
本地千万级 XLSX/CSV 客服工单文本结构化拆分实战:用 AI 工作流零代码、零 SQL 完成字段清洗、正则提取与关联分析
今天分享一个客服工单文本字段结构化拆分的实战案例:对原始工单数据完成清洗,并从工单描述中提取客户ID、产品编码、故障现象等字段,再关联客户和产品信息,完成后续统计分析。
这里要介绍是小白都能用的AI 工作流方案:
不用写 Python,也不用懂 SQL,直接在本地电脑上就能完成千万级 XLSX/CSV 客服工单数据的清洗、文本字段提取、关联分析和结果输出。
二、案例需求分析
有三张原始数据表,数据量在百万到千万级别,如下:
- 工单记录表.csv (工单ID、创建时间、状态、优先级、工单描述)— 300万行
- 客户信息表.csv (客户ID、客户名称、客户等级、所属地区)— 50万行
- 产品目录表.csv (产品编码、产品名称、产品线、是否停产)— 2万行
本案例要先清洗 3 张表的数据,再从工单描述中提取客户ID、产品编码、故障现象等字段,随后关联客户和产品信息,最后输出多个统计分析结果表和可视化大盘。
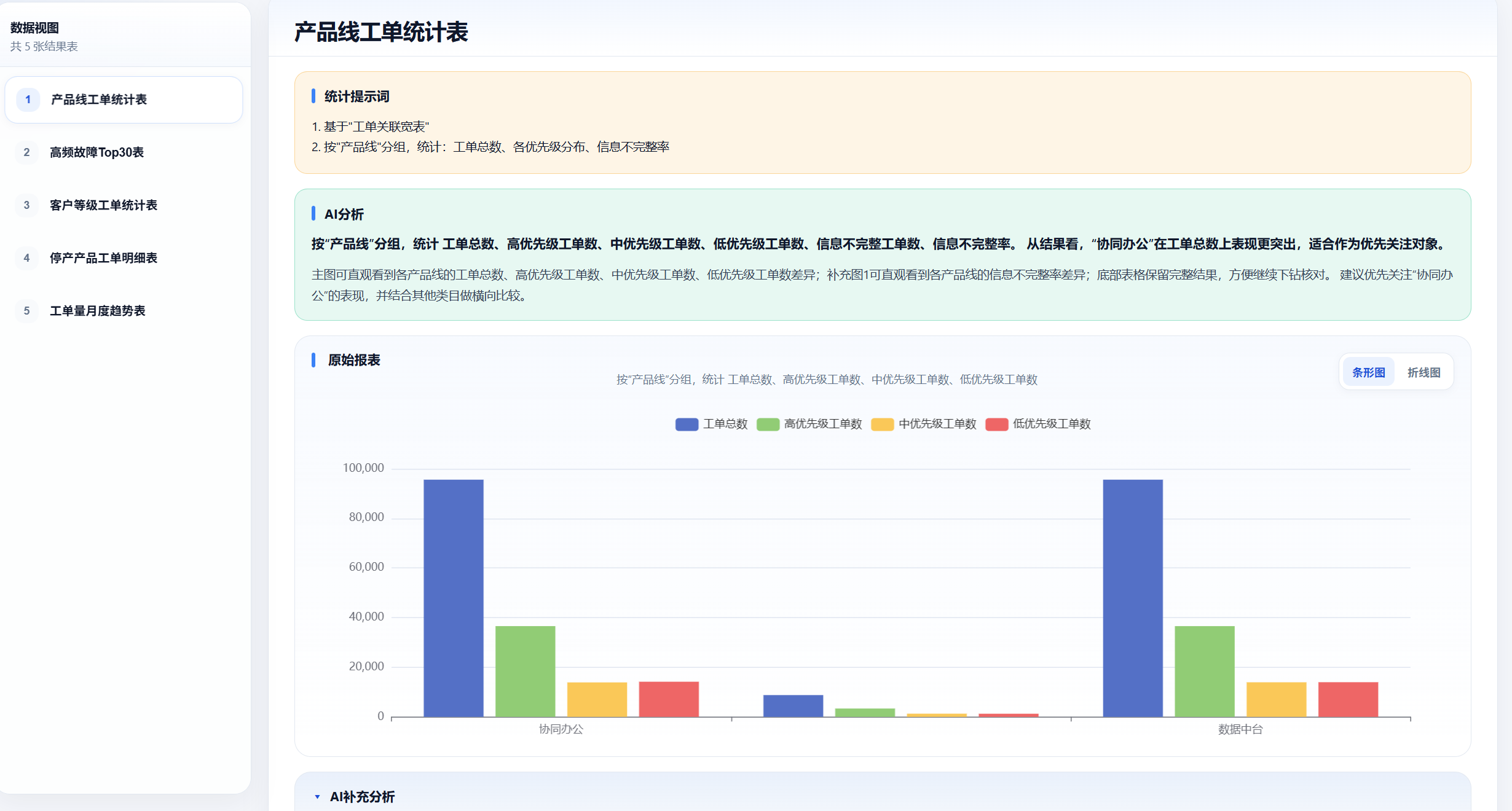
