
自媒体标题关键词效果分析:从零代码ETL到Lift提升度实战
最近在做内容运营的数据分析,想搞清楚一个问题:标题里加什么词,能让互动数据更好看? 于是拿5702条自媒体作品数据(B站和CSDN两个平台)做了次完整的特征工程实践。从关键词提取、互动指标聚合,到最后的Lift提升度分析,全程可视化ETL工具搞定,没写一行SQL。踩了不少坑,也学到了不少东西,记录下来分享给大家。
一、为什么要做这个分析?
做自媒体的朋友都知道,标题决定了80%的打开率。但"标题党"和"好标题"之间有一条微妙的界限——你不仅要让人点进来,还要让人愿意互动(点赞、收藏、评论)。
我手头有一份5702条的作品数据,分布在B站和CSDN两个平台。数据里有标题、点赞、收藏、分享、投币、浏览量这些字段。我想回答几个问题:
-
标题里带"保姆级""实战""零代码"这些词,互动数据真的会更好吗?
-
同样的关键词,在B站和CSDN的效果一样吗?
-
有没有比"平均数"更直观的指标,能告诉我这个词到底"值不值得用"?
带着这三个问题,我开始搭建ETL流程。
二、数据准备:两张表的设计
这次分析涉及两张表,一张是更新现有数据,一张是新建汇总表。
2.1 给现有作品表加"标签"
我需要在每条作品数据上打几个标签:标题里有没有"保姆级"?有没有"实战"?有没有"零代码"?……这些标签后续做过滤和分组时会用到。
另外,原始数据里点赞、收藏、分享、投币是分开的,我需要把它们加总成一个"互动总数",这样后续分析更方便。
所以给现有表 content_analysis 加了6个新字段:
| 新字段 | 含义 |
|---|---|
total_interaction |
互动总数 = 点赞+收藏+分享+投币 |
has_best |
标题含"保姆级"(1=有,0=无) |
has_lowcode |
标题含"零代码" |
has_practice |
标题含"实战" |
has_tutorial |
标题含"教程"或"指南" |
has_pit |
标题含"踩坑" |
2.2 新建关键词汇总表
最终要输出一张汇总表 title_feature_analysis,每个关键词在每个平台上占一行,包含:
| 字段 | 含义 |
|---|---|
platform |
B站或CSDN |
feature_name |
关键词名称 |
avg_interaction |
带这个词的作品平均互动数 |
overall_avg |
该平台所有作品的平均互动数(基准线) |
sample_count |
带这个词的作品数量 |
三、第一部分:给作品打标签、算互动总数
3.1 整体思路
流程很简单:读数据 → 提取标题关键词 → 算互动总数 → 更新回数据库。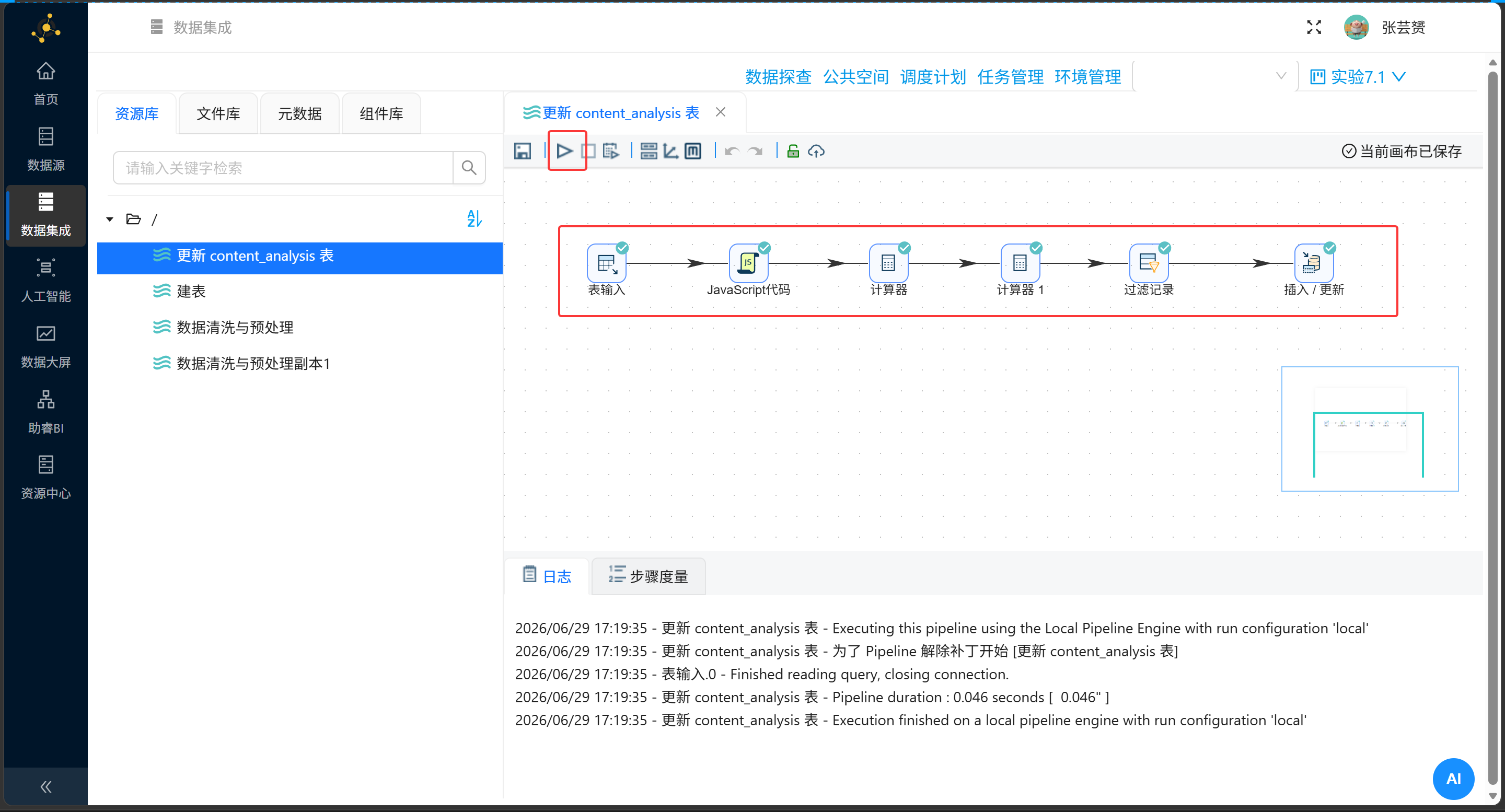
表输入 → JavaScript代码(关键词提取)→ 计算器(互动总数)→ 插入/更新3.2 关键词提取:JavaScript代码组件
这是整个流程里最容易踩坑的地方。我一开始写的代码是这样的:
// ❌ 错误写法,会报错!
var has_best = title.indexOf("保姆级") !== -1 ? 1 : 0;
// ...
