
基于助睿的自媒体多平台数据清洗实验
1 实验目的
本实验依托全班同学多平台自媒体作品互动原始数据集,借助助睿 ETL 工具完成多源数据抽取、清洗与标准化预处理,生成两张业务分层数据表,为后续特征衍生、指标计算与可视化看板搭建提供合规可用数据源。
通过实操训练,要求掌握以下核心能力:
- 明晰数据清洗在完整数据分析链路中的前置核心作用,理解脏数据对统计、建模、可视化的干扰影响;
- 熟练运用助睿 ETL 可视化组件,实现多源数据筛选、空值补齐、分组聚合等标准化预处理操作;
- 掌握 ETL 分流分支开发思想:拆分全量平台汇总统计、头部平台精细化分析两条并行处理链路;
- 产出结构规范、分层明确的业务数据表,分别适配可视化看板总览模块与深度分析模块的数据读取需求。
2 实验环境
本次实验使用助睿数智(Uniplore) 作为一站式数据科学平台。该平台覆盖从数据接入、ETL处理、机器学习建模到可视化展示的全链路零代码功能,适用于数据分析教学与企业数据加工场景。
- 数据处理工具:助睿ETL(数据集成平台)
助睿ETL核心优势:
全元数据驱动架构:平台内所有对象类型均通过元数据标准化定义,覆盖数据读取、处理、写入的全流程
零代码拖拽式操作:通过可视化方式完成数据的抽取(Extract)、转换(Transform)、加载(Load),无需编写复杂代码
丰富的预处理组件:内置筛选、填充、聚合、连接、字段选择等多种转换节点,灵活应对各类数据清洗场景
Pipeline(转换)机制:面向数据流通处理的核心功能单元,由多个不同功能的Transform步骤组合构成,聚焦数据本身的加工转换操作
开源内核高可用引擎:基于开源内核的高可用引擎架构,通过标准化插件体系可灵活扩展引擎能力
3 核心设计思路
3.1 为什么需要数据清洗?
直接采集的原始业务数据存在大量脏数据、冗余数据、缺失数据,无法直接用于指标统计与深度分析,必须先执行清洗规整。 读取数据源「自媒体作品数据明细.csv」后,可识别出三类典型数据问题:
- 平台数据冗余:数据集涵盖 B 站、CSDN、微信公众号、知乎、小红书多渠道,但微信、知乎、小红书绝大多数作品浏览量数值为 0,缺少有效流量数据,无法开展深度价值分析;
