
助睿实验作业7-1-自媒体作品原始数据清洗入库ETL加
一、实验背景
1. 实验目的
本次实验依托助睿数智零代码平台,完成自媒体作品原始数据的ETL清洗与入库操作,核心学习与实操目的如下:
1. 掌握零代码平台完整ETL流程,包含CSV数据接入、脏数据过滤、空值处理、字段标准化、数据库批量写入等核心操作;
2. 对原始自媒体爬虫数据进行规范化清洗,统一字段名称、剔除冗余字段、修复空值异常,实现数据结构化标准化;
3. 将清洗后的高质量有效数据写入数据库数据表,为后续7-2标题特征构建、指标计算实验提供标准数据源;
4. 熟练排查流水线运行报错、数据空值、字段丢失、数据匹配失败等常见问题,培养数据预处理思维。
2. 实验环境
1. 实验平台:助睿数智(Uniplore)一站式数据科学实验平台,覆盖数据接入、ETL处理、机器学习建模到可视化分析的全链路Agentic零代码数据智能平台;
2. 平台地址:https://lab.guilian.cn/
3. 实验数据:自媒体作品数据明细CSV文件,包含作品日期、作者、标题、发布平台、点赞、收藏、分享、投币、播放量、作品链接及部分冗余字段;
4. 存储环境:平台内置MySQL数据库,数据存储模式为se_group_2,目标数据表为content_analysis。
3. 实验整体流程
本次实验采用标准ETL数据加工逻辑:CSV文件原始数据读取 → 过滤无效脏数据 → 替换NULL空值 → 字段重命名、剔除冗余字段 → 标准化数据批量入库,完成自媒体原始数据清洗落地,为后续特征工程实验奠定数据基础。
二、实验步骤
步骤1:新建流水线,接入CSV数据源
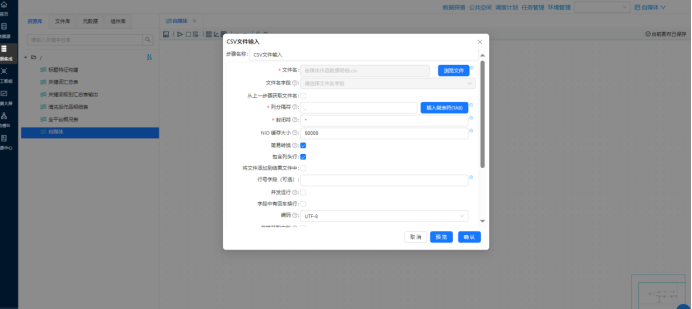
操作说明:登录助睿数智平台,新建Pipeline流水线,命名为「自媒体」,拖拽【CSV文件输入】组件,上传实验指定的自媒体作品数据明细CSV文件。
配置要点:开启跳过表头第一行设置,文件编码选择UTF-8,以英文逗号为分隔符,自动解析全部原始数据字段,完成原始数据批量读取。
步骤2:过滤无效脏数据
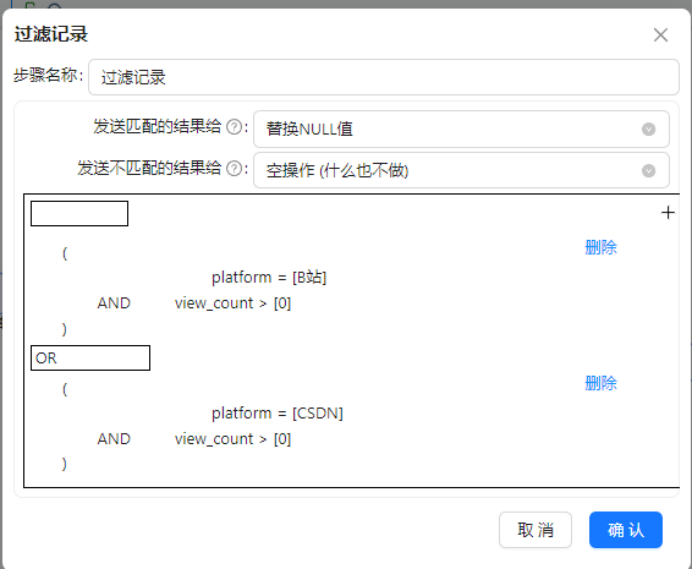
