
零代码 ETL 实战:自媒体多源数据清洗与预处理
1 实验目的
本实验以全班同学多平台自媒体作品互动原始数据为研究对象,依托助睿ETL数据集成工具完成多源异构数据的清洗、过滤、填充、聚合等全流程预处理操作,最终输出两张标准化核心数据表,为后续特征工程、数据挖掘与可视化大屏分析工作提供规范、有效的数据支撑。
通过本次实验,学生可熟练掌握数据分析前置处理核心能力,具体学习目标如下:
(1)理解数据清洗在数据分析全流程中的基础性、必要性与核心价值,明确原始数据缺陷对后续分析、建模及可视化的影响;
(2)熟练运用助睿ETL工具,完成多源自媒体数据的过滤、缺失值填充、分组聚合、字段筛选等标准化预处理操作,掌握零代码数据加工方法;
(3)规范输出两类差异化数据表,精准适配可视化仪表盘不同模块的数据需求,建立“数据处理-数据输出-业务应用”的闭环思维。
本次实验依托助睿在线实验平台开展,平台地址:https://lab.guilian.cn/。该平台搭载Uniplore iDIS大数据智能服务平台,是面向教学与企业应用的一站式零代码大数据基础软件,融合DataOps数据运营理念,具备数据接入、ETL加工、AI建模、可视化分析全链路能力,适配数据分析教学实训场景。
Uniplore优联博睿官方平台地址:https://www.uniplore.com//,平台拥有自主可控的技术架构,内置200+ETL处理组件、200+AI算法组件、20+可视化图表组件,可高效完成多源数据加工与智能分析工作。
助睿ETL是平台自研的零代码数据集成工具,专为多源数据抽取、转换、加载场景设计,适配教学实训与企业数据治理场景,核心优势如下:
(1)元数据标准化架构:采用全元数据驱动设计,对数据读取、转换、写入全流程对象进行标准化定义,保障数据处理的规范性与一致性;
(2)零代码可视化操作:全程采用拖拽式操作,无需编写代码,即可完成数据抽取(Extract)、转换(Transform)、加载(Load)全流程处理,上手门槛低、实操性强;
