
B站、CSDN流量分析!保姆级教程:用零代码ETL与Lift提升度,扒下“爆款标题”的底裤
互联网的文字海里,最不缺的就是自嗨。最近深扒内容运营的数据黑盒,我一直死磕一个灵魂拷问:标题里到底塞什么词,才能让数据好看得令人心动?于是,我顺手爬了5702条B站和CSDN的野生数据,来了一场蓄谋已久的“特征工程”实战。从抽丝剥茧提取词根,到互动指标的暴力聚合,再到最后用Lift提升度看透爆款真相——全程零代码ETL丝滑跑通,没敲一行SQL。踩过坑,也见过光,权当一份数据人的深夜告白,且看且分享。
一、起手式:我们为什么需要这场赛博解剖?
码字的心血,往往生死于标题折叠的方寸之间。80%的打开率定生死,但“标题党”与“好标题”的楚河汉界其实极其暧昧——你不仅要诱人撩起门帘,还要让人心甘情愿地留下喝茶(点赞、收藏、评论三连)。
摊开手头的5702条沉甸甸的数据样本,它们静静躺在B站和CSDN两个平行宇宙里。点赞、收藏、分享、投币、浏览量……这些冰冷的数字背后,藏着用户的呼吸和偏好。面对它们,我想逼问出几个答案:
-
当我们在标题里刻意堆砌“保姆级”、“实战”、“零代码”时,算法之神真的会偏爱我们吗?
-
同一套词汇的魔法,在B站的Z世代和CSDN的极客眼中,会泛起同样的涟漪吗?
-
当“平均数”撒下均贫富的谎言时,有没有一把更锋利的尺子,能丈量出一个词汇真正的“带货身价”?
揣着这三个执念,我的ETL齿轮开始转动。
二、搭台唱戏:两张底表的美学构建
万丈高楼平地起,这次的戏台子搭在两张表上:一张是在岁月的原表上修旧如旧,另一张是平地起高楼的汇总新表。
2.1 撕下伪装,给现有作品表“打标”
每一条数据都需要一个身份证明。我得给它们贴上宿命的标签:你的皮囊里有没有“保姆级”的温柔?有没有“实战”的锋芒?有没有“零代码”的轻狂?这些标签,将是后续命运分流的筹码。
繁杂的互动数据总是散落天涯。点赞、收藏、分享、投币,我决定将它们糅合进一个叫“互动总数”的灵魂容器里,让后续的审视更加纯粹。