- 无效数据行:部分作品记录的浏览、点赞、收藏三项互动指标全部为 0,大概率为采集失败数据或零曝光内容,无分析价值;
- 字段空值缺陷:点赞、收藏、分享等互动字段存在空值,若不填充处理,后续求和、比率计算会直接报错中断流程。
数据清洗环节就是针对性消除上述三类数据缺陷,产出干净、可用、统一格式的结构化数据。
3.2 数据处理流程
本次实验存在两类差异化数据分析需求,对数据源筛选、聚合规则要求完全不同,因此采用分支并行处理架构:
- 全平台整体概览统计:统计班级整体创作规模,包含全部平台所有作品记录,即使流量为 0 的数据也需要纳入计数,用于看板顶部总览指标;
- 头部平台精细化分析:仅针对 B 站、CSDN 两大有效流量平台,过滤零曝光无效作品,用于后续播放量、互动率、内容标签深度拆解。
两条处理分支独立加工,分别落地两张数据表:
- summary_all_platforms:供给可视化看板顶部总览指标卡片;
- cleaned_details:中间清洗明细表,作为下一阶段特征工程实验的基础输入数据源。
4 实验步骤
步骤1:创建目标表
在助睿ETL中创建两张目标表。
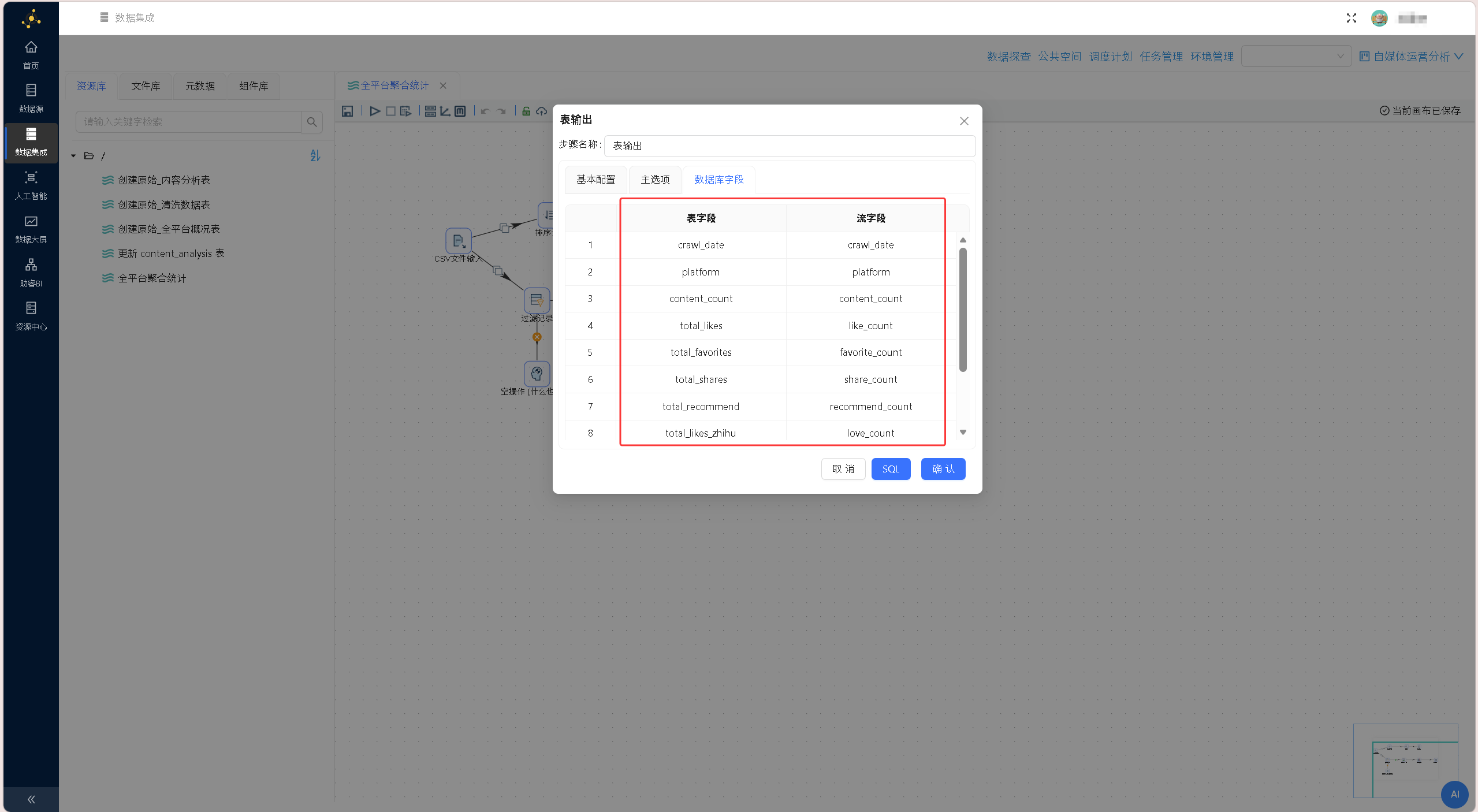
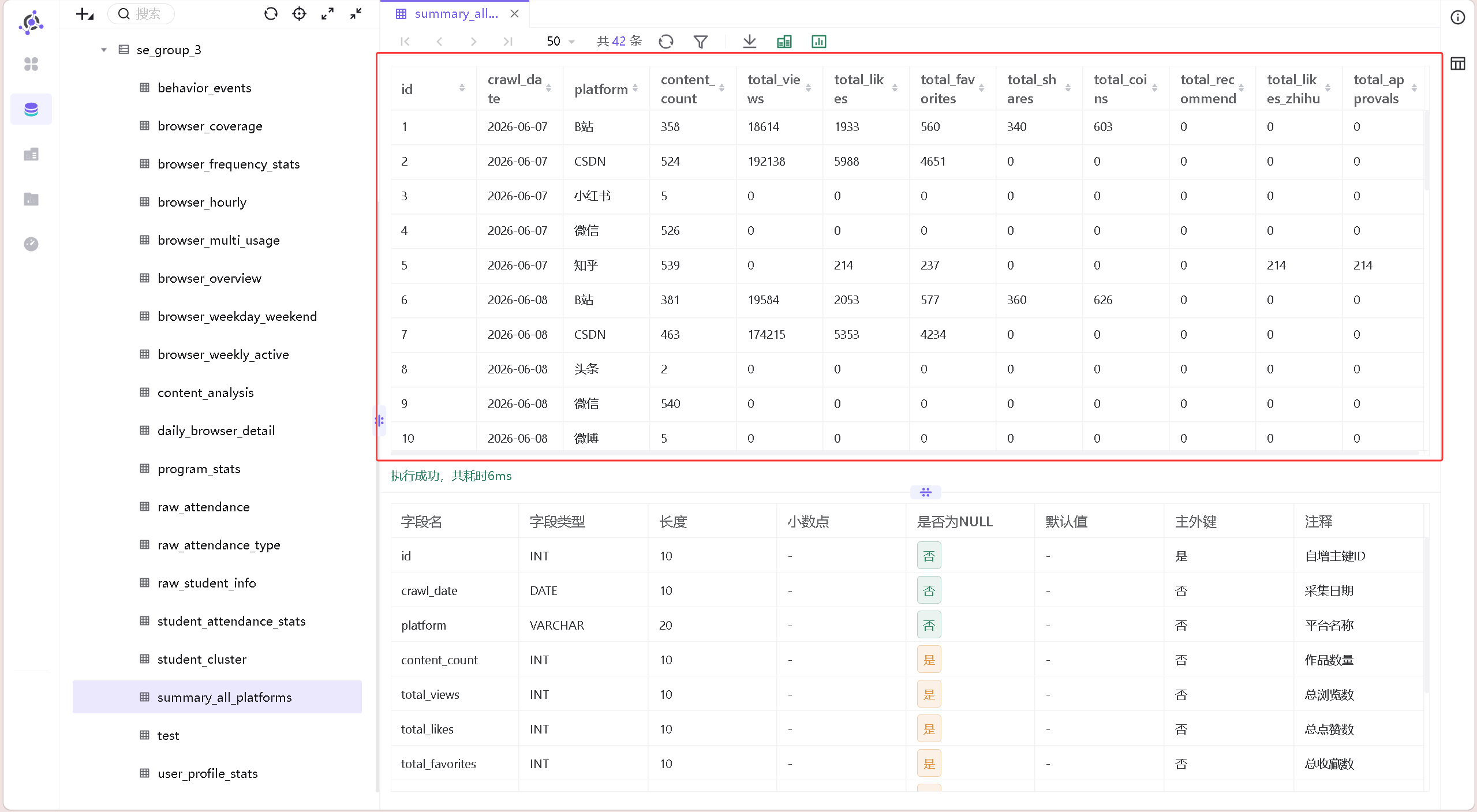
第一张是全平台概况表(summary_all_platforms),用于存放所有平台的汇总数据。字段设计如下:
| 字段 | 类型 | 说明 |
|---|---|---|
| crawl_date | DATE | 采集日期 |
| platform | VARCHAR(20) | 平台名称 |
| content_count | INT | 作品数量 |
| total_views | INT | 总浏览数 |
| total_likes | INT | 总点赞数 |
| total_favorites | INT | 总收藏数 |
| total_shares | INT | 总分享数 |
| total_coins | INT | 总投币数(仅B站) |
