
ISME Comm | 机器学习和深度学习在微生物组研究中的应用
Review Article,2022-10-06,ISME Communications,DOI:https://doi.org/10.1038/s43705-022-00182-9第一作者:Ricardo Hernández Medina通讯作者:Mads Nielsen;Simon Rasmussen主要单位:哥本哈根大学- 摘要 -我们把在生态系统中与我们息息相关的许多微生物群落统称为微生

Review Article,2022-10-06,ISME Communications,
DOI:https://doi.org/10.1038/s43705-022-00182-9
第一作者:Ricardo Hernández Medina
通讯作者:Mads Nielsen;Simon Rasmussen
主要单位:哥本哈根大学
- 摘要 -
我们把在生态系统中与我们息息相关的许多微生物群落统称为微生物组。虽然肉眼不可见,但是微生物组主宰或影响着宏观系统,如人类健康,植物胁迫以及生化循环。这一现象吸引了科学界的兴趣,并且最近尝试用机器学习和深度学习来寻找微生物组的组分和功能之间的关系。本文回顾了最新的微生物组研究如何利用人工智能技术的归纳能力。我们首先强调微生物组数据是成份类型的、稀疏和高维的,因此需要进行特殊处理。然后,我们介绍了传统和新颖的方法,并讨论了它们的优势和应用。最后,我们讨论了机器学习和深度学习的前景,重点关注瓶颈和解决这些问题的注意事项。最后,我们展望了机器学习和深度学习在微生物组研究中的未来,重点关注瓶颈和解决瓶颈的方法。
- 引言 -
我们周围无时无刻都有微生物群落在工作。这些微生物群落有助于生物地球化学循环,增加或缓冲环境变化,对于了解人类和其他生物的健康和疾病至关重要。在一个动态的、相互作用的微环境中特有的微生物群落及其代谢物统称为微生物组。对于这些网络中的运作和关系的见解有望为可持续农业,疾病预防和治疗以及人类活动影响评估带来希望。微生物研究的一个前沿是通过微生物工程来建立一个支持预期结果的微生物组,如更健康或者增加作物产量。然而,成功的工程需要一些特定的知识,如,什么构建了微生物群落的功能、在群落中是否有关键物种以及何种程度的组分和功能可以被操纵。
为了解决这些微生物组的复杂难题,研究人员转向人工智能方法。由于它们强大的预测能力和信息潜力,机器学习和深度学习最近作为一个重要的工具被用于微生物研究领域以推进该领域的发展。本文中,我们展示了这些新的技术是如何用来研究微生物与表型之间的联系。
- 微生物组数据类型 -
现今只有一小部分微生物物种可以进行分离和培养,而近年来组学和高通量测序技术的发展打开了对微生物物种进行全面描述的大门,并产生了大量的微生物组数据。最常用的微生物组分析手段是扩增子和宏基因组测序。扩增子的方法中,以进化相对保守的16S和ITS区域为标记基因对样本进行标记。通常以一个预定义的相似度阈值来粗略的鉴定物种,并聚类为OTU。扩增子序列变异体ASVs是一个新提出的类似OTU的定义。它由降噪算法产生,并且不需要指定相异性阈值,因此可以用来解析群落中数量稀少的物种。相比之下,鸟枪宏基因组法基于非特异性测序对样品内的总基因组进行全面的分类。通过不同的算法,鸟枪宏基因组的读长可以与精选的数据库比对来进行功能和分类上的注释。此外,鸟枪宏基因组可以使用分箱的方式将装配好的宏基因组恢复成单个基因组,例如通过重叠群(contig)聚类的方式的MetaBAT2和VAMB。最近的病毒组分析使用鸟枪法对微生物组进行了更全面的表征。
这些方式产生的特征表,表内的每一个单元格都表示每一个样本中特定物种或者功能的丰度或存在与否。然而是否物种或者功能装配对下游的分析提供了很好的区分能力仍有待商榷。无论如何,这都说明了这种特征表类型的数据具有一定的特殊性和挑战性。首先,特征表数据是成份类的。成份类的数据描述了其中各成份之间的关系,因此,各特征之间相互依赖,且对他们和为定值。另外,特征表通常情况下是稀疏的(存在很多0值),以及具有极高的维度。这使得下游的分析通常受着高维度的影响。这种影响是双重的,高维的是数据增加了计算成本,而相对较少的样本量又对模型的精准度以及泛化性能造成了很大的影响。
处理微生物组数据的方式有很多。由于普通的距离分析和关联分析对组成型数据是无效的,因此很多数据分析方法适用于这类数据,例如对数比变换(log-ratio transformation),保持单纯形法(staying-in-the-simplex approach)以及计算组分比(calculating component ratios)。但传统的对数比变换无法处理稀疏型数据,并且通常0值被替换成伪值。另一方面,特征选择和提取可以用来帮助克服维度问题。特征选择可以剔除不相关以及冗余变量,而特征提取通过对输入数据压缩的方式来解决来实现减少数据的维度。总的来说微生物组的数据本质使得他的分析需要对其数据进行预处理,值得注意的是,这一步也同样是影响模型性能的关键。
- 机器学习 -
机器学习是人工智能领域下的一个分支,可以在依赖大数据的情况下解决识别、分类、回归等一系列问题。在微生物组领域,机器学习已经被应用于解决表型(如预测环境或宿主的表型),微生物特征分类(如确定丰度,多样性以及微生物物种分布),微生物组分之间的复杂物理化学互作,监测微生物组分变化等各个方面。在表1中,我们列举了一些任务的示例.