(3)丰富的预处理组件:内置数据筛选、缺失值填充、分组聚合、表连接、字段筛选、排序等通用组件,可灵活解决各类原始数据质量问题;
(4)Pipeline流水线机制:支持多组件组合搭建数据处理流水线,分步完成复杂数据加工逻辑,流程可追溯、可复用、可修改;
(5)高可用开源内核:基于开源引擎架构,搭配标准化插件体系,性能稳定且可灵活扩展,适配教学场景下的各类数据处理需求。
本次实验原始数据为《自媒体作品数据明细.csv》,采集了全班同学在B站、CSDN、微信、知乎、小红书等多平台的作品发布及互动数据。原始数据为多源采集数据,存在大量数据质量缺陷,无法直接用于统计分析与可视化展示,具体问题如下:
(1)平台数据冗余无效:微信、知乎、小红书等平台的核心浏览数据大多为0,仅有作品记录无有效互动数据,无法支撑深度分析,造成数据冗余;
(2)无效数据记录过多:部分作品的浏览、点赞、收藏、分享等核心互动字段全部为0,大概率为采集失败或无曝光作品,无数据分析价值;
(3)字段存在缺失值:作者昵称、作品标题等文本字段存在空值,若不处理,会导致后续数据统计、特征计算、可视化展示出现异常报错;
(4)数据维度混杂:各平台存在差异化特色指标(B站投币、微信推荐、知乎赞同/喜欢),原始数据未做区分,直接合并统计会导致数据逻辑混乱。
因此,必须通过ETL数据清洗,剔除无效数据、修补缺失数据、规范数据维度、分流数据链路,提升数据质量,为后续实验奠定基础。
本次实验的核心特色为双分支分流处理,核心原因是后续可视化仪表盘需要两类维度完全不同的数据支撑,两类数据的筛选规则、统计逻辑、应用场景存在明显差异:
(1)全平台概况统计分支:面向仪表盘整体指标展示,需要统计全班作品全域发布情况,需保留所有平台全部原始记录,即使浏览量、互动量为0,也需计入作品总数、平台覆盖数等整体指标,客观反映整体发布概况;
