
【大模型LLM第十篇】利用One-Shot Learning从数据集中辨别和选择高质量sft数据
前言One-Shot Learning as Instruction Data Prospector for Large Language ModelsACL2024的文章,来自中科院深圳先进技术研究院link:https://arxiv.org/pdf/2312.10302github:https://github.com/pldlgb/nuggets一、摘要sft目前的实践通常取决于扩大数据规
前言

One-Shot Learning as Instruction Data Prospector for Large Language Models
ACL2024的文章,来自中科院深圳先进技术研究院
link:https://arxiv.org/pdf/2312.10302
github:https://github.com/pldlgb/nuggets
一、摘要
sft目前的实践通常取决于扩大数据规模,而没有明确的策略来确保数据质量,从而无意中引入可能会损害模型性能的噪声。
为了应对这一挑战,引入了Nuggets,它利用one shot learning从广泛的数据集中辨别和选择高质量的sft数据。
Nuggets评估单个指令示例作为有效的一次性学习实例的潜力,从而确定那些可以显着提高跨不同任务性能的实例。
通过对 MT-Bench 和 Alpaca-Eval 等两个基准的综合评估,发现使用NUGGETS的前1% examples进行sft明显优于使用整个数据集的传统方法。
二、与传统的区别
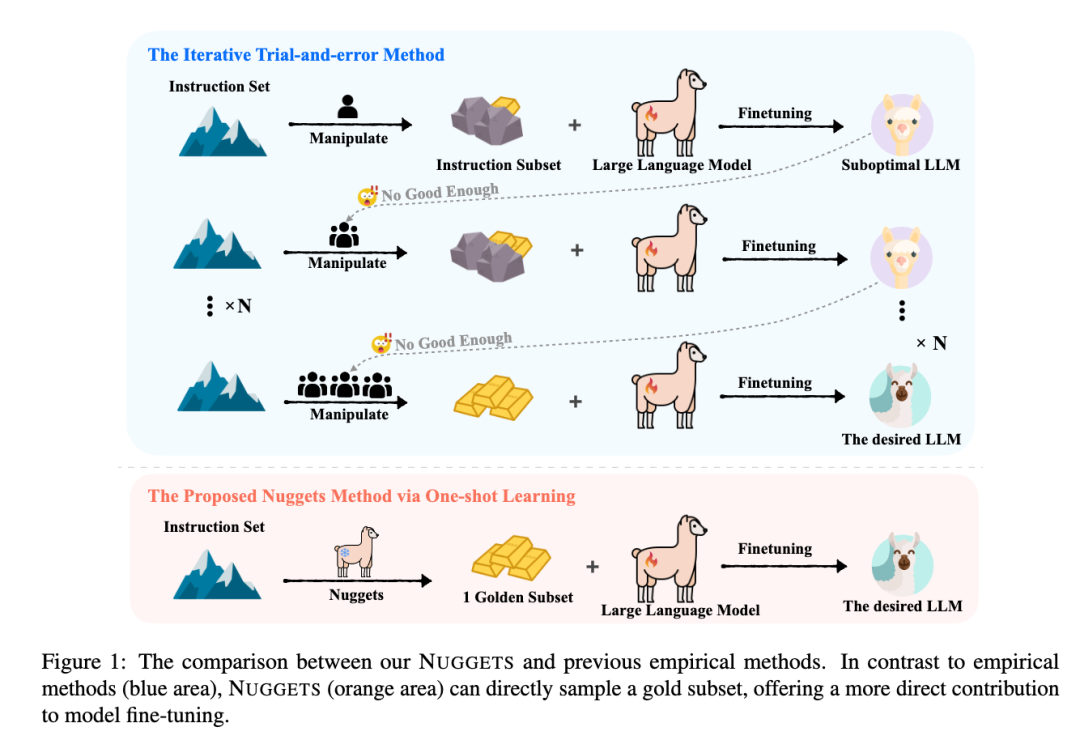
在sft过程中增加sft数据主要依靠经验方法。这些方法包括应用启发式规则、专家分析以及根据模型性能反馈对数据进行迭代调整,不用说也知道相对来说不自动化且耗费大量人力和时间成本。
三、方法
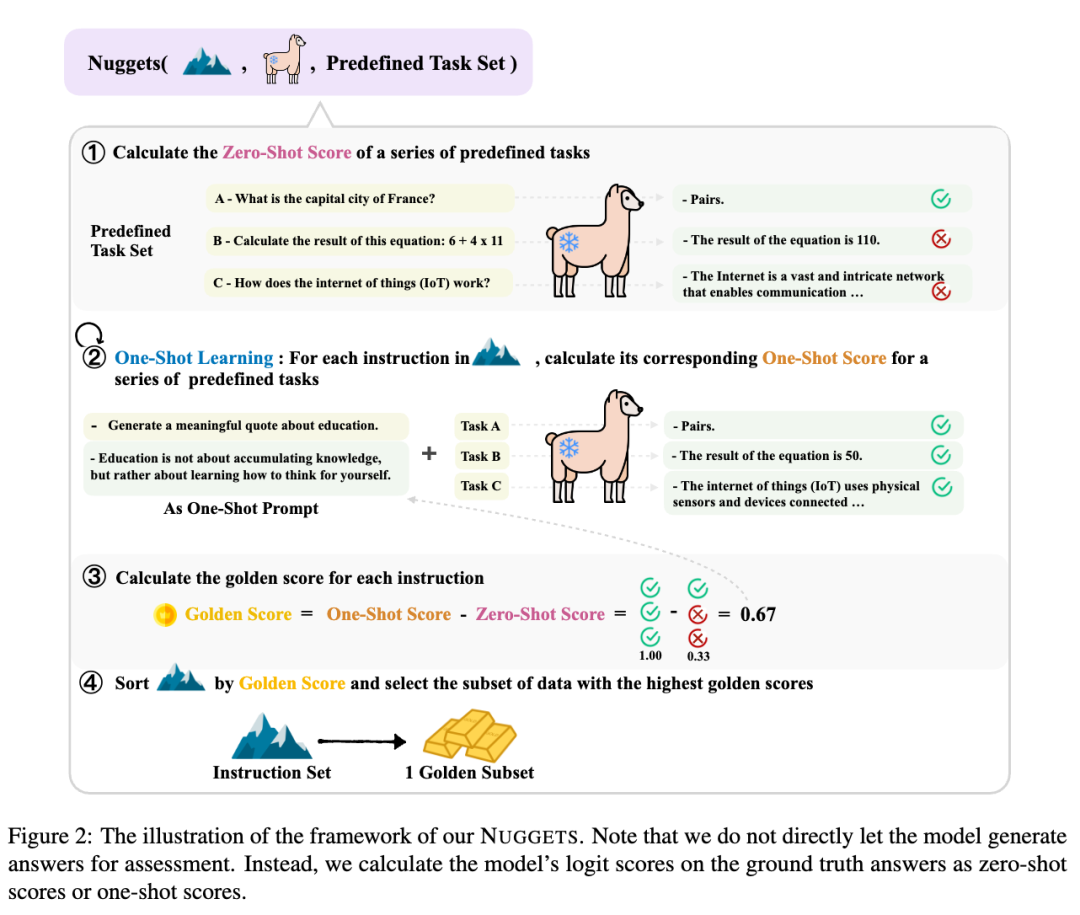
看图大概明白意思了:
-
首先用模型推理sft数据,之后计算zero-shot score
-
将增加one-shot的prompt,之后再推理,计算one-shot score
-
通过两次score计算出差值 = golden score
-
最终取top k的score的样本作为golden subset
这种思想其实在prompt + RAG 的玩法里很常见:类似于有个examples的池子,之后通过输入的样本,动态的通过RAG选择最相似的example当作one shot或者few shot并提升效果,则这些example为优质的例子。
https://zhuanlan.zhihu.com/p/690428176
这里的code paper中的1和4也是类似的思想
3.1 zero-shot score
给予一个由多个task组成的predefined task set。(这个task set就是用来评估三个score的)
score计算的就是连续预测下一个token的概率,L为label中word的个数

