
ETL高阶实战:基于JS的非结构化特征提取与高并发回填架构(附保姆级配置指南)
#数据分析 #特征工程 #ETL #自媒体数据
1. 实验背景与业务痛点
在“多平台自媒体运营效果量化分析”的前期数据清洗工作中,我们已经成功提纯了分布于B站与CSDN的有效交互底表(content_analysis)。然而,在进入数据可视化展示前,当前的底层数据仍面临两个极具挑战性的特征工程难题:
- 核心交互指标极度碎片化: 衡量作品传播效果的点赞、收藏、分享、投币等指标,目前散落在多个独立字段中。在进行宏观漏斗分析时,亟需一个统一的“互动总数(TotalInteractions)”作为综合评估依据,但常规SQL处理跨字段相加不够直观。
- 文本特征处于“非结构化”黑盒状态: 决定技术自媒体文章流量上限的核心要素往往隐藏在“标题”中。诸如“保姆级”、“零代码”、“实战”等具有强引流属性的关键词,目前仍是一段纯文本。传统的BI分析工具无法直接对其进行量化统计,必须将其转化为结构化的二值(0/1)特征标签。
本期实验目标:
完成两套数据特征加工流:
特征提取与防重回填: 利用内置JS引擎提取文本特征,利用级联计算器汇总指标,并基于主键安全回填至原明细表。
高并发基准拼接汇总: 构建单源多分支的流式拓扑架构,将5个核心关键词的引流效果与平台大盘基准线进行横向拼接,输出一份高质量的特征分析宽表。
2. 总体设计思路
针对上述复杂的业务需求,我们设计了两个独立的转换流(Pipeline):
流一:特征提取与数据防重回填流
总体架构:表输入 ➔ JavaScript代码 ➔ 计算器 ➔ 计算器 1 ➔ 字段选择 ➔ 插入/更新
此流的设计重点在于“无损更新”。通过 JavaScript 脚本的高效子串匹配能力降维处理复杂文本;摒弃传统的全量覆盖写入,改用基于唯一主键 id 的“插入/更新”操作,保障数据处理的绝对幂等性。
流二:关键词级基准对比汇总流(5路并发)
总体架构:单源输入 ➔ 5路并行的 Y字形拼接流 ➔ 5路并发追加输出
此流的设计重点在于“逻辑解耦与并发吞吐”。为了计算“包含某特征词的作品平均互动量”并与“大盘均值”同构对比,我们为5个特征词各开辟一条独立的支流,每条支流独立过滤、独立聚合、独立打标,最终5路数据流在内存中并发执行,依次追加写入至同一张特征汇总表。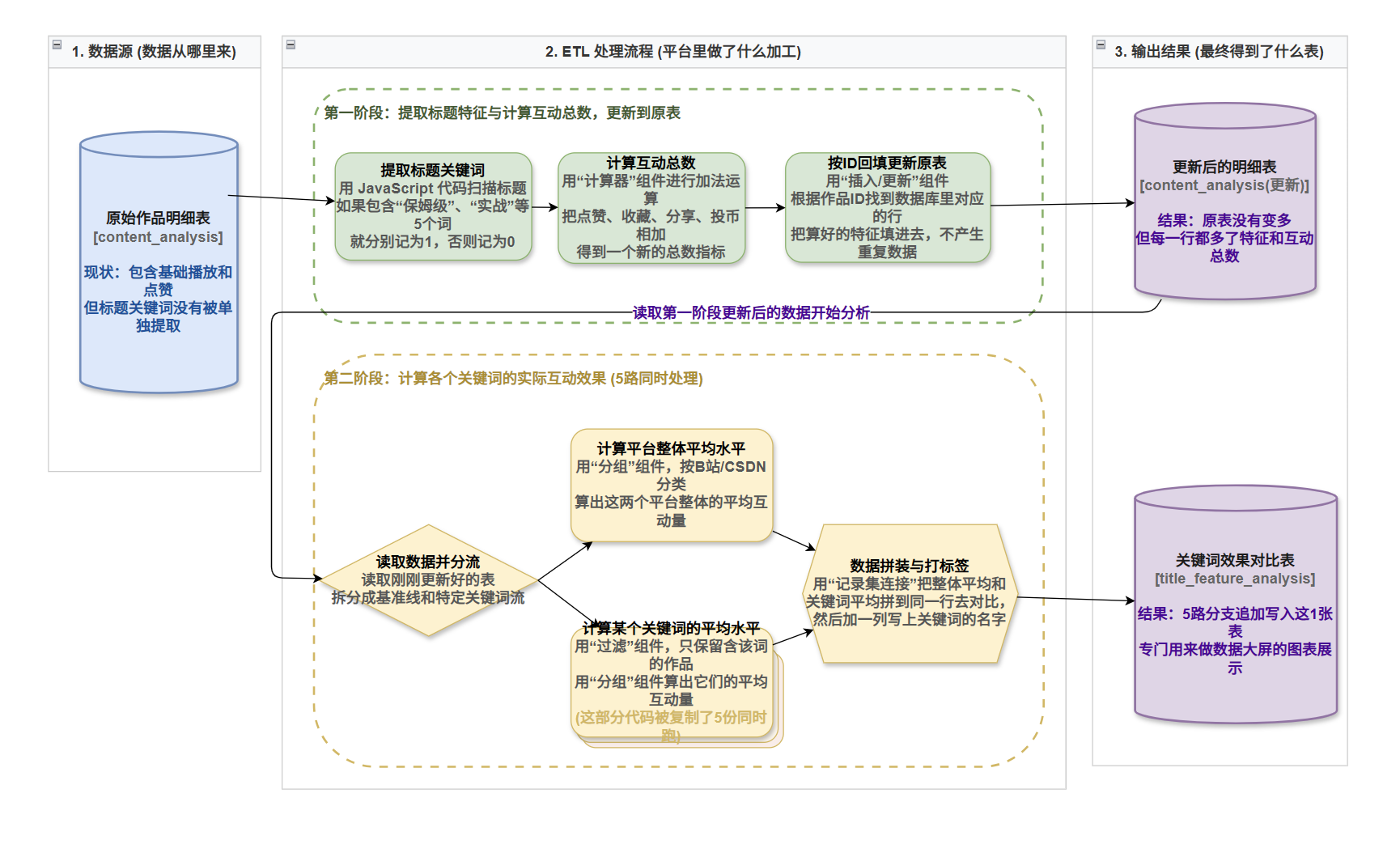
3. 实验保姆级详细步骤
3.1 阶段一:更新 content_analysis 表(特征提取与指标聚合)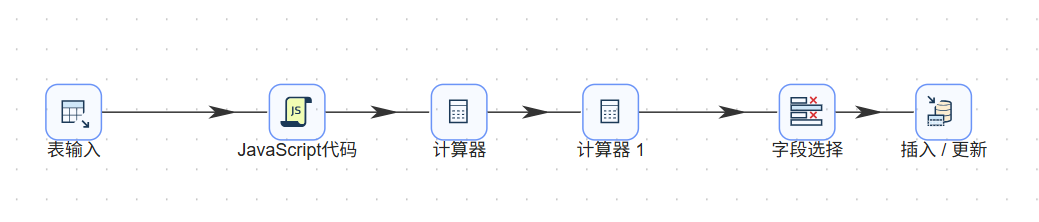
