
Python与Linux Shell脚本在数据库与操作系统运维中的实战指南
欢迎来到"Python与Linux Shell脚本在数据库与操作系统运维中的实战指南"课程!本课程专为0基础的运维新手设计,旨在帮助您掌握现代运维工程师必备的两项核心技能:Python编程与Linux Shell脚本编写,并将其应用于数据库与操作系统的日常运维工作中。在当今数字化时代,随着服务器规模扩大和业务复杂度提升,单纯依靠手动操作进行运维管理已变得不现实。据统计,掌握自动化运维技能的工程师能
目录标题
Python与Linux Shell脚本在数据库与操作系统运维中的实战指南
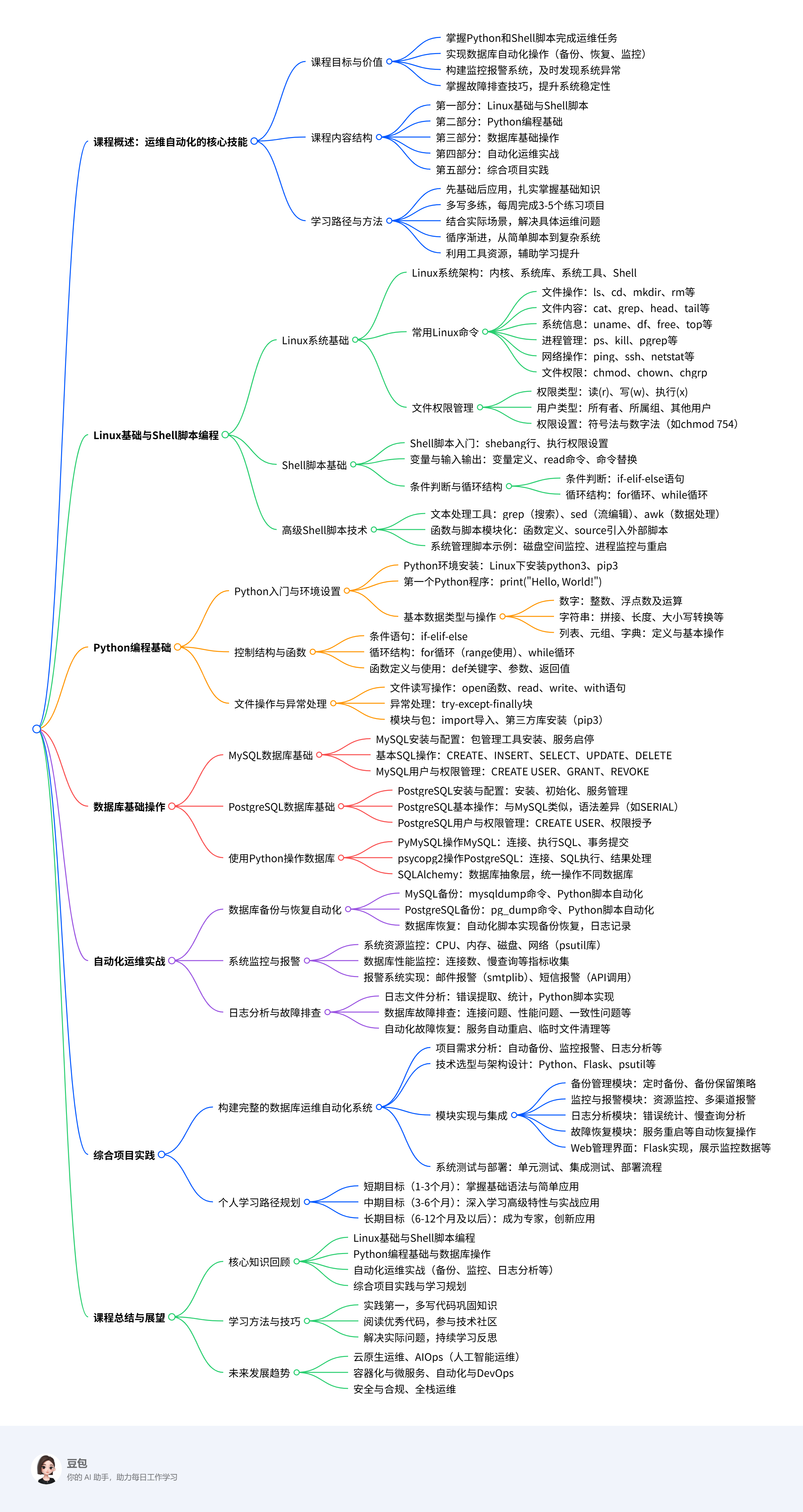
一、课程概述:运维自动化的核心技能
1.1 课程目标与价值
欢迎来到"Python与Linux Shell脚本在数据库与操作系统运维中的实战指南"课程!本课程专为0基础的运维新手设计,旨在帮助您掌握现代运维工程师必备的两项核心技能:Python编程与Linux Shell脚本编写,并将其应用于数据库与操作系统的日常运维工作中。
在当今数字化时代,随着服务器规模扩大和业务复杂度提升,单纯依靠手动操作进行运维管理已变得不现实。据统计,掌握自动化运维技能的工程师能够将日常工作效率提升30%以上,同时将人为错误减少60%。通过本课程的学习,您将能够:
- 熟练使用Python和Linux Shell脚本完成数据库与系统的日常运维任务
- 实现数据库备份、恢复、监控等操作的自动化
- 构建基础的监控报警系统,及时发现并解决系统异常
- 掌握常见故障排查技巧,提升系统稳定性和可靠性
1.2 课程内容结构
本课程采用循序渐进的教学方式,从基础语法开始,逐步过渡到实际运维场景的综合应用。课程内容主要分为以下几个部分:
| 模块 | 主题 | 核心内容 |
|---|---|---|
| 第一部分 | Linux基础与Shell脚本 | Linux系统基础、Shell脚本语法、文本处理工具 |
| 第二部分 | Python编程基础 | Python语法基础、文件操作、异常处理 |
| 第三部分 | 数据库基础操作 | MySQL与PostgreSQL基础管理 |
| 第四部分 | 自动化运维实战 | 数据库备份恢复、监控报警、日志分析 |
| 第五部分 | 综合项目实践 | 构建完整的数据库运维自动化系统 |
1.3 学习路径与方法
作为0基础学员,建议您按照以下路径进行学习:
-
先掌握基础,再实践应用:先扎实掌握Linux和Python的基础知识,再尝试解决实际运维问题。
-
多写多练:编程是一门实践性很强的技能,每周至少完成3-5个小型练习项目。
-
结合实际场景学习:将所学知识应用到实际运维场景中,解决具体问题。
-
循序渐进:从简单的脚本开始,逐步过渡到复杂的自动化系统。
-
利用工具与资源:充分利用课程中提供的工具和资源,如图书、在线课程等。
在课程学习过程中,我们将通过大量的实际案例和练习项目,帮助您掌握Python和Shell脚本在数据库与系统运维中的应用技巧,使您能够独立完成常见的运维自动化任务。
二、Linux基础与Shell脚本编程
2.1 Linux系统基础
作为运维工程师,Linux系统是我们工作的主要平台。本节将介绍Linux系统的基础知识,为后续学习Shell脚本和系统管理打下基础。
2.1.1 Linux系统架构
Linux系统主要由以下几个部分组成:
-
内核(Kernel):Linux系统的核心,负责管理硬件资源、进程调度、内存管理等。
-
系统库(System Libraries):提供操作系统的基本功能接口,如文件操作、网络通信等。
-
系统工具(System Utilities):完成特定系统功能的命令行工具,如文件管理、进程管理等。
-
Shell:用户与操作系统之间的接口,允许用户执行命令和脚本。
2.1.2 常用Linux命令
以下是运维工作中常用的Linux命令,需要熟练掌握:
| 命令分类 | 常用命令 | 功能说明 |
|---|---|---|
| 文件操作 | ls, cd, pwd, mkdir, rm, cp, mv | 管理文件和目录 |
| 文件内容 | cat, less, more, head, tail, grep | 查看和搜索文件内容 |
| 系统信息 | uname, hostname, df, du, free, top | 获取系统信息 |
| 进程管理 | ps, top, kill, pgrep | 管理系统进程 |
| 网络操作 | ping, ssh, curl, wget, netstat | 网络测试和数据传输 |
| 文件权限 | chmod, chown, chgrp | 管理文件权限和所有权 |
练习:尝试使用上述命令完成以下任务:
- 列出当前目录下的所有文件和目录
- 切换到home目录
- 创建一个名为"project"的新目录
- 在该目录下创建一个名为"test.txt"的文件
- 向文件中添加一些内容
- 查看文件内容
- 搜索包含特定字符串的行
2.1.3 文件权限管理
Linux系统采用权限管理机制控制用户对文件和目录的访问。文件权限分为三种类型:
- 读®:允许查看文件内容或列出目录内容
- 写(w):允许修改文件内容或删除/创建目录中的文件
- 执行(x):允许执行文件或进入目录
权限可以分配给三种用户类型:
- 所有者(Owner):文件或目录的创建者
- 所属组(Group):与所有者同组的用户
- 其他用户(Other):系统中的其他用户
使用chmod命令可以修改文件权限,例如:
chmod u+rwx,g+rw,o+r filename # 为所有者添加读写执行权限,为组添加读写权限,为其他用户添加读权限
chmod 754 filename # 等价于上述命令的数字表示法
练习:尝试使用chmod命令完成以下任务:
- 将文件设置为所有人都可以读取
- 仅允许文件所有者进行修改
- 使脚本文件可执行
2.2 Shell脚本基础
Shell脚本是运维自动化的基础工具,它允许您将一系列Linux命令组合在一起,实现复杂的自动化任务。
2.2.1 Shell脚本入门
Shell脚本是一个包含一系列Shell命令的文本文件。要创建一个Shell脚本:
- 使用文本编辑器创建一个新文件
- 在文件开头添加
#!/bin/bash(指定解释器) - 写入要执行的命令
- 给文件添加可执行权限
- 执行脚本
例如,创建一个简单的问候脚本:
#!/bin/bash
echo "Hello, World!"
保存为greet.sh,然后执行:
chmod +x greet.sh
./greet.sh
2.2.2 变量与输入输出
在Shell脚本中,您可以使用变量来存储数据。定义变量的方式:
name="John"
echo "Hello, $name"
接收用户输入:
echo "Enter your name:"
read name
echo "Hello, $name"
命令替换允许您将命令的输出赋值给变量:
current_dir=$(pwd)
echo "Current directory: $current_dir"
练习:创建一个脚本,获取用户输入的两个数字,计算它们的和并输出结果。
2.2.3 条件判断与循环结构
Shell脚本支持条件判断和循环结构,使脚本能够根据不同情况执行不同的操作。
条件判断示例:
if [ $1 -gt 10 ]; then
echo "The number is greater than 10"
elif [ $1 -eq 10 ]; then
echo "The number is equal to 10"
else
echo "The number is less than 10"
fi
循环结构示例(遍历目录中的所有文件):
for file in *; do
echo "Processing file: $file"
done
练习:创建一个脚本,检查指定目录是否存在,如果不存在则创建它,并列出该目录中的所有文件。
2.3 高级Shell脚本技术
2.3.1 文本处理工具
在Linux系统中,有几个强大的文本处理工具,如grep、sed和awk,它们在日志分析和数据处理中非常有用。
grep用于在文件中搜索指定模式:
grep "error" /var/log/syslog # 搜索包含"error"的行
grep -v "warning" /var/log/syslog # 搜索不包含"warning"的行
sed用于流编辑,可以对文本进行替换、删除、插入等操作:
sed 's/old/new/g' file.txt # 将文件中的所有"old"替换为"new"
awk是一个强大的文本处理工具,擅长处理结构化数据:
awk '{print $1}' file.txt # 打印文件中的第一列
awk -F: '{print $1}' /etc/passwd # 使用冒号作为分隔符
练习:使用文本处理工具完成以下任务:
- 从日志文件中提取所有包含"ERROR"的行
- 将文件中的所有小写字母转换为大写
- 统计文件中每个单词的出现次数
2.3.2 函数与脚本模块化
在Shell脚本中,您可以定义函数来组织代码,提高代码的可重用性和可读性。
定义函数的方式:
function greet() {
echo "Hello, $1"
}
greet "John"
脚本模块化允许您将常用功能封装在独立的脚本中,然后在其他脚本中调用它们。例如,创建一个包含常用函数的库文件common_functions.sh:
#!/bin/bash
function greet() {
echo "Hello, $1"
}
然后在另一个脚本中使用这些函数:
#!/bin/bash
source ./common_functions.sh
greet "Alice"
练习:创建一个包含文件操作相关函数的库,如创建目录、删除文件、备份文件等。
2.3.3 系统管理脚本示例
以下是一些常见的系统管理脚本示例:
磁盘空间监控脚本:
#!/bin/bash
# 获取根分区的使用百分比
used=$(df -h / | awk 'NR==2 {print $5}' | cut -d'%' -f1)
# 如果使用超过80%,发送警告
if [ $used -gt 80 ]; then
echo "Disk space usage critical: $used%"
# 这里可以添加发送邮件或报警的代码
fi
进程监控脚本:
#!/bin/bash
# 检查指定进程是否运行
process="nginx"
if ! pgrep -x "$process" >/dev/null; then
echo "Process $process is not running. Restarting..."