has_best = has_best; // 这行会报错!结果运行时报错:"找不到字段 [has_best]"。
原因:Hop引擎(底层执行环境)在初始化时会扫描脚本,把等号右边的变量当成"需要从上游传入的输入字段"。has_best = has_best 这行,右边的 has_best 被当成了输入字段,但上游根本没有这个字段,所以报错。
正确写法:
// ✅ 正确写法
var title = title;
has_best = title.indexOf("保姆级") !== -1 ? 1 : 0;
has_lowcode = title.indexOf("零代码") !== -1 ? 1 : 0;
has_practice = title.indexOf("实战") !== -1 ? 1 : 0;
has_tutorial = (title.indexOf("教程") !== -1 || title.indexOf("指南") !== -1) ? 1 : 0;
has_pit = title.indexOf("踩坑") !== -1 ? 1 : 0;关键点:
-
不要写
var has_best = ...,直接赋值 -
不要写
has_best = has_best这种自赋值 -
title需要先用var title = title读取进来
然后在组件的"字段"标签页里,把这5个字段声明为输出字段(类型选Integer)。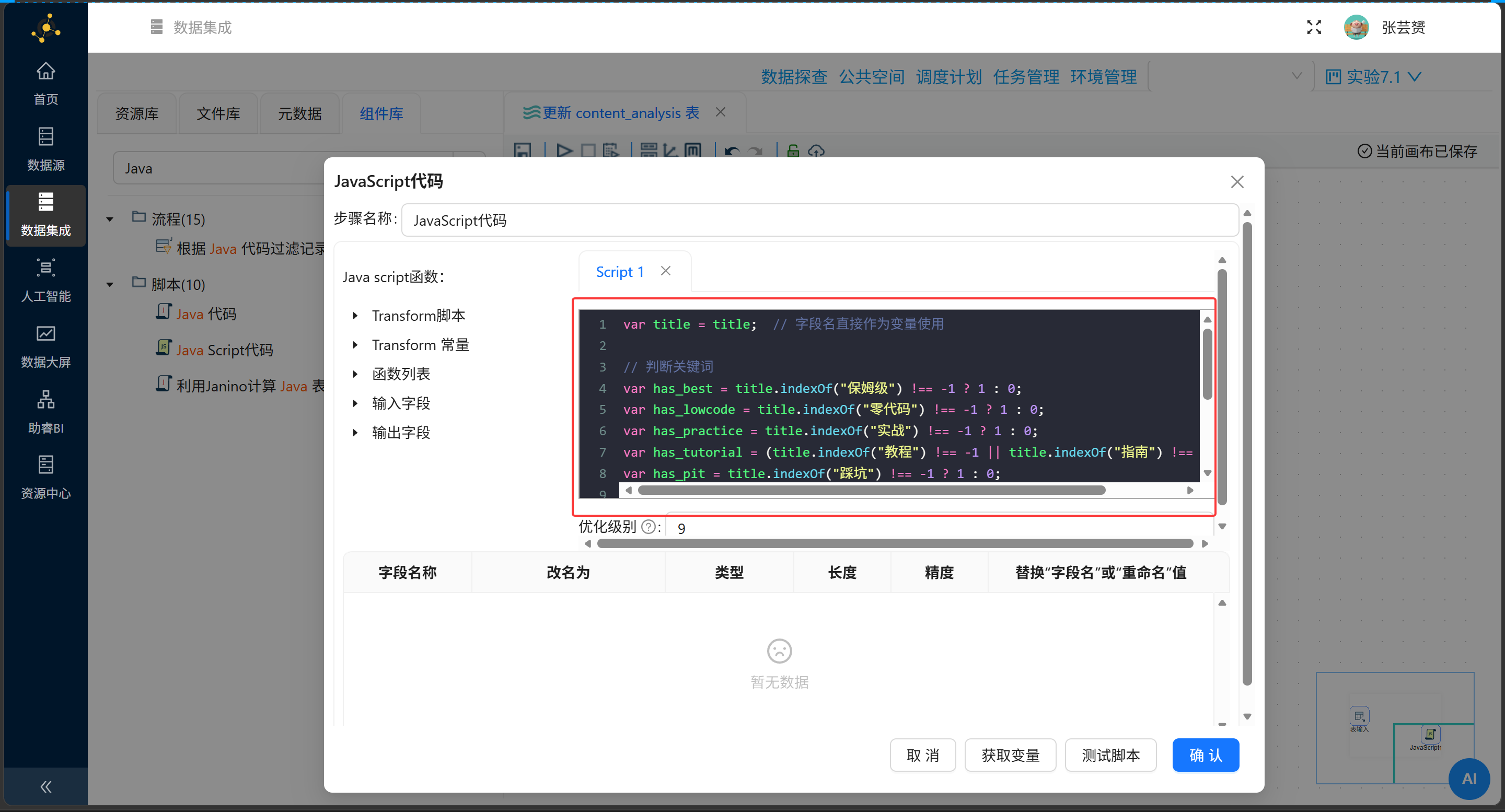
3.3 互动总数:计算器组件
用计算器把四个互动指标加起来:
| 新字段 | 计算方式 | 字段A | 字段B | 字段C | 字段D |
|---|---|---|---|---|---|
interactions |
A+B+C+D | likes |
favorites |
shares |
coins |
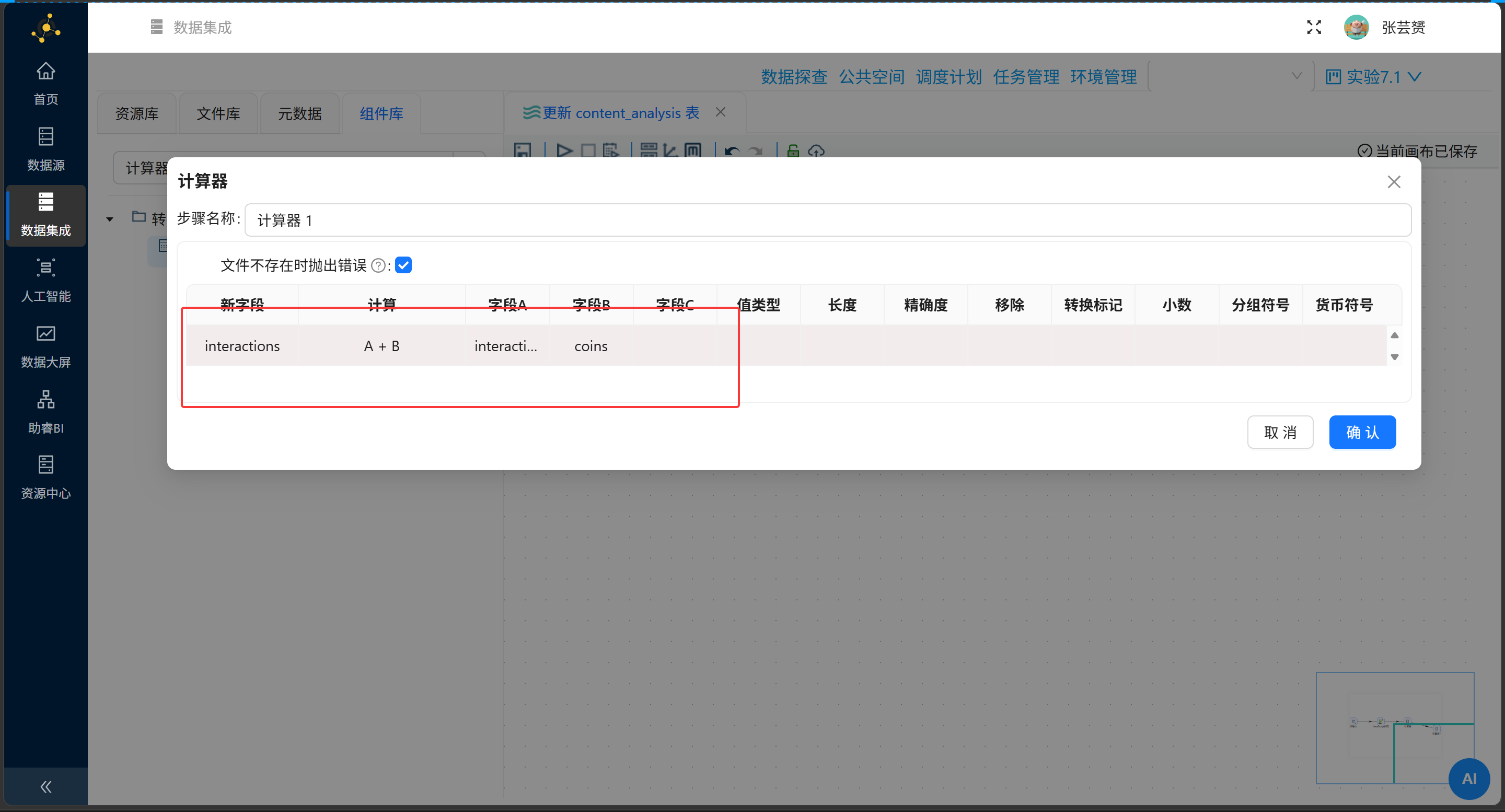
3.4 数据回填:插入/更新组件
这里要用"插入/更新"而不是"表输出",因为我们是更新已有记录,而不是插入新记录。
查询关键字:id = id(用作品ID匹配)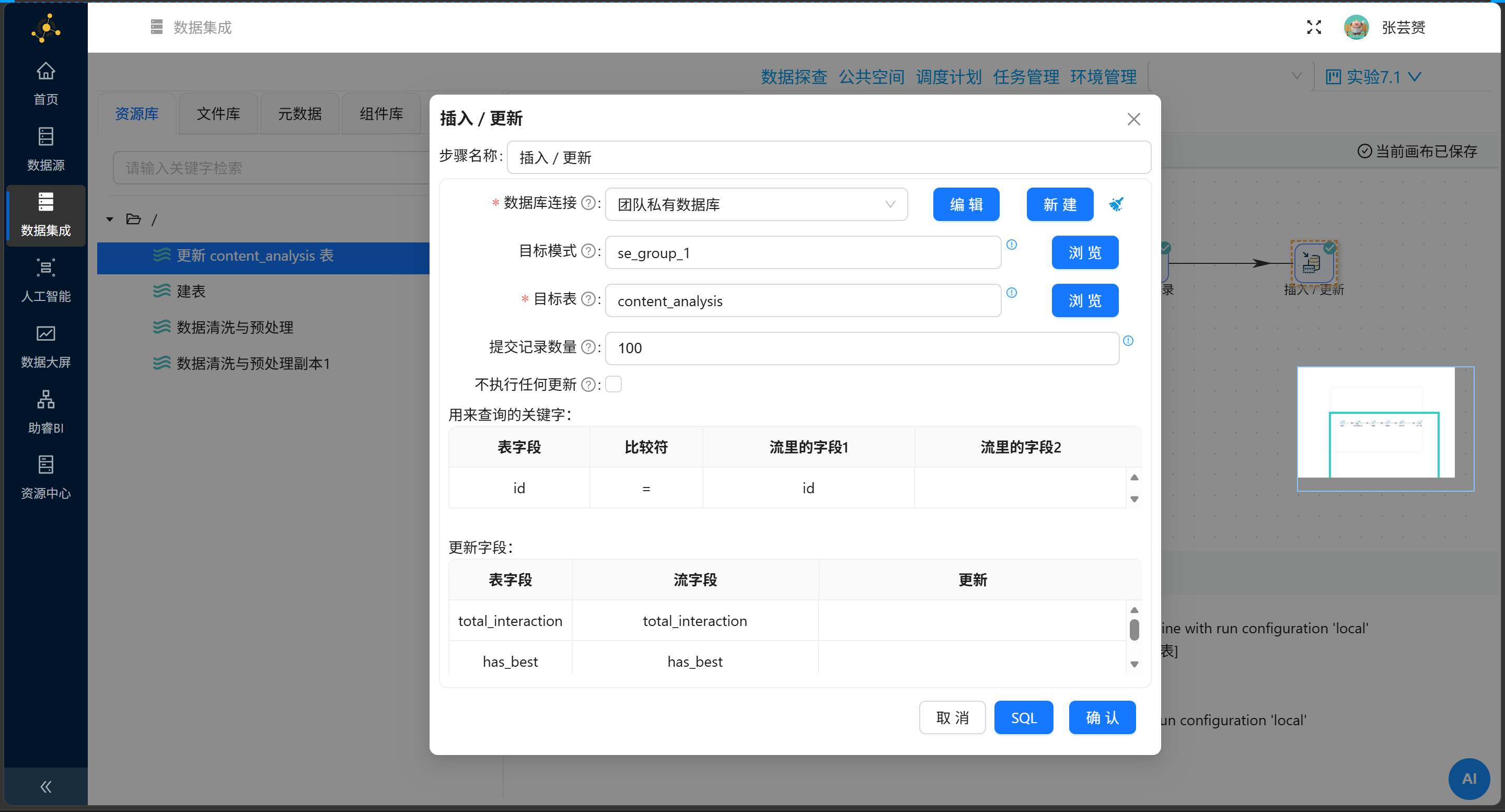
更新字段映射:
| 表字段 | 流字段 | 是否更新 |