步骤 1:接入基础清洗底表
从组件库中拖入【表输入】组件,双击打开。配置数据库连接,并输入 SELECT * FROM content_analysis将全量有效明细数据抽取至ETL内存流中。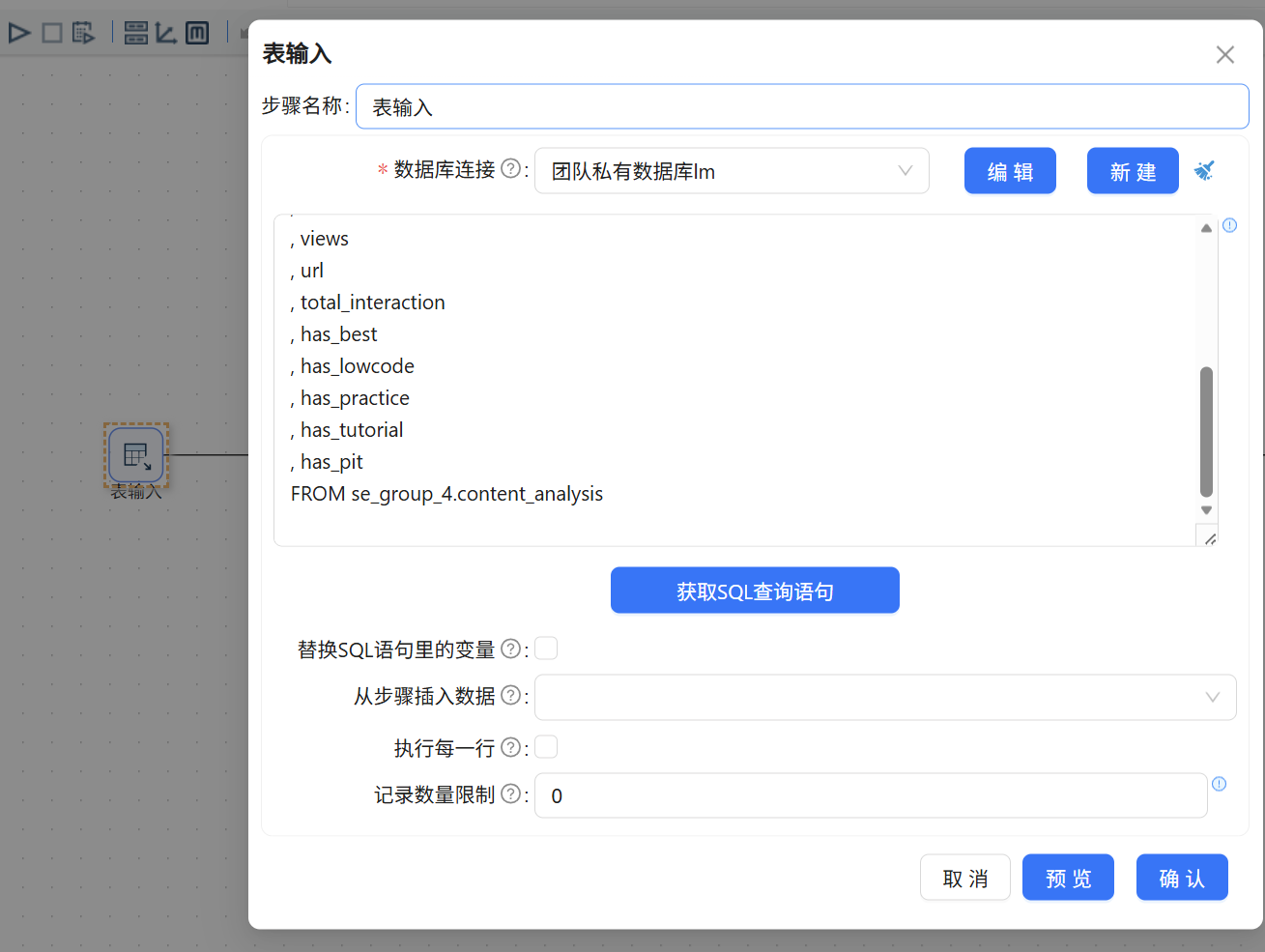
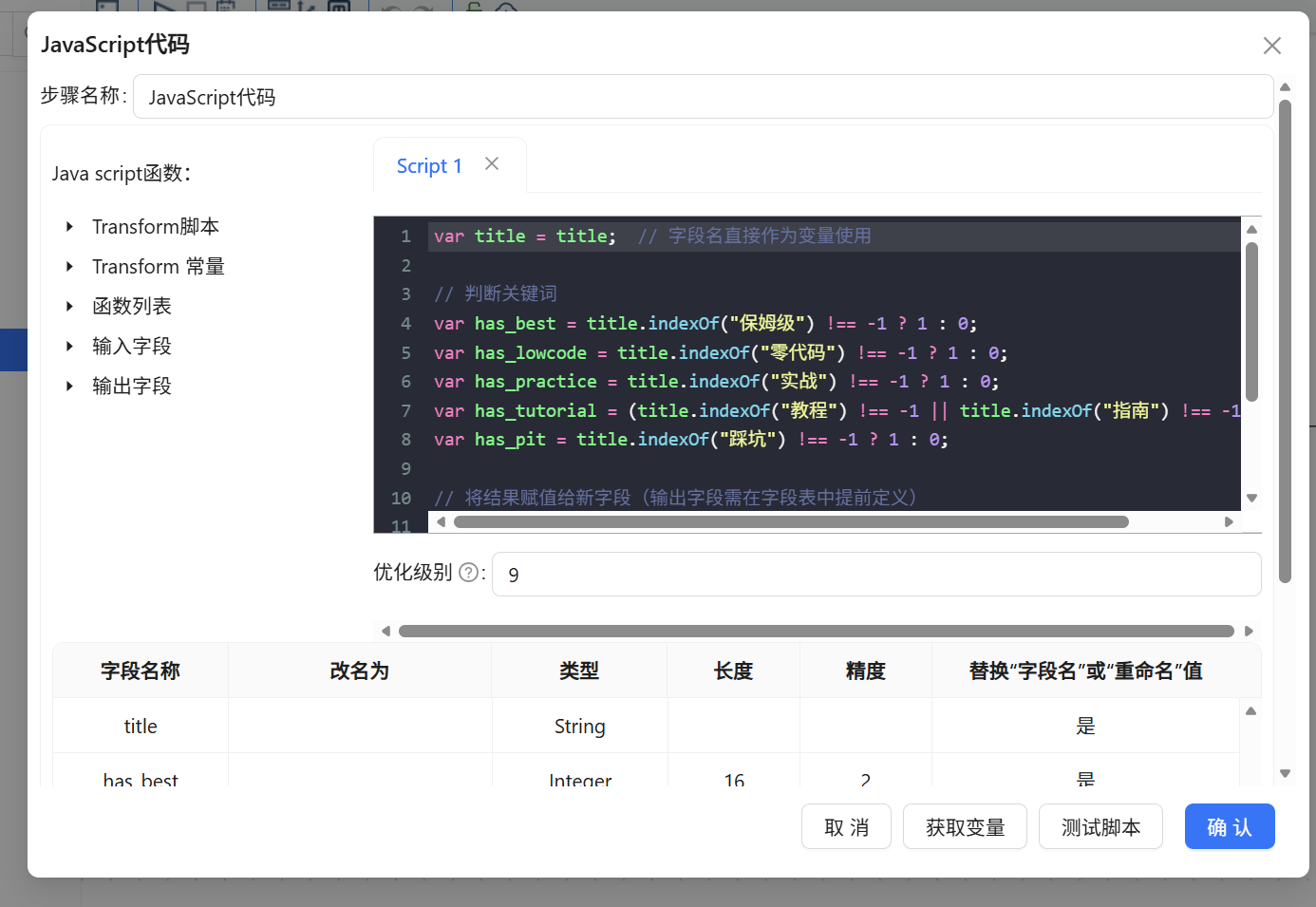
步骤 2:利用JS 提取非结构化文本特征
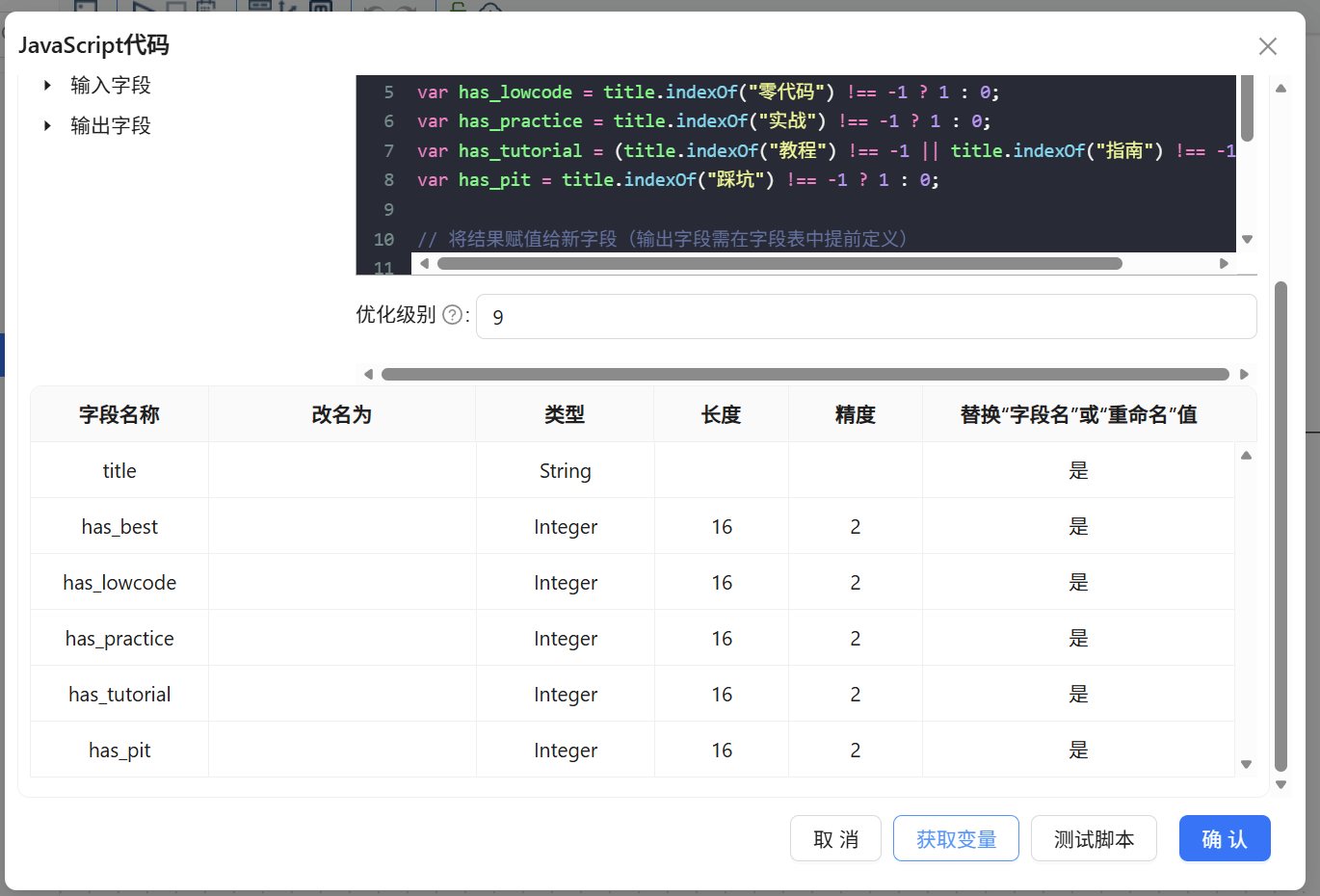
由于ETL内置的常规字符串处理组件难以胜任多条件复合逻辑(如:“包含A或B则为1,否则为0”),我们接入【JavaScript代码】组件,双击编辑,输入以下基于 indexOf() 方法的扫描脚本:
var title = title; // 将数据流中的 title 字段实例化为内部 JS 变量
// 核心提取逻辑:利用三元运算符进行关键词匹配 (命中赋1,未命中赋0)
var has_best = title.indexOf("保姆级") !== -1 ? 1 : 0;
var has_lowcode = title.indexOf("零代码") !== -1 ? 1 : 0;
var has_practice = title.indexOf("实战") !== -1 ? 1 : 0;
// 复合逻辑示例:包含"教程"或"指南"均视为同一特征类别
var has_tutorial = (title.indexOf("教程") !== -1 || title.indexOf("指南") !== -1) ? 1 : 0;
var has_pit = title.indexOf("踩坑") !== -1 ? 1 : 0;
// 将计算完毕的局部变量强制回写给底层数据流
has_best = has_best;
has_lowcode = has_lowcode;
has_practice = has_practice;
has_tutorial = has_tutorial;
has_pit = has_pit;
🔴 【极易踩坑警告】元数据参数配置:
代码写完后千万别直接点确认!你必须在组件底部的“字段名称”网格中,手动逐一添加这5个新字段(has_best等)。
- 类型: 选
Integer(长度16,精度2)。- 替换“字段名”或“重命名”值: 必须双击选择 “是”。若遗漏此项,引擎会将这些变量作为内部临时变量丢弃,新特征将无法注入后续数据流!