|
任务 |
预计目标 |
方法 |
参考文献(DOI) |
|
预测表型 |
海绵细菌的密度分类 |
随机森林 |
10.3389/fmicb.2017.00752 |
|
预测表型 |
作物产量预测 |
随机森林 |
10.3389/fmicb.2017.00519 |
|
预测表型 |
食物过敏 |
递归神经网络LSTM |
10.1371/journal.pcbi.1006693 |
|
预测表型 |
疾病(如Ⅱ型糖尿病和肠炎) |
随机森林、lasso、elastic net |
10.1186/s13059-021-02306-1 |
|
预测表型 |
疾病(如肝硬化,Ⅱ型糖尿病和肠炎) |
卷积神经网络 |
10.1093/bioinformatics/btaa542 10.1109/EMBC.2017.8037799 10.1109/JBHI.2020.2993761 |
|
微生物特征分类 |
微生物组成 |
自编码器 |
10.1109/JBHI.2020.2993761 |
|
微生物特征分类 |
代谢装配 |
自编码器 |
10.1186/s12864-020-6652-7 |
|
互作分析 |
微生物-代谢组互作 |
嵌入算法 |
10.1038/s41592-019-0616-3 |
|
互作分析 |
微生物共现模式 |
嵌入算法 |
10.1371/journal.pcbi.1007859 |
|
微生物组分监测 |
微生物对饮食改变的响应 |
自编码器 |
10.1109/BIBM47256.2019.8983124 |
表1 微生物组研究中使用的常见任务和ML方法示例。
- 经典方法 -
虽然经典的机器学习算法,如线性回归,随机森林,支持向量机等在微生物组数据中表现良好。但是随着算法的迭代更新,这些模型早已被降级为基础模型。现在的线性回归模型更多的是用于将其他模型的输出作为输入来更直观的解释这些模型。这一方法最近被应用于宿主生态失调预测研究,并且将其结果与其他方式,如随机森林做了一个比较。随机森林使用决策树,流程图式的结构,通过做决定的方式将数据集进行合理划分。通过从随机取样的特征子集中生成多个树的方式来组装一个随机森林,其性能远远要好于单一树。随机森林可以解决微生物领域的问题,如海绵共生密度,预测玉米产量以及区分有或判断个体是否处于疾病状态。
- 降维方法 -
无监督排序手段可以降低维度并且简化数据。这些算法适合用来进行可视化或者所谓的投影。通过对现有特征进行线性或者非线性的合并,这些手段产生了一个压缩的,具有代表性的输入数据。线性手段,例如主成分分析(principal component analysis, PCA)和主坐标分析(principal coordinate analysis, PCoA)是现阶段非常受欢迎的微生物群落可视化及对比工具,比如鉴定样本栖息地以及地理起源。如非线性的降维技术t相邻域嵌入(t-stochastic neighbor embedding, t-SNE),和统一流形逼近与投影算法(uniform manifold approximation and projection, UMAP)可以很好的在微生物数据集中捕捉和揭示非线性关系,但是他们的调参很难。
- 深度学习 -
深度学习是机器学习的一个分支,它涉及了大量的神经网络结构。深度学习依赖于神经元,其作用是对输入进行转换并且向前传播给下一个的神经元。神经元之间的连接导致了神经网络是由多层组成,因此神经网络可以具有多样化的结构。
