
自媒体运营分析:用ETL完成作品特征构建
#自媒体运营 #数据可视化 #数据清洗 #数据处理 #特征构建 #数据分析
上一篇我们完成了自媒体作品数据的清洗与预处理,本篇继续往下做:基于清洗后的
content_analysis表,计算作品互动总数、提取标题关键词特征,并输出关键词级别的互动分析表。
一、为什么要做作品特征构建?
在实验7-1中,我们已经把原始的自媒体作品数据清洗成了可分析的明细表 content_analysis。
这张表中已经包含了作品标题、平台、点赞数、收藏数、分享数、投币数、浏览量等基础字段。
但如果只是停留在这些原始字段上,后续分析仍然不够直观。
比如我们想回答下面这些问题:
-
哪些作品综合互动表现更好?
-
标题中包含“保姆级”的作品,互动效果是不是更高?
-
“零代码”“实战”“教程/指南”“踩坑”这些关键词,对作品传播有没有影响?
-
某个关键词作品的平均互动数,是否高于整体平均水平?
这些问题不能直接从原始字段中得到答案,需要先进行特征工程。
本次实验的核心就是:
把基础数据加工成更适合分析和可视化的特征字段。
二、本次实验要完成什么?
本次实验主要完成两部分内容。
第一部分:更新 content_analysis 表。
给每一条作品记录计算互动总数,并提取标题关键词标志字段。
第二部分:新建 title_feature_analysis 表。
统计每个关键词对应作品的平均互动表现,用于后续可视化分析。
|
任务 |
输入数据 |
输出结果 |
用途 |
|---|---|---|---|
|
更新作品级特征 |
content_analysis |
更新后的 |
用于作品排名、趋势分析、明细分析 |
|
输出关键词级汇总 |
更新后的 |
title_feature_analysis |
用于标题关键词效果分析 |
三、实验环境与核心组件
本实验继续使用ETL完成。
-
数据处理工具:ETL
-
输入表:
content_analysis -
输出表:
-
更新后的
content_analysis -
新建的
title_feature_analysis
-
本次实验会用到以下组件:
|
组件 |
作用 |
|---|---|
|
表输入 |
读取 |
|
字段选择 |
保留后续计算需要的字段 |
|
JavaScript代码 |
判断标题中是否包含指定关键词 |
|
计算器 |
计算互动总数 |
|
插入/更新 |
按 |
|
执行一个SQL脚本 |
创建关键词汇总目标表 |
|
过滤记录 |
筛选包含某个关键词的作品 |
|
排序记录 |
为聚合和连接做准备 |
|
分组 |
计算平均互动数和样本数量 |
|
增加常量 |
给结果添加关键词名称 |
|
记录集连接 |
合并整体平均值和关键词平均值 |
|
表输出 |
写入 |
四、核心思路:从“字段”到“特征”
4.1 互动总数
作品的互动行为不只有点赞,还包括收藏、分享、投币等。
为了更直观地衡量一篇作品的综合互动表现,可以计算互动总数:
total_interaction = likes + favorites + shares + coins
其中:
-
likes表示点赞数; -
favorites表示收藏数; -
shares表示分享数; -
coins表示投币数,主要用于 B站。
计算完成后,total_interaction 就可以作为后续作品排名、标题效果分析和图表展示的重要指标。
4.2 标题关键词特征
标题是自媒体内容传播中非常重要的因素。 本实验选择五类关键词作为标题特征:
|
字段名 |
判断规则 |
|---|---|
has_best |
标题是否包含“保姆级” |
has_lowcode |
标题是否包含“零代码” |
has_practice |
标题是否包含“实战” |
has_tutorial |
标题是否包含“教程”或“指南” |
