
借助零代码助睿平台的自媒体运营数据分析——数据清洗与预处理环节
一、实验背景
1.1 实验目标
本实验以全班同学在多个平台发布的作品互动数据为基础,借助助睿ETL工具开展数据清洗与预处理工作,最终产出了两张核心数据表,为后续的特征工程与可视化分析打下基础。通过本次实验,学生需要达到以下目标:
- 认识数据清洗在整个数据分析流程中的基础地位与重要价值
- 能够运用助睿ETL对多来源数据进行筛选、补全、汇总等预处理操作
- 领会“分支处理”的设计理念,即全平台宏观统计与重点平台深入分析两条线索并行推进
- 生成两张标准化数据表,满足仪表盘各功能模块的数据调用需求
1.2 实验环境
- 实验所用平台:助睿数智(Uniplore)—— 一站式数据科学实验平台
- 系统入口:https://lab.guilian.cn/
- 官方网站:https://www.uniplore.com/
- 存储引擎:MySQL
- 原始数据:自媒体作品数据明细.csv
1.3 处理流程概述
1. 目标表的建立与原始数据接入:首先在 ETL 工具中定义目标数据表的结构,明确各字段的数据类型与约束规则;然后利用输入节点将分散在多平台的原始业务数据批量加载到临时表中,实现数据的初步导入与格式检测,为后续处理环节提供可靠的数据来源。
2. 跨平台数据汇总与无效记录过滤:以原始数据为依托进行跨平台的汇总统计,将不同来源的业务数据整合为一套统一的明细数据集;接着使用过滤节点去除异常值、重复项以及不符合业务逻辑的无效条目,确保数据在有效范围内,从而提高数据集的整体质量与分析可信度。
3. 空值填补与字段裁剪:对于汇总后数据集中存在的缺失字段,分别采用均值替代、业务层面的默认值或通过关联字段推导补全等方式进行处理;再借助字段选择组件剔除重复、无关的列,压缩数据集的宽度,只保留与目标分析密切相关的核心字段,以此优化存储空间和运算效率。
4. 结果表落地与流程自动化执行:把经过清洗和加工的数据写入预先建好的目标表中,完成持久化存储;随后配置 ETL 转换流中各节点之间的依赖关系与调度策略,启动全流程的自动化运行,实现从源头数据到最终数据集的端到端处理,为后续业务分析提供支撑。
