
浏览器用户行为数据分析与可视化综合实验第一部分
本次实验完成了数据清洗与基础加工的全流程,成功构建了用户-日-浏览器-小时明细表(daily_browser_detail)以及浏览器市场覆盖率、时段活跃等基础统计表。通过ETL平台掌握了字段映射、排序分组、聚合计算、JavaScript代码处理等核心操作,为后续多维度分析奠定了统一的数据基础。平台评价:助睿数智平台在本实验中表现出色。零代码的ETL组件设计直观,拖拽即可完成复杂的数据加工流程;排
浏览器用户行为数据分析与可视化综合实验第一部分
第一部分:实验一数据清洗与基础加工
1实验目的
本实验基于“用户-日-浏览器-小时”明细表,完成数据清洗与基础加工目标:对原始行为日志数据进行清洗、过滤、映射和聚合,生成可用于分析的用户行为明细表及基础统计表,包括:
用户-日-浏览器-小时明细表(daily_browser_detail)
浏览器市场覆盖率统计表(browser_coverage)
浏览器时段活跃统计表(browser_hourly)
2实验环境
实验平台:助睿在线实验平台https://lab.guilian.cn/
数据处理:助睿ETL数据集成平台
建模平台:助睿AI人工智能平台
数据规模:1000用户,800万+条行为记录,约825MB
3实验数据
本实验基于上个实验《浏览器用户行为分析与流失预测-数据加工》产出的数据。
上个实验已输出的数据:
daily_browser_detail、browser_coverage、browser_hourly
实验步骤
上个实验中的“互联网用户行为日志数据清洗抽取”转换流已经包含了生成明细数据的完整逻辑,但只输出了分支A和B(browser_coverage和browser_hourly)。我们需要将其复制一份,改为输出明细表,作为本实验后续加工的基础。
6.1.1创建用户_日_浏览器_小时明细表
首先,我们先在团队私有数据库中创建用于存放用户-日-浏览器-小时明细表的数据表
打开上个实验创建的项目“互联网用户行为日志”
新建转换流“创建用户_日_浏览器_小时明细表”,拖入“执行一个SQL脚本”组件
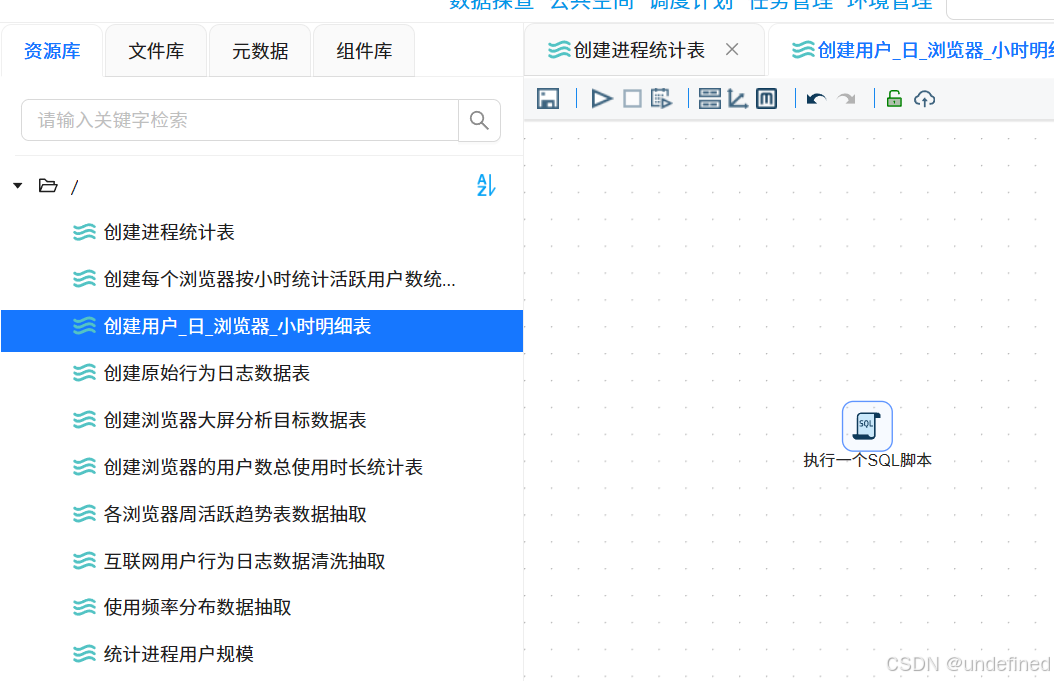
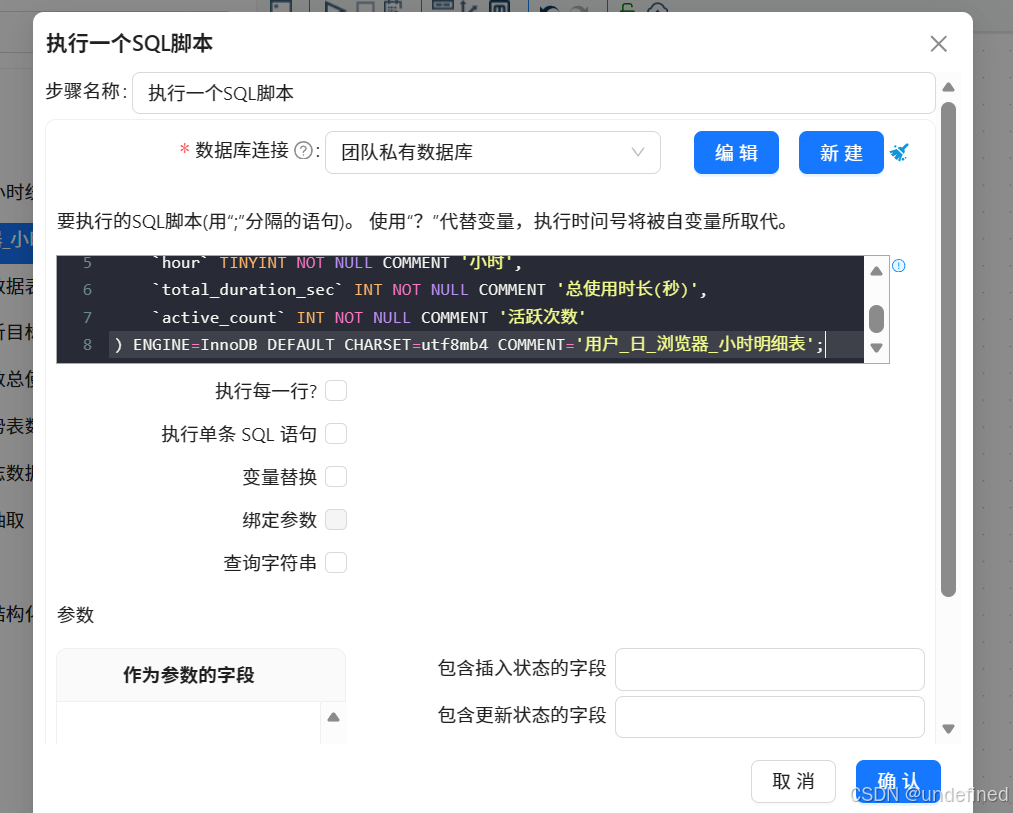
双击“执行一个SQL脚本”组件,数据库连接选择“团队私有数据库”,并输入以下SQL:
CREATE TABLE IF NOT EXISTS`daily_browser_detail`(
`user_id`VARCHAR(50)NOT NULL COMMENT'用户ID',
`usage_date`DATE NOT NULL COMMENT'使用日期',
`browser_name`VARCHAR(50)NOT NULL COMMENT'浏览器名称',
`hour`TINYINT NOT NULL COMMENT'小时',
`total_duration_sec`INT NOT NULL COMMENT'总使用时长(秒)',
`active_count`INT NOT NULL COMMENT'活跃次数'
)ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='用户_日_浏览器_小时明细表';
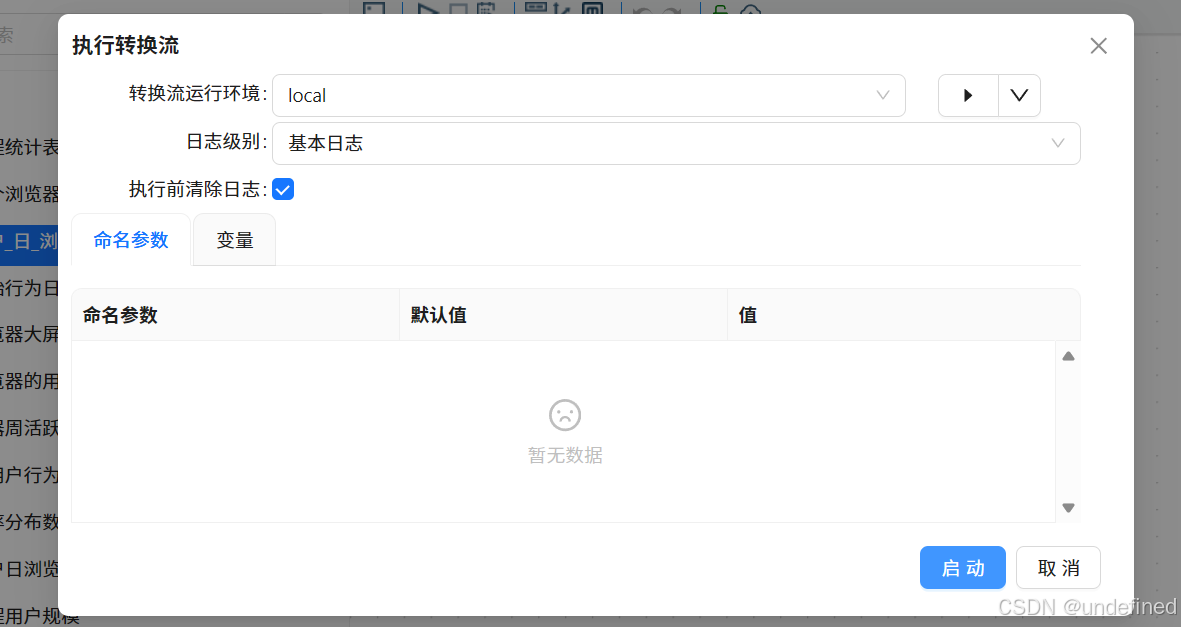
点击“运行”按钮,执行转换流
6.1.2复制转换流
在上个实验的项目中,找到“互联网用户行为日志数据清洗抽取”转换流,右键选择“复制”
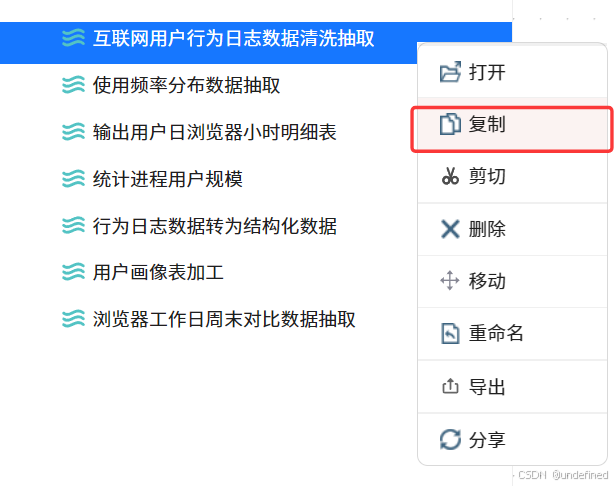
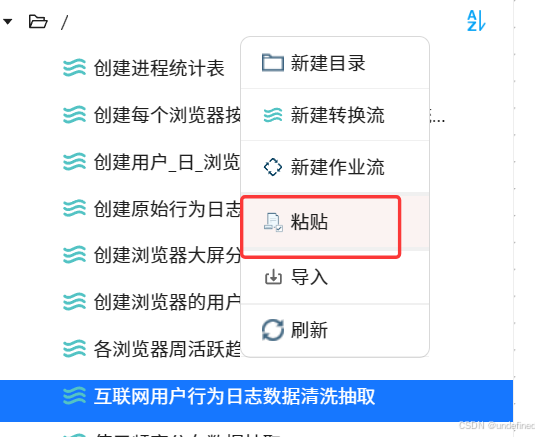
右键根目录,点击“粘贴”
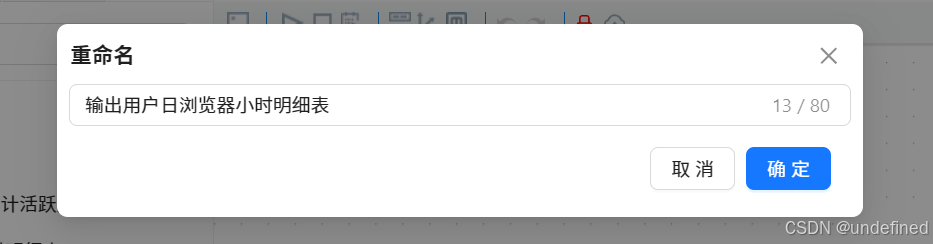
粘贴后右键重命名为“输出用户日浏览器小时明细表”
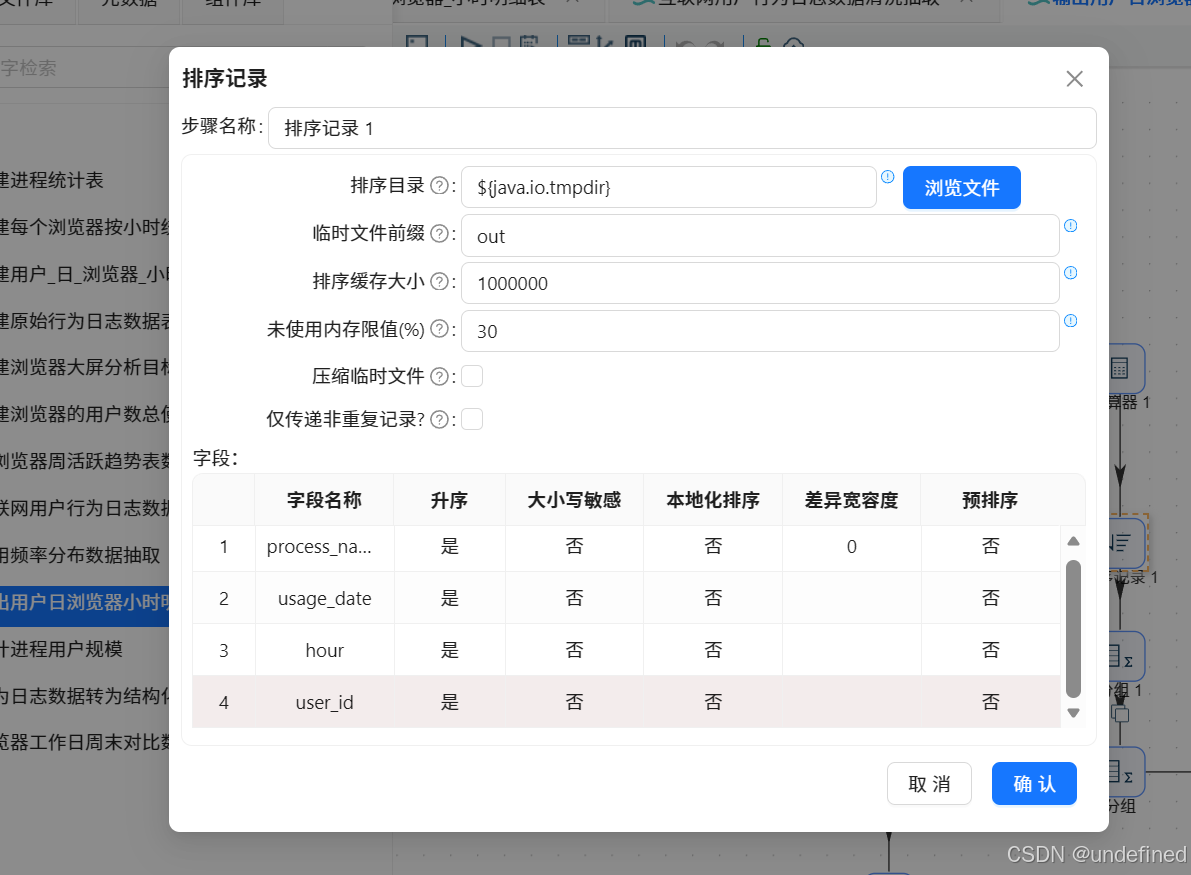
注意:上个实验中“排序记录1”组件仅按照process_name升序排序,而分组组件的分组字段是:user_id、usage_date、process_name、hour,所以,需要更正“排序记录1”组件的排序字段与分组组件的分组字段一致,否则会出现多条重复数据
6.1.3浏览器名称映射
在分组组件后添加“值映射”组件,“值映射”组件连接到原分支A的分组1组件、复制发送到原分支B的排序记录2组件