has_pit |
标题是否包含“踩坑” |
每个字段都是 0/1 标志:
-
包含关键词,记为 1;
-
不包含关键词,记为 0。
这样就把原本不方便计算的标题文本,转换成了可以统计和可视化的数值字段。
五、实验前置检查
开始之前,先确认实验7-1已经完成,并且数据库中存在 content_analysis 表。
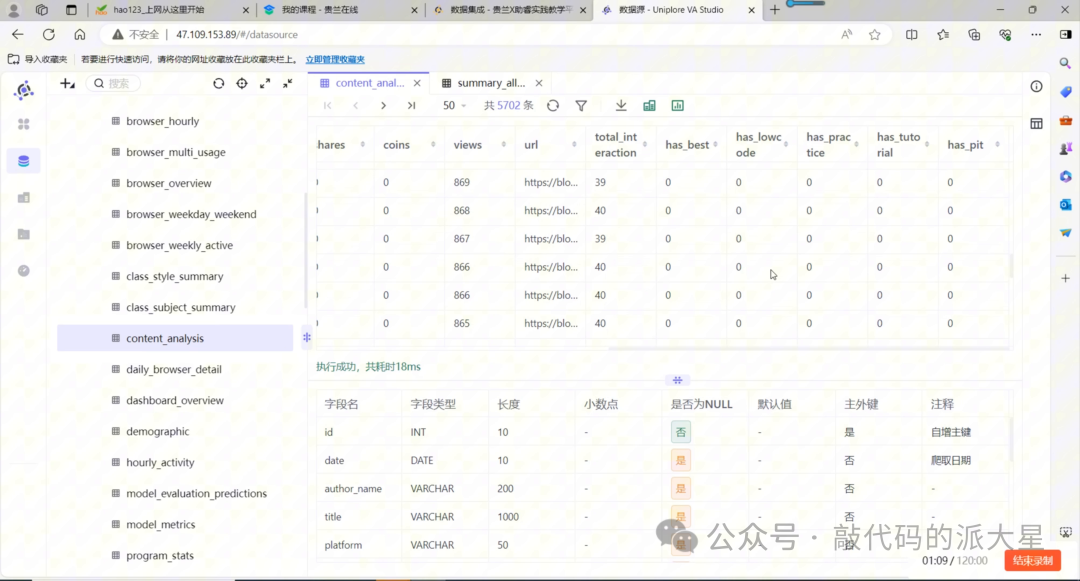
图2 检查实验7-1输出的 content_analysis 表是否已经生成
5.1 检查是否有 id 字段
本实验后面要使用“插入/更新”组件更新原表。 这个组件需要一个匹配字段,用来判断当前数据流中的记录应该更新到数据库表中的哪一行。
一般使用 id 字段作为匹配依据。
如果 content_analysis 中已经有 id 字段,可以直接继续操作。 如果没有,可以执行下面的 SQL 添加:
ALTER TABLE content_analysis
ADD COLUMN id INT NOT NULL AUTO_INCREMENT PRIMARY KEY FIRST;
注意:如果表中已经存在主键,不要重复添加,否则可能报错。
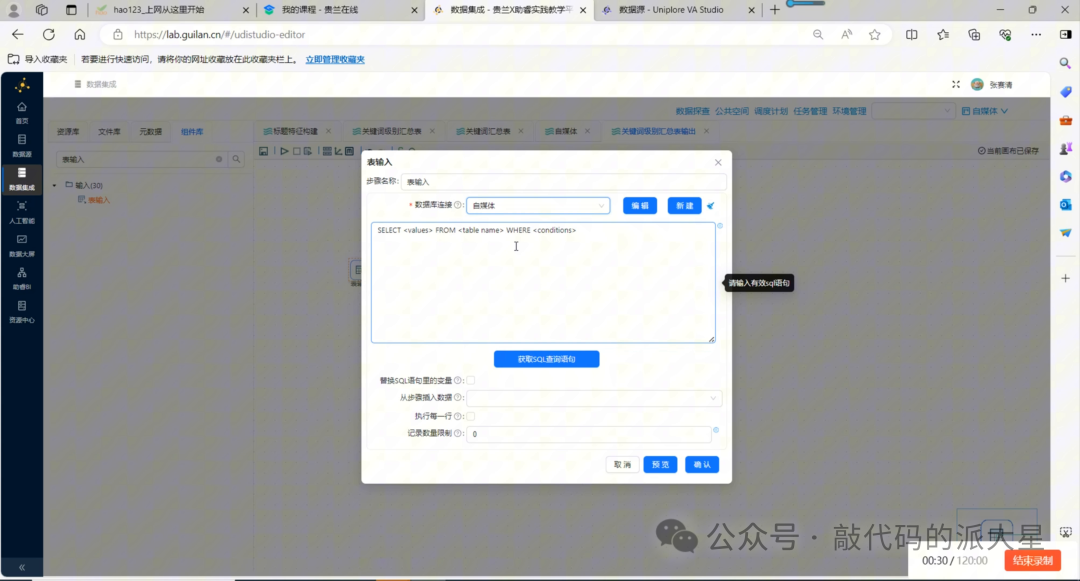
图3 检查 content_analysis 表中是否包含 id、total_interaction 和标题特征字段
5.2 检查是否有待更新字段
content_analysis 中需要包含以下字段:
total_interaction
has_best
has_lowcode
has_practice
has_tutorial
has_pit
如果实验7-1建表时已经预留了这些字段,就不用重复添加。 如果没有,可以执行:
ALTER TABLE content_analysis
ADDCOLUMN total_interaction INTDEFAULTNULLCOMMENT'互动总数',
ADDCOLUMN has_best TINYINT(1) DEFAULTNULLCOMMENT'是否含保姆级',
ADDCOLUMN has_lowcode TINYINT(1) DEFAULTNULLCOMMENT'是否含零代码',
ADDCOLUMN has_practice TINYINT(1) DEFAULTNULLCOMMENT'是否含实战',
ADDCOLUMN has_tutorial TINYINT(1) DEFAULTNULLCOMMENT'是否含教程或指南',
ADDCOLUMN has_pit TINYINT(1) DEFAULTNULLCOMMENT'是否含踩坑';
六、第一部分:更新 content_analysis 表
这一部分的目标是更新作品级特征。
最终转换流结构如下:
表输入 → 字段选择 → JavaScript代码 → 计算器 → 插入/更新
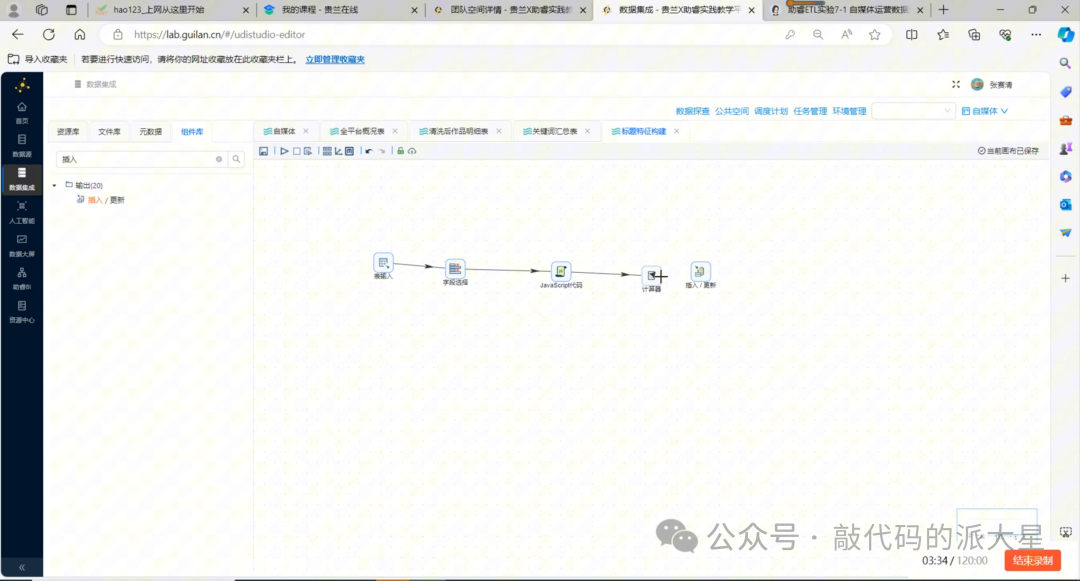
图4 作品级特征构建转换流:读取明细表、提取标题特征、计算互动总数并回填
6.1 新建“标题特征构建”转换
进入助睿ETL后,新建一个转换。
建议命名为:
标题特征构建
这个转换专门用于处理 content_analysis 中的作品级数据。
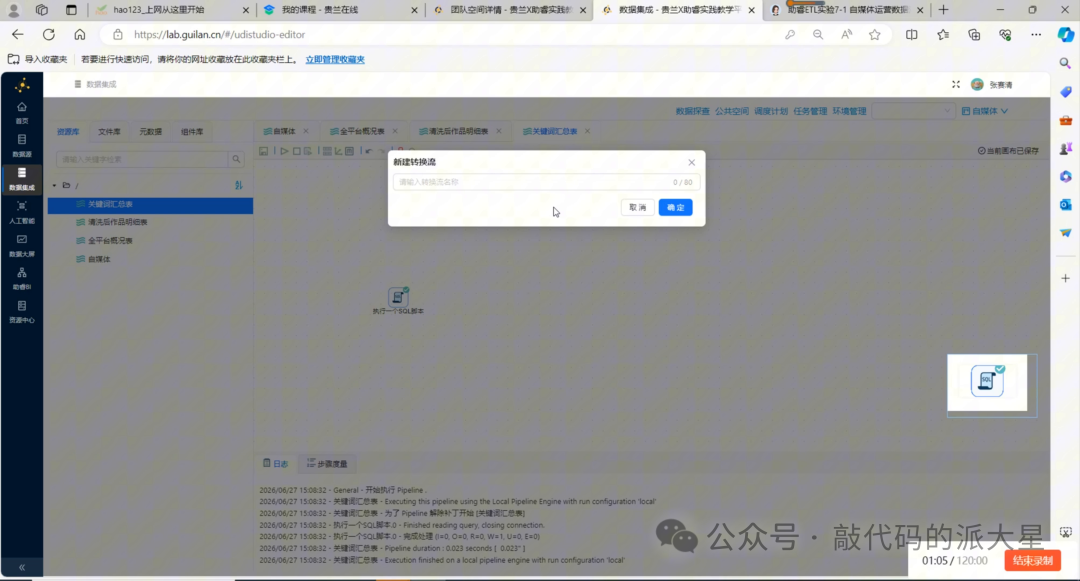
图5 新建“标题特征构建”转换,准备计算作品级特征
6.2 表输入:读取 content_analysis
拖入“表输入”组件,选择实验7-1使用的数据库连接。
SQL 可以写成:
SELECT
id,
`date`,
author_name,
title,
platform,
likes,
favorites,
shares,
coins,
views,
url,
