
别只看能不能调通:国内模型 API 中转站选型要先验证这五件事
别只看能不能调通:国内模型 API 中转站选型要先验证这五件事

摘要:
很多团队接入模型 API 时,第一步只验证 Base URL 能不能跑通。
但真正上线后暴露的问题,往往不是“能不能请求成功”,而是限流、成本、错误码、日志边界和合规责任。
这篇文章从开发者视角整理一套可落地的选型与排查方法,并用通用 HTTP 请求示例说明如何验证国内 AI API 中转站或聚合型平台。
一句话先说结论
模型 API 中转站不是只用来“换一个 Base URL”的,它更像是模型调用链路里的工程入口。
能调通,只是第一步。
能稳定、能排查、能算账、能控制风险,才适合放进真实项目。
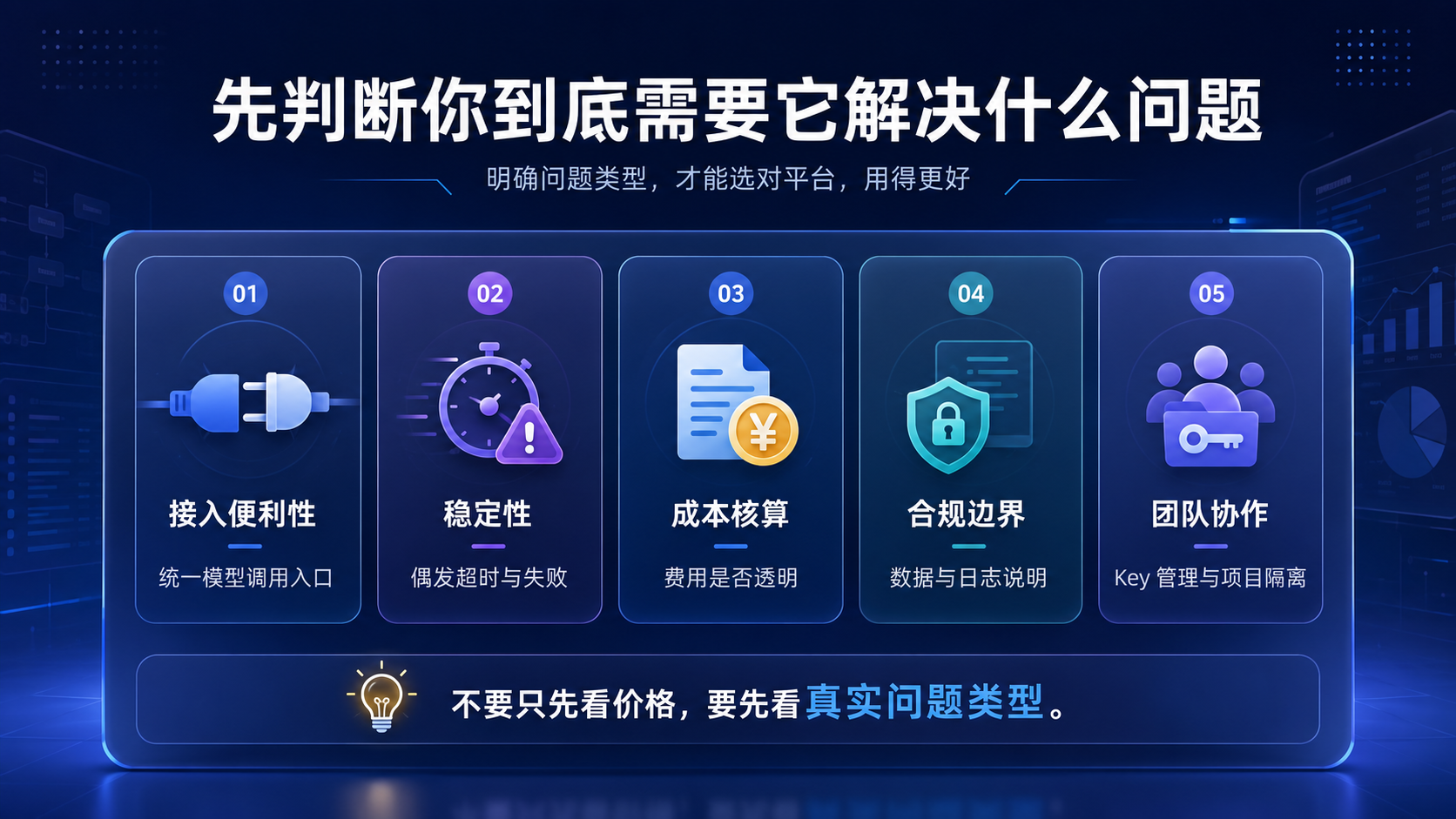
一、先判断你到底需要中转站解决什么问题
很多人选平台时,第一反应是看价格。
但开发者真正要先问的是:
我现在遇到的是接入问题、稳定性问题、成本问题,还是团队管理问题?
