
本地千万级医疗数据分析实战:用AI工作流零代码、零SQL完成医院年度运营全景分析 | DTBot
本文介绍了一种利用AI工作流实现医院多源数据自动化清洗与分析的方法。该方法无需编写代码或SQL,即可处理门诊、住院、药品、医生、科室等千万级异构数据。核心流程包括:1)数据清洗(日期标准化、金额转换、空值处理等);2)统计分析(分组汇总、多表关联、指标计算等);3)结果输出(6张关键运营报表及可视化展示)。通过配置自然语言提示词指导AI工作流执行,实现了从原始数据到经营分析的全流程自动化,大幅降低
医院运营分析难的不是报表本身,而是门诊、住院、药品、医生、科室等多源数据口径不一,清洗、整合和统计链路长,分析成本很高。
这篇案例介绍一种更轻量的 AI 工作流做法:不写代码、不写 SQL,直接在本地完成千万量级医院多源数据的整理与分析。
核心技术可以分成两部分:
- 清洗技术 :日期标准化、金额转数值、空值填补、科室编码归一化、字段派生、明细粒度保留。
- 统计技术 :分组汇总、多表关联、全量合并、占比计算、人均指标计算、TopN 排名、月度趋势分析。
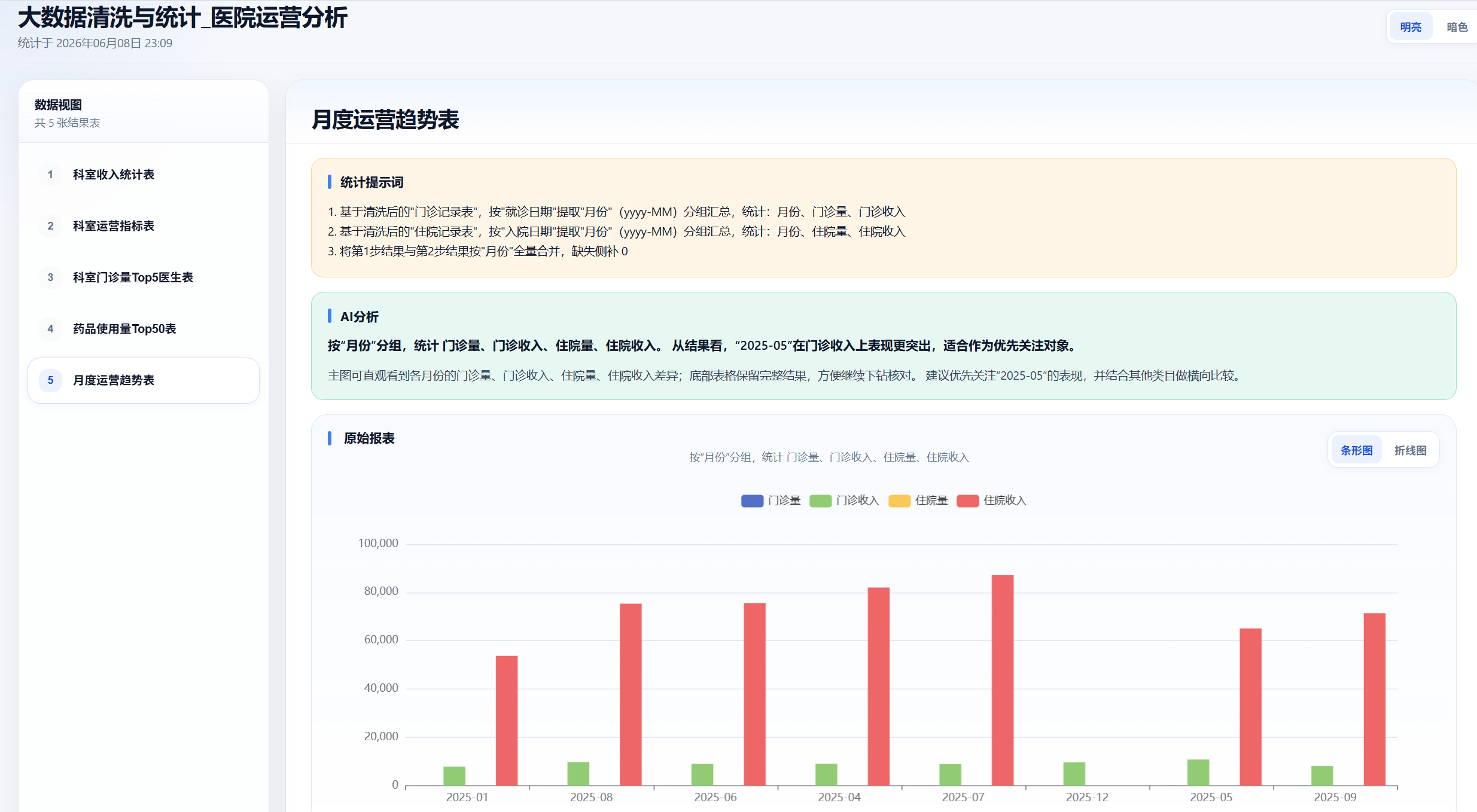
通过提示词配置好AI工作流,可以生成统计结果表与可视化大盘,如下图:
接下来,我们就用一个典型业务场景,来完整演示这个过程:医院运营分析(门诊表 + 住院表 + 药品表 + 医生表 + 科室表)
一、案例需求分析
这个案例的重点,是把门诊、住院、药品、医生、科室等多源数据统一整理后,再完成医院运营分析所需的汇总、关联和统计,最终输出可直接用于经营判断的结果表。
