
Tetrate高洪涛:解密SkyWalking的APM专用数据库BanyanDB
将Log、Tracing、Metrics作为一类模型,完全融入一个单一的数据库平台

嘉宾 | 高洪涛 整理 | 夏昕雨
出品 | CSDN云原生
2022年5月10日,在CSDN云原生系列在线峰会第4期“Apache SkyWalking峰会”上,Tetrate创始工程师高洪涛分享了可观测性的基本知识,并对SkyWalking的APM专用数据库BanyanDB进行了解密。
戳👇观看高洪涛分享视频
解密SkyWalking的APM专用数据库—BanyanDB

APM存储特性
提到APM系统,目前业界有一个比较流行的词汇是Observability(简称为O11Y,可观测性)。O11Y涵盖三种数据模型,分别是 Metrics、Logs和Tracing。
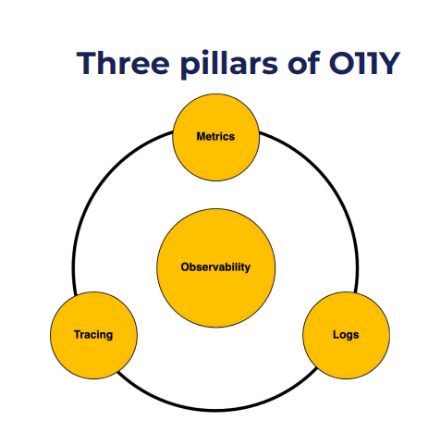
Metrics是被最广泛使用的数据采样指标,适用于大规模的系统部署及数据分析。
Logs一般作为Debug或根因分析的数据来源。由于它会产生大量的数据,所以使用者往往需要借助数据存储和分析平台来对其进行分析。
Tracing一般是Logs的升级,数据信息详细且数据量巨大。
这三种数据基石一起构成了整个可观测性。不论是传统的可观测性还是云原生可观测性,都需要同时处理好这三种数据。而若想处理好这三种数据,往往需要使用许多不同的异构方案来构建一个复杂的数据平台。
Tracing
针对Tracing的存储部分,最早明确使用的是Bigtable。
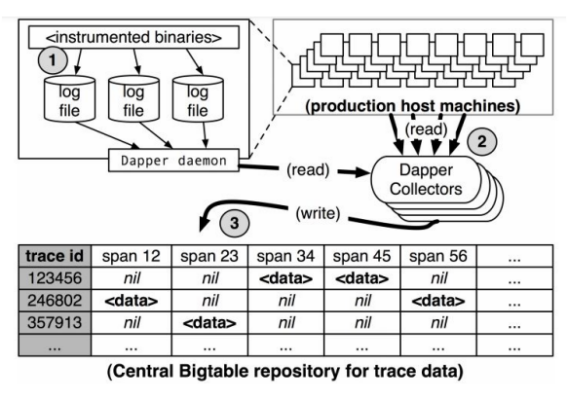
为什么使用Bigtable呢?
Bigtable是天然的分布式系统,它可以处理大量的数据。如上面的图表所示,被采集的Span日志通过中间的Dapper进行汇聚,然后发送至Bigtable的远程节点,将数据写入Cell中。
Cell除了具有高吞吐的特点外,其列的长度也是任意的。这一点的好处非常明显,因为在实际运行阶段,一个Trace中的磁盘数量难以预测,此时需要底层存储帮助支撑这种灵活的顺序结构,而Bigtable天生就有这样的结构。
从上面的表格可以看到,Trace的前几个Span是空值。造成这种现象的原因有两种,一种是该Span还未被搜集,属于预留的位置;另外一种情况是该位置本身没有数据,这样的话便能够将整条链路有机地串接在一起。
Trace ID可以一次性地对数据进行查询,但对于写入来说,还具有较大的挑战性。可以看到该存储实际上只是逻辑存储,虽然一个Trace ID将所有Span串联起来,但实际上这些Span也有可能散落在分布式系统的各个数据节点上。虽然查询阶段也会扫描到各数据节点,但并不像所显示的如此高效。
Logs
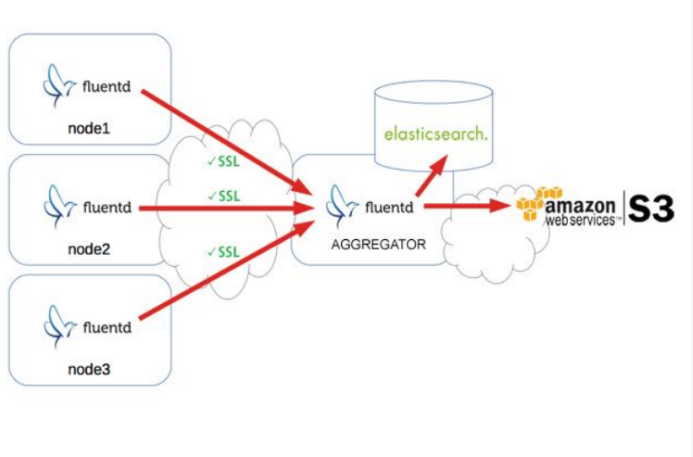
对于Logs的搜集方式,起初使用Agent采集,然后在中间过程做聚合,最后进行存储。存储有两个方向,一个是分析平台存储,另一个是归档存储。
分析平台存储要对日志进行索引、聚集,并进行可视化的展示,以帮助最终用户过滤日志内容,做依据日志的统计、分析工作。因为放在存储分析平台的数据量不能过大,并且日志的价值在超过一定期限后会逐渐降低,故需要对分析平台的日志进行清除、归档。
Metrics
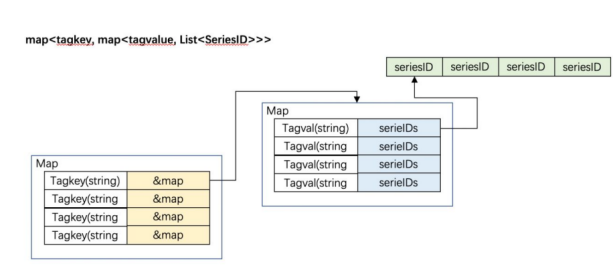
当前,不论是InfluxDB还是Prometheus分析平台等,实际上都在使用Time Series结构。
Series本质是以时间维度为主键的数据,非常适合按照时间范围做数据查询,通过该模式可以迅速命中一组Series,同时可以通过其时间维度筛选合适时间范围内的数据。
Series具有两个优势:
-
内存使用具有高效性
-
便于时间轴查询
总之,若想要构建APM系统存储引擎,不可能通过一个数据库完成所有事情,需要搭建一套具有高吞吐性、可线性扩展、支持任意数据的数据平台。