| 问题类型 | 典型表现 | 重点检查项 |
|---|---|---|
| 接入便利性 | 想统一模型调用入口 | Base URL、鉴权方式、模型名称 |
| 稳定性 | 偶发超时、请求失败 | 响应耗时、限流、错误码 |
| 成本核算 | 调用量上来后费用不透明 | 用量记录、模型单价、重试次数 |
| 合规边界 | 业务数据是否能发出去不清楚 | 日志保存、数据处理说明、账号权限 |
| 团队协作 | 多人共用 Key,难以追踪 | Key 管理、项目隔离、调用明细 |
如果只是个人测试,一个能跑通的入口就够了。
如果要接入知识库、客服、AI IDE、工作流或内部系统,就不能只看“能不能请求成功”。
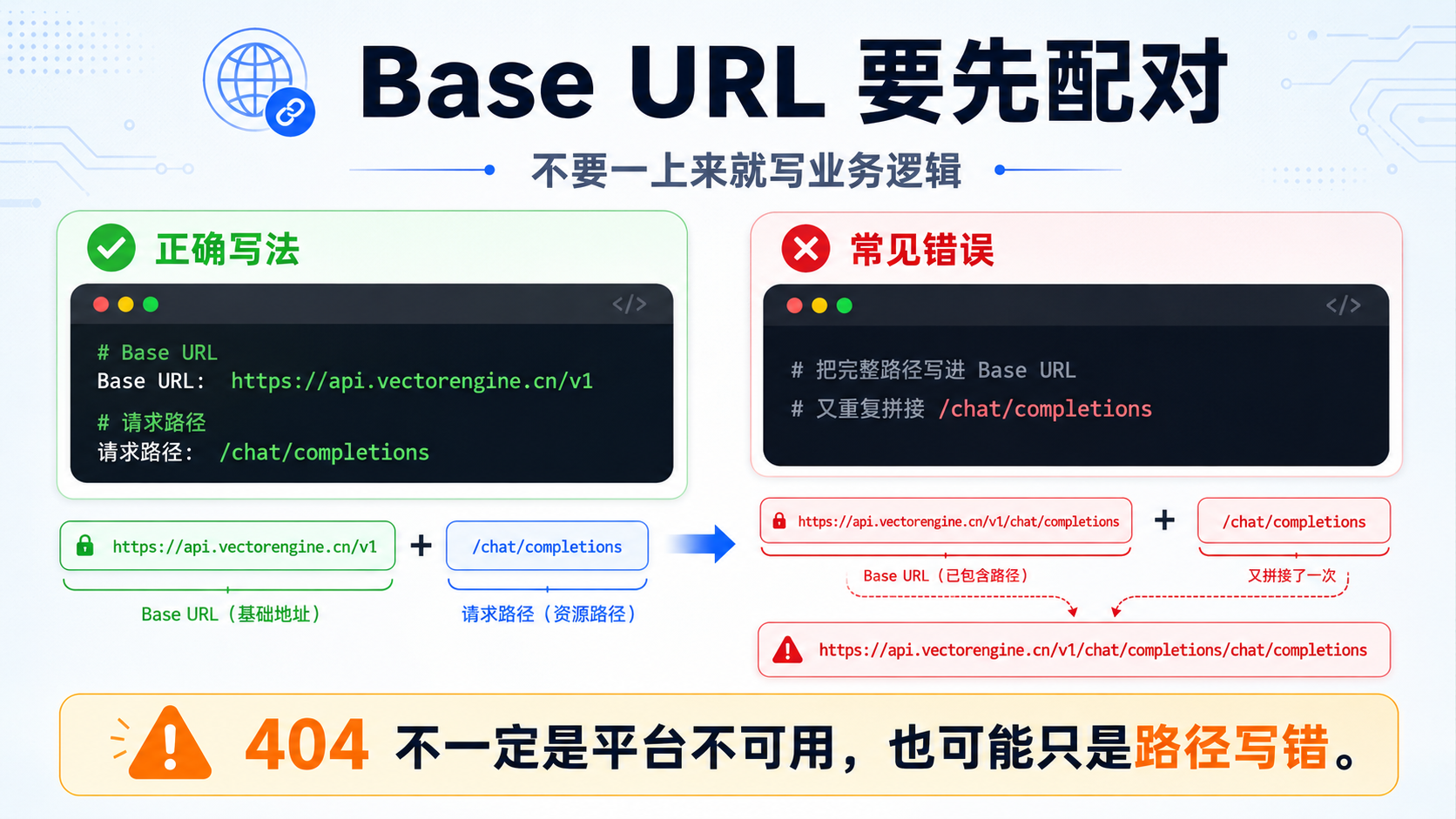
二、Base URL 要先配对,不要一上来就写业务逻辑
很多接口问题,根本不是模型问题。
而是 Base URL 写错了。
常见配置方式如下:
Base URL:
https://api.vectorengine.cn/v1
完整接口路径:
https://api.vectorengine.cn/v1/chat/completions
如果代码里已经拼接了 /chat/completions,Base URL 就不要再写完整路径。
错误写法示例:
MODEL_BASE_URL=https://api.vectorengine.cn/v1/chat/completions
请求时又拼接:
/chat/completions
最后可能变成:
https://api.vectorengine.cn/v1/chat/completions/chat/completions
这类错误很隐蔽。
返回 404 时,很多人会误以为是平台不可用。
其实只是路径拼错了。
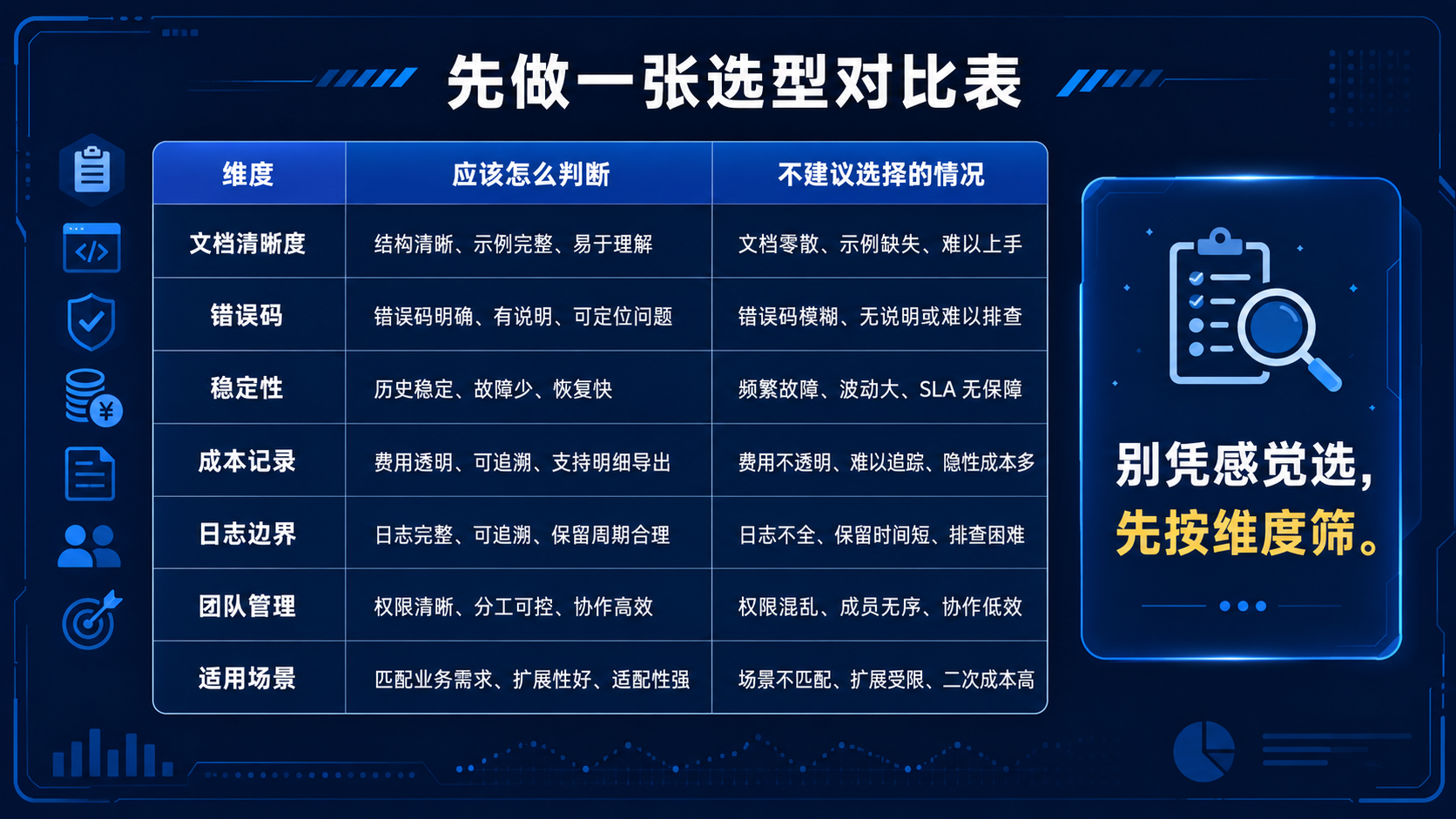
三、先做一张选型对比表,不要凭感觉选
选国内模型 API 中转站,可以先用下面这张表筛选。
| 维度 | 应该怎么判断 | 不建议选择的情况 |
|---|---|---|
| 文档清晰度 | 是否明确写出 Base URL、请求路径、鉴权方式 | 只给示例,不解释参数 |