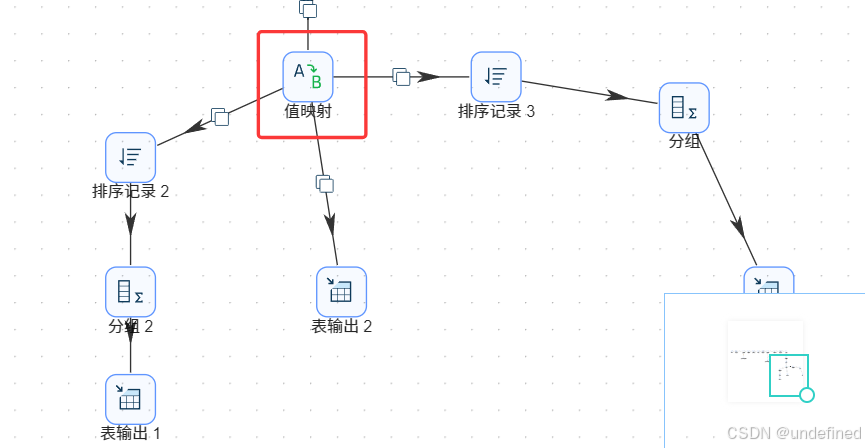
值映射组件按照以下添加映射
|
进程名 |
说明 |
|
iexplore.exe |
IE浏览器 |
|
360chrome.exe |
360极速 |
|
360se.exe |
360se |
|
chrome.exe |
|
|
sogouexplorer.exe |
搜狗 |
|
QQBrowser.exe |
QQ浏览器 |
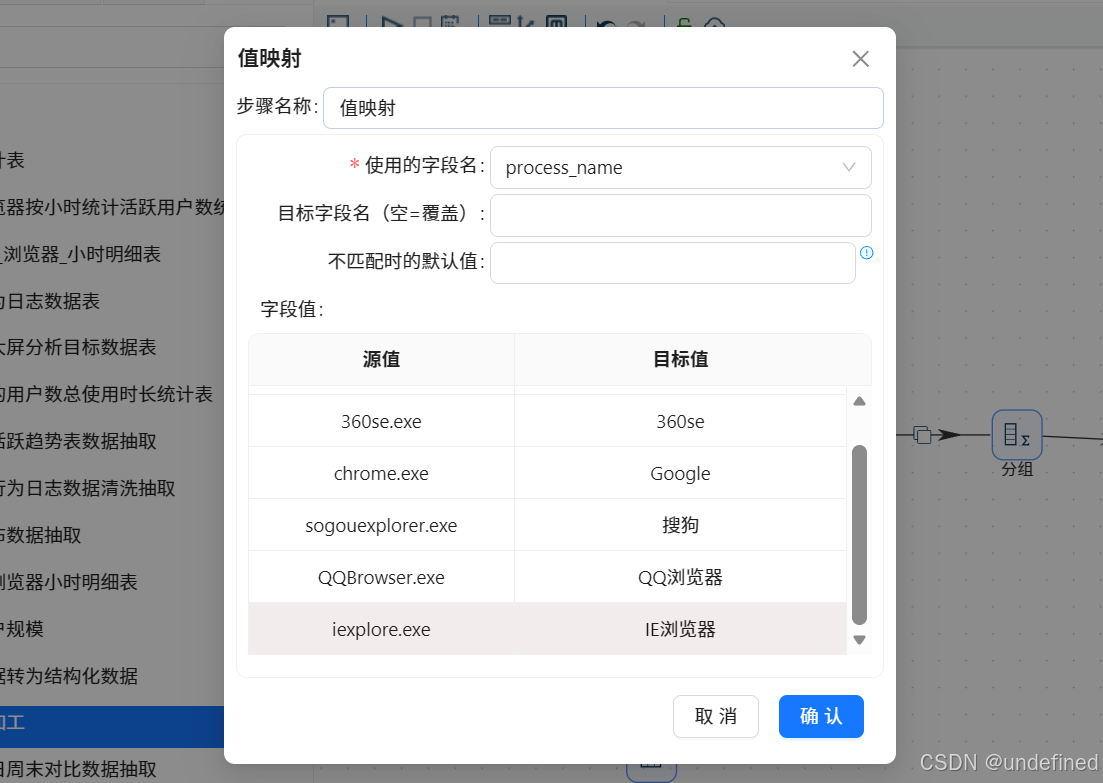
上个实验的“4.5.3过滤记录:筛选进程为主要浏览器的数据”步骤中
如果匹配条件是process_name IN LIST“iexplore.exe;360chrome.exe;360se.exe;chrome.exe;sogouexplorer.exe;QQBrowser.exe”,则继续下一步骤
如果匹配条件与以上不同,则删除匹配值中的EXCEL.EXE、WINWORD.EXE、AlilM.exe,因为这3个不是浏览器
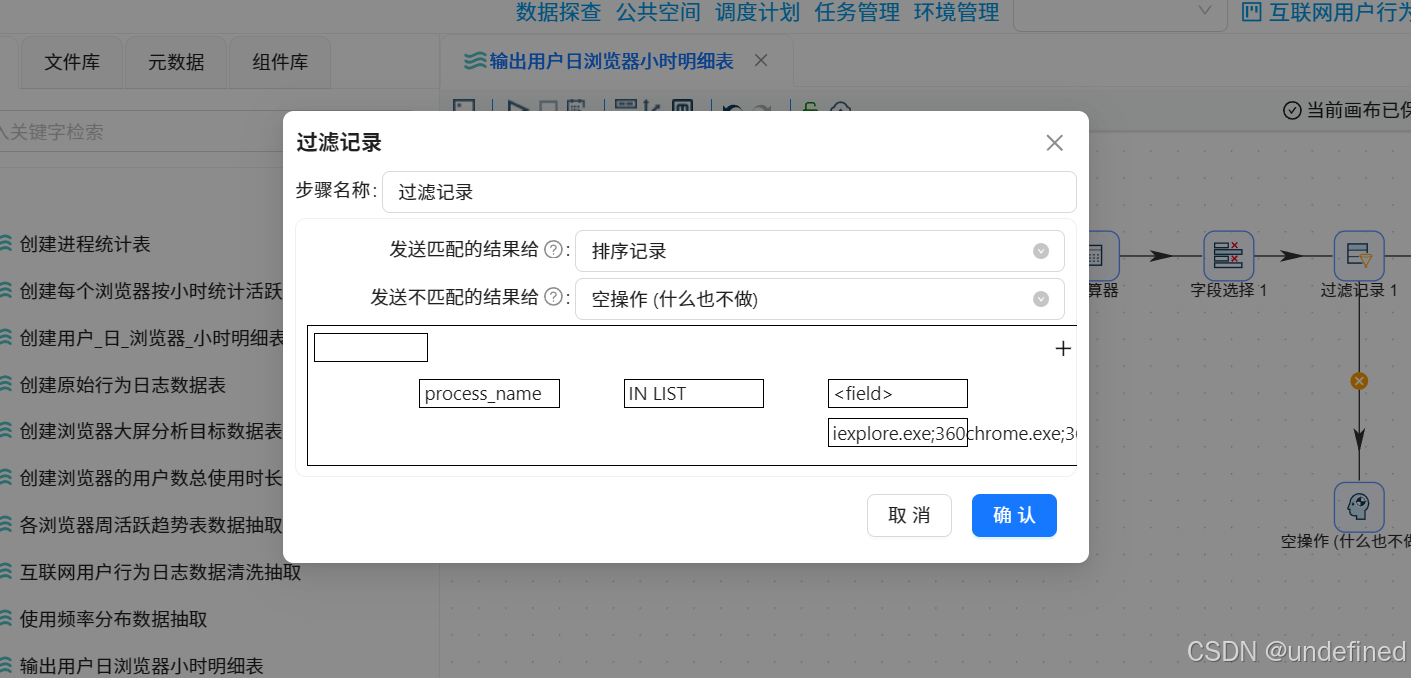
转换流中的分组组件中聚合字段的聚合类型是“个数”的,需要改成“统计不同值的数量(N)”,并在分支A的“分组1”组件前添加排序记录组件,按process_name升序排序
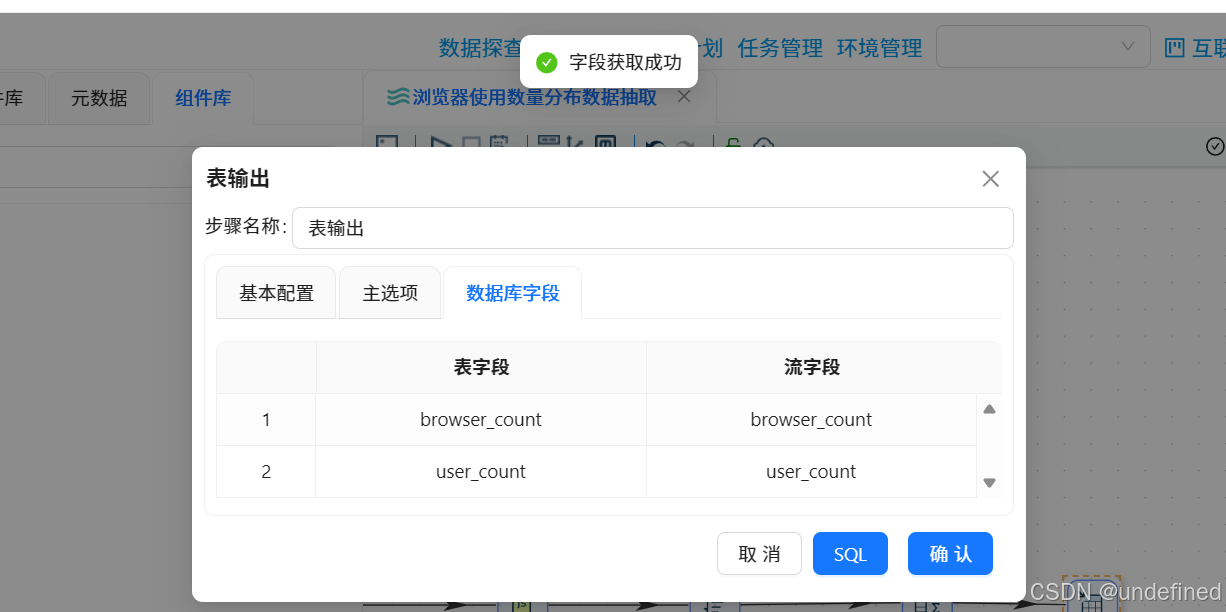
6.1.5添加表输出组件
拖拽“表输出”组件到画布中,值映射组件连接到“表输出”组件
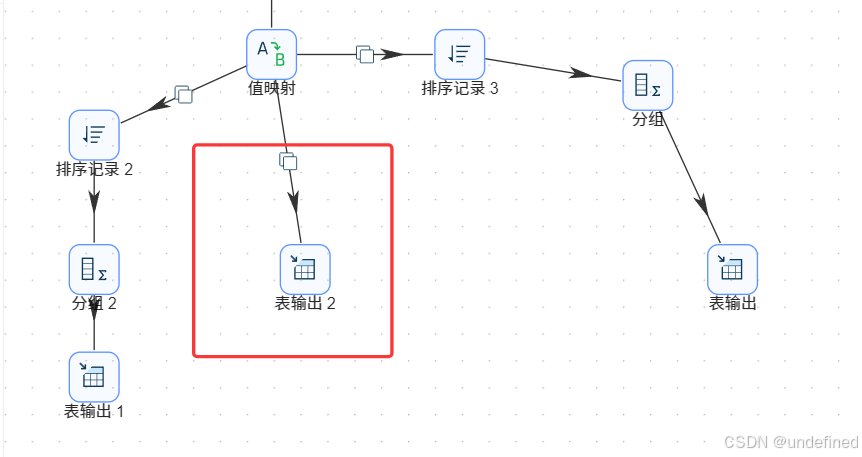
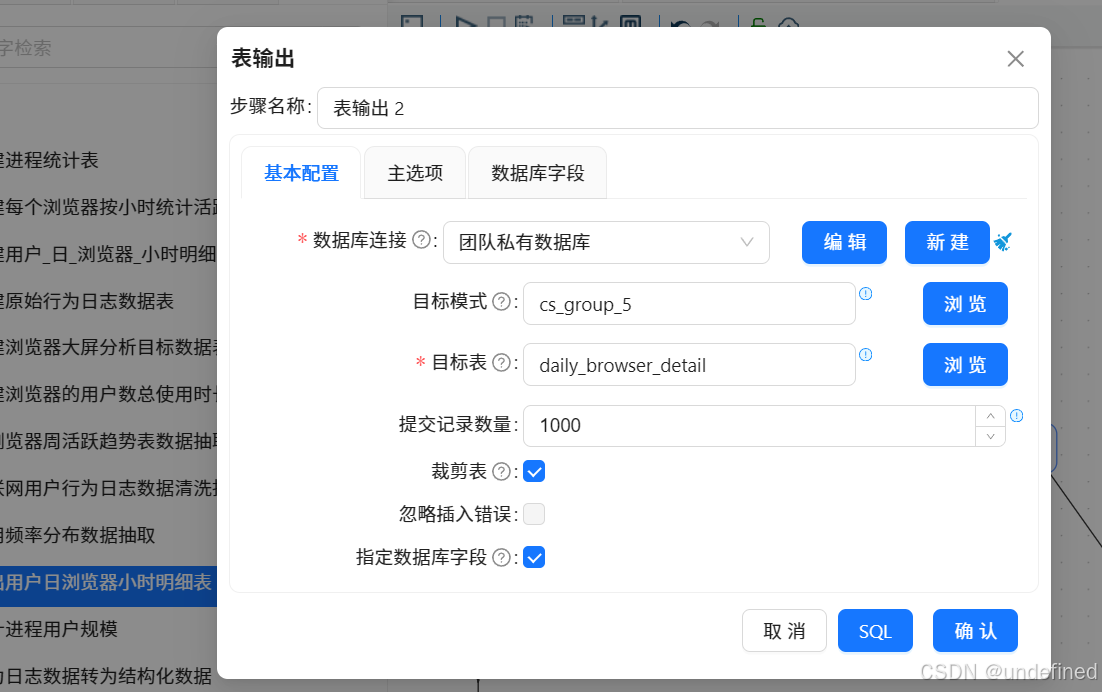
双击“表输出”组件,配置如下:
数据库连接:选择“团队私有数据库”
目标表:daily_browser_detail
勾选“裁剪表”,清空原有数据
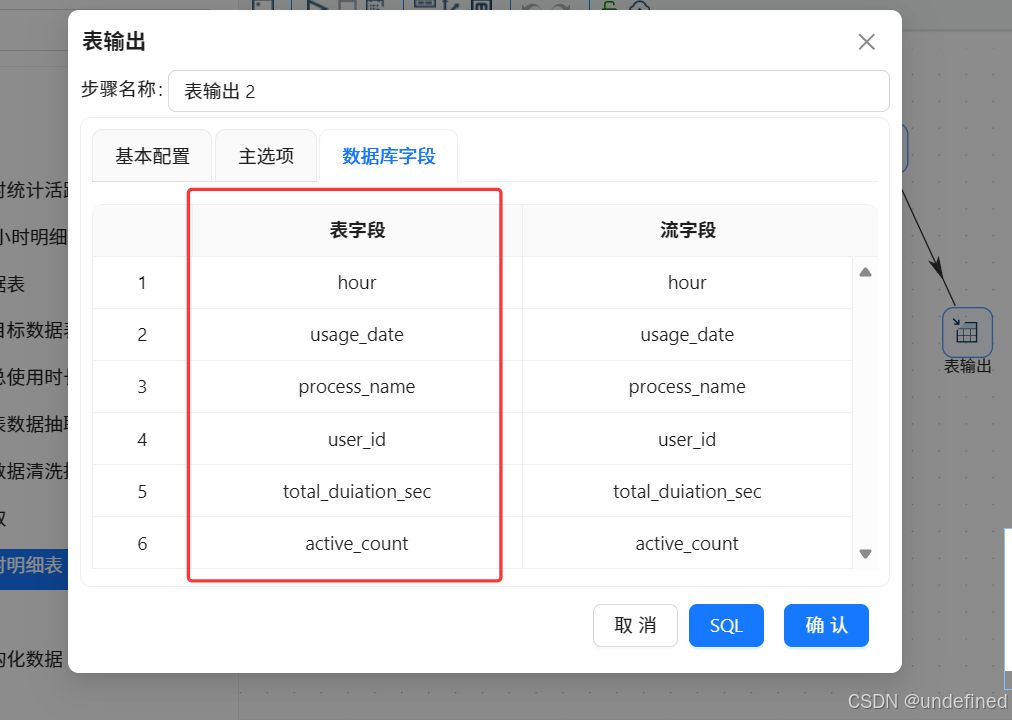
勾选“指定数据库字段”,建立字段映射
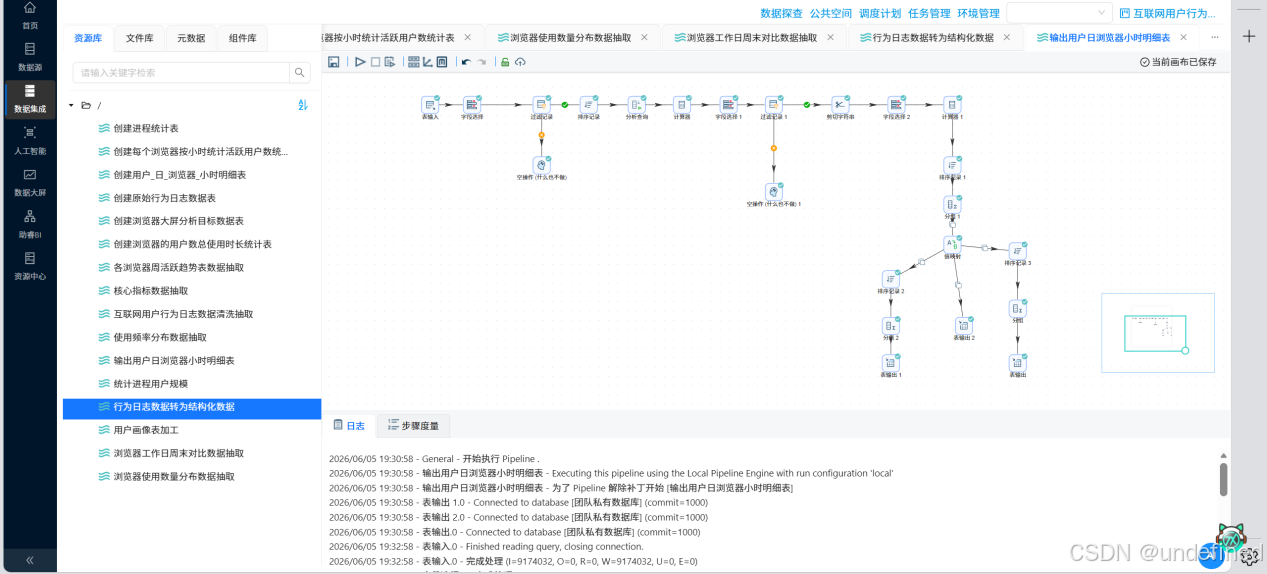
6.1.6执行转换流
击“运行”按钮,执行转换流
6.2创建目标数据表
在团队私有数据库中创建本实验需要输出的目标表
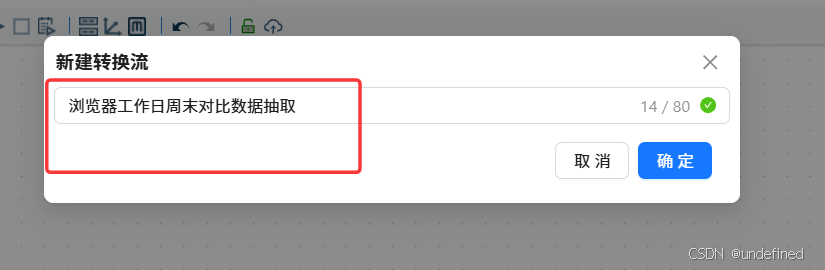
新建转换流“创建浏览器大屏分析目标数据表”,拖拽“执行一个SQL脚本”组件
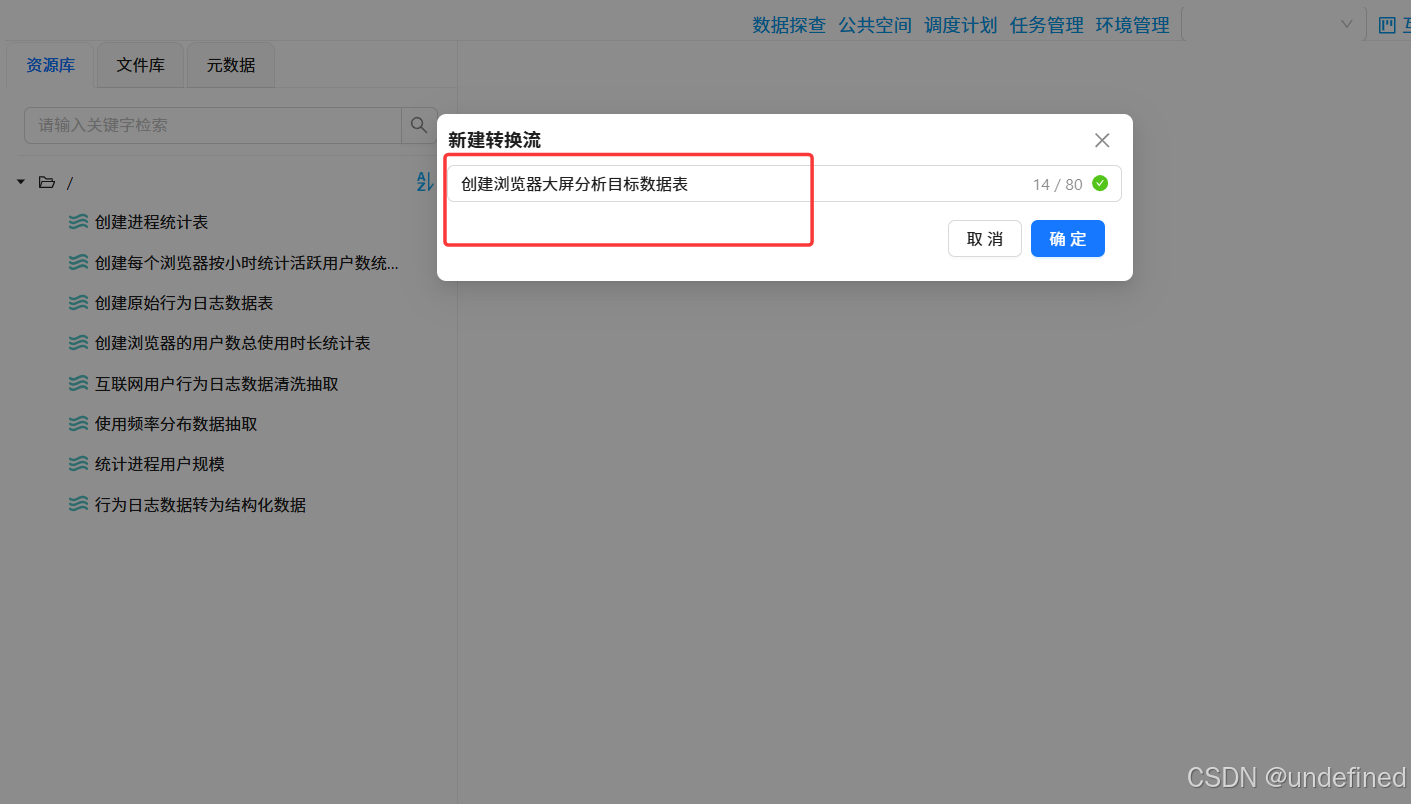
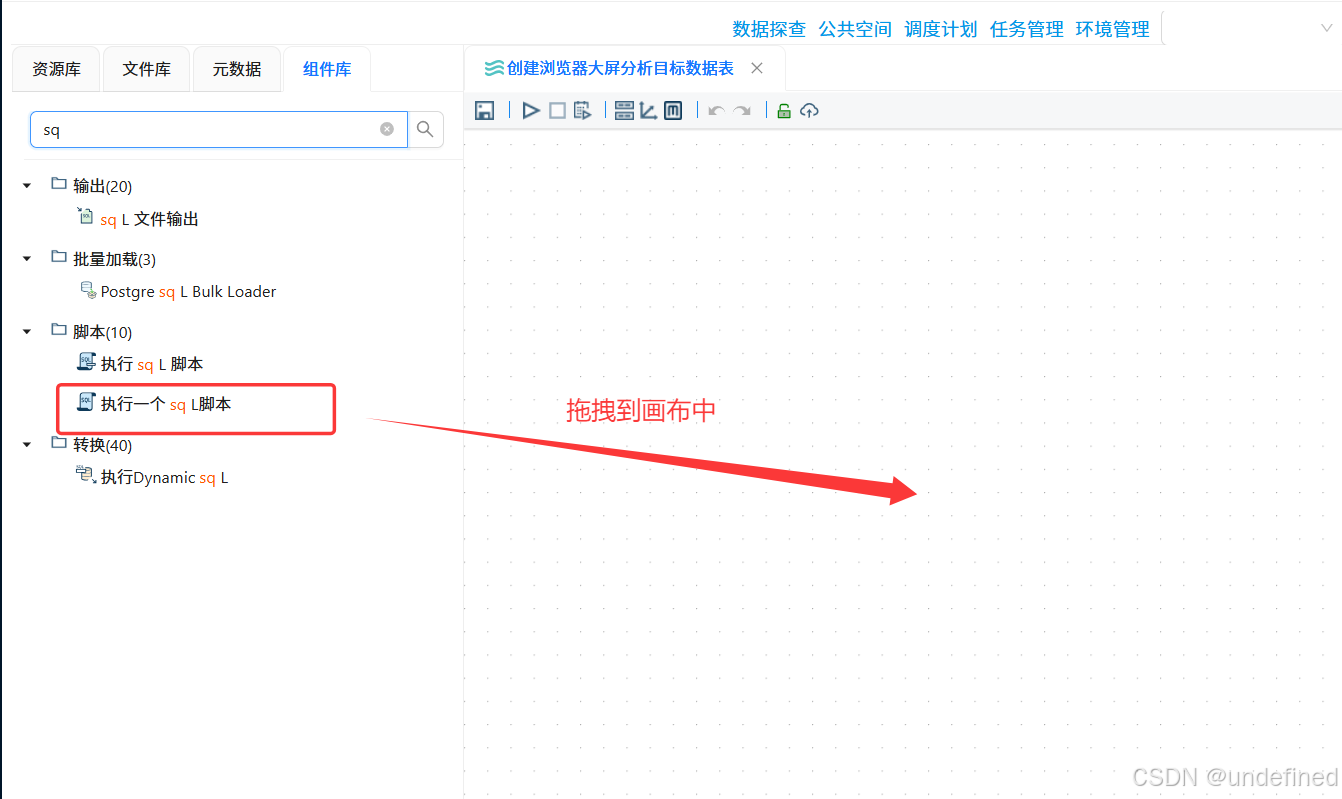
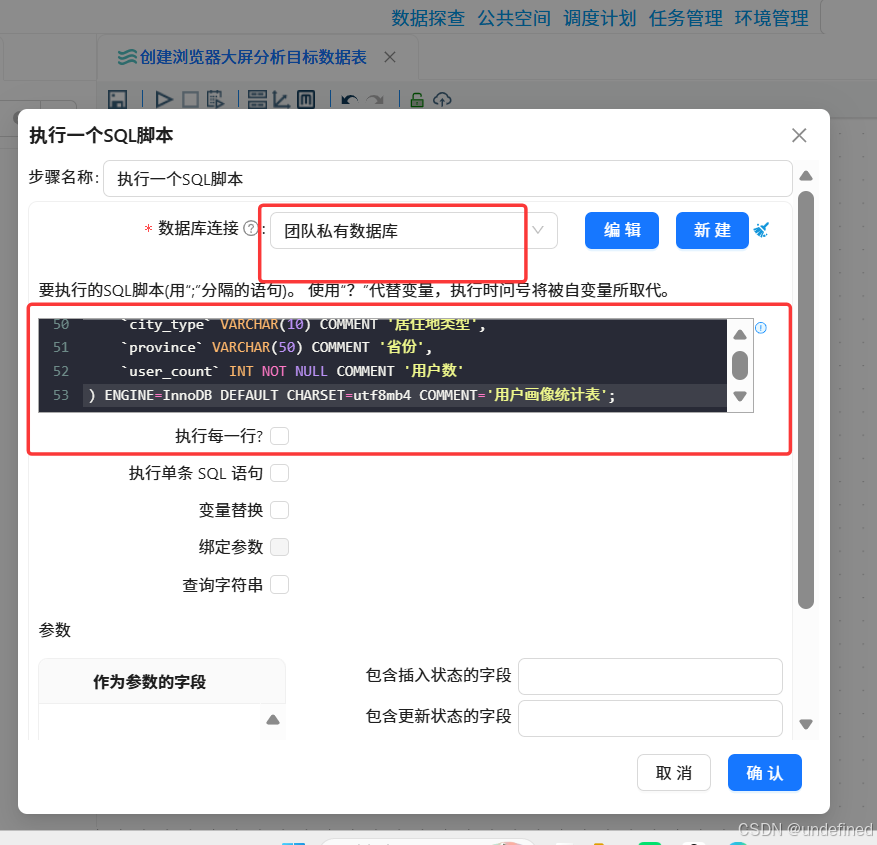
双击“执行一个SQL脚本”组件,数据库连接选择“团队私有数据库”,并输入以下SQL,使用DROP TABLE可以避免需要重新建表时语句报错:
--1.核心指标概览表
DROP TABLE IF EXISTS`browser_overview`;
CREATE TABLE`browser_overview`(
`metric_name`VARCHAR(50)NOT NULL COMMENT'指标名称',
`metric_value`DECIMAL(12,2)NOT NULL COMMENT'指标值'
)ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='核心指标概览表';
--2.各浏览器周活跃趋势表
DROP TABLE IF EXISTS browser_weekly_active;
CREATE TABLE`browser_weekly_active`(
`browser_name`VARCHAR(50)NOT NULL COMMENT'浏览器名称',
`week_range`VARCHAR(20)NOT NULL COMMENT'周日期范围',
`active_user_count`INT NOT NULL COMMENT'活跃用户数'
)ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='各浏览器周活跃趋势表';
--3.浏览器使用频率分布表
DROP TABLE IF EXISTS browser_frequency_stats;
CREATE TABLE`browser_frequency_stats`(
`browser_name`VARCHAR(50)NOT NULL COMMENT'浏览器名称',