total_interaction,
has_best,
has_lowcode,
has_practice,
has_tutorial,
has_pit
FROM content_analysis;
如果你不确定字段是否完整,也可以先使用:
SELECT *
FROM content_analysis;
不过在正式实验中,更建议显式写出字段,后续配置时更清楚。
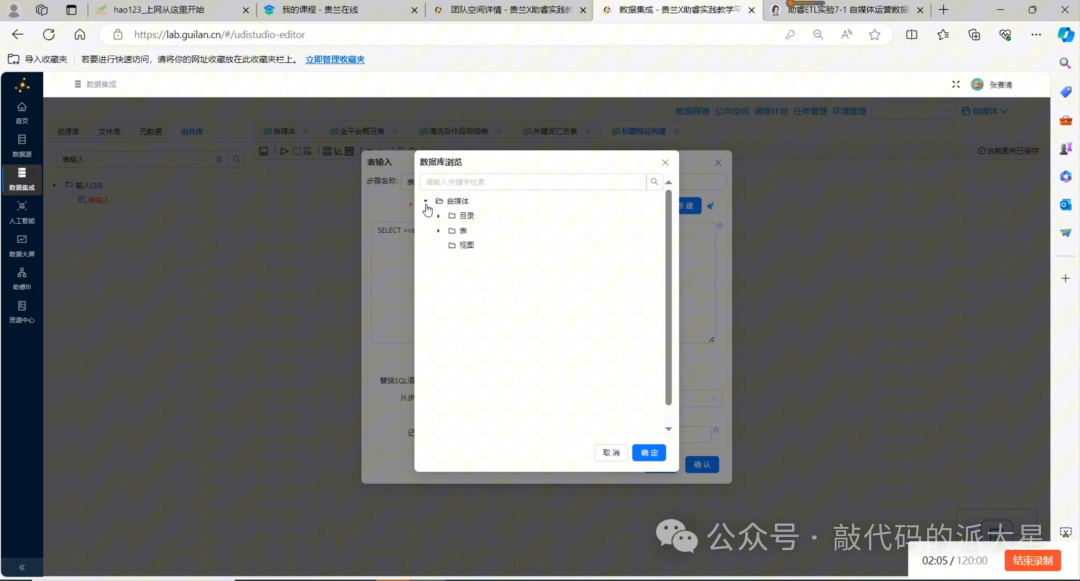
图6 使用表输入组件读取 content_analysis 表中的作品明细数据
6.3 字段选择:保留计算字段
表输入之后,接入“字段选择”组件。
这里保留后续计算需要的字段即可,主要包括:
|
字段 |
用途 |
|---|---|
id |
插入/更新时作为匹配关键字 |
title |
用于提取标题关键词 |
likes |
计算互动总数 |
favorites |
计算互动总数 |
shares |
计算互动总数 |
coins |
计算互动总数 |
total_interaction |
待更新字段 |
has_best |
待更新字段 |
has_lowcode |
待更新字段 |
has_practice |
待更新字段 |
has_tutorial |
待更新字段 |
has_pit |
待更新字段 |
字段选择不是必须的,但建议保留。 它可以让后续 JavaScript 和计算器组件接收到的字段更加清晰。
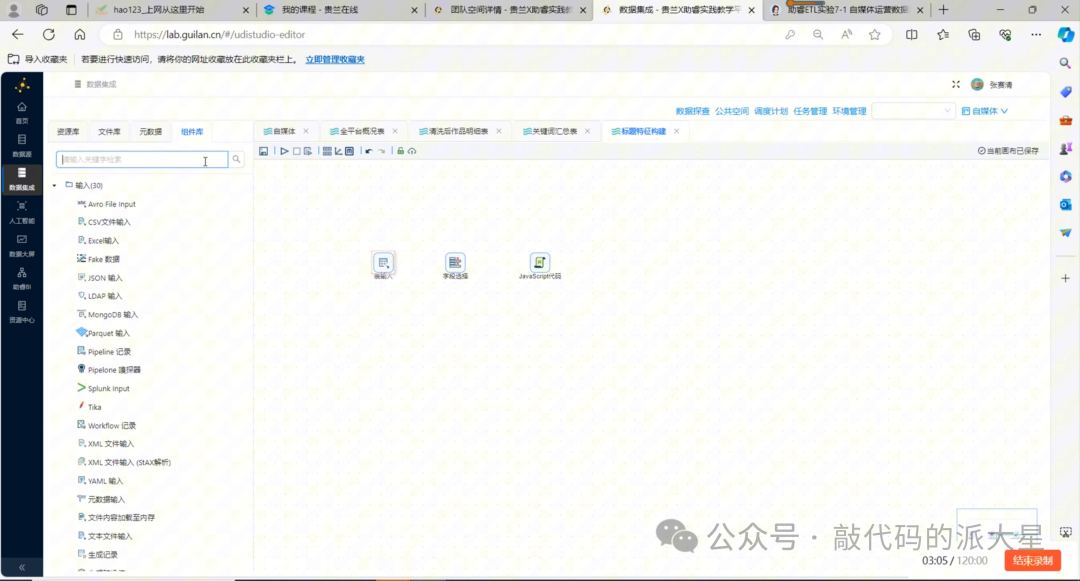
图7 保留 id、title、likes、favorites、shares、coins 等后续计算字段
6.4 JavaScript代码:提取标题关键词
接下来拖入“JavaScript代码”组件,并连接到字段选择组件后面。
这个组件用于判断标题中是否包含指定关键词。
推荐代码如下:
var t = title == null ? "" : String(title);
has_best = t.indexOf("保姆级") !== -1 ? 1 : 0;
has_lowcode = t.indexOf("零代码") !== -1 ? 1 : 0;
has_practice = t.indexOf("实战") !== -1 ? 1 : 0;
has_tutorial = (t.indexOf("教程") !== -1 || t.indexOf("指南") !== -1) ? 1 : 0;
has_pit = t.indexOf("踩坑") !== -1 ? 1 : 0;
这里的逻辑是:
-
标题包含“保姆级”,
has_best = 1; -
标题包含“零代码”,
has_lowcode = 1; -
标题包含“实战”,
has_practice = 1; -
标题包含“教程”或“指南”,
has_tutorial = 1; -
标题包含“踩坑”,
has_pit = 1; -
不包含则为 0。
第一行代码:
var t = title == null ? "" : String(title);
是为了避免标题为空时报错。 如果标题为空,就当作空字符串处理。
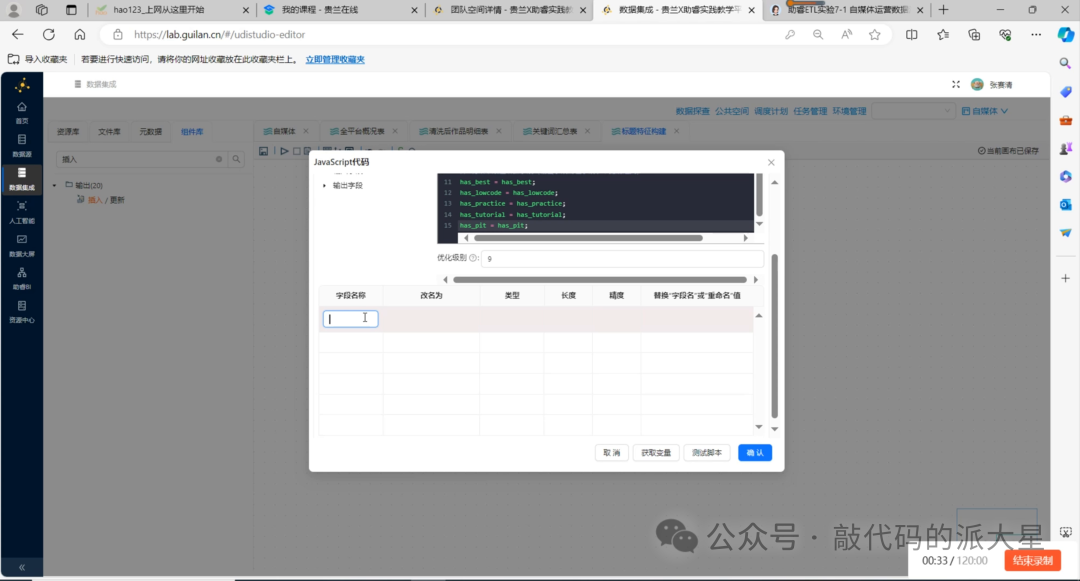
图8 在 JavaScript 代码组件中编写标题关键词匹配逻辑
6.5 配置 JavaScript 输出字段
只写代码还不够,还要在 JavaScript 组件的输出字段区域添加新字段。
需要添加:
|
字段名 |
类型 |
|---|---|
has_best |
Integer |
has_lowcode |
Integer |
has_practice |
Integer |
has_tutorial |
Integer |
has_pit |
Integer |