于是,在原始的 content_analysis 表上,我硬生生凿出了6个新维度的烙印:
|
新字段 |
含义 |
|---|---|
|
|
互动总数 = 点赞+收藏+分享+投币 |
|
|
标题含"保姆级"(1=有,0=无) |
|
|
标题含"零代码" |
|
|
标题含"实战" |
|
|
标题含"教程"或"指南" |
|
|
标题含"踩坑" |
2.2 另起炉灶:新建关键词的“封神榜”
故事的最后,所有的数据都将殊途同归于一张汇总表 title_feature_analysis。每个词汇在不同平台上的前世今生,都将被凝缩成一行行判词:
|
字段 |
含义 |
|---|---|
|
|
B站或CSDN |
|
|
关键词名称 |
|
|
带这个词的作品平均互动数 |
|
|
该平台所有作品的平均互动数(基准线) |
|
|
带这个词的作品数量 |
三、第一幕:为作品刻下烙印,计算互动原力
3.1 极简的底层逻辑
大道至简,整个水管的流向非常清晰:唤醒数据 → 榨取标题词根 → 聚合互动总数 → 灵魂反哺回流数据库。
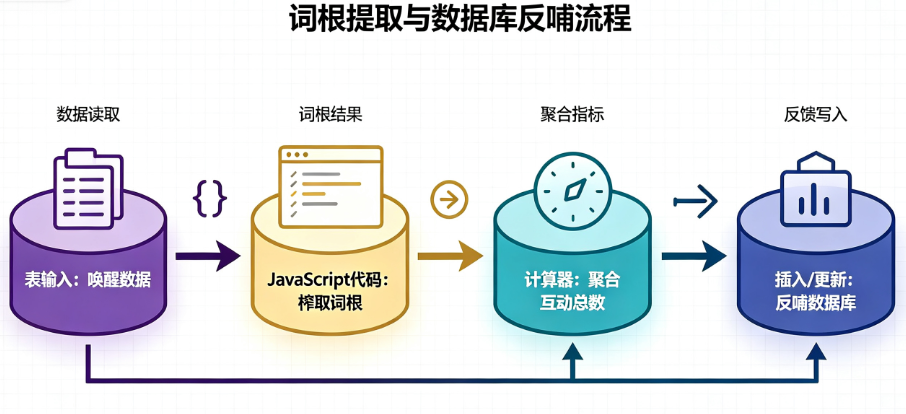
💡 节点运行日志:ETL流程搭建完毕
3.2 提取关键词:在JavaScript组件里跳舞
这里是全场事故的高发地段。初出茅庐时,我敲下的代码带着一种天真的盲目:
// ❌ 错误写法,会报错!
var has_best = title.indexOf("保姆级") !== -1 ? 1 : 0;
// ...
has_best = has_best; // 这行会报错!
💡 节点运行日志:引擎拦截,发生错误
结果一跑,直接翻车,红字赫然写着:“找不到字段 [has_best]”。
剖开表象看本质:Hop引擎(底层执行环境)在苏醒扫描脚本时,有着近乎古板的轴劲——它会把等号右边的变量,统统默认为“上游老天爷赏饭吃的输入字段”。在 has_best = has_best 这一句里,右边的兄弟被当成了天外来客,但上游的字典里根本查无此人,于是引擎直接罢工。
