
零代码玩转多源文件抽取:基于助睿ETL的多源数据处理
#商业数据分析 #助睿数智 #大数据分析 #ETL平台
1 实验背景与目的
在数据仓库与数据集成项目中,ETL 的第一步往往是从各类数据源中获取数据,这恰恰是整个流程中最具挑战性的环节。数据源的多样性——关系型数据库、CSV、Excel、文本日志——以及访问权限的限制,使得数据抽取方式必须灵活多变。尤其当数据以文件形式共享,或散落在不同业务系统导出的文本、表格中时,快速、准确地解析这些文件,便成为数据处理人员的一项必备技能。
本次实验借助助睿数智(Uniplore)平台中的助睿ETL数据集成子系统,在零代码环境下,系统地实践了 CSV、特定分隔符的文本文件以及 Excel 三种主流文件格式的抽取、字段筛选与轻量级加工。目的在于:
- 掌握文件输入组件的核心配置方法与参数含义;
- 理解字段选择、计算器、数值范围等转换组件在数据预处理流程中的作用;
- 独立完成从文件读取到结果验证的完整数据流水线搭建,为后续数据建模打下基础。
2 实验概况
- 实验平台:助睿在线实验平台(
lab.guilian.cn),使用产品“助睿数智 - AI驱动的一站式零代码数据智能服务系统”中的 ETL 子平台。 - 实验数据:所有数据文件均从平台公共空间导出至项目文件库,共涉及三个文件:
project.csv:项目信息数据,包含项目编号、开工日期、结束日期等字段;usa_201209.txt:足球比赛数据,以分号分隔,包含比赛日期、主客队、比分等;custinfo.xlsx:购房者个人信息,记录年龄、学历、雇佣状态等多维特征。
- 核心任务:
- 解析 CSV 文件并计算项目工期,根据工期自动评定绩效等级,最终输出结果文件;
- 读取以分号分隔的文本文件,剔除冗余字段,验证数据链路连通性;
- 读取 Excel 文件,按需筛选出学历和雇佣状态两个目标字段,完成基础预处理。
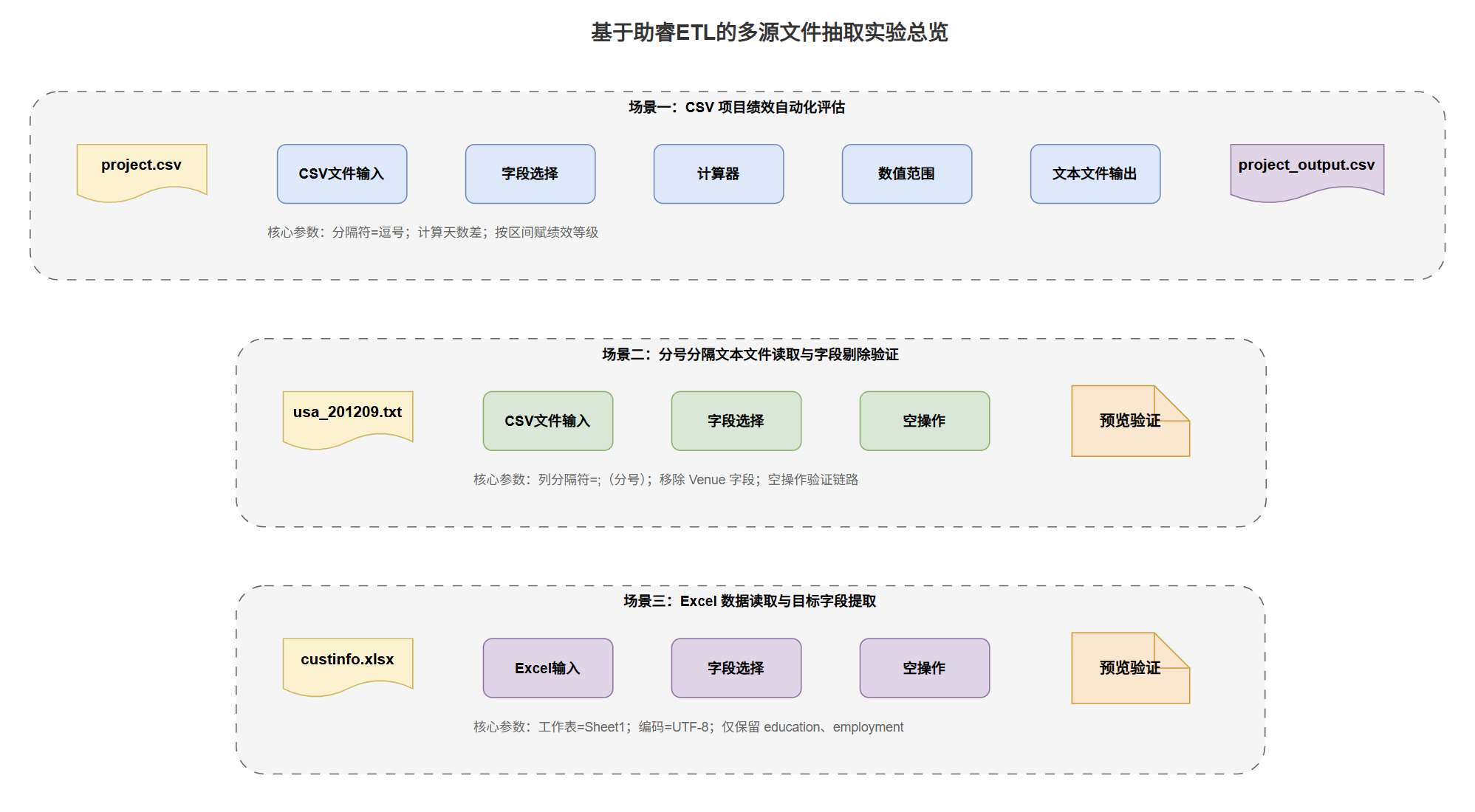
3 实验步骤
3.1 CSV 数据提取与项目绩效自动化评估
本环节的目标是将原始项目信息从 CSV 文件抽取出来,依据开工日期与结束日期计算执行天数,再按预设的区间规则生成绩效等级,最后将加工结果写入新的 CSV 文件。整个转换流程包含五个核心组件。
(1) 构建数据源接入
在项目中新建转换,将组件库内的「CSV 文件输入」拖入画布。通选中已导出到文件库的 project.csv。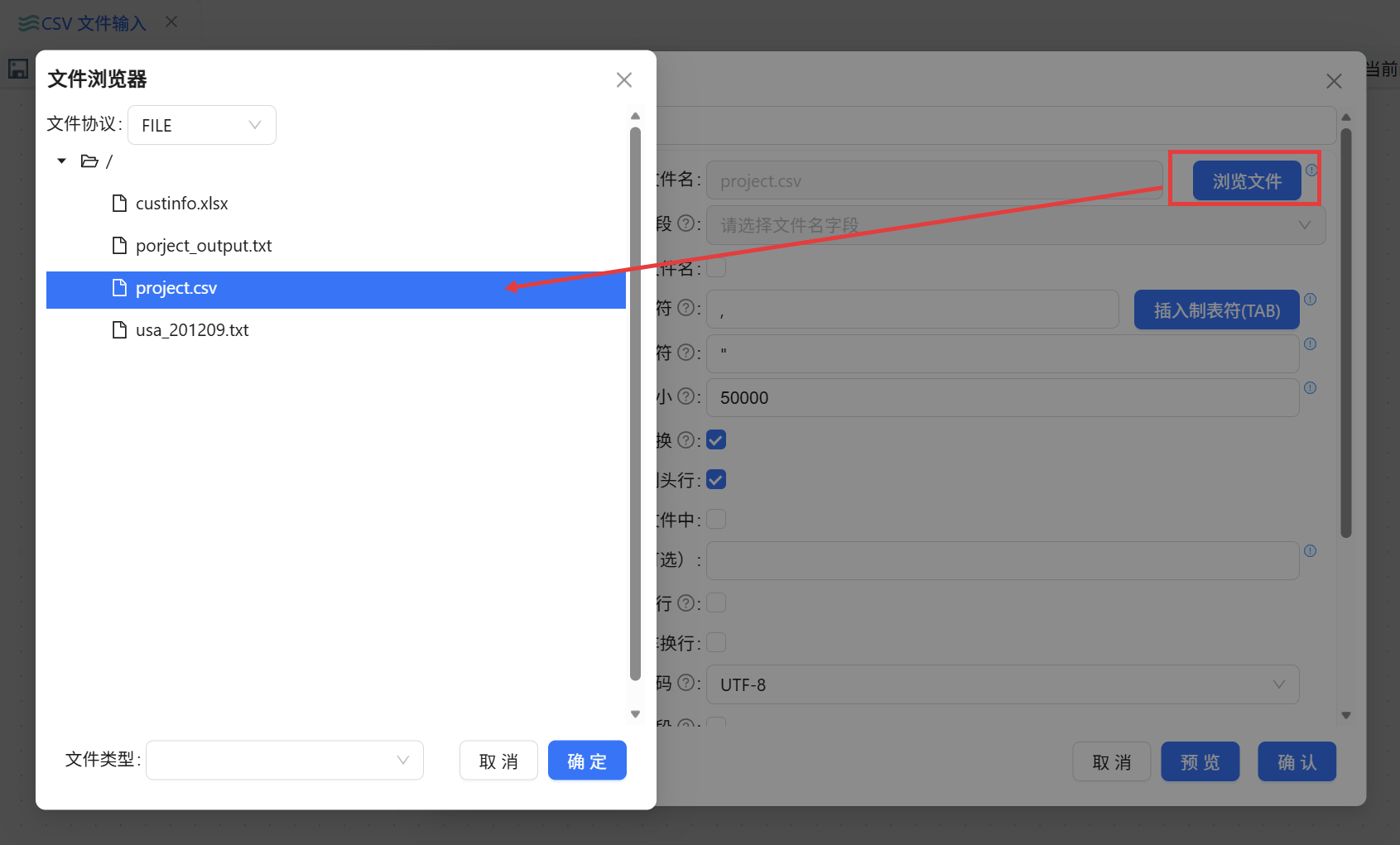
随后,在组件下方的数据预览区右键选择“获取字段”,平台立刻解析出 CSV 的列信息,包括项目标识、名称、起止日期等。通过“预览”功能可快速核对数据是否完整载入,日期等字段能否正确识别。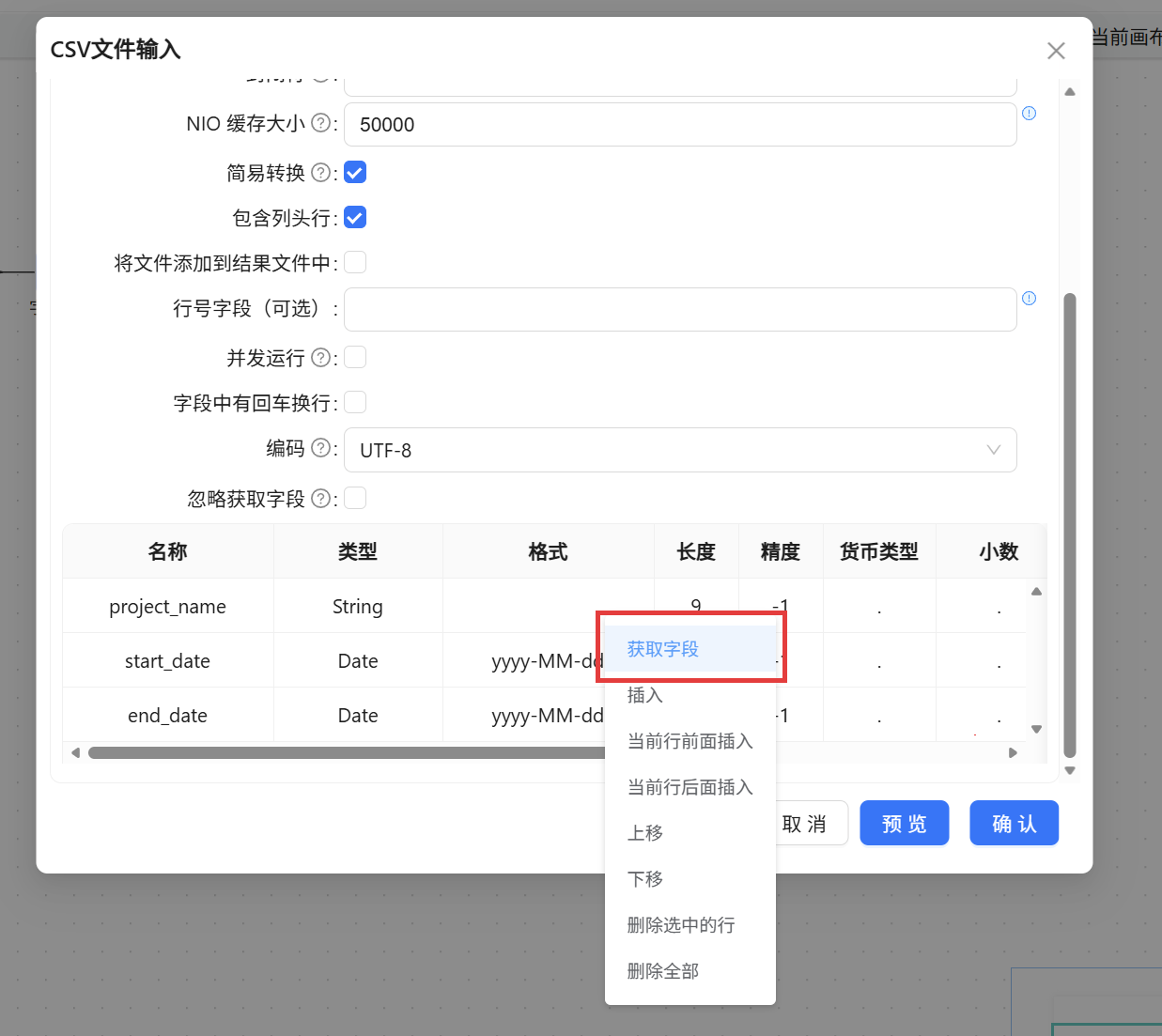
(2) 字段校验与筛选