| 错误码 | 是否能区分鉴权、限流、模型不存在、余额不足 | 所有失败都返回“请求失败” |
| 稳定性 | 是否能连续请求并保持可接受耗时 | 低频测试正常,高频就大量失败 |
| 成本记录 | 是否能查看调用量和费用明细 | 只能看到余额减少,看不到明细 |
| 日志边界 | 是否说明日志保存范围 | 默认长期保存完整业务文本 |
| 团队管理 | 是否支持 Key 管理、项目区分 | 所有人共用一个 Key |
| 适用场景 | 是否适合知识库、客服、开发工具等场景 | 只适合个人临时测试 |
这张表看起来简单。
但真正执行一遍,能过滤掉很多后期维护成本很高的平台。
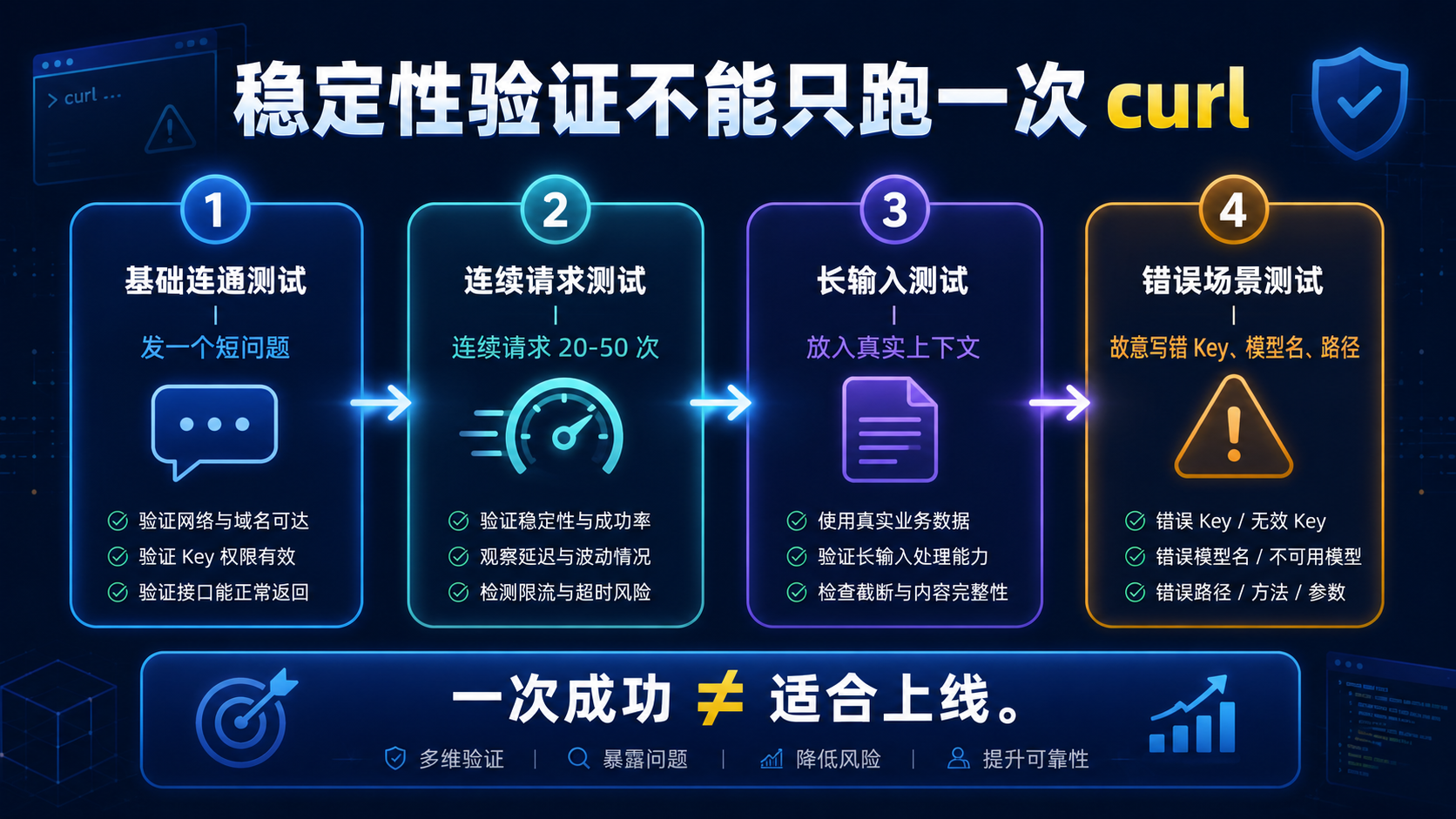
四、稳定性验证不能只跑一次 curl
一次请求成功,只能说明账号、路径和参数大体没问题。
它不能说明这个入口适合上线。
更稳妥的验证流程是分四步走:
| 验证步骤 | 验证目标 | 建议做法 |
|---|---|---|
| 基础连通测试 | 看接口能不能正常返回 | 发一个短问题 |
| 连续请求测试 | 看是否有明显抖动 | 连续请求 20 到 50 次 |
| 长输入测试 | 看真实业务上下文下的表现 | 放入知识库片段或长对话 |
| 错误场景测试 | 看错误提示是否清楚 | 故意写错 Key、模型名、路径 |
如果只是想找一个国内模型 API 接入入口做小流量验证,可以把向量引擎中转站作为候选工具之一,注册入口是 https://178.nz/csdn。
重点不是把某个平台当成唯一答案。
重点是用同一套验证方法去比较 Base URL、耗时、错误码、费用和适用场景。
五、通用 HTTP 请求示例:先把耗时和错误码记下来
下面这个示例不依赖特定 SDK。
它更接近真实工程里的写法。
const MODEL_BASE_URL = process.env.MODEL_BASE_URL || "https://api.vectorengine.cn/v1";
const MODEL_API_KEY = process.env.MODEL_API_KEY;
const MODEL_NAME = process.env.MODEL_NAME || "your-model-name";