(2)重点平台深度分析分支:面向精细化数据分析,仅聚焦数据有效、分析价值高的B站、CSDN平台,筛选产生真实浏览、互动的有效作品,剔除零曝光无效记录,用于后续互动分析、内容特征挖掘、趋势分析。
基于以上需求,本次实验通过ETL流水线搭建双处理分支,分别输出两张规范数据表,各司其职、精准适配不同业务场景。
基于实验需求和可视化应用场景,在助睿ETL平台创建两张结构差异化的目标表,分别适配全域统计和深度分析场景。
4.1.1 全平台概况统计表(summary_all_platforms)
该表用于支撑仪表盘顶部整体指标卡展示,保留全平台所有数据,不做任何过滤,完整统计各平台整体发布与互动情况,各平台特色指标独立存储,避免数据逻辑混淆,字段设计如下:
|
字段名 |
字段类型 |
字段说明 |
|
crawl_date |
DATE |
数据采集日期 |
|
platform |
VARCHAR(20) |
自媒体平台名称 |
|
content_count |
INT |
对应平台、日期的作品发布总量 |
|
total_views |
INT |
总浏览/播放量 |
|
total_likes |
INT |
总点赞数 |
|
total_favorites |
INT |
总收藏数 |
|
total_shares |
INT |
总分享数 |
|
total_coins |
INT |
B站专属:总投币数 |
|
total_recommend |
INT |
微信专属:总推荐数 |
|
total_likes_zhihu |
INT |
知乎专属:总喜欢数 |
|
total_approvals |
INT |
知乎专属:总赞同数 |
4.1.2 重点平台内容分析表(content_analysis)
该表为后续特征工程、数据分析实验的核心输入数据,仅保留B站、CSDN有效曝光作品数据,精简冗余字段,保留核心分析维度,预留后续特征加工字段,字段设计如下:
|
字段名 |
字段类型 |
字段说明 |
|
date |
DATE |
数据采集日期 |
|
author_name |
VARCHAR(100) |
作品作者昵称 |
|
title |
VARCHAR(500) |
作品标题 |
|
platform |
VARCHAR(20) |
平台名称(仅B站、CSDN) |
|
likes |
INT |
作品点赞数 |
|
favorites |
INT |
作品收藏数 |
|
shares |
INT |
作品分享数 |
|
coins |
INT |
B站作品投币数 |
|
views |
INT |
作品浏览/播放量 |
|
url |
VARCHAR(500) |
作品原始链接 |
|
total_interaction |
INT |
作品互动总数 |
|
has_best |
TINYINT(1) |
标题是否含“保姆级” |
|
has_lowcode |
TINYINT(1) |
标题是否含“零代码” |
|
has_practice |
TINYINT(1) |
标题是否含“实战” |
|
has_tutorial |
TINYINT(1) |
标题是否含“教程/指南” |
|
has_pit |
TINYINT(1) |
标题是否含“踩坑” |
本次实验数据源为平台公共空间的《自媒体作品数据明细.csv》。助睿ETL支持CSV文件直接导入、在线解析,可快速完成多源文件数据接入。
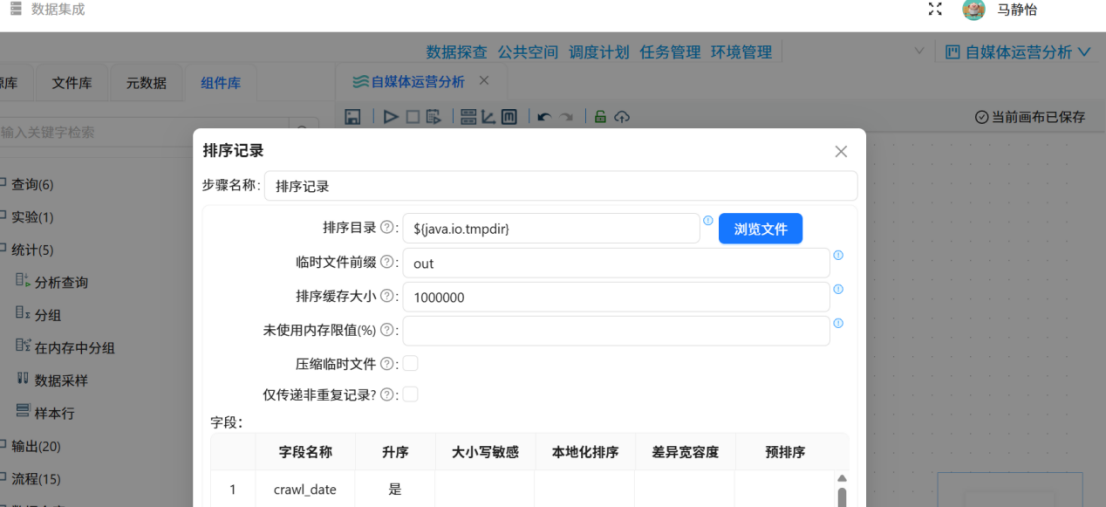
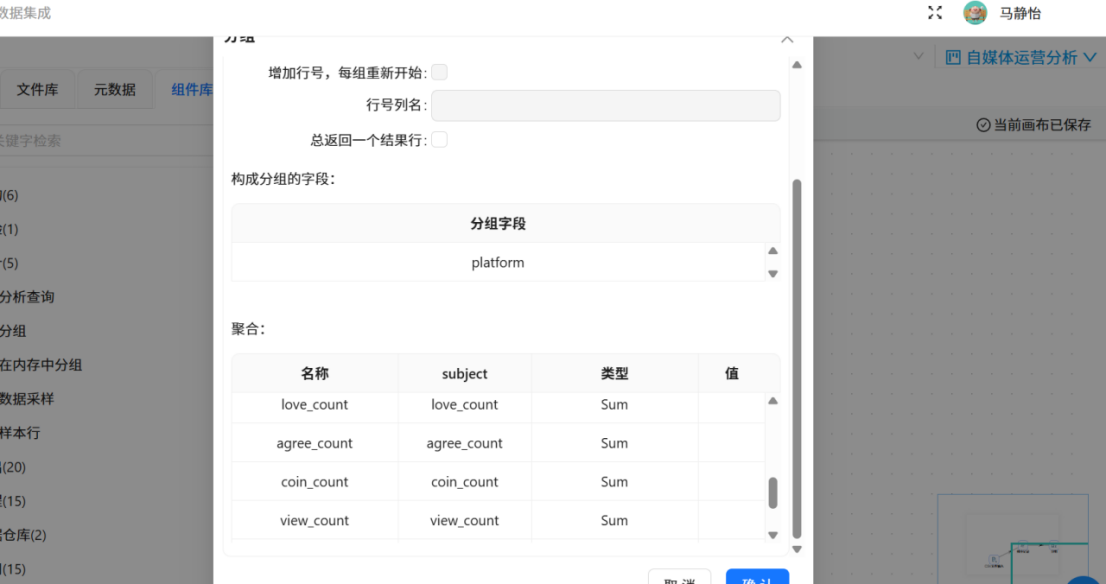
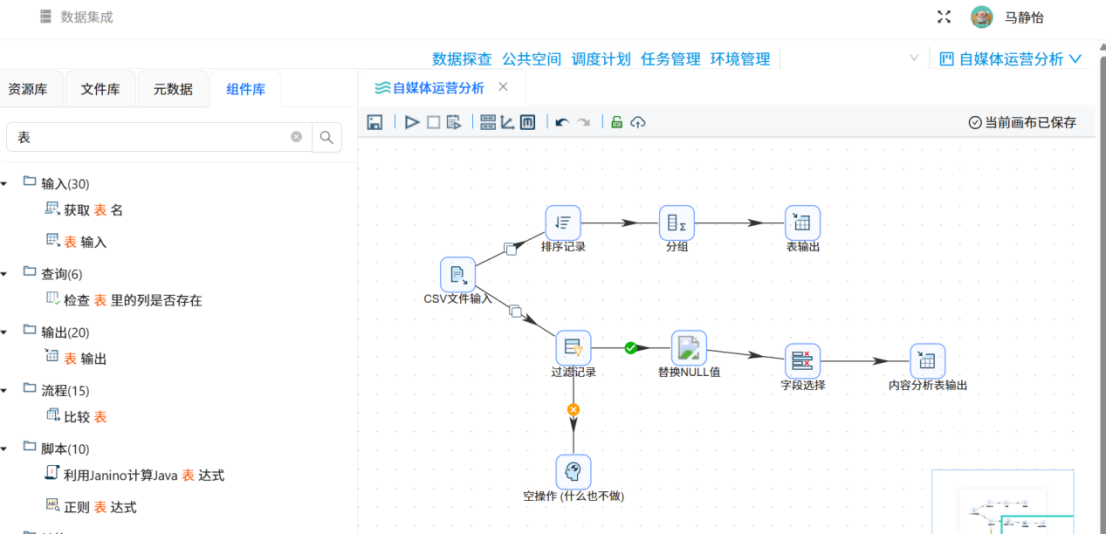