1、最终输出哪些结果表
完成门诊、住院、药品、医生和科室数据的清洗、汇总和关联后,这个案例最终会产出 6 张重点结果表:
- 科室收入统计表 :统计各科室的总收入、门诊人次、住院人次和人均产值,用来观察各科室的收入规模与产出水平。
- 科室运营指标表 :统计药占比、平均住院天数、平均住院费用、平均门诊费用、床位周转率、医生人数等指标,用来分析科室运营效率。
- 科室门诊量 Top5 医生表 :按科室筛选门诊量排名前 5 的医生,展示姓名、职称、门诊人次和门诊收入,用来识别重点医生资源分布。
- 药品使用量 Top50 表 :统计药品的总使用量、总金额和使用科室分布,用来分析重点药品的消耗情况和科室使用结构。
- 月度运营趋势表 :按月份统计门诊量、住院量以及相关收入指标,用来观察医院整体运营变化趋势。
2、业务数据涉及哪些源表
源表 指的是直接承接原始业务数据的基础表。它们不是最终分析结果表,而是后续做数据清洗、字段统一、表间关联和统计汇总的起点。
这次案例一共涉及 5 张核心源表:
- 门诊记录表 :记录门诊号、患者 ID、科室代码、医生工号、就诊日期、挂号费、检查费、药费等信息,是门诊量、门诊收入和门诊费用分析的基础来源。
- 住院记录表 :记录住院号、患者 ID、科室代码、主治医生工号、入院日期、出院日期、住院天数、总费用等信息,是住院量、住院收入、住院天数和住院费用分析的核心来源。
- 药品处方表 :记录处方号、门诊号/住院号、药品编码、药品名称、数量、单价、金额、开方日期等信息,用来补充药品使用明细,支撑药品消耗、药品金额和药占比分析。