步骤 3:级联计算器突破底层参数瓶颈
业务要求的互动总数计算逻辑为:likes + favorites + shares + coins。
但【计算器】组件最多只支持3个入参(即 A+B+C)。我们必须采用级联运算:
-
串联第一个【计算器】:
-
在“新字段”列输入
interactions。 -
“计算”列选择
A + B + C。 -
字段A、B、C 分别下拉选择
likes、favorites、shares。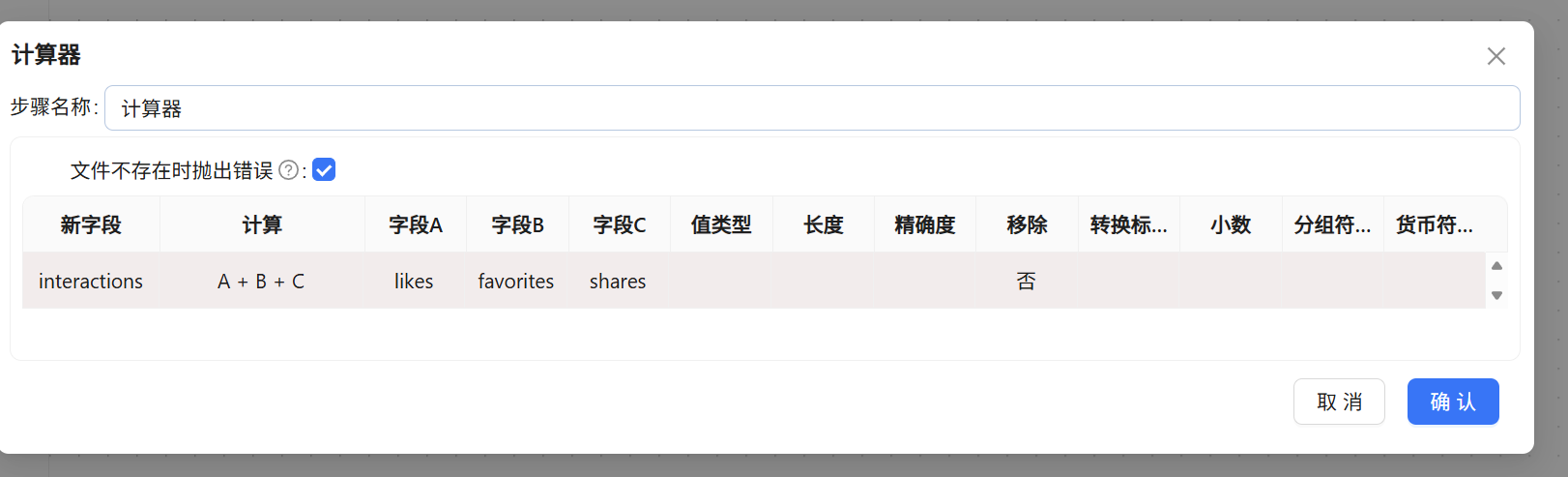
-
串联第二个【计算器 1】:
-
在“新字段”列依然输入
interactions。(系统为防止内存覆写,会自动将其变更为带后缀的interactions_1)。 -
“计算”列选择
A + B。 -
字段A选择上一步的
interactions,字段B选择coins。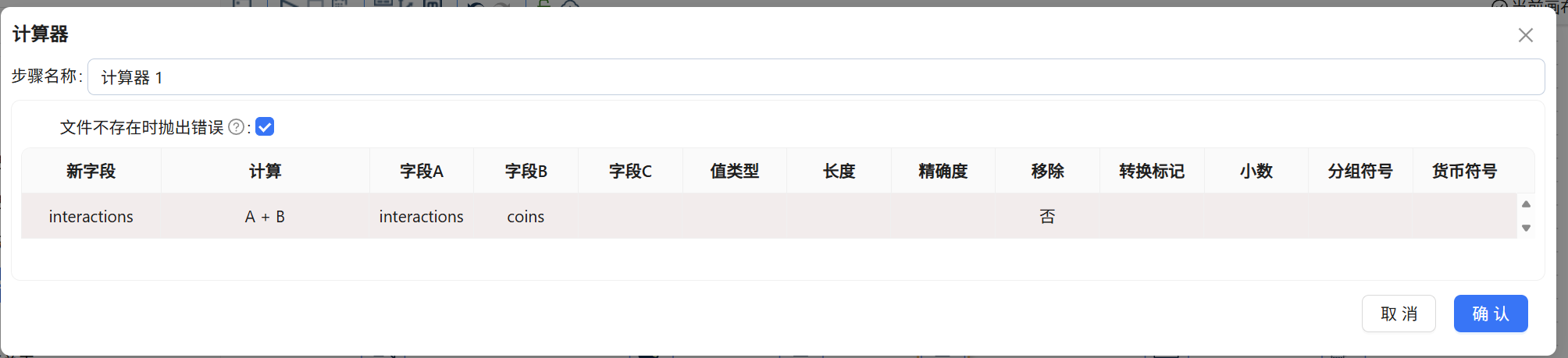
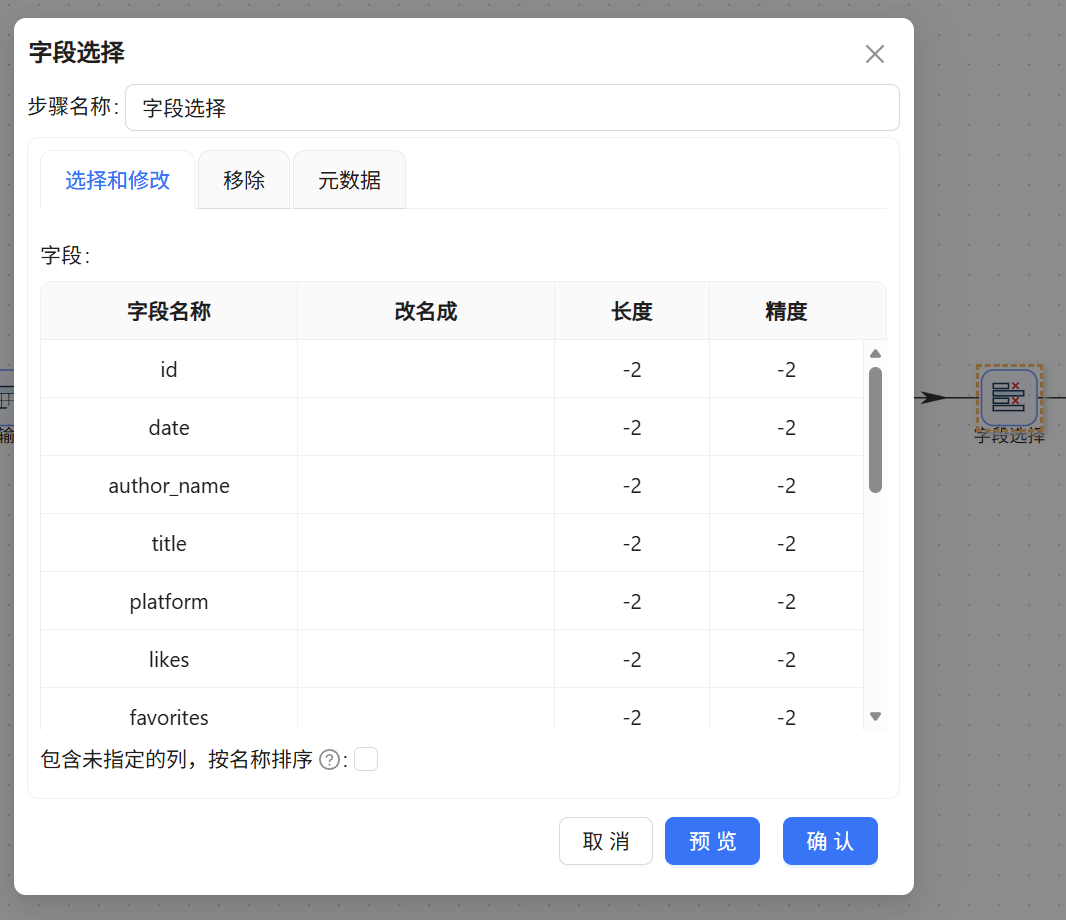
步骤 4:流内元数据规范化清洗
此时数据流中有冗余后缀,接入【字段选择】组件。
- 在“移除”标签页,将不需要的中间临时计算字段删除,保持数据流的纯净。