|---|---|---|
total_interaction |
interactions |
✅ |
has_best |
has_best |
✅ |
has_lowcode |
has_lowcode |
✅ |
has_practice |
has_practice |
✅ |
has_tutorial |
has_tutorial |
✅ |
has_pit |
has_pit |
✅ |
验证成功的标志:日志里 U=5702(Update计数等于数据总量),E=0(零错误)。
我第一次运行时 U=0,排查了半天,最后发现是流字段名写错了——计算器输出的字段叫 interactions,但我在插入/更新里写成了 total_interaction。表字段是 total_interaction,但流字段必须是 interactions,这两个名字不一样,要注意区分。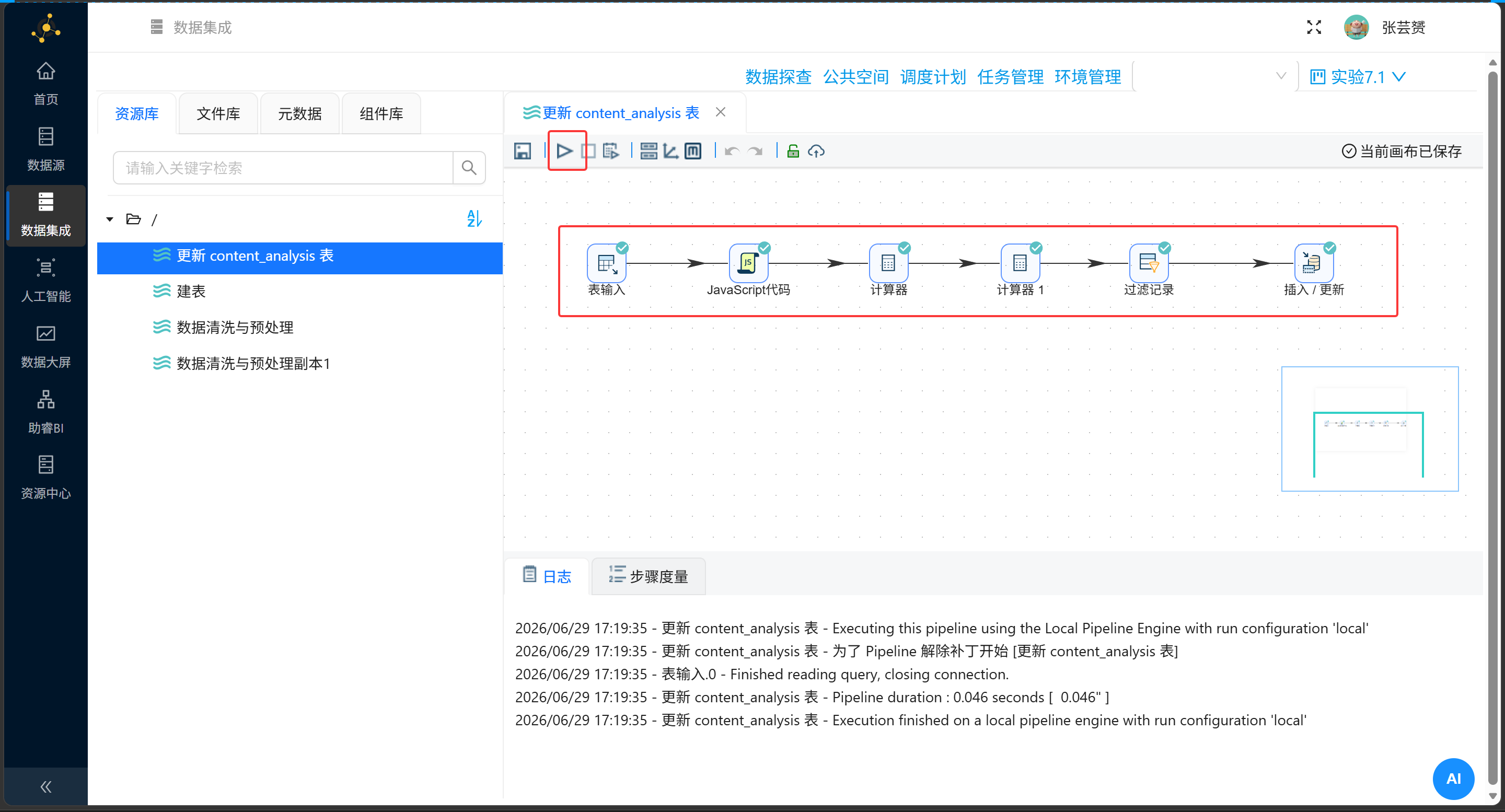
四、第二部分:关键词级别汇总分析
4.1 设计思路
以单个关键词(如"保姆级")为例,需要计算:
-
整体平均互动数:该平台所有作品的平均互动数(基准线)
-
关键词平均互动数:含该关键词作品的平均互动数
-
样本量:含该关键词的作品数量
通过"记录集连接"将整体平均和关键词平均合并到同一行,便于对比分析。
4.2 流程架构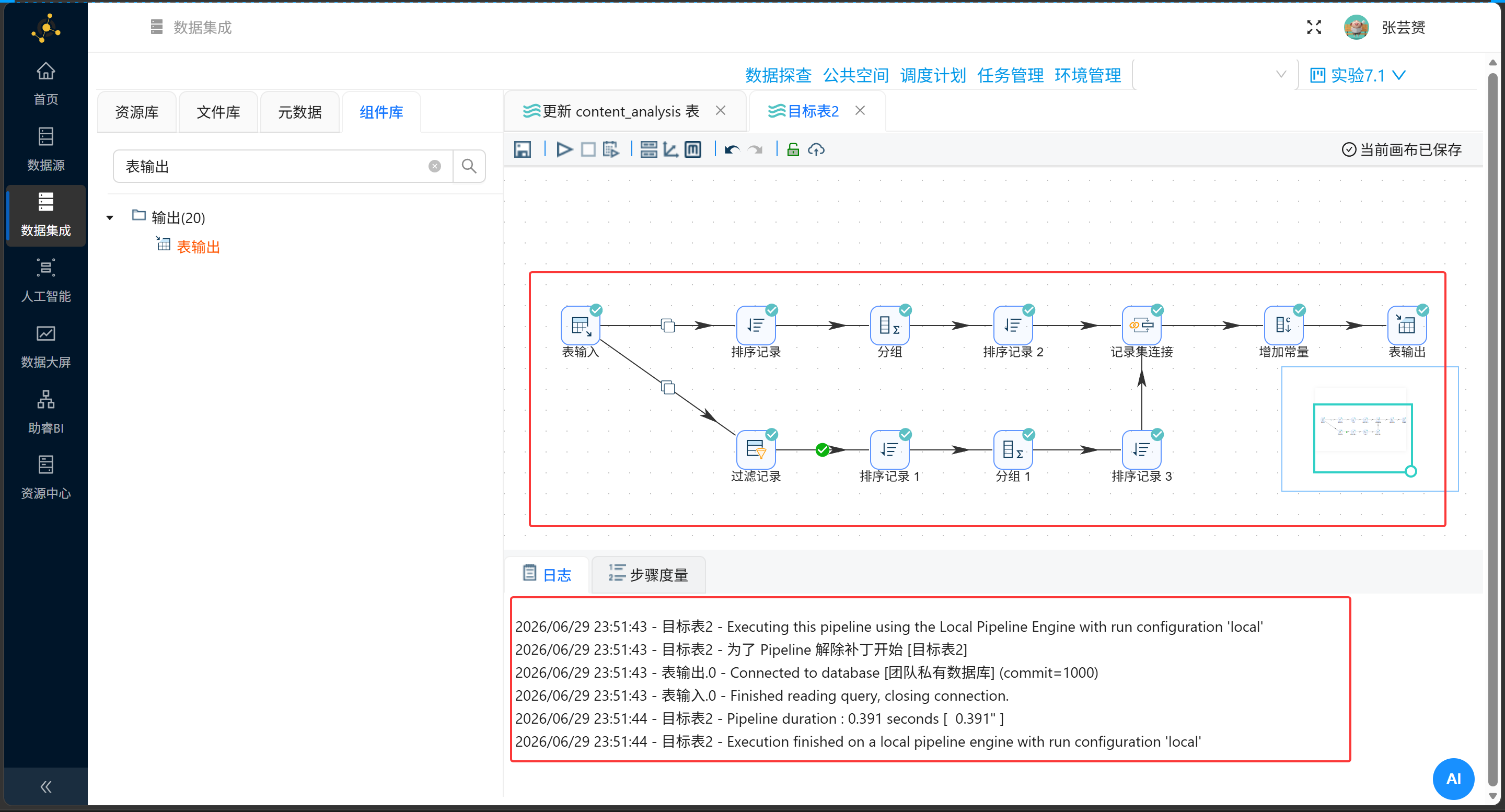
┌─→ 排序记录 → 分组(整体AVG)→ 排序 → 增加常量("保姆级") ─┐
表输入 ──→ 过滤记录 记录集连接 → 表输出
(has_best=1) └─→ 排序记录 → 分组(关键词AVG+COUNT)→ 排序 → 增加常量("保姆级") ─┘
│
└─→ 空操作(丢弃不满足条件的)4.3 步骤详解
步骤1:计算整体平均互动数(上分支)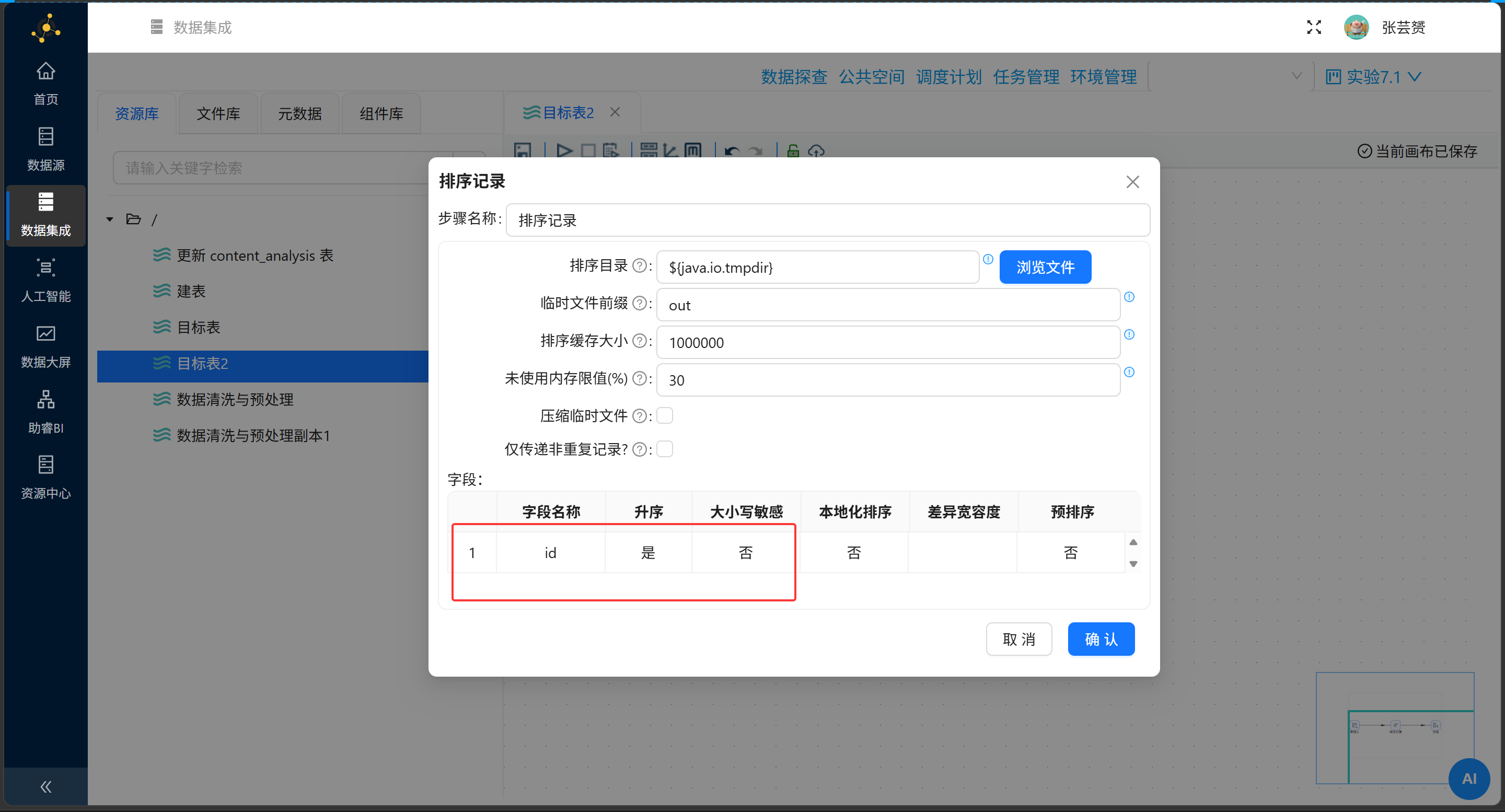
| 组件 | 配置 |
|---|---|
| 排序记录 | 按 id 升序 |
| 分组 | 分组字段:platform;聚合:AVG(total_interaction) → overall_avg |
| 增加常量 | feature_name = '保姆级' |