SkyWalking存储模块
SkyWalking使用一种数据存储来处理这三种数据,每一种存储都各有特点,每种存储也有其最适合的数据模式,其他类型的数据会通过放弃本身的部分特点以适应当前的存储。这就是SkyWalking目前选择存储的总原则。
目前生产级别常用的存储类型有三种:
-
MySQL
-
Elasticsearch
-
InfluxDB
MySQL需要Data Sharding的支持,ShardingShpere或其他数据库中间件使MySQL能够存储跟踪数据。MySQL能作为存储的最关键原因在于其维护性较强,这一点与HBase形成鲜明对比。
Elasticsearch是目前SkyWalking最重要的数据存储,可以使三类数据达到一定的平衡。同时也要清晰地认识到,Elasticsearch虽然对Logs以及Tracing的处理是完美的,但对于Metrics的处理是较为原始、粗糙的。
InfluxDB对于Metrics的处理是十分方便高效的,但对于Logs和Tracing的处理难以达到生产级别,它们的结构、吞吐模式,决定了很难对其进行大批量数据的处理。

RUM Conjecture
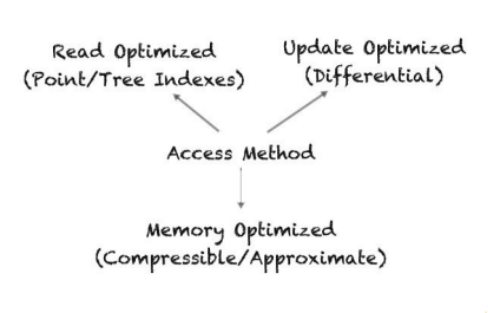
在正式分享BanyanDB之前,我们先来介绍它最核心的设计理论——RUM假说。
什么是RUM?如上图所示,可以看到三个操作:Read、Update、Memory。
中间的概念叫做Access Method,即数据库的访问方式,可以认为这是数据库内部存储引擎层面的读取流程和写入流程所构成的模式,我们称为访问方式。
为什么称之为Rum假说?假说的意思是若要对外部空间三个元素中的两个元素进行优化,那么一定会对第三个元素造成负面影响。
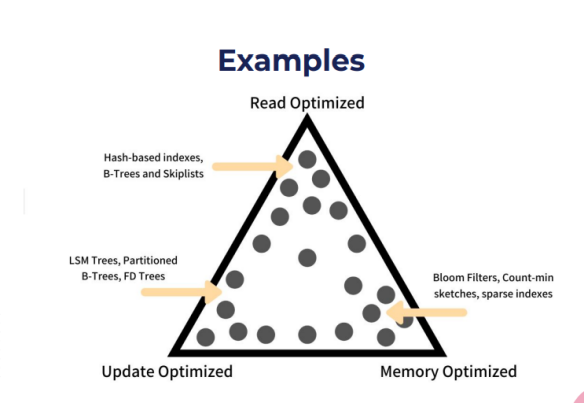
接下来,针对三角结构给出不同的优化方案:
-
优化读取——Hash-based indexes,B-Trees and Skiplists
-
优化更新——LSM Trees,Partitioned b-Trees,FD Trees
-
优化内存——Bloom Fliters,Count-min sKETCHES,sparse indexes
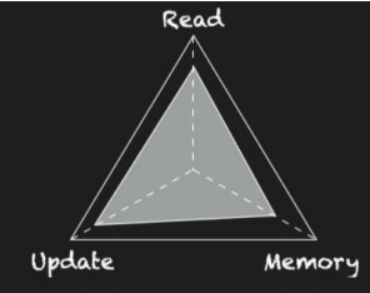
回到RUM假说本身,如果在设计访问模式时为RUM的两个开销设定了一个上限,这意味着第三个开销有一个硬性的下限,这个开销不能进一步减少。
需要注意的是,两点的优化并非一定会导致第三点的性能下降。实际上,在长期、动态的技术演进过程中,这三点的性能最终都会得到优化及加强。
这为我们设计特定类型范围内的系统带来了启发,可以利用RUM的特性打造特定类型的数据库,而不用再依赖于传统数据库。
传统数据库不管是InfluxDB、Elasticsearch还是MySQL,实际上面向的都是独有化场景。
数据库起初是为了读取方便所使用的,多用于获取数据,较少地写入数据。加之硬件资源的宝贵,往往会压缩存储空间,放弃写入空间。