步骤 5:基于主键的幂等性安全回填
绝不能用【表输出】,否则重复运行会导致数据翻倍!接入【插入/更新】组件,指定目标表为 content_analysis。
- 用来查询的关键字(匹配机制): 添加一行:表字段选
id,比较符选=,流里的字段选id。这保证了引擎精准锚定唯一主键。 - 更新字段(字段映射):
将表字段total_interaction映射为流内的interactions;将其余5个has_xxx表字段逐一对应流里的has_xxx。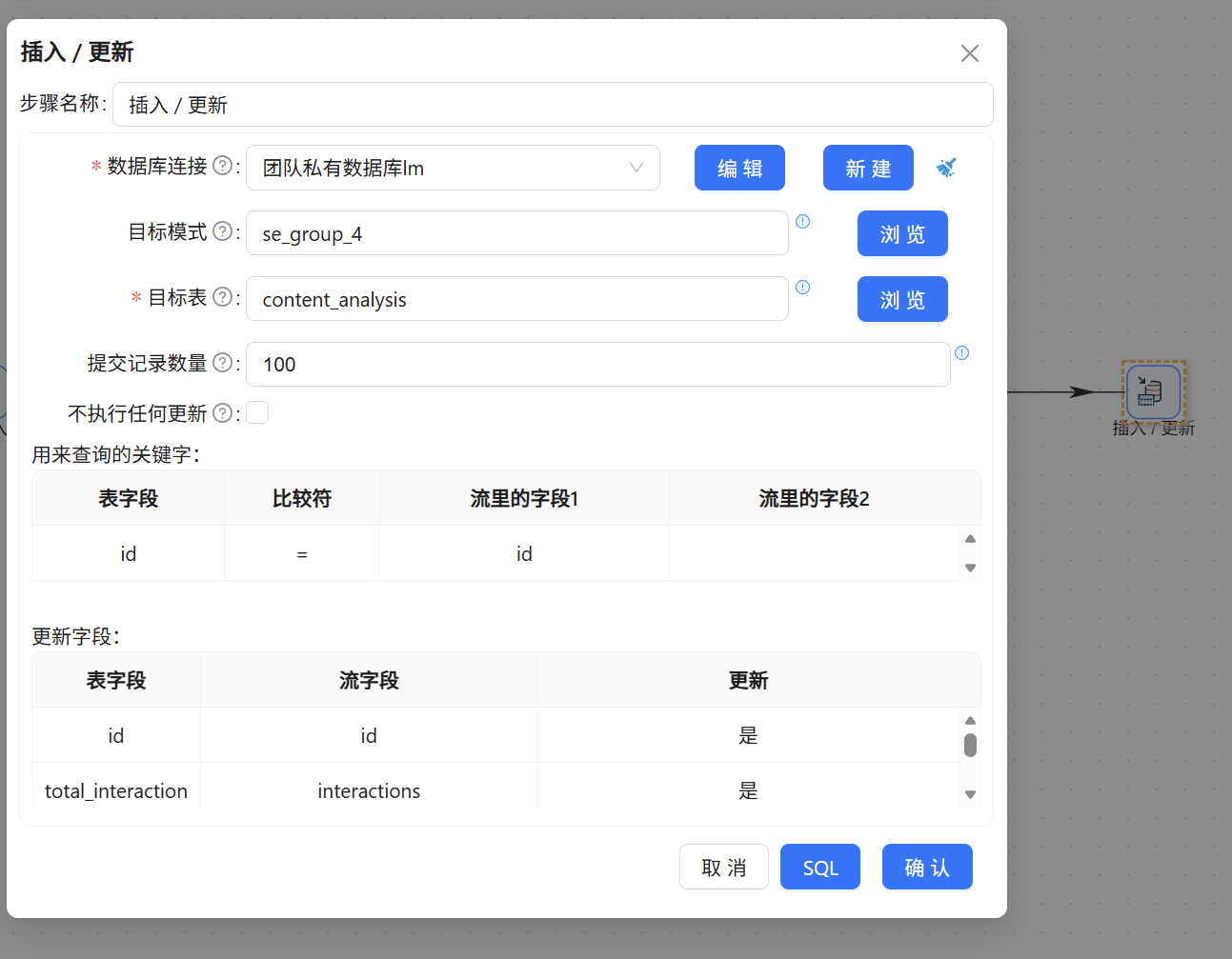
3.2 阶段二:输出关键词级别的特征汇总表(5路高并发流)
目标表 title_feature_analysis 结构包含:platform (平台)、feature_name (关键词)、overall_avg (大盘均值)、avg_interaction (特征均值)、sample_count (样本数)。
步骤 1:构建标准单路聚合流(以“保姆级”为例)
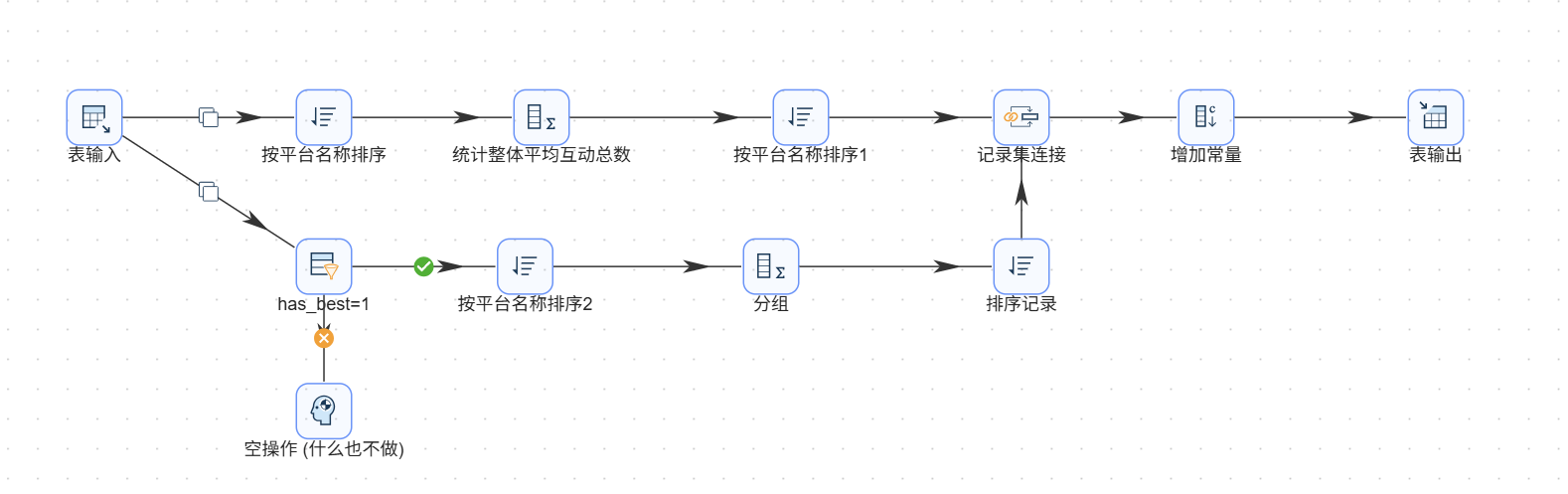
在画布上,我们需要为单一关键词构建一个 Y字形 的汇合流:
- 源头分流: 从一个【表输入】节点引出两条独立连线。
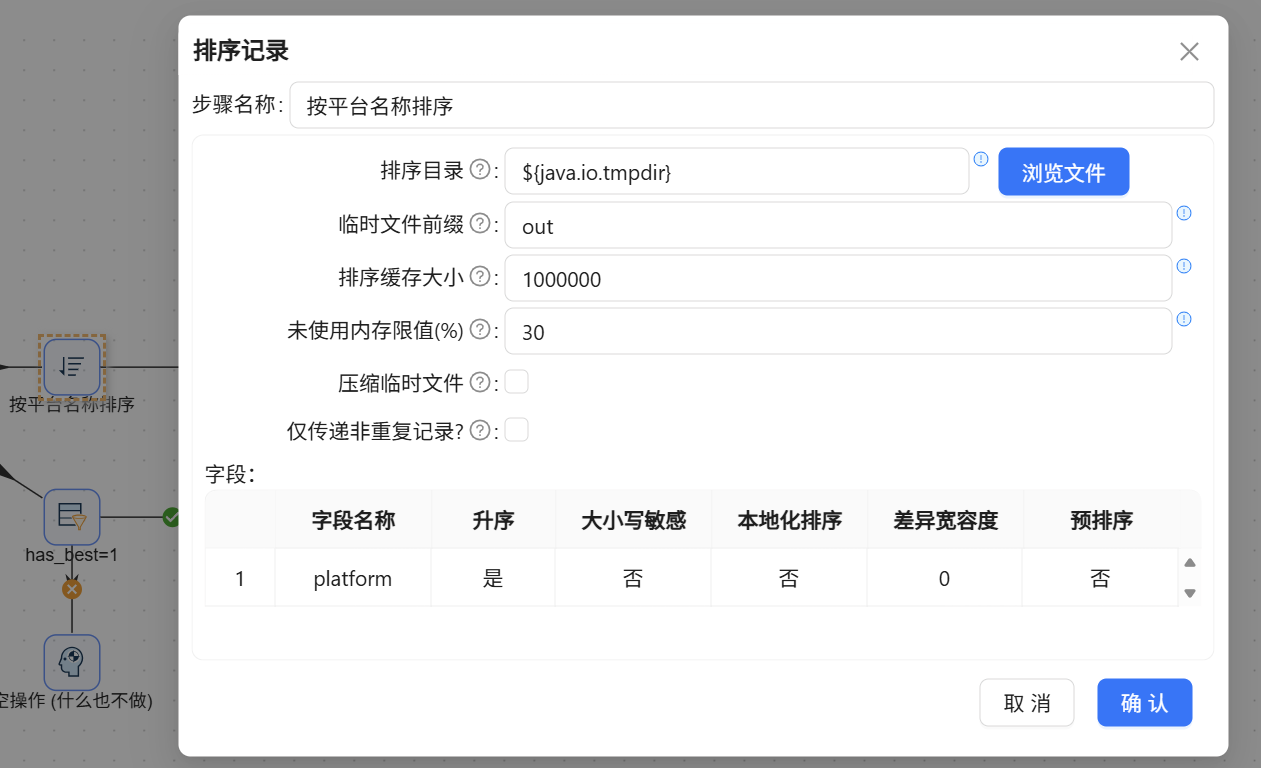
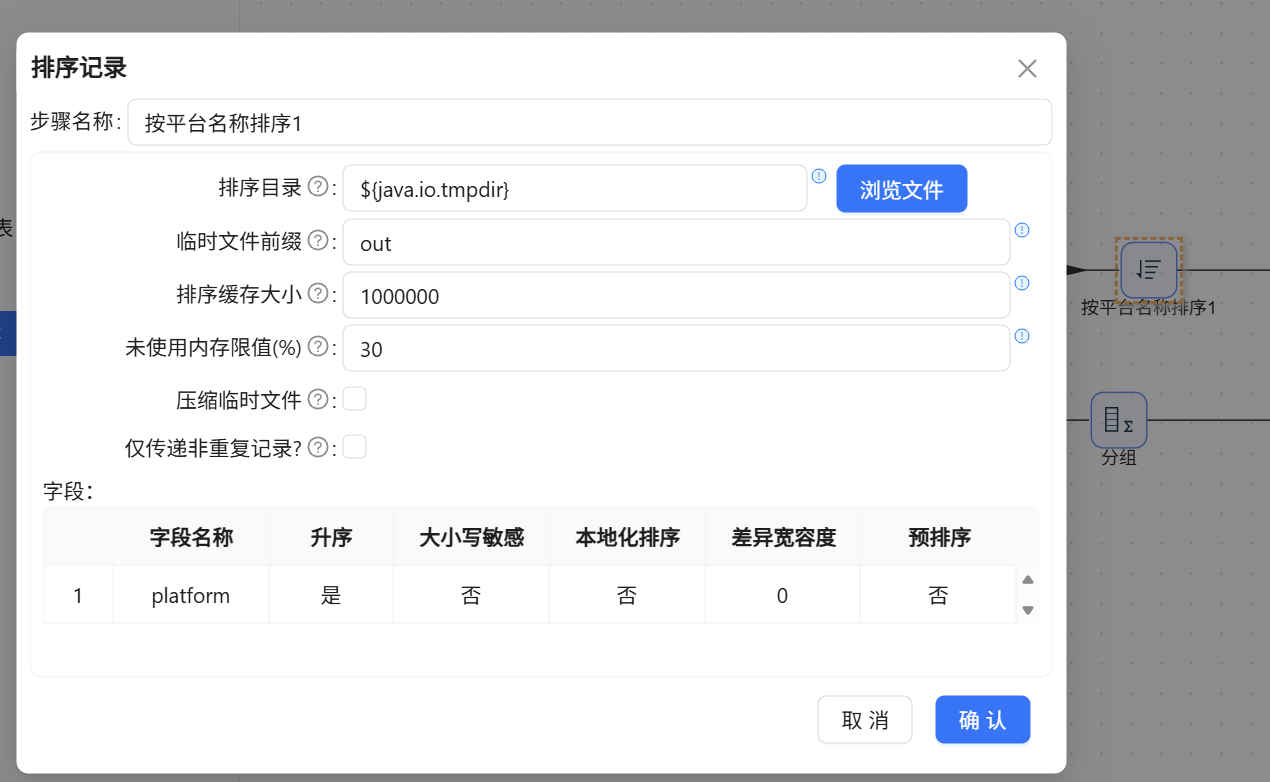
- 基准支流(整体大盘): 1. 接入【按平台名称排序】(分组前必须排序)
-
接入【分组】算子,分组字段选
platform,聚合字段选total_interaction(聚合方式:平均,命名为overall_avg)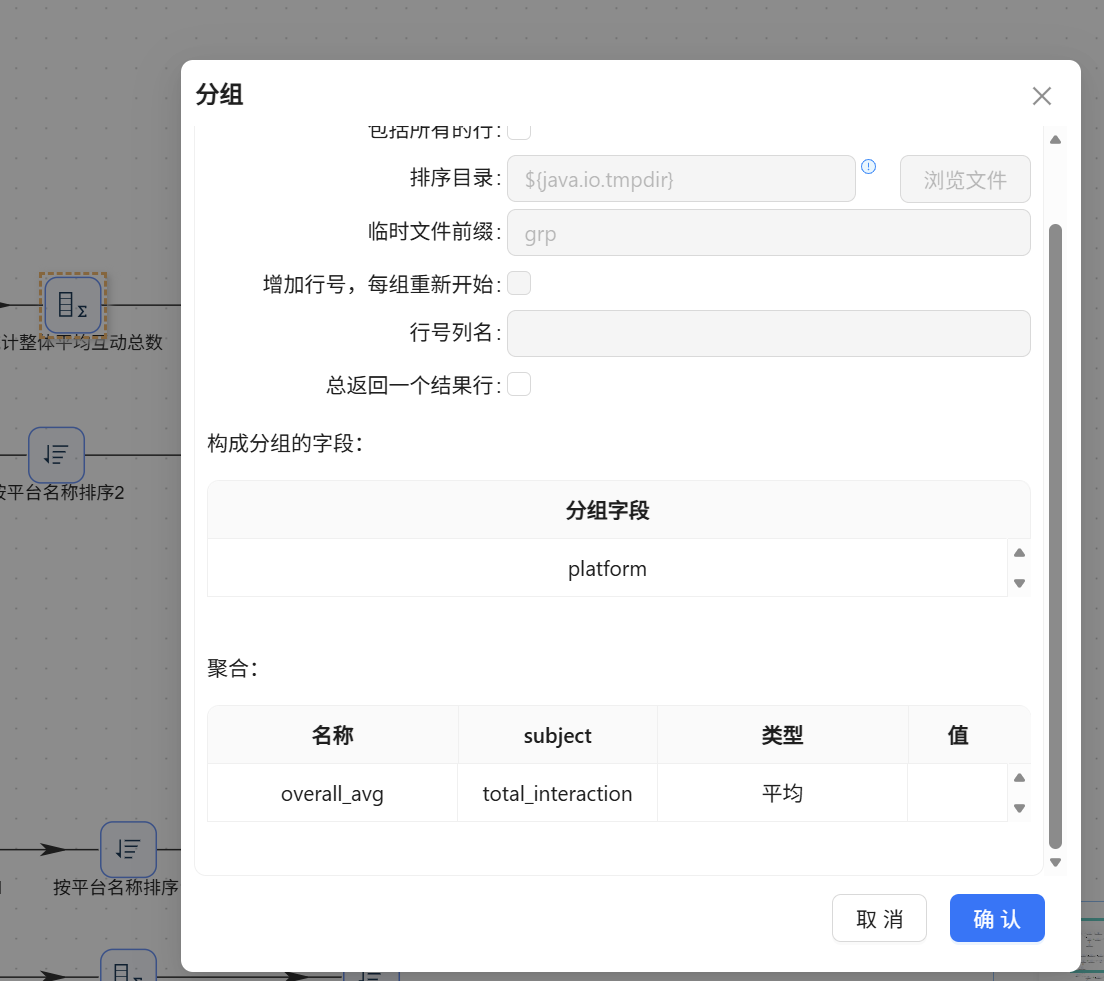
-
再次接入【按平台名称排序 1】待合并
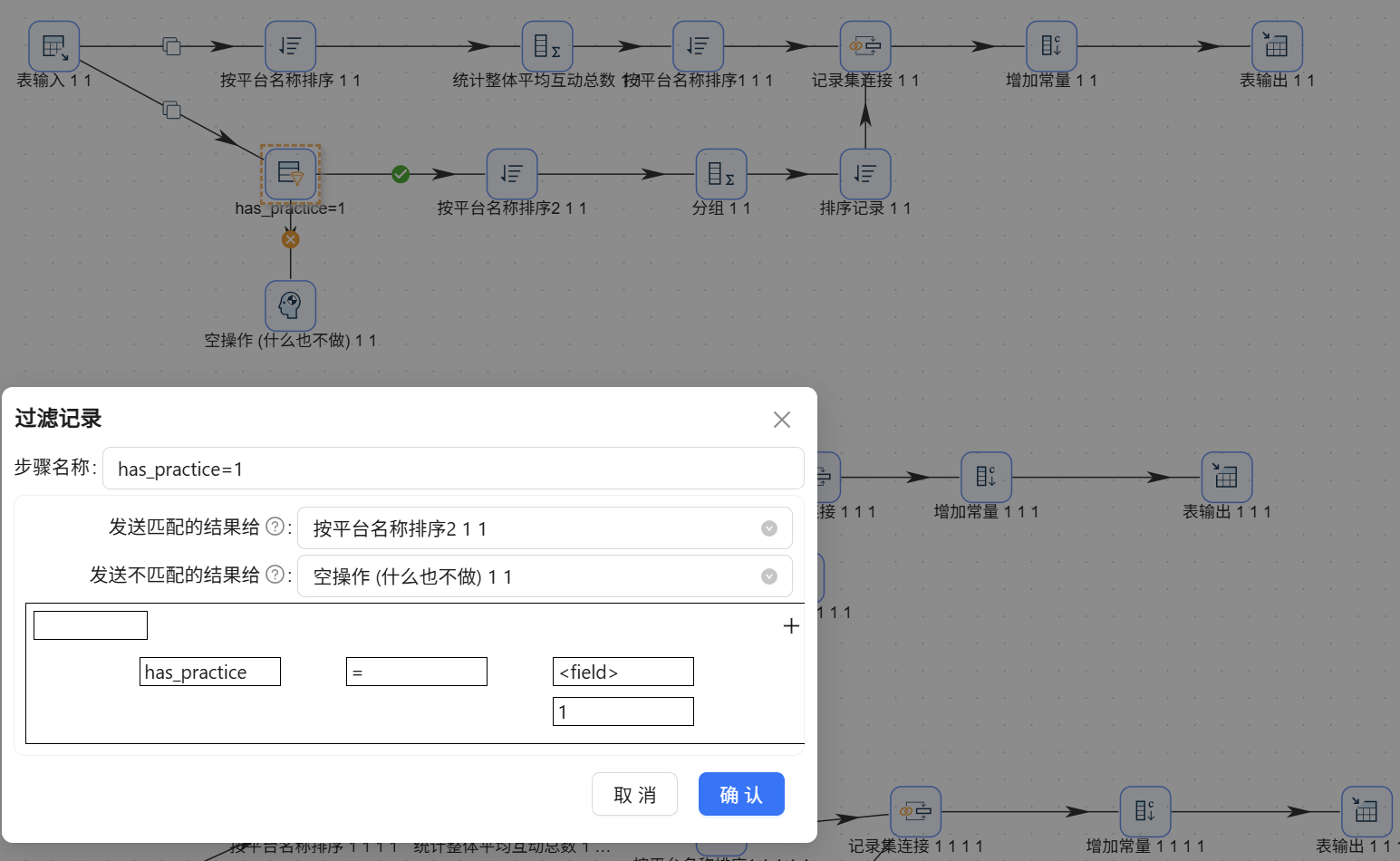
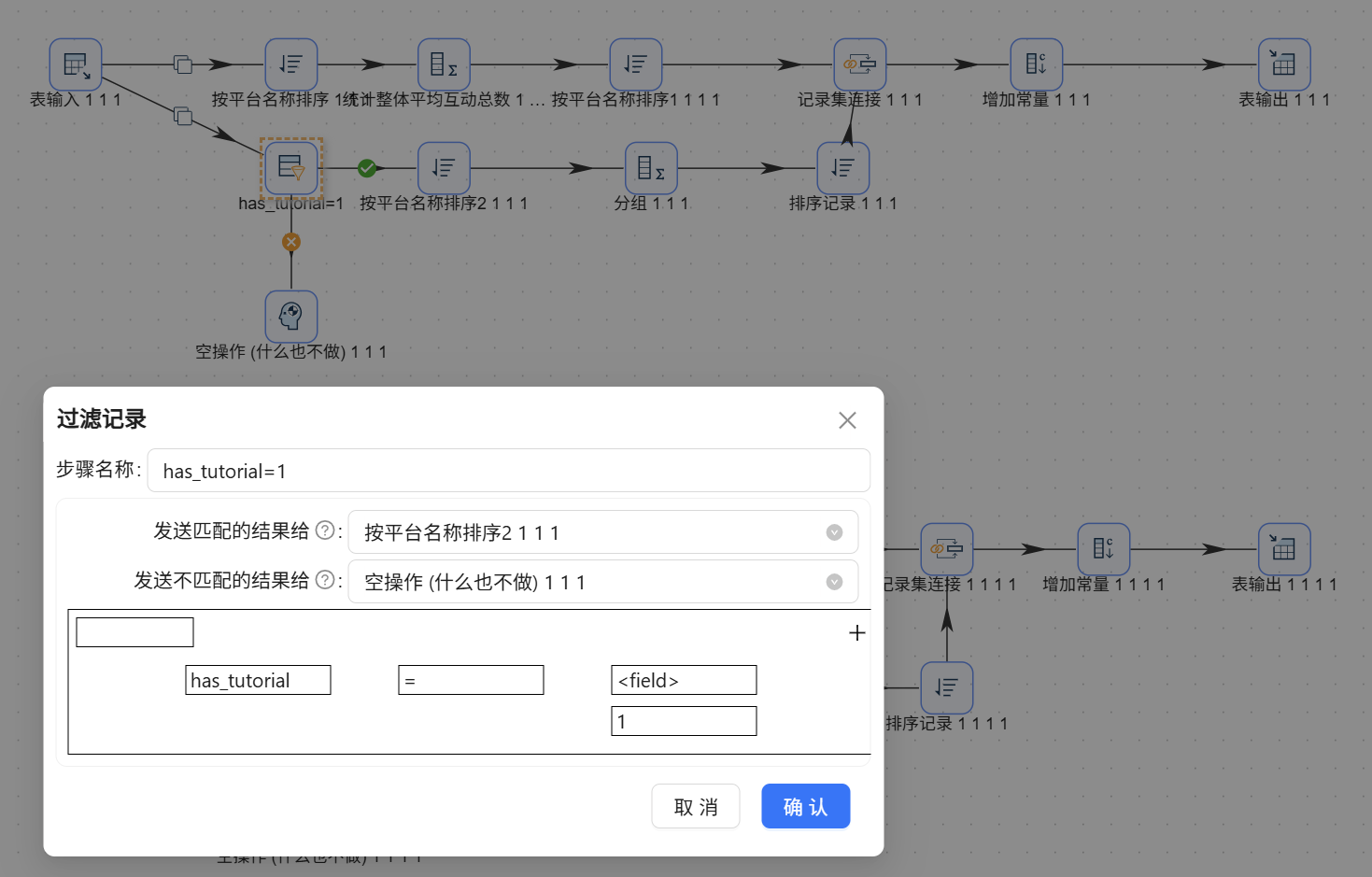
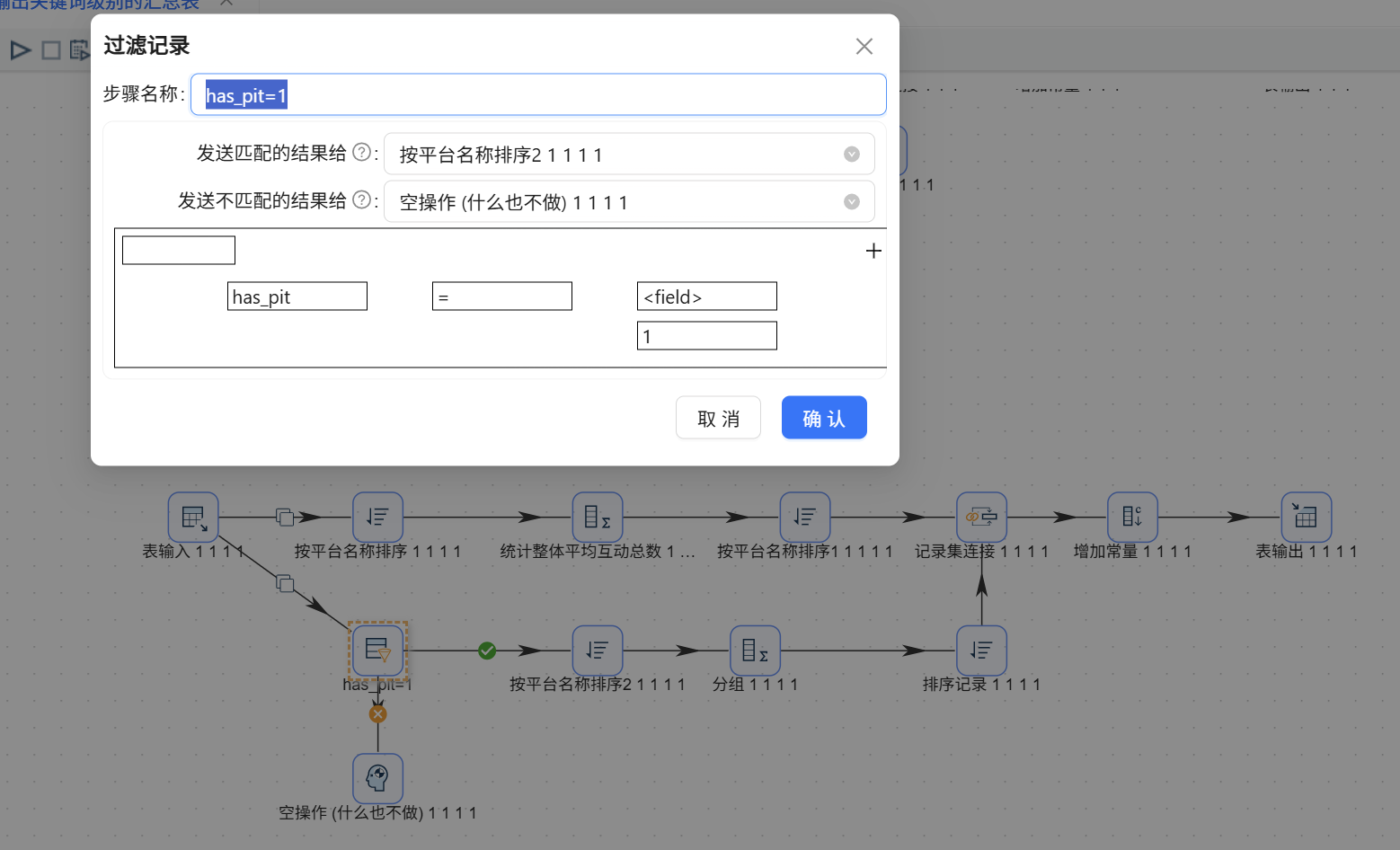
- 特征支流(局部特征): 1. 接入【过滤记录】,设置条件:
has_best = 1。为 false 的数据流向“空操作”丢弃。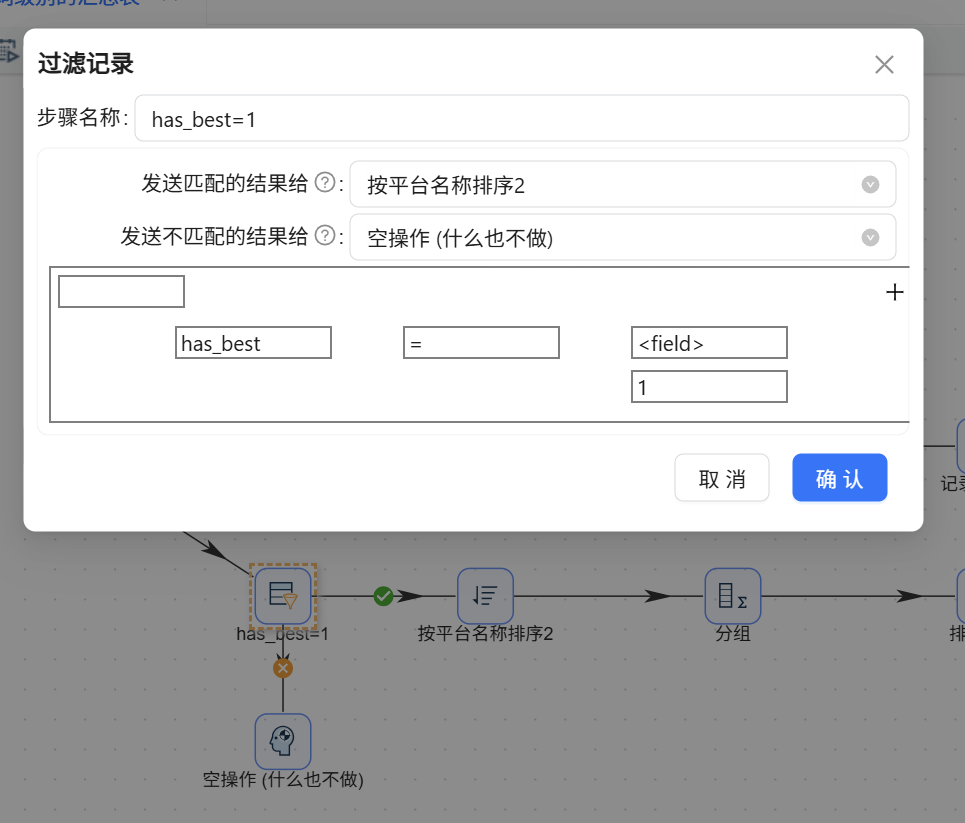
-
数据流经【按平台名称排序 2】