| 排序记录 | 按 platform 升序(为记录集连接做准备) |
步骤2:计算关键词平均互动数(下分支)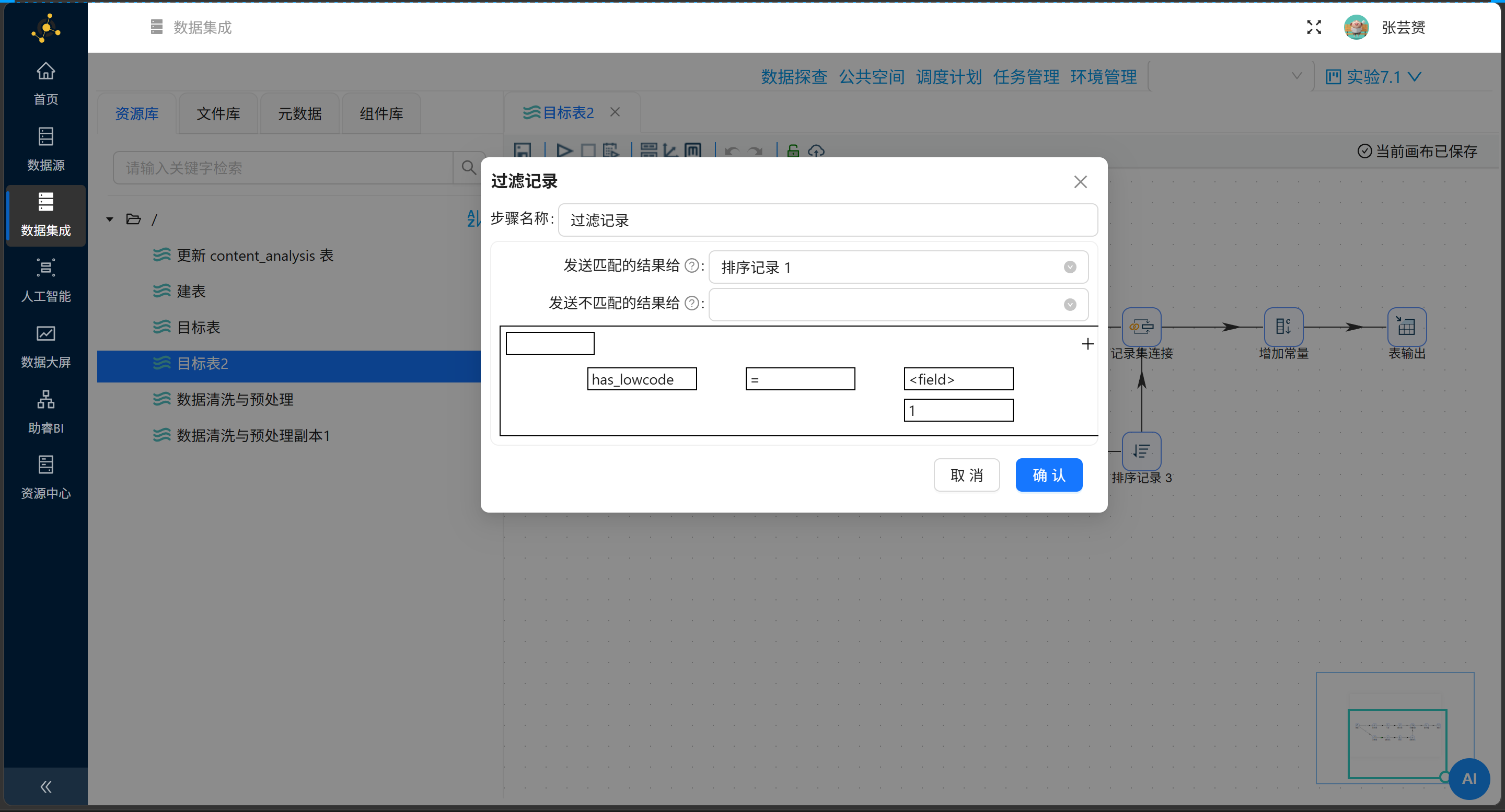
| 组件 | 配置 |
|---|---|
| 过滤记录 | 条件:has_best = 1;True→继续,False→空操作 |
| 排序记录 | 按 id 升序 |
| 分组 | 分组字段:platform;聚合1:AVG(total_interaction) → avg_interaction;聚合2:COUNT(id) → sample_count |
| 增加常量 | feature_name = '保姆级' |
| 排序记录 | 按 platform 升序 |
为什么需要"增加常量"? 聚合后的数据只有数值,没有关键词名称。
feature_name常量相当于给数据"贴标签",告诉下游"这一行是保姆级的数据"。
步骤3:记录集连接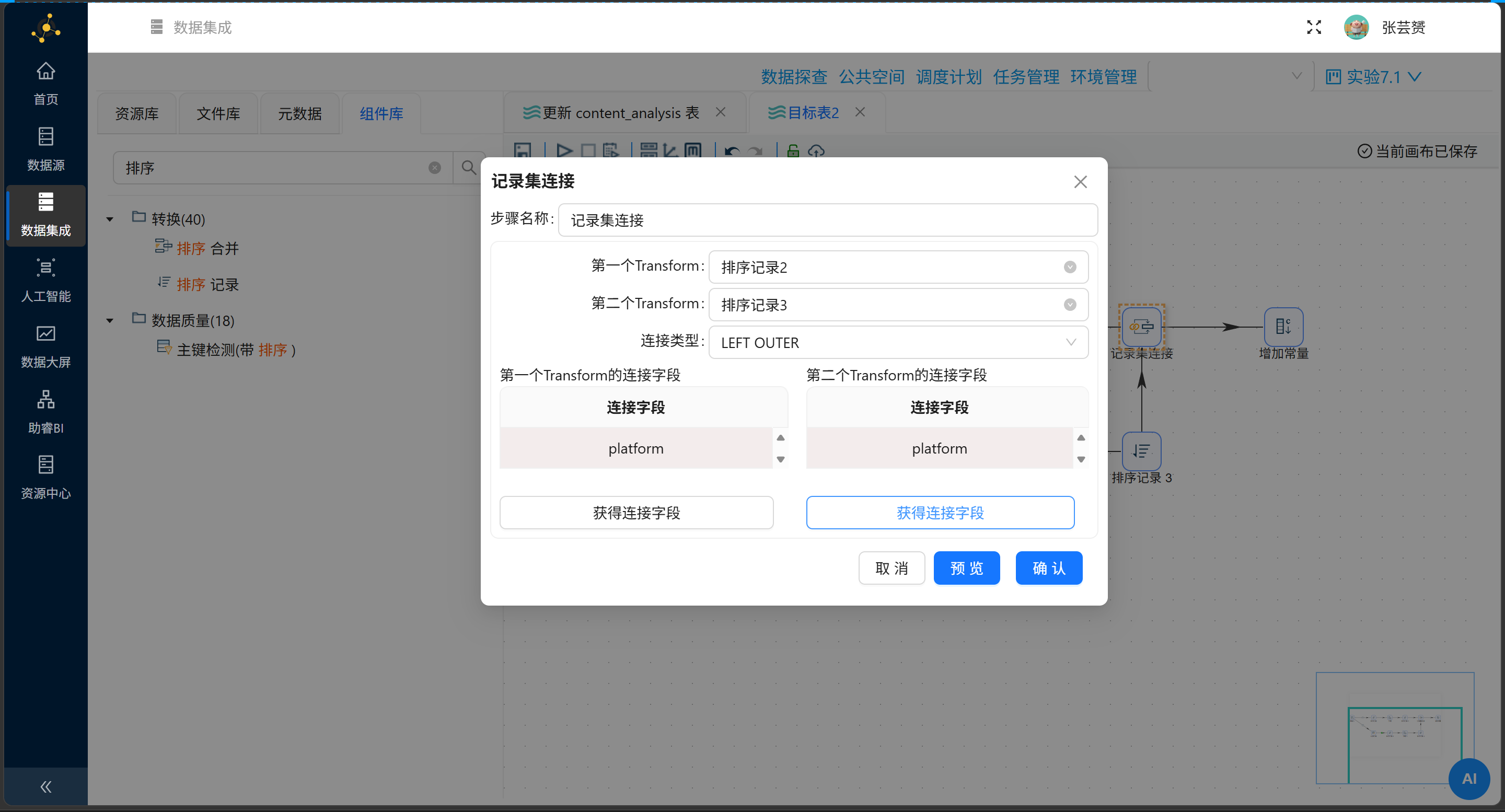
| 配置项 | 值 |
|---|---|
| 第一个Transform | 上分支(整体平均) |
| 第二个Transform | 下分支(关键词平均) |
| 连接类型 | LEFT OUTER |
| 连接字段 | platform = platform |
注意:两个分支都有
platform字段,连接后会自动将第二个重命名为platform_1。需要在连接后加"字段选择"组件移除platform_1,只保留一个platform。
步骤4:表输出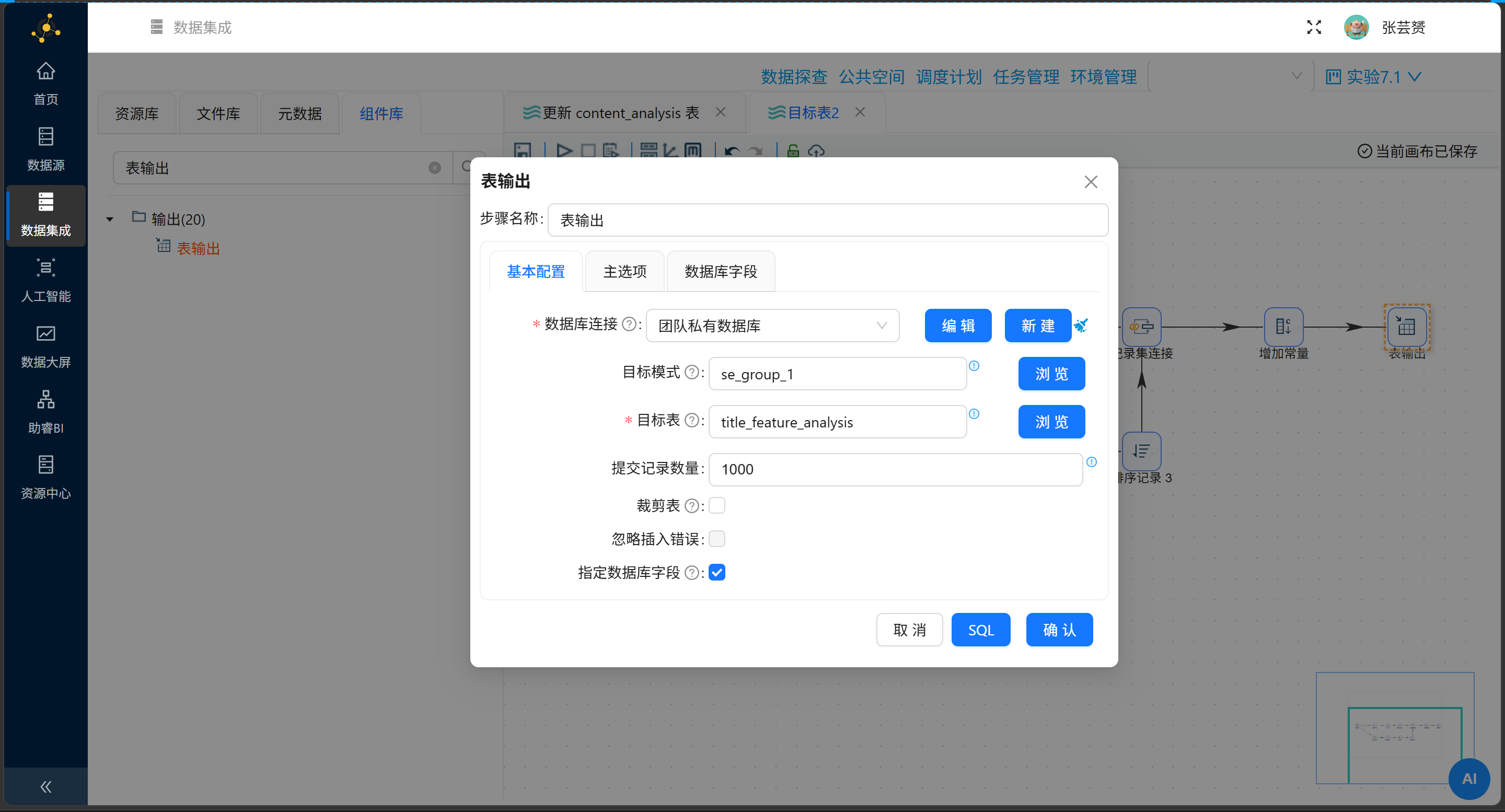
| 配置项 | 值 |
|---|---|
| 目标表 | title_feature_analysis |
| 裁剪表 | ❌ 不勾选 |
| 指定数据库字段 | ✅ 勾选 |
字段映射:
| 表字段 | 流字段 |
|---|---|
platform |
platform |
feature_name |
feature_name |
avg_interaction |
avg_interaction |
overall_avg |
overall_avg |
sample_count |
sample_count |
步骤5:复制分支处理其他关键词
复制整个Pipeline,只修改两处:
| 关键词 | 过滤条件 | 常量值 |
|---|---|---|
| 保姆级 | has_best = 1 |
保姆级 |
| 零代码 | has_lowcode = 1 |
零代码 |
| 实战 | has_practice = 1 |
实战 |
| 教程 | has_tutorial = 1 |
教程 |
| 踩坑 | has_pit = 1 |
踩坑 |
五、实验结果与分析
5.1 基础实验输出
title_feature_analysis 表最终数据: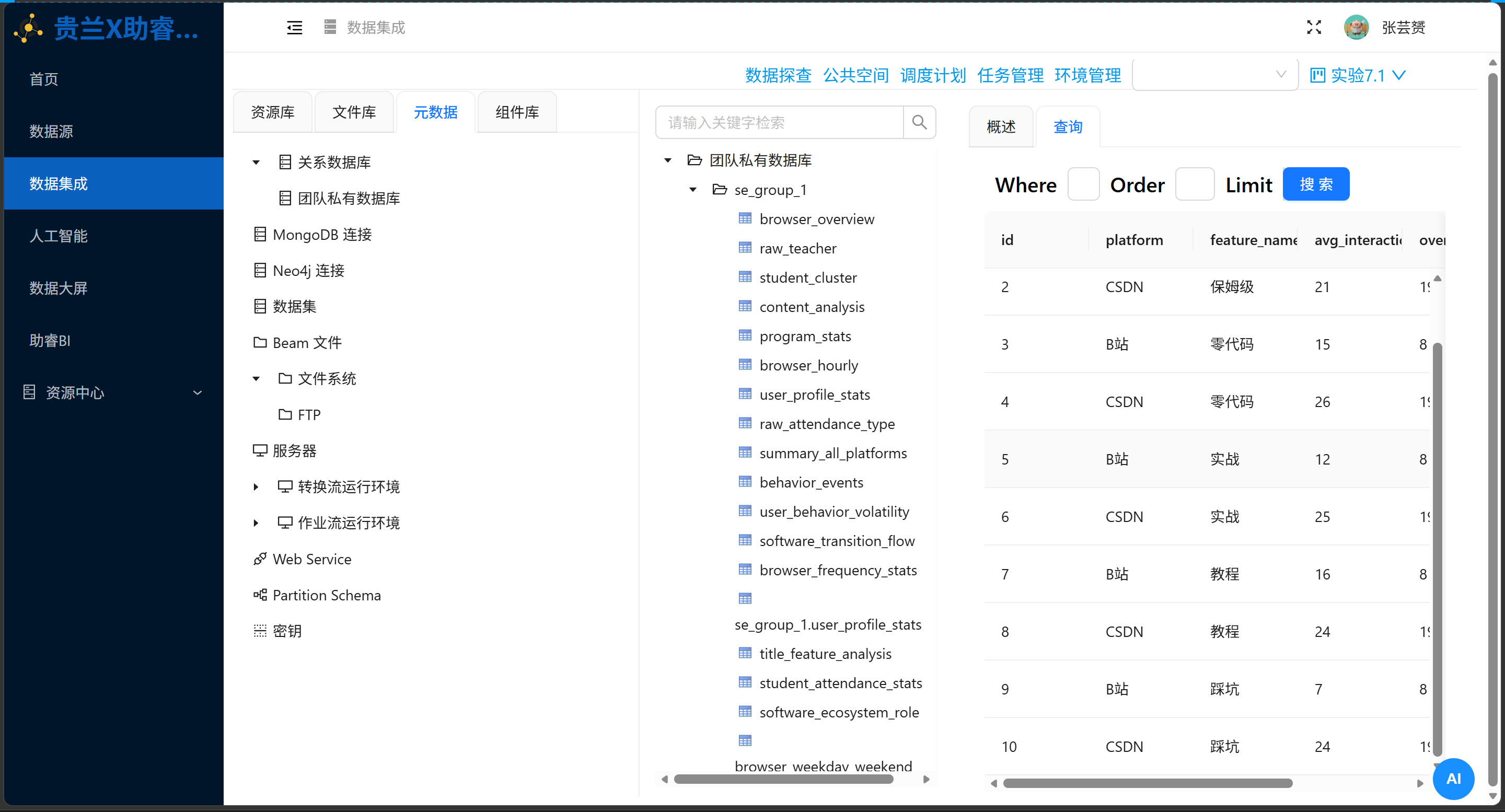
| id | platform | feature_name | avg_interaction | overall_avg | sample_count |
|---|---|---|---|---|---|
| 1 | B站 | 保姆级 | 12.00 | 8.00 | 159 |
| 2 | CSDN | 保姆级 | 21.00 | 19.00 | 178 |
| 3 | B站 | 零代码 | 15.00 | 8.00 | 279 |
| 4 | CSDN | 零代码 | 26.00 | 19.00 | 578 |
| 5 | B站 | 实战 | 12.00 | 8.00 | 200 |
| 6 | CSDN | 实战 | 25.00 | 19.00 | 403 |
| 7 | B站 | 教程 | 16.00 | 8.00 | 222 |
| 8 | CSDN | 教程 | 24.00 | 19.00 | 335 |
| 9 | B站 | 踩坑 | 7.00 | 8.00 | 29 |
| 10 | CSDN | 踩坑 | 24.00 | 19.00 | 107 |
5.2 结果解读
-
B站:"教程"关键词效果最佳(avg=16),"踩坑"效果最差(avg=7,低于平台平均)
-
CSDN:"零代码"效果最佳(avg=26),所有关键词均高于平台平均
-
平台差异:CSDN用户对技术类关键词(零代码、实战、教程)的响应度普遍高于B站
六、额外优化:Lift提升度与特征排名(加分项)
6.1 优化动机
基础实验只能看出"哪个关键词平均互动更高",但无法回答:"这个关键词比平台平均好多少?"为此引入Lift(提升度)指标:
Lift=平台整体平均互动数关键词平均互动数
-
Lift > 1:关键词表现优于平台平均(超额收益)
-
Lift = 1:与平台平均持平
-
Lift < 1:低于平台平均
6.2 实现步骤
步骤1:扩展表结构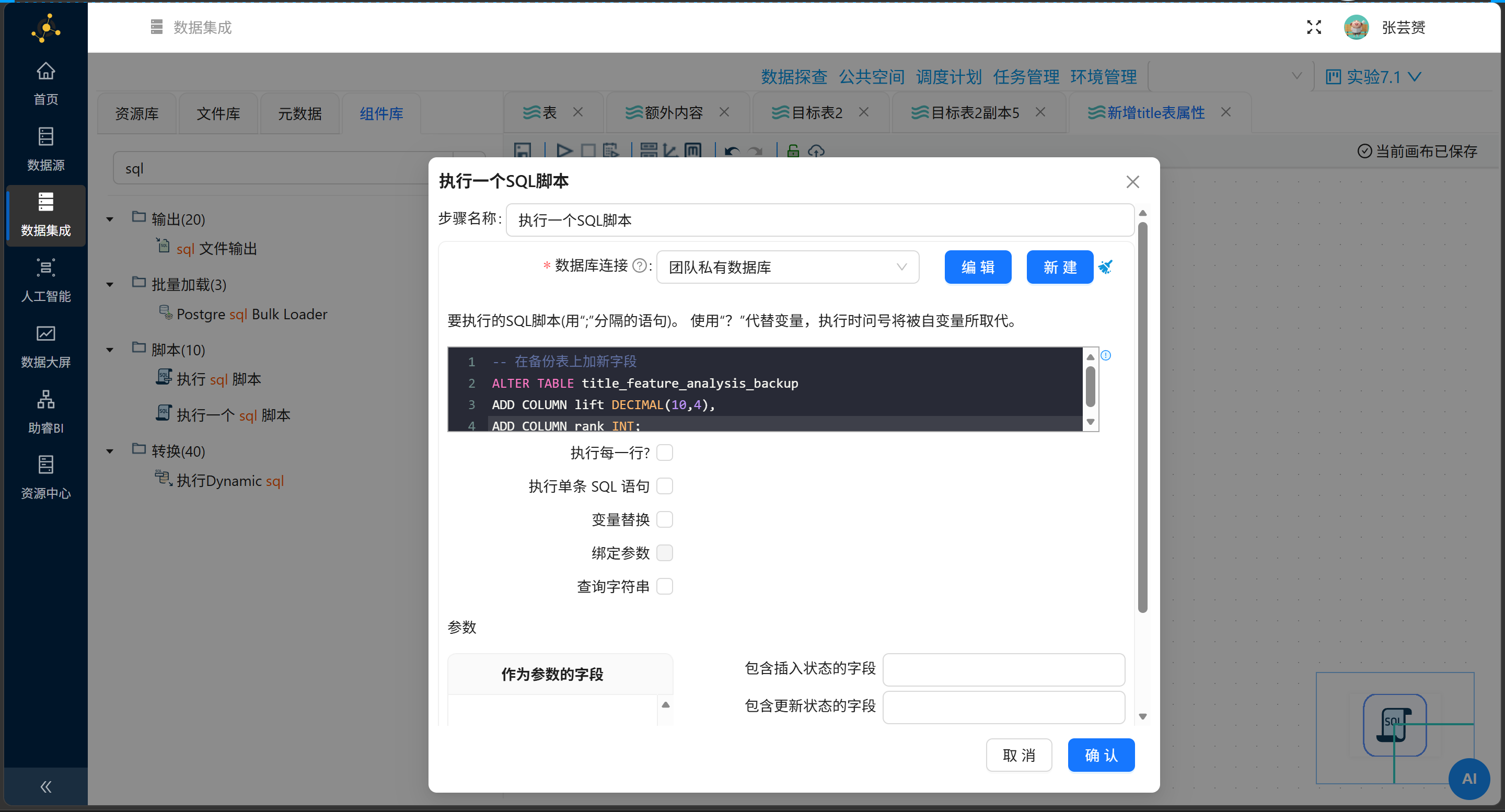
ALTER TABLE title_feature_analysis_backup
ADD COLUMN lift DECIMAL(10,4),
ADD COLUMN feature_rank INT;注意:
rank是MySQL保留关键字,需用反引号或改名(如feature_rank)。
步骤2:Pipeline中增加"计算器"组件
在"记录集连接"之后,"增加常量"之前插入: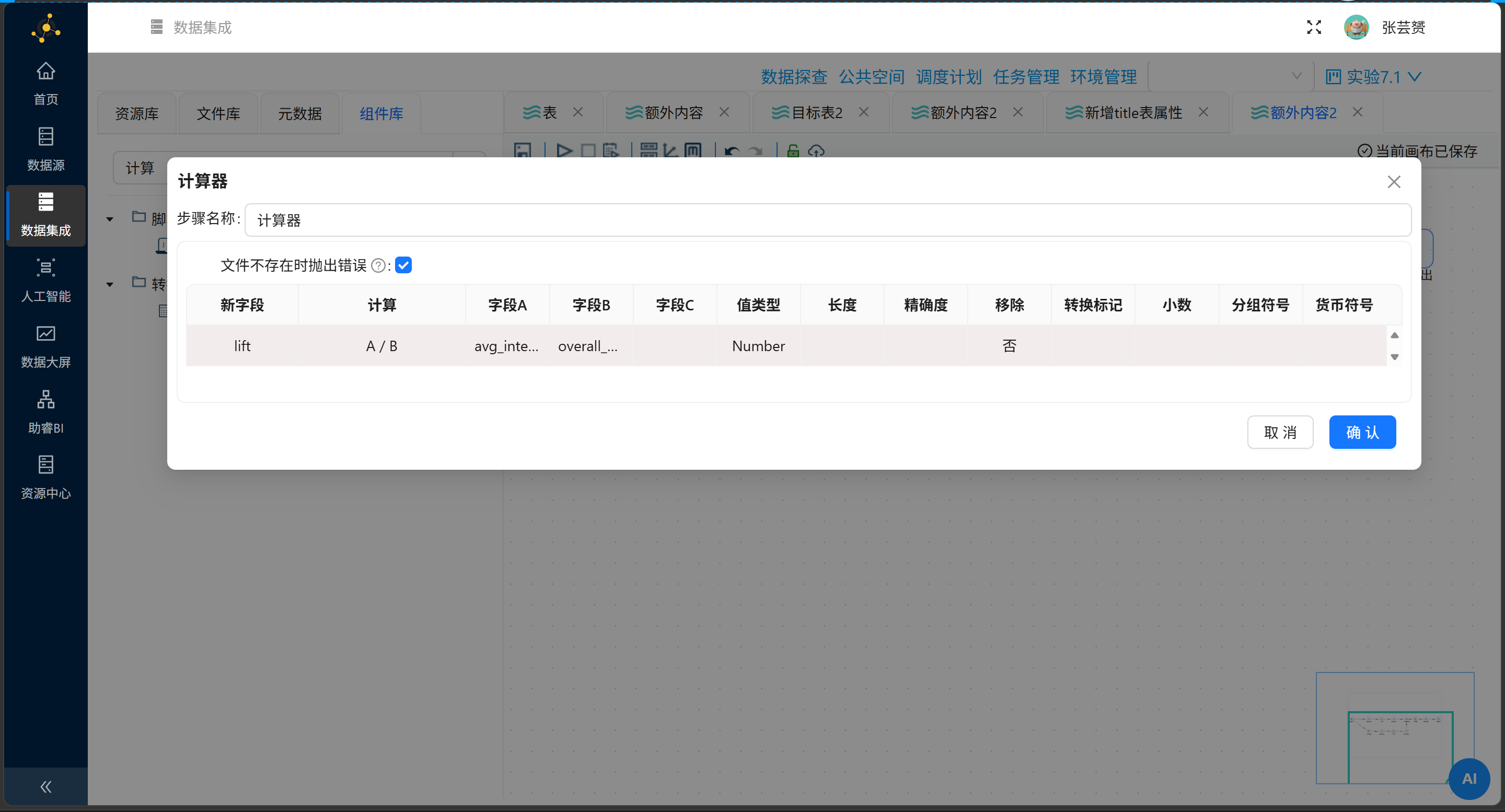
| 新字段 | 计算 | 字段A | 字段B |
|---|---|---|---|
lift |
A / B | avg_interaction |
overall_avg |
步骤3:增加"增加序列"组件
在"计算器"之后,用于生成排名: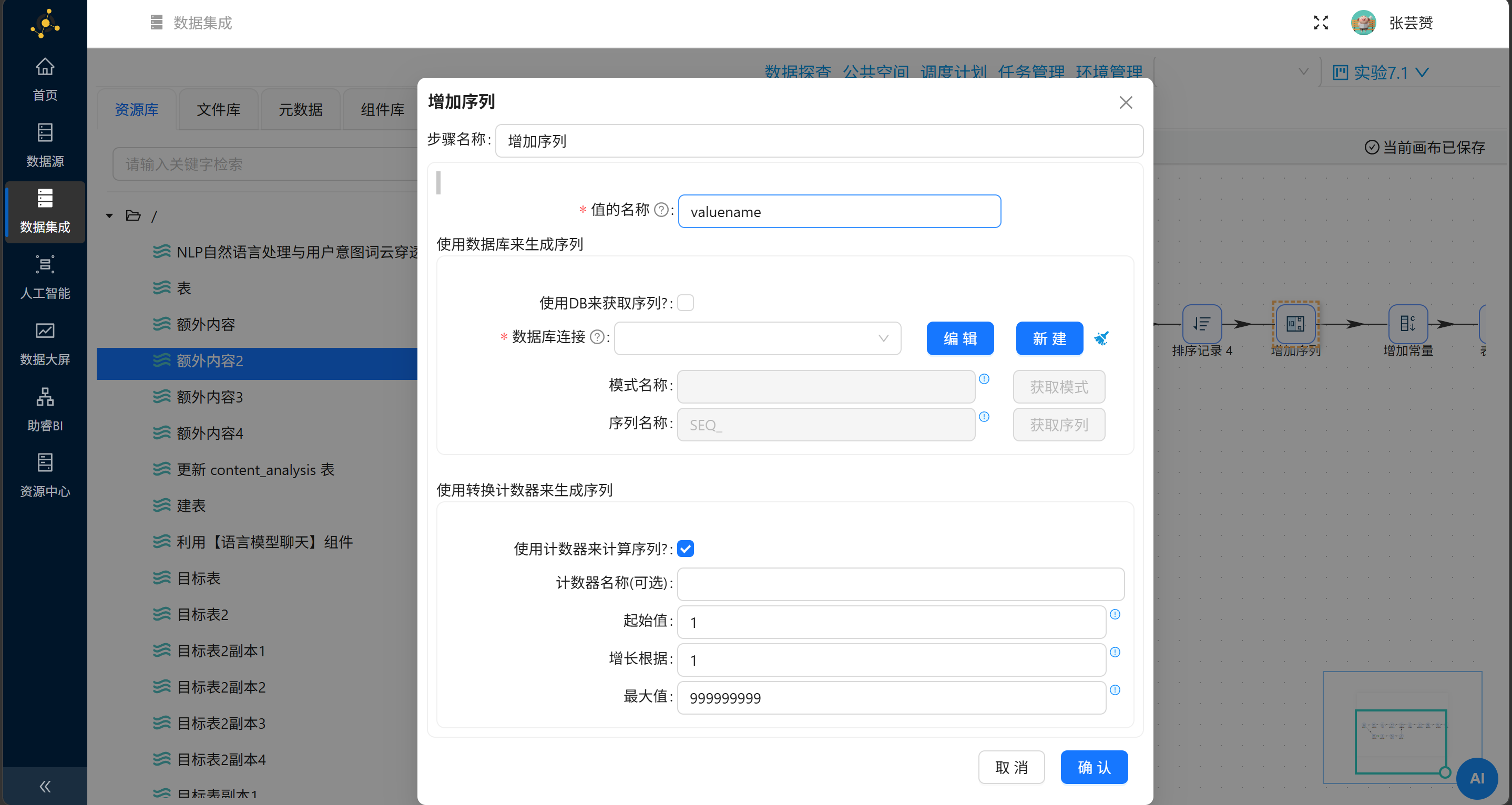
| 配置项 | 值 |
|---|---|
| 值的名称 | feature_rank |
| 使用计数器来计算序列 | ✅ 勾选 |
| 起始值 | 1 |
| 增长根据 | 1 |
步骤4:修改表输出字段映射
新增映射:
| 表字段 | 流字段 |
|---|---|
lift |
lift |
feature_rank |
feature_rank |
 6.3 优化后输出
6.3 优化后输出
| 排名 | 平台 | 关键词 | 平均互动 | 平台基准 | Lift | 效果评级 |
|---|---|---|---|---|---|---|
| 1 | B站 | 教程 | 16 | 8 | 2.0000 | 🏆 超强 |
| 2 | B站 | 零代码 | 15 | 8 | 1.8750 | 🏆 超强 |
| 3 | B站 | 实战 | 12 | 8 | 1.5000 | ✅ 优秀 |
| 4 | B站 | 保姆级 | 12 | 8 | 1.5000 | ✅ 优秀 |
| 5 | B站 | 踩坑 | 7 | 8 | 0.8750 | ⚠️ 低于平均 |