`usage_level`VARCHAR(10)NOT NULL COMMENT'使用等级',
`user_count`INT NOT NULL COMMENT'用户数'
)ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='浏览器使用频率分布表';
--4.用户使用浏览器数量分布表
DROP TABLE IF EXISTS browser_multi_usage;
CREATE TABLE`browser_multi_usage`(
`browser_count`VARCHAR(10)NOT NULL COMMENT'使用浏览器数量',
`user_count`DECIMAL(5,2)NOT NULL COMMENT'用户数量'
)ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='用户使用浏览器数量分布表';
--5.浏览器工作日周末对比表
DROP TABLE IF EXISTS browser_weekday_weekend;
CREATE TABLE`browser_weekday_weekend`(
`browser_name`VARCHAR(50)NOT NULL COMMENT'浏览器名称',
`day_type`VARCHAR(10)NOT NULL COMMENT'工作日/周末',
`avg_duration_sec`INT NOT NULL COMMENT'人均使用时长(秒)',
`total_duration_hour`BIGINT NOT NULL COMMENT'总使用时长(小时)',
`user_count`INT NOT NULL COMMENT'用户数'
)COMMENT'浏览器工作日周末对比表';
--6.用户画像统计表
DROP TABLE IF EXISTS`user_profile_stats`;
CREATE TABLE`user_profile_stats`(
`browser_name`VARCHAR(50)NOT NULL COMMENT'浏览器名称',
`gender`VARCHAR(10)COMMENT'性别',
`age_group`VARCHAR(10)COMMENT'年龄段',
`edu`VARCHAR(50)COMMENT'学历',
`job`VARCHAR(50)COMMENT'职业',
`income`VARCHAR(50)COMMENT'收入',
`city_type`VARCHAR(10)COMMENT'居住地类型',
`province`VARCHAR(50)COMMENT'省份',
`user_count`INT NOT NULL COMMENT'用户数'
)ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='用户画像统计表';
点击“运行”按钮,执行转换流
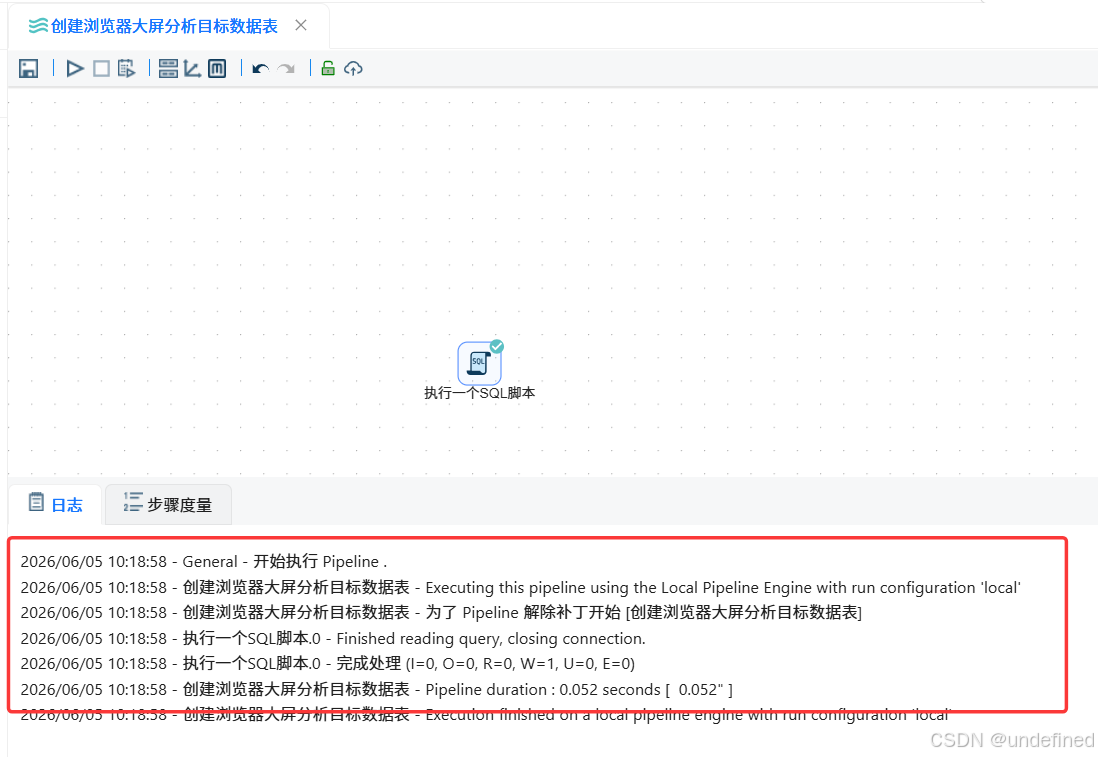
目标:统计每个浏览器在第1-4周的每周活跃用户数
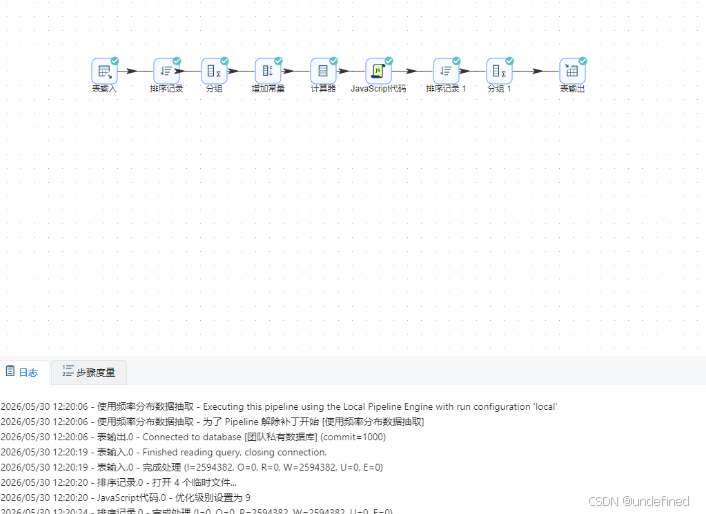
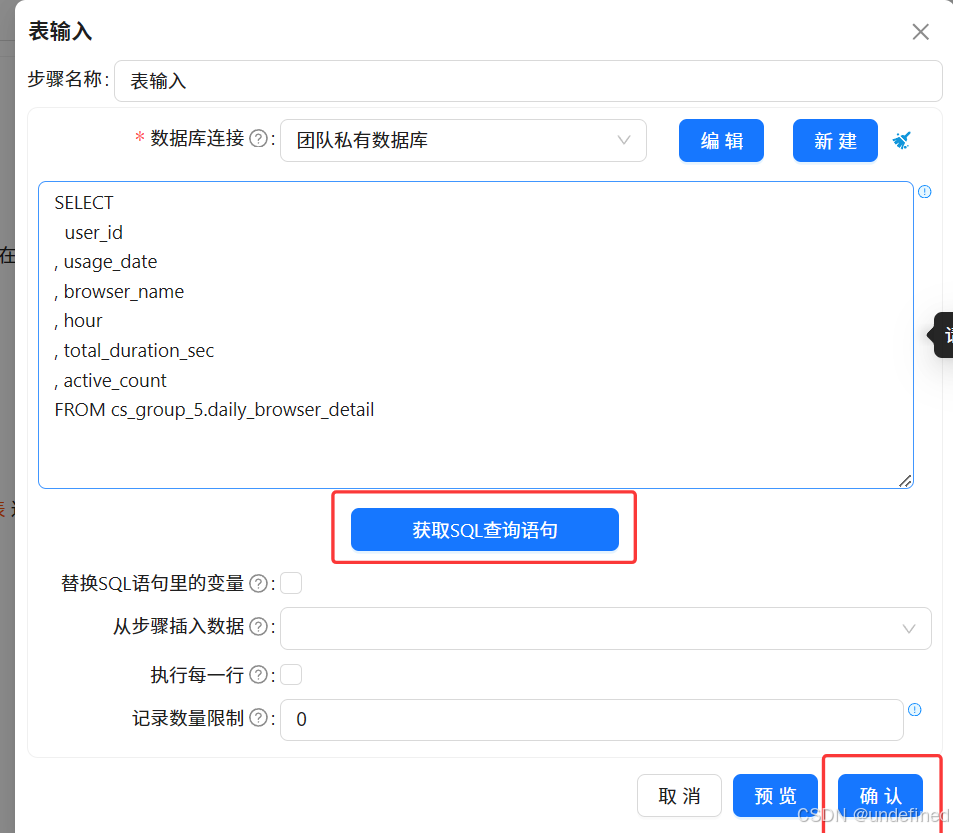
新建转换流“各浏览器周活跃趋势表数据抽取”,拖拽“表输入”组件画布中,数据库连接选择“团队私有数据库”,点击“获取SQL查询语句”,选择daily_browser_detail获取所有查询语句
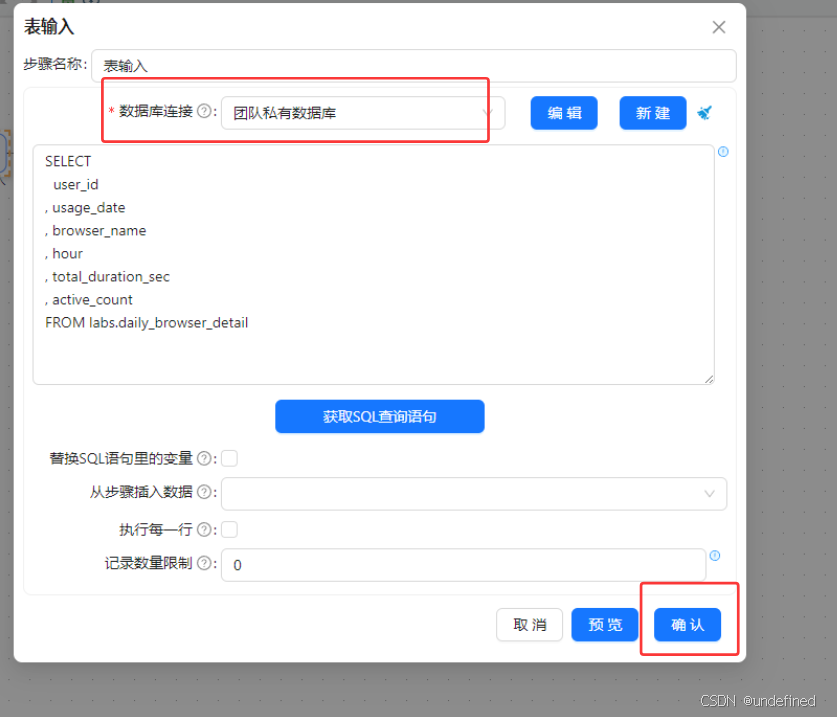
这里我们需要将每个浏览器的使用日期转为周:5/7-5/13、6/4-6/10、7/2-7/8、8/6-8/12,可以使用值映射组件完成,但是在此之前,需要使用字段选择组件对usage_date进行格式转换。
拖拽字段选择组件到画布中,创建表输入组件到字段选择组件的连线
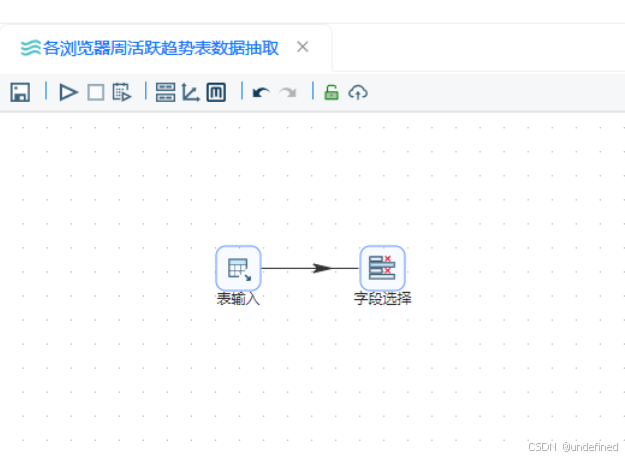
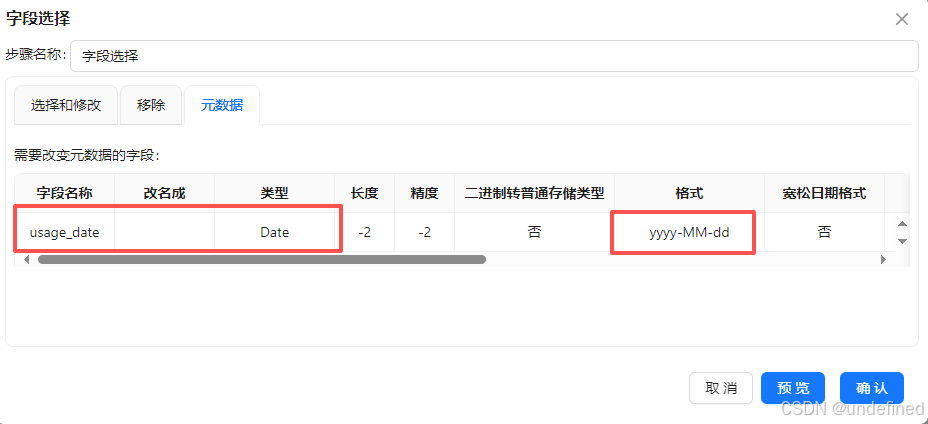
双击字段选择组件,点击“元数据”,右键插入,输入字段名称usage_date,类型为Date,格式为“yyyy-MM-dd”
再拖拽值映射组件,字段选择组件连接值映射组件
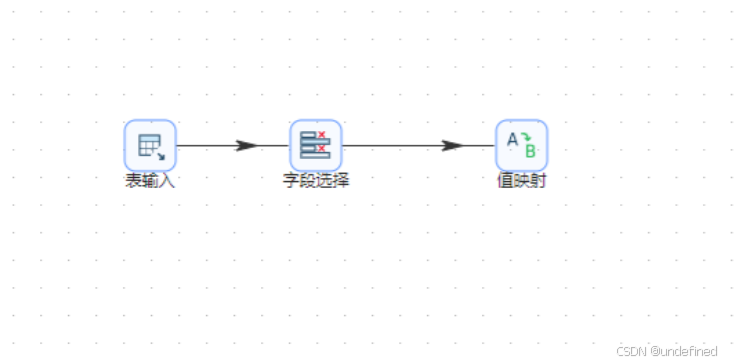