大多数基础的神经网络结构是全连接神经网络结构,也就是一个网络层里的全部神经元都完全连接到下一个网络层上的神经元。Lo 和Marculescu使用这种结构从宏基因组的原始数据预测了宿主的表型,在不同的数据集上都表现出了比传统方法更好的分类准确率。全连接神经网络算是一个有效的独立模型,也是在复杂模型中最常用的基础模块。
- 图形化微生物组 -
研究人员发现先了一种创造性的方式,通过空间信息来表示OTU丰富度参数(比如在系统发育中包含的信息)。这一特点也正是卷积神经网络CNN所擅长的。CNN精通于总结输入信息的局部结构,因此他们常用于表达空间信息,如图片中的像素值的位置关系。Nguyen 把OTU表转化成图片,像素值代表了物种的丰度或是否存在(图1A)。TaxNN根据系统发育信息对OTU表进行重排序,而PopPhy-CNN将系统发育树和OTU丰度做成了一个树并且重塑成了一个二维矩阵(图1B)。通常情况下,这些方法在宿主表型预测任务中的表现优于其基准(传统ML方法和FCNNs)。
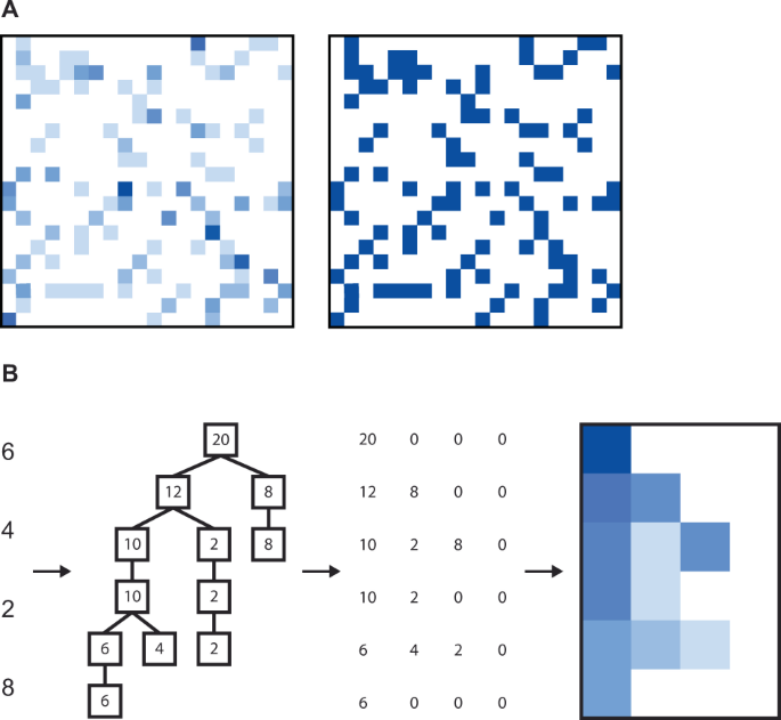
图1. 从OTU表生成的CNN图像输入示例。
A. 图像中充满了物种丰度(左)或存在(右)。B. 对于单个样本,构建系统发育树,填充物种丰度,并重新排列成矩阵。
- 时序数据 -
循环神经网络(Recurrent neural networks, RNN)经常会被用于探索时序上的信息。这些模型的结构通常是链式的,表现为将前一个时间段的信息传递到下一个时间点。在微生物组的研究中,RNN用于探测时序上的依赖以及动态信息,并进行预测。Metwally是第一个建立基于时序的微生物装配预测模型的人之一。基于三年的婴儿过敏表型追踪数据,他们建立的模型性能超过了其他模型,但是仍然未达到合适的临床可信的性能。phyLoLSTM 是一个使用了taxoNN来进行特征提取的RNN框架,taxoNN提升了LSTM的分类性能。与此同时,Chen提出了不同的时间自适应框架,结合清除异常的时序数据以及进行特征工程(让数据更干净)等方式来优化输入的带有系统发育信息的OTU表。他们在不同的数据集上进行了测试。
- 揭示潜在信息 -
由于计算花费以及效率等原因,通常会对微生物组数据进行降维。在深度学习中,这种低维度的隐藏信息的显示通常被称为嵌入,且经常使用自编码器Autoencoder来实现。自编码器由一个学习隐藏信息的编码器encoder(用于将特征压缩至低维)和一个重塑数据的解码器decoder组成。通过最小化原始输入数据和解码后的数据之间的差异,自编码器可以学习到数据中潜在的压缩信息。DeepMicro 是一个基于多层自编码器变体的神经网络,揭示了每种不同的潜在信息如何改进肠易激综合征以及二型糖尿病的预测。
自编码器的特质使得它可以进行多模式数据的整合。Reiman 和Dai提出的二模式自编码器 (Bimodal Autoencoder) 可以整合饮食以及微生物组分来预测微生物组分对于饮食变化的反应。Grazioli 引进了一种基于专家产品方法 (product-of-experts approach) 的疾病预测模型,可以整合来自两个自编码器的信息 (species-level和strain-level)。
其他的算法的灵感来自于自然语言处理,比如word2vec和 GloVe 。这些模式可以创造密度嵌入层来实现捕捉共存模式。
