
基于 Uniplore 助睿 ETL 的多类型文件数据抽取实验
1 案例说明
ETL数据集成工作的首要核心环节,是从各类异构数据源中完成数据采集。数据采集工作落地难度较高,核心痛点在于数据源种类繁杂、存储格式不统一,适配处理逻辑存在较大差异。
在传统数据仓库的应用场景中,企业数据大多源自内部财务系统、ERP业务系统等事务型平台,这类数据多存储于MySQL、Oracle、SQL Server等关系型数据库中,行业常规做法是通过JDBC直连的方式快速抽取数据。但面对非关系型数据库,或是无适配驱动的特殊数据源时,直连抽取的方式将无法适用,数据采集难度会大幅增加。
除此之外,部分数据因归属外部供应商、合作客户,或部署在企业外网、防火墙外部,存在权限、物理位置的访问限制,无法通过数据库直连的方式获取。此时,文件数据交换就成为高效、便捷且适配性极强的数据采集方案。
本实训案例依托Uniplore助睿ETL数据集成平台,详细讲解平台内置的CSV、Text、Excel三类主流文件数据抽取组件的实操用法,手把手演示不同格式文件数据的快速解析、精准抽取与预处理流程,帮助使用者掌握文件类数据源的ETL基础处理能力。
2 实验环境
-
平台名称:助睿在线实验平台
-
使用产品:助睿数智(Uniplore)- AI驱动的一站式零代码数据智能服务平台系统
-
子平台:助睿ETL数据集成平台
该平台覆盖数据接入、ETL数据加工、AI机器学习建模、数据可视化展示全业务链路,全程支持零代码可视化拖拽操作,操作门槛低、实用性强,既适配高校大数据、数据挖掘相关课程的教学实训场景,也可满足企业日常数据加工、数据预处理的业务需求。
3 数据准备
本次实训所需的全部数据文件,均可在助睿ETL平台的「公共空间」资源库中获取,不同实训环节对应专属数据源文件,具体分配如下:
1. CSV文件数据读取实训:使用 project.csv 数据源文件;
2. 文本文件数据读取实训:使用足球比赛数据集 usa_201209.txt;
3. Excel文件数据读取实训:使用购房者信息数据集 custinfo.xlsx。
数据文件具体获取步骤如下:
登录助睿ETL数据集成平台,进入「数据集成」功能模块,打开「我的项目」列表,点击目标项目右侧的更多按钮(…),选择「打开项目」,进入项目操作页面;
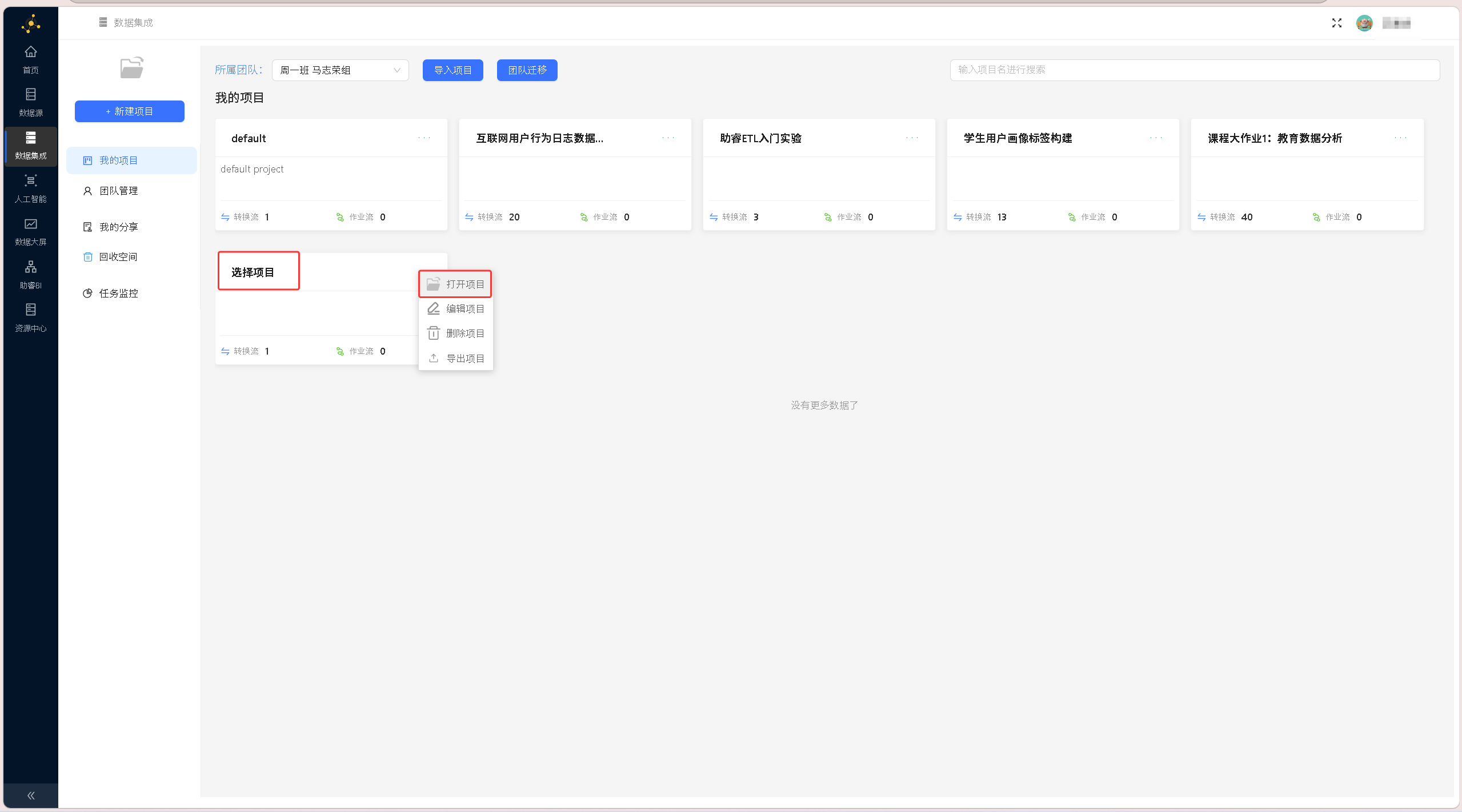 点击页面右侧「公共空间」栏目,切换至「数据资源」标签页,在资源列表中找到 project.csv 文件,点击文件右侧更多按钮,选择「导出」功能;
点击页面右侧「公共空间」栏目,切换至「数据资源」标签页,在资源列表中找到 project.csv 文件,点击文件右侧更多按钮,选择「导出」功能;
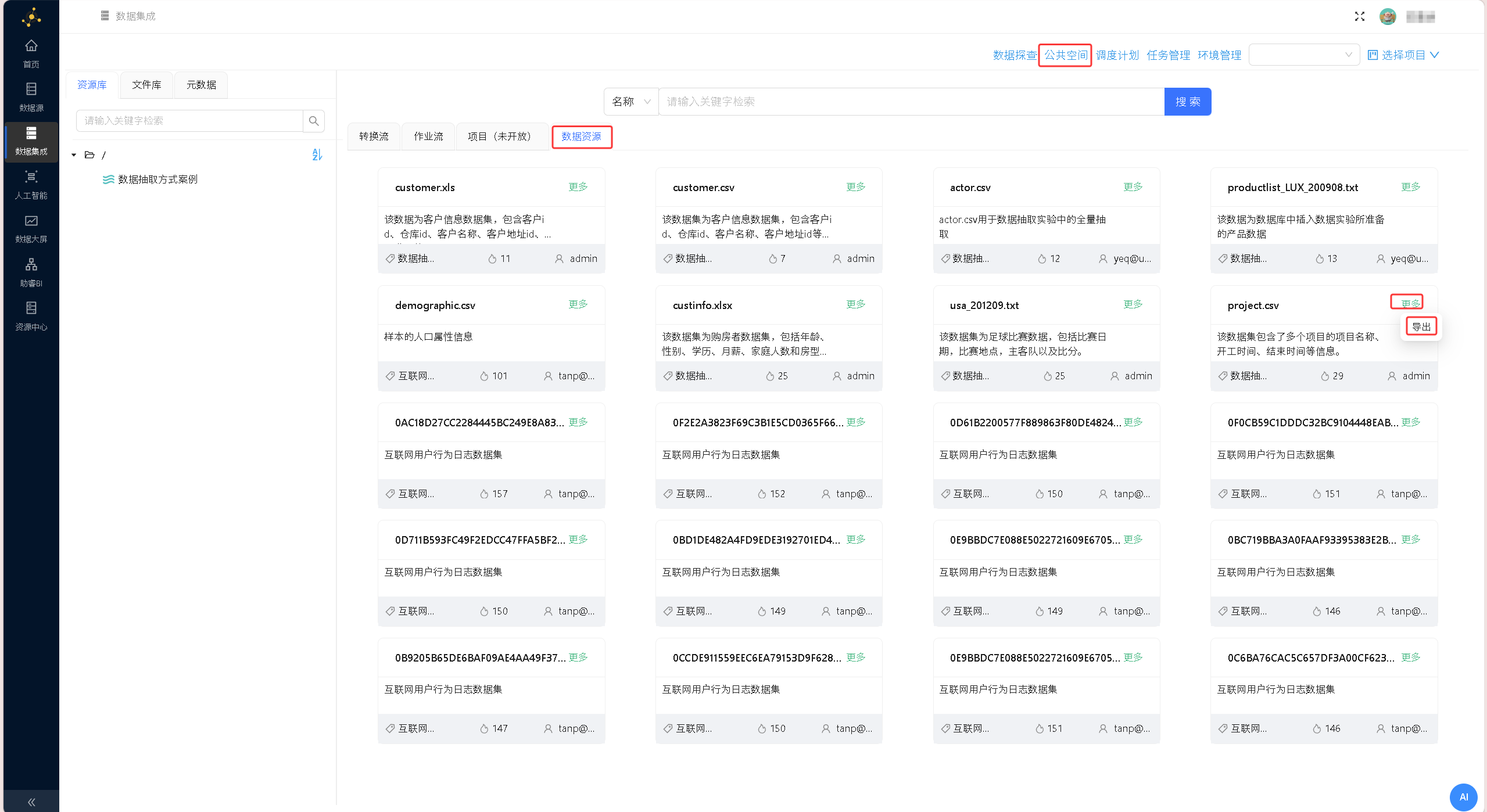
在弹出的导出配置窗口中,确认待导出文件无误,自定义选择文件导出路径(默认根目录即可),点击「确定」,即可将数据源文件导出至项目文件库中;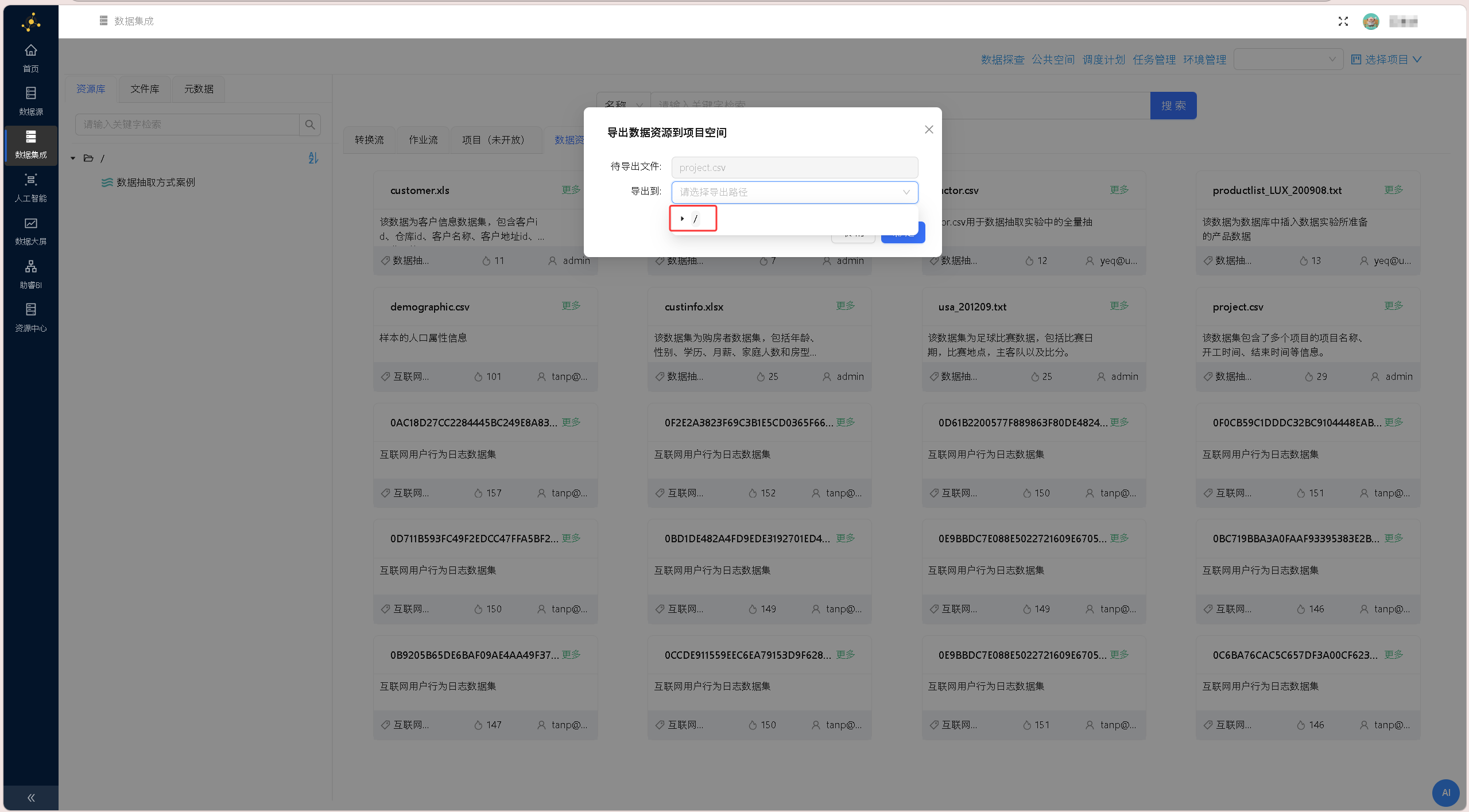