二、实验步骤
2.1 创建目标表
首先新建名为“创建平台概况表”的转换流,将 SQL 组件拖拽到画布上,双击该组件后选择“团队私有数据库”,在脚本编辑区输入对应的建表 SQL 语句,随后执行该转换流。
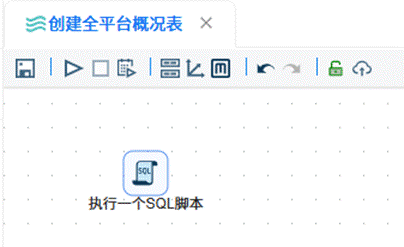
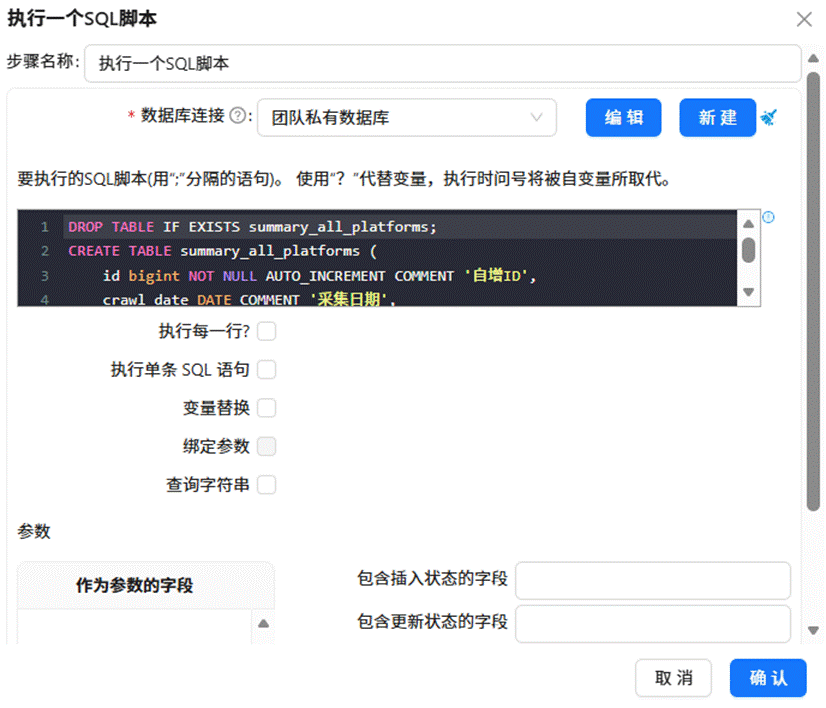
接着再新建一个“创建内容分析表”的转换流,同样拖入 SQL 组件,双击后选定“团队私有数据库”,编写相应的建表脚本,执行转换流完成内容分析表的创建。
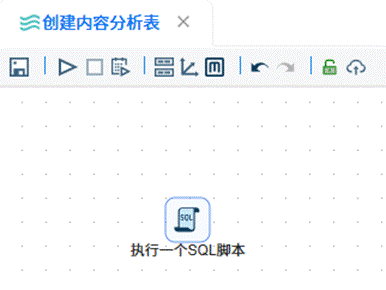
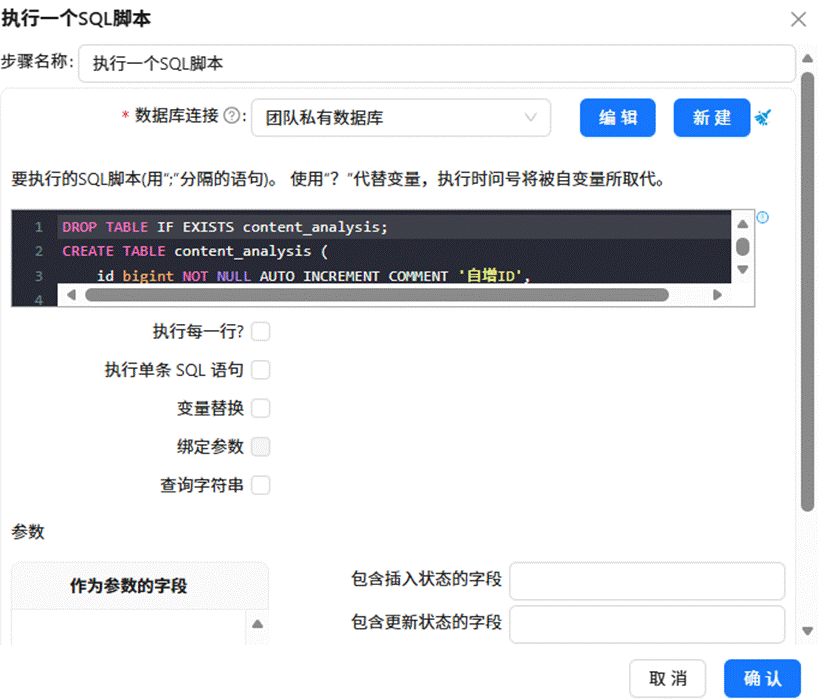
2.2 导入原始数据
进入平台的公共空间模块,将“自媒体作品数据明细.csv”文件上传导入至文件库中。
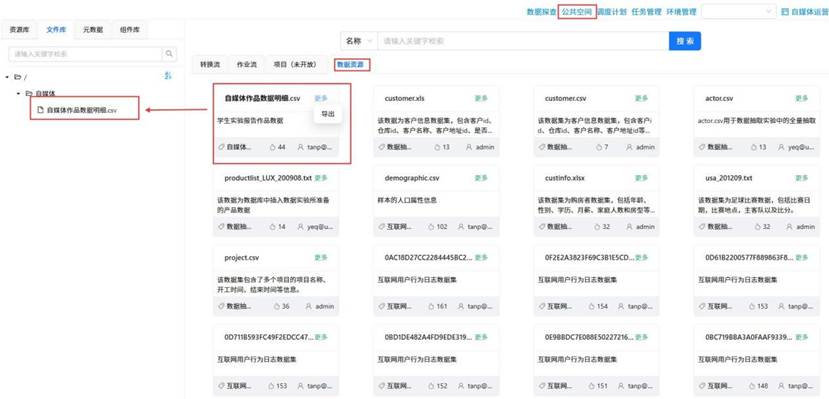
2.3 全平台聚合统计