生成的可视化大盘如图(HTML文件):
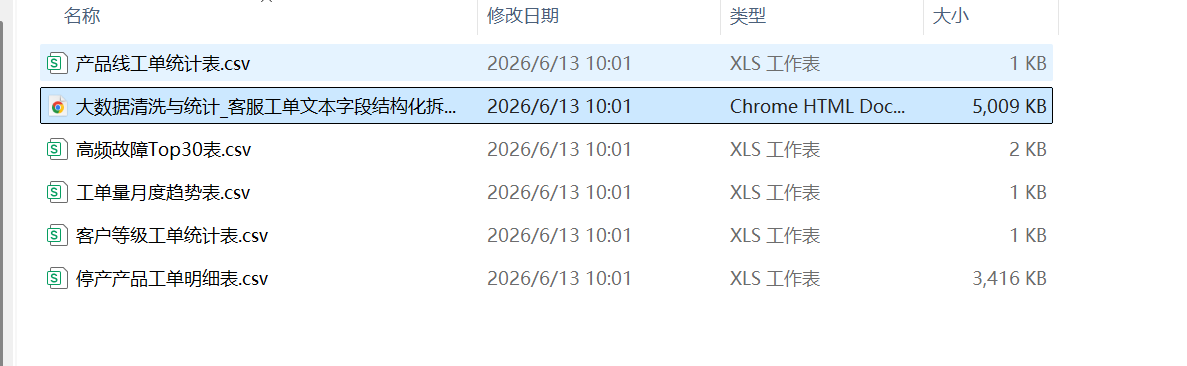
生成的结果数据表,如图:
1. 清洗数据
清洗数据就是将一些带有脏数据,格式有问题的数据都清洗成统一的, AI 工作流内置了 Python Agent,通过提示词就能实现任意清洗逻辑,如下提示词:
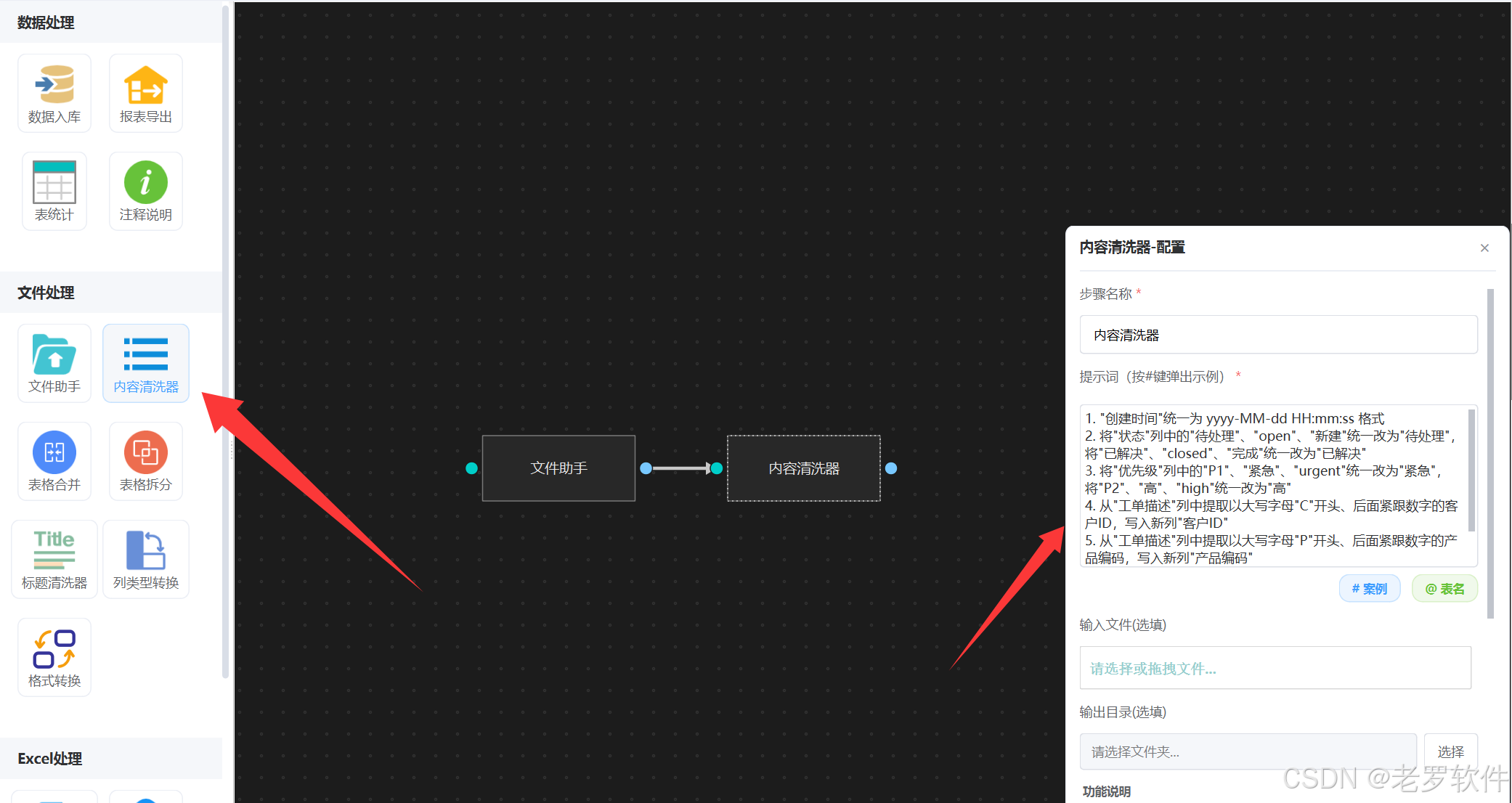
1. "创建时间"统一为 yyyy-MM-dd HH:mm:ss 格式
2. 将"状态"列中的"待处理"、"open"、"新建"统一改为"待处理",将"已解决"、"closed"、"完成"统一改为"已解决"
3. 将"优先级"列中的"P1"、"紧急"、"urgent"统一改为"紧急",将"P2"、"高"、"high"统一改为"高"
4. 从"工单描述"列中提取以大写字母"C"开头、后面紧跟数字的客户ID,写入新列"客户ID"
5. 从"工单描述"列中提取以大写字母"P"开头、后面紧跟数字的产品编码,写入新列"产品编码"
6. 从"工单描述"列中提取"故障:"后到下一个逗号或句号之前的文本,写入新列"故障现象"2. 关联数据