点击左侧导航栏「文件库」,右键点击菜单处选择「刷新」,即可查看已成功导入的实训数据源文件。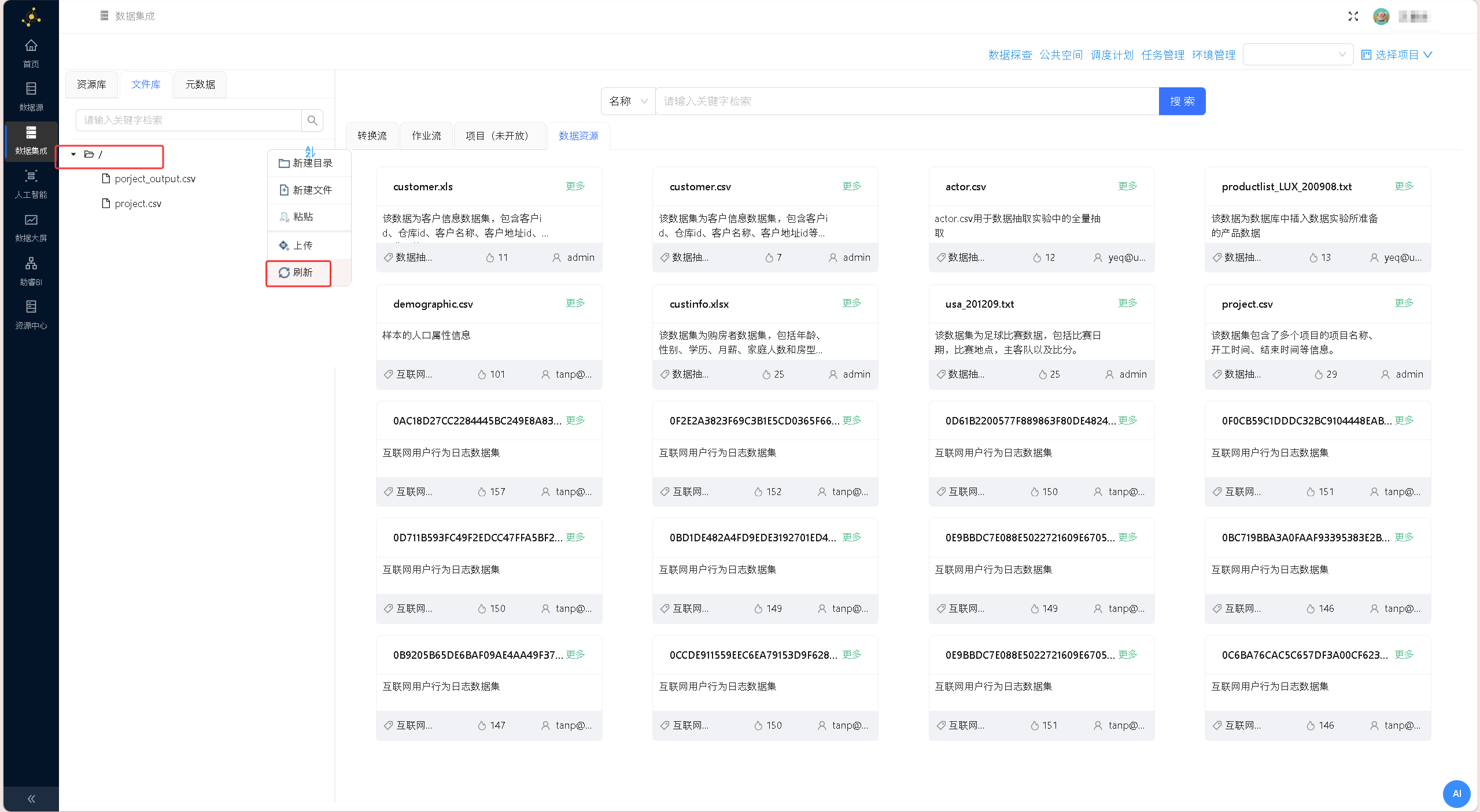
4 从 CSV 文件中读取数据
本环节依托助睿ETL平台搭建数据处理工作流,完成CSV格式项目数据的抽取、清洗、计算与分级处理。首先读取project.csv中的原始项目数据,通过筛选核心字段、计算项目开工与结束的时间间隔,结合天数区间自动判定项目绩效等级,最终实现项目绩效数据的自动化处理与标准化输出。
整体处理流程:通过「CSV文件输入」组件采集原始数据,借助「字段选择」组件精简有效字段,利用「计算器」组件计算项目执行天数,再通过「数值范围」组件匹配规则生成绩效等级,最后通过文件输出组件导出最终处理结果。
具体实操步骤如下:
新建数据转换流,在项目页面切换至「组件库」,拖拽「CSV文件输入」组件至编辑画布,完成基础组件部署。
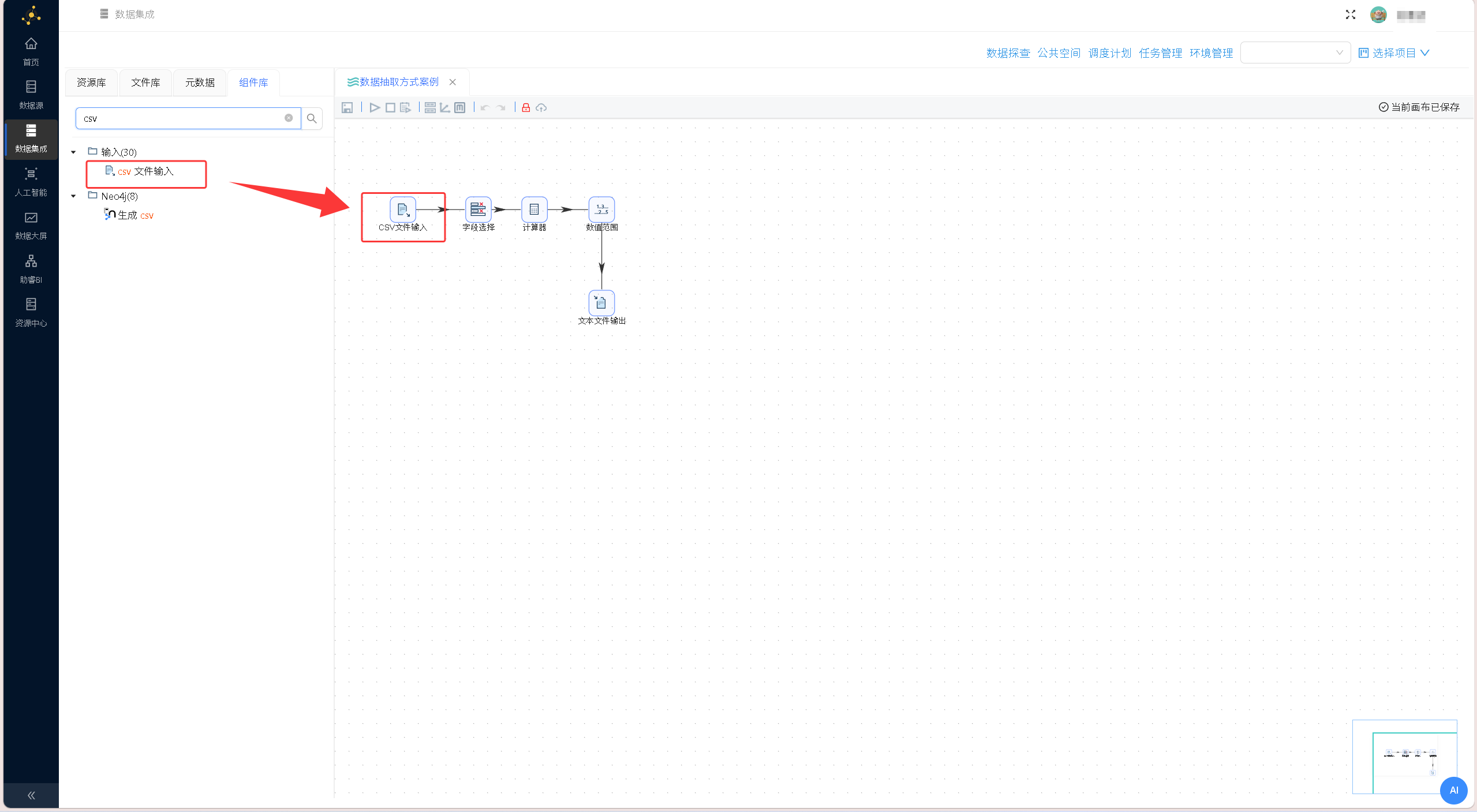 双击画布中的「CSV文件输入」组件,打开配置窗口,点击「浏览文件」,在文件浏览器中选中已导入的 project.csv 数据源文件,完成文件路径绑定。
双击画布中的「CSV文件输入」组件,打开配置窗口,点击「浏览文件」,在文件浏览器中选中已导入的 project.csv 数据源文件,完成文件路径绑定。
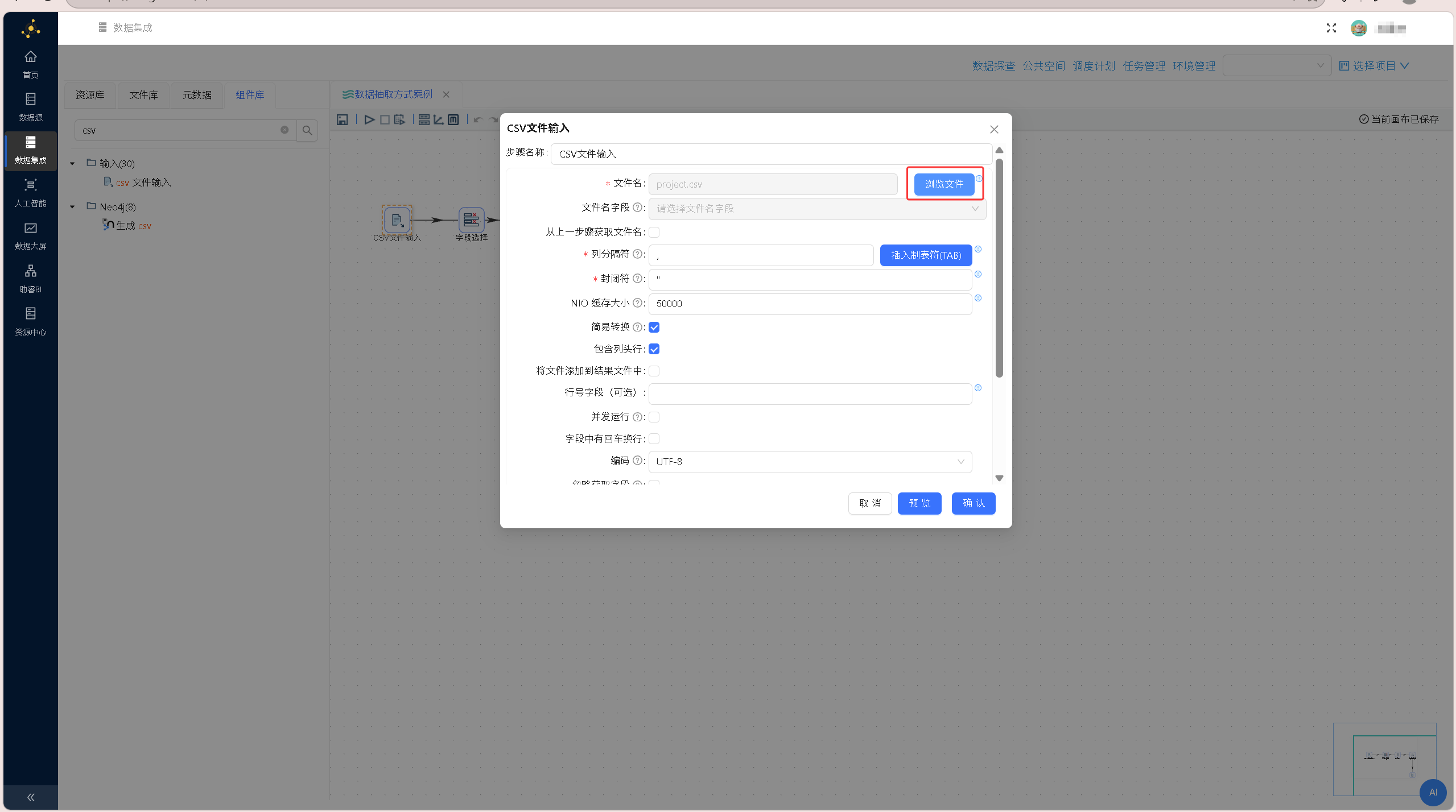
在文件浏览器组件中选中需要读取的 CSV 文件「porject.csv」,点击确定,文件浏览器组件会自动解析文件路径,并回填至「CSV 文件输入」组件中,配置如下图所示: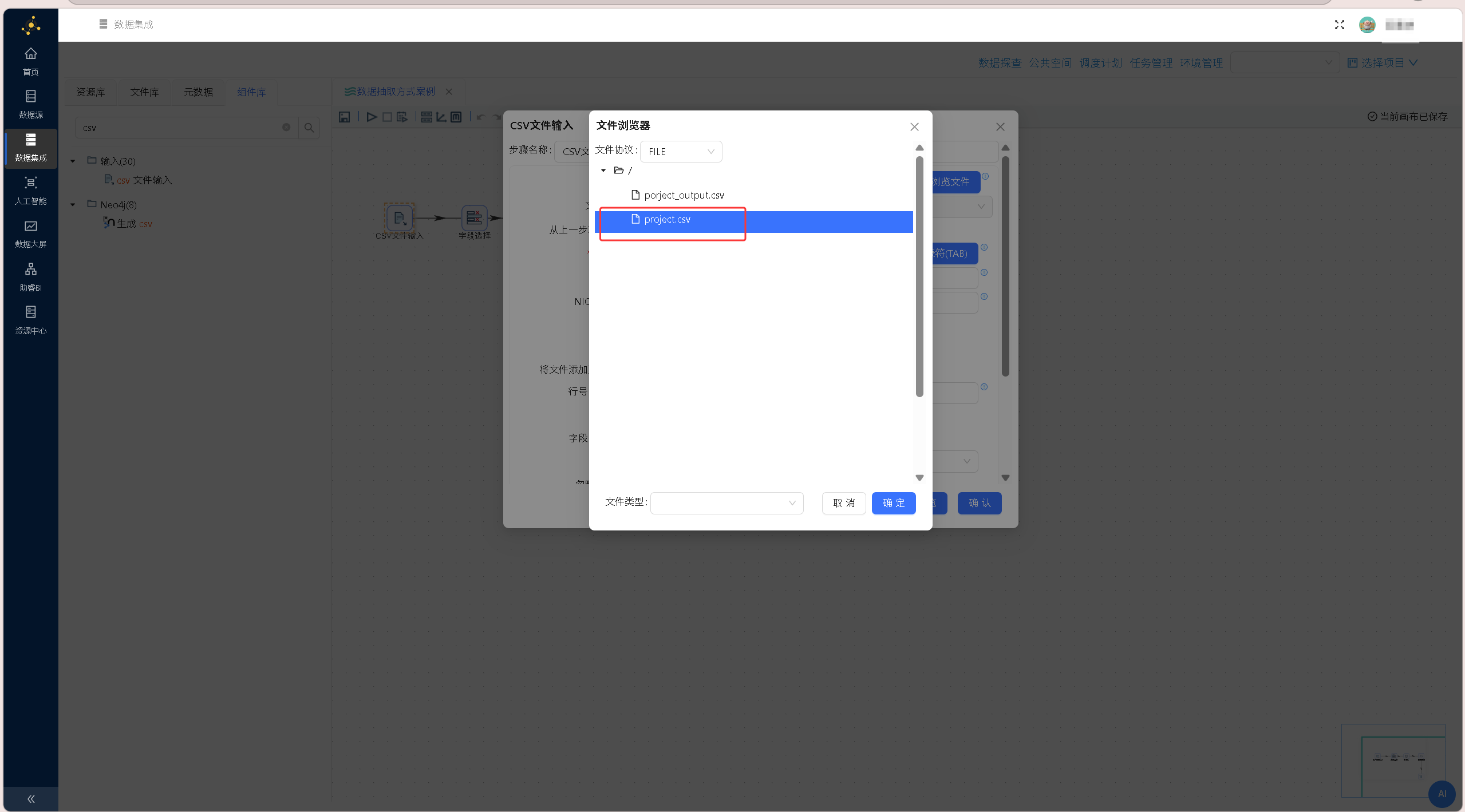 在组件下方的数据预览区域右键单击,选择「获取字段」,系统将自动解析CSV文件结构,批量提取文件内所有字段信息,完成数据结构适配。
在组件下方的数据预览区域右键单击,选择「获取字段」,系统将自动解析CSV文件结构,批量提取文件内所有字段信息,完成数据结构适配。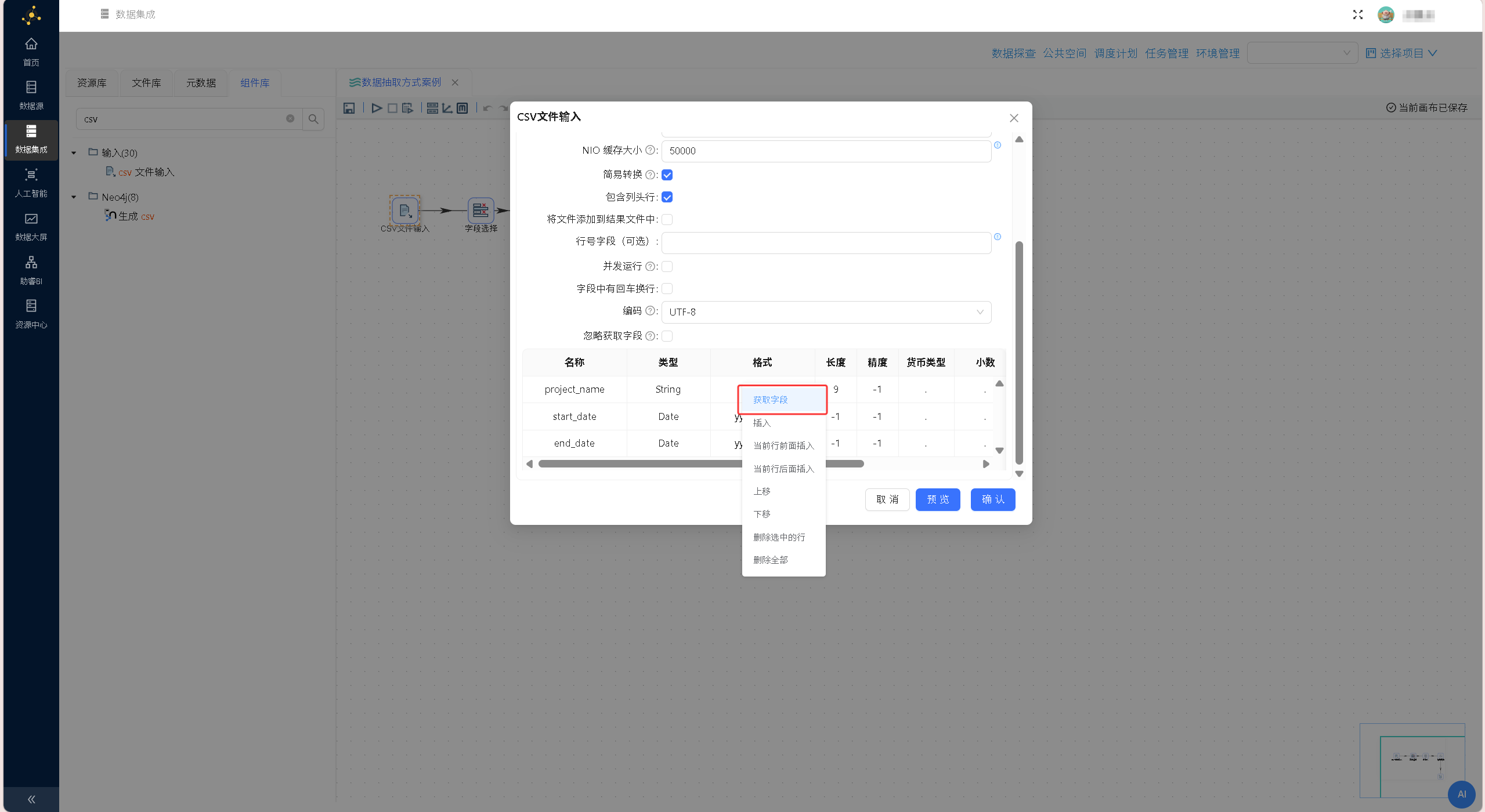 配置完成后,通过组件「预览」功能查看原始数据,核验文件读取状态、字段解析准确性,确保原始数据无异常。
配置完成后,通过组件「预览」功能查看原始数据,核验文件读取状态、字段解析准确性,确保原始数据无异常。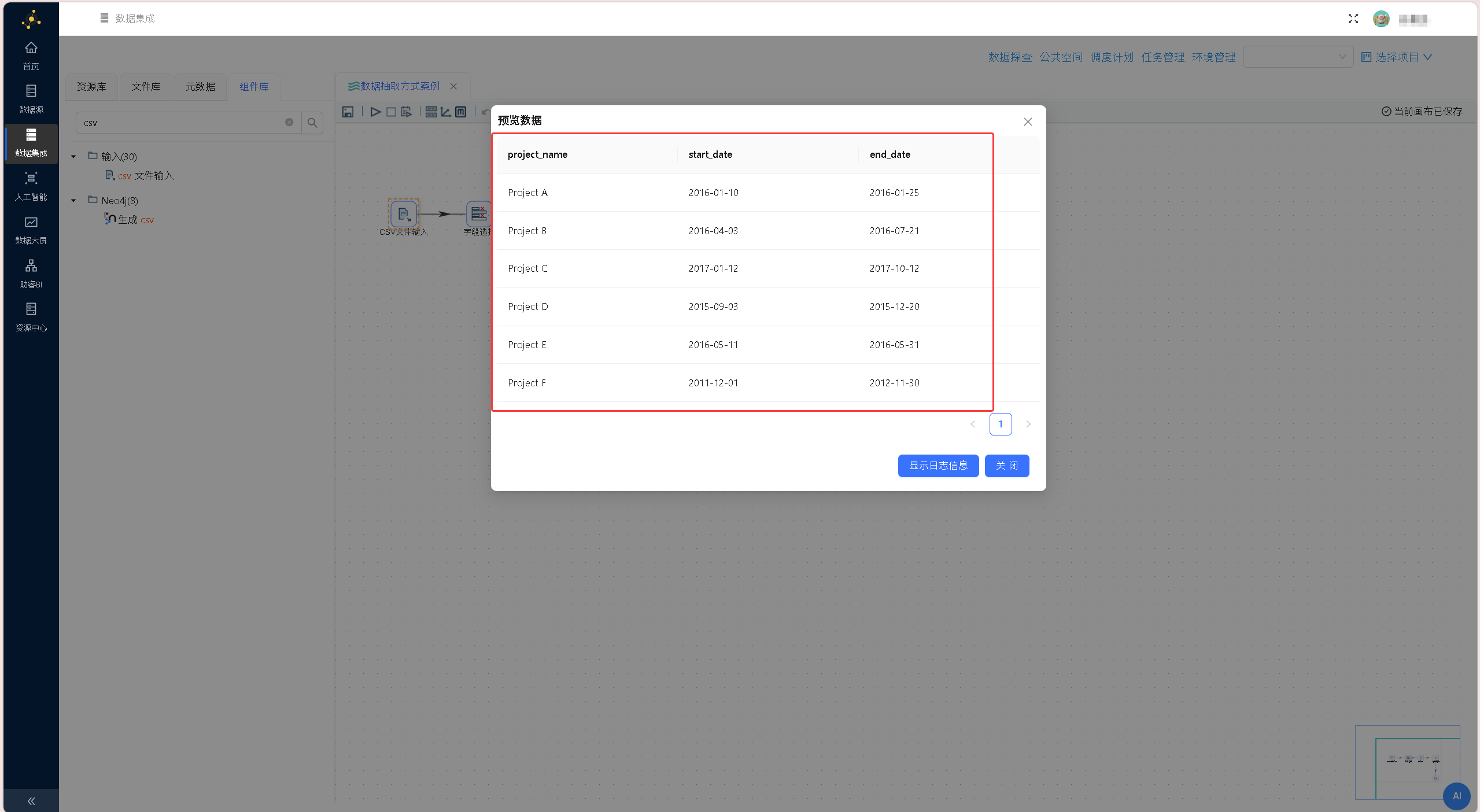 完成原始数据读取核验后,从组件库拖拽「字段选择」组件至画布,将「CSV文件输入」组件与「字段选择」组件进行连线,搭建数据流转链路。
完成原始数据读取核验后,从组件库拖拽「字段选择」组件至画布,将「CSV文件输入」组件与「字段选择」组件进行连线,搭建数据流转链路。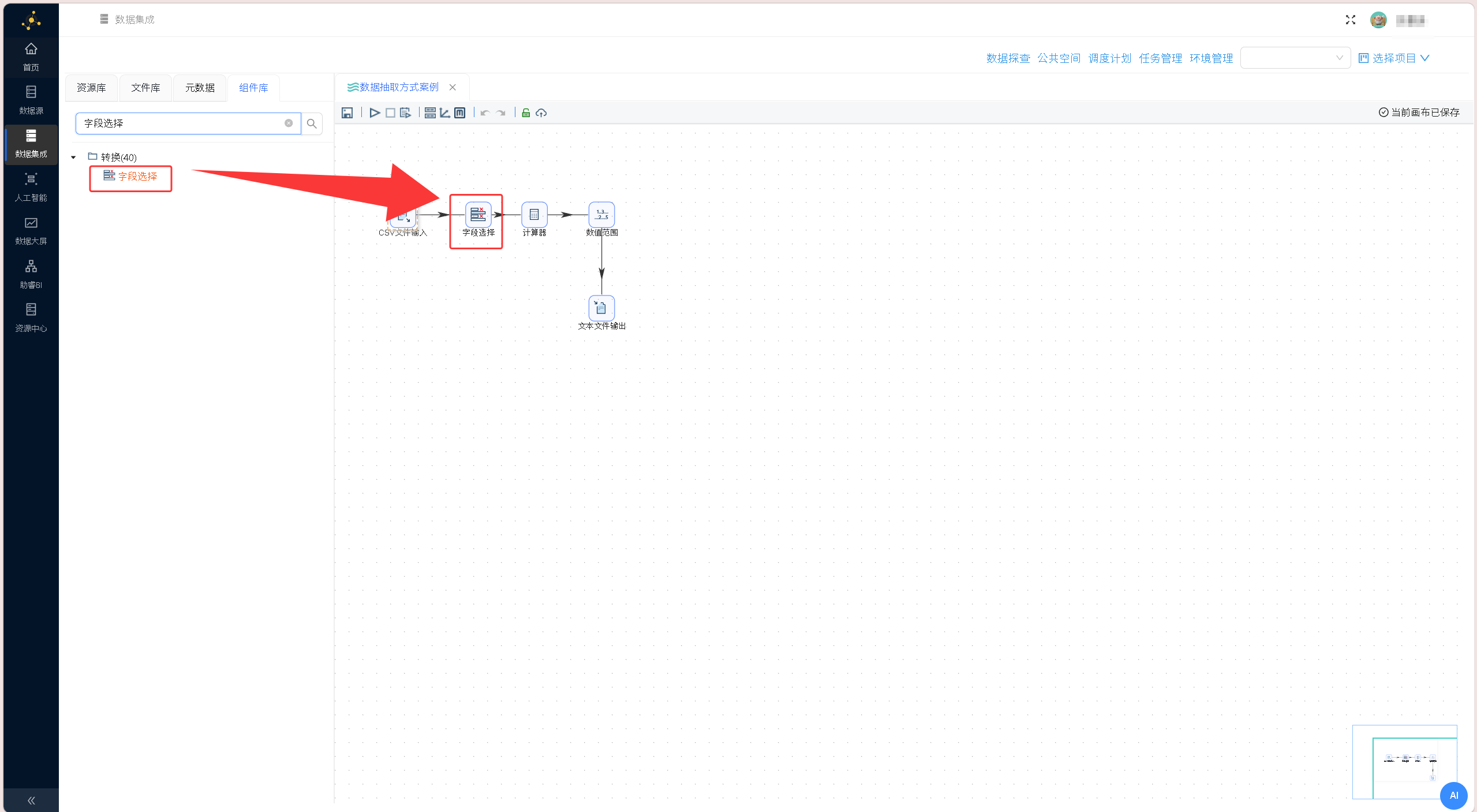 双击「字段选择」组件进入配置界面,在默认的「选择和修改」标签页右键点击空白区域,选择「获取字段」,自动同步上游CSV组件解析的所有字段数据。