systemctl restart $process
fi
练习:创建一个系统监控脚本,检查CPU使用率、内存使用率和磁盘空间,并在超过阈值时输出警告信息。
三、Python编程基础
3.1 Python入门与环境设置
Python是一种高级编程语言,因其简洁的语法和强大的功能,成为现代运维自动化的首选工具。
3.1.1 Python环境安装
在开始学习Python之前,需要先安装Python环境。对于Linux系统,通常已经预装了Python,但建议安装最新版本的Python 3。
检查Python版本:
python3 --version
如果系统中没有安装Python 3,可以使用包管理工具进行安装:
# Ubuntu/Debian系统
sudo apt update
sudo apt install python3 python3-pip
# CentOS/RHEL系统
sudo yum install python3 python3-pip
安装完成后,可以使用以下命令进入Python交互式环境:
python3
3.1.2 第一个Python程序
在Python中,最简单的程序是输出"Hello, World!":
print("Hello, World!")
将上述代码保存到文件hello.py中,然后在命令行中执行:
python3 hello.py
Python的语法特点:
- 使用缩进表示代码块
- 不需要分号结尾
- 变量不需要声明类型
3.1.3 基本数据类型与操作
Python支持多种基本数据类型,包括:
- 数字:整数、浮点数、复数
- 字符串:文本数据
- 布尔值:True和False
- 列表:有序的可变序列
- 元组:有序的不可变序列
- 字典:键值对集合
示例代码:
# 数字运算
a = 5
b = 3
print(a + b) # 加法
print(a - b) # 减法
print(a * b) # 乘法
print(a / b) # 除法
print(a % b) # 取余
print(a ** b) # 幂运算
# 字符串操作
name = "John"
print("Hello, " + name)
print(len(name))
print(name.upper())
print(name.lower())
# 列表操作
numbers = [1, 2, 3, 4, 5]
print(numbers[0])
numbers.append(6)
print(numbers)
# 字典操作
person = {"name": "John", "age": 30}
print(person["name"])
person["age"] = 31
print(person)
练习:编写一个Python程序,获取用户输入的两个数字,计算它们的和、差、积、商,并输出结果。
3.2 控制结构与函数
3.2.1 条件语句
Python中的条件语句使用if、elif和else关键字。
示例代码:
x = 10
if x > 0:
print("Positive")
elif x == 0:
print("Zero")
else:
print("Negative")
练习:编写一个Python程序,根据用户输入的年龄判断其是否成年(18岁及以上)。
3.2.2 循环结构
Python支持for循环和while循环。
for循环示例:
for i in range(1, 11):
print(i)
while循环示例:
count = 0
while count < 5:
print(count)
count += 1
练习:编写一个Python程序,使用循环计算1到100之间所有偶数的和。
3.2.3 函数定义与使用
函数是组织代码的重要方式,可以提高代码的可重用性和可读性。
定义函数的方式:
def greet(name):
print(f"Hello, {name}")
greet("Alice")
带返回值的函数:
def add(a, b):
return a + b
result = add(3, 5)
print(result)
练习:编写一个函数,计算一个数的阶乘,并测试该函数。
3.3 文件操作与异常处理
3.3.1 文件读写操作
Python提供了强大的文件操作功能,支持各种文件操作。
读取文件内容:
with open("file.txt", "r") as file:
content = file.read()
print(content)
逐行读取文件:
with open("file.txt", "r") as file:
for line in file:
print(line.strip())
写入文件:
with open("output.txt", "w") as file:
file.write("Hello, World!\n")
练习:编写一个Python程序,读取一个文本文件,统计其中包含的单词数量,并将结果写入另一个文件。
3.3.2 异常处理
在Python中,使用try-except块来处理异常。
示例代码:
try:
x = 10 / 0
except ZeroDivisionError:
print("Error: Division by zero")
except Exception as e:
print(f"An error occurred: {e}")
finally:
print("Cleaning up...")