双击值映射组件,使用的字段名选择“usage_date”,目标字段名(空=覆盖)输入“week_range”,表示创建新字段week_range用来存储映射结果,接下来就插入行,将每个日期映射为对应的周区间
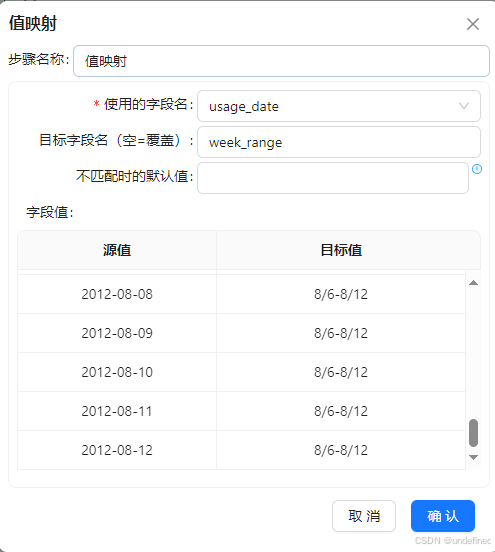
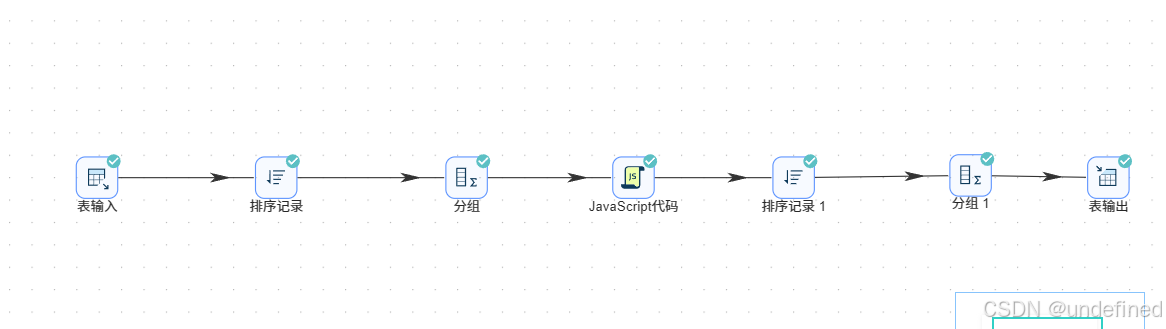
接下来我们按各浏览器、周分组统计用户数,分组之前需要对数据进行排序,避免统计结果出错。拖拽排序记录组件到画布中,创建值映射组件到排序记录组件的连线
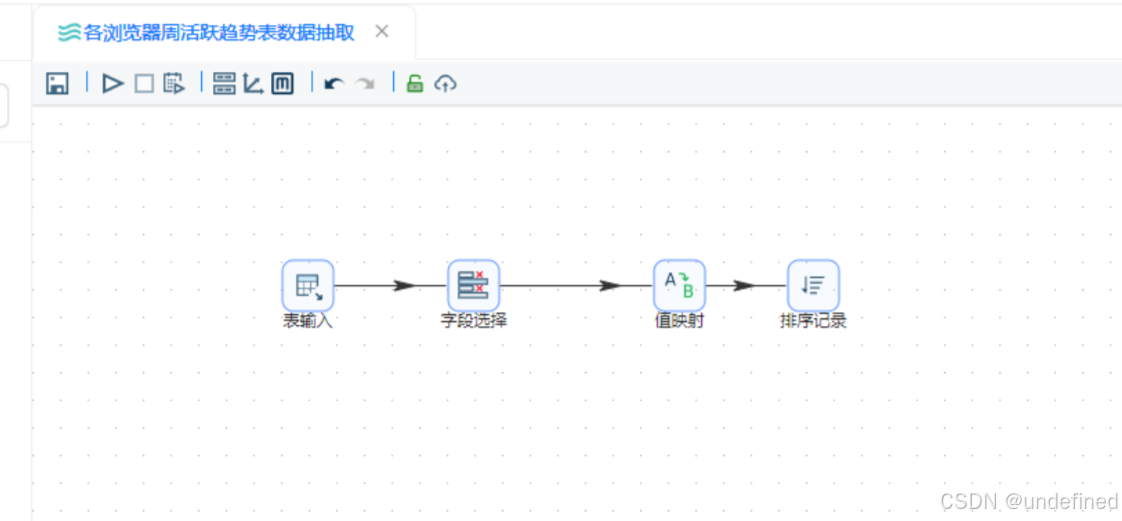
排序记录组件设置为按照browser_name、week_range升序排序
排序后拖拽分组组件,排序记录组件连接到分组组件
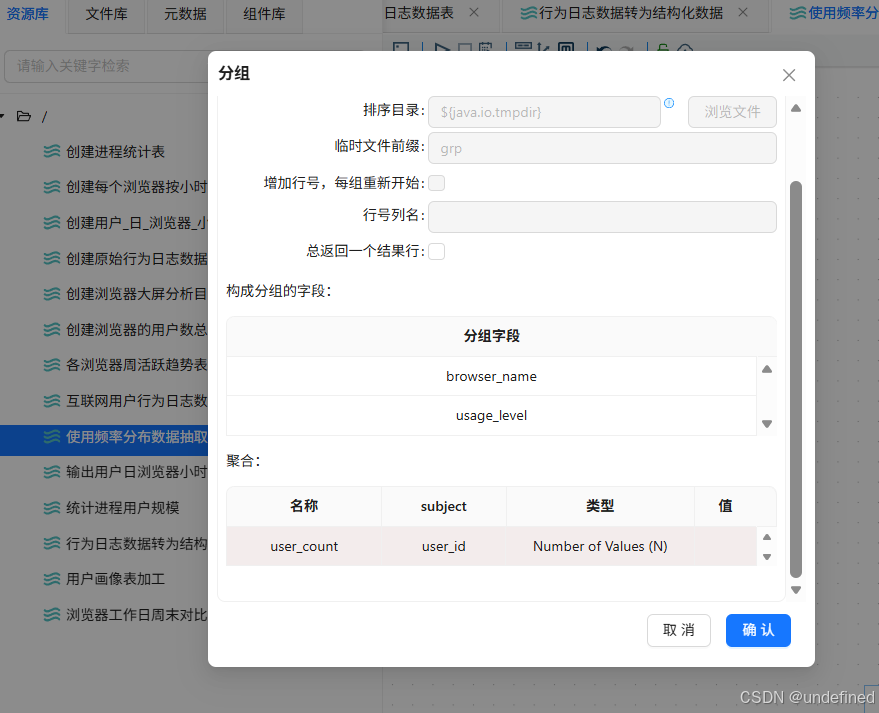
分组字段为browser_name、week_range,聚合时对user_id进行去重计数,得到active_user_count,因此,聚合配置中输入字段“active_user_count”,subject为“user_id”,类型为“统计不同值的数量(N)”
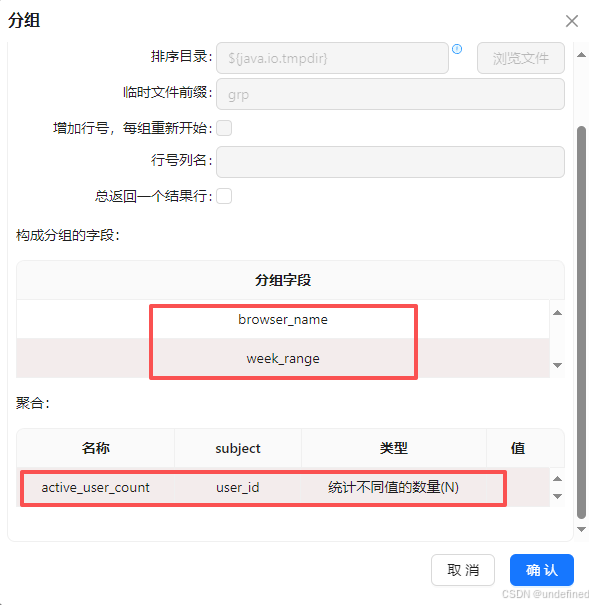
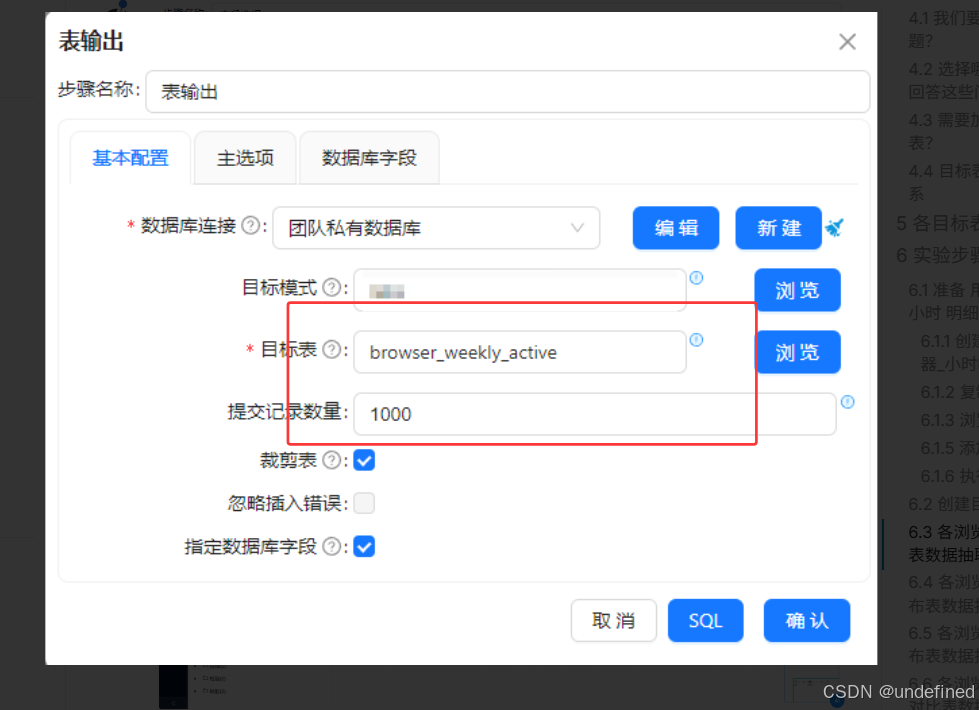
最后拖入表输出组件,将分组聚合结果入库,表输出组件配置为:
数据库连接:选择“团队私有数据库”
目标表:browser_weekly_active
勾选“裁剪表”,清空原有数据
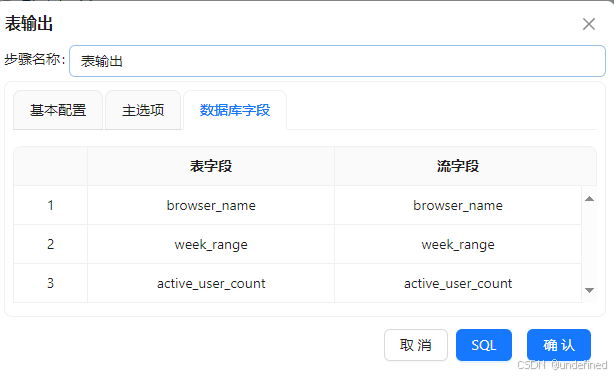
勾选“指定数据库字段”,建立字段映射
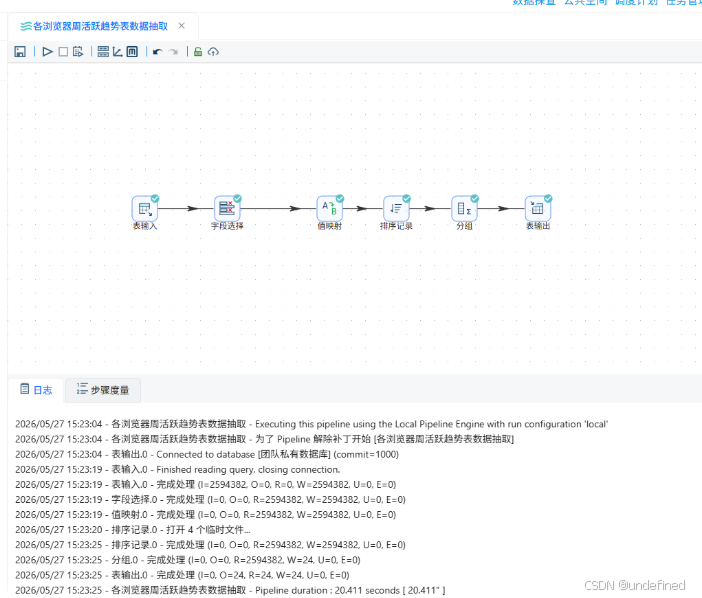
执行转换流:
6.4各浏览器使用频率分布表数据抽取
目标:按轻/中/重度划分用户使用频率
新建转换流“使用频率分布数据抽取”,拖拽“表输入”组件画布中,数据库连接选择“团队私有数据库”,点击“获取SQL查询语句”,选择daily_browser_detail获取所有查询语句
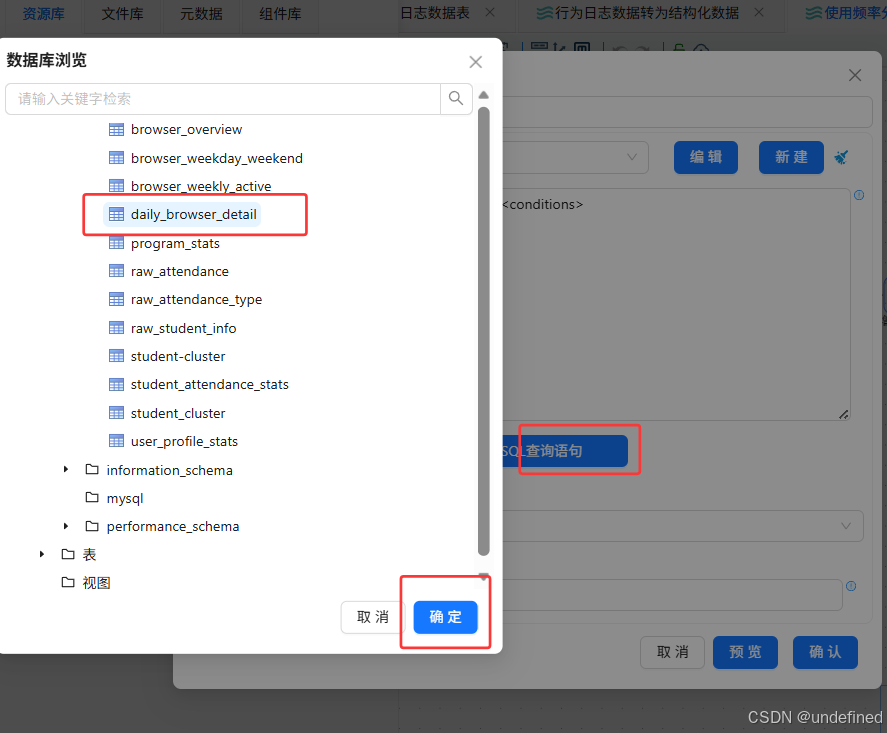
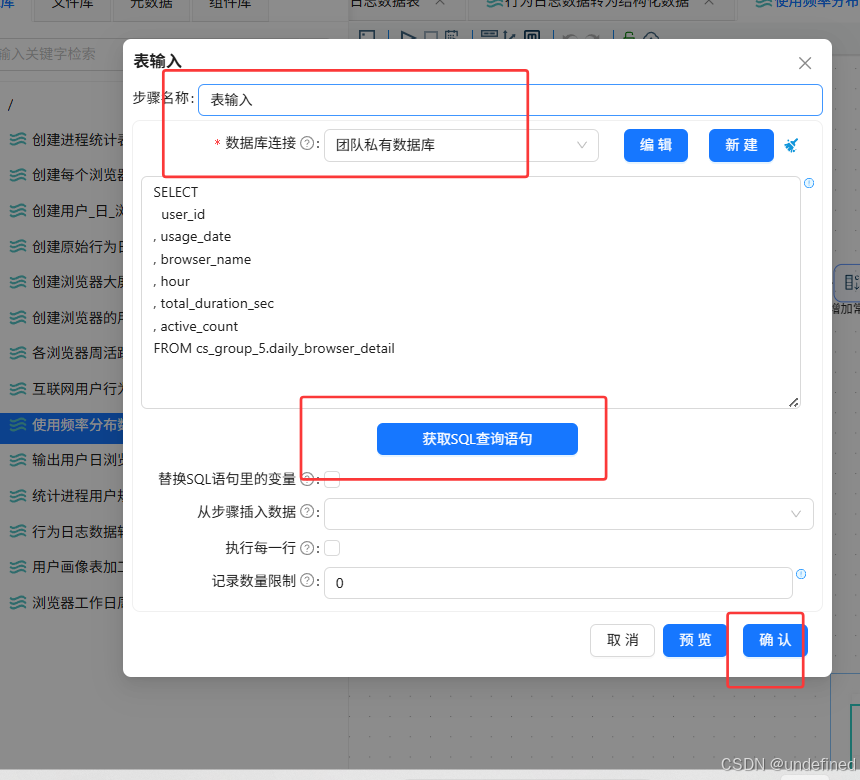
接下来,我们统计每个用户使用各浏览器的使用时长,拖拽排序记录组件到画布中,创建表输入组件到排序记录组件的连线
排序记录组件设置为按照user_id、browser_name升序排序
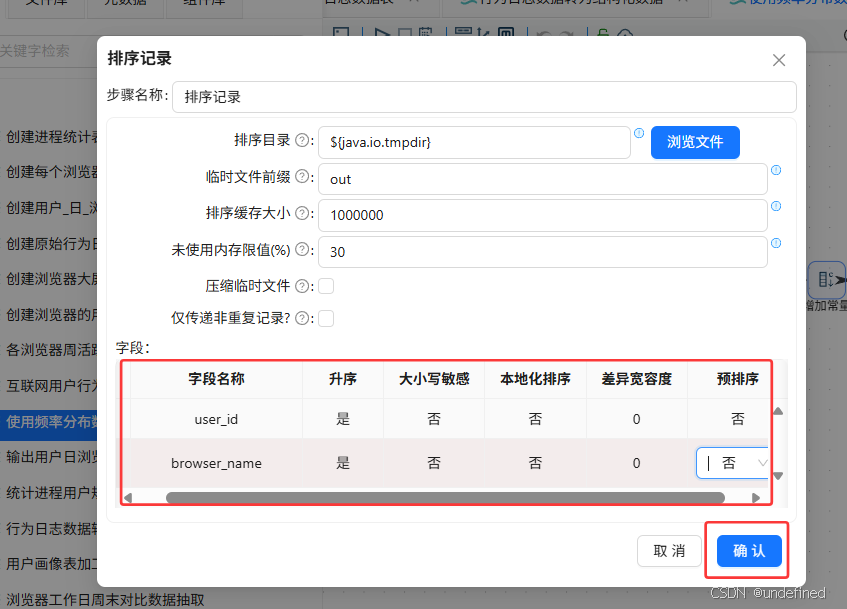
排序后拖拽分组组件,排序记录组件连接到分组组件
分组组件的分组字段为user_id、browser_name,总使用时长=每天总使用时长total_duration_sec求和
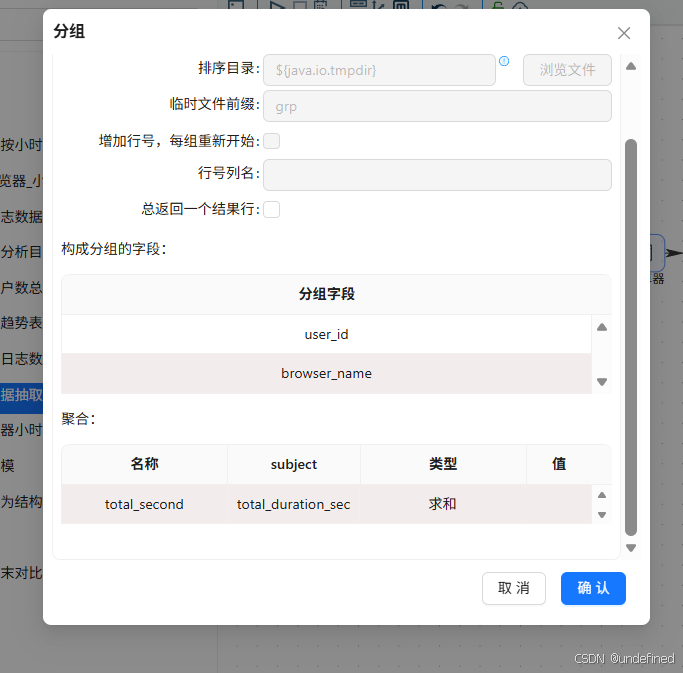
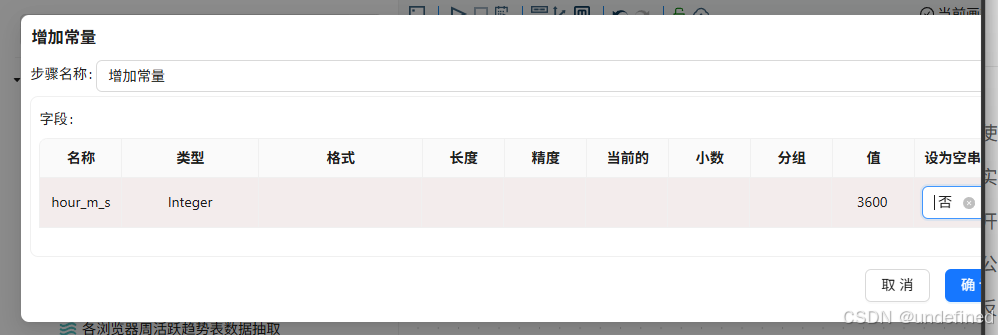
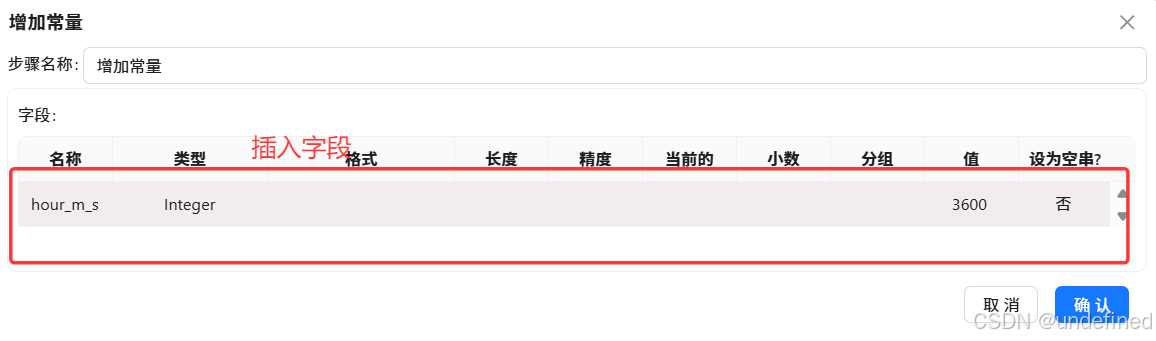
这样计算的总时长单位是秒,我们将其转换为小时更直观,小时=秒÷3600,由于我们的数据中没有3600这个字段,所以需要先增加这个常量字段。拖拽增加常量组件到画布中,分组组件连接到增加常量组件
增加常量组件配置中增加新字段“hour_m_s”,将其类型设置为Integer,并且值固定为3600,如下
接下来,拖入计算器组件
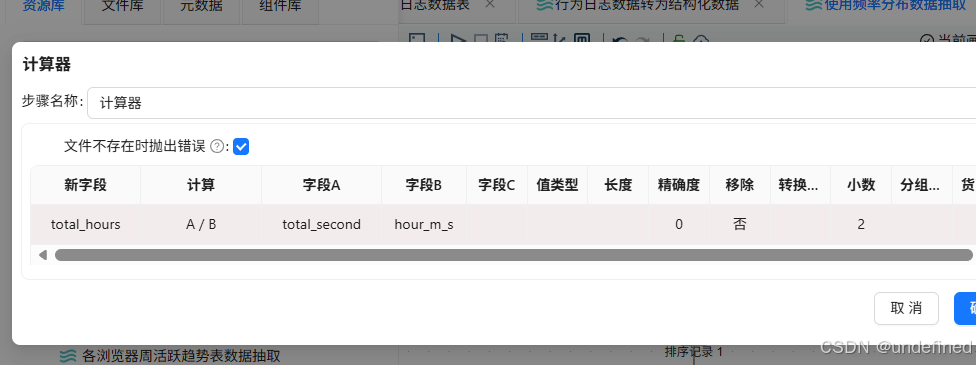
通过计算器,计算小时,新增使用时长单位为小时的字段“total_hours”,计算公式为“A/B”,字段A为“total_seconds”,字段B为“hour_m_s”,保留2位小数
接下来,我们为使用频率划分等级。拖入JavaScript代码组件,计算器组件连接到JavaScript代码组件
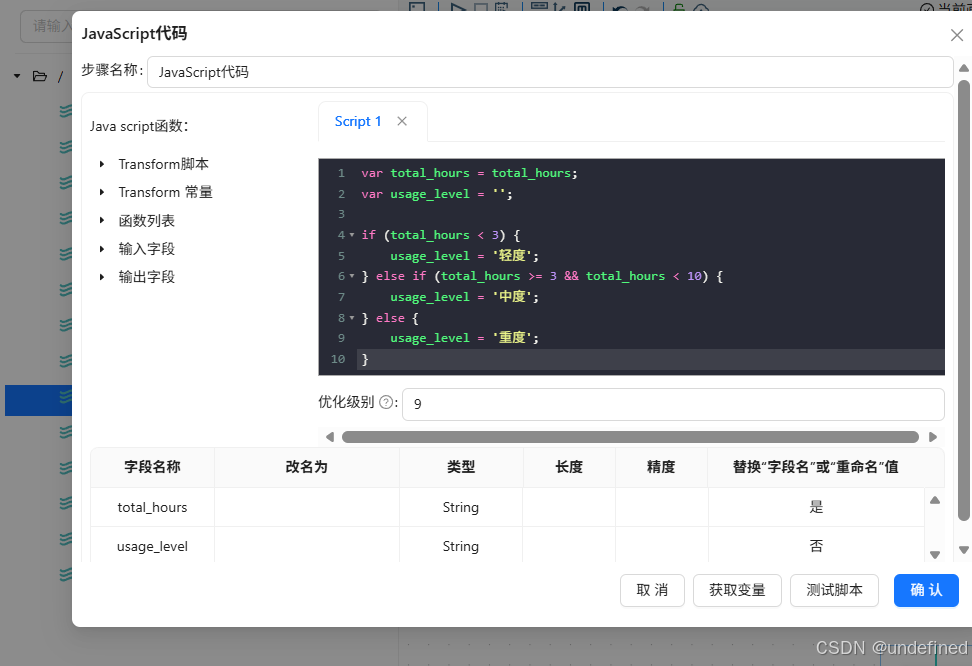
双击JavaScript代码组件,如下以下代码,点击”获取变量”,自动获取代码中的变量
var total_hours=total_hours;var usage_level='';
if(total_hours<3){
usage_level='轻度';
}else if(total_hours>=3&&total_hours<10){
usage_level='中度';
}else{
usage_level='重度';
}
