
助睿实验指导7:自媒体运营分析三次过程合并-CSDN博客
助睿实验指导:自媒体运营分析全流程(数据清洗→特征构建→可视化探索)-CSDN博客
实验概述:本文基于助睿数智(Uniplore)平台,完整记录“自媒体运营分析”三阶段实验——从原始数据清洗、标题特征工程,到多维度可视化仪表盘搭建。通过零代码拖拽式操作,掌握数据分析全链路实战技能。
一、实验背景与整体设计
1.1 实验目的
本系列实验基于全班同学在多平台(B站、CSDN、微信、知乎等)发布的作品互动数据,使用助睿ETL完成数据清洗与预处理,再通过特征工程挖掘标题影响力,最后利用助睿BI搭建可视化仪表盘,输出数据驱动的运营优化报告。
通过三阶段实验,你将掌握:
- ✅ 使用助睿ETL完成多源数据的过滤、填充、聚合等预处理操作
- ✅ 利用“JavaScript代码”组件实现文本关键词自动标注
- ✅ 设计分支处理流程,同时支撑全平台概况统计与重点平台深度分析
- ✅ 使用助睿BI制作指标卡、排名图、标题影响分析、趋势图等可视化图表
- ✅ 掌握“从图表到洞察”的分析方法,撰写数据驱动的优化报告
1.2 实验环境
| 项目 | 说明 |
|---|---|
| 实验平台 | 助睿在线实验平台 |
| 数据处理工具 | 助睿ETL(数据集成平台)—零代码拖拽式操作 |
| 可视化工具 | 助睿BI(可视化探索平台)—自助式分析 |
助睿ETL核心优势:全元数据驱动架构、零代码拖拽、丰富的预处理组件(筛选、填充、聚合等)、基于开源内核的高可用引擎。
助睿BI核心优势:工作表机制、交互式仪表盘、自助分析(无需SQL)、丰富图表类型。