如果这里不添加输出字段,后面的计算器或插入/更新组件可能无法接收到这些结果。
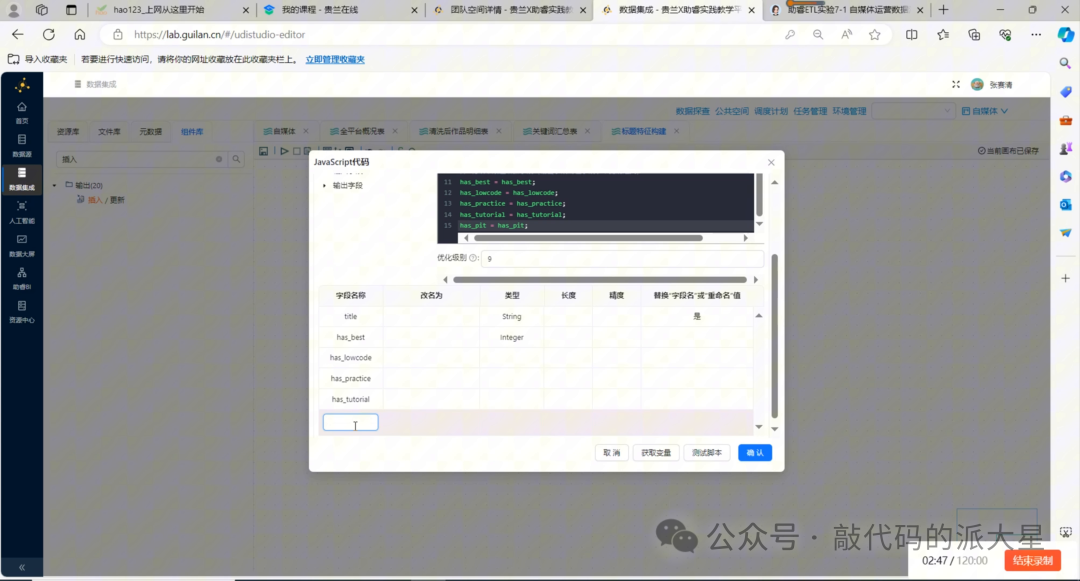
图9 添加 has_best、has_lowcode、has_practice、has_tutorial、has_pit 五个输出字段
6.6 计算器:计算互动总数
JavaScript 代码之后,接入“计算器”组件。
互动总数公式为:
total_interaction = likes + favorites + shares + coins
如果计算器支持多个字段直接相加,可以直接生成 total_interaction。
如果只能两个字段相加,可以分三步计算:
|
新字段 |
计算公式 |
|---|---|
tmp_1 |
likes + favorites |
tmp_2 |
shares + coins |
total_interaction |
tmp_1 + tmp_2 |
这样就能得到每篇作品的综合互动总数。
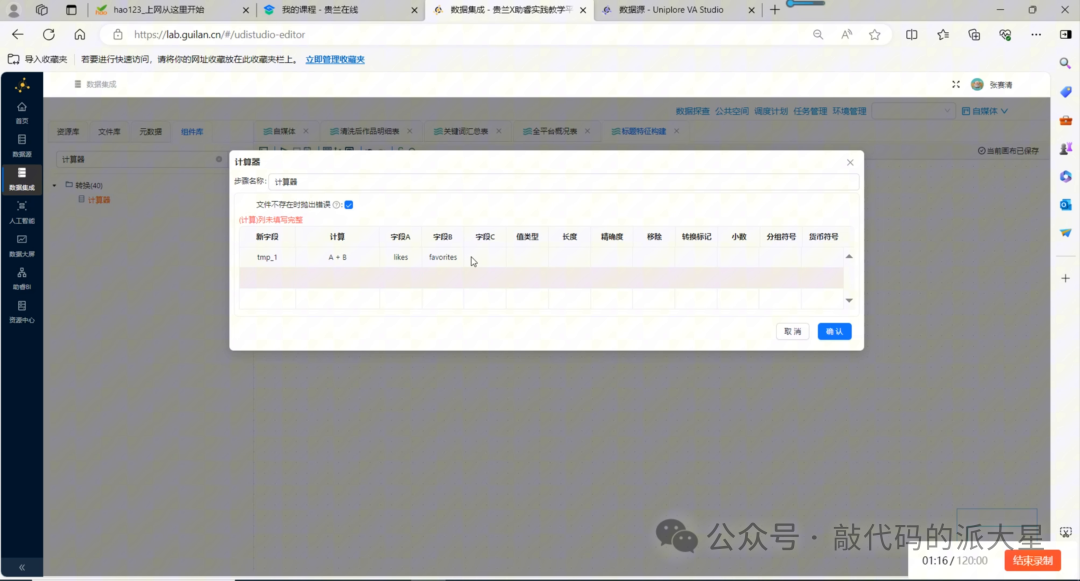
图10 使用计算器计算 total_interaction = likes + favorites + shares + coins
6.7 插入/更新:回填 content_analysis
计算完成后,拖入“插入/更新”组件。
这里不要使用“表输出”。 因为本步骤不是新增作品记录,而是更新原有记录中的字段。
“插入/更新”组件可以按照 id 匹配原表中的记录,只更新指定字段。
关键配置如下:
|
配置项 |
设置内容 |
|---|---|
|
数据库连接 |
选择实验7-1同一个数据库连接 |
|
目标表 |
content_analysis |
|
查询关键字 |
id |
|
更新字段 |
total_interaction
、 |
字段映射如下:
|
流字段 |
表字段 |
|---|---|
id |
id |
total_interaction |
total_interaction |
has_best |
has_best |
has_lowcode |
has_lowcode |
has_practice |
has_practice |
has_tutorial |
has_tutorial |
has_pit |
has_pit |
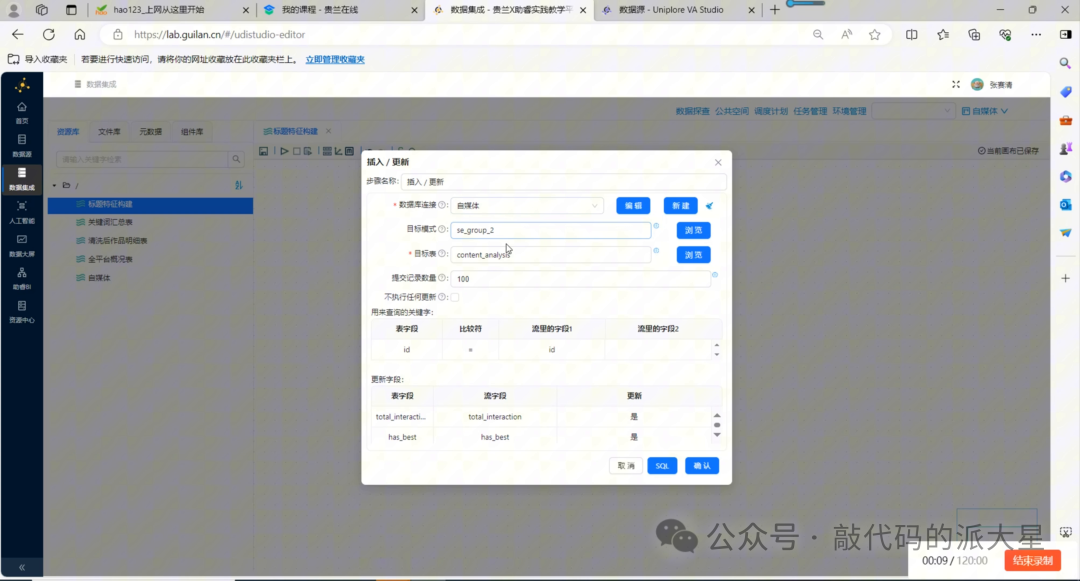
图11 配置插入/更新组件,按 id 回填互动总数和标题特征字段
6.8 运行并检查 content_analysis
保存转换流,点击运行。
运行成功后,关键节点会显示绿色对勾,日志中不应出现 ERROR。
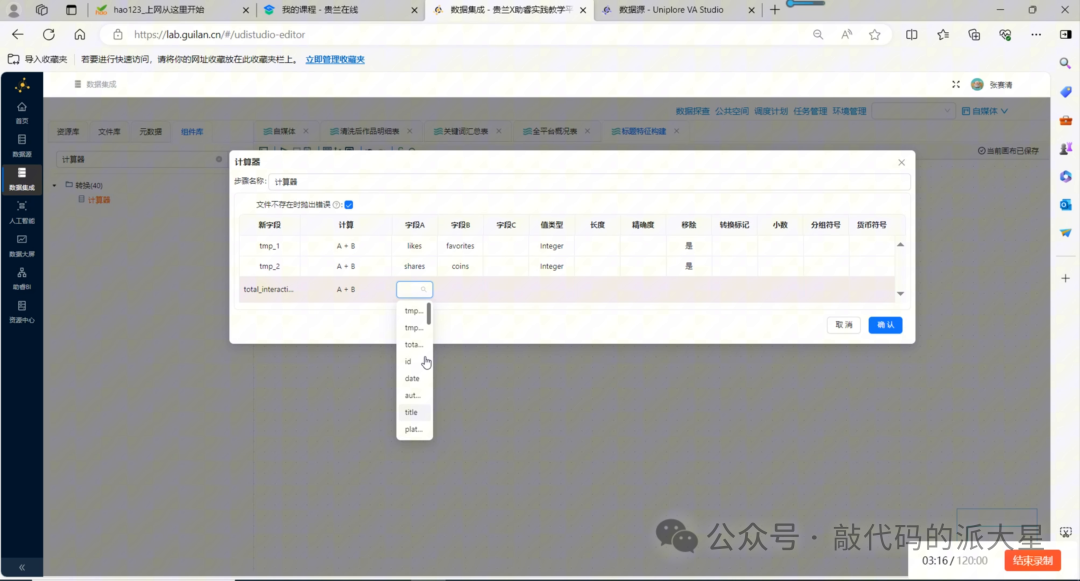
图12 运行“标题特征构建”转换,确认节点显示绿色对勾
运行完成后,预览 content_analysis 表,检查以下字段是否已经有值:
total_interaction
has_best
has_lowcode
has_practice
has_tutorial
has_pit
可以使用 SQL 检查:
SELECT
id,
title,
likes,
favorites,
shares,
coins,
total_interaction,
has_best,
has_lowcode,
has_practice,
has_tutorial,
has_pit
FROM content_analysis
LIMIT20;
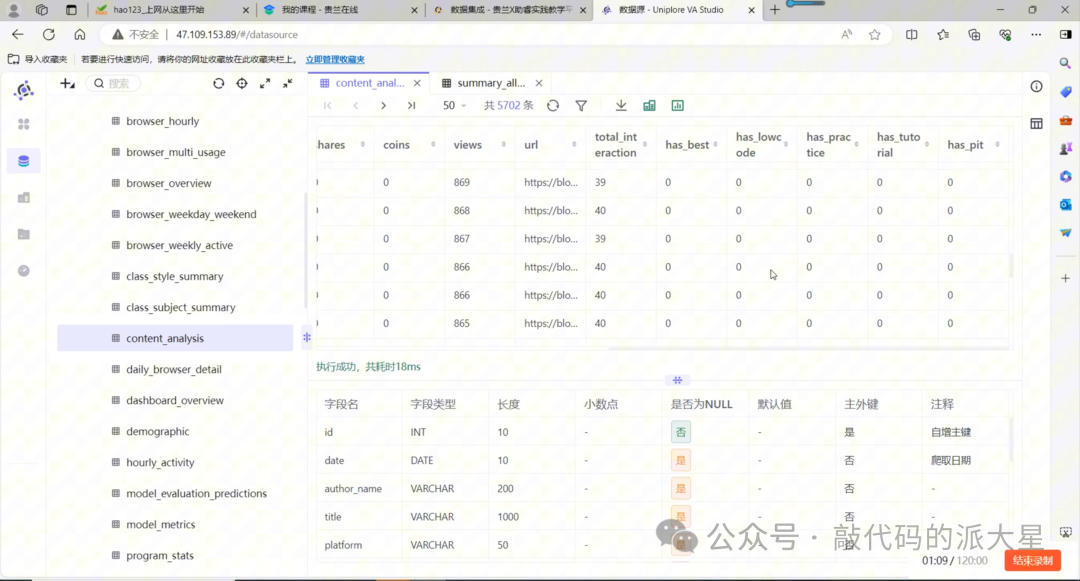
图13 查看 content_analysis 表,确认互动总数和标题关键词字段已经生成
七、第二部分:创建 title_feature_analysis 表