完成清洗和字段提取后,下一步就是把工单表、客户信息表、产品目录表关联起来,生成一张工单关联宽表。
AI 工作流内置了 SQL Agent,只需要用自然语言描述关联逻辑,就可以自动完成多表关联、字段补充和结果输出,如下提示词:
1. 将工单表按"客户ID"关联客户信息表,再按"产品编码"关联产品目录表
2. 新增"信息完整性"列;按"客户ID"找不到客户,或按"产品编码"找不到产品时写为"信息不完整",客户和产品都匹配成功时写为"信息完整"3. 统计分析
拿到工单关联宽表之后,就可以继续做统计分析。
AI 工作流通过SQL Agent,可以根据提示词自动完成分组统计、排序、筛选和结果输出,不需要手写 SQL,如下提示词:
1. 按"产品线"分组,统计工单总数、各优先级分布、信息不完整率,输出"产品线工单统计表"
2. 按"故障现象"+"产品线"分组,统计工单数,并按工单数降序取 Top30,输出"高频故障Top30表"
3. 按"客户等级"分组,统计工单数量、紧急工单占比,输出"客户等级工单统计表"
4. 筛出"是否停产"="已停产"且仍有工单提交的记录,输出"停产产品工单明细表"
5. 按"月份"分组统计工单量,输出"工单量月度趋势表"二、案例要完成的任务提示词
这个提示词就是案例需要完成的任务,直接用于配置到工作流智能体里面。
需要说明一点: 提示词不一定非要写成固定模板 。只要表达得 清晰 、 明确 、 简洁 ,让人一眼能看懂要做什么、按什么顺序做、最后输出什么结果,就可以了。
本次案例整理出的提示词如下:
整体要求:从客服工单描述中提取结构化字段,生成工单分析报告:
第一步 - 清洗并提取工单记录表:
1. "创建时间"统一为 yyyy-MM-dd HH:mm:ss 格式
2. 将"状态"列中的"待处理"、"open"、"新建"统一改为"待处理",将"已解决"、"closed"、"完成"统一改为"已解决"
3. 将"优先级"列中的"P1"、"紧急"、"urgent"统一改为"紧急",将"P2"、"高"、"high"统一改为"高"
4. 从"工单描述"列中提取以大写字母"C"开头、后面紧跟数字的客户ID,写入新列"客户ID"
5. 从"工单描述"列中提取以大写字母"P"开头、后面紧跟数字的产品编码,写入新列"产品编码"
