
如何快速对比不同模型表现?从大模型评测指标到选型实战指南
选大模型就像挑队友。如今市面上的基础模型多到让人眼花缭乱,开源的(Deepseek、Qwen、Kimi)、商业的(Claude、GPT)、文本的、多模态的……每天都有新模型宣称自己“在特定跑分上全方位碾压同行”。
但作为技术负责人或开发者,我们心里都清楚:没有绝对完美的模型,只有最适合具体业务场景的AI模型。 盲目跟风最直接的后果,就是白白烧掉研发预算,甚至因为模型能力错配导致项目重头来过。
那么,怎么才能科学、快速地看出哪个大模型更适合你?自己写脚本测嫌麻烦,看官方跑分又觉得有水分。今天我们就坐下来聊聊,对比大模型时到底该看哪些“硬指标”与“工程潜规则”,以及如何利用现代化云平台的 Model Playground(可以理解为 模型沙箱),用最优雅、最省头发的方式完成这场大模型版的“横向测试”。
一、 挑大模型时,我们到底在比什么?
很多人对比模型,习惯上来就问一句话:“这个模型好用吗?够聪明吗?”
但在真实的工程落地世界里,“聪明”是个很难被量化的词。为了不踩坑,还是需要把主观的评价拆解成三个具体的评估维度:
1. 文本与推理指标
首先是上下文长度(Context Length)。你可以把它理解为模型的“工作记忆”(即当前可处理的上下文窗口大小)。如果你的业务要塞进整本用户手册做垂直客服,或者需要读长篇法律合同,那基础模型的该指标就得足够大(比如 128k 甚至更高)。与此相对应的,是最大输出 Token 数(Max Tokens),它决定了模型一口气最多能吐出多少字,直接影响到长文创作或复杂代码生成的完整性。
接着是推理准确度与指令遵循能力。有些模型虽然死记硬背很厉害,但你给它写了一堆 System Prompt(系统提示词),规定“必须输出标准的 JSON 格式”、“绝对不能说任何客套话”,它偏偏不听,这就是指令遵循能力不够,在自动化工作流中极易引发下游报错。
2. 跨界实力:多模态输出质量
如果你的应用涉及文生图或文生视频等生成式多模态任务,在常规理解能力之外,还要专门评测其生成精细度:
- 文生图/视: 需要比对分辨率、宽高比和画面细节。如果是视频生成,还要测试帧率(FPS)以及镜头移动时的画面运动强度(Motion Strength),防止动作过大时画面崩坏。(注:此类生成指标主要适用于扩散类生成模型,与纯文本理解或图文识别类LLM的评测赛道有所区别。)
- 文生语音: 则要考核音频的采样率(Sample Rate)和音色风格(Voice Style)是否足够自然逼真。
3. 现实骨感度:速度与搞钱成本
大模型再聪明,如果回一句话要让用户等半分钟,业务早就凉了。所以工程上非常在乎首字延迟(TTFT, Time to First Token)——也就是模型流式吐出第一个字的速度,它直接决定了终端用户的交互丝滑度。
紧接着是吞吐量,即每秒能跑多少个 Token。当然,这一切的背后都挂着计费秤砣。输入和输出 Token 的每百万(M)单价是多少?自托管开源模型前期投入较大,但长期来看在高并发场景下边际成本更低;商业模型虽然省心但用量大了肉疼,两者需要根据业务量仔细权衡,这些都是要算在账本里的。
二、 指标之外:那些容易被忽略的“隐形成本”
看完了纸面参数,很多团队就急着去写代码接 API 了。且慢,真实的业务工程里还有几个隐藏的“参数潜规则”。很多时候,模型输出效果不好,不是模型不够聪明,而是你没摸透它的“脾气”。
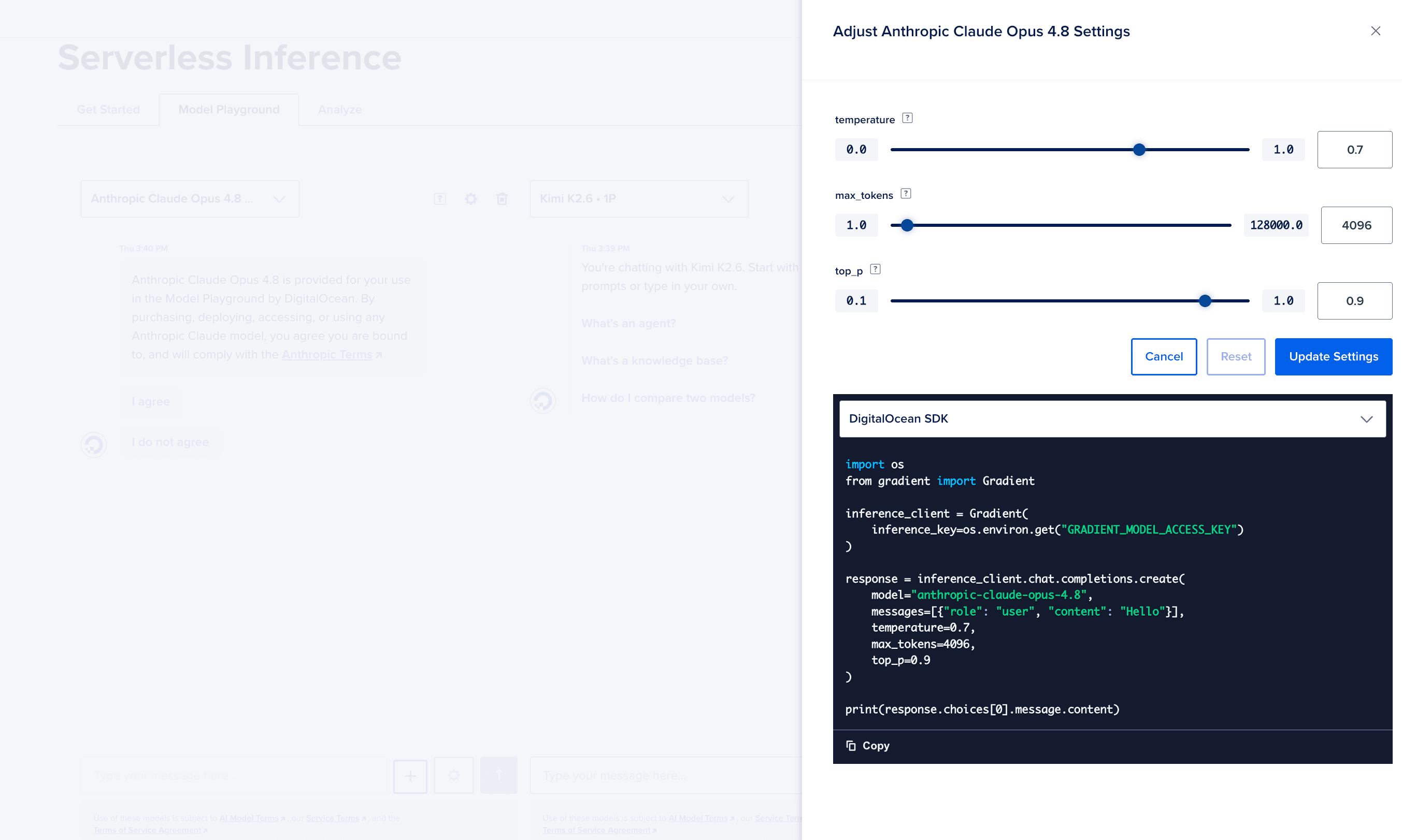
通过调整 Max Tokens、Temperature 和 Top P 这三个核心参数,看清它们对模型表达产生的微妙化学反应。不管你是自己接入模型官方API,还是通过云服务(比如DigitalOcean)通过一个API接入多个模型,都可以调整这三个参数。
1. Max Tokens(最大 Token 数):输出长度的“裁剪剪刀”
你可以把 Max Tokens 理解为给模型输出加的一道“硬关卡”。如果设置得太低,模型的回答就会被无情截断;设得太高,不仅可能超出模型上限被底层供应商强行拦截(Clamped),还可能因为模型“太话痨”而无形中拉高每笔请求的计费成本。