- 医生信息表 :记录医生工号、姓名、科室代码、科室名称、职称、入职日期等信息,用来补充医生维度数据,支撑医生人数、职称分布和科室医生资源分析。
- 科室信息表 :记录科室代码、科室名称、科室类型、楼层、床位数等信息,用来补充科室基础属性,支撑科室收入、床位周转率和运营效率分析。
这 5 张源表共同构成了医院运营分析的数据基础,整体数据量达到千万级,需要先完成标准化清洗和口径统一,再进行后续统计分析。
3、这次主要做了哪些清洗
数据清洗,指的是把原始业务数据中格式不统一、无法直接计算、不能直接关联的内容先整理成统一标准的数据,例如统一日期格式、处理金额字段、规范编码字段、补充缺失值和派生分析所需字段。完成这一步之后,后面的多表关联、分组汇总和经营分析才能顺利展开。
这个案例我们需要清洗下面几张源表:
清洗门诊记录表
- 将“就诊日期”统一为 yyyy-MM-dd 格式
- 将挂号费、检查费、药费等金额字段去除符号后转为数值
- 将“科室代码”去除前后空格并统一为大写
- 空值按规则补齐,保证后续统计可直接使用
- 新增“门诊总费用” = 挂号费 + 检查费 + 药费
清洗住院记录表
- 将“入院日期”“出院日期”统一为 yyyy-MM-dd 格式
- 将“总费用”去除货币符号和千分位后转为数值
- 将“住院天数”缺失值按出院日期减入院日期自动补算
- 将“科室代码”统一为大写,保证能与其它表正常关联
清洗药品处方表
- 将“开方日期”统一为 yyyy-MM-dd 格式
- 将“金额”“单价”去除符号后转为数值