二、实验7-1:数据清洗与预处理
2.1 为什么需要数据清洗?
采集到的原始数据自媒体作品数据明细.csv存在以下问题:
- 平台冗余:微信、知乎等平台浏览数几乎为0,无法支撑分析
- 无效记录:部分作品浏览、点赞、收藏全为0
- 字段缺失:点赞、分享等字段存在空值
2.2 核心设计思路:分支处理
本次实验需输出两张表,分别满足不同分析需求:
| 输出表 | 用途 | 处理逻辑 |
|---|---|---|
| summary_all_platforms | 全平台概况指标卡 | 保留所有平台原始数据,按日期+平台分组聚合 |
| cleaned_details(后命名为content_analysis) | 重点平台深度分析 | 只保留B站和CSDN且浏览数>0的记录 |
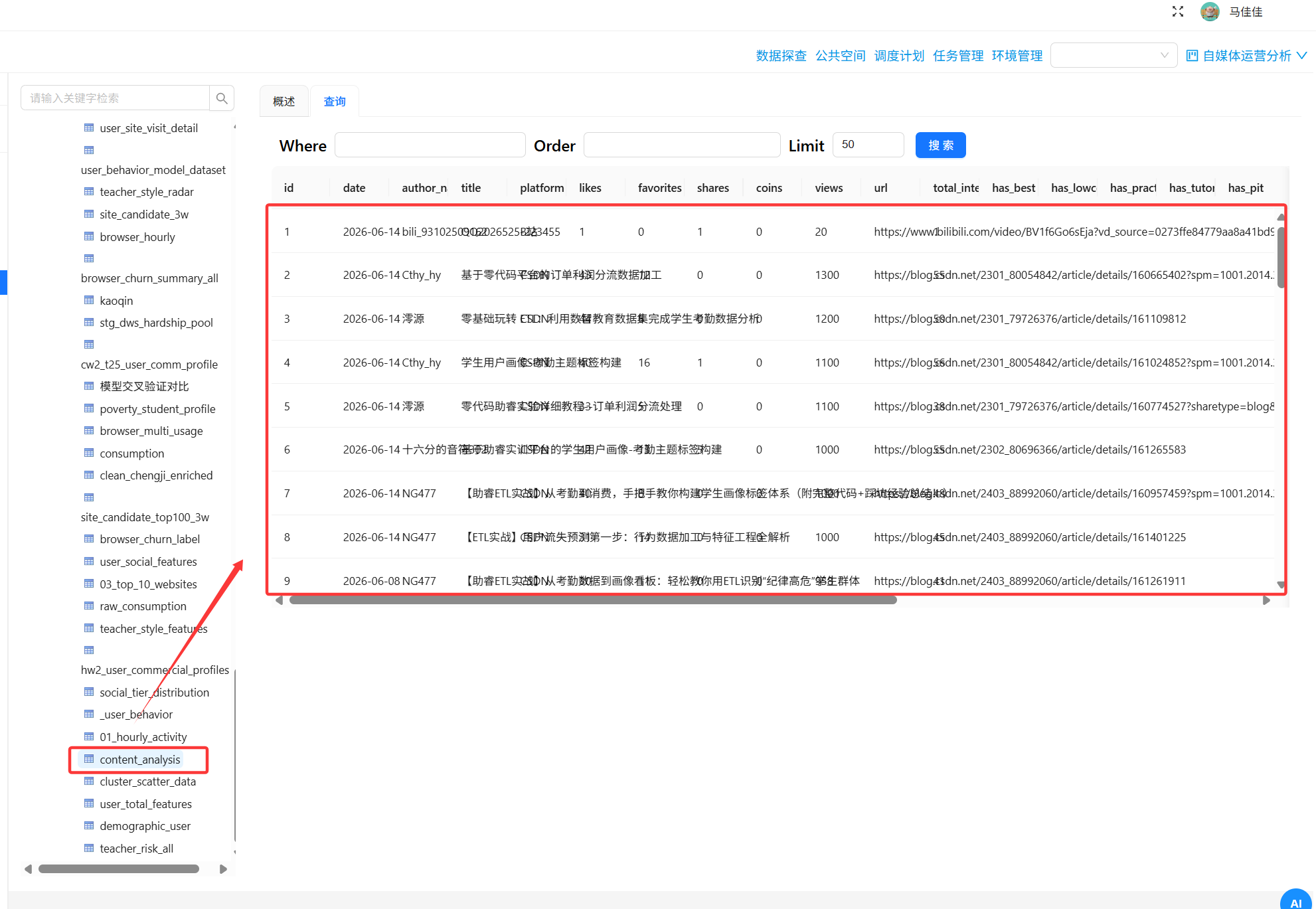
2.3 实验步骤(关键操作截图位置)
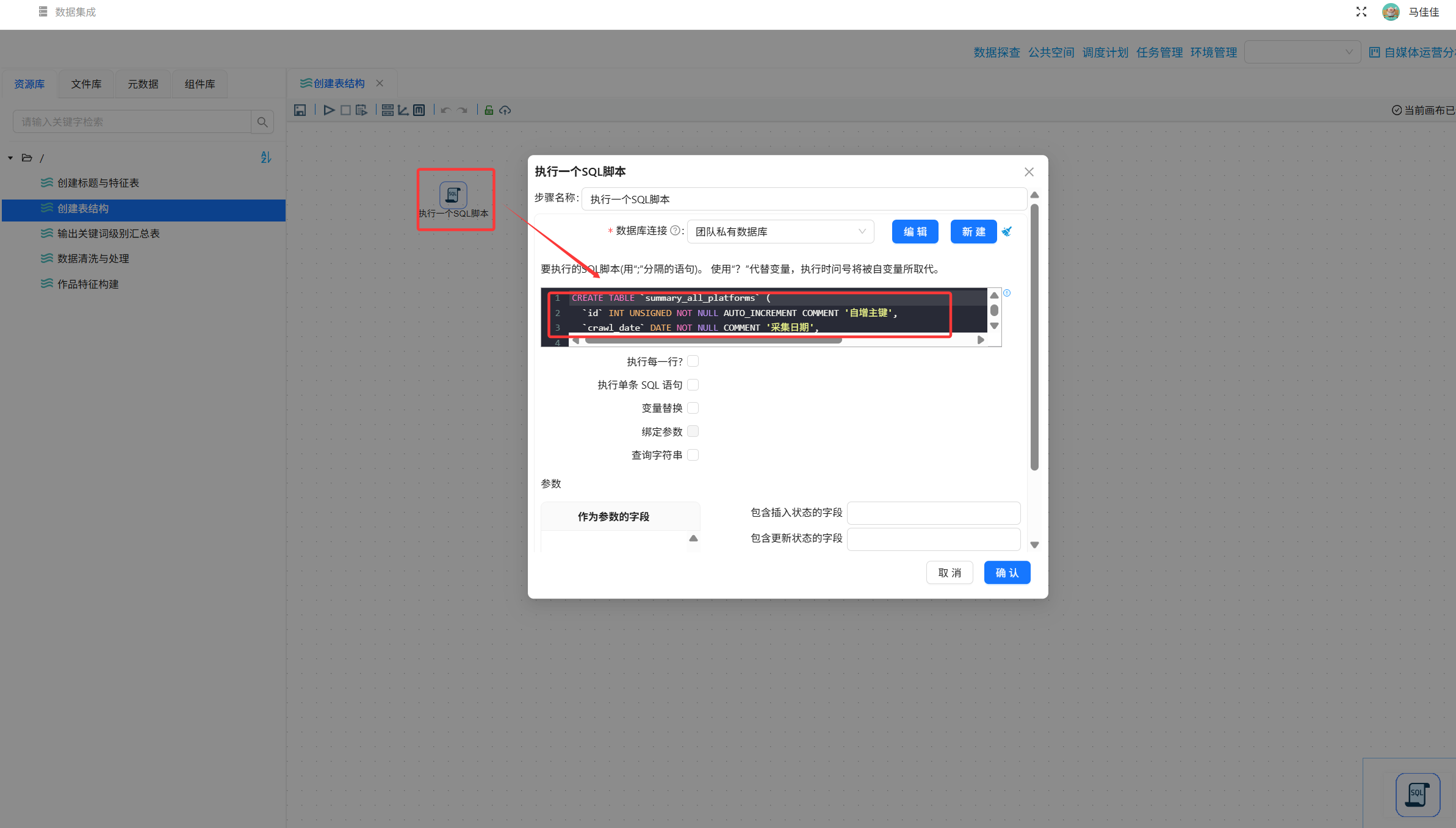
步骤1:创建目标表
在助睿ETL中创建两张目标表,字段设计如下(仅展示关键字段):
- 全平台概况表(summary_all_platforms):
crawl_date,platform,content_count,total_views,total_likes…… - 内容分析表(content_analysis):
date,author_name,title,platform,likes,favorites,shares,coins,views,url