我们对同一个提示词 “什么是联合国(What is the UN?)” 做了限制,你可以直观地看看两者的区别:
- 当 Max Tokens 设为 200 时: 模型像一个克制的发言人,只给你最核心的定义:“联合国是一个旨在促进其成员国之间和平、安全与合作的国际组织……” 话音刚落,戛然而止。
- 当 Max Tokens 放宽到 512 时: 模型瞬间打开了话匣子。不仅告诉你它成立于 1945 年、有 193 个成员国、总部在纽约,还顺便把它的五大目标(维护和平、保护人权等)以及六大核心机构(大会、安全理事会、秘书处等)给你盘得清清楚楚。
2. Temperature(温度):模型的“创造力开关”
这是一个最容易让人踩坑的参数。Temperature 决定了模型的创造力和放飞程度。数值越接近 0,模型越像个严谨的会计,只说最保险的话;数值越接近 1,模型就越像个喝了酒的艺术家,开始天马行空。
我们用一句话来测试它:“天空是什么颜色的?(What color is the sky?)”:
- 温度 0.0(极端保守): “天空是蓝色的。” 没有任何废话,标准且确定。
- 温度 0.5(恰到好处): “天空在白天通常是蓝色的,但根据天气条件和一天中的时间,它可能会呈现出不同的颜色。” 开始考虑客观环境,逻辑很严密。
- 温度 0.7(文采斐然): “天空的颜色变化很大。虽然它经常被认为是蓝色的,但在日出或日落时它也会呈现出淡蓝色、蔚蓝色、青色,甚至带上橙色、粉红色或紫色的色调……” 措辞明显变得丰富且有画面感。
- 温度 1.0(彻底放飞): “啊,头顶上那神秘的画布!有人说这是一片无尽的蔚蓝海洋,也有人说它是色彩的变色龙。也许这是大自然母亲的心情戒指,从最温柔的婴儿蓝变成最深的靛蓝……” 这时候的模型已经完全脱离了“科普”的范畴,开始写诗、发感慨,甚至开始探讨天空是不是人类的集体幻觉。