练习:编写一个Python程序,尝试打开一个可能不存在的文件,并处理可能出现的异常。
3.3.3 模块与包
Python的强大之处在于其丰富的标准库和第三方库。您可以使用import语句导入模块。
导入模块示例:
import math
print(math.pi)
print(math.sqrt(16))
导入特定函数:
from math import pi, sqrt
print(pi)
print(sqrt(16))
安装第三方库使用pip:
pip3 install requests
练习:安装requests库,并编写一个简单的程序,使用该库发送HTTP请求并打印响应内容。
四、数据库基础操作
4.1 MySQL数据库基础
4.1.1 MySQL安装与配置
MySQL是最常用的开源关系型数据库之一,在运维工作中经常需要与MySQL打交道。
在Linux系统上安装MySQL:
# Ubuntu/Debian系统
sudo apt update
sudo apt install mysql-server
# CentOS/RHEL系统
sudo yum install mysql-server
启动MySQL服务:
sudo systemctl start mysql
sudo systemctl enable mysql
安全配置:
sudo mysql_secure_installation
登录MySQL:
mysql -u root -p
4.1.2 基本SQL操作
以下是一些基本的SQL操作命令:
创建数据库:
CREATE DATABASE mydb;
创建表:
USE mydb;
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50),
email VARCHAR(100) UNIQUE,
age INT
);
插入数据:
INSERT INTO users (name, email, age) VALUES
('John Doe', 'john@example.com', 30),
('Jane Smith', 'jane@example.com', 25);
查询数据:
SELECT * FROM users;
SELECT name, age FROM users WHERE age > 25;
更新数据:
UPDATE users SET age = 31 WHERE name = 'John Doe';
删除数据:
DELETE FROM users WHERE age < 25;
练习:使用MySQL命令行工具完成以下任务:
- 创建一个名为"employees"的数据库
- 在该数据库中创建一个"employees"表,包含id、name、position、salary等字段
- 插入至少5条测试数据
- 查询所有月薪超过5000的员工
- 更新某位员工的职位和薪资
4.1.3 MySQL用户与权限管理
在MySQL中,用户和权限管理非常重要,它确保数据库的安全性。
创建用户:
CREATE USER 'user'@'localhost' IDENTIFIED BY 'password';
授予权限:
GRANT ALL PRIVILEGES ON mydb.* TO 'user'@'localhost';
FLUSH PRIVILEGES;
撤销权限:
REVOKE ALL PRIVILEGES ON mydb.* FROM 'user'@'localhost';
删除用户:
DROP USER 'user'@'localhost';
练习:创建一个新用户,授予其对"employees"数据库的只读权限,并测试该用户的访问权限。
4.2 PostgreSQL数据库基础
4.2.1 PostgreSQL安装与配置
PostgreSQL是另一个流行的开源关系型数据库,以其强大的功能和稳定性著称。
在Linux系统上安装PostgreSQL:
# Ubuntu/Debian系统
sudo apt update
sudo apt install postgresql postgresql-contrib
# CentOS/RHEL系统
sudo yum install postgresql-server postgresql-contrib
初始化数据库:
sudo postgresql-setup initdb
启动PostgreSQL服务:
sudo systemctl start postgresql
sudo systemctl enable postgresql
切换到postgres用户:
sudo su - postgres
登录PostgreSQL:
psql
退出PostgreSQL和postgres用户:
\q
exit
4.2.2 PostgreSQL基本操作
PostgreSQL的基本操作与MySQL类似,但有一些语法差异。
创建数据库:
CREATE DATABASE mydb;
创建表:
CREATE TABLE users (
id SERIAL PRIMARY KEY,
name VARCHAR(50),
email VARCHAR(100) UNIQUE,
age INTEGER
);
插入数据:
INSERT INTO users (name, email, age) VALUES
('John Doe', 'john@example.com', 30),
('Jane Smith', 'jane@example.com', 25);
查询数据:
SELECT * FROM users;
SELECT name, age FROM users WHERE age > 25;
更新数据:
UPDATE users SET age = 31 WHERE name = 'John Doe';
删除数据:
DELETE FROM users WHERE age < 25;
练习:使用PostgreSQL命令行工具完成以下任务:
- 创建一个名为"employees"的数据库
- 在该数据库中创建一个"employees"表,包含id、name、position、salary等字段
- 插入至少5条测试数据
- 查询所有月薪超过5000的员工
- 更新某位员工的职位和薪资
4.2.3 PostgreSQL用户与权限管理
PostgreSQL的用户和权限管理与MySQL有所不同。
创建用户:
CREATE USER user WITH PASSWORD 'password';
创建数据库并指定所有者:
CREATE DATABASE mydb OWNER user;
授予权限:
GRANT ALL PRIVILEGES ON DATABASE mydb TO user;
撤销权限:
REVOKE ALL PRIVILEGES ON DATABASE mydb FROM user;
删除用户:
DROP USER user;
练习:创建一个新用户,授予其对"employees"数据库的只读权限,并测试该用户的访问权限。
4.3 使用Python操作数据库
4.3.1 使用PyMySQL操作MySQL
PyMySQL是一个纯Python实现的MySQL客户端库,允许您使用Python代码操作MySQL数据库。
安装PyMySQL:
pip3 install pymysql
连接到MySQL数据库:
import pymysql
connection = pymysql.connect(
host='localhost',
user='user',
password='password',
database='mydb'
)
cursor = connection.cursor()
执行SQL查询:
# 插入数据
sql = "INSERT INTO users (name, email, age) VALUES (%s, %s, %s)"
values = ('Bob Smith', 'bob@example.com', 35)
cursor.execute(sql, values)
connection.commit()
# 查询数据
sql = "SELECT * FROM users"
cursor.execute(sql)
results = cursor.fetchall()
for row in results:
print(row)
cursor.close()
connection.close()
练习:编写一个Python程序,连接到MySQL数据库,插入一条新记录,然后查询并打印所有记录。
4.3.2 使用psycopg2操作PostgreSQL
psycopg2是Python操作PostgreSQL的标准库。
安装psycopg2:
pip3 install psycopg2-binary
连接到PostgreSQL数据库:
import psycopg2
connection = psycopg2.connect(
host="localhost",