搭建全平台统计处理流水线,对原始全量数据进行分组聚合,生成全域概况数据。依次拖入「排序记录」「分组统计」组件,以采集日期、平台名称为分组依据,对作品数量、浏览、点赞、收藏、分享及各平台特色指标进行求和统计。处理过程不做任何数据过滤,保留所有平台、所有记录的统计结果,最终输出全平台概况统计表summary_all_platforms,用于支撑仪表盘整体数据指标展示。
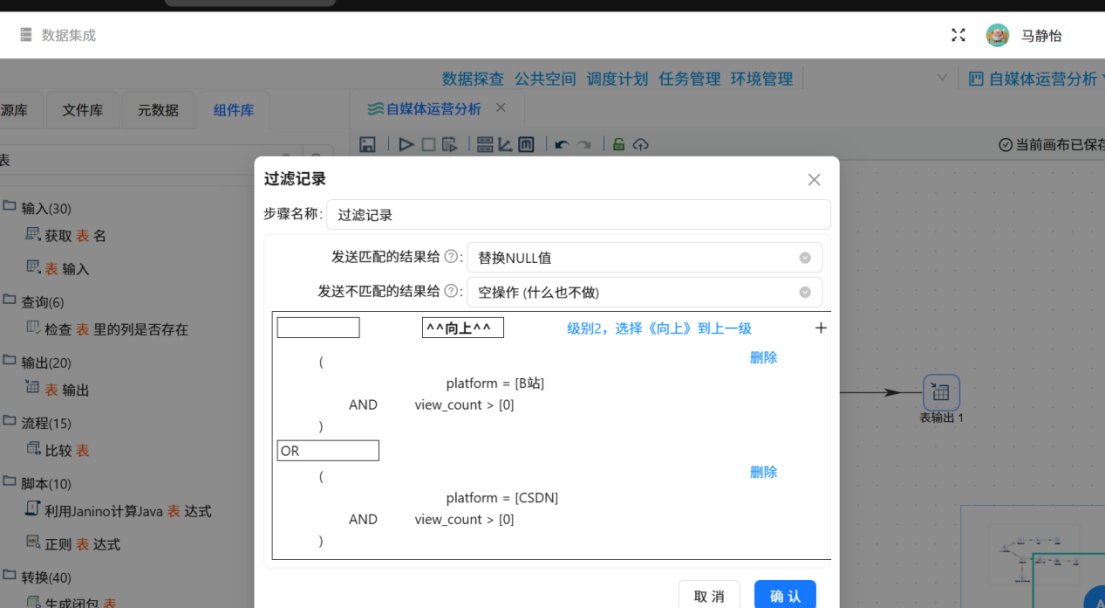
针对重点平台深度分析需求,搭建第二条数据处理分支,利用「过滤记录」组件完成双重精准过滤,筛选有效分析数据,过滤逻辑采用AND、OR多条件组合,具体规则如下:
(平台 = 'B站' AND 浏览数量 > 0) OR (平台 = 'CSDN' AND 浏览数量 > 0)
该条件可一次性实现双重筛选:一是剔除微信、知乎、小红书等无有效数据的冗余平台,仅保留B站、CSDN两大核心分析平台;二是剔除两大平台中浏览量为0的零曝光无效作品,仅保留产生真实用户互动的有效记录,保障后续分析数据的有效性与价值性。
对过滤后的有效数据进行质量修复,经探查,数值类互动字段无空值,但作者昵称、作品标题等文本字段存在少量缺失值。为避免后续数据统计、特征计算、可视化展示出现异常,使用「缺失值填充」组件,将所有文本空值统一填充为“未知”,规范数据格式,保证数据集完整性与可用性。
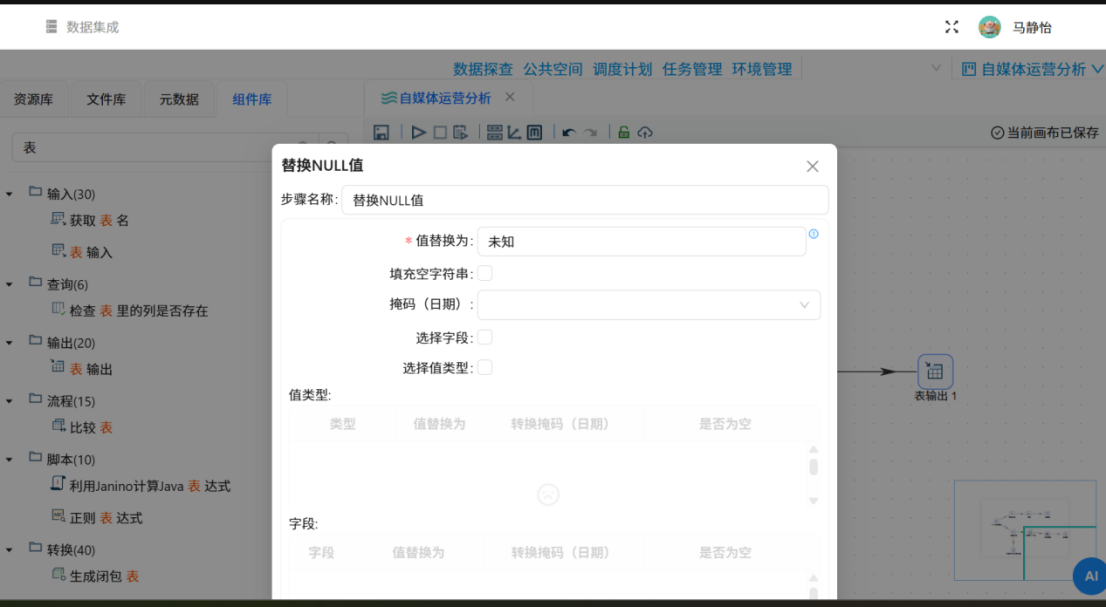
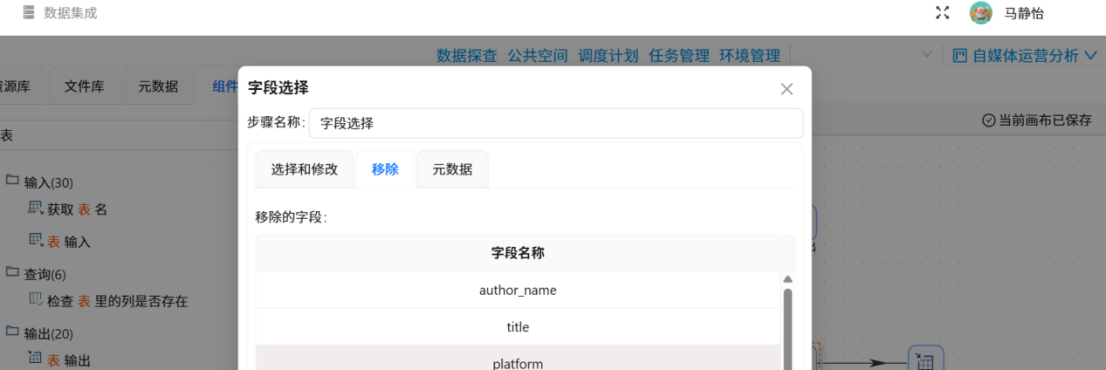
原始数据中包含source_file等采集批次标记字段,无实际分析价值,为精简数据集、降低后续计算压力,使用「字段选择」组件剔除冗余字段,仅保留date、author_name、title、platform、likes、favorites、shares、coins、views、url核心分析字段,完成数据精简规整。