在实际业务中,如果你做的是财务报表审计或法律合同检查,温度必须无限趋近于 0;如果你做的是营销文案撰写或小红书文案生成,把温度拉到 0.7 - 0.8 才能迸发出让人眼前一亮的灵感。
3. Top P(核采样):控制词汇多元度的“过滤器”
Top P 和温度类似,但它是从词汇选择的概率叠加来控制输出的。Top P 越低,模型越倾向于在概率最高的几个词里打转,回答专注且可控;Top P 越高,模型就能看到那些不常出现但很有意思的词汇。
同样面对 “天空是什么颜色的?” 这个提问:
- Top P 0.1: 模型只会干巴巴地回你一句:“天空是蓝色的。”
- Top P 1.0: 模型的词汇库完全向你敞开。它不仅会用“不断变化的织锦(ever-changing tapestry)”、“动态的画布(dynamic canvas)”这种高级词汇,甚至还会带你畅想“北极光的空灵之绿”以及“龙卷风来临前那不祥的绿色阴影”。
4. 算力成本的下降与生态后劲
在评估长期运营成本时,不少企业会被当前的 API 价格吓退。但事实上,大模型的推理成本正在遵循类似摩尔定律的轨迹疯狂下降。根据权威研究机构 Epoch AI 最新发布的数据显示:在同等性能水平下,大模型的推理成本平均每 2 个月就会降低一半,一年内能实现接近百倍的成本暴跌。
因此,在沙箱中测试时,不仅要看现在的价格,更要看这个模型背后的工程部署生态。
比如在实际落地时,普通平台可能只提供单一的 API 接口,但先进的推理云平台会把选择权交给你。以 DigitalOcean 的 AI推理服务 为例,它就直接拆分出了两种截然不同的部署路径:
- Serverless Inference(无服务器推理): 适合初创团队或创新项目。你不需要管理任何底层的 GPU 算力,直接创建密钥、按量(Token)计费,免运维且成本极低。它甚至还支持“零改动平替”方案——你只需要在