拨乱反正后的正确姿势:
// ✅ 正确写法
var title = title;
has_best = title.indexOf("保姆级") !== -1 ? 1 : 0;
has_lowcode = title.indexOf("零代码") !== -1 ? 1 : 0;
has_practice = title.indexOf("实战") !== -1 ? 1 : 0;
has_tutorial = (title.indexOf("教程") !== -1 || title.indexOf("指南") !== -1) ? 1 : 0;
has_pit = title.indexOf("踩坑") !== -1 ? 1 : 0;
💡 节点运行日志:绿灯通行,代码生效
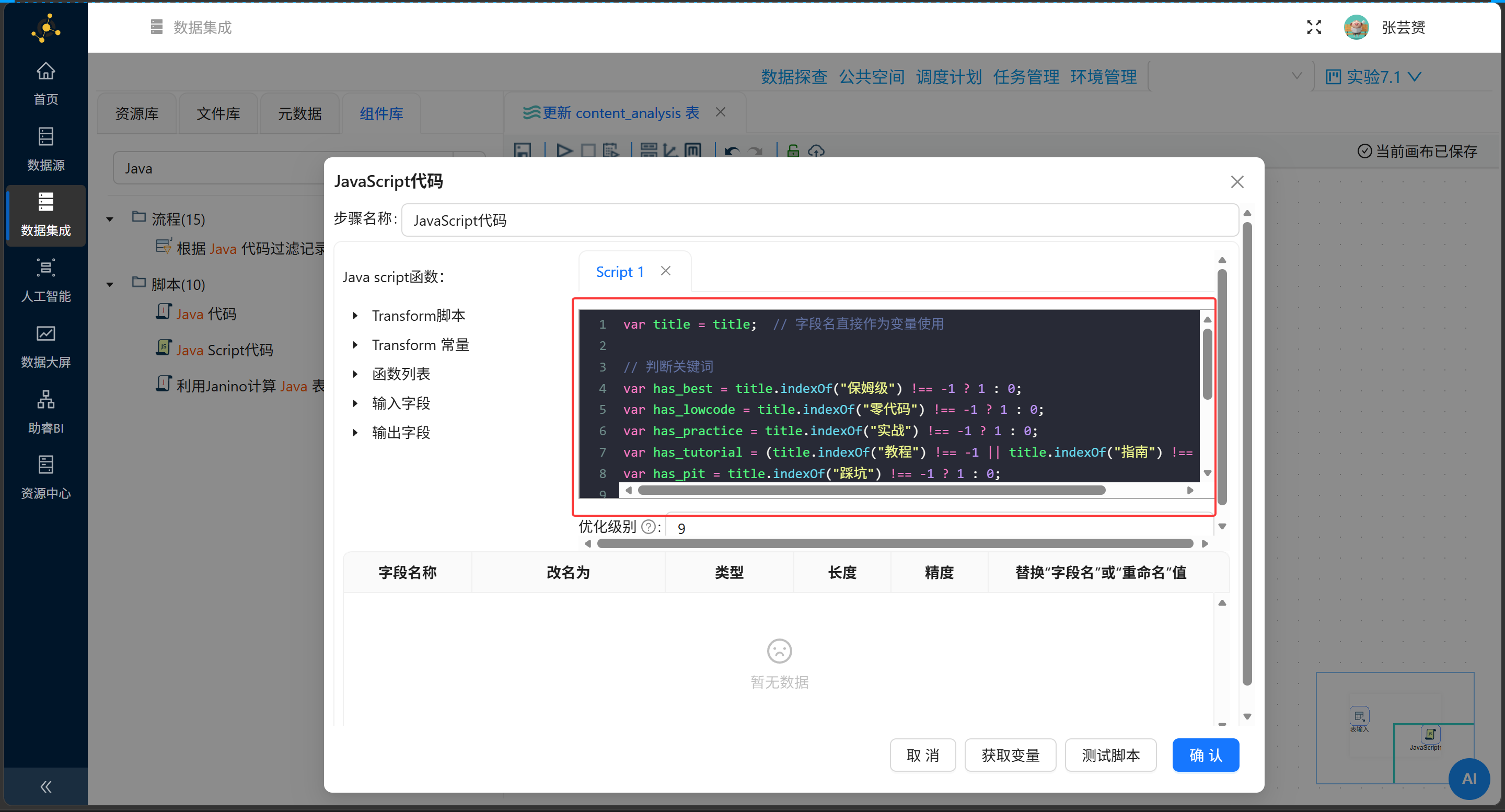
避坑心法:
-
扔掉
var has_best = ...的执念,简单粗暴直接赋值。 -
戒掉
has_best = has_best这种原地转圈的废话。 -
title是个傲娇的主,必须先用var title = title把它请进大堂。 -
最后,在组件的“字段”户口本上,郑重其事地把这5位列为输出字段(类型锁死Integer)。
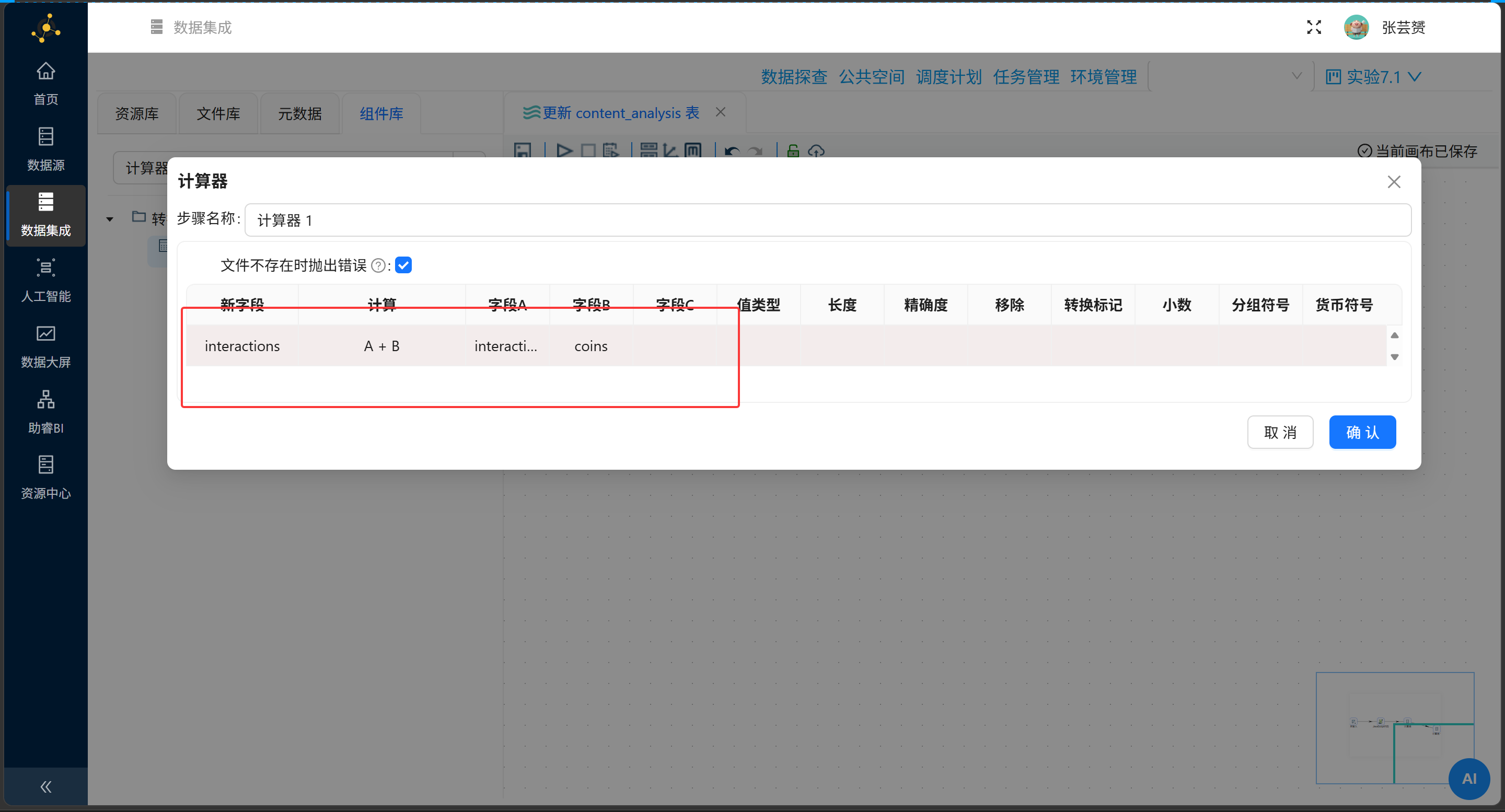
3.3 互动总数:让计算器来做加法哲学
调用计算器组件,把散落的四维互动能量一键融会贯通:
|
新字段 |
计算方式 |
字段A |
字段B |
字段C |
字段D |
|---|---|---|---|---|---|
|
|
A+B+C+D |
|
|
|
|
3.4 数据反哺:精准制导的插入/更新组件
这里是强迫症的福音:必须用“插入/更新”组件,绝不能用“表输出”。我们要的是为旧日数据披上新战袍,而不是盲目制造影分身。