| total_recommend | INT | 总推荐数(仅微信) |
| total_likes_zhihu | INT | 总喜欢数(仅知乎) |
| total_approvals | INT | 总赞同数(仅知乎) |
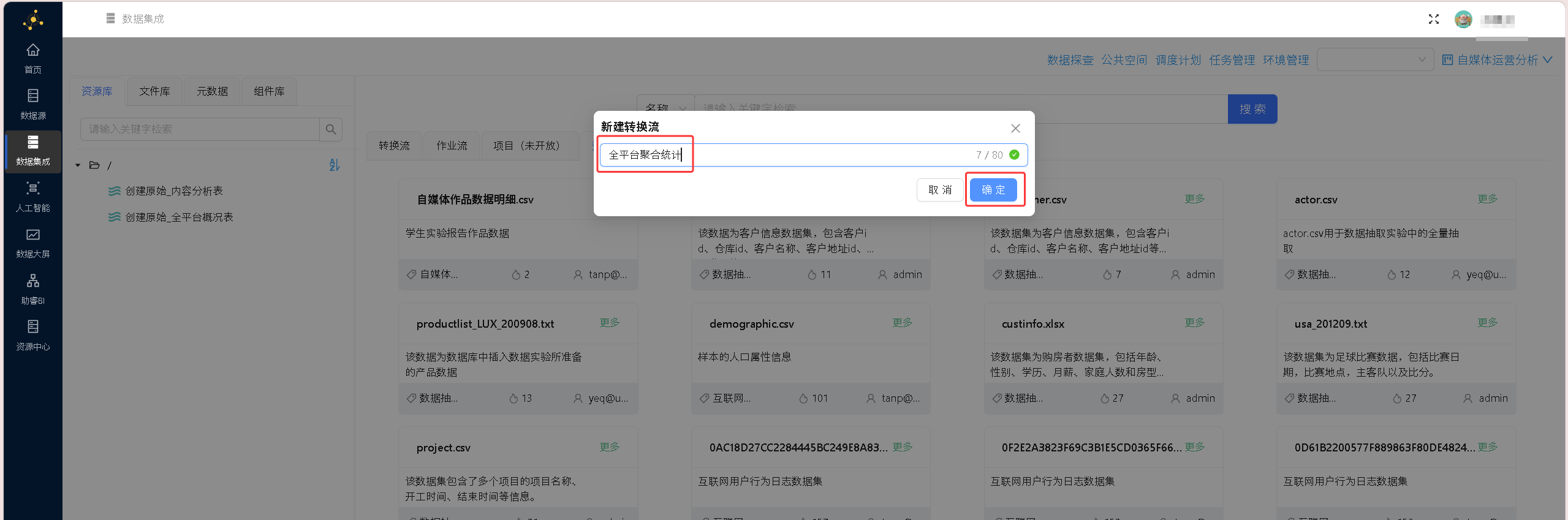
新建转换流
拖入执行一个sql脚本组件
选择数据源,插入建表语句
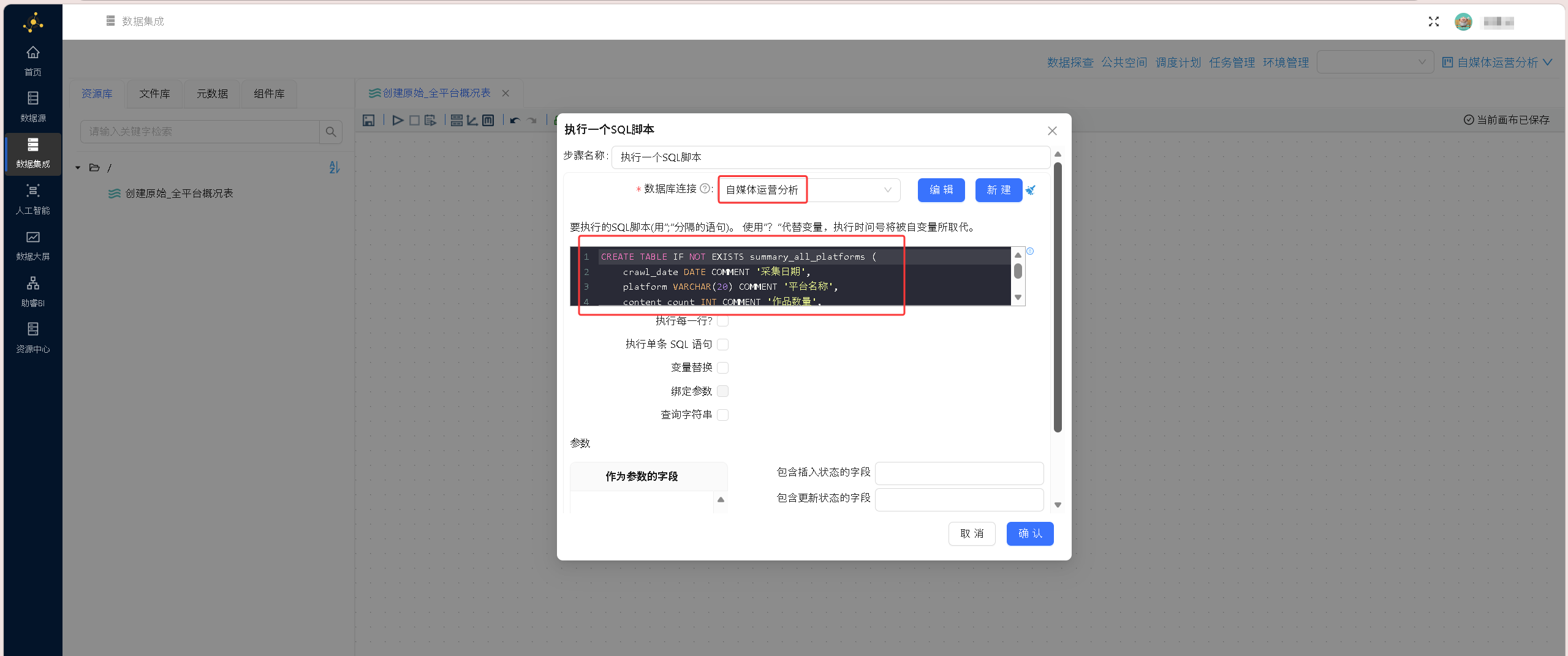
DROP TABLE IF EXISTS summary_all_platforms;
CREATE TABLE IF NOT EXISTS summary_all_platforms (
id INT AUTO_INCREMENT PRIMARY KEY COMMENT '自增主键ID',
crawl_date DATE NOT NULL COMMENT '采集日期',
platform VARCHAR(20) NOT NULL COMMENT '平台名称',
content_count INT COMMENT '作品数量',
total_views INT COMMENT '总浏览数',
total_likes INT COMMENT '总点赞数',
total_favorites INT COMMENT '总收藏数',
total_shares INT COMMENT '总分享数',
total_coins INT COMMENT '总投币数(仅B站)',
total_recommend INT COMMENT '总推荐数(仅微信)',
total_likes_zhihu INT COMMENT '总喜欢数(仅知乎)',
total_approvals INT COMMENT '总赞同数(仅知乎)'
) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4 COMMENT = '全平台概况汇总表';执行并查看日志
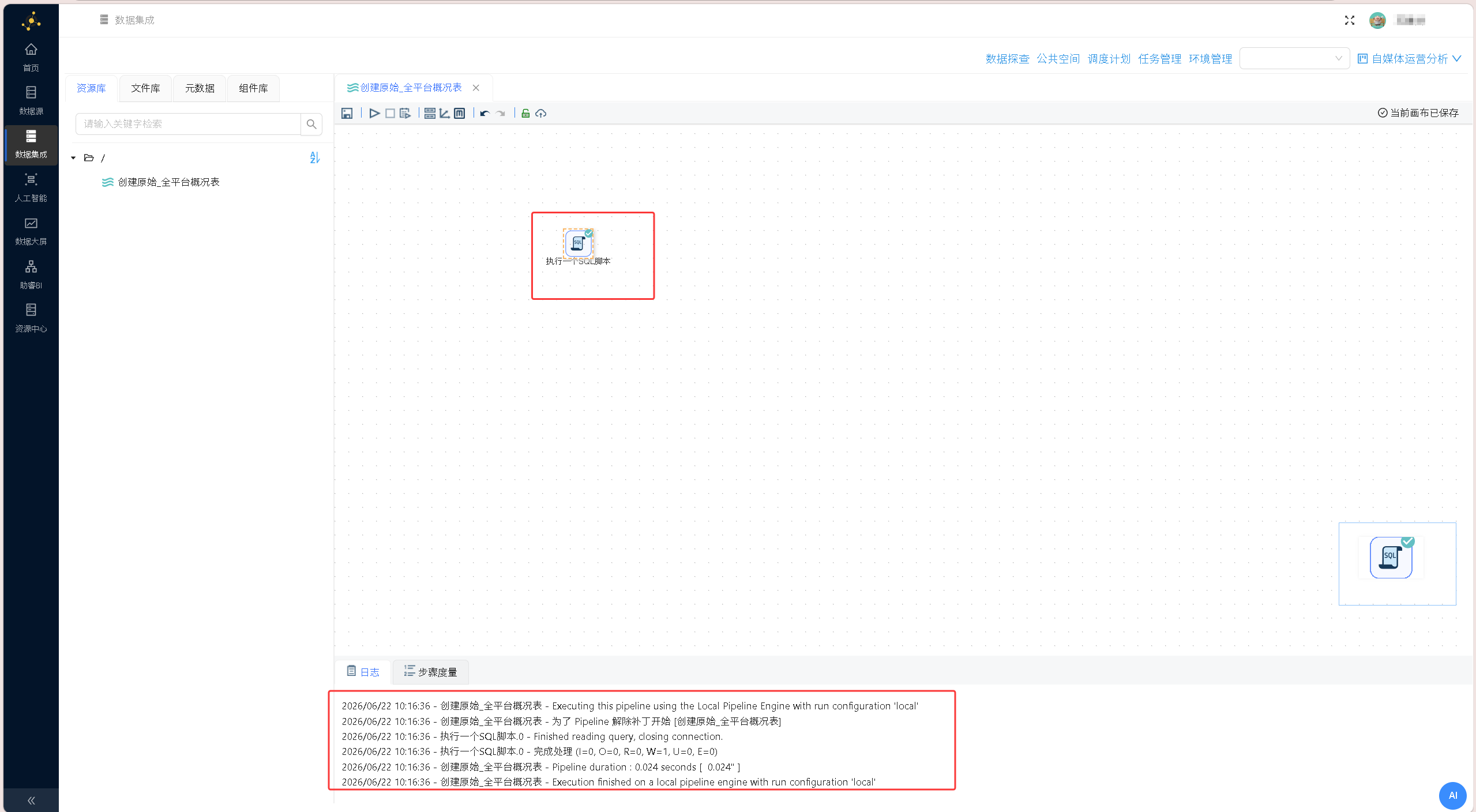