user="user",
password="password",
database="mydb"
)
cursor = connection.cursor()
执行SQL查询:
# 插入数据
sql = "INSERT INTO users (name, email, age) VALUES (%s, %s, %s)"
values = ('Alice Williams', 'alice@example.com', 28)
cursor.execute(sql, values)
connection.commit()
# 查询数据
sql = "SELECT * FROM users"
cursor.execute(sql)
results = cursor.fetchall()
for row in results:
print(row)
cursor.close()
connection.close()
练习:编写一个Python程序,连接到PostgreSQL数据库,插入一条新记录,然后查询并打印所有记录。
4.3.3 使用SQLAlchemy进行数据库抽象
SQLAlchemy是一个强大的数据库抽象层,允许您使用统一的API操作不同类型的数据库。
安装SQLAlchemy:
pip3 install sqlalchemy
使用SQLAlchemy连接到MySQL:
from sqlalchemy import create_engine, text
engine = create_engine("mysql+pymysql://user:password@localhost/mydb")
with engine.connect() as connection:
result = connection.execute(text("SELECT * FROM users"))
for row in result:
print(row)
使用SQLAlchemy连接到PostgreSQL:
from sqlalchemy import create_engine, text
engine = create_engine("postgresql://user:password@localhost/mydb")
with engine.connect() as connection:
result = connection.execute(text("SELECT * FROM users"))
for row in result:
print(row)
练习:使用SQLAlchemy编写一个跨数据库的查询程序,能够同时适用于MySQL和PostgreSQL。
五、自动化运维实战
5.1 数据库备份与恢复自动化
5.1.1 MySQL备份自动化
手动备份数据库效率低下且容易出错,自动化备份是运维工作的重要内容。
使用mysqldump命令备份MySQL数据库:
mysqldump -u user -p password mydb > backup.sql
使用Python脚本自动化MySQL备份:
import subprocess
import datetime
backup_time = datetime.datetime.now().strftime("%Y%m%d_%H%M%S")
backup_file = f"backup_{backup_time}.sql"
command = [
'mysqldump',
'-u', 'user',
'-p', 'password',
'mydb',
'--result-file', backup_file
]
subprocess.run(command, check=True)
print(f"Backup created successfully: {backup_file}")
练习:编写一个Python脚本,实现以下功能:
- 每周自动备份MySQL数据库
- 备份文件按日期命名
- 保留最近7天的备份
- 在备份失败时发送邮件通知
5.1.2 PostgreSQL备份自动化
PostgreSQL提供了pg_dump工具用于数据库备份。
使用pg_dump命令备份PostgreSQL数据库:
pg_dump -U user -d mydb -f backup.sql
使用Python脚本自动化PostgreSQL备份:
import subprocess
import datetime
backup_time = datetime.datetime.now().strftime("%Y%m%d_%H%M%S")
backup_file = f"backup_{backup_time}.sql"
command = [
'pg_dump',
'-U', 'user',
'-d', 'mydb',
'-f', backup_file
]
subprocess.run(command, check=True)
print(f"Backup created successfully: {backup_file}")
练习:编写一个Python脚本,实现以下功能:
- 每天自动备份PostgreSQL数据库
- 备份文件按日期和时间命名
- 压缩备份文件以节省空间
- 将备份文件上传到云存储服务(如AWS S3)
5.1.3 数据库恢复自动化
数据库恢复是备份的重要组成部分,也需要实现自动化。
恢复MySQL备份:
mysql -u user -p password mydb < backup.sql
使用Python脚本自动化MySQL恢复:
import subprocess
backup_file = "backup_20231001_120000.sql"
command = [
'mysql',
'-u', 'user',
'-p', 'password',
'mydb',
'<', backup_file
]
subprocess.run(command, check=True)
print("Database restored successfully")
恢复PostgreSQL备份:
psql -U user -d mydb -f backup.sql
使用Python脚本自动化PostgreSQL恢复:
import subprocess
backup_file = "backup_20231001_120000.sql"
command = [
'psql',
'-U', 'user',
'-d', 'mydb',
'-f', backup_file
]
subprocess.run(command, check=True)
print("Database restored successfully")
练习:编写一个Python脚本,实现以下功能:
- 从指定备份文件恢复MySQL或PostgreSQL数据库
- 在恢复前自动创建数据库(如果不存在)
- 记录恢复操作的详细日志
- 在恢复成功或失败时发送通知
5.2 系统监控与报警
5.2.1 系统资源监控
系统资源监控是运维工作的基础,通过监控可以及时发现系统异常。
使用Python监控系统资源:
import psutil
# CPU使用率
print("CPU使用率:", psutil.cpu_percent(interval=1))
# 内存使用情况
memory = psutil.virtual_memory()
print("内存总量:", memory.total)
print("内存可用量:", memory.available)
print("内存使用率:", memory.percent)
# 磁盘使用情况
disk = psutil.disk_usage('/')
print("磁盘总量:", disk.total)
print("磁盘可用量:", disk.free)
print("磁盘使用率:", disk.percent)
使用Shell脚本监控系统资源:
#!/bin/bash
echo "CPU使用率:$(top -bn1 | grep 'Cpu(s)' | awk '{print $2 + $4}')%"
echo "内存使用率:$(free | awk 'NR==2 {printf "%.2f%%", ($3/$2)*100}')"
echo "磁盘使用率:$(df -h / | awk 'NR==2 {print $5}')"
练习:编写一个综合监控脚本,同时监控CPU、内存、磁盘和网络使用情况,并在资源使用超过阈值时发出警告。
5.2.2 数据库性能监控
数据库性能直接影响应用程序的性能,因此需要密切监控。
使用Python监控MySQL性能:
import pymysql
connection = pymysql.connect(
host='localhost',
user='user',
password='password',
database='mydb'
)
cursor = connection.cursor()