async function callModel(message) {
const startedAt = Date.now();
const response = await fetch(`${MODEL_BASE_URL}/chat/completions`, {
method: "POST",
headers: {
"Authorization": `Bearer ${MODEL_API_KEY}`,
"Content-Type": "application/json"
},
body: JSON.stringify({
model: MODEL_NAME,
messages: [
{ role: "system", content: "你是一个谨慎的技术助手,回答要简洁、可验证。" },
{ role: "user", content: message }
],
temperature: 0.3
}),
signal: AbortSignal.timeout(30000)
});
const elapsedMs = Date.now() - startedAt;
const text = await response.text();
let payload;
try {
payload = JSON.parse(text);
} catch {
payload = { raw: text };
}
if (!response.ok) {
console.error("model request failed", {
status: response.status,
elapsedMs,
error: payload
});
throw new Error(`model request failed: ${response.status}`);
}
console.log("model request succeeded", {
status: response.status,
elapsedMs,
usage: payload.usage || null
});
return payload;
}
这段代码里最重要的不是请求本身。
而是三件事:
记录状态码
记录响应耗时
记录错误文本
这三项数据,是后面排查问题的基础。
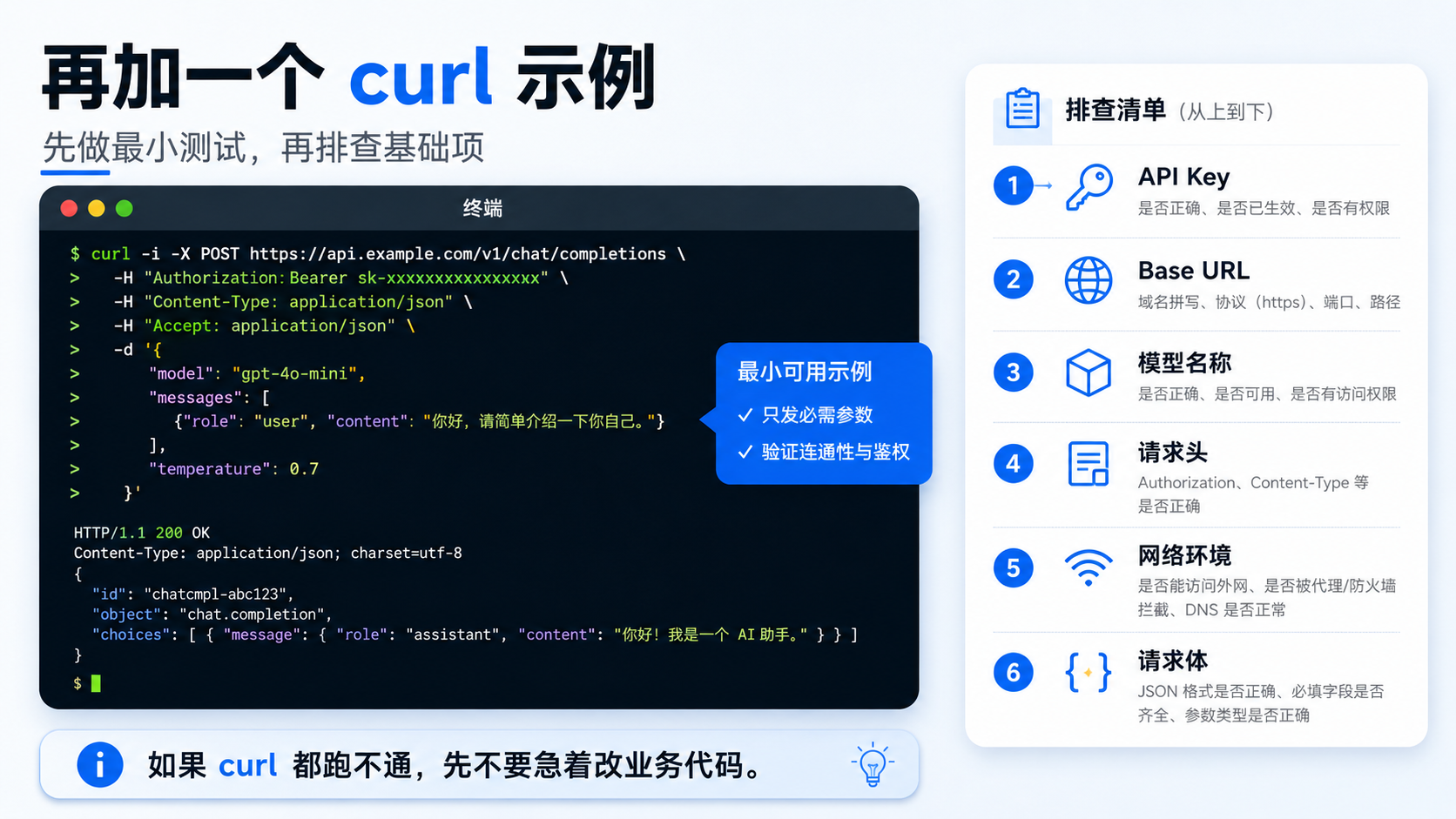
六、再加一个 curl 示例,方便快速排查
如果你只是想先验证接口是否通,可以用 curl 做最小测试。
curl -X POST "https://api.vectorengine.cn/v1/chat/completions" \
-H "Authorization: Bearer $MODEL_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "your-model-name",
"messages": [
{
"role": "user",
"content": "请用三句话解释为什么模型 API 接入要记录耗时和错误码。"
}
],
"temperature": 0.3
}'
如果 curl 都跑不通,先不要急着改业务代码。
先检查下面几项:
| 检查项 | 可能问题 |
|---|---|
| API Key | Key 错误、过期、未启用 |
| Base URL | 地址写错、路径重复 |
| 模型名称 | 模型名不存在、账号无权限 |
| 请求头 | Authorization 格式错误 |
| 网络环境 | 服务器出口网络异常 |
| 请求体 | JSON 格式错误 |
七、成本核算不能只看单次调用价格

很多团队低估模型成本,是因为只看了开发阶段的小样本测试。
真实业务上线后,成本通常来自这些地方:
| 成本来源 | 为什么容易被忽略 |
|---|---|
| 输入长度 | 知识库、客服、代码助手都会带大量上下文 |
| 输出长度 | 报告、总结、代码生成会输出较长内容 |
| 重试次数 | 超时和限流会放大请求量 |
| 失败请求 | 某些失败也可能产生部分用量 |
| 模型档位 | 不同任务不一定要用同一档模型 |
| 批量任务 | 单次便宜,但总量上来后明显增加 |
一个简单的成本估算公式可以这样写:
预计日成本 =
单次平均成本 × 日请求量 × 失败重试系数
例如:
单次平均成本:0.003 元
日请求量:2000 次
失败重试系数:1.03
预计日成本:
0.003 × 2000 × 1.03 = 6.18 元
