
AgentForge 深度解析:一句话出 Agent、7 层 Prompt、零侵入 Java,阿里飞猪如何把 Agent 工程化卷到极致
文章目录
1. 问题与背景:四类人,四种痛
2026 年,Agent 的火已经从 Demo 烧到了生产环境。但真正上手造 Agent 时,飞猪团队观察到四类人各自卡在不同的地方:
| 角色 | 痛点 | 卡在哪 |
|---|---|---|
| 非技术同学 | 有 AI 自动化需求,但不会写代码、不懂 Prompt 结构、不会接 MCP、搞不动容器部署 | 想法烂在脑子里 |
| 前端/Node 同学 | 能写,但每造一个 Agent 要从 0 搭一遍:Dockerfile、容器适配、启动脚本、调度框架、钉钉对接 | 重复劳动比业务逻辑还多 |
| Java 同学 | 集团绝对主力,但 Agent 生态全是 Node/Python 系,要么自学陌生栈,要么自造半成品框架 | 想要的是 HTTP 调用一个能跑业务的 Agent |
| 想玩一下的人 | 现有平台太轻(idealab),框架太重(LangGraph、OpenAI Agents SDK) | 中间地带是真空 |
AgentForge 的目标是把这一段路一次性填上——一边让非技术同学不写代码就能造 Agent,一边给 Node 技术同学一套企业级 SOP,再让 Java 同学无痛复用完整 Agent 架构。
核心数据:73 秒出一个云端可运行的 Agent Team,5 分钟出首个 Loop Agent,目前已私有化部署多个业务线,沉淀了客服路由、研发派单、行程规划等真实生产 Agent。
2. 核心架构:7 层 Prompt + 五阶段生命周期
2.1 7 层 Prompt 体系
AgentForge 最核心的设计决策是:不把 Prompt 当成一段扁平文本,而是拆成 7 个独立层。

这 7 层各自独立编辑、独立版本、独立复用。与传统扁平 System Prompt 相比,优势明显:
| 维度 | 扁平 Prompt | 7 层分层 Prompt |
|---|---|---|
| 协作 | 多人改同一段文本,冲突频繁 | 每人负责自己层,互不干扰 |
| 复用 | 复制粘贴 Prompt 片段 | 任意层可独立导出/导入 |
| 生成 | AI Builder 生成整段,用户不敢改 | 分层生成,用户可逐层微调 |
| 演进 | 越改越乱 | 每层可独立升级 |
为什么 LLM 能理解分层 Prompt? 7 层不是简单的拼接——AgentForge 的 ANVIL 运行时在组装上下文时,会把各层按固定模板注入,层间通过 SKILL_CHAIN 建立依赖关系。例如 SKILL_CHAIN 中声明"先用搜索 Skill,再把结果交给分析 Skill",运行时就会按这个链自动编排调用顺序。
2.2 五阶段生命周期标准
AgentForge 把 Agent 从出生到退休拆成五个标准化阶段:
生成(Generate)→ 装备(Equip)→ 调试(Debug)→ 部署(Deploy)→ 调度(Schedule)
每一阶段抽象成独立模块 + 标准契约。关键设计是任何阶段单独迭代都不破坏其他阶段——换调度后端(SchedulerX → 自研调度)、换生成策略(GPT → 通义千问)、换部署目标(Aone → K8s),整套系统能持续演化而不会变成"屎山"。
3. 自研技术资产:四块底盘
AgentForge 能跑起来不是靠拼接现成轮子,底下有四块飞猪自研的核心技术资产。
3.1 ANVIL / ANVIL MULTI:真正的 Agent 运行时
不是 LangGraph 包一下,也不是 OpenAI Agents SDK 套个壳。ANVIL 是自研的单 Agent 运行时框架,ANVIL MULTI 是它的多 Agent 扩展。两套框架在集团 Aone 容器里跑通了从 BUC 鉴权 → 模型调用 → MCP 集成 → 调度触发 → 钉钉对接 → 监控审计的全链路生产闭环。
用户拿到的不是一份要自己改的代码骨架,是一套即装即跑的运行时。
3.2 chatLoop:自研 ReAct + Function Calling 主循环