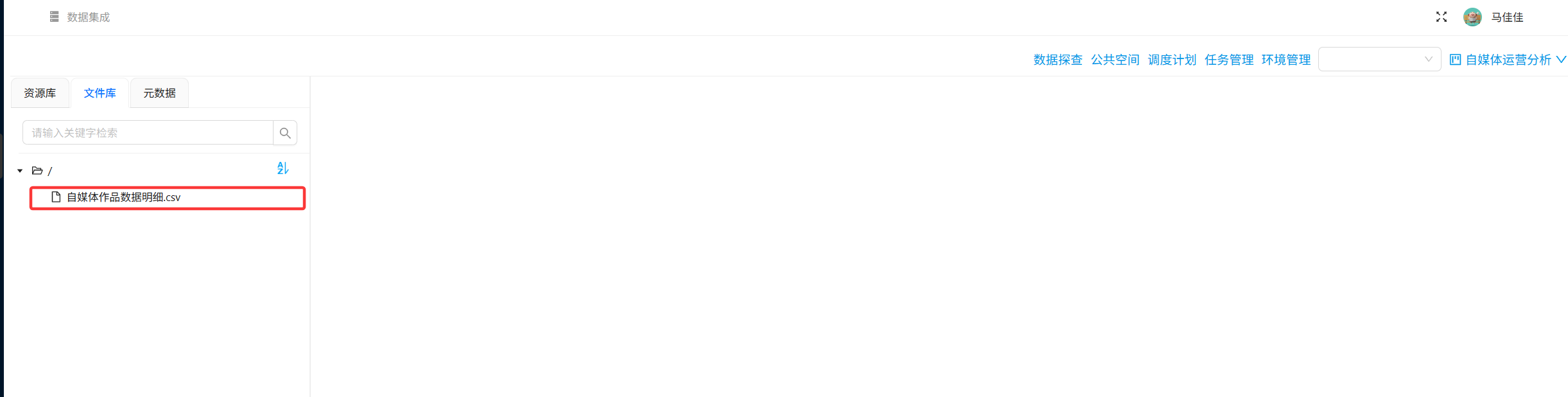
步骤2:导入原始数据
从助睿ETL公共空间复制自媒体作品数据明细.csv到自己的文件库。
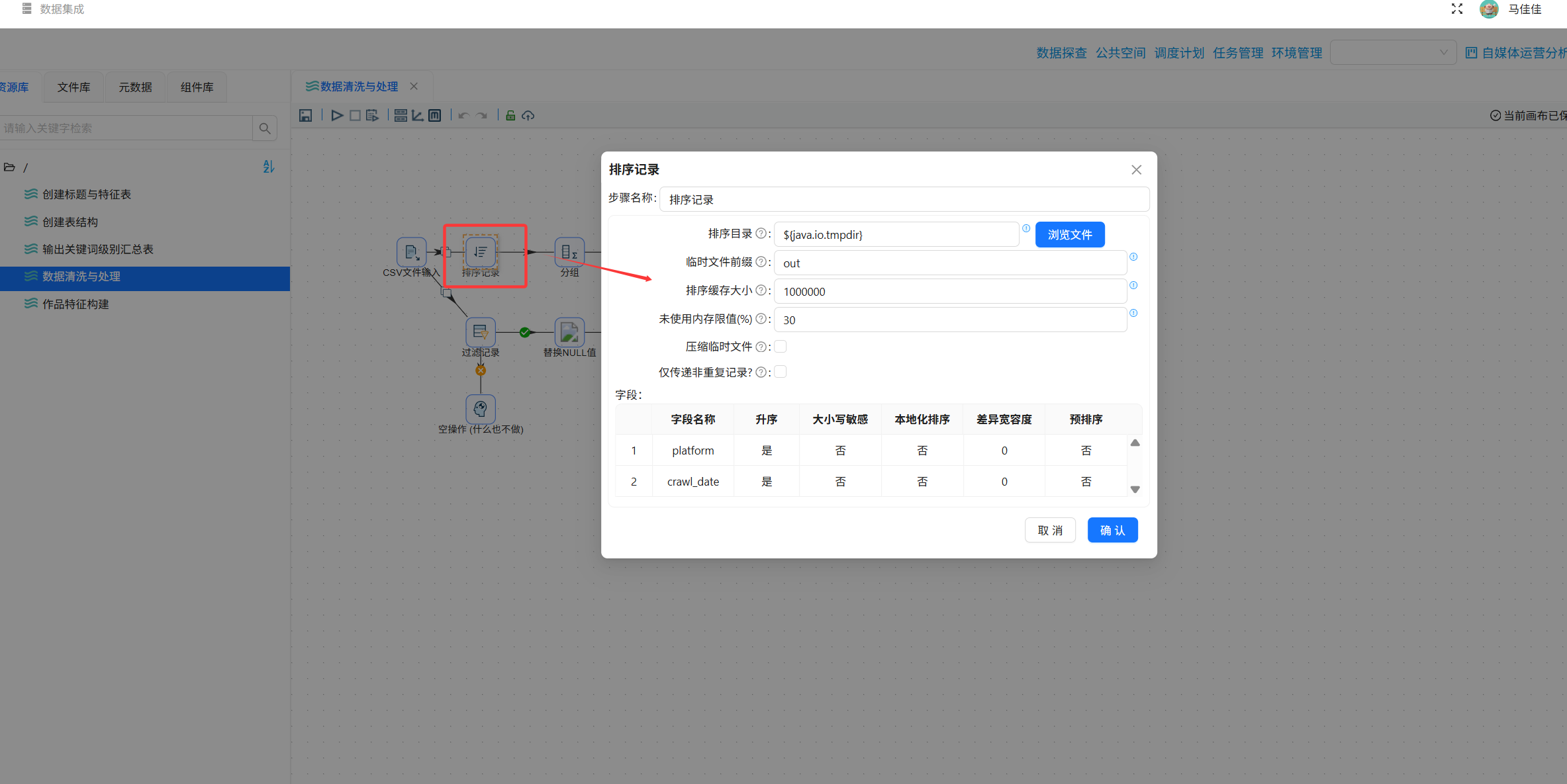
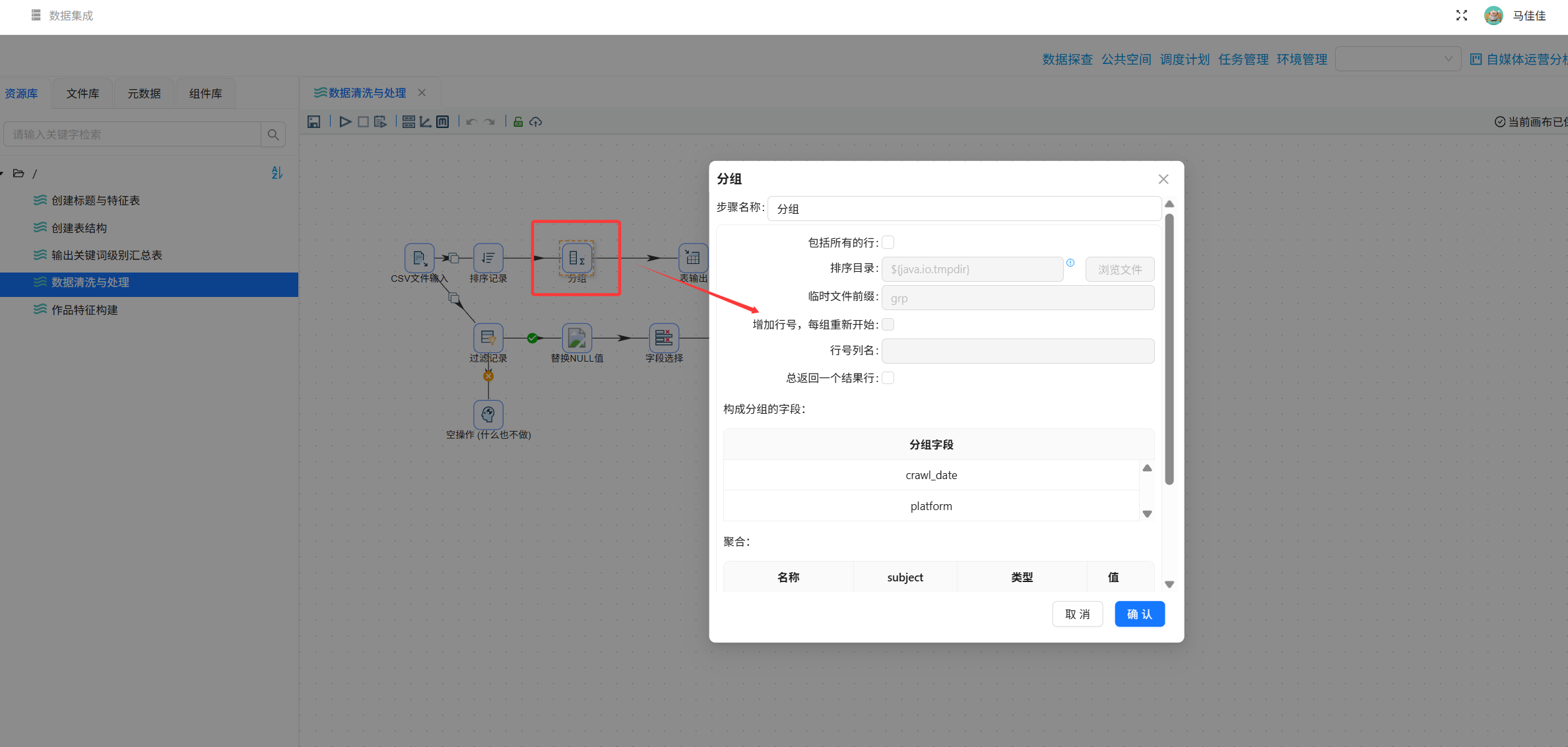
步骤3:全平台聚合统计
拖入“排序记录”+“分组”组件,按日期和平台分组,数值字段求和,输出summary_all_platforms。
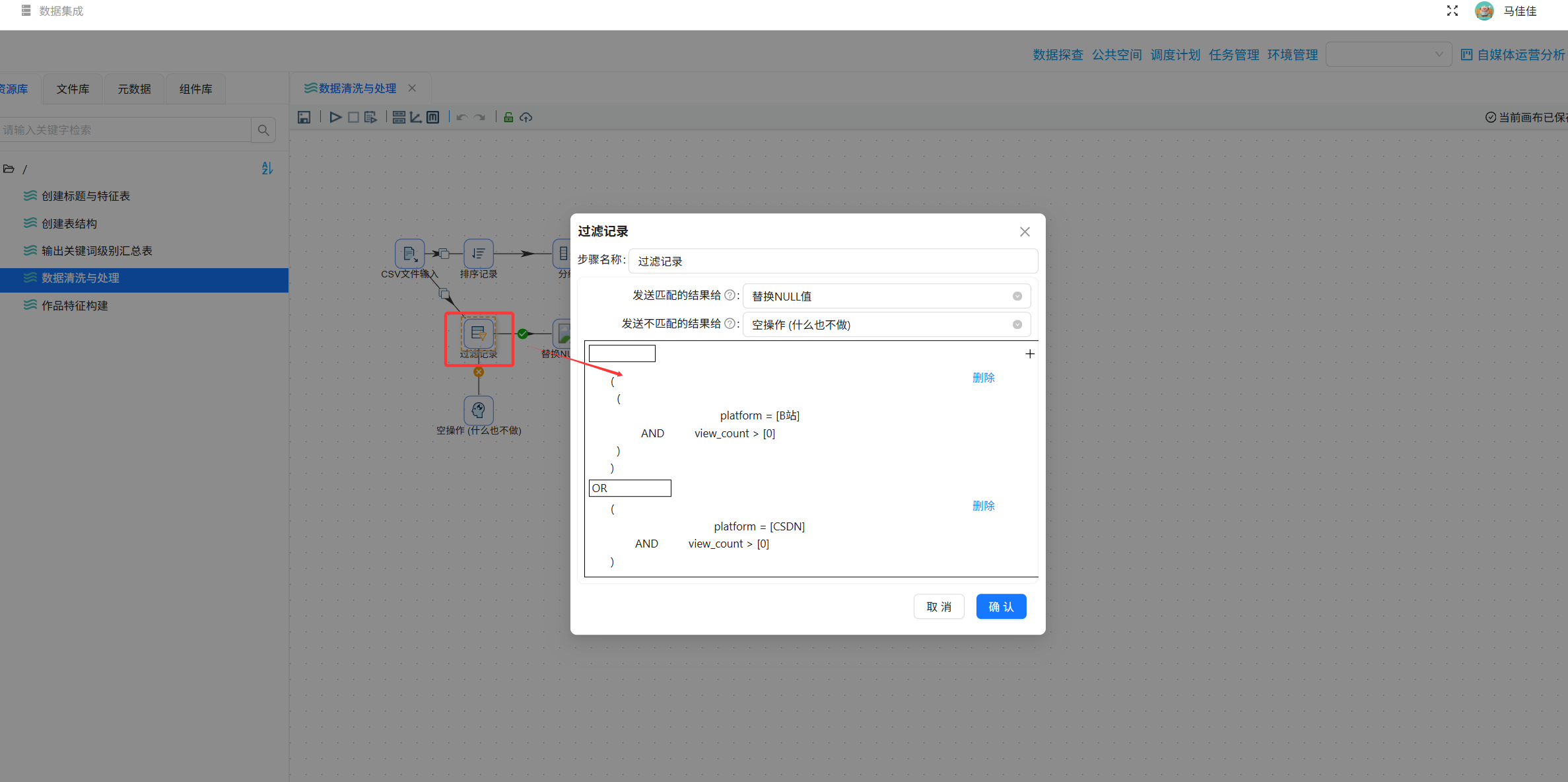
步骤4:过滤记录(核心操作)
在另一分支中,使用“过滤记录”组件筛选有效数据:
text
(平台 = 'B站' AND 浏览数量 > 0) OR (平台 = 'CSDN' AND 浏览数量 > 0)
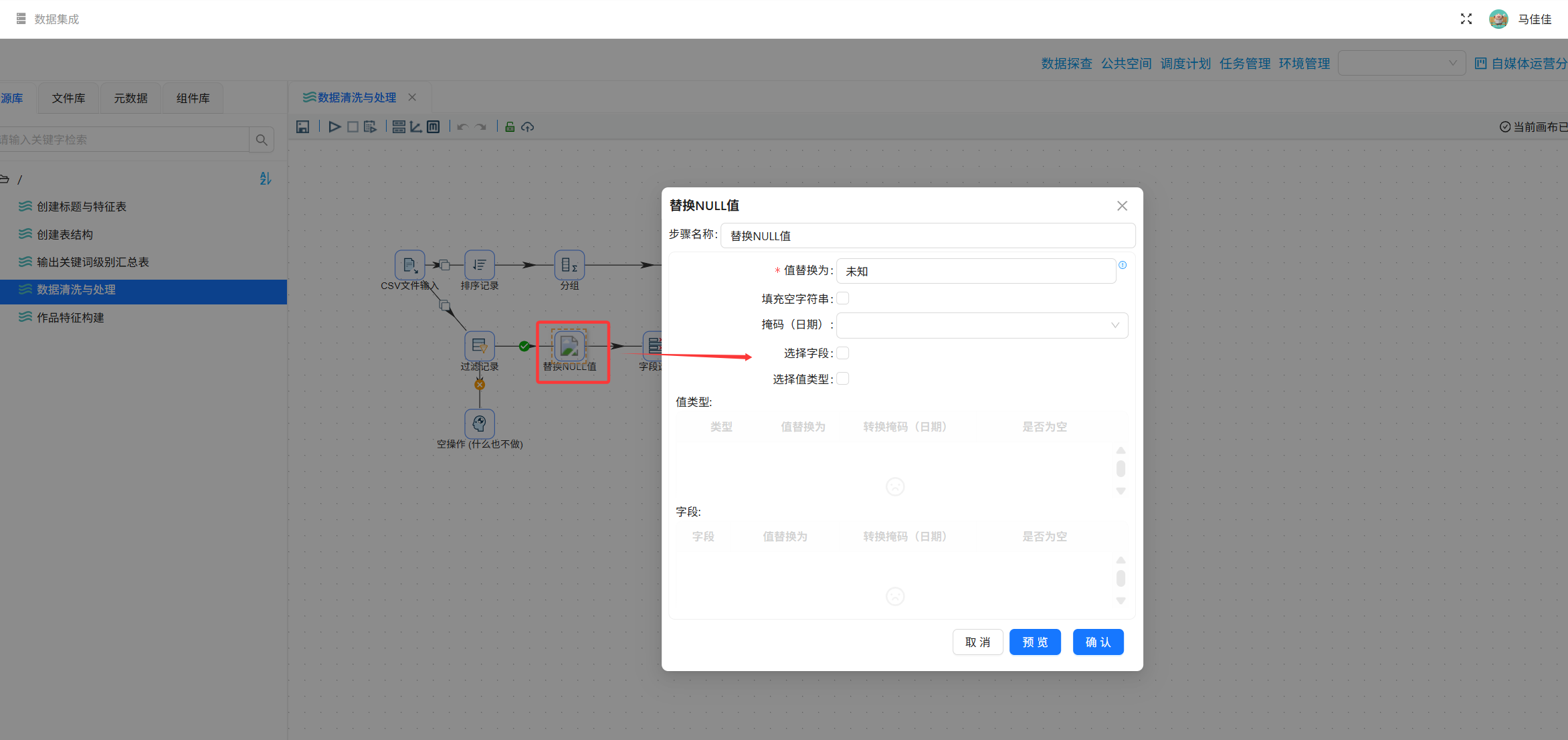
步骤5:填充缺失值
使用“填充缺失值”组件,将作者名称和作品标题的空值统一填充为“未知”。
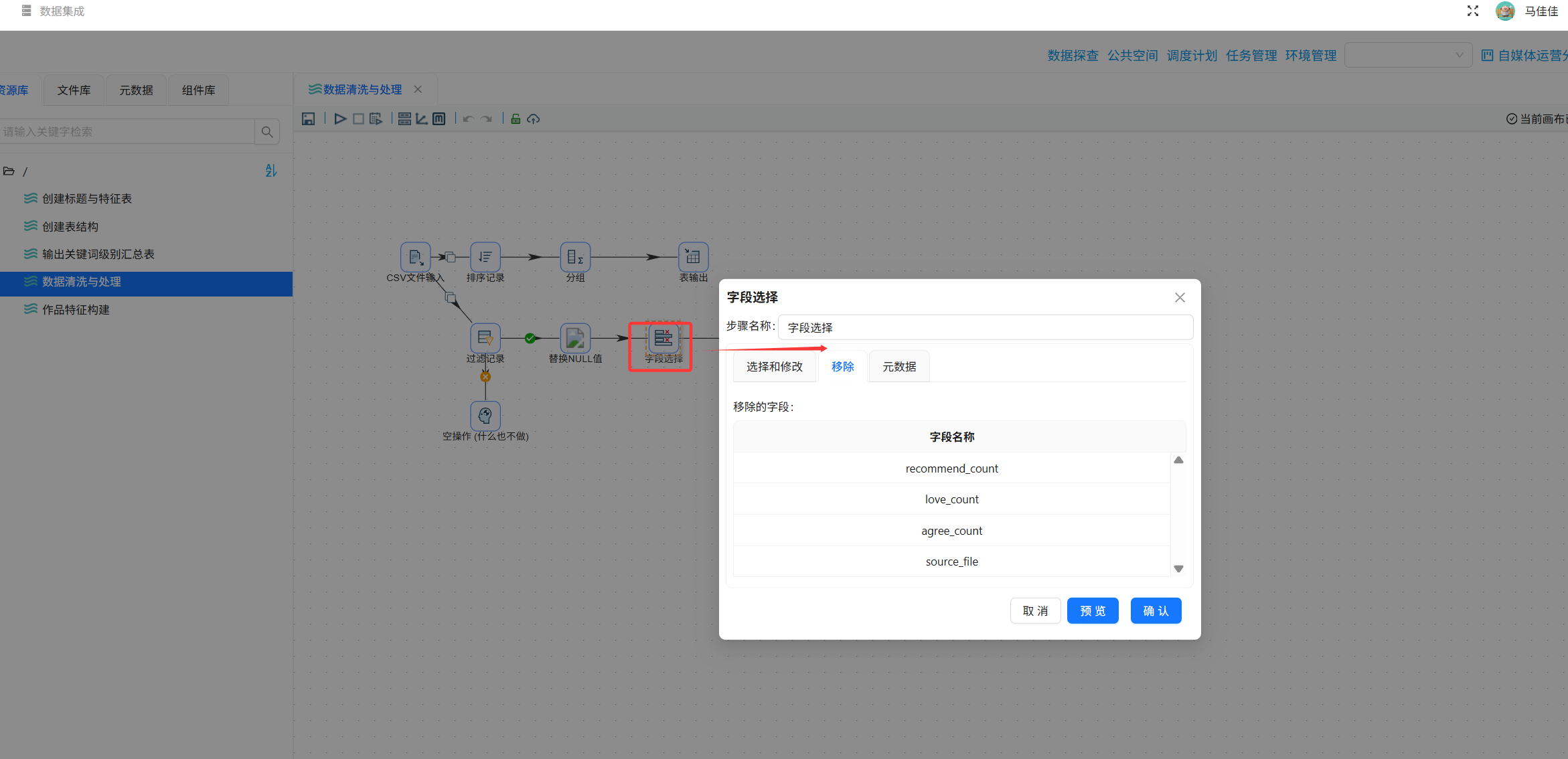
步骤6:字段选择
剔除无关字段source_file,保留date, author_name, title, platform, likes, favorites, shares, coins, views, url。
步骤7-8:输出目标表并执行
将处理后的数据输出为content_analysis,运行完整转换流。