- 将“药品名称”去除前后空格,统一名称口径
- 保留处方明细粒度,不提前做汇总
- 新增“使用量”字段,直接取“数量”
清洗医生信息表
- 将“科室代码”统一为大写
- 将“职称”做归一化处理,例如把不同写法统一到标准职称口径
- 根据“入职日期”补充“从业年限”,为后续医生和科室统计做准备
清洗科室信息表
- 将“科室代码”统一为大写
- 将“床位数”转为纯数字,空值补 0
- 将“科室名称”“科室类型”去除前后空格,统一基础维度口径
二、提示词整理
在工作流配置之前,需要先把这次业务处理逻辑整理成一份提示词。
这一步的作用,就是先明确 清洗哪些表 、 怎么关联 、 输出哪些报表 。整理好之后,这份提示词就可以作为工作流配置输入,指导后续执行。
这里也需要说明一点: 提示词不一定非要写成固定模板 。只要表达得 清晰 、 明确 、 简洁 ,让人一眼能看懂要做什么、按什么顺序做、最后输出什么结果,就可以了。
本次案例整理出的提示词如下:
整体要求:生成医院年度运营分析报告:
第一步 - 清洗门诊记录表:
1. "就诊日期"统一为 yyyy-MM-dd 格式
2. 所有费用字段去除¥和"元"后缀,空值填充为 0
3. "科室代码"去除前后空格,统一为大写
4. 新增"门诊总费用" = 挂号费 + 检查费 + 药费
第二步 - 清洗住院记录表:
1. "入院日期""出院日期"统一为 yyyy-MM-dd 格式
2. "总费用"去除¥和千分位逗号
3. "住院天数"空值时自动计算 = 出院日期 - 入院日期
4. "科室代码"统一为大写
第三步 - 清洗药品处方表:
1. "开方日期"统一为 yyyy-MM-dd 格式
2. "金额""单价"去除¥符号
3. "药品名称"去除前后空格
4. 保留处方明细粒度,不提前按"门诊号/住院号"汇总
5. 新增"使用量" = 数量
6. 后续如需按就诊单据统计药品金额或种类数,再单独生成汇总表
第四步 - 清洗医生信息表:
1. "科室代码"统一为大写
2. "职称"归一化:"主任医师""正高""主任"统一为"主任医师"
3. 根据"入职日期"计算"从业年限"
第五步 - 清洗科室信息表:
1. "科室代码"统一为大写
2. "床位数"转为纯数字,空值填充为 0
3. "科室名称""科室类型"去除前后空格
第六步 - 生成门诊科室统计表:
1. 门诊记录表按"科室代码"汇总:门诊总人次、门诊总收入、平均门诊费用、药占比(药费/总费用)
第七步 - 生成住院科室统计表:
1. 住院记录表按"科室代码"汇总:住院总人次、住院总收入、平均住院天数、平均住院费用
第八步 - 生成医生科室汇总表:
1. 医生信息表按"科室代码"汇总:医生人数、主任医师人数、平均从业年限
第九步 - 生成科室全景表:
1. 门诊科室统计表 与 住院科室统计表 按"科室代码"全量合并(两侧数据都保留)
2. 再关联科室信息表(按"科室代码"匹配)
3. 再关联医生科室汇总表(按"科室代码"匹配)
4. 新增"科室总收入" = 门诊收入 + 住院收入
5. 新增"床位周转率" = 住院总人次 / 床位数(床位数为 0 时记为空)
6. 新增"人均产值" = 科室总收入 / 医生人数(医生人数为 0 时记为空)