创建一个新的转换流,先拖入 CSV 文件输入组件,选择并加载“自媒体作品数据明细”文件。
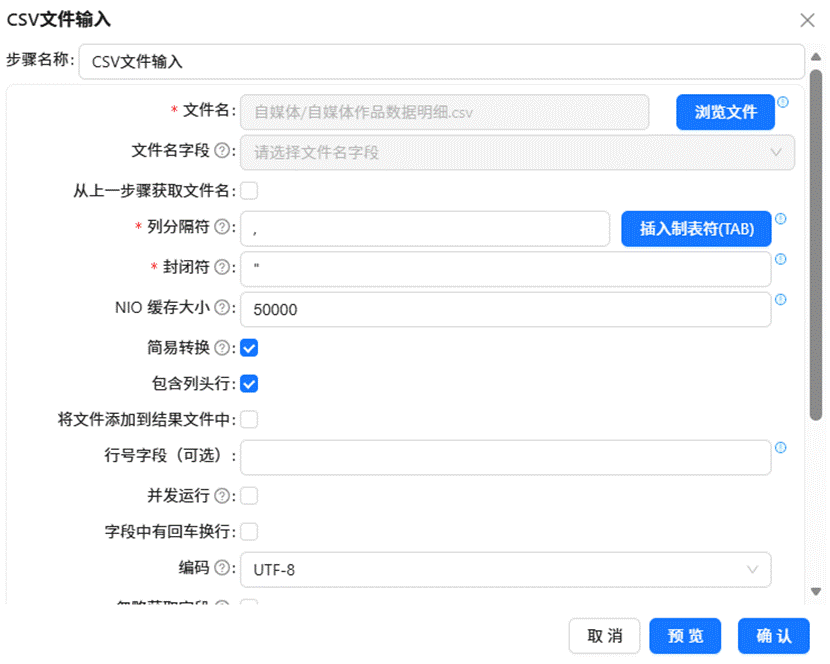
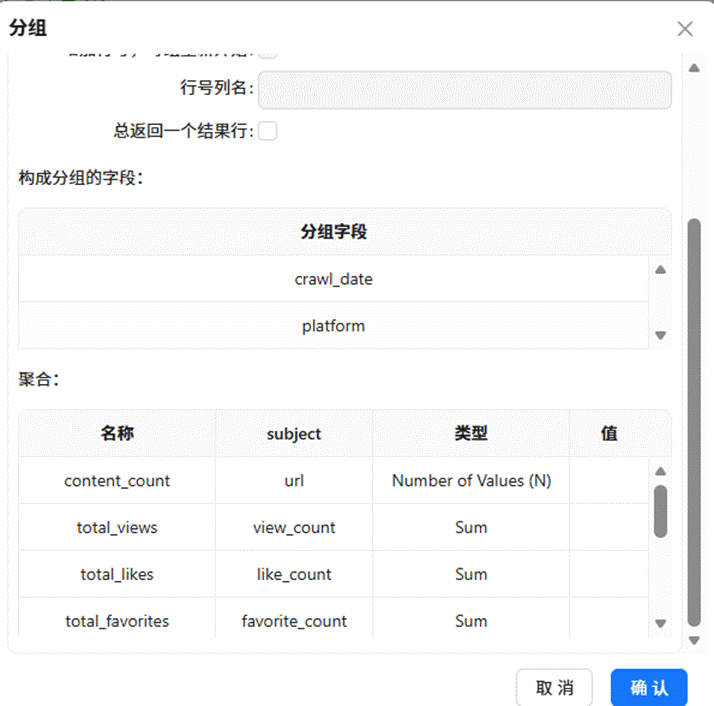
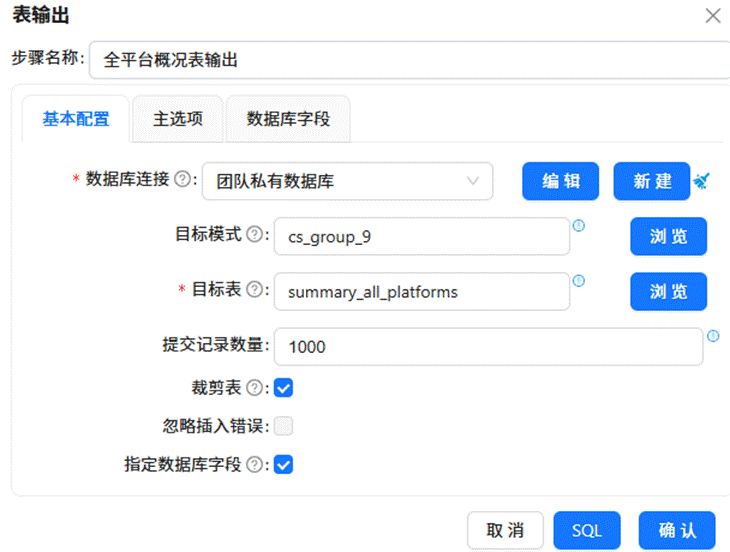
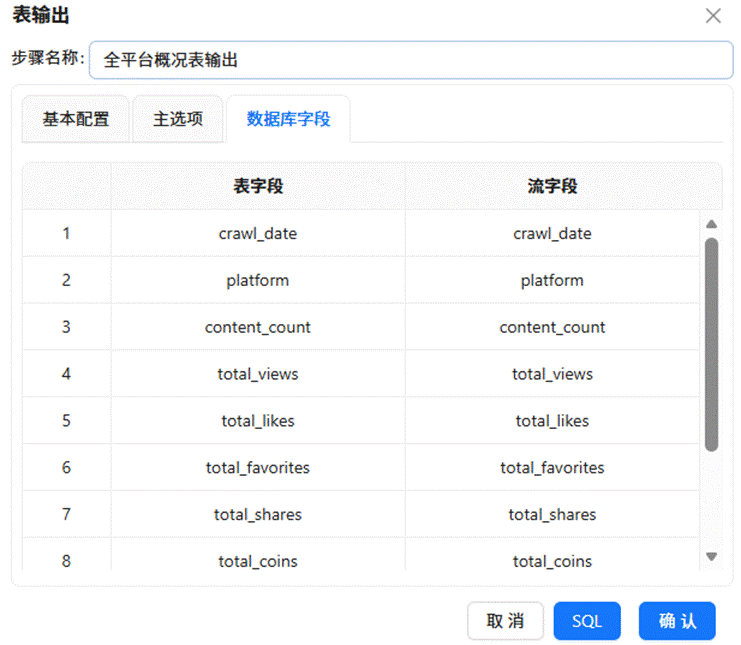
随后依次拖入“排序记录”、“分组”以及“表输出”组件。配置排序和分组依据为“日期”和“平台”两个维度,其余所有数值型字段均采用求和聚合方式。最终将结果输出至 summary_all_platforms 表中。
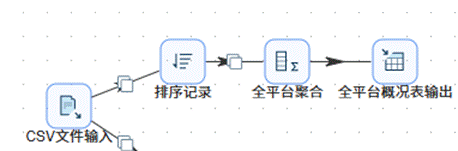
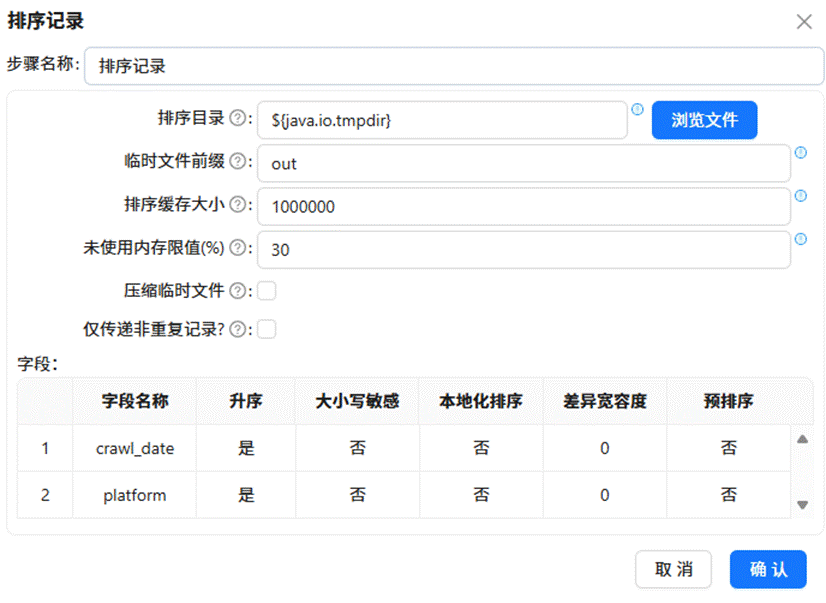
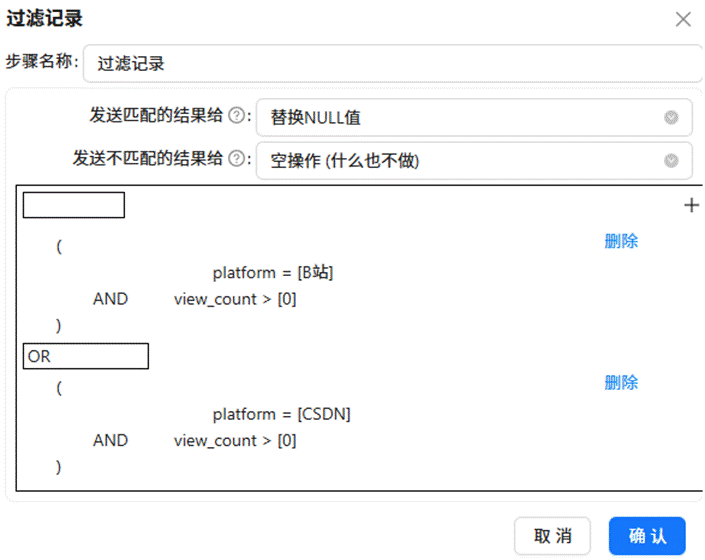
2.4 过滤记录