接头暗号:id = id(作品ID就是唯一的心智锚点)。
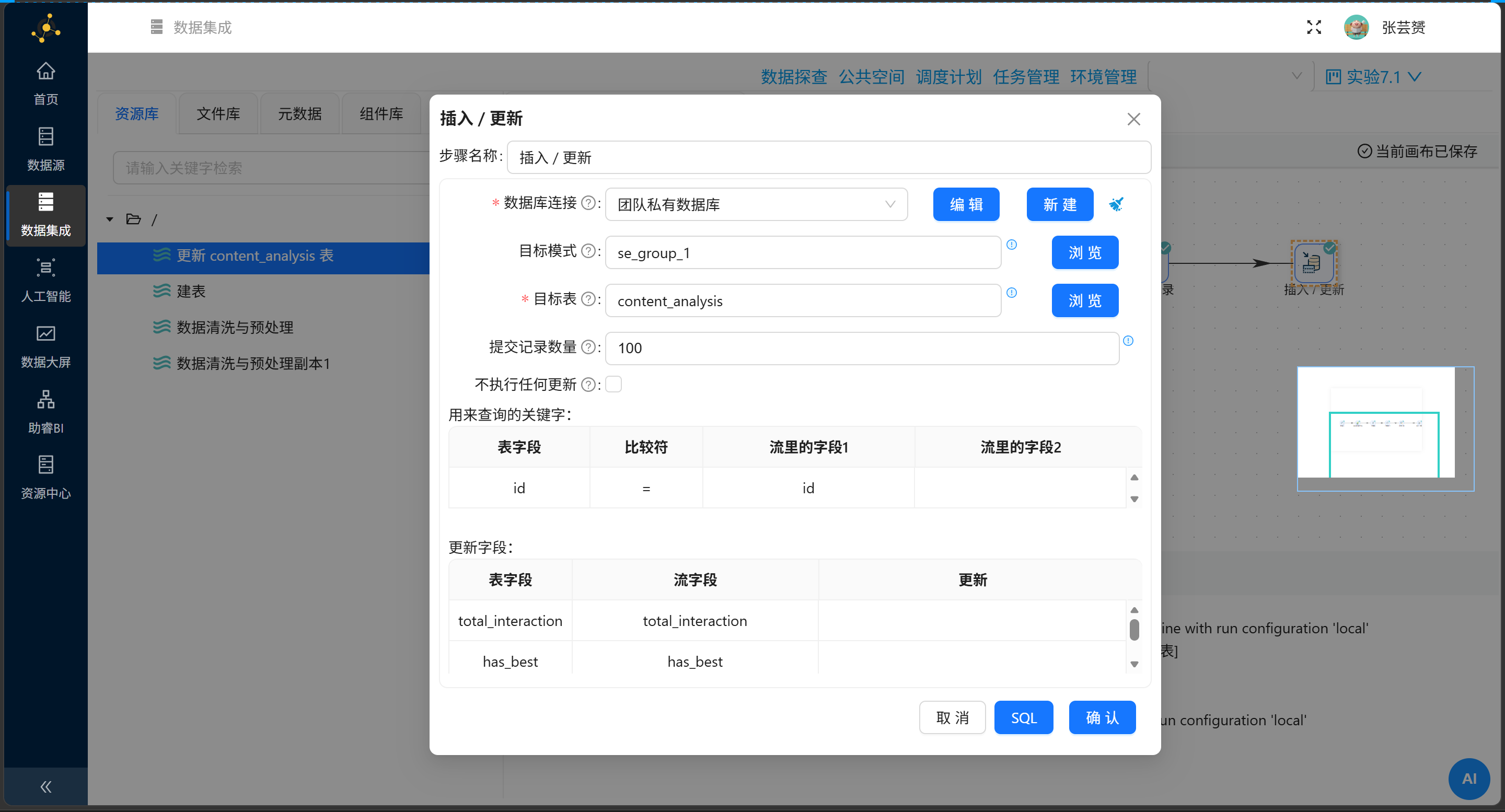
血脉联结的字段映射法则:
|
表字段 |
流字段 |
是否更新 |
|---|---|---|
|
|
|
✅ |
|
|
|
✅ |
|
|
|
✅ |
|
|
|
✅ |
|
|
|
✅ |
|
|
|
✅ |
跑通的那一刻,终端日志会赐予你最迷人的诗句:U=5702(更新数严丝合缝对齐总数),且 E=0(绝对的零误差纯洁度)。
回想初遇时,冷冰冰的 U=0 让我原地破防。顺藤摸瓜半天才揪出真凶:我在流字段映射时昏了头。计算器生出的野孩子叫 interactions,到了插入更新环节,我却妄想直接喊它的大名 total_interaction。记住,表里的户口名叫 total_interaction,但水管里流淌的依然是 interactions,名字之防,不可不察。
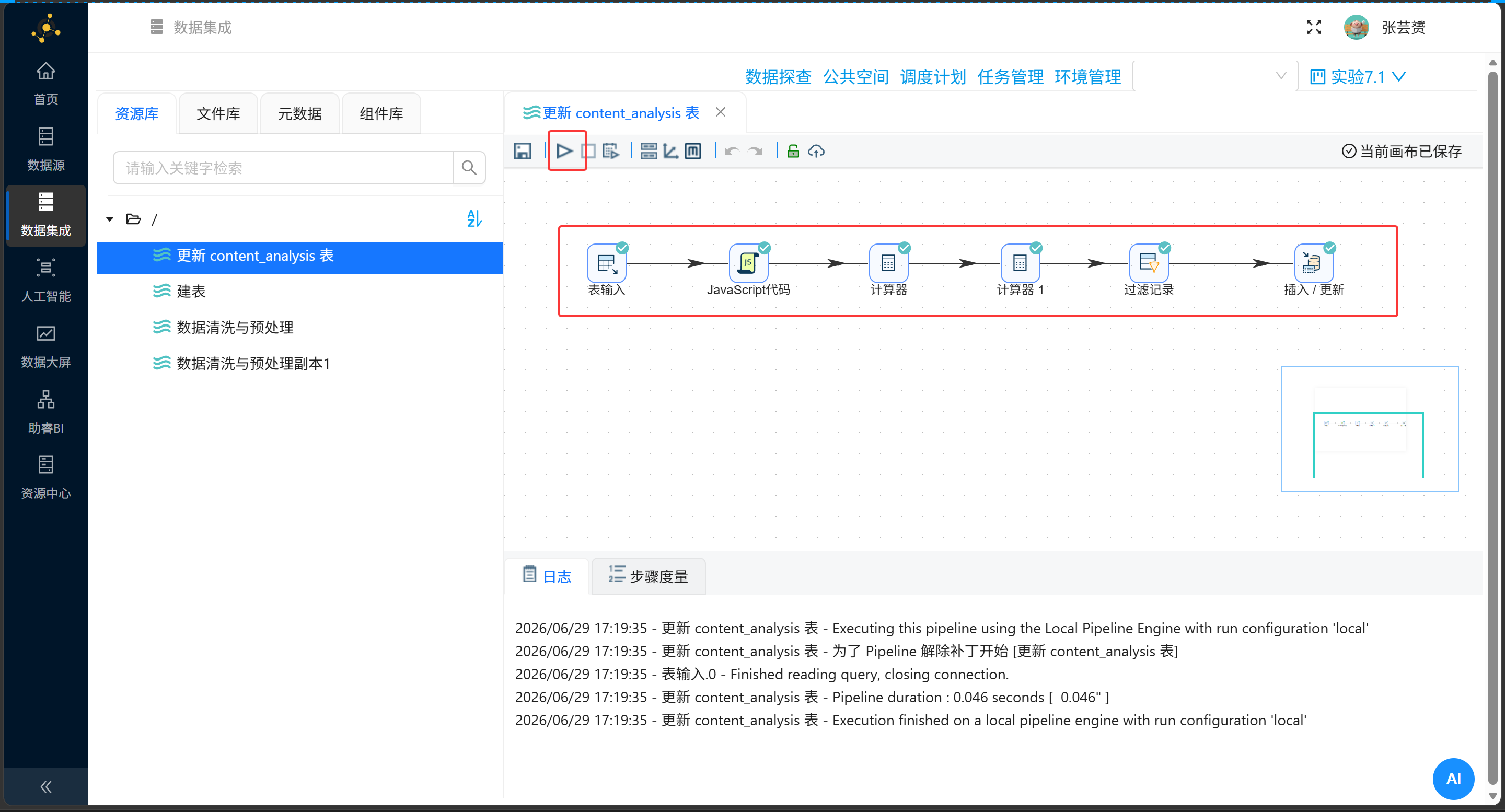
四、第二幕:关键词维度的降维打击与汇总
4.1 剥茧抽丝的谋篇布局
如果把“保姆级”这个词单独拎上解剖台,我们需要给它出具三份体检报告:
-
整体大盘水位:该平台所有作品的平均互动数(这是不可逾越的基准线)。
-
单体爆发力:携带该词汇作品的平均互动数。
-
群众基础:到底有多少个作品在蹭这个词(样本量)。
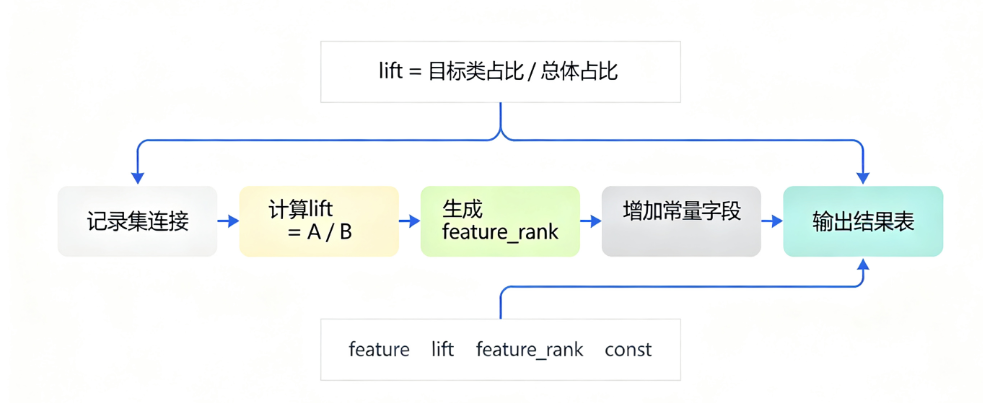
最后,用一招“记录集连接”的奇门遁甲,把大盘水位和单体爆发力揉碎在同一行里,让后期的对比分析一目了然。
4.2 水管架构图(赛博解析版)
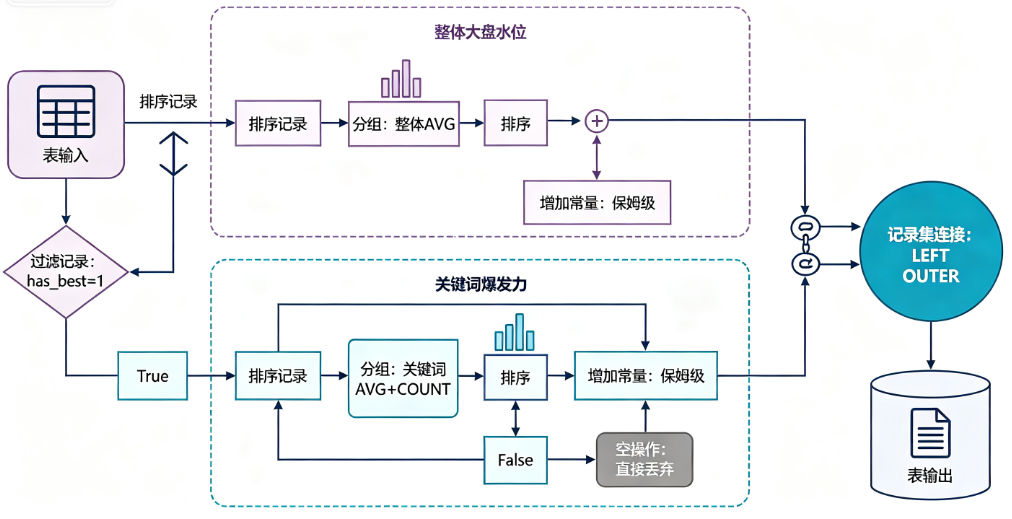
💡 节点运行日志:分支流向构建完成
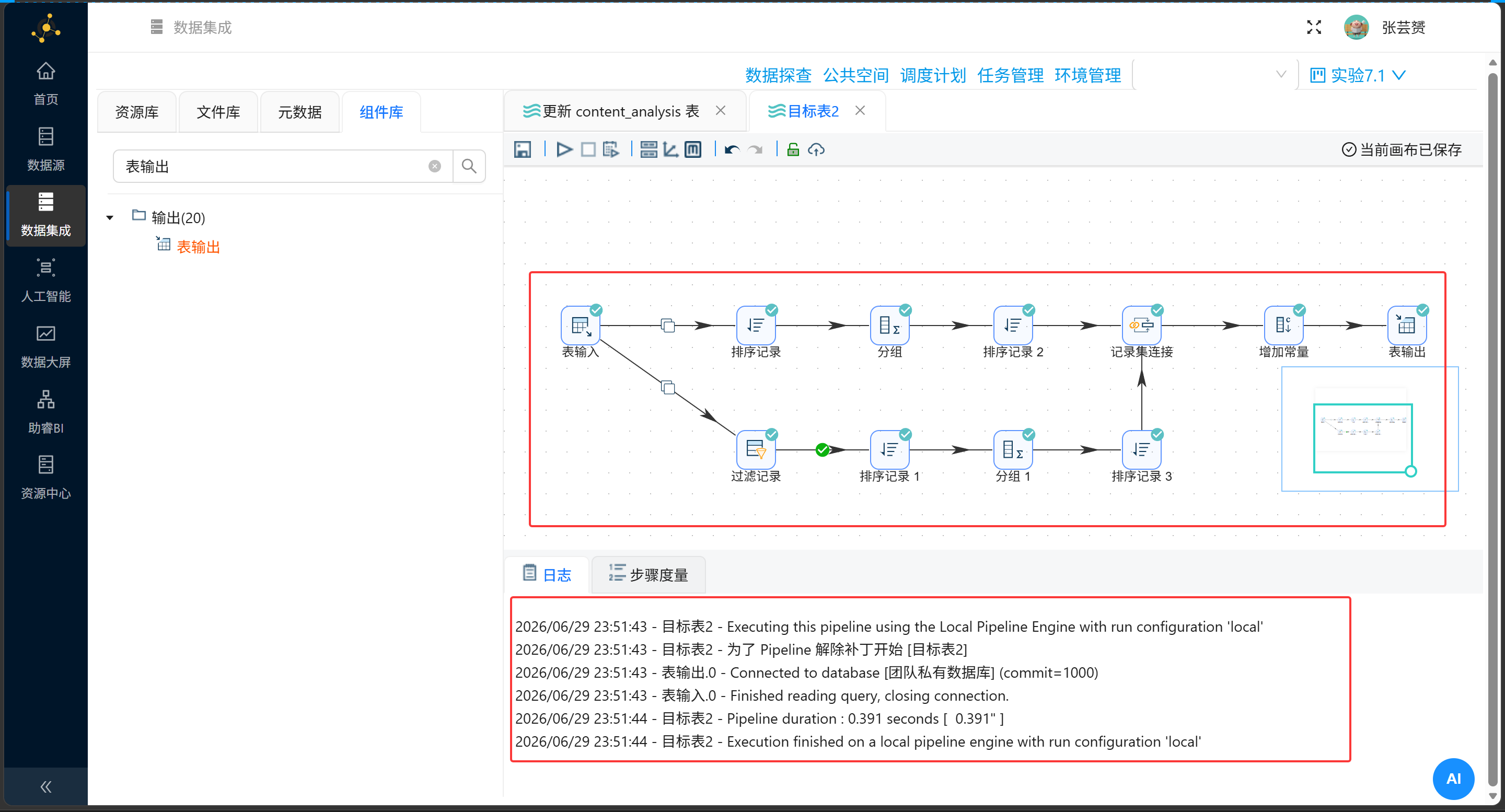
4.3 庖丁解牛:步骤详解