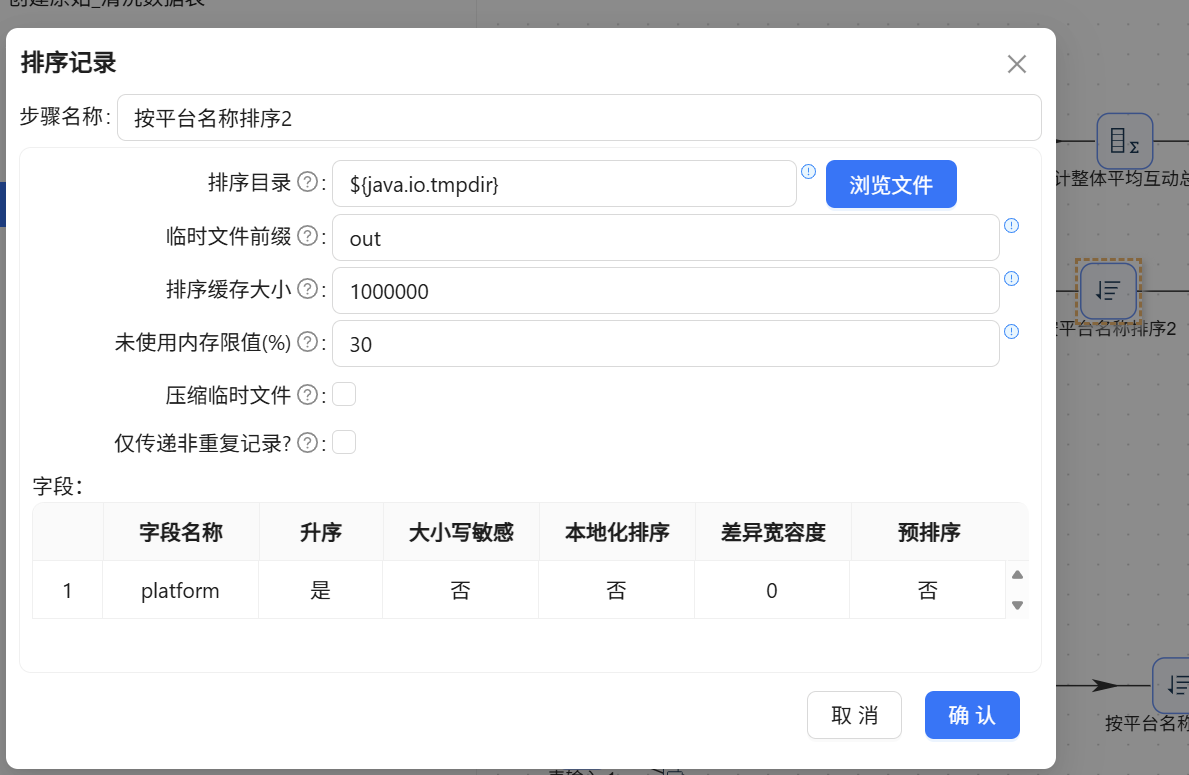
-
接入【分组 1】算子,分组字段选
platform。聚合字段一:total_interaction(均值,命名为avg_interaction);聚合字段二:id(计数,命名为sample_count)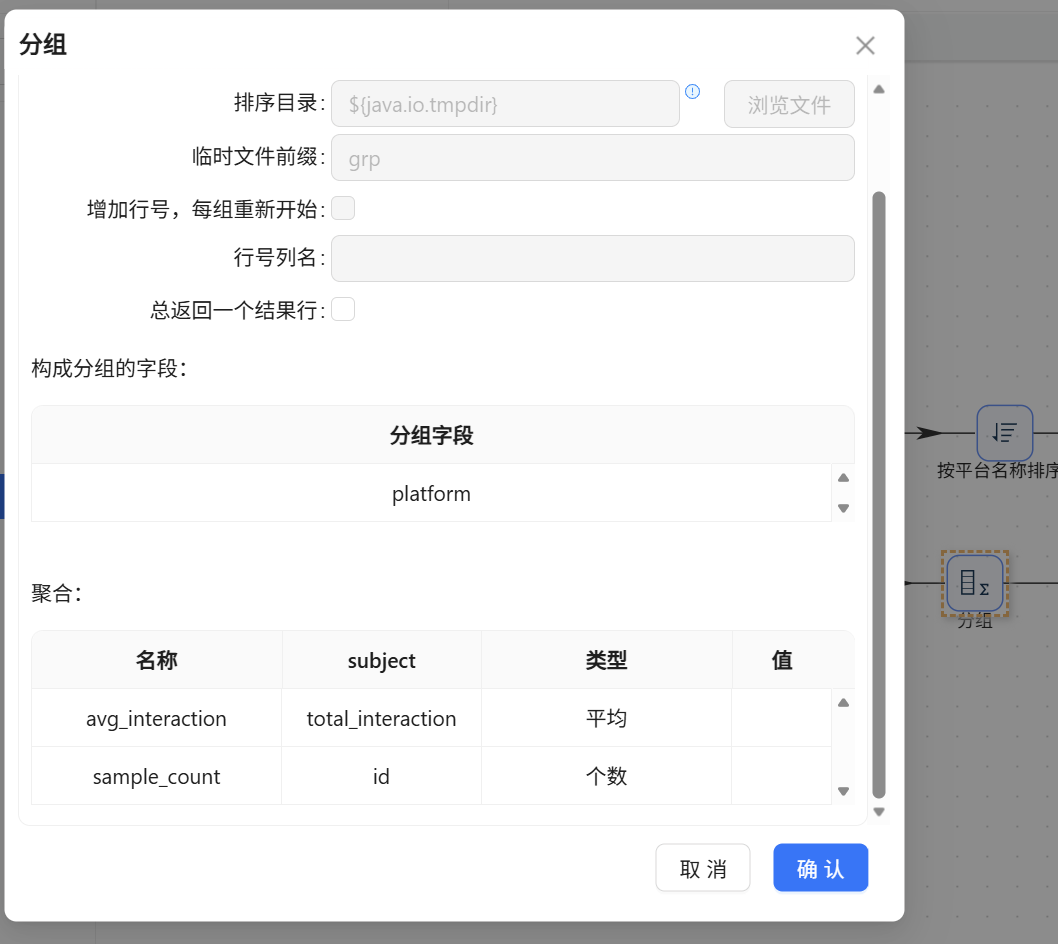
-
接入【排序记录 1】待合并。
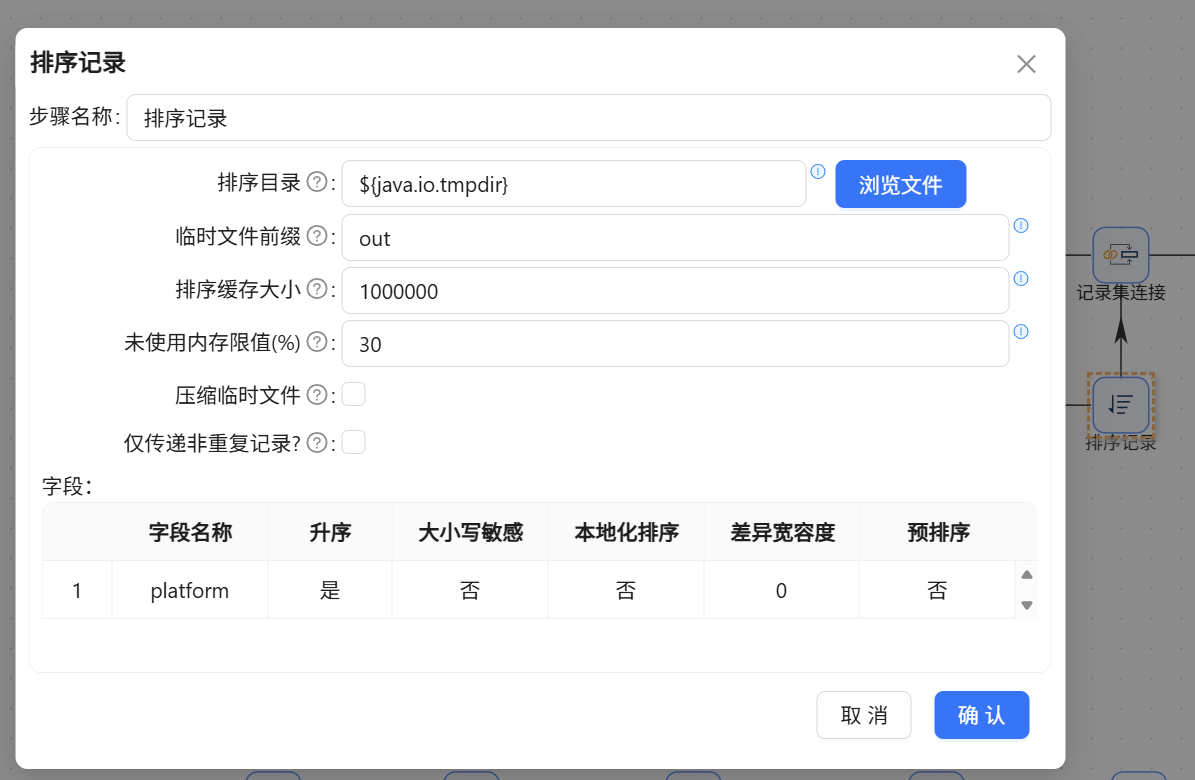
- Y字合流(记录集连接): 两条支流在【记录集连接】算子交汇。连接类型选择
INNER JOIN,连接字段双边均选择platform。至此,宏观基准线与局部均值拼接至同一行。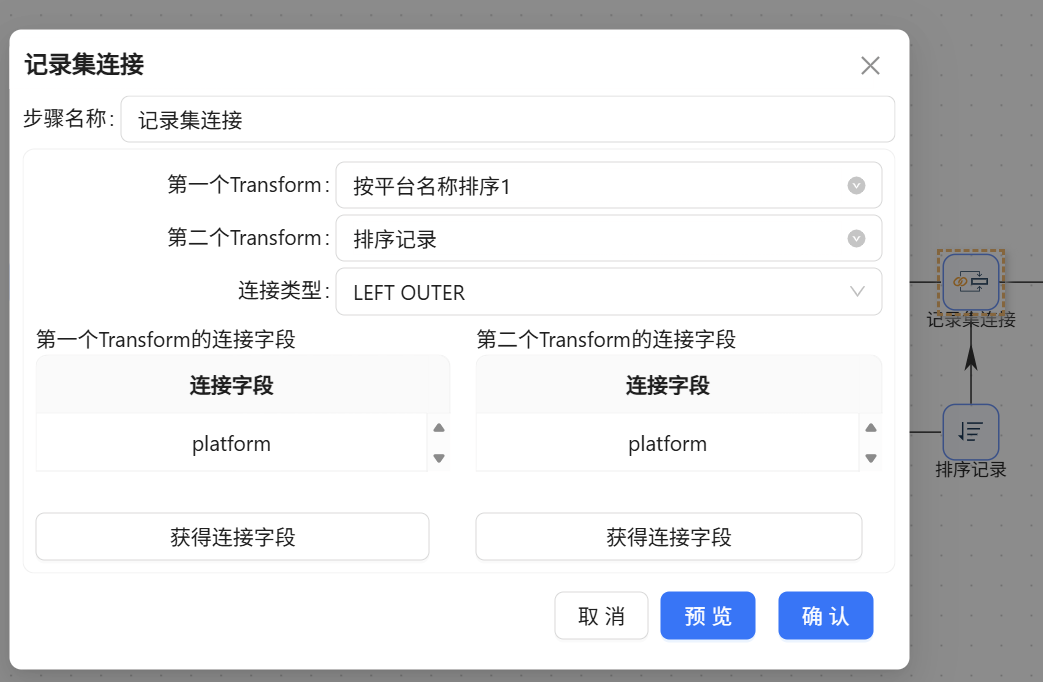
步骤 2:特征常量强制打标
聚合操作会丢失业务维度,必须在合流后接入【增加常量】组件。
- 新增字段:
feature_name。 - 类型设为:
String。 - 值填入:
保姆级。这就为该行记录打上了专属标签。
步骤 3:防清空追加输出
接入【表输出】组件,指定写入 title_feature_analysis。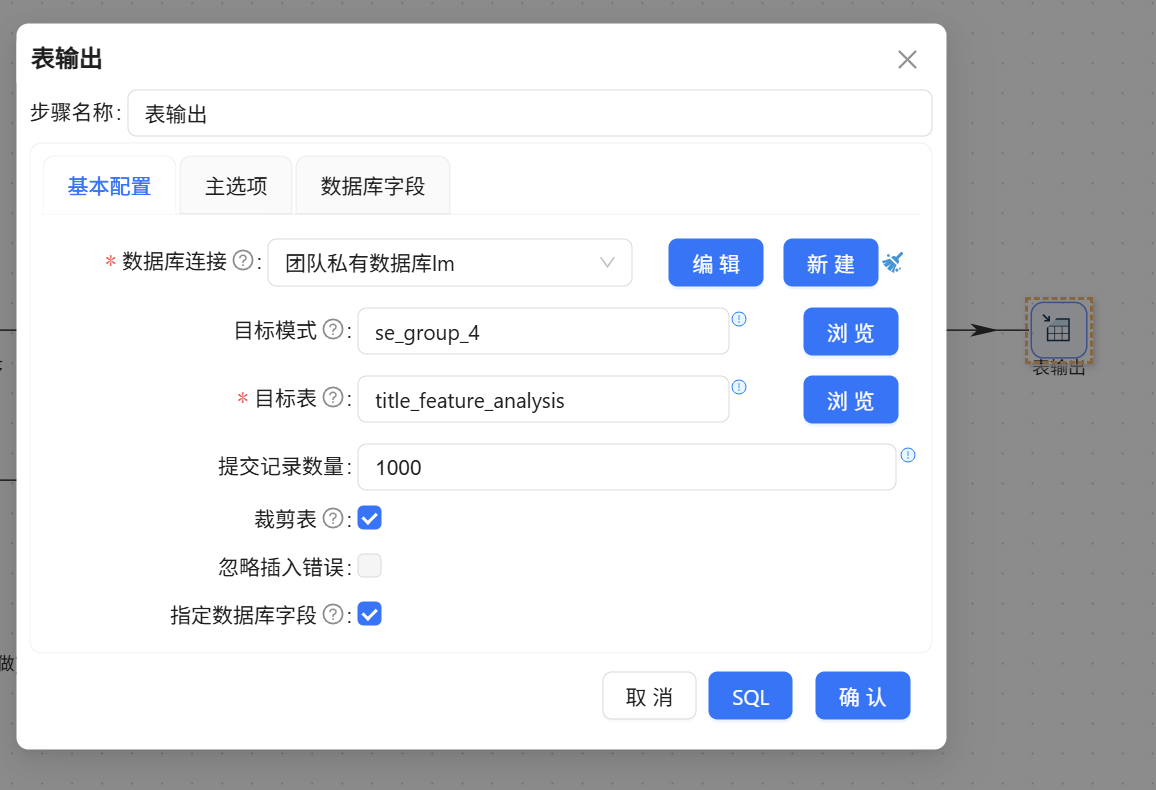