作品级特征更新完成后,接下来要生成关键词级汇总表。
这张表用于保存不同标题关键词对应作品的平均互动表现。
7.1 创建目标表
使用“执行一个SQL脚本”组件创建 title_feature_analysis 表。
SQL 如下:
DROP TABLEIFEXISTS title_feature_analysis;
CREATETABLE title_feature_analysis (
idINTNOTNULL AUTO_INCREMENT COMMENT'自增主键',
platform VARCHAR(20) COMMENT'平台名称',
feature_name VARCHAR(50) COMMENT'标题关键词名称',
avg_interaction DECIMAL(10,2) COMMENT'含该关键词作品的平均互动总数',
overall_avg DECIMAL(10,2) COMMENT'整体平均互动总数',
sample_count INTCOMMENT'含该关键词的作品数量',
PRIMARY KEY (id)
) ENGINE=InnoDBDEFAULTCHARSET=utf8mb4 COMMENT='标题关键词互动分析表';
说明一下几个关键字段:
|
字段 |
含义 |
|---|---|
platform |
平台名称 |
feature_name |
关键词名称 |
avg_interaction |
含该关键词作品的平均互动总数 |
overall_avg |
整体平均互动总数 |
sample_count |
含该关键词的作品数量 |
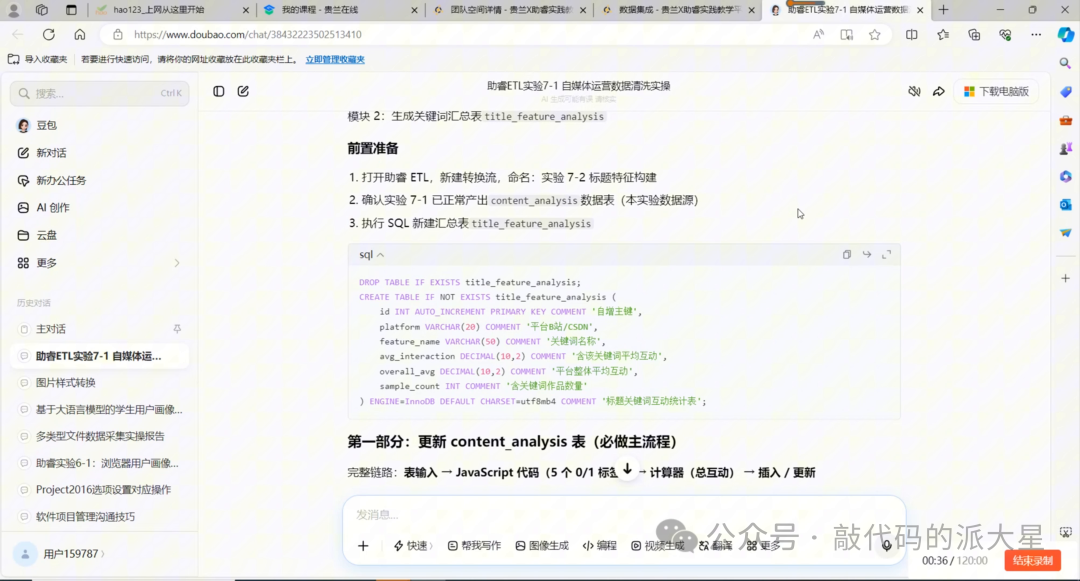
图14 创建 title_feature_analysis 关键词级汇总表
八、第三部分:生成关键词级汇总数据
新建一个转换,建议命名为:
关键词级别汇总输出
这一部分的目标是: 基于更新后的 content_analysis 表,统计每个关键词的平均互动数,并和整体平均互动数进行对比。
图15 新建关键词级汇总转换,准备统计关键词互动表现
8.1 表输入:读取特征字段
拖入“表输入”组件,读取更新后的 content_analysis 表。
SQL 建议写成:
SELECT
id,
platform,
total_interaction,
has_best,
has_lowcode,
has_practice,
has_tutorial,
has_pit
FROM content_analysis
WHERE total_interaction IS NOT NULL;
这里只读取关键词汇总需要用到的字段即可。
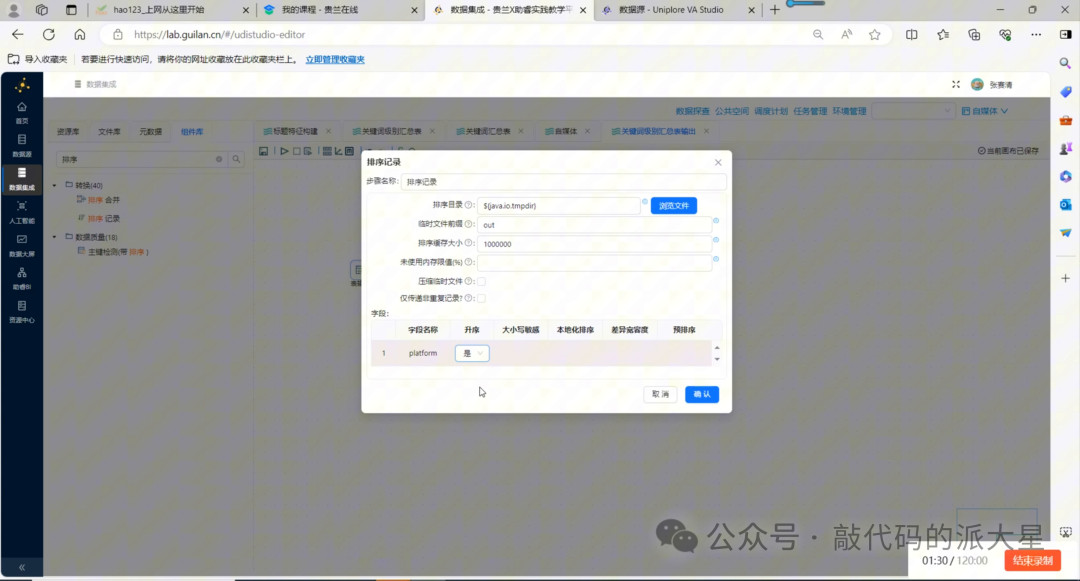
图16 使用表输入读取平台、互动总数和五个标题特征字段
8.2 整体平均分支:计算 overall_avg
从表输入组件拉出第一条分支,用来计算整体平均互动数。
流程为:
表输入 → 排序记录 → 分组 → 增加常量
排序记录
排序字段可以选择 id 升序。
分组
不设置分组字段,直接对 total_interaction 求平均值,输出字段命名为:
overall_avg
增加常量
因为后面要和关键词分支连接,所以需要添加一个关键词名称标签。 以“保姆级”为例,添加:
feature_name = 保姆级
这样整体平均值这一行也带有相同的关键词标签,后面可以和“保姆级”关键词分支连接。
图17 整体平均分支:排序后直接计算 overall_avg,并增加 feature_name 常量
8.3 关键词分支:以“保姆级”为例
从同一个表输入组件再拉出第二条分支,用来计算某个关键词作品的平均互动表现。
以“保姆级”为例,流程为:
表输入 → 过滤记录 → 排序记录1 → 分组1 → 增加常量
过滤记录
过滤条件设置为:
has_best = 1
表示只保留标题中包含“保姆级”的作品。
过滤记录组件需要设置两个输出方向:
|
输出方向 |
连接组件 |
含义 |
|---|---|---|
|
匹配成功 |
排序记录1 |
保留含关键词作品 |
|
匹配失败 |
空操作 |
丢弃不含关键词作品 |
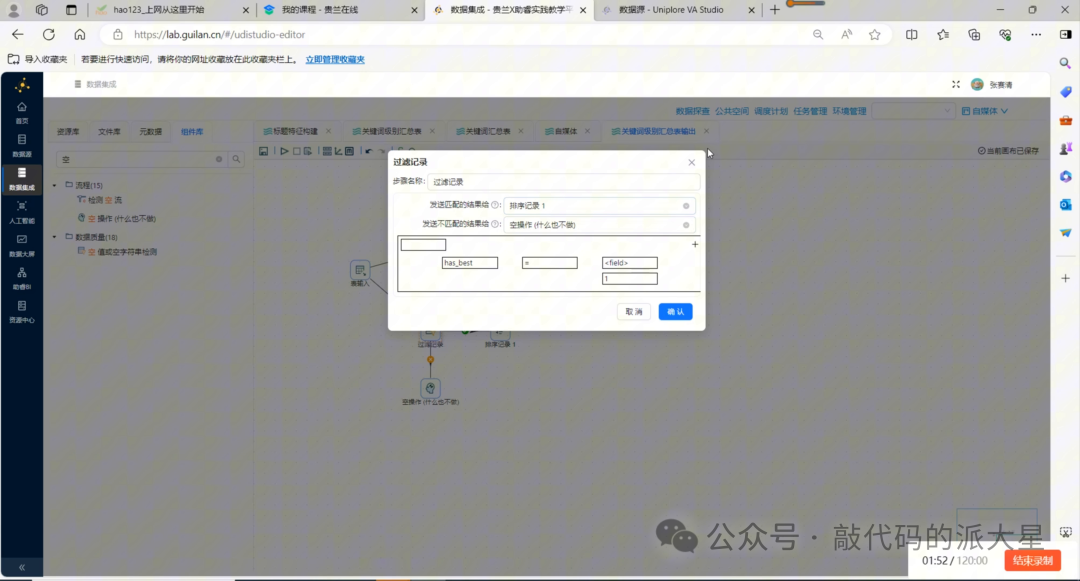
图18 以“保姆级”为例,过滤 has_best = 1 的作品记录
8.4 关键词分支:计算 avg_interaction 和 sample_count
过滤成功后,接入“排序记录1”和“分组1”。
排序字段可以选择 id 升序。
分组组件不设置分组字段,直接计算:
|
输出字段名 |
源字段 |
聚合方式 |
含义 |
|---|---|---|---|
avg_interaction |
total_interaction |
Average / 平均值 |
含该关键词作品的平均互动总数 |
sample_count |
id |
Count / 计数 |
含该关键词的作品数量 |
聚合后,再接入“增加常量”组件,添加:
feature_name = 保姆级
这样关键词分支也会带有 feature_name 字段。
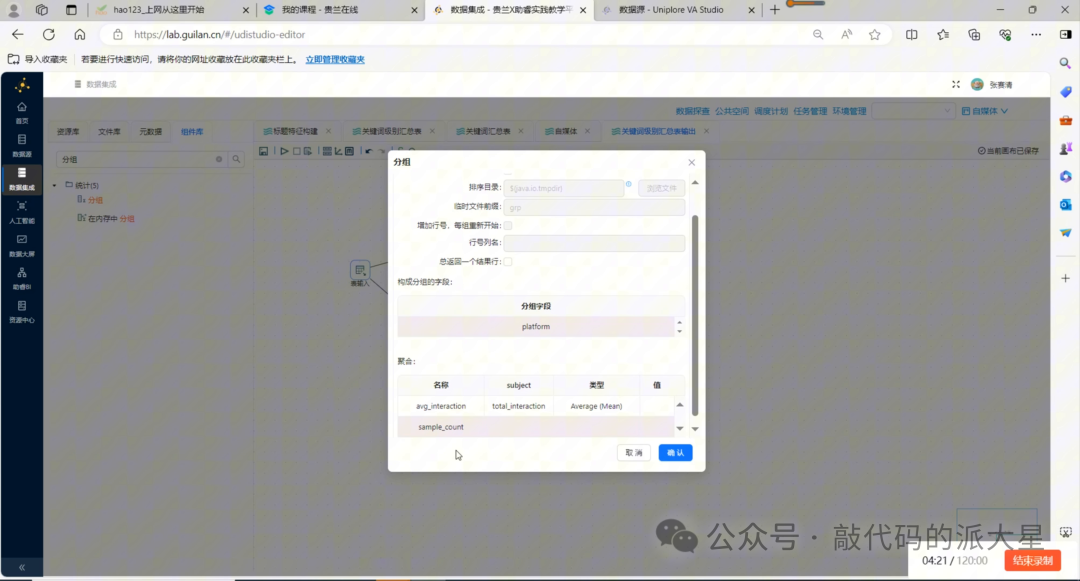
图19 关键词分支配置:计算 avg_interaction 和 sample_count,并增加 feature_name 常量
8.5 记录集连接:合并整体平均值和关键词平均值
接下来拖入“记录集连接”组件。
连接两个分支:
-
第一条分支:整体平均分支;
-
第二条分支:关键词平均分支。
连接字段设置为:
|
第一个输入字段 |
第二个输入字段 |
|---|---|
feature_name |
feature_name |
连接后,同一关键词下的整体平均互动数和关键词平均互动数就会合并到同一行。
最终得到的字段主要包括:
feature_name
overall_avg
avg_interaction
sample_count
如果你的转换流中保留了 platform 字段,也可以把 platform 一起输出到结果表中。
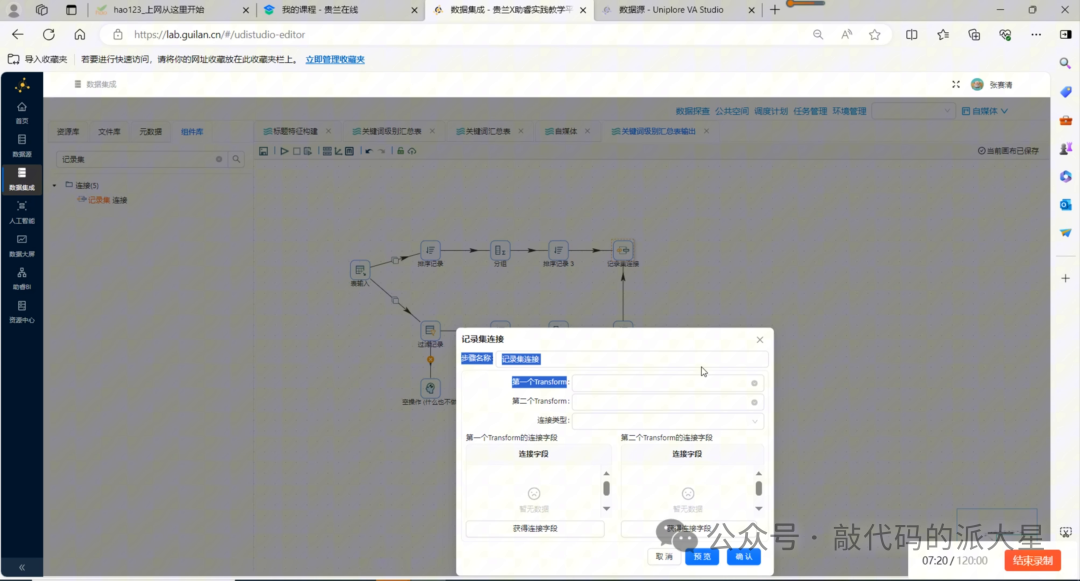
图20 按 feature_name 连接整体平均值和关键词平均值
8.6 表输出:写入 title_feature_analysis
最后接入“表输出”组件,将结果写入 title_feature_analysis。
字段映射如下:
|
流字段 |
目标表字段 |
|---|---|
platform |
platform |
feature_name |
feature_name |
avg_interaction |
avg_interaction |
overall_avg |
overall_avg |
sample_count |
sample_count |
注意:如果当前流程没有输出 platform 字段,可以在“增加常量”中补充平台值,或者根据你的视频操作保持平台字段为空/默认值。 如果后续可视化需要区分 B站 和 CSDN,建议在表输入或分组阶段保留 platform 维度。
另外,如果要连续写入多个关键词,不要每次都勾选“清空表”或“裁剪表”。 否则前一个关键词的数据会被删除。
更稳妥的方式是:第一次运行前手动清空一次表:
TRUNCATE TABLE title_feature_analysis;
然后依次写入五个关键词的数据。
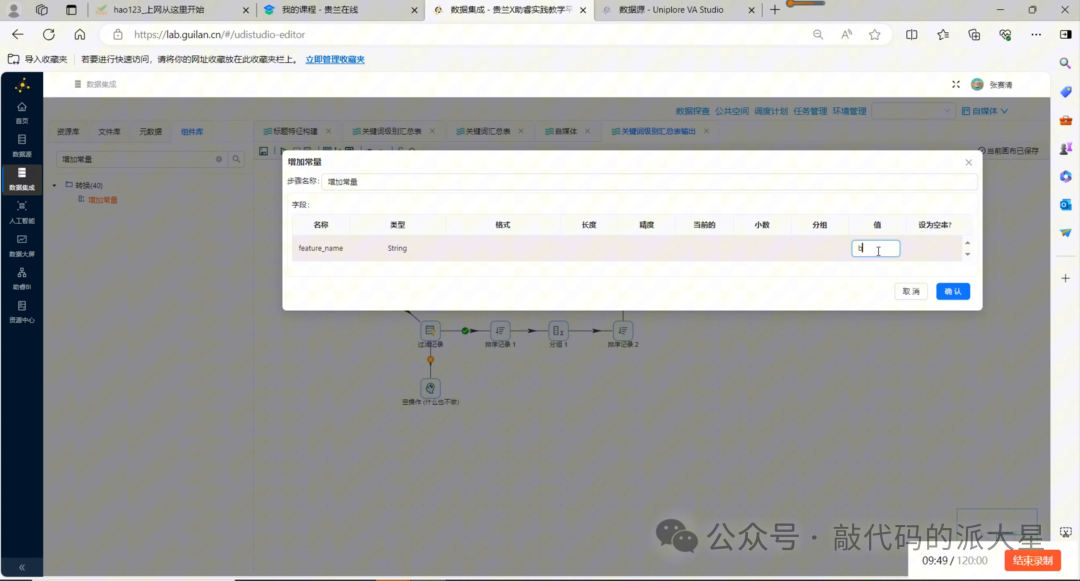
图21 将关键词汇总结果写入 title_feature_analysis
8.7 其他关键词怎么处理?
完成“保姆级”后,其他关键词的处理逻辑完全一样。