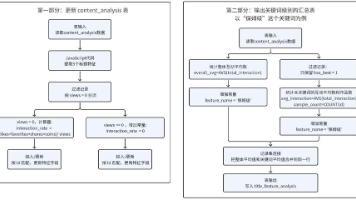
三、实验7-2:作品特征构建
3.1 核心设计思路
本实验在实验7-1基础上完成两类特征构建:
- 更新明细表:计算互动总数 + 提取5个标题关键词标志
- 新建汇总表:分别计算含每个关键词的作品的平均互动总数
3.2 更新 content_analysis 表
步骤1:导入数据
将实验7-1输出的content_analysis表作为输入。
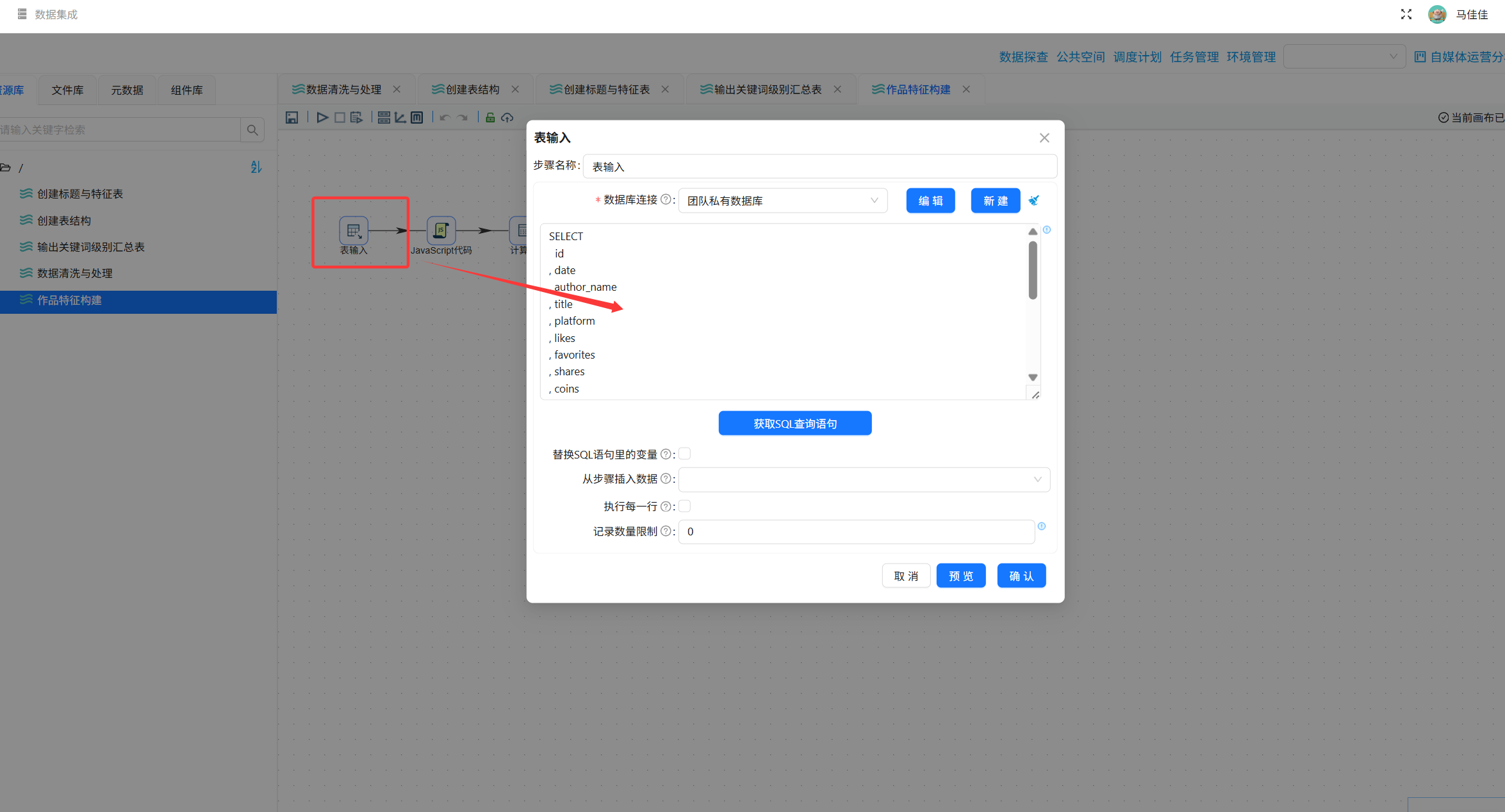
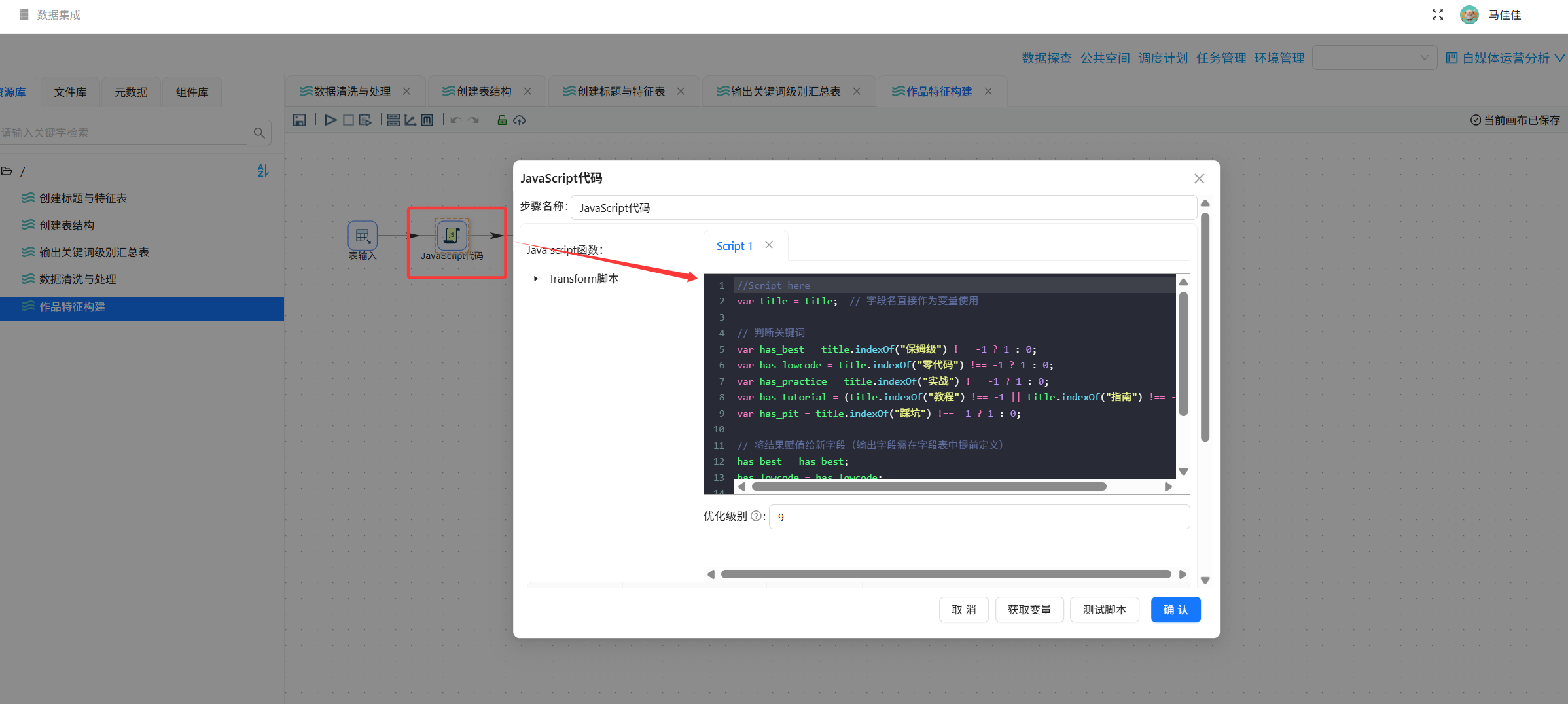
步骤2:提取标题特征(JavaScript代码)
在“JavaScript代码”组件中编写以下逻辑:
javascript
//Script here
var title = title; // 字段名直接作为变量使用
// 判断关键词
var has_best = title.indexOf("保姆级") !== -1 ? 1 : 0;
var has_lowcode = title.indexOf("零代码") !== -1 ? 1 : 0;
var has_practice = title.indexOf("实战") !== -1 ? 1 : 0;
var has_tutorial = (title.indexOf("教程") !== -1 || title.indexOf("指南") !== -1) ? 1 : 0;
var has_pit = title.indexOf("踩坑") !== -1 ? 1 : 0;