对于Metrics、Tracing和Logs,Metrics的读取场景大于写入场景,而Tracing与Logs的写入场景则是远大于读取场景。
在系统比较稳定情况下,对日志及Tracing的访问需求不高,导致其数据量远大于常需要被读取的Metrics的数据量。由于它们使用相同的物理介质进行存储,造成APM系统的可用信息的存储密度非常低,从中提炼有价值信息的难度大。

BanyanDB
BanyanDB的设计目标十分明确:
-
将Log、Tracing、Metrics作为一类模型对待,将它们完全融入到一个单一的数据库平台之中
-
根据RUM理论优化写入与内存

基于RUM对内存和写入进行优化,存储优化的关键在于压缩。
对于Tracing、Logs是如何压缩的呢?之前已经提到,Tracing的Span并没有存储在一起,需要一个二级索引才能够做查询。而实际上我们会把同一个数据源产生的Span存储在一起,同一数据源产生的Span,其内部结构往往是相似的,便于做压缩处理,从而释放空间,提高整体存储的信息密度。同时由于对象存储非常适合于长期归档存储,所以后续也会将数据对接到对象存储上以进一步提高信息密度。
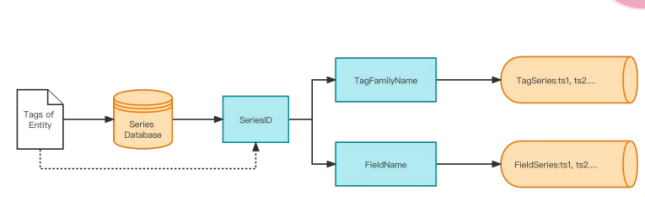
Series的部分使用了Series的典型结构,首先将Tag的Entity进行一个打标,通过数据平台将其转为Series ID,再结合Tag或Feild形成节点存储在数据库中。
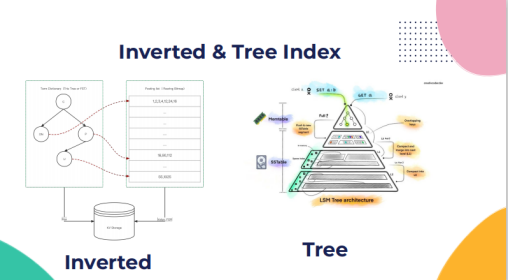
同时有二级索引结构对特定片段类的Series数据进行索引。索引模式有两种,分别是Inverted与Tree Index,根据不同的情况选择相应的索引模式。

总结
BanyanDB实际上是针对APM系统的三种数据做了统一安排,三种数据可以根据自身的特点存储在BanyanDB内部,从而达到磁盘资源的平衡。未来SkyWalking会继续支持这种分布式模式,将不同的数据建到不同的系统上,也可以将读取分析与数据写入进行分离,从而提高资源利用率。
目前BanyanDB 0.1正在积极测试之中,未来很快会发布,希望各位能够有机会去试用BanyanDB,也希望对特殊类型数据库感兴趣的朋友,一起为整个社区的发展来提供更强的助力。
聚焦云原生新技术、新实践,帮助开发者群体赢在开发范式转移的新时代。欢迎关注CSDN云原生微信公众号~
扫这里↓↓↓加入CSDN云原生交流群


一站式 AI 云服务平台
更多推荐

 2
2 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)