接入「字段选择」组件。将其与上游 CSV 输入组件连接,在弹出框中选择“主输出步骤”,双击该组件,在“选择和修改”页签右键获取前一步骤的所有字段,并保持默认不变。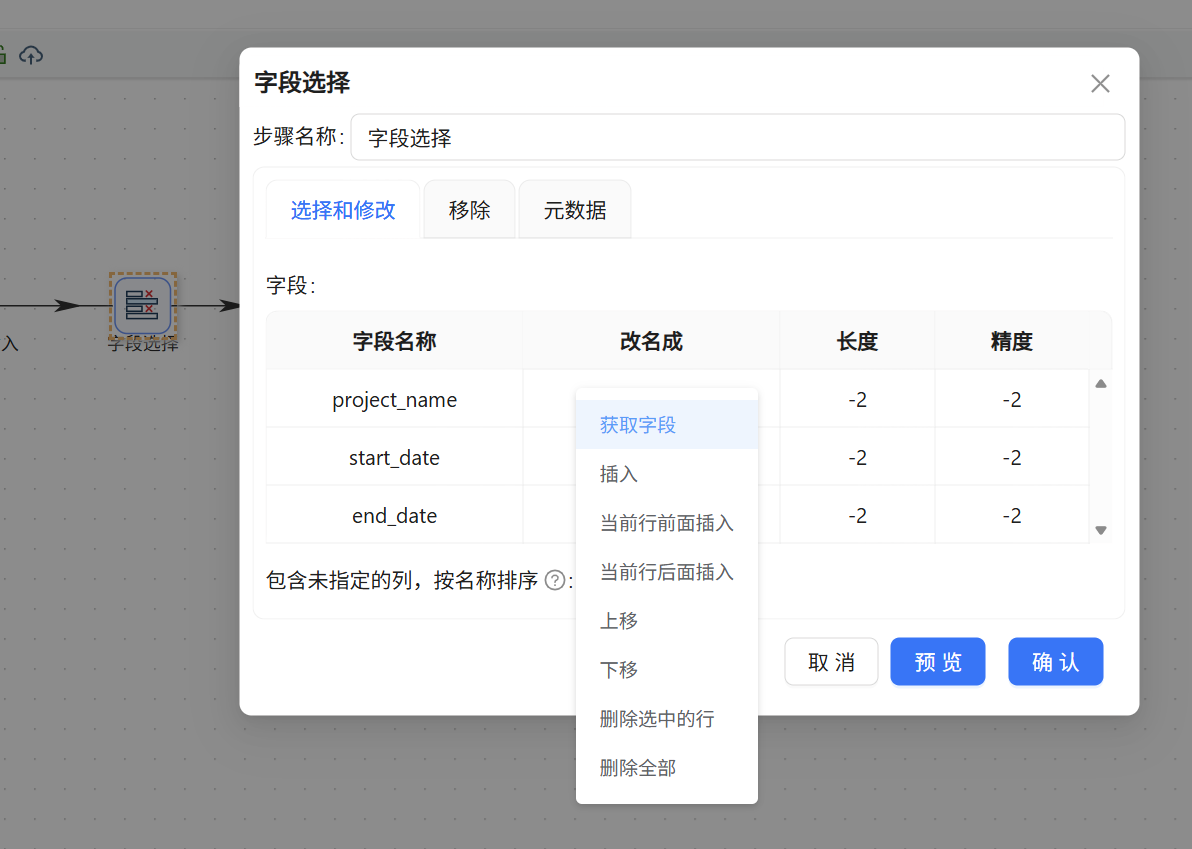
(3) 计算项目时长
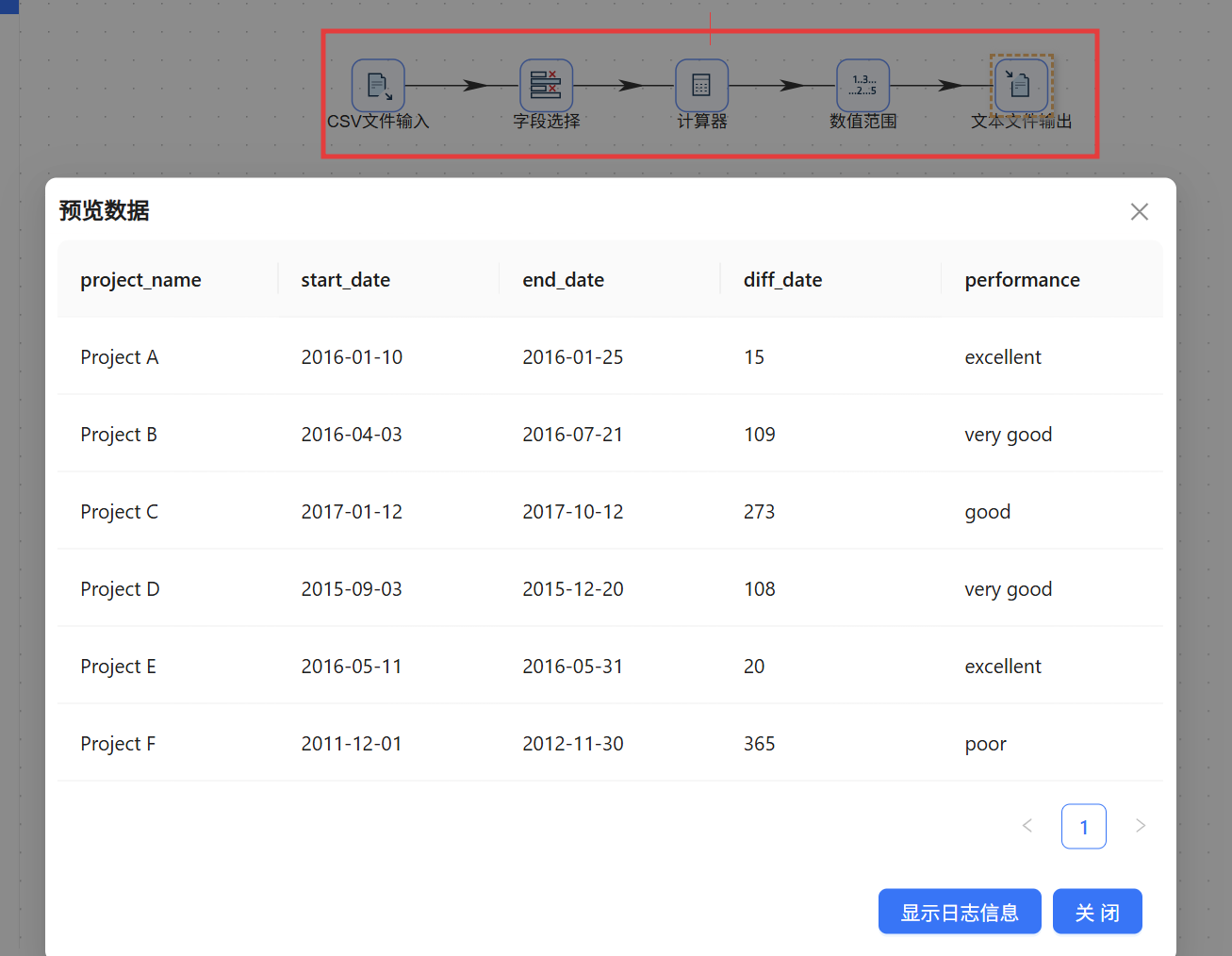
从字段选择的后方拉出「计算器」组件。双击打开配置,插入一条新计算规则:在“新字段”列填入 diff_date,作为工期天数的存储字段;“计算”下拉选择 Date A - Date B (in days);“字段 A”设为 end_date(结束日期),“字段 B”设为 start_date(开工日期);值类型指定为 Integer。如此,每一行数据都会自动计算结束日与开始日之间的天数差,结果以整数形式写入 diff_date。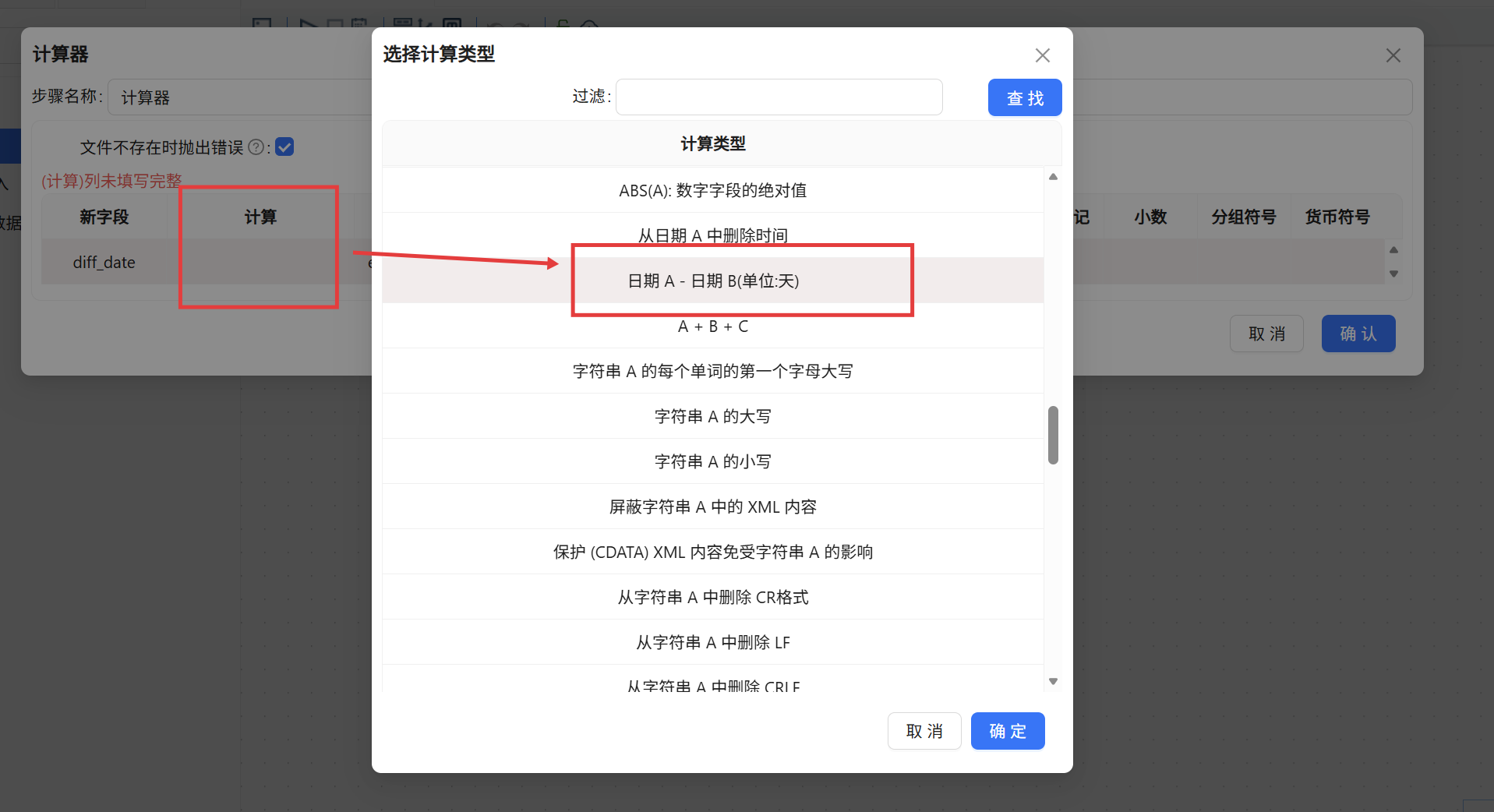
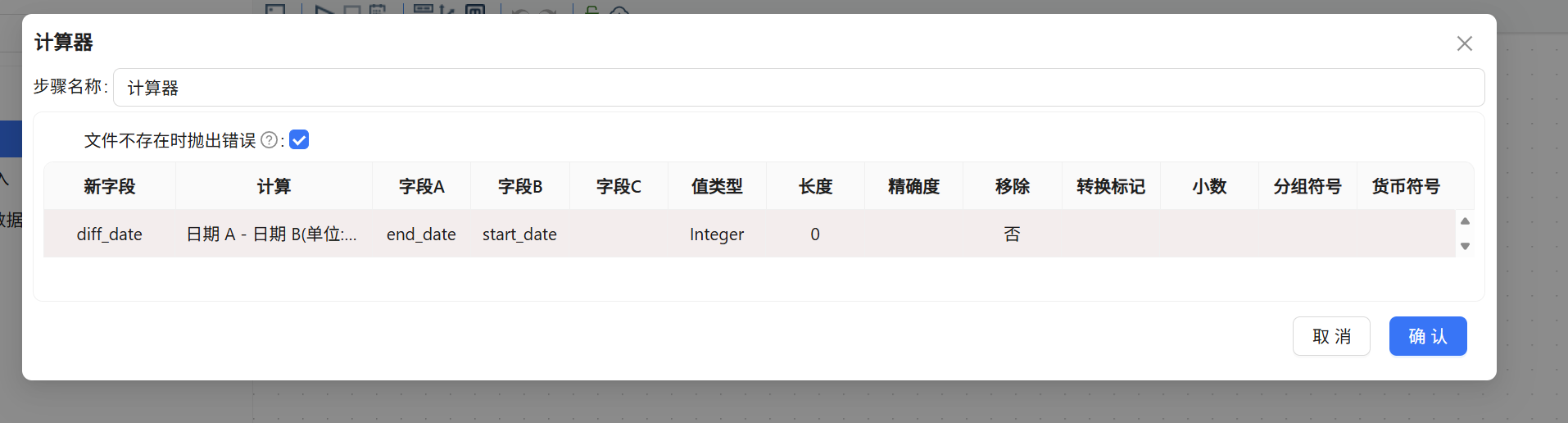
(4) 绩效等级判定
连接到计算器的下一个组件是「数值范围」。打开配置后,输入字段选择刚计算出来的 diff_date,输出字段手动命名为 performance。接下来设置四组区间规则(均为左闭右开区间):
- 0 ≤ diff_date < 30 → 赋值为
excellent - 30 ≤ diff_date < 180 →