拖入“过滤记录”组件,设置筛选条件以保留 B 站(Bilibili)和 CSDN 两个平台的有效数据。具体的过滤配置如下图所示:
2.5 填充缺失值
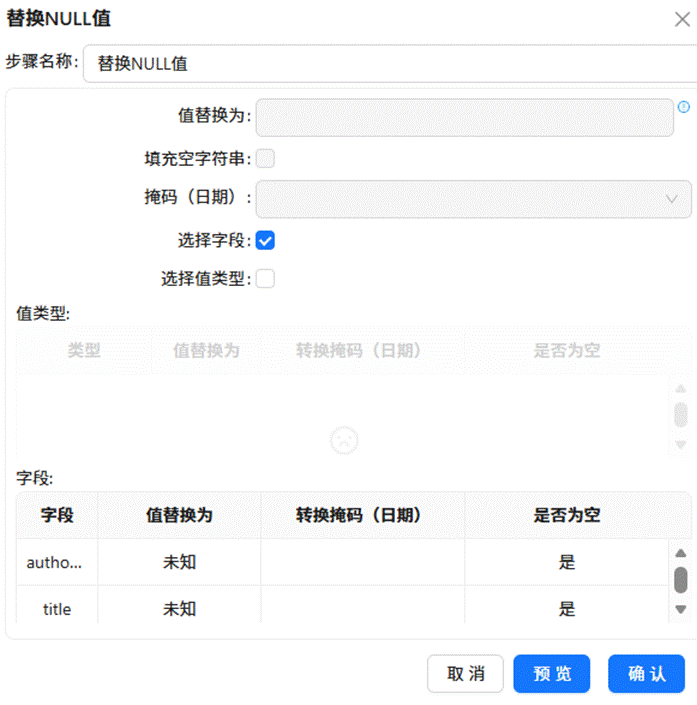
拖入“替换NULL值”组件,针对作者名称(author_name)和作品标题(title)两个字段,将其中的空值统一替换为字符串“未知”。
2.6 字段选择
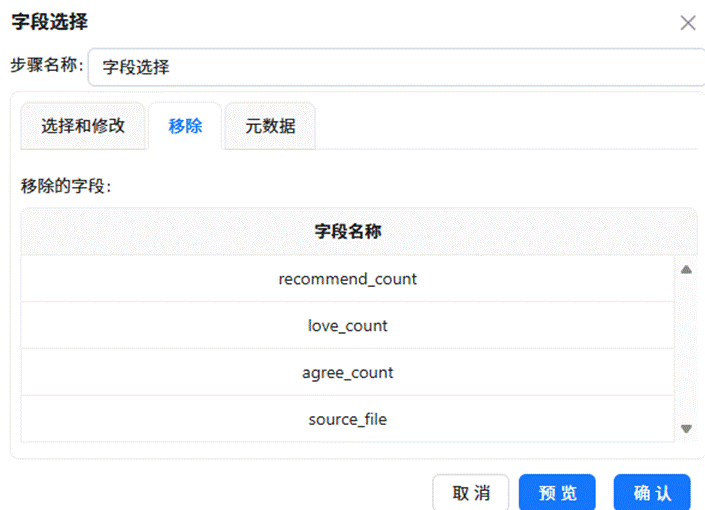
拖入“字段选择”组件,在配置中移除不需要的列,仅保留以下十个核心字段:date、author_name、title、platform、likes、favorites、shares、coins、views、url。
2.7 输出目标表
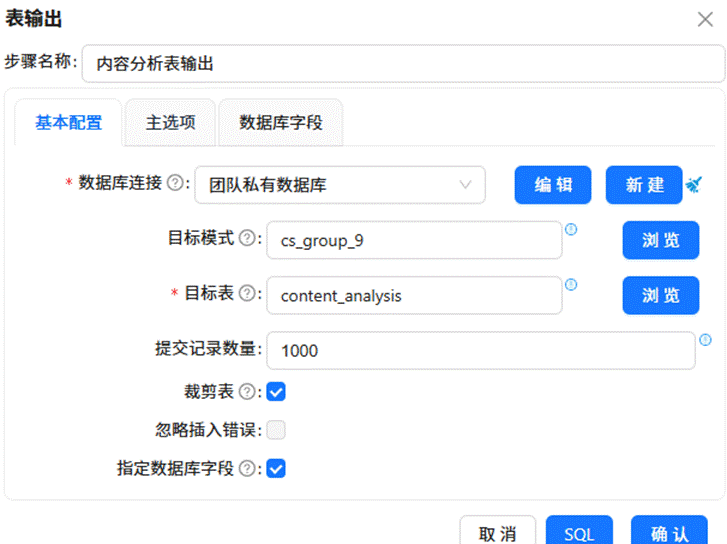
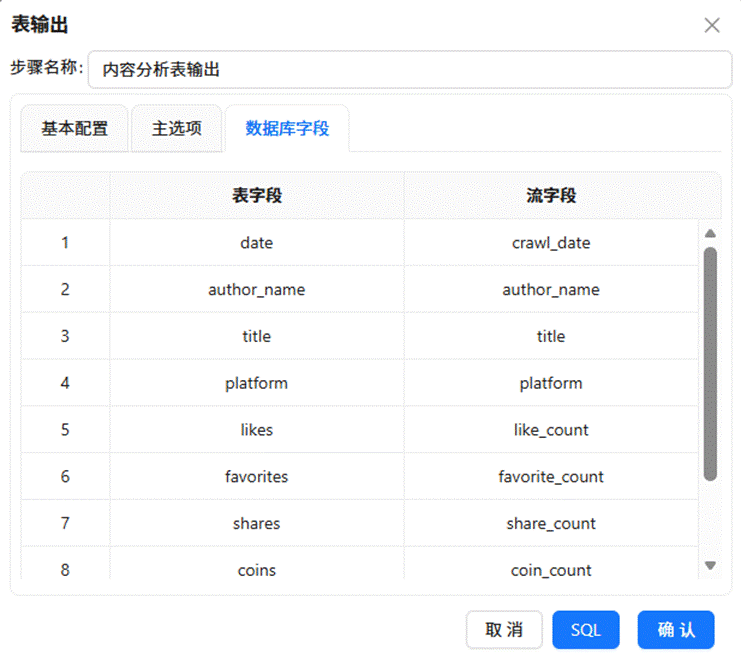
拖入“表输出”组件,配置目标表为 content_analysis,将经过前述步骤处理完毕的数据写入该表中。