6. 从"工单描述"列中提取"故障:"后到下一个逗号或句号之前的文本,写入新列"故障现象"
7. "客户ID"、"产品编码"、"故障现象"提取不到时写为"未提取到"
第二步 - 清洗客户信息表:
1. 将客户信息表中"客户等级"列里的"VIP"、"vip"、"贵宾"统一改为"VIP",将"普通"、"normal"、"一般客户"统一改为"普通"
第三步 - 清洗产品目录表:
1. 将产品目录表中"是否停产"列里的"Y"、"是"、"true"统一改为"已停产",将"N"、"否"、"false"统一改为"未停产"
第四步 - 生成工单关联宽表:
1. 将工单表按"客户ID"关联客户信息表,再按"产品编码"关联产品目录表
2. 新增"信息完整性"列;按"客户ID"找不到客户,或按"产品编码"找不到产品时写为"信息不完整",客户和产品都匹配成功时写为"信息完整"
第五步 - 生成产品线工单统计表:
1. 基于"工单关联宽表"
2. 按"产品线"分组,统计:工单总数、各优先级分布、信息不完整率
3. 输出"产品线工单统计表"
第六步 - 生成高频故障Top30表:
1. 基于"工单关联宽表"
2. 按"故障现象"+"产品线"分组,统计工单数