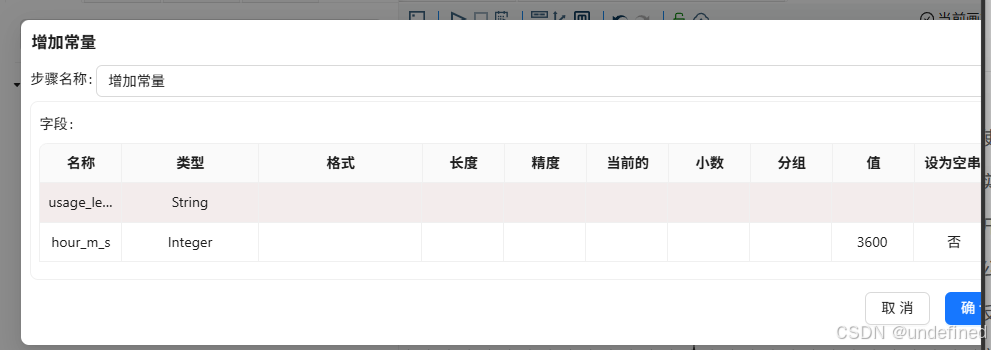
usage_level这个字段我们需要在之前的增加常量组件中新增:
接下来,我们就可以统计每个浏览器的各使用等级的用户数了
同样的,先拖入排序记录组件,将数据按照browser_name、usage_level升序排序
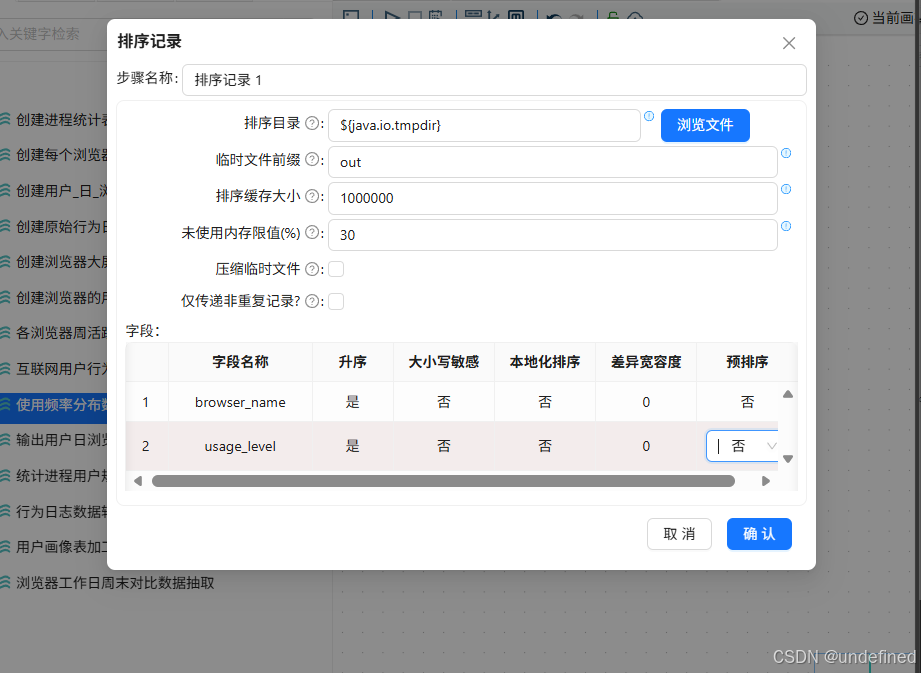
再拖入分组组件,按browser_name、usage_level分组,统计user_count(user_id去重计数)
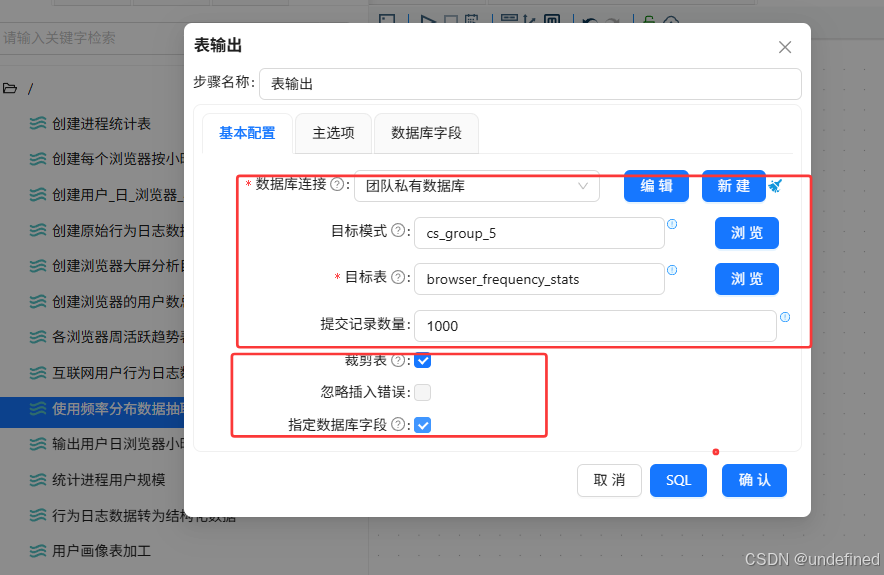
 最后拖入表输出组件,将分组聚合结果入库,表输出组件配置为:
最后拖入表输出组件,将分组聚合结果入库,表输出组件配置为:
数据库连接:选择“团队私有数据库”
目标表:browser_frequency_stats
勾选“裁剪表”,清空原有数据
勾选“指定数据库字段”,建立字段映射
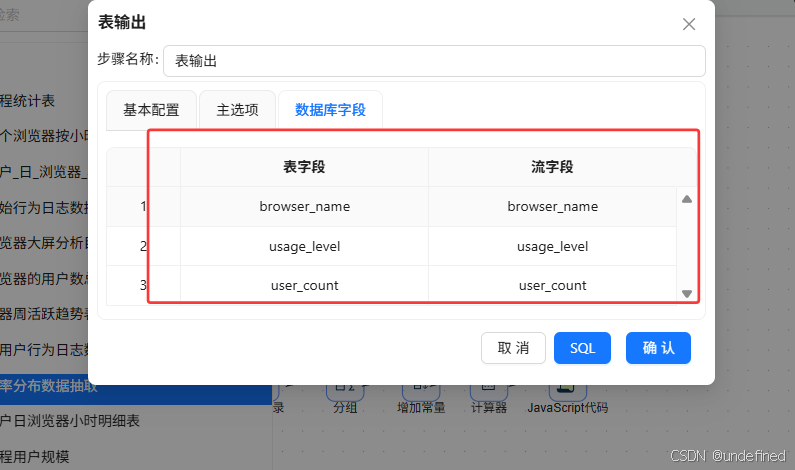
执行转换流:
6.5各浏览器使用数量分布表数据抽取
目标:统计用户使用1种、2种、3种及以上浏览器的用户数
新建转换流“浏览器使用数量分布数据抽取”,拖拽“表输入”组件画布中,数据库连接选择“团队私有数据库”,点击“获取SQL查询语句”,选择daily_browser_detail获取所有查询语句
我们统计每个用户使用各浏览器的种类数量,拖拽排序记录组件到画布中,创建表输入组件到排序记录组件的连线
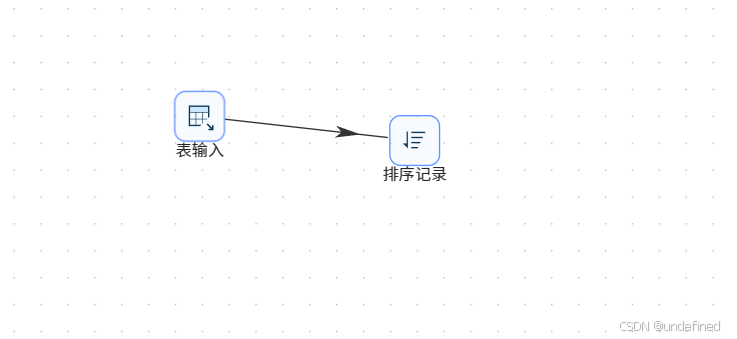
排序记录组件设置为按照user_id升序排序
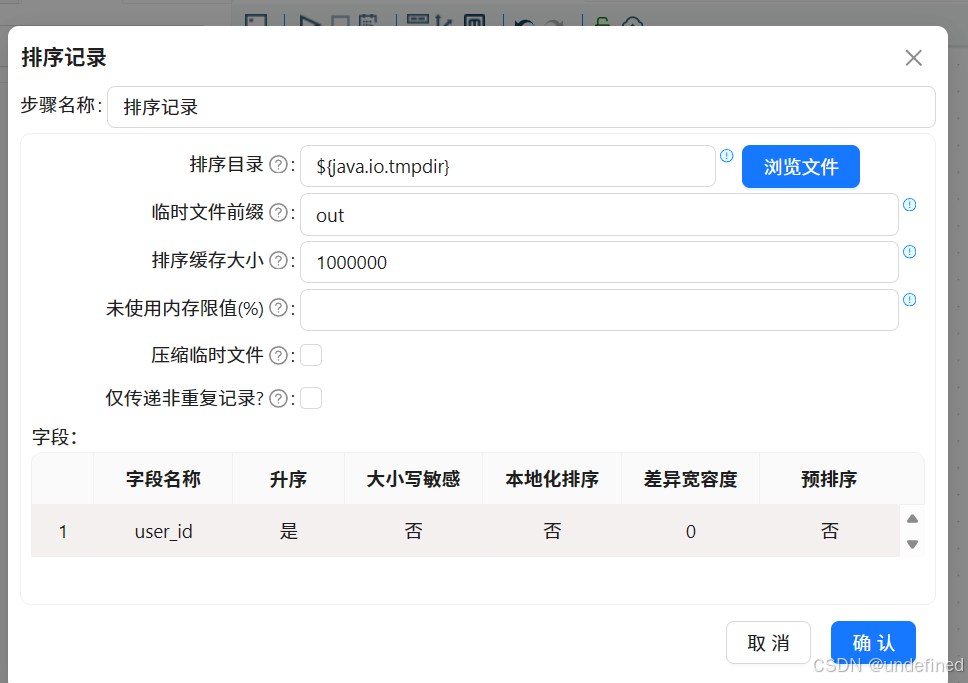
排序后拖拽分组组件,排序记录组件连接到分组组件
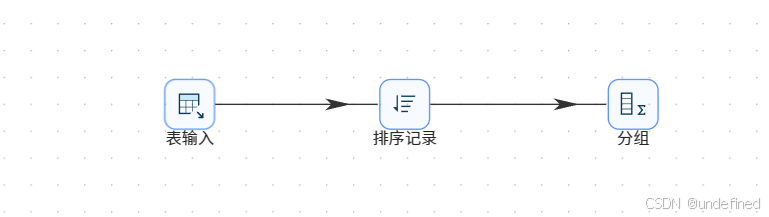
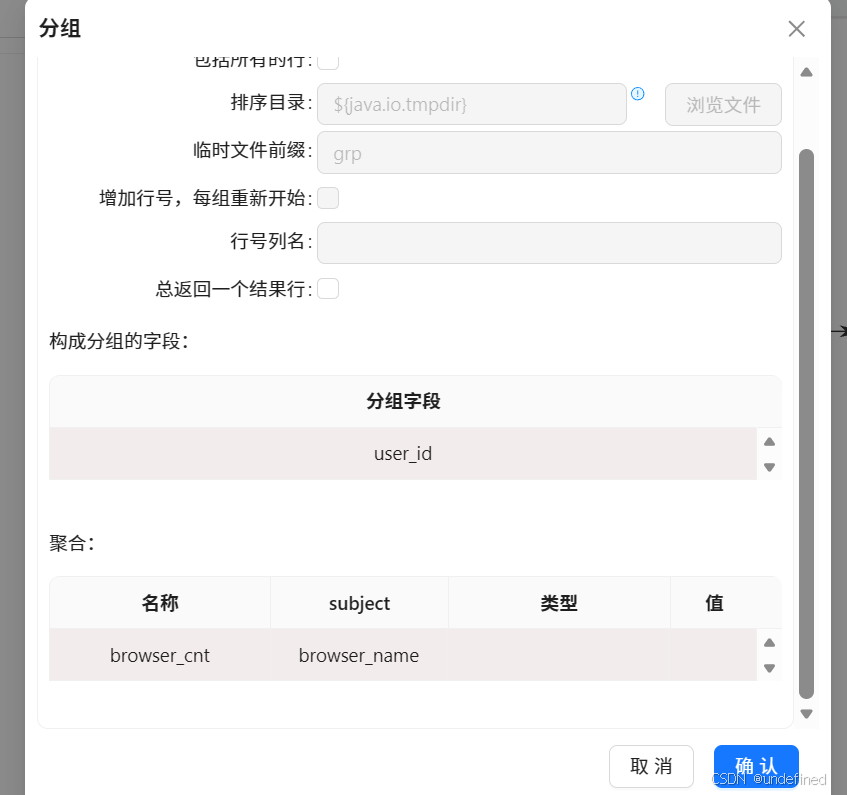
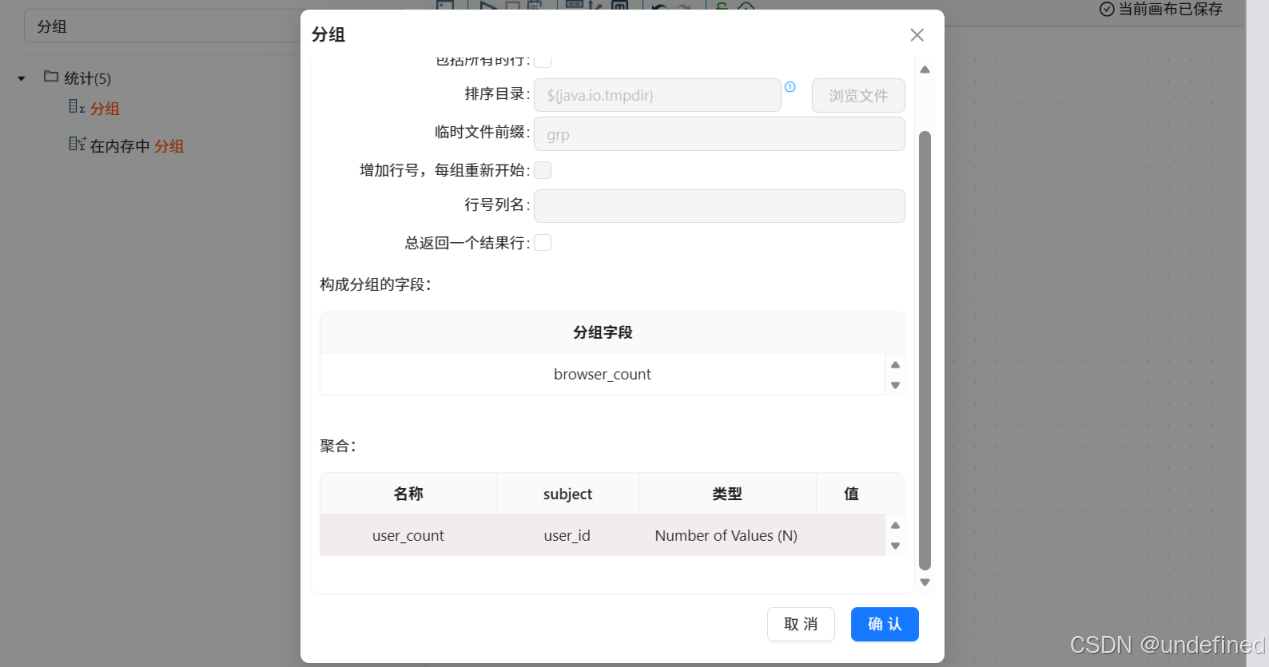
分组组件的分组字段为user_id,使用浏览种类数量=浏览器名称去重计数
接下来,我们划分浏览器数量等级。拖入JavaScript代码组件,计算器组件连接到JavaScript代码组件
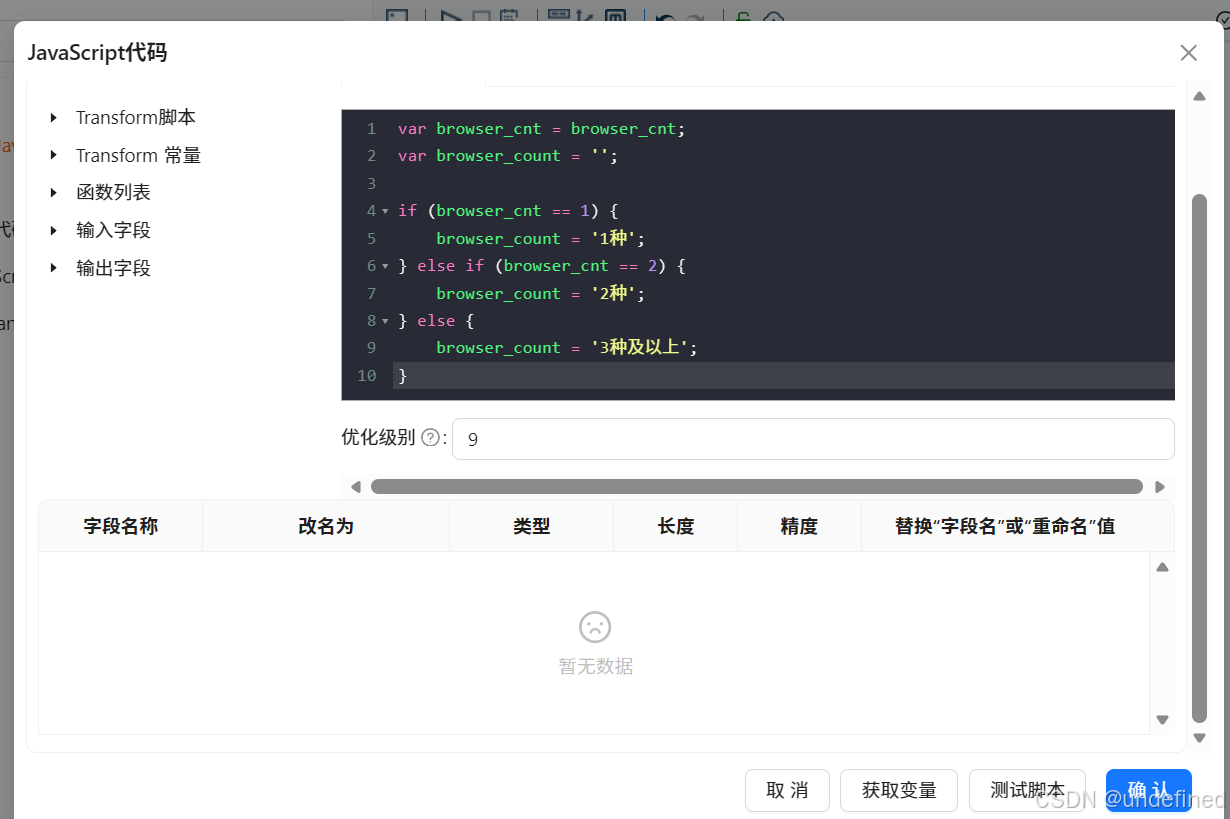
双击JavaScript代码组件,如下以下代码,点击”获取变量”,自动获取代码中的变量
var browser_cnt=browser_cnt;
var browser_count='';
if(browser_cnt==1){
browser_count='1种';
}else if(browser_cnt==2){
browser_count='2种';
}else{
browser_count='3种及以上';
}
接下来,我们就可以统计使用1种、2种、3种浏览器的用户数了
同样的,先拖入排序记录组件,将数据按照browser_count升序排序
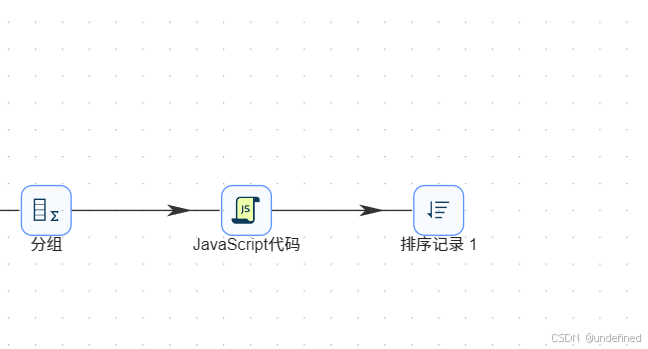
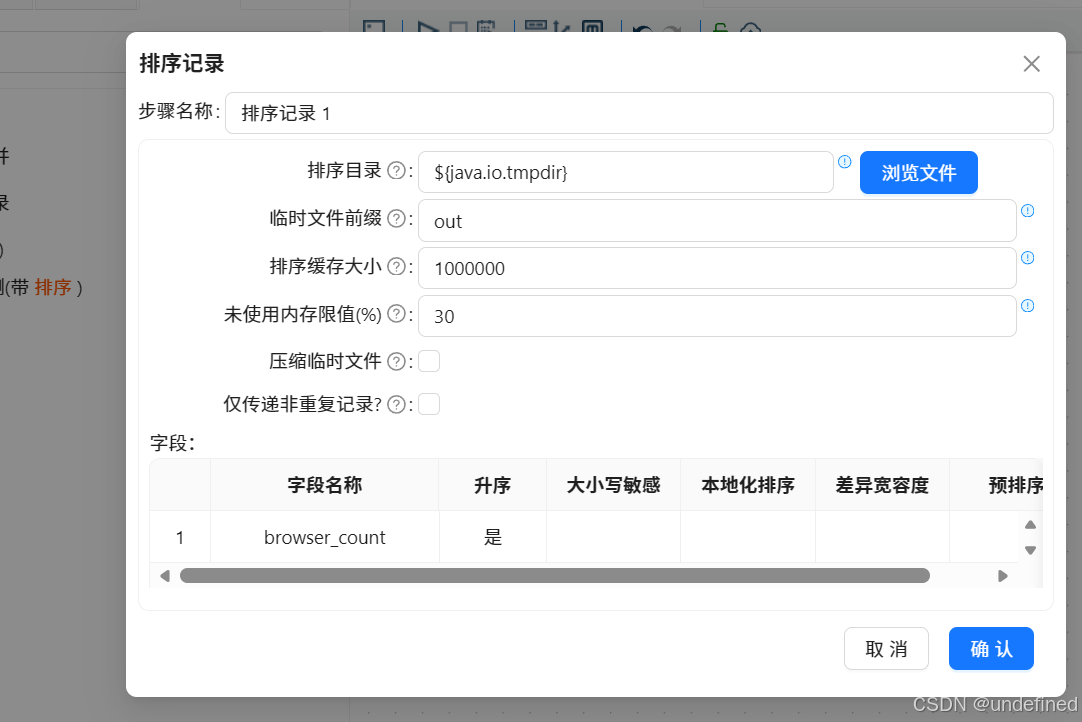
再拖入分组组件,按browser_count分组,统计user_count(user_id去重计数)
最后拖入表输出组件,将分组聚合结果入库,表输出组件配置为:
数据库连接:选择“团队私有数据库”
目标表:browser_multi_usage
勾选“裁剪表”,清空原有数据
勾选“指定数据库字段”,建立字段映射
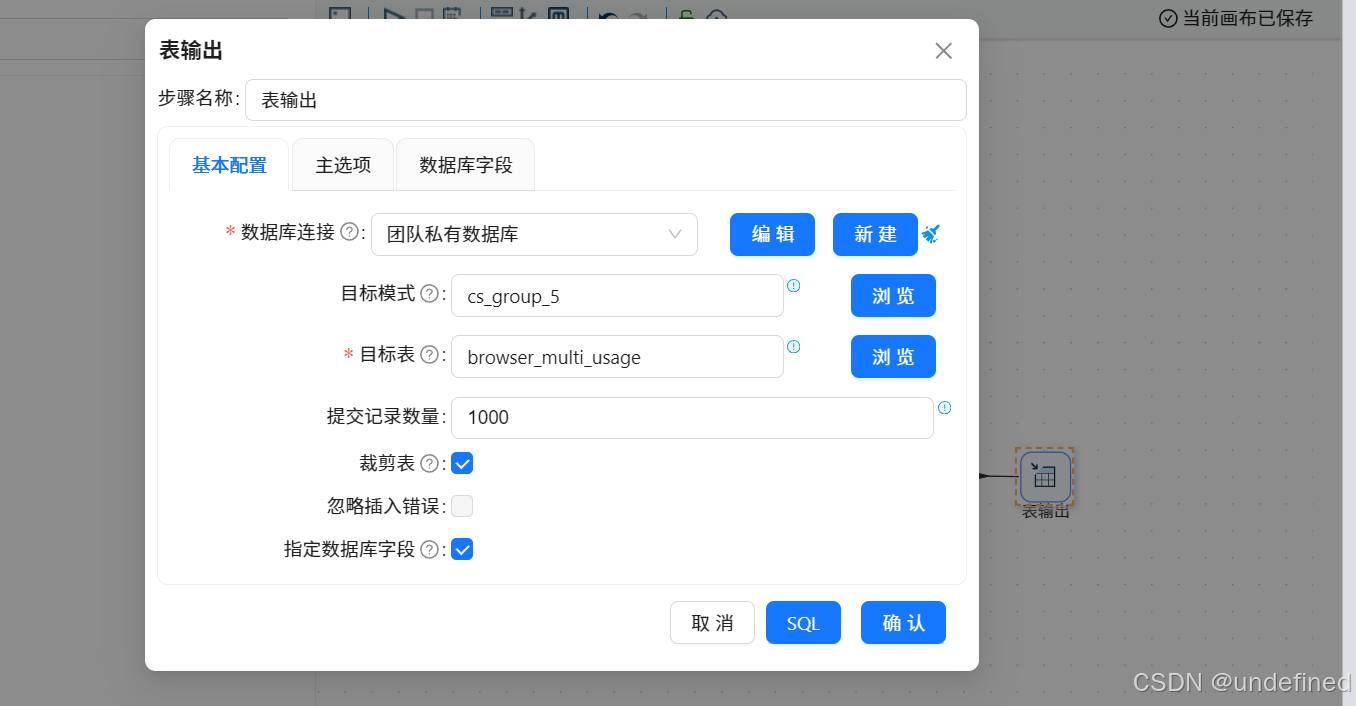
执行转换流
6.6各浏览器工作日周末对比表数据抽取
目标:统计各浏览器工作日周末使用时长对比
新建转换流“浏览器工作日周末对比数据抽取”,拖拽“表输入”组件画布中,数据库连接选择“团队私有数据库”,点击“获取SQL查询语句”,选择daily_browser_detail获取所有查询语句
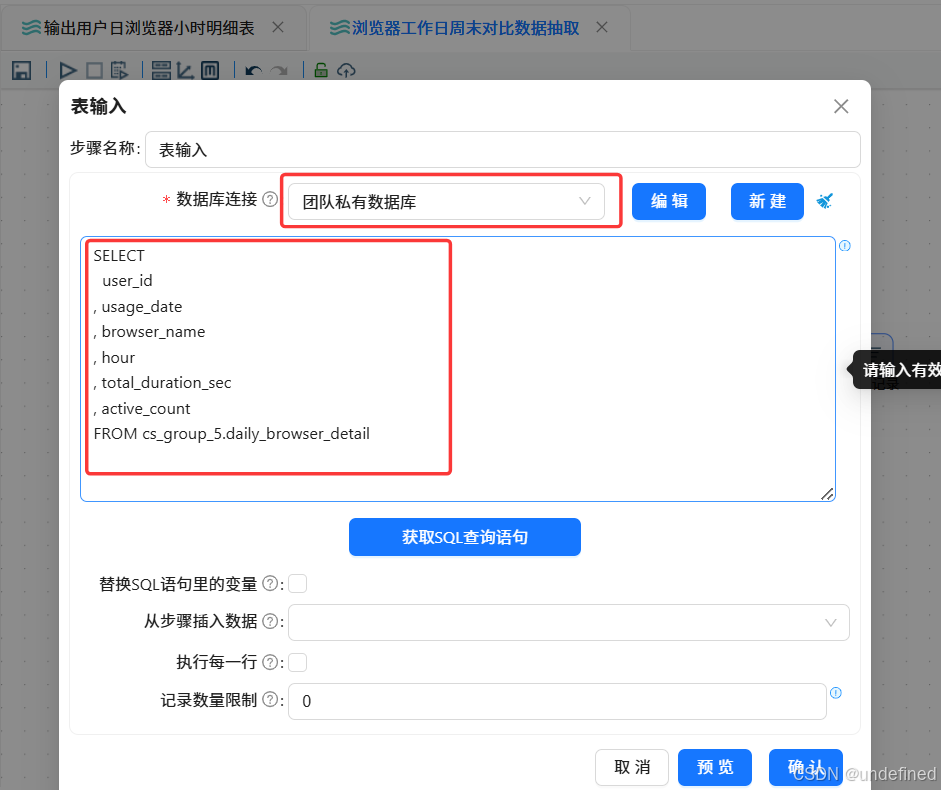
接下来,根据使用日期获取星期几,拖拽JavaScript代码组件到画布中,表输入组件连接JavaScript代码组件
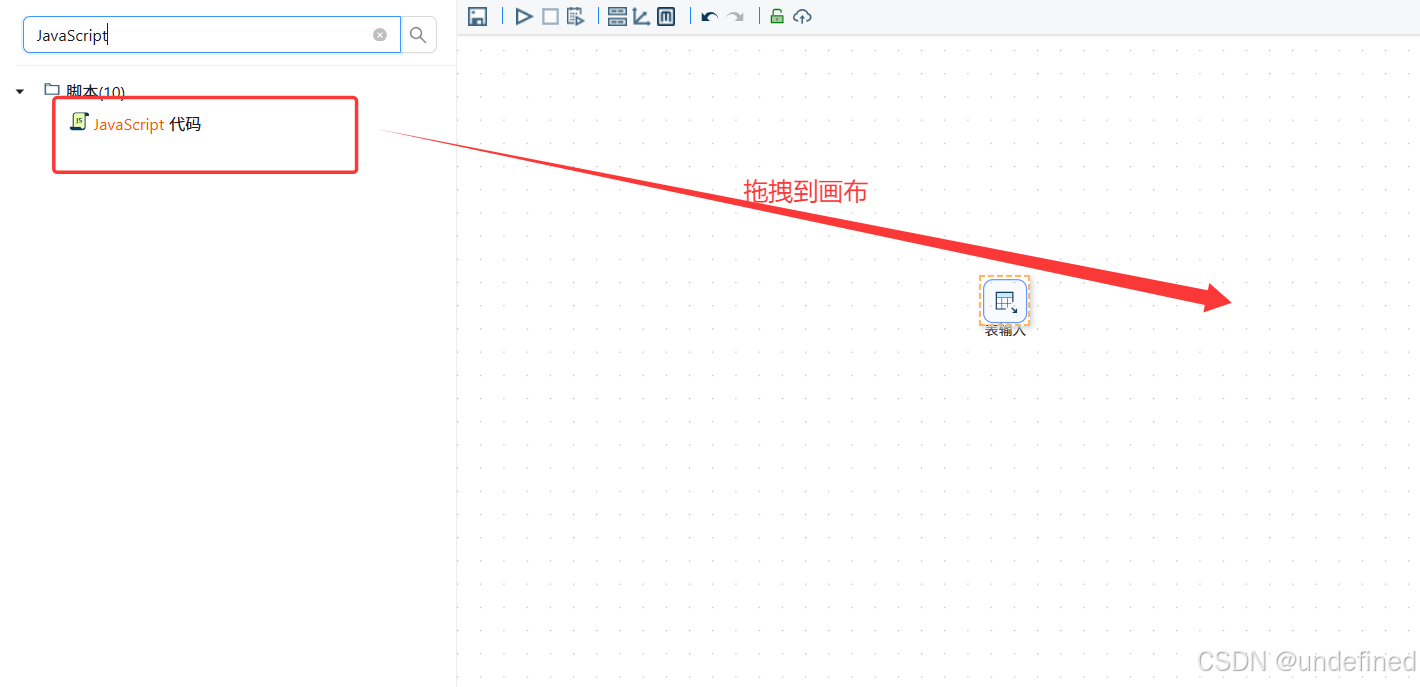
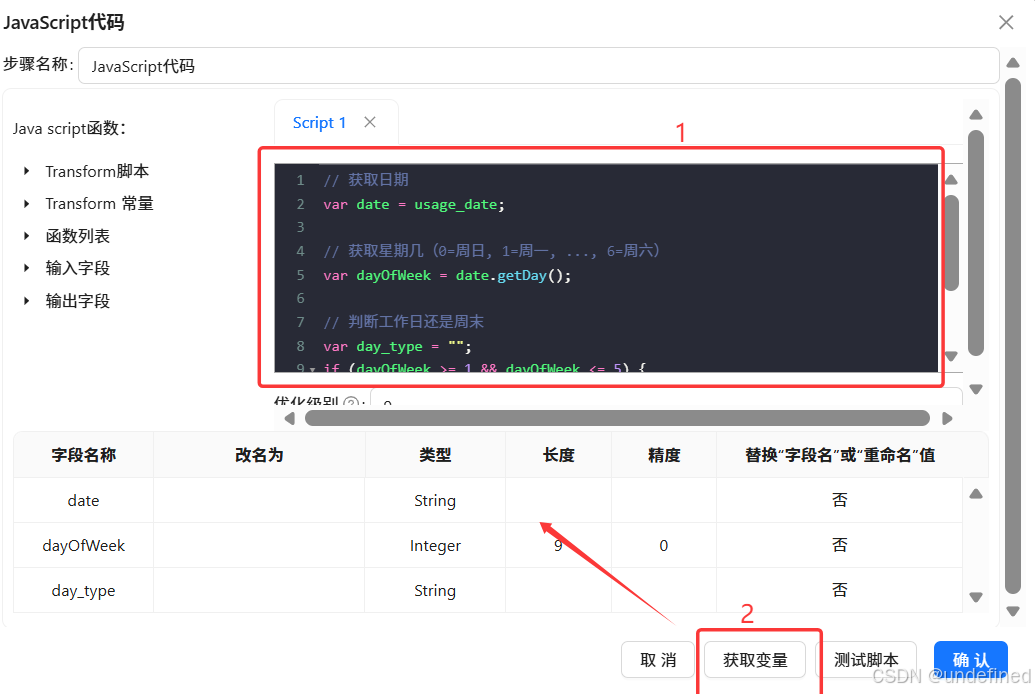