very good - 180 ≤ diff_date < 360 →
good - diff_date ≥ 360 →
poor
该组件将按照优先级从上到下进行匹配,每条记录的工期落入某个区间后,立即为 performance 字段赋予对应的文本值。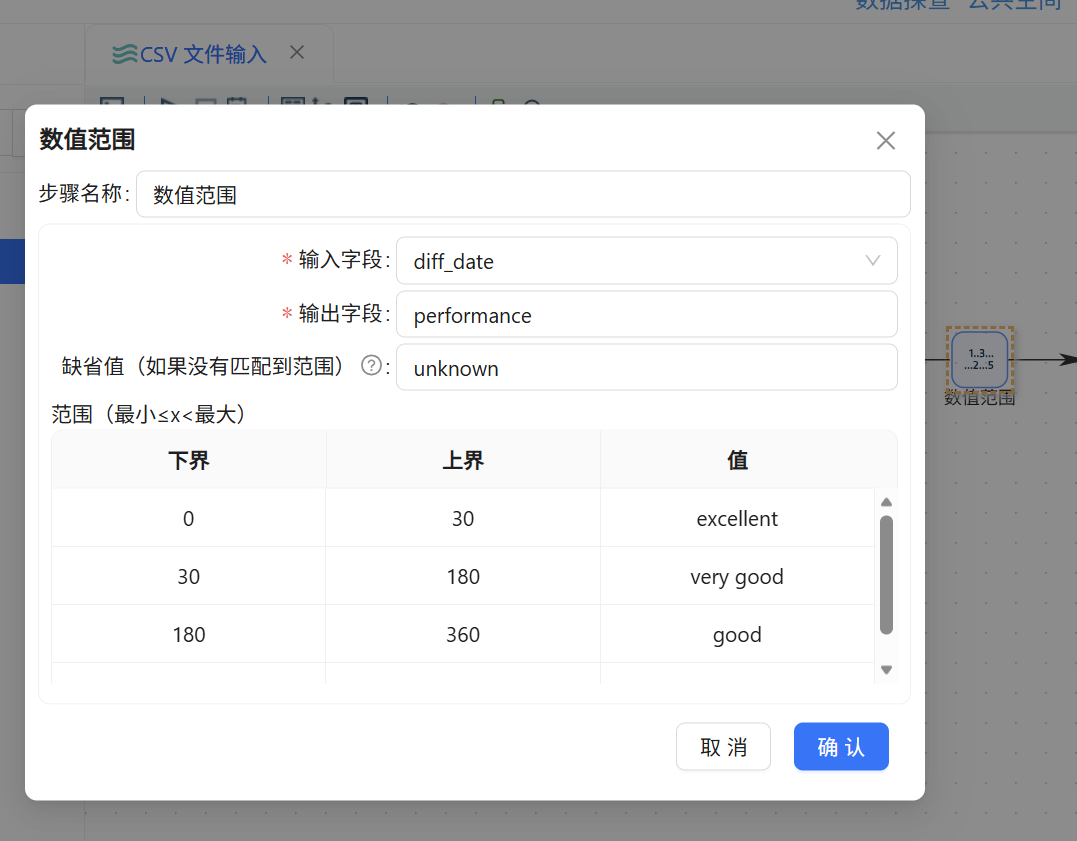
(5) 结果输出
最后,将「文本文件输出」组件拖入。配置时指定文件名称为 project_output,扩展名为 csv,并在“内容”标签页将分隔符改为英文逗号。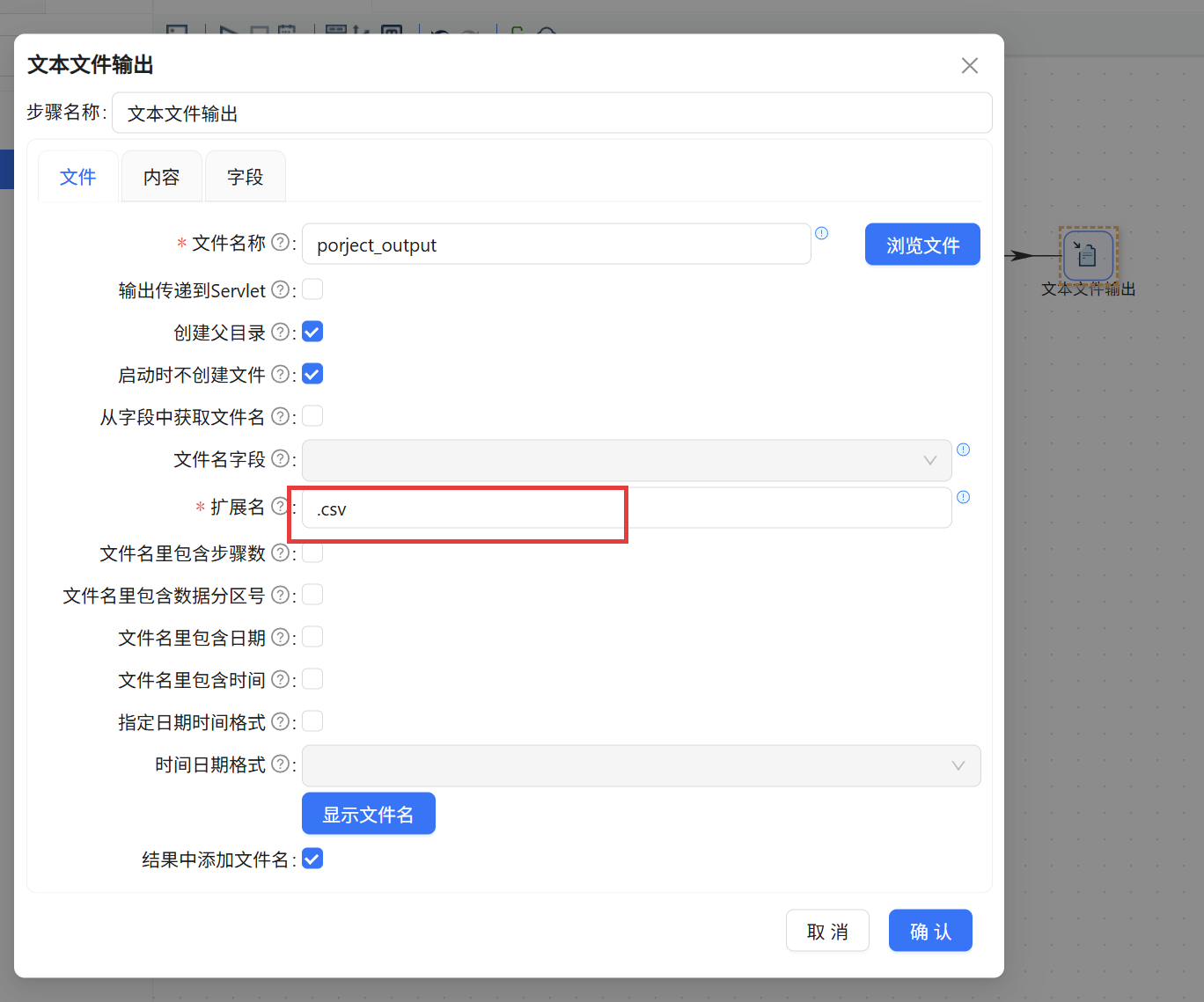
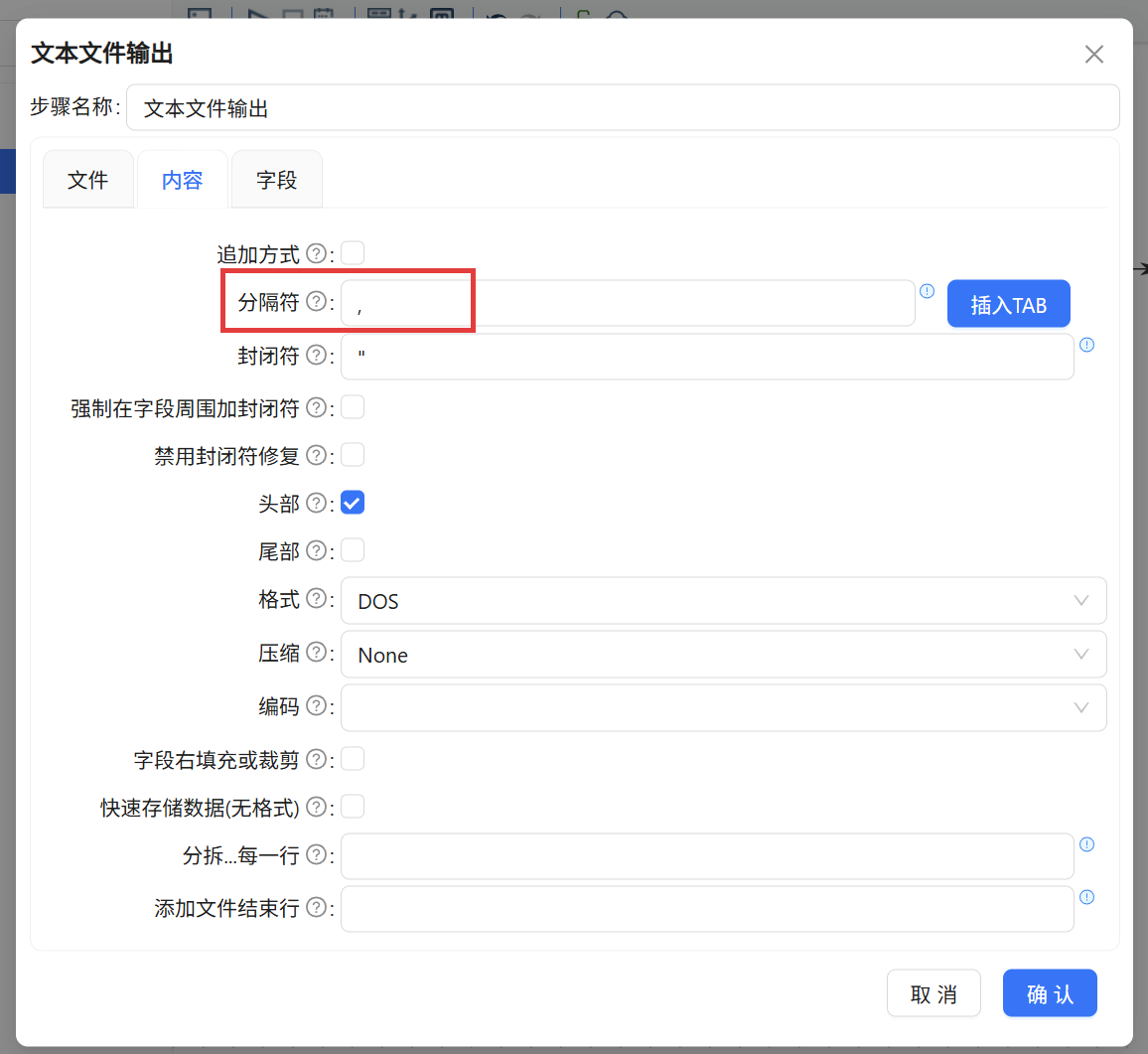
在“字段”页签通过“获取字段”继承上游的所有字段信息,确保新增的 diff_date 和 performance 一并写入目标文件。点击画布左上角的“运行”按钮启动转换后,文件库中成功生成了 project_output.csv,其内容完全符合预期,每一位项目均被自动赋予了绩效标签。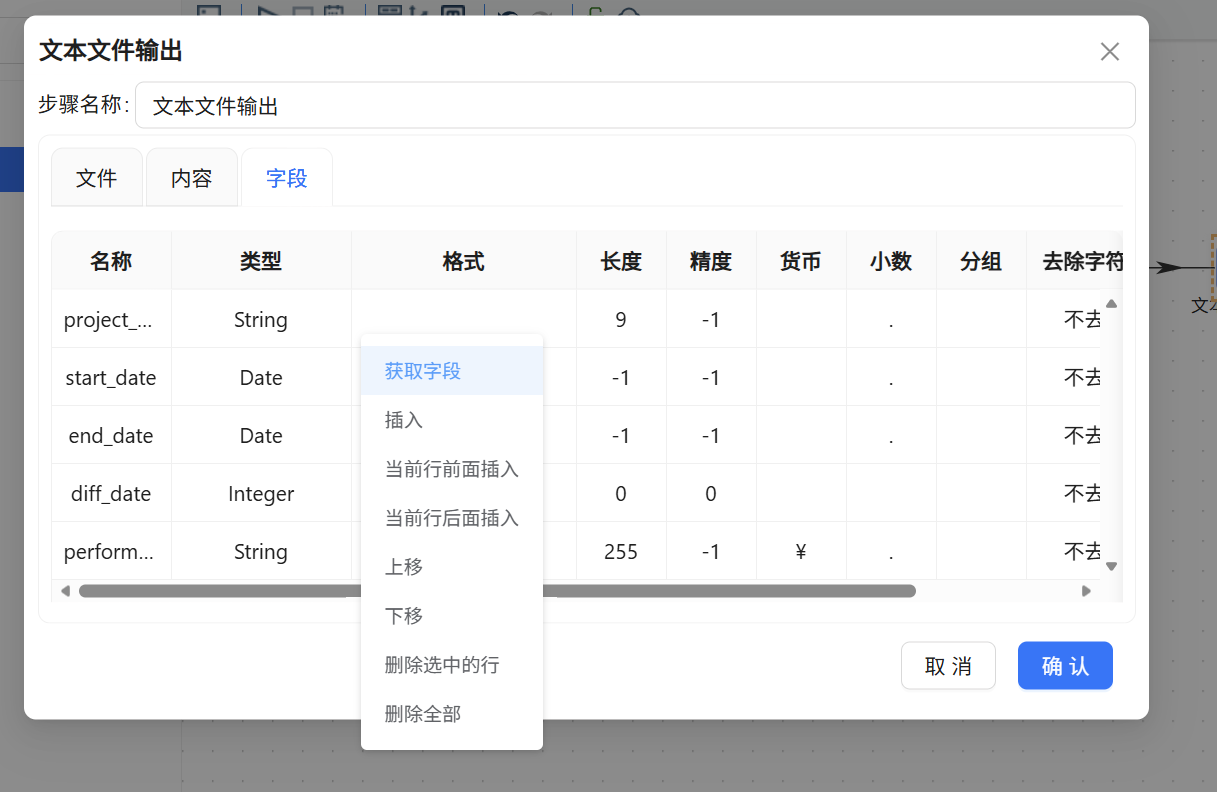
3.2 分号分隔文本文件的读取与字段剔除
第二部分实验以足球比赛数据 usa_201209.txt 为例,展示如何用 ETL 处理非逗号分隔的文本数据,并验证字段筛选后的数据传递情况。