这个数字只是示例。
真实项目里,要结合平台的实际用量统计来修正。
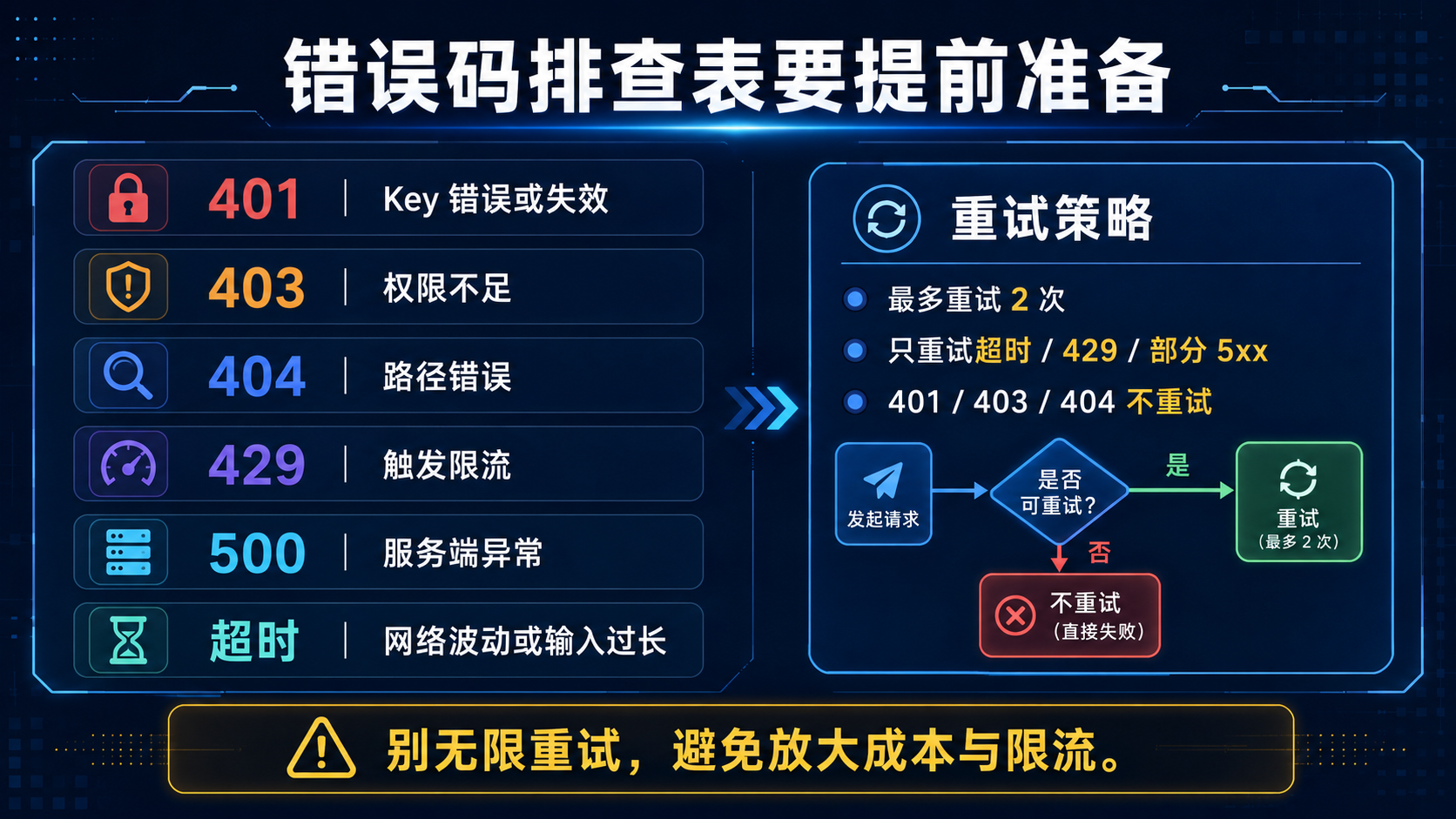
八、错误码排查表要提前准备
上线前,最好先准备一张错误排查表。
不要等线上报错了才临时猜。
| 现象 | 可能原因 | 排查方法 |
|---|---|---|
| 401 | API Key 错误或失效 | 重新生成 Key,检查请求头 |
| 403 | 权限不足 | 确认账号是否有模型权限 |
| 404 | 路径错误 | 检查 Base URL 和接口路径 |
| 429 | 触发限流 | 降低并发,加入退避重试 |
| 500 | 服务端异常 | 记录请求 ID,稍后重试 |
| 超时 | 网络波动或输入过长 | 缩短输入,记录耗时 |
| 模型不存在 | 模型名称错误 | 从控制台复制模型名 |
| 费用异常 | 重试过多或上下文变长 | 查看调用明细和业务来源 |
这一张表很有用。
尤其是在团队协作时,它能让前端、后端、运维和产品对问题有同一套判断语言。
九、重试逻辑要有限制,不能无限重试

很多人写模型调用时,会直接加重试。
但重试不是越多越好。
无限重试会放大成本,也会让限流更严重。
一个更稳妥的重试策略是:
最多重试 2 次
只对超时、429、部分 5xx 错误重试
每次重试前等待更长时间
对 401、403、404 不重试
示例伪代码:
async function callWithRetry(task) {
const maxRetries = 2;
for (let attempt = 0; attempt <= maxRetries; attempt++) {
try {
return await task();
} catch (error) {
const status = error.status;
if ([401, 403, 404].includes(status)) {
throw error;
}
if (attempt === maxRetries) {
throw error;
}
const delayMs = 1000 * Math.pow(2, attempt);