第十步 - 生成科室收入统计表:
1. 基于"科室全景表"
2. 按"科室代码"+"科室名称"输出:总收入、门诊人次、住院人次、人均产值,按总收入降序排名
3. 输出"科室收入统计表"
第十一步 - 生成科室运营指标表:
1. 基于"科室全景表"
2. 按"科室代码"+"科室名称"输出:药占比、平均住院天数、平均住院费用、平均门诊费用、床位周转率、医生人数
3. 输出"科室运营指标表"
第十二步 - 生成科室门诊量Top5医生表:
1. 基于"门诊记录表"(清洗后) 关联 "医生信息表"(按"医生工号"匹配)
2. 按"科室代码"+"科室名称"分组,在每个科室内按门诊人次降序取Top5医生
3. 输出"科室门诊量Top5医生表"(含姓名、职称、门诊人次、门诊收入)
第十三步 - 生成药品使用量Top50表:
1. 基于"药品处方表"清洗后明细,分别关联"门诊记录表"和"住院记录表"补齐"科室代码"
2. 按"药品名称"分组,统计:总使用量、总金额、使用科室分布,按总使用量降序取Top50
3. 输出"药品使用量Top50表"(含药品名称、总使用量、总金额、使用科室分布)
第十四步 - 生成月度运营趋势表:
1. 基于清洗后的"门诊记录表",按"就诊日期"提取"月份"(yyyy-MM)分组汇总,统计:月份、门诊量、门诊收入
2. 基于清洗后的"住院记录表",按"入院日期"提取"月份"(yyyy-MM)分组汇总,统计:月份、住院量、住院收入
3. 将第1步结果与第2步结果按"月份"全量合并,缺失侧补 0三、落地实现:工作流配置