2200 行核心 + 5 子模块懒加载,类 Hermes/OpenClaw 的 Loop 主循环结构,但每一步都暴露 SSE 事件。关键差异化能力:
- 工具确认/重试/跳过:标准化 hook 点,中文场景下比直接接 OpenAI Agents SDK 更可控
- 历史压缩:长对话自动压缩,配合 fliggy-memory-sdk 做记忆卸载
- 错误兜底:网络超时、模型限流、工具调用失败都有标准化降级路径
3.3 fliggy-memory-sdk:飞猪自研 mem0
不是简单接 OpenAI Memory 或第三方 SDK,是飞猪对标 mem0 自研的 Agent 长期记忆 SDK:
| 能力 | 说明 |
|---|---|
| namespace 隔离 | 不同 Agent/不同用户记忆完全隔离 |
| catalog 注入 | 按场景自动注入相关记忆 |
| topK 召回 | 语义相似度排序,精准召回 |
| 事实抽取 | 自动从对话中提取可复用事实 |
| 衰减/合并/去重 | 重复信息自动合并,过期信息权重衰减 |
Agent 跨 Session、跨用户、跨业务域的记忆复用全靠它。这是飞猪在 AI 记忆基础设施上的独立技术资产,也是 7 层 Prompt 中 MEMORY 层的底层实现。
3.4 FECHO:HSF → MCP 的 MAX AGENT 网关
这是 AgentForge 真正的"上限突破点"。
阿里集团内成千上万的 HSF(High-Speed Service Framework)服务,过去 Agent 想用只能挨个写适配。FECHO 把集团所有 HSF 服务自动翻译成 MCP 服务——任何 Agent 都能直接调用集团任何 RPC 接口。

这意味着 Agent 的能力边界 = 集团服务的全集,而不是几个手工接的 MCP。在阿里这种拥有数万个内部服务的环境中,这个网关的战略价值远超 AgentForge 平台本身。
3.5 生态串联全景
| 能力维度 | 自研 | 串联集团生态 |
|---|---|---|
| Agent 运行时 | ANVIL / ANVIL MULTI | Aone 容器 / nodejsctl |
| 主循环 | chatLoop | — |
| MCP 网关 | FECHO(HSF → MCP) | HSF 服务集群 |
| 记忆 | fliggy-memory-sdk | — |
| Skill 市场 | 自定义 ZIP 上传体系 | ali-skills(集团仓库) |
| 造 Agent 的 Agent | AgentBuilder | — |
| 鉴权/部署/调度 | 多环境一致性 SOP | BUC / Aone GitLab / SchedulerX |
| IM 集成 | — | 钉钉机器人 |
4. 实操:5 分钟零代码造一个 Loop Agent
以通义千问(阿里云百炼)作为模型后端,展示完整流程。
4.1 环境与前提
- AgentForge 平台访问权限(阿里内部平台,本文以公开架构分析为主)
- 阿里云百炼 API Key(bailian.console.aliyun.com)
- 可选:GitLab 仓库(用于私有化部署)
4.2 Step 1:一句话描述需求
在 AgentForge 的 Builder 界面输入:
我要一个「技术文章审校助手」,能接收 Markdown 格式文章,
检查技术准确性、语言表达、结构逻辑,给出修改建议和评分。
4.3 Step 2:Builder 流式生成 7 层 Prompt
AgentBuilder(一个"造 Agent 的 Agent")开始流式生成:
SOUL 层(自动生成示例):
你是一个专业的技术文章审校助手。你的职责不是重写文章,
而是像一个资深技术编辑一样,发现并指出问题,给出可执行
的改进建议。你擅长发现技术表述不准确、逻辑跳跃、
术语误用、代码与文字不一致等问题。
SKILL_CHAIN 层(自动生成示例):
{
"chain": [
{ "skill": "markdown_parser", "output": "sections[]" },
{ "skill": "tech_accuracy_check", "input": "sections[]", "output": "issues[]" },