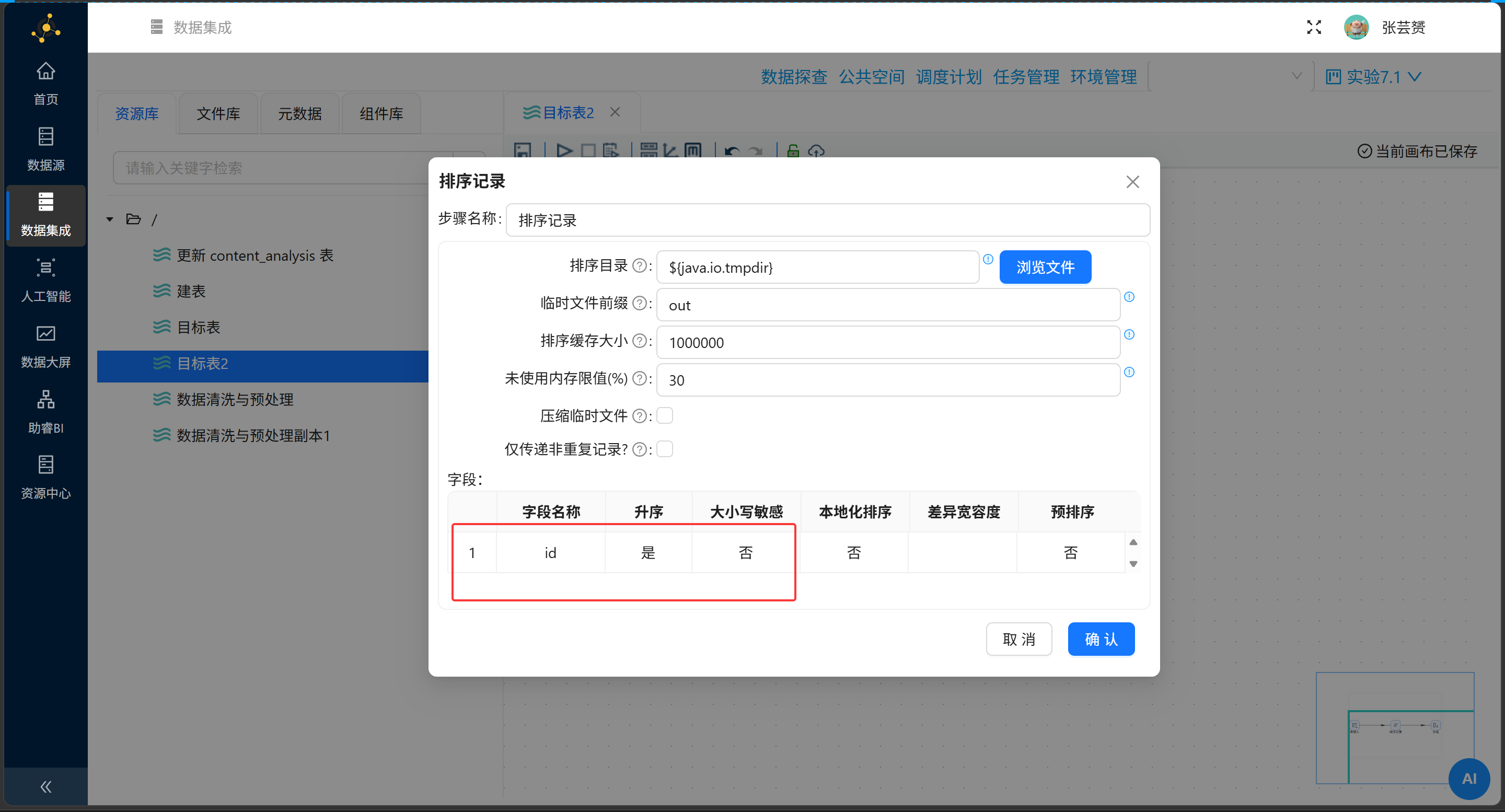
第一式:丈量大盘平均水温(水管上分支)
|
组件 |
配置 |
|---|---|
|
排序记录 |
按 |
|
分组 |
分组字段: |
|
增加常量 |
|
|
排序记录 |
按 |
第二式:榨取关键词核心爆发力(水管下分支)
|
组件 |
配置 |
|---|---|
|
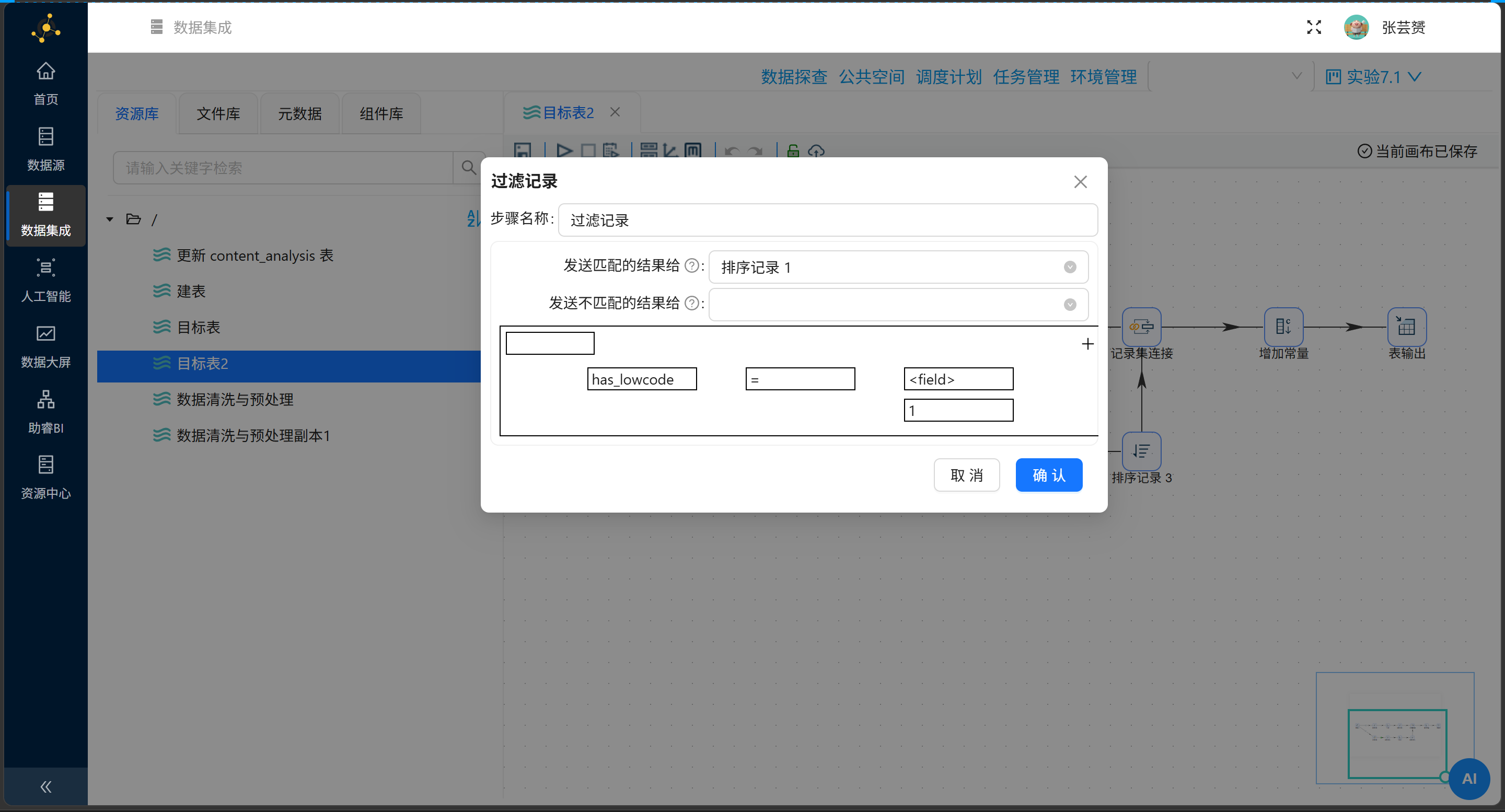
过滤记录 |
条件: |
|
排序记录 |
按 |
|
分组 |
分组字段: |
|
增加常量 |
|
|
排序记录 |
按 |
为啥非得插一个“增加常量”?因为数据被聚合碾压后,就只剩下光秃秃的肉身数值了。feature_name 常量就像是一把纹身枪,硬生生给这串数字刻上“保姆级”三个大字,好让下游兄弟认得出这是谁家的兵。
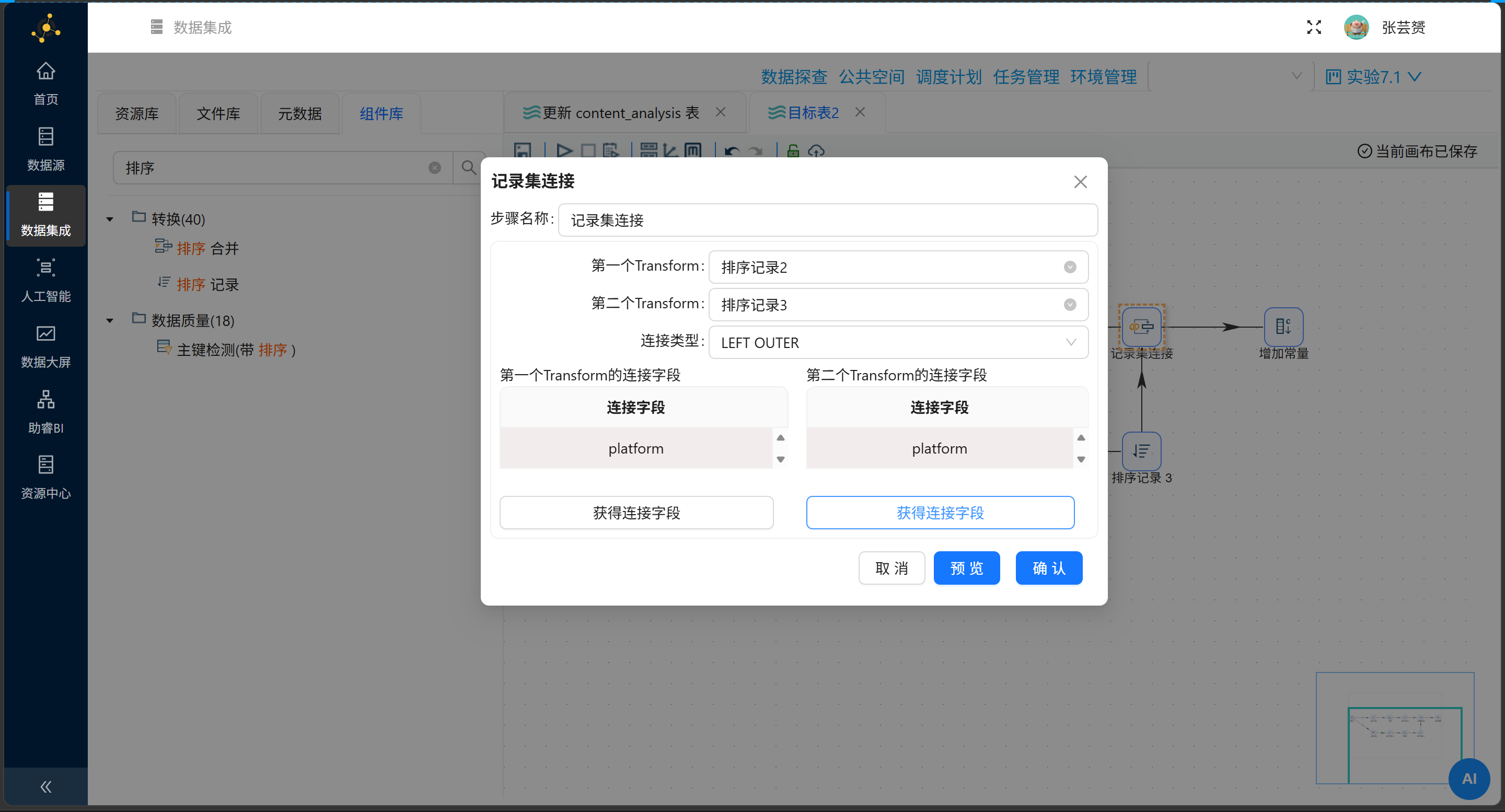
第三式:用记录集连接让两股真气交汇
|
配置项 |
值 |
|---|---|
|
第一个Transform |
上分支(整体平均) |
|
第二个Transform |
下分支(关键词平均) |
|
连接类型 |
LEFT OUTER |
|
连接字段 |
|
避坑高能警告:两军会师时都有 platform 这面旗帜,系统会自作聪明把后者叫作 platform_1。务必在会师后补一个“字段选择”组件,把冒牌货 platform_1 斩落马下,留存唯一纯净的血脉。
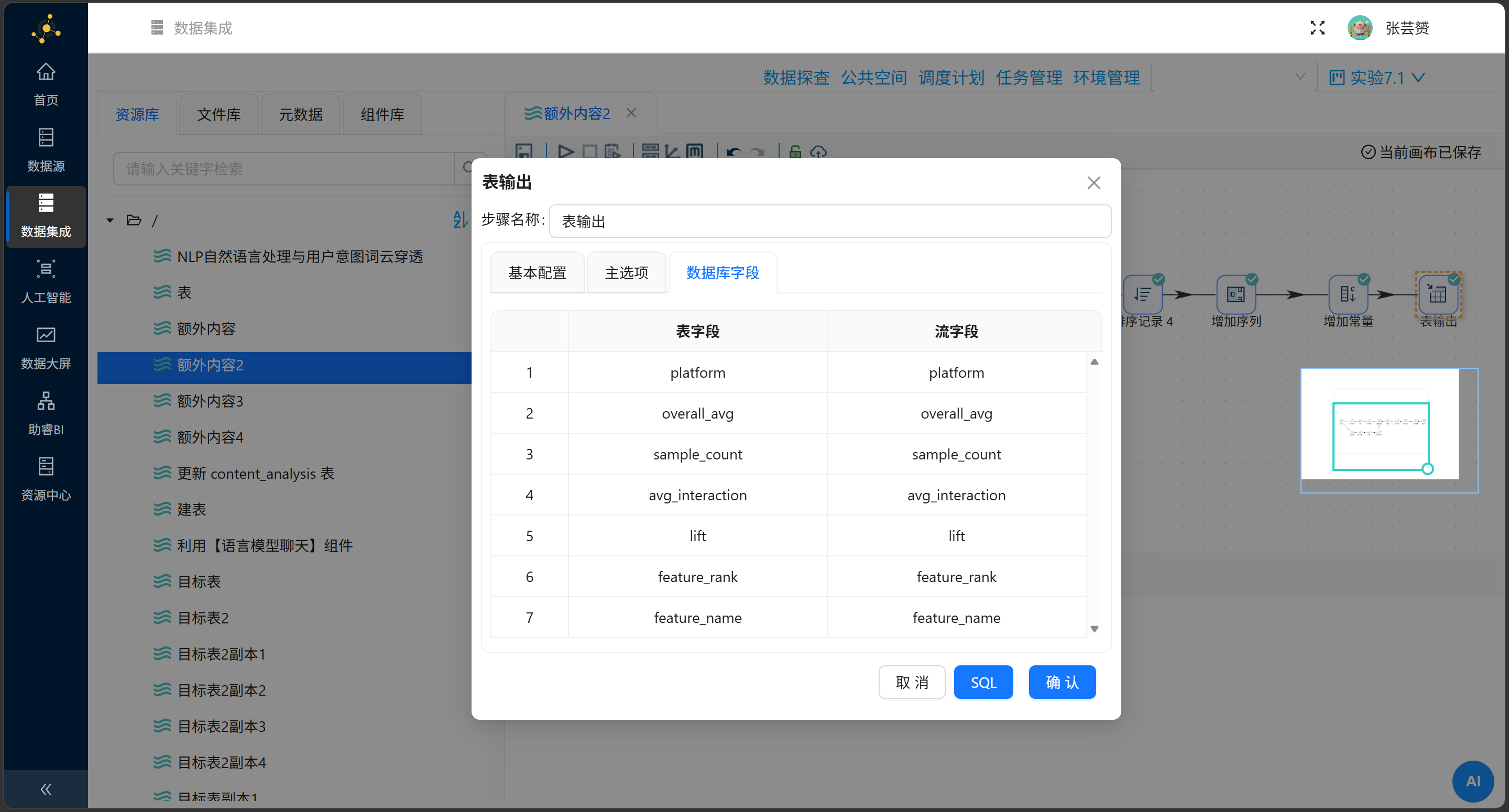
第四式:表输出,尘埃落定
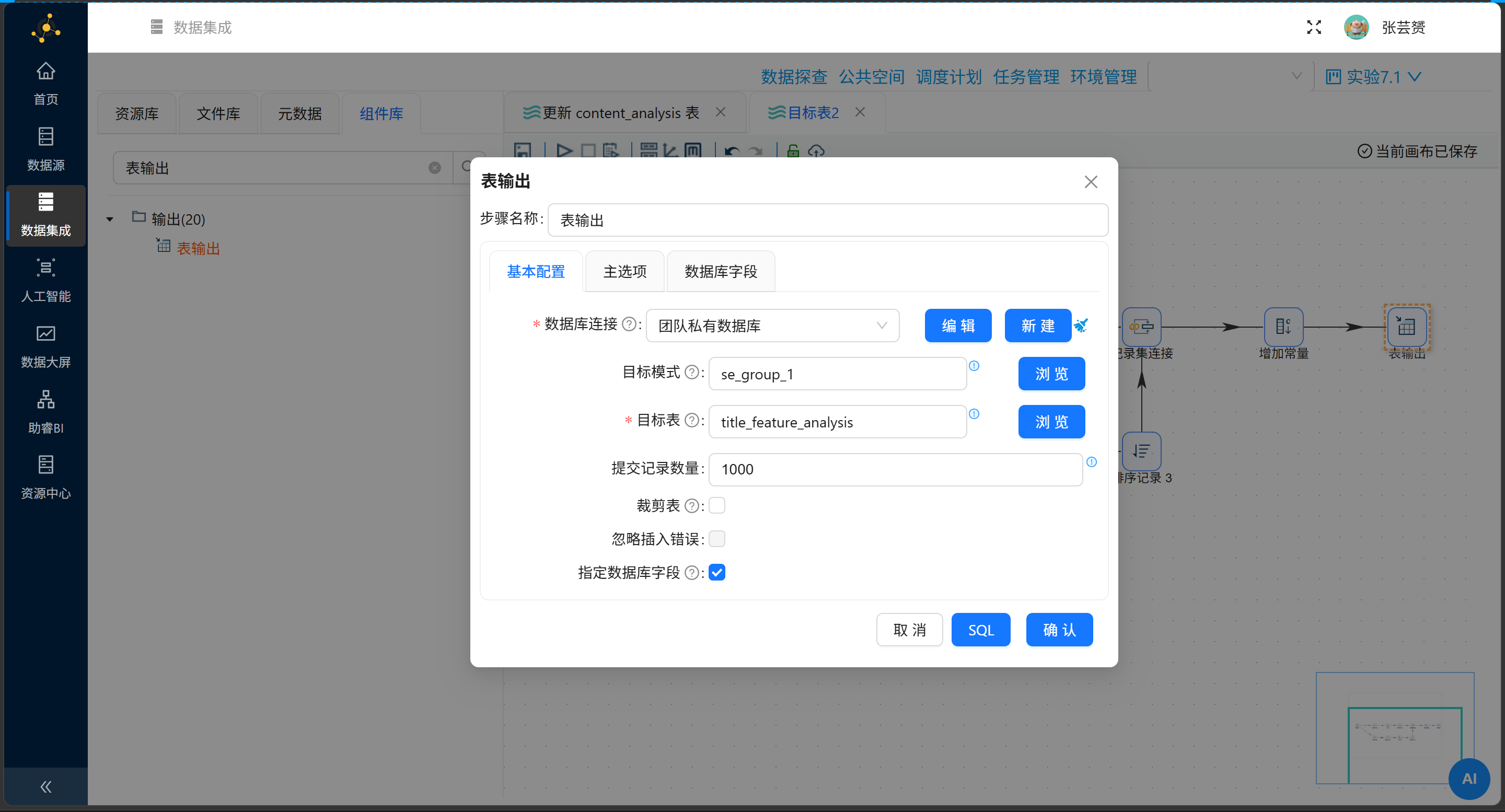
|
配置项 |
值 |
|---|---|
|
目标表 |
|
|
裁剪表 |
❌ 不勾选 |
|
指定数据库字段 |
✅ 勾选 |
命运的坐标映射:
|
表字段 |