这张表不做任何过滤,保留所有平台的原始数据。各平台特色指标(B站的投币、微信的推荐、知乎的喜欢/赞同)单独保留列,不合并到通用指标中。因为B站的投币和知乎的赞同含义不同,加在一起反而说不清楚,让它们各自独立,读者能清晰地看到每个平台有哪些互动行为。
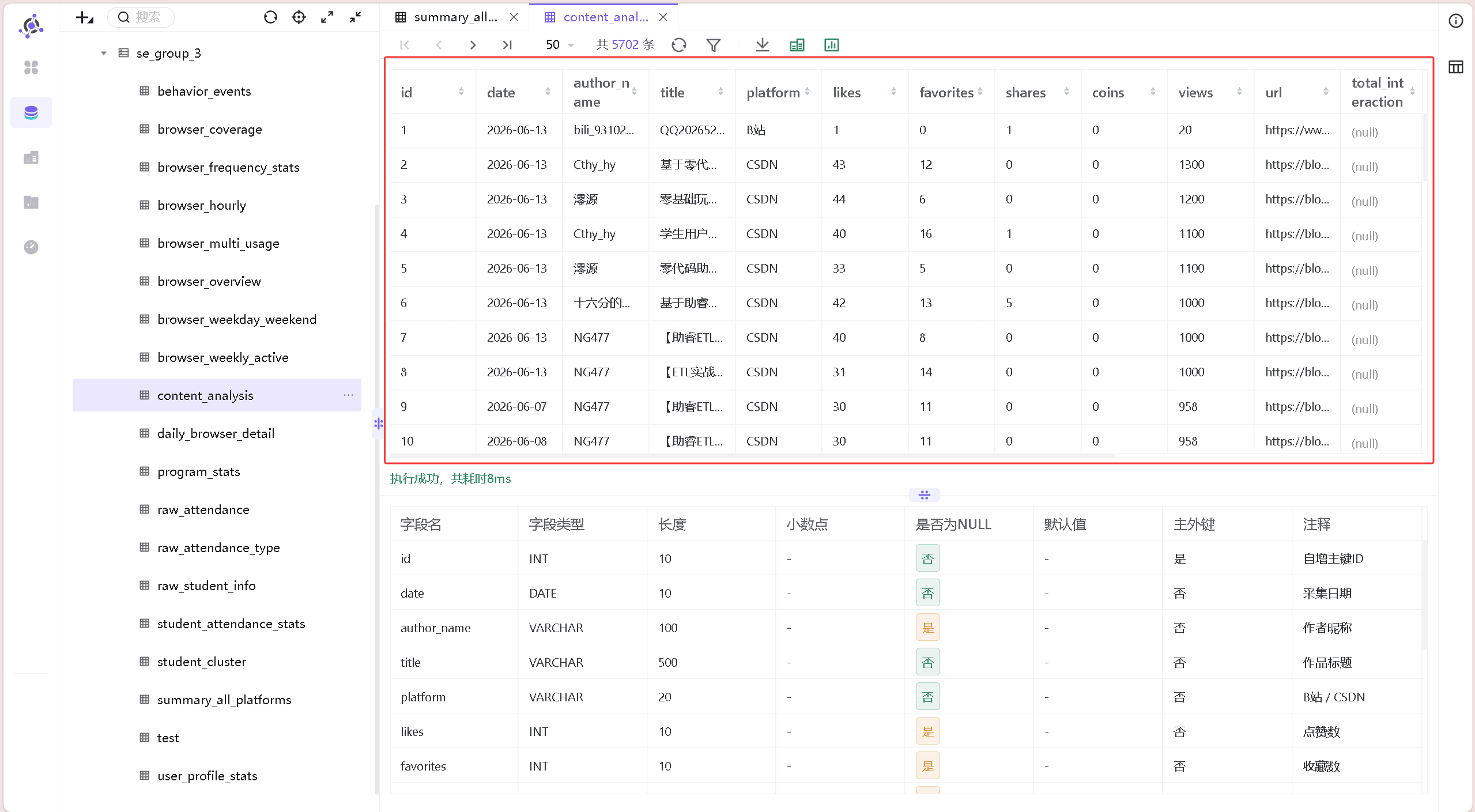
第二张是内容分析表(content_analysis),作为实验二的输入。字段与原始数据基本一致,但只包含B站和CSDN的有效记录:
| 字段 | 类型 | 说明 |
|---|---|---|
| date | DATE | 采集日期 |
| author_name | VARCHAR(100) | 作者昵称 |
| title | VARCHAR(500) | 作品标题 |
| platform | VARCHAR(20) | B站 / CSDN |
| likes | INT | 点赞数 |
| favorites | INT | 收藏数 |
| shares | INT | 分享数 |
| coins | INT | 投币数(仅B站) |
| views | INT | 播放量/阅读量 |
| url | VARCHAR(500) | 作品链接 |
| total_interaction | INT | 互动总数 |
| has_best | TINYINT(1) | 是否含“保姆级” |
| has_lowcode | TINYINT(1) | 是否含“零代码” |
| has_practice | TINYINT(1) | 是否含“实战” |
| has_tutorial | TINYINT(1) | 是否含“教程/指南” |
| has_pit | TINYINT(1) | 是否含“踩坑” |
其中 interaction_rate, has_best, has_lowcode, has_practice, has_tutorial, has_pit 字段的数据加工将在下一个实验中完成。
新建转换流:
同样拖入执行一个sql脚本组件