2.8 执行转换流
确认所有节点配置无误后,点击运行按钮,执行完整的转换流。
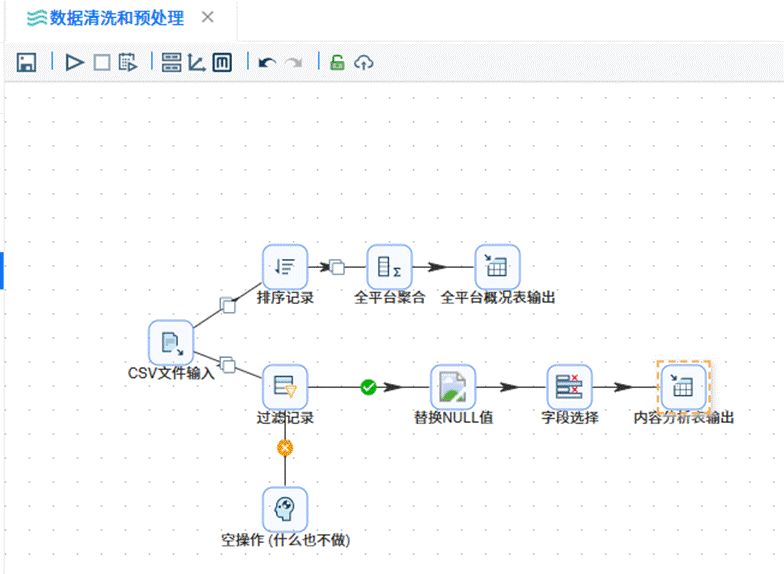
三、实验结果
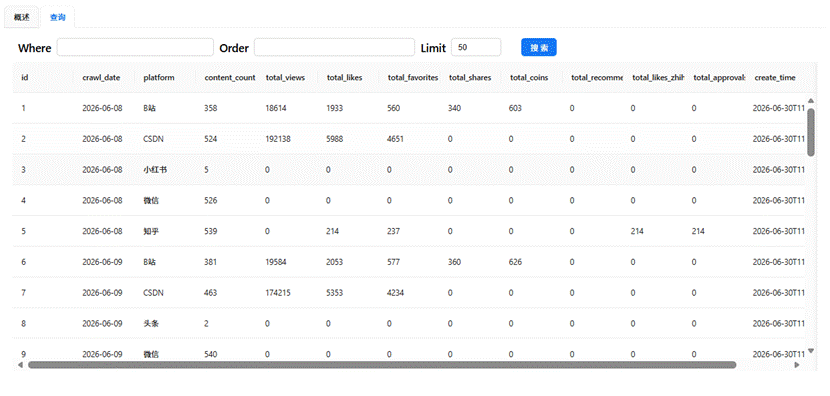
全平台概况表(summary_all_platforms)的数据预览如下所示。
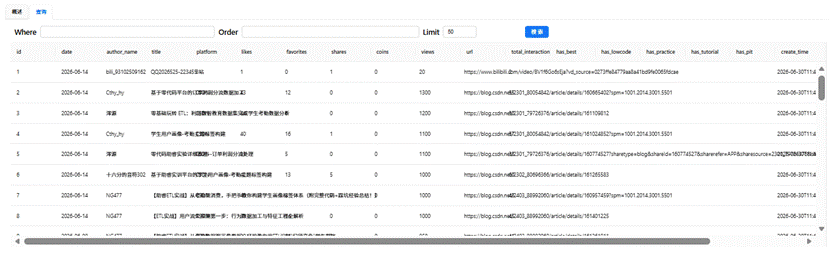
内容分析表(content_analysis)的数据预览如下所示。
四、实验总结
本次实验基于助睿数智 ETL 平台,针对自媒体多源数据完成了系统性的清洗与预处理工作,通过构建分支式处理流水线,成功输出全平台概况表和内容分析表两张数据表,达到了数据整理与质量提升的预期目标。在具体操作流程上,首先利用 SQL 脚本分别创建两张目标数据表,将自媒体原始 CSV 数据导入系统后即按照两条分支进行差异化处理:第一条分支按采集日期与平台维度进行分组聚合,统计各平台每天的作品发布数量、播放量、点赞数等关键汇总指标,结果存入概况表中;第二条分支则筛选出 B 站与 CSDN 两个重点平台的有效数据,对作者名称和作品标题字段的空缺值以“未知”进行填补,去除冗余字段后生成内容分析明细表。
在实践过程中,逐步熟悉并掌握了数据导入、条件过滤、空值填补、分组聚合以及字段裁剪等一系列 ETL 核心操作技能,同时深刻体会到分支分流架构在兼顾宏观统计与单篇作品精细分析方面的重要价值。原始数据中存在平台来源混杂、字段缺失、包含无用列等问题,经过上述清洗流程后,数据的完整度和规范性均得到显著改善,为后续的可视化呈现和特征分析提供了高质量的数据基础。通过此次实验也认识到,数据预处理在整个数据分析链路中扮演着基础且关键的角色,不恰当的过滤规则或填充策略会直接影响后续分析的结论,未来可以在异常值检测规则方面加以优化,以进一步提升数据处理的精度和可靠性。

一站式 AI 云服务平台
更多推荐

 3
3 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)