机器学习进行数据分析的关键步骤。通常,分析从描述功能或分类的特征表开始微生物组的概况。作为预处理步骤的一部分,可以转换、插补或增强此表以及其他过程。预处理的结果可以是表格数据,也可以是每个样本的一组类似图像的表示或嵌入。下一步需要训练和调优 ML 或 DL 模型,例如随机森林、全连接神经网络、卷积神经网络、递归神经网络和自动编码器。最后,这些结果有助于阐明微生物组组成与连续(回归)或离散描述(分类、聚类和可视化)表型。
- 展望 -
01
未来应用瓶颈
虽然机器学习算法在微生物组研究中是一个非常有潜力的工具,但是他在实际应用中仍然面临很多困难。普遍存在的局限性有以下几个方面,如模型可解释性,数据饥渴性,模型评估及选择。通俗来讲,机器学习方法建立了一个输入和靶标之间的连接,即使在缺少对输入和靶标之间潜在逻辑关系的理解的前提下也可以很好的找到真实的关系。这也使得机器学习通常被认为是不可解释的黑匣子。这一问题往往在临床决策制定等场景中具有很大应用争议。虽然可解释性的定义并不明确,但是人们越来越趋向于可解释的机器学习模型。例如深度森林算法对特征的重要性进行排序,已经早就用于微生物组相关的研究中。Zhou等人将微生物互作网络嵌入到全连接神经网络中去,使得学习过程带有了先验知识。其他框架,比如DeepCoDA 通过线性转化来初始特征贡献。SparseNED 通过稀疏和可解释的隐藏空间来捕获关节炎中微生物-代谢之间的关系。
第二个局限性是机器学习往往需要大量的数据,以及高质量的,正确标记的数据集。Adadi 提出了解决数据缺乏的策略,如数据增强,无监督学习,迁移学习以及混合模型。数据增强是一种通过创造同质化数据来增加数据量的方式。Lo等人通过负二项分布来扩大他们的训练集,并且提高了了表型分类性能。Sayyari等人提出了通过树基关联数据增强方式从推测的发育树产生新的OTU来弥补低样本量以及样本并不均衡所导致的局限。无监督以及半监督学习方式不需要过多的标签量,迁移学习和混合模型还没有在微生物组领域应用。
一个最主要的考虑是数据质量,我们的建议是关注数据集的来源、不足之处以及差异。控制这些的方法有去重、类别平衡、极端值移除等方式,这些方式影响了模型的性能。虽然采集大量的数据以及完美注释的样本大小在微生物数据集中很难实现,但是研究人员可以从多个研究中获取数据。无论如何,机器学习非常依赖训练集的数据质量,因此应给予特别关注。
另一个对于微生物生态学者来说比较重要的挑战是对于一个指定任务应进行合适的选择、调参、评估。在众多模型中进行选择以及寻找一组合适的超参数的工作量极大,因此我们推荐利用成熟的机器学习生态系统。如pytorch/tensorflow/keras等。跨多个数据集进行比较可以评估ML 方法的稳健性。参考数据集的选择是对确保公平比较至关重要。
最后,我们总结了 ML 辅助微生物组的关键步骤,(图 2)中的分析,并提供以下快速提示和启发式方法:
1. 熟悉数据集。前期检查输入数据可以帮助衡量特征空间的大小,识别数据集是否包含不平衡的类,或确定插补或特征工程是否是一种选择。
2. 建立模型选择和基准测试策略。将数据集拆分为训练、验证和测试子集(在大型数据集的情况)或交叉验证(对于较小的数据集)。选择适当的指标进行比较模型并估计它们的性能。
3. 选择合适的方法。虽然选择取决于数据和任务,但传统的 ML 算法还是不错的选择,因为它们需要最小的调整并且是相对容易实现。如果大规模或多模态数据是可用的,考虑像自动编码器这样的 DL 方法将所有数据方面合并到信息嵌入中。在里面在具有纵向微生物群落的序列数据的情况下,尝试一个适合捕获的 RNN 框架时间依赖性。如果空间信息可以嵌入到输入中,例如系统发育树可以分解为二维矩阵,考虑 CNN。