双击「字段选择」组件进入配置界面,在默认的「选择和修改」标签页右键点击空白区域,选择「获取字段」,自动同步上游CSV组件解析的所有字段数据。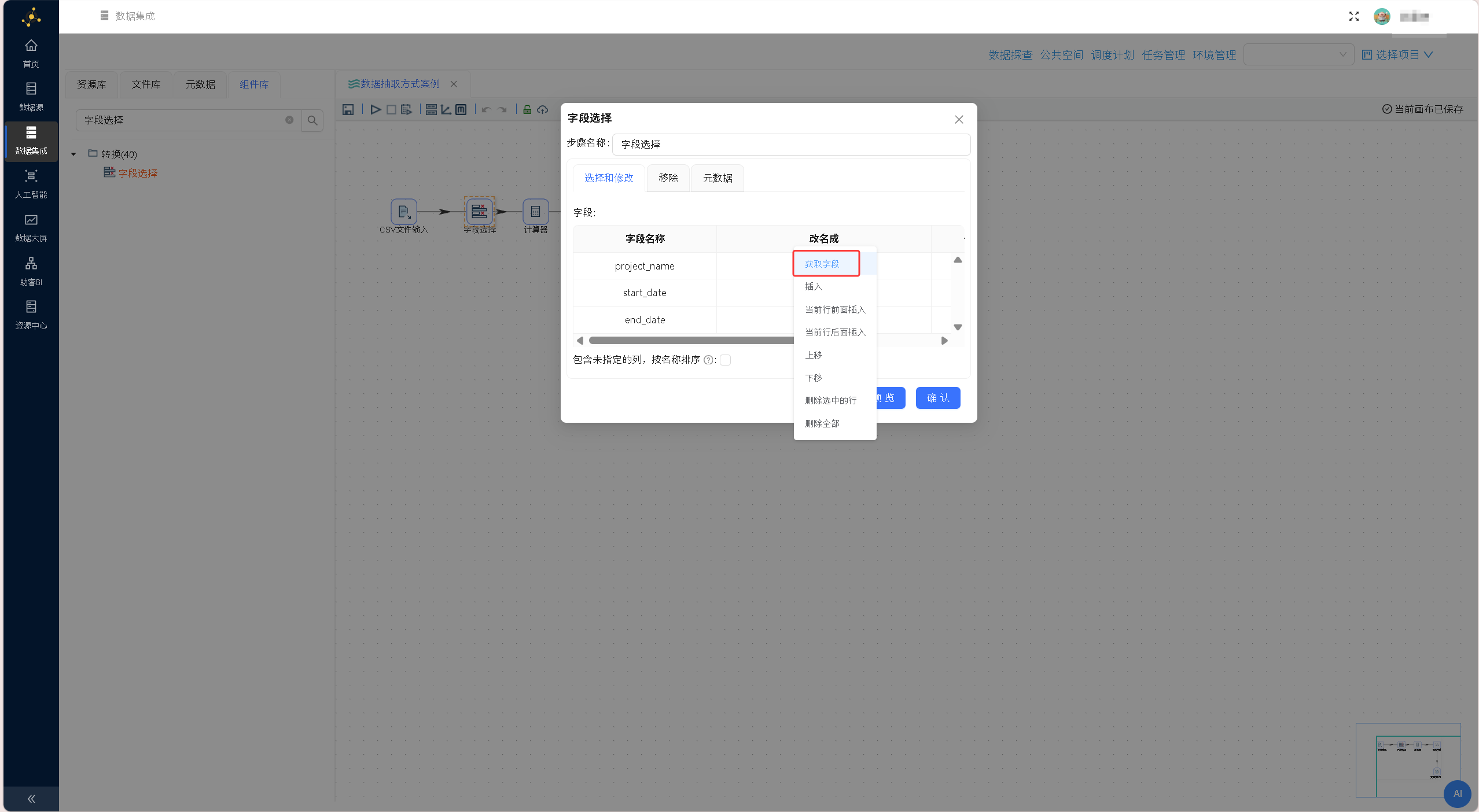 在「字段选择」组件的配置窗口中,选择和修改页签提供了字段管理功能,可对字段信息如名称、长度、精度等进行调整。在本节案例中,不涉及到字段信息的调整,所以这里保持默认即可,配置如下图所示:
在「字段选择」组件的配置窗口中,选择和修改页签提供了字段管理功能,可对字段信息如名称、长度、精度等进行调整。在本节案例中,不涉及到字段信息的调整,所以这里保持默认即可,配置如下图所示: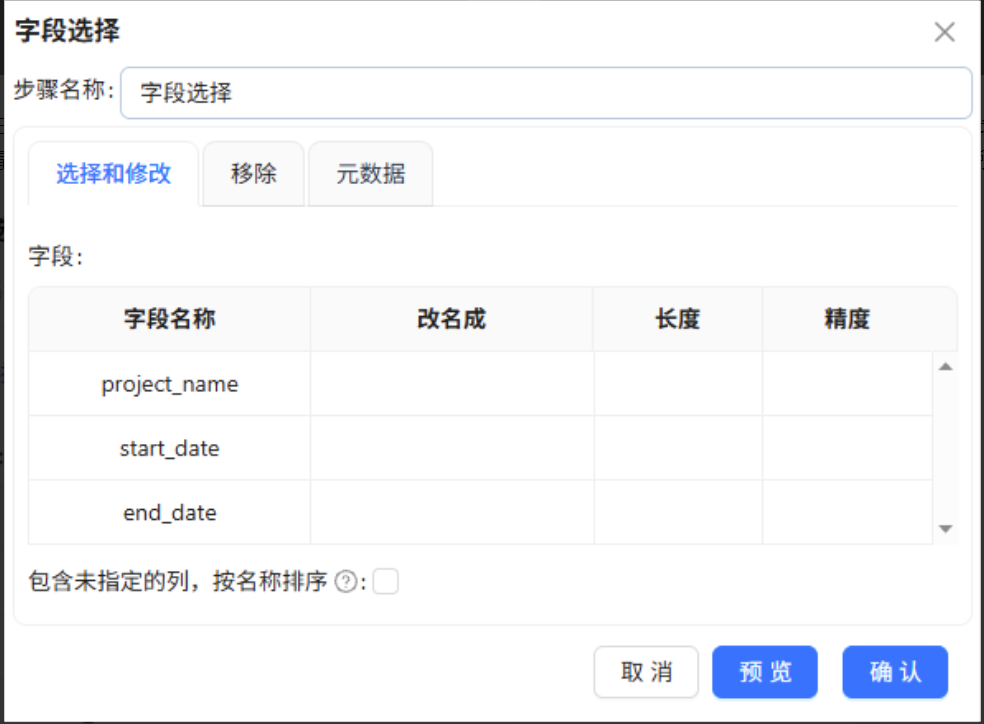 完成「字段选择」组件的配置后,拖拽「计算器」组件至画布,建立从「字段选择」组件到「计算器」组件的连接,此时弹出的提示框中有两个可选值:主输出步骤和错误步骤。主输出步骤是指正常数据的处理链路,错误步骤是错误数据的处理链路。因为字段选择组件涉及到字段信息的修改,字段类型、长度,数据在进行类型、长度等转换过程中会出错,这些出错的数据就会流入错误数据处理链路,而正常的数据就会流入主输出数据链路。在本节案例中,我们只处理正常数据,因此选择「主输出步骤」。配置如下图所示:
完成「字段选择」组件的配置后,拖拽「计算器」组件至画布,建立从「字段选择」组件到「计算器」组件的连接,此时弹出的提示框中有两个可选值:主输出步骤和错误步骤。主输出步骤是指正常数据的处理链路,错误步骤是错误数据的处理链路。因为字段选择组件涉及到字段信息的修改,字段类型、长度,数据在进行类型、长度等转换过程中会出错,这些出错的数据就会流入错误数据处理链路,而正常的数据就会流入主输出数据链路。在本节案例中,我们只处理正常数据,因此选择「主输出步骤」。配置如下图所示: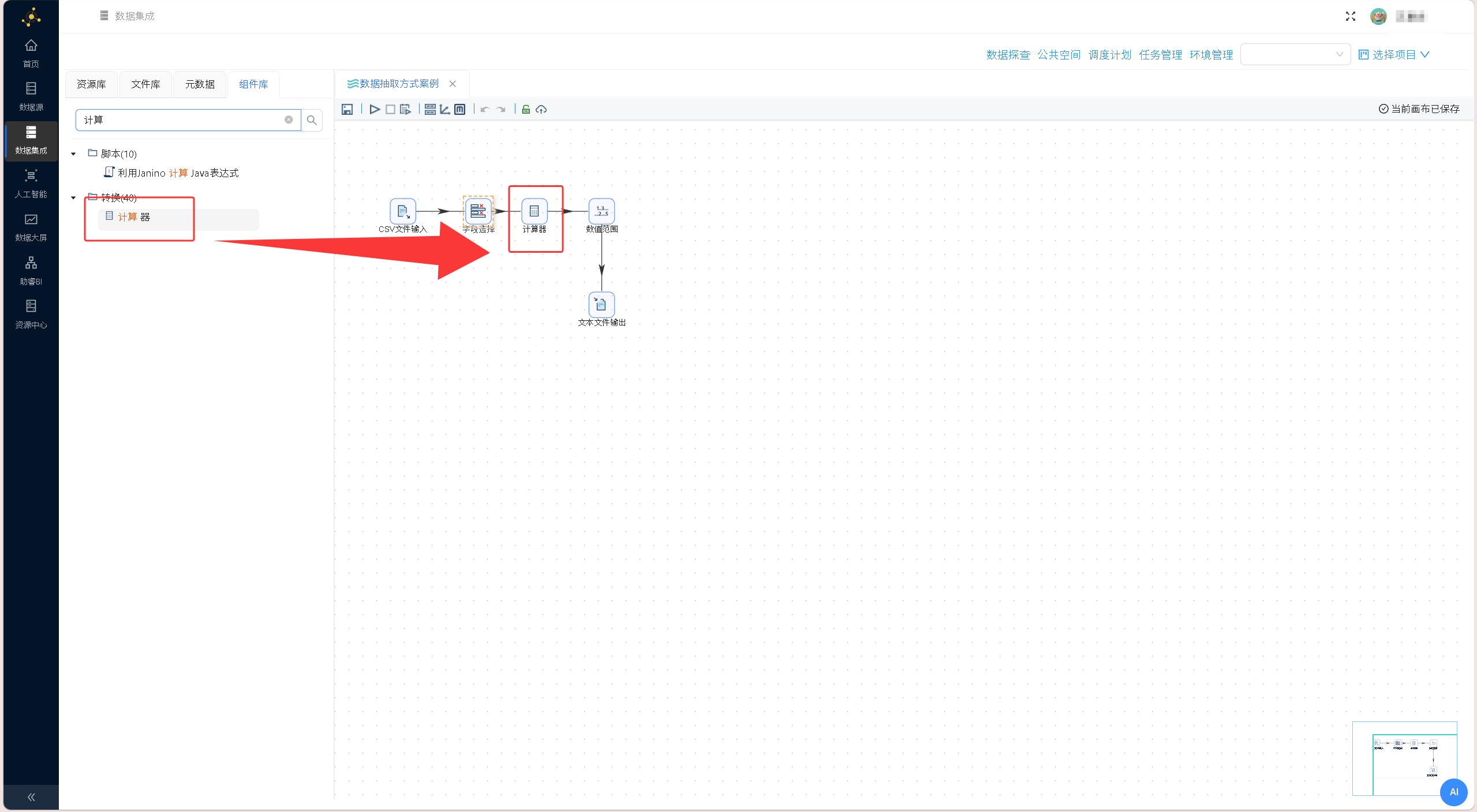 双击「计算器」组件进入配置界面,点击「插入」新增一行配置,此时相当于增加一个数据计算逻辑。在「计算器」组件中,一个数据计算逻辑由新字段、计算公式、字段A/B/C等结构组成。新字段是指计算逻辑输出的字段,计算公式指数据的计算方法,字段A/B/C是指计算逻辑的输入数据。界面如下图所示:
双击「计算器」组件进入配置界面,点击「插入」新增一行配置,此时相当于增加一个数据计算逻辑。在「计算器」组件中,一个数据计算逻辑由新字段、计算公式、字段A/B/C等结构组成。新字段是指计算逻辑输出的字段,计算公式指数据的计算方法,字段A/B/C是指计算逻辑的输入数据。界面如下图所示: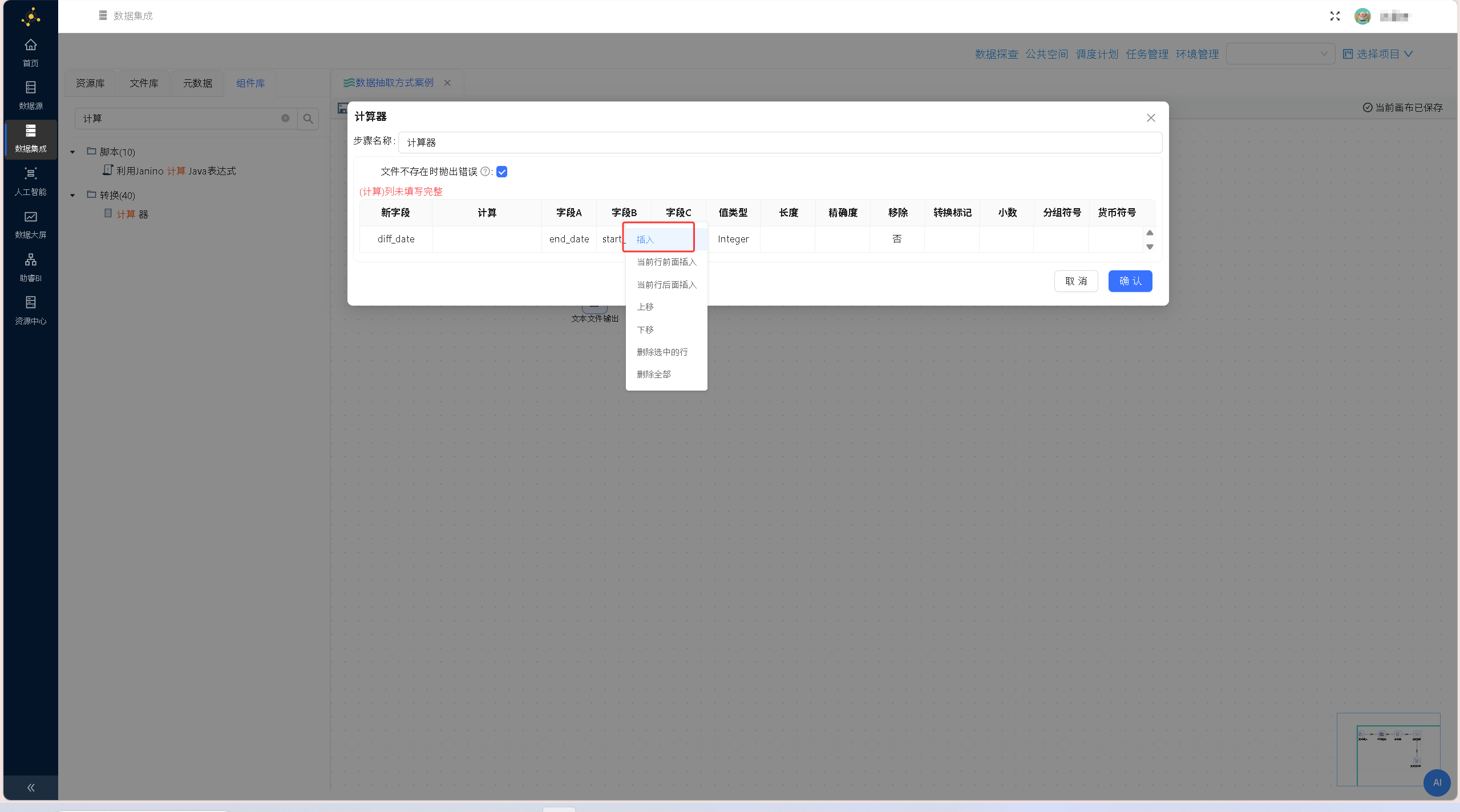 具体计算参数配置:新字段命名为diff_date,计算公式选择「Date A - Date B (in days)」,字段A选择end_date(结束日期),字段B选择start_date(开工日期),值类型设置为Integer(整数型),配置完成后点击确认,实现项目执行天数的自动计算。