只需要修改两个地方:
-
过滤条件;
-
feature_name常量值。
|
关键词 |
过滤条件 |
常量值 |
|---|---|---|
|
保姆级 |
has_best = 1 |
保姆级 |
|
零代码 |
has_lowcode = 1 |
零代码 |
|
实战 |
has_practice = 1 |
实战 |
|
教程/指南 |
has_tutorial = 1 |
教程/指南 |
|
踩坑 |
has_pit = 1 |
踩坑 |
最简单的方式是复制“保姆级”这一整套流程,然后只修改过滤条件和常量值。
例如处理“零代码”时:
过滤条件改为:
has_lowcode = 1
常量值改为:
零代码
其他组件配置保持不变。
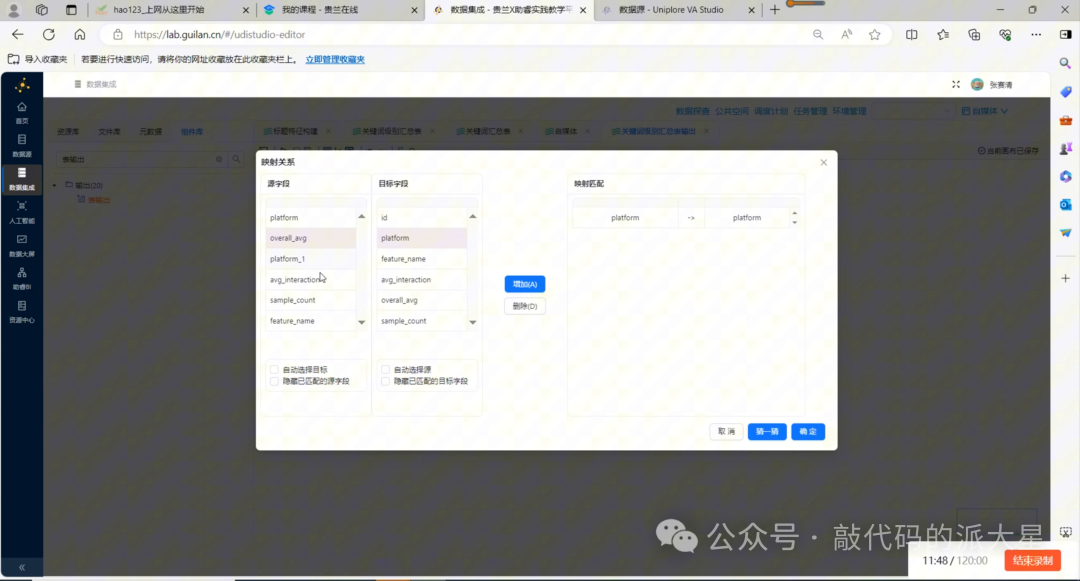
图22 复制关键词分支,只修改过滤条件和 feature_name 常量值即可生成其他关键词数据
九、检查最终结果
全部关键词处理完成后,打开 title_feature_analysis 表查看结果。
可以使用:
SELECT *
FROM title_feature_analysis;
也可以按关键词排序查看:
SELECT
feature_name,
platform,
avg_interaction,
overall_avg,
sample_count
FROM title_feature_analysis
ORDER BY feature_name, platform;
正常情况下,表中应该能够看到不同关键词对应的平均互动数、整体平均互动数和样本数量。
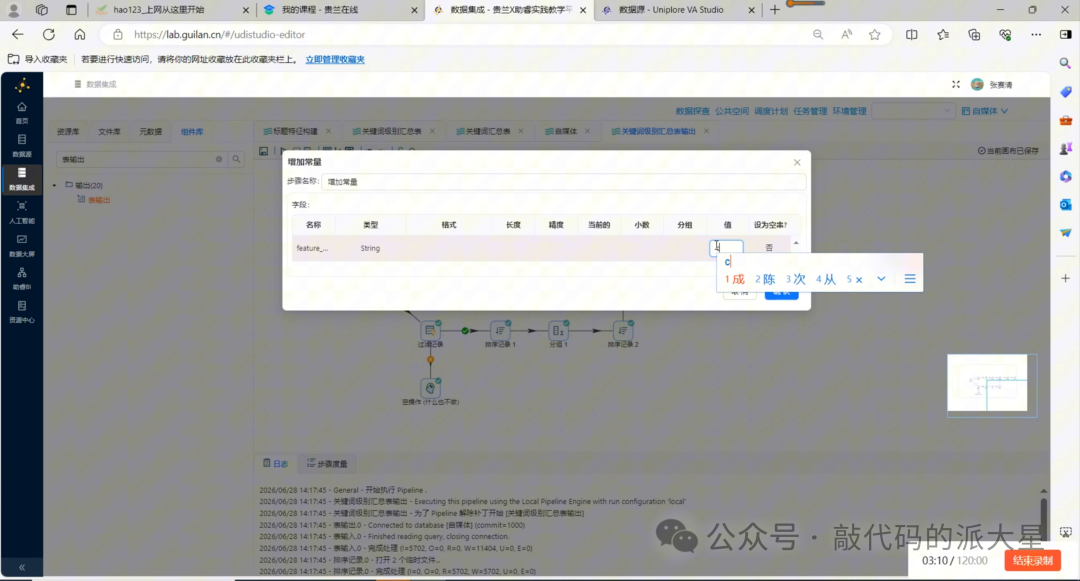
图23 查看关键词级汇总结果,确认 avg_interaction、overall_avg、sample_count 正常生成
十、实验结果说明
完成本次实验后,我们得到了两类数据结果。
第一类是更新后的 content_analysis。 它仍然是作品级明细表,但已经新增了互动总数和标题关键词特征字段。
第二类是新建的 title_feature_analysis。 它是关键词级汇总表,用于分析不同标题关键词对应作品的互动效果。
|
表名 |
数据粒度 |
用途 |
|---|---|---|
content_analysis |
作品级 |
作品排名、互动趋势、平台明细分析 |
title_feature_analysis |
关键词级 |
标题关键词互动效果分析 |
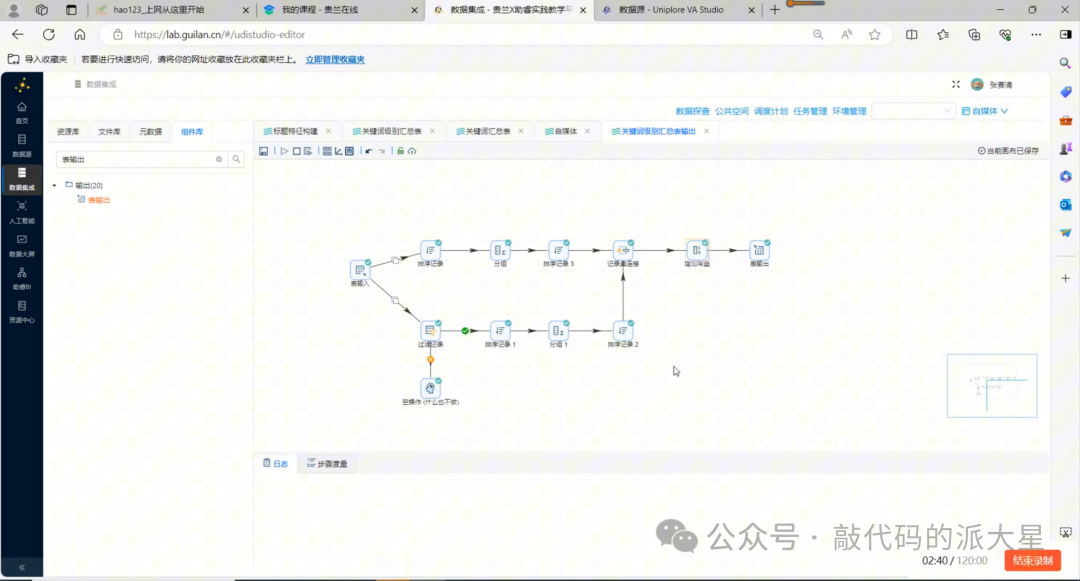
图24 实验7-2最终输出:更新后的 content_analysis 和新建的 title_feature_analysis
十一、常见问题与解决办法
11.1 插入/更新组件找不到 id
原因通常是 content_analysis 表中没有 id 字段。
可以执行:
ALTER TABLE content_analysis
ADD COLUMN id INT NOT NULL AUTO_INCREMENT PRIMARY KEY FIRST;
如果表中已有主键,不要重复添加。
11.2 JavaScript 运行后没有生成特征字段
常见原因是只写了代码,但没有在输出字段区域添加字段。
解决办法:在 JavaScript 输出字段区域添加:
has_best
has_lowcode
has_practice
has_tutorial
has_pit
字段类型设置为 Integer。
11.3 total_interaction 为空
可能原因包括:
-
计算器字段选错;
-
likes、favorites、shares、coins中存在 NULL; -
计算器输出字段没有映射到
total_interaction。