cursor.execute("SHOW STATUS LIKE 'Threads_connected'")
print("当前连接数:", cursor.fetchone()[1])
cursor.execute("SHOW STATUS LIKE 'Slow_queries'")
print("慢查询数量:", cursor.fetchone()[1])
cursor.close()
connection.close()
使用Python监控PostgreSQL性能:
import psycopg2
connection = psycopg2.connect(
host="localhost",
user="user",
password="password",
database="mydb"
)
cursor = connection.cursor()
cursor.execute("SELECT numbackends FROM pg_stat_database WHERE datname = 'mydb'")
print("当前连接数:", cursor.fetchone()[0])
cursor.execute("SELECT count(*) FROM pg_stat_statements WHERE total_time > 1000")
print("慢查询数量:", cursor.fetchone()[0])
cursor.close()
connection.close()
练习:编写一个数据库性能监控脚本,定期收集并记录数据库的关键性能指标,如连接数、查询执行时间、锁等待等。
5.2.3 报警系统实现
及时的报警系统可以确保运维人员在系统出现问题时能够迅速响应。
使用Python发送邮件报警:
import smtplib
from email.message import EmailMessage
def send_alert(subject, body):
msg = EmailMessage()
msg.set_content(body)
msg['Subject'] = subject
msg['From'] = 'sender@example.com'
msg['To'] = 'recipient@example.com'
with smtplib.SMTP('smtp.example.com', 587) as server:
server.starttls()
server.login('sender@example.com', 'password')
server.send_message(msg)
send_alert("系统警告", "服务器磁盘使用率超过90%")
使用Shell脚本发送短信报警(需要安装相关工具):
#!/bin/bash
curl -X POST "https://api.twilio.com/2010-04-01/Accounts/{ACCOUNT_SID}/Messages.json" \
--data-urlencode "From=+1234567890" \
--data-urlencode "To=+0987654321" \
--data-urlencode "Body=服务器CPU使用率超过80%" \
-u "{ACCOUNT_SID}:{AUTH_TOKEN}"
练习:编写一个综合报警系统,能够在系统或数据库出现异常时通过多种渠道(如邮件、短信、即时通讯工具)发送报警通知。
5.3 日志分析与故障排查
5.3.1 日志文件分析
日志是故障排查的重要依据,自动化日志分析可以提高排查效率。
使用Python分析日志文件:
with open('/var/log/syslog', 'r') as file:
for line in file:
if 'ERROR' in line:
print(line.strip())
统计日志中不同类型的错误数量:
error_counts = {}
with open('/var/log/syslog', 'r') as file:
for line in file:
if 'ERROR' in line:
error_type = line.split()[3] # 假设错误类型在第四个字段
error_counts[error_type] = error_counts.get(error_type, 0) + 1
for error_type, count in error_counts.items():
print(f"{error_type}: {count}次")
练习:编写一个Python程序,分析Apache服务器日志,统计不同HTTP状态码的出现次数,并找出访问量最高的IP地址。
5.3.2 数据库故障排查
数据库故障排查是运维工作中的重要技能,需要结合多种工具和方法。
常见的数据库故障包括:
- 连接问题:检查数据库服务是否运行,网络是否畅通,端口是否开放。
- 性能问题:分析慢查询,检查索引使用情况,调整数据库配置。
- 数据一致性问题:使用数据库自带的工具检查数据一致性,执行修复操作。
- 存储空间不足:监控磁盘使用情况,清理不必要的数据,增加存储空间。
使用Python脚本检查数据库连接:
import pymysql
def check_mysql_connection(host, user, password, database):
try:
connection = pymysql.connect(
host=host,
user=user,
password=password,
database=database,
connect_timeout=5
)
connection.close()
return True
except Exception as e:
print(f"连接失败:{e}")
return False
if check_mysql_connection('localhost', 'user', 'password', 'mydb'):
print("MySQL连接正常")
else:
print("MySQL连接失败")
练习:编写一个数据库健康检查脚本,定期检查数据库的连接状态、性能指标和数据完整性,并生成健康报告。
5.3.3 自动化故障恢复
在某些情况下,系统可以自动恢复一些常见的故障,减少人工干预。
自动重启数据库服务的Python脚本:
import subprocess
import time
def restart_mysql():
print("尝试重启MySQL服务...")
subprocess.run(['sudo', 'systemctl', 'restart', 'mysql'])
time.sleep(5)
if check_mysql_connection('localhost', 'user', 'password', 'mydb'):
print("MySQL服务重启成功")
return True
else:
print("MySQL服务重启失败")
return False
restart_mysql()
自动清理数据库临时文件的Shell脚本:
#!/bin/bash
# 查找并删除超过7天的临时文件
find /var/lib/mysql/tmp -type f -mtime +7 -delete
练习:编写一个自动故障恢复系统,能够检测并自动恢复常见的数据库和系统故障,如服务崩溃、临时文件堆积等。
六、综合项目实践
6.1 构建完整的数据库运维自动化系统
在这个综合项目中,您将把所学的知识应用到实际场景中,构建一个完整的数据库运维自动化系统。
6.1.1 项目需求分析
您需要为一个拥有多个MySQL和PostgreSQL数据库的小型公司构建自动化运维系统,满足以下需求:
- 自动化备份:每天自动备份所有数据库,保留最近7天的备份。
- 监控报警:监控数据库和服务器资源使用情况,超过阈值时发送报警。
- 日志分析:定期分析数据库和系统日志,生成报告。
- 故障恢复:自动检测并恢复常见的数据库故障。
- 管理界面:提供一个简单的Web界面,查看备份状态、监控数据和日志报告。
6.1.2 技术选型与架构设计
基于项目需求,选择以下技术栈:
- 编程语言:Python(主要)和Shell脚本(辅助)
- 数据库:MySQL和PostgreSQL(需要同时支持)
- Web框架:Flask(用于管理界面)
- 监控工具:psutil(系统监控)、SQLAlchemy(数据库监控)
- 报警渠道:邮件和短信(使用第三方API)
- 存储:本地存储和云存储(如AWS S3)
系统架构图:
+-----------------+
| 数据库服务器 |
| (MySQL/PostgreSQL) |
+--------+---------+
|
+--------v---------+
| 自动化运维系统 |
| (Python脚本) |
+--------+---------+
|
