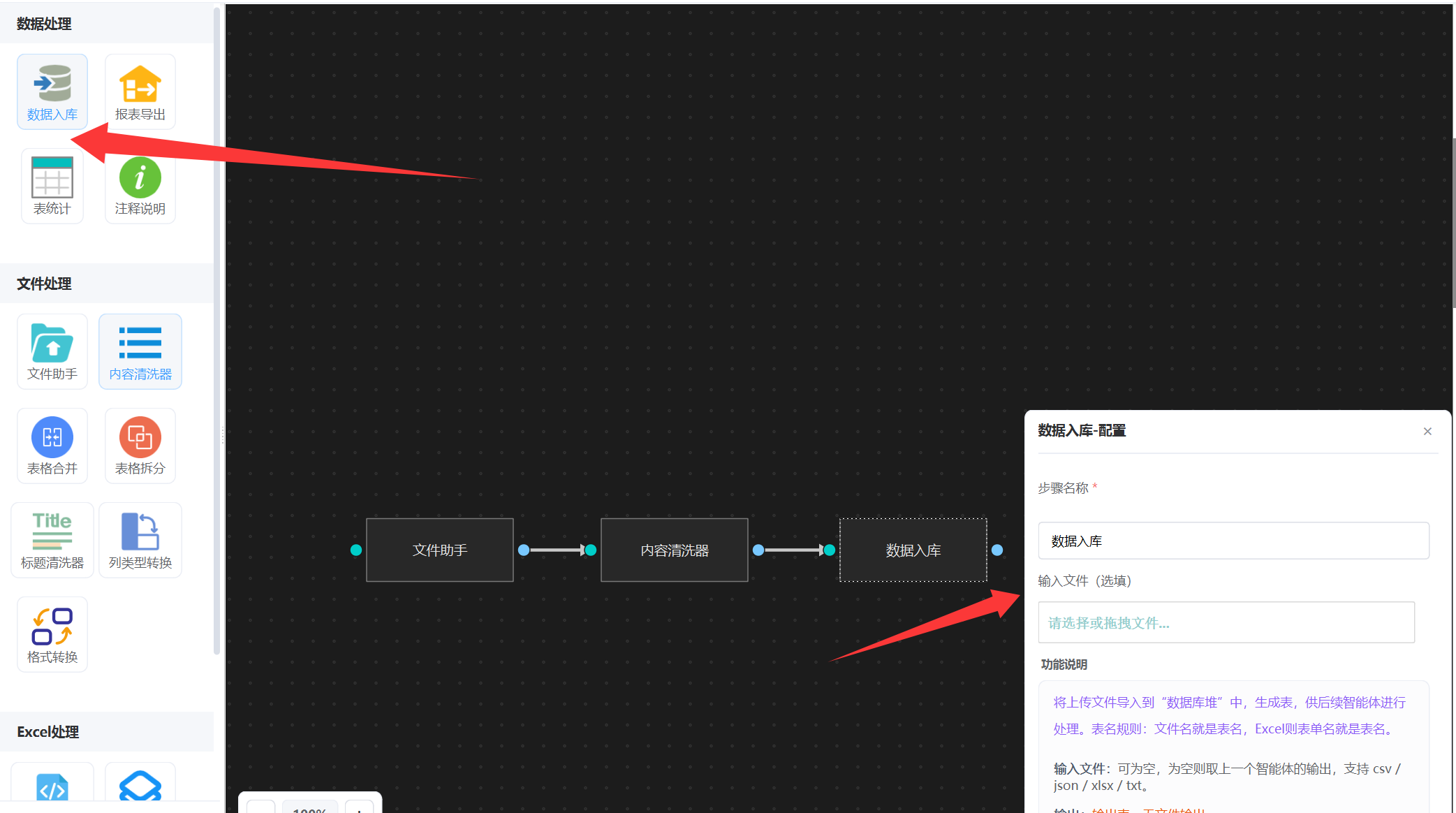
第一步就完成了,同理,所有的源表清洗都是这个套路。
2. 表统计
接下来我们需要进行表统计,直接用“表统计”智能体就好了, 也是直接输入提示词描述,工作流内部会生成相关sql进行统计(全程不用你操心),下面是我配置完成的图:
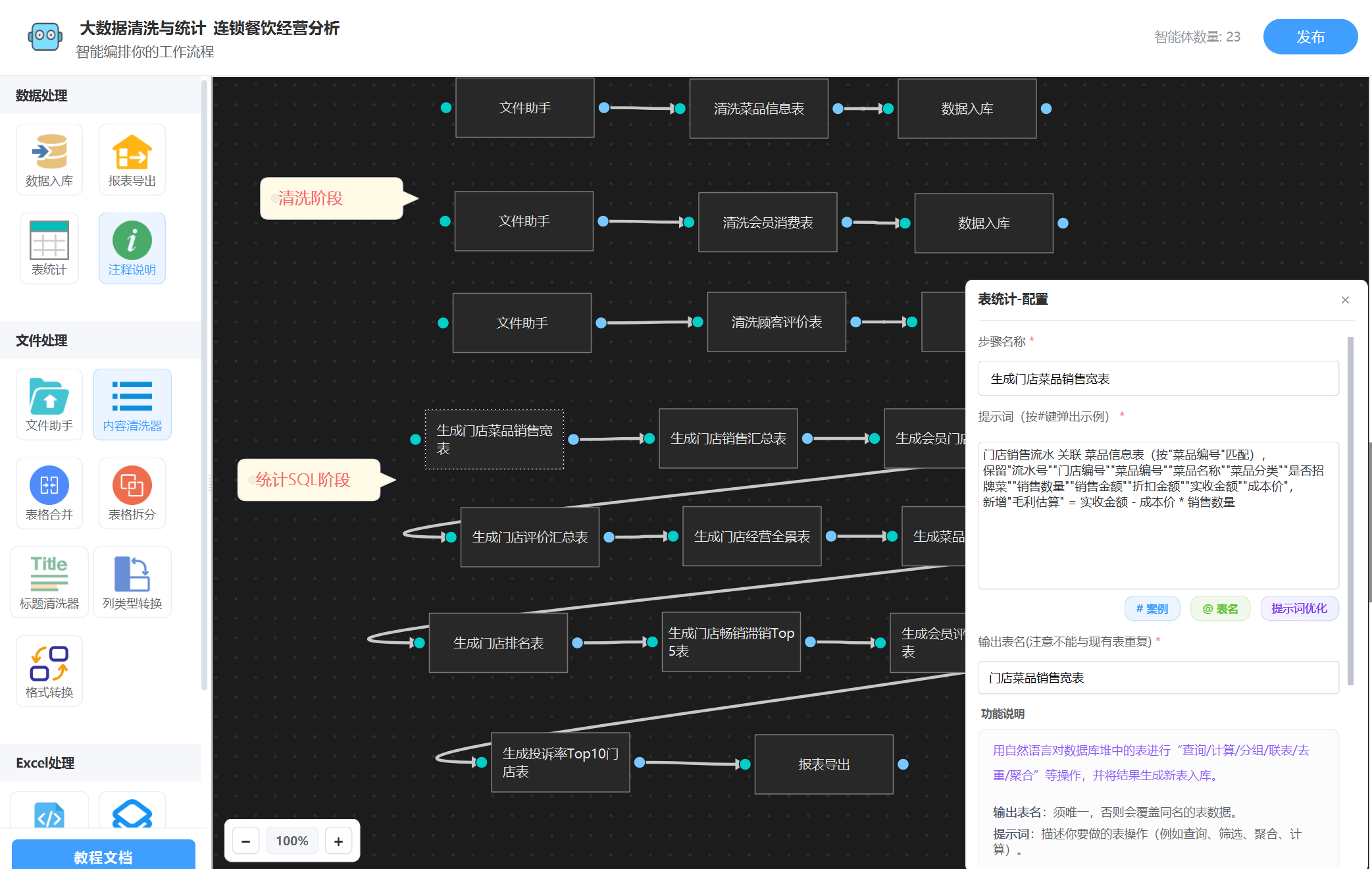
3. 导出报表