可以在表输入 SQL 中提前处理空值:
SELECT
id,
title,
platform,
IFNULL(likes, 0) AS likes,
IFNULL(favorites, 0) AS favorites,
IFNULL(shares, 0) AS shares,
IFNULL(coins, 0) AS coins
FROM content_analysis;
11.4 title_feature_analysis 没有数据
可能原因包括:
-
关键词过滤条件写错;
-
content_analysis中标题特征字段还没有更新; -
表输出字段映射错误;
-
结果表被清空后没有重新写入。
可以先检查某个关键词是否有数据:
SELECT COUNT(*)
FROM content_analysis
WHERE has_best = 1;
如果结果为 0,需要先重新运行“标题特征构建”转换。
11.5 多个关键词结果被覆盖
如果每次运行关键词汇总时都勾选“清空表”或“裁剪表”,前面关键词的结果会被删除。
正确做法是:
-
第一次运行前清空一次
title_feature_analysis; -
后续写入不同关键词时不要再清空表。
可以先执行:
TRUNCATE TABLE title_feature_analysis;
十二、实验小结
本次实验完成了自媒体运营分析中的作品特征构建。
整个实验可以分成两个阶段:
第一阶段是更新作品级明细表。 我们使用 JavaScript 代码提取标题关键词特征,使用计算器计算互动总数,再通过插入/更新组件把结果回填到 content_analysis 表中。
第二阶段是输出关键词级汇总表。 我们通过过滤、排序、分组、增加常量、记录集连接和表输出等组件,统计不同标题关键词对应作品的平均互动表现,并输出到 title_feature_analysis 表中。
完成这一步后,数据就不只是清洗后的明细数据,而是进一步变成了可以直接用于分析和可视化的特征数据。
下一步,实验7-3就可以基于这些数据制作:
-
作品互动排名;
-
平台表现对比;
-
标题关键词效果分析;
-
自媒体运营综合仪表板。
十三、完整流程回顾
最后用一张流程回顾本次实验:
实验7-2:作品特征构建
阶段一:更新 content_analysis
├── 表输入读取 content_analysis
├── 字段选择保留必要字段
├── JavaScript代码提取标题关键词
├── 计算器计算 total_interaction
└── 插入/更新回填作品级特征
阶段二:生成 title_feature_analysis
├── 创建 title_feature_analysis 表
├── 表输入读取更新后的 content_analysis
├── 整体平均分支计算 overall_avg
├── 关键词分支计算 avg_interaction 和 sample_count
├── 增加常量添加 feature_name
├── 记录集连接合并平均值
└── 表输出写入 title_feature_analysis
数据分析并不是把数据导入工具后直接画图。 真正有价值的分析,往往需要先把原始字段加工成能够表达业务含义的特征。
在本次实验中,我们把点赞、收藏、分享、投币加工成了互动总数; 把标题文本中的关键词加工成了 0/1 标志字段; 又进一步把关键词作品的互动表现汇总成了可视化分析表。
这样,后续制作图表时就不只是“展示数据”,而是可以真正回答:
什么样的标题更容易获得互动? 哪类关键词更适合用于自媒体内容运营? 不同标题特征之间的互动效果是否存在差异?
到这里,自媒体运营分析的数据基础就更加完整了。

一站式 AI 云服务平台
更多推荐
 1
1 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)