具体计算参数配置:新字段命名为diff_date,计算公式选择「Date A - Date B (in days)」,字段A选择end_date(结束日期),字段B选择start_date(开工日期),值类型设置为Integer(整数型),配置完成后点击确认,实现项目执行天数的自动计算。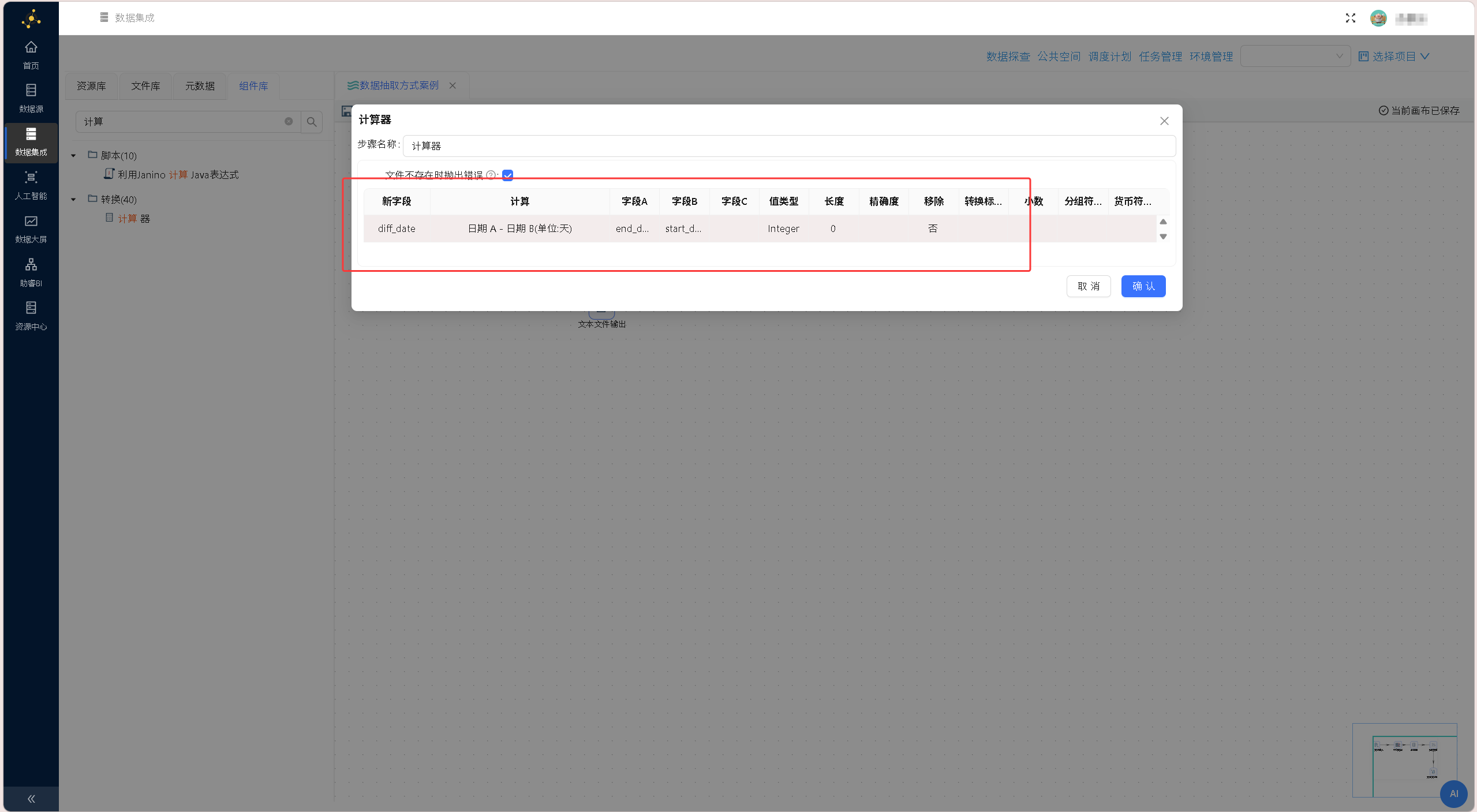 天数计算规则配置完成后,拖拽「数值范围」组件至画布,建立「计算器」组件与「数值范围」组件的数据流转连线。
天数计算规则配置完成后,拖拽「数值范围」组件至画布,建立「计算器」组件与「数值范围」组件的数据流转连线。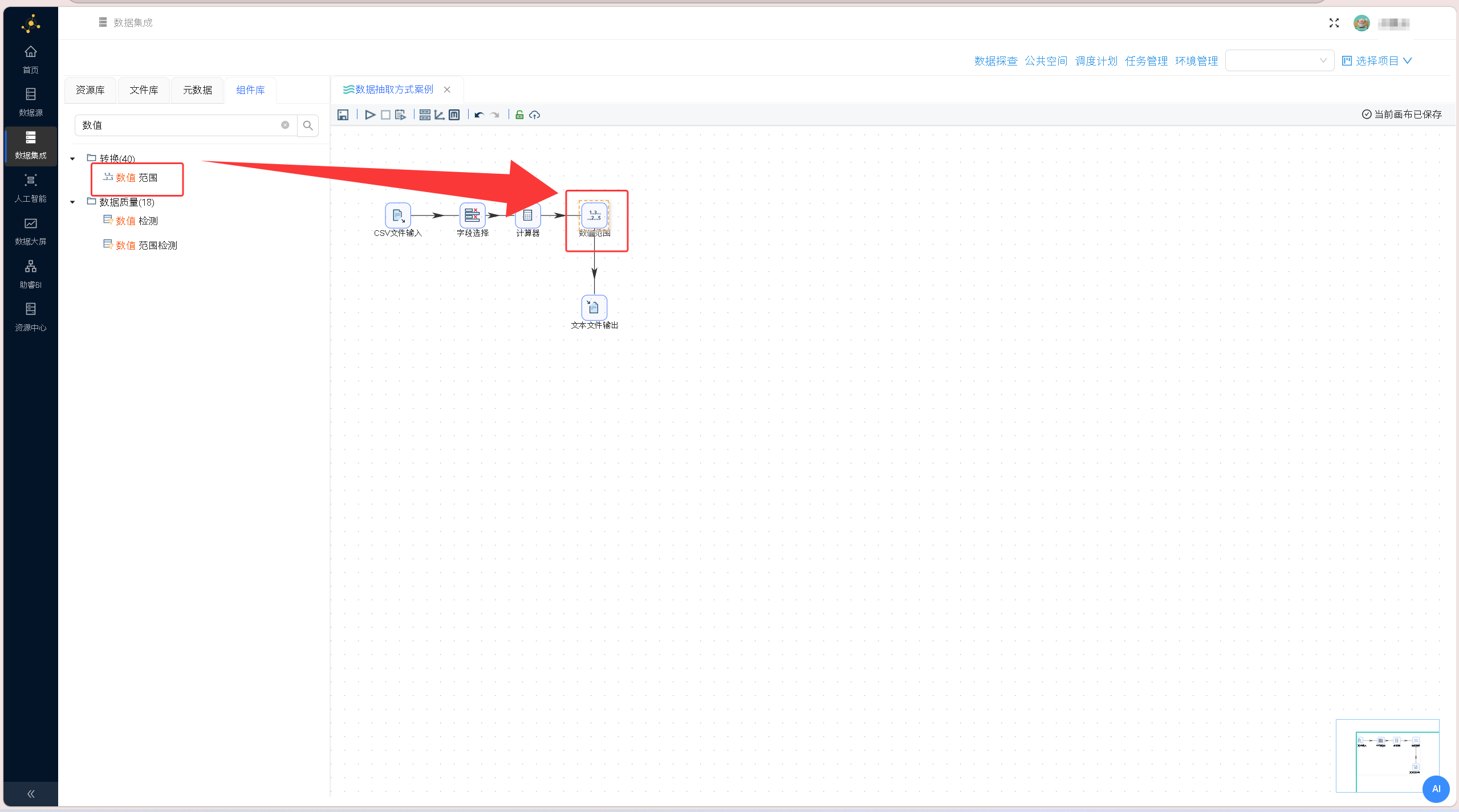 双击「数值范围」组件,配置绩效分级规则:输入字段选择diff_date(执行天数),输出字段命名为performance(绩效等级),按照业务标准设置区间规则:0≤天数<30为excellent、30≤天数<180为very good、180≤天数<360为good、天数≥360为poor,完成后确认保存配置。
双击「数值范围」组件,配置绩效分级规则:输入字段选择diff_date(执行天数),输出字段命名为performance(绩效等级),按照业务标准设置区间规则:0≤天数<30为excellent、30≤天数<180为very good、180≤天数<360为good、天数≥360为poor,完成后确认保存配置。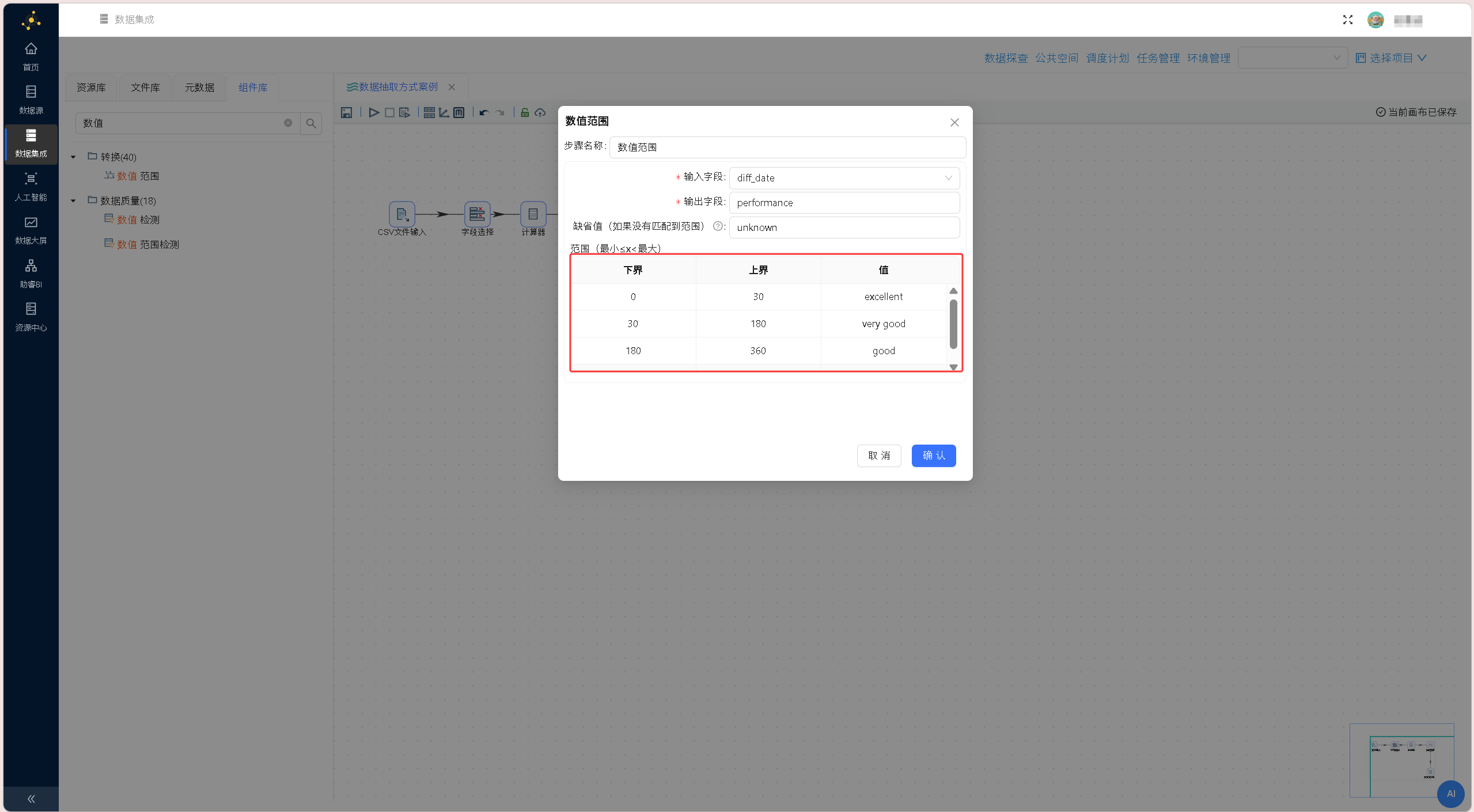 拖拽「文本文件输出」组件至画布,连接「数值范围」组件与输出组件,搭建最终数据导出链路。
拖拽「文本文件输出」组件至画布,连接「数值范围」组件与输出组件,搭建最终数据导出链路。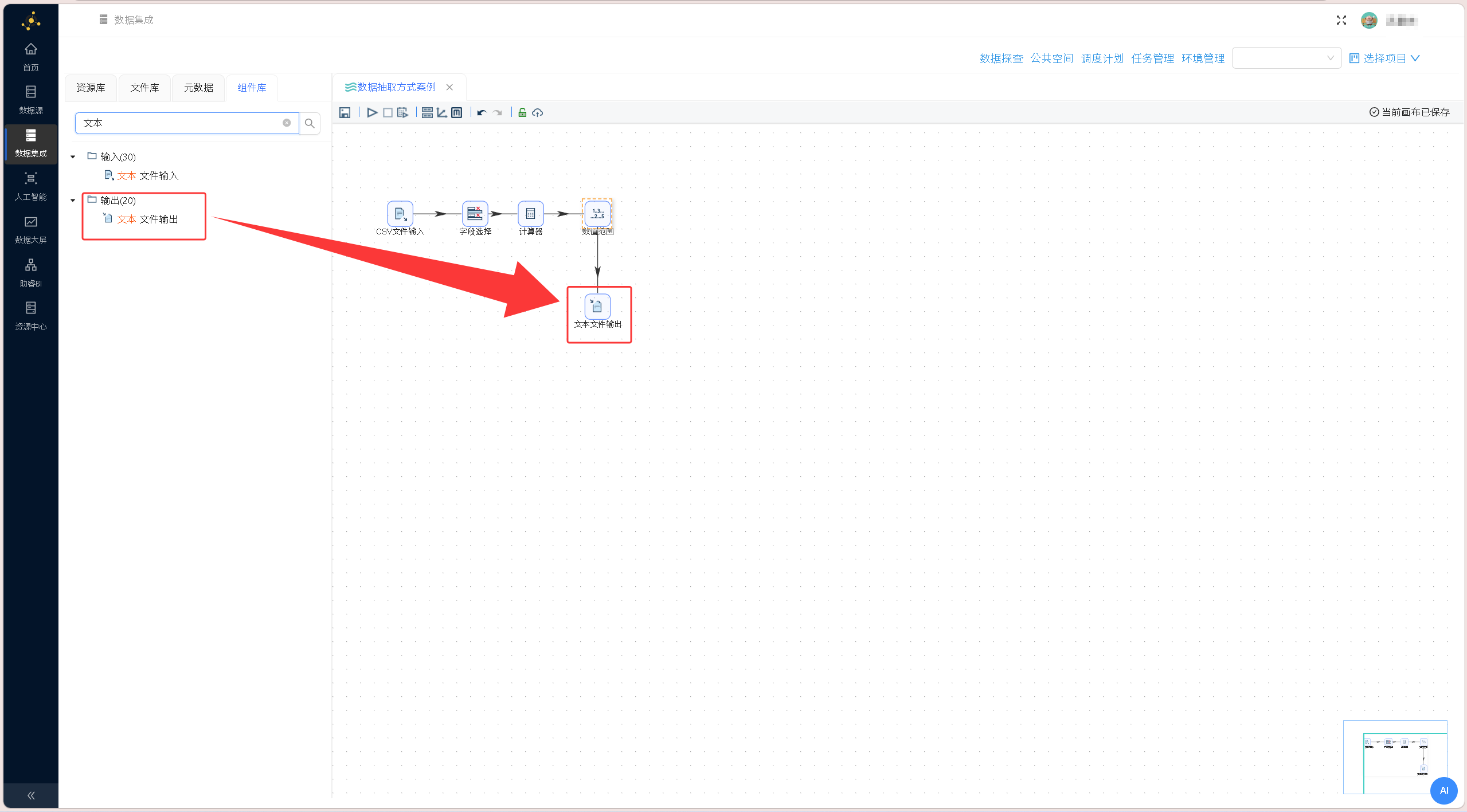 双击「文本文件输出」组件打开组件配置窗口,完成文件输出路径、字段映射等相关配置界面如下图所示:
双击「文本文件输出」组件打开组件配置窗口,完成文件输出路径、字段映射等相关配置界面如下图所示:
手动输入「文件名称」为 porject_output;
手动输入「扩展名」为 csv;
即通过「文本文件输出」组件将数据写入到porject_output.csv 文件中。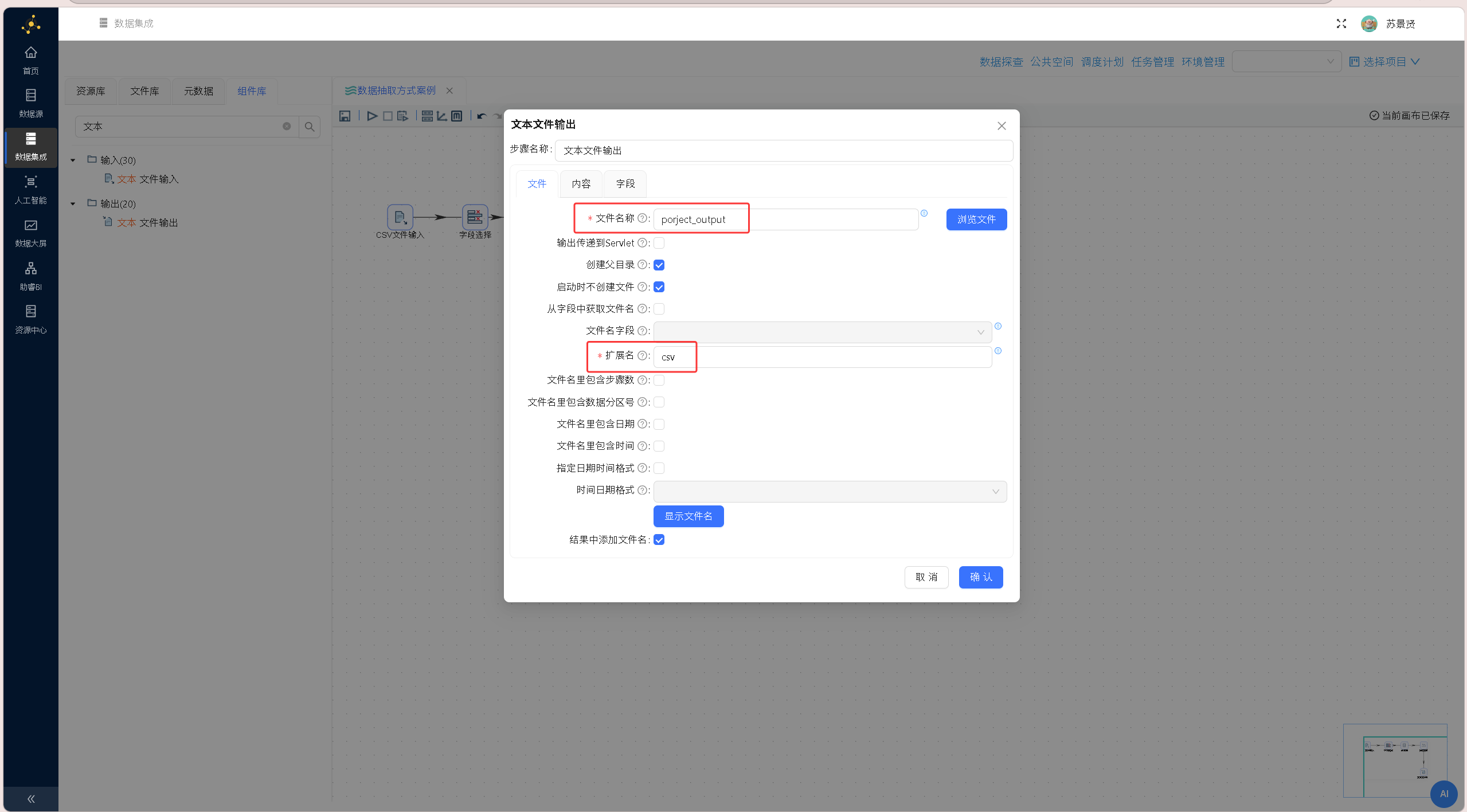 切换至「内容」标签页,将文件分隔符修改为英文逗号,匹配常规CSV文件的通用分隔格式,保证输出文件可正常解析读取。
切换至「内容」标签页,将文件分隔符修改为英文逗号,匹配常规CSV文件的通用分隔格式,保证输出文件可正常解析读取。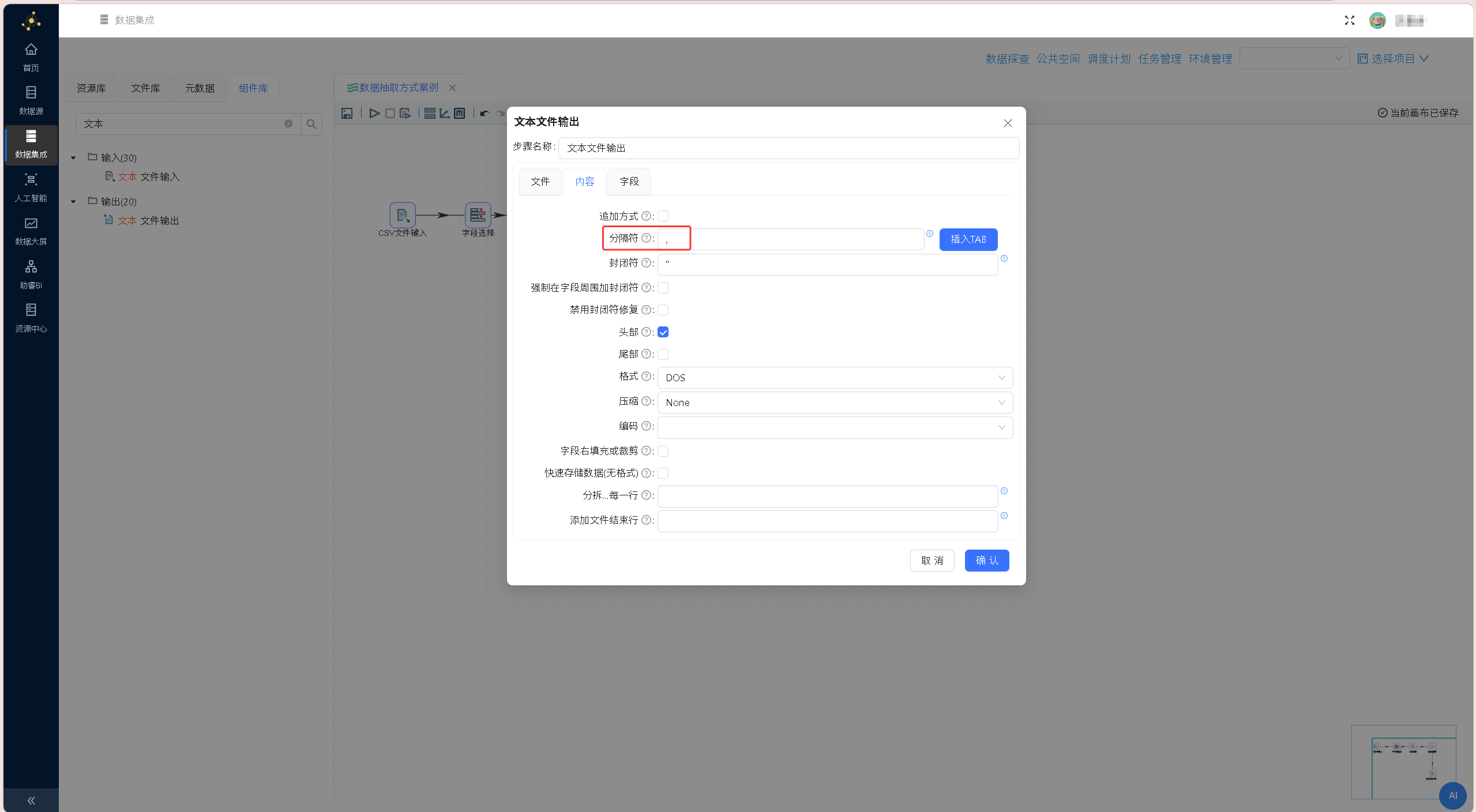 切换至「字段」标签页,在字段列表区域右键单击,选择「获取字段」,自动加载上游组件传递的所有字段信息,即将上游组件传递的字段都写入到文件中;
切换至「字段」标签页,在字段列表区域右键单击,选择「获取字段」,自动加载上游组件传递的所有字段信息,即将上游组件传递的字段都写入到文件中;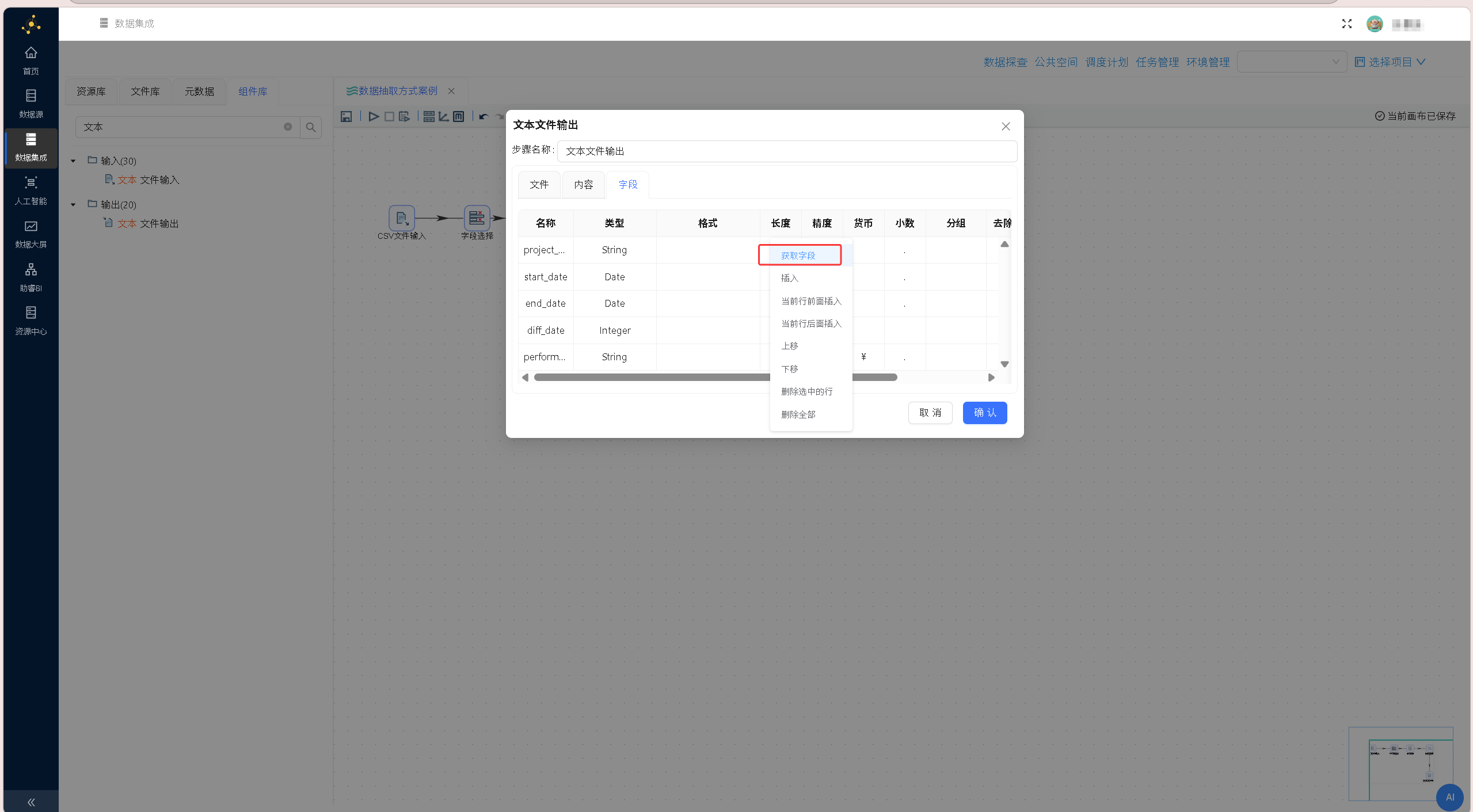 所有参数配置完成后,点击确认保存输出组件设置,完整的数据处理工作流搭建完成
所有参数配置完成后,点击确认保存输出组件设置,完整的数据处理工作流搭建完成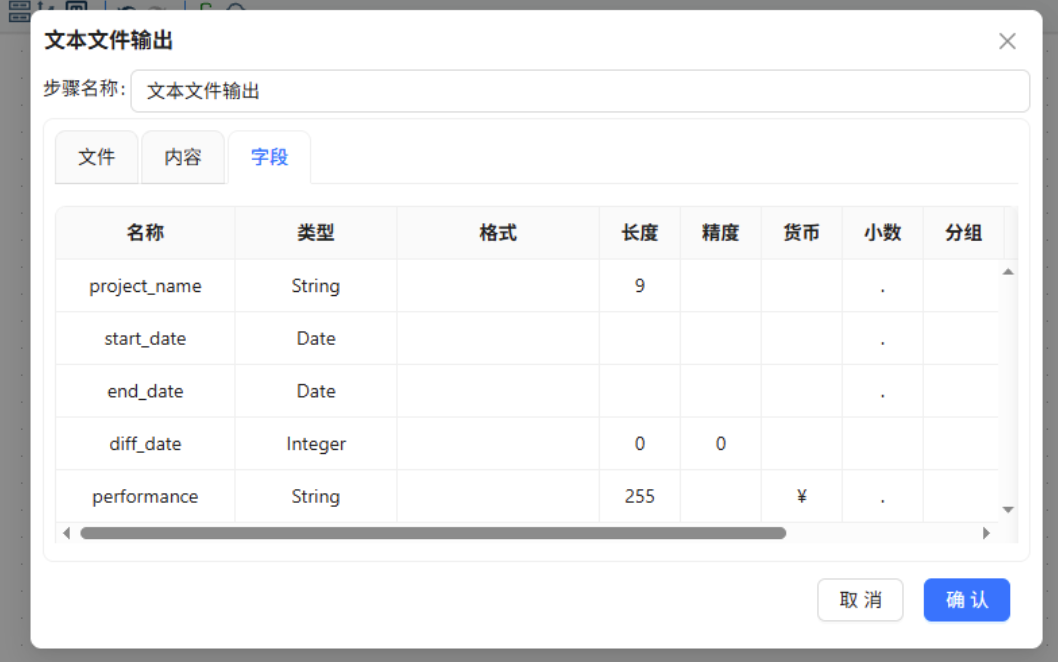 最终完整的CSV数据处理工作流视图如下:
最终完整的CSV数据处理工作流视图如下: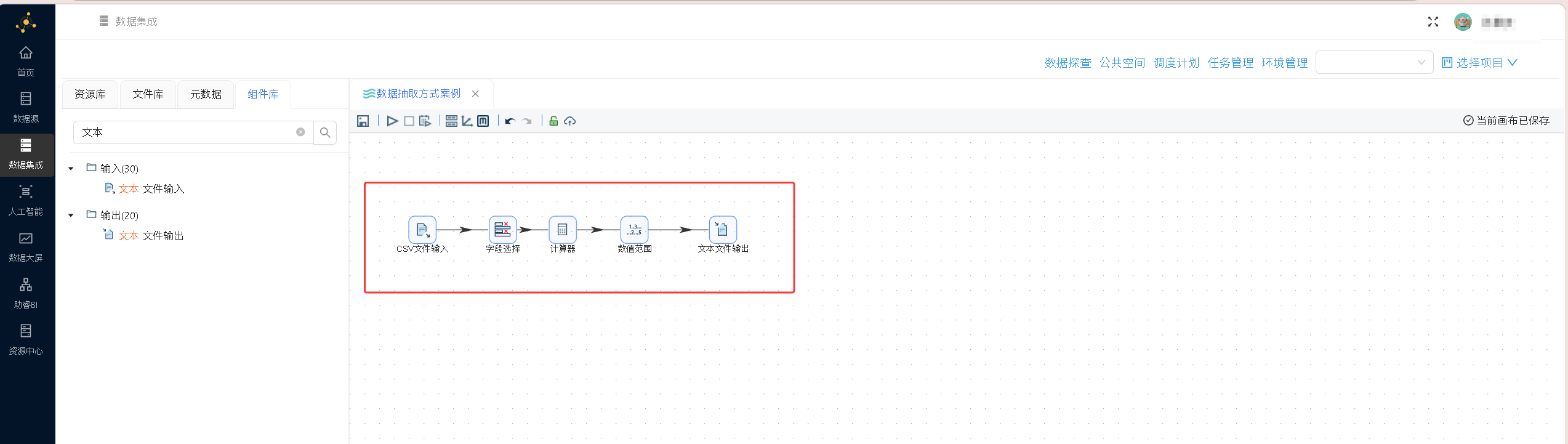 点击画布左上角「运行」按钮,在弹出的启动提示框中点击「启动」,执行完整的数据转换流程。
点击画布左上角「运行」按钮,在弹出的启动提示框中点击「启动」,执行完整的数据转换流程。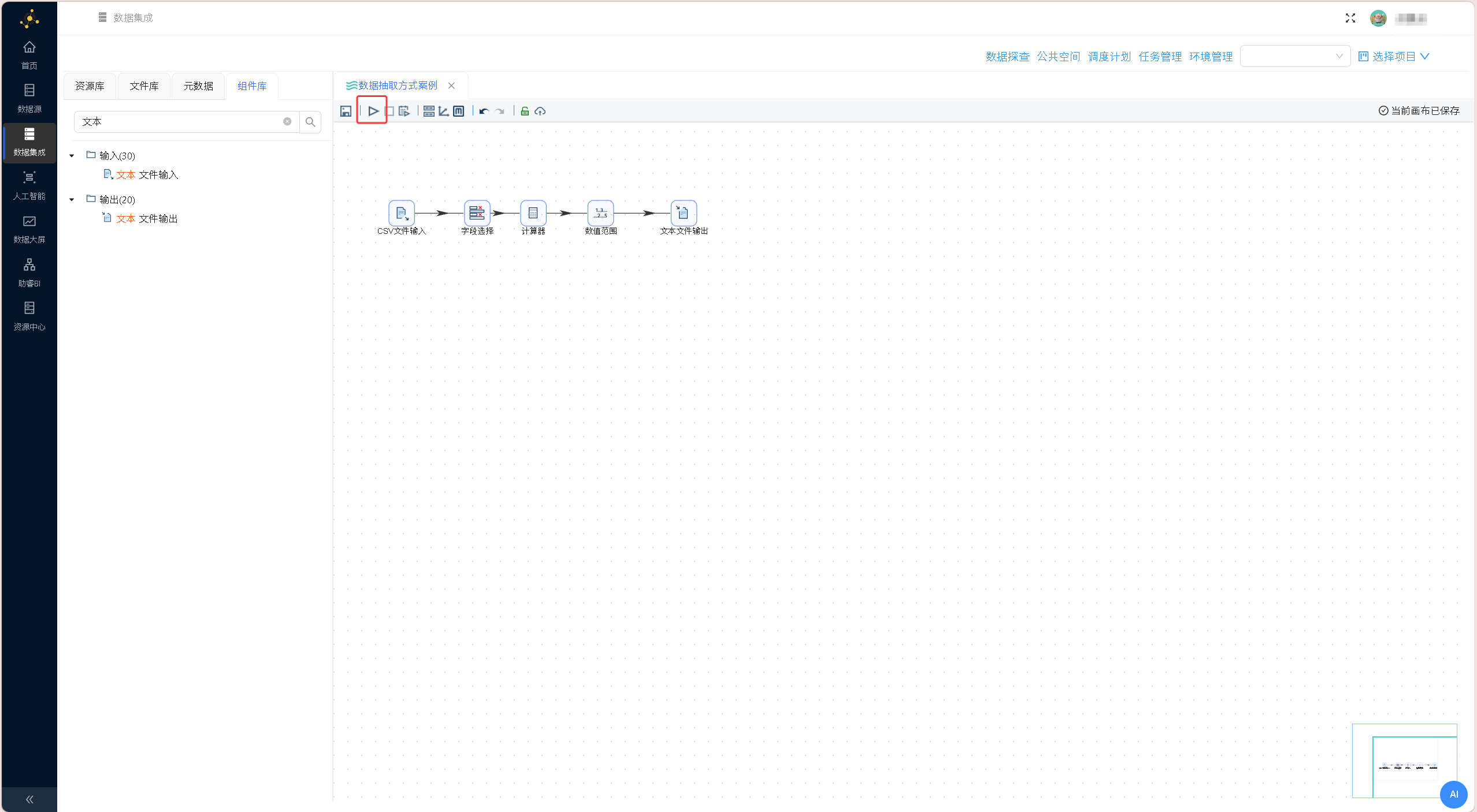 运行结果如下图所示:
运行结果如下图所示: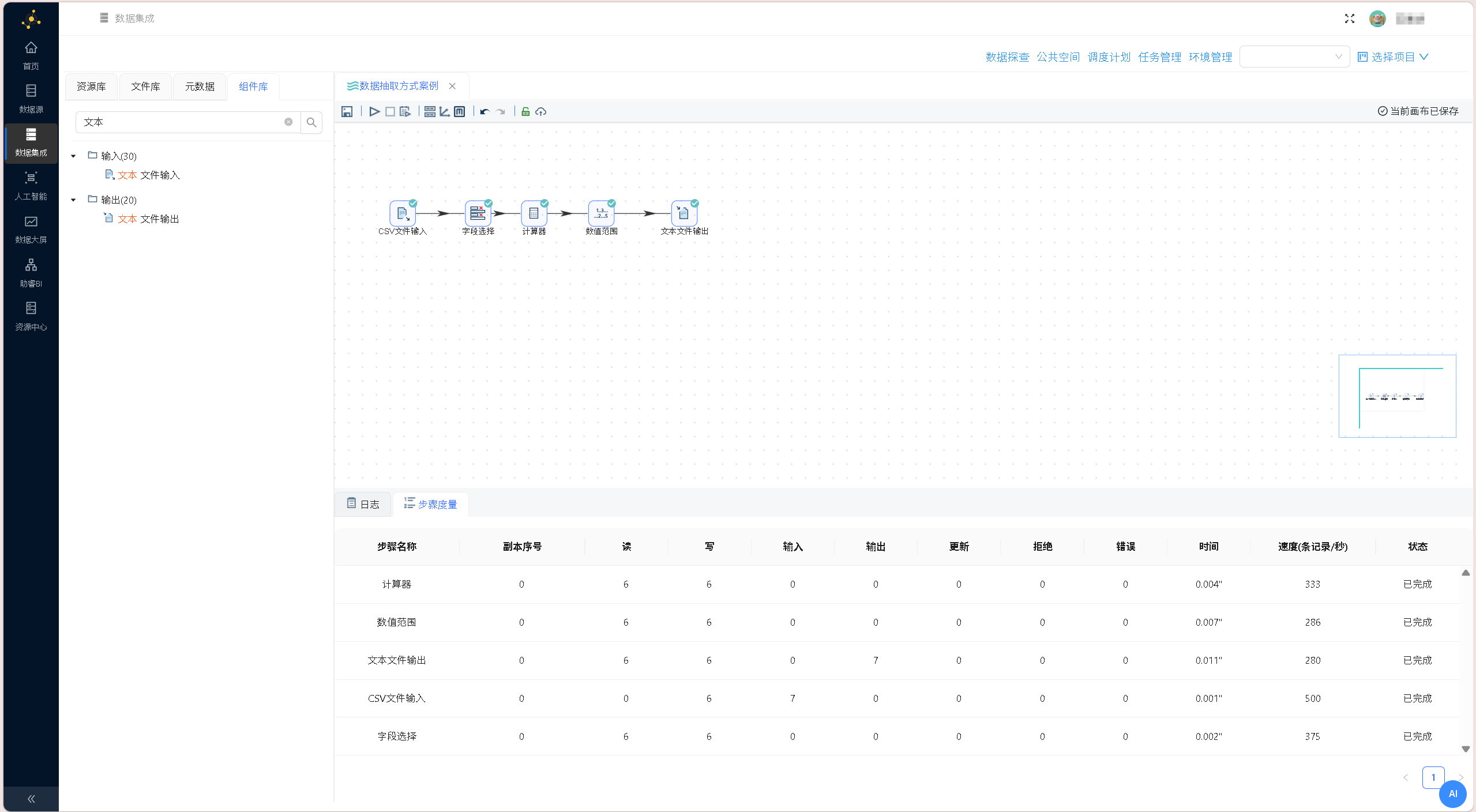 流程执行完成后,项目文件库自动生成porject_output.csv结果文件,最终处理数据如下:
流程执行完成后,项目文件库自动生成porject_output.csv结果文件,最终处理数据如下: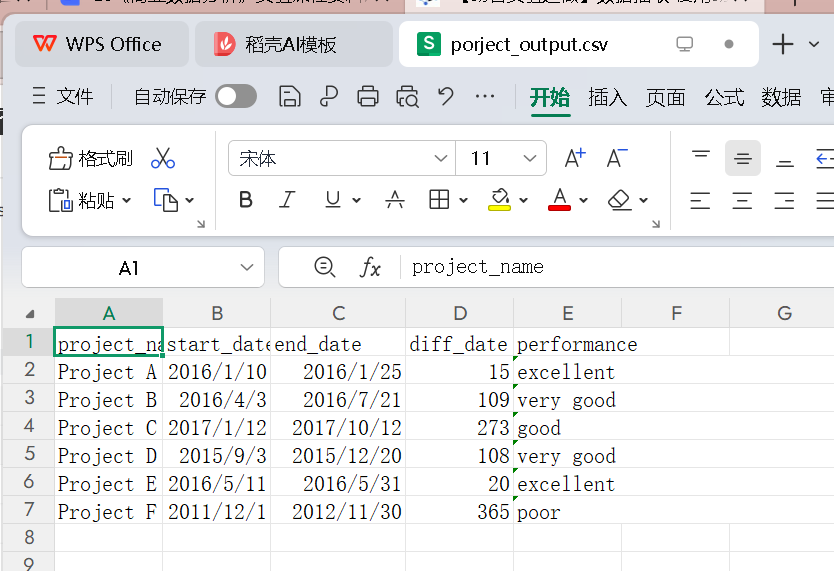
5 从文本文件中读取数据
本环节以足球比赛文本数据集为实训对象,依托助睿ETL平台完成TXT文本数据的标准化采集、字段精简与流程校验。数据集包含比赛日期、场地、主客队、比分等核心赛事信息,通过标准化操作完成原始文本数据的规整处理,剔除冗余字段,验证数据流转完整性,为后续赛事数据统计、比分分析等深度应用奠定数据基础。
核心实操逻辑分为三步:一是通过CSV输入组件适配文本分隔格式,完成TXT文件数据接入与解析;二是利用字段选择组件剔除无效字段,精简数据集结构;三是搭配空操作组件测试全流程数据连通性,保障数据流转稳定可用。
具体实操步骤如下:
新建空白数据转换流,从组件库拖拽「CSV文件输入」组件至编辑画布,用于读取文本格式数据源。
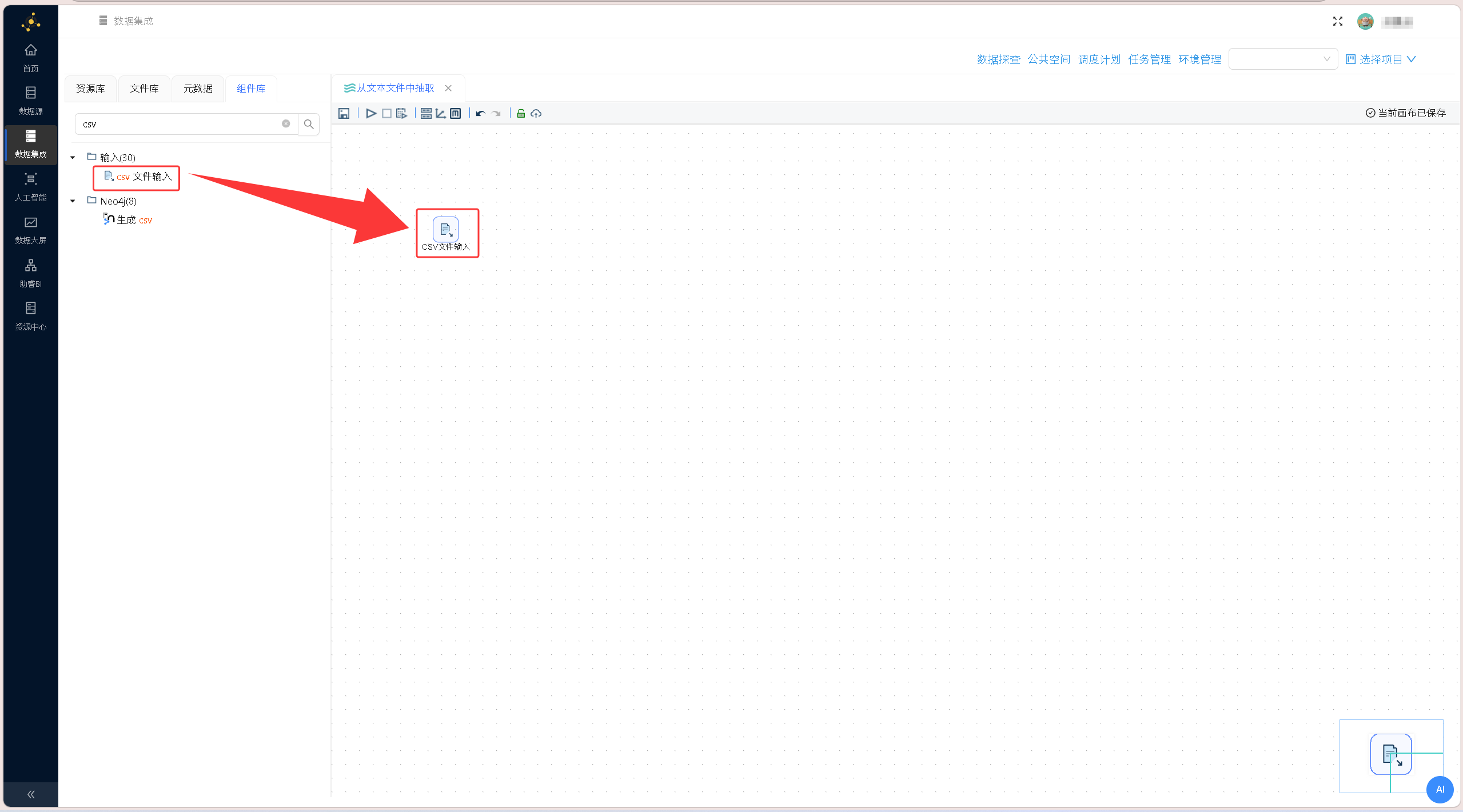 双击组件打开配置界面,点击浏览文件选中usa_201209.txt赛事文本文件,根据文件格式特点,将列分隔符设置为英文分号,勾选「包含列头行」选项,指定文件首行为字段名称,完成文本数据解析规则配置。
双击组件打开配置界面,点击浏览文件选中usa_201209.txt赛事文本文件,根据文件格式特点,将列分隔符设置为英文分号,勾选「包含列头行」选项,指定文件首行为字段名称,完成文本数据解析规则配置。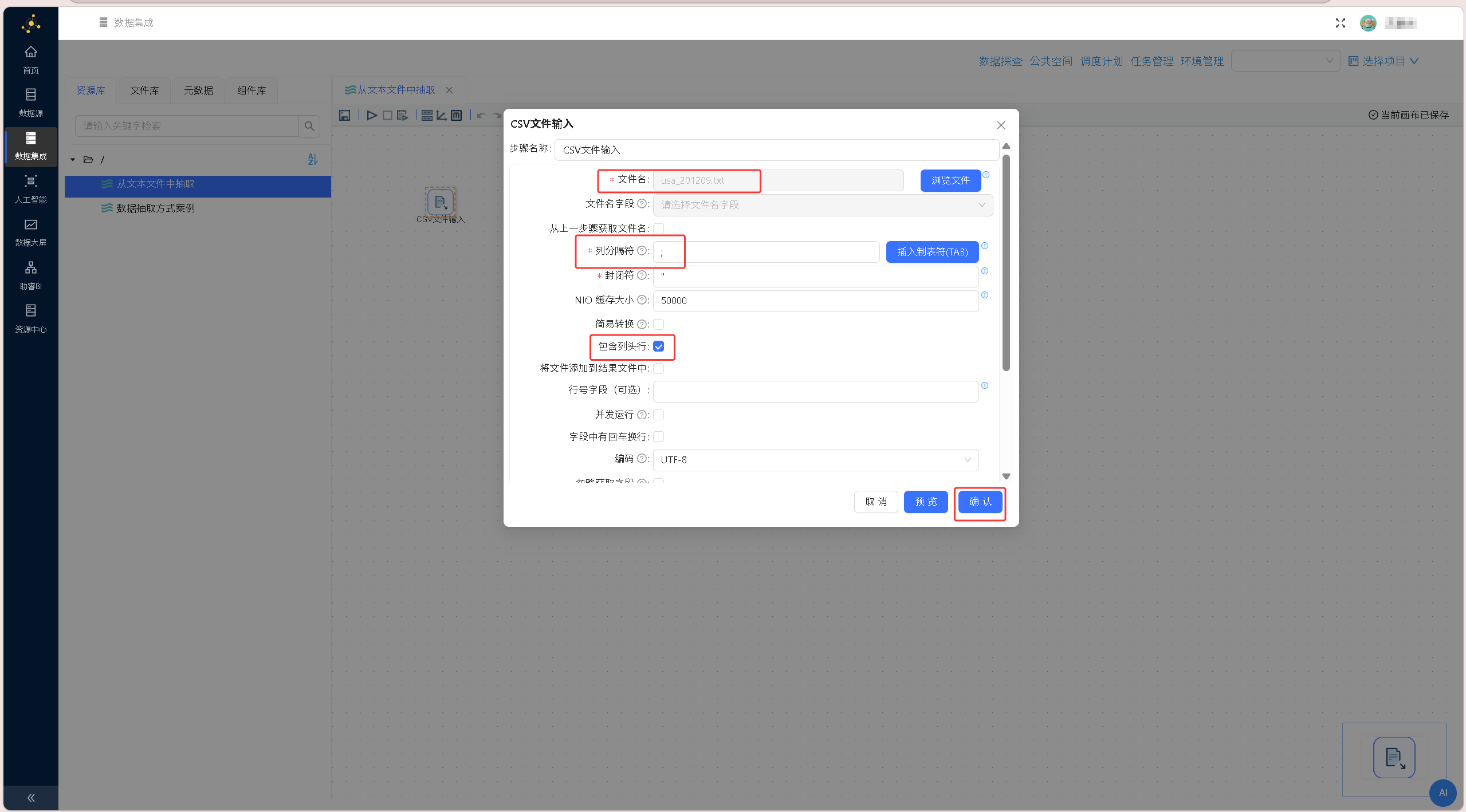 在数据预览区域右键单击,选择「获取字段」,系统自动解析文本文件字段结构,完成数据结构适配,确认配置后保存设置。
在数据预览区域右键单击,选择「获取字段」,系统自动解析文本文件字段结构,完成数据结构适配,确认配置后保存设置。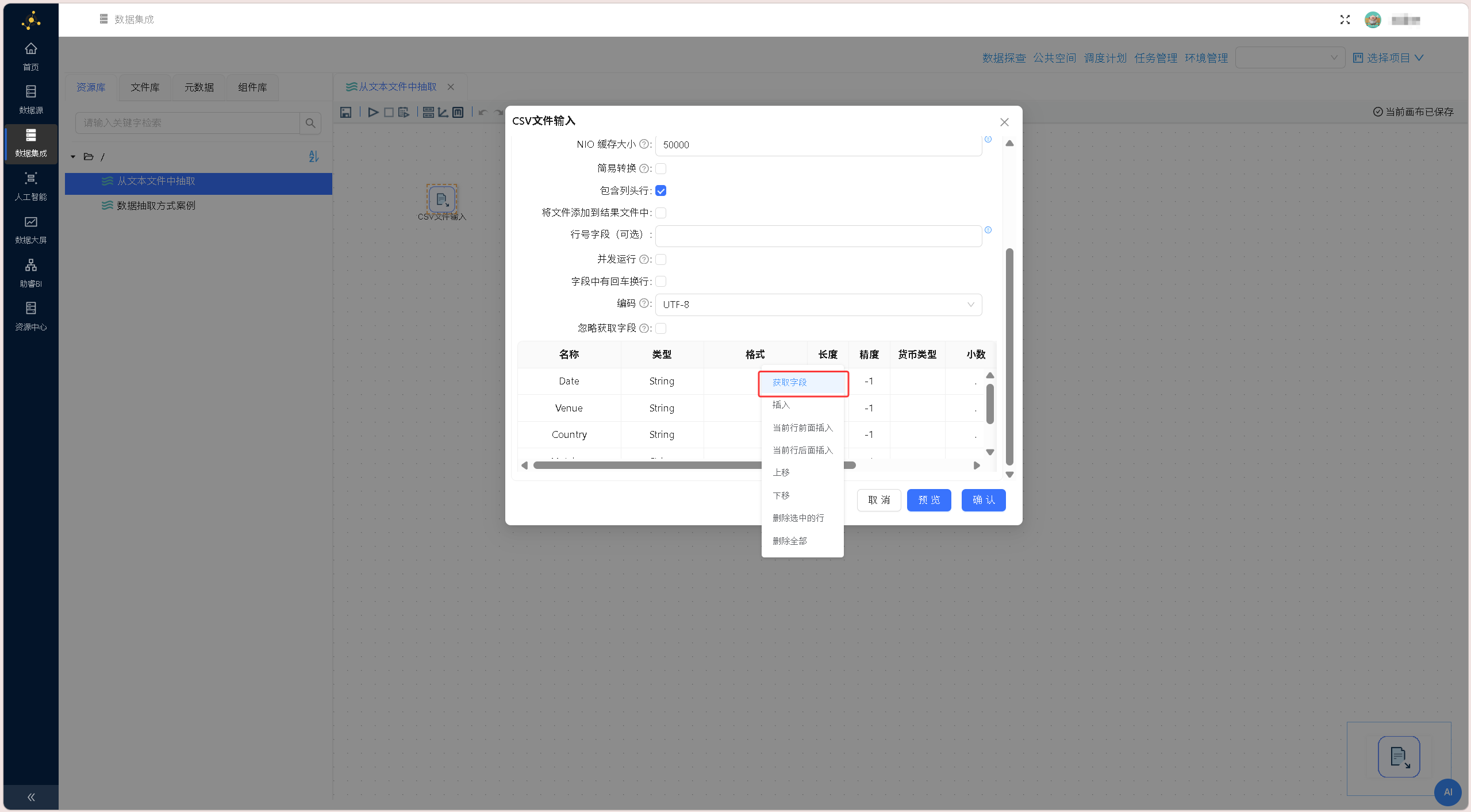 右键点击「CSV文件输入」组件,选择「预览输出」,核验文本数据读取效果、字段解析精度,确保原始数据无乱码、缺失问题。
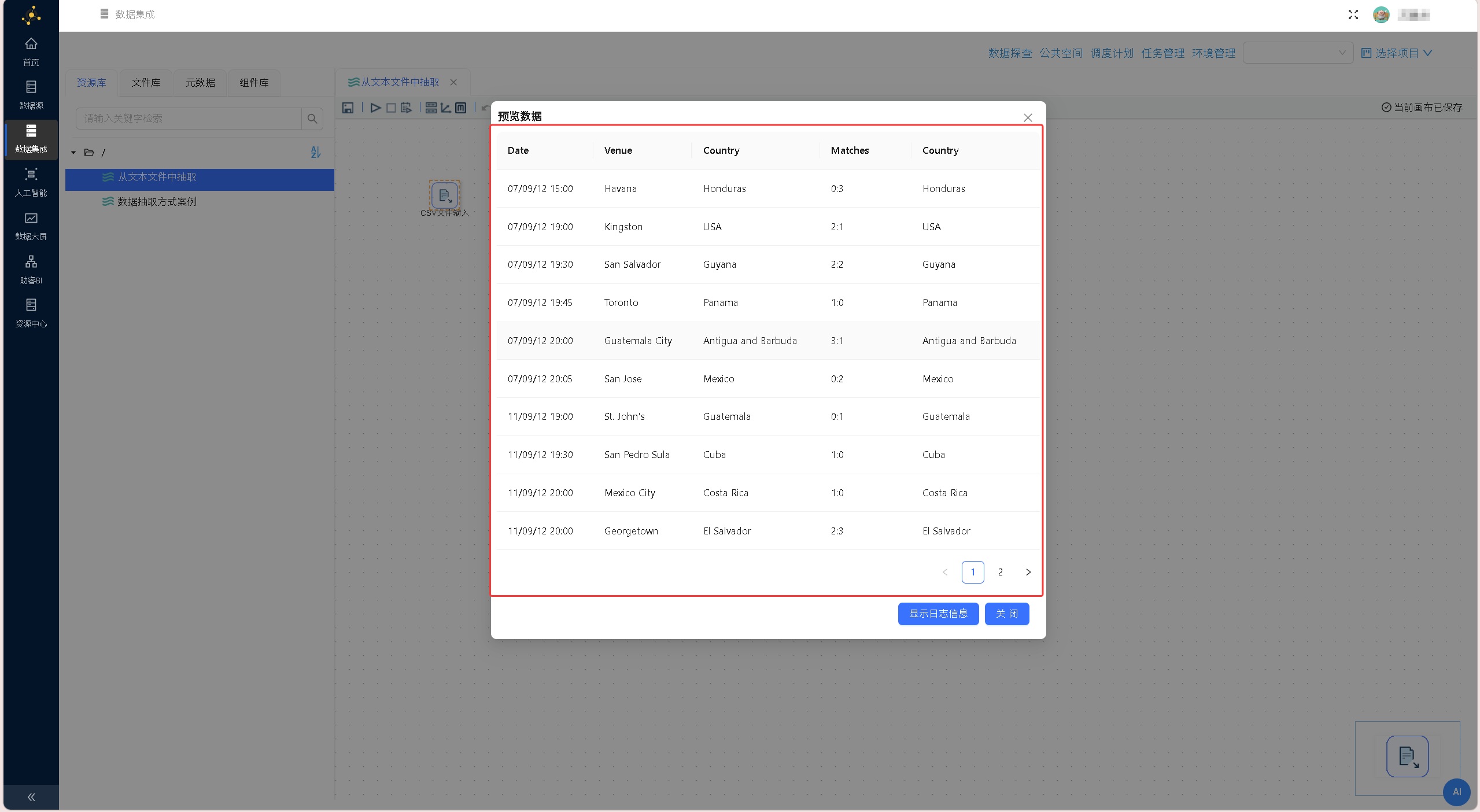
右键点击「CSV文件输入」组件,选择「预览输出」,核验文本数据读取效果、字段解析精度,确保原始数据无乱码、缺失问题。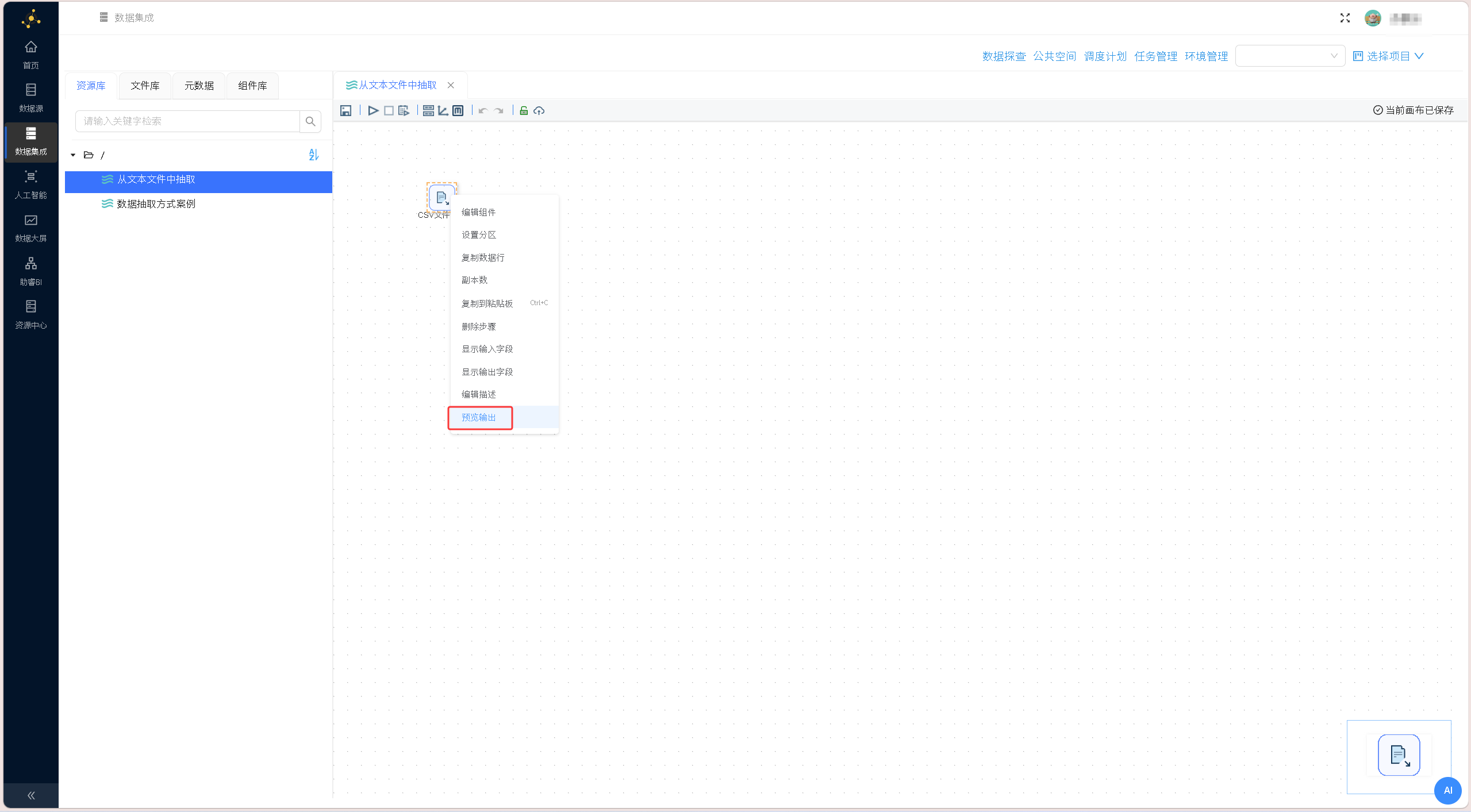