表统计后,只生成了结果表到数据库里面,还需要从数据库里面下载出来,这是要用“报表导出”智能体,可以指定哪些表,下载类型,如下图:
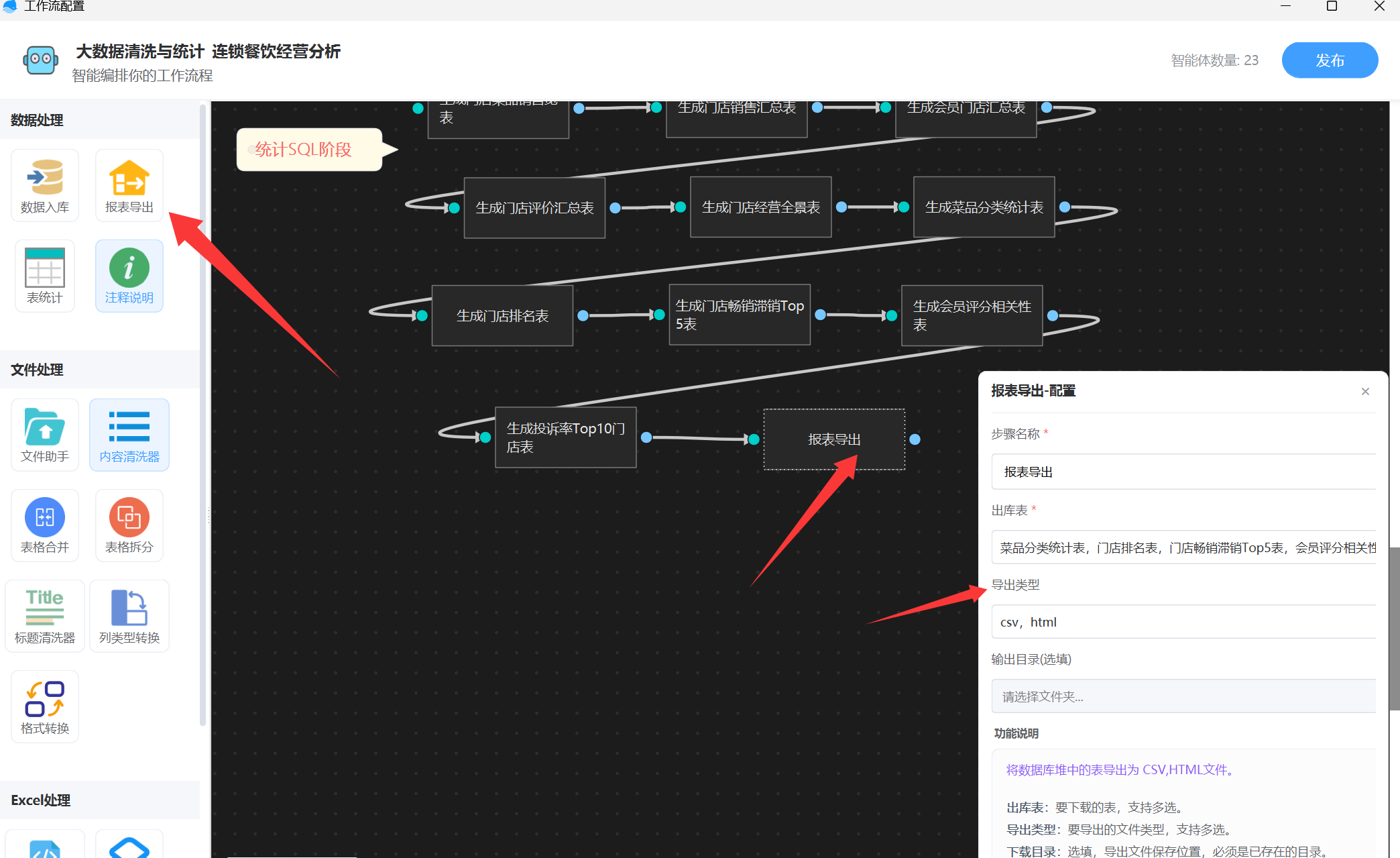
配置完成后,我们发布工作流执行就可以了。
四、结尾语
千万级连锁餐饮数据分析,并不一定意味着很高的技术门槛。只要先把业务链路梳理清楚,把分析目标描述清楚,再结合 AI 工作流逐步执行,就能够把门店销售、菜品、会员、评价这些原始业务数据,整理成可清洗、可关联、可统计、可输出的经营分析结果。
对于这类场景来说,真正重要的并不是写了多少 SQL、搭了多少技术环境,而是能不能把门店经营问题讲清楚,把分析流程跑顺,把结果稳定产出出来。连锁餐饮经营分析只是一个开始,后面还可以继续扩展到供应链、人力、销售、财务等更多业务场景,用同样的方式完成千万级数据清洗、统计分析和报表输出。

一站式 AI 云服务平台
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)