最终每个task计算一个zero-shot score,score越高代表模型能力更好,越低代表模型能力更差
3.2 one-shot score
增加sft数据集的样本作为one-shot进行一致的计算:

3.3 golden score
通过比较k个task的性能优化的百分比,作为这个被当作one-shot样本的golden score
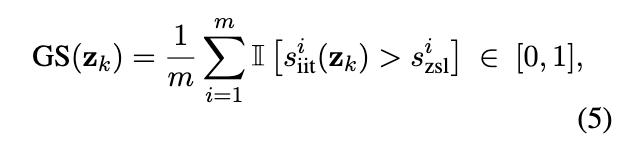
选择样本的golden score的topk作为subset训练模型完成整体流程
四、实验
还是用gpt-4 winrate来做
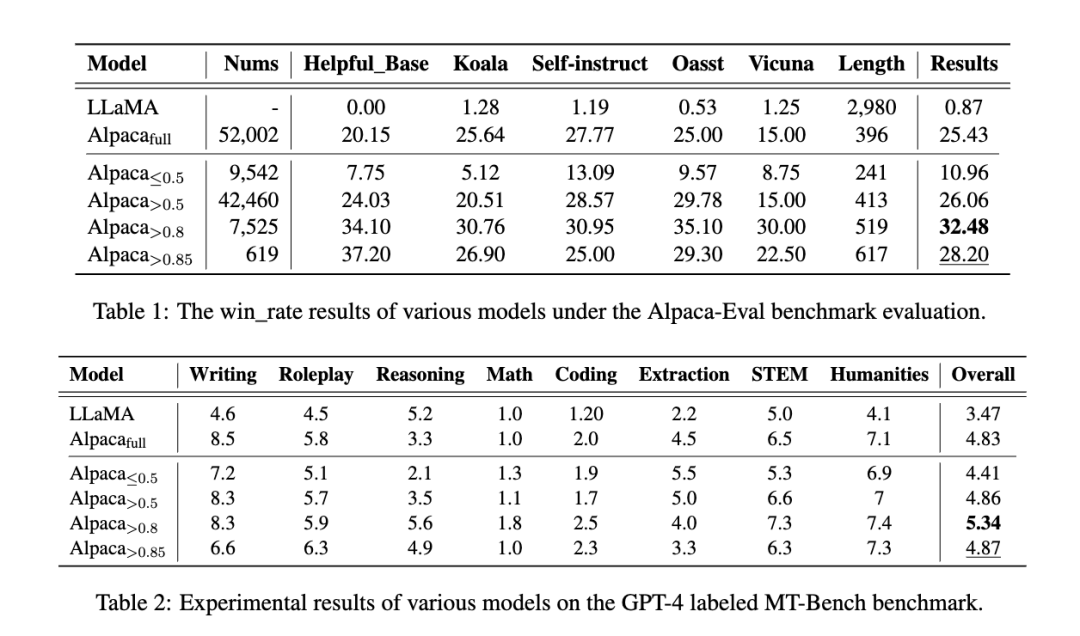
< 以及>是指的计算数据集的 golden score的大于或者小于删选的sft数据集
其中大于0.8 golden score选出7,525个样本训练的效果是最佳的,超过全部数据的效果。
其他还有很多补充实验,感兴趣的可以自行查阅,我这里主要讲个思路。
推荐阅读:
公众号:AI蜗牛车
保持谦逊、保持自律、保持进步

发送【蜗牛】获取一份《手把手AI项目》(AI蜗牛车著)
发送【1222】获取一份不错的leetcode刷题笔记
发送【AI四大名著】获取四本经典AI电子书

一站式 AI 云服务平台
更多推荐

 24
24 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)