3. 按工单数降序取Top30
4. 输出"高频故障Top30表"
第七步 - 生成客户等级工单统计表:
1. 基于"工单关联宽表"
2. 按"客户等级"分组,统计:工单数量、紧急工单占比
3. 输出"客户等级工单统计表"
第八步 - 生成停产产品工单明细表:
1. 基于"工单关联宽表"
2. 筛出"是否停产"="已停产"且仍有工单提交的记录
3. 输出"停产产品工单明细表"
第九步 - 生成工单量月度趋势表:
1. 基于"工单关联宽表"
2. 按"月份"分组,统计:工单量
3. 输出"工单量月度趋势表"三、落地实现:工作流配置
工作流是由多个智能体节点组成的,这个案例我们涉及到下面几个智能体:
- 文件助手: 获取磁盘的文件或目录。
- 内容清洗器: 专门用来做数据清洗的,只要输入清洗描述就可以对文件数据进行任意整理。
- 数据入库:将文件数据转成本地数据库,用于后面作SQL统计。
- 表统计: 对本地数据库表进行SQL统计,不需要写sql,只需要统计的描述就可以了。
- 报表导出: 对数据库表进行导出,支持导出csv,xlsx,HTML(可视化显示) 。
根据这几个智能体还有上面描述的提示词,我们就可以完成工作流的配置了。
1. 配置文件助手
”文件助手“ 可以用来获取磁盘上任意的一个或多个文件。打开DT-Bot工作流, 配置一个 “文件助手”智能体节点,描述原始数据文件位置,如图:
DT-Bot工作流,解决方案获取可以看文章末尾名片。
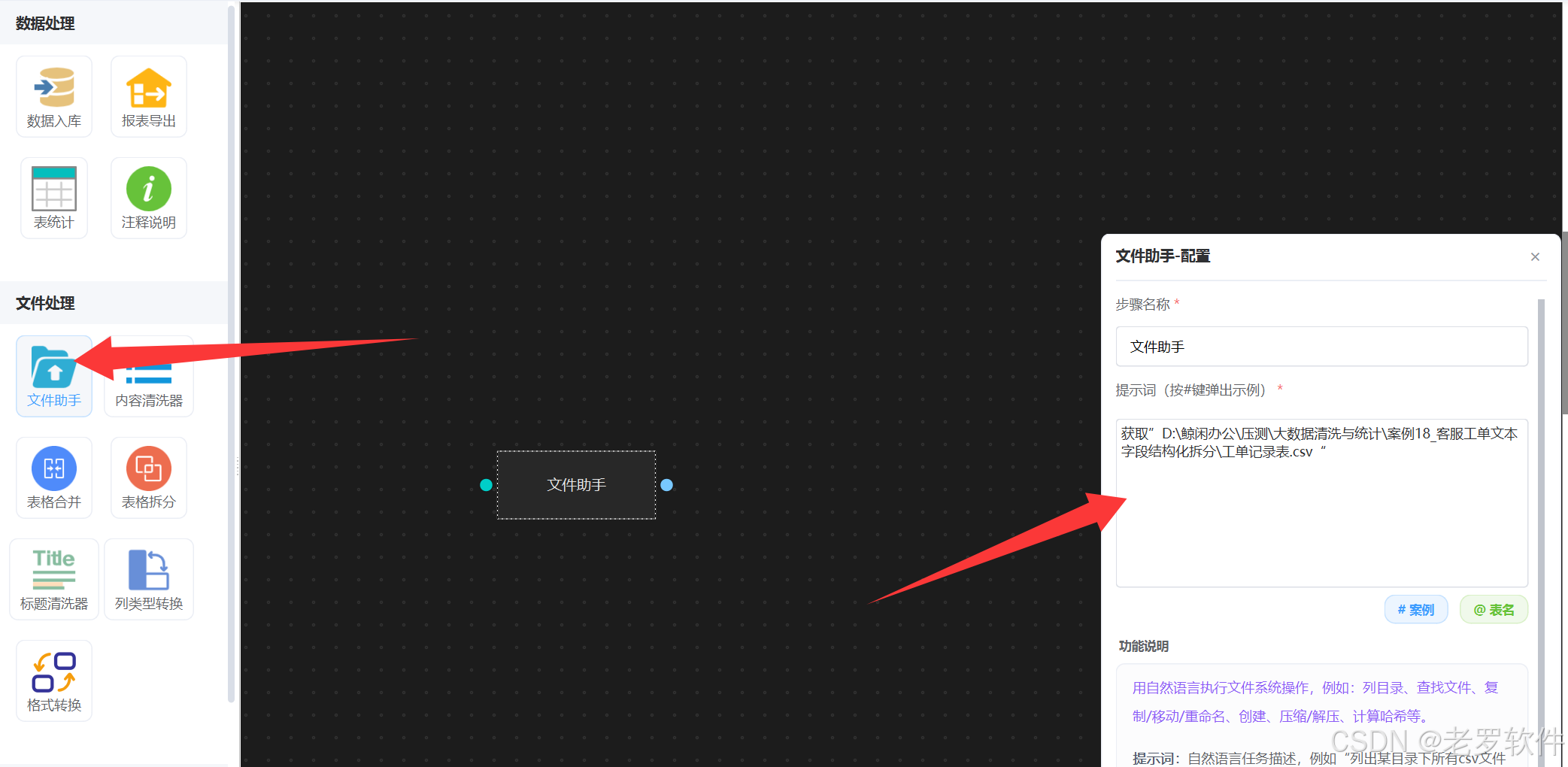
根据提示词描述,获取到了”工单记录表.csv“原始表格,给后面智能体使用。
2. 配置内容清洗
“内容清洗器” 很强大,内部是通过python agent执行引擎处理的, 可以对文件进行任意数据整理,我们直接输入清洗提示词就可以了, 如图:
清洗完成后,还是输出的文件,下面需要进行SQL统计,需要先将文件进行入库。
3. 数据入库
”数据入库“ 智能体可以将文件导入到本地数据库引擎,然后形成数据库表,无需任何提示词,如图配置入库:
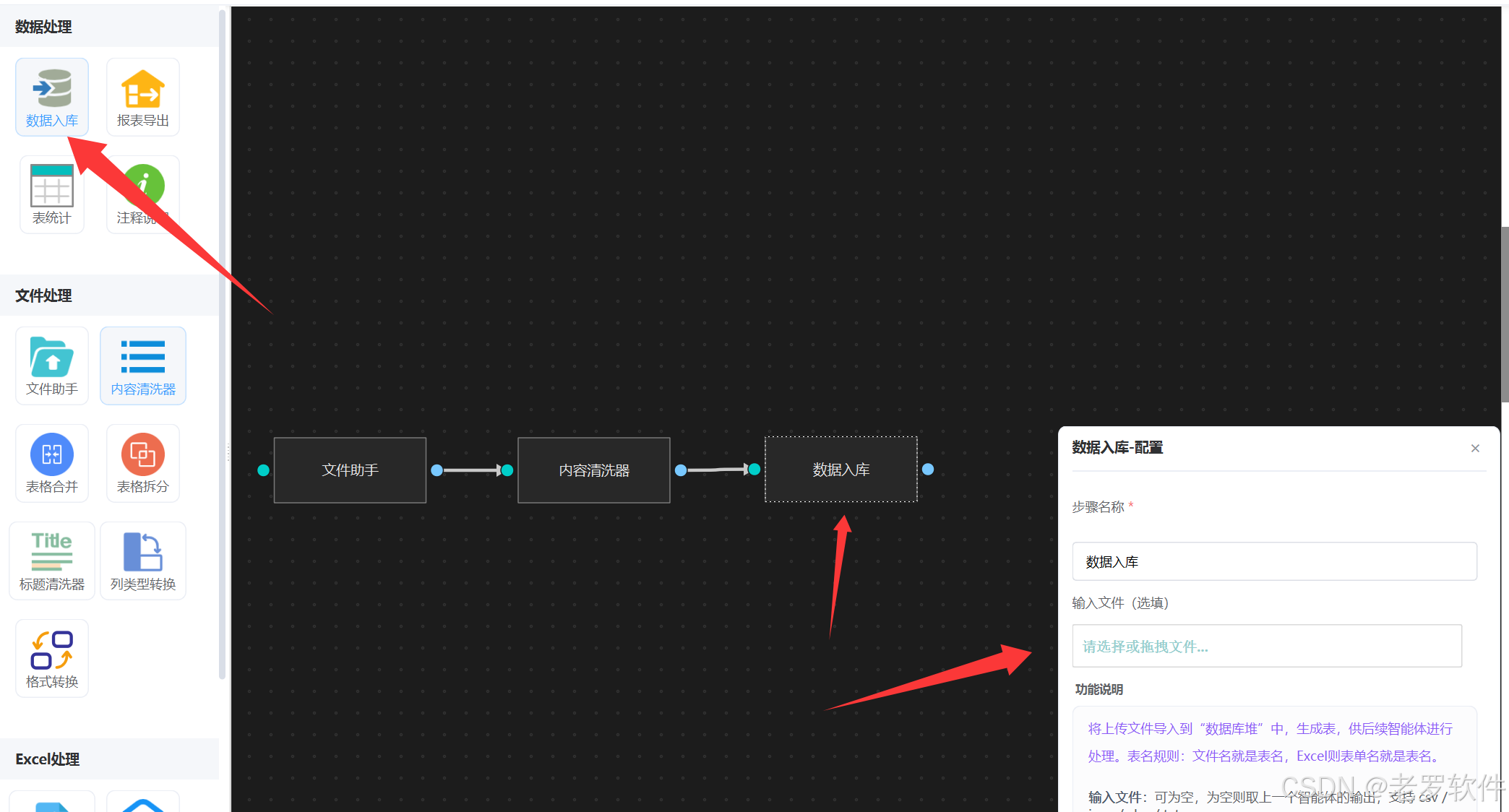
到此,我们 工单记录表.csv 的清洗,入库就完成了, 其余的表也是如此配置。
4. 表统计