流字段 |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
第五式:影分身之术,收割全量词汇
一通百通,复制整条Pipeline流水线,只需优雅地微调两处机关:
|
关键词 |
过滤条件 |
常量值 |
|---|---|---|
|
保姆级 |
|
保姆级 |
|
零代码 |
|
零代码 |
|
实战 |
|
实战 |
|
教程 |
|
教程 |
|
踩坑 |
|
踩坑 |
五、开盲盒时刻:数据背后的体感反转
5.1 揭晓底牌的素颜数据
大浪淘沙后,title_feature_analysis 表端出了它的最终答卷:
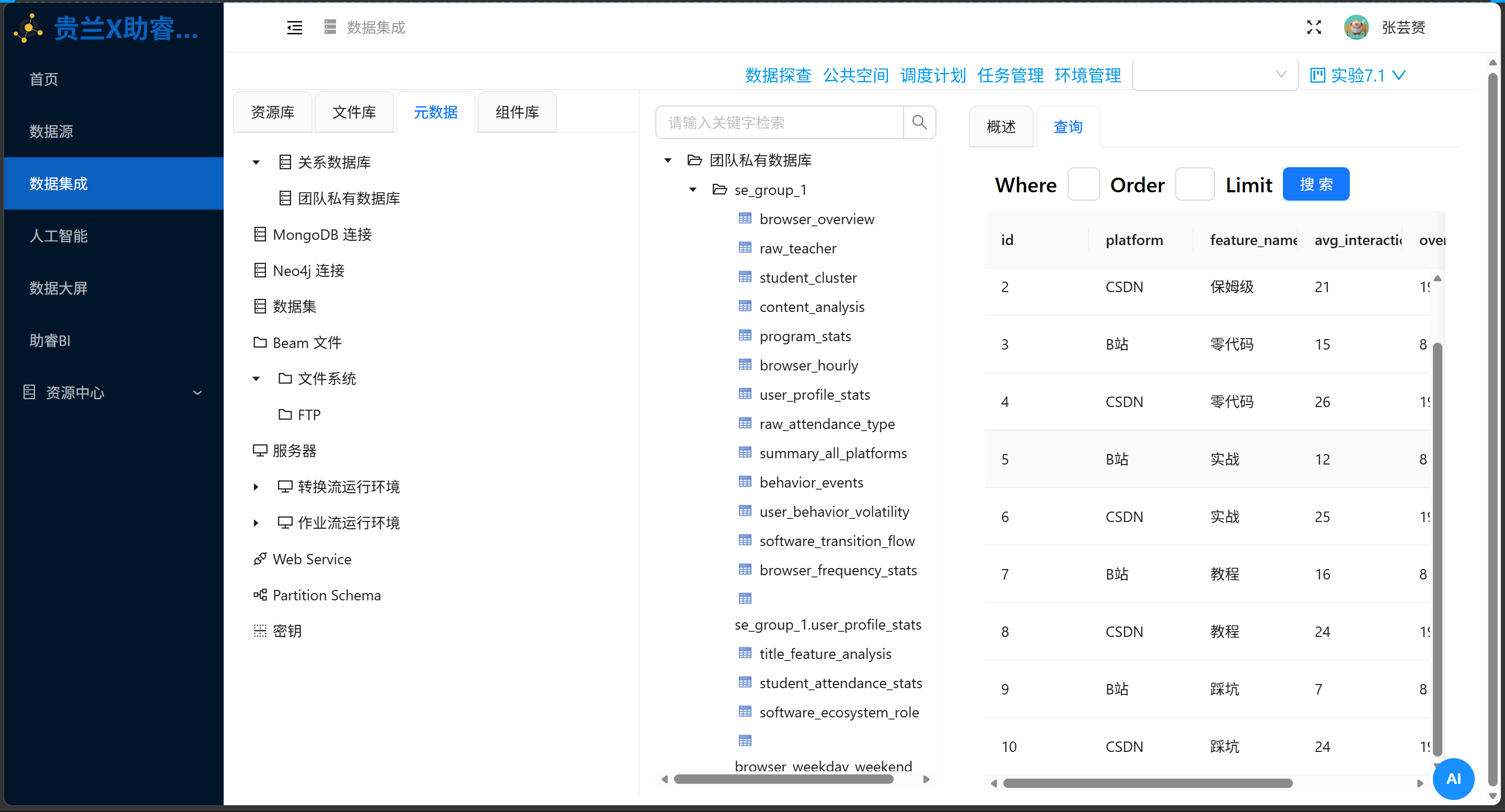
|
id |
platform |
feature_name |
avg_interaction |
overall_avg |
sample_count |
|---|---|---|---|---|---|
|
1 |
B站 |
保姆级 |
12.00 |
8.00 |
159 |
|
2 |
CSDN |
保姆级 |
21.00 |
19.00 |
178 |
|
3 |
B站 |
零代码 |
15.00 |
8.00 |
279 |
|
4 |
CSDN |
零代码 |
26.00 |
19.00 |
578 |
|
5 |
B站 |
实战 |
12.00 |
8.00 |
200 |
|
6 |
CSDN |
实战 |
25.00 |
19.00 |
403 |
|
7 |
B站 |
教程 |
16.00 |
8.00 |
222 |
|
8 |
CSDN |
教程 |
24.00 |
19.00 |
335 |
|
9 |
B站 |
踩坑 |
7.00 |
8.00 |
29 |
|
10 |
CSDN |
踩坑 |
24.00 |
19.00 |
107 |
5.2 滤镜碎裂:我们看到了什么?