新建一个转换,将「CSV 文件输入」组件置于画布。在配置窗口中浏览选择 usa_201209.txt 文件。关键点在于,该文本实际采用英文分号 ; 作为列分隔符,因此在“列分隔符”处必须填入 ;,并勾选“包含列头行”。随后在预览区右键获取字段,即可看到 Date、Venue、HomeTeam 等字段被准确拆分,数据结构一目了然。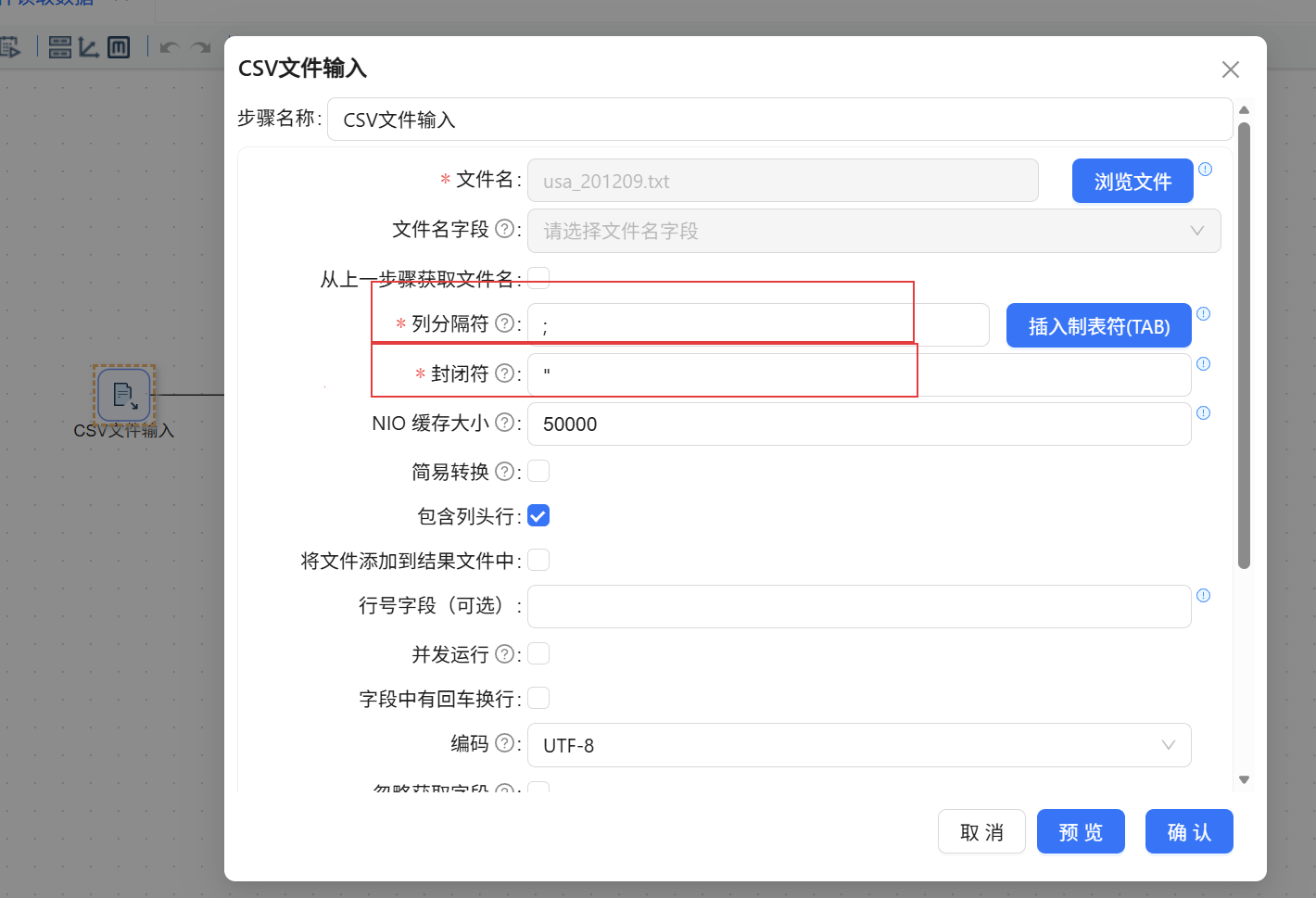
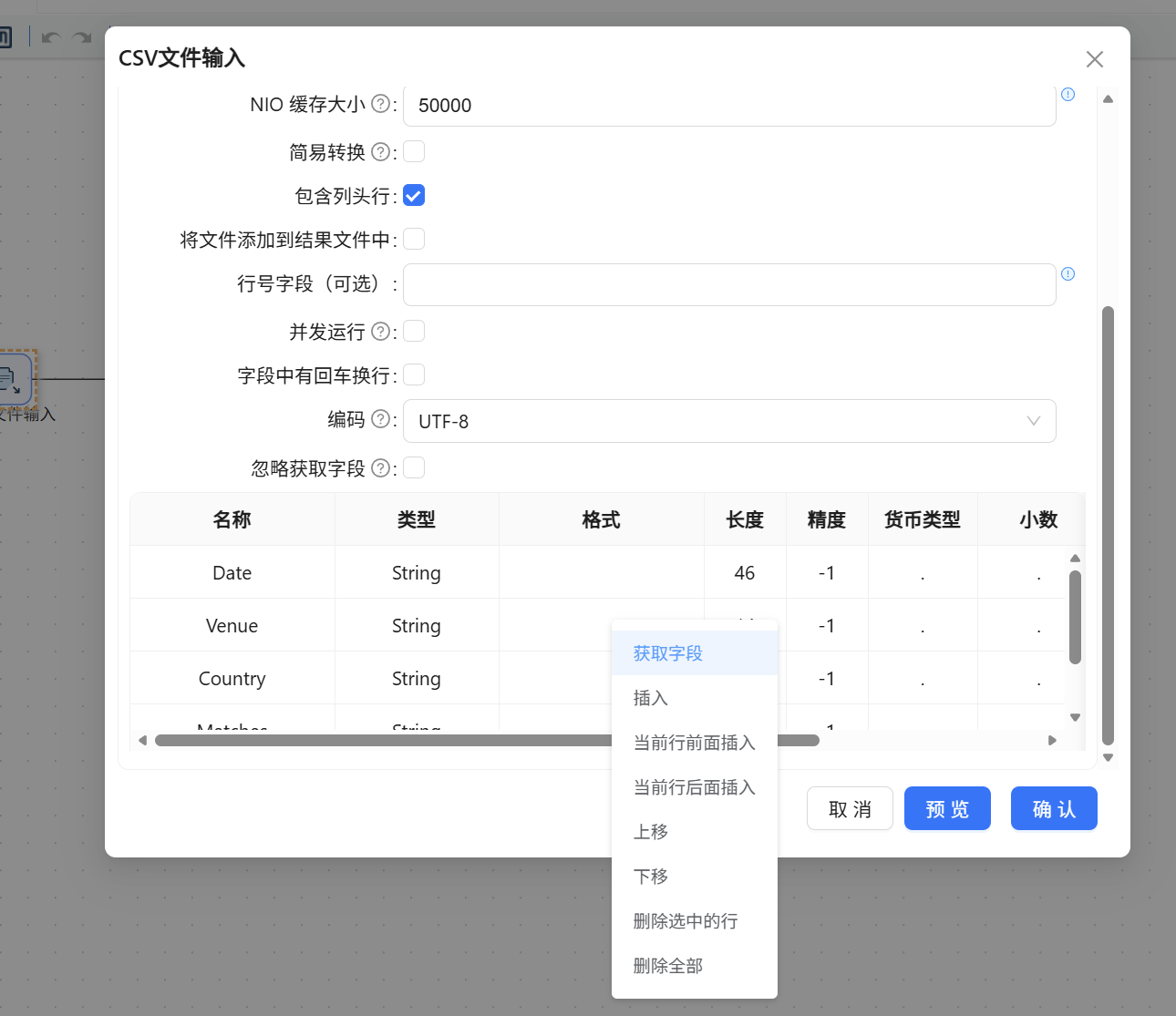
为进一步精简数据,依次连接「字段选择」和「空操作(什么也不做)」两个组件。在字段选择组件中,切换至“移除”标签页,获取字段后删除不想保留的 Venue 字段行,其余字段默认全部通过。这样,场馆信息就被从字段流中剔除,不影响后续传递。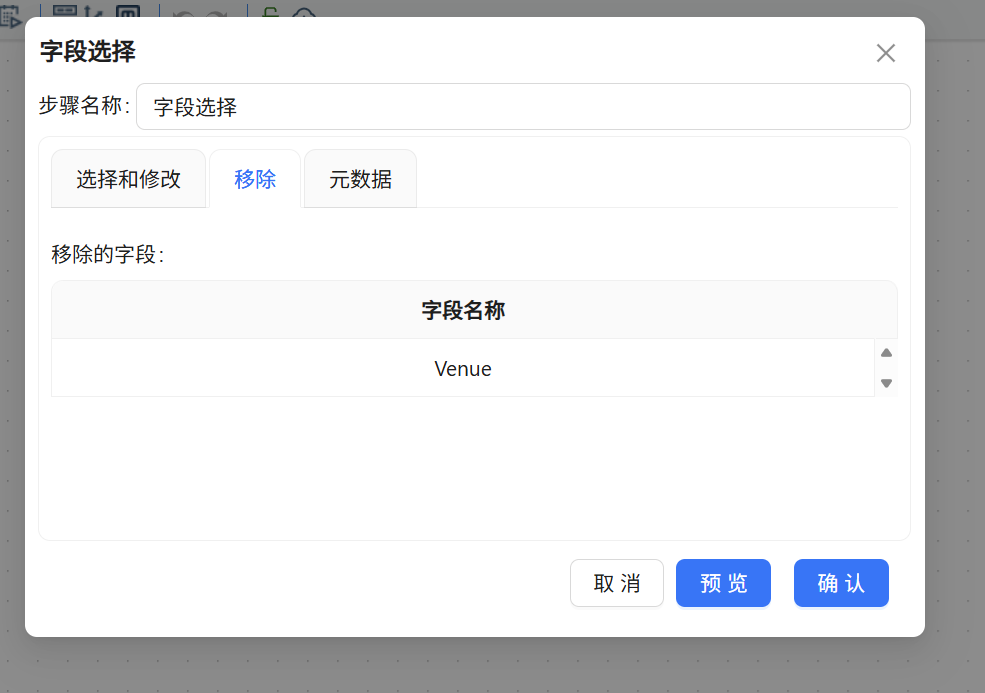
运行转换后,右键预览空操作组件的输出,可以清晰地看到所有数据均已成功移除 Venue 列,比赛日期、球队、比分等信息完整无缺,整个流程的连通性和筛选逻辑得到了充分证实。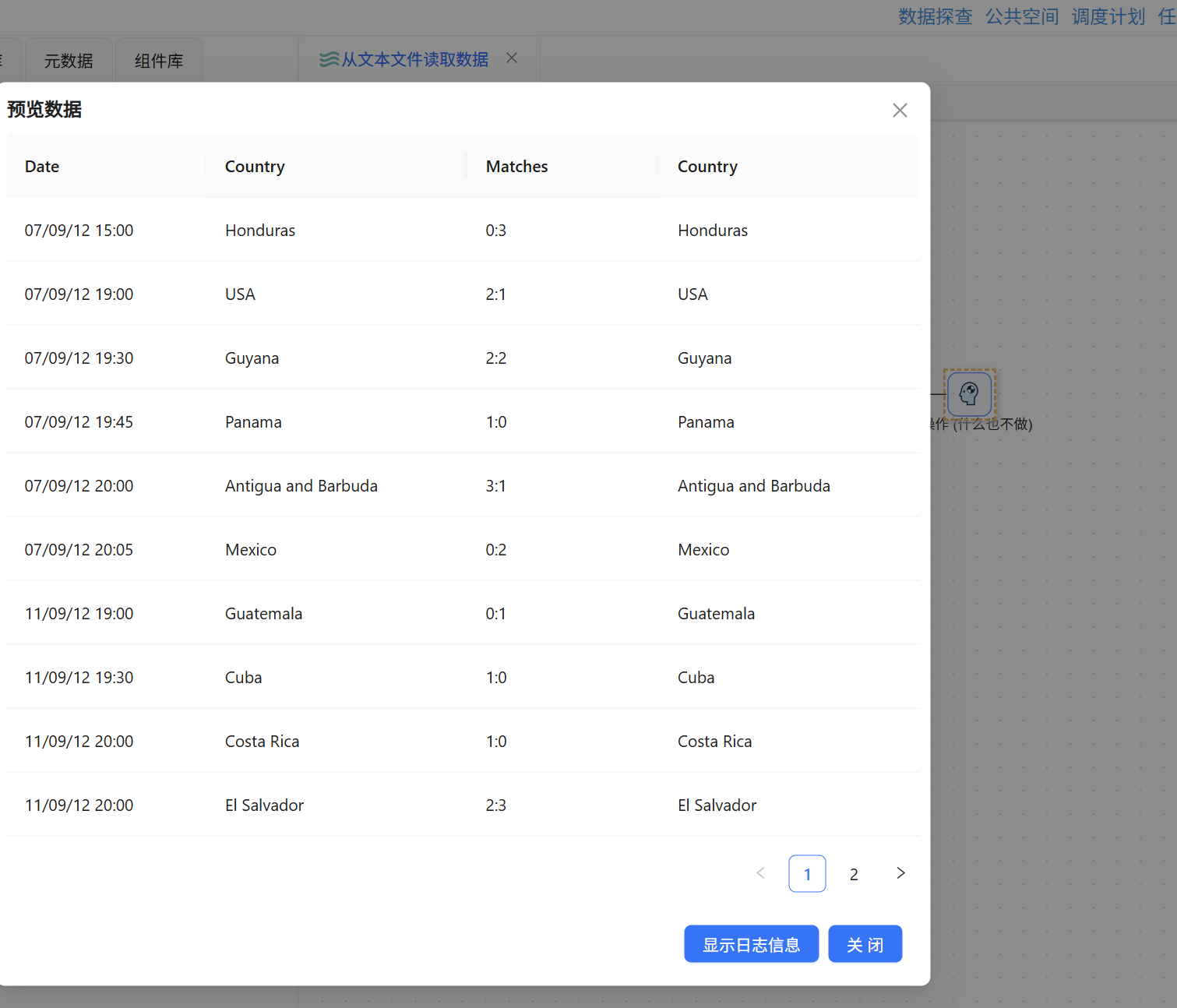
3.3 Excel 文件解析与目标字段提取
第三部分针对真实业务场景中常见的 Excel 数据源,使用购房者信息表 custinfo.xlsx,完成工作表选择与关键特征字段的提取。
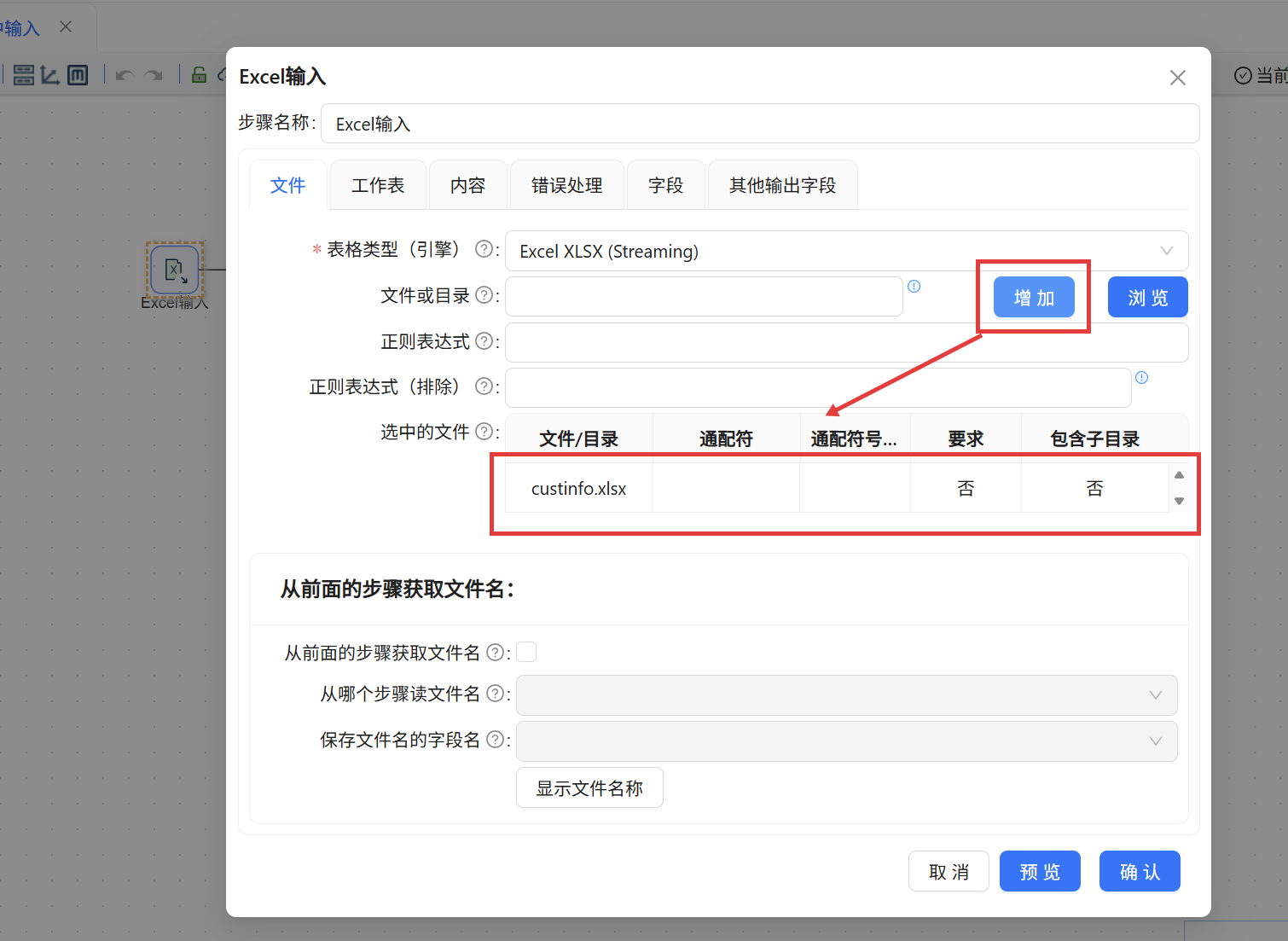