步骤 4:全量并发克隆与微调
将上述跑通的 Y字形单路流整体用鼠标框选,复制(Ctrl+C)并粘贴(Ctrl+V) 4 次。针对复制出的每一路新分支,仅需执行两处极其简单的微调:
- 改过滤条件: 将【过滤记录】的拦截条件依次修改为
has_lowcode = 1、has_practice = 1、has_tutorial=1、has_pit=1 - 改常量标签: 将【增加常量】的值依次修改为
零代码、实战、教程、踩坑。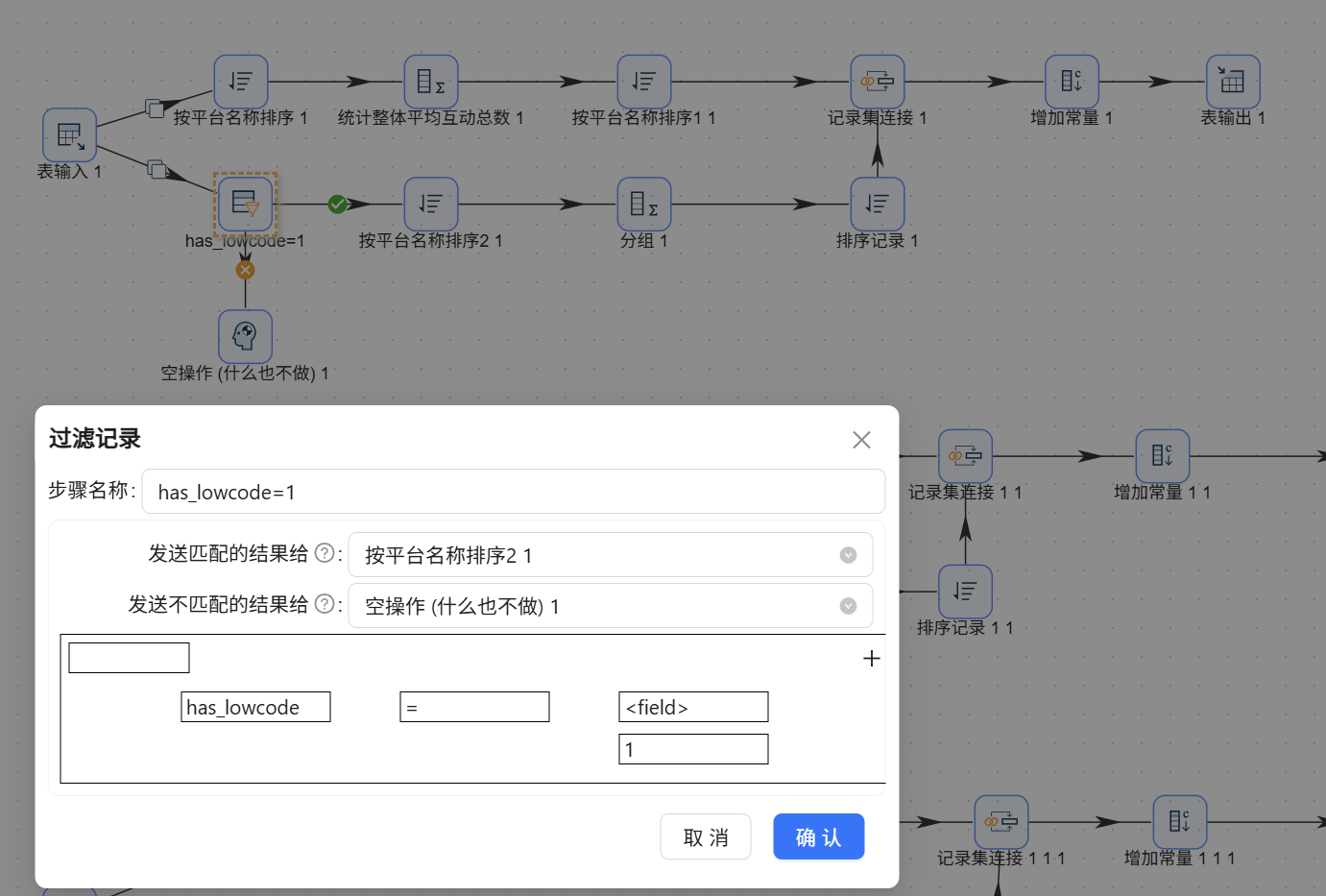
点击顶部的“▶ 运行”按钮!此时,ETL引擎的多线程机制被彻底激活,5条平行的主数据流将高并发执行,最终有序地将5个特征维度的汇总数据追加写入目标数据库。
4. 实验问题与解决
问题:底层计算算子的输入参数瓶颈
- 现象: 在计算
互动总数时,业务公式包含4个加数(点赞、收藏、分享、投币),但平台【计算器】的A+B+C模式无法容纳。 - 解决思路: 采用级联运算策略(Cascading)。先用一个计算器对前三项求和,将输出的临时变量传递给第二个计算器与第四项相加,最后配合【字段选择】组件重命名,完美化解底层算力限制。
5. 实验总结
本次实战是一次典型的从“理论分析模型”向“复杂数据工程”落地的跨越。我们通过组件拖拽和少量JS脚本,成功规避了诸多底层技术限制。
- 在纵深维度上: 【JavaScript代码】与【插入/更新】的黄金组合,为我们展示了如何在保障历史数据资产安全的前提下,优雅且高效地为海量底表打上NLP衍生标签。
- 在横向拓扑上: 极具代表性的【5路并发 Y字流】架构,完美诠释了数据集成开发中“解耦”的工程美学。它用画布空间的复杂度换取了引擎计算的极高吞吐率,让海量数据的多维特征交叉对比变得异常清晰。
至此,我们的数据仓库中已经备齐了高价值的结构化弹药。
在下一期的进阶实战中,我们将转战可视化仪表盘,通过直连本期产出的 title_feature_analysis 宽表,零代码搭建出极具商业洞察力的“标题特征提升倍率条形图”,用数据直观揭秘:
到底选用什么核心词,才能让你的技术博文流量倍增!
后续我会继续更新特征工程与大屏联动的实战教程,如果上面的内容对你有帮助,请点赞、收藏、转发,关注我,共同进步!
^ - ^

一站式 AI 云服务平台
更多推荐


 6
6 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)