工作流是由多个智能体节点组成的,这个案例我们涉及到下面几个智能体:
- 文件助手: 获取磁盘的文件或目录。
- 内容清洗器: 专门用来做数据清洗的,只要输入清洗描述就可以对文件数据进行任意整理。
- 数据入库:将文件数据转成本地数据库,用于后面作SQL统计。
- 表统计: 对本地数据库表进行SQL统计,不需要写sql,只需要统计的描述就可以了。
- 报表导出: 对数据库表进行导出,支持导出csv,xlsx,HTML(可视化显示) 。
根据这几个智能体还有上面描述的提示词,我们就可以完成工作流的配置了。
1. 清洗数据表
清洗数据流程总共分为三步:
- 配置文件助手 : 获取待清洗的源文件。
- 配置内容清洗器: 描述清洗内容。
- 数据入库: 将文件数据搞成表放到本地数据库(后面好进行sql统计)。
打开DT-Bot工作流, 配置一个 “文件助手”智能体节点,描述原始数据文件位置,文件助手配置如图:
DT-Bot工作流,解决方案获取可以看文章末尾名片。
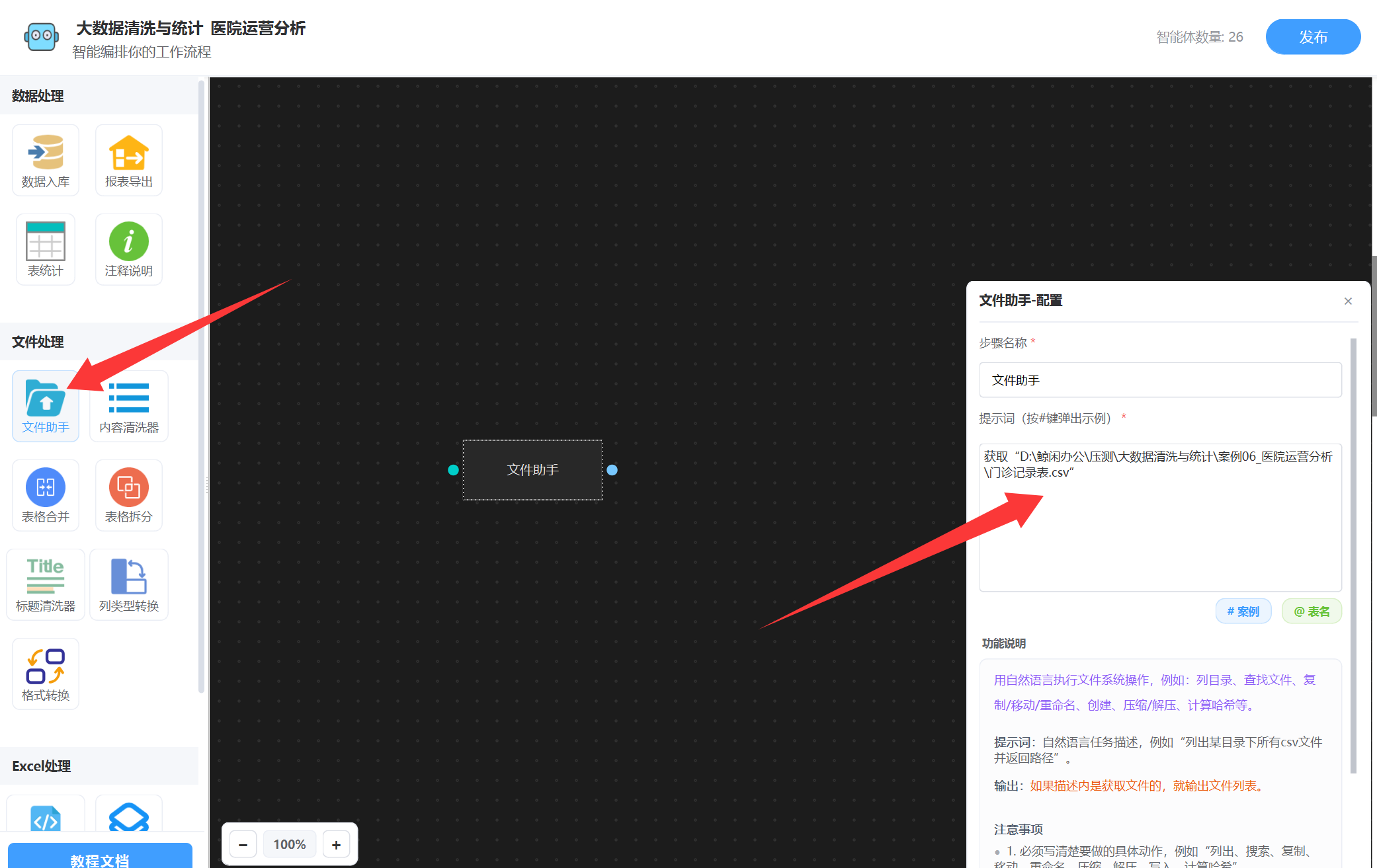
根据提示词描述,获取到了”门诊记录表.csv“原始表格,然后就会输出该文件,然后我们接下一个智能体 “内容清洗器”,如图:
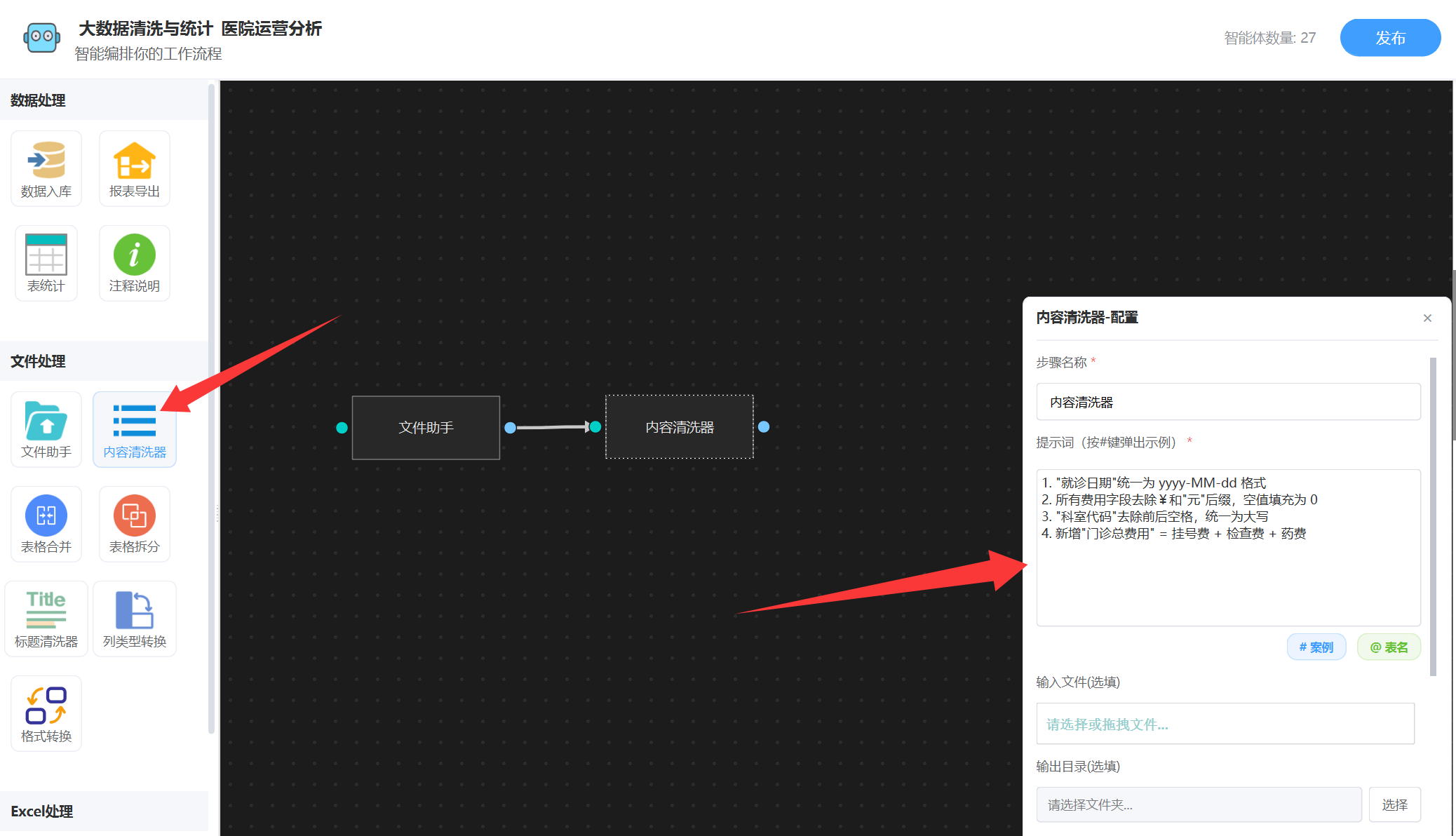
直接将清洗的提示词写进来就可以了,清洗之后,我们需要将表格文件的数据放到数据库里面,后面好进行SQL统计,所以还要接入一个“数据入库”,不需要输入任何提示词,如下图:
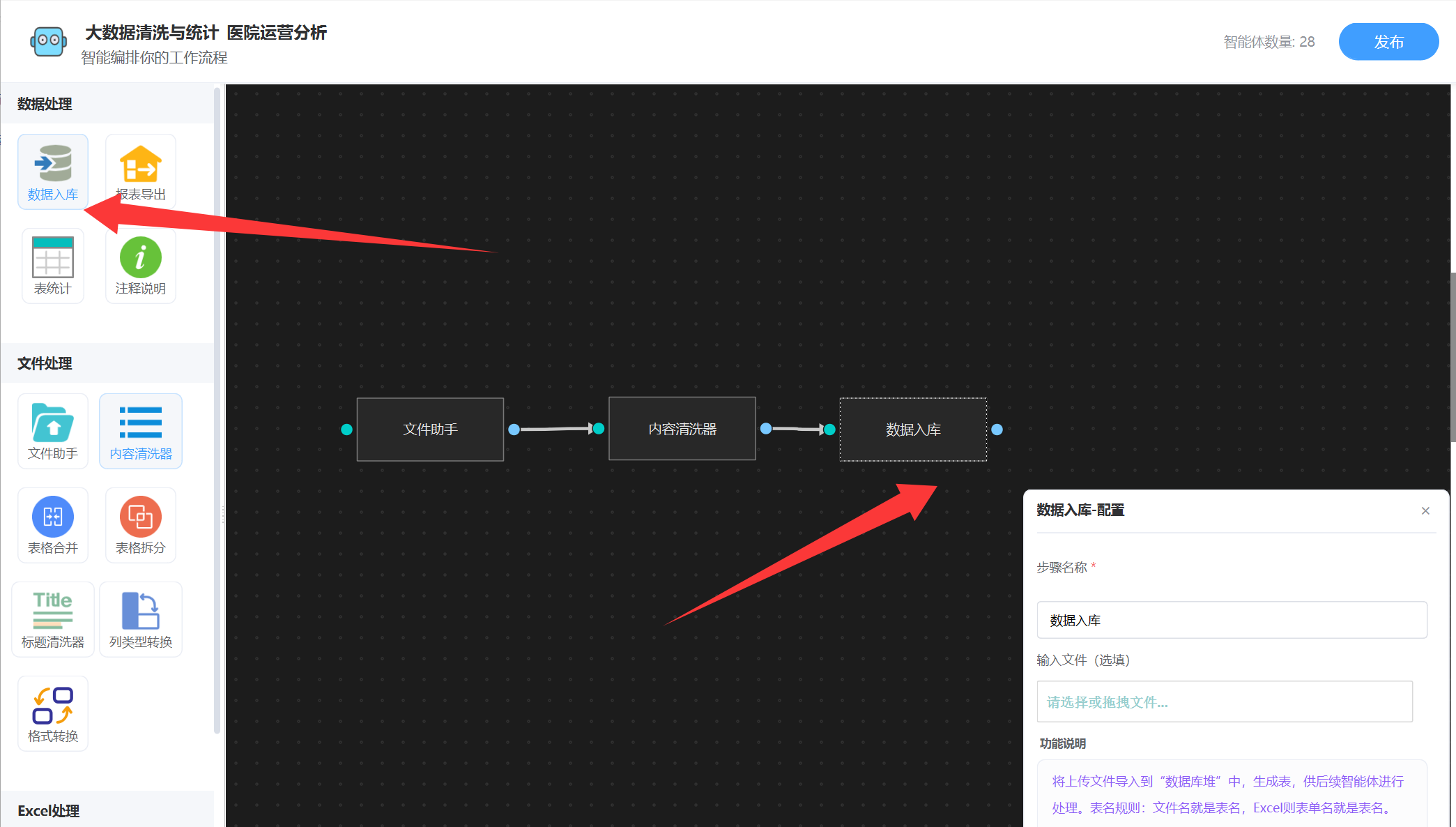