await new Promise(resolve => setTimeout(resolve, delayMs));
}
}
}
这里的关键点是:
鉴权错误不要重试。
路径错误不要重试。
模型名称错误不要重试。
限流和超时才考虑有限重试。
十、哪些场景适合使用模型 API 中转站
比较适合的场景有这些:
| 场景 | 为什么适合 |
|---|---|
| 开发者工具验证 | 可以快速比较不同模型接口 |
| AI IDE 接入 | 统一 Base URL 和模型配置 |
| 知识库问答 | 便于观察上下文成本和响应耗时 |
| 智能客服 | 方便记录错误码和降级处理 |
| 批量摘要分类 | 有利于控制调用量和费用 |
| 小团队统一入口 | 减少多人各自管理密钥的问题 |
一句话总结:
只要你的项目开始关心稳定性、成本和日志,中转站就不只是一个临时入口。
它会变成模型调用链路里的管理层。
十一、哪些场景不适合直接接入
也有一些场景不适合直接上。
| 场景 | 风险 |
|---|---|
| 高敏感数据未脱敏 | 可能带来数据泄露风险 |
| 强实时核心链路 | 普通模型接口延迟不可控 |
| 无预算上限的批处理 | 成本可能被快速放大 |
| 完全依赖单一入口 | 平台异常时缺少降级方案 |
| 缺少日志边界说明 | 后期合规和排查都会麻烦 |
不要为了快速接入,把风险都留给上线后。
上线后的每一次排查,都会比上线前多花很多时间。
十二、团队上线前检查清单
上线前可以按下面这张表逐项确认。
| 检查项 | 是否完成 |
|---|---|
| 已确认 Base URL 和完整接口路径 | 待确认 |
| 已确认模型名称和账号权限 | 待确认 |
| 已使用环境变量保存 API Key | 待确认 |
| 已设置请求超时时间 | 待确认 |
| 已设置最大重试次数 | 待确认 |
| 已记录状态码和耗时 | 待确认 |
| 已记录用量信息 | 待确认 |
| 已确认日志不保存敏感内容 | 待确认 |
| 已完成连续请求测试 | 待确认 |
| 已完成长输入测试 | 待确认 |
| 已估算日调用成本 | 待确认 |
| 已准备降级方案 | 待确认 |
这张表不复杂。
但它能避免很多“上线后才发现”的问题。