接下来我们需要进行sql统计,直接用“表统计”智能体就好了, 也是直接输入提示词描述,工作流内部会生成相关sql进行统计(全程不用你操心),下面是我配置完成的图:
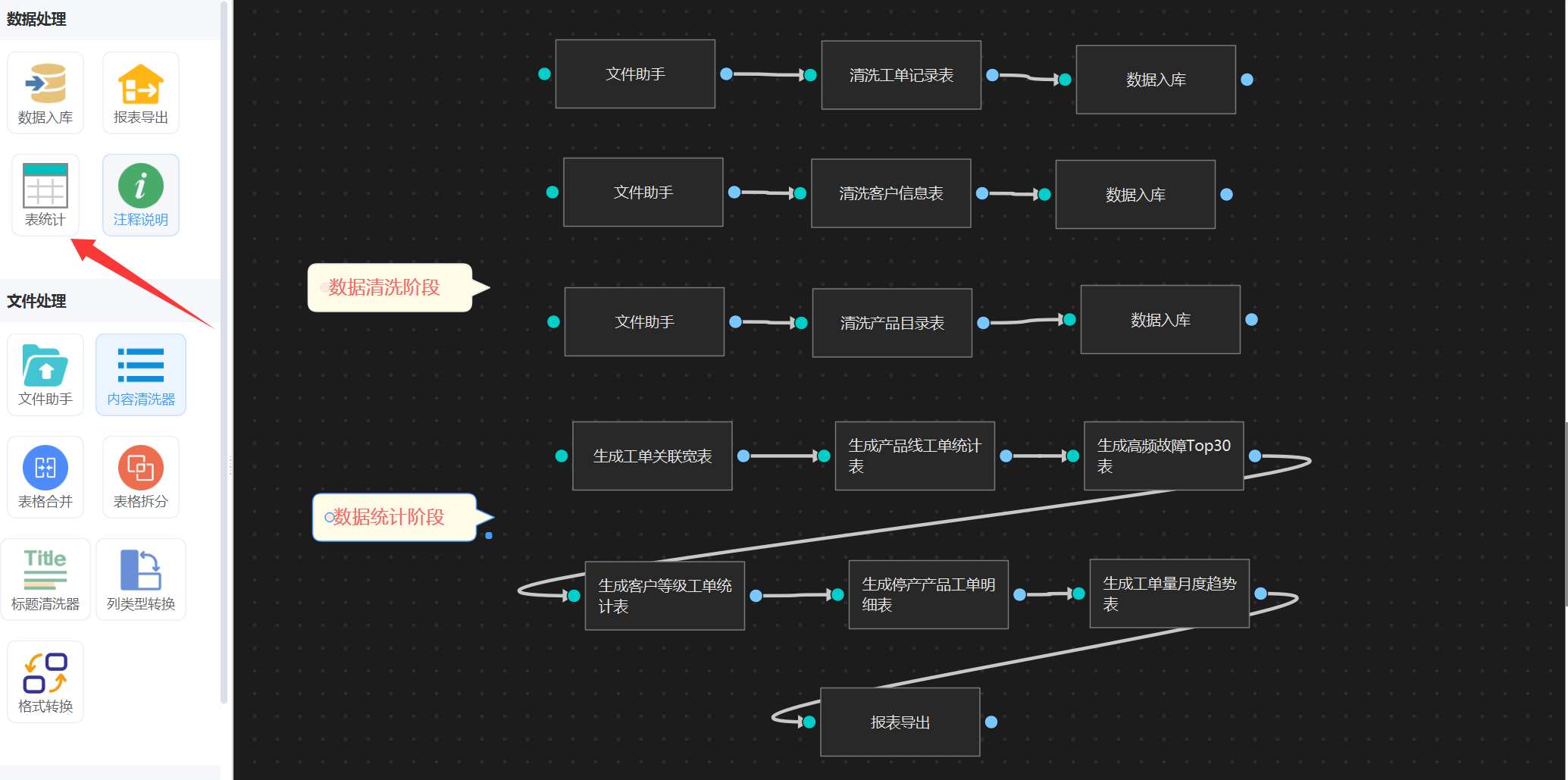
5. 导出报表
表统计后,只生成了结果表到数据库里面,还需要从数据库里面下载出来,这是要用“报表导出”智能体,可以指定哪些表,下载类型(支持CSV+HTML),如下图:
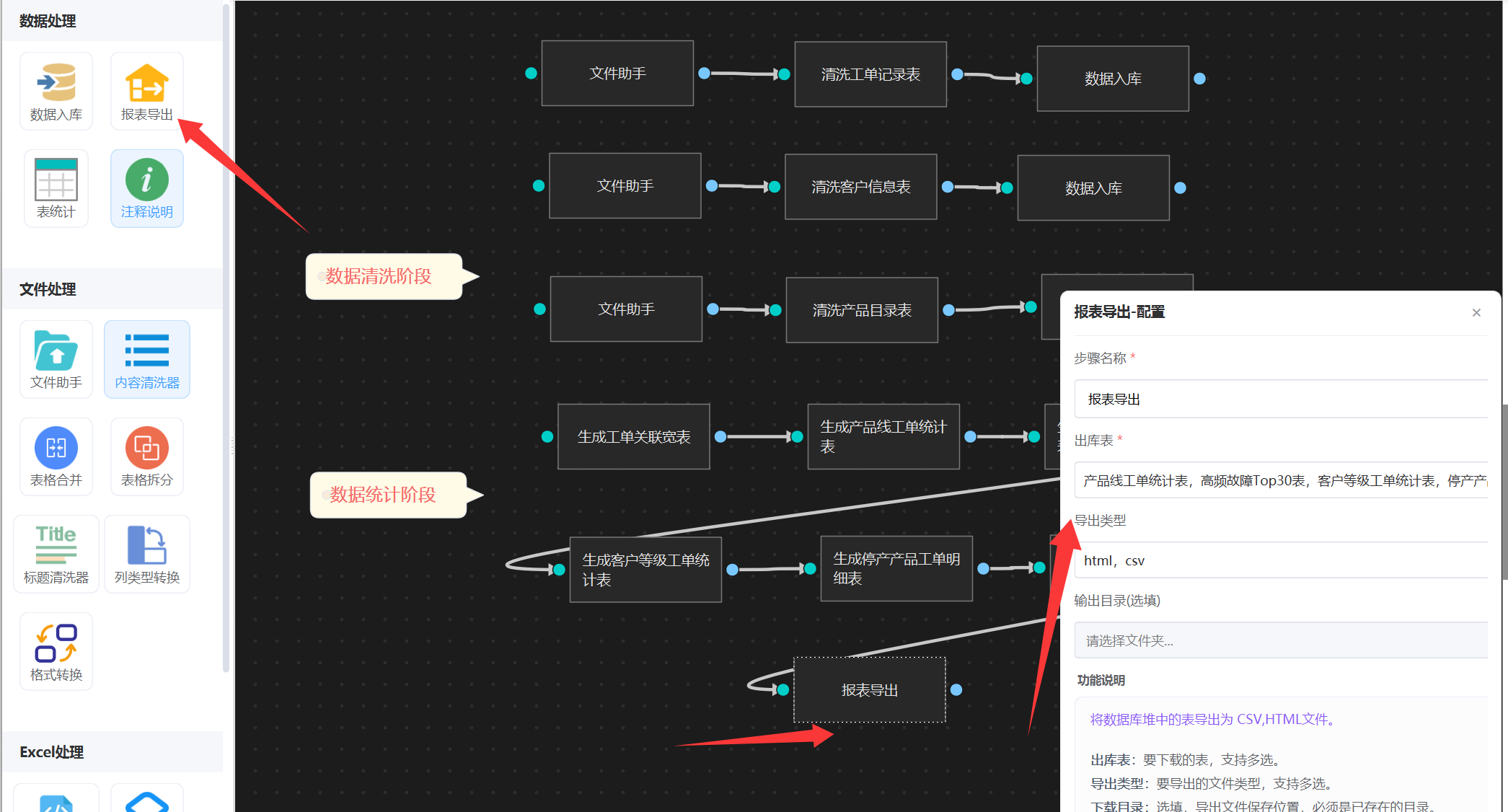
配置完成后,我们发布工作流执行就可以了。
四、结尾语
这个案例的价值,不只是完成了工单数据清洗,更重要的是把工单描述中的关键信息提取出来,并和客户、产品数据关联起来,形成可直接分析的结果表。通过字段清洗、文本提取、信息关联和统计分析,整个处理过程更清晰,也更贴近真实业务场景。
按照 AI 工作流配置好处理要求后,不需要手写 Python 和 SQL,也可以把原始工单数据快速整理成可直接用于分析和管理的结果表。

一站式 AI 云服务平台
更多推荐
 1
1 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)