// 将结果赋值给新字段(输出字段需在字段表中提前定义)
has_best = has_best;
has_lowcode = has_lowcode;
has_practice = has_practice;
has_tutorial = has_tutorial;
has_pit = has_pit;
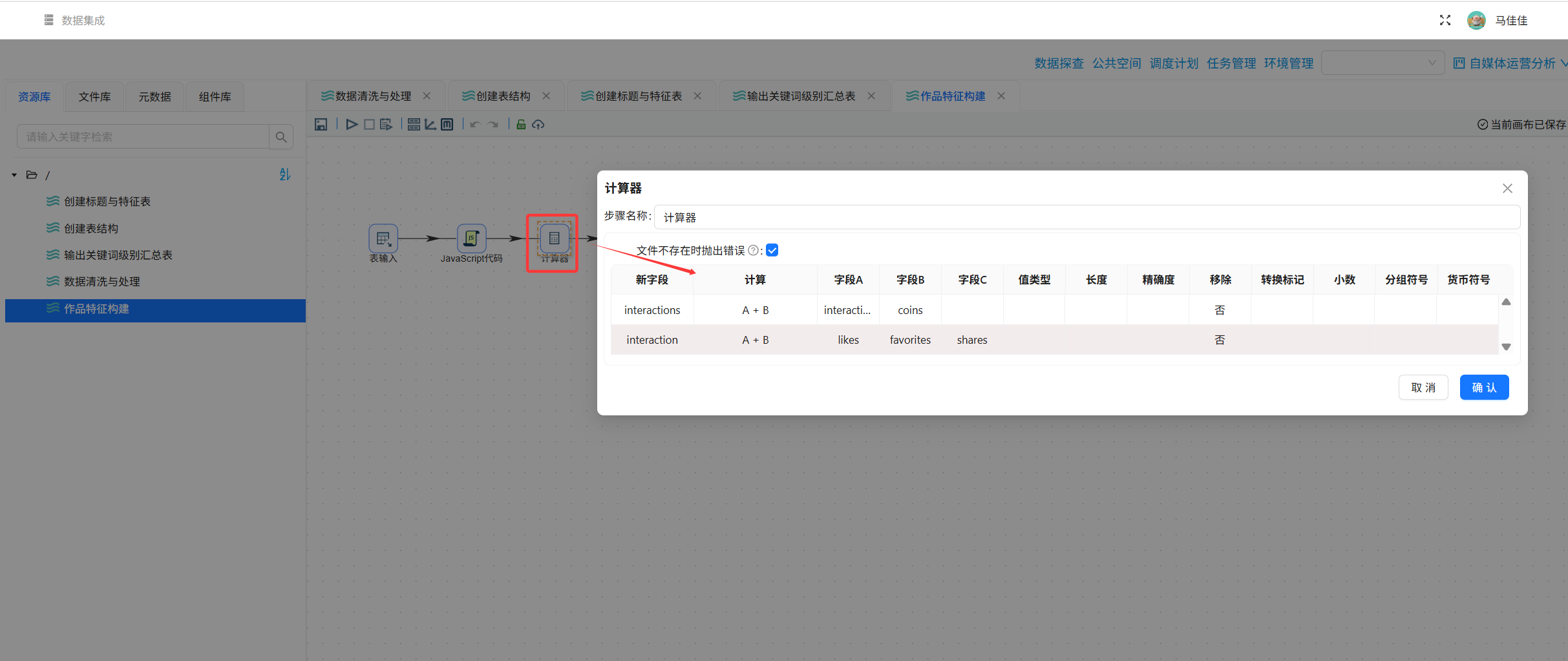
步骤3:计算互动总数
使用“计算器”组件:interactions = likes + favorites + shares + coins
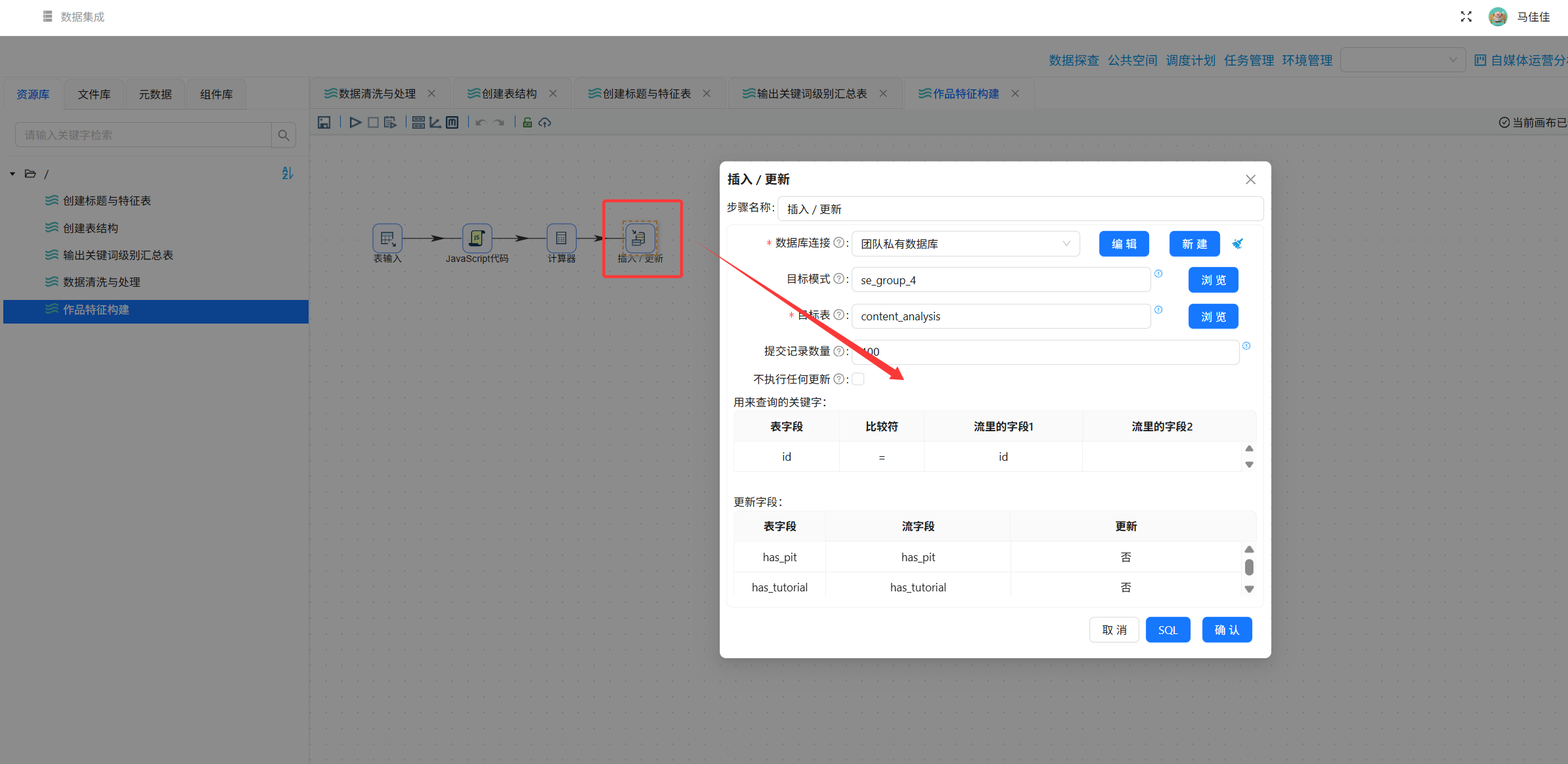
步骤4:数据更新(插入/更新)
使用“插入/更新”组件,按id匹配,更新content_analysis表中的total_interaction及5个特征字段。
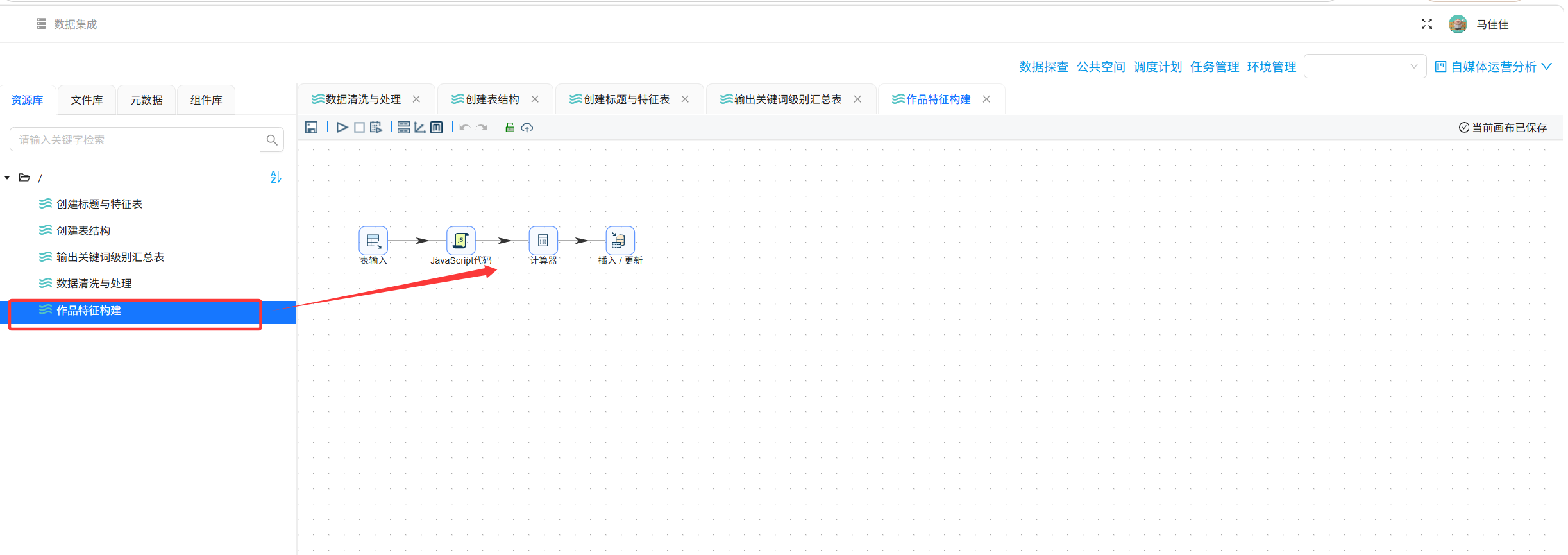
步骤5:执行转换流
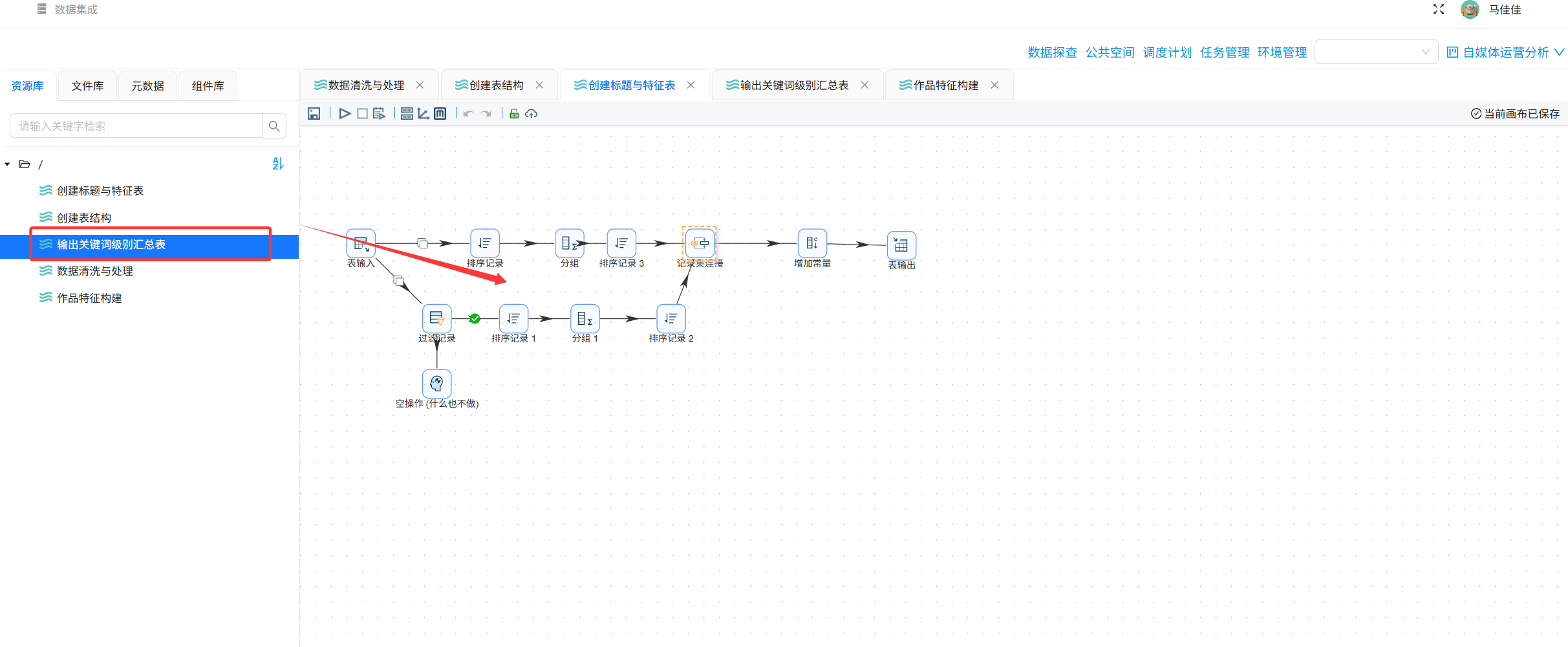
3.3 输出关键词级别汇总表
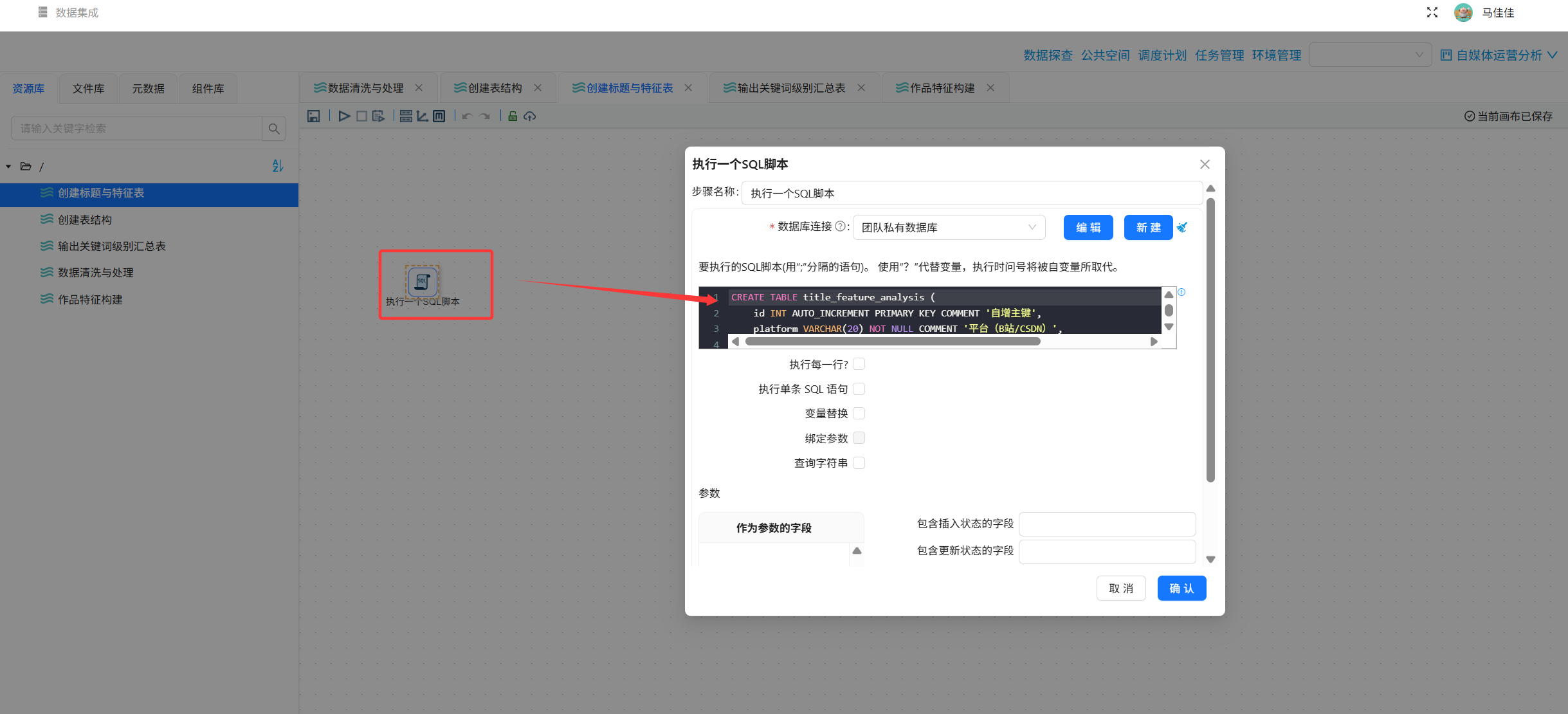
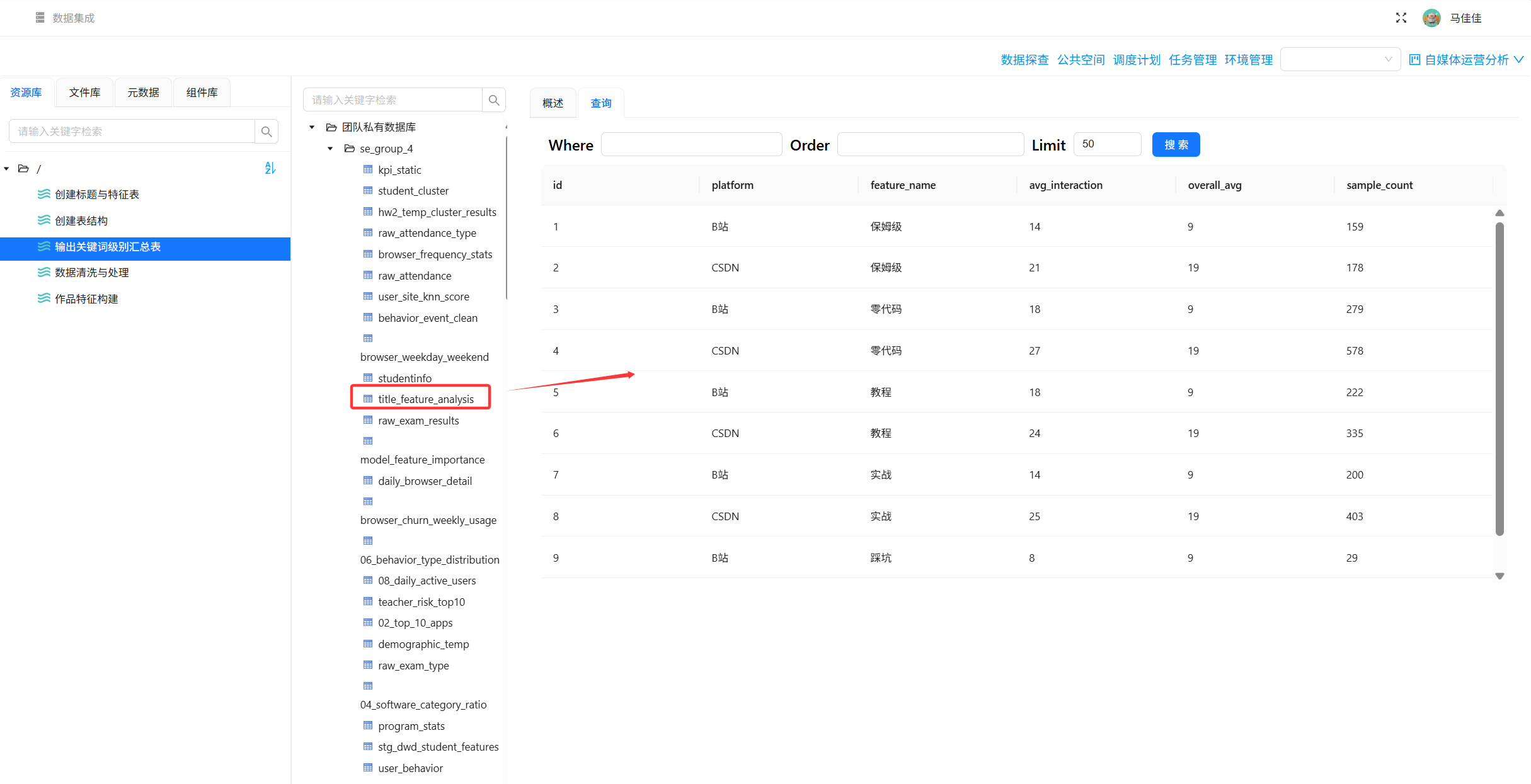
步骤1:创建目标表 title_feature_analysis
字段:id, platform, feature_name, avg_interaction, overall_avg, sample_count