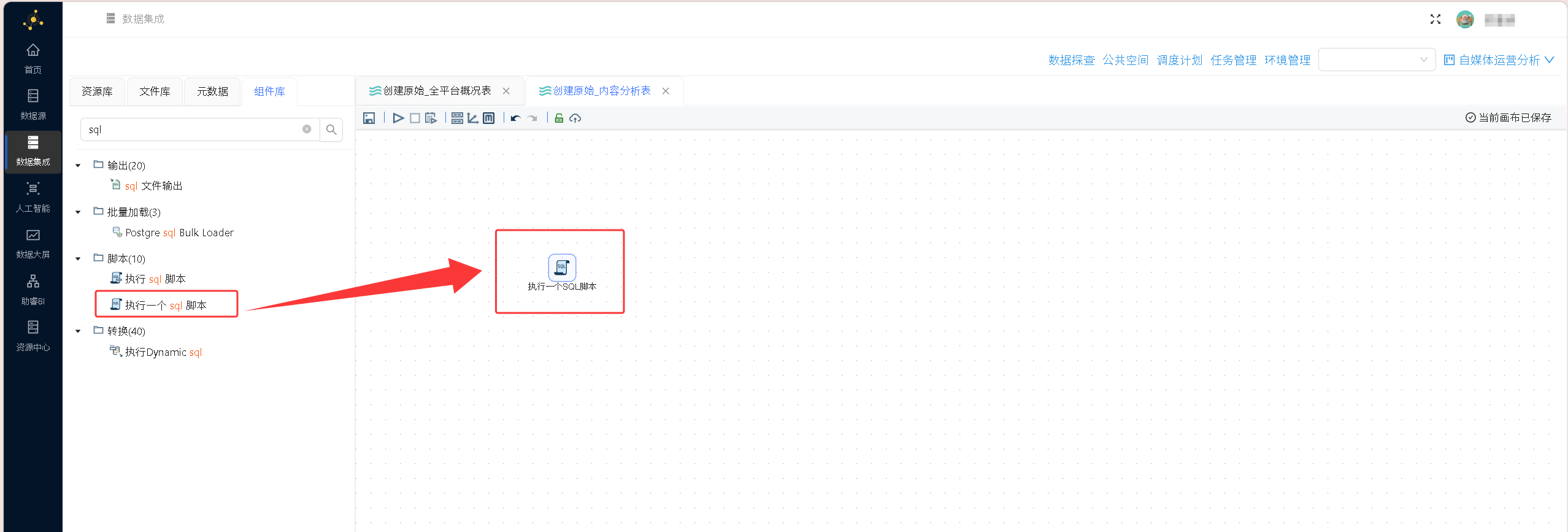
连接数据源,插入sql语句:
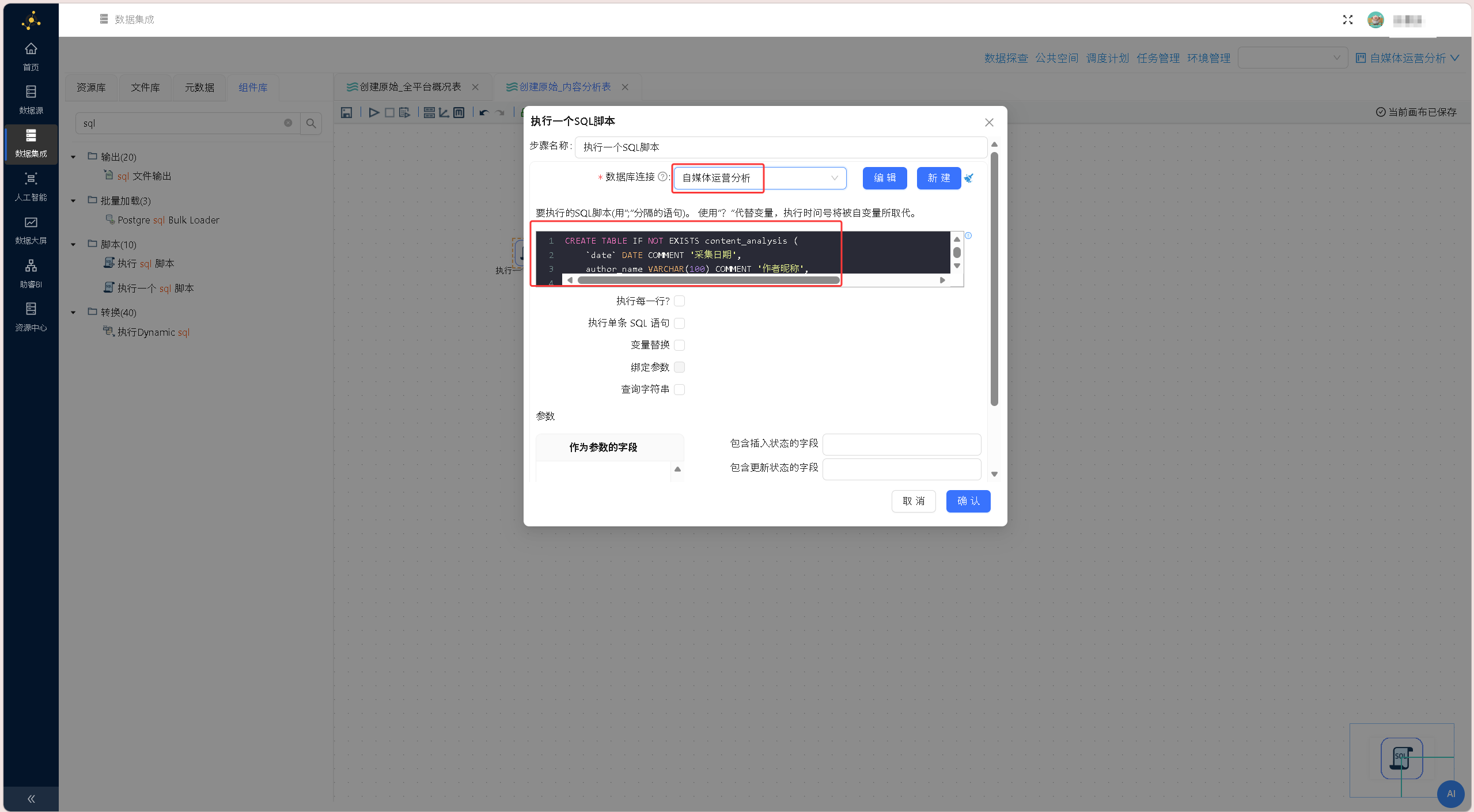
DROP TABLE IF EXISTS content_analysis;
CREATE TABLE IF NOT EXISTS content_analysis (
id INT AUTO_INCREMENT PRIMARY KEY COMMENT '自增主键ID',
date DATE NOT NULL COMMENT '采集日期',
author_name VARCHAR(100) COMMENT '作者昵称',
title VARCHAR(500) NOT NULL COMMENT '作品标题',
platform VARCHAR(20) NOT NULL COMMENT 'B站 / CSDN',
likes INT COMMENT '点赞数',
favorites INT COMMENT '收藏数',
shares INT COMMENT '分享数',
coins INT COMMENT '投币数(仅B站)',
views INT COMMENT '播放量/阅读量',
url VARCHAR(500) COMMENT '作品链接',
total_interaction INT COMMENT '互动总数',
has_best TINYINT(1) COMMENT '是否含“保姆级” 0否1是',
has_lowcode TINYINT(1) COMMENT '是否含“零代码” 0否1是',
has_practice TINYINT(1) COMMENT '是否含“实战” 0否1是',
has_tutorial TINYINT(1) COMMENT '是否含“教程/指南” 0否1是',
has_pit TINYINT(1) COMMENT '是否含“踩坑” 0否1是'
) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4 COMMENT = '内容分析明细表(实验二输入,仅B站、CSDN有效数据)';执行转换流并查看日志: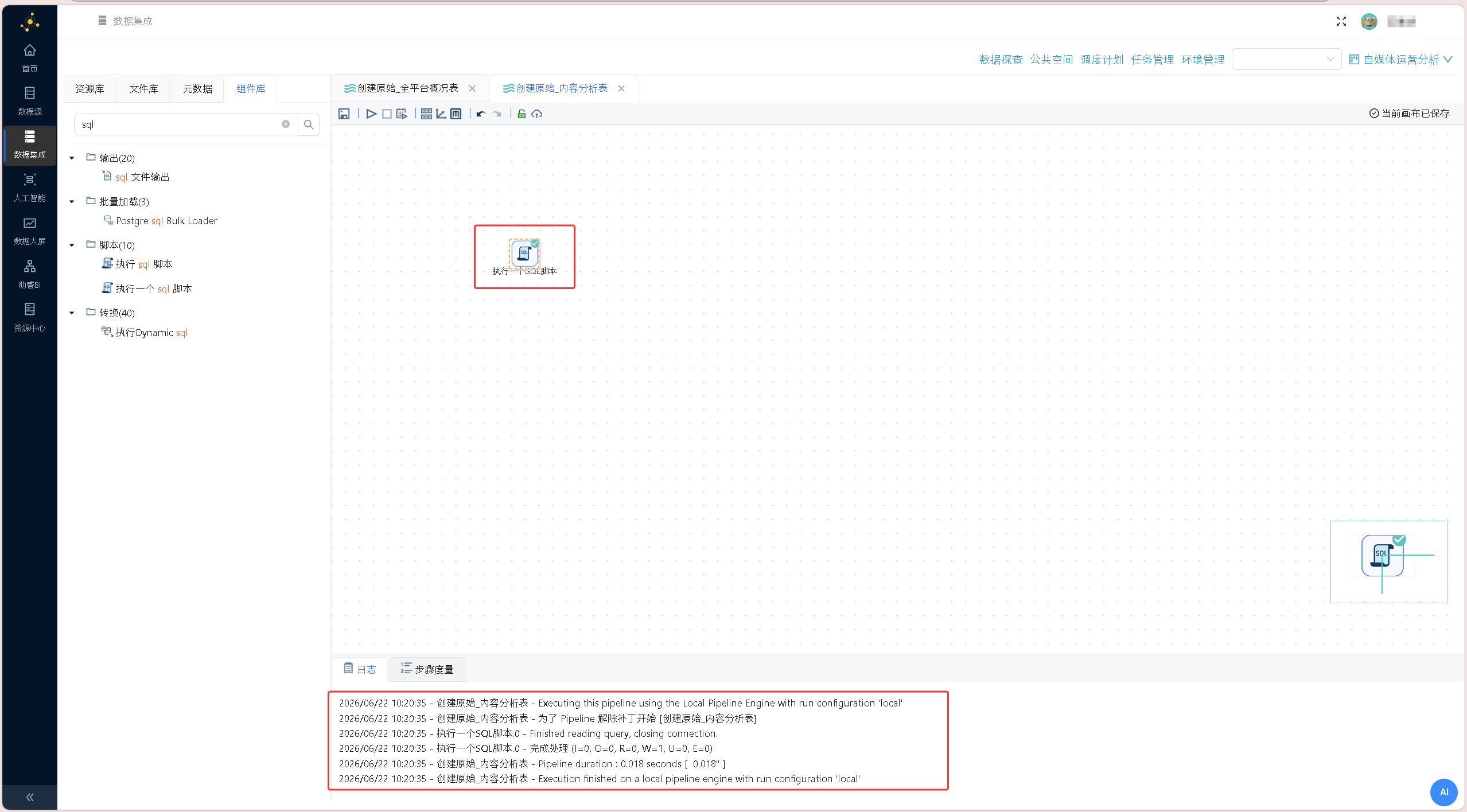
步骤2:导入原始数据
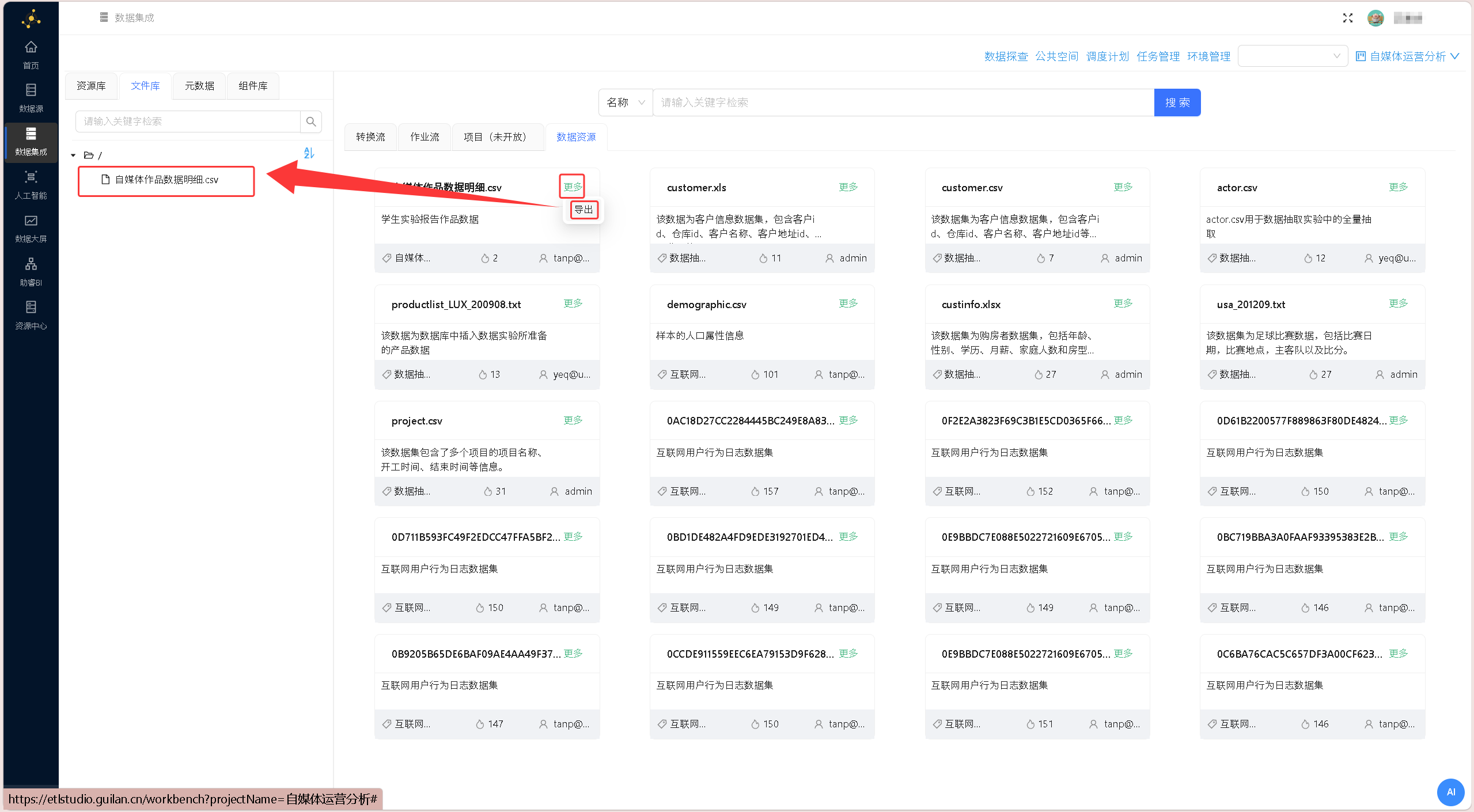
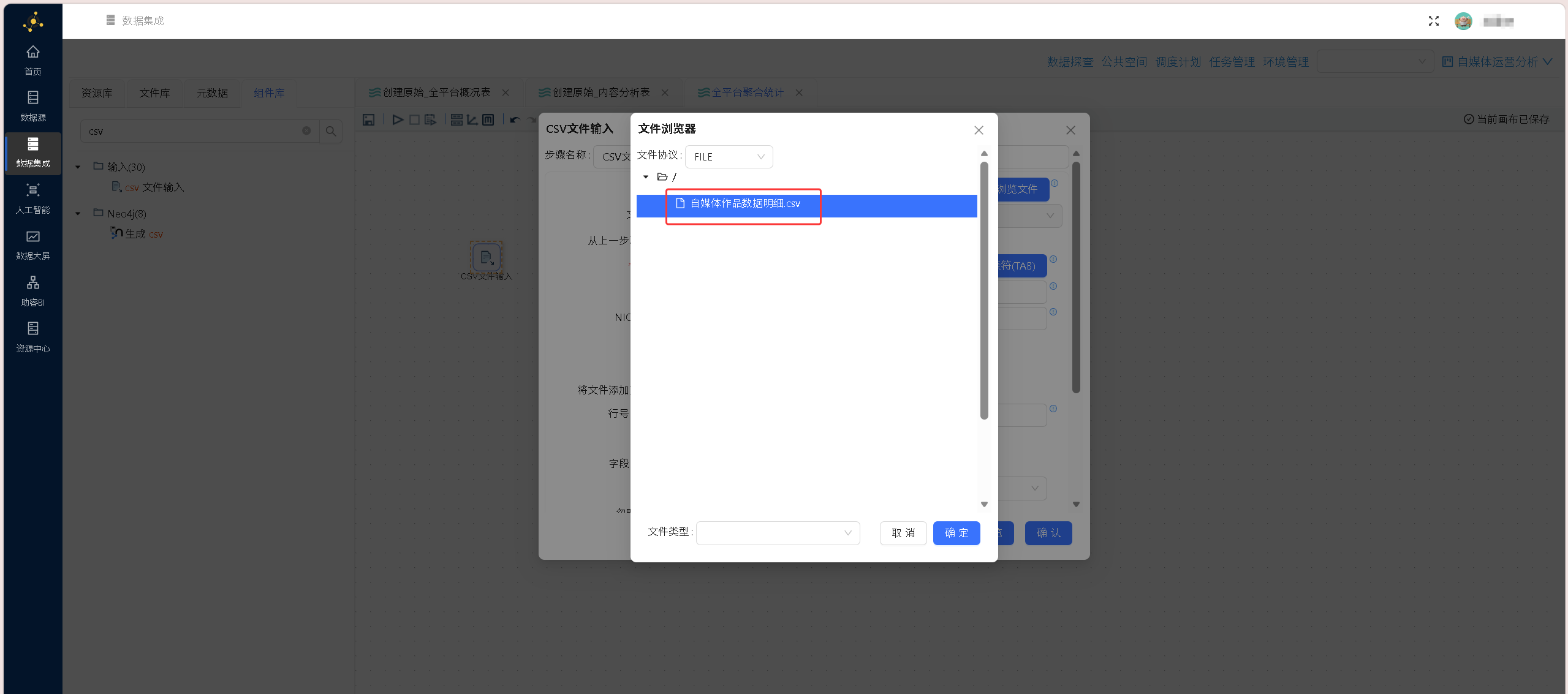
在助睿 ETL 公共文件库找到「自媒体作品数据明细.csv」,将文件复制至个人专属文件库,作为数据源输入。助睿ETL支持多种数据源接入,CSV文件可直接导入。
本次分析使用的数据来源于助睿ETL公共空间的
自媒体作品数据明细.csv,已采集了同学们在6月8日-6月15日前提交的作品互动数据。需要说明的是,该数据集仅覆盖采集时间节点前已发布且未被删除的作品,之后新提交或已删除的作品不在此次分析范围内。导入前请先将该文件从公共空间复制到自己的文件库中。
步骤3:全平台聚合统计
从原始数据源节点引出第一条分支链路,依次拖拽排序组件、分组聚合组件,以采集日期、平台名称作为分组维度,所有数值类互动字段配置求和聚合逻辑,最终输出汇总结果写入 summary_all_platforms 表。
新建转换流:
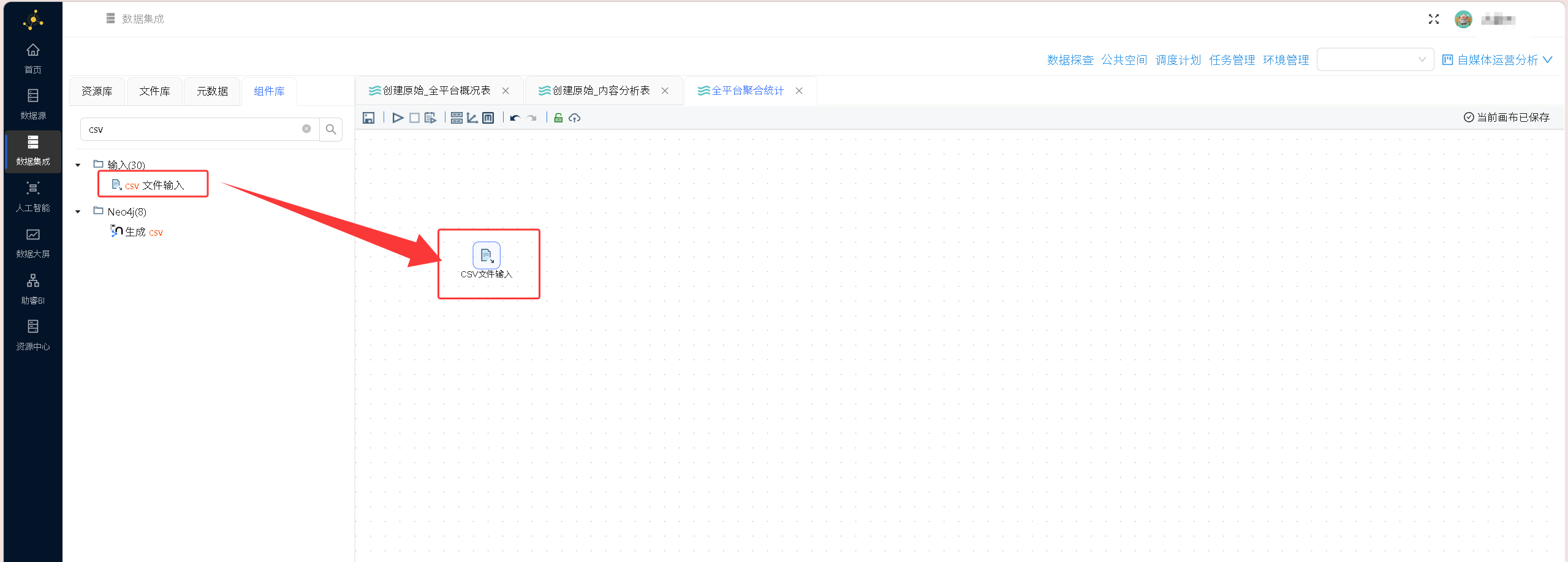
拖入csv文件输入
配置如下:
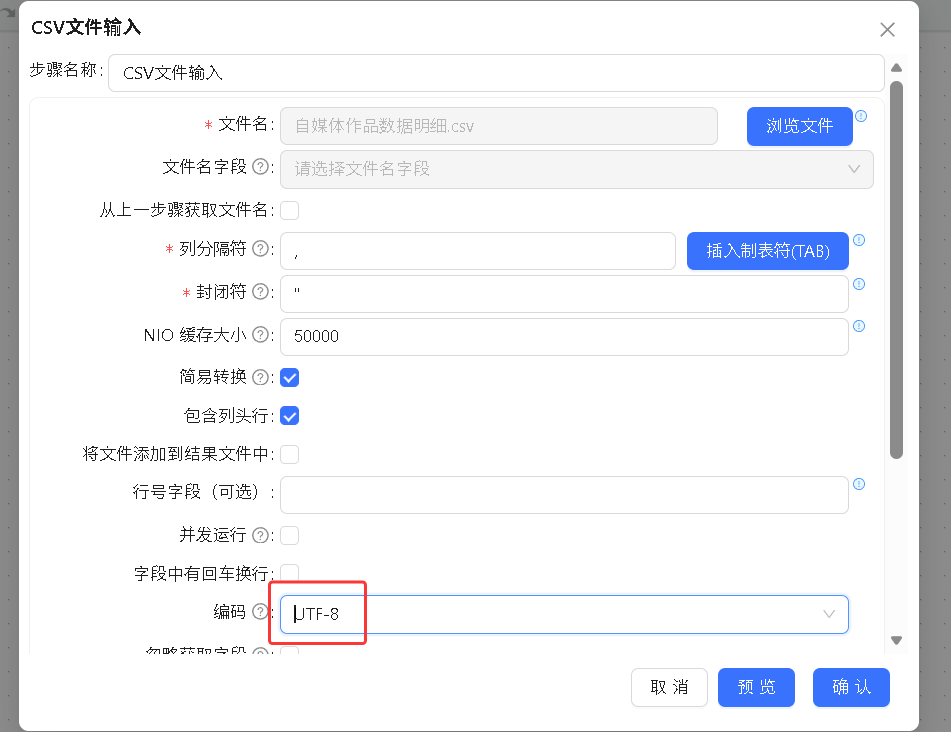
拖入排序记录组件:
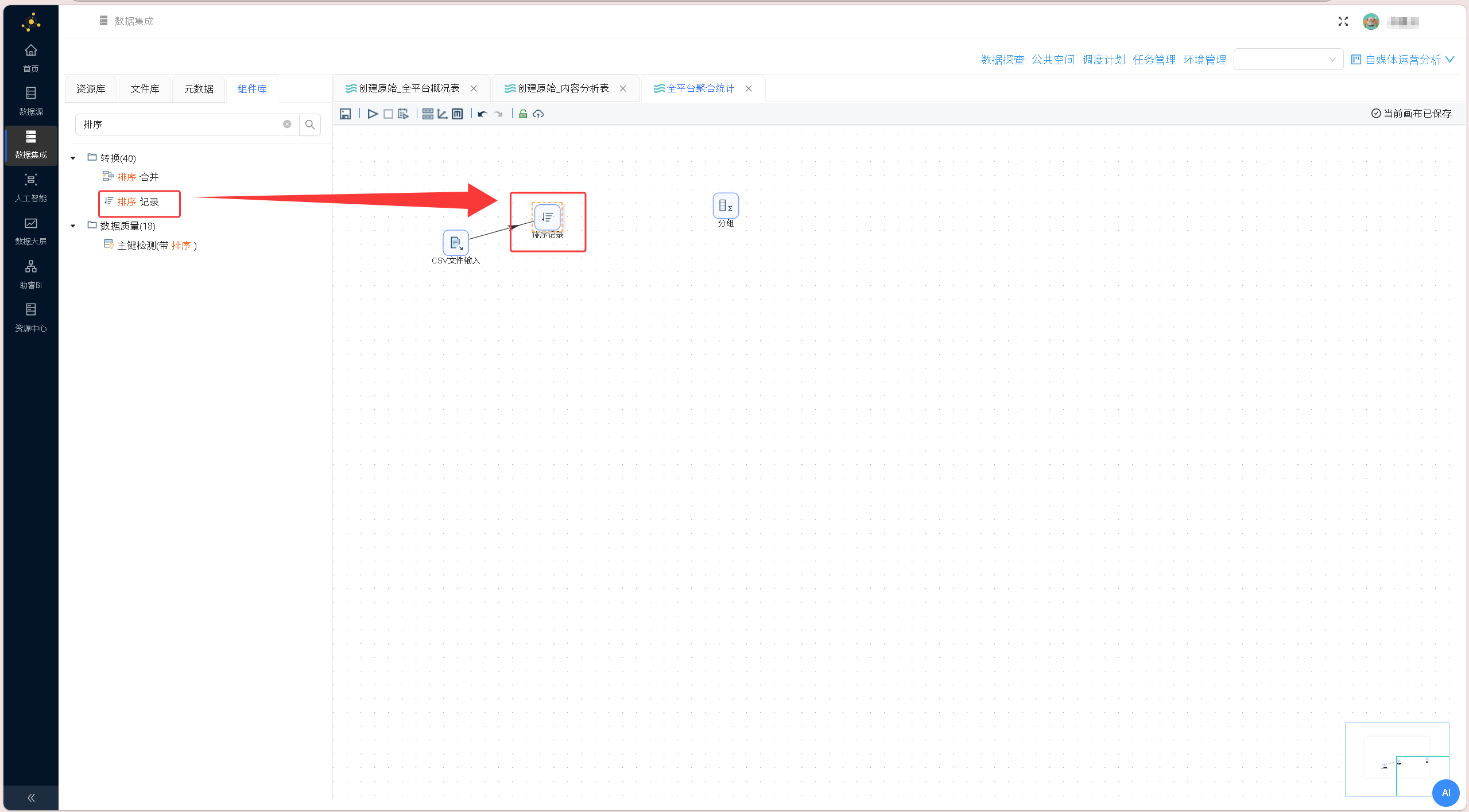
获取字段,并保留需要分组的字段:
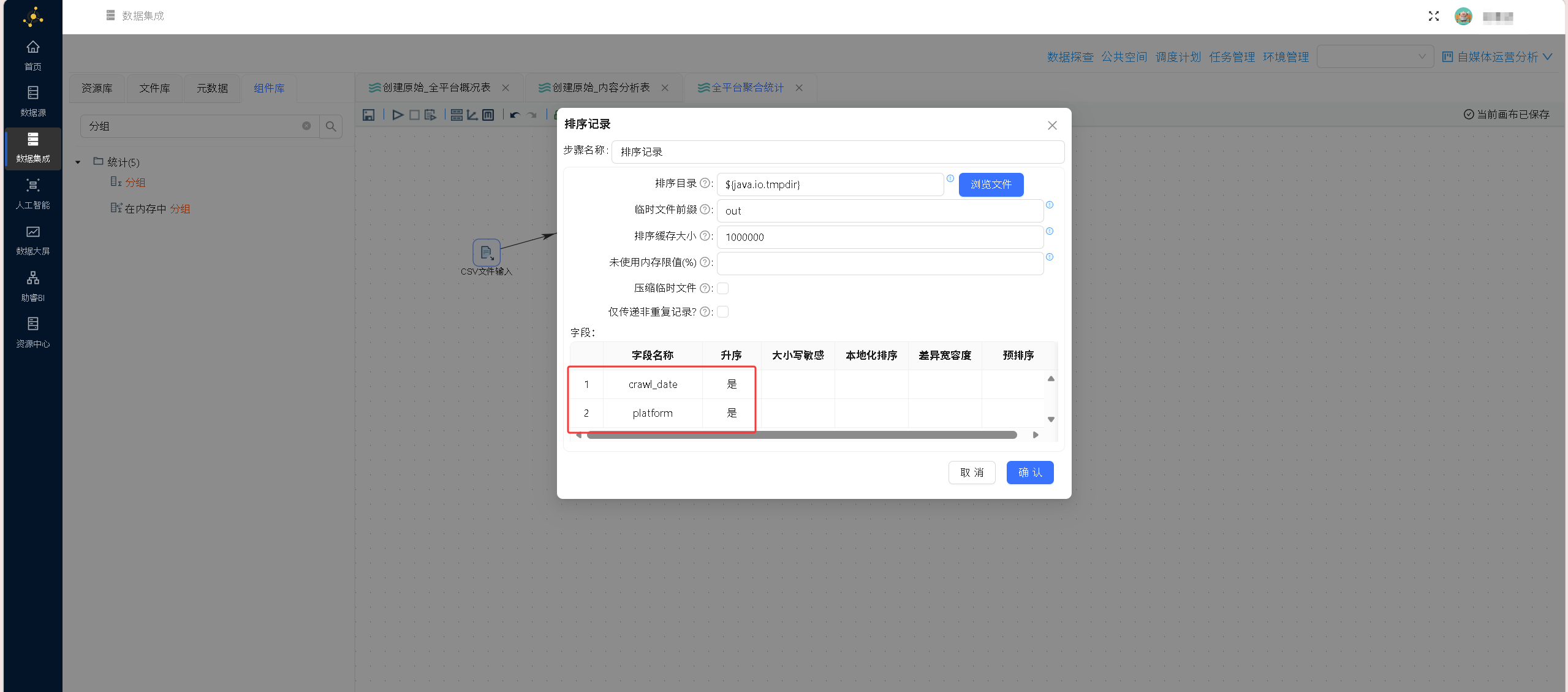
拖入分组组件:
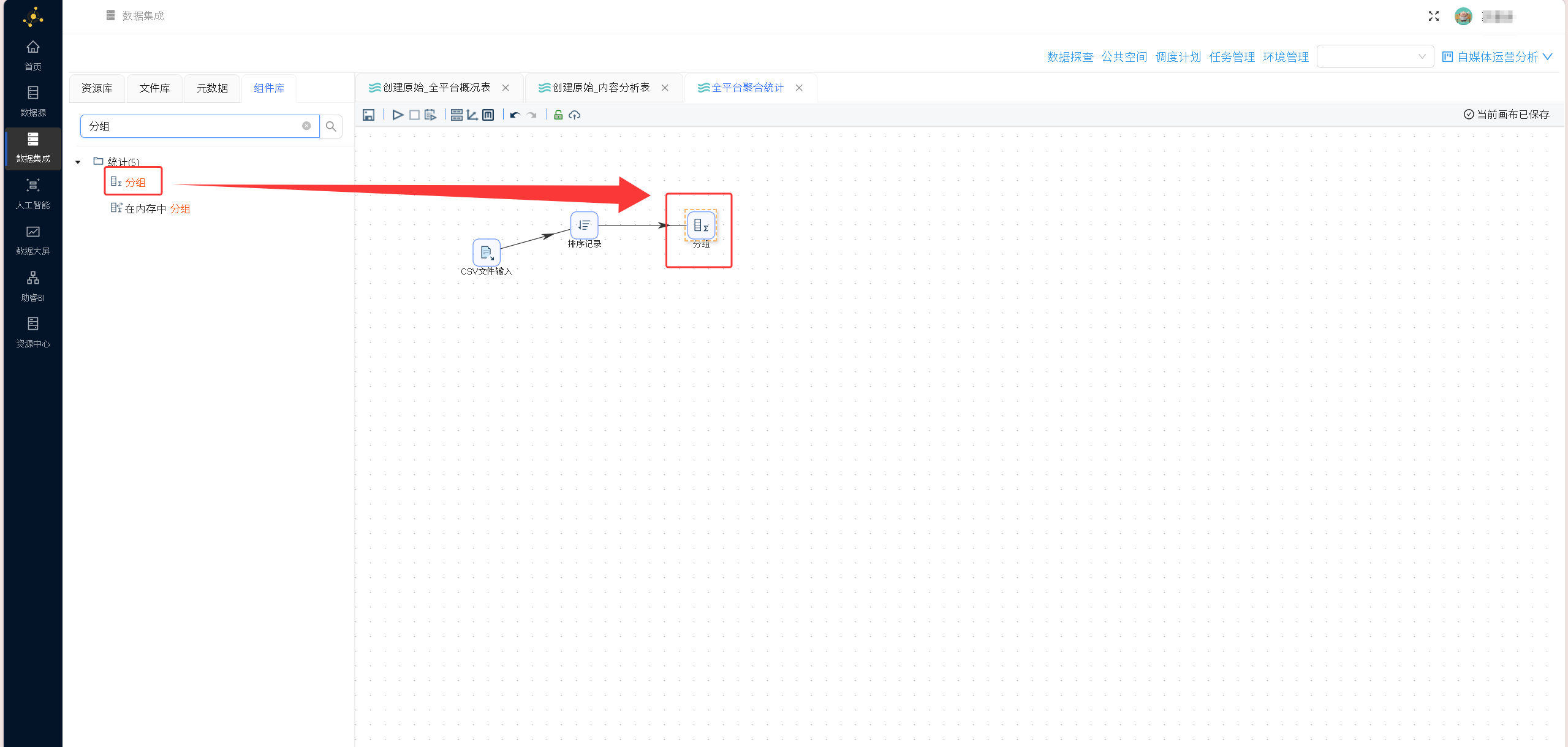
获取字段后,保留需要进行分组的字段
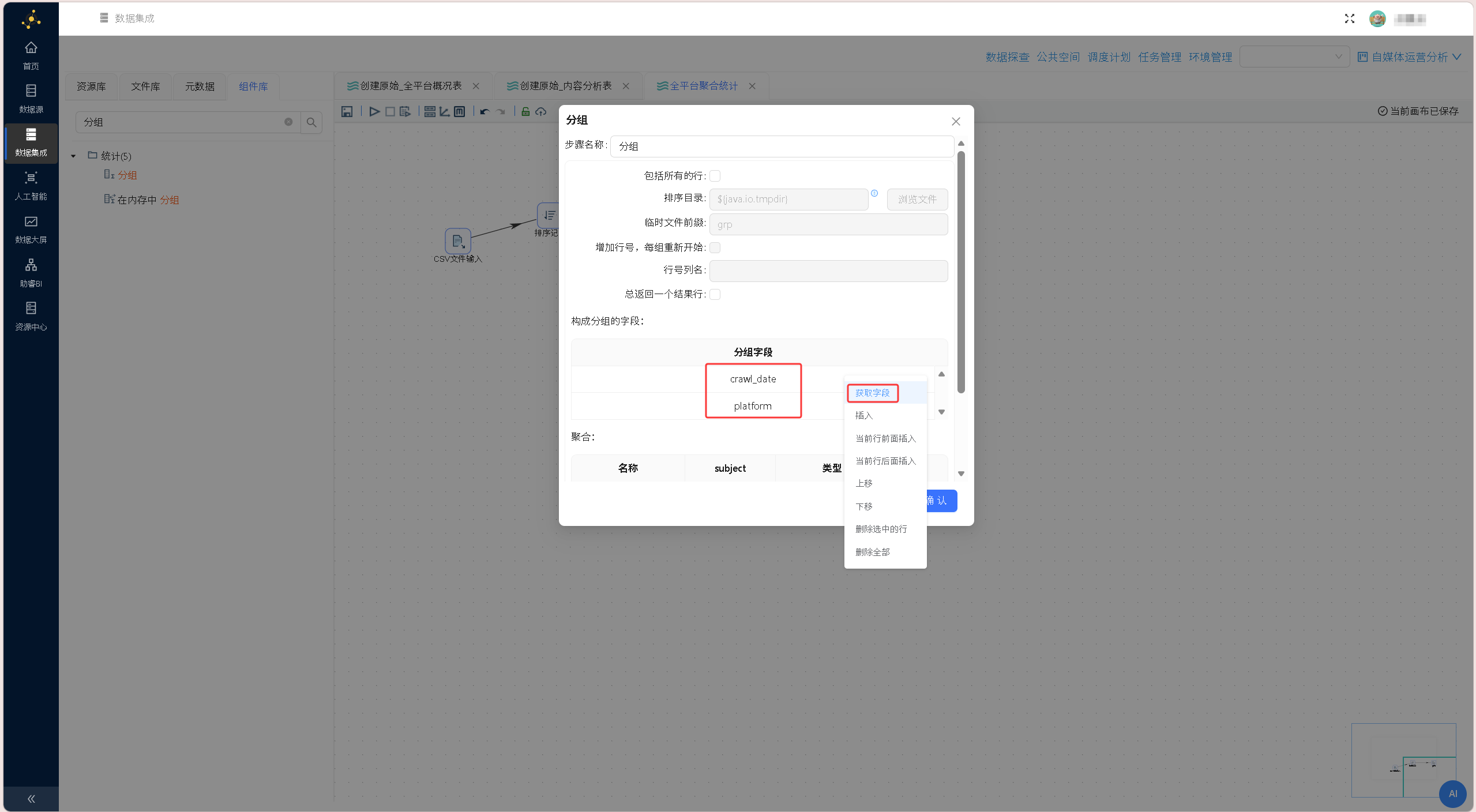
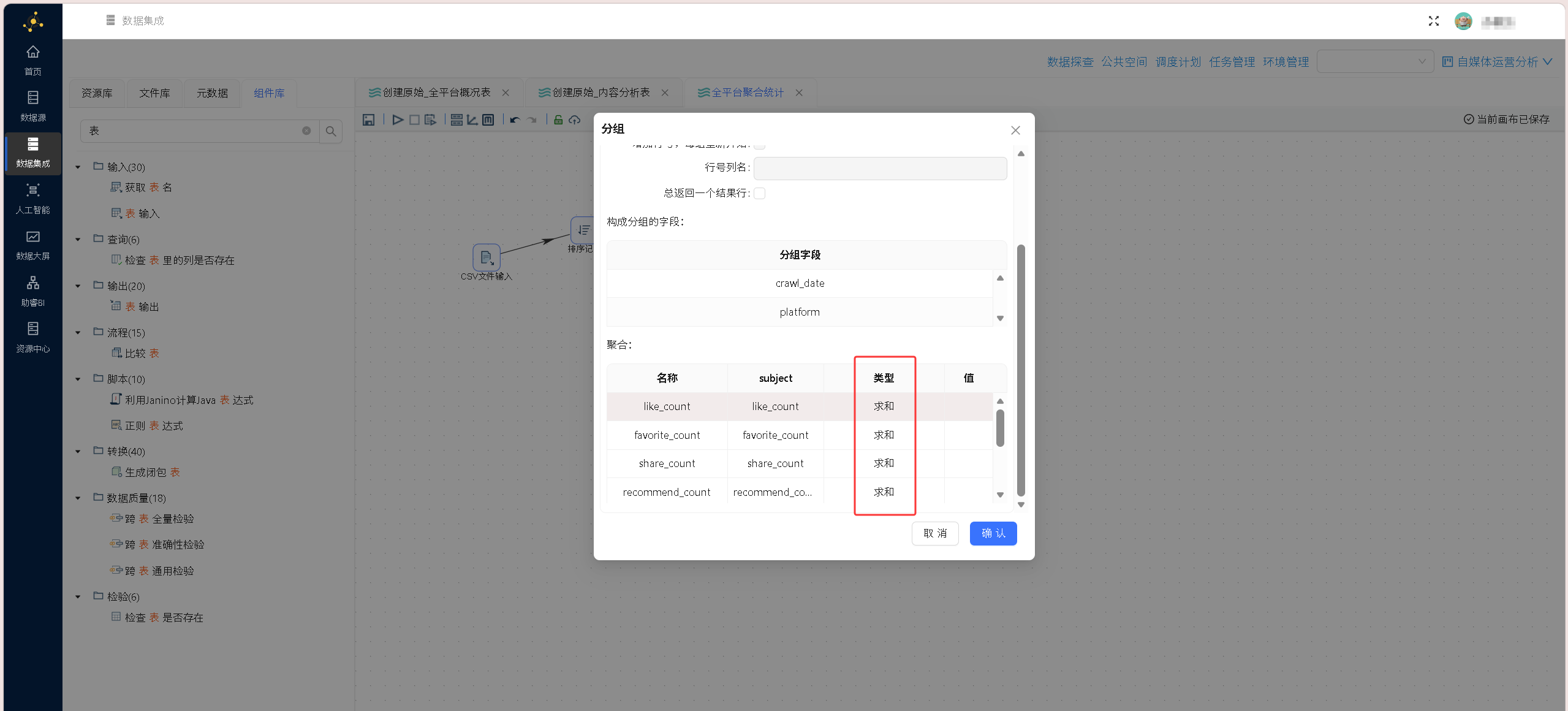
删除作者名字、url、source_file、title字段后其余字段全部求和:
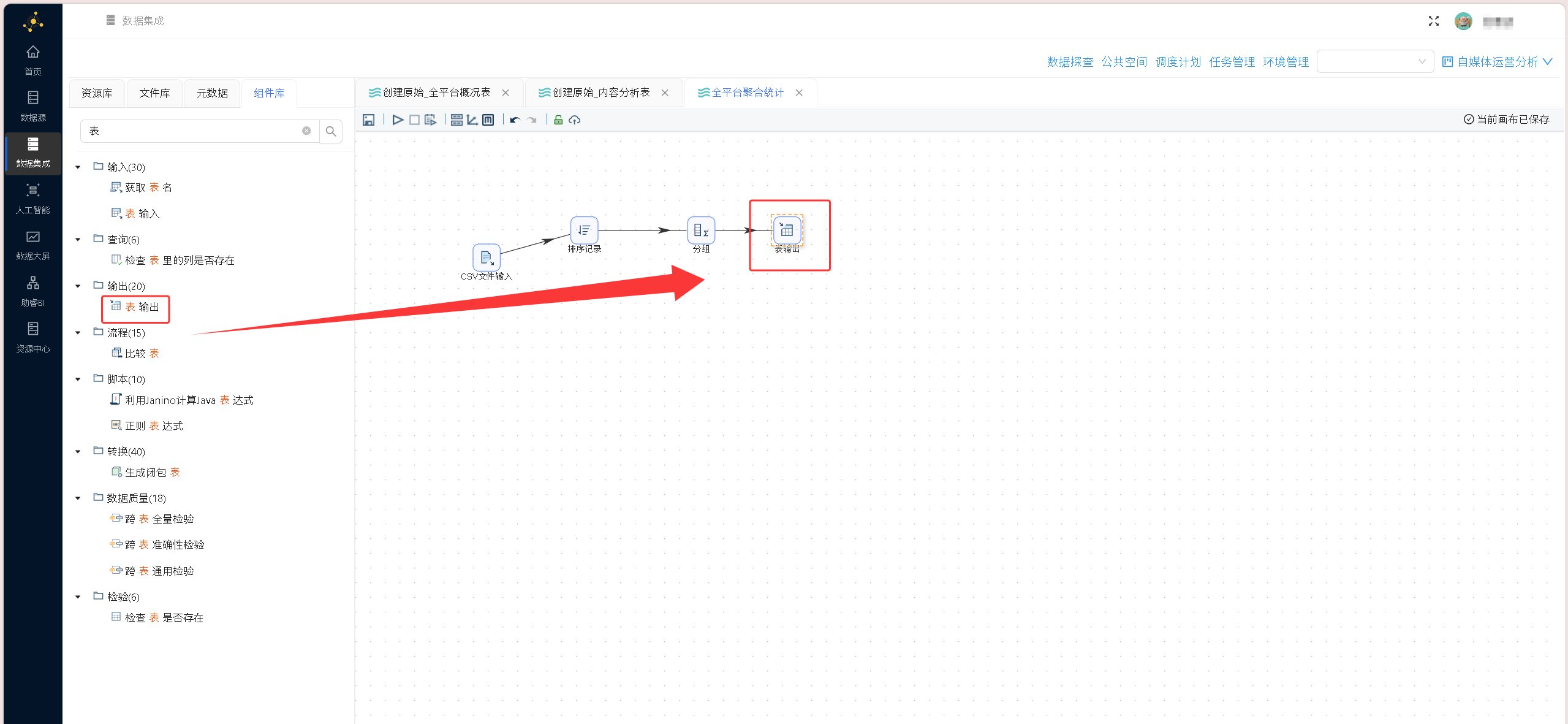
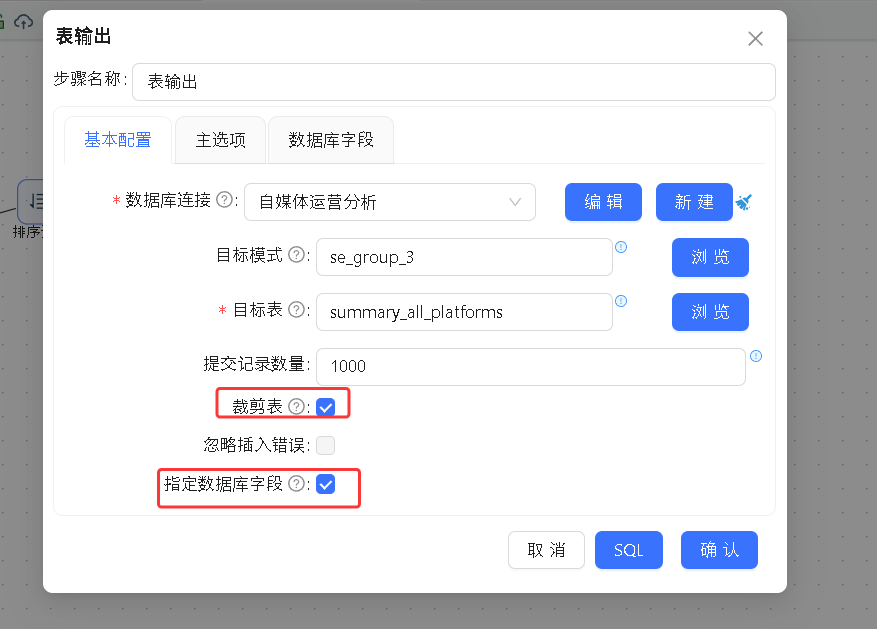
拖入表输出组件:
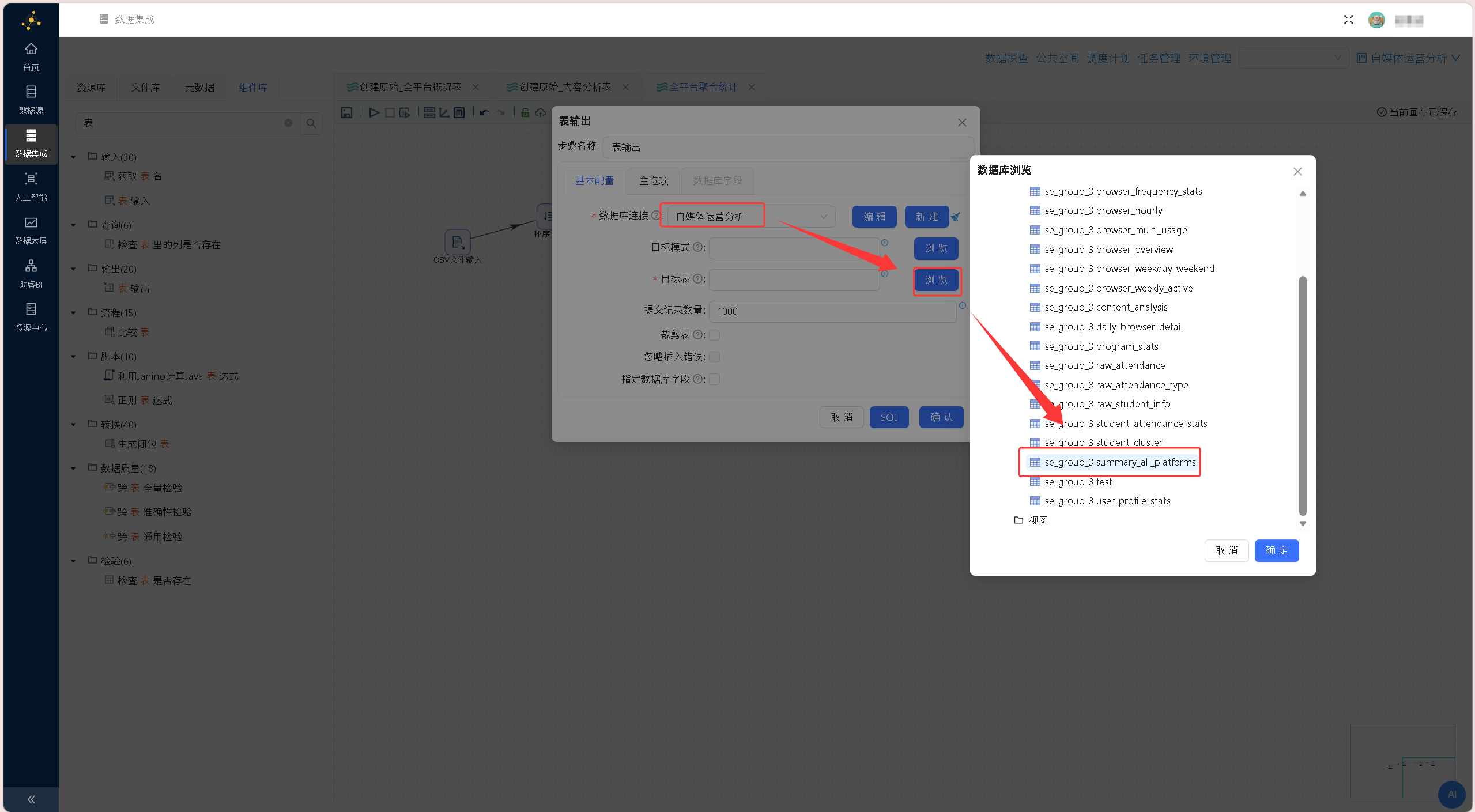
选择目标表:
勾选:
获取字段:
步骤4:过滤记录
从原始数据源节点引出第二条并行分支,添加「过滤记录」组件配置复合筛选条件,筛选规则逻辑:
(平台字段 = 'B 站 ' 并且 浏览数量> 0) OR (平台字段 = 'CSDN' 并且 浏览数量 > 0)
过滤逻辑拆解:
- 渠道限定:仅保留 B 站、CSDN,剔除微信、知乎、小红书等低有效流量平台;
- 曝光过滤:剔除两大平台内浏览量等于 0 的零曝光无效作品; 组件支持 AND、OR 多条件自由组合,单节点完成渠道 + 有效流量双重筛选,无需拆分多次过滤。
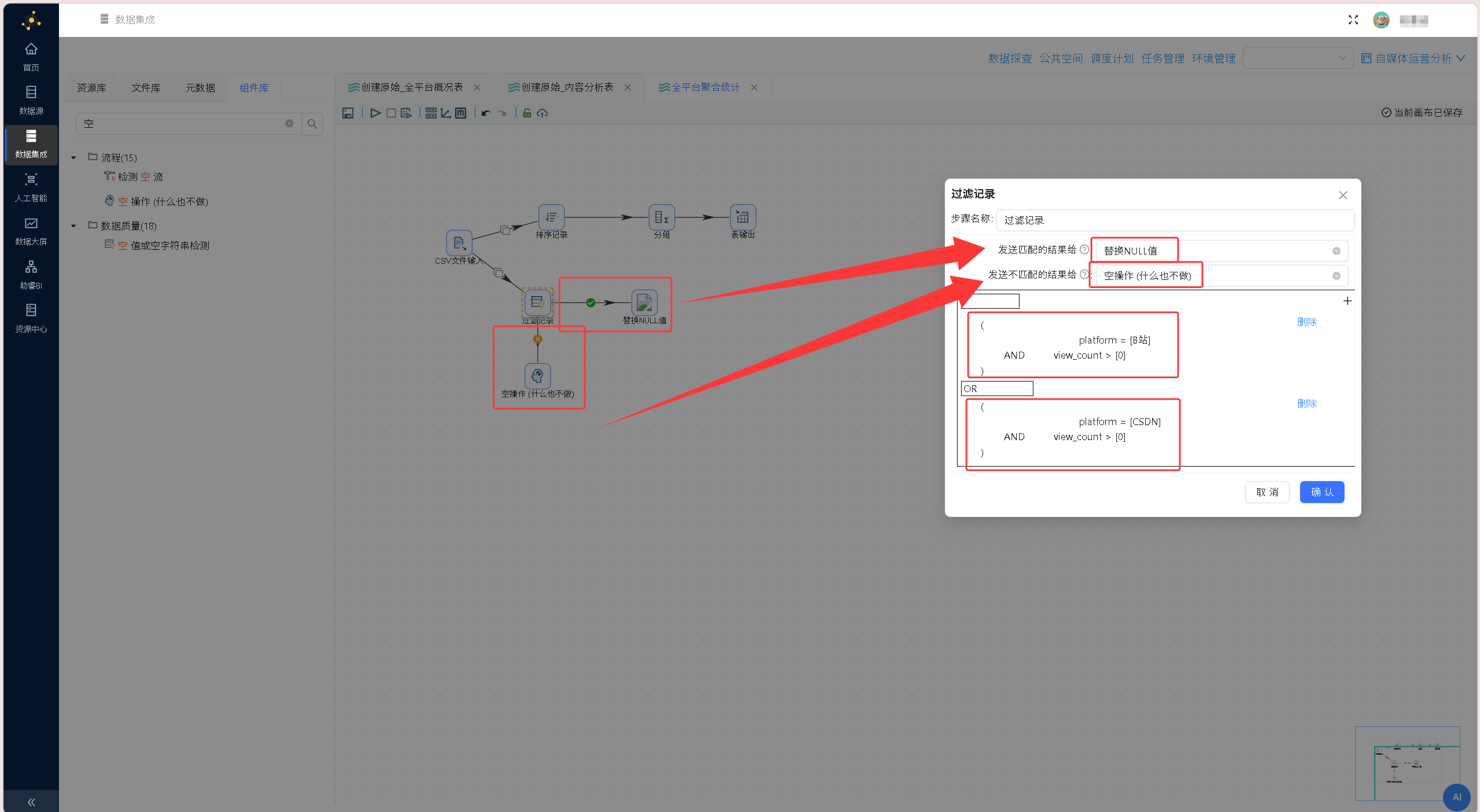
逻辑说明:括号内的条件组合确保“平台”与“有效记录判定”同时满足,一个组件完成双重过滤。助睿ETL的过滤记录组件支持编写复杂条件表达式,可通过 AND、OR 灵活组合多条件,一步到位完成精细化数据筛选。
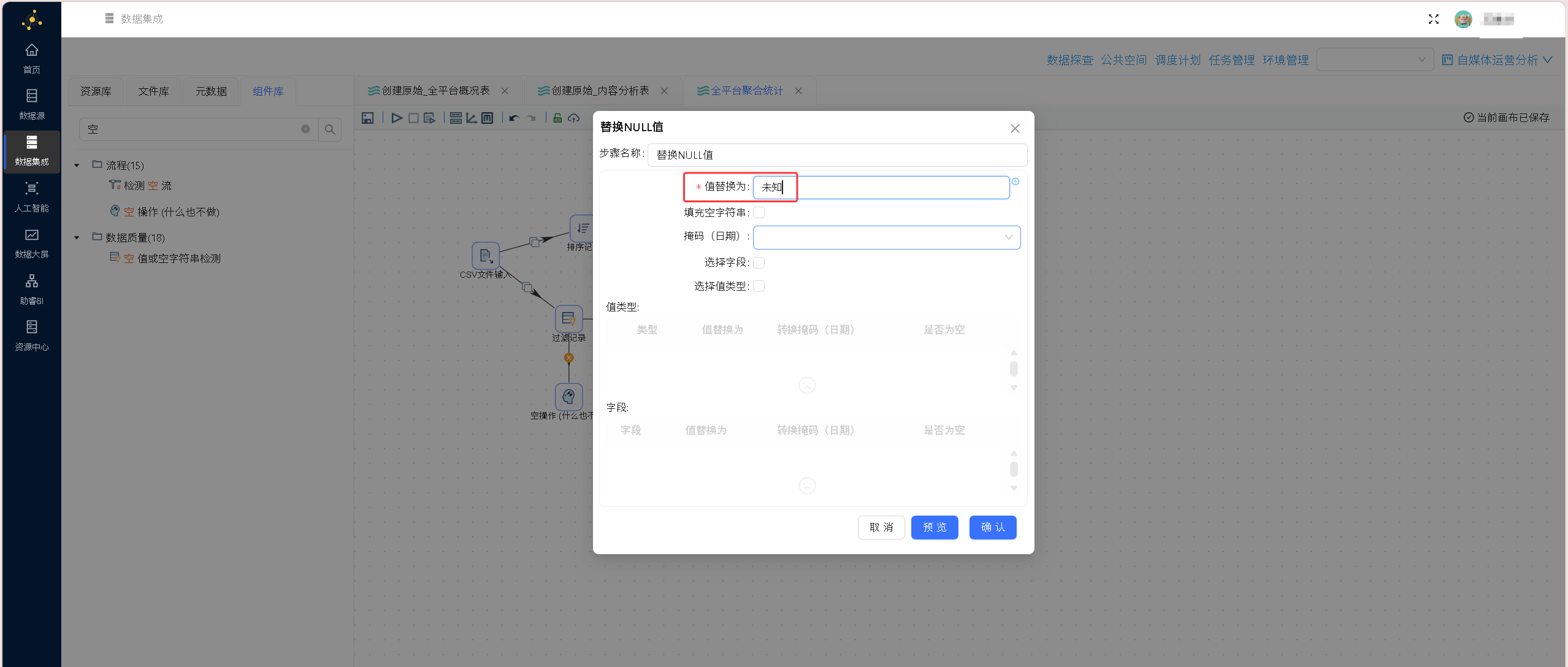
步骤5:填充缺失值
经过滤后的明细数据中,点赞、收藏等数值字段无缺失,但作者昵称、作品标题文本字段存在空值,添加「空值填充」转换节点,对文本类空字段统一填充固定占位字符,规避后续字符串匹配、统计计算流程报错。
步骤6:字段选择
拖拽「字段选择」节点裁剪冗余字段,丢弃采集批次标记 source_file 等无分析价值字段,仅保留业务核心字段:
date, author_name, title, platform, likes, favorites, shares, coins, views, url
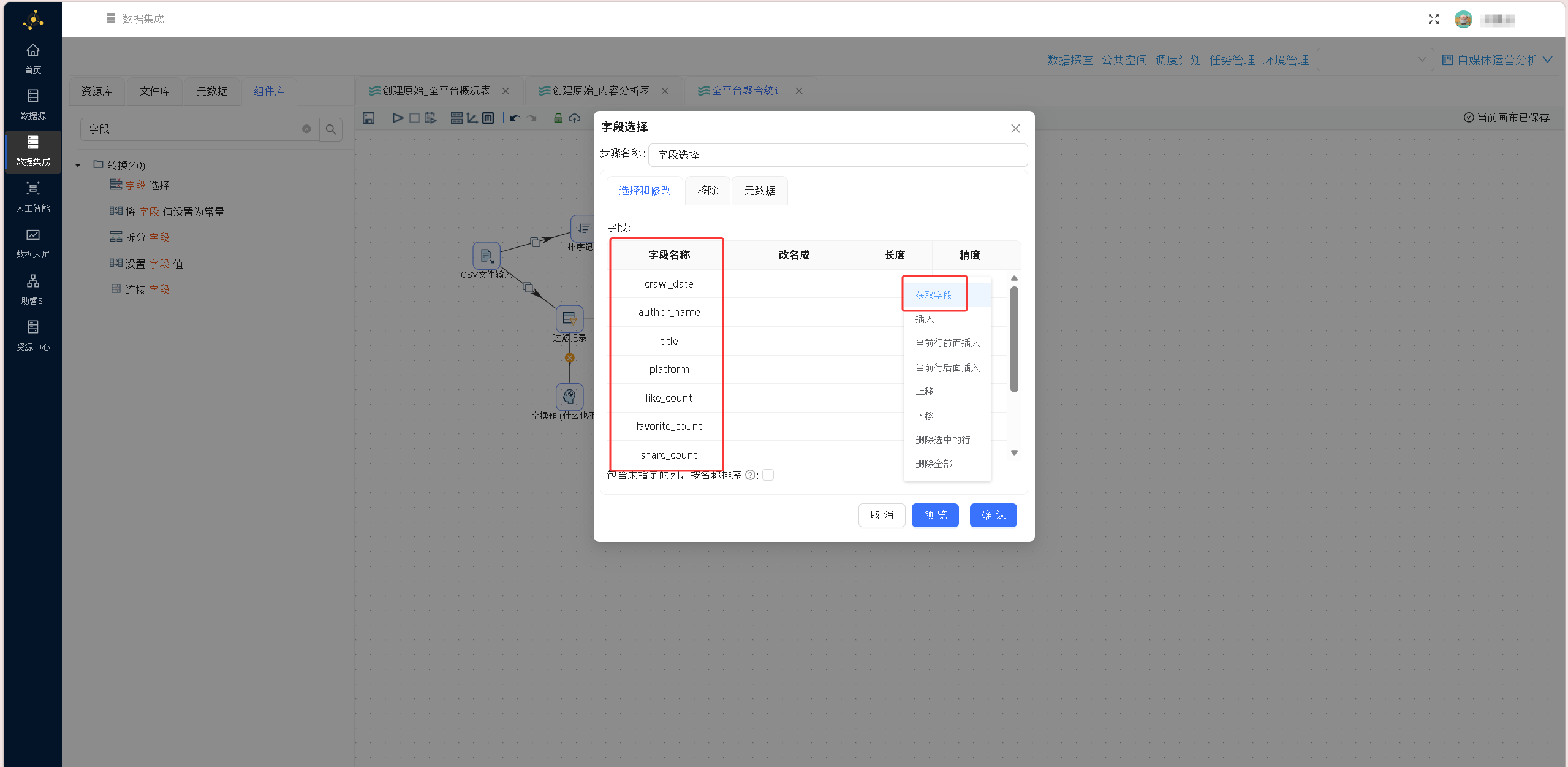
步骤7:输出清洗后中间表
将字段筛选完成后的干净明细数据,落地生成 cleaned_details 中间表,作为7.2实验的基础输入数据。
