
细胞注释还在手动查文献?这个零代码国产数据库上传即用
做单细胞测序的同学都知道,拿到聚类结果只是万里长征第一步,真正的"噩梦"是细胞类型注释。
当你面对几十个甚至上百个cluster,每个cluster里几百个差异基因,你需要的不是耐心,而是一个能告诉你"这个cluster大概率是什么细胞"的智能参考系统。
今天给大家介绍一个由百创智造(BMKMANU)推出的在线工具——BMKMANU Cellgenemodel Database,这可能是目前国内最实用的单细胞自动注释平台之一。直接上传你的h5ad文件,就能自动预测细胞类型。
为什么我们需要"基因表达模型"?
传统细胞注释流程大概是:
-
找差异基因
-
查询CellMarker/PanglaoDB等专业网站
-
文献交叉验证
-
人工最终判断
这个流程有几个痛点:
-
文献碎片化:一个基因可能在T细胞里高表达,但在NK细胞里也高表达,如何权衡?
-
物种差异大:人和小鼠的marker基因并不完全通用
-
组织特异性:同一个基因在不同组织中的表达模式可能完全不同
-
主观性强:依赖研究者的经验积累,新手容易"翻车"
而基因表达模型的思路是:与其让你一个个查marker,不如让系统基于海量参考数据,告诉你"这个基因表达谱最像已知的哪种细胞类型"。
这本质上是一个模式识别问题——把细胞的基因表达谱当作"指纹",与数据库中的标准模型进行比对匹配。
BMKMANU Cellgenemodel 能做什么?
访问地址:BMKMANU Cellgenemodel Database
打开工具首页,映入眼帘的是一组令人印象深刻的数据:
| 物种数目 | 2(Human + Mouse) |
| 组织类型 | 114种 |
| 参考模型 | 265个 |
| 总细胞数 | 81,639,861(超过8100万!) |
物种分布上,Human占了绝对大头——78,417,405个细胞,Mouse也有3,222,456个细胞。这意味着无论你是做人源样本还是小鼠样本,都能找到充足的参考数据。
这个工具最吸引人的地方在于它的使用门槛极低:
Step 1:选择物种
-
下拉框选择 Human 或 Mouse
Step 2:数据上传
-
点击"选择文件",上传你的
.h5ad文件
-
文件要求:
-
仅支持 h5ad 格式文件
-
h5ad 文件需包含 counts 矩阵
-
支持单细胞和空间转录组数据
-
文件大小限制在 2GB 以内
-
Step 3:选择数据类型
-
scRNA/snRNA(单细胞/单核RNA测序)
-
Spatial(空间转录组)

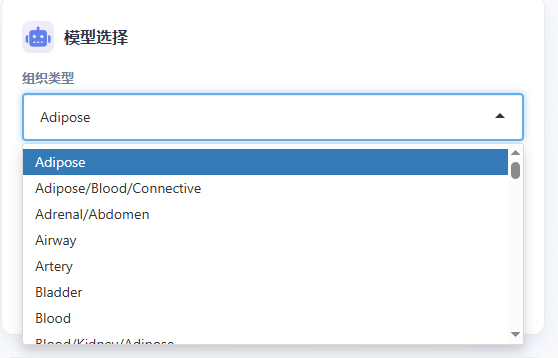
Step 4:模型选择
-
下拉框选择组织类型(如 Adipose、Brain、Heart 等)
选定参数后,右侧"当前参数"面板会实时展示匹配到的参考模型详情:
| 参数项 | 示例值(Adipose组织) |
|---|---|
| 物种 | Human |
| 数据类型 | scRNA/snRNA |
| 参考模型 | 5e5e7a2f-8f1c-42ac-90dc-b4f80f38e84c |
| 组织类型 | Adipose |
| 细胞类型数 | 28种 |
| 细胞数目 | 94,415个 |
| 模型描述 | adipose tissue, subcutaneous adipose tissue, brown adipose tissue |
为了更方便上手,内置了pbmc的demo数据,:

鼠标点击Demo数据,即可开始执行任务:
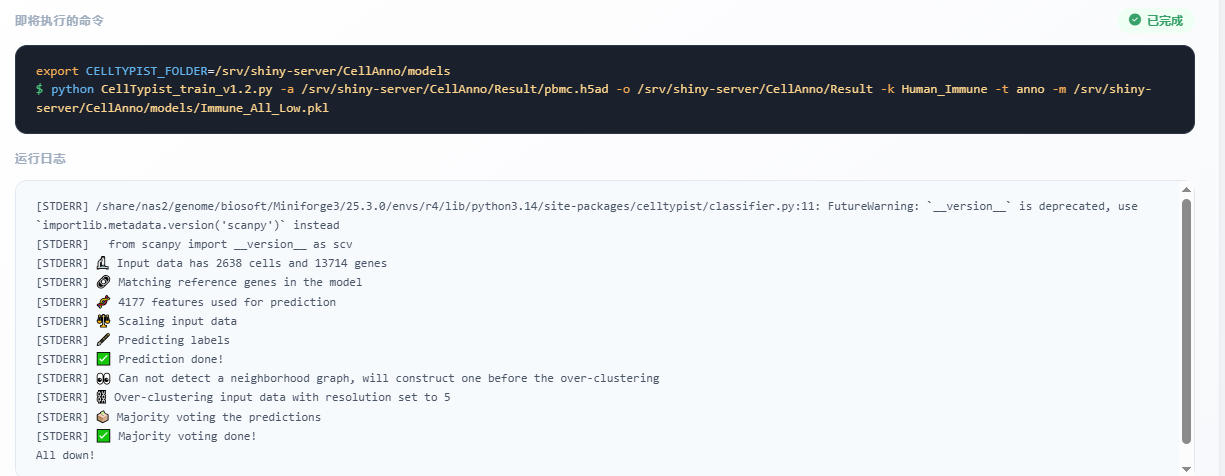
分析结果如下:
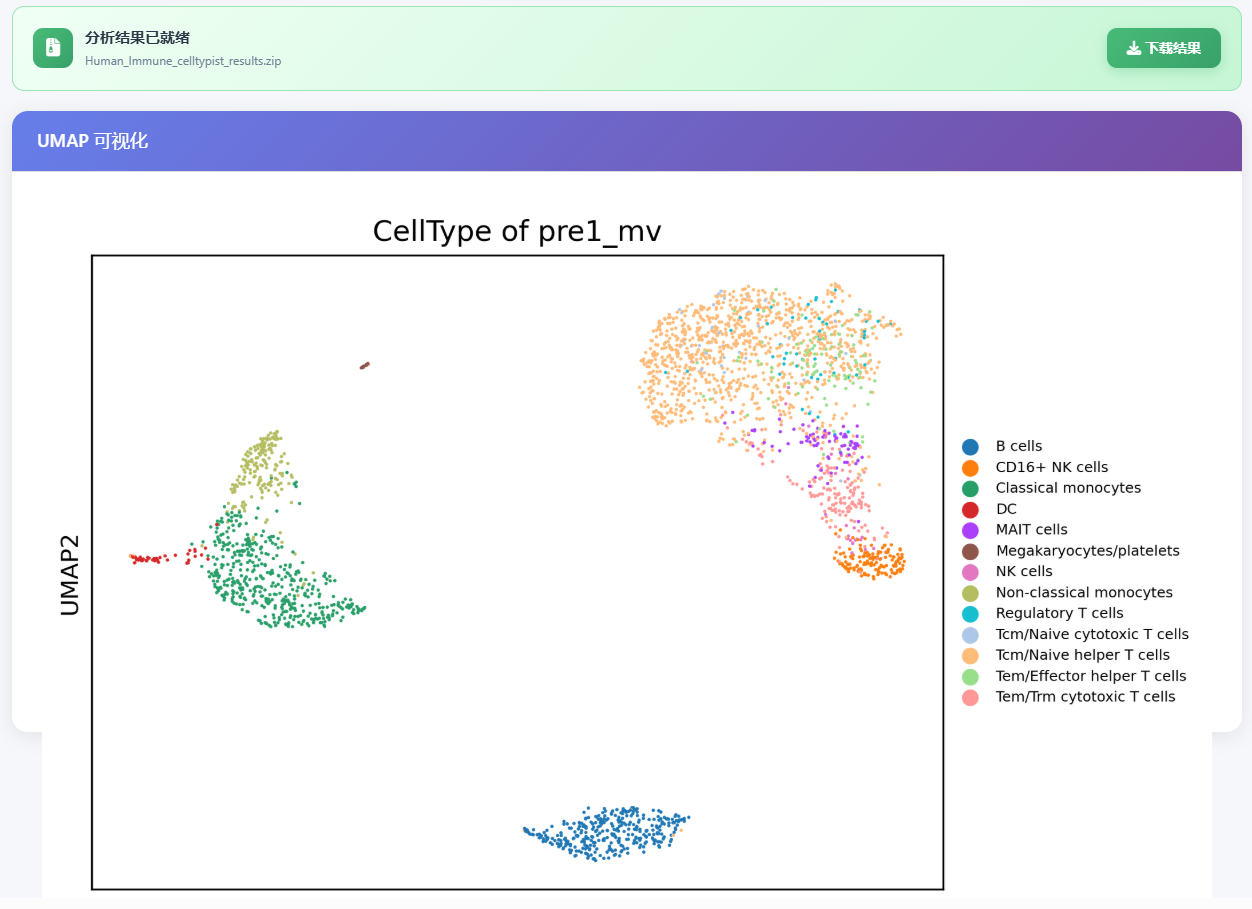
百创智造的在线工具平台还提供了配套资源:
-
BMKMANU Cell Marker Database:专门的基因标记检索和细胞注释工具
-
Marker检索和注释工具:更轻量级的快速查询入口
这些工具与百创智造的分析软件生态(如BSTMatrix、BSCMatrix等)形成闭环,从原始数据处理到下游注释都有对应解决方案。
访问地址:软件工具 – 百创智造

一站式 AI 云服务平台
更多推荐


 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)