+--------v---------+
| 监控与报警模块 |
+--------+---------+
|
+--------v---------+
| 备份管理模块 |
+--------+---------+
|
+--------v---------+
| 日志分析模块 |
+--------+---------+
|
+--------v---------+
| 故障恢复模块 |
+--------+---------+
|
+--------v---------+
| Web管理界面 |
+-----------------+
6.1.3 模块实现与集成
备份管理模块实现:
import os
import shutil
import datetime
import subprocess
from threading import Timer
def backup_database(database_type, host, user, password, database, backup_dir):
backup_time = datetime.datetime.now().strftime("%Y%m%d_%H%M%S")
backup_file = os.path.join(backup_dir, f"{database}_{backup_time}.sql")
if database_type == 'mysql':
command = [
'mysqldump',
'-h', host,
'-u', user,
'-p', password,
database,
'--result-file', backup_file
]
elif database_type == 'postgresql':
command = [
'pg_dump',
'-h', host,
'-U', user,
'-d', database,
'-f', backup_file
]
else:
raise ValueError("不支持的数据库类型")
subprocess.run(command, check=True)
print(f"备份成功:{backup_file}")
def schedule_backup(database_type, host, user, password, database, backup_dir, interval):
backup_database(database_type, host, user, password, database, backup_dir)
Timer(interval, schedule_backup, args=[database_type, host, user, password, database, backup_dir, interval]).start()
# 示例用法
# schedule_backup('mysql', 'localhost', 'user', 'password', 'mydb', '/backups', 86400) # 每天备份一次
监控与报警模块实现:
import psutil
import smtplib
from email.message import EmailMessage
def monitor_system_resources(thresholds):
cpu_usage = psutil.cpu_percent()
memory_usage = psutil.virtual_memory().percent
disk_usage = psutil.disk_usage('/').percent
alerts = []
if cpu_usage > thresholds['cpu']:
alerts.append(f"CPU使用率过高:{cpu_usage}%")
if memory_usage > thresholds['memory']:
alerts.append(f"内存使用率过高:{memory_usage}%")
if disk_usage > thresholds['disk']:
alerts.append(f"磁盘使用率过高:{disk_usage}%")
return alerts
def send_alert(subject, body):
msg = EmailMessage()
msg.set_content(body)
msg['Subject'] = subject
msg['From'] = 'sender@example.com'
msg['To'] = 'recipient@example.com'
with smtplib.SMTP('smtp.example.com', 587) as server:
server.starttls()
server.login('sender@example.com', 'password')
server.send_message(msg)
# 示例用法
# thresholds = {'cpu': 80, 'memory': 90, 'disk': 95}
# alerts = monitor_system_resources(thresholds)
# if alerts:
# send_alert("系统警告", "\n".join(alerts))
日志分析模块实现:
import re
from collections import defaultdict
def analyze_log(log_file):
error_counts = defaultdict(int)
warning_counts = defaultdict(int)
slow_queries = []
with open(log_file, 'r') as file:
for line in file:
# 分析错误日志
error_match = re.search(r'ERROR: (.+)', line)
if error_match:
error_type = error_match.group(1)
error_counts[error_type] += 1
# 分析警告日志
warning_match = re.search(r'WARNING: (.+)', line)
if warning_match:
warning_type = warning_match.group(1)
warning_counts[warning_type] += 1
# 分析慢查询(假设日志格式为:[慢查询] 查询内容 (时间: 1.5s)
slow_query_match = re.search(r'\[慢查询\] (.+) \(时间: (\d+\.?\d*)s\)', line)
if slow_query_match:
query = slow_query_match.group(1)
time = float(slow_query_match.group(2))
slow_queries.append((query, time))
return {
'errors': dict(error_counts),
'warnings': dict(warning_counts),
'slow_queries': slow_queries
}
# 示例用法
# report = analyze_log('/var/log/mysql/slow.log')
# print("错误统计:", report['errors'])
# print("警告统计:", report['warnings'])
# print("慢查询:", report['slow_queries'])
故障恢复模块实现:
import subprocess
import time
def restart_database_service(service_name):
print(f"尝试重启{service_name}服务...")
subprocess.run(['sudo', 'systemctl', 'restart', service_name])
time.sleep(5)
status = subprocess.run(['systemctl', 'is-active', service_name], capture_output=True, text=True)
if status.stdout.strip() == 'active':
print(f"{service_name}服务重启成功")
return True
else:
print(f"{service_name}服务重启失败")
return False
# 示例用法
# restart_database_service('mysql')
# restart_database_service('postgresql')
Web管理界面实现(使用Flask):