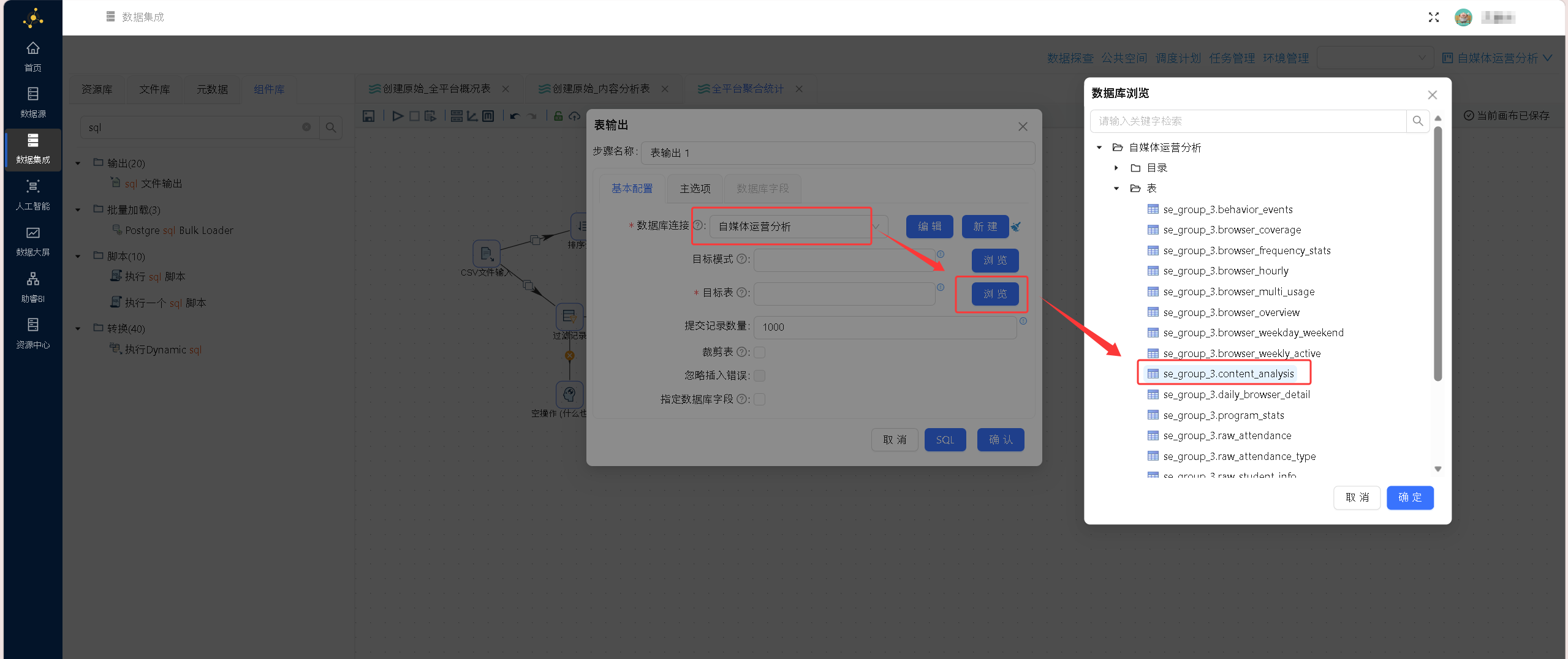
步骤8:执行转换流
将两条分支所有节点按逻辑连线完成完整数据流搭建,保存当前 ETL 转换流程,点击执行按钮启动数据处理任务,任务运行完成后打开数据探查面板,核对两张落地表的数据行数、字段分布、指标数值校验清洗结果。
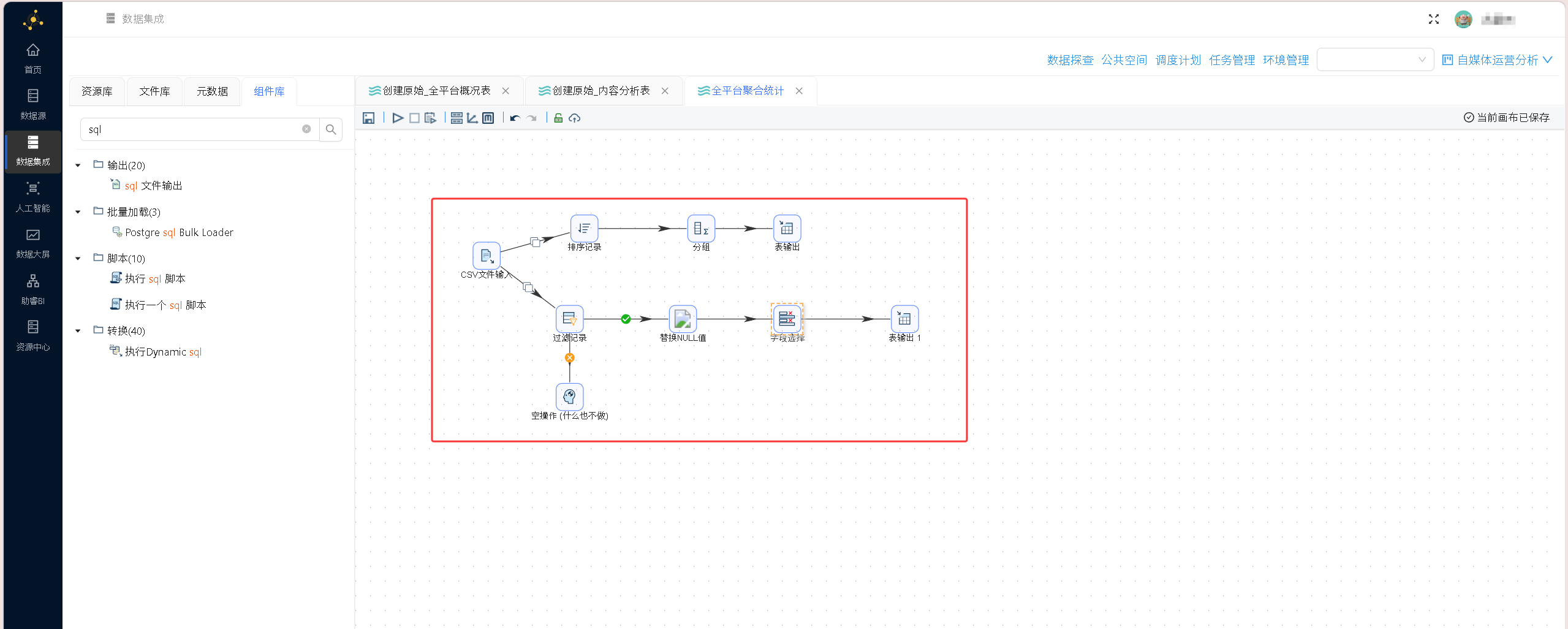
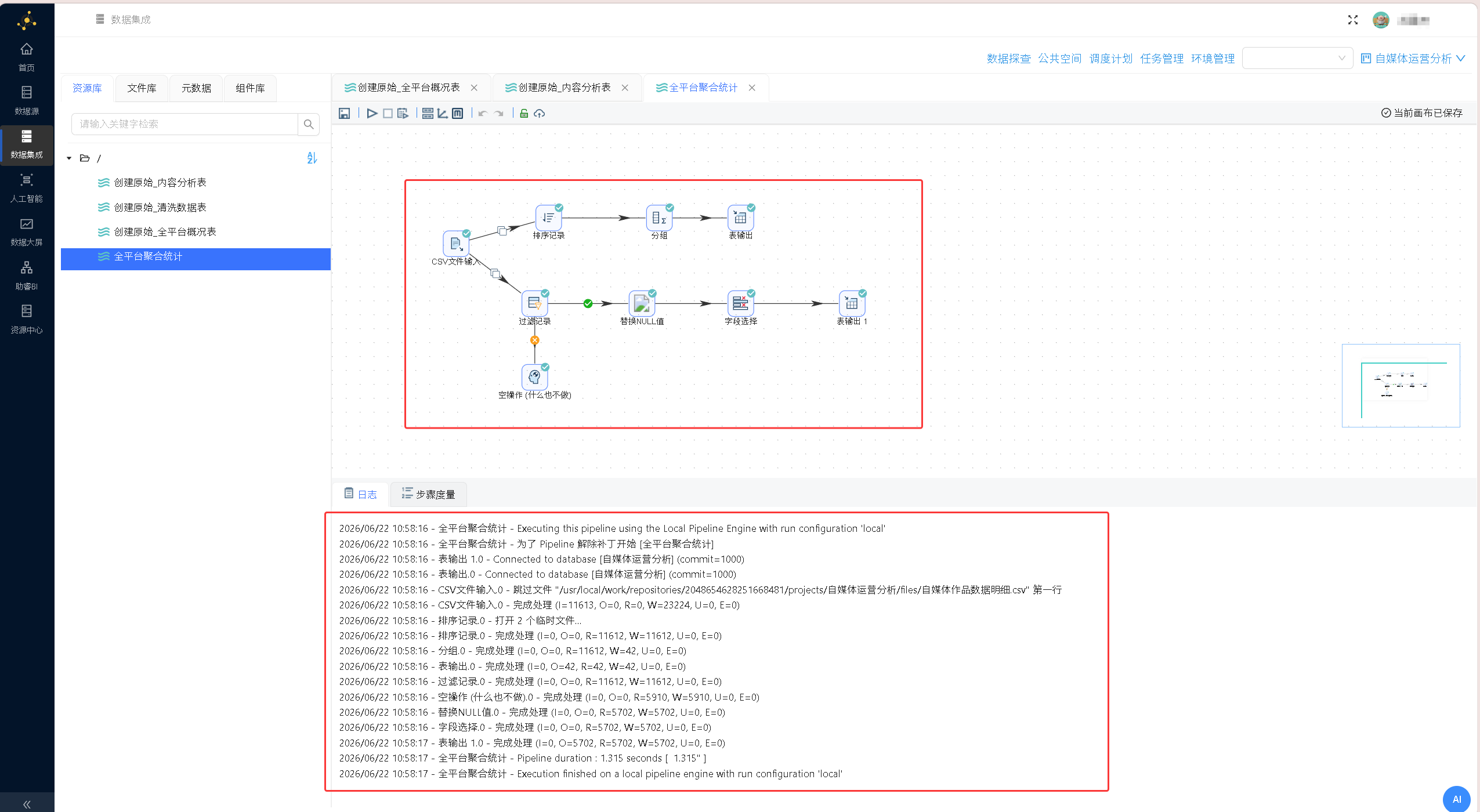
数据探查结果:
5 核心知识点总结
- 多条件复合筛选:借助 AND、OR 逻辑运算符组合渠道、流量双重筛选条件,单过滤节点实现精细化数据行提取;
- 缺失值标准化处理:针对文本、数值字段区分填充规则,统一补齐空值保障下游计算稳定;
- 时间维度留存策略:完整保留采集日期字段,用于后续时间趋势分析,不做重复数据去重操作;
- 助睿 ETL Pipeline 开发模式:多个功能转换节点串联组成完整处理链路,可视化完成全流程数据加工;
- 分层数据表设计思路:一次 ETL 清洗产出分层数据表,分别适配总览看板、深度分析两类业务需求,实现一套原始数据多次复用。
6 实验心得与收获
本次实验让我充分认识到数据清洗是数据分析的关键前置环节,原始脏数据会严重影响分析结果。通过实操,我熟练掌握了助睿ETL的基础操作与多场景数据处理方法,建立了分层、分流的数据处理思维。同时摆脱了代码限制,专注于数据逻辑与业务分析,有效提升了自身的数据处理能力与实操严谨性,为后续数据可视化、特征工程学习积累了扎实的实践经验。
7 平台使用评价
助睿数智实训平台操作简洁、功能完善,拖拽式零代码操作门槛低,非常适合教学实训。平台ETL组件齐全、流程可视化清晰,数据流转直观,便于理解数据治理逻辑。整体运行稳定、支持实时数据校验,贴合课堂教学场景,能够满足大数据基础实训与进阶实验需求,实用性与教学适配性极强。

一站式 AI 云服务平台
更多推荐


 2
2 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)