操作说明:在流水线中添加【过滤记录】组件,连接CSV输入组件,对原始数据进行筛选,剔除无分析价值的脏数据。
配置要点:设置过滤条件,剔除标题为空、播放量为0的无效作品数据,仅保留信息完整、具备分析意义的有效数据,提升入库数据质量。
步骤3:空值统一替换处理
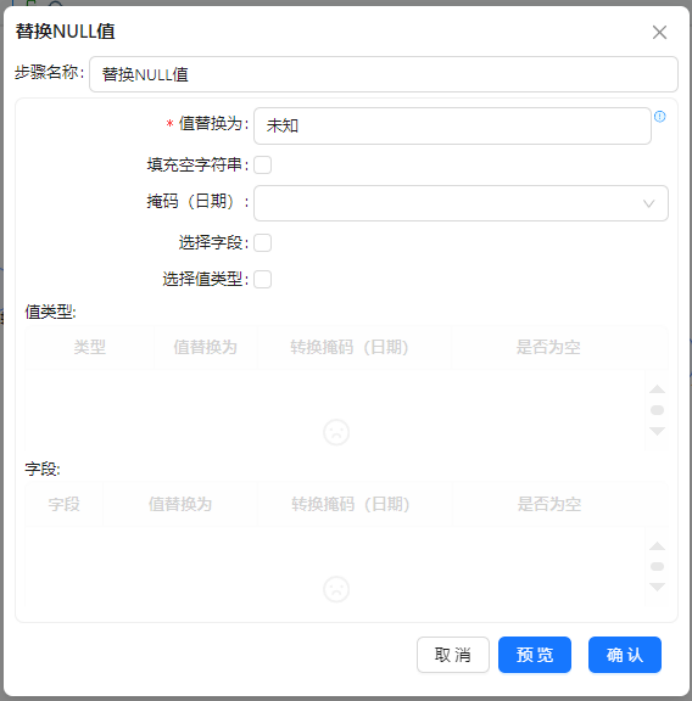
操作说明:添加【替换NULL值】组件,对接过滤后的有效数据流,统一处理数值字段空值问题,规避后续计算报错。
配置要点:将点赞、收藏、分享、投币、播放量等所有互动数值字段的NULL空值统一替换为0,文本字段保留原始内容不做修改,保证数值字段可正常参与后续运算。
步骤4:字段标准化处理
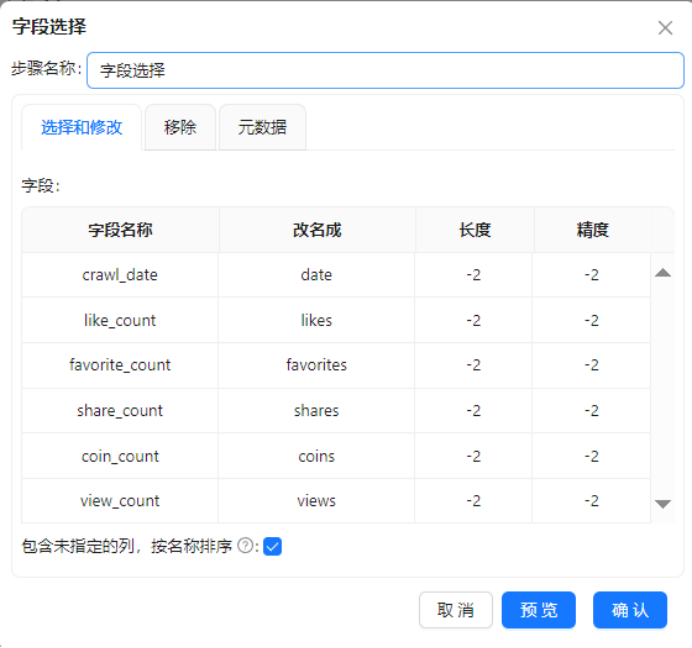
操作说明:添加【字段选择】组件,完成字段重命名、冗余字段删除、字段精简等标准化操作,统一数据结构。
配置要点:1. 字段重命名映射:crawl_date→date、like_count→likes、favorite_count→favorites、share_count→shares、coin_count→coins、view_count→views;2. 勾选「包含未指定的列,按名称排序」,自动保留作者名、标题、平台、链接等核心文本字段;3. 移除agree_count、source_file等冗余无用字段,最终保留10个核心业务字段。
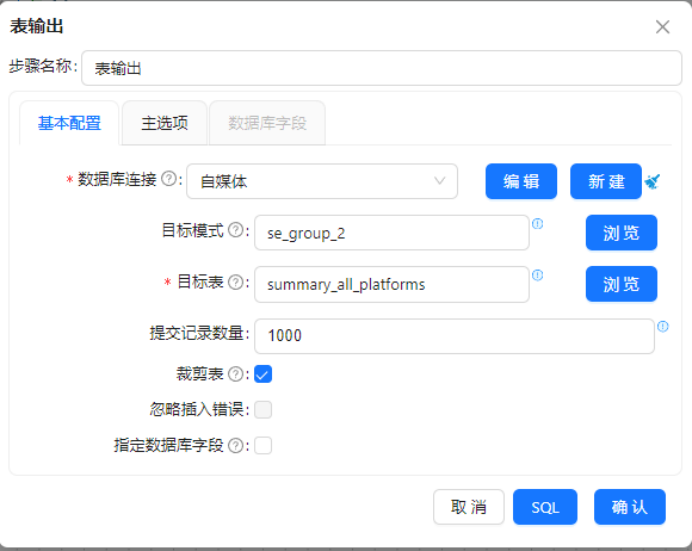
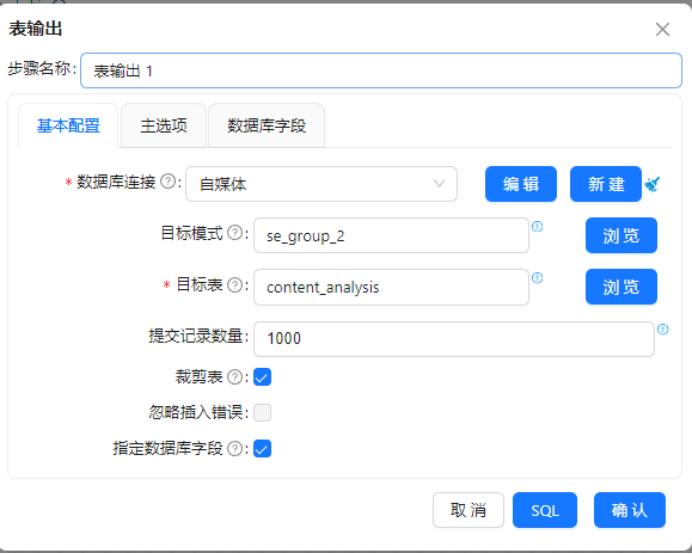
步骤5:配置表输出,批量数据入库
操作说明:添加【表输出】组件,对接字段选择输出数据流,配置数据库连接信息,将清洗完成的标准化数据批量写入目标数据表。
配置要点:数据库连接选择「自媒体」,指定模式se_group_2、目标表content_analysis;批量提交条数设置为1000,提升入库效率;流字段与数据表字段一一映射,数据库自增主键id无需手动配置,由系统自动生成;不开启截断表,防止误删有效数据。
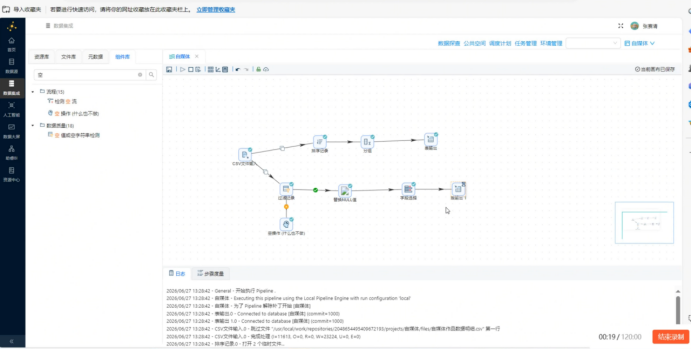