十三、一个更稳妥的接入流程
建议按这个顺序推进:
第一步:短请求连通测试
第二步:错误场景测试
第三步:连续请求稳定性测试
第四步:真实业务输入测试
第五步:成本估算
第六步:日志和合规确认
第七步:小流量灰度
第八步:正式接入
不要跳过灰度。
不要直接把所有请求切过去。
尤其是客服、知识库、批量任务这类场景,灰度阶段能提前暴露很多问题。
十四、FAQ
问:国内模型 API 中转站是不是只适合个人开发者?
不是。
个人开发者可以用它降低接入门槛。
小团队也可以用它统一 Base URL、模型配置、调用记录和费用核算。
问:Base URL 能调通,是不是就可以上线?
不建议。
能调通只说明基础接入成功。
上线前还要测试连续请求、长输入、错误码、限流、费用记录和超时处理。
问:为什么不直接把 API Key 写进代码?
因为这样很容易泄露。
也不方便切换环境、轮换密钥和定位问题。
更稳妥的方式是使用环境变量或密钥管理工具。
问:中转站最应该关注什么指标?
至少要看这些:
响应耗时
错误码清晰度
限流规则
费用明细
日志边界
Base URL 配置方式
团队 Key 管理能力
问:触发限流后应该怎么办?
不要盲目重试。
应该先降低并发,加入退避重试,设置最大重试次数,并记录触发限流的业务来源。
问:怎样判断平台适不适合团队使用?
看它是否能支持清晰配置、稳定请求、错误追踪、费用复盘、日志边界和服务说明。
如果这些都不清楚,就先停留在测试阶段。

总结:中转站选型,本质上是工程可靠性问题
国内模型 API 中转站和 AI 聚合型平台的价值,不只是让开发者换一个 Base URL 就能调模型。
更重要的是,它能不能帮助你把模型调用纳入工程管理。
配置要可控。
错误要可查。
费用要可算。
日志要有边界。
失败要能降级。
如果只是个人尝鲜,跑通一次请求当然有价值。
但如果要接入知识库、客服、AI IDE、工作流或团队内部系统,就必须按更严谨的方式验证。
不要被“能调通”迷惑。
也不要只被低价吸引。
真正能长期减少维护成本的,是清楚的接口、稳定的响应、可追踪的日志和可解释的账单。

一站式 AI 云服务平台
更多推荐

 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)