步骤2-3:计算整体平均值与各关键词平均值(以“保姆级”为例)
- 整体平均:分组组件不设分组条件,计算
AVG(total_interaction)→ 得到overall_avg - 关键词平均:过滤
has_best=1→ 聚合计算AVG(total_interaction)和COUNT(id)
两个分支都接入“增加常量”组件,添加feature_name = '保姆级'标签。
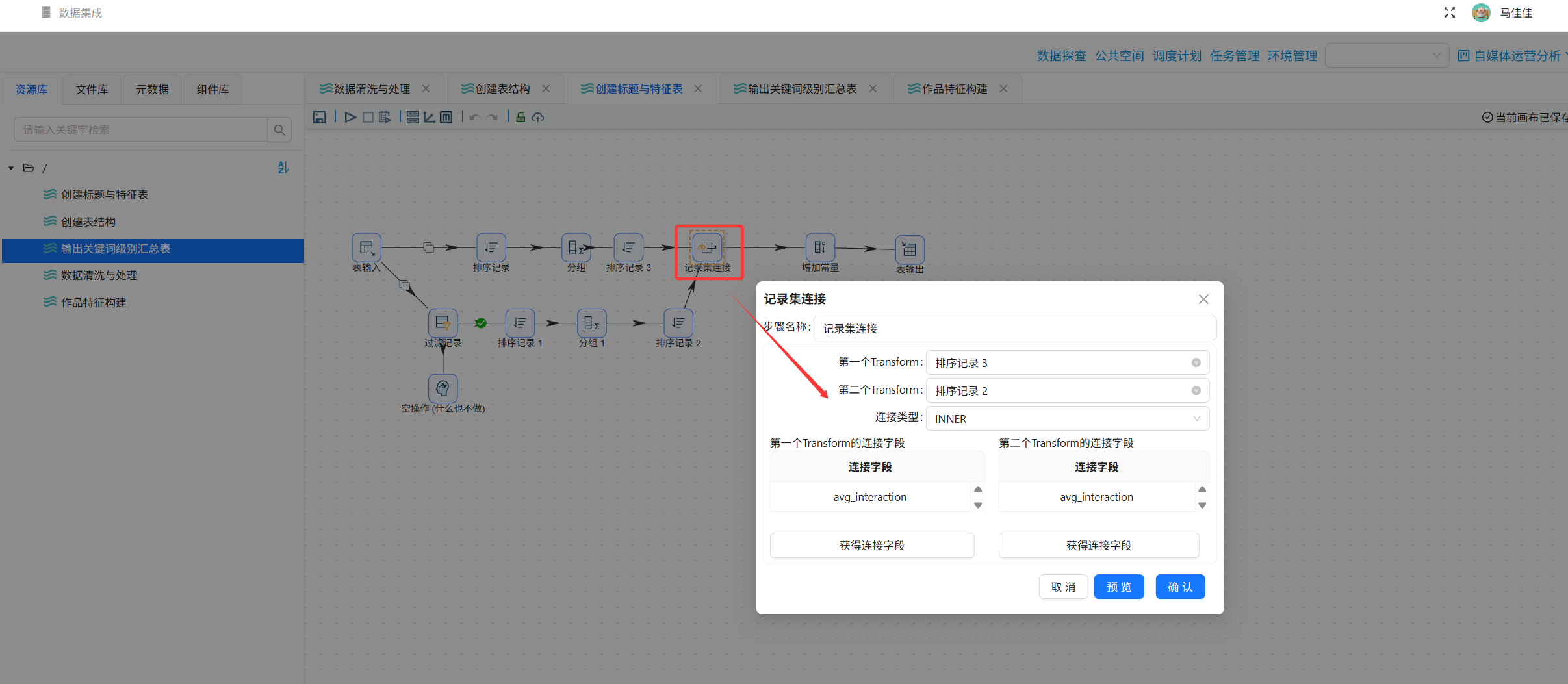
步骤4-5:合并记录并入库
使用“记录集连接”按feature_name合并整体平均值和关键词平均值,然后用“表输出”写入title_feature_analysis。
步骤6:复制分支加工其他关键词
复制整个分支,仅修改过滤条件(如has_lowcode=1)和常量值(如“零代码”),逐个加工所有关键词。
四、实验7-3:可视化探索
4.1 分析框架
由于数据特点为内容同质化、平台固定、标题是主要差异来源,因此分析聚焦于5个维度:
- 核心指标:整体表现如何?
- 排名分析:谁做得好?什么内容做得好?
- 标题影响:标题关键词如何影响数据?
- 趋势分析:数据随时间如何变化?
- 平台对比:B站与CSDN表现差异?
4.2 仪表盘布局
采用“先总后分、左右对照”的布局:
- 顶部指标卡(两行):全平台概况 + B站/CSDN分平台指标
- 左右两栏:左栏B站分析,右栏CSDN分析
- 每栏内部按“排名 → 标题分析 → 趋势”排列
4.3 实验步骤(关键图表制作)