双击JavaScript代码组件,如下以下代码,点击”获取变量”,自动获取代码中的变量
//获取日期var date=usage_date;
//获取星期几(0=周日,1=周一,...,6=周六)var dayOfWeek=date.getDay();
//判断工作日还是周末var day_type="";if(dayOfWeek>=1&&dayOfWeek<=5){
day_type="工作日";
}else{
day_type="周末";
}
接下来,我们就可以统计工作日和周末的使用时长和用户数了
同样的,先拖入排序记录组件
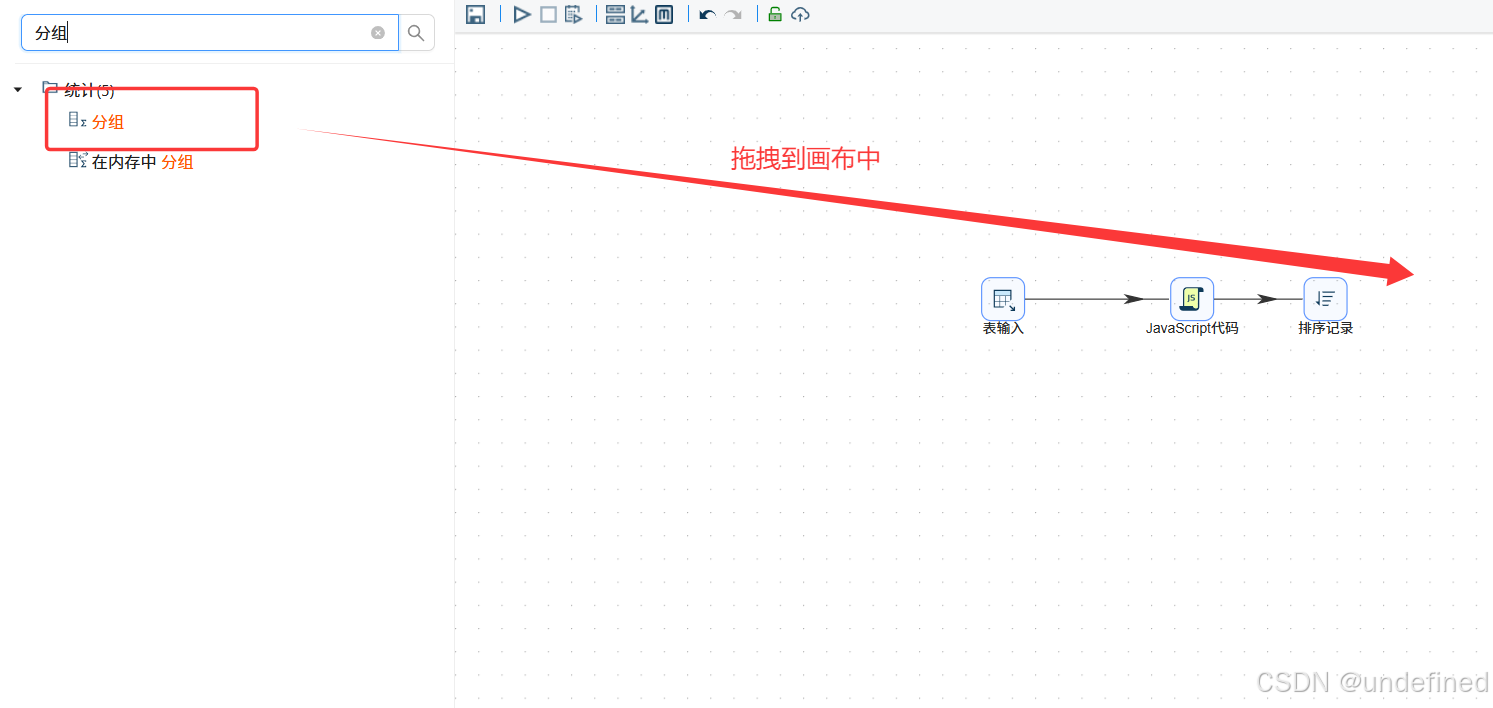
将数据按照browser_name、day_type升序排序
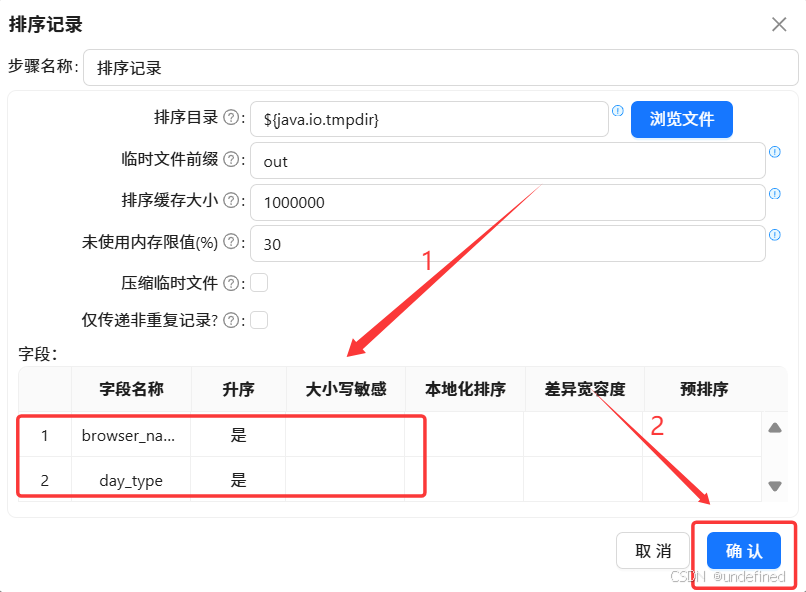
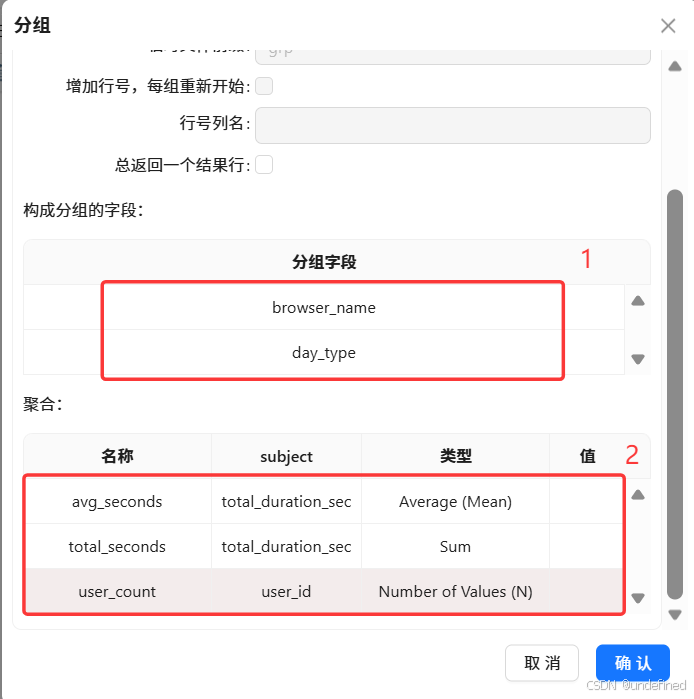
再拖入分组组件,按browser_name、day_type分组
聚合:
avg_seconds=平均使用时长(秒)
total_seconds=总使用时长(秒)
user_count=COUNT(DISTINCT user_id)
平均使用时长单位是秒的数值不会太大,是比较好观察,但是总使用时长的单位是秒的话数值很大,不够直观,所以将其转为小时,参考“6.4各浏览器使用频率分布表数据抽取”种计算小时的方法,使用增加常量组件和计算器组件来实现
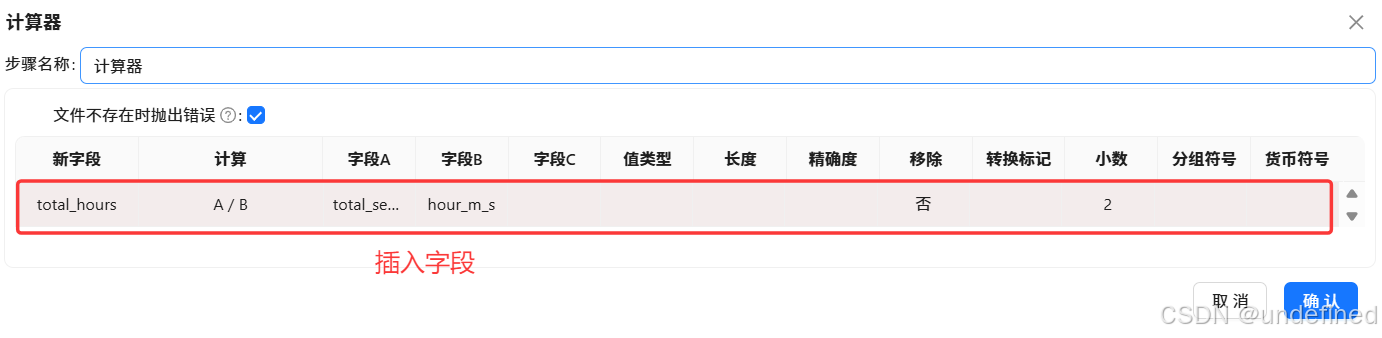
在计算过程中出现了一些中间字段,我们使用字段选择组件来删除冗余字段
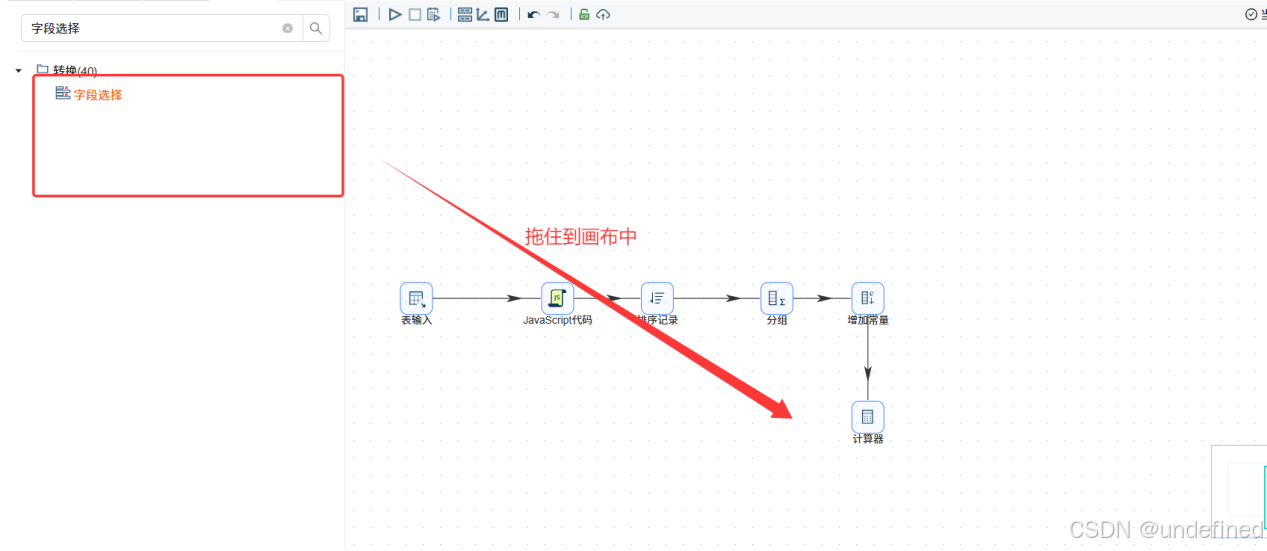
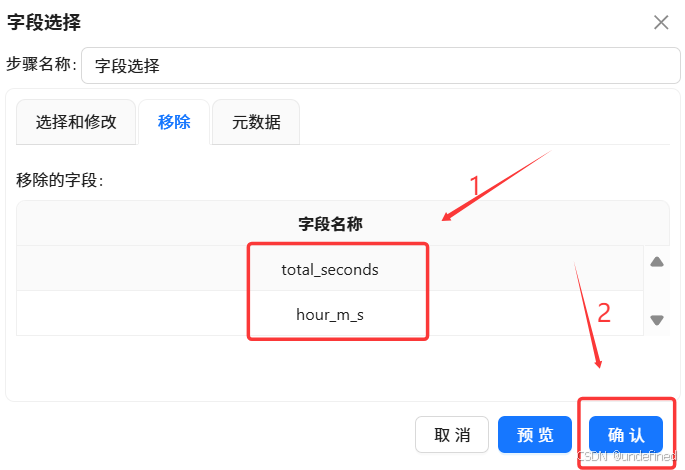
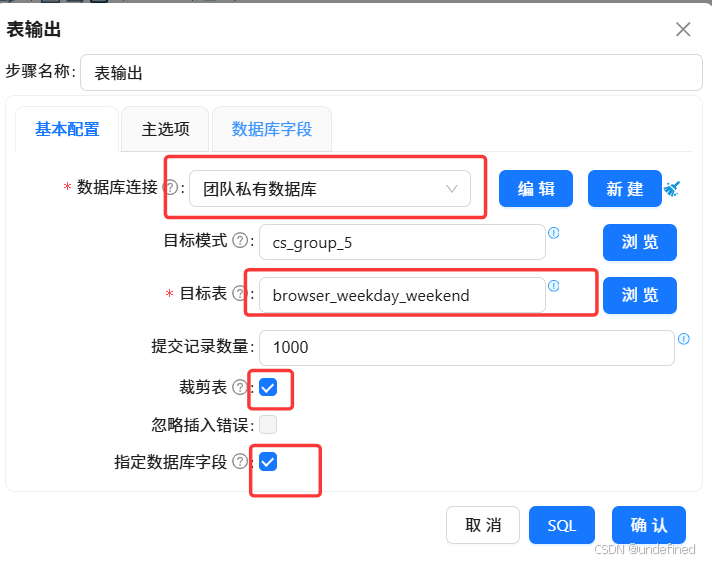
最后拖入表输出组件,将分组聚合结果入库,表输出组件配置为:
数据库连接:选择“团队私有数据库”
目标表:browser_weekday_weekend
勾选“裁剪表”,清空原有数据
勾选“指定数据库字段”,建立字段映射
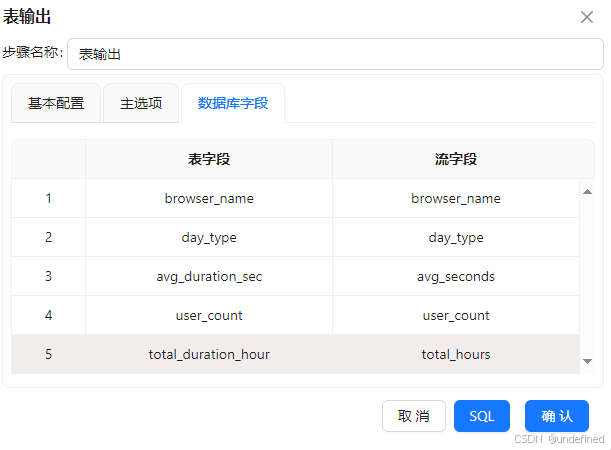
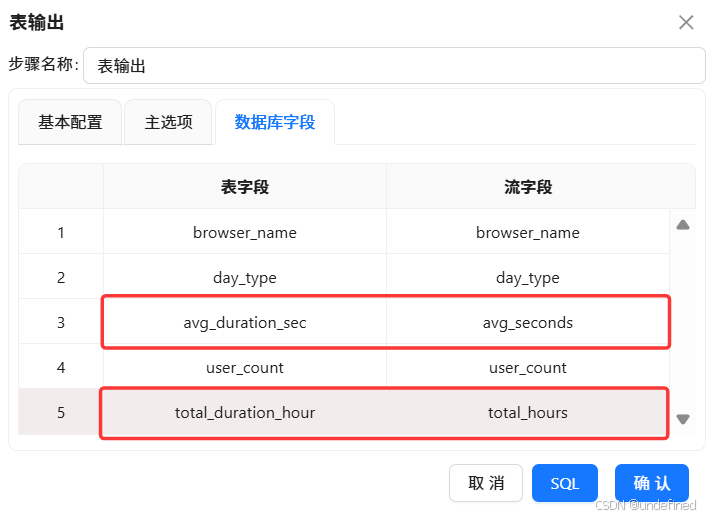
执行转换流:

目标:将大屏顶部四个指标卡的数据存入一张通用的键值对表中
在以上数据抽取中,我们已经获取了各浏览器的用户数、使用时长、活跃用户数、重度用户数,但我们设计的核心指标是全局数据,除了使用时长,其他用户数相关的数据在不同浏览器之间是存在重叠的,所以需要重新计算。
用一个表输入组件,直接SQL一次性算出所有指标,然后通过列转行将一行转为四行
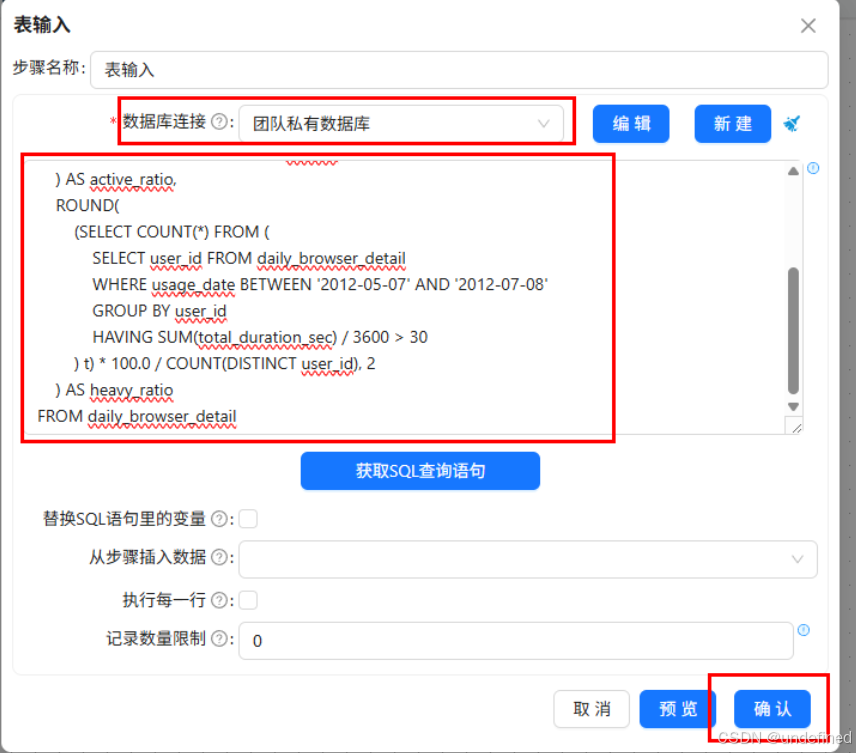
新建转换流“”,拖入表输入组件,数据库连接团队私有数据库,在SQL语句框中输入以下SQL:
SELECT
ROUND(SUM(total_duration_sec)/3600,2)AS total_hours,
ROUND(SUM(total_duration_sec)/3600/COUNT(DISTINCT user_id),2)AS avg_hours,
ROUND(
(SELECT COUNT(DISTINCT user_id)FROM daily_browser_detail
WHERE usage_date BETWEEN'2012-08-06'AND'2012-08-12'
)*100.0/COUNT(DISTINCT user_id),2
)AS active_ratio,
ROUND(
(SELECT COUNT(*)FROM(
SELECT user_id FROM daily_browser_detail
WHERE usage_date BETWEEN'2012-05-07'AND'2012-07-08'
GROUP BY user_id
HAVING SUM(total_duration_sec)/3600>30
)t)*100.0/COUNT(DISTINCT user_id),2
)AS heavy_ratioFROM daily_browser_detail
接下来使用行转列组件将字段名称转为指标名称,字段值转为指标值
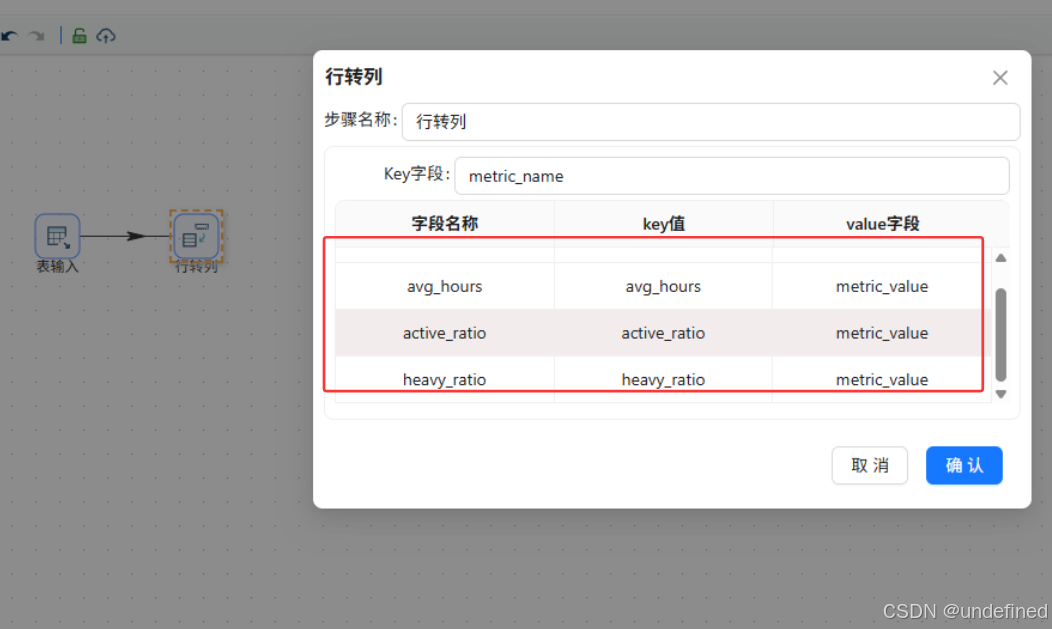
|
字段名称 |
key值 |
value字段 |
|---|---|---|
|