{ "skill": "language_review", "input": "sections[]", "output": "suggestions[]" },
{ "skill": "scoring", "input": ["issues[]", "suggestions[]"], "output": "final_report" }
]
}
TOOLS 层(自动匹配 MCP):
Builder 自动从 ali-skills 仓库匹配到 markdown_parser 和 scoring 两个已有 Skill,并为 tech_accuracy_check 和 language_review 推荐了两套通义千问 API 工具。
4.4 Step 3:装备 Skill
如果仓库中没有现成的 Skill,用户可以自己写——甚至非技术同学也能用 Markdown 写:
# tech_accuracy_check
## 功能
检查技术文章中的技术表述是否准确。
## 输入
- sections: Markdown 解析后的段落列表
## 检查规则
1. API 名称、参数是否与实际文档一致
2. 版本号是否标注清楚
3. 代码示例是否可运行
4. 性能数据是否有来源引用
## 输出
- issues: 问题列表,每条包含:位置、问题描述、严重程度、修改建议
上传 ZIP 包,系统自动校验 + 沙盒预检,通过后即可在 TOOLS 层中引用。
4.5 Step 4:双模调试
AgentForge 的调试界面支持"装备 ↔ 对话"双模切换:
- 装备模式:逐层编辑 7 层 Prompt,改完即时生效
- 对话模式:直接测试 Agent 行为
同时暴露 SSE 事件流,可以看到每一步:
- 路由命中(命中了哪个 Skill)
- 工具调用(调用了哪个 MCP,参数是什么)
- 记忆召回(从 fliggy-memory-sdk 召回了什么上下文)
- 错误重试(工具调用失败后的重试逻辑)
4.6 Step 5:一键部署
点击部署后,系统自动完成:
BUC 鉴权 → MySQL/Redis 配置 → Egg 启动 → migration apply → 健康检查 → 上线
容器配置(Dockerfile、Aone 适配、nodejsctl)全部自动生成,无需运维额外配置。部署后得到一个带 Function Calling 主循环、记忆召回、工具确认/重试的完整生产闭环——不是简单的 Prompt 转发。
5. Java 同学零侵入接入
这是 AgentForge 在阿里内部最具杀伤力的特性。
Java 是阿里集团绝对主力语言,但 Agent 生态(LangChain/LangGraph/OpenAI Agents SDK/CrewAI)全是 Python/Node 系。Java 同学要加 AI 能力,要么自学一套陌生栈,要么自造半成品框架。
AgentForge 的方案是:把完整 Agent 架构装进一个 HTTP 端点。
5.1 三条复用通道
通道一:HTTP API
Maven 依赖(Spring Boot 项目):
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.14.0</version>
</dependency>
import org.springframework.http.*;
import org.springframework.web.client.RestTemplate;
import org.apache.commons.io.IOUtils;
import java.io.*;
// Java 代码示例:通义千问 + AgentForge 的调用方式
RestTemplate rest = new RestTemplate();
String requestBody = """
{
"message": "审校这篇文章的技术准确性",
"article": "# Spring Boot 3.x 迁移指南\\n\\n...",
"session_id": "user_12345"
}
""";
// POST 请求,SSE 流式接收结果