 依次拖拽「字段选择」组件、「空操作(什么也不做)」组件至画布,按照「CSV文件输入→字段选择→空操作」的顺序搭建数据流转链路,两次连线均选择「主输出步骤」,完成整体流程框架搭建。
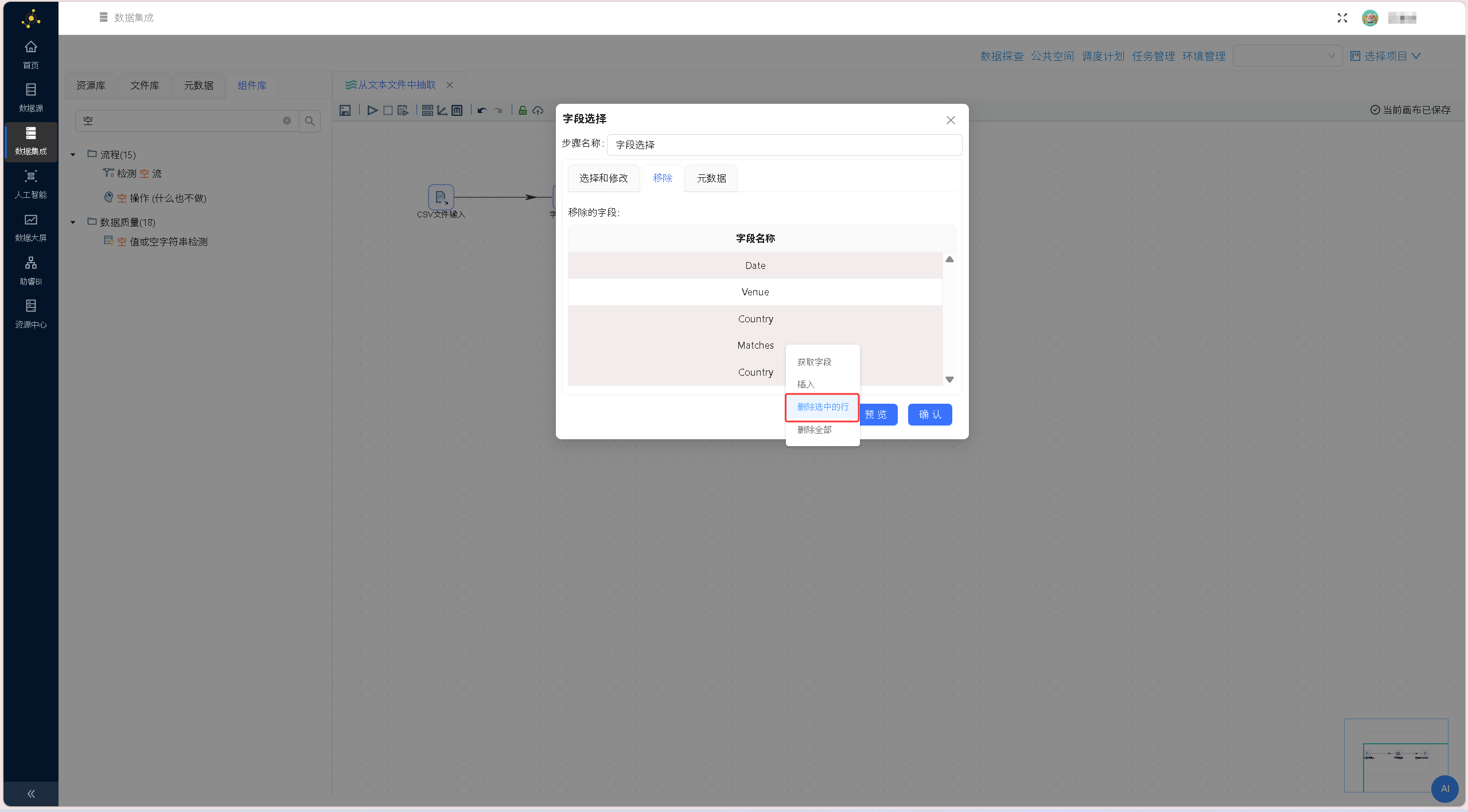
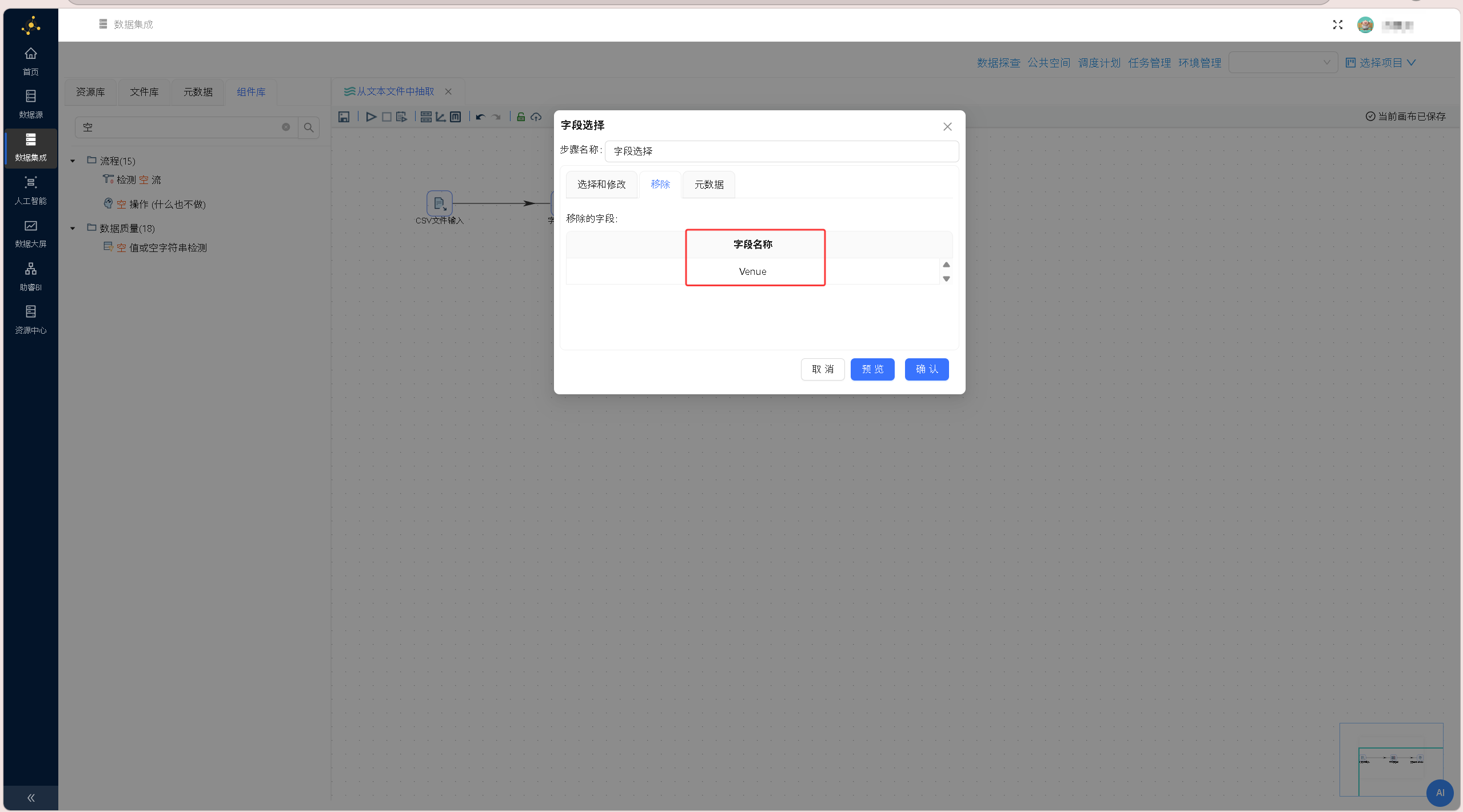
依次拖拽「字段选择」组件、「空操作(什么也不做)」组件至画布,按照「CSV文件输入→字段选择→空操作」的顺序搭建数据流转链路,两次连线均选择「主输出步骤」,完成整体流程框架搭建。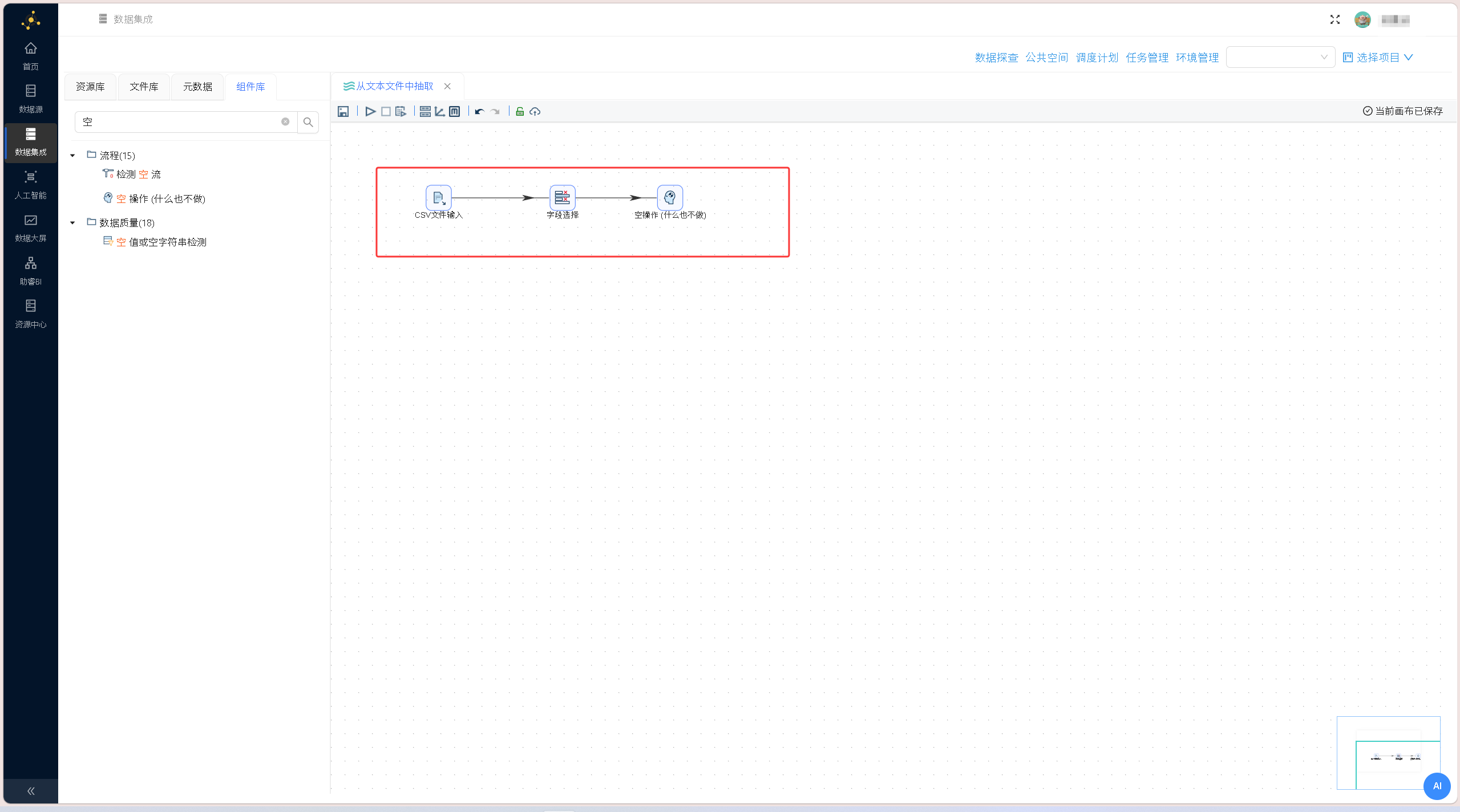 双击「字段选择」组件,切换至「移除」标签页,右键获取上游全部字段,选中Venue字段并删除,剔除场地冗余字段,精简数据集维度,确认后保存配置。
双击「字段选择」组件,切换至「移除」标签页,右键获取上游全部字段,选中Venue字段并删除,剔除场地冗余字段,精简数据集维度,确认后保存配置。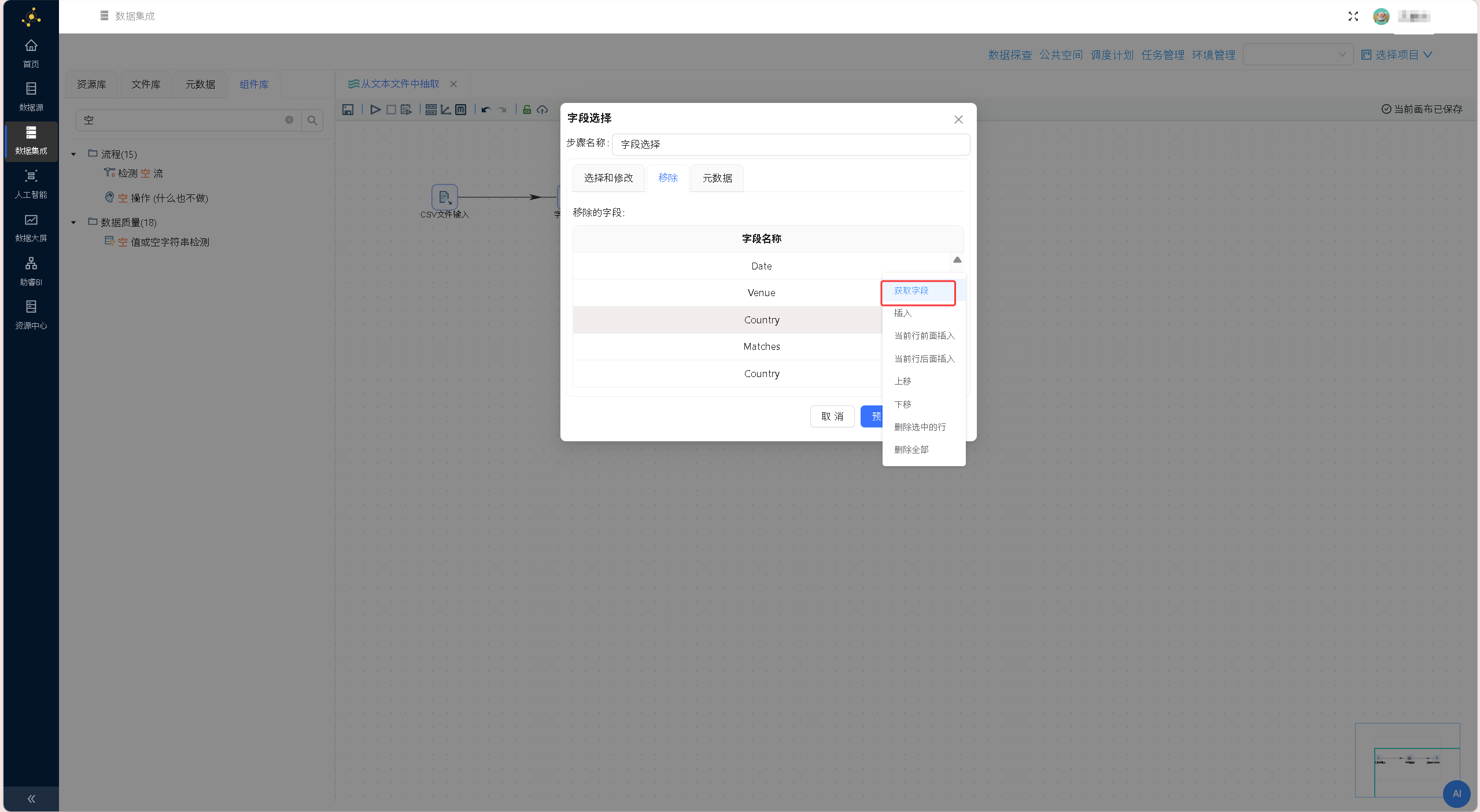
 点击画布左上角的「运行」按钮,在弹出的提示框中点击「启动」,即可运行整个转换流程,执行结果如下图所示:
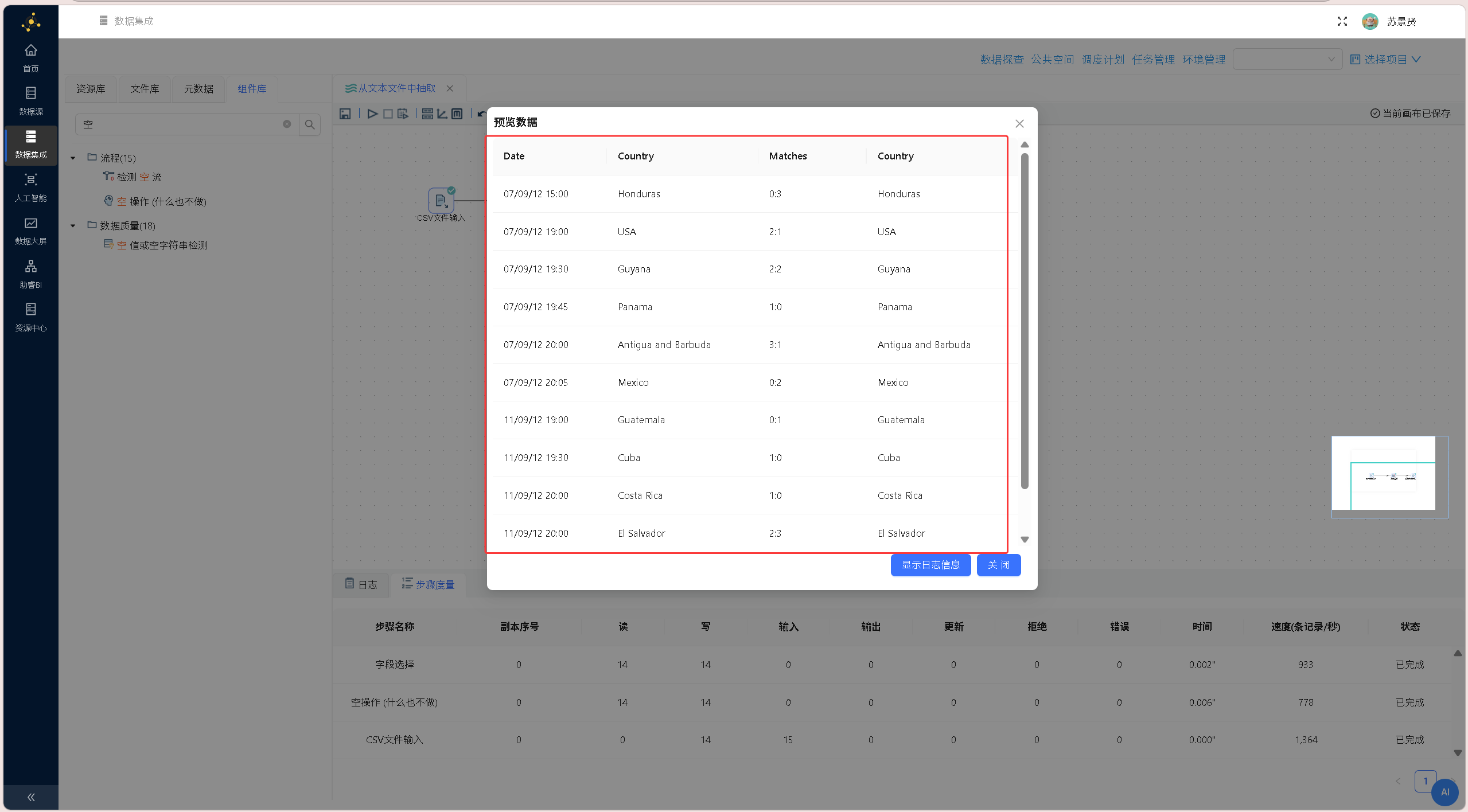
点击画布左上角的「运行」按钮,在弹出的提示框中点击「启动」,即可运行整个转换流程,执行结果如下图所示: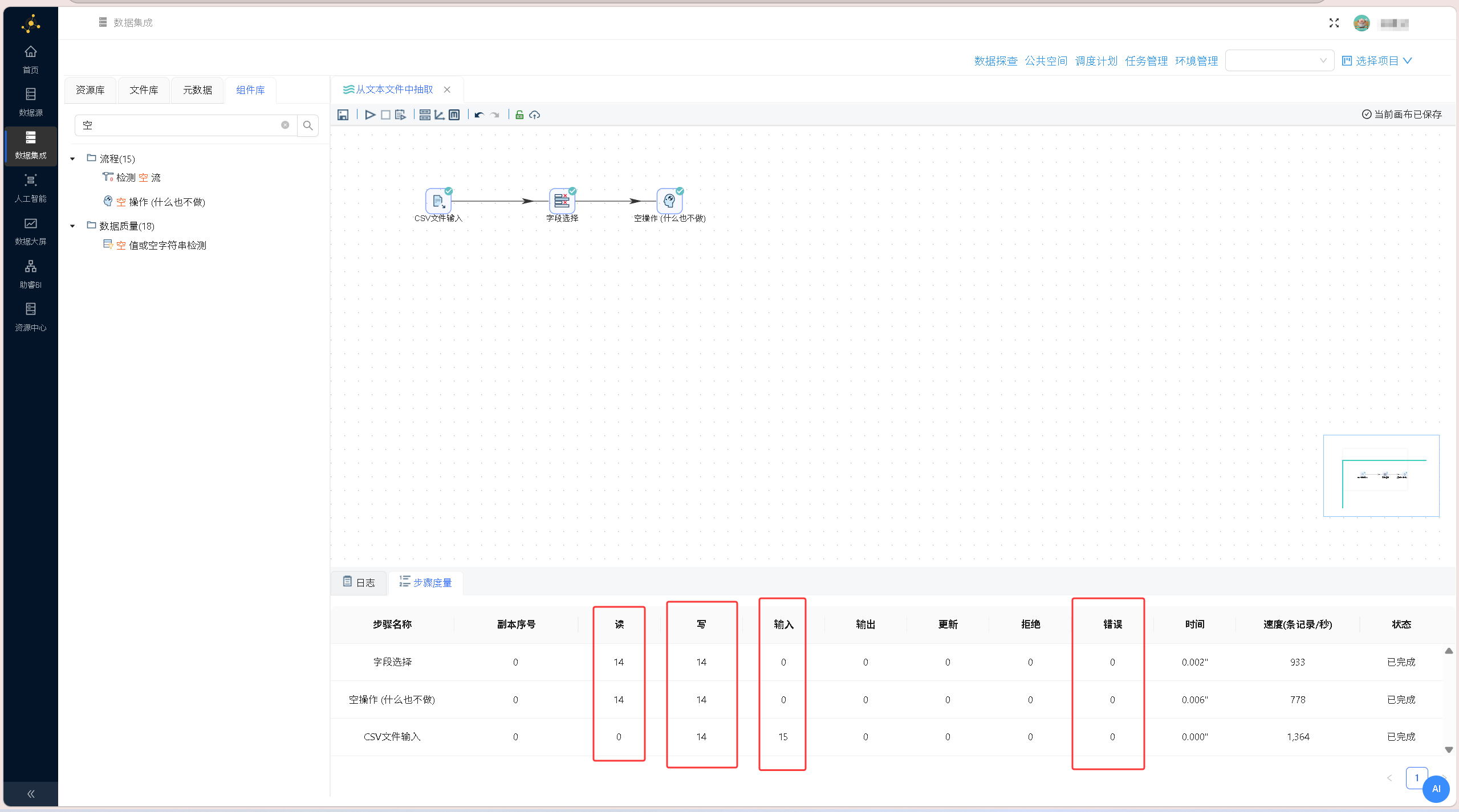 选中「空操作(什么也不做)」组件,右键单击并选择「预览」,查看经过字段筛选后的数据输出结果,验证字段剔除是否生效、数据传递是否完整,结果如下图所示:
选中「空操作(什么也不做)」组件,右键单击并选择「预览」,查看经过字段筛选后的数据输出结果,验证字段剔除是否生效、数据传递是否完整,结果如下图所示: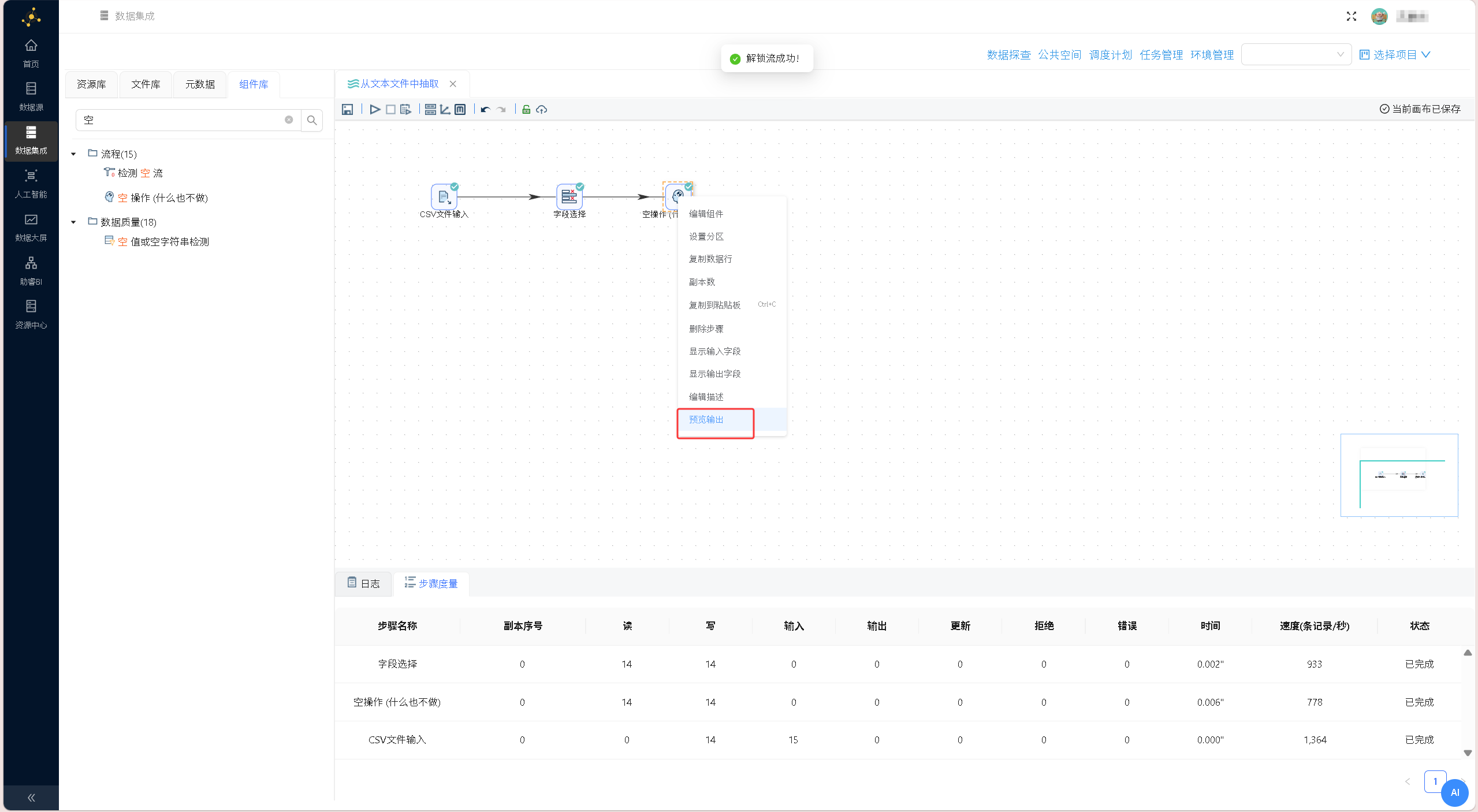
6 从 Excel 文件中读取数据
房地产购房决策受购房者个人属性、家庭情况、经济条件等多维度因素影响,原始购房数据集维度繁杂,直接用于建模分析易产生数据冗余、分析偏差等问题。因此在开展购房影响因素数据建模前,需对Excel格式的原始购房者数据进行采集、过滤与字段筛选,提取核心有效字段,完成数据预处理,为后续数据分析建模提供精准、精简的数据源。
本环节依托助睿ETL平台,读取custinfo.xlsx购房者信息数据集,通过Excel专属输入组件完成数据接入,结合字段选择组件筛选出学历、就业状态等核心分析字段,实现Excel数据的标准化预处理与流程校验。
具体实操步骤如下:
新建数据转换工作流,在组件库中拖拽「Excel输入」组件至编辑画布,用于解析读取Excel格式数据源。 双击Excel输入组件,点击「浏览」按钮,选中项目文件库中的custinfo.xlsx购房者数据文件。