total_hours |
total_hours |
metric_value |
|
avg_hours |
avg_hours |
metric_value |
|
active_ratio |
active_ratio |
metric_value |
|
heavy_ratio |
heavy_ratio |
metric_value |
接下来使用值映射组件将指标名称映射为中文
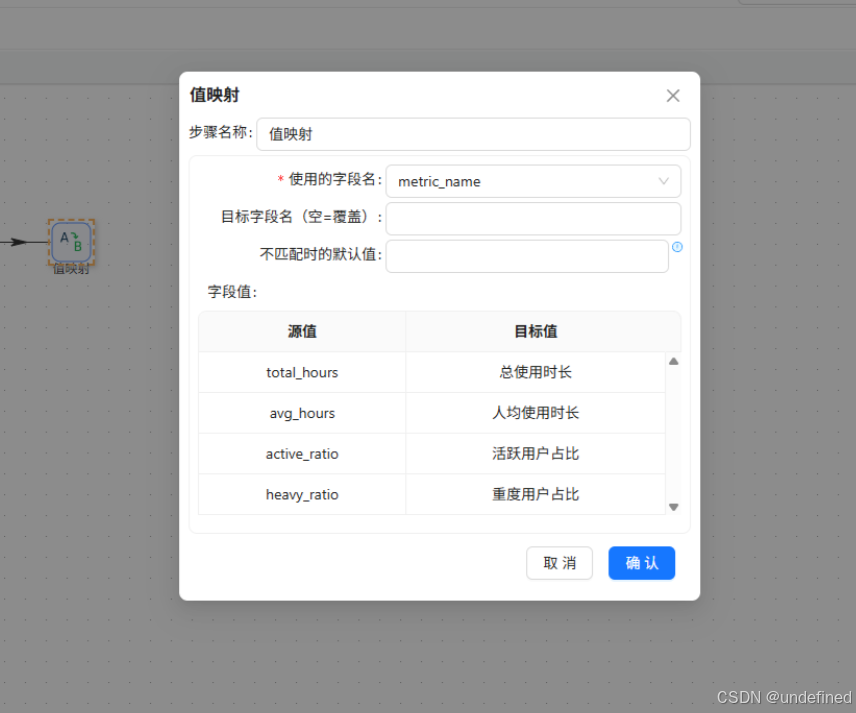
最后使用表输出组件写入目标表browser_overview
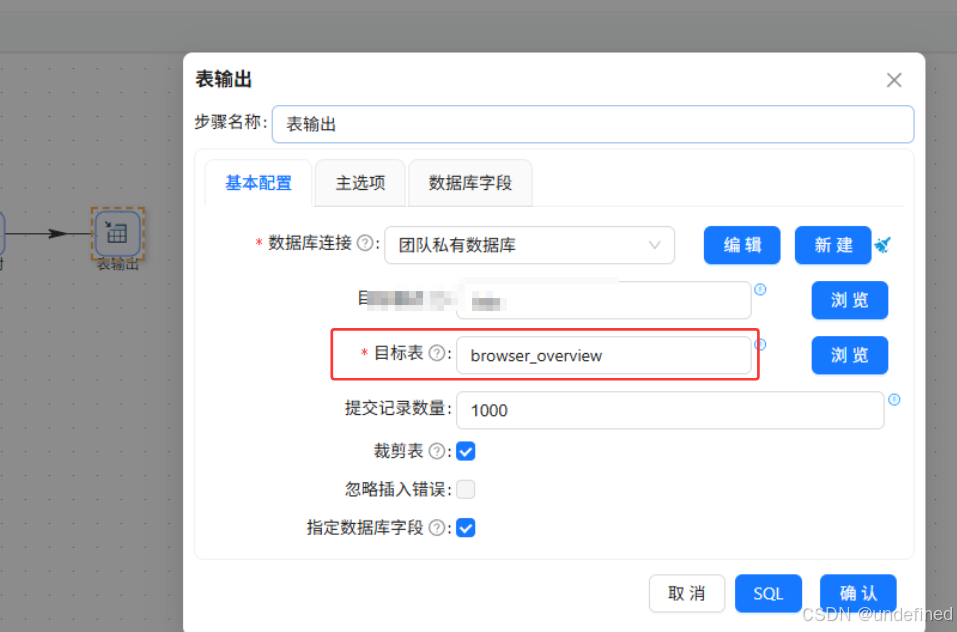
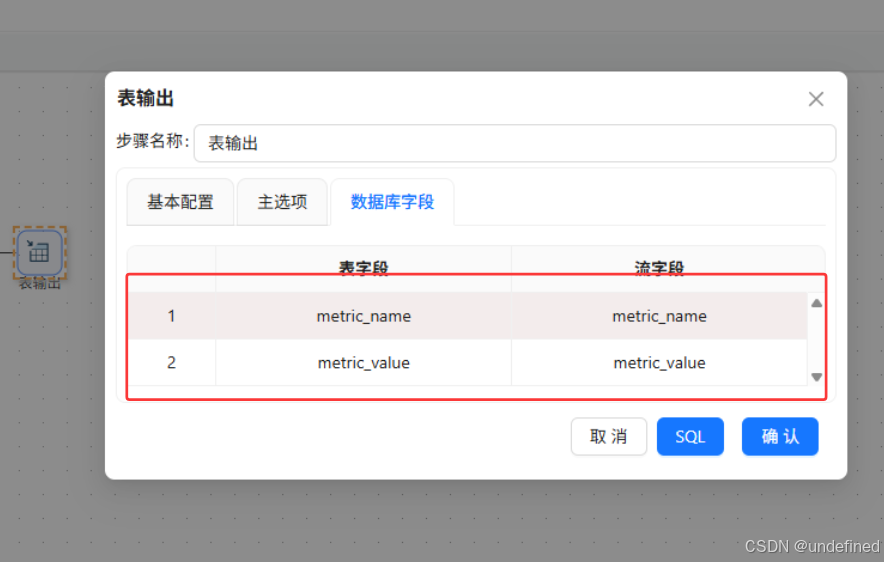 最后执行转换流即可
最后执行转换流即可
目标:统计每个浏览器按性别、年龄、学历、职业、收入、居住地类型的用户分布
用户画像表需要用户的属性信息,行为日志的数据中仅包含行为数据,缺少用户属性数据,因此需要获取数据集中的人口属性信息表demographic.csv,行为日志数据与人口属性数据通过用户ID关联
本次实验已经将demographic.csv预先存放在实验平台的公共空间数据资源中,可以直接导出到我们的项目文件目库中
点击“公共空间”
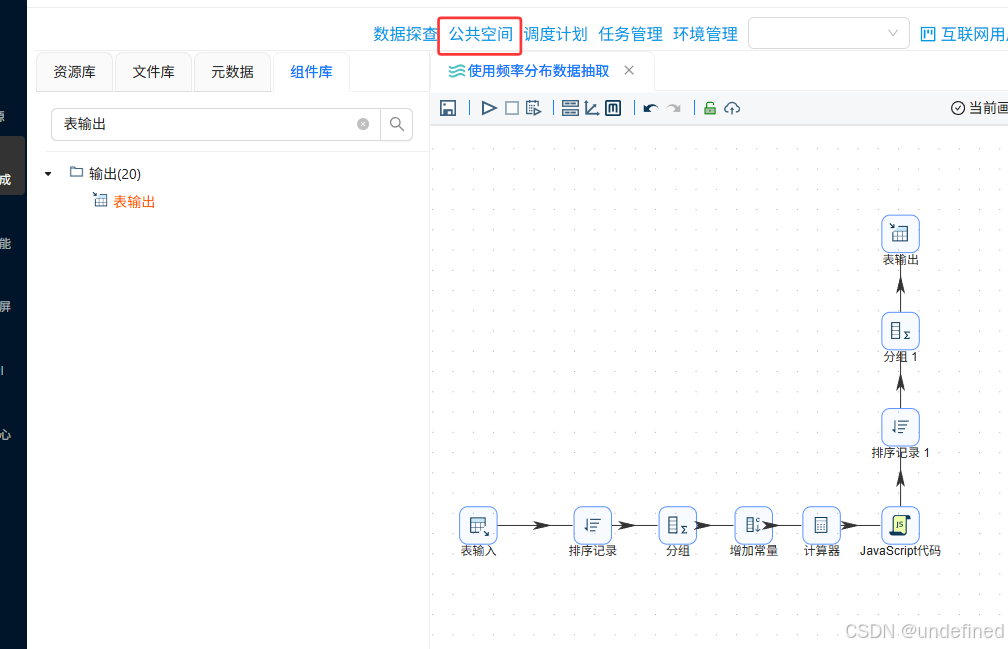
点击tab选项“数据资源”,可以看到demographic.csv
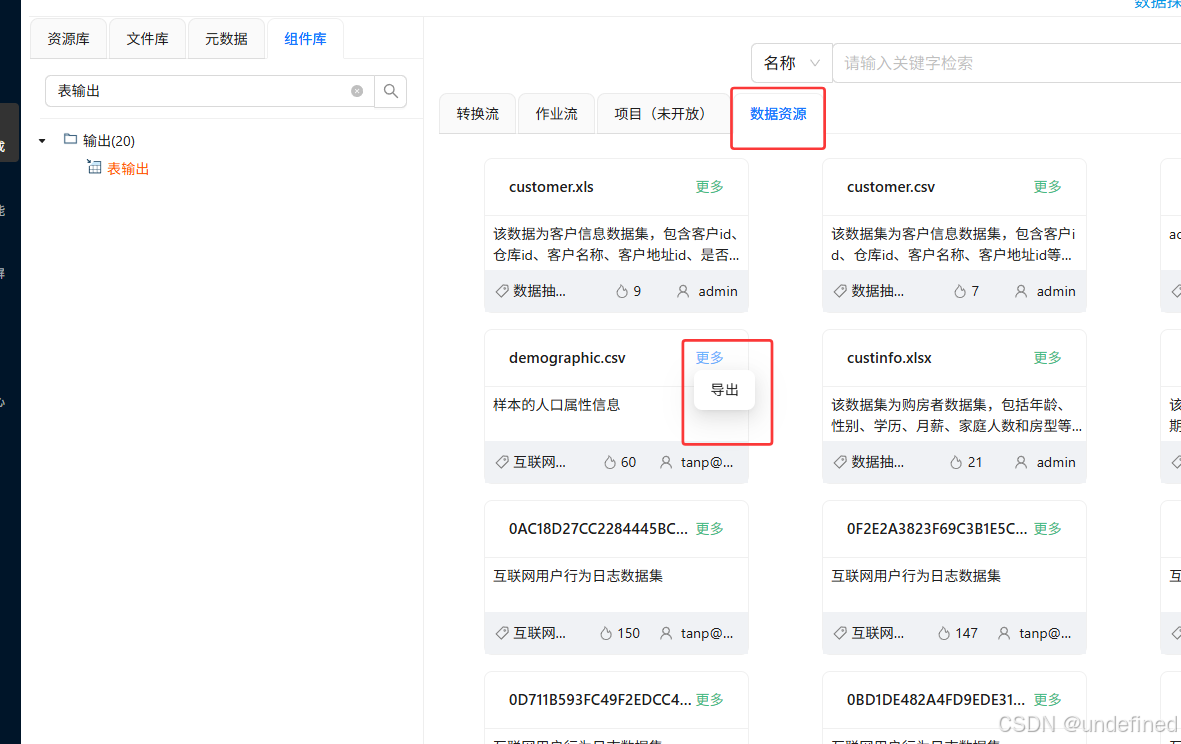
点击demographic.csv卡片右上角的“更多”-“导出”
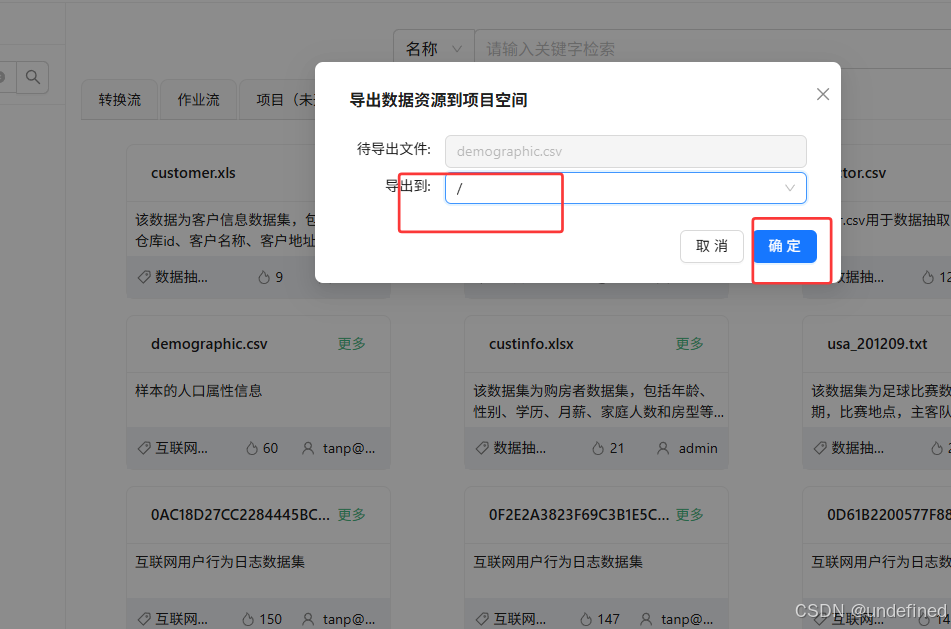
选择导出到的目录,例如根目录
最后点击“确定”
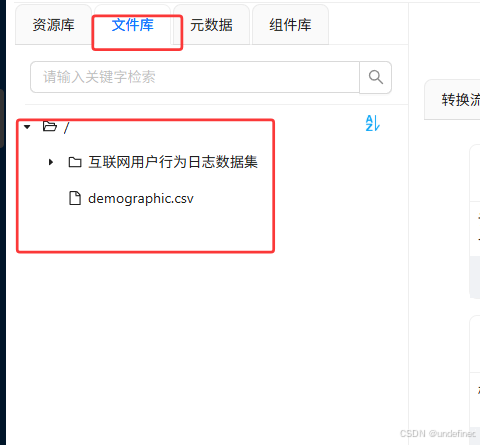
刷新文件库的根目录,即可看到demographic.csv
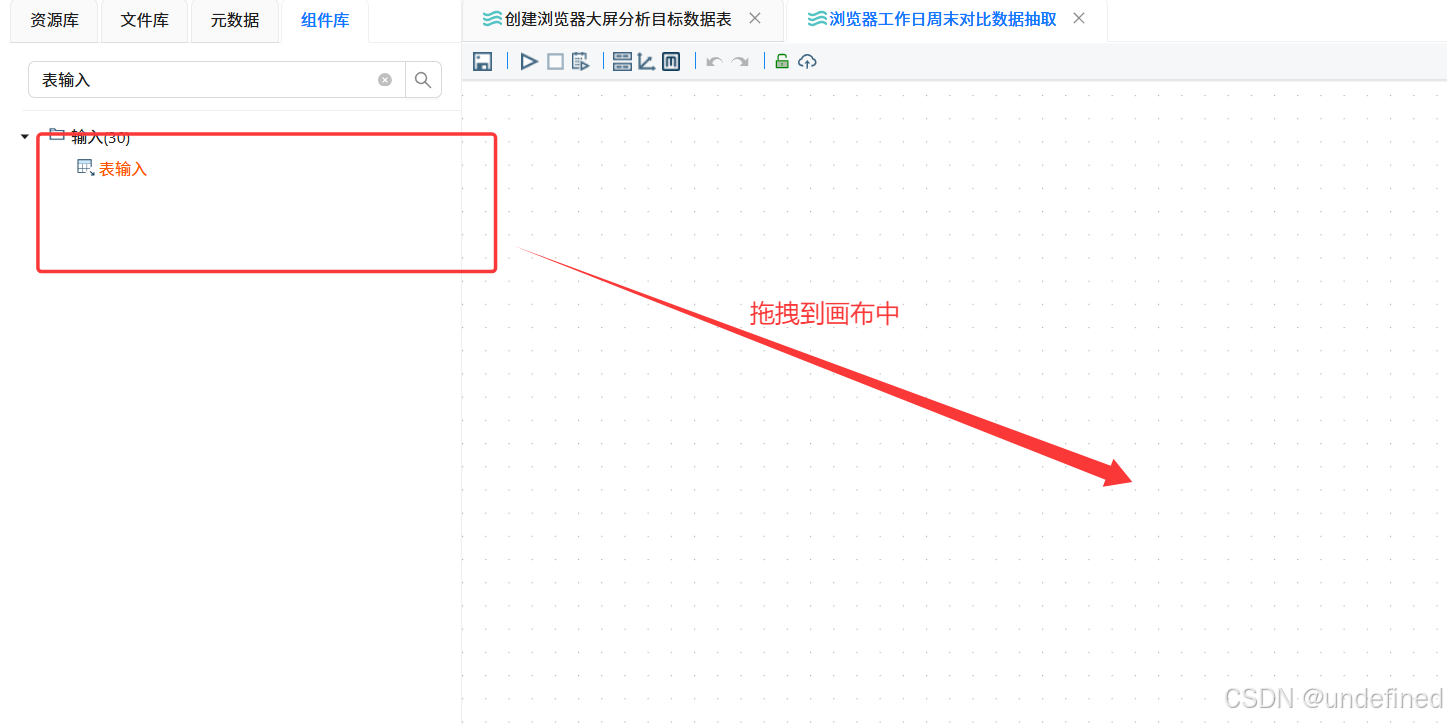
新建转换流“用户画像表加工”,拖拽“CSV文件输入”组件到画布中
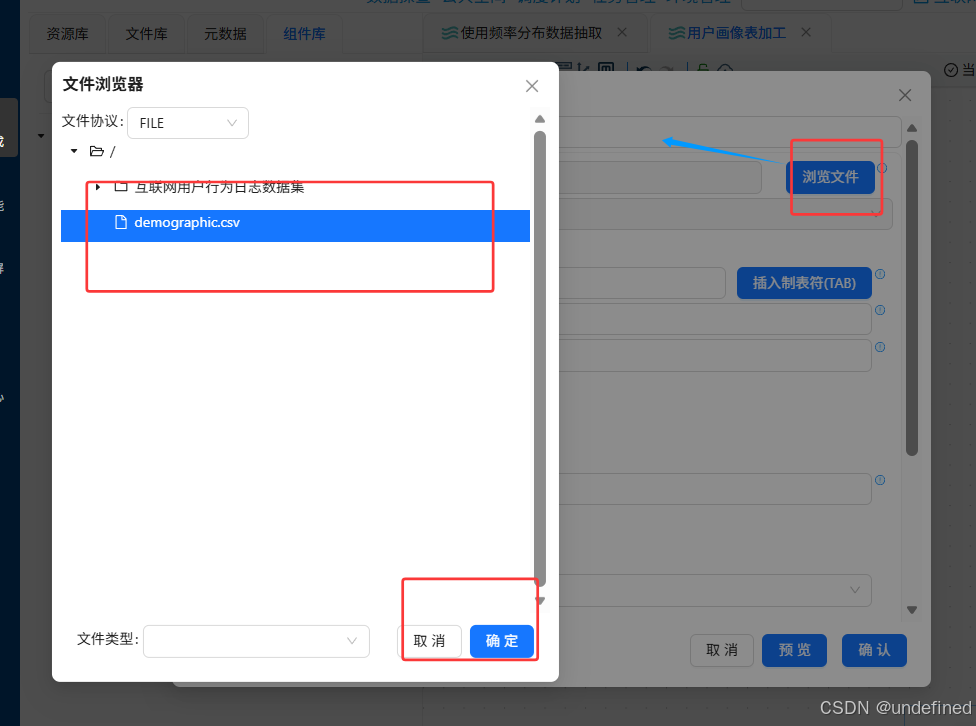
双击“CSV文件输入”组件,点击“浏览文件”按钮,在弹出的窗口中选择demographic.csv,然后点击“确定”
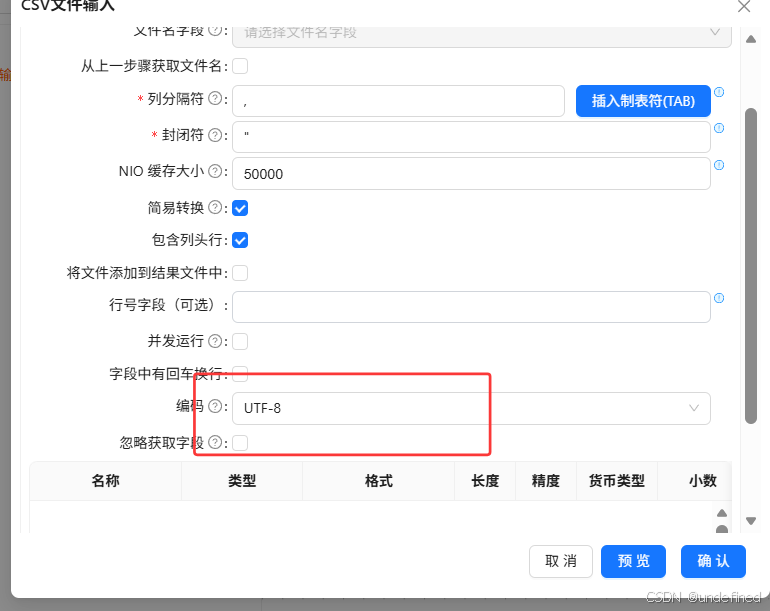
列分隔符和封闭符保持不变,编码选择“UTF-8”
往下滑一点,在空白表格处右键点击“获取字段”
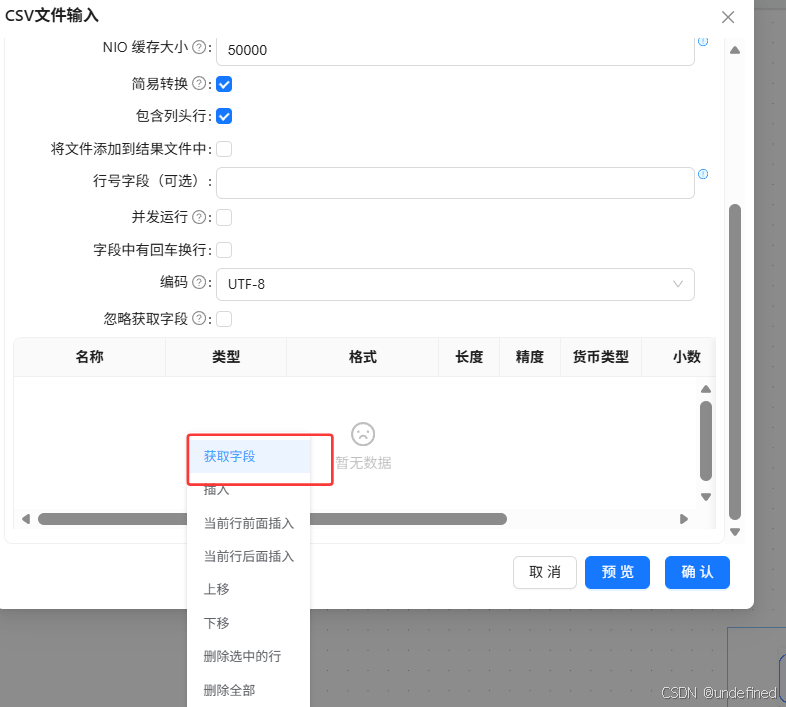
字段获取成功后点击“确认”
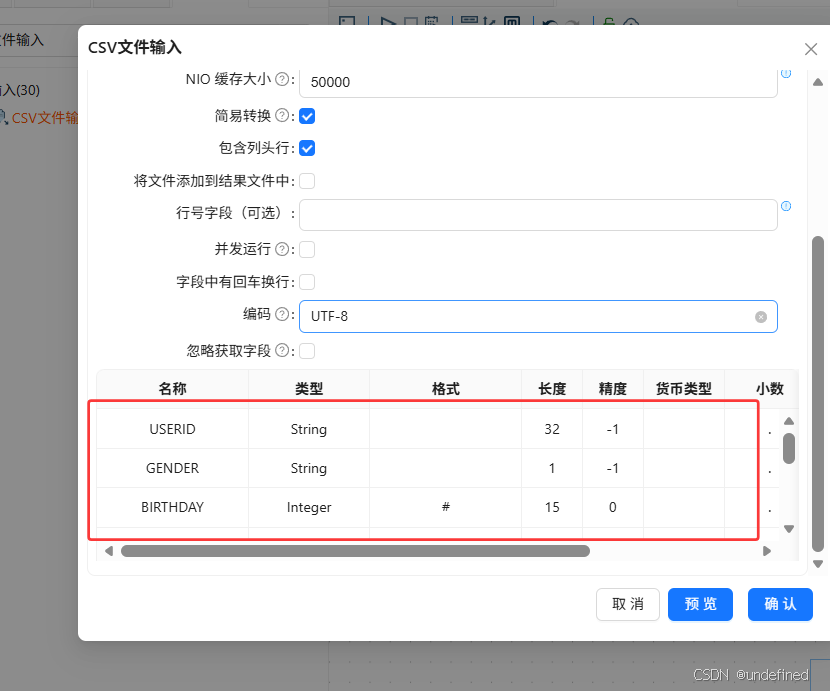
原人口属性数据中没有年龄字段,但是有出生年份,因此我们可以通过计算获取用户的年龄属性
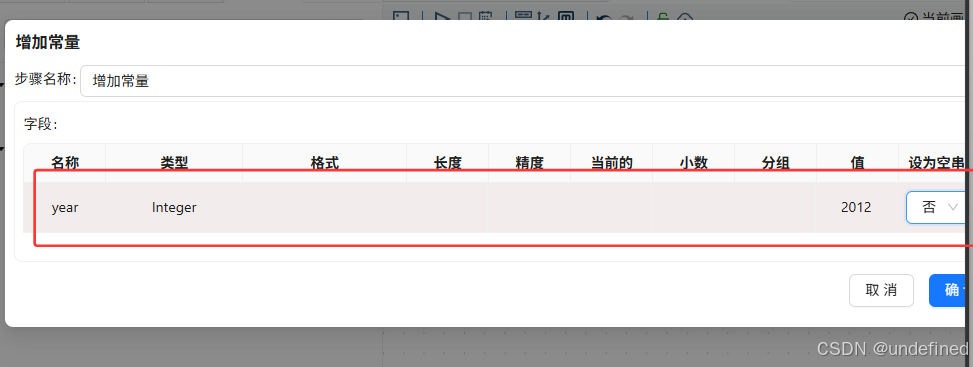
首先我们拖入增加常量组件,增加常量字段“year”,值设为“2012”(数据是2012年的)
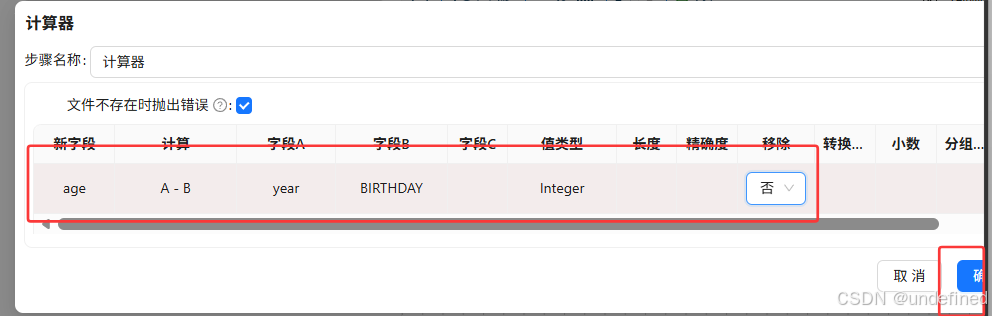
拖入“计算器”组件来计算用户在2012年的年龄,年龄=2012-出生年份,即:age=year-BIRTHDAY
接下来我们将年龄划分为四段:<18、18-25、26-35、>35
拖入JavaScript代码组件,计算器组件连接到JavaScript代码组件
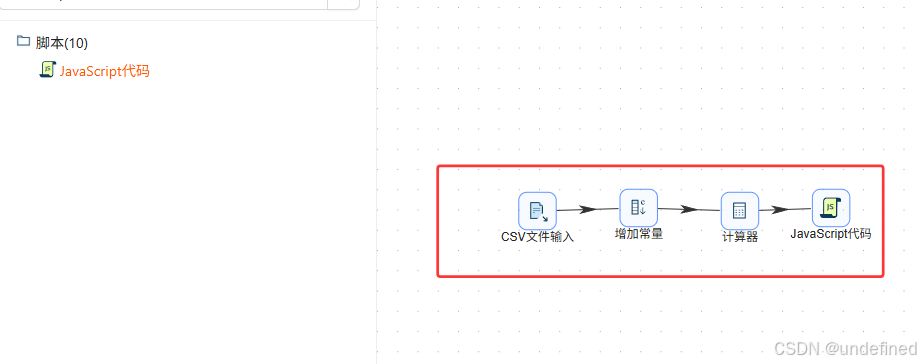
双击JavaScript代码组件,输入以下代码,点击“获取变量”,自动获取代码输出的变量
var age_group='';
if(age<18){
age_group='<18';
}else if(age<=25){
age_group='18-25';
}else if(age<=35){
age_group='26-35';
}else{
age_group='>35';
}
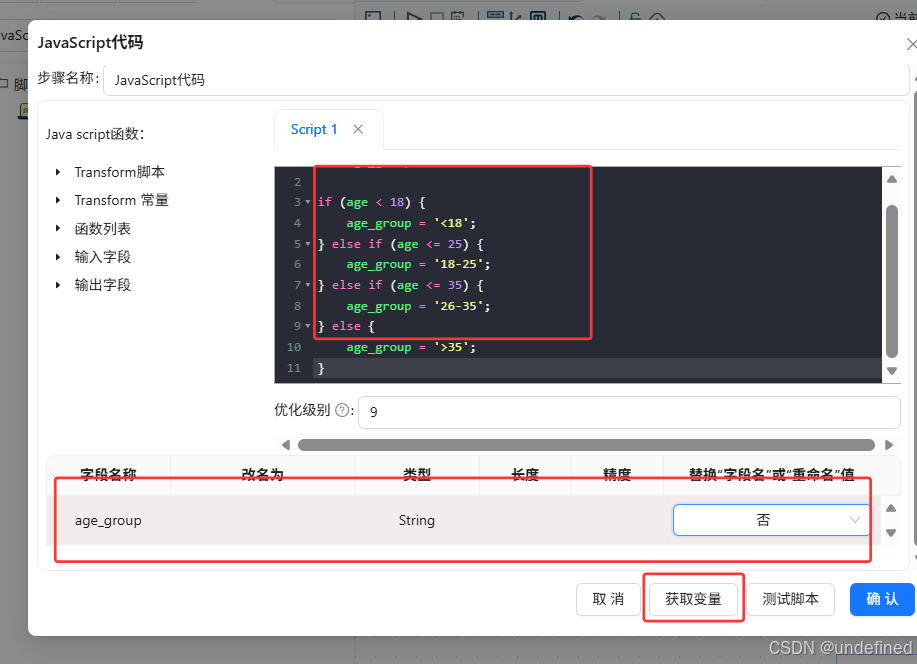
拖入“表输入”组件到画布中
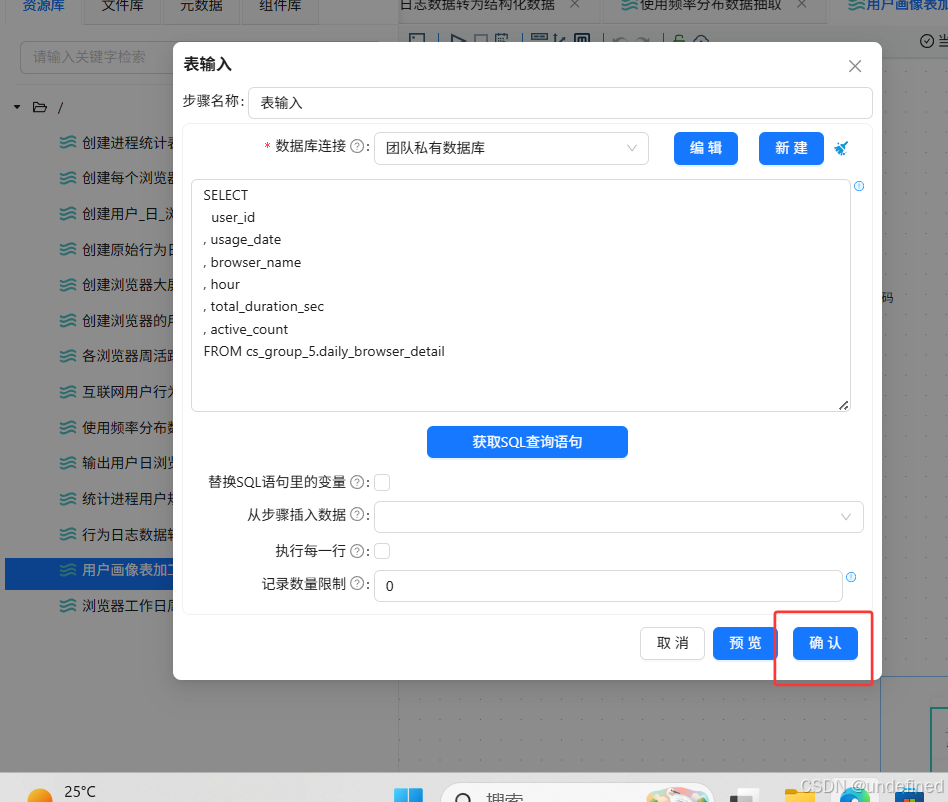
双击“表输入”组件,数据库连接选择“团队私有数据库”,点击“获取SQL查询语句”
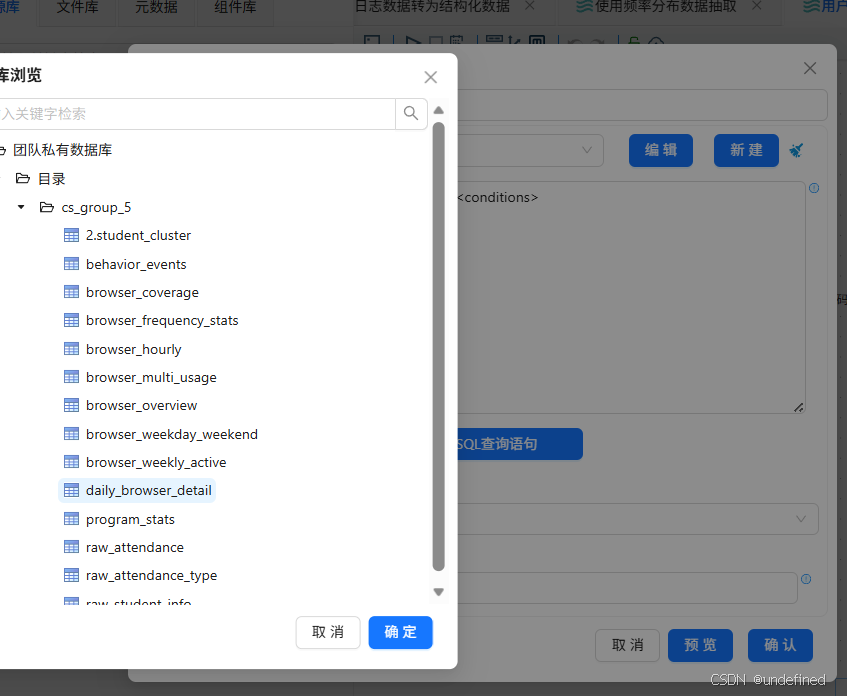