步骤6:运行流水线并校验数据
操作说明:保存所有组件配置,完整运行ETL流水线,查看执行日志,运行结束后进入平台元数据页面预览数据表,验证入库结果。
配置要点:等待流水线无报错执行完毕,核对日志数据处理条数,确认数据完整入库,无丢失、无异常。
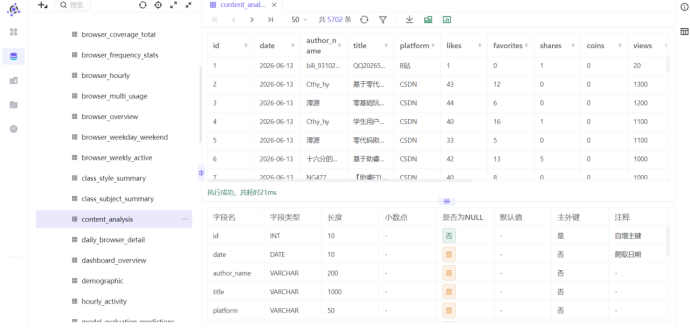
三、实验结果
1. 流水线执行日志结果
本次流水线全程无报错、无数据异常,核心执行日志如下:
CSV文件输入读取原始数据11613条,经过过滤、空值处理、字段筛选后,最终筛选出5702条有效合规数据,全部成功写入数据库。流水线总耗时1.166秒,数据处理高效稳定,E=0无任何异常报错。
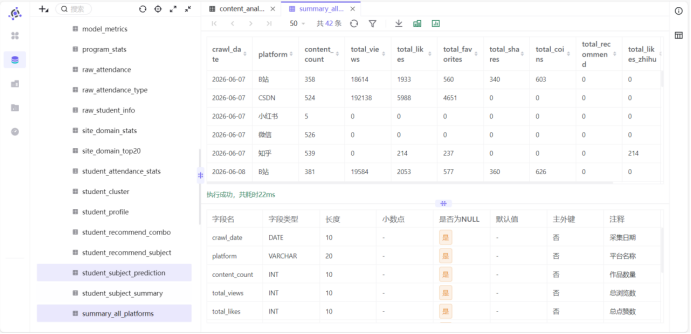
2. 数据入库验证结果
通过元数据预览content_analysis数据表,结果符合实验预期:
1. 文本类字段(日期、作者、标题、平台、作品链接)均保留真实原始数据,无大面积空值;
2. 所有互动数值字段空值已统一填充为0,数据格式规范,满足后续计算要求;
3. 数据表无冗余字段,仅保留核心业务字段,数据结构精简标准化;
4. 自增主键id有序递增,每条数据具备唯一标识,可用于后续数据匹配、更新计算。
3. 结果分析
本次实验完成了自媒体原始爬虫数据的全维度预处理,解决了原始数据杂乱、空值过多、冗余字段繁杂、脏数据干扰等问题。清洗后的结构化数据完整、规范、无异常,能够稳定支撑后续标题关键词标记、总互动量统计等特征工程实验,为自媒体数据分析提供了高质量底层数据支撑。
四、问题与解决
问题1:字段配置后丢失核心文本字段
问题现象:配置字段重命名后,数据流仅显示数值字段,作者、标题、平台等核心文本字段全部丢失。
问题原因:未勾选「包含未指定的列,按名称排序」,平台仅保留手动配置字段,自动丢弃未配置的原生文本字段。
解决方法:勾选对应配置选项,仅手动配置需要重命名的字段,其余原生核心字段自动保留,无需手动新增。
问题2:数据表出现大量空值脏数据
问题现象:多次重复运行流水线后,数据表出现大量null空值行,业务字段全部为空,仅默认字段为0。
