
助睿 ETL 实战:自媒体作品标题特征工程与互动指标分析
1 实验目的
本实验基于7-1清洗完成的有效作品数据集,依托助睿ETL完成指标衍生计算与文本特征挖掘,实现数据特征工程处理,主要完成两项核心任务:一是计算作品综合互动总量、自动提取5类标题关键词特征,回填更新作品明细表;二是统计各关键词作品的平均互动数据,生成关键词汇总分析表。
通过实验掌握以下核心能力:
(1)理解特征工程对数据分析、对比挖掘的支撑作用;
(2)熟练使用计算器组件完成衍生指标计算,通过JS组件实现文本关键词自动标注;
(3)掌握插入/更新组件的增量写入逻辑,避免数据重复;
(4)运用过滤、聚合、合并组件,完成分组统计与多分支数据整合。
实验平台:助睿在线实验平台(https://lab.guilian.cn/)
工具支撑:Uniplore iDIS一站式零代码大数据平台,依托助睿ETL实现全流程可视化数据加工,支持多组件组合搭建数据流水线,无需代码即可完成指标计算、特征提取、数据统计与入库。
|
组件名称 |
核心用途 |
|
表输入 |
读取7-1成品数据表 content_analysis |
|
计算器 |
计算作品综合互动总数 |
|
JavaScript代码 |
批量提取标题0/1特征标签 |
|
插入/更新 |
增量回填特征与指标数据,不重复新增数据 |
|
过滤+聚合 |
筛选关键词样本、统计平均互动数据 |
|
增加常量、合并记录 |
标记关键词名称、整合多分支统计结果 |
|
表输出 |
写入关键词汇总分析表 |
本次实验分为作品级特征更新和关键词级汇总统计两大模块。基于清洗后的有效作品数据,一方面量化作品互动能力、结构化标题文本特征,完善明细数据;另一方面对比不同标题关键词的作品互动表现,挖掘标题内容对传播效果的影响,为后续可视化分析和规律挖掘提供标准化特征数据。
核心指标规则:
1. 综合互动总数:total_interaction = 点赞+收藏+分享+投币
2. 标题特征:通过关键词匹配生成0/1二值字段,精准区分作品内容属性。
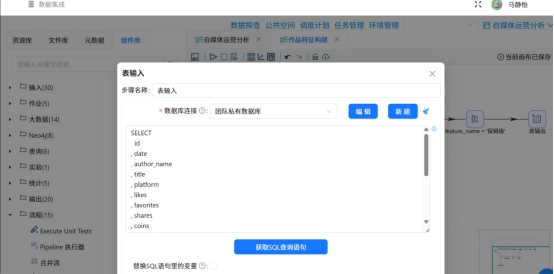
步骤1:加载数据源
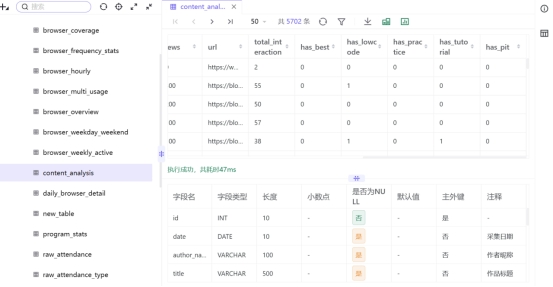
通过表输入组件,读取实验7-1输出的 content_analysis 清洗数据表,作为本次特征计算的基础数据源。
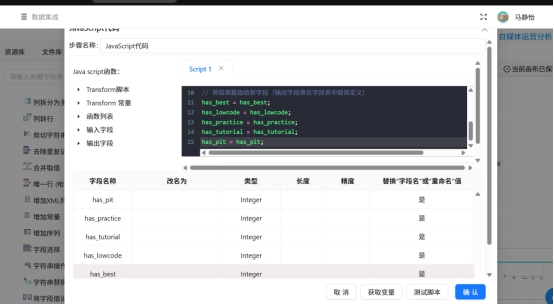
步骤2:JS组件提取标题特征
接入JavaScript代码组件,通过字符串匹配规则,自动生成5类标题特征字段,匹配规则如下:
包含“保姆级”→has_best=1;包含“零代码”→has_lowcode=1;包含“实战”→has_practice=1;包含“教程/指南”→has_tutorial=1;包含“踩坑”→has_pit=1;无对应关键词则为0。
步骤3:计算器计算互动总数
新增衍生字段 total_interaction,通过公式累加点赞、收藏、分享、投币数据,量化作品整体互动效果。
步骤4:增量更新数据表