从组件库拖出「Excel 输入」组件。双击进入配置,第一步通过“浏览”按钮定位到 custinfo.xlsx 文件,并点击“增加”将其加入“选中的文件”列表。引擎采用 Excel XLSX (Streaming) 方式读取。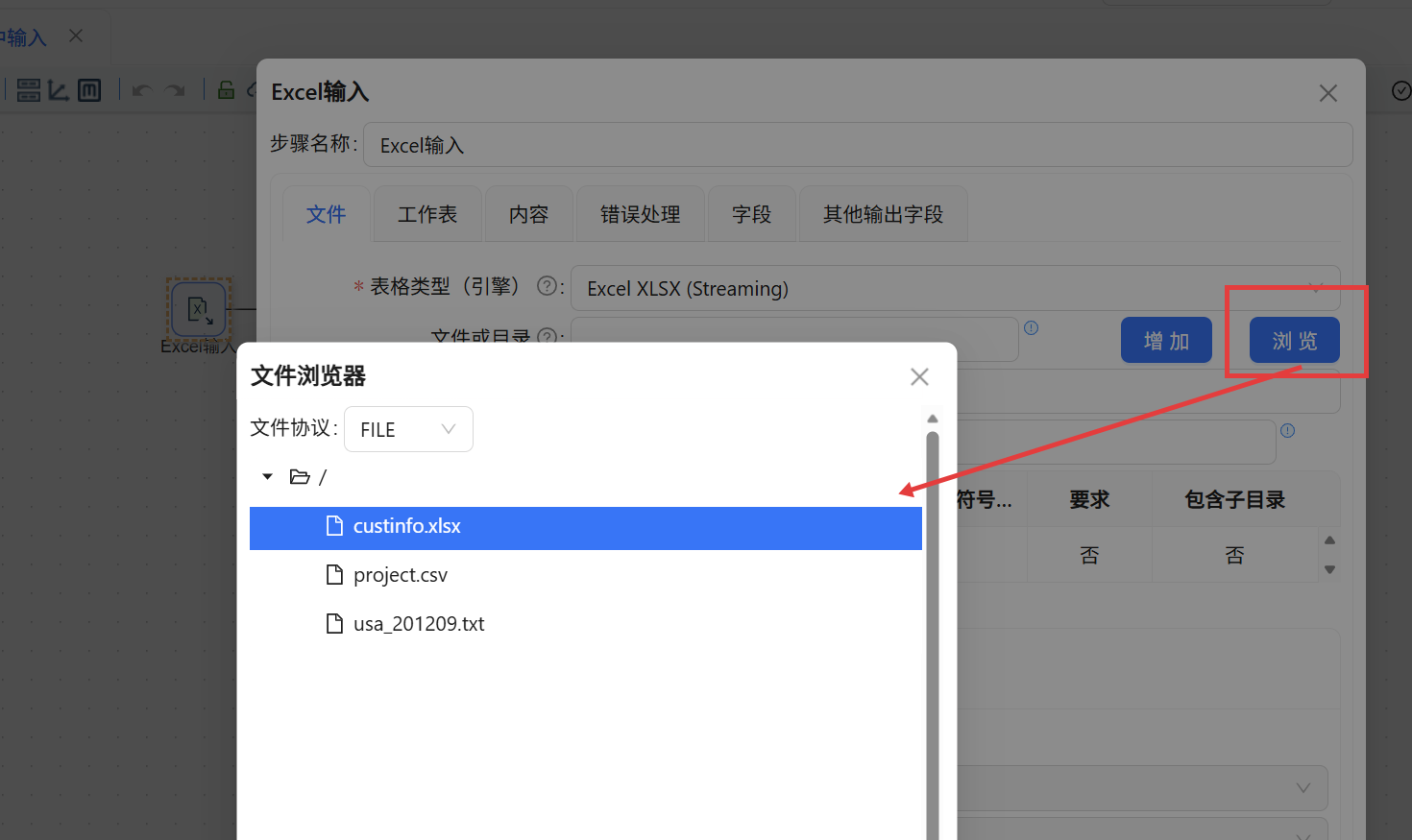
接着在“内容”标签页编码选择 UTF-8,以保证中文字段兼容。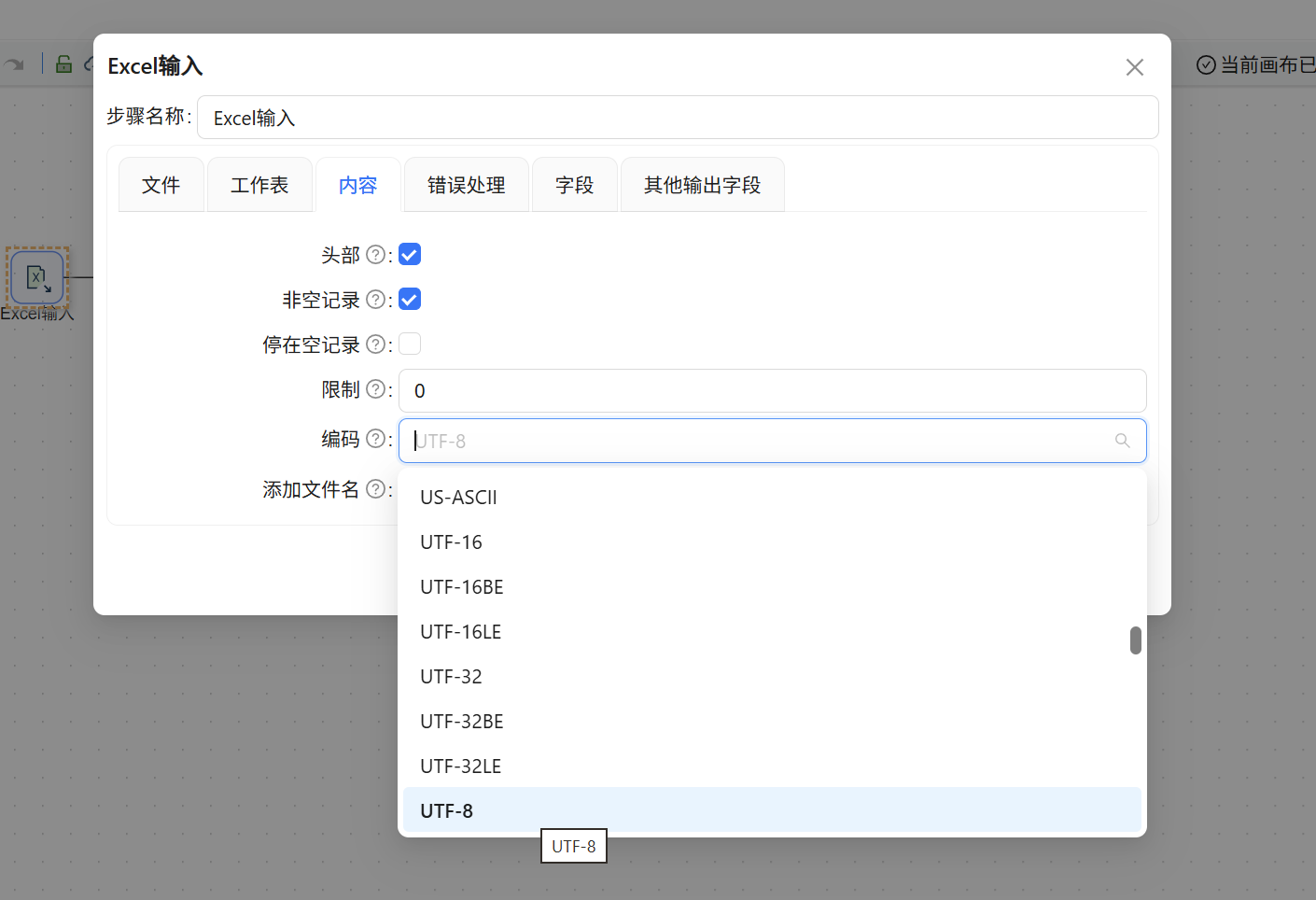
切换至“工作表”页签,点击“获取工作表名称”,组件自动识别出文件中包含的 Sheet1。随后在“字段”页签右键选择“获取来自头部的字段”,组件立即根据 Sheet1 第一行的内容生成了年龄、性别、学历、雇佣状态、月薪等全部字段信息。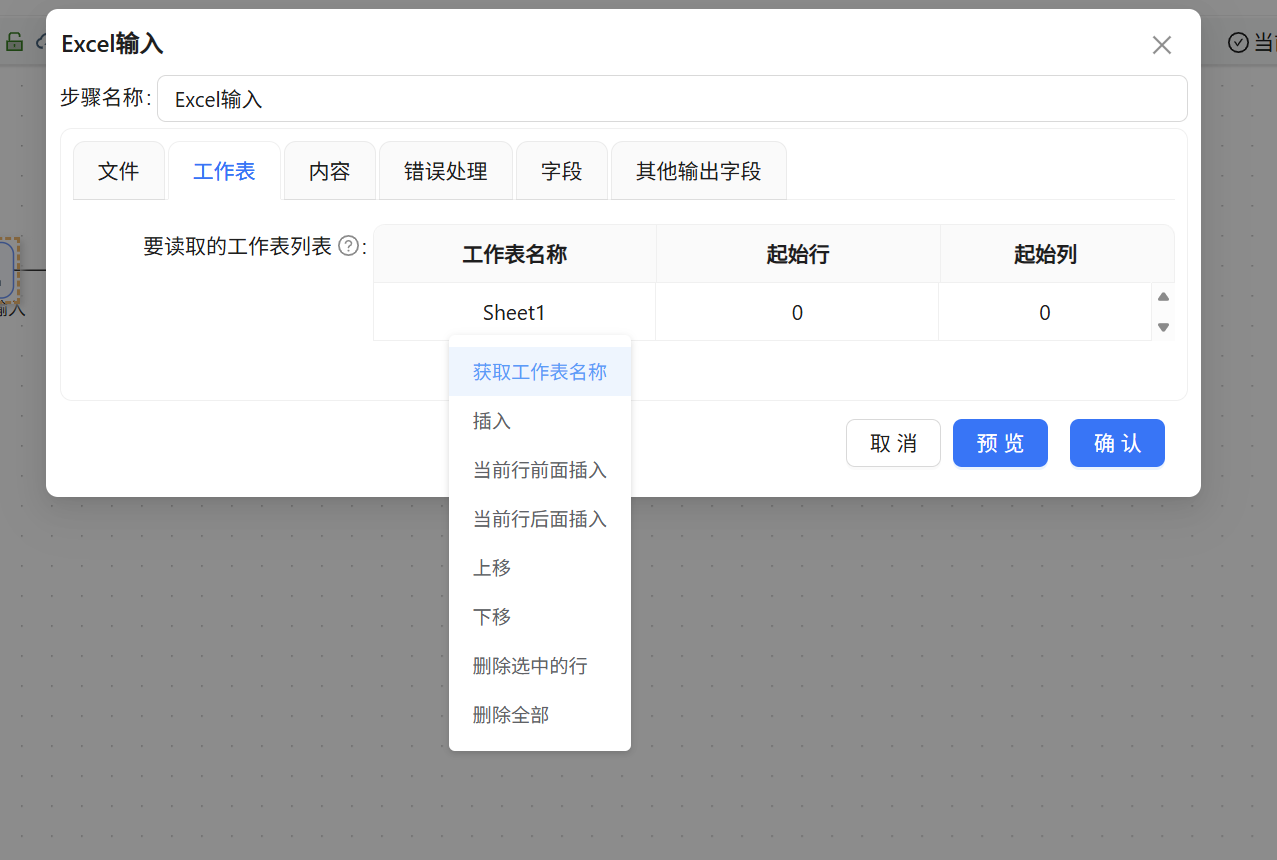
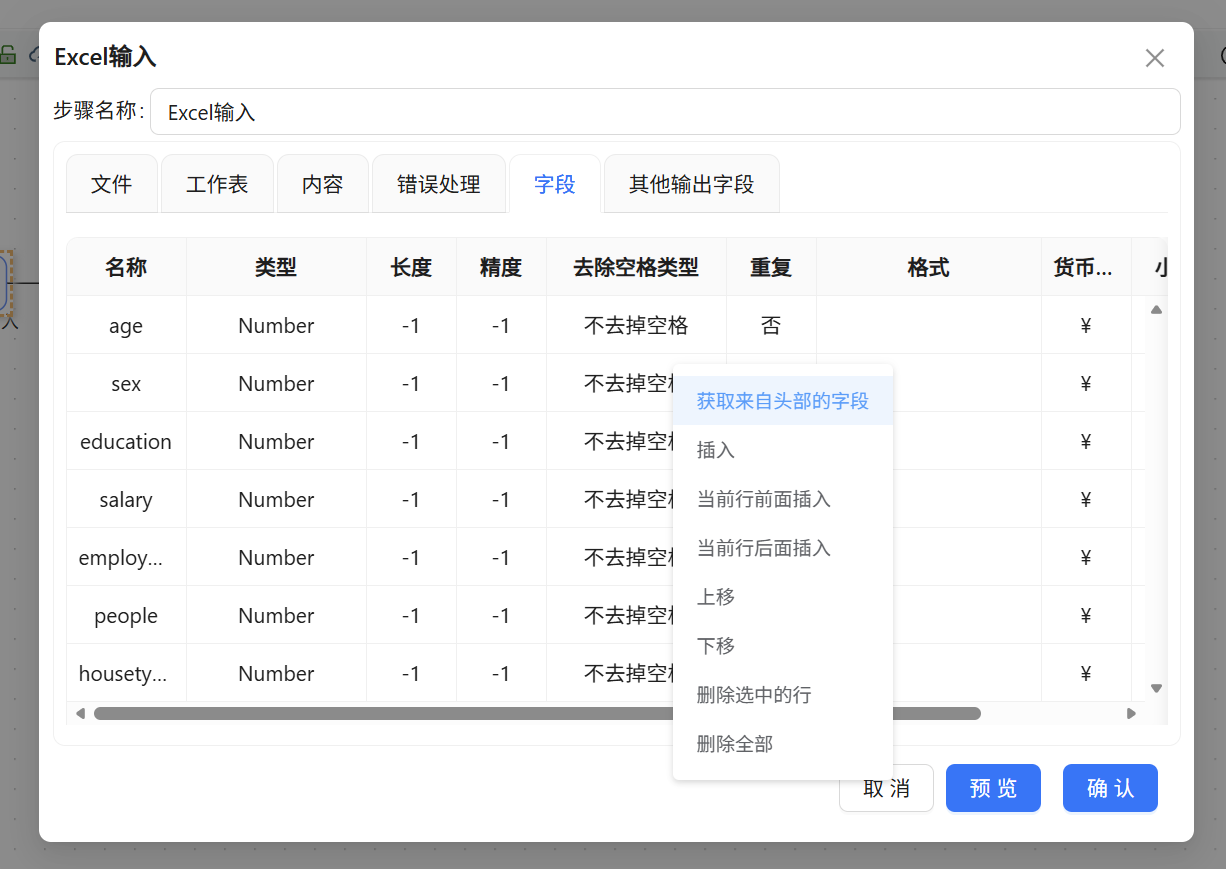
字段筛选需求十分明确——我们只需要学历(education)和雇佣状态(employment)。于是加入「字段选择」组件,连接线选择“主输出步骤”。进入字段选择配置,先在“选择和修改”页签获取上游所有字段,然后仅保留 education 和 employment 两个字段,其余全部删除。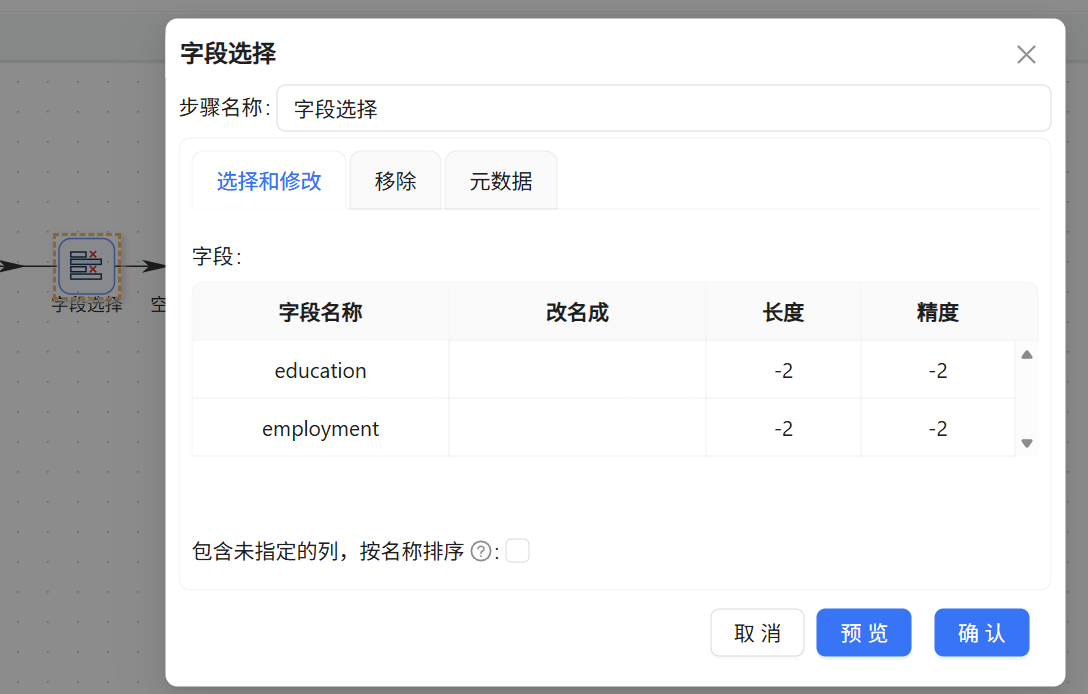