双击Excel输入组件,点击「浏览」按钮,选中项目文件库中的custinfo.xlsx购房者数据文件。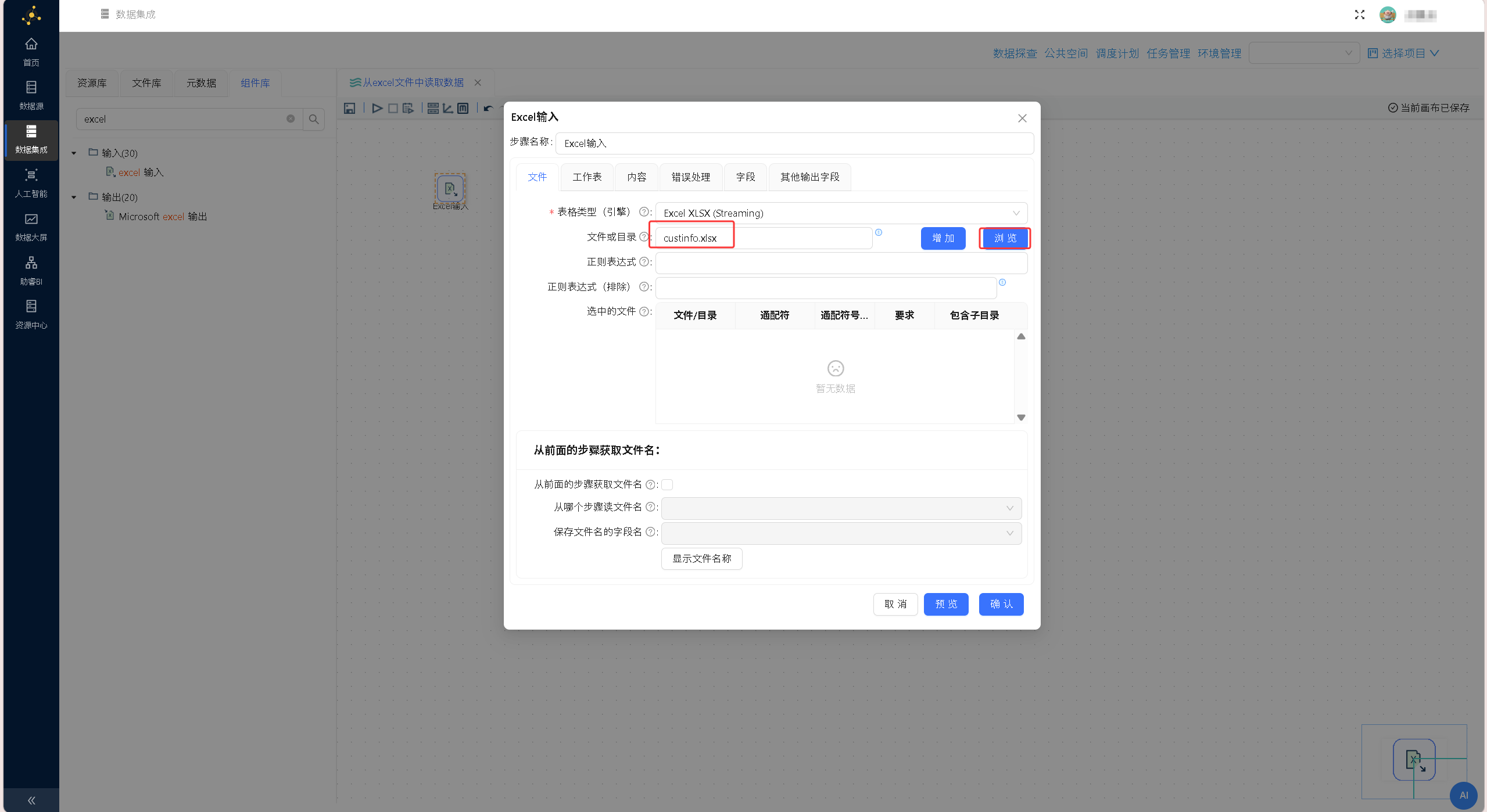 再点击「增加」按钮将文件添加至「选中的文件」中,完成基础文件配置。即通过 Excel XLSX(Streaming)引擎解析和读取 custinfo.xlsx 文件。配置界面如下图所示:
再点击「增加」按钮将文件添加至「选中的文件」中,完成基础文件配置。即通过 Excel XLSX(Streaming)引擎解析和读取 custinfo.xlsx 文件。配置界面如下图所示: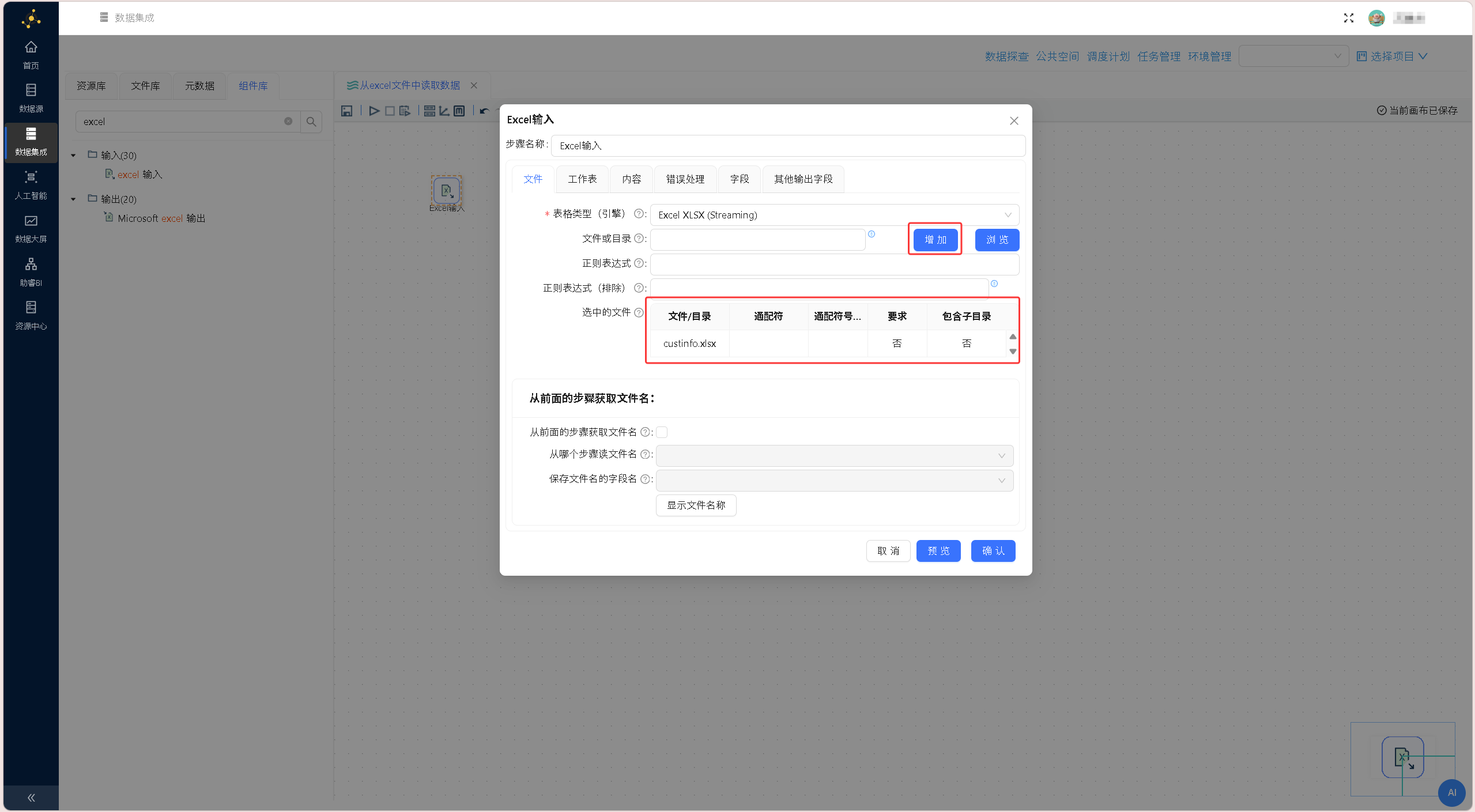 切换至「内容」标签页,完成相关配置:勾选「头部」「非空记录」,在「编码」下拉列表中选择「UTF-8」,即custinfo.xlsx 文件中第一行为字段名称,只读取文件中非空记录,且文件编码为UTF-8。配置界面如下图所示:
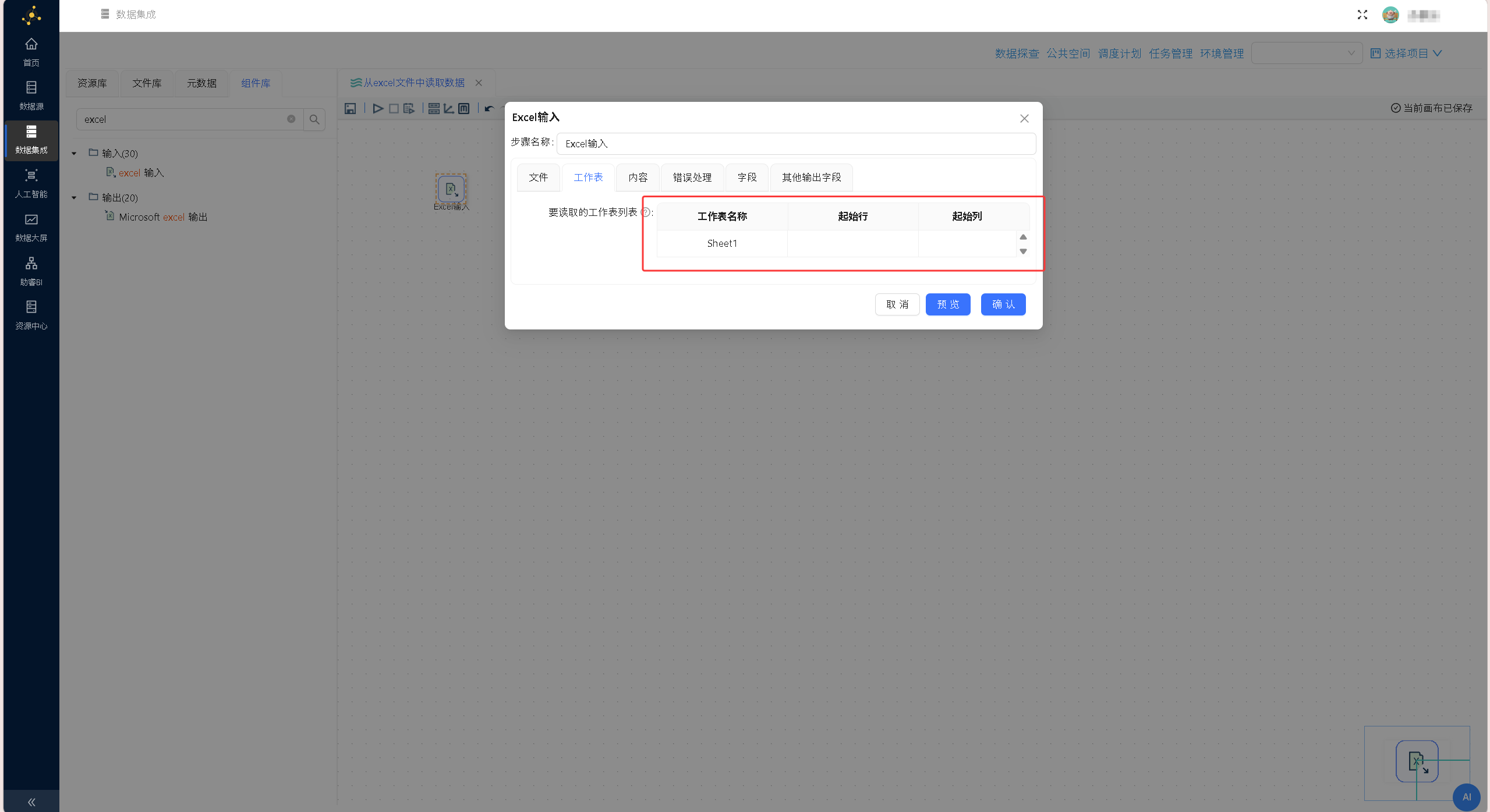
切换至「内容」标签页,完成相关配置:勾选「头部」「非空记录」,在「编码」下拉列表中选择「UTF-8」,即custinfo.xlsx 文件中第一行为字段名称,只读取文件中非空记录,且文件编码为UTF-8。配置界面如下图所示: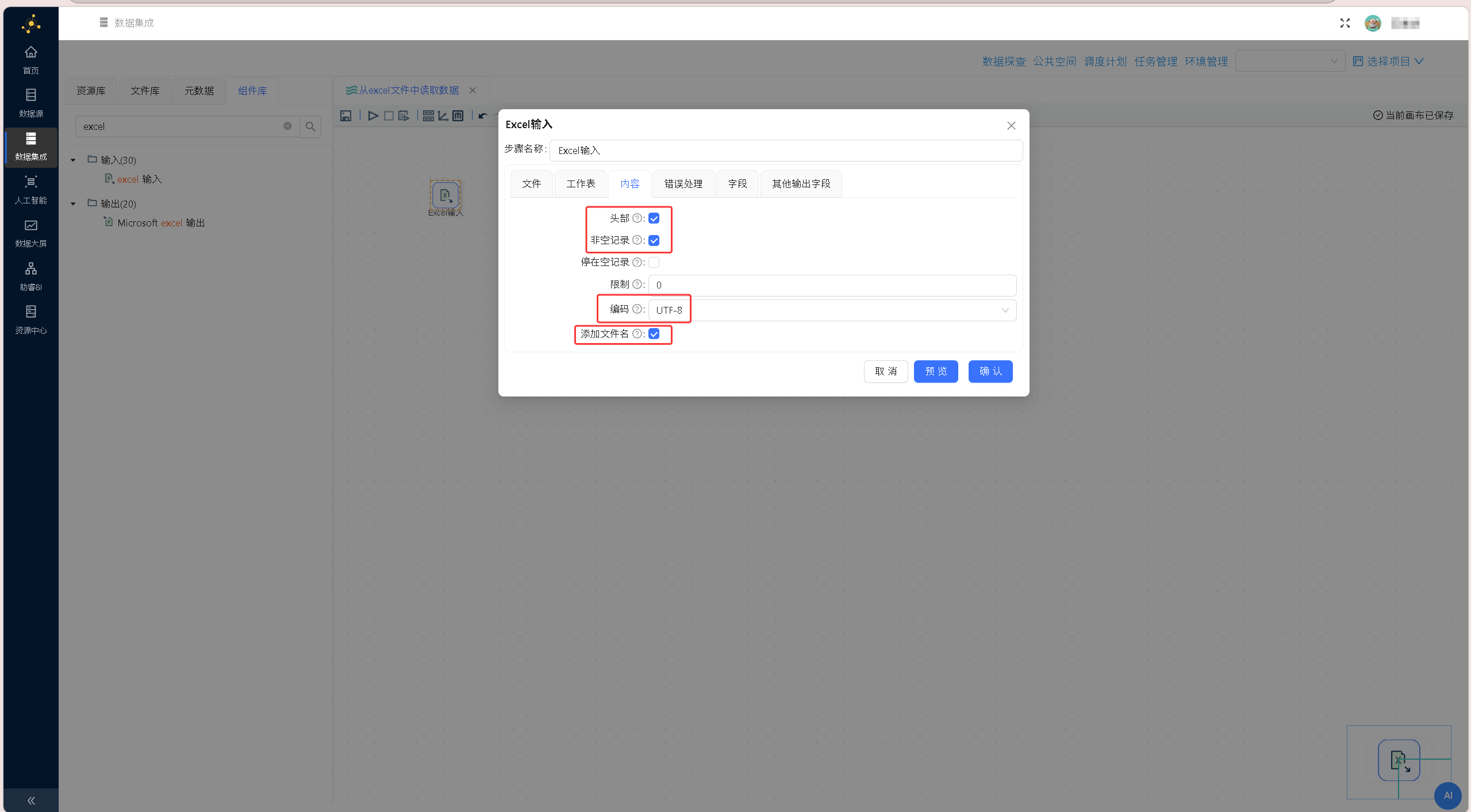 切换至「工作表」标签页,点击页面下方的「获取工作表名称」按钮,此时组件将读取文件并获取文件的工作簿信息。配置界面如下图所示:
切换至「工作表」标签页,点击页面下方的「获取工作表名称」按钮,此时组件将读取文件并获取文件的工作簿信息。配置界面如下图所示: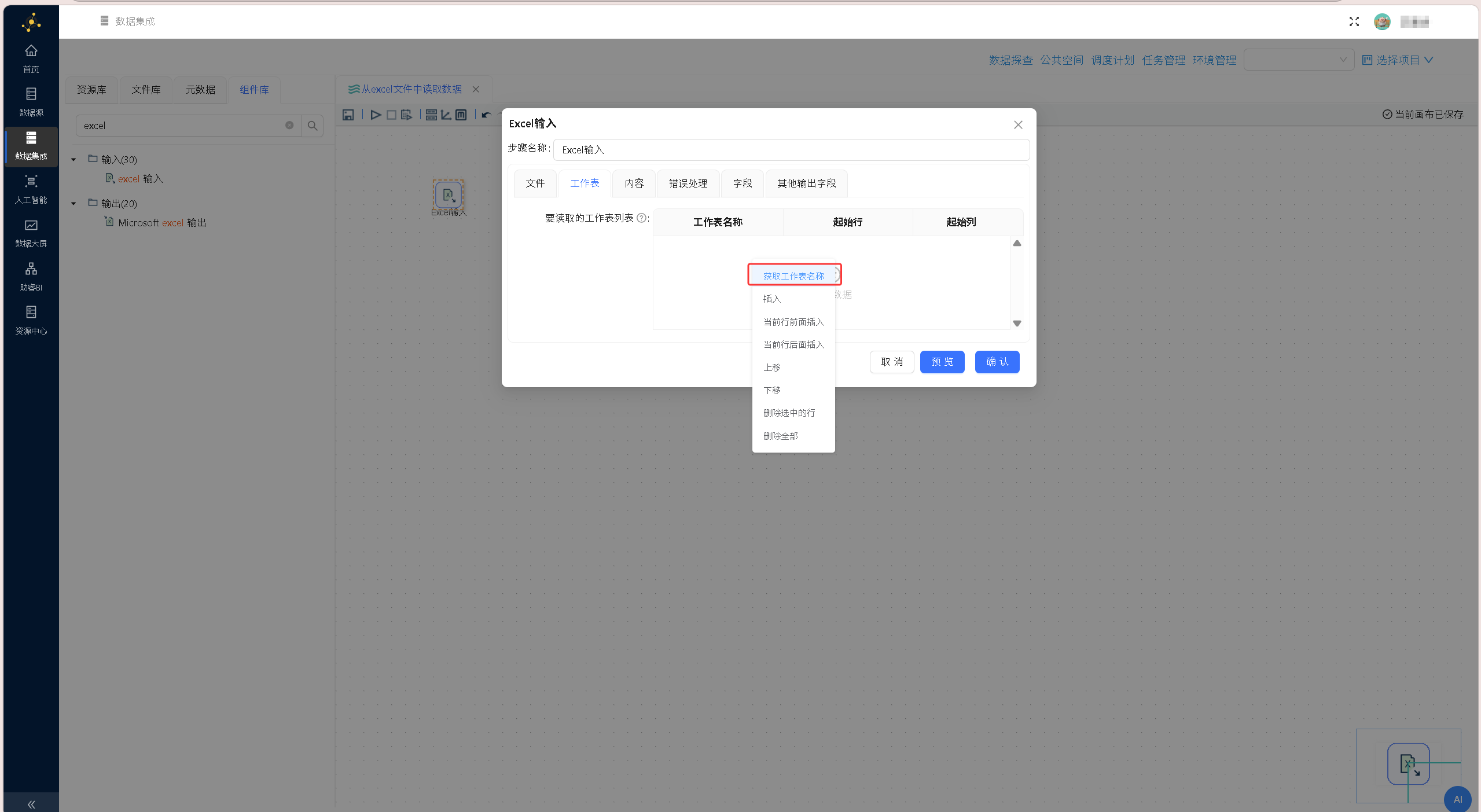 在弹出的工作表选择窗口中,勾选该工作表前的复选框。点击两栏中间的右向箭头按钮,将选中的
在弹出的工作表选择窗口中,勾选该工作表前的复选框。点击两栏中间的右向箭头按钮,将选中的Sheet1工作表添加至右栏列表中,完成后点击「确定」按钮。此时组件只会读取工作簿Sheet1的数据。配置界面如下图所示: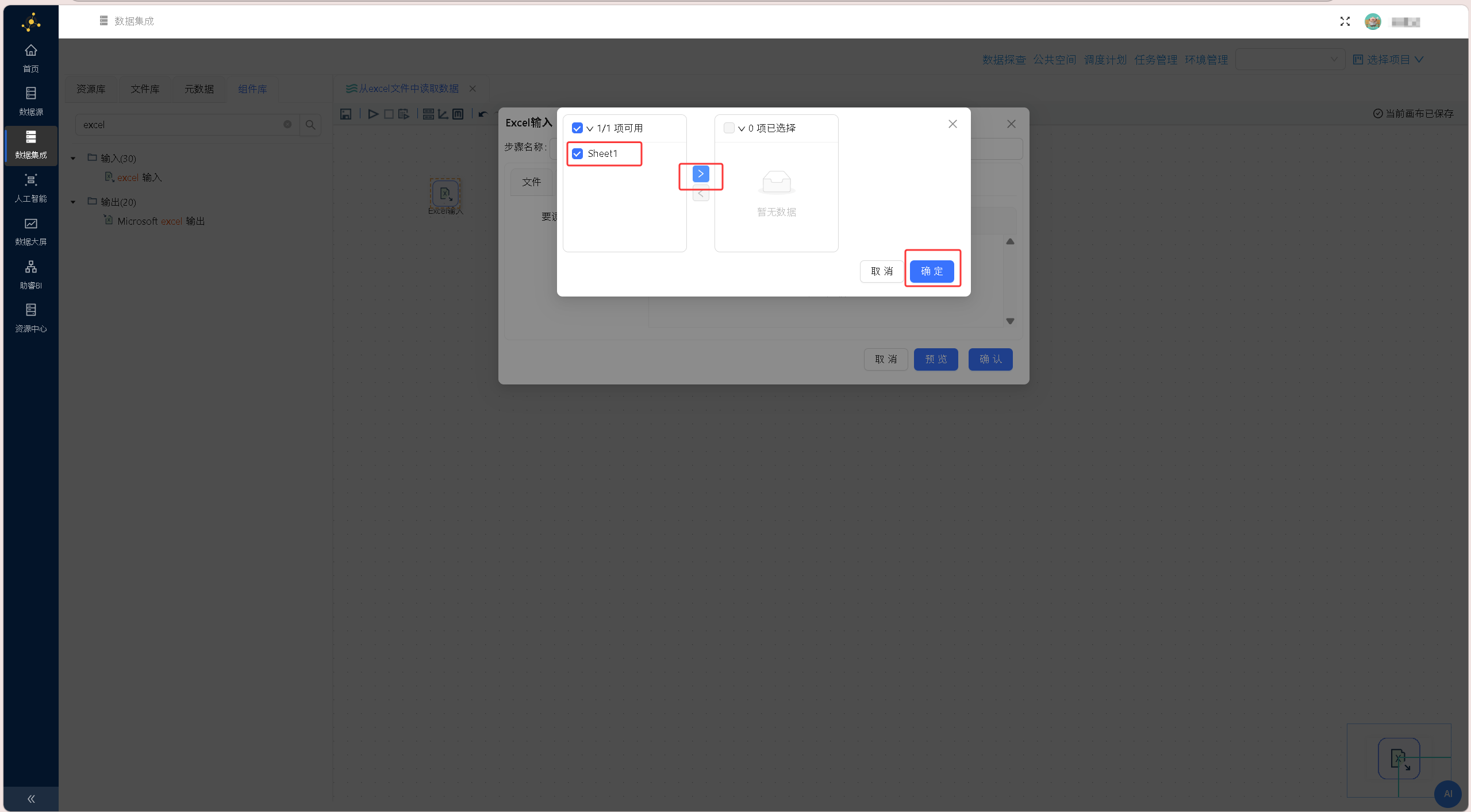
 切换至「字段」标签页,右键点击空白区域,选择「获取来自头部的字段」,系统自动抓取表格首行内容,解析生成标准化字段结构
切换至「字段」标签页,右键点击空白区域,选择「获取来自头部的字段」,系统自动抓取表格首行内容,解析生成标准化字段结构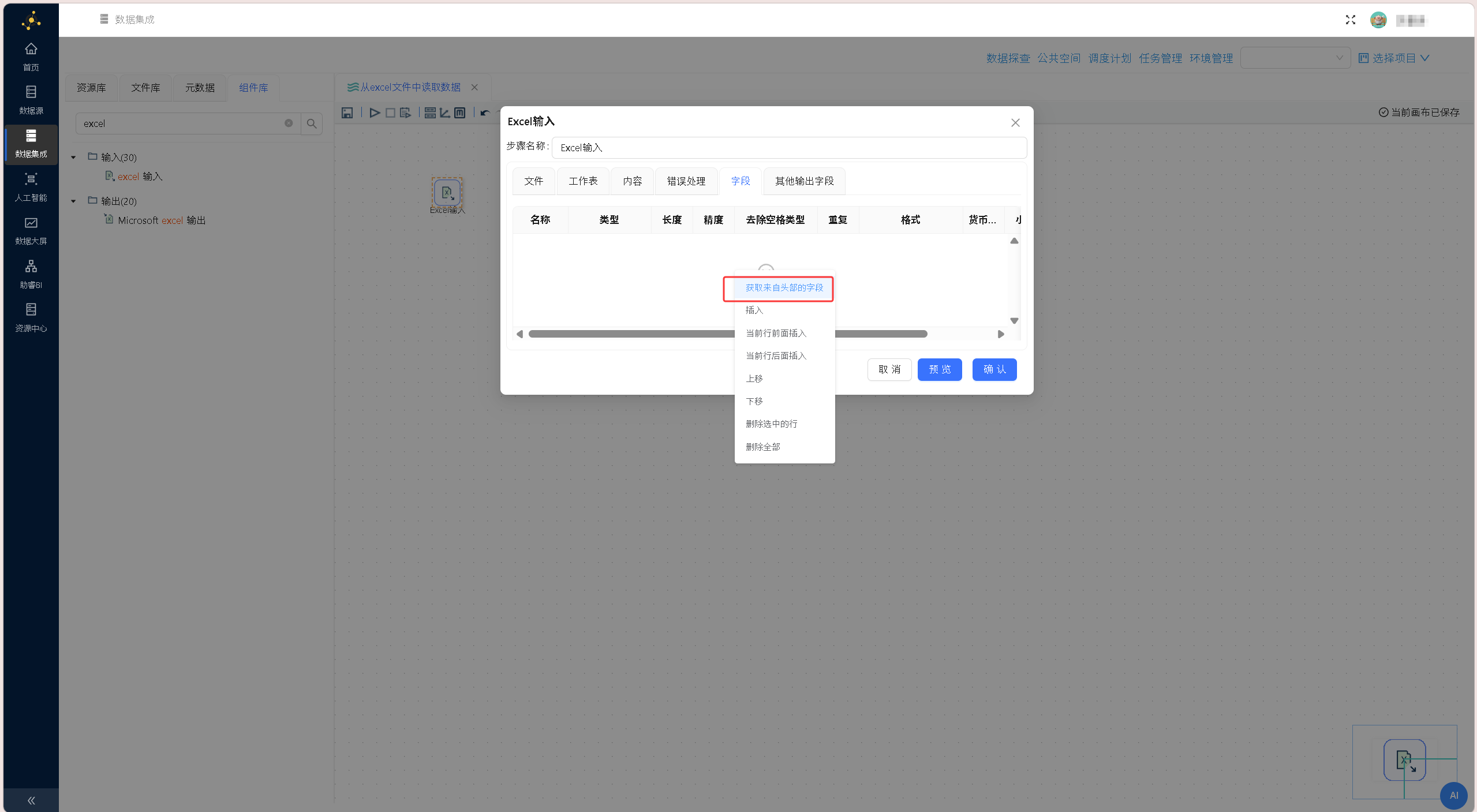 将字段名称、数据类型等属性自动加载到字段列表中,点击「确认」按钮。配置界面如下图所示:
将字段名称、数据类型等属性自动加载到字段列表中,点击「确认」按钮。配置界面如下图所示: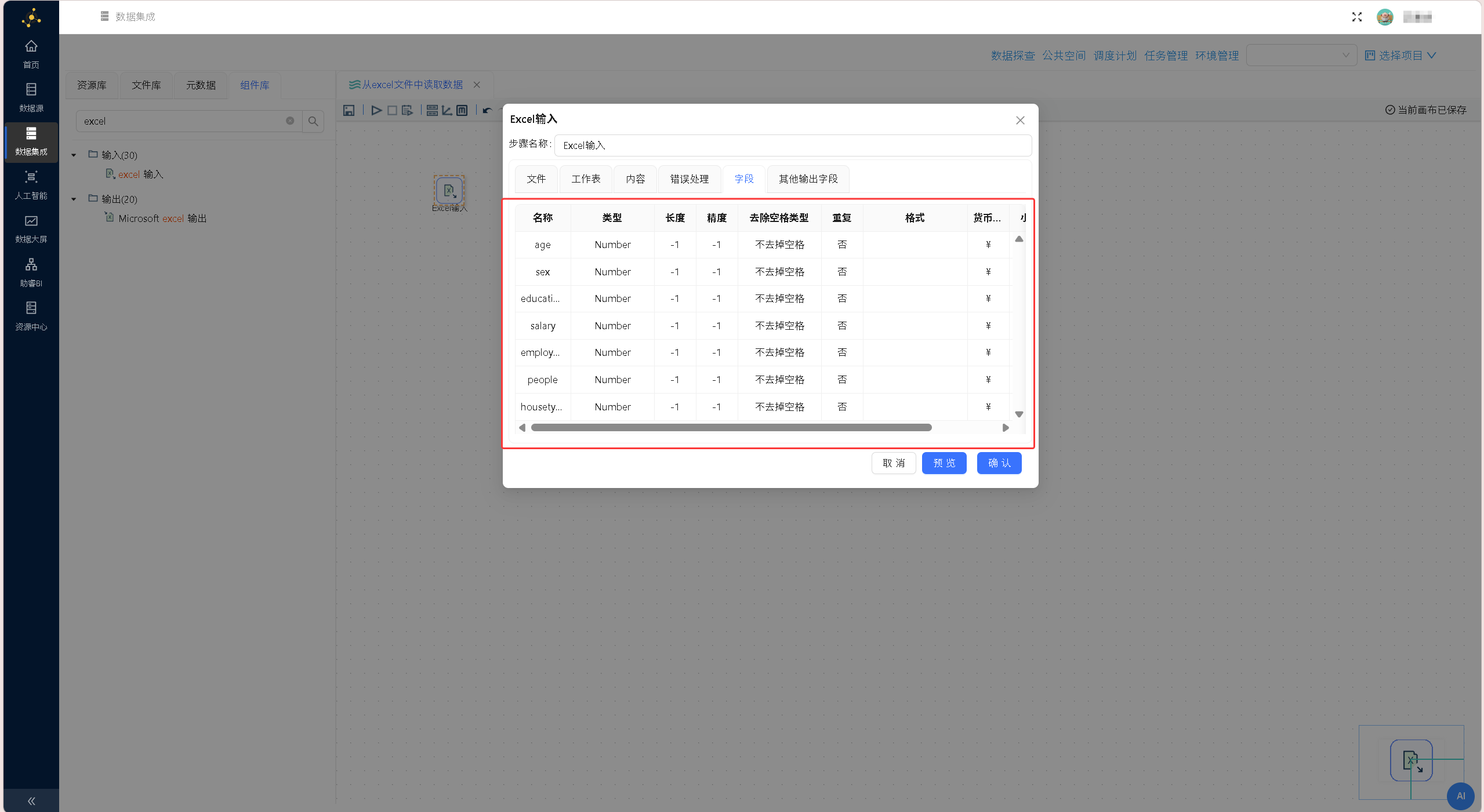 从「组件库」中拖拽「字段选择」组件、「空操作(什么也不做)」组件至画布,按「Excel 输入」→「字段选择」→「空操作(什么也不做)」的顺序依次建立组件连接,在弹出的连接线类型选择提示框中,均选择「主输出步骤」,完整转换流程如下图所示:
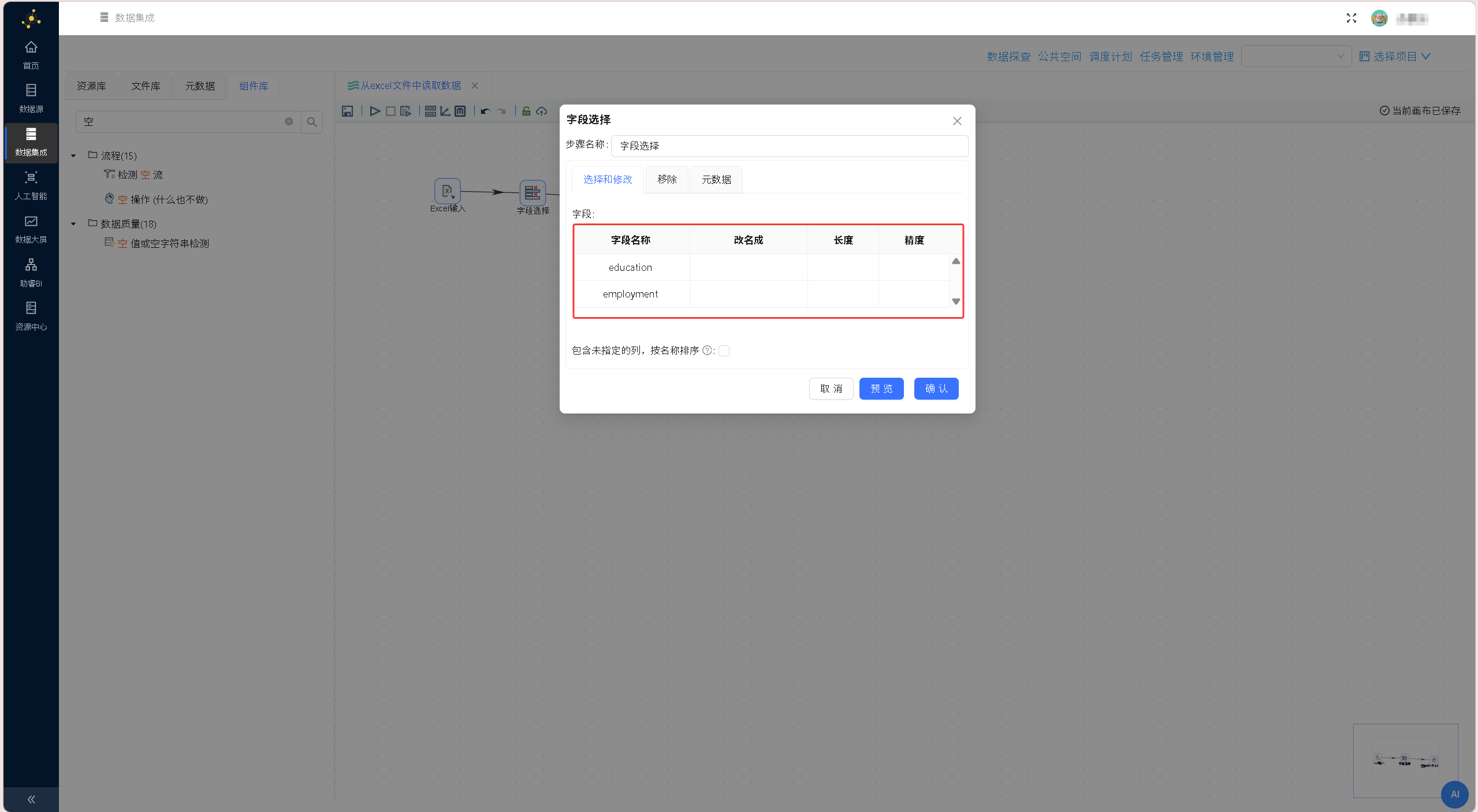