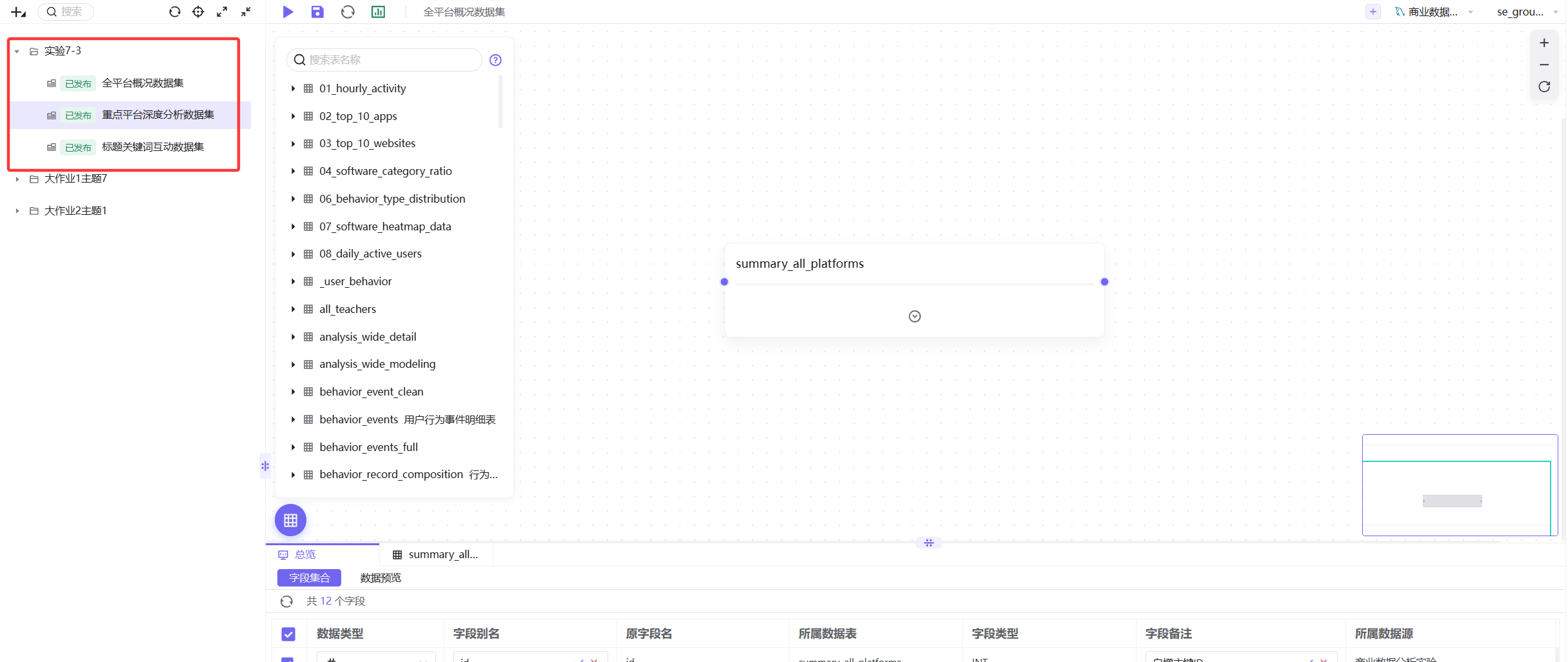
步骤1-2:连接数据源并构建数据集
使用summary_all_platforms、content_analysis、title_feature_analysis三张表构建3个数据集。
步骤3:制作工作表
(1)核心指标卡
| 指标卡 | 数据源 | 配置要点 |
|---|---|---|
| 全平台作品数 | 全平台概况 | 求和所有平台content_count |
| 分发平台数 | 全平台概况 | 平台去重计数 |
| 全平台总浏览数 | 全平台概况 | 求和total_views |
| 全平台总互动数 | 全平台概况 | 求和总互动(需计算字段) |
| B站作品数 | 全平台概况 | 平台=B站 的计数 |
| CSDN作品数 | 全平台概况 | 平台=CSDN 的计数 |
| B站总播放量 | 全平台概况 | 平台=B站 的求和views |
| CSDN总阅读量 | 全平台概况 | 平台=CSDN 的求和views |


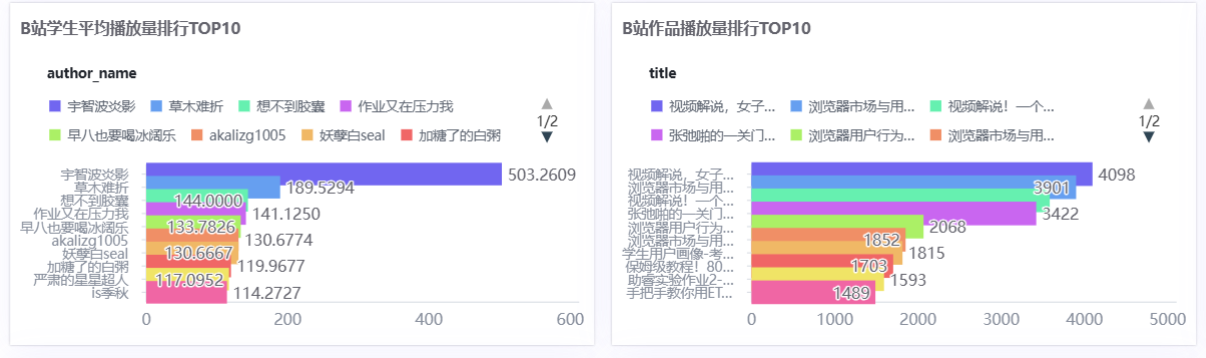
(2)排名图表
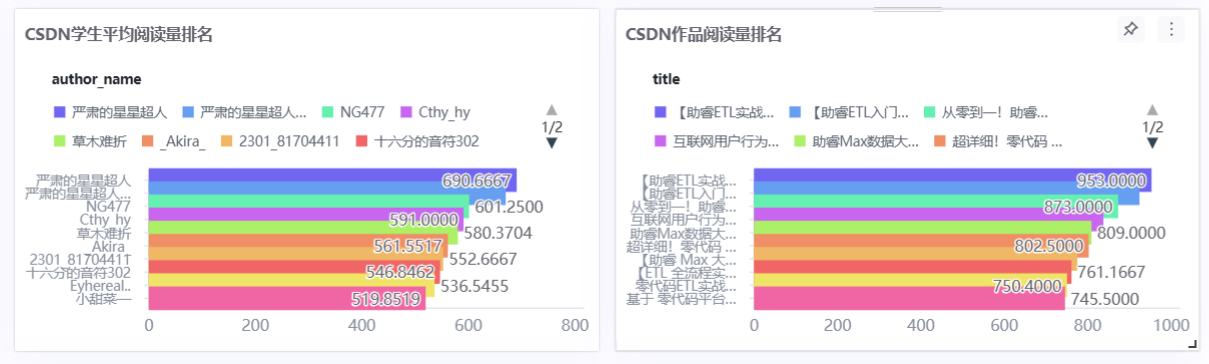
- B站/CSDN学生平均播放量排名TOP10:维度=作者名称,指标=平均值(浏览数量)
- B站/CSDN作品播放量排名TOP10:维度=作品标题,指标=浏览数量
(3)标题影响分析
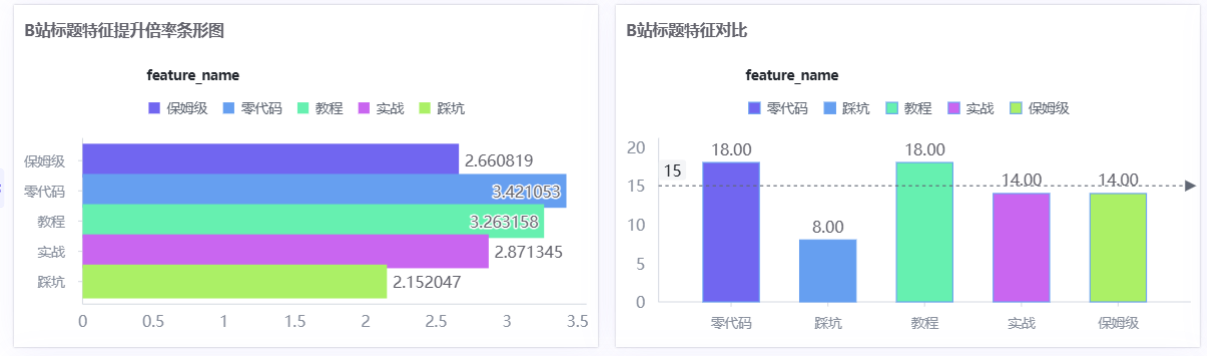
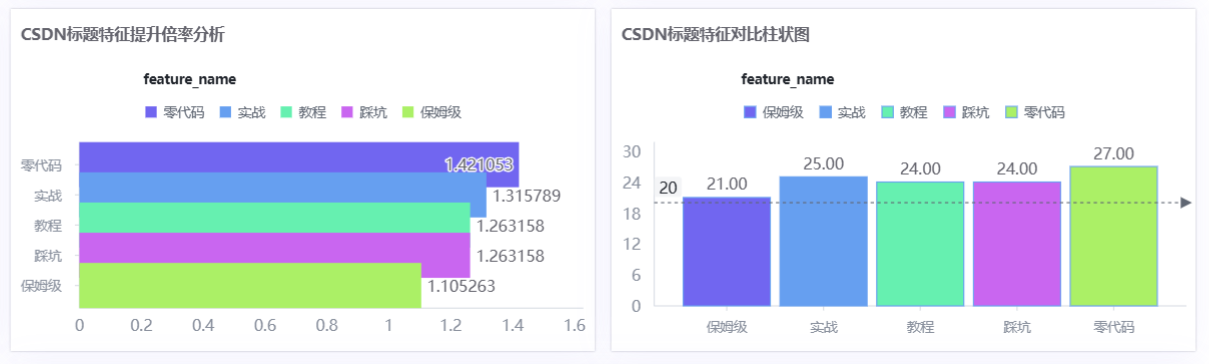
- 提升倍率条形图:分别计算含某关键词的平均播放量 ÷ 整体平均播放量
- 标题特征对比柱状图:含关键词vs不含关键词的平均互动对比(含整体平均线)
(4)趋势分析
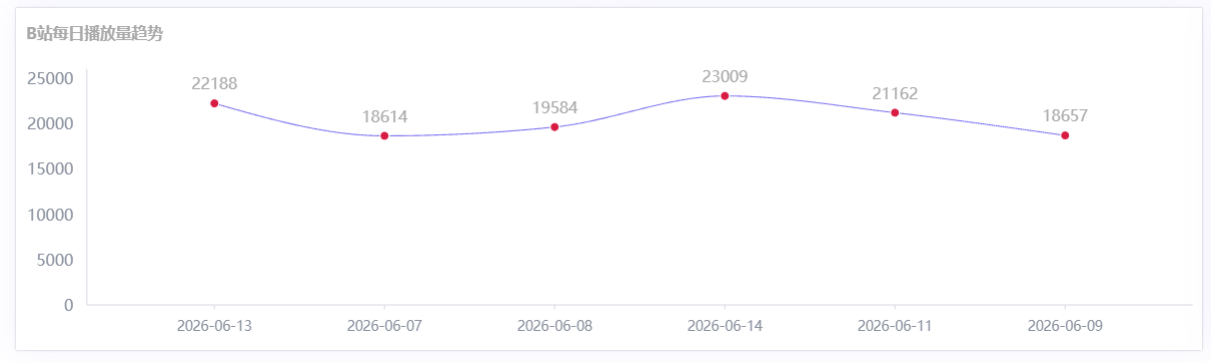
- B站每日播放量趋势折线图:维度=日期,指标=求和(浏览数量)
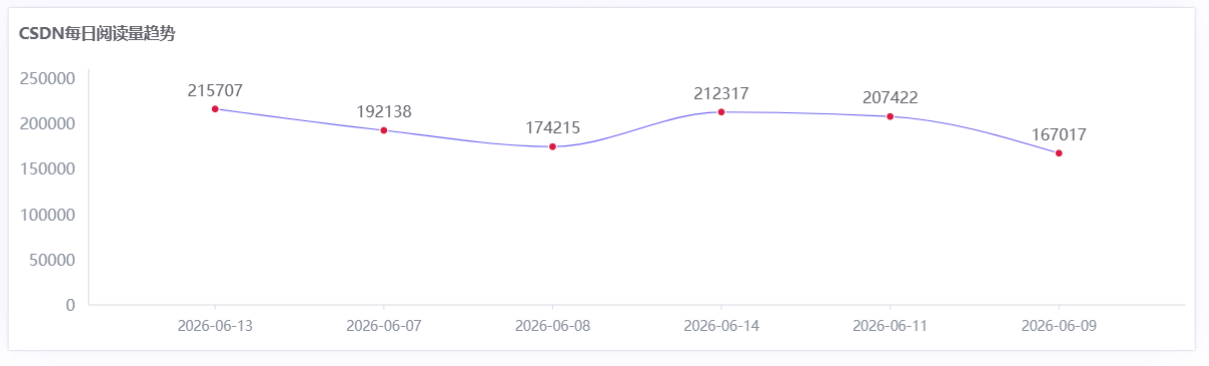
- CSDN每日阅读量趋势折线图:同上
五、核心知识点总结
| 知识点 | 说明 |
|---|---|
| 多条件过滤 | 使用AND/OR组合实现“平台+有效记录”双重过滤 |
| 缺失值处理 | 统一填充默认值(如“未知”),避免计算异常 |
| 宽表设计 | 一次清洗、多次使用,支撑后续全部分析 |
| JavaScript代码组件 | 用于文本关键词自动标注,实现特征工程 |
| 插入/更新 vs 表输出 | 按主键更新,避免重复数据 |
| 分支处理 + 常量标识 | 多分支聚合后通过常量标签区分不同分组 |
| 指标卡设计 | 核心KPI突出展示,让读者几秒内建立整体认知 |
| 排名+标题+趋势组合 | 从“谁做得好”到“为什么好”再到“规律如何”的完整分析链 |
| 提升倍率计算 | 量化标题关键词的实际影响(含该词平均 ÷ 整体平均) |

一站式 AI 云服务平台
更多推荐

 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)