将清洗、过滤、填充、精简后的有效数据,输出为标准化数据表content_analysis。该数据表结构规范、数据质量合格,将作为下一阶段特征工程、指标计算、内容特征分析实验的核心输入数据源。
整合双分支所有组件,搭建完整ETL数据处理流水线,检查各组件配置、条件规则、字段映射无误后,点击运行任务。
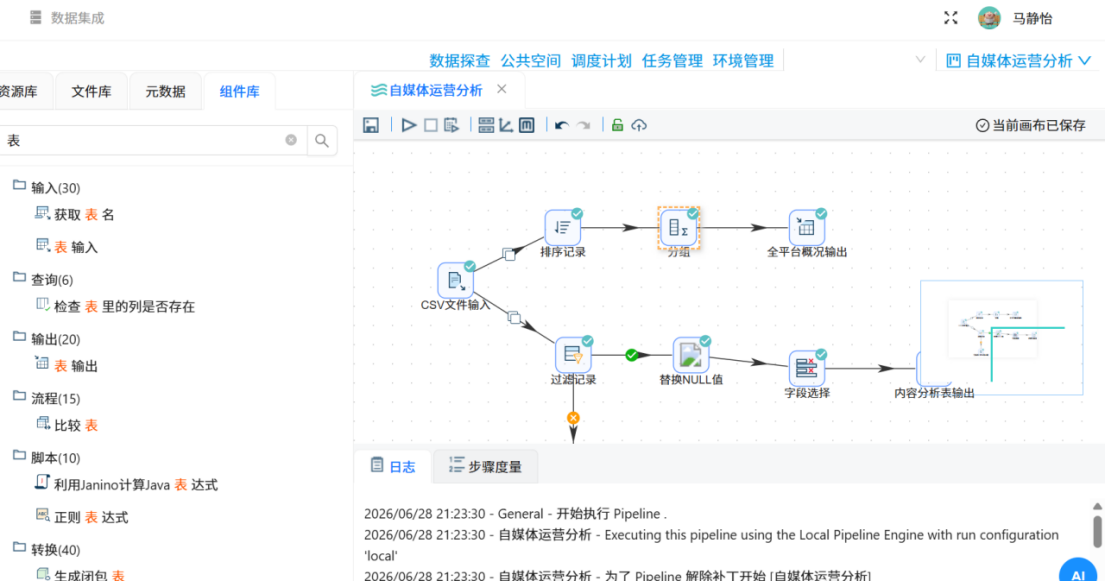
查看结果
5 遇到的问题及解决方案
问题:过滤后 content_analysis 表标题、作者出现空值,JS 特征组件后续会报错
故障现象:数据探查发现少量记录author_name、title为空,若直接流转到下一节特征工程的 JavaScript 组件,会因空字符串匹配失败抛出异常。
故障原因:原始 CSV 采集数据存在漏抓取情况,文本字段存在 NULL 空值,未做填充处理。
解决方案:
(1)在过滤组件后新增「缺失值填充」组件;
(2)选择字段author_name、title,填充内容统一设置为文本 “未知”;
(3)再次探查数据集,确认无空文本字段,规避后续特征提取报错。
6 实验总结
本次实验依托助睿ETL零代码大数据平台,完成了多源自媒体原始数据的全流程清洗与预处理工作。针对原始数据冗余、缺失、无效记录多、维度混杂等问题,通过双分支ETL处理思路,分别输出适配全域统计和深度分析的两张标准化数据表,完美适配可视化大屏的差异化数据需求。
通过实验,我掌握了数据清洗的核心逻辑与实操方法,理解了ETL流水线分步处理、多条件筛选、分支分流的设计思想,熟练运用平台各类预处理组件完成数据治理工作,夯实了数据分析的前置基础能力。同时,建立了“按需处理数据、数据适配业务”的数据分析思维,为后续数据特征挖掘、可视化分析、智能建模等进阶实验提供了有力支撑。

一站式 AI 云服务平台
更多推荐
 6
6 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)