from flask import Flask, render_template, request
import json
app = Flask(__name__)
# 假设这些数据来自实际的监控和日志分析
mock_data = {
'system_status': {
'cpu': 75,
'memory': 80,
'disk': 85
},
'database_status': {
'mysql': {
'connections': 25,
'slow_queries': 5
},
'postgresql': {
'connections': 18,
'slow_queries': 3
}
},
'logs': [
{'timestamp': '2023-10-01 12:00:00', 'level': 'ERROR', 'message': '数据库连接失败'},
{'timestamp': '2023-10-01 13:00:00', 'level': 'WARNING', 'message': '磁盘空间不足'}
]
}
@app.route('/')
def dashboard():
return render_template('dashboard.html', data=mock_data)
@app.route('/backups')
def backups():
# 从备份目录获取备份文件列表
backup_files = ['backup_mydb_20231001_120000.sql', 'backup_mydb_20231002_120000.sql']
return render_template('backups.html', backup_files=backup_files)
@app.route('/logs')
def logs():
return render_template('logs.html', logs=mock_data['logs'])
@app.route('/settings', methods=['GET', 'POST'])
def settings():
if request.method == 'POST':
# 处理设置更新
pass
return render_template('settings.html')
if __name__ == '__main__':
app.run(debug=True)
6.1.4 系统测试与部署
在完成系统开发后,需要进行全面的测试,确保各功能模块正常工作。
测试步骤:
- 单元测试:分别测试各个模块的功能,如备份、监控、日志分析等。
- 集成测试:测试模块之间的协作是否正常。
- 压力测试:模拟高负载情况下系统的表现。
- 恢复测试:测试系统在故障情况下的恢复能力。
部署步骤:
- 环境准备:在目标服务器上安装所需的软件和依赖。
- 配置文件:创建系统配置文件,包括数据库连接信息、报警设置等。
- 服务启动:将自动化脚本设置为系统服务,随系统启动而运行。
- 监控设置:配置监控工具,定期收集系统和数据库指标。
- 用户培训:对运维人员进行系统使用培训。
练习:根据上述设计,完成数据库运维自动化系统的完整实现,并进行测试和部署。
6.2 个人学习路径规划
为了帮助您更好地掌握Python和Shell脚本在数据库与系统运维中的应用,以下是一个个人学习路径规划。
6.2.1 短期目标(1-3个月)
-
掌握基础语法:
- 熟练掌握Linux Shell脚本的基本语法和常用命令
- 掌握Python的基本语法、数据结构和控制流
-
基础应用:
- 能够编写简单的Shell脚本完成日常系统管理任务
- 能够使用Python操作MySQL和PostgreSQL数据库
- 了解数据库备份和恢复的基本方法
-
学习资源:
- 完成本课程中的所有练习和项目
- 阅读《Linux命令行与Shell脚本编程大全》和《Python编程:从入门到实践》
- 参加在线课程,如Udemy的"Python for Beginners"和"Linux Administration"
6.2.2 中期目标(3-6个月)
-
深入学习:
- 掌握高级Shell脚本技术,如文本处理、函数和模块化
- 掌握Python的高级特性,如面向对象编程、异常处理和模块开发
- 深入理解数据库原理和性能优化
-
实战应用:
- 能够编写复杂的自动化脚本,实现系统和数据库的全面监控
- 能够设计和实现完整的数据库备份和恢复解决方案
- 能够分析和优化数据库性能问题
-
学习资源:
- 阅读《Effective Python》和《Database Systems: The Complete Book》
- 参与开源项目,如自动化运维工具的开发
- 参加专业培训和认证,如Python认证和数据库管理员认证
6.2.3 长期目标(6-12个月及以后)
-
专家水平:
- 成为Python和Shell脚本的专家,能够解决复杂的自动化问题
- 成为数据库管理专家,能够设计和管理大型数据库系统
- 具备系统架构设计能力,能够设计高效可靠的运维系统
-
创新应用:
- 开发自己的自动化运维工具和框架
- 研究和应用新技术,如云计算、容器化和AI在运维中的应用
- 发表技术文章和演讲,分享自己的经验和成果
-
学习资源:
- 阅读《The Practice of System and Network Administration》和《Designing Data-Intensive Applications》
- 参加行业会议和技术社区活动
- 指导和帮助其他运维工程师提升技能
练习:根据您的实际情况,制定一个详细的个人学习计划,明确每个阶段的学习目标和学习资源。
七、课程总结与展望
7.1 核心知识回顾
在本课程中,您学习了以下核心知识和技能:
-
Linux基础与Shell脚本:
- Linux系统架构和常用命令
- Shell脚本基础和高级技术
- 文本处理工具(grep、sed、awk)的使用
- 系统管理脚本的编写和应用
-
Python编程基础:
- Python环境设置和基本语法
- 控制结构、函数和模块
- 文件操作和异常处理
- 使用Python操作数据库
-
数据库基础操作:
- MySQL和PostgreSQL的安装与配置
- 数据库的基本操作和高级管理
- 使用Python操作数据库的方法
- 数据库性能优化和安全管理
-
自动化运维实战:
- 数据库备份与恢复自动化
- 系统和数据库监控与报警
- 日志分析和故障排查
- 自动化故障恢复
-
综合项目实践:
- 构建完整的数据库运维自动化系统
- 系统测试和部署
- 个人学习路径规划
这些知识和技能将帮助您在运维工作中提高效率,减少错误,实现自动化管理,成为一名优秀的运维工程师。
7.2 学习方法与技巧
以下是一些学习和应用Python与Shell脚本的有效方法和技巧:
-
实践第一:编程是一门实践性很强的技能,只有通过不断实践才能真正掌握。
-
多写代码:每天坚持编写代码,即使是简单的脚本也能帮助您巩固知识。
-
阅读优秀代码:学习开源项目和优秀的代码示例,提高自己的编程水平。
-
参与社区:加入技术社区和论坛,与其他开发者交流经验和问题。
-
解决实际问题:将所学知识应用到实际工作中,解决具体问题。
-
持续学习:技术发展迅速,保持学习的热情,不断更新自己的知识体系。
-
总结反思:定期总结自己的学习和实践经验,反思不足,不断改进。
7.3 未来发展趋势
随着技术的不断发展,运维领域也在不断演进。以下是一些未来的发展趋势:
-
云原生运维:随着云计算的普及,云原生技术将成为运维的主流方向。
-
AIOps:人工智能在运维中的应用将越来越广泛,实现智能监控、预测和自动化决策。
-
容器化与微服务:Docker和Kubernetes等容器技术将继续主导应用部署和管理。
-
自动化与DevOps:自动化将进一步深入,DevOps理念将成为标准实践。
-
安全与合规:随着网络安全威胁的增加,安全运维将变得更加重要。
-
全栈运维:运维工程师需要具备更广泛的技能,包括开发、测试和部署等多个方面。
通过不断学习和实践,您将能够适应这些变化,在运维领域取得更大的成就。
最后,希望本课程能够帮助您开启自动化运维的大门,成为一名高效、专业的运维工程师!祝您学习愉快,工作顺利!
参考资源
以下是一些推荐的学习资源,帮助您进一步提升Python和Shell脚本在数据库与系统运维中的应用能力:
-
书籍:
- 《Linux命令行与Shell脚本编程大全》
- 《Python编程:从入门到实践》
- 《Effective Python》
- 《Database Systems: The Complete Book》
- 《The Practice of System and Network Administration》
-
在线课程:
-
官方文档:
-
开源工具:
-
技术社区:

一站式 AI 云服务平台
更多推荐

 22
22 0
0- 0



 已为社区贡献40条内容
已为社区贡献40条内容

所有评论(0)