最后,拖入一个「空操作」组件作为接收器,形成一条完整的 Excel 输入 → 字段筛选 → 空操作的数据验证链路。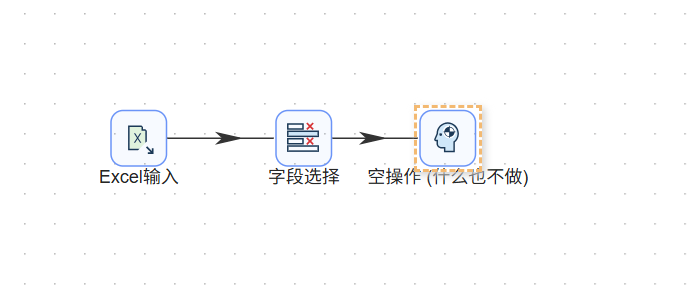
执行转换后,预览空操作组件输出,结果正确显示了购房者的学历与雇佣状态信息,没有多余列,也没有空值混入,基础预处理目标顺利达成。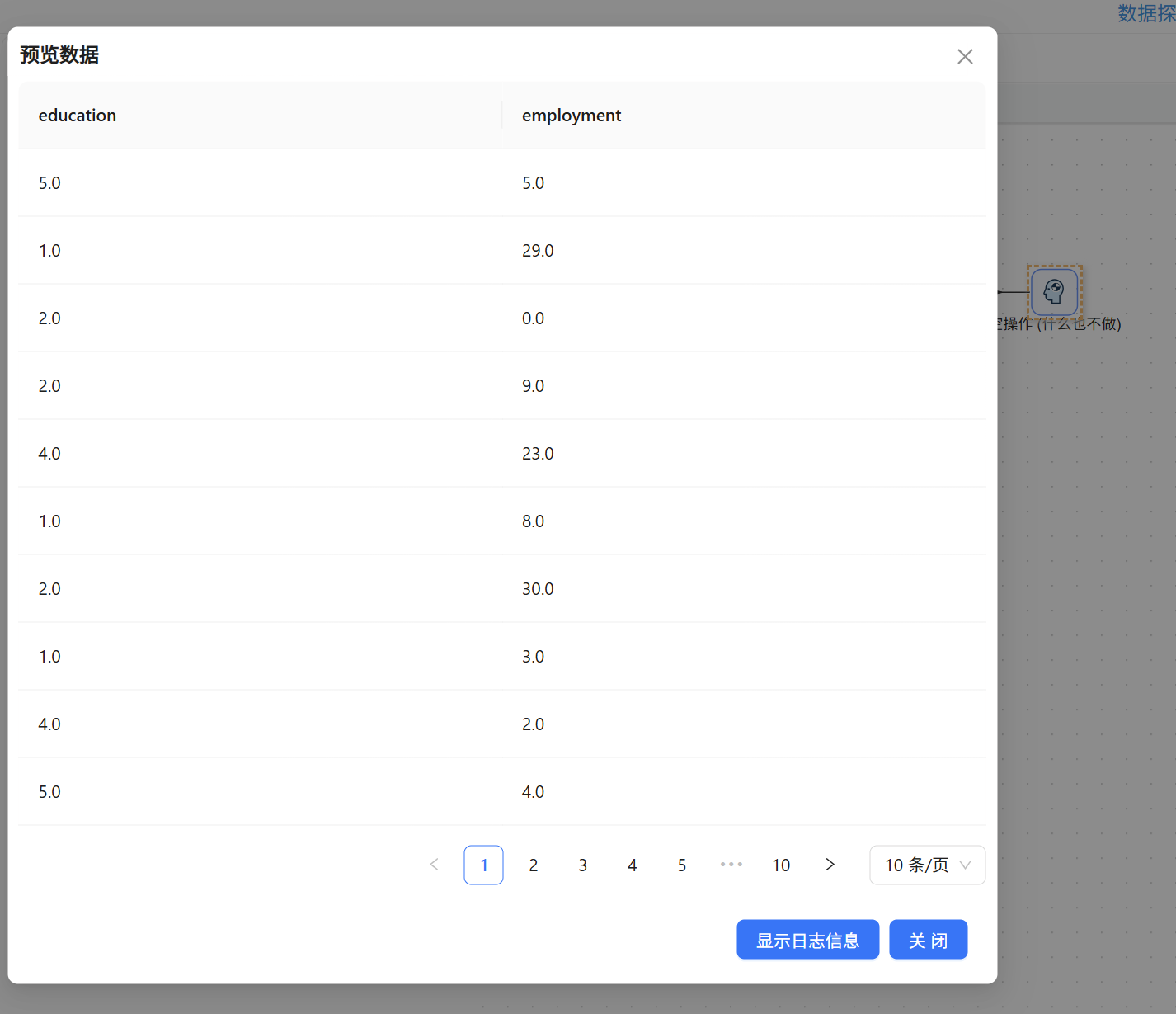
4 易错点问题与解决
在零代码操作过程中,虽然省去了手写代码的繁琐,但配置细节仍然容易踩坑。总结本次实验遇到的几个典型问题及解决方法:
-
分隔符与文件实际格式不匹配
文本文件usa_201209.txt使用的是英文分号;,若误设为逗号,获取字段时将出现所有数据挤在一列的情况。应先用文本编辑器查看原始文件的分隔符,再在组件中精准配置。 -
Excel 工作表未正确指定
若跳过“获取工作表名称”并直接尝试获取字段,组件可能无法定位到有效数据区。务必先通过“工作表”页签指定要读取的 Sheet,再获取头部字段,确保字段列表正确映射。 -
文本文件输出扩展名与内容不统一
文本文件输出组件的扩展名若定义为txt,而内容分隔符为逗号,虽然本质是纯文本,但不利于表格工具打开。建议输出为csv时扩展名与之对应,且分隔符和实际使用的保持一致。
5 总结
本次实验以助睿ETL一站式零代码平台为工具,从实践角度覆盖了 CSV、自定义分隔符文本以及 Excel 三种异构文件的数据抽取场景,并结合字段选择、计算器、数值范围等组件完成了简单的转换与加工。实验过程中深刻体会到:
- 零代码并不意味着零思考。文件输入组件的分隔符、工作表、字符编码等参数直接影响数据解析的准确性,必须细心核对源数据的真实格式。
- 字段选择组件是数据流骨架的“守门人”。合理运用“选择和修改”及“移除”两种模式,既可以保持字段传递的灵活性,又能有效控制数据宽度,为后续处理减负。
- 善用空操作组件进行链路验证。在没有最终输出目标或只想测试转换逻辑时,空操作组件能够快速确认上游各步骤是否正常流转,是一个简单又实用的调试手段。
- 参数化的范围判断大大提升了业务规则落地效率。数值范围组件将复杂的分段逻辑转换为直观的区间配置,对于绩效评定、客户分层等场景具有很高的适用性。
通过几个完整的端到端流程,我不仅掌握了助睿ETL平台抽取文件数据的标准操作,更理解了数据预处理中“接入—筛选—计算—输出”的闭环逻辑。这种基于画布、组件化的数据处理方式,显著降低了技术门槛,也对后续接入更多数据源、构建复杂ETL任务充满了信心。未来在数据分析、特征工程乃至数据建模工作中,这些基础而扎实的预处理能力将不断发挥价值。
我后续也会继续分享相关实验经验,如果本篇博客对你有帮助的话请点赞收藏关注多多支持!
^ - ^

一站式 AI 云服务平台
更多推荐



 4
4 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)