使用「插入/更新」组件,以id为唯一匹配主键,仅更新新增的特征字段与互动指标,不新增、不重复生成数据,保障基础数据完整性,完成content_analysis表迭代更新。
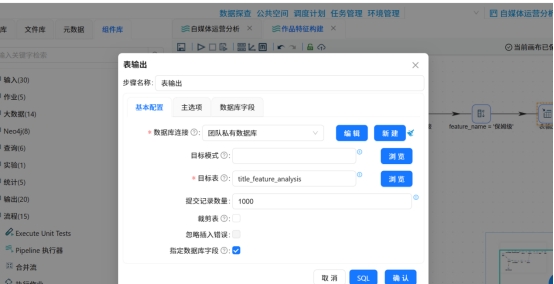
4.2 生成关键词汇总表(title_feature_analysis)
步骤1:创建目标表
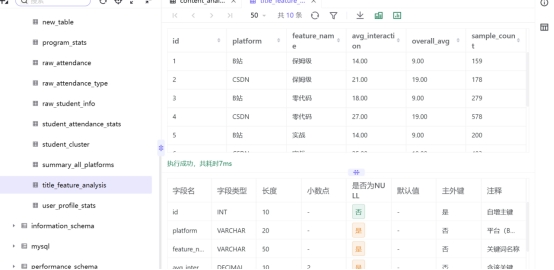
新建汇总统计表,存储平台、关键词名称、样本量、单关键词平均互动量、平台整体平均互动量等核心数据。
步骤2:计算平台整体互动均值
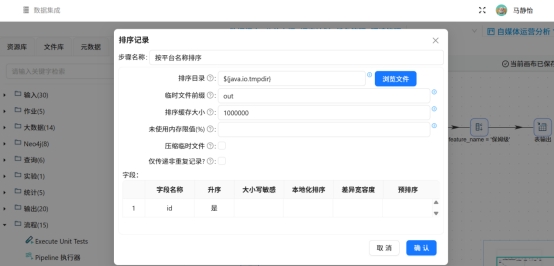
对全量有效作品数据做聚合统计,接入“排序记录”、“分组”组件,按id升序排序,计算全站作品平均互动总数
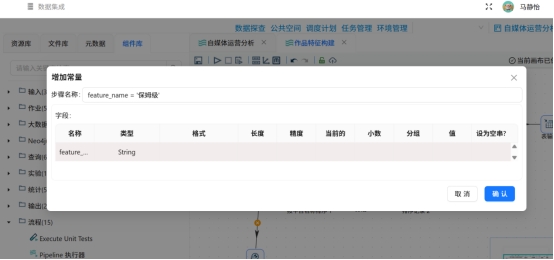
通过增加常量组件标记整体均值标签,用于后续对比分析。
步骤3:单关键词数据统计
采用分支处理逻辑:通过过滤组件筛选对应关键词的作品样本,经聚合计算该关键词作品的平均互动量、作品样本数,同时添加常量标签区分关键词类别。依次完成5类关键词的数据统计,接“过滤记录”组件,设置 has_best = 1,只保留含“保姆级”的作品。
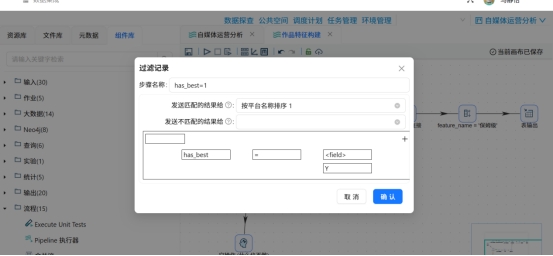
步骤4:数据合并与入库
通过合并组件整合整体均值与各关键词统计数据,保留全量数据不裁剪数据表,最终通过表输出组件写入title_feature_analysis汇总表。
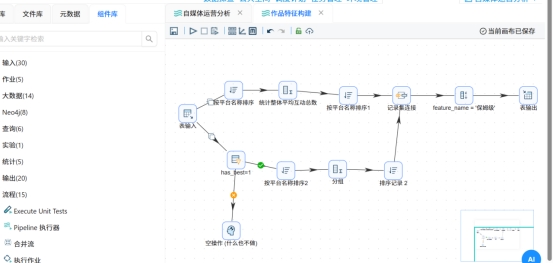
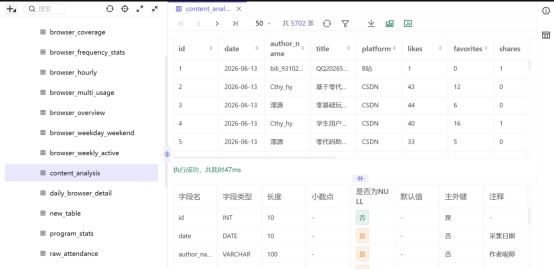
查看结果
5 遇到的问题
1、问题:分组聚合时报错,字符串字段无法转为数字
故障现象:计算关键词平均互动的分组组件抛出转换异常,提示author_name字符串无法转为数值,流水线终止。
故障原因:分组组件配置失误,将文本类型的作者名称author_name误添加至 SUM 求和聚合列表,求和运算仅支持数值字段,文本转换触发报错。
2、解决方案:
(1)双击报错的分组组件,进入聚合配置面板,删除author_name聚合配置行;
(2)核对分组与聚合规则:仅以平台、关键词作为分组维度,仅对 total_interaction 数值字段配置 AVG 均值计算;
(3)保存配置重新运行,聚合统计正常输出各关键词平均互动数据。
6 实验小结
本次实验完成了作品数据的特征工程加工,实现了数值指标衍生与文本特征结构化,将非结构化的标题文本转化为可统计、可对比的量化字段。同时通过ETL多分支流水线设计,完成了明细数据更新与聚合数据统计,熟练掌握了零代码特征提取、增量更新、分组聚合的核心操作,为后续数据可视化、内容效果分析提供了规范、高质量的特征数据集。

一站式 AI 云服务平台
更多推荐


 7
7 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)