问题原因:重复运行未清空数据表,堆积无效脏数据;同时存在流水线执行顺序颠倒问题,先运行7-2特征流程,空表生成大量无效空白数据行。
解决方法:执行DROP+CREATE语句重建数据表,彻底清空所有脏数据;严格遵循先7-1清洗入库、后7-2特征计算的固定执行顺序。
问题3:空字段选择组件初始化报错
问题现象:字段选择组件无任何配置,运行提示初始化失败,流水线无法启动。
问题原因:平台规则限制,字段选择组件不能为空配置,无任何操作配置时会触发初始化异常。
解决方法:无字段处理需求时直接删除冗余字段选择组件,简化流水线链路,规避报错。
问题4:删除不存在字段导致流水线中断
问题现象:运行流水线提示无法删除指定字段,数据流找不到对应字段,流程执行中断报错。
问题原因:移除列表中填写了数据流不存在的字段,系统无法执行删除操作,触发异常。
解决方法:清空无效移除字段,仅对数据流真实存在的冗余字段执行删除操作,无冗余字段时清空移除列表。
五、实验总结
1. 实验收获
通过本次7-1实验,我熟练掌握了助睿数智平台零代码ETL数据清洗全流程,能够独立完成CSV数据接入、脏数据过滤、空值修复、字段标准化、批量入库等核心操作。同时掌握了数据表重建、脏数据清理、流水线报错排查的实操技巧,深刻理解了数据预处理的重要性。原始数据的空值、冗余、脏数据会直接影响后续数据分析与计算结果,只有经过标准化清洗的数据,才能保证后续实验的准确性与稳定性。此外,我明确了ETL实验的标准执行顺序,规避了流程颠倒、配置错误等常见问题,建立了规范的数据处理思维。
2. 平台评价
助睿数智(Uniplore)一站式数据科学实验平台采用零代码可视化操作模式,操作简单直观,大幅降低了大数据ETL实验的学习门槛。平台组件功能齐全、运行日志清晰,能够精准定位配置错误、数据异常等问题,方便学习者排查问题、梳理数据处理逻辑。平台覆盖数据接入、清洗、建模、分析全链路功能,适配大数据入门实训,能够有效帮助学习者掌握数据处理核心技能,整体使用体验良好,非常适合课程实验学习使用。

一站式 AI 云服务平台
更多推荐


 0
0 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)