
对于大模型,微调还是不微调?
点击下方“JavaEdge”,选择“设为星标”第一时间关注技术干货!免责声明~任何文章不要过度深思!万事万物都经不起审视,因为世上没有同样的成长环境,也没有同样的认知水平,更「没有适用于所有人的解决方案」;别急着评判文章列出的观点,只需代入其中,适度审视一番自己即可,能「跳脱出来从外人的角度看看现在的自己处在什么样的阶段」才不为俗人。怎么想、怎么做,全在乎自己「不断实践中寻找适合自己的大道」本..
点击下方“JavaEdge”,选择“设为星标”
第一时间关注技术干货!
免责声明~ 任何文章不要过度深思!万事万物都经不起审视,因为世上没有同样的成长环境,也没有同样的认知水平,更「没有适用于所有人的解决方案」;
别急着评判文章列出的观点,只需代入其中,适度审视一番自己即可,能「跳脱出来从外人的角度看看现在的自己处在什么样的阶段」才不为俗人。
怎么想、怎么做,全在乎自己「不断实践中寻找适合自己的大道」
本文讨论以下问题:“什么时候应该进行微调,什么时候应该考虑其他技术?”
引言
在 LLM 出现之前,微调通常用于小规模模型(100M – 300M 参数)。当时,最先进的领域应用通过监督微调(SFT)构建,即使用标注数据对预训练模型进行进一步训练,以适应自己的领域和下游任务。
然而,随大模型(>1B 参数)兴起,微调问题变得更加复杂。最重要的是,大模型微调需要更大的资源和商业硬件。
表 1 列出在三种情况下,微调Llama27B和Llama213B模型的峰值 GPU内存使用量。你可能会注意到,像 QLoRA 这样的算法使得使用有限资源对大模型进行微调变得更加可行。作为示例,表 1 显示了 Llama 2 7B 的三种微调模式(全微调、LoRA 和 QLoRA)的峰值 GPU 内存。类似的内存减少也在使用 PEFT 或量化技术对 Llama 1 进行的微调中被报道。除了计算资源外,参数全量微调的一个常见问题是灾难性遗忘(见本系列的第一部分)。PEFT 技术旨在通过对少量参数进行训练来解决这些问题。
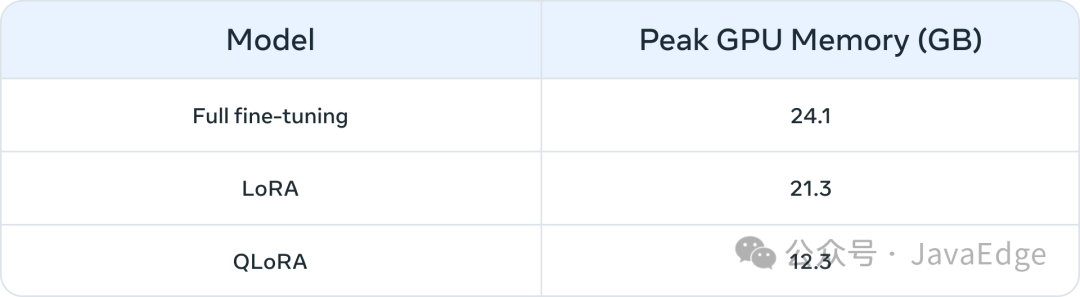
表 1:在 Llama 2 7B 上使用不同微调方法(来源)的内存消耗(单位:GB)。QLoRA 使用了 4-bit NormalFloat 量化。
适合微调的场景类型
以下几种微调可能有益的常见使用场景:
-
**语气、风格和格式定制:**某些用例可能需要 LLM 反映特定的个性或为特定的受众服务。通过使用自定义数据集微调 LLM,我们可以调整聊天机器人的响应,使其更贴近特定用户的需求或预期体验。我们还可能希望以特定格式输出结果,例如 JSON、YAML 或 Markdown。
-
提升准确性和处理边缘案例:
微调可以纠正通过提示词工程和上下文学习难以解决的幻觉或错误。它还可以增强模型执行新技能或任务的能力,而这些技能或任务难以通过提示表达。这一过程有助于纠正模型在执行复杂提示时的失误,并提高其生成预期输出的可靠性。我们提供两个示例:
-
Phi-2 在金融数据情感分析中的准确性从 34% 提升至 85%。
-
ChatGPT 在 Reddit 评论情感分析中的准确性使用 100 个示例后提升了 25 个百分点(从 48% 到 73%)。通常,对于初始准确率较低的情况(< 50%),微调使用几百个示例就能带来显著提升。
处理代表性不足的领域:
尽管 LLM 经过大量通用数据训练,但它们并不总是能够掌握每个小众领域的细微差别、术语或特定性。在法律、医疗或金融等领域,微调已被证明可以提高下游任务的准确性。我们提供两个示例:
-
如文章中所述,患者的病历包含高度敏感的数据,通常不在公共领域中出现。因此,基于 LLM 的病历总结系统需要进行微调。
-
对于像印度语言这样的代表性不足的语言,使用 PEFT 技术的微调在所有任务中都有所帮助。
**成本节约:**微调可以将 Llama 2 70B/GPT-4 等大模型的技能提炼到较小的模型中,如 Llama 2 7B,从而在不影响质量的情况下降低成本和延迟。此外,微调减少了对冗长或特定提示词(提示词工程中使用)的需求,从而节省 Token 并进一步降低成本。例如,这篇文章展示了如何通过微调 GPT-3.5 评审模型,将其从更昂贵的 GPT-4 模型中提炼出来,最终节省了成本。
新任务/能力:
通过微调,往往可以实现新的能力。我们提供三个示例:
-
微调 LLM 以[更好地使用或忽略](https://ar
xiv.org/pdf/2310.01352.pdf)来自检索器的上下文
-
微调 LLM 评审模型来评估其他 LLM 的指标,如扎根性、合规性或有用性
-
微调 LLM 来增加上下文窗口
微调与其他领域适应技术的比较
微调 vs. 上下文学习(少样本学习)
上下文学习(ICL)是一种强大的提升 LLM 系统性能的方式。由于其简便性,ICL 应在进行任何微调活动之前尝试。此外,ICL 实验有助于评估微调是否能提升下游任务的性能。使用 ICL 时的一些常见考虑因素包括:
-
随着需要展示的示例数量增加,推理成本和延迟也随之增加。
-
示例越多,LLM 忽略部分示例的情况也越常见。这意味着你可能需要一个基于 RAG 的系统,根据输入找到最相关的示例。
-
LLM 可能会直接输出作为示例提供给它的知识。这种担忧在微调时也存在。
微调 vs. RAG
共识是,当 LLM 的基础性能不令人满意时,你可以“从 RAG 开始,评估其性能,如果不够理想,再转向微调”,或者“RAG 可能比微调更有优势” (来源)。然而,我们认为这种范式过于简化,因为在多个场景下,RAG 不仅不是微调的替代方案,反而更多的是微调的补充方法。根据问题的特性,可能需要尝试一种或两种方法。采用这篇文章的框架,以下是一些问题,帮助你确定微调或 RAG(或两者)是否适合你的问题:
-
你的应用程序是否需要外部知识?微调通常不适合用于注入新知识。
-
你的应用程序是否需要自定义语调/行为/词汇或风格?对于这些类型的需求,微调通常是正确的方法。
-
你的应用程序对幻觉有多宽容?在压制虚假信息和想象性编造至关重要的应用中,RAG 系统提供了内置的机制来最小化幻觉。
-
有多少标注的训练数据可用?
-
数据的静态性/动态性如何?如果问题需要访问动态的数据语料库,微调可能不是正确的方法,因为 LLM 的知识可能很快变得过时。
-
LLM 应用程序需要多大的透明性/可解释性?RAG 天生可以提供参考文献,这对于解释 LLM 输出非常有用。
-
成本和复杂性:团队是否具备构建搜索系统的专业知识或以前的微调经验?
-
应用程序中的任务多样性如何?
在大多数情况下,微调和 RAG 的混合解决方案将带来最佳效果——问题随之变成了做两者的成本、时间和独立收益。请参考上述问题,以指导你是否需要 RAG 和/或微调,并通过内部实验来分析错误并理解可能的指标提升。最后,微调探索确实需要一个稳健的数据收集和数据改进策略,我们建议在开始微调之前进行这一步!
关注我,紧跟本系列专栏文章,咱们下篇再续!★作者简介:魔都架构师,多家大厂后端一线研发经验,在分布式系统设计、数据平台架构和AI应用开发等领域都有丰富实践经验。
各大技术社区头部专家博主。具有丰富的引领团队经验,深厚业务架构和解决方案的积累。
负责:
中央/分销预订系统性能优化
活动&券等营销中台建设
交易平台及数据中台等架构和开发设计
车联网核心平台-物联网连接平台、大数据平台架构设计及优化
LLM Agent应用开发
区块链应用开发
大数据开发挖掘经验
推荐系统项目
目前主攻市级软件项目设计、构建服务全社会的应用系统。
”
参考:
-
编程严选网
写在最后
编程严选网:
http://www.javaedge.cn/专注分享软件开发全生态相关
技术文章、视频教程资源、热点资讯等,全站资源免费学习,快来看看吧~
【编程严选】星球
欢迎长按图片加好友,我会第一时间和你分享软件行业趋势,面试资源,学习方法等等。
公众号后台私信:
-
回复【架构师】,获取架构师学习资源教程
-
回复【面试】,获取最新最全的互联网大厂面试资料
-
回复【简历】,获取各种样式精美、内容丰富的简历模板
-
回复 【路线图】,获取直升P7技术管理的全网最全学习路线图
-
回复 【大数据】,获取Java转型大数据研发的全网最全思维导图
-
更多教程资源应有尽有,欢迎
关注并加技术交流群,慢慢获取
想先人一步获取以上所有资源?加入《编程严选》星球一键获取!

一站式 AI 云服务平台
更多推荐

 32
32 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)