第一步就完成了,同理,所有的源表清洗都是这个套路。
2. 表统计
接下来我们需要进行表统计,直接用“表统计”智能体就好了, 也是直接输入提示词描述,工作流内部会生成相关sql进行统计(全程不用你操心),下面是我配置完成的图:
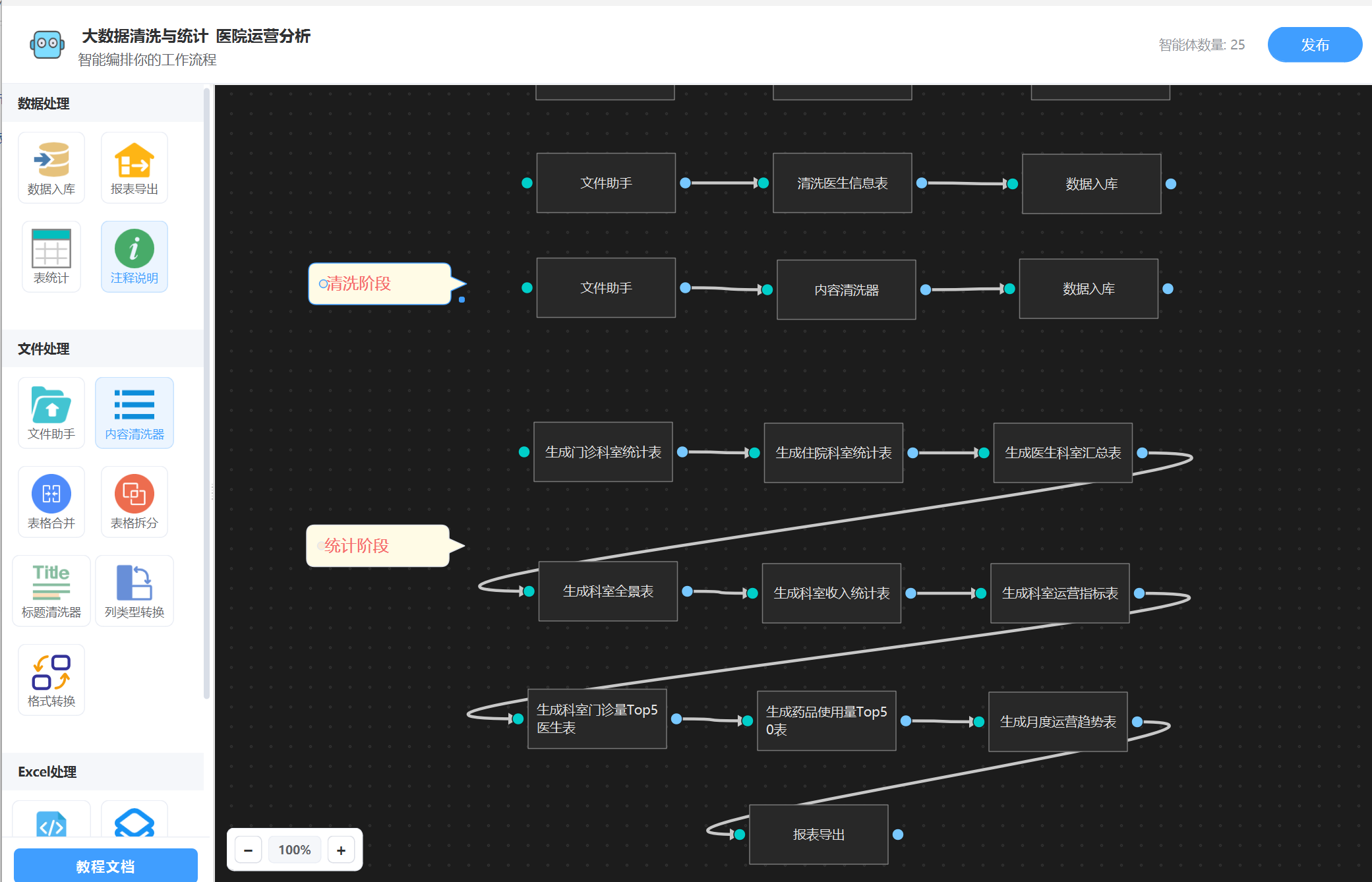
3. 导出报表
表统计后,只生成了结果表到数据库里面,还需要从数据库里面下载出来,这是要用“报表导出”智能体,可以指定哪些表,下载类型,如下图:
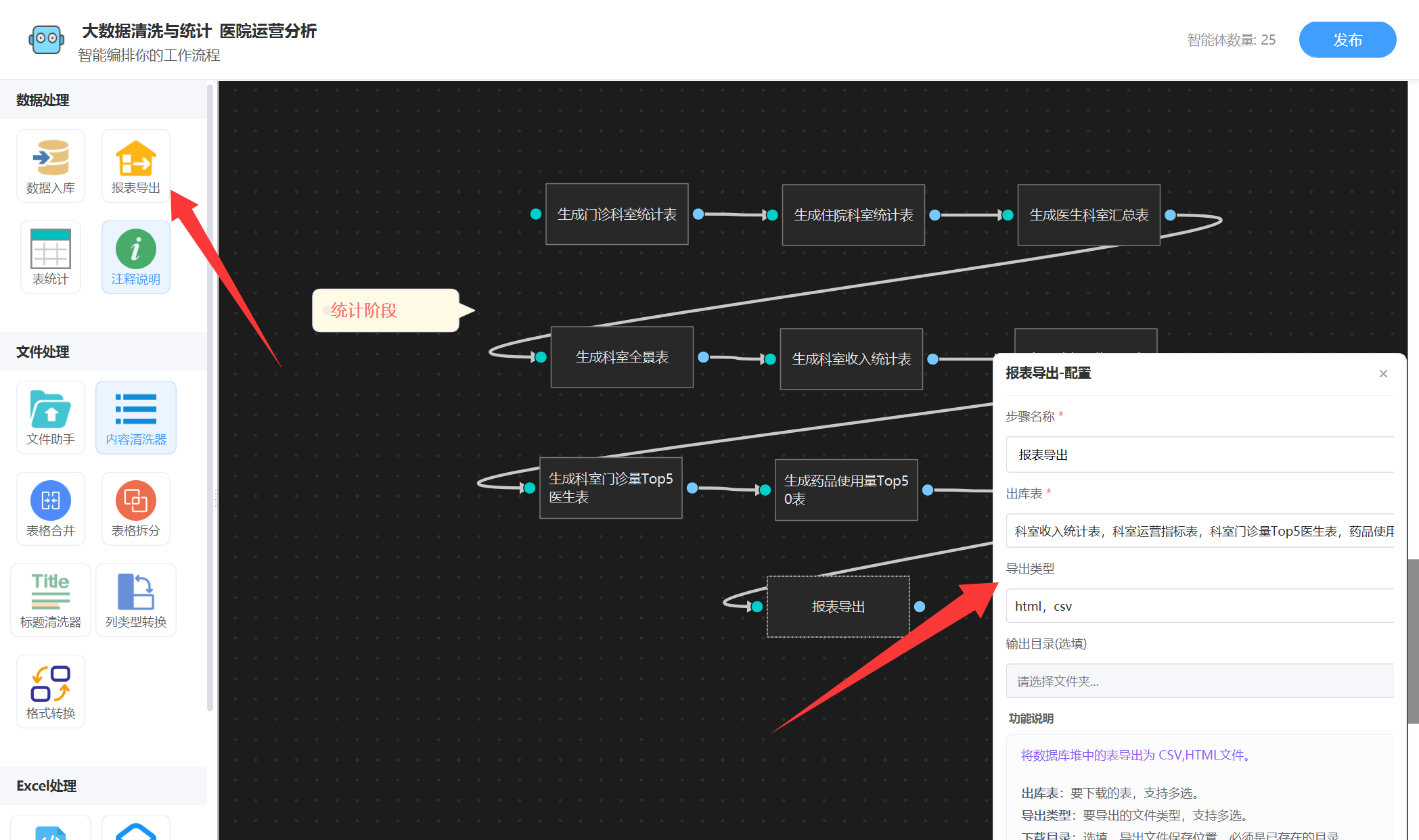
配置完成后,我们发布工作流执行就可以了。
四、结尾语
医院运营分析真正复杂的地方,往往不在最后那几张结果表,而在前面多源数据的整理、清洗、关联和统计过程。门诊、住院、药品、医生、科室这些数据分散在不同表里,口径不统一、字段不一致,如果没有一套清晰的处理流程,分析工作很容易停留在反复整理数据的阶段。
这个案例展示的价值,在于把原本偏复杂的数据分析过程,拆成业务人员也能理解和使用的步骤:先清洗,再汇总,再关联,最后输出结果。借助 AI 工作流,即使不写代码、不写 SQL,也可以在本地把千万级医院运营数据逐步整理清楚,并完成经营分析所需的关键结果产出。对业务团队来说,这不仅意味着效率更高,也意味着很多原本依赖技术人员完成的分析任务,开始能够以更低门槛、更标准化的方式落地。

一站式 AI 云服务平台
更多推荐
 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)