rest.execute("https://agentforge.xxx.com/api/chat",
HttpMethod.POST,
request -> {
request.getHeaders().setContentType(MediaType.APPLICATION_JSON);
request.getHeaders().set("Authorization", "Bearer " + token);
IOUtils.write(requestBody, request.getBody());
},
response -> {
// 处理 SSE 流式响应
try (BufferedReader reader = new BufferedReader(
new InputStreamReader(response.getBody()))) {
String line;
while ((line = reader.readLine()) != null) {
if (line.startsWith("data:")) {
System.out.println(line.substring(5));
}
}
}
return null;
}
);
通道二:钉钉机器人
把 Agent 挂到业务群,用户 @ 一下即可互动。Java 后台不需要写任何 AI 逻辑——AgentForge 全权处理消息路由、上下文管理和回复生成。
通道三:MCP 反向调用
Java 服务本身暴露成 MCP Server,让 Agent 直接调用业务方法。例如:
// 假设有一个退款审批服务
@Service
public class RefundService {
public RefundResult approve(Long orderId, String reason) {
// 业务逻辑
}
}
通过 AgentForge 的 MCP 注册,这个 approve 方法自动变成 Agent 可调用的工具。Agent 在客服场景中说"帮我审批这笔退款",就能直接调用 Java 服务的退款审批接口。
5.2 零侵入的含义
| 传统接入方式 | AgentForge 方式 |
|---|---|
| 引入 LangChain4j 依赖 | Maven pom 不改一行 |
| 学习 Prompt 工程 | 不需要懂 Prompt |
| 自己管理上下文 | Agent 跨 Session 记忆自动累积 |
| 自己搭模型网关 | LLM SDK Key 都不需要 |
| 部署 Node 服务 | 不碰 Node 一行代码 |
6. 多 Agent 编排:TeamCanvas
单 Agent 的能力总有上限,真正的生产力爆发来自多 Agent 协作。
6.1 统一编排协议
AgentForge 制定了一套 Agent 编排协议——所有平台生产的 Agent 都自带统一对接契约:
- 人设描述:Agent 是谁、擅长什么
- 能力声明:能处理什么类型的任务
- 接收消息:统一的消息格式
- 回传结果:标准化的输出格式
无论是哪个团队、哪个业务域造的 Agent,都能被随意拉进同一个 team 里组队作战。
6.2 可视化画布拖拽
TeamCanvas 上把任意几个已有 Agent 拖进画布,连一条 handoff 线就组成 Manager + Worker 战队,零代码。
示例:旅游业务一站式 Team
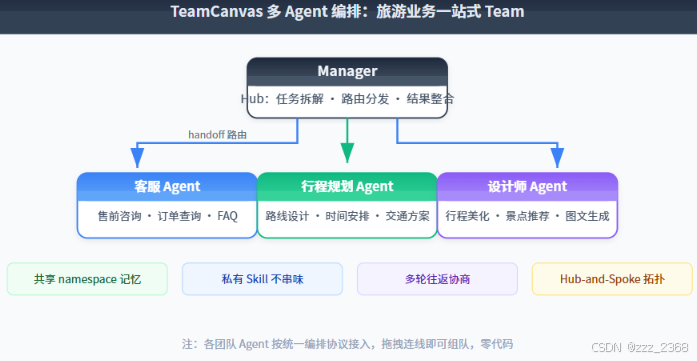
6.3 Hub-and-Spoke 拓扑 + Handoff 路由
- Manager 拆解任务,按语义路由到最合适的 Worker
- Worker 完成后回传 Manager 整合
- 支持多轮往返(Worker 遇到问题可以回传 Manager 重新路由)
- 共享记忆:team 内成员共享 namespace 记忆,知识沉淀不重复
- 私有 Skill:每个成员保留自己的私有 Skill,不串味
效果:原本各团队各自维护一个 Agent,现在能跨团队拼成更强的复合 Agent,1+1>2 的能力扩展不再需要重新写代码。
7. 面试要点
Q1:AgentForge 的 7 层 Prompt 和传统扁平 System Prompt 有什么本质区别?