-
B站的生态结界:“教程”一词犹如流量春药,稳居C位(均值16);而“踩坑”则成了票房毒药(均值7,惨遭大盘底线碾压)。
-
CSDN的极客浪漫:“零代码”成了降维打击的神器(均值26),这里的每一个测试词汇,表现都神奇地跃出平台均线之上。
-
平行宇宙的温差:CSDN的老哥们对硬核技术词汇(零代码、实战、教程)的饥渴度,肉眼可见地高过B站的二次元圈层。
六、神仙打架:祭出Lift提升度,刺穿表面繁荣(高能预警)
6.1 撕开假象的动机
裸奔的平均数只能告诉你“谁看起来活儿更好”,却无法回答最致命的问题:“它到底比大盘的平庸之辈强出多少倍?” 于是,我拔出了数据分析界的屠龙刀——Lift(提升度)指标:

-
Lift > 1:这就是破圈的阿尔法收益,绝对的优等生。
-
Lift = 1:芸芸众生,不功不过的隐形人。
-
Lift < 1:拖后腿的战五渣,谁碰谁倒霉。
6.2 升维重构的艺术
第一招:撑开底表的骨架
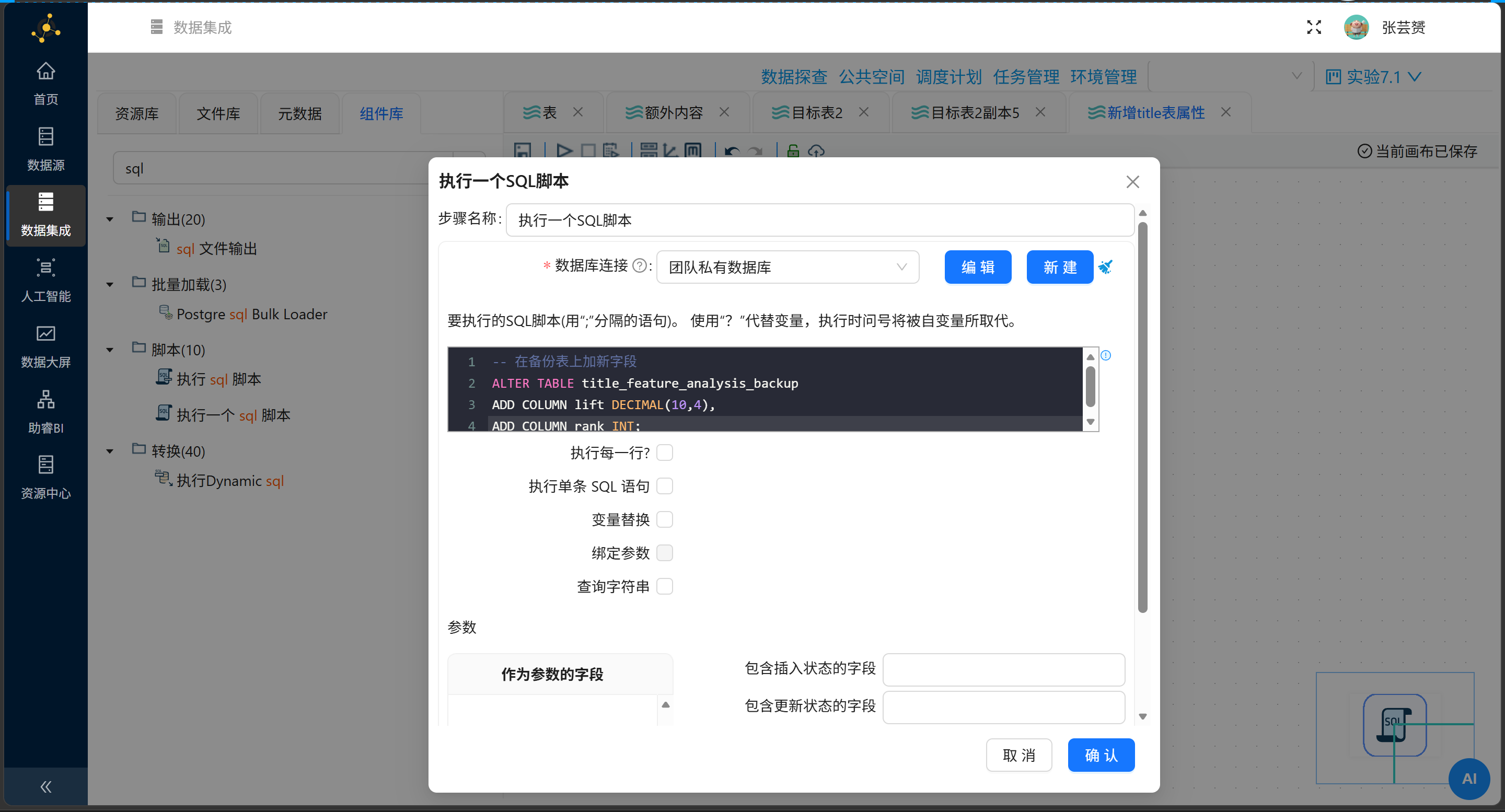
ALTER TABLE title_feature_analysis_backup
ADD COLUMN lift DECIMAL(10,4),
ADD COLUMN feature_rank INT;
💡 节点运行日志:SQL表结构拓展完成
善意提醒:rank 可是MySQL神龛里的神圣关键字,凡人勿碰,要么加反引号,要么老老实实改名叫 feature_rank。
第二招:在流水线里塞入“计算器”引擎
在“记录集连接”后、“增加常量”前,精准安插这一道关卡:
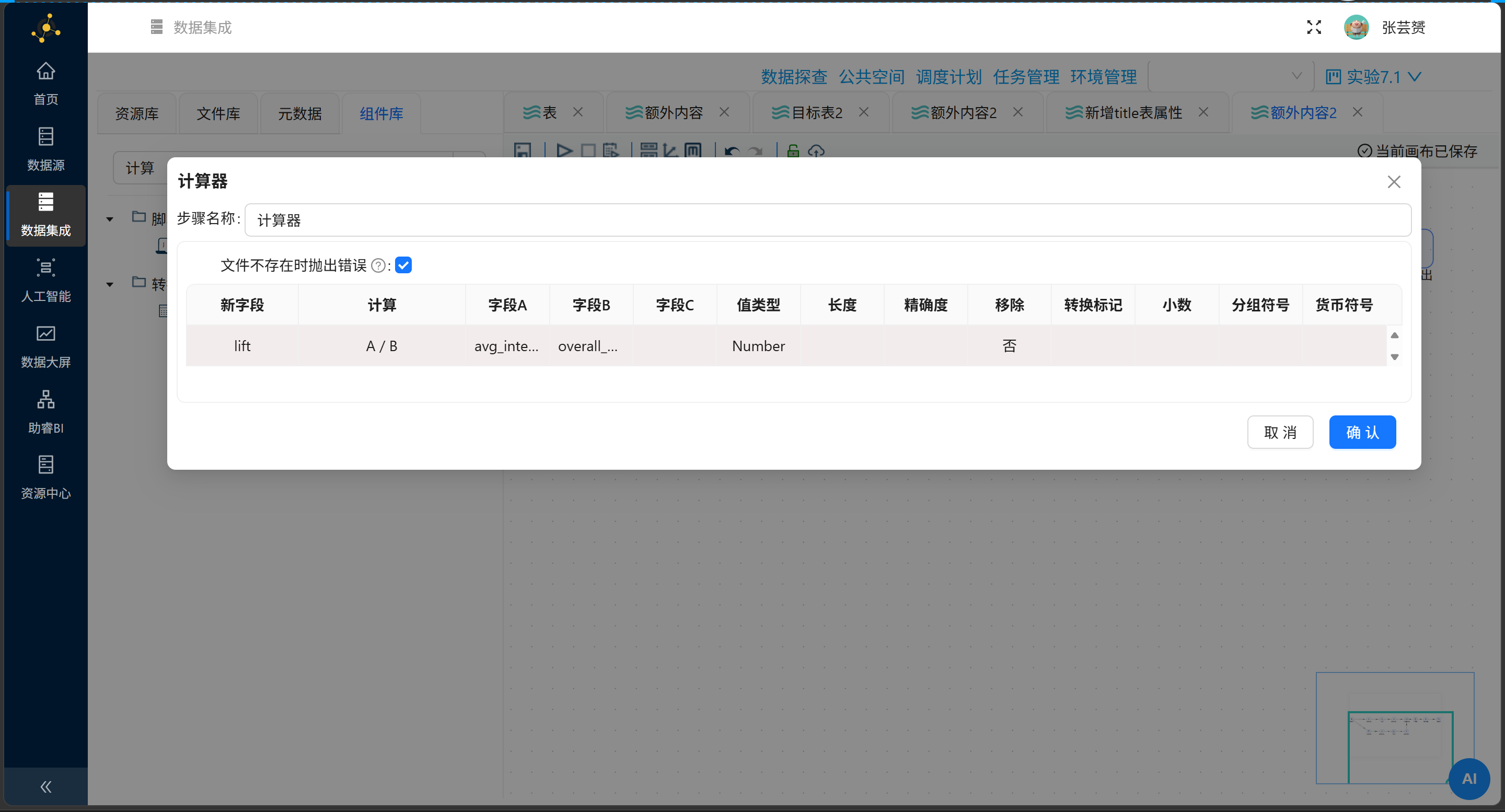
|
新字段 |
计算 |
字段A |
字段B |
|---|---|---|---|
|
|
A / B |
|
|
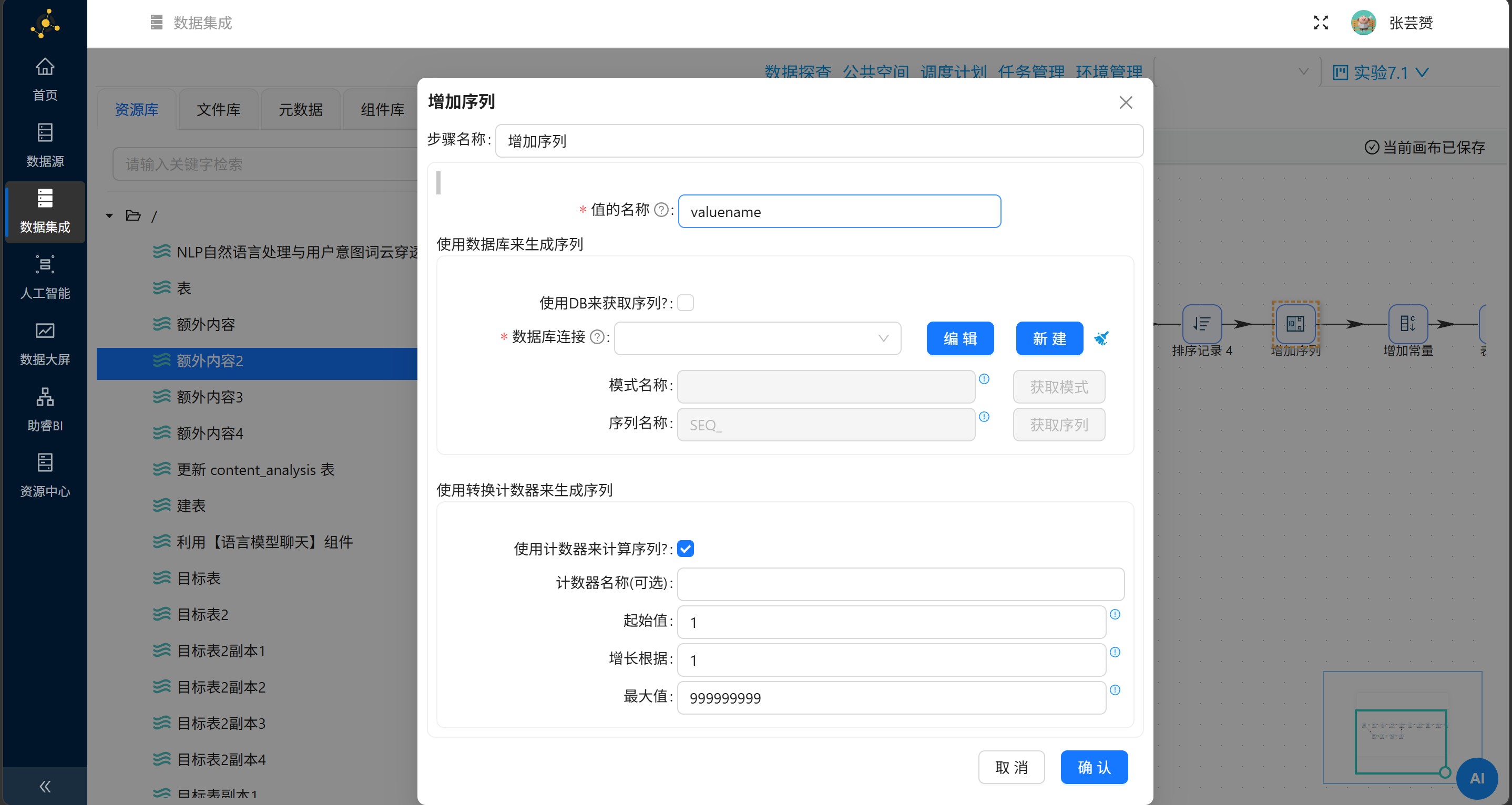
第三招:召唤“增加序列”赋予荣耀排名
紧随计算器其后,为每一个跑出来的数字颁发座次牌:
|
配置项 |
值 |
|---|---|
|
值的名称 |
|
|
使用计数器来计算序列 |
✅ 勾选 |
|
起始值 |
1 |
|
增长根据 |
1 |
第四招:在命运的出口更新映射
追加这两条灵魂链接:
|
表字段 |
流字段 |
|---|---|
|
|
|
|
|
|
6.3 涅槃后的封神榜
|
排名 |
平台 |
关键词 |
平均互动 |
平台基准 |
Lift |
效果评级 |
|---|---|---|---|---|---|---|
|
1 |
B站 |
教程 |
16 |
8 |
2.0000 |
🏆 超强 |
|
2 |
B站 |
零代码 |
15 |
8 |
1.8750 |
🏆 超强 |
|
3 |
B站 |
实战 |
12 |
8 |
1.5000 |
✅ 优秀 |
|
4 |
B站 |
保姆级 |
12 |
8 |
1.5000 |
✅ 优秀 |
|
5 |
B站 |
踩坑 |
7 |
8 |
0.8750 |
⚠️ 低于平均 |
|
1 |
CSDN |
零代码 |
26 |
19 |
1.3684 |
✅ 优秀 |
|
2 |
CSDN |
实战 |
25 |
19 |
1.3158 |
✅ 优秀 |
|
3 |
CSDN |
教程 |
24 |
19 |
1.2632 |
✅ 良好 |
|
4 |
CSDN |
踩坑 |
24 |
19 |
1.2632 |
✅ 良好 |
|
5 |
CSDN |
保姆级 |
21 |
19 |
1.1053 |
⚠️ 略高于平均 |
6.4 拨开云雾的顶层体感
-
B站的残忍真相:“教程”二字带出了惊为天人的 2.0 Lift值,流量杠杆直接拉满两倍;而“踩坑”则毫不留情地击穿了1.0的生命线,透彻心凉。
-
CSDN的进阶执念:全员Lift > 1 的盛况,印证了技术词汇在这里的免死金牌地位。但“保姆级”仅勉强拿下1.1的垫底成绩,仿佛在暗戳戳地鄙视:这里的极客,不屑于吃嚼过的馍。