Claude Code或Codex等编码智能体中修改一下 API 基地址(Base URL),就能无缝切到低成本的云端算力,原有的代码和工作流一行都不用改,直接调用Claude系列模型和GPT系列模型,而且支持支付宝付款、免去anthropic的认证审查(具体使用条件可咨询卓普云AI Droplet)。 - Dedicated Inference(专用推理): 适合对数据隐私极度敏感、或者业务量巨大需要专属吞吐保障的企业。它支持你把开源或商业 LLM 直接托管在独占的独立 GPU 上,不仅算力专属、数据不出圈,还能自由实现弹性扩缩容。
配合DigitalOcean平台自带的 Knowledge Base(知识库) 功能、服务端工具,无论你选哪种路径,都能一键把测试好的模型挂载上企业的 PDF 或 CSV 文档,零代码秒变专属 RAG 应用。通过在沙箱里手动微调这些滑块、评估真实的返回质量,直到模型的表现完全切中你的业务与架构预期,你才算真正拿到了进入生产环境的门票。
三、 实战演练:用云端 Playground 玩转多模型“双拼对比”
说一千道一万,不如直接上手测。如果你不想为了测试三个模型而去申请三家平台的 API Key,再去哼哧哼哧写一个对比的前端页面,那么现在主流云厂商(如 DigitalOcean 的 Servelrless Inference 服务)提供的 Model Playground 简直就是为你量身定做的。
它就像是一个大模型沙箱,把市面上不管是云平台自己托管的开源模型(如 DeepSeek、Qwen、Kimi、),还是第三方的商业顶级模型(如 Claude、GPT),全放进了一个统一的控制面板(Single Control Plane)里。
它的操作流程非常直观,不需要你写一行代码。
第一步:推开沙箱的大门
登录控制面板后,在左侧菜单的 Serverless Inference 栏目下找到 Model PlayGround。点击下拉菜单,就能选择你需要测试的模型。
第二步:调教单个模型的参数
进入 Playground 后,你会看到一个非常清爽的聊天界面。右侧有一个齿轮图标(Settings),点开它,可以对比其他更多模型。

第三步:开启“双拼同步”神技(核心推荐)