在弹出的窗口中,选择用户_日_浏览器_小时明细表daily_browser_detail
系统提示选择“确认”
获取SQL查询语句后点击“确认”、
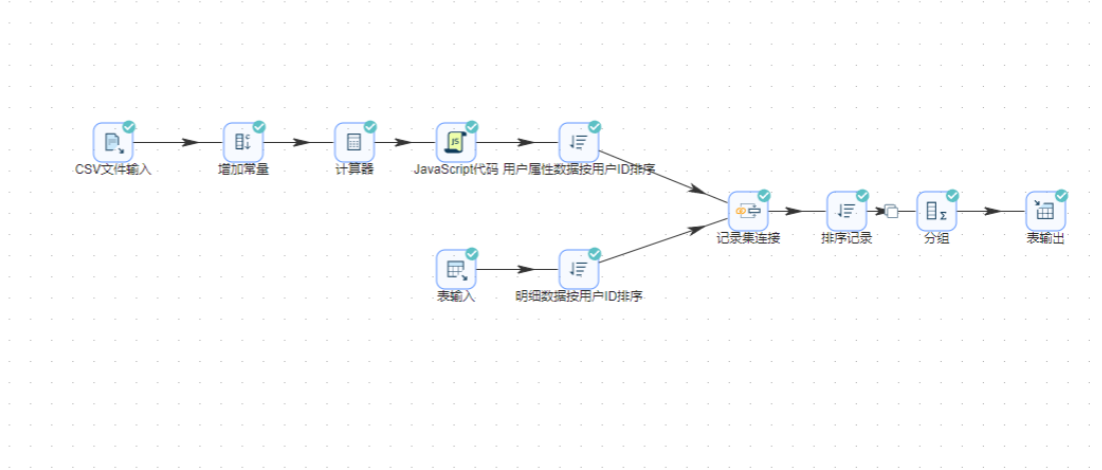
记录集连接组件可以将两个表进行连接,就是数据库中的join操作。数据连接时注意两个连接的数据集是否存在同一个字段。
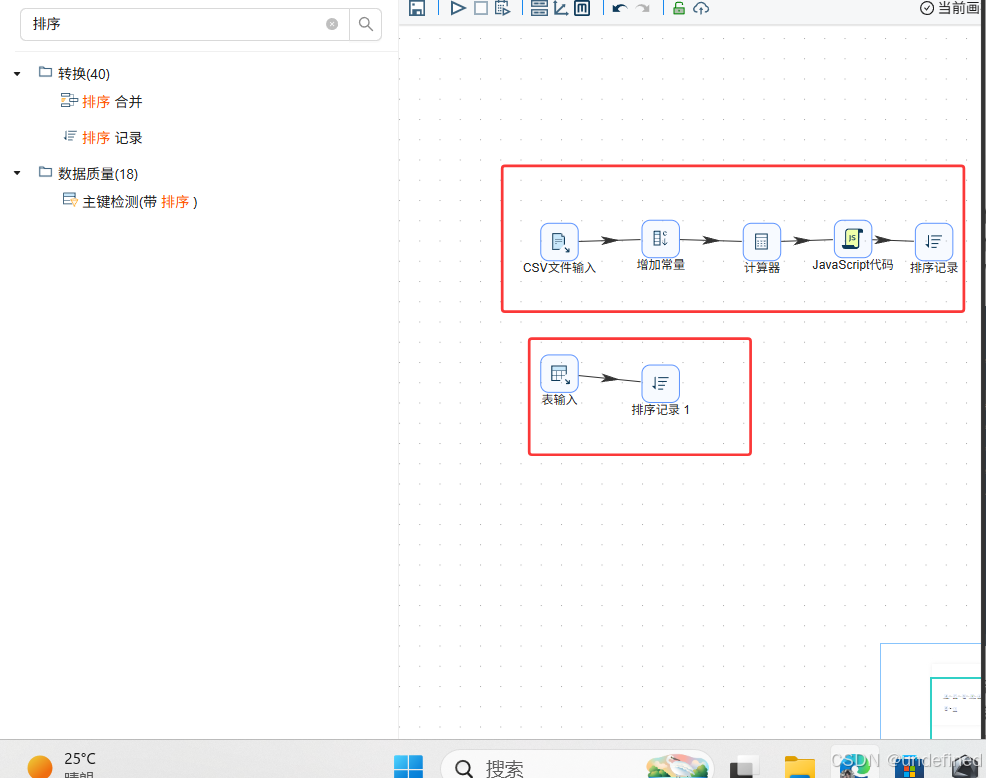
“记录集连接”组件之前需要先对数据进行排序,否则可能出错
我们先拖拽2个“排序记录”组件到画布中,分别创建“表输入”组件到“排序记录1”组件的连线、“CSV文件输入”组件到“排序记录”组件的连线,其中“CSV文件输入”组件到“排序记录”组件的连线类型选择“主输出步骤”
双击“排序记录1”组件,命名为“明细数据按用户ID排序”,在空白表格处右键点击“获取字段”
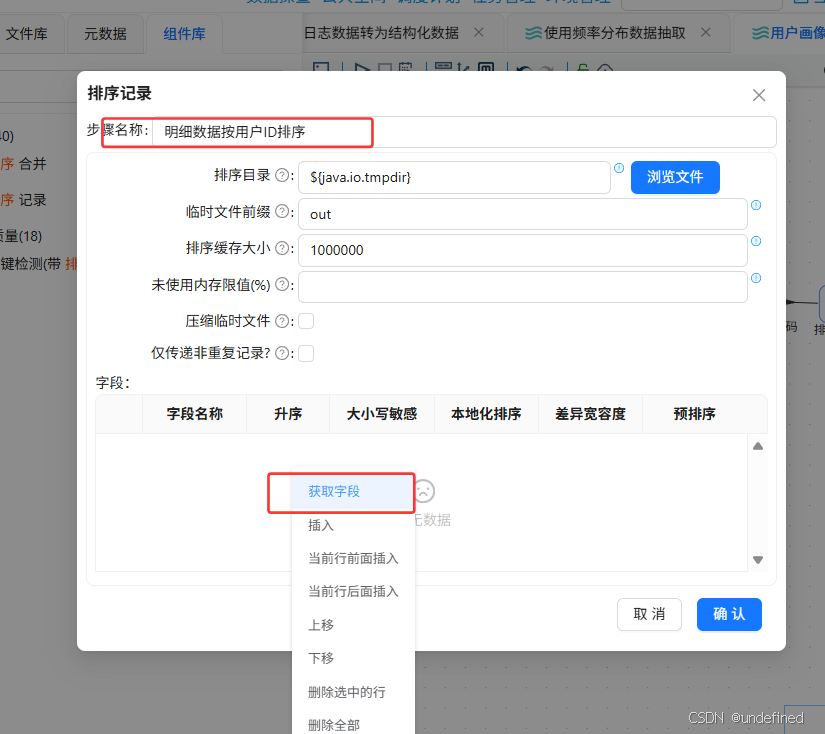
仅保留“user-id”,其他字段选中后右键点击“删除选中的行”
设置user_id升序排序后点击“确认”
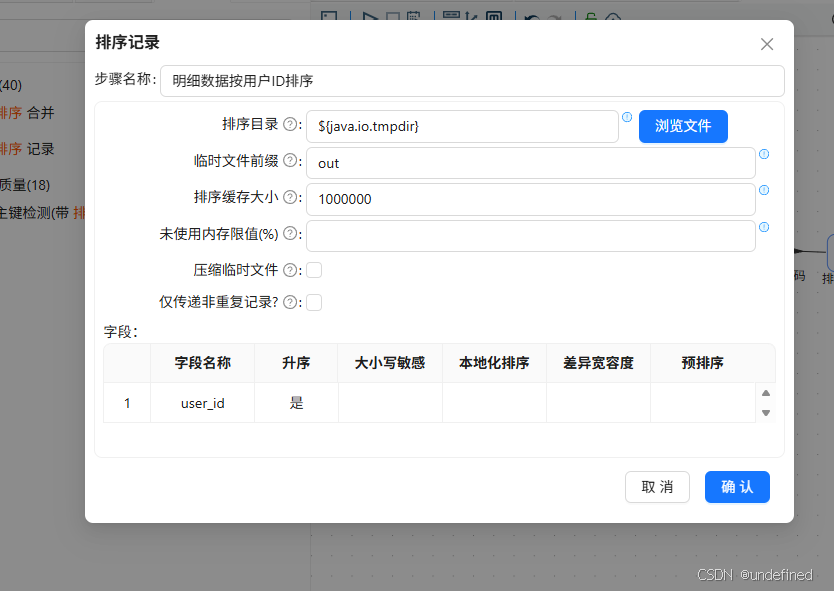
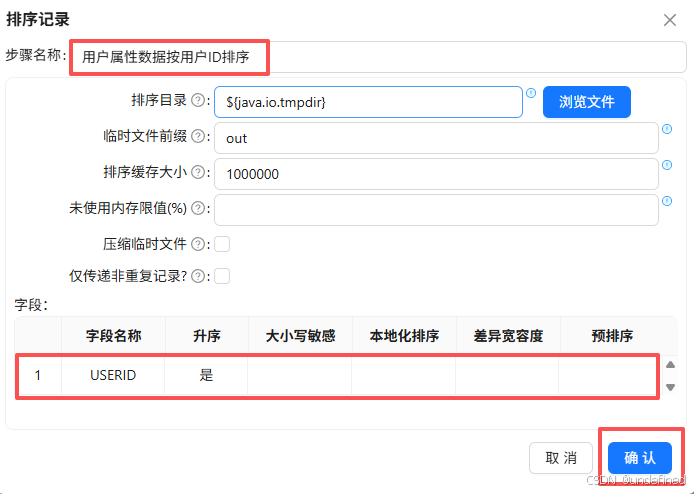
同样的双击“排序记录”组件,命名为“用户属性数据按用户ID排序”,设置按USERID升序排序
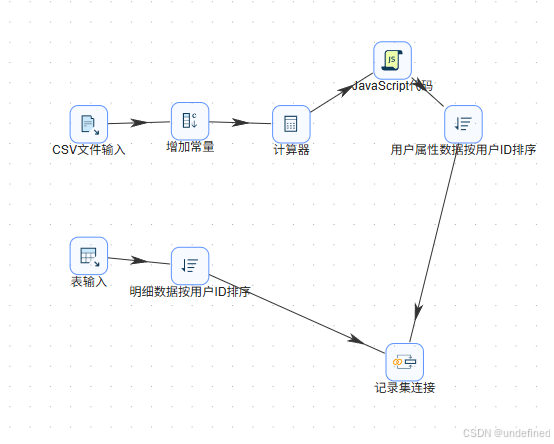
接下来,两个数据就可以通过记录集连接组件来关联了,拖拽“记录集连接”组件到画布中,2个排序记录组件分别连接到记录集连接组件,因为数据已经排序了,右上角的提示可以忽略
双击“记录集连接”组件,第一个Transform选择“明细数据按用户ID排序”,第二个Transform选择“用户属性数据按用户ID排序”,连接类型选择“LEFT OUTER”
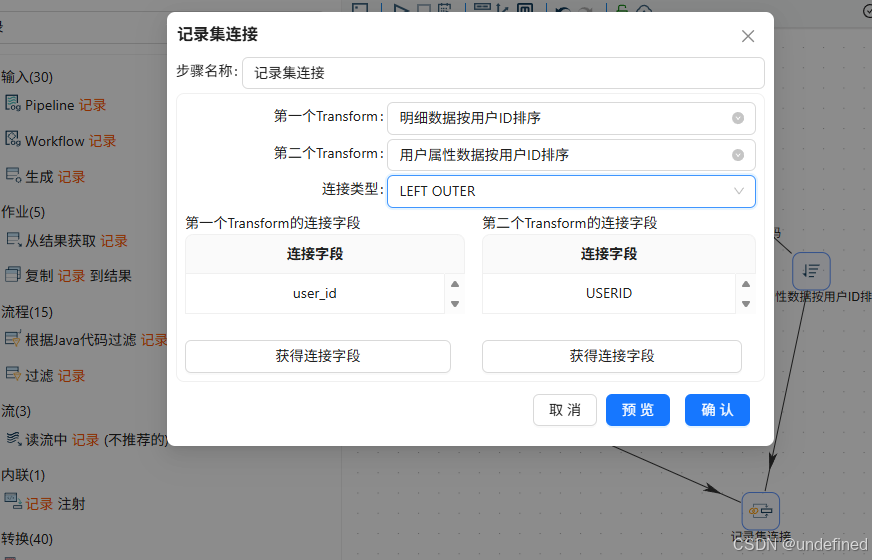
分别点击两个“获得连接字段”按钮,获取2个数据的字段
2个数据是通过用户ID关联的,所以第一个Transform的连接字段保留“user_id”,第二个Transform的连接字段保留“USERID”,其他字段通过删除选中的行来删除
分组统计之前,需要先对数据进行排序,拖入排序记录组件,记录集连接组件连接到排序记录组件,按照等下分组聚合的分组字段升序排序,即:browser_name、GENDER、EDU、JOB、INCOME、PROVINCE、ISCITY、age_group
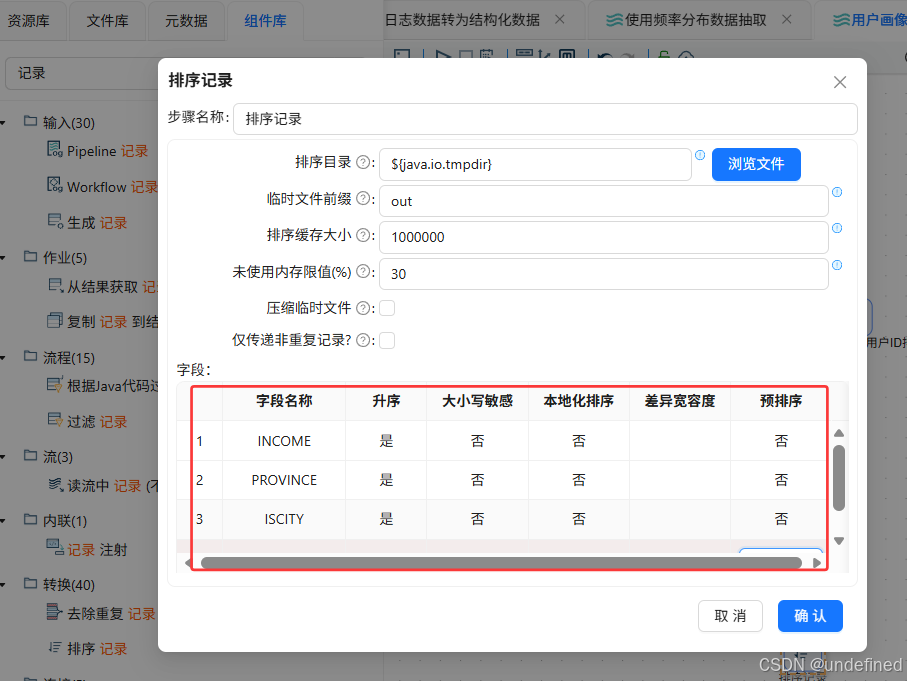
拖入分组组件,排序记录组件连接到分组组件,按browser_name、GENDER、EDU、JOB、INCOME、PROVINCE、ISCITY、age_group分组,聚合user_count=user_id(统计不同值的数量(N))
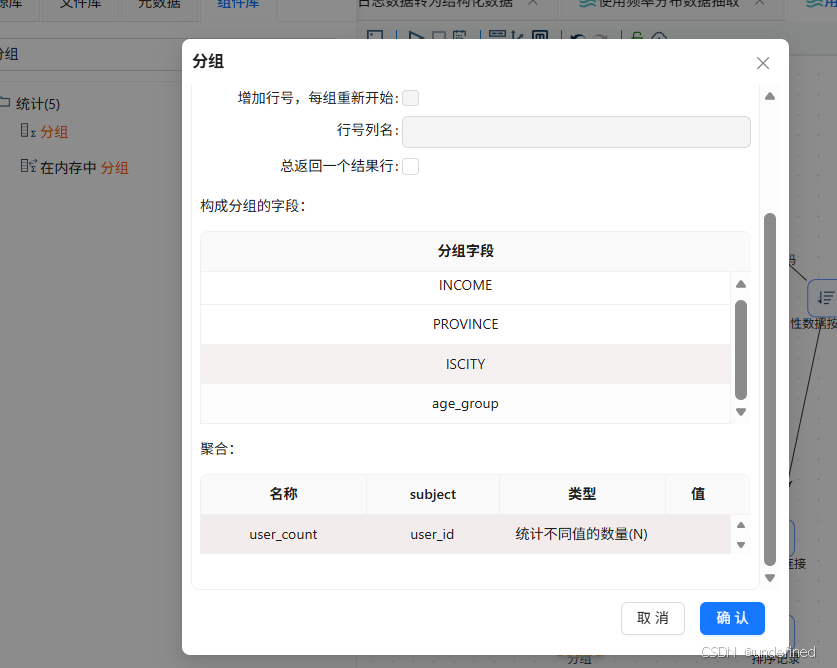
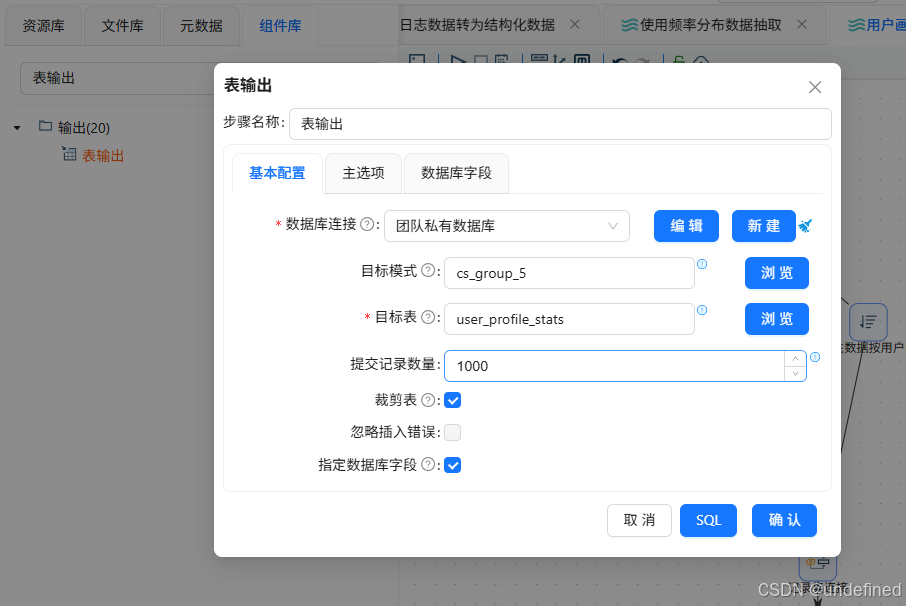
拖入表输出组件,将分组聚合结果入库,表输出组件配置为:
数据库连接:选择“团队私有数据库”
目标表:user_profile_stats
勾选“裁剪表”,清空原有数据
勾选“指定数据库字段”,建立字段映射

点击“运行”按钮
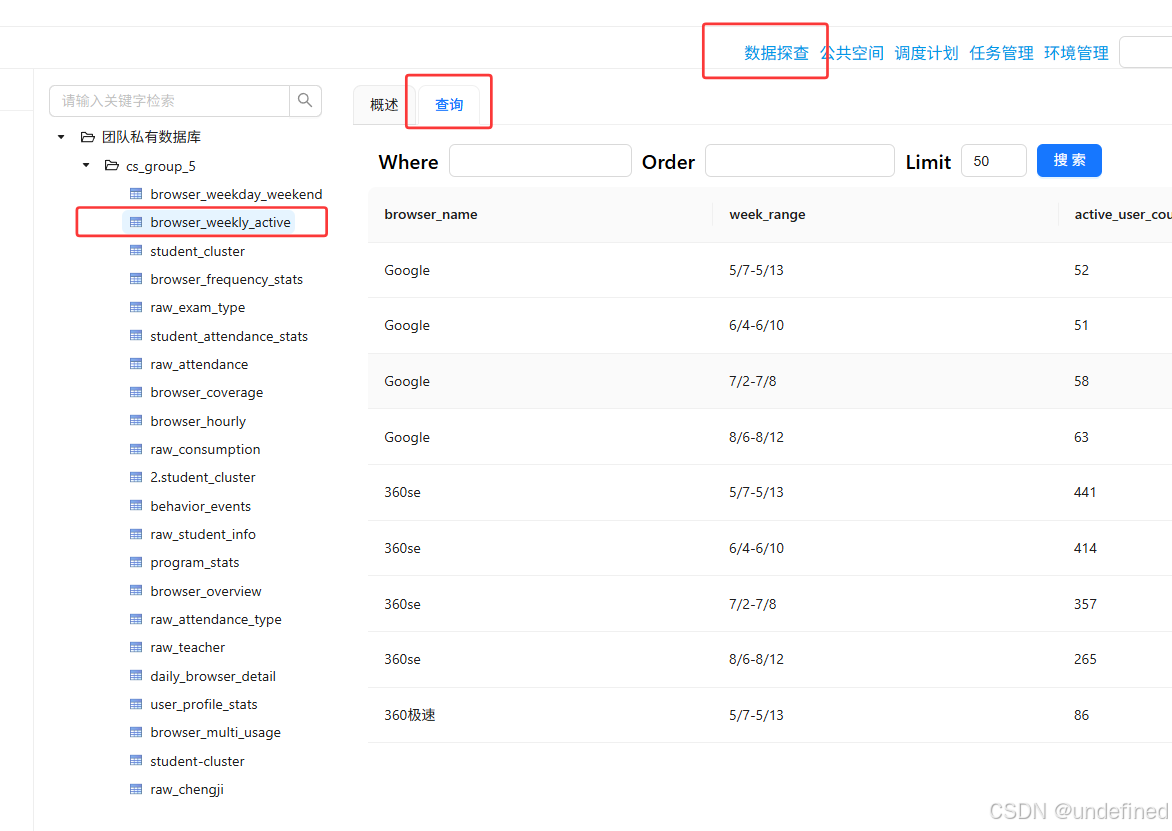
点击“元数据”tab选项,右键团队私有数据库,点击“加载元数据”
点击“数据探查”,查看以上生成的目标表是否符合预期
实验总结
本次实验完成了数据清洗与基础加工的全流程,成功构建了用户-日-浏览器-小时明细表(daily_browser_detail)以及浏览器市场覆盖率、时段活跃等基础统计表。通过ETL平台掌握了字段映射、排序分组、聚合计算、JavaScript代码处理等核心操作,为后续多维度分析奠定了统一的数据基础。
平台评价:助睿数智平台在本实验中表现出色。零代码的ETL组件设计直观,拖拽即可完成复杂的数据加工流程;排序记录、分组、值映射、记录集连接等组件功能完善,执行效率高;同时平台支持SQL脚本和自定义JavaScript代码,兼顾了灵活性与易用性,非常适合数据分析教学场景。
实验成果:成功生成了6张业务分析目标表,构建了一套可复用的浏览器行为数据加工流程。

一站式 AI 云服务平台
更多推荐
 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)