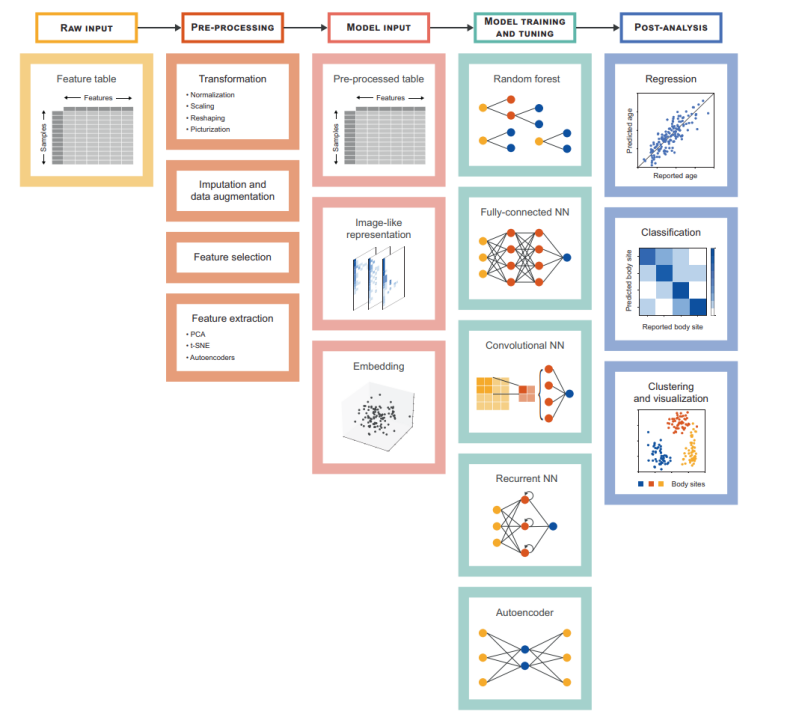
图2. 机器学习进行数据分析的关键步骤。
通常,分析从描述功能或分类的特征表开始微生物组的概况。作为预处理步骤的一部分,可以转换、插补或增强此表以及其他过程。预处理的结果可以是表格数据,也可以是每个样本的一组类似图像的代表或嵌入。下一步需要训练和调优 ML 或 DL 模型,例如随机森林、全连接神经网络、卷积神经网络、递归神经网络和自动编码器。最后,这些结果有助于阐明微生物组组成与连续(回归)或离散描述(分类、聚类和可视化)表型。
02
需要关注的新技术
LaPierre 等人对 DL 模型的综合评估表明预测准确性的上限可能仅来自宏基因组数据。尽管如此,先前的研究表明预测能力有所提高可以通过结合不同的数据模式来实现,例如微生物组、遗传和环境数据。例如,García-Jiménez等人实现了多模式的概念通过最小化两个潜在之间的距离来嵌入由两种模式的独立编码器创建的空间(环境变量和微生物组成)。一个谱系多模态变分自编码器的工作研究了组合单个模态的潜在空间的合适方法取决于数据集属性。虽然多模态已被用于分析单细胞多组学数据,据我们所知,这种算法还没有已应用于多组学微生物组数据。
- 展望 -
微生物群落的研究十分丰富。扩增子和宏基因组测序产生的特征表在分类上或功能上描述了微生物组,并且通过适当的标记,可以支持基于ML和DL的方法。DL模型是一种强大的工具,在微生物组研究领域具有广泛的应用。值得注意的是,这些方法能够将特定分类群与宿主表型联系起来,或监测动态和宿主对微生物组组成变化的反应。尽管存在不同的ML和DL模型配置,但选择取决于任务和输入。在这篇综述中,我们不仅提供了人工智能在微生物组研究领域的应用实例,还列出了使用这些模型时需要注意的事项。对当前数据可用性和模型可解释性瓶颈的进一步研究将进一步推动DL在微生物组研究中的应用,并扩大我们对影响我们世界的微生物相互作用的理解。
- 作者简介 -
第一作者

哥本哈根大学
Ricardo Hernández Medina
在读博士
Ricardo Hernández Medina,哥本哈根大学在读博士,主要研究兴趣为合成生物学,深度学习,微生物组。目前在 The ISME Journal发表文章一篇。
图片来源:https://twitter.com/ricardo_heme
信息来源:https://scholar.google.com/citations?user=TNWqa0IAAAAJ&hl=zh-CN&oi=ao
通讯作者

哥本哈根大学
Simon Rasmussen
教授
Simon Rasmussen,哥本哈根大学教授。主要从事多组学,和生物信息学等方面研究,至今已在国际主流期刊Science, Nature, Cell, Nature Microbiology等刊物发表论文171篇。
往期精品(点击图片直达文字对应教程)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|




























后台回复“生信宝典福利第一波”或点击阅读原文获取教程合集



一站式 AI 云服务平台
更多推荐

 0
0 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)