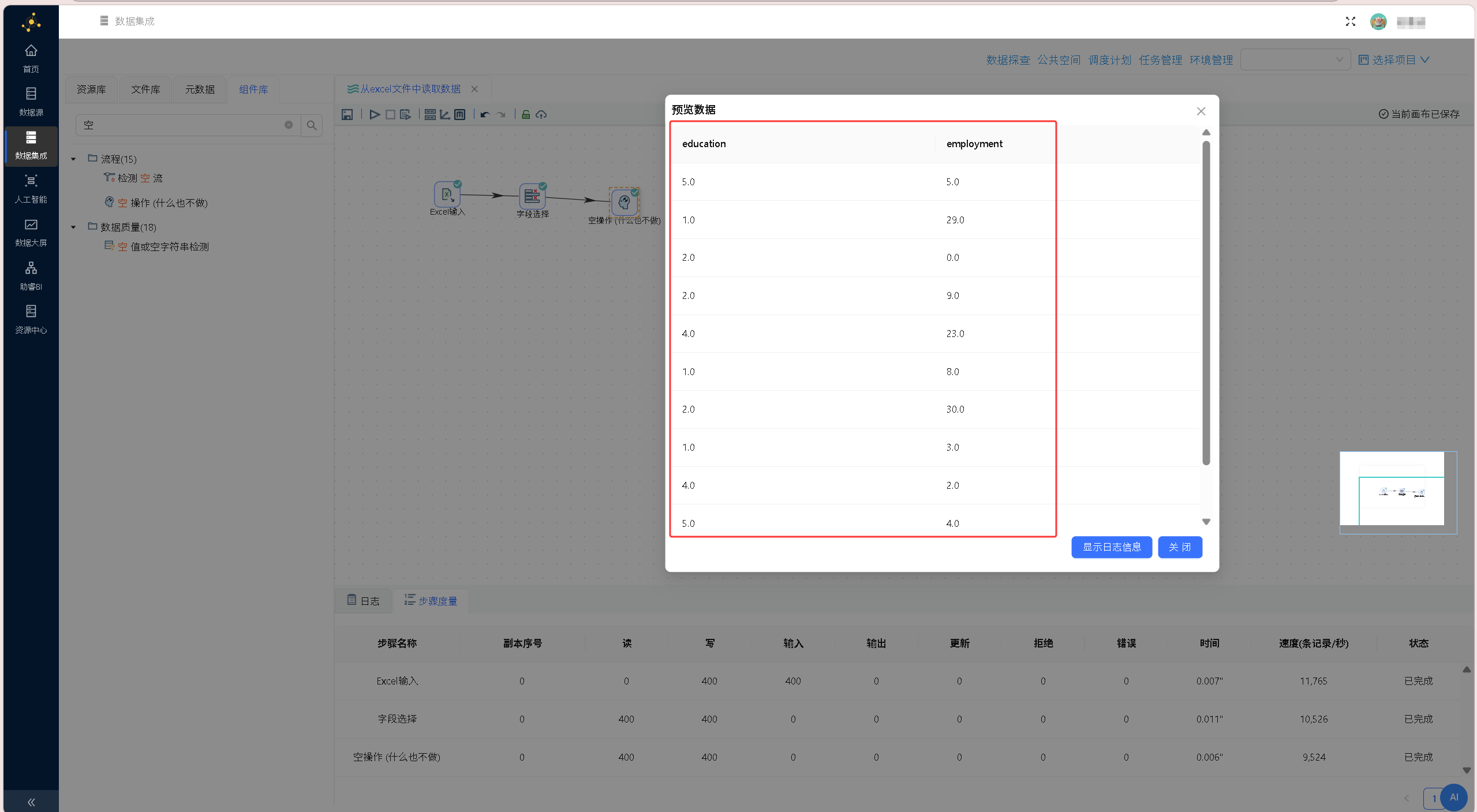
从「组件库」中拖拽「字段选择」组件、「空操作(什么也不做)」组件至画布,按「Excel 输入」→「字段选择」→「空操作(什么也不做)」的顺序依次建立组件连接,在弹出的连接线类型选择提示框中,均选择「主输出步骤」,完整转换流程如下图所示: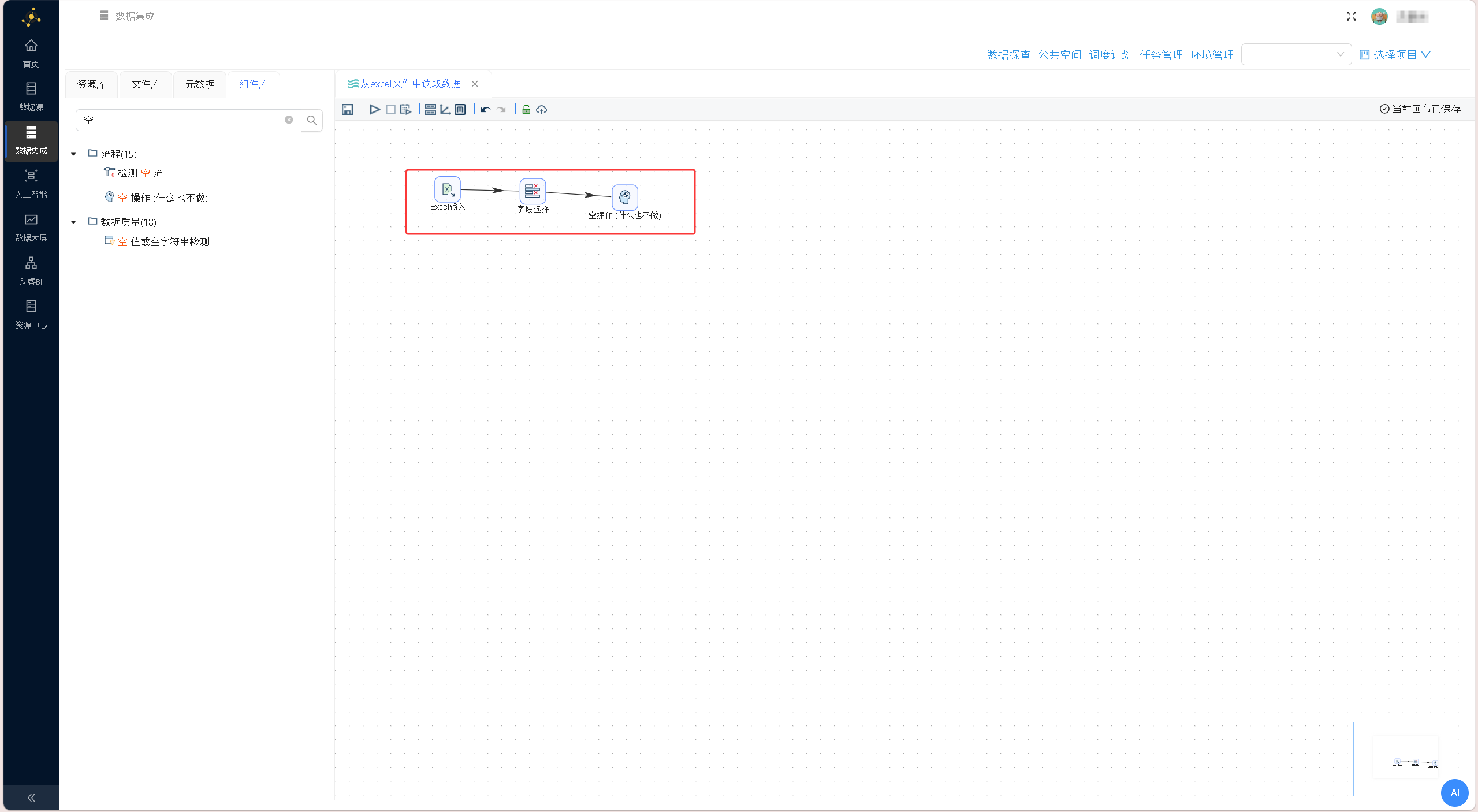 双击「字段选择」组件,在「选择和修改」标签页获取上游全部字段,仅保留education(学历)、employment(就业情况)两个核心分析字段,删除其余冗余字段,确认保存配置。
双击「字段选择」组件,在「选择和修改」标签页获取上游全部字段,仅保留education(学历)、employment(就业情况)两个核心分析字段,删除其余冗余字段,确认保存配置。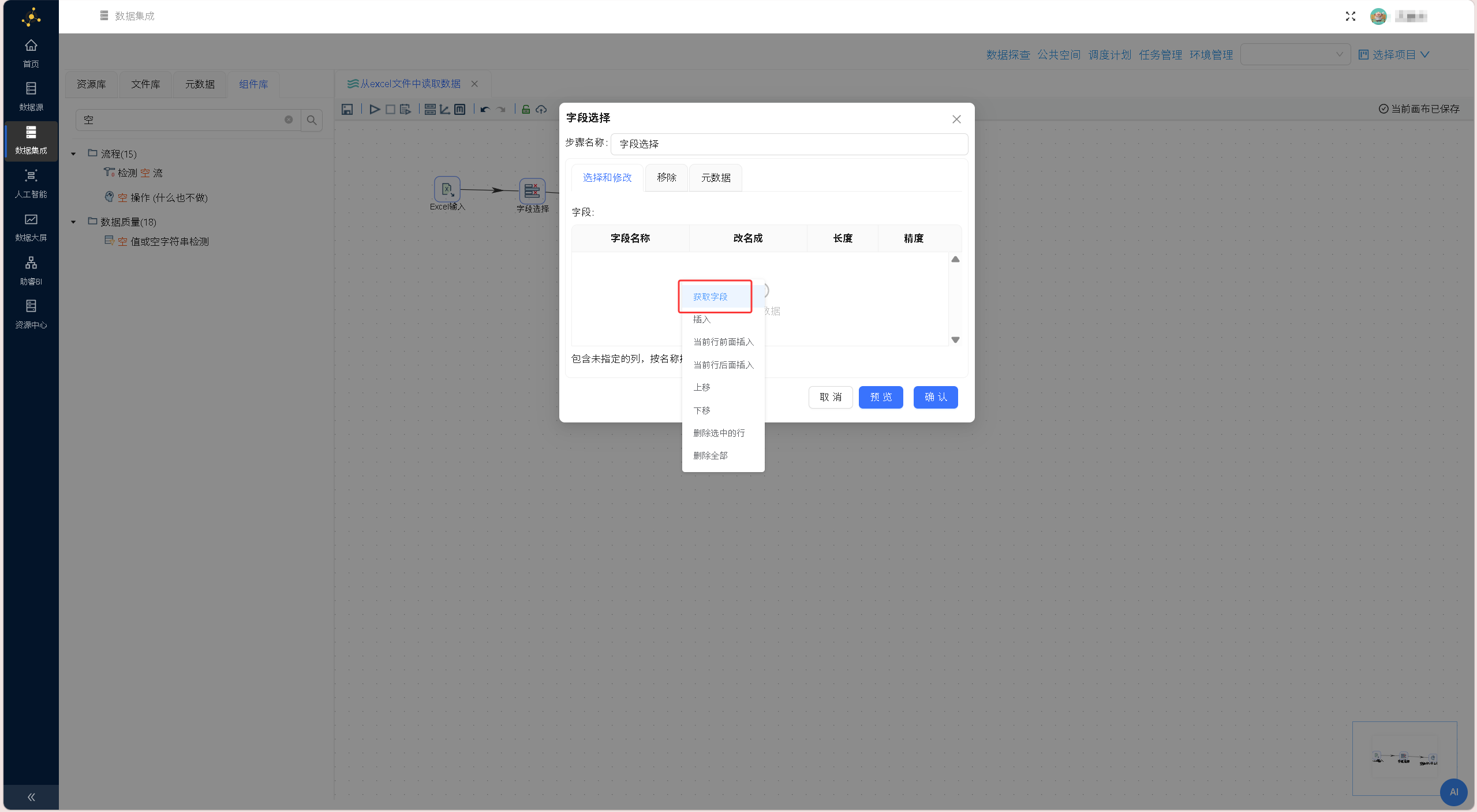
 点击画布左上角「运行-启动」,执行Excel数据预处理全流程。
点击画布左上角「运行-启动」,执行Excel数据预处理全流程。 选中「空操作(什么也不做)」组件,右键单击并选择「预览输出」,查看经过 Excel 数据读取、字段筛选后的最终数据输出结果,验证目标字段筛选是否生效、数据传递是否完整,结果如下图所示:
选中「空操作(什么也不做)」组件,右键单击并选择「预览输出」,查看经过 Excel 数据读取、字段筛选后的最终数据输出结果,验证目标字段筛选是否生效、数据传递是否完整,结果如下图所示: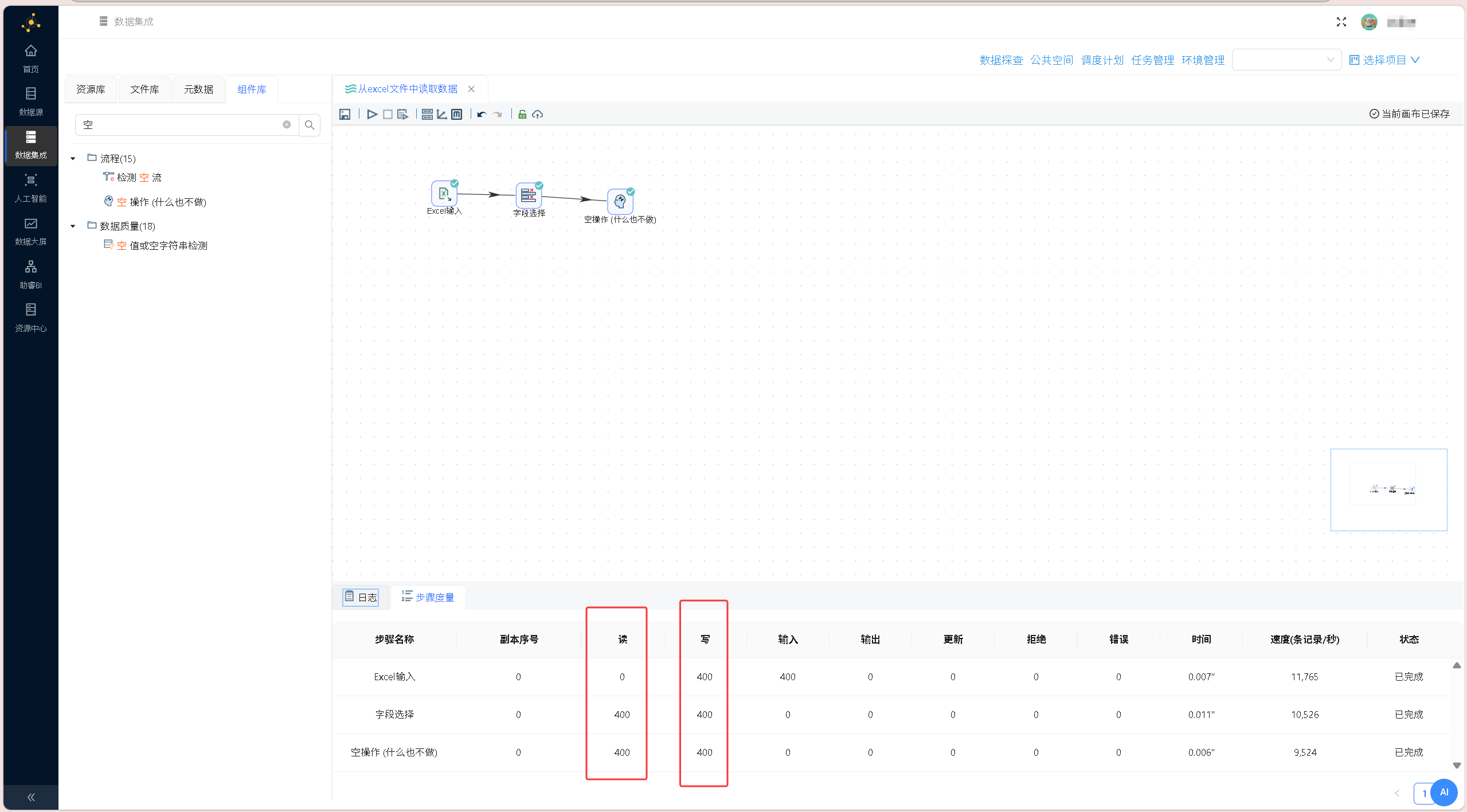
7 实验总结与平台评价
7.1 实验收获
本次实训依托Uniplore助睿ETL平台,系统完成了CSV、TXT文本、Excel三类主流结构化文件的全流程数据预处理实操,全面掌握了文件类数据源的ETL核心处理逻辑与落地方法。通过分步实操,我熟练掌握了不同格式文件的专属数据接入方式,能够根据文件分隔符、编码、表头规则等属性精准配置组件参数,解决了异构文件数据解析适配的核心问题。
同时,我熟练掌握了字段筛选、数据计算、数值分级、数据输出、流程校验等核心预处理操作,能够根据业务需求精简数据集、自定义数据运算规则与分级标准,实现原始数据的标准化、精细化处理。
7.2 平台评价
Uniplore助睿数智大数据平台整体实用性、易用性极强,是适配教学实训与企业基础数据处理的优质工具。平台采用零代码可视化拖拽操作模式,无需编写代码即可快速搭建ETL工作流,大幅降低了大数据技术的学习门槛,适合大数据入门学习者快速上手实操。
此外,平台搭载专属公共实训资源库,内置各类实训数据源,无需额外准备数据,极大简化了实训流程。整体来看,该平台兼顾教学性与实用性,既能满足高校大数据课程的实训教学需求,帮助学习者夯实ETL基础能力,也可适配企业日常轻量化数据处理工作,是一款轻量化、高效率、易上手的一站式大数据智能服务平台。

一站式 AI 云服务平台
更多推荐


 10
10 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)