| 1 | CSDN | 零代码 | 26 | 19 | 1.3684 | ✅ 优秀 |
| 2 | CSDN | 实战 | 25 | 19 | 1.3158 | ✅ 优秀 |
| 3 | CSDN | 教程 | 24 | 19 | 1.2632 | ✅ 良好 |
| 4 | CSDN | 踩坑 | 24 | 19 | 1.2632 | ✅ 良好 |
| 5 | CSDN | 保姆级 | 21 | 19 | 1.1053 | ⚠️ 略高于平均 |
6.4 优化洞察
-
B站:"教程"的Lift高达2.0,是平台平均的2倍,是绝对的优质特征词;"踩坑"Lift<1,效果低于平均
-
CSDN:所有关键词Lift均>1,说明技术类内容在CSDN整体更受欢迎;"保姆级"Lift最低(1.1),说明CSDN用户可能更偏好进阶内容
-
运营建议:B站标题可多用"教程""零代码",CSDN可全面覆盖技术关键词,但"保姆级"在CSDN效果一般
关键词 B站 Lift CSDN Lift 差异 解读 教程 2.00 1.26 +0.74 B站更爱教程,CSDN认为"太基础" 零代码 1.88 1.37 +0.51 两边都吃香,B站相对优势更大 实战 1.50 1.32 +0.18 CSDN实战氛围更浓 保姆级 1.50 1.11 +0.39 CSDN对"保姆级"不感冒 踩坑 0.88 1.26 -0.38 ⚠️ 唯一跨平台反转!B站避雷,CSDN推荐
七、我踩过的坑(血泪总结)
| 坑 | 现象 | 怎么爬出来的 |
|---|---|---|
| JavaScript自赋值 | 报错"找不到字段[has_best]" | 删掉var和has_best = has_best,直接赋值 |
| 字段名混淆 | 插入/更新U=0 | 计算器输出叫interactions,表字段叫total_interaction,映射时别写反 |
| 过滤条件不匹配 | 过滤记录W=0 | 确认上游数据已正确写入,数值类型才能用=,字符串要用"" |
| 分组字段为空 | overall_avg为NULL |
检查total_interaction是不是字符串,是的话先转数字 |
| 字段重名 | platform_1报错 |
记录集连接后加"字段选择"把platform_1扔掉 |