-
操盘指南:混B站,多用“教程”和“零代码”喂养粉丝;去CSDN踢馆,请大肆堆砌硬核技术词,顺便把“保姆级”这种娇气的词汇扔进垃圾桶。
|
关键词 |
B站 Lift |
CSDN Lift |
差异 |
解读 |
|---|---|---|---|---|
|
教程 |
2.00 |
1.26 |
+0.74 |
B站更爱教程,CSDN认为"太基础" |
|
零代码 |
1.88 |
1.37 |
+0.51 |
两边都吃香,B站相对优势更大 |
|
实战 |
1.50 |
1.32 |
+0.18 |
CSDN实战氛围更浓 |
|
保姆级 |
1.50 |
1.11 |
+0.39 |
CSDN对"保姆级"不感冒 |
|
踩坑 |
0.88 |
1.26 |
-0.38 |
⚠️ 唯一跨平台反转!B站避雷,CSDN推荐 |
七、黑夜里蹚过的雷区(血泪避坑指南)
|
坑 |
现象 |
怎么爬出来的 |
|---|---|---|
|
JavaScript自赋值 |
报错"找不到字段 $$has_best$$" |
删掉var和 |
|
字段名混淆 |
插入/更新U=0 |
计算器输出叫 |
|
过滤条件不匹配 |
过滤记录W=0 |
确认上游数据已正确写入,数值类型才能用=,字符串要用"" |
|
分组字段为空 |
|
检查 |
|
字段重名 |
|
记录集连接后加"字段选择"把 |
|
保留关键字 |
|
改成 |
|
前端Bug |
保存时getBoolean为null |
勾选"使用计数器来计算序列",或者刷新页面再试 |
八、写在最后的数据乌托邦
8.1 特征工程:你如何提问,决定了你得到什么答案
这场数据荒原的奔跑让我顿悟:特征工程绝不仅是机械的“词根提取”,它本质上是你审视世界的滤镜。面对同一段文本,你可以冷酷地标记“是否有词”(0/1),可以功利地数“出现频率”,甚至可以诗意地感受“情绪烈度”。你怎么捏造特征,数据就怎么向你袒露真相。
这次我只挥舞了最粗糙的0/1二进制战斧,就已经劈开了这么多隐秘的角落。倘若下次上了TF-IDF或是NLP情感分析的重型机甲,那该是一幅多深邃的宇宙图景?
8.2 指标玄学:别做那个只看平均数的懒人
“平均数”是一剂极具欺骗性的温柔乡,直观,却也让人懒惰。Lift提升度则像一面照妖镜,它撕裂了绝对值的幻象,告诉你:一个词的性感与否,不在于它本身多耀眼,而在于它能把大盘的地平线拔高几分。
这种底层逻辑足以在这个浮躁的行业里四处套现:商品转化的AB测试、用户ARPU的高低维分层……说到底,数据之美,无非就是在一堆破铜烂铁里“找奇观、抓锐角”。
8.3 趁手兵器:工具永远是为灵感让路的
全程拖拽跑通可视化ETL,一行SQL不写,这体感对于灵感的快速验证简直是降维打击。当然,真要到了正则生抠、分词深挖的硬核区,代码老大哥还是得镇场子。工具本无阶级,谁能让你的想法最快落地,谁就是今晚的神明。
九、彩蛋:核心组件武器库速览
|
组件 |
我用它做了什么 |
|---|---|
|
表输入 |
读原始数据 |
|
JavaScript代码 |
从标题里提取5个关键词标志 |
|
计算器 |
算互动总数、算Lift |
|
插入/更新 |
按ID更新已有记录 |
|
过滤记录 |
筛出含某关键词的作品 |
|
分组 |
算平台平均、关键词平均、样本量 |
|
增加常量 |
给数据贴标签( |
|
记录集连接 |
把"整体平均"和"关键词平均"拼到一行 |
|
增加序列 |
生成排名 |
|
表输出 |
写入结果表 |
如果你也在这片内容运营的苦海里寻找数据的光标,或者手握更绝的特征工程秘籍,来评论区交个朋友吧!用数据驯服流量池,注定是一场无止境的西西弗斯推石头——今天的“教程”还在称王,明夜又会有新的造浪词拔地而起。保持你的野生嗅觉,保持你的持续试错。永远年轻,永远数据驱动。

一站式 AI 云服务平台
更多推荐

 1
1 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)