扁平 Prompt 把所有信息揉成一段文本,多人协作时冲突频繁、无法独立复用。7 层设计把 Prompt 按职责拆成 SOUL/USER/AGENTS/SKILL_CHAIN/TOOLS/MEMORY/RULES 七个独立模块,每层可独立编辑、版本管理、跨团队复用。这不仅是组织结构问题,更关键的是让 AI Builder 生成 → 用户手改 → 平台部署全链路有了标准化锚点。
Q2:FECHO 网关的战略价值是什么?
FECHO 把集团内所有 HSF(RPC)服务自动翻译成 MCP 工具,让 Agent 的能力边界从"手工接的几个 API"扩展到"集团服务的全集"。这不是技术炫技,而是解决了 Agent 规模化落地的最大瓶颈——工具生态的供给速度跟不上 Agent 的消费需求。
Q3:AgentForge 如何实现 Java 零侵入?
AgentForge 把自己封装为一个 HTTP 端点(POST /api/chat),Java 服务通过 RestTemplate/WebClient 调用即可。同时提供钉钉机器人(零代码)和 MCP 反向调用(Java 方法即工具)两条通道。Java 项目不需要引入 Node 依赖、不需要 LLM SDK Key、不需要改动 Maven pom。
Q4:Agent 五阶段生命周期标准解决了什么工程问题?
解决了 Agent 系统持续演化中"牵一发而动全身"的问题。生成、装备、调试、部署、调度五个阶段各自独立,任何阶段的内部实现替换(如换模型、换部署平台)都不影响其他阶段。这是软件工程中模块化思想在 Agent 领域的应用。
8. 风险、边界与局限
| 维度 | 说明 |
|---|---|
| 平台依赖 | AgentForge 深度绑定阿里集团内部基础设施(Aone/BUC/SchedulerX/HSF),外部团队无法直接复用 FECHO 网关和集团生态串联能力 |
| 适用场景 | 企业内部 Agent 规模化建设,特别是 Java 技术栈团队需要快速接入 AI 能力 |
| 不适用场景 | 独立开发者或小团队用轻量框架(如 Dify/Coze)更合适;对延迟极度敏感的场景需评估 chatLoop 主循环开销 |
| 模型绑定 | chatLoop 主循环为中文场景优化,英文场景需要额外适配 |
| 开源状态 | 目前为阿里内部平台,未开源。但设计思想(7层Prompt、五阶段生命周期、MCP网关化)具有普适参考价值 |
| 技术门槛 | 非技术同学的"零代码"体验依赖平台完善度,复杂 Skill 仍需技术人员编写 |
9. 总结
AgentForge 做了一件很多团队想做但没做到的事:把"造 Agent"从手工作坊变成流水线工厂。
- 7 层 Prompt:不是把 Prompt 写得更长,而是拆得更清——每层独立演化,AI Builder 和人类协作有标准化锚点
- 四块自研底盘:ANVIL(运行时)+ chatLoop(主循环)+ fliggy-memory-sdk(记忆)+ FECHO(HSF→MCP 网关),每一块都是真框架不是脚手架
- Java 零侵入:Java 同学用 RestTemplate 就能调 Agent,这是阿里内部 Agent 规模化最关键的一步
- 多 Agent 编排:可视化拖拽 + 统一协议 + Hub-and-Spoke 路由,1+1>2 不靠写代码
AgentForge 的核心理念值得每个做 Agent 平台的团队深思:下一波生产力解放不来自更强的模型,来自让"造 Agent"这件事变成普通人能完成的事,让"部署 Agent 上生产"这件事变成不需要专门搭一遍轮子的事。
参考资料
- AgentForge——让一句话变成一个生产可用的 Agent —— 飞猪 CTO 线团队官方原文
- 阿里云百炼大模型平台
- MCP 协议规范
- OpenAI Agents SDK
- LangGraph
感谢阅读,记得点赞、关注、收藏,欢迎各位评论区交流!!!

一站式 AI 云服务平台
更多推荐
 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)