单测一个模型没意思,我们要看的是模型之间的区别。点击页面上的 Compare Another Model 按钮,整个屏幕就会一分为二,变成双栏对比视图。在第二栏里选入你想挑战的另一个模型。
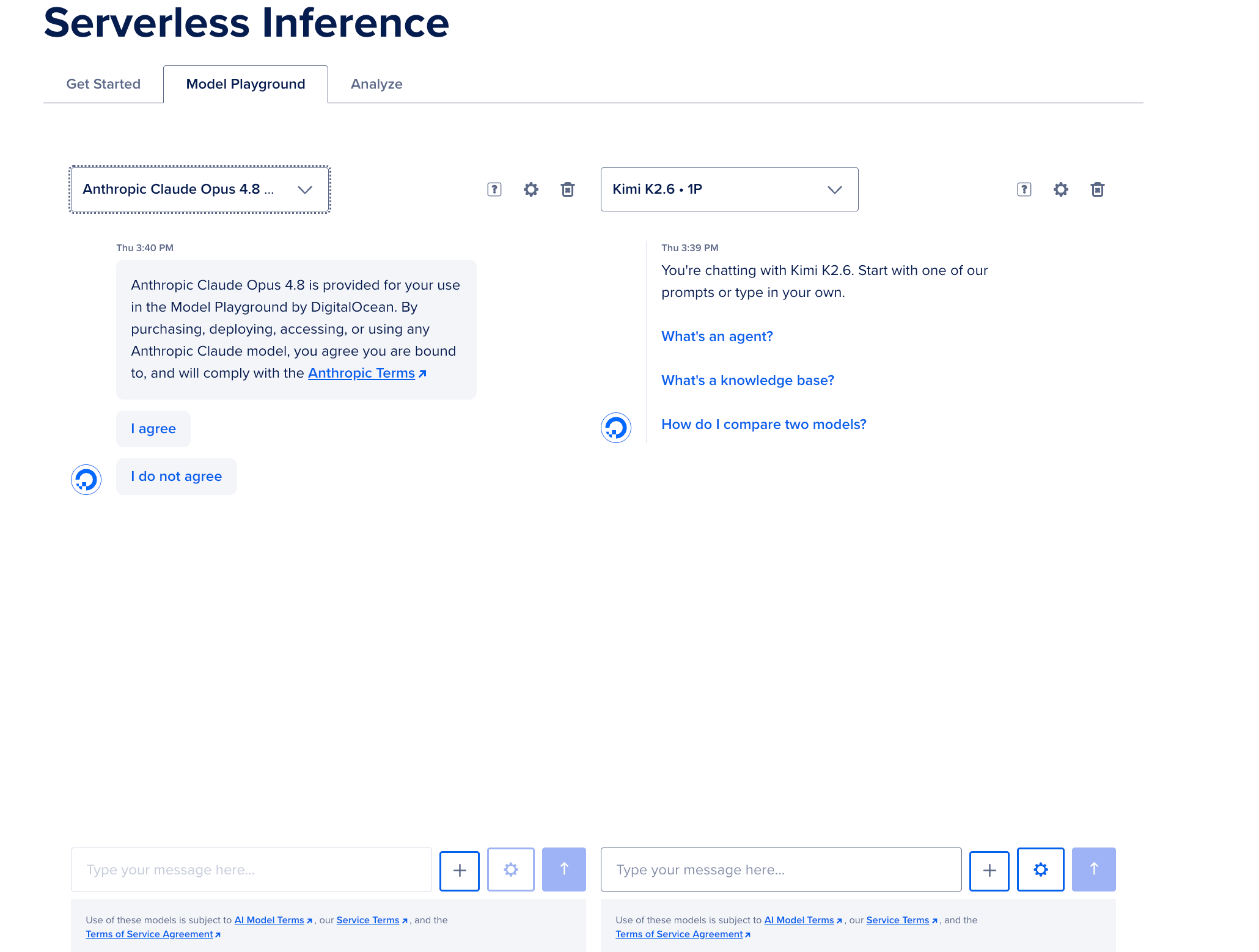
点击不同模型右上角的小齿轮,还可以调整模型的一些指标。
接下来,你只需要在底部的输入框里敲下一个 Prompt,按下回车——两个模型会同时接收到一模一样的指令,并在各自的窗口里并排输出答案。
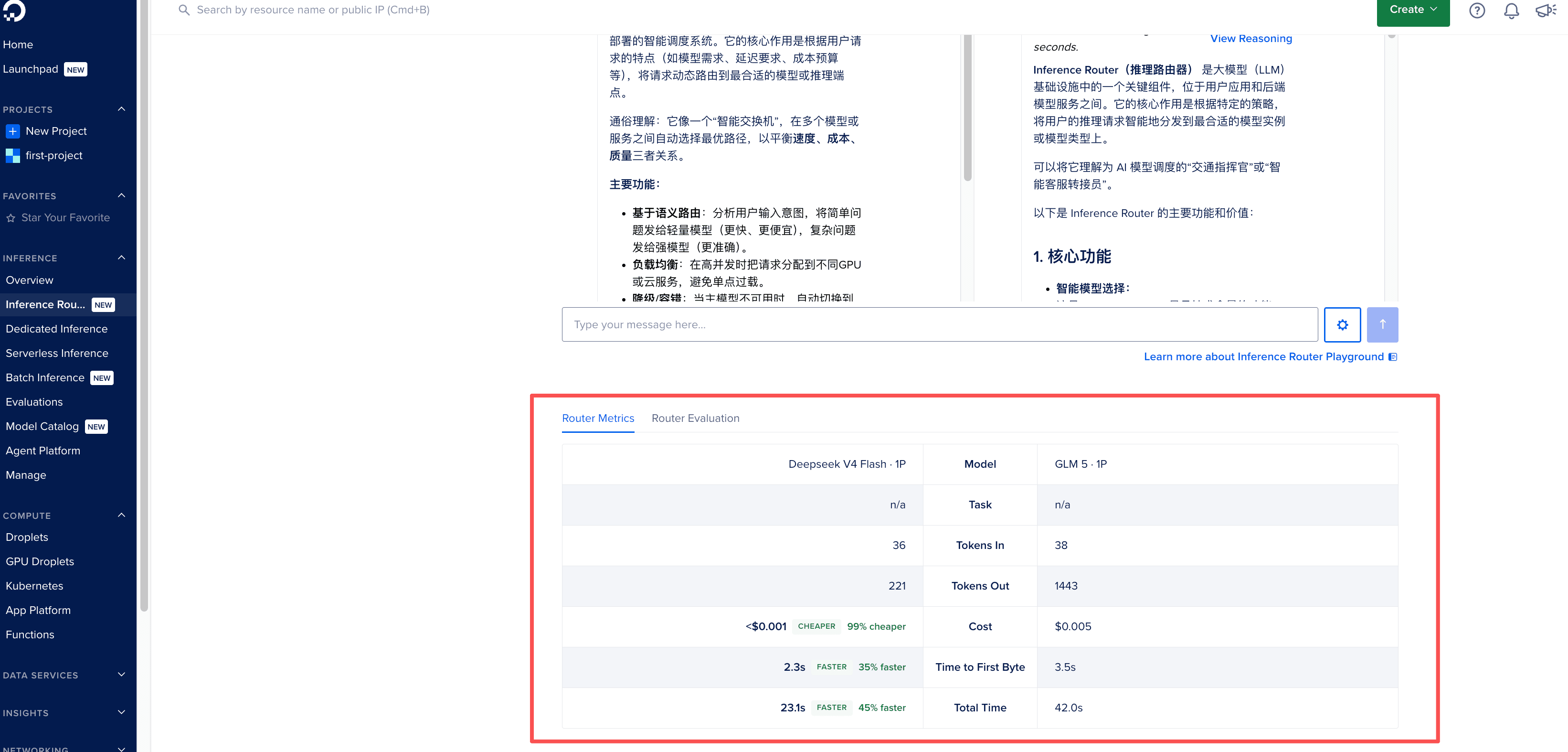
如果你需要看到的不仅仅是不同模型能给出什么样的答案,而是跟深层的指标,比如两个模型的响应时间、回答同一个问题的Token成本。那么你需要打开左边栏的 Inference Router(推理路由器)页面,点击页面中的 Playground,你还可以对比两个模型回答同一个问题的Tokens用量、成本、Time to First Byte。这个功能可以帮助你提前判断针对不同任务应该选择哪种模型。

总结
选模型这事,实践是检验真理的唯一标准。快速找到最佳模型的秘诀,无非就是“控制变量”和“直观反馈”。
通过云端现成的 Model Playground,我们成功把过去需要搭建几天的基准测试环境缩短到了几分钟。通过同步输入、微调参数、比对质量与成本,你可以用极其低廉的测试成本,帮自己的团队避开大模型落地路上的重重暗礁,为你的下一款 AI 应用选定最坚实、最划算的技术基石。
最后,如果你是企业团队,可以直接注册DigitalOcean 使用30+款主流的大语言模型。DigitalOcean的Serverless Inference的 API支持包括Claude Code、VS code、OpenCode等工具。新注册的企业团队只需向卓普云(aidroplet.com)申请权限,即可直接使用Anthropic、OpenAI的所有商业模型。

一站式 AI 云服务平台
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)