| 保留关键字 | rank字段报错 |
改成feature_rank,或者加反引号`rank` |
| 前端Bug | 保存时getBoolean为null |
勾选"使用计数器来计算序列",或者刷新页面再试 |
八、一些心得
8.1 关于特征工程
这次实验让我体会到,特征工程不只是"提取特征",更是"定义问题的方式"。同样是标题文本,你可以提取"是否含某关键词"(0/1),也可以提取"关键词出现次数",还可以提取"情感倾向"。不同的特征定义,会导向完全不同的分析结论。
我这次用的是最简单的0/1标志,但已经能发现很多有趣的规律。如果后续做TF-IDF或情感分析,应该能挖掘出更深层的模式。
8.2 关于指标设计
"平均数"是最直观的指标,但也是最"懒"的指标。Lift提升度让我看到了相对表现——一个词好不好,不是看它绝对值多高,而是看它比平台基准线高多少。
这个思路可以复用到很多场景:商品品类分析(品类转化率 vs 全站转化率)、用户分层分析(某人群ARPU vs 整体ARPU)……本质上都是"找异常、找亮点"。
8.3 关于工具选择
全程可视化ETL,没写一行SQL,对于快速验证想法非常友好。但复杂逻辑(比如正则提取、文本分词)还是需要代码组件补充。工具没有好坏,适合当前阶段的就是最好的。
九、附录:用到的核心组件速查
| 组件 | 我用它做了什么 |
|---|---|
| 表输入 | 读原始数据 |
| JavaScript代码 | 从标题里提取5个关键词标志 |
| 计算器 | 算互动总数、算Lift |
| 插入/更新 | 按ID更新已有记录 |
| 过滤记录 | 筛出含某关键词的作品 |
| 分组 | 算平台平均、关键词平均、样本量 |
| 增加常量 | 给数据贴标签(feature_name) |
| 记录集连接 | 把"整体平均"和"关键词平均"拼到一行 |
| 增加序列 | 生成排名 |
| 表输出 | 写入结果表 |
如果你也在做内容运营的数据分析,或者有更好的特征工程思路,欢迎在评论区交流!数据驱动的标题优化,本质上是一个持续迭代的过程——今天"教程"是Lift之王,明天可能就有新词冒出来。保持好奇,保持实验。

一站式